Матрица парных коэффициентов корреляции
| Y | X1 | X2 | X3 | X4 | X5 | |
| Y | ||||||
| X1 | 0,732705 | |||||
| X2 | 0,785156 | 0,706287 | ||||
| X3 | 0,179211 | -0,29849 | 0,208514 | |||
| X4 | 0,667343 | 0,924333 | 0,70069 | 0,299583 | ||
| X5 | 0,709204 | 0,940488 | 0,691809 | 0,326602 | 0,992945 |
В узлах матрицы находятся парные коэффициенты корреляции, характеризующие тесноту взаимосвязи между факторными признаками. Анализируя эти коэффициенты, отметим, что чем больше их абсолютная величина, тем большее влияние оказывает соответствующий факторный признак на результативный. Анализ полученной матрицы осуществляется в два этапа:
1. Если в первом столбце матрицы есть коэффициенты корреляции, для которых /r / < 0,5, то соответствующие признаки из модели исключаются. В данном случае в первом столбце матрицы коэффициентов корреляции исключается фактор или коэффициент роста уровня инфляции. Данный фактор оказывает меньшее влияние на результативный признак, нежели оставшиеся четыре признака.
2. Анализируя парные коэффициенты корреляции факторных признаков друг с другом, (r XiXj), характеризующие тесноту их взаимосвязи, необходимо оценить их независимость друг от друга, поскольку это необходимое условие для дальнейшего проведения регрессионного анализа. В виду того, что в экономике абсолютно независимых признаков нет, необходимо выделить, по возможности, максимально независимые. Факторные признаки, находящиеся в тесной корреляционной зависимости друг с другом, называются мультиколлинеарными. Включение в модель мультиколлинеарных признаков делает невозможным экономическую интерпретацию регрессионной модели, так как изменение одного фактора влечет за собой изменение факторов с ним связанных, что может привести к «поломке» модели в целом.
Критерий мультиколлениарности факторов выглядит следующим образом:
/r XiXj / > 0,8
В полученной матрице парных коэффициентов корреляции этому критерию отвечают два показателя, находящиеся на пересечении строк ![]() и . Из каждой пары этих признаков в модели необходимо оставить один, он должен оказывать большее влияние на результативный признак. В итоге из модели исключаются факторы и , т.е. коэффициент роста себестоимости реализованной продукции и коэффициент роста объёма её реализации.
и . Из каждой пары этих признаков в модели необходимо оставить один, он должен оказывать большее влияние на результативный признак. В итоге из модели исключаются факторы и , т.е. коэффициент роста себестоимости реализованной продукции и коэффициент роста объёма её реализации.
Итак, в регрессионную модель вводим факторы Х1 и Х2.
Далее осуществляется регрессионный анализ (сервис, анализ данных, регрессия). Вновь составляет таблица исходных данных с факторами Х1 и Х2. Регрессия в целом используется для анализа воздействия на отдельную зависимую переменную значений независимых переменных (факторов) и позволяет корреляционную связь между признаками представить в виде некоторой функциональной зависимости называемой уравнением регрессии или корреляционно-регрессионной моделью.
В результате регрессионного анализа получаем результаты расчета многомерной регрессии. Проанализируем полученные результаты.
Все коэффициенты регрессии значимы по критерию Стьюдента. Коэффициент множественной корреляции R составил 0,925, квадрат этой величины (коэффициент детерминации) означает, что вариация результативного признака в среднем на 85,5% объясняется за счет вариации факторных признаков, включенных в модель. Коэффициент детерминированности характеризует тесноту взаимосвязи между совокупностью факторных признаков и результативным показателем. Чем ближе значение R-квадрат к 1, тем теснее взаимосвязь. В нашем случае показатель, равный 0,855, указывает на правильный подбор факторов и на наличие взаимосвязи факторов с результативным показателем.
Рассматриваемая модель адекватна, поскольку расчетное значение F-критерия Фишера существенно превышает его табличное значение (F набл =52,401; F табл =1,53).
В качестве общего результата проведенного корреляционно-регрессионного анализа выступает множественное уравнение регрессии, которое имеет вид:
Полученное уравнение регрессии отвечает цели корреляционно-регрессионного анализа и является линейной моделью зависимости балансовой прибыли предприятия от двух факторов: коэффициента роста производительности труда и коэффициента имущества производственного назначения.
На основании полученной модели можно сделать вывод о том, что при увеличении уровня производительности труда на 1% к уровню предыдущего периода величина балансовой прибыли возрастет на 0,95 п.п.; увеличение же коэффициента имущества производственного назначения на 1% приведет к росту результативного показателя на 27,9 п.п. Слелдовательно, доминирующее влияние на рост балансовой прибыли оказывает увеличение стоимости имущества производственного назначения (обновление и рост основных средств предприятия).
По множественной регрессионной модели выполняется многофакторный прогноз результативного признака. Пусть известно, что Х1 = 3,0, а Х3 = 0,7. Подставим значения факторных признаков в модель, получим Упр = 0,95*3,0 + 27,9*0,7 – 19,4 = 2,98. Таким образом, при увеличении производительности труда и модернизации основных средств на предприятии балансовая прибыль в 1 квартале 2005 г. по отношению к предыдущему периоду (IV квартал 2004 г.) возрастет на 2,98%.
Коллинеарными являются факторы …
И коллинеарны.
