Метод перебора. В данном методе производится сравнение с некоторой базой данных, где для каждого из объектов представлены разные варианты модификации отображения. Например, для оптического распознавания образов можно применить метод перебора под разными углами или масштабами, смещениями, деформациями и т. д. Для букв можно перебирать шрифт или его свойства. В случае распознавания звуковых образов происходит сравнение с некоторыми известными шаблонами (слово, произнесенное многими людьми). Далее, производится более глубокий анализ характеристик образа. В случае оптического распознавания - это может быть определение геометрических характеристик. Звуковой образец в этом случае подвергается частотному и амплитудному анализу.
Следующий метод - использование искусственных нейронных сетей (ИНС). Он требует либо огромного количества примеров задачи распознавания, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Но, тем не менее, этот метод отличается высокой эффективностью и производительностью.
Методы, основанные на оценках плотностей распределения значений признаков . Заимствованы из классической теории статистических решений, в которой объекты исследования рассматриваются как реализации многомерной случайной величины, распределенной в пространстве признаков по какому-либо закону. Они базируются на байесовской схеме принятия решений, апеллирующей к начальным вероятностям принадлежности объектов к тому или иному классу и условным плотностям распределения признаков.
Группа методов, основанных на оценке плотностей распределения значений признаков, имеет непосредственное отношение к методам дискриминантного анализа. Байесовский подход к принятию решений относится к наиболее разработанным в современной статистике параметрическим методам, для которых считается известным аналитическое выражение закона распределения (нормальный закон) и требуется только оценить лишь небольшое количество параметров (векторы средних значений и ковариационные матрицы). Основными трудностями применения данного метода считается необходимость запоминания всей обучающей выборки для вычисления оценок плотностей и высокая чувствительность к обучающей выборки.
Методы, основанные на предположениях о классе решающих функций. В данной группе считается известным вид решающей функции и задан функционал ее качества. На основании этого функционала по обучающей последовательности находят оптимальное приближение к решающей функции. Функционал качества решающего правила обычно связывают с ошибкой. Основным достоинством метода является ясность математической постановки задачи распознавания. Возможность извлечения новых знаний о природе объекта, в частности знаний о механизмах взаимодействия атрибутов, здесь принципиально ограничена заданной структурой взаимодействия, зафиксированной в выбранной форме решающих функций.
Метод сравнения с прототипом. Это наиболее легкий на практике экстенсиональный метод распознавания. Он применяется, в том случае, когда распознаваемые классы показываются компактными геометрическими классами. Тогда в качестве точки - прототипа выбирается центр геометрической группировки (или ближайший к центру объект).
Для классификации неопределенного объекта находится ближайший к нему прототип, и объект относится к тому же классу, что и он. Очевидно, никаких обобщенных образов в данном методе не формируется. В качестве меры могут применяться различные типы расстояний.
Метод k ближайших соседей. Метод заключается в том, что при классификации неизвестного объекта находится заданное число (k) геометрически ближайших пространстве признаков других ближайших соседей с уже известной принадлежностью к какому-либо классу. Решение об отнесении неизвестного объекта принимается путем анализа информации о его ближайших соседей. Необходимость сокращения числа объектов в обучающей выборке (диагностических прецедентов) является недостатком данного метода, так как это уменьшает представительность обучающей выборки.
Исходя из того, что различные алгоритмы распознавания проявляют себя по-разному на одной и той же выборке, то встает вопрос о синтетическом решающем правиле, которое бы использовало сильные стороны всех алгоритмов. Для этого существует синтетический метод или коллективы решающих правил, которые объединяют в себе максимально положительные стороны каждого из методов.
В заключение обзора методов распознавания представим суть вышеизложенного в сводной таблице, добавив туда также некоторые другие используемые на практике методы.
Таблица 1. Таблица классификации методов распознавания, сравнения их областей применения и ограничений
|
Классификация методов распознавания |
Область применения |
Ограничения (недостатки) |
|
|
Интенсиальные методы распознавания |
Методы, основанные на оценках плотностей |
Задачи с известным распределением (нормальным), необходимость набора большой статистики |
Необходимость перебора всей обучающей выборки при распознавании, высокая чувствительность к не представительности обучающей выборки и артефактам |
|
Методы, основанные на предположениях |
Классы должны быть хорошо разделяемыми |
Должен быть заранее известен вид решающей функции. Невозможность учета новых знаний о корреляциях между признаками |
|
|
Логические методы |
Задачи небольшой размерности |
При отборе логических решающих правил необходим полный перебор. Высокая трудоемкость |
|
|
Лингвистические методы |
Задача определения грамматики по некоторому множеству высказываний (описаний объектов), является трудно формализуемой. Нерешенность теоретических проблем |
||
|
Экстенсиальные методы распознавания |
Метод сравнения с прототипом |
Задачи небольшой размерности пространства признаков |
Высокая зависимость результатов классификации от метрики. Неизвестность оптимальной метрики |
|
Метод k ближайших соседей |
Высокая зависимость результатов классификации от метрики. Необходимость полного перебора обучающей выборки при распознавании. Вычислительная трудоемкость |
||
|
Алгоритмы вычисления оценок (АВО) |
Задачи небольшой размерности по количеству классов и признаков |
Зависимость результатов классификации от метрики. Необходимость полного перебора обучающей выборки при распознавании. Высокая техническая сложность метода |
|
|
Коллективы решающих правил (КРП) - синтетический метод. |
Задачи небольшой размерности по количеству классов и признаков |
Очень высокая техническая сложность метода, нерешенность ряда теоретических проблем, как при определении областей компетенции частных методов, так и в самих частных методах |
Лекция № 17. МЕТОДЫ РАСПОЗНАВАНИЯ ОБРАЗОВ
Различают следующие группы методов распознавания:
Методы функций близости
Методы дискриминантных функций
Статистические методы распознавания.
Лингвистические методы
Эвристические методы.
Первые три группы методов ориентированы на анализ признаков, выражаемых числами либо векторами с числовыми компонентами.
Группа лингвистических методов обеспечивает распознавание образов на основе анализа их структуры, описываемой соответствующими структурными признаками и отношениями между ними.
Группа эвристических методов объединяет характерные приемы и логические процедуры, используемые человеком при распознавании образов.
Методы функций близости
Методы данной группы основаны на использовании функций, оценивающих меру близости между распознаваемым образом с вектором x * = (x * 1 ,….,x * n ), и эталонными образами различных классов, представленными векторами x i = (x i 1 ,…, x i n ), i= 1,…,N , где i – номер класса образов.
Процедура распознавания согласно данному методу состоит в вычислении расстояния между точкой распознаваемого образа и каждой из точек, представляющих эталонный образ, т.е. в вычислении всех значений d i , i= 1,…,N . Образ относится к классу, для которого значение d i имеет наименьшее значение среди всех i= 1,…,N .
Функция, ставящая в соответствие каждой паре векторов x i , x * вещественное число как меру их близости, т.е. определяющая расстояние между ними может быть достаточно произвольной. В математике такую функцию называют метрикой пространства. Она должна удовлетворять следующим аксиомам:
r (x,y )= r (y,x );
r (x,y ) > 0, если x не равен y и r (x,y )=0 если x=y ;
r (x,y ) <= r (x,z )+ r (z,y )
Перечисленным аксиомам удовлетворяют, в частности, следующие функции
a i = 1/2 , j =1,2,…n .
b i =sum, j =1,2,…n .
c i =max abs (x i ‑ x j * ), j =1,2,…n .
Первая из них называется евклидовой нормой векторного пространства. Соответственно пространства, в которых в качестве метрики используется указанная функция называется Евклидовым пространством.
Часто в качестве функции близости выбирают среднеквадратическую разность координат распознаваемого образа x * и эталона x i , т.е. функцию
d i = (1/n ) sum(x i j ‑ x j * ) 2 , j =1,2,…n .
Величина d i геометрически интерпретируется как квадрат расстояния между точками в пространстве признаков, отнесенный к размерности пространства.
Часто оказывается, что разные признаки неодинаково важны при распознавании. С целью учета данного обстоятельства при вычислении функций близости разности координат, соответствующие более важным признакам умножают на большие коэффициенты, а менее важным – на меньшие.
В таком случае d i = (1/n ) sum w j (x i j ‑ x j * ) 2 , j =1,2,…n ,
где w j – весовые коэффициенты.
Введение весовых коэффициентов эквивалентно масштабированию осей пространства признаков и, соответственно растяжению либо сжатию пространства в отдельных направлениях.
Указанные деформации пространства признаков преследуют цель такого размещения точек эталонных образов, которое соответствует наиболее надежному распознаванию в условиях значительного разброса образов каждого класса в окрестности точки эталонного образа.
Группы близких друг другу точек образов (скопления образов) в пространстве признаков называют кластерами, а задачу выделения таких групп – задачей кластеризации.
Задачу выявления кластеров относят к задачам распознавания образов без учителя, т.е. к задачам распознавания в условиях отсутствия примера правильного распознавания.
Методы дискриминантных функций
Идея методов данной группы состоит в построении функций, определяющих в пространстве образов границы, разделяющие пространство на области, соответствующие классам образов. Простейшими и наиболее часто используемыми функциями такого рода являются функции, линейно зависящие от значений признаков. Им в пространстве признаков соответствуют разделяющие поверхности в виде гиперплоскостей. В случае двумерного пространства признаков в качестве разделяющей функции выступает прямая линия.
Общий вид линейной решающей функции задается формулой
d (x )=w 1 x 1 + w 2 x 2 +…+ w n x n + w n +1 = Wx +w n
где x - вектор образа, w= ( w 1 , w 2 ,…w n ) – вектор весовых коэффициентов.
В случае разбиения на два класса X 1 и X 2 дискриминантная функция d (x) позволяет осуществить распознавание в соответствии с правилом:
x принадлежит X 1 , если d (x )>0;
x принадлежит X 2 , если d (x )<0.
Если d (x )=0, то имеет место случай неопределенности.
В случае разбиения на несколько классов вводится несколько функций. При этом каждому классу образов ставится в соответствие определенная комбинация знаков дискриминационных функций.
Например, если введены три дискриминантные функции, то возможен следующий вариант выделения классов образов:
x принадлежит X 1 , если d 1 (x )>0, d 2 (x )<0, d 3 (x )<0;
x принадлежит X 2 , если d (x )<0, d 2 (x )>0, d 3 (x )<0;
x принадлежит X 3 , если d (x )<0, d 2 (x )<0, d 3 (x )>0.
При этом считается, что для других комбинаций значений d 1 (x ), d 2 (x ), d 3 (x ) имеет место случай неопределенности.
Разновидностью метода дискриминантных функций является метод решающих функций. В нем при наличии m классов предполагается существование m функций d i (x ), называемых решающими, таких, что если x принадлежит X i , то d i (x ) > d j (x ) для всех j не равных i ,т.е. решающая функция d i (x ) имеет максимальное значение среди всех функций d j (x ), j =1,...,n ..
Иллюстрацией такого метода может служить классификатор, основанный на оценке минимума евклидова расстояния в пространстве признаков между точкой образа и эталоном. Покажем это.
Евклидово расстояние между вектором признаков распознаваемого образа x и вектором эталонного образа определяется формулой ||x i ‑ x || = 1/2 , j =1,2,…n .
Вектор x будет отнесен к классу i , для которого значение ||x i ‑ x * || минимально.
Вместо расстояния можно сравнивать квадрат расстояния, т.е.
||x i ‑ x || 2 = (x i ‑ x )( x i ‑ x ) т = x x - 2x x i + x i x i
Поскольку величина x x одинакова для всех i , минимум функции ||x i ‑ x || 2 будет совпадать с максимумом решающей функции
d i (x ) = 2x x i - x i x i .
то есть x принадлежит X i , если d i (x ) > d j (x ) для всех j не равных i .
Т.о. машина, классифицирующая по минимуму расстояния, основывается на линейных решающих функциях. Общая структура такой машины, использует решающие функции вида
d i (x )=w i 1 x 1 + w i 2 x 2 +…+ w in x n + w i n +1
Она может быть наглядно представлена соответствующей структурной схемой.
Для машины, осуществляющей классификацию по минимуму расстояния имеют место равенства: w ij = -2x i j , w i n +1 = x i x i .
Эквивалентное распознавание методом дискриминантных функций может быть осуществлено, если определить дискриминантные функции как разности d ij (x )= d i (x )‑ d j (x ).
Достоинством метода дискриминантных функций является простая структура распознающей машины, а также возможность ее реализации преимущественно посредством преимущественно линейных решающих блоков.
Еще одним важным достоинством метода дискриминаннтных функций является возможность автоматического обучения машины правильному распознаванию по заданной (обучающей) выборке образов.
При этом алгоритм автоматического обучения оказывается весьма простым в сравнении с другими методами распознавания.
В силу указанных причин метод дискриминантных функций завоевал широкую популярность весьма часто используется на практике.
Процедуры самообученя распознаванию образов
Рассмотрим методы построения дискриминантной функции по заданной (обучающей) выборке применительно к задаче о разделении образов на два класса. Если заданы два множества образов, принадлежащих соответственно классам А и В, то решение задачи построения линейной дискриминантной функции ищется в виде вектора весовых коэффициентов W =(w 1 ,w 2 ,...,w n ,w n +1), обладающего тем свойством, что для любого образа выполняются условия
x принадлежит классу A, если >0, j =1,2,…n .
x принадлежит классу B, если <0, j =1,2,…n .
Если обучающую выборку составляют N образов обоих классов, задача сводится к отысканию вектора w, обеспечивающего справедливость системы неравенств Если обучающую выборку составляют N образов обоих классов, задача сводится к отысканию вектора w , обеспечивающего справедливость системы неравенств
x 1 1 w i +x 21 w 2 +...+x n 1 w n +w n +1 >0;
x 1 2 w i +x 22 w 2 +...+x n 2 w n +w n +1 <0;
x 1 i w i +x 2i w 2 +...+x ni w n +w n +1 >0;
................................................
x 1 N w i +x 2N w 2 +...+x nN w n +w n + 1>0;
