Directives in AngularJS play an important role. Directives can be used to teach new tricks to HTML, and you can even create your own HTML tags or attributes. Directives also help in keeping the mark-up more fluent and defines a nice way of separating code and mark-up from each other.
View is a HTML template. View is nothing but the information you want to render to the end user’s browser. A view in AngularJS is also called as compiled DOM . View makes use of directives to render the data with HTML template.
This article is Part IV of the Project Tracking Website built in AngularJS and ASP.NET Web API. So far, we have , created a , and have .
Thanks to to review this Angular series and fix the bugs.
We have already seen the $scope object which provides a Model to the View. Model code is not intermixed with the HTML code we write into our views. Rather data is moved from the model to views by using data binding expressions. This way developers can achieve Separation of Concerns (SoC). Since Models are independent of Views, they can be bound to any View. This binding of model is done with the help of AngularJS Directives.
We have already seen some Angular directives in our like ng-app which bootstraps AngularJS, as well as ng-controller that makes the controller available to HTML. From the controller, we can bind the data to the views using Angular {{expression}}.
In this article, we will look at a couple of additional AngularJS directives which come out-of-the-box with Angular. One of them is ng-repeat . Let’s try using ng-repeat directive into our EmployeeDetails.html page that can be found in the accompanying this article. Modify the service URL in our EmployeesController.js file. The service URL is as follows:
http://localhost:2464/api/ptemployees
Now we will modify the EmployeeDetails.html page as shown in following code -
Replace the
of EmployeeDetails.html page with above code. The output of the above code is shown here:In this code, we have used the ng-repeat directive of AngularJS. It is similar to the for or foreach loop in .NET. Here we are getting an IEnumerable
Now let’s try adding a filter to search a particular Employee from the collection and display the employee based on given Employee Name or Employee Name character. Till now, we have fetched the model and used it in our Views. It also works the other way. We can make our views talk back to our models which are there in our controllers.
To add a search filter based on Employee Name, we will modify the EmployeeDetails.html page by adding HTML input elements as shown below -
Add the above code just after the
tag. In the above code, we are using ng-model directive which enables us to send the data back to the model. Based on this data, we will make a search for an employee using EmployeeName property. Make sure that EmployeeName property is declared in our model, which we will do in the following steps. Also notice that we are using ng-submit directive which will give a call to SearchEmployee function from our controller.
Now let’s modify the EmployeesController.js file so that we can search the employee based on EmployeeName property as a searching criteria. The code is shown below -
(function () { var EmployeesController = function ($scope,$http) { var employees = function (serviceResp) { $scope.Employees = serviceResp.data; }; $scope.SearchEmployees = function (EmployeeName) { $http.get("http://localhost:2464/api/ptemployees/" + EmployeeName) .then(employees, errorDetails); }; var errorDetails = function (serviceResp) { $scope.Error="Something went wrong ??"; }; $http.get("http://localhost:2464/api/ptemployees") .then(employees,errorDetails); $scope.Title = "Employee Details Page"; $scope.EmployeeName = null; }; app.controller("EmployeesController", EmployeesController); }());
In the above code, we have added the SearchEmployee() method to our $scope object as a model. This method will search for Employees based on employee name or the character of an employee name. We have also declared EmployeeName property in our controller at the end of this code. The SearchEmployees method fetches the Web API method. I have modified the method GET as shown here:
Public HttpResponseMessage Get(string name) { var employees = EmployeesRepository.SearchEmployeesByName(name); HttpResponseMessage response = Request.CreateResponse(HttpStatusCode.OK, employees); return response; }
The Employee Repository code is as shown here:
Public static List
After all these changes, now run the EmployeeDetails.html page and see the output.