4. В модели множественной регрессии определитель матрицы парных коэффициентов корреляции между факторами , и близок к нулю. Это означает, что факторы , и … мультиколлинеарность факторов.
5. Для эконометрической модели линейного уравнения множественной регрессии вида построена матрица парных коэффициентов линейной корреляции (y – зависимая переменная; х (1) , х (2) , х (3) , x (4) – независимые переменные):

Коллинеарными (тесно связанными) независимыми (объясняющими) переменными не являются
…x (2)
и x (3)
1. Дана таблица исходных данных для построения эконометрической регрессионной модели:
 Фиктивными переменными не являются
…
Фиктивными переменными не являются
…
стаж работы
производительность труда
2. При исследовании зависимости потребления мяса от уровня дохода и пола потребителя можно рекомендовать …
использовать фиктивную переменную – пол потребителя
разделить совокупность на две: для потребителей женского пола и для потребителей мужского пола
3. Изучается зависимость цены квартиры (у
) от ее жилой площади (х
) и типа дома. В модель включены фиктивные переменные, отражающие рассматриваемые типы домов: монолитный, панельный, кирпичный. Получено уравнение регрессии: ,
где  ,
, 
Частными уравнениями регрессии для кирпичного и монолитного являются …
для типа дома кирпичный ![]()
для типа дома монолитный ![]()
4. При анализе промышленных предприятий в трех регионах (Республика Марий Эл, Республика Чувашия, Республика Татарстан) были построены три частных уравнения регрессии:
![]() для Республики Марий Эл;
для Республики Марий Эл;
![]() для Республики Чувашия;
для Республики Чувашия;
![]() для Республики Татарстан.
для Республики Татарстан.
Укажите вид фиктивных переменных и уравнение с фиктивными переменными, обобщающее три частных уравнения регрессии.
5. В эконометрике фиктивной переменной принято считать …
переменную, принимающую значения 0 и 1
описывающую количественным образом качественный признак
1. Для регрессионной модели зависимости среднедушевого денежного дохода населения (руб., у ) от объема валового регионального продукта (тыс. р., х 1 ) и уровня безработицы в субъекте (%, х 2 ) получено уравнение . Величина коэффициента регрессии при переменной х 2 свидетельствует о том, что при изменении уровня безработицы на 1% среднедушевой денежный доход ______ рубля при неизменной величине валового регионального продукта.
изменится на (-1,67)
2. В уравнении линейной множественной регрессии:
![]() , где – стоимость основных фондов (тыс. руб.); – численность занятых (тыс. чел.); y
– объем промышленного производства (тыс. руб.) параметр при переменной х 1
, равный 10,8, означает, что при увеличении объема основных фондов на _____ объем промышленного производства _____ при постоянной численности занятых.
, где – стоимость основных фондов (тыс. руб.); – численность занятых (тыс. чел.); y
– объем промышленного производства (тыс. руб.) параметр при переменной х 1
, равный 10,8, означает, что при увеличении объема основных фондов на _____ объем промышленного производства _____ при постоянной численности занятых.
на 1 тыс. руб. … увеличится на 10,8 тыс. руб.
3. Известно, что доля остаточной дисперсии зависимой переменной в ее общей дисперсии равна 0,2. Тогда значение коэффициента детерминации составляет … 0,8
4. Построена эконометрическая модель для зависимости прибыли от реализации единицы продукции (руб., у ) от величины оборотных средств предприятия (тыс. р., х 1 ): . Следовательно, средний размер прибыли от реализации, не зависящий от объема оборотных средств предприятия, составляет _____ рубля. 10,75
5. F-статистика рассчитывается как отношение ______ дисперсии к ________ дисперсии, рассчитанных на одну степень свободы. факторной … остаточной
1. Для эконометрической модели уравнения регрессии ошибка модели определяется как ______ между фактическим значением зависимой переменной и ее расчетным значением. Разность
2. Величина называется … случайной составляющей
3. В эконометрической модели уравнения регрессии величина отклонения фактического значения зависимой переменной от ее расчетного значения характеризует … ошибку модели
4. Известно, что доля объясненной дисперсии в общей дисперсии равна 0,2. Тогда значение коэффициента детерминации составляет … 0,2
5. При методе наименьших квадратов параметры уравнения парной линейной регрессии ![]() определяются из условия ______ остатков .
минимизации суммы квадратов
определяются из условия ______ остатков .
минимизации суммы квадратов
1. Для обнаружения автокорреляции в остатках используется …
статистика Дарбина – Уотсона
2. Известно, что коэффициент автокорреляции остатков первого порядка равен –0,3. Также даны критические значения статистики Дарбина – Уотсона для заданного количества параметров при неизвестном и количестве наблюдений , . По данным характеристикам можно сделать вывод о том, что …автокорреляция остатков отсутствует
1. Рассчитать матрицу парных коэффициентов корреляции; проанализировать тесноту и направление связи результирующего признака Y с каждым из факторов Х ; оценить статистическую значимость коэффициентов корреляции r (Y , X i); выбрать наиболее информативный фактор.
2. Построить модель парной регрессии с наиболее информативным фактором; дать экономическую интерпретацию коэффициента регрессии.
3. Оценить качество модели с помощью средней относительной ошибки аппроксимации, коэффициента детерминации и F – критерия Фишера (принять уровень значимости α=0,05).
4. С доверительной вероятностью γ=80% осуществить прогнозирование среднего значения показателя Y (прогнозные значения факторов приведены в Приложении 6). Представить графически фактические и модельные значения Y , результаты прогнозирования.
