Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL ХИ2.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат (Х 2 , ХИ2, англ. Chi - squared distribution ) применяется в различных методах математической статистики:
- при построении ;
- при ;
- при (согласуются ли эмпирические данные с нашим предположением о теоретической функции распределения или нет, англ. Goodness-of-fit)
- при (используется для определения связи между двумя категориальными переменными, англ. Chi-square test of association).
Определение : Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1 2 + x 2 2 +…+ x n 2 имеет распределение Х 2 с n степенями свободы.
Распределение Х 2 зависит от одного параметра, который называется степенью свободы (df , degrees of freedom ). Например, при построении число степеней свободы равно df=n-1, где n – размер выборки .
Плотность распределения
Х 2
выражается формулой:
Графики функций
Распределение Х 2 имеет несимметричную форму, равно n, равна 2n.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .

Полезное свойство ХИ2-распределения
Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x.
Тогда случайная величина y
равная

Имеет Х 2 -распределение с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом:

Следовательно, выборочное распределение статистики y, при выборке из нормального распределения , имеет Х 2 -распределение с n-1 степенью свободы.
Это свойство нам потребуется при . Т.к. дисперсия может быть только положительным числом, а Х 2 -распределение используется для его оценки, то y д.б. >0, как и указано в определении.
ХИ2-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Х 2 -распределения имеется специальная функция ХИ2.РАСП() , английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2 -распределение , примет значение меньше или равное х, P{X <= x}).
Примечание : Т.к. ХИ2-распределение является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.
До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП() , которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП() и ХИ2.РАСП.ПХ() перекрывают возможности этой функции. Функция ХИ2РАСП() оставлена в MS EXCEL 2010 для совместимости.
ХИ2.РАСП() является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}.
Вышеуказанные функции MS EXCEL приведены в .
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x : P{X <= x}. Это можно сделать несколькими функциями:
ХИ2.РАСП(x; n; ИСТИНА)
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
Функция ХИ2.РАСП.ПХ() возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1.
Найдем вероятность, что случайная величина Х примет значение больше заданного x : P{X > x}. Это можно сделать несколькими функциями:
1-ХИ2.РАСП(x; n; ИСТИНА)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
Обратная функция используется для вычисления альфа - , т.е. для вычисления значений x при заданной вероятности альфа , причем х должен удовлетворять выражению P{X <= x}=альфа .
Функция ХИ2.ОБР() используется для вычисления доверительных интервалов дисперсии нормального распределения .
Функция ХИ2.ОБР.ПХ() используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР() вернет такое значение случайной величины х, для которого P{X<=x}=0,05.
В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ() использовалась функция ХИ2ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат:
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Функции MS EXCEL, использующие ХИ2-распределение
Ниже приведено соответствие русских и английских названий функций:
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerse
Оценка параметров распределения
Т.к. обычно ХИ2-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
Приближение ХИ2-распределения нормальным распределением
При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).
Хи-квадрат критерий – универсальный метод проверки согласия результатов эксперимента и используемой статистической модели.
Расстояние Пирсона X 2
Пятницкий А.М.
Российский Государственный Медицинский Университет
В 1900 году Карл Пирсон предложил простой, универсальный и эффективный способ проверки согласия между предсказаниями модели и опытными данными. Предложенный им “хи-квадрат критерий” – это самый важный и наиболее часто используемыйстатистический критерий. Большинство задач, связанных с оценкой неизвестных параметров модели и проверки согласия модели и опытных данных, можно решить с его помощью.
Пусть имеется априорная (“до опытная”) модельизучаемого объекта или процесса (в статистике говорят о “нулевой гипотезе” H 0), и результаты опыта с этим объектом. Следует решить, адекватна ли модель (соответствует ли она реальности)? Не противоречат ли результаты опыта нашим представлениям о том, как устроена реальность, или иными словами - следует ли отвергнуть H 0 ? Часто эту задачу можно свести к сравнению наблюдаемых (O i = Observed )и ожидаемых согласно модели (E i =Expected ) средних частот появления неких событий. Считается, что наблюдаемые частоты получены в серии N независимых (!) наблюдений, производимых в постоянных (!) условиях. В результате каждого наблюдения регистрируется одно из M событий. Эти события не могут происходить одновременно (попарно несовместны) и одно из них обязательно происходит (их объединение образует достоверное событие). Совокупность всех наблюдений сводится к таблице (вектору) частот {O i }=(O 1 ,… O M ), которая полностью описывает результаты опыта. Значение O 2 =4 означает, что событие номер 2 произошло 4 раза. Сумма частот O 1 +… O M =N . Важно различать два случая: N – фиксировано, неслучайно, N – случайная величина. При фиксированном общем числе опытов N частоты имеют полиномиальное распределение. Поясним эту общую схему простым примером.
Применение хи-квадрат критерия для проверки простых гипотез.