здесь x i =(x i 1 ,x i 2 ,...,x i n ,x i n+ 1 ) - вектор значений признаков образа из обучающей выборки, знак > соответствует векторам образов x , принадлежащих классу A, а знак < - векторам x , принадлежащих классу B.
Искомый вектор w существует, если классы A и B разделимы и не существует в противном случае. Значения компонент вектора w могут быть найдены либо предварительно, на этапе, предшествующем аппаратной реализации СРО, либо непосредственно самой СРО в процессе ее функционирования. Последний из указанных подходов обеспечивает большую гибкость и автономность СРО. Рассмотрим его на примере устройства, называемого перцентроном. изобретенного в 1957 году американским ученым Розенблатом. Схематичное представление перцентрона, обеспечивающего отнесение образа к одному из двух классов, представлено на следующем рисунке.
Сетчатка S Сетчатка A Сетчатка R
о о x 1
о о x 2
о о x 3
о (sum)-------> R (реакция)
о о x i
о о x n
о о x n +1
Устройство состоит из сетчатки сенсорных элементов S , которые случайным образом соединены с ассоциативными элементами сетчатки A . Каждый элемент второй сетчатки воспроизводит выходной сигнал только в том случае, если достаточное число сенсорных элементов, соединенных с его входом, находятся в возбужденном состоянии. Реакция всей системы R пропорциональна сумме взятых с определенными весами реакций элементов ассоциативной сетчатки.
Обозначив через x i реакцию i -го ассоциативного элемента и через w i - весовой коэффициент реакции i -го ассоциативного элемента, реакцию системы можно записать как R =sum(w j x j ), j =1,..,n . Если R >0, то предъявленный системе образ принадлежит классу A, а если R <0, то образ относится к классу B. Описание этой процедуры классификации соответствует рассмотренным нами раньше принципам классификации, и, очевидно, перцентронная модель распознавания образов представляет собой, за исключением сенсорной сетчатки, реализацию линейной дискриминантной функции. Принятый в перцентроне принцип формирования значений x 1 , x 2 ,...,x n соответствует некоторому алгоритму формирования признаков на основе сигналов первичных датчиков.
В общем случае может быть несколько элементов R , формирующих реакцию перцептрона. В таком случае говорят о присутствии в перцептроне сетчатки R реагирующих элементов.
Схему перцентрона можно распространить на случай, когда число классов более двух, путем увеличения числа элементов сетчатки R до числа различаемых классов и введение блока определения максимальной реакции в соответствии со схемой, представленной на выше приведенном рисунке. При этом образ причисляется к классу с номером i , если R i >R j , для всех j .
Процесс обучения перцентрона состоит в подборе значений весовых коэффициентов w j так, чтобы выходной сигнал соответствовал тому классу, которому принадлежит распознаваемый образ.
Рассмотрим алгоритм действия перцентрона на примере распознавания объектов двух классов: A и B. Объектам класса A должно соответствовать значение R = +1, а классу B - значение R = -1.
Алгоритм обучения состоит в следующем.
Если очередной образ x принадлежит классу A, но R <0 (имеет место ошибка распознавания), тогда коэффициенты w j c индексами, которым соответствуют значения x j >0, увеличивают на некоторую величину dw , а остальные коэффициенты w j уменьшают на dw . При этом значение реакции R получает приращение в сторону ее положительных значений, соответствующих правильной классификации.
Если x принадлежит классу B, но R >0 (имеет место ошибка распознавания), то коэффициенты w j с индексами, которым соответствуют x j <0, увеличивают на dw , а остальные коэффициенты w j уменьшают на ту же величину. При этом значение реакции R получает приращение в сторону отрицательных значений, соответствующих правильной классификации.
Алгоритм таким образом вносит изменение в вектор весов w в том и только в том случае, если образ, предъявляемый на k -ом шаге обучения, был при выполнении этого шага неправильно классифицирован, и оставляет вектор весов w без изменений в случае правильной классификации. Доказательство сходимости данного алгоритма представлено в работе [Ту, Гонсалес]. Такое обучение в конечном итоге (при надлежащем выборе dw и линейной разделимости классов образов) приводит к получению вектора w , обеспечивающего правильную классификацию.
Статистические методы распознавания.
Статистические методы основываются на минимизации вероятности ошибки классификации. Вероятность P неправильной классификации поступившего на распознавание образа, описываемого вектором признаков x , определяется формулой
P = sum[p (i )·prob(D (x )+i | x классу i )]
где m - число классов,
p (i ) = prob (x принадлежит классу i ) - априорная вероятность принадлежности произвольного образа x к i -му классу (частота появления образов i -го класса),
D (x ) - функция, принимающая классификационное решение (вектору признаков x ставит в соответствие номер класса i из множества {1,2,...,m }),
prob(D (x ) не равно i | x принадлежит классу i ) - вероятность события "D (x ) не равно i " при выполнении условия принадлежности x классу i , т.е. вероятность вынесения ошибочного решения функцией D (x ) для данного значения x , принадлежащего i -му классу.
Можно показать, что вероятность неправильной классификации достигает минимума, если D (x )=i в том и только в том случае, если p (x |i )·p (i )>p (x|j )·p (j ), для всех i+j , где p (x|i ) - плотность распределения образов i -го класса в пространстве признаков.
Согласно приведенному правилу точка x относится к тому классу, которому соответствует максимальное значение p (i ) p (x|i ), т.е. произведение априорной вероятности (частоты) появления образов i -го класса и плотности распределения образов i -го класса в пространстве признаков. Представленное правило классификации называется байесовским, т.к. оно следует из известной в теории вероятности формулы Байеса.
Пример. Пусть необходимо осуществить распознавание дискретных сигналов на выходе информационного канала, подверженного воздействию шума.
Каждый входной сигнал представляет собой 0 или 1. В результате передачи сигнала на выходе канала появляется величина x , на которую налагается Гауссовский шум с нулевым средним значением и дисперсией б.
Воспользуемся для синтеза классификатора, осуществляющего распознавание сигналов, байесовским правилом классификации.
В класс №1 объединим сигналы, представляющие единицы, в класс №2 - сигналы, представляющие нули. Пусть заранее известно, что в среднем из каждой 1000 сигналов a сигналов представляют собой единицы и b сигналов - нули. Тогда значения априорных вероятностей появления сигналов 1-го и 2-го классов (единиц и нулей), соответственно можно принять равными
p(1)=a/1000, p(2)=b/1000.
Т.к. шум является гауссовским, т.е. подчиняется нормальному (гауссовскому) закону распределения, то плотность распределения образов первого класса в зависимости от значения x , или, что тоже самое, вероятность получения на выходе величины x при подаче на входе сигнала 1 определяется выражением
p (x ¦1) =(2piб) -1/2 exp(-(x -1) 2 /(2б 2)),
а плотность распределения в зависимости от значения x образов второго класса, т.е. вероятность получения на выходе величины x при подаче на входе сигнала 0 определяется выражением
p (x ¦2)= (2piб) -1/2 exp(-x 2 /(2б 2)),
Применение байесовского решающего правила приводит к выводу, что передан сигнал класса 2, т.е. передан ноль, если
p (2) p (x ¦2) > p (1) p (x ¦1)
или, более конкретно, если
b exp(-x 2 /(2б 2)) > a exp(-(x -1) 2 /(2б 2)),
Поделив левую часть неравенства на правую, получим
(b /a ) exp((1-2 x )/(2б 2)) >1,
откуда после логарифмирования находим
1-2x > 2б 2 ln(a/b)
x < 0.5 - б 2 ln(a/b)
Из полученного неравенства следует, что при a=b , т.е. при одинаковых априорных вероятностях появления сигналов 0 и 1, образу присваивается значение 0 когда x <0.5, а значение 1, когда x >0.5.
Если заранее известно, что один из сигналов появляется чаще, а другой реже, т.е. в случае неодинаковых значений a и b , порог срабатывания классификатора смещается в ту или другую сторону.
Так при a/b =2.71 (что соответствует в 2.71 раза более частой передаче единиц) и б 2 =0.1, образу присваивается значение 0, если x <0.4, и значение 1, если x >0.4. Если информация об априорных вероятностях распределения отсутствует, то могут быть использованы статистические методы распознавания, в основу которых положены иные, отличные от байесовского, правила классификации.
Однако, на практике наиболее распространены методы, основанные на правилах Байеса в силу их большей эффективности, а также в связи с тем обстоятельством, что в большинстве задач распознавания образов оказывается возможным задать априорные вероятности появления образов каждого класса.
Лингвистические методы распознавания образов.
Лингвистические методы распознавания образов основываются на анализе описания идеализированного изображения, представленного в виде графа или цепочки символов, являющейся фразой или предложением некоторого языка.
Рассмотрим идеализированные изображения букв, полученные в результате первого этапа лингвистического распознавания, описанного выше. Эти идеализированные изображения можно задать описаниями графов, представленных, например, в виде матриц связей, как это было сделано в рассмотренном выше примере. Это же описание можно представить фразой формального языка (выражением).
Пример. Пусть заданы три изображения буквы А, полученные в результате предварительной обработки изображений. Обозначим эти изображения идентификаторами А1, А2 и А3.
Для лингвистического описания представленных образов воспользуемся языком PDL (Picture Description Language). Словарь языка PDL включает следующие символы:
1. Имена простейших изображений (примитивов). Применительно к рассматриваемому случаю примитивы и соответствующие им имена следующие.
Изображения в виде линии, направленной:
вверх и влево (leF t), на север(north)), вверх и вправо (right), на восток(east)).
Имена: L, N, R, E .
2. Символы бинарных операций. {+,*,-} Их смысл соответствует последовательному соединению примитивов (+), соединению начал и окончаний примитивов (*), соединению только окончаний примитивов (-).
3. Правую и левую скобки. {(,)} Скобки позволяют определять последовательность выполненияопераций в выражении.
Рассматриваемые изображения А1, А2 и А3 описываются на языке PDL соответственно следующими выражениями.
T(1)=R+((R-(L+N))*E-L
T(2)=(R+N)+((N+R)-L)*E-L
T(3)=(N+R)+(R-L)*E-(L+N)
После того как лингвистическое описание изображения построено, необходимо с помощью некоторой распознающей процедуры проанализировать, принадлежит или нет данное изображение к интересующему нас классу (классу букв А), т.е. обладает или нет это изображение некоторой структурой. Для этого прежде всего необходимо описать класс изображений, имеющих интересующую нас структуру.
Очевидно, буква А всегда содержит следующие структурные элементы: левую "ножку", правую "ножку" и головную часть. Назовем эти элементы соответственно STL, STR, TR.
Тогда на языке PDL класс символов А - SIMB A описывается выражением
SIMB A = STL + TR - STR
Левая "ножка" STL всегда есть цепочка элементов R и N, что можно записать так
STL ‑> R ¦ N ¦ (STL + R)¦(STL + N)
(STL есть символ R или N, или цепочка, полученная добавлением кисходной цепочке STL символов R или N)
Правая "ножка" STR всегда есть цепочка элементов L и N, что можно записать так, т.е.
STR ‑> L¦N¦ (STR + L)¦(STR + N)
Головная часть буквы - TR представляет собой замкнутый контур, составленный из элемента E и цепочек типа STL и STR.
На языке PDLструктура TR описывается выражением
TR ‑> (STL - STR) * E
Окончательно получим следующее описание класса букв А:
SIMB A ‑> (STL + TR - STR),
STL ‑> R¦N¦ (STL + R)¦(STL + N)
STR ‑> L¦N¦ (STR + L)¦(STR + N)
TR ‑> (STL - STR) * E
Процедура распознавания в данном случае может быть реализована следующим образом.
1. Выражение, соответствующее образу, сравнивается с эталоннойструктурой STL + TR - STR.
2. Каждому элементу структуры STL, TR, STR, если это возможно, т.е. если описание изображения сравнимо с эталоном, ставится в соответствиенекоторое подвыражение из выражения T(А). Например,
для А1: STL=R, STR=L, TR=(R-(L+N))*E
для А2: STL = R + N, STR = L, TR = ((N + R) - L) * E
для А3: STL = N + R, STR = L + N, TR = (R - L) * E 3.
Выражения STL, STR, TR сравниваются с соответствующими им эталонными структурами.
4. Если структура каждого выражения STL, STR, TR соответствует эталонной, делается вывод о принадлежности образа к классу букв А. Если на каком-либо из этапов 2, 3, 4 обнаруживается несоответствие структуры анализируемого выражения эталону, делается вывод о непринадлежности образа классу SIMB A. Сопоставление структур выражений может проводиться с помощью алгоритмических языков LISP, PLANER, PROLOG и других подобных им языков искусственного интеллекта.
В рассматриваемом примере все цепочки STL составлены из символов N и R, а цепочки STR из символов L и N, что соответствует заданной структуре этих цепочек. Структура TR в рассматриваемых образах также соответствует эталонной, т.к. состоит из "разности" цепочек типа STL, STR, "умноженной" на символ E.
Т.о., приходим к выводу о принадлежности рассматриваемых образов классу SIMB A.
Синтез нечеткого регулятора электропривода постоянного тока в среде «MatLab»
Синтез нечеткого регулятора с одним входом и выходом.
Проблема состоит в том, чтобы заставить привод точно следить за различными входными сигналами. Выработка управляющего воздействия осуществляется нечетким регулятором, в котором структурно можно выделить следующие функциональные блоки: фаззификатор, блок правил и дефаззификатор.
Рис.4 Обобщенная функциональная схема системы с двумя лингвистическими переменными.
 Рис.5 Принципиальная схема нечеткого регулятора с двумя лингвистическими переменными.
Рис.5 Принципиальная схема нечеткого регулятора с двумя лингвистическими переменными.
Алгоритм нечеткого управления в общем случае представляет собой преобразование входных переменных нечеткого регулятора в его выходные переменные с помощью следующих взаимосвязанных процедур:
1. преобразование входных физических переменных, получаемых от измерительных датчиков с объекта управления во входные лингвистические переменные нечеткого регулятора;
2. обработка логических высказываний, называемых лингвистическими правилами, относительно входных и выходных лингвистических переменных регулятора;
3. преобразование выходных лингвистических переменных нечеткого регулятора в физические управляющие переменные.
Рассмотрим сначала самый простой случай, когда для управления следящим электроприводом вводятся всего две лингвистические переменные:
«угол» - входная переменная;
«управляющее воздействие» - выходная переменная.
Синтез регулятора будем осуществлять в среде «MatLab» с помощью тулбокса «Fuzzy Logic». Он позволяет создавать системы нечеткого логического вывода и нечеткой классификации в рамках среды MatLab, с возможностью их интегрирования в Simulink. Базовым понятием Fuzzy Logic Toolbox является FIS-структура - система нечеткого вывода (Fuzzy Inference System). FIS-структура содержит все необходимые данные для реализации функционального отображения “входы-выходы” на основе нечеткого логического вывода согласно схеме, приведенной на рис. 6.