5. Методом включения построить двухфакторные модели, сохраняя в них наиболее информативный фактор; построить трехфакторную модель с полным перечнем факторов.
6. Выбрать лучшую из построенных множественных моделей. Дать экономическую интерпретацию ее коэффициентов.
7. Проверить значимость коэффициентов множественной регрессии с помощью t –критерия Стьюдента (принять уровень значимости α=0,05). Улучшилось ли качество множественной модели по сравнению с парной?
8. Дать оценку влияния факторов на результат с помощью коэффициентов эластичности, бета– и дельта– коэффициентов.
Задача 2. Моделирование одномерного временного ряда
В Приложении 7 приведены временные ряды Y(t) социально-экономических показателей по Алтайскому краю за период с 2000 г. по 2011 г. Требуется исследовать динамику показателя, соответствующего варианту задания.
| Вариант | Обозначение, наименование, единица измерения показателя | |
| Y1 | Потребительские расходы в среднем на душу населения (в месяц), руб. | |
| Y2 | Выбросы загрязняющих веществ в атмосферный воздух, тыс. тонн | |
| Y3 | Средние цены на вторичном рынке жилья (на конец года, за квадратный метр общей площади), руб | |
| Y4 | Объем платных услуг на душу населения, руб | |
| Y5 | Среднегодовая численность занятых в экономике, тыс. человек | |
| Y6 | Число собственных легковых автомобилей на 1000 человек населения (на конец года), штук | |
| Y7 | Среднедушевые денежные доходы (в месяц), руб | |
| Y8 | Индекс потребительских цен (декабрь к декабрю предыдущего года), % | |
| Y9 | Инвестиции в основной капитал (в фактически действовавших ценах), млн. руб | |
| Y10 | Оборот розничной торговли на душу населения (в фактически действовавших ценах), руб |
Порядок выполнения работы
1. Построить линейную модель временного ряда , параметры которой оценить МНК. Пояснить смысл коэффициента регрессии.
2. Оценить адекватность построенной модели, используя свойства случайности, независимости и соответствия остаточной компоненты нормальному закону распределения.
3. Оценить точность модели на основе использования средней относительной ошибки аппроксимации.
4. Осуществить прогнозирование рассматриваемого показателя на год вперед (прогнозный интервал рассчитать при доверительной вероятности 70%).
5. Представить графически фактические значения показателя, результаты моделирования и прогнозирования.
6. Провести расчет параметров логарифмического, полиномиального (полином 2-й степени), степенного, экспоненциального и гиперболического трендов. На основании графического изображения и значения индекса детерминации выбрать наиболее подходящий вид тренда.
7. С помощью лучшей нелинейной модели осуществить точечное прогнозирование рассматриваемого показателя на год вперед. Сопоставить полученный результат с доверительным прогнозным интервалом, построенным при использовании линейной модели.
ПРИМЕР
Выполнения контрольной работы
Задача 1
Фирма занимается реализацией подержанных автомобилей. Наименования показателей и исходные данные для эконометрического моделирования представлены в таблице:
| Цена реализации, тыс.у.е. (Y ) | Цена нового авт., тыс.у.е. (Х1 ) | Срок эксплуатации, годы (Х2 ) | Левый руль - 1, правый руль - 0, (Х3 ) |
| 8,33 | 13,99 | 3,8 | |
| 10,40 | 19,05 | 2,4 | |
| 10,60 | 17,36 | 4,5 | |
| 16,58 | 25,00 | 3,5 | |
| 20,94 | 25,45 | 3,0 | |
| 19,13 | 31,81 | 3,5 | |
| 13,88 | 22,53 | 3,0 | |
| 8,80 | 16,24 | 5,0 | |
| 13,89 | 16,54 | 2,0 | |
| 11,03 | 19,04 | 4,5 | |
| 14,88 | 22,61 | 4,6 | |
| 20,43 | 27,56 | 4,0 | |
| 14,80 | 22,51 | 3,3 | |
| 26,05 | 31,75 | 2,3 |
Требуется:
1. Рассчитать матрицу парных коэффициентов корреляции; проанализировать тесноту и направление связи результирующего признака Y с каждым из факторов Х; оценить статистическую значимость коэффициентов корреляции r(Y, X i); выбрать наиболее информативный фактор.
Используем Excel (Данные / Анализ данных / КОРРЕЛЯЦИЯ):

Получим матрицу коэффициентов парной корреляции между всеми имеющимися переменными:
| У | Х1 | Х2 | Х3 | |
| У | ||||
| Х1 | 0,910987 | |||
| Х2 | -0,4156 | -0,2603 | ||
| Х3 | 0,190785 | 0,221927 | -0,30308 |
Проанализируем коэффициенты корреляции между результирующим признаком Y и каждым из факторов X j:
![]() > 0, следовательно, между переменными Y
и Х
1 наблюдается прямая корреляционная зависимость: чем выше цена нового автомобиля, тем выше цена реализации.
> 0, следовательно, между переменными Y
и Х
1 наблюдается прямая корреляционная зависимость: чем выше цена нового автомобиля, тем выше цена реализации.
![]() > 0,7 – эта зависимость является тесной.
> 0,7 – эта зависимость является тесной.
![]() < 0, значит, между переменными Y
и Х
2 наблюдается
< 0, значит, между переменными Y
и Х
2 наблюдается
обратная корреляционная зависимость: цена реализации ниже для авто-
мобилей с большим сроком эксплуатации.
