Como mencionado anteriormente, exemplos de distribuições de probabilidade variável aleatória contínua X são:
- distribuição de probabilidade uniforme de uma variável aleatória contínua;
- distribuição de probabilidade exponencial de uma variável aleatória contínua;
- distribuição normal probabilidades de uma variável aleatória contínua.
Vamos dar o conceito de leis de distribuição uniforme e exponencial, fórmulas de probabilidade e características numéricas das funções consideradas.
| Indicador | Lei de distribuição aleatória | A lei exponencial da distribuição |
|---|---|---|
| Definição | O uniforme é chamado a distribuição de probabilidade de uma variável aleatória contínua X, cuja densidade permanece constante no intervalo e tem a forma | Um exponencial (exponencial) é chamado a distribuição de probabilidade de uma variável aleatória contínua X, que é descrita por uma densidade tendo a forma |
 onde λ é um valor positivo constante |
||
| função de distribuição |  |
|
| Probabilidade acertando o intervalo |  |
|
| Valor esperado | ||
| Dispersão |  |
|
| Desvio padrão |  |
Exemplos de resolução de problemas no tópico "Leis uniformes e exponenciais de distribuição"
Tarefa 1.
Os ônibus funcionam estritamente de acordo com o horário. Intervalo de movimento 7 min. Encontre: (a) a probabilidade de que um passageiro ao parar espere pelo próximo ônibus por menos de dois minutos; b) a probabilidade de um passageiro que se aproxima da parada esperar pelo próximo ônibus por pelo menos três minutos; c) a expectativa matemática e o desvio padrão da variável aleatória X - tempo de espera do passageiro.
Decisão. 1. Pela condição do problema, uma variável aleatória contínua X=(tempo de espera do passageiro) distribuído uniformemente entre as chegadas de dois ônibus. O comprimento do intervalo de distribuição da variável aleatória X é igual a b-a=7, onde a=0, b=7.
2. O tempo de espera será inferior a dois minutos se o valor aleatório X estiver dentro do intervalo (5;7). A probabilidade de cair em um determinado intervalo é encontrada pela fórmula: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(5< Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
3. O tempo de espera será de pelo menos três minutos (ou seja, de três a sete minutos) se o valor aleatório X cair no intervalo (0; 4). A probabilidade de cair em um determinado intervalo é encontrada pela fórmula: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(0< Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
4. Expectativa matemática de uma variável aleatória contínua uniformemente distribuída X - o tempo de espera do passageiro, encontramos pela fórmula: M(X)=(a+b)/2. M (X) \u003d (0 + 7) / 2 \u003d 7/2 \u003d 3.5.
5. O desvio padrão de uma variável aleatória contínua uniformemente distribuída X - o tempo de espera do passageiro, encontramos pela fórmula: σ(X)=√D=(b-a)/2√3. σ(X)=(7-0)/2√3=7/2√3≈2,02.
Tarefa 2.
A distribuição exponencial é dada para x ≥ 0 pela densidade f(x) = 5e – 5x. Necessário: a) escrever uma expressão para a função de distribuição; b) encontre a probabilidade de que, como resultado do teste, X caia no intervalo (1; 4); c) encontre a probabilidade de que como resultado do teste X ≥ 2; d) calcule M(X), D(X), σ(X).
Decisão. 1. Uma vez que, por condição, distribuição exponencial , então da fórmula para a densidade de distribuição de probabilidade da variável aleatória X obtemos λ = 5. Então a função de distribuição será semelhante a:
2. A probabilidade de que como resultado do teste X caia no intervalo (1; 4) será encontrada pela fórmula:
P(a< X < b) = e −λa − e −λb
.
P(1< X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. A probabilidade de que como resultado do teste X ≥ 2 seja encontrada pela fórmula: P(a< X < b) = e −λa − e −λb при a=2, b=∞.
Р(Х≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. Encontramos para a distribuição exponencial:
- esperança matemática de acordo com a fórmula M(X) =1/λ = 1/5 = 0,2;
- dispersão de acordo com a fórmula D (X) \u003d 1 / λ 2 \u003d 1/25 \u003d 0,04;
- desvio padrão de acordo com a fórmula σ(X) = 1/λ = 1/5 = 1,2.
Esta questão tem sido estudada em detalhes, e o método de coordenadas polares, proposto por George Box, Mervyn Muller e George Marsaglia em 1958, foi o mais utilizado. Este método permite obter um par de variáveis aleatórias independentes normalmente distribuídas com média 0 e variância 1 da seguinte forma:
Onde Z 0 e Z 1 são os valores desejados, s \u003d u 2 + v 2, e u e v são variáveis aleatórias uniformemente distribuídas no segmento (-1, 1), selecionadas de tal forma que a condição 0 seja satisfeita< s < 1.
Muitos usam essas fórmulas sem nem pensar, e muitos nem suspeitam de sua existência, pois usam implementações prontas. Mas tem gente que tem dúvidas: “De onde veio essa fórmula? E por que você recebe um par de valores de uma só vez? A seguir, tentarei dar uma resposta clara a essas perguntas.
Para começar, deixe-me lembrá-lo do que são a densidade de probabilidade, a função de distribuição de uma variável aleatória e a função inversa. Suponha que haja alguma variável aleatória, cuja distribuição é dada pela função densidade f(x), que tem a seguinte forma:

Isso significa que a probabilidade de que o valor dessa variável aleatória esteja no intervalo (A, B) é igual à área da área sombreada. E, como consequência, a área de toda a área sombreada deve ser igual à unidade, pois em qualquer caso o valor da variável aleatória cairá no domínio da função f.
A função de distribuição de uma variável aleatória é uma integral da função de densidade. E neste caso, sua forma aproximada será a seguinte:

Aqui o significado é que o valor da variável aleatória será menor que A com probabilidade B. E, como resultado, a função nunca diminui e seus valores estão no intervalo .
Uma função inversa é uma função que retorna o argumento da função original se você passar o valor da função original para ela. Por exemplo, para a função x 2 o inverso será a função de extração de raiz, para sen (x) é arcsin (x), etc.
Como a maioria dos geradores de números pseudo-aleatórios fornece apenas uma distribuição uniforme na saída, muitas vezes torna-se necessário convertê-la para outra. Neste caso, para uma gaussiana normal:

A base de todos os métodos para transformar uma distribuição uniforme em qualquer outra distribuição é o método da transformação inversa. Funciona da seguinte forma. Uma função é encontrada que é inversa à função da distribuição requerida, e uma variável aleatória uniformemente distribuída no segmento (0, 1) é passada para ela como um argumento. Na saída, obtemos um valor com a distribuição necessária. Para maior clareza, aqui está a imagem a seguir.

Assim, um segmento uniforme é, por assim dizer, manchado de acordo com a nova distribuição, sendo projetado em outro eixo através de uma função inversa. Mas o problema é que a integral da densidade da distribuição gaussiana não é fácil de calcular, então os cientistas acima tiveram que trapacear.
Existe uma distribuição qui-quadrado (distribuição de Pearson), que é a distribuição da soma dos quadrados de k variáveis aleatórias normais independentes. E no caso em que k = 2, essa distribuição é exponencial.

Isso significa que se um ponto em um sistema de coordenadas retangulares tem coordenadas aleatórias X e Y distribuídas normalmente, então depois de converter essas coordenadas para o sistema polar (r, θ), o quadrado do raio (a distância da origem ao ponto) será distribuído exponencialmente, pois o quadrado do raio é a soma dos quadrados das coordenadas (de acordo com a lei de Pitágoras). A densidade de distribuição de tais pontos no plano ficará assim:


Como é igual em todas as direções, o ângulo θ terá uma distribuição uniforme na faixa de 0 a 2π. O inverso também é verdadeiro: se você especificar um ponto no sistema de coordenadas polares usando duas variáveis aleatórias independentes (o ângulo distribuído uniformemente e o raio distribuído exponencialmente), as coordenadas retangulares desse ponto serão variáveis aleatórias normais independentes. E a distribuição exponencial da distribuição uniforme já é muito mais fácil de obter, usando o mesmo método de transformação inversa. Esta é a essência do método polar Box-Muller.
Agora vamos pegar as fórmulas.
![]() (1)
(1)
Para obter r e θ, é necessário gerar duas variáveis aleatórias uniformemente distribuídas no segmento (0, 1) (vamos chamá-las de u e v), cuja distribuição de uma delas (digamos v) deve ser convertida em exponencial para obter o raio. A função de distribuição exponencial fica assim:
Sua função inversa:
![]()
Como a distribuição uniforme é simétrica, a transformação funcionará de forma semelhante com a função
![]()
Segue da fórmula de distribuição qui-quadrado que λ = 0,5. Substituímos λ, v nesta função e obtemos o quadrado do raio e, em seguida, o próprio raio:

Obtemos o ângulo esticando o segmento unitário para 2π:
Agora substituímos r e θ nas fórmulas (1) e obtemos:
 (2)
(2)
Essas fórmulas estão prontas para uso. X e Y serão independentes e normalmente distribuídos com variância 1 e média 0. Para obter uma distribuição com outras características, basta multiplicar o resultado da função pelo desvio padrão e somar a média.
Mas é possível se livrar das funções trigonométricas especificando o ângulo não diretamente, mas indiretamente através das coordenadas retangulares de um ponto aleatório em um círculo. Então, através dessas coordenadas, será possível calcular o comprimento do raio vetor, e então encontrar o cosseno e o seno dividindo xey por ele, respectivamente. Como e por que funciona?
Escolhemos um ponto aleatório uniformemente distribuído no círculo de raio unitário e denotamos o quadrado do comprimento do vetor raio desse ponto pela letra s:

A escolha é feita atribuindo aleatoriamente coordenadas retangulares x e y uniformemente distribuídas no intervalo (-1, 1), e descartando pontos que não pertencem ao círculo, bem como o ponto central em que o ângulo do vetor raio é não definido. Ou seja, a condição 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Obtemos as fórmulas, como no início do artigo. A desvantagem deste método é a rejeição de pontos que não estão incluídos no círculo. Ou seja, utilizando apenas 78,5% das variáveis aleatórias geradas. Em computadores mais antigos, a falta de funções trigonométricas ainda era uma grande vantagem. Agora, quando uma instrução de processador calcula simultaneamente seno e cosseno em um instante, acho que esses métodos ainda podem competir.
Pessoalmente, tenho mais duas perguntas:
- Por que o valor de s é distribuído uniformemente?
- Por que a soma dos quadrados de duas variáveis aleatórias normais é distribuída exponencialmente?

Se uma transformação semelhante for feita para uma variável aleatória normal, a função densidade de seu quadrado será semelhante a uma hipérbole. E a adição de dois quadrados de variáveis aleatórias normais já é um processo muito mais complexo associado à dupla integração. E o fato de o resultado ser uma distribuição exponencial, pessoalmente, me resta verificar com um método prático ou aceitá-lo como um axioma. E para quem se interessar, sugiro que se familiarize mais com o tema, extraindo conhecimento desses livros:
- Wentzel E.S. Teoria da probabilidade
- Knut D. E. A Arte de Programar Volume 2
Para concluir, darei um exemplo da implementação de um gerador de números aleatórios normalmente distribuído em JavaScript:
Function Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1,0; s = u * u + v * v; ) while (s > 1,0 || s == 0,0); var r = Math.sqrt(-2,0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + média; ) ); ) g = new Gauss(); // cria um objeto a = g.next(); // gera um par de valores e obtém o primeiro b = g.next(); // obtém o segundo c = g.next(); // gera novamente um par de valores e obtém o primeiro
Os parâmetros médio (expectativa matemática) e dev (desvio padrão) são opcionais. Chamo sua atenção para o fato de que o logaritmo é natural.
Uma distribuição é considerada uniforme se todos os valores de uma variável aleatória (na região de sua existência, por exemplo, no intervalo) forem igualmente prováveis. A função de distribuição para tal variável aleatória tem a forma:
Densidade de distribuição: 
 1
1