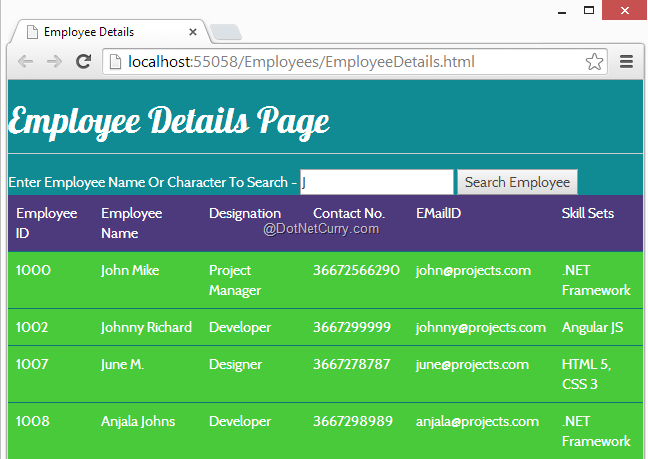
In the above output, we are searching for employees whose name contains the ‘J’ character in it.
AngularJS Filters extend the behavior of binding expressions or directives. Filters are used with binding expressions to format the data being bound. When they are used with directives, they add some additional actions to the directives. Out-of-the-box, AngularJS provides a number of filters which we can use to format the values of an expression and display the values/data into our views. You can make use of filters in Views, Controllers and Services. The syntax of using filters into views is {{ expression | filter1 | filter2 | ...}}.
We will now try a filter which will sort the data using employee name. To sort the data, let’s add a filter in our ng-repeat using a | operator as shown here:
In the above code, we are adding filter in our ng-repeat directive. The orderBy:’employeeName’ will sort the data using Employee name in an ascending order. You can observe the output here:

To display the data in descending order, you can change the filter as shown here:
In the above code, to sort the employee names in descending order, we have used (-) minus sign. Likewise, you can make use of (+) sign to sort it in ascending.
You can also make use limitTo filter to limit the number of records. For example, let us say at a time you want to display 5 employees. To display the restricted number of records in our EmployeeDetails.html page, let’s modify the ng-repeat directive as shown here-
The output is shown here:

Now if you run the ProjectDetails.html page, the date is getting displayed with time. You can apply the date filter as shown in following code -
The output of this page is as follows:

You can make use of different date formats like - fulldate, longdate, mediumdate, shortdate etc. Now let’s open EmployeeDetails.html page and run it. I am using the ‘Z’ character to display employees whose employee name contains Z.
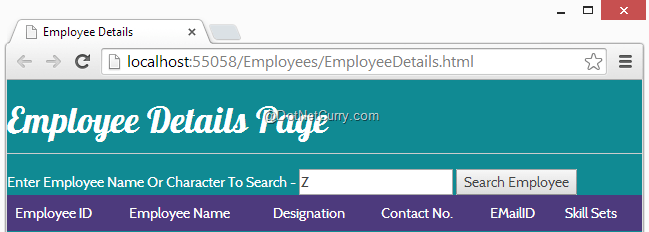
If you observe, the output displays an Employee table heading without data. We can make the heading invisible using the ng-show directive when the filter doesn’t produce any result. Apply ng-show directive in our table tag as shown in the below code and try running the application with Z character. Now you will not see the table columns when Employees model is null. The ng-show attribute will evaluate the Employees model and accordingly it will either display the table or hide the table.
<%@ Register TagPrefix="ch" Namespace="ControlsSharp.HtmlControls" Assembly="ControlsSharp"%> <%@ Register TagPrefix="cw" Namespace="ControlsSharp.WebControls" Assembly="ControlsSharp"%> <%@ Register TagPrefix="c" Namespace="ControlsSharp.CustomControls" Assembly="ControlsSharp"%> <%@ Register TagPrefix="b" Namespace="ControlsBasic.CustomControls" Assembly="ControlsBasic"%> <%@ Register TagPrefix="cu" TagName="bottommenu" Src="~/UserControls/Menu/cu_menu_bottom.ascx" %> <%@ Register TagPrefix="cu" TagName="leftmenu" Src="~/UserControls/Menu/cu_menu_left.ascx" %> <%@ Register TagPrefix="cu" TagName="topmenu" Src="~/UserControls/Menu/cu_menu_top.ascx" %> |
Назовем файл register.inc и поместим в папку /inc нашего веб-проекта.
Этот файл будет содержать все нужные нам ссылки, добавление или изменение регистрации пользовательского или серверного элемента управления мы будем осуществлять именно в нем.