– эта зависимость умеренная, ближе к слабой.
![]() > 0, значит, между переменными Y
и Х
3 наблюдается прямая корреляционная зависимость: цена реализации выше для автомобилей с левым рулем.
> 0, значит, между переменными Y
и Х
3 наблюдается прямая корреляционная зависимость: цена реализации выше для автомобилей с левым рулем.
![]() < 0,4 – эта зависимость слабая.
< 0,4 – эта зависимость слабая.
Для проверки значимости найденных коэффициентов корреляции используем критерий Стьюдента.
Для каждого коэффициента корреляции
вычислим t
-статистику по формуле  и занесем результаты расчетов в дополнительный столбец корреляционной таблицы:
и занесем результаты расчетов в дополнительный столбец корреляционной таблицы:
| У | Х1 | Х2 | Х3 | t-статистики | |
| У | |||||
| Х1 | 0,910987 | 7,651524603 | |||
| Х2 | -0,4156 | -0,2603 | 1,582847988 | ||
| Х3 | 0,190785 | 0,221927 | -0,30308 | 0,673265587 |
По таблице критических точек распределения Стъюдента при уровне значимости ![]() и числе степеней свободы определим критическое значение (Приложение 1, или функция СТЬЮДРАСПОБР).Y
и сроком эксплуатации Х
2 достоверна.
и числе степеней свободы определим критическое значение (Приложение 1, или функция СТЬЮДРАСПОБР).Y
и сроком эксплуатации Х
2 достоверна.
![]() < , следовательно, коэффициент не является значимым. На основании выборочных данных нет оснований утверждать, что зависимость между ценой реализации Y
и расположением руля Х
3 достоверна.
< , следовательно, коэффициент не является значимым. На основании выборочных данных нет оснований утверждать, что зависимость между ценой реализации Y
и расположением руля Х
3 достоверна.
Таким образом, наиболее тесная и значимая зависимость наблюдается между ценой реализации Y и ценой нового автомобиля Х 1 ; фактор Х 1 является наиболее информативным.
Анализ матрицы парных коэффициентов корреляции показывает, что результативный показатель наиболее тесно связан с показателем x (4) - количество удобрений, расходуемых на 1 га ().
В то же время
связь между признаками-аргументами
достаточно тесная. Так, существует
практически функциональная связь между
числом колесных тракторов (x
(1))
и числом орудий поверхностной обработки
почвы .
.
О наличии
мультиколлинеарности свидетельствуют
также коэффициенты корреляции
 и
и .
Учитывая тесную взаимосвязь показателейx
(1) , x
(2) и x
(3) ,
в регрессионную модель урожайности
может войти лишь один из них.
.
Учитывая тесную взаимосвязь показателейx
(1) , x
(2) и x
(3) ,
в регрессионную модель урожайности
может войти лишь один из них.
Чтобы продемонстрировать отрицательное влияние мультиколлинеарности, рассмотрим регрессионную модель урожайности, включив в нее все исходные показатели:

 F набл
= 121.
F набл
= 121.
В скобках
указаны значения исправленных оценок
среднеквадратических отклонений оценок
коэффициентов уравнения
 .
.
Под уравнением
регрессии представлены следующие его
параметры адекватности: множественный
коэффициент детерминации
 ;
исправленная оценка остаточной дисперсии
;
исправленная оценка остаточной дисперсии ,
средняя относительная ошибка аппроксимациии расчетное значение-критерия
F набл = 121.
,
средняя относительная ошибка аппроксимациии расчетное значение-критерия
F набл = 121.
Уравнение регрессии значимо, т.к. F набл = 121 > F kp = 2,85 найденного по таблицеF -распределения при=0,05; 1 =6 и 2 =14.
Из этого следует, что 0, т.е. и хотя бы один из коэффициентов уравнения j (j = 0, 1, 2, ..., 5) не равен нулю.
Для проверки
гипотезы о значимости отдельных
коэффициентов регрессии H0: j =0,
гдеj
=1,2,3,4,5, сравнивают критическое
значениеt
kp = 2,14, найденное по
таблицеt
-распределения при уровне
значимости=2Q
=0,05
и числе степеней свободы=14,
с расчетным значением .
Из уравнения следует, что статистически
значимым является коэффициент регрессии
только при x
(4) , так какt
4 =2,90
>t
kp =2,14.
.
Из уравнения следует, что статистически
значимым является коэффициент регрессии
только при x
(4) , так какt
4 =2,90
>t
kp =2,14.
Не поддаются экономической интерпретации отрицательные знаки коэффициентов регрессии при x (1) и x (5) . Из отрицательных значений коэффициентов следует, что повышение насыщенности сельского хозяйства колесными тракторами (x (1)) и средствами оздоровления растений (x (5)) отрицательно сказывается на урожайности. Таким образом, полученное уравнение регрессии неприемлемо.
Для получения уравнения регрессии со значимыми коэффициентами используем пошаговый алгоритм регрессионного анализа. Первоначально используем пошаговый алгоритм с исключением переменных.