Пусть модель (нулевая гипотеза H 0) заключается в том, что игральная кость является правильной - все грани выпадают одинаково часто с вероятностью p i =1/6, i =, M=6. Проведен опыт, который состоял в том, что кость бросили 60 раз (провели N =60 независимых испытаний). Согласно модели мы ожидаем, что все наблюдаемые частоты O i появления 1,2,... 6 очков должны быть близки к своим средним значениям E i =Np i =60∙(1/6)=10. Согласно H 0 вектор средних частот {E i }={Np i }=(10, 10, 10, 10, 10, 10). (Гипотезы, в которых средние частоты полностью известны до начала опыта, называются простыми.) Если бы наблюдаемый вектор {O i } был равен (34,0,0,0,0,26) , то сразу ясно, что модель неверна – кость не может быть правильной, так как60 раз выпадали только 1 и 6. Вероятность такого события для правильной игральной кости ничтожна: P = (2/6) 60 =2.4*10 -29 . Однако появление столь явных расхождений между моделью и опытом исключение. Пусть вектор наблюдаемых частот {O i } равен (5, 15, 6, 14, 4, 16). Согласуется ли это с H 0 ? Итак, нам надо сравнить два вектора частот {E i } и {O i }. При этом вектор ожидаемых частот {E i } не случаен, а вектор наблюдаемых {O i } случаен – при следующем опыте (в новой серии из 60 бросков) он окажется другим. Полезно ввести геометрическую интерпретацию задачи и считать, что в пространстве частот (в данном случае 6 мерном) даны две точки с координатами(5, 15, 6, 14, 4, 16) и (10, 10, 10, 10, 10, 10). Достаточно ли далеко они удалены друг от друга, чтобы счесть это несовместным сH 0 ? Иными словами нам надо:
- научиться измерять расстояния между частотами (точками пространства частот),
- иметь критерий того, какое расстояние следует считать слишком (“неправдоподобно”) большим, то есть несовместным с H 0 .
Квадрат обычного евклидова расстояниябыл бы равен:
X 2 Euclid = S (O i -E i) 2 = (5-10) 2 +(15-10) 2 + (6-10) 2 +(14-10) 2 +(4-10) 2 +(16-10) 2
При этом поверхности X 2 Euclid = const всегда являются сферами, если мы фиксируем значения E i и меняем O i . Карл Пирсон заметил, что использовать евклидово расстояние в пространстве частот не следует. Так, неправильно считать, что точки (O =1030 и E =1000) и (O =40 и E =10) находятся на равном расстоянии друг от друга, хотя в обоих случаях разность O -E =30. Ведь чем больше ожидаемая частота, тем большие отклонения от нее следует считать возможными. Поэтому точки (O =1030 и E =1000) должны считаться “близкими”, а точки (O =40 и E =10) “далекими” друг от друга. Можно показать, что если верна гипотеза H 0 , то флуктуации частоты O i относительно E i имеют величину порядка квадратного корня(!) из E i . Поэтому Пирсон предложил при вычислении расстояния возводить в квадраты не разности (O i -E i ), а нормированные разности (O i -E i )/E i 1/2 . Итак, вот формула, по которой вычисляется расстояние Пирсона (фактически это квадрат расстояния):
X 2 Pearson = S ((O i -E i )/E i 1/2) 2 =S (O i -E i ) 2 /E i
В нашем примере:
X 2 Pearson = (5-10) 2 /10+(15-10) 2 /10 +(6-10) 2 /10+(14-10) 2 /10+(4-10) 2 /10+(16-10) 2 /10=15.4
Для правильной игральной кости все ожидаемые частоты E i одинаковы, но обычно они различны, поэтому поверхности, на которых расстояние Пирсона постоянно (X 2 Pearson =const) оказываются уже эллипсоидами, а не сферами.
Теперь после того, как выбрана формула для подсчета расстояний, необходимо выяснить, какие расстояния следует считать “не слишком большими” (согласующимися с H 0).Так, например, что можно сказать по поводу вычисленного нами расстояния 15.4? В каком проценте случаев (или с какой вероятностью), проводя опыты с правильной игральной костью, мы получали бы расстояние большее, чем 15.4? Если этот процент будет мал (<0.05), то H 0 надо отвергнуть. Иными словами требуется найти распределение длярасстояния Пирсона. Если все ожидаемые частоты E i не слишком малы (≥5), и верна H 0 , то нормированные разности (O i - E i )/E i 1/2 приближенно эквивалентны стандартным гауссовским случайным величинам: (O i - E i )/E i 1/2 ≈N (0,1). Это, например, означает, что в 95% случаев| (O i - E i )/E i 1/2 | < 1.96 ≈ 2 (правило “двух сигм”).