Теперь созданный файл нужно каким-то образом включить в код страницы. Мы сделаем это с помощью директивы SSI (server side includes) #include. Эта директива позволяет включать в код страницы статические и динамические файлы, обрабатывая их на основе маппинга IIS, т.е. указание в качестве источника файла asp или aspx приведет к обработке файла соответствующим процессом и копированию результатов этой обработки в выдаваемую страницу. В ASP директива #include очень широко использовалась и позволяла реализовать модульность сайта. С появлением ASP.NET это стало удобнее делать другими способами, например, с помощью user controls. В следующих версиях ASP.NET модульность будет реализована с использованием master pages. В общем, директива #include потеряла свое значение и была сохранена в основном для обратной совместимостью и для упрощенной миграции ASP проектов на.Net.
Так как у нас простой текстовый файл, никакой обработки произведено не будет, и до выполнения любого динамического контента все содержимое файла будет скопировано в код страницы. Т.е. добавление нашего файла register.inc, например, в начало страницы, это почти то же самое как будто бы мы напишем там все директивы @ Register.
Для того чтобы не зависеть от физического размещения файла, мы снова используем синтаксис с указанием виртуального пути и добавим в код aspx файла вот такую строчку:
Убедитесь, что все работает, если нет, поправьте неверно указанные пути.
Осталось осуществить еще одну операцию. Сейчас, если вы попробуете по ссылке в браузере получить файл /inc/register.inc, вы без труда сможете это сделать. IIS отдает его в ваши руки, так же как в руки злоумышленника, совершенно свободно, хотя там содержатся пути физической структуры вашего сайта.
Для того чтобы этого не происходило, мы используем возможности синхронного обработчика HttpForbiddenHandler, позволяющего защищать файлы определенного типа от выдачи по запросам пользователя. Этот подход удобен и часто используется, например, для защиты файлов баз данных MS Access, используемых в проекте. Для того чтобы файлы с расширение *.inc можно было защитить с помощью этого обработчика нужно сообщить IIS что эти файлы будет обрабатывать процесс ASP.NET, другими словами настроить в IIS маппинг на файлы этого типа.
Подробное описание процесса настройки для IIS описано в статье HOW TO: Use ASP.NET to Protect File Types (http://support.microsoft.com/kb/815152/EN-US/). Нам потребуется создать маппинг только для файлов типа *.inc. После выполнения описанных там шагов, все запросы к файлам с таким расширением будут обрабатываться процессом ASP.NET, и вам останется отредактировать файл web.config следующим образом:
|
Все, теперь при попытке получить файл /inc/register.inc по прямой ссылке пользователь получит ошибку В.
Чтобы не регистрировать aspnet_isapi.dll,
например, ваш провайдер не хочет этого делать можно воспользоваться возможностью
SSI указывать файлы любого типа и схитрить, использовав для файла с директивами
@Register расширение одного из типов, уже маппированных в IIS по умолчанию. Для
этого будут удобны расширения *.cs или *.vb. Эти файлы содержат исходный код и
обычно не копируются на сервер. Если вы вдруг ошиблись и скопировали, по запросу
из браузера их получить не удастся, - при попытке это сделать пользователь
получит ошибку В. Так происходит потому, что
для фалов этого типа маппинг в IIS настроен по умолчанию а соответствующее
расширение уже прописано в секции
Заключение
Описанный способ позволяет регистрировать элементы управления в одном месте для всего проекта. Последующая модификация этого файла требует меньше усилий по сравнению с тем, как если бы пришлось делать это обычным способом. Попробуйте использовать SSI #include внутри самих вставляемых файлов – это позволяет организовать подобие иерархии и наследования, что может быть удобно для крупных проектов
Поисковая система Google (www.google.com) предоставляет множество возможностей для поиска. Все эти возможности – неоценимый инструмент поиска для пользователя впервые попавшего в Интернет и в то же время еще более мощное оружие вторжения и разрушения в руках людей с злыми намерениями, включая не только хакеров, но и некомпьютерных преступников и даже террористов.