Исключим из модели переменную x (1) , которой соответствует минимальное по абсолютной величине значениеt 1 =0,01. Для оставшихся переменных вновь построим уравнение регрессии:
Полученное уравнение значимо, т.к. F набл = 155 > F kp = 2,90, найденного при уровне значимости=0,05 и числах степеней свободы 1 =5 и 2 =15 по таблицеF -распределения, т.е. вектор0. Однако в уравнении значим только коэффициент регрессии приx (4) . Расчетные значенияt j для остальных коэффициентов меньшеt кр = 2,131, найденного по таблицеt -распределения при=2Q =0,05 и=15.
Исключив из модели переменную x (3) , которой соответствует минимальное значениеt 3 =0,35 и получим уравнение регрессии:
 (2.9)
(2.9)
В полученном уравнении статистически не значим и экономически не интерпретируем коэффициент при x (5) . Исключивx (5) получим уравнение регрессии:
 (2.10)
(2.10)
Мы получили значимое уравнение регрессии со значимыми и интерпретируемыми коэффициентами.
Однако полученное уравнение является не единственно “хорошей” и не “самой лучшей” моделью урожайности в нашем примере.
Покажем, что в условии мультиколлинеарности пошаговый алгоритм с включением переменных является более эффективным. На первом шаге в модель урожайностиy входит переменная x (4) , имеющая самый высокий коэффициент корреляции сy , объясняемой переменнойr (y , x (4))=0,58. На втором шаге, включая уравнение наряду сx (4) переменныеx (1) илиx (3) , мы получим модели, которые по экономическим соображениям и статистическим характеристикам превосходят (2.10):
 (2.11)
(2.11)
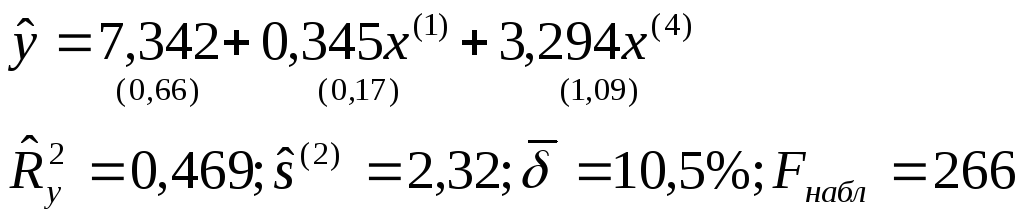 (2.12)
(2.12)
Включение в уравнение любой из трех оставшихся переменных ухудшает его свойства. Смотри, например, уравнение (2.9).
Таким образом, мы имеем три “хороших” модели урожайности, из которых нужно выбрать по экономическим и статистическим соображениям одну.
По статистическим
критериям наиболее адекватна модель
(2.11). Ей соответствуют минимальные
значения остаточной дисперсии
 =2,26
и средней относительной ошибки
аппроксимациии наибольшие значения
=2,26
и средней относительной ошибки
аппроксимациии наибольшие значения и F набл = 273.
и F набл = 273.
Несколько худшие показатели адекватности имеет модель (2.12), а затем - модель (2.10).
Будем теперь выбирать наилучшую из моделей (2.11) и (2.12). Эти модели отличаются друг от друга переменными x (1) иx (3) . Однако в моделях урожайностей переменнаяx (1) (число колесных тракторов на 100 га) более предпочтительна, чем переменнаяx (3) (число орудий поверхностной обработки почвы на 100 га), которая является в некоторой степени вторичной (или производной от x (1)).
В этой связи из экономических соображений предпочтение следует отдать модели (2.12). Таким образом, после реализации алгоритма пошагового регрессионного анализа с включением переменных и учета того, что в уравнение должна войти только одна из трех связанных переменных (x (1) ,x (2) илиx (3)) выбираем окончательное уравнение регрессии:

Уравнение
значимо при =0,05,
т.к. F набл = 266 > F kp = 3,20,
найденного по таблицеF
-распределения
при=Q
=0,05; 1 =3
и 2 =17. Значимы
и все коэффициенты регрессии и
и в уравненииt
j >t
kp (=2Q
=0,05;=17)=2,11. Коэффициент
регрессии 1 следует признать значимым ( 1 0)
из экономических соображений, при этомt
1 =2,09 лишь незначительно меньшеt
kp = 2,11.
в уравненииt
j >t
kp (=2Q
=0,05;=17)=2,11. Коэффициент
регрессии 1 следует признать значимым ( 1 0)
из экономических соображений, при этомt
1 =2,09 лишь незначительно меньшеt
kp = 2,11.
Из уравнения регрессии следует, что увеличение на единицу числа тракторов на 100 га пашни (при фиксированном значении x (4)) приводит к росту урожайности зерновых в среднем на 0,345 ц/га.
Приближенный расчет коэффициентов эластичности э 1 0,068 и э 2 0,161 показывает, что при увеличении показателейx (1) иx (4) на 1% урожайность зерновых повышается в среднем соответственно на 0,068% и 0,161%.
Множественный
коэффициент детерминации
 свидетельствует о том, что только 46,9%
вариации урожайности объясняется
вошедшими в модель показателями (x
(1) иx
(4)), то есть насыщенностью
растениеводства тракторами и удобрениями.
Остальная часть вариации обусловлена
действием неучтенных факторов (x
(2) ,x
(3) ,x
(5) , погодные
условия и др.). Средняя относительная
ошибка аппроксимациихарактеризует адекватность модели, так
же как и величина остаточной дисперсии
свидетельствует о том, что только 46,9%
вариации урожайности объясняется
вошедшими в модель показателями (x
(1) иx
(4)), то есть насыщенностью
растениеводства тракторами и удобрениями.