Пояснение . Число измерений O i , попадающих в ячейку таблицы с номером i , имеет биномиальное распределение с параметрами: m =Np i =E i ,σ =(Np i (1-p i )) 1/2 , где N - число измерений (N »1), p i – вероятность для одного измерения попасть в данную ячейку (напомним, что измерения независимы и производятся в постоянных условиях). Если p i мало, то: σ≈(Np i ) 1/2 =E i и биномиальное распределение близко к пуассоновскому, в котором среднее число наблюдений E i =λ, а среднее квадратичное отклонение σ=λ 1/2 = E i 1/2 . Для λ≥5пуассоновскоераспределение близко к нормальному N (m =E i =λ, σ=E i 1/2 =λ 1/2), а нормированная величина (O i - E i )/E i 1/2 ≈ N (0,1).
Пирсон определил случайную величину χ 2 n – “хи-квадрат с n степенями свободы”, как сумму квадратов n независимых стандартных нормальных с.в.:
χ 2 n = T 1 2 + T 2 2 + …+ T n 2 , гдевсе T i = N(0,1) - н. о. р. с. в.
Попытаемся наглядно понять смысл этой важнейшей в статистике случайной величины. Для этого на плоскости (при n
=2) или в пространстве (при n
=3) представим облако точек, координаты которых независимы и имеют стандартное нормальное распределениеf
T
(x
) ~exp
(-x
2 /2). На плоскости согласно правилу “двух сигм”, которое независимо применяется к обеим координатам, 90% (0.95*0.95≈0.90) точек заключены внутри квадрата(-2 f χ 2 2 (a) =
Сexp(-a/2) = 0.5exp(-a/2).
При достаточно большом числе степеней свободы n
(n
>30) хи-квадрат распределение приближается к нормальному: N
(m
= n
; σ = (2n
) ½). Это следствие “центральной предельной теоремы”: сумма одинаково распределенных величин имеющих конечную дисперсию приближается к нормальному закону с ростом числа слагаемых. Практически надо запомнить, что средний квадрат расстояния равен m
(χ
2 n
)=n
, а его дисперсия σ 2 (χ
2 n
)=2n
. Отсюда легко заключить какие значения хи-квадрат следует считать слишком малыми и слишком большими:большая часть распределения заключена в пределахот n
-2∙(2n
) ½ до n
+2∙(2n
) ½ . Итак, расстояния Пирсона существенно превышающие n
+2∙ (2n
) ½ , следует считать неправдоподобно большими (не согласующимися с H
0) . Если результат близок к n
+2∙(2n
) ½ , то следует воспользоваться таблицами, в которых можно точно узнать в какой доле случаев могут появляться такие и большие значения хи-квадрат. Важно знать, как правильно выбирать значение числа степеней свободы (number degrees of freedom , сокращенно n
.d
.f
.). Казалось естественным считать, что n
просто равно числу разрядов: n
=M
. В своей статье Пирсон так и предположил. В примере с игральной костью это означало бы, что n
=6. Однако спустя несколько лет было показано, что Пирсон ошибся. Число степеней свободы всегда меньше числа разрядов, если между случайными величинами O i
есть связи. Для примера с игральной костью сумма O i
равна 60, и независимо менять можно лишь 5 частот, так что правильное значение n
=6-1=5. Для этого значения n
получаем n
+2∙(2n
) ½ =5+2∙(10) ½ =11.3. Так как15.4>11.3, то гипотезу H
0 - игральная кость правильная, следует отвергнуть. После выяснения ошибки, существовавшие таблицы χ
2 пришлось дополнить, так как исходно в них не было случая n
=1, так как наименьшее число разрядов =2. Теперь же оказалось, что могут быть случаи, когда расстояние Пирсона имеет распределение χ
2 n
=1 . Пример
. При 100 бросаниях монеты число гербов равно O
1 = 65, а решек O
2 = 35. Число разрядов M
=2. Если монета симметрична, то ожидаемые частотыE
1 =50, E
2 =50. X 2 Pearson =
S
(O i -E i) 2 /E i = (65-50) 2 /50 + (35-50) 2 /50 = 2*225/50 = 9.