(9475 просмотров за 1 неделю)
Денис Батранков
denisNOSPAMixi.ru
Внимание: Эта статья не руководство к действию. Эта статья написана для Вас, администраторы WEB серверов, чтобы у Вас пропало ложное ощущение, что Вы в безопасности, и Вы, наконец, поняли коварность этого метода получения информации и взялись за защиту своего сайта.
Введение
Я, например, за 0.14 секунд нашел 1670 страниц!
2. Введем другую строку, например:
inurl:"auth_user_file.txt"немного меньше, но этого уже достаточно для свободного скачивания и для подбора паролей (при помощи того же John The Ripper). Ниже я приведу еще ряд примеров.
Итак, Вам надо осознать, что поисковая машина Google посетила большинство из сайтов Интернет и сохранила в кэше информацию, содержащуюся на них. Эта кэшированная информация позволяет получить информацию о сайте и о содержимом сайта без прямого подключения к сайту, лишь копаясь в той информации, которая хранится внутри Google. Причем, если информация на сайте уже недоступна, то информация в кэше еще, возможно, сохранилась. Все что нужно для этого метода: знать некоторые ключевые слова Google. Этот технический прием называется Google Hacking.
Впервые информация о Google Hacking появилась на рассылке Bugtruck еще 3 года назад. В 2001 году эта тема была поднята одним французским студентом. Вот ссылка на это письмо http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html . В нем приведены первые примеры таких запросов:
1) Index of /admin
2) Index of /password
3) Index of /mail
4) Index of / +banques +filetype:xls (for france...)
5) Index of / +passwd
6) Index of / password.txt
Нашумела эта тема в англо-читающей части Интернета совершенно недавно: после статьи Johnny Long вышедшей 7 мая 2004 года. Для более полного изучения Google Hacking советую зайти на сайт этого автора http://johnny.ihackstuff.com . В этой статье я лишь хочу ввести вас в курс дела.
Кем это может быть использовано:
- Журналисты, шпионы и все те люди, кто любит совать нос не в свои дела, могут использовать это для поиска компромата.
- Хакеры, разыскивающие подходящие цели для взлома.
Как работает Google.
Для продолжения разговора напомню некоторые из ключевых слов, используемых в запросах Google.
Поиск при помощи знака +
Google исключает из поиска неважные, по его мнению, слова. Например вопросительные слова, предлоги и артикли в английском языке: например are, of, where. В русском языке Google, похоже, все слова считает важными. Если слово исключается из поиска, то Google пишет об этом. Чтобы Google начал искать страницы с этими словами перед ними нужно добавить знак + без пробела перед словом. Например:
ace +of base
Поиск при помощи знака –
Если Google находит большое количество станиц, из которых необходимо исключить страницы с определенной тематикой, то можно заставить Google искать только страницы, на которых нет определенных слов. Для этого надо указать эти слова, поставив перед каждым знак – без пробела перед словом. Например:
рыбалка -водка
Поиск при помощи знака ~
Возможно, что вы захотите найти не только указанное слово, но также и его синонимы. Для этого перед словом укажите символ ~.
Поиск точной фразы при помощи двойных кавычек
Google ищет на каждой странице все вхождения слов, которые вы написали в строке запроса, причем ему неважно взаимное расположение слов, главное чтобы все указанные слова были на странице одновременно (это действие по умолчанию). Чтобы найти точную фразу – ее нужно взять в кавычки. Например:
"подставка для книг"
Чтобы было хоть одно из указанных слов нужно указать логическую операцию явно: OR. Например:
книга безопасность OR защита
Кроме того в строке поиска можно использовать знак * для обозначения любого слова и. для обозначения любого символа.
Поиск слов при помощи дополнительных операторов
Существуют поисковые операторы, которые указываются в строке поиска в формате:
operator:search_term
Пробелы рядом с двоеточием не нужны. Если вы вставите пробел после двоеточия, то увидите сообщение об ошибке, а перед ним, то Google будет использовать их как обычную строку для поиска.