Остальная часть вариации обусловлена
действием неучтенных факторов (x
(2) ,x
(3) ,x
(5) , погодные
условия и др.). Средняя относительная
ошибка аппроксимациихарактеризует адекватность модели, так
же как и величина остаточной дисперсии .
При интерпретации уравнения регрессии
интерес представляют значения
относительных ошибок аппроксимации
.
При интерпретации уравнения регрессии
интерес представляют значения
относительных ошибок аппроксимации .
Напомним, что
.
Напомним, что -
модельное значение результативного
показателя, характеризует среднее для
совокупности рассматриваемых районов
значение урожайности при условии, что
значения объясняющих переменныхx
(1) иx
(4) зафиксированы на одном
и том же уровне, а именноx
(1) =x
i
(1) иx
(4)
= x
i
(4) . Тогда по значениям i
можно
сопоставлять районы по урожайности.
Районы, которым соответствуют значения i
>0, имеют
урожайность выше среднего, а i
<0
- ниже среднего.
-
модельное значение результативного
показателя, характеризует среднее для
совокупности рассматриваемых районов
значение урожайности при условии, что
значения объясняющих переменныхx
(1) иx
(4) зафиксированы на одном
и том же уровне, а именноx
(1) =x
i
(1) иx
(4)
= x
i
(4) . Тогда по значениям i
можно
сопоставлять районы по урожайности.
Районы, которым соответствуют значения i
>0, имеют
урожайность выше среднего, а i
<0
- ниже среднего.
В нашем примере, по урожайности наиболее эффективно растениеводство ведется в районе, которому соответствует 7 =28%, где урожайность на 28% выше средней по региону, и наименее эффективно - в районе с 20 =27,3%.
Матрица парных коэффициентов корреляции представляет собой матрицу, элементами которой являются парные коэффициенты корреляции. Например, для трех переменных эта матрица имеет вид:| - | y | x 1 | x 2 | x 3 |
| y | 1 | r yx1 | r yx2 | r yx3 |
| x 1 | r x1y | 1 | r x1x2 | r x1x3 |
| x 2 | r x2y | r x2x1 | 1 | r x2x3 |
| x 3 | r x3y | r x3x1 | r x3x2 | 1 |
Вставьте в поле матрицу парных коэффициентов.
Пример . По данным 154 сельскохозяйственных предприятий Кемеровской области 2003 г. изучить эффективность производства зерновых (табл. 13).
- Определите факторы, формирующие рентабельность зерновых в сельскохозяйственных предприятий в 2003 г.
- Постройте матрицу парных коэффициентов корреляции. Установите, какие факторы мультиколлинеарны.
- Постройте уравнение регрессии, характеризующее зависимость рентабельности зерновых от всех факторов.
- Оцените значимость полученного уравнения регрессии. Какие факторы значимо воздействуют на формирование рентабельности зерновых в этой модели?
- Оцените значение рентабельности производства зерновых в сельскохозяйственном предприятии № 3.
Решение получаем с помощью калькулятора Уравнение множественной регрессии :
1. Оценка уравнения регрессии.
Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (X T X) -1 X T Y
Матрица X
| 1 | 0.43 | 2.02 | 0.29 |
| 1 | 0.87 | 1.29 | 0.55 |
| 1 | 1.01 | 1.09 | 0.7 |
| 1 | 0.63 | 1.68 | 0.41 |
| 1 | 0.52 | 0.3 | 0.37 |
| 1 | 0.44 | 1.98 | 0.3 |
| 1 | 1.52 | 0.87 | 1.03 |
| 1 | 2.19 | 0.8 | 1.3 |
| 1 | 1.8 | 0.81 | 1.17 |
| 1 | 1.57 | 0.84 | 1.06 |
| 1 | 0.94 | 1.16 | 0.64 |
| 1 | 0.72 | 1.52 | 0.44 |
| 1 | 0.73 | 1.47 | 0.46 |
| 1 | 0.77 | 1.41 | 0.49 |
| 1 | 1.21 | 0.97 | 0.88 |
| 1 | 1.25 | 0.93 | 0.91 |
| 1 | 1.31 | 0.91 | 0.94 |
| 1 | 0.38 | 2.08 | 0.27 |
| 1 | 0.41 | 2.05 | 0.28 |
| 1 | 0.48 | 1.9 | 0.32 |
| 1 | 0.58 | 1.73 | 0.38 |