Рисунок 6. Нечеткий логический вывод.
X - входной четкий вектор; - вектор нечетких множеств, соответствующий входному вектору X;
- результат логического вывода в виде вектора нечетких множеств;Y - выходной четкий вектор.
Модуль fuzzy позволяет строить нечеткие системы двух типов - Мамдани и Сугэно. В системах типа Мамдани база знаний состоит из правил вида “Если x 1 =низкий и x 2 =средний, то y=высокий” . В системах типа Сугэно база знаний состоит из правил вида “Если x 1 =низкий и x 2 =средний, то y=a 0 +a 1 x 1 +a 2 x 2 " . Таким образом, основное отличие между системами Мамдани и Сугэно заключается в разных способах задания значений выходной переменной в правилах, образующих базу знаний. В системах типа Мамдани значения выходной переменной задаются нечеткими термами, в системах типа Сугэно - как линейная комбинация входных переменных. В нашем случаем будем использовать систему Сугэно, т.к. она лучше поддается оптимизации.
Для управления следящим электроприводом, вводятся две лингвистические переменные: «ошибка» (по положению) и «управляющее воздействие». Первая из них является входной, вторая – выходная. Определим терм-множество для указанный переменных.
Основные компоненты нечеткого логического вывода. Фаззификатор.
Для каждой лингвистической переменной определим базовое терм-множество вида, включающее в себя нечеткие множества, которые можно обозначить: отрицательная высокая, отрицателная низкая, нуль, положительная низкая, положительная высокая.
Прежде всего субъективно определим что подразумевается под термами «большая ошибка», «малая ошибка» и т.д., определяя функции принадлежности для соответствующих нечетких множеств. Здесь пока можно руководствоваться только требуемой точностью, известными параметрами для класса входных сигналов и здравым смыслом. Никакого жесткого алгоритма для выбора параметров функций принадлежности пока никому предложить не удалось. В нашем случае лингвистическая переменная «ошибка» будет выглядеть следующим образом.
 Рис.7. Лингвистическая переменная «ошибка».
Рис.7. Лингвистическая переменная «ошибка».
Лингвистическую переменную «управление» удобнее представить в виде таблицы:
Таблица 1
Блок правил .
Рассмотрим последовательность определения нескольких правил, которые описывают некоторые ситуации:
Предположим, например, что выходной угол равен входному сигналу (т.е. ошибка - нуль). Очевидно, что это желаемая ситуация, и следовательно мы не должны ничего делать (управляющее воздействие - нуль).
Теперь рассмотрим другой случай: ошибка по положению сильно больше нуля. Естественно мы должны её компенсировать, формируя большой положительный сигнал управления.
Т.о. составлены два правила, которые могут быть формально определены так:
если ошибка = нуль, то управляющее воздействие = нуль.
если ошибка = большая положительная, то управляющее воздействие = большое положительное.
 Рис.8. Формирование управления при малой положительной ошибке по положению.
Рис.8. Формирование управления при малой положительной ошибке по положению.
 Рис.9. Формирование управления при нулевой ошибке по положению.
Рис.9. Формирование управления при нулевой ошибке по положению.
Ниже в таблице приведены все правила, соответствующие всем ситуациям для этого простого случая.
Таблица 2
Всего для нечеткого регулятора, имеющего n входов и 1 выход может быть определено правил управления, где – количество нечетких множеств для i-го входа, но для нормального функционирования регулятора не обязательно использовать все возможные правила, а можно обойтись и меньшим их числом. В нашем случае для формирования нечеткого сигнала управления используются все 5 возможных правил.
Дефаззификатор.
Таким образом, результирующее воздействие U будет определяться соответственно выполнению какого-либо правила. Если возникает ситуация, когда выполняются сразу несколько правил, то результирующее воздействие U находится по следующей зависимости:
 , где n-число сработавших правил (дефаззификация методом центра области), u n
– физическое значение управляющего сигнала, сответствующее каждому из нечетких множеств UBO
, UMo
, U
Z
, UMp
, UB
P
. m
Un(u)
– степень принадлежности управляющего сигнала u к соответствующему нечеткому множеству Un={UBO
, UMo
, U
Z
, UMp
, UB
P
}. Существуют также и другие методы дефаззификации, когда выходная лингвистическая переменная пропорциональна самомому «сильному» или «слабому» правилу.
, где n-число сработавших правил (дефаззификация методом центра области), u n
– физическое значение управляющего сигнала, сответствующее каждому из нечетких множеств UBO
, UMo
, U
Z
, UMp
, UB
P
. m
Un(u)
– степень принадлежности управляющего сигнала u к соответствующему нечеткому множеству Un={UBO
, UMo
, U
Z
, UMp
, UB
P
}. Существуют также и другие методы дефаззификации, когда выходная лингвистическая переменная пропорциональна самомому «сильному» или «слабому» правилу.
Промоделируем процесс управления электроприводом с помощью вышеописанного нечеткого регулятора.
 Рис.10. Структурная схема системы в среде
Matlab
.
Рис.10. Структурная схема системы в среде
Matlab
.