Полученное значение следует сравнивать с теми, которые может принимать случайная величина χ
2 n
=1 , определенная как квадрат стандартной нормальной величины χ
2 n
=1 =T
1 2 ≥ 9 ó
T
1 ≥3 или T
1 ≤-3. Вероятность такого события весьма мала P
(χ
2 n
=1 ≥9) = 0.006. Поэтому монету нельзя считать симметричной: H
0 следует отвергнуть. То, что число степеней свободы не может быть равно числу разрядов видно из того, что сумма наблюдаемых частот всегда равна сумме ожидаемых, например O
1 +O
2 =65+35 = E
1 +E
2 =50+50=100. Поэтому случайные точки с координатами O
1 и O
2 располагаются на прямой: O
1 +O
2 =E
1 +E
2 =100 и расстояние до центра оказывается меньше, чем, если бы этого ограничения не было, и они располагались на всей плоскости. Действительно для двух независимые случайных величин с математическими ожиданиями E
1 =50, E
2 =50, сумма их реализаций не должна быть всегда равной 100 – допустимыми были бы, например, значения O
1 =60, O
2 =55. Пояснение
. Сравним результат, критерия Пирсона при M
=2 с тем, что дает формула Муавра Лапласа при оценке случайных колебаний частоты появления события ν
=K
/N
имеющего вероятность p
в серии N
независимых испытаний Бернулли (K
-число успехов): χ
2 n
=1 =S
(O i
-E i
) 2 /E i
= (O
1 -E
1) 2 /E
1 + (O
2 -E
2) 2 /E
2 = (Nν
-Np
) 2 /(Np
) + (N
(1-ν
)-N
(1-p
)) 2 /(N
(1-p
))= =(Nν-Np) 2 (1/p + 1/(1-p))/N=(Nν-Np) 2 /(Np(1-p))=((K-Np)/(Npq) ½) 2 = T 2
Величина T
=(K
-Np
)/(Npq
) ½ = (K
-m
(K
))/σ(K
) ≈N
(0,1) при σ(K
)=(Npq
) ½ ≥3. Мы видим, что в этом случае результат Пирсона в точности совпадает с тем, что дает применение нормальной аппроксимации для биномиального распределения. До сих пор мы рассматривали простые гипотезы, для которых ожидаемые средние частоты E i
полностью известны заранее. О том, как правильно выбирать число степеней свободы для сложных гипотез см. ниже. В примерах с правильной игральной костью и монетой ожидаемые частоты можно было определить до(!) проведения опыта. Подобные гипотезы называются “простыми”. На практике чаще встречаются “сложные гипотезы”. При этом для того, чтобы найти ожидаемые частоты E i
надо предварительно оценить одну или несколько величин (параметры модели), и сделать это можно только, воспользовавшись данными опыта. В результате для “сложных гипотез” ожидаемые частоты E i
оказываются зависящими от наблюдаемых частот O i
и потому сами становятся случайными величинами, меняющимися в зависимости от результатов опыта. В процессе подбора параметров расстояние Пирсона уменьшается – параметры подбираются так, чтобы улучшить согласие модели и опыта. Поэтому число степеней свободы должно уменьшаться. Как оценить параметры модели? Есть много разных способов оценки – “метод максимального правдоподобия”, “метод моментов”, “метод подстановки”. Однако можно не привлекать никаких дополнительных средств и найти оценки параметров минимизируя расстояние Пирсона. В докомпьютерную эпоху такой подход использовался редко: приручных расчетах он неудобен и, как правило, не поддается аналитическому решению. При расчетах на компьютере численная минимизация обычно легко осуществляется, а преимуществом такого способа является его универсальность. Итак, согласно “методу минимизации хи-квадрат”, мы подбираем значения неизвестных параметров так, чтобы расстояние Пирсона стало наименьшим. (Кстати, изучая изменения этого расстояния при небольших смещениях относительно найденного минимума можно оценить меру точности оценки: построить доверительные интервалы.) После того как параметры и само это минимальное расстояние найдено опять требуется ответить на вопрос достаточно ли оно мало. Общая последовательность действий такова:
P
(χ
2 n
> χ
2 крит)=1-α, где α – “уровень значимости” или ”размер критерия” или “величина ошибки первого рода” (типичное значение α=0.05). Обычно число степеней свободы n
вычисляют по формуле n
= (число разрядов) – 1 – (число оцениваемых параметров) Если X
2 > χ
2 крит, то гипотеза H
0 отвергается, в противном случае принимается. В α∙100% случаев (то есть достаточно редко) такой способ проверки H
0 приведет к “ошибке первого рода”: гипотеза H
0 будет отвергнута ошибочно. Пример.
При исследовании 10 серий из 100 семян подсчитывалось число зараженных мухой-зеленоглазкой. Получены данные: O i
=(16, 18, 11, 18, 21, 10, 20, 18, 17, 21); Здесь неизвестен заранее вектор ожидаемых частот. Если данные однородны и получены для биномиального распределения, то неизвестен один параметр доля p
зараженных семян. Заметим, что в исходной таблице фактически имеется не 10 а 20 частот, удовлетворяющих 10 связям: 16+84=100, … 21+79=100.
X 2 = (16-100p) 2 /100p +(84-100(1-p)) 2 /(100(1-p))+…+
(21-100p) 2 /100p +(79-100(1-p)) 2 /(100(1-p))
Объединяя слагаемые в пары (как в примере с монетой), получаем ту форму записи критерия Пирсона, которую обычно пишут сразу: X 2 = (16-100p) 2 /(100p(1-p))+…+ (21-100p) 2 /(100p(1-p)).