| 1 | 0 | 0 | 0 |
Матрица Y
| 0.22 |
| 0.67 |
| 0.79 |
| 0.42 |
| 0.32 |
| 0.24 |
| 0.95 |
| 1.05 |
| 0.99 |
| 0.96 |
| 0.73 |
| 0.52 |
| 2.1 |
| 0.58 |
| 0.87 |
| 0.89 |
| 0.91 |
| 0.14 |
| 0.18 |
| 0.27 |
| 0.37 |
| 0 |
Матрица X T
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 0.43 | 0.87 | 1.01 | 0.63 | 0.52 | 0.44 | 1.52 | 2.19 | 1.8 | 1.57 | 0.94 | 0.72 | 0.73 | 0.77 | 1.21 | 1.25 | 1.31 | 0.38 | 0.41 | 0.48 | 0.58 | 0 |
| 2.02 | 1.29 | 1.09 | 1.68 | 0.3 | 1.98 | 0.87 | 0.8 | 0.81 | 0.84 | 1.16 | 1.52 | 1.47 | 1.41 | 0.97 | 0.93 | 0.91 | 2.08 | 2.05 | 1.9 | 1.73 | 0 |
| 0.29 | 0.55 | 0.7 | 0.41 | 0.37 | 0.3 | 1.03 | 1.3 | 1.17 | 1.06 | 0.64 | 0.44 | 0.46 | 0.49 | 0.88 | 0.91 | 0.94 | 0.27 | 0.28 | 0.32 | 0.38 | 0 |
Умножаем матрицы, (X T X)
Находим определитель det(X T X) T = 34.35
Находим обратную матрицу (X T X) -1
| 0.6821 | 0.3795 | -0.2934 | -1.0118 |
| 0.3795 | 9.4402 | -0.133 | -14.4949 |
| -0.2934 | -0.133 | 0.1746 | 0.3204 |
| -1.0118 | -14.4949 | 0.3204 | 22.7272 |
Вектор оценок коэффициентов регрессии равен
s = (X T X) -1 X T Y =
| 0.1565 |
| 0.3375 |
| 0.0043 |
| 0.2986 |
Уравнение регрессии (оценка уравнения регрессии)
Y = 0.1565 + 0.3375X 1 + 0.0043X 2 + 0.2986X 3
Матрица парных коэффициентов корреляции
Число наблюдений n = 22. Число независимых переменных в модели ровно 3, а число регрессоров с учетом единичного вектора равно числу неизвестных коэффициентов. С учетом признака Y, размерность матрицы становится равным 5. Матрица, независимых переменных Х имеет размерность (22 х 5). Матрица Х T Х определяется непосредственным умножением или по следующим предварительно вычисленным суммам.Матрица составленная из Y и X
| 1 | 0.22 | 0.43 | 2.02 | 0.29 |
| 1 | 0.67 | 0.87 | 1.29 | 0.55 |
| 1 | 0.79 | 1.01 | 1.09 | 0.7 |
| 1 | 0.42 | 0.63 | 1.68 | 0.41 |
| 1 | 0.32 | 0.52 | 0.3 | 0.37 |
| 1 | 0.24 | 0.44 | 1.98 | 0.3 |
| 1 | 0.95 | 1.52 | 0.87 | 1.03 |
| 1 | 1.05 | 2.19 | 0.8 | 1.3 |
| 1 | 0.99 | 1.8 | 0.81 | 1.17 |
| 1 | 0.96 | 1.57 | 0.84 | 1.06 |
| 1 | 0.73 | 0.94 | 1.16 | 0.64 |
| 1 | 0.52 | 0.72 | 1.52 | 0.44 |
| 1 | 2.1 | 0.73 | 1.47 | 0.46 |
| 1 | 0.58 | 0.77 | 1.41 | 0.49 |
| 1 | 0.87 | 1.21 | 0.97 | 0.88 |
| 1 | 0.89 | 1.25 | 0.93 | 0.91 |
| 1 | 0.91 | 1.31 | 0.91 | 0.94 |
| 1 | 0.14 | 0.38 | 2.08 | 0.27 |
| 1 | 0.18 | 0.41 | 2.05 | 0.28 |
| 1 | 0.27 | 0.48 | 1.9 | 0.32 |
| 1 | 0.37 | 0.58 | 1.73 | 0.38 |
| 1 | 0 | 0 | 0 | 0 |
Транспонированная матрица.
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 0.22 | 0.67 | 0.79 | 0.42 | 0.32 | 0.24 | 0.95 | 1.05 | 0.99 | 0.96 | 0.73 | 0.52 | 2.1 | 0.58 | 0.87 | 0.89 | 0.91 | 0.14 | 0.18 | 0.27 | 0.37 | 0 |
| 0.43 | 0.87 | 1.01 | 0.63 | 0.52 | 0.44 | 1.52 | 2.19 | 1.8 | 1.57 | 0.94 | 0.72 | 0.73 | 0.77 | 1.21 | 1.25 | 1.31 | 0.38 | 0.41 | 0.48 | 0.58 | 0 |
| 2.02 | 1.29 | 1.09 | 1.68 | 0.3 | 1.98 | 0.87 | 0.8 | 0.81 | 0.84 | 1.16 | 1.52 | 1.47 | 1.41 | 0.97 | 0.93 | 0.91 | 2.08 | 2.05 | 1.9 | 1.73 | 0 |
| 0.29 | 0.55 | 0.7 | 0.41 | 0.37 | 0.3 | 1.03 | 1.3 | 1.17 | 1.06 | 0.64 | 0.44 | 0.46 | 0.49 | 0.88 | 0.91 | 0.94 | 0.27 | 0.28 | 0.32 | 0.38 | 0 |
Матрица A T A.
| 22 | 14.17 | 19.76 | 27.81 | 13.19 |
| 14.17 | 13.55 | 15.91 | 16.58 | 10.56 |
| 19.76 | 15.91 | 23.78 | 22.45 | 15.73 |
| 27.81 | 16.58 | 22.45 | 42.09 | 14.96 |
| 13.19 | 10.56 | 15.73 | 14.96 | 10.45 |
Полученная матрица имеет следующее соответствие:
Найдем парные коэффициенты корреляции.