Arroz. Gráficos da função de distribuição (esquerda) e densidade de distribuição (direita).
Distribuição uniforme - conceito e tipos. Classificação e características da categoria "Distribuição uniforme" 2017, 2018.
Distribuições discretas básicas de variáveis aleatórias Definição 1. Variável aleatória Х, tomando valores 1, 2, …, n, tem uma distribuição uniforme se Pm = P(Х = m) = 1/n, m = 1, …, n . É óbvio isso. Considere o seguinte problema: Há N bolas em uma urna, das quais M são brancas... .
Leis de distribuição de variáveis aleatórias contínuas Definição 5. Uma variável aleatória contínua X, tomando um valor no intervalo , tem uma distribuição uniforme se a densidade de distribuição tem a forma. (1) É fácil verificar que, . Se uma variável aleatória... .
Uma distribuição é considerada uniforme se todos os valores de uma variável aleatória (na região de sua existência, por exemplo, no intervalo ) são igualmente prováveis. A função de distribuição para tal variável aleatória tem a forma: Densidade de distribuição: F(x) f(x) 1 0 a b x 0 a b x ... .
Leis de distribuição normal Uniform, exponencial e A função densidade de probabilidade da lei uniforme é: (10.17) onde aeb são dados números, a< b; a и b – это параметры равномерного закона. Найдем функцию распределения F(x)... .
A distribuição de probabilidade uniforme é a mais simples e pode ser discreta ou contínua. Uma distribuição uniforme discreta é uma distribuição para a qual a probabilidade de cada um dos valores de CB é a mesma, ou seja: onde N é o número ... .
Definição 16. Uma variável aleatória contínua tem uma distribuição uniforme no intervalo, se neste segmento a densidade de distribuição desta variável aleatória é constante, e fora dela é igual a zero, ou seja (45) O gráfico de densidade para uma distribuição uniforme é mostrando ...
Como exemplo de uma variável aleatória contínua, considere uma variável aleatória X uniformemente distribuída ao longo do intervalo (a; b). Dizemos que a variável aleatória X distribuído uniformemente no intervalo (a; b), se sua densidade de distribuição não for constante nesse intervalo:
A partir da condição de normalização, determinamos o valor da constante c . A área sob a curva de densidade de distribuição deve ser igual a um, mas no nosso caso é a área de um retângulo com base (b - α) e altura c (Fig. 1). 
Arroz. 1 Densidade de distribuição uniforme
A partir daqui encontramos o valor da constante c: ![]()
Assim, a densidade de uma variável aleatória uniformemente distribuída é igual a 
Vamos agora encontrar a função de distribuição pela fórmula:
1) para ![]()
2) para
3) para 0+1+0=1.
Por isso, 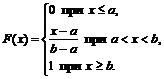
A função de distribuição é contínua e não decresce (Fig. 2). 
Arroz. 2 Função de distribuição de uma variável aleatória uniformemente distribuída
Vamos encontrar expectativa matemática de uma variável aleatória uniformemente distribuída de acordo com a fórmula:
Variação de distribuição uniformeé calculado pela fórmula e é igual a
Exemplo 1. O valor da divisão de escala do instrumento de medição é 0,2. As leituras do instrumento são arredondadas para a divisão inteira mais próxima. Encontre a probabilidade de que um erro seja cometido durante a leitura: a) menor que 0,04; b) grande 0,02
Decisão. O erro de arredondamento é uma variável aleatória uniformemente distribuída no intervalo entre divisões de inteiros adjacentes. Considere o intervalo (0; 0,2) como tal divisão (Fig. a). O arredondamento pode ser realizado tanto para a borda esquerda - 0 quanto para a direita - 0,2, o que significa que um erro menor ou igual a 0,04 pode ser feito duas vezes, o que deve ser levado em consideração ao calcular a probabilidade: 