Существуют группы дополнительных операторов поиска: языки - указывают на каком языке вы хотите увидеть результат, дата - ограничивают результаты за прошедшие три, шесть или 12 месяцев, вхождения - указывают в каком месте документа нужно искать строку: везде, в заголовке, в URL, домены - производить поиск по указанному сайту или наоборот исключить его из поиска, безопасный поиск - блокируют сайты содержащие указанный тип информации и удаляют их со страниц результатов поиска.
При этом некоторые операторы не нуждаются в дополнительном параметре, например запрос "cache:www.google.com
" может быть вызван, как полноценная строка для поиска, а некоторые ключевые слова, наоборот, требуют наличия слова для поиска, например " site:www.google.com help
". В свете нашей тематики посмотрим на следующие операторы:
Оператор |
Описание |
Требует дополнительного параметра? |
поиск только по указанному в search_term сайту |
||
поиск только в документах с типом search_term |
||
найти страницы, содержащие search_term в заголовке |
||
найти страницы, содержащие все слова search_term в заголовке |
||
найти страницы, содержащие слово search_term в своем адресе |
||
найти страницы, содержащие все слова search_term в своем адресе |
Оператор site: ограничивает поиск только по указанному сайту, причем можно указать не только доменное имя, но и IP адрес. Например, введите:
Оператор filetype: ограничивает поиск в файлах определенного типа. Например:
На дату выхода статьи Googlе может искать внутри 13 различных форматов файлов:
- Adobe Portable Document Format (pdf)
- Adobe PostScript (ps)
- Lotus 1-2-3 (wk1, wk2, wk3, wk4, wk5, wki, wks, wku)
- Lotus WordPro (lwp)
- MacWrite (mw)
- Microsoft Excel (xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word (doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (wri)
- Rich Text Format (rtf)
- Shockwave Flash (swf)
- Text (ans, txt)
Оператор link:
показывает все страницы, которые указывают на указанную страницу.
Наверно всегда интересно посмотреть, как много мест в Интернете знают о тебе. Пробуем:
Оператор cache: показывает версию сайта в кеше Google, как она выглядела, когда Google последний раз посещал эту страницу. Берем любой, часто меняющийся сайт и смотрим:
Оператор intitle: ищет указанное слово в заголовке страницы. Оператор allintitle: является расширением – он ищет все указанные несколько слов в заголовке страницы. Сравните:
intitle:полет на марс
intitle:полет intitle:на intitle:марс
allintitle:полет на марс
Оператор inurl: заставляет Google показать все страницы содержащие в URL указанную строку. Оператор allinurl: ищет все слова в URL. Например:
allinurl:acid acid_stat_alerts.php
Эта команда особенно полезна для тех, у кого нет SNORT – хоть смогут посмотреть, как он работает на реальной системе.
Методы взлома при помощи Google
Итак, мы выяснили что, используя комбинацию вышеперечисленных операторов и ключевых слов, любой человек может заняться сбором нужной информации и поиском уязвимостей. Эти технические приемы часто называют Google Hacking.
Карта сайта
Можно использовать оператор site: для просмотра всех ссылок, которые Google нашел на сайте. Обычно страницы, которые динамически создаются скриптами, при помощи параметров не индексируются, поэтому некоторые сайты используют ISAPI фильтры, чтобы ссылки были не в виде /article.asp?num=10&dst=5 , а со слешами /article/abc/num/10/dst/5 . Это сделано для того, чтобы сайт вообще индексировался поисковиками.
Попробуем:
site:www.whitehouse.gov whitehouse
Google думает, что каждая страница сайта содержит слово whitehouse. Этим мы и пользуемся, чтобы получить все страницы.
Есть и упрощенный вариант:
site:whitehouse.gov
И что самое приятное - товарищи с whitehouse.gov даже не узнали, что мы посмотрели на структуру их сайта и даже заглянули в кэшированные странички, которые скачал себе Google. Это может быть использовано для изучения структуры сайтов и просмотра содержимого, оставаясь незамеченным до поры до времени.