Рис.11. Структурная схема нечеткого регулятора в среде Matlab .

Рис.12. Переходный процесс при единичном ступенчатом воздействии.

Рис. 13. Переходный процесс при гармоническом входном воздействии для модели с нечетким регулятором, содержащим одну входную лингвистическую переменную.
Анализ характеристик привода с синтезированным алгоритмом управления показывает, что они далеки от оптимальных и хуже, чем при синтезе управления другими методами (слишком большое время регулирования при единичном ступенчатом воздействии и ошибка при гармоническом). Объясняется это тем, что параметры функций принадлежности выбирались достаточно произвольно, а в качестве входов регулятора использовалась только величина ошибки по положению. Естественно ни о какой оптимальности полученного регулятора не может идти и речи. Поэтому актуальной становится задача оптимизации нечеткого регулятора, с целью достижения им максимально возможных показателей качества управления. Т.е. стоит задача оптимизации целевой функции f(a 1 ,a 2 …a n), где a 1 ,a 2 …a n – коэффициенты, определяющие вид и характеристики нечеткого регулятора. Для оптимизации нечеткого регулятора воспользуемся блоком ANFIS из среды Matlab. Также одним из способов улучшения характеристик регулятора может являться увеличение числа его входов. Это сделает регулятор более гибким и улучшит его характеристики. Добавим еще одну входную лингвистическую переменную – скорость изменения входного сигнала (его производную). Соответственно возрастет и число правил. Тогда принципиальная схема регулятора примет вид:

Рис.14 Принципиальная схема нечеткого регулятора с тремя лингвистическими переменными.
Пусть - значение скорости входного сигнала. Базовое терм-множество Тn определим в виде:
Тn={”отрицательная (ВО)”, “нулевая (Z)”, ”положительная (ВР)”}.
Расположение функций принадлежности для всех лингвистических переменных показано на рисунке.
Рис.15. Функции принадлежности лингвистической переменной «ошибка».

Рис.16. Функции принадлежности лингвистической переменной «скорость входного сигнала» .
В связи с добавлением еще одной лингвистической переменной, количество правил возрастет до 3x5=15. Принцип их составления полностью аналогичен рассмотренному выше. Все они приведены в следующей таблице:
Таблица 3
| Нечеткий сигнал управления | Ошибка по положению |
|||||
| Скорость | ||||||
Например, если если ошибка = нуль, а производная входного сигнала = большая положительная, то управляющее воздействие = малое отрицательное.
 Рис.17. Формирование управления при трех лингвистических переменных.
Рис.17. Формирование управления при трех лингвистических переменных.
В связи с увеличением числа входов и соответственно самих правил, усложнится и структура нечеткого регулятора.
 Рис.18. Структурная схема нечеткого регулятора с двумя входами.
Рис.18. Структурная схема нечеткого регулятора с двумя входами.
Добавить рисунок

Рис.20. Переходный процесс при гармоническом входном воздействии для модели с нечетким регулятором, содержащим две входные лингвистические переменные.