Теперь если в качестве метода оценки р использовать минимум расстояния Пирсона, то необходимо найти такое p
, при котором X
2 =min
. (Модель старается по возможности “подстроиться” под данные эксперимента.) Критерий Пирсона - это наиболее универсальный из всех используемых в статистике. Его можно применять к одномерным и многомерным данным, количественным и качественным признакам. Однако именно в силу универсальности следует быть осторожным, чтобы не совершить ошибки. 1.Выбор разрядов.
Оценка параметров
. Использование “самодельных”, неэффективных методов оценки может привести к завышенным значениям расстояния Пирсона. Выбор правильного числа степеней свободы
. Если оценки параметров делаются не по частотам, а непосредственно по данным (например, в качестве оценки среднего берется среднее арифметическое), то точное число степеней свободы n
неизвестно. Известно лишь, что оно удовлетворяет неравенству: (число разрядов – 1 – число оцениваемых параметров) < n
< (число разрядов – 1) Поэтому необходимо сравнить X
2 с критическими значениями χ
2 крит вычисленными во всем этом диапазоне n
. Как интерпретировать неправдоподобно малые значения хи-квадрат?
Следует ли считать монету симметричной, если при 10000 бросаний, она 5000 раз выпала гербом? Ранее многие статистики считали, что H
0 при этом также следует отвергнуть. Теперь предлагается другой подход: принять H
0 , но подвергнуть данные и методику их анализа дополнительной проверке. Есть две возможности: либо слишком малое расстояние Пирсона означает, что увеличение числа параметров модели не сопровождалось должным уменьшением числа степеней свободы, или сами данные были сфальсифицированы (возможно ненамеренно подогнаны под ожидаемый результат). Пример.
Два исследователя А и B
подсчитывали долю рецессивных гомозигот aa
во втором поколении при моногибридном скрещивании AA
* aa
. Согласно законам Менделя эта доля равна 0.25. Каждый исследователь провел по 5 опытов, и в каждом опыте изучалось 100 организмов. Результаты А: 25, 24, 26, 25, 24. Вывод исследователя: закон Менделя справедлив(?). Результаты B
: 29, 21, 23, 30, 19. Вывод исследователя: закон Менделя не справедлив(?). Однако закон Менделя имеет статистическую природу, и количественный анализ результатов меняет выводы на обратные! Объединив пять опытов в один, мы приходим к хи-квадрат распределению с 5 степенями свободы (проверяется простая гипотеза): X 2 A = ((25-25) 2 +(24-25) 2 +(26-25) 2 +(25-25) 2 +(24-25) 2)/(100∙0.25∙0.75)=0.16
X 2 B = ((29-25) 2 +(21-25) 2 +(23-25) 2 +(30-25) 2 +(19-25) 2)/(100∙0.25∙0.75)=5.17
Среднее значение m
[χ
2 n
=5 ]=5, среднеквадратичное отклонение σ[χ
2 n
=5 ]=(2∙5) 1/2 =3.2. Поэтому без обращения к таблицам ясно, что значение X
2 B
типично, а значение X
2 A
неправдоподобно мало. Согласно таблицам P
(χ
2 n
=5 <0.16)<0.0001. Этот пример – адаптированный вариант реального случая, произошедшего в 1930-е годы (см. работу Колмогорова “Об еще одном доказательстве законов Менделя”). Любопытно, что исследователь A
был сторонником генетики, а исследователь B
– ее противником. Путаница в обозначениях.
Следует различать расстояние Пирсона, которое при своем вычислении требует дополнительных соглашений,от математического понятия случайной величины хи-квадрат. Расстояние Пирсона при определенных условиях имеет распределение близкое к хи-квадрат с n
степенями свободы. Поэтому желательно НЕ обозначать расстояние Пирсона символом χ
2 n
, а использовать похожее, но другое обозначение X
2. . Критерий Пирсона не всесилен.
Существует бесконечное множество альтернатив для H
0 , которые он не в состоянии учесть. Пусть вы проверяете гипотезу о том, что признак имел равномерное распределение, у вас имеется 10 разрядов и вектор наблюдаемых частот равен (130,125,121,118,116,115,114,113,111,110). Критерий Пирсона не c
может “заметить” того, что частоты монотонно уменьшаются и H
0 не будет отклонена. Если бы его дополнить критерием серий то да! Рассмотрим применение в
MS
EXCEL
критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая выборка
) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной выборкой
. Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием критериев согласия
. Нулевой гипотезой
, обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону. Сначала рассмотрим применение критерия согласия Пирсона Х 2 (хи-квадрат)
в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем - , когда задается только форма распределения, а параметры этого распределения и значение статистики
Х 2
оцениваются/рассчитываются на основании одной и той же выборки
. Примечание
: В англоязычной литературе процедура применения критерия согласия Пирсона Х 2
имеет название The chi-square goodness of fit test
. Напомним процедуру проверки гипотез: Проведем проверку гипотез
для различных распределений. Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника. Примечание
: Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения. Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется . Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы В формуле предполагается, что в ячейке А7
содержится соответствующее количество выпавших шестерок в одном раунде. Примечание
: Расчеты приведены в файле примера на листе Дискретное
. Для сравнения наблюденных
(Observed) и теоретических частот
(Expected) удобно пользоваться . При значительном отклонении наблюденных частот от теоретического распределения, нулевая гипотеза
о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от биномиального распределения
. В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим критерий согласия Пирсона Х 2
, чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения гистограмм
, использовать математически корректное утверждение. Используем тот факт, что в силу закона больших чисел
наблюденная частота (Observed) с ростом объема выборки
n стремится к вероятности, соответствующей теоретическому закону (в нашем случае, биномиальному закону
). В нашем случае объем выборки n равен 100. Введем тестовую
статистику
, которую обозначим Х 2: где O l – это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E l – это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4). Как видно из формулы, эта статистика
является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим биномиальный закон
), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение статистики
Х 2 (статистика
Х 2 вычислена на основе случайной выборки
, поэтому она является случайной величиной и, следовательно, имеет свое распределение вероятностей
). Из многомерного аналога интегральной теоремы Муавра-Лапласа
известно, что при n->∞ наша случайная величина Х 2 асимптотически с L - 1 степенями свободы. Итак, если вычисленное значение статистики
Х 2 (сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть нулевую гипотезу
. Как и при проверке параметрических гипотез
, предельное значение задается через уровень значимости
. Если вероятность того, что статистика Х 2 примет значение меньше или равное вычисленному (p
-значение
), будет меньше уровня значимости
, то нулевую гипотезу
можно отвергнуть. В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х 2 примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам Примечание
: Функция ХИ2.ТЕСТ()
специально создана для проверки связи между двумя категориальными переменными (см. ). Вероятность 0,000045 существенно меньше обычного уровня значимости
0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (нулевая гипотеза
о его честности отвергается). При применении критерия Х 2
необходимо следить за тем, чтобы объем выборки
n был достаточно большой, иначе будет неправомочна аппроксимация распределения статистики Х 2
. Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы Х 2 -распределения
. Для того чтобы улучшить качество применения критерия Х 2
(), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество степеней свободы
), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5). Критерий согласия Пирсона Х 2
можно применить так же в случае . Рассмотрим некую выборку
, состоящую из 200 значений. Нулевая гипотеза
утверждает, что выборка
сделана из . Примечание
: Cлучайные величины в файле примера на листе Непрерывное
сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС())
. Поэтому, новые значения выборки
генерируются при каждом пересчете листа. Соответствует ли имеющийся набор данных можно визуально оценить . Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в для проверки гипотезы
применим Критерий согласия Пирсона Х 2 .
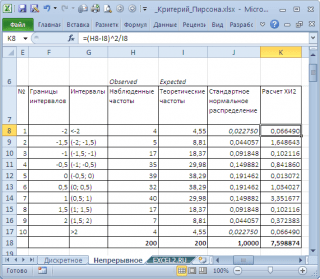
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5 . Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции ЧАСТОТА()
, а теоретические – с помощью функции НОРМ.СТ.РАСП()
. Примечание
: Как и для дискретного случая
, необходимо следить, чтобы выборка
была достаточно большая, а в интервал попадало >5 значений. Вычислим статистику Х 2 и сравним ее с критическим значением для заданного уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше критического значения
– нулевая гипотеза
не отвергается. Ниже приведена , на которой выборка
приняла маловероятное значение и на основании критерия