Просмотр списка файлов в директориях
WEB серверы могут показывать списки директорий сервера вместо обычных HTML страниц. Обычно это делается для того, чтобы пользователи выбирали и скачивали определенные файлы. Однако во многих случаях у администраторов нет цели показать содержимое директории. Это возникает вследствие неправильной конфигурации сервера или отсутствия главной страницы в директории. В результате у хакера появляется шанс найти что-нибудь интересное в директории и воспользоваться этим для своих целей. Чтобы найти все такие страницы, достаточно заметить, что все они содержат в своем заголовке слова: index of. Но поскольку слова index of содержат не только такие страницы, то нужно уточнить запрос и учесть ключевые слова на самой странице, поэтому нам подойдут запросы вида:
intitle:index.of parent directory
intitle:index.of name size
Поскольку в основном листинги директорий сделаны намеренно, то вам, возможно, трудно будет найти ошибочно выведенные листинги с первого раза. Но, по крайней мере, вы уже сможете использовать листинги для определения версии WEB сервера, как описано ниже.
Получение версии WEB сервера.
Знание версии WEB сервера всегда полезно перед началом любой атака хакера. Опять же благодаря Google можно получить эту информацию без подключения к серверу. Если внимательно посмотреть на листинг директории, то можно увидеть, что там выводится имя WEB сервера и его версия.
Apache1.3.29 - ProXad Server at trf296.free.fr Port 80
Опытный администратор может подменить эту информацию, но, как правило, она соответствует истине. Таким образом, чтобы получить эту информацию достаточно послать запрос:
intitle:index.of server.at
Чтобы получить информацию для конкретного сервера уточняем запрос:
intitle:index.of server.at site:ibm.com
Или наоборот ищем сервера работающие на определенной версии сервера:
intitle:index.of Apache/2.0.40 Server at
Эта техника может быть использована хакером для поиска жертвы. Если у него, к примеру, есть эксплойт для определенной версии WEB сервера, то он может найти его и попробовать имеющийся эксплойт.
Также можно получить версию сервера, просматривая страницы, которые по умолчанию устанавливаются при установке свежей версии WEB сервера. Например, чтобы увидеть тестовую страницу Apache 1.2.6 достаточно набрать
intitle:Test.Page.for.Apache it.worked!
Мало того, некоторые операционные системы при установке сразу ставят и запускают WEB сервер. При этом некоторые пользователи даже об этом не подозревают. Естественно если вы увидите, что кто-то не удалил страницу по умолчанию, то логично предположить, что компьютер вообще не подвергался какой-либо настройке и, вероятно, уязвим для атак.
Попробуйте найти страницы IIS 5.0
allintitle:Welcome to Windows 2000 Internet Services
В случае с IIS можно определить не только версию сервера, но и версию Windows и Service Pack.
Еще одним способом определения версии WEB сервера является поиск руководств (страниц подсказок) и примеров, которые могут быть установлены на сайте по умолчанию. Хакеры нашли достаточно много способов использовать эти компоненты, чтобы получить привилегированный доступ к сайту. Именно поэтому нужно на боевом сайте удалить эти компоненты. Не говоря уже о том, что по наличию этих компонентов можно получить информацию о типе сервера и его версии. Например, найдем руководство по apache:
inurl:manual apache directives modules
Использование Google как CGI сканера.
CGI сканер или WEB сканер – утилита для поиска уязвимых скриптов и программ на сервере жертвы. Эти утилиты должны знать что искать, для этого у них есть целый список уязвимых файлов, например:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Мы может найти каждый из этих файлов с помощью Google, используя дополнительно с именем файла в строке поиска слова index of или inurl: мы можем найти сайты с уязвимыми скриптами, например:
allinurl:/random_banner/index.cgi
Пользуясь дополнительными знаниями, хакер может использовать уязвимость скрипта и с помощью этой уязвимости заставить скрипт выдать любой файл, хранящийся на сервере. Например файл паролей.
Как защитить себя от взлома через Google.
1. Не выкладывайте важные данные на WEB сервер.
Даже если вы выложили данные временно, то вы можете забыть об этом или кто-то успеет найти и забрать эти данные пока вы их не стерли. Не делайте так. Есть много других способов передачи данных, защищающих их от кражи.
2. Проверьте свой сайт.
Используйте описанные методы, для исследования своего сайта. Проверяйте периодически свой сайт новыми методами, которые появляются на сайте http://johnny.ihackstuff.com . Помните, что если вы хотите автоматизировать свои действия, то нужно получить специальное разрешение от Google. Если внимательно прочитать http://www.google.com/terms_of_service.html , то вы увидите фразу: You may not send automated queries of any sort to Google"s system without express permission in advance from Google.
3. Возможно, вам не нужно чтобы Google индексировал ваш сайт или его часть.
Google позволяет удалить ссылку на свой сайт или его часть из своей базы, а также удалить страницы из кэша. Кроме того вы можете запретить поиск изображений на вашем сайте, запретить показывать короткие фрагменты страниц в результатах поиска Все возможности по удалению сайта описаны на сранице http://www.google.com/remove.html . Для этого вы должны подтвердить, что вы действительно владелец этого сайта или вставить на страницу теги или
4. Используйте robots.txt
Известно, что поисковые машины заглядывают в файл robots.txt лежащий в корне сайта и не индексируют те части, которые помечены словом Disallow . Вы можете воспользоваться этим, для того чтобы часть сайта не индексировалась. Например, чтобы не индексировался весь сайт, создайте файл robots.txt содержащий две строчки:
User-agent: *
Disallow: /
Что еще бывает
Чтобы жизнь вам медом не казалась, скажу напоследок, что существуют сайты, которые следят за теми людьми, которые, используя вышеизложенные выше методы, разыскивают дыры в скриптах и WEB серверах. Примером такой страницы является
Приложение.
Немного сладкого. Попробуйте сами что-нибудь из следующего списка:
1. #mysql dump filetype:sql - поиск дампов баз данных mySQL
2. Host Vulnerability Summary Report - покажет вам какие уязвимости нашли другие люди
3. phpMyAdmin running on inurl:main.php - это заставит закрыть управление через панель phpmyadmin
4. not for distribution confidential
5. Request Details Control Tree Server Variables
6. Running in Child mode
7. This report was generated by WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs – может кому нужны кофигурационные файлы файрволов? :)
10. intitle:index.of finances.xls – мда....
11. intitle:Index of dbconvert.exe chats – логи icq чата
12. intext:Tobias Oetiker traffic analysis
13. intitle:Usage Statistics for Generated by Webalizer
14. intitle:statistics of advanced web statistics
15. intitle:index.of ws_ftp.ini – конфиг ws ftp
16. inurl:ipsec.secrets holds shared secrets – секретный ключ – хорошая находка
17. inurl:main.php Welcome to phpMyAdmin
18. inurl:server-info Apache Server Information
19. site:edu admin grades
20. ORA-00921: unexpected end of SQL command – получаем пути
21. intitle:index.of trillian.ini
22. intitle:Index of pwd.db
23. intitle:index.of people.lst
24. intitle:index.of master.passwd
25. inurl:passlist.txt
26. intitle:Index of .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.of administrators.pwd
29. intitle:Index.of etc shadow
30. intitle:index.of secring.pgp
31. inurl:config.php dbuname dbpass
32. inurl:perform filetype:ini
Учебный центр "Информзащита" http://www.itsecurity.ru - ведущий специализированный центр в области обучения информационной безопасности (Лицензия Московского Комитета образования № 015470, Государственная аккредитация № 004251). Единственный авторизованный учебный центр компаний Internet Security Systems и Clearswift на территории России и стран СНГ. Авторизованный учебный центр компании Microsoft (специализация Security). Программы обучения согласованы с Гостехкомиссией России, ФСБ (ФАПСИ). Свидетельства об обучении и государственные документы о повышении квалификации.
Компания SoftKey – это уникальный сервис для покупателей, разработчиков, дилеров и аффилиат–партнеров. Кроме того, это один из лучших Интернет-магазинов ПО в России, Украине, Казахстане, который предлагает покупателям широкий ассортимент, множество способов оплаты, оперативную (часто мгновенную) обработку заказа, отслеживание процесса выполнения заказа в персональном разделе, различные скидки от магазина и производителей ПО.