Рис. 21. Сигнал ошибки при гармоническом входном воздействии для модели с нечетким регулятором, содержащим две входные лингвистические переменные.
Промоделируем работу нечеткого регулятора с двумя входами в среде Matlab. Структурная схема модели будет точно такой же, как на рис. 19. Из графика переходного процесса для гармонического входного воздействия можно видеть, что точность системы значительно возросла, но при этом увеличилась её колебательность, особенно в местах, где производная выходной координаты стремится к нулю. Очевидно, что причинами этого, как уже говорилось выше, является неоптимальный выбор параметров функций принадлежности, как для входных, так и для выходных лингвистических переменных. Поэтому оптимизируем нечеткий регулятор с помощью блока ANFISedit в среде Matlab.
Оптимизация нечеткого регулятора.
Рассмотрим использование генетических алгоритмов для оптимизации нечеткого регулятора. Генетические алгоритмы – адаптивные методы поиска, которые в последнее время часто используются для решения задач функциональной оптимизации. Они основаны на подобии генетическим процессам биологических организмов: биологические популяции развиваются в течении нескольких поколений, подчиняясь законам естественного отбора и по принципу "выживает наиболее приспособленный" (survival of the fittest), открытому Чарльзом Дарвином. Подражая этому процессу генетические алгоритмы способны "развивать" решения реальных задач, если те соответствующим образом закодированы.
Генетические алгоритмы работают с совокупностью "особей" - популяцией, каждая из которых представляет возможное решение данной проблемы. Каждая особь оценивается мерой ее "приспособленности" согласно тому, насколько "хорошо" соответствующее ей решение задачи. Наиболее приспособленные особи получают возможность "воспроизводить" потомство с помощью "перекрестного скрещивания" с другими особями популяции. Это приводит к появлению новых особей, которые сочетают в себе некоторые характеристики, наследуемые ими от родителей. Наименее приспособленные особи с меньшей вероятностью смогут воспроизвести потомков, так что те свойства, которыми они обладали, будут постепенно исчезать из популяции.
Так и воспроизводится вся новая популяция допустимых решений, выбирая лучших представителей предыдущего поколения, скрещивая их и получая множество новых особей. Это новое поколение содержит более высокое соотношение характеристик, которыми обладают хорошие члены предыдущего поколения. Таким образом, из поколения в поколение, хорошие характеристики распространяются по всей популяции. В конечном итоге, популяция будет сходиться к оптимальному решению задачи.
Имеются много способов реализации идеи биологической эволюции в рамках генетических алгоритмов. Традиционный, можно представить в виде следующей блок-схемы показанной на рисунке 22, где:
1. Инициализация начальной популяции – генерация заданного числа решений задачи, с которых начинается процесс оптимизации;
2. Применение операторов кроссовера и мутации;
3.  Условия останова – обычно процесс оптимизации продолжают до тех пор, пока не будет найдено решение задачи с заданной точностью, или пока не будет выявлено, что процесс сошелся (т.е. не произошло улучшения решения задачи за последние N поколений).
Условия останова – обычно процесс оптимизации продолжают до тех пор, пока не будет найдено решение задачи с заданной точностью, или пока не будет выявлено, что процесс сошелся (т.е. не произошло улучшения решения задачи за последние N поколений).
В среде Matlab генетические алгоритмы представлены отдельным тулбоксом, а также пакетом ANFIS. ANFIS - это аббревиатура Adaptive-Network-Based Fuzzy Inference System - адаптивная сеть нечеткого вывода. ANFIS является одним из первых вариантов гибридных нейро-нечетких сетей - нейронной сети прямого распространения сигнала особого типа. Архитектура нейро-нечеткой сети изоморфна нечеткой базе знаний. В нейро-нечетких сетях используются дифференцируемые реализации треугольных норм (умножение и вероятностное ИЛИ), а также гладкие функции принадлежности. Это позволяет применять для настройки нейро-нечетких сетей быстрые и генетические алгоритмы обучения нейронных сетей, основанные на методе обратного распространения ошибки. Ниже описываются архитектура и правила функционирования каждого слоя ANFIS-сети.
ANFIS реализует систему нечеткого вывода Сугено в виде пятислойной нейронной сети прямого распространения сигнала. Назначение слоев следующее: первый слой - термы входных переменных; второй слой - антецеденты (посылки) нечетких правил; третий слой - нормализация степеней выполнения правил; четвертый слой - заключения правил; пятый слой - агрегирование результата, полученного по различным правилам.
Входы сети в отдельный слой не выделяются. На рис.23 изображена ANFIS-сеть с одной входной переменной («ошибка») и пятью нечеткими правилами. Для лингвистической оценки входной переменной «ошибка» используется 5 термов.

Рис.23. Структура ANFIS -сети.
Введем следующие обозначения, необходимые для дальнейшего изложения:
Пусть - входы сети;
y - выход сети;
Нечеткое правило с порядковым номером r;
m - количество правил,;
Нечеткий терм с функцией принадлежности , применяемый для лингвистической оценки переменной в r-ом правиле (,);
Действительные числа в заключении r-го правила (,).
ANFIS-сеть функционирует следующим образом.
Слой 1. Каждый узел первого слоя представляет один терм с колокообразной функцией принадлежности. Входы сети соединены только со своими термами. Количество узлов первого слоя равно сумме мощностей терм-множеств входных переменных. Выходом узла являются степень принадлежности значения входной переменной соответствующему нечеткому терму:
 ,
,
где a, b и c - настраиваемые параметры функции принадлежности.
Слой 2. Количество узлов второго слоя равно m. Каждый узел этого слоя соответствует одному нечеткому правилу. Узел второго слоя соединен с теми узлами первого слоя, которые формируют антецеденты соответствующего правила. Следовательно, каждый узел второго слоя может принимать от 1 до n входных сигналов. Выходом узла является степень выполнения правила, которая рассчитывается как произведение входных сигналов. Обозначим выходы узлов этого слоя через , .
Слой 3. Количество узлов третьего слоя также равно m. Каждый узел этого слоя рассчитывает относительную степень выполнения нечеткого правила:
Слой 4. Количество узлов четвертого слоя также равно m. Каждый узел соединен с одним узлом третьего слоя а также со всеми входами сети (на рис. 18 связи с входами не показаны). Узел четвертого слоя рассчитывает вклад одного нечеткого правила в выход сети:
Слой 5. Единственный узел этого слоя суммирует вклады всех правил:
![]() .
.
Типовые процедуры обучения нейронных сетей могут быть применены для настройки ANFIS-сети так как, в ней использует только дифференцируемые функции. Обычно применяется комбинация градиентного спуска в виде алгоритма обратного распространения ошибки и метода наименьших квадратов. Алгоритм обратного распространения ошибки настраивает параметры антецедентов правил, т.е. функций принадлежности. Методом наименьших квадратов оцениваются коэффициенты заключений правил, так как они линейно связаны с выходом сети. Каждая итерация процедуры настройки выполняется в два этапа. На первом этапе на входы подается обучающая выборка, и по невязке между желаемым и действительным поведением сети итерационным методом наименьших квадратов находятся оптимальные параметры узлов четвертого слоя. На втором этапе остаточная невязка передается с выхода сети на входы, и методом обратного распространения ошибки модифицируются параметры узлов первого слоя. При этом найденные на первом этапе коэффициенты заключений правил не изменяются. Итерационная процедура настройки продолжается пока невязка превышает заранее установленное значение. Для настройки функций принадлежностей кроме метода обратного распространения ошибки могут использоваться и другие алгоритмы оптимизации, например, метод Левенберга-Марквардта.

Рис.24. Рабочая область ANFISedit.
Попробуем теперь оптимизировать нечеткий регулятор для единичного ступенчатого воздействия. Желаемый переходный процесс имеет приблизительно следующий вид:

Рис.25. Желаемый переходный процесс.
Из графика изображенного на рис. следует, что большую часть времени двигатель должен работать на полную мощность, чтобы обеспечить максимальное быстродействие, а при приближении к желаемому значению должен плавно притормаживать. Руководствуясь этими простыми рассуждениями, в качестве обучающей возьмем следующую выборку значений, представленную ниже в виде таблицы:
Таблица 4
| Значение ошибки | Значение управления |
| Значение ошибки | Значение управления |
| Значение ошибки | Значение управления |

Рис.26. Вид обучающей выборки.
Обучение будем проводить на 100 шагах. Этого более чем достаточно для сходимости используемого метода.

Рис.27. Процесс обучения нейросети.
В процессе обучения параметры функций принадлежности формируются таким образом, чтобы при заданной величине ошибки регулятор создавал необходимое управление. На участке между узловыми точками зависимость управления от ошибки является интерполяцией данных таблицы. Метод интерполяции зависит от способа обучения нейросети. Фактически после обучения модель нечеткого регулятора можно представить нелинейной функцией одной переменной, график которой представлен ниже.

Рис.28. График зависимости управления от ошибки поп положению внутри регулятора.
Сохранив найденные параметры функций принадлежности, промоделируем систему с оптимизированным нечетким регулятором.


Рис. 29. Переходный процесс при гармоническом входном воздействии для модели с оптимизированным нечетким регулятором, содержащим одну входную лингвистическую переменную.
Рис.30. Сигнал ошибки при гармоническом входном воздействии для модели с нечетким регулятором, содержащим две входные лингвистические переменные.
Из графиков следует, что оптимизация нечеткого регулятора с помощью обучения нейросети удалась. Значительно снизилась колебательность и величина ошибки. Поэтому использование нейросети является вполне обоснованным для оптимизации регуляторов, принцип действия которых основан на нечеткой логике. Тем не менее, даже оптимизированный регулятор не может удовлетворить предъявленные требования по точности, поэтому целесообразно рассмотреть еще один способ управления, когда нечеткий регулятор управляет не непосредственно объектом, а занимается соединением нескольких законов управления в зависимости от сложившейся ситуации.
Sun, Mar 29, 2015
В настоящее время существует множество задач, в которых требуется принять некоторое решение в зависимости от присутствия на изображении объекта или классифицировать его. Способность «распознавать» считается основным свойством биологических существ, в то время как компьютерные системы этим свойством в полной мере не обладают.
Рассмотрим общие элементы модели классификации.
Класс - множество объектом имеющие общие свойства. Для объектов одного класса предполагается наличие «схожести». Для задачи распознавания может быть определено произвольное количество классов, больше 1. Количество классов обозначается числом S. Каждый класс имеет свою идентифицирующую метку класса.
Классификация - процесс назначения меток класса объектам, согласно некоторому описанию свойств этих объектов. Классификатор - устройство, которое в качестве входных данных получает набор признаков объекта, а в качестве результата выдающий метку класса.
Верификация - процесс сопоставления экземпляра объекта с одной моделью объекта или описанием класса.
Под образом будем понимать наименование области в пространстве признаков, в которой отображается множество объектов или явлений материального мира. Признак - количественное описание того или иного свойства исследуемого предмета или явления.
Пространство признаков это N-мерное пространство, определенное для данной задачи распознавания, где N - фиксированное число измеряемых признаков для любых объектов. Вектор из пространства признаков x, соответствующий объекту задачи распознавания это N-мерный вектор с компонентами (x_1,x_2,…,x_N), которые являются значениями признаков для данного объекта.
Другими словами, распознавание образов можно определить, как отнесение исходных данных к определенному классу с помощью выделение существенных признаков или свойств, характеризующих эти данные, из общей массы несущественных деталей.
Примерами задач классификации являются:
- распознавание символов;
- распознавание речи;
- установление медицинского диагноза;
- прогноз погоды;
- распознавание лиц
- классификация документов и др.
Чаще всего исходным материалом служит полученное с камеры изображение. Задачу можно сформулировать как получение векторов признаков для каждого класса на рассматриваемом изображении. Процесс можно рассматривать как процесс кодирования, заключающийся в присвоении значения каждому признаку из пространства признаков для каждого класса.
Если рассмотреть 2 класса объектов: взрослые и дети. В качестве признаков можно выбрать рост и вес. Как следует из рисунка эти два класса образуют два непересекающихся множества, что можно объяснить выбранными признаками. Однако не всегда удается выбрать правильные измеряемые параметры в качестве признаков классов. Например выбранные параметры не подойдут для создания непересекающихся классов футболистов и баскетболистов.
Второй задачей распознавания является выделение характерных признаков или свойств из исходных изображений. Эту задачу можно отнести к предварительной обработке. Если рассмотреть задачу распознавания речи, можно выделить такие признаки как гласные и согласные звуки. Признак должен представлять из себя характерное свойство конкретного класса, при этом общие для этого класса. Признаки, характеризующие отличия между - межклассовые признаки. Признаки общие для всех классов не несут полезной информации и не рассматриваются как признаки в задаче распознавания. Выбор признаков является одной из важных задач, связанных с построением системы распознавания.
После того, как определены признаки необходимо определить оптимальную решающую процедуру для классификации. Рассмотрим систему распознавания образов, предназначенную для распознавания различных M классов, обозначенных как m_1,m_2,…,m3. Тогда можно считать, что пространство образов состоит из M областей, каждая содержит точки, соответствующие образом из одного класса. Тогда задача распознавания может рассматриваться как построение границ, разделяющих M классов, исходя из принятых векторов измерений.
Решение задачи предварительной обработки изображения, выделение признаков и задачи получения оптимального решения и классификации обычно связано с необходимостью произвести оценку ряда параметров. Это приводит к задаче оценки параметров. Кроме того, очевидно, что выделение признаков может использовать дополнительную информацию исходя из природы классов.
Сравнение объектов можно производить на основе их представления в виде векторов измерений. Данные измерений удобно представлять в виде вещественных чисел. Тогда сходство векторов признаков двух объектов может быть описано с помощью евклидова расстояния.

где d - размерность вектора признака.
Разделяют 3 группы методов распознавания образов:
- Сравнение с образцом . В эту группу входит классификация по ближайшему среднему, классификация по расстоянию до ближайшего соседа. Также в группу сравнения с образцом можно отнести структурные методы распознавания.
- Статистические методы . Как видно из названия, статистические методы используют некоторую статистическую информацию при решении задачи распознавания. Метод определяет принадлежность объекта к конкретному классу на основе вероятности В ряде случаев это сводится к определению апостериорной вероятности принадлежности объекта к определенному классу, при условии, что признаки этого объекта приняли соответствующие значения. Примером служит метод на основе байесовского решающего правила.
- Нейронные сети . Отдельный класс методов распознавания. Отличительной особенностью от других является способность обучаться.
Классификация по ближайшему среднему значению
В классическом подходе распознавания образов, в котором неизвестный объект для классификации представляется в виде вектора элементарных признаков. Система распознавания на основе признаков может быть разработана различными способами. Эти векторы могут быть известны системе заранее в результате обучения или предсказаны в режиме реального времени на основе каких-либо моделей.
Простой алгоритм классификации заключается в группировке эталонных данных класса с использованием вектора математического ожидания класса (среднего значения).

где x(i,j)- j-й эталонный признак класса i, n_j- количество эталонных векторов класса i.
Тогда неизвестный объект будет относиться к классу i, если он существенно ближе к вектору математического ожидания класса i, чем к векторам математических ожиданий других классов. Этот метод подходит для задач, в которых точки каждого класса располагаются компактно и далеко от точек других классов.

Трудности возникнут, если классы будут иметь несколько более сложную структуру, например, как на рисунке. В данном случае класс 2 разделен на два непересекающихся участка, которые плохо описываются одним средним значением. Также класс 3 слишком вытянут, образцы 3-го класса с большими значениями координат x_2 ближе к среднему значению 1-го класса, нежели 3-го.

Описанная проблема в некоторых случаях может быть решена изменением расчета расстояния.
Будем учитывать характеристику «разброса» значений класса - σ_i, вдоль каждого координатного направления i. Среднеквадратичное отклонение равно квадратному корню из дисперсии. Шкалированное евклидово расстояние между вектором x и вектором математического ожидания x_c равно