Для y и x 1
Средние значения
Дисперсия
Коэффициент корреляции
Для y и x 2
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Для y и x 3
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Для x 1 и x 2
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Для x 1 и x 3
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Для x 2 и x 3
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Матрица парных коэффициентов корреляции.
| - | y | x 1 | x 2 | x 3 |
| y | 1 | 0.62 | -0.24 | 0.61 |
| x 1 | 0.62 | 1 | -0.39 | 0.99 |
| x 2 | -0.24 | -0.39 | 1 | -0.41 |
| x 3 | 0.61 | 0.99 | -0.41 | 1 |
Анализ первой строки этой матрицы позволяет произвести отбор факторных признаков, которые могут быть включены в модель множественной корреляционной зависимости. Факторные признаки, у которых r yxi < 0.5 исключают из модели.
Коллинеарность – зависимость между факторами. В качестве критерия мультиколлинеарности может быть принято соблюдение следующих неравенств:
r(x j y) > r(x k x j) ; r(x k y) > r(x k x j).
Если одно из неравенств не соблюдается, то исключается тот параметр x k или x j , связь которого с результативным показателем Y оказывается наименее тесной.
3. Анализ параметров уравнения регрессии.
Перейдем к статистическому анализу полученного уравнения регрессии: проверке значимости уравнения и его коэффициентов, исследованию абсолютных и относительных ошибок аппроксимации
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y - X*s (абсолютная ошибка аппроксимации)
| -0.18 |
| 0.05 |
| 0.08 |
| -0.08 |
| -0.12 |
| -0.16 |
| -0.03 |
| -0.24 |
| -0.13 |
| -0.05 |
| 0.06 |
| -0.02 |
| 1.55 |
| 0.01 |
| 0.04 |
| 0.04 |
| 0.03 |
| -0.23 |
| -0.21 |
| -0.15 |
| -0.1 |
| -0.16 |
s e 2 = (Y - X*s) T (Y - X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = a*(X T X) -1
| 0.26 | 0.15 | -0.11 | -0.39 |
| 0.15 | 3.66 | -0.05 | -5.61 |
| -0.11 | -0.05 | 0.07 | 0.12 |
| -0.39 | -5.61 | 0.12 | 8.8 |
Дисперсии параметров модели определяются соотношением S 2 i = K ii , т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности , которые определяются по формуле:
Частные коэффициент эластичности E 1 < 1. Следовательно, его влияние на результативный признак Y незначительно.
Частные коэффициент эластичности E 2 < 1. Следовательно, его влияние на результативный признак Y незначительно.
Частные коэффициент эластичности E 3 < 1. Следовательно, его влияние на результативный признак Y незначительно.
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции (от 0 до 1)
Связь между признаком Y факторами X умеренная
Коэффициент детерминации
R 2 = 0.62 2 = 0.38
т.е. в 38.0855 % случаев изменения х приводят к изменению y. Другими словами - точность подбора уравнения регрессии - средняя
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
T табл (n-m-1;a) = (18;0.05) = 1.734
Поскольку Tнабл > Tтабл, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически - значим
Интервальная оценка для коэффициента корреляции (доверительный интервал)
Доверительный интервал для коэффициента корреляции
r(0.3882;0.846)
5. Проверка гипотез относительно коэффициентов уравнения регрессии (проверка значимости параметров множественного уравнения регрессии).
1) t-статистика
Статистическая значимость коэффициента регрессии b 0 не подтверждается
Статистическая значимость коэффициента регрессии b 1 не подтверждается
Статистическая значимость коэффициента регрессии b 2 не подтверждается
Статистическая значимость коэффициента регрессии b 3 не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b i - t i S i ; b i + t i S i)
b 0: (-0.7348;1.0478)
b 1: (-2.9781;3.6531)
b 2: (-0.4466;0.4553)
b 3: (-4.8459;5.4431)
2) F-статистика. Критерий Фишера
Fkp = 2.93
Поскольку F < Fkp, то коэффициент детерминации статистически не значим и уравнение регрессии статистически ненадежно.
6. Проверка на наличие гетероскедастичности методом графического анализа остатков.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X i , а по оси ординат квадраты отклонения e i 2 .
| y | y(x) | e=y-y(x) | e 2 |
| 0.22 | 0.4 | -0.18 | 0.03 |
| 0.67 | 0.62 | 0.05 | 0 |
| 0.79 | 0.71 | 0.08 | 0.01 |
| 0.42 | 0.5 | -0.08 | 0.01 |
| 0.32 | 0.44 | -0.12 | 0.02 |
| 0.24 | 0.4 | -0.16 | 0.03 |
| 0.95 | 0.98 | -0.03 | 0 |
| 1.05 | 1.29 | -0.24 | 0.06 |
| 0.99 | 1.12 | -0.13 | 0.02 |
| 0.96 | 1.01 | -0.05 | 0 |
| 0.73 | 0.67 | 0.06 | 0 |
| 0.52 | 0.54 | -0.02 | 0 |
| 2.1 | 0.55 | 1.55 | 2.41 |
| 0.58 | 0.57 | 0.01 | 0 |
| 0.87 | 0.83 | 0.04 | 0 |
| 0.89 | 0.85 | 0.04 | 0 |
| 0.91 | 0.88 | 0.03 | 0 |
| 0.14 | 0.37 | -0.23 | 0.05 |
| 0.18 | 0.39 | -0.21 | 0.04 |
| 0.27 | 0.42 | -0.15 | 0.02 |
| 0.37 | 0.47 | -0.1 | 0.01 |
| 0.16 | -0.16 | 0.02 |