согласия Пирсона Х 2
нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС())
, обеспечивающей выборку
из стандартного нормального распределения
). Нулевая гипотеза
отклонена, хотя визуально данные располагаются довольно близко к прямой линии. В качестве примера также возьмем выборку
из U(-3; 3). В этом случае, даже из графика очевидно, что нулевая гипотеза
должна быть отклонена. Критерий
согласия Пирсона Х 2
также подтверждает, что нулевая гипотеза
должна быть отклонена. Министерство образования и науки Российской Федерации Федеральное агентство по образованию города Иркутска Байкальский государственный университет экономики и права Кафедра Информатики и Кибернетики Распределение "хи-квадрат" и его применение Колмыкова Анна Андреевна студентка 2 курса группы ИС-09-1 Для обработки полученных данных используем критерий хи-квадрат. Для этого построим таблицу распределения эмпирических частот, т.е. тех частот, которые мы наблюдаем: Теоретически, мы ожидаем, что частоты распределятся равновероятно, т.е. частота распределится пропорционально между мальчиками и девочками. Построим таблицу теоретических частот. Для этого умножим сумму по строке на сумму по столбцу и разделим получившееся число на общую сумму (s). Итоговая таблица для вычислений будет выглядеть так: χ2 = ∑(Э - Т)² / Т n = (R - 1), где R – количество строк в таблице. В нашем случае хи-квадрат = 4,21; n = 2. По таблице критических значений критерия находим: при n = 2 и уровне ошибки 0,05 критическое значение χ2 = 5,99. Полученное значение меньше критического, а значит принимается нулевая гипотеза. Вывод: учителя не придают значение полу ребенка при написании ему характеристики. Таблица 1 Студенты почти всех специальностей изучают в конце курса высшей математики раздел "теория вероятностей и математическая статистика", реально они знакомятся лишь с некоторыми основными понятиями и результатами, которых явно не достаточно для практической работы. С некоторыми математическими методами исследования студенты встречаются в специальных курсах (например, таких, как "Прогнозирование и технико-экономическое планирование", "Технико-экономический анализ", "Контроль качества продукции", "Маркетинг", "Контроллинг", "Математические методы прогнозирования", "Статистика" и др. – в случае студентов экономических специальностей), однако изложение в большинстве случаев носит весьма сокращенный и рецептурный характер. В результате знаний у специалистов по прикладной статистике недостаточно. Поэтому большое значение имеет курс "Прикладная статистика" в технических вузах, а в экономических вузах – курса "Эконометрика", поскольку эконометрика – это, как известно, статистический анализ конкретных экономических данных. 1. Орлов А.И. Прикладная статистика. М.: Издательство "Экзамен", 2004. 2. Гмурман В.Е. Теория вероятностей и математическая статистика. М.: Высшая школа, 1999. – 479с. 3. Айвозян С.А. Теория вероятностей и прикладная статистика, т.1. М.: Юнити, 2001. – 656с. 4. Хамитов Г.П., Ведерникова Т.И. Вероятности и статистика. Иркутск: БГУЭП, 2006 – 272с. 5. Ежова Л.Н. Эконометрика. Иркутск: БГУЭП, 2002. – 314с. 6. Мостеллер Ф. Пятьдесят занимательных вероятностных задач с решениями. М. : Наука, 1975. – 111с. 7. Мостеллер Ф. Вероятность. М. : Мир, 1969. – 428с. 8. Яглом А.М. Вероятность и информация. М. : Наука, 1973. – 511с. 9. Чистяков В.П. Курс теории вероятностей. М.: Наука, 1982. – 256с. 10. Кремер Н.Ш. Теория вероятностей и математическая статистика. М.: ЮНИТИ, 2000. – 543с. 11. Математическая энциклопедия, т.1. М.: Советская энциклопедия, 1976. – 655с. 12. http://psystat.at.ua/ - Статистика в психологии и педагогике. Статья Критерий Хи-квадрат.
Использование
этого критерия основано на применении
такой меры (статистики) расхождения
между теоретическим F
(x
)
и эмпирическим распределением F
*
п
(x
)
,
которая приближенно подчиняется закону
распределения χ
2
. Гипотеза
Н
0
о согласованности распределений
проверяется путем анализа распределения
этой статистики. Применение критерия
требует построения статистического
ряда. Итак,
пусть выборка представлена статистическим
рядом с количеством разрядов M
.
Наблюдаемая частота попаданий в i
-
й
разряд n
i
.
В соответствии с теоретическим законом
распределения ожидаемая частота
попаданий в i
-й
разряд составляет F
i
.
Разность между наблюдаемой и ожидаемой
частотой составит величину (n
i
– F
i
).
Для нахождения общей степени расхождения
между F
(x
)
и F
*
п
(x
)
необходимо подсчитать взвешенную сумму
квадратов разностей по всем разрядам
статистического ряда Величина
χ 2
при неограниченном увеличении n
имеет
χ 2 -распределение
(асимптотически распределена как χ 2).
Это распределение зависит от числа
степеней свободы k
,
т.е. количества независимых значений
слагаемых в выражении (3.7). Число степеней
свободы равно числу y
минус число линейных связей, наложенных
на выборку. Одна связь существует в силу
того, что любая частота может быть
вычислена по совокупности частот в
оставшихся M
–1
разрядах. Кроме того, если параметры
распределения неизвестны заранее, то
имеется еще одно ограничение, обусловленное
подгонкой распределения к выборке. Если
по выборке определяются S
параметров
распределения, то число степеней свободы
составит k
=
M
–
S
–1.
Область
принятия гипотезы Н
0
определяется условием χ
2
<
χ 2
(k
;
a
)
,
где χ 2
(k
;
a
)
– критическая точка
χ2-распределения с уровнем значимости
a
.
Вероятность ошибки первого рода равна
a
,
вероятность ошибки второго рода четко
определить нельзя, потому что существует
бесконечно большое множество различных
способов несовпадения распределений.
Мощность критерия зависит от количества
разрядов и объема выборки. Критерий
рекомендуется применять при n
>200,
допускается применение при n
>40,
именно при таких условиях критерий
состоятелен (как правило, отвергает
неверную нулевую гипотезу). Алгоритм проверки
по критерию 1. Построить
гистограмму равновероятностным способом. 2. По виду гистограммы
выдвинуть гипотезу H
0: f
(x
)
= f
0 (x
), H
1: f
(x
)
¹
f
0 (x
), где
f
0 (x
)
- плотность вероятности гипотетического
закона распределения
(например, равномерного,
экспоненциального,
нормального). Замечание
.
Гипотезу об экспоненциальном законе
распределения можно выдвигать в том
случае, если все числа в выборке
положительные. 3. Вычислить значение
критерия по формуле где p
i
- теоретическая вероятность
попадания случайной величины вi
-
тый интервал при условии, что гипотезаH
0 верна. Формулы
для расчета p
i
в случае экспоненциального, равномерного
и нормального законов соответственно
равны. Экспоненциальный
закон
При
этом A
1
= 0, B
m
= +¥. Равномерный
закон
Нормальный закон
При
этом A
1
= -¥,
B M
= +¥. Замечания
.
После вычисления всех вероятностей p
i
проверить, выполняется ли контрольное
соотношение Функция
Ф(х
)-
нечетная. Ф(+¥)
= 1. 4.
Из таблицы " Хи-квадрат" Приложения
выбирается значение
k
= M
- 1 - S
. Здесь
S
- число параметров, от которых зависит
выбранный гипотезой H
0
закон распределения. Значения S
для равномерного закона равно 2, для
экспоненциального - 1, для нормального
- 2. 5.
Если
Пример3
.
1.
С помощью критерия c 2
выдвинуть и проверить гипотезу о законе
распределения случайной величины X
,
вариационный ряд, интервальные
таблицы и гистограммы распределения
которой приведены в примере 1.2. Уровень
значимости a
равен 0,05. Решение
.
По виду гистограмм выдвигаем гипотезу
о том, что случайная величина X
распределена по нормальному закону: H
0: f
(x
)
= N
(m
,
s); H
1: f
(x
)
¹
N
(m
,
s). Значение критерия
вычисляем по формуле: Как отмечалось
выше, при проверке гипотезы предпочтительнее
использовать равновероятностную
гистограмму. В этом случае Теоретические
вероятности p
i
рассчитываем по формуле (3.10). При этом
полагаем, что p
1
= 0,5(Ф((-4,5245+1,7)/1,98)-Ф((-¥+1,7)/1,98))
= 0,5(Ф(-1,427)-Ф(-¥))
= 0,5(-0,845+1) = 0,078. p
2
=
0,5(Ф((-3,8865+1,7)/1,98)-Ф((-4,5245+1,7)/1,98)) = 0,5(Ф(-1,104)+0,845) = 0,5(-0,729+0,845) = 0,058. p
3
=
0,094; p
4
=
0,135; p
5
=
0,118; p
6
=
0,097; p
7
=
0,073; p
8
=
0,059; p
9
=
0,174; p
10
=
0,5(Ф((+¥+1,7)/1,98)-Ф((0,6932+1,7)/1,98))
= 0,114. После этого
проверяем выполнение контрольного
соотношения 100 ×
(0,0062 + 0,0304 + 0,0004 + 0,0091 + 0,0028 + 0,0001 + 0,0100 + 0,0285 + 0,0315 + 0,0017) = 100 ×
0,1207 = 12,07. После этого из
таблицы "Хи - квадрат" выбираем
критическое значение Так
как
Применение хи-квадрат критерия для проверки сложных гипотез
Важные моменты
Дискретный случай
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100


=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)

Непрерывный случай

=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)


Приложение
Критические точки распределения χ2

Заключение
Теория вероятности и математическая статистика дают фундаментальные знания для прикладной статистики и эконометрики.
Они необходимы специалистам для практической работы.
Я рассмотрела непрерывную вероятностную модель и постаралась на примерах показать ее используемость.
Список используемой литературы
 ,
, частота
попадания вi
-тый интервал;
частота
попадания вi
-тый интервал; . (3.8)
. (3.8) . (3.10)
. (3.10)
 ,
гдеa
- заданный уровень значимости (a
= 0,05 или a
= 0,01), а k
-
число степеней свободы, определяемое
по формуле
,
гдеa
- заданный уровень значимости (a
= 0,05 или a
= 0,01), а k
-
число степеней свободы, определяемое
по формуле ,
то гипотезаH
0
отклоняется. В противном случае нет
оснований ее отклонить: с вероятностью
1 - b
она верна, а с вероятностью - b
неверна, но величина b
неизвестна.
,
то гипотезаH
0
отклоняется. В противном случае нет
оснований ее отклонить: с вероятностью
1 - b
она верна, а с вероятностью - b
неверна, но величина b
неизвестна. (3.11)
(3.11)


 .
. то гипотезаH
0
принимается (нет основания ее отклонить).
то гипотезаH
0
принимается (нет основания ее отклонить).