Эта формула расстояния уменьшит количество ошибок классификации, но на деле большинство задач не удается представить таким простым классом.
Классификация по расстоянию до ближайшего соседа
Другой подход при классификации заключается в отнесении неизвестного вектора признаков x к тому классу, к отдельному образцу которого этот вектор наиболее близок. Это правило называется правилом ближайшего соседа. Классификация по ближайшему соседу может быть более эффективна, даже если классы имеют сложную структуру или когда классы пересекаются.
При таком подходе не требуется предположений о моделях распределения векторов признаков в пространстве. Алгоритм использует только информацию об известных эталонных образцах. Метод решения основан на вычислении расстояния x до каждого образца в базе данных и нахождения минимального расстояния. Преимущества такого подхода очевидны:
- в любой момент можно добавить новые образцы в базу данных;
- древовидные и сеточные структуры данных позволяют сократить количество вычисляемых расстояний.
Кроме того, решение будет лучше, если искать в базе не одного ближайшего соседа, а k. Тогда при k > 1 обеспечивает наилучшую выборку распределения векторов в d-мерном пространстве. Однако эффективное использование значений k зависит от того, имеется ли достаточное количество в каждой области пространства. Если имеется больше двух классов то принять верное решение оказывается сложнее.
Литература
- M. Castrillón, . O. Déniz, . D. Hernández и J. Lorenzo, «A comparison of face and facial feature detectors based on the Viola-Jones general object detection framework,» International Journal of Computer Vision, № 22, pp. 481-494, 2011.
- Y.-Q. Wang, «An Analysis of Viola-Jones Face Detection Algorithm,» IPOL Journal, 2013.
- Л. Шапиро и Д. Стокман, Компьютерное зрение, Бином. Лаборатория знаний, 2006.
- З. Н. Г., Методы распознавания и их применение, Советское радио, 1972.
- Дж. Ту, Р. Гонсалес, Математические принципы распознавания образов, Москва: “Мир” Москва, 1974.
- Khan, H. Abdullah и M. Shamian Bin Zainal, «Efficient eyes and mouth detection algorithm using combination of viola jones and skin color pixel detection» International Journal of Engineering and Applied Sciences, № Vol. 3 № 4, 2013.
- V. Gaede и O. Gunther, «Multidimensional Access Methods,» ACM Computing Surveys, pp. 170-231, 1998.
С задачей распознавания образов живые системы, в том числе и человек, сталкиваются постоянно с момента своего появления. В частности, информация, поступающая с органов чувств, обрабатывается мозгом, который в свою очередь сортирует информацию, обеспечивает принятие решения, а далее с помощью электрохимических импульсов передает необходимый сигнал далее, например, органам движения, которые реализуют необходимые действия. Затем происходит изменение окружающей обстановки, и вышеуказанные явления происходят заново. И если разобраться, то каждый этап сопровождается распознаванием.
С развитием вычислительной техники стало возможным решить ряд задач, возникающих в процессе жизнедеятельности, облегчить, ускорить, повысить качество результата. К примеру, работа различных систем жизнеобеспечения, взаимодействие человека с компьютером, появление роботизированных систем и др. Тем не менее, отметим, что обеспечить удовлетворительный результат в некоторых задачах (распознавание быстродвижущихся подобных объектов, рукописного текста) в настоящее время не удается.
Цель работы: изучить историю систем распознавания образов.
Указать качественные изменения произошедшие в области распознавания образов как теоретические, так и технические, с указанием причин;
Обсудить методы и принципы, применяемые в вычислительной технике;
Привести примеры перспектив, которые ожидаются в ближайшем будущем.
1. Что такое распознавание образов?
Первые исследования с вычислительной техникой в основном следовали классической схеме математического моделирования - математическая модель, алгоритм и расчет. Таковыми были задачи моделирования процессов происходящих при взрывах атомных бомб, расчета баллистических траекторий, экономических и прочих приложений. Однако помимо классических идей этого ряда возникали и методы основанные на совершенно иной природе, и как показывала практика решения некоторых задач, они зачастую давали лучший результат нежели решения, основанные на переусложненных математических моделях. Их идея заключалась в отказе от стремления создать исчерпывающую математическую модель изучаемого объекта (причем зачастую адекватные модели было практически невозможно построить), а вместо этого удовлетвориться ответом лишь на конкретные интересующие нас вопросы, причем эти ответы искать из общих для широкого класса задач соображений. К исследованиям такого рода относились распознавание зрительных образов, прогнозирование урожайности, уровня рек, задача различения нефтеносных и водоносных пластов по косвенным геофизическим данным и т. д. Конкретный ответ в этих задачах требовался в довольно простой форме, как например, принадлежность объекта одному из заранее фиксированных классов. А исходные данные этих задач, как правило, задавались в виде обрывочных сведений об изучаемых объектах, например в виде набора заранее расклассифицированных объектов. С математической точки зрения это означает, что распознавание образов (а так и был назван в нашей стране этот класс задач) представляет собой далеко идущее обобщение идеи экстраполяции функции.
Важность такой постановки для технических наук не вызывает никаких сомнений и уже это само по себе оправдывает многочисленные исследования в этой области. Однако задача распознавания образов имеет и более широкий аспект для естествознания (впрочем, было бы странно если нечто столь важное для искусственных кибернетических систем не u1080 имело бы значения для естественных). В контекст данной науки органично вошли и поставленные еще древними философами вопросы о природе нашего познания, нашей способности распознавать образы, закономерности, ситуации окружающего мира. В действительности, можно практически не сомневаться в том, что механизмы распознавания простейших образов, типа образов приближающегося опасного хищника или еды, сформировались значительно ранее, чем возник элементарный язык и формально-логический аппарат. И не вызывает никаких сомнений, что такие механизмы достаточно развиты и у высших животных, которым так же в жизнедеятельности крайне необходима способность различения достаточно сложной системы знаков природы. Таким образом, в природе мы видим, что феномен мышления и сознания явно базируется на способностях к распознаванию образов и дальнейший прогресс науки об интеллекте непосредственно связан с глубиной понимания фундаментальных законов распознавания. Понимая тот факт, что вышеперечисленные вопросы выходят далеко за рамки стандартного определения распознавания образов (в англоязычной литературе более распространен термин supervised learning), необходимо так же понимать, что они имеют глубокие связи с этим относительно узким(но все еще далеко неисчерпанным) направлением .
Уже сейчас распознавание образов плотно вошло в повседневную жизнь и является одним из самых насущных знаний современного инженера. В медицине распознавание образов помогает врачам ставить более точные диагнозы, на заводах оно используется для прогноза брака в партиях товаров. Системы биометрической идентификации личности в качестве своего алгоритмического ядра так же основаны на результатах этой дисциплины. Дальнейшее развитие искусственного интеллекта, в частности проектирование компьютеров пятого поколения, способных к более непосредственному общению с человеком на естественных для людей языках и посредством речи, немыслимы без распознавания. Здесь рукой подать и до робототехники, искусственных систем управления, содержащих в качестве жизненно важных подсистем системы распознавания.
Именно поэтому к развитию распознавания образов с самого начала было приковано немало внимания со стороны специалистов самого различного профиля - кибернетиков, нейрофизиологов, психологов, математиков, экономистов и т.д. Во многом именно по этой причине современное распознавание образов само питается идеями этих дисциплин. Не претендуя на полноту (а на нее в небольшом эссе претендовать невозможно) опишем историю распознавания образов, ключевые идеи .
Определения
Прежде, чем приступить к основным методам распознавания образов, приведем несколько необходимых определений.
Распознавание образов (объектов, сигналов, ситуаций, явлений или процессов) - задача идентификации объекта или определения каких-либо его свойств по его изображению (оптическое распознавание) или аудиозаписи (акустическое распознавание) и другим характеристикам.
Одним из базовых является не имеющее конкретной формулировки понятие множества. В компьютере множество представляется набором неповторяющихся однотипных элементов. Слово "неповторяющихся" означает, что какой-то элемент в множестве либо есть, либо его там нет. Универсальное множество включает все возможные для решаемой задачи элементы, пустое не содержит ни одного.
Образ - классификационная группировка в системе классификации, объединяющая (выделяющая) определенную группу объектов по некоторому признаку. Образы обладают характерным свойством, проявляющимся в том, что ознакомление с конечным числом явлений из одного и того же множества дает возможность узнавать сколь угодно большое число его представителей. Образы обладают характерными объективными свойствами в том смысле, что разные люди, обучающиеся на различном материале наблюдений, большей частью одинаково и независимо друг от друга классифицируют одни и те же объекты. В классической постановке задачи распознавания универсальное множество разбивается на части-образы. Каждое отображение какого-либо объекта на воспринимающие органы распознающей системы, независимо от его положения относительно этих органов, принято называть изображением объекта, а множества таких изображений, объединенные какими-либо общими свойствами, представляют собой образы.
Методика отнесения элемента к какому-либо образу называется решающим правилом. Еще одно важное понятие - метрика, способ определения расстояния между элементами универсального множества. Чем меньше это расстояние, тем более похожими являются объекты (символы, звуки и др.) - то, что мы распознаем. Обычно элементы задаются в виде набора чисел, а метрика - в виде функции. От выбора представления образов и реализации метрики зависит эффективность программы, один алгоритм распознавания с разными метриками будет ошибаться с разной частотой.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на группы внешних идентичных сигналов путем многократного воздействия на систему внешней корректировки. Такую внешнюю корректировку в обучении принято называть "поощрениями" и "наказаниями". Механизм генерации этой корректировки практически полностью определяет алгоритм обучения. Самообучение отличается от обучения тем, что здесь дополнительная информация о верности реакции системе не сообщается.
Адаптация - это процесс изменения параметров и структуры системы, а возможно - и управляющих воздействий, на основе текущей информации с целью достижения определенного состояния системы при начальной неопределенности и изменяющихся условиях работы.
Обучение - это процесс, в результате которого система постепенно приобретает способность отвечать нужными реакциями на определенные совокупности внешних воздействий, а адаптация - это подстройка параметров и структуры системы с целью достижения требуемого качества управления в условиях непрерывных изменений внешних условий.
Примеры задач распознавания образов: - Распознавание букв;
В целом, можно выделить три метода распознавания образов: Метод перебора. В этом случае производится сравнение с базой данных, где для каждого вида объектов представлены всевозможные модификации отображения. Например, для оптического распознавания образов можно применить метод перебора вида объекта под различными углами, масштабами, смещениями, деформациями и т. д. Для букв нужно перебирать шрифт, свойства шрифта и т. д. В случае распознавания звуковых образов, соответственно, происходит сравнение с некоторыми известными шаблонами (например, слово, произнесенное несколькими людьми).
Второй подход - производится более глубокий анализ характеристик образа. В случае оптического распознавания это может быть определение различных геометрических характеристик. Звуковой образец в этом случае подвергается частотному, амплитудному анализу и т. д.
Следующий метод - использование искусственных нейронных сетей (ИНС). Этот метод требует либо большого количества примеров задачи распознавания при обучении, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Тем не менее, его отличает более высокая эффективность и производительность.
4. История распознавания образов
Рассмотрим кратко математический формализм распознавания образов. Объект в распознавании образов описывается совокупностью основных характеристик (признаков, свойств). Основные характеристики могут иметь различную природу: они могут браться из упорядоченного множества типа вещественной прямой, либо из дискретного множества (которое, впрочем, так же может быть наделено структурой). Такое понимание объекта согласуется как потребностью практических приложений распознавания образов, так и с нашим пониманием механизма восприятия объекта человеком. Действительно, мы полагаем, что при наблюдении (измерении) объекта человеком, сведения о нем поступают по конечному числу сенсоров (анализируемых каналов) в мозг, и каждому сенсору можно сопоставить соответствующую характеристику объекта. Помимо признаков, соответствующих нашим измерениям объекта, существует так же выделенный признак, либо группа признаков, которые мы называем классифицирующими признаками, и в выяснении их значений при заданном векторе Х и состоит задача, которую выполняют естественные и искусственные распознающие системы.
Понятно, что для того, чтобы установить значения этих признаков, необходимо иметь информацию о том, как связаны известные признаки с классифицирующими. Информация об этой связи задается в форме прецедентов, то есть множества описаний объектов с известными значениями классифицирующих признаков. И по этой прецедентной информации и требуется построить решающее правило, которое будет ставить произвольному описанию объекта значения его классифицирующих признаков.
Такое понимание задачи распознавания образов утвердилось в науке начиная с 50-х годов прошлого века. И тогда же было замечено что такая постановка вовсе не является новой. С подобной формулировкой сталкивались и уже существовали вполне не плохо зарекомендовавшие себя методы статистического анализа данных, которые активно использовались для многих практических задач, таких как например, техническая диагностика. Поэтому первые шаги распознавания образов прошли под знаком статистического подхода, который и диктовал основную проблематику.
Статистический подход основывается на идее, что исходное пространство объектов представляет собой вероятностное пространство, а признаки (характеристики) объектов являют собой случайные величины заданные на нем. Тогда задача исследователя данных состояла в том, чтобы из некоторых соображений выдвинуть статистическую гипотезу о распределении признаков, а точнее о зависимости классифицирующих признаков от остальных. Статистическая гипотеза, как правило, представляла собой параметрически заданное множество функций распределения признаков. Типичной и классической статистической гипотезой является гипотеза о нормальности этого распределения (разновидностей таких гипотез статистики придумали великое множество). После формулировки гипотезы оставалось проверить эту гипотезу на прецедентных данных. Это проверка состояла в выборе некоторого распределения из первоначально заданного множества распределений (параметра гипотезы о распределении) и оценки надежности(доверительного интервала) этого выбора. Собственно эта функция распределения и была ответом к задаче, только объект классифицировался уже не однозначно, но с некоторыми вероятностями принадлежности к классам. Статистиками были разработано так же и ассимптотическое обоснование таких методов. Такие обоснования делались по следующей схеме: устанавливался некоторый функционал качества выбора распределения (доверительный интервал) и показывалось, что при увеличении числа прецедентов, наш выбор с вероятностью стремящейся к 1 становился верным в смысле этого функционала (доверительный интервал стремился к 0). Забегая вперед скажем, что статистический взгляд на проблему распознавания оказался весьма плодотворным не только в смысле разработанных алгоритмов (в число которых входят методы кластерного, дискриминантного анализов, непараметрическая регрессия и т.д.), но и привел впоследствии Вапника к созданию глубокой статистической теории распознавания.
Тем не менее существует серьезная аргументация в пользу того, что задачи распознавания образов не сводятся к статистике. Любую такую задачу, в принципе, можно рассматривать со статистической точки зрения и результаты ее решения могут интерпретироваться статистически. Для этого необходимо лишь предположить, что пространство объектов задачи является вероятностным. Но с точки зрения инструментализма, критерием удачности статистической интерпретации некоторого метода распознавания может служить лишь наличие обоснавания этого метода на языке статистики как раздела математики. Под обоснаванием здесь понимается выработка основных требований к задаче которые обеспечивают успех в применении этого метода. Однако на данный момент для большей части методов распознавания, в том числе и для тех, которые напрямую возникли в рамках статистического подхода, подобных удовлетворительных обоснований не найдено. Кроме этого, наиболее часто применяемые на данный момент статистические алгоритмы, типа линейного дискриминанта Фишера, парзеновского окна, EM-алгоритма, метода ближайших соседей, не говоря уже о байесовских сетях доверия, имеют сильно выраженный эвристический характер и могут иметь интерпретации отличные от статистических. И наконец, ко всему вышесказанному следует добавить, что помимо асимптотического поведения методов распознавания, которое и является основным вопросом статистики, практика распознавания ставит вопросы вычислительной и структурной сложности методов, которые выводят далеко за рамки одной лишь теории вероятностей.
Итого, вопреки стремлениям статистиков рассматривать распознавание образов как раздел статистики, в практику и идеологию распознавания входили совершенно другие идеи. Одна из них была вызвана исследованиями в области распознавания зрительных образов и основана на следующей аналогии.
Как уже отмечалось, в повседневной жизни люди постоянно решают (зачастую бессознательно) проблемы распознавания различных ситуаций, слуховых и зрительных образов. Подобная способность для ЭВМ представляет собой в лучшем случае дело будущего. Отсюда некоторыми пионерами распознавания образов был сделан вывод, что решение этих проблем на ЭВМ должно в общих чертах моделировать процессы человеческого мышления. Наиболее известной попыткой подойти к проблеме с этой стороны было знаменитое исследование Ф. Розенблатта по перцептронам .
К середине 50-х годов казалось, что нейрофизиологами были поняты физические принципы работы мозга (в книге "Новый Разум Короля" знаменитый британский физик-теоретик Р. Пенроуз интересно ставит под сомнение нейросетевую модель мозга, обосновывая существенную роль в его функционировании квантово-механических эффектов; хотя, впрочем, эта модель подвергалась сомнению с самого начала. Отталкиваясь от этих открытий Ф.Розенблатт разработал модель обучения распознаванию зрительных образов, названную им персептроном. Персептрон Розенблатта представляет собой следующую функцию (рис. 1):
Рис 1. Схема Персептрона
На входе персептрон получает вектор объекта, который в работах Розенблатта представлял собой бинарный вектор, показывавший какой из пикселов экрана зачернен изображением а какой нет. Далее каждый из признаков подается на вход нейрона, действие которого представляет собой простое умножение на некоторый вес нейрона. Результаты подаются на последний нейрон, который их складывает и общую сумму сравнивает с некоторым порогом. В зависимости от результатов сравнения входной объект Х признается нужным образом либо нет. Тогда задача обучения распознаванию образов состояла в таком подборе весов нейронов и значения порога, чтобы персептрон давал на прецедентных зрительных образах правильные ответы. Розенблатт полагал, что получившаяся функция будет неплохо распознавать нужный зрительный образ даже если входного объекта и не было среди прецедентов. Из бионических соображений им так же был придуман и метод подбора весов и порога, на котором останавливаться мы не будем. Скажем лишь, что его подход оказался успешным в ряде задач распознавания и породил собой целое направление исследований алгоритмов обучения основанных на нейронных сетях, частным случаем которых и является персептрон.
Далее были придуманы различные обобщения персептрона, функция нейронов была усложнена: нейроны теперь могли не только умножать входные числа или складывать их и сравнивать результат с порогами, но применять по отношению к ним более сложные функции. На рисунке 2 изображено одно из подобных усложнений нейрона:

Рис. 2 Схема нейронной сети.
Кроме того топология нейронной сети могла быть значительно сложнее той, что рассматривал Розенблатт, например такой:
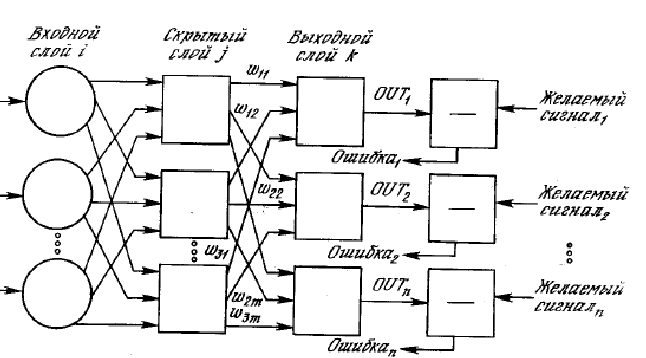
Рис. 3. Схема нейронной сети Розенблатта.
Усложнения приводили к увеличению числа настраиваемых параметров при обучении, но при этом увеличивали возможность настраиваться на очень сложные закономерности. Исследования в этой области сейчас идут по двум тесно связанным направлениям - изучаются и различные топологии сетей и различные методы настроек.
Нейронные сети на данный момент являются не только инструментом решения задач распознавания образов, но получили применение в исследованиях по ассоциативной памяти, сжатию изображений. Хотя это направление исследований и пересекается сильно с проблематикой распознавания образов, но представляет собой отдельный раздел кибернетики. Для распознавателя на данный момент, нейронные сети не более чем очень специфически определенное, параметрически заданное множество отображений, которое в этом смысле не имеет каких-либо существенных преимуществ над многими другим подобными моделями обучения которые далее будут кратко перечислены.
В связи с данной оценкой роли нейронных сетей для собственно распознавания (то есть не для бионики, для которой они имеют первостепенное значение уже сейчас) хотелось бы отметить следующее: нейронные сети, будучи чрезвычайно сложным объектом для математического анализа, при грамотном их использовании, позволяют находить весьма нетривиальные законы в данных. Их трудность для анализа, в общем случае, объясняется их сложной структурой и как следствие, практически неисчерпаемыми возможностями для обобщения самых различных закономерностей. Но эти достоинства, как это часто и бывает, являются источником потенциальных ошибок, возможности переобучения. Как будет рассказано далее, подобный двоякий взгляд на перспективы всякой модели обучения является одним из принципов машинного обучения.
Еще одним популярным направлением в распознавании являются логические правила и деревья решений. В сравнении с вышеупомянутыми методами распознавания эти методы наиболее активно используют идею выражения наших знаний о предметной области в виде, вероятно самых естественных (на сознательном уровне) структур - логических правил. Под элементарным логическим правилом подразумевается высказывание типа «если неклассифицируемые признаки находятся в соотношении X то классифицируемые находятся в соотношении Y». Примером такого правила в медицинской диагностике служит следующее: если возраст пациента выше 60 лет и ранее он перенёс инфаркт, то операцию не делать - риск отрицательного исхода велик.
Для поиска логических правил в данных необходимы 2 вещи: определить меру «информативности» правила и пространство правил. И задача поиска правил после этого превращается в задачу полного либо частичного перебора в пространстве правил с целью нахождения наиболее информативных из них. Определение информативности может быть введено самыми различными способами и мы не будем останавливаться на этом, считая что это тоже некоторый параметр модели. Пространство же поиска определяется стандартно.
После нахождения достаточно информативных правил наступает фаза «сборки» правил в конечный классификатор. Не обсуждая глубоко проблемы которые здесь возникают (а их возникает немалое количество) перечислим 2 основных способа «сборки». Первый тип - линейный список. Второй тип – взвешенное голосование, когда каждому правилу ставится в соответствие некоторый вес, и объект относится классификатором к тому классу за который проголосовало наибольшее количество правил.
В действительности, этап построения правил и этап «сборки» выполняются сообща и, при построении взвешенного голосования либо списка, поиск правил на частях прецедентных данных вызывается снова и снова, чтобы обеспечить лучшее согласование данных и модели.