P = 0,2 + 0,2 = 0,4
Para o segundo caso, o valor do erro também pode exceder 0,02 em ambos os limites de divisão, ou seja, pode ser maior que 0,02 ou menor que 0,18. 
Então a probabilidade de um erro como este:
Exemplo #2. Assumiu-se que a estabilidade da situação econômica do país (ausência de guerras, desastres naturais, etc.) nos últimos 50 anos pode ser julgada pela natureza da distribuição da população por idade: em uma situação calma, deveria ser uniforme. Como resultado do estudo, foram obtidos os seguintes dados para um dos países.
Há alguma razão para acreditar que houve uma situação instável no país?Realizamos a decisão usando a calculadora Teste de hipóteses. Tabela para cálculo de indicadores.
| Grupos | Intervalo médio, x i | Quantidade, fi | x e * f | Frequência acumulada, S | |x - x cf |*f | (x - x sr) 2 *f | Frequência, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
média ponderada
Indicadores de variação.
Taxas de variação absoluta.
A faixa de variação é a diferença entre os valores máximo e mínimo do atributo da série primária.
R = X max - X min
R=70 - 0=70
Dispersão- caracteriza a medida de dispersão em torno de seu valor médio (medida de dispersão, ou seja, desvio da média).
Desvio padrão.
Cada valor da série difere do valor médio de 43 por não mais que 23,92
Testando hipóteses sobre o tipo de distribuição.
4. Testando a hipótese sobre distribuição uniforme a população em geral.
Para testar a hipótese sobre a distribuição uniforme de X, i.e. de acordo com a lei: f(x) = 1/(b-a) no intervalo (a,b)
necessário:
1. Estime os parâmetros a e b - as extremidades do intervalo em que os possíveis valores de X foram observados, de acordo com as fórmulas (o * denota as estimativas dos parâmetros):
2. Encontre a densidade de probabilidade da distribuição estimada f(x) = 1/(b * - a *)
3. Encontre frequências teóricas:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Compare as frequências empíricas e teóricas usando o teste de Pearson, assumindo o número de graus de liberdade k = s-3, onde s é o número de intervalos de amostragem inicial; se, no entanto, foi feita uma combinação de pequenas frequências e, portanto, os próprios intervalos, então s é o número de intervalos restantes após a combinação.
Decisão:
1. Encontre as estimativas dos parâmetros a * e b * da distribuição uniforme usando as fórmulas:
2. Encontre a densidade da distribuição uniforme assumida:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Encontre as frequências teóricas:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
Os restantes n s serão iguais:
n s = n*f(x)(x i - x i-1)
| eu | eu | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Total | 1 | 0.0532 |
Portanto, a região crítica para esta estatística é sempre destra: , se neste segmento a densidade de distribuição de probabilidade da variável aleatória for constante, ou seja, se a função de distribuição diferencial f(x) tem a seguinte forma:
![]()
Essa distribuição às vezes é chamada de lei da densidade uniforme. Sobre uma quantidade que tem distribuição uniforme em um determinado segmento, diremos que ela é distribuída uniformemente nesse segmento.
Encontre o valor da constante c. Uma vez que a área limitada pela curva de distribuição e o eixo Oh,é igual a 1, então
Onde com=1/(b-uma).
Agora a função f(x)pode ser representado como

Vamos construir a função de distribuição
F(x ), para o qual encontramos a expressão F (x ) no intervalo [ a, b]:


Os gráficos das funções f (x) e F (x) se parecem com:

Vamos encontrar características numéricas.
Usando a fórmula para calcular a esperança matemática do NSW, temos:

Assim, a expectativa matemática de uma variável aleatória uniformemente distribuída no intervalo [a, b] coincide com o meio deste segmento.
Encontre a variância de uma variável aleatória uniformemente distribuída:
de onde se segue imediatamente que o desvio padrão:
![]()
Vamos agora encontrar a probabilidade de que o valor de uma variável aleatória com uma distribuição uniforme caia no intervalo(a, b), pertencente inteiramente ao segmento [uma, b
]:

|
|

Geometricamente, essa probabilidade é a área do retângulo sombreado. Números uma e
bchamado parâmetros de distribuição e definir exclusivamente uma distribuição uniforme.Exemplo 1. Os ônibus de uma determinada rota funcionam estritamente de acordo com o horário. Intervalo de movimento 5 minutos. Encontre a probabilidade de que o passageiro tenha se aproximado do ponto de ônibus. Vai esperar pelo próximo ônibus menos de 3 minutos.
Decisão:
ST - o tempo de espera do ônibus tem distribuição uniforme. Então a probabilidade desejada será igual a:
![]()
Exemplo2. A aresta do cubo x é medida aproximadamente. E
Considerando a aresta do cubo como uma variável aleatória distribuída uniformemente no intervalo (
uma,b), encontre a esperança matemática e a variância do volume do cubo.Decisão:
O volume do cubo é uma variável aleatória determinada pela expressão Y \u003d X 3. Então a esperança matemática é:
Dispersão:
Serviço on-line:
