Дисперсионный анализ используется для выявления влияния на изучаемый показатель некоторых факторов, обычно не поддающихся количественному измерению. Суть метода состоит в разложении общей вариации изучаемого показателя на части, соответствующие раздельному и совместному влиянию факторов, и статистическом изучении этих частей с целью выяснения приемлемости гипотез об отсутствии этих влияний. Модели дисперсионного анализа в зависимости от числа факторов классифицируются на однофакторные , двухфакторные и т.д. По цели исследования выделяют следующие модели: детерминированная (Ml) - здесь уровни всех факторов заранее фиксированы, и проверяют именно их влияние, случайная (М2) - здесь уровни каждого фактора получены как случайная выборка из генеральной совокупности уровней фактора, и смешанная (М3) - здесь уровни одних факторов заранее фиксированы, а уровни других - случайная выборка.
Однофакторный дисперсионный анализ
В основе однофакторного дисперсионного анализа лежит следующая вероятностная модель:
где - значение случайной величины У, принимаемое при уровне Д (,) , / =
1,2,..., v, фактора Л в &-м наблюдении, к = 1,2, ..., п,;
О 1 " 1 - эффект влияния на УГ уровня Д®;
е® - независимые случайные величины, отражающие влияние на У/"* неконтролируемых остаточных факторов, причем все е* 1 ~ N(0, o R).
При этом в модели Ml все 0 (,) - детерминированные величины
и?е ("Ч = 0 ; а в модели М2 0 (,) - случайные величины (значения слу-
чайного эффекта 0), 0® = 0 где 0 - ;V(0, ст в), и все 0® и е* ’ - независимы.
Найдем общую вариацию S 2
результативного признака У и две ее составляющие - S 2 A
и S R
, отражающие соответственно влияние фактора А
и влияние остаточных факторов:

Нетрудно убедиться в том, что S 2 = S 2 A + . Разделив все части
этого равенства на я, получим:
Это правило читается так: «Общая дисперсия наблюдений равна сумме межгрупповой дисперсии (это дисперсия Су (0 групповых средних) и внутригрупповой дисперсии (это средняя а 2 из групповых дисперсий)».
Для выяснения того, влияет ли фактор А на результативный признак:
- ? в модели Ml проверяют гипотезу Н 0 : 0 (|) = 0 (2) = ... = 0 (v) =0 (если она будет принята, то для всех ink математическое ожидание МУ/"* = А/У [см. формулу (8.4.1)], а это означает, что при изменении уровня фактора групповая генеральная средняя не изменяется, т.е. рассматриваемые уровни фактора А не влияют на У;
- ? в модели М2 проверяют гипотезу Н 0 = 0 (ее принятие означает что эффект 0 - постоянная величина, а с учетом условия М0 = 0 получим, что 0 = 0, т.е. фактор А не влияет на У).
Критерии проверки этих и других гипотез, а также оценки параметров модели (8.4.1) приведены в табл. 8.5.
Задача 8.7. Исследователь хочет выяснить, отличаются ли четыре способа рекламирования товара по влиянию на объем его продажи. Для этого в каждом из четырех однотипных городов (в них использовались различные способы рекламы) были собраны сведения об объемах продажи товара (в денежных единицах) в четырех случайно отобранных магазинах и вычислены соответствующие выборочные характеристики:
Решение. Здесь фактором А является способ рекламы; зафиксированы четыре его уровня, и выясняется, различаются ли по своему влиянию именно эти уровни, - это модель Ml однофакторного анализа.
где е** независимый?** N(0,g r).
Так как MY и все 0 (,) - постоянные величины, то при выполнении (8.4.3) наблюдения независимы и все
Допустим, что независимость наблюдений гарантируется организацией эксперимента; условие же (8.4.4) означает, что объем продаж при г"-м способе рекламы имеет нормальный закон распределения с математическим ожиданием а, = MY + 0 (,) и с дисперсией, одинаковой для всех способов. Допустим, что нормальное распределение имеет место. Используя критерий Бартлетта (см. табл. 8.3), убедимся, что результаты испытаний позволяют принять гипотезу Н"п : о? =... = ol. Вычислим

по табл. П. 6.3 при k=v-l=3np=a= 0,05 найдем % 2 а = Ха = 7,82 ; так как 1,538 Н" 0 принимаем.
Теперь проверим ключевую гипотезу дисперсионного анализа Н 0
: 0 м =... = 0 S 2 A = 220,19, S 2 R
=39,27, S" 2 = 259,46; убедившись в справедливости равенства (8.4.2), найдем оценку (8.4.5) (см. табл. 8.5) s 2 =
39,27/12 = 3,27 дисперсии а 2 к
; проверим, выполняется ли неравенство (8.4.6) (см. табл. 8.5):

по табл. П. 6.4 при = 3, к 2 = 12 и р = а = 0,05 найдем F 2a = F a = 3,49 . Так как 22,43 > 3,49, неравенство (8.4.6) выполняется. Поэтому гипотезу
Условия и критерии проверки гипотез однофакторного дисперсионного анализа

Н 0: 0 (|) = ... = 0 (4) = 0 отклоняем: считаем, что зафиксированные способы рекламирования продукции влияют на объем продаж; при этом вли-
= 84,9% вариации объема продаж.
Изменим условие задачи. Предположим, что способы рекламирования товара заранее нс фиксированы, а выбраны случайным образом из всего набора способов. Тогда выяснение вопроса о том, влияет или нет способ рекламирования, сводится к проверке гипотезы Н 0: Og = 0 модели М2. Критерий ее проверки такой же, как и в модели Ml. Так как условие (8.4.6) отклонения гипотезы Н 0: о 2 в = 0 выполняется, гипотезу забраковываем, по крайней мере до получения дополнительных данных: считаем, что способ рекламирования товаров (во всем наборе этих способов) влияет на объем продаж.
Двухфакторный дисперсионный анализ
(с одинаковым числом т > 1 наблюдений при различных сочетаниях уровней факторов)
В основе двухфакторного дисперсионного анализа лежит следующая вероятностная модель:
где У/ 1 ’ 7) значение случайной величины У, принимаемое при уровне А (" i = 1,2, ..., v A , фактора А и уровне 5®, у =1,2, ..., v B , фактора В в к -м наблюдении, к = 1,2, ..., /и; 0^, 0 (й у) , 0^д у) - эффекты влияния на У/ 1 ’ соответственно уровней А (" 5® и взаимодействия А (0 и B ; - независимые случайные величины, отражающие влияние на У/ 1 ’ у) неконтролируемых остаточных факторов, причем е?’ л ~ /V((), а л).
Найдем общую вариацию S 2 признака У и ее четыре составляющие - S 2 a , S 2 B , S 2 ab , S 2 r , отражающие влияние соответственно факторов А, В, их взаимодействия и остаточных факторов:

Нетрудно убедится в том, что S 2 = + S 2 B + S 2 iB + S B .
Оценки параметров всех трех типов модели (8.4.9): Ml, М2 и М3, проверяемые гипотезы и критерии их проверки приведены в табл. 8.6. В моделях М2 и М3 предполагается, что все случайные эффекты независимы как между собой, так и с e^’ J) .
Дисперсионный анализ - это статистический метод оценки связи между факторными и результативным признаками в различных группах, отобранный случайным образом, основанный на определении различий (разнообразия) значений признаков. В основе дисперсионного анализа лежит анализ отклонений всех единиц исследуемой совокупности от среднего арифметического. В качестве меры отклонений берется дисперсия (В)- средний квадрат отклонений. Отклонения, вызываемые воздействием факторного признака (фактора) сравниваются с величиной отклонений, вызываемых случайными обстоятельствами. Если отклонения, вызываемые факторным признаком, более существенны, чем случайные отклонения, то считается, что фактор оказывает существенное влияние на результативный признак.
Для того, чтобы вычислить дисперсию значения отклонений каждой варианты (каждого зарегистрированного числового значения признака) от среднего арифметического возводят в квадрат. Тем самым избавляются от отрицательных знаков. Затем эти отклонения (разности) суммируют и делят на число наблюдений, т.е. усредняют отклонения. Таким образом, получают значения дисперсий.
Важным методическим значением для применения дисперсионного анализа является правильное формирование выборки. В зависимости от поставленной цели и задач выборочные группы могут формироваться случайным образом независимо друг от друга (контрольная и экспериментальная группы для изучения некоторого показателя, например, влияние высокого артериального давления на развитие инсульта). Такие выборки называются независимыми.
Нередко результаты воздействия факторов исследуются у одной и той же выборочной группы (например, у одних и тех же пациентов) до и после воздействия (лечение, профилактика, реабилитационные мероприятия), такие выборки называются зависимыми.
Дисперсионный анализ, в котором проверяется влияние одного фактора, называется однофакторным (одномерный анализ). При изучении влияния более чем одного фактора используют многофакторный дисперсионный анализ (многомерный анализ).
Факторные признаки - это те признаки, которые влияют на изучаемое явление.
Результативные признаки - это те признаки, которые изменяются под влиянием факторных признаков.
Условия применения дисперсионного анализа:
Задачей исследования является определение силы влияния одного (до 3) факторов на результат или определение силы совместного влияния различных факторов (пол и возраст, физическая активность и питание и т.д.).
Изучаемые факторы должны быть независимые (несвязанные) между собой. Например, нельзя изучать совместное влияние стажа работы и возраста, роста и веса детей и т.д. на заболеваемость населения.
Подбор групп для исследования проводится рандомизированно (случайный отбор). Организация дисперсионного комплекса с выполнением принципа случайности отбора вариантов называется рандомизацией (перев. с англ. - random), т.е. выбранные наугад.
Можно применять как количественные, так и качественные (атрибутивные) признаки.
При проведении однофакторного дисперсионного анализа рекомендуется (необходимое условие применения):
1. Нормальность распределения анализируемых групп или соответствие выборочных групп генеральным совокупностям с нормальным распределением.
2. Независимость (не связанность) распределения наблюдений в группах.
3. Наличие частоты (повторность) наблюдений.
Сначала формулируется нулевая гипотеза, то есть предполагается, что исследуемые факторы не оказывают никакого влияния на значения результативного признака и полученные различия случайны.
Затем определяем, какова вероятность получить наблюдаемые (или более сильные) различия при условии справедливости нулевой гипотезы.
Если эта вероятность мала, то мы отвергаем нулевую гипотезу и заключаем, что результаты исследования статистически значимы. Это еще не означает, что доказано действие именно изучаемых факторов (это вопрос, прежде всего, планирования исследования), но все же маловероятно, что результат обусловлен случайностью.
При выполнении всех условий применения дисперсионного анализа, разложение общей дисперсии математически выглядит следующим образом:
Doбщ. = Dфакт + D ост.,
Doбщ. - общая дисперсия наблюдаемых значений (вариант), характеризуется разбросом вариант от общего среднего. Измеряет вариацию признака во всей совокупности под влиянием всех факторов, обусловивших эту вариацию. Общее разнообразие складывается из межгруппового и внутригруппового;
Dфакт - факторная (межгрупповая) дисперсия, характеризуется различием средних в каждой группе и зависит от влияния исследуемого фактора, по которому дифференцируется каждая группа. Например, в группах различных по этиологическому фактору клинического течения пневмонии средний уровень проведенного койко-дня неодинаков - наблюдается межгрупповое разнообразие.
D ост. - остаточная (внутригрупповая) дисперсия, которая характеризует рассеяние вариант внутри групп. Отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неуточненных факторов и не зависящую от признака - фактора, положенного в основание группировки. Вариация изучаемого признака зависит от силы влияния каких-то неучтенных случайных факторов, как от организованных (заданных исследователем), так и от случайных (неизвестных) факторов.
Поэтому общая вариация (дисперсия) слагается из вариации, вызванной организованными (заданными) факторами, называемыми факториальной вариацией и неорганизованными факторами, т.е. остаточной вариацией (случайной, неизвестной).
Для выборки объема n выборочная дисперсия вычисляется как сумма квадратов отклонений от выборочного среднего, деленная на n-1 (объем выборки минус единица). Таким образом, при фиксированном объеме выборки n дисперсия есть функция суммы квадратов (отклонений), обозначаемая, для краткости, SS (от английского Sum of Squares - Сумма квадратов). Далее слово выборочная мы часто опускаем, прекрасно понимая, что рассматривается выборочная дисперсия или оценка дисперсии. В основе дисперсионного анализа лежит разделение дисперсии на части или компоненты. Рассмотрим следующий набор данных:
Средние двух групп существенно различны (2 и 6 соответственно). Сумма квадратов отклонений внутри каждой группы равна 2. Складывая их, получаем 4. Если теперь повторить эти вычисления без учета групповой принадлежности, то есть, если вычислить SS исходя из общего среднего этих двух выборок, то получим величину 28. Иными словами, дисперсия (сумма квадратов), основанная на внутригрупповой изменчивости, приводит к гораздо меньшим значениям, чем при вычислении на основе общей изменчивости (относительно общего среднего). Причина этого, очевидно, заключается в существенной разнице между средними значениями, и это различие между средними и объясняет существующее различие между суммами квадратов.
| SS | ст.св. | MS | F | p | |
| Эффект | 24.0 | 24.0 | 24.0 | .008 | |
| Ошибка | 4.0 | 1.0 |
Как видно из таблицы, общая сумма квадратов SS = 28 разбита на компоненты: сумму квадратов, обусловленную внутригрупповой изменчивостью (2+2=4; см. вторую строку таблицы) и сумму квадратов, обусловленную различием средних значений между группами (28-(2+2)=24; см первую строку таблицы). Заметим, что MS в этой таблице есть средний квадрат, равный SS, деленная на число степеней свободы (ст.св).
В рассмотренном выше простом примере вы могли бы сразу вычислить t-критерий для независимых выборок. Полученные результаты, естественно, совпадут с результатами дисперсионного анализа.
Однако, ситуации, когда некоторое явление полностью описывается одной переменной, чрезвычайно редки. Например, если мы пытаемся научиться выращивать большие помидоры, следует рассматривать факторы, связанные с генетической структурой растений, типом почвы, освещенностью, температурой и т.д. Таким образом, при проведении типичного эксперимента приходится иметь дело с большим количеством факторов. Основная причина, по которой использование дисперсионного анализа предпочтительнее повторного сравнения двух выборок при разных уровнях факторов с помощью серий t-критерия, заключается в том, что дисперсионный анализ существенно более эффективен и, для малых выборок, более информативен.
Предположим, что в рассмотренном выше примере анализа двух выборок мы добавим еще один фактор, например, Пол. Пусть каждая группа теперь состоит из 3 мужчин и 3 женщин. План этого эксперимента можно представить в виде таблицы:
До проведения вычислений можно заметить, что в этом примере общая дисперсия имеет, по крайней мере, три источника:
1) случайная ошибка (внутригрупповая дисперсия),
2) изменчивость, связанная с принадлежностью к экспериментальной группе
3) изменчивость, обусловленная полом объектов наблюдения.
Отметим, что существует еще один возможный источник изменчивости - взаимодействие факторов, который мы обсудим позднее). Что произойдет, если мы не будем включать пол как фактор при проведении анализа и вычислим обычный t-критерий? Если мы будем вычислять суммы квадратов, игнорируя пол (т.е. объединяя объекты разного пола в одну группу при вычислении внутригрупповой дисперсии и получив при этом сумму квадратов для каждой группы равную SS =10 и общую сумму квадратов SS = 10+10 = 20), то получим большее значение внутригрупповая дисперсии, чем при более точном анализе с дополнительным разбиением на подгруппы по полу (при этом внутригрупповые средние будут равны 2, а общая внутригрупповая сумма квадратов равна SS = 2+2+2+2 = 8).
Итак, при введении дополнительного фактора: пол, остаточная дисперсия уменьшилась. Это связано с тем, что среднее значение для мужчин меньше, чем среднее значение для женщин, и это различие в средних значениях увеличивает суммарную внутригрупповую изменчивость, если фактор пола не учитывается. Управление дисперсией ошибки увеличивает чувствительность (мощность) критерия.
На этом примере видно еще одно преимущество дисперсионного анализа по сравнению с обычным t-критерием для двух выборок. Дисперсионный анализ позволяет изучать каждый фактор, управляя значениями других факторов. Это, в действительности, и является основной причиной его большей статистической мощности (для получения значимых результатов требуются меньшие объемы выборок). По этой причине дисперсионный анализ даже на небольших выборках дает статистически более значимые результаты, чем простой t-критерий.
Чтобы проанализировать изменчивость признака под воздействием контролируемых переменных, применяется дисперсионный метод.
Для изучения связи между значениями – факторный метод. Рассмотрим подробнее аналитические инструменты: факторный, дисперсионный и двухфакторный дисперсионный метод оценки изменчивости.
Дисперсионный анализ в Excel
Условно цель дисперсионного метода можно сформулировать так: вычленить из общей вариативности параметра 3 частные вариативности:
- 1 – определенную действием каждого из изучаемых значений;
- 2 – продиктованную взаимосвязью между исследуемыми значениями;
- 3 – случайную, продиктованную всеми неучтенными обстоятельствами.
В программе Microsoft Excel дисперсионный анализ можно выполнить с помощью инструмента «Анализ данных» (вкладка «Данные» - «Анализ»). Это надстройка табличного процессора. Если надстройка недоступна, нужно открыть «Параметры Excel» и включить настройку для анализа .
Работа начинается с оформления таблицы. Правила:
- В каждом столбце должны быть значения одного исследуемого фактора.
- Столбцы расположить по возрастанию/убыванию величины исследуемого параметра.
Рассмотрим дисперсионный анализ в Excel на примере.
Психолог фирмы проанализировал с помощью специальной методики стратегии поведения сотрудников в конфликтной ситуации. Предполагается, что на поведение влияет уровень образования (1 – среднее, 2 – среднее специальное, 3 – высшее).
Внесем данные в таблицу Excel:


Значимый параметр залит желтым цветом. Так как Р-Значение между группами больше 1, критерий Фишера нельзя считать значимым. Следовательно, поведение в конфликтной ситуации не зависит от уровня образования.
Факторный анализ в Excel: пример
Факторным называют многомерный анализ взаимосвязей между значениями переменных. С помощью данного метода можно решить важнейшие задачи:
- всесторонне описать измеряемый объект (причем емко, компактно);
- выявить скрытые переменные значения, определяющие наличие линейных статистических корреляций;
- классифицировать переменные (определить взаимосвязи между ними);
- сократить число необходимых переменных.
Рассмотрим на примере проведение факторного анализа. Допустим, нам известны продажи каких-либо товаров за последние 4 месяца. Необходимо проанализировать, какие наименования пользуются спросом, а какие нет.


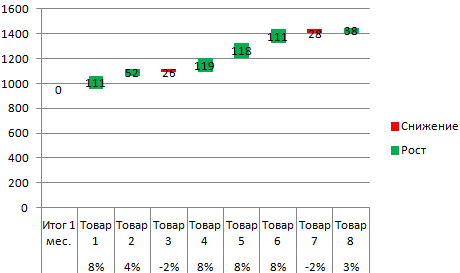
Теперь наглядно видно, продажи какого товара дают основной рост.
Двухфакторный дисперсионный анализ в Excel
Показывает, как влияет два фактора на изменение значения случайной величины. Рассмотрим двухфакторный дисперсионный анализ в Excel на примере.
Задача. Группе мужчин и женщин предъявляли звук разной громкости: 1 – 10 дБ, 2 – 30 дБ, 3 – 50 дБ. Время ответа фиксировали в миллисекундах. Необходимо определить, влияет ли пол на реакцию; влияет ли громкость на реакцию.
Основной целью дисперсионного анализа, фундаментальная концепция которого была предложена Фишером в 1920 г., Является исследование значимости различия между средними нескольких групп данных или переменных. Если сравниваются средние двух групп, дисперсионный анализ даст тот же результат, что и обычный г-критерий для независимых или зависимых выборок. Однако использование дисперсионного анализа имеет преимущества особенно для малых выборок.
В дисперсионном анализе проверка статистической значимости различия между средними нескольких групп осуществляется на основе выборочных дисперсий. Эта проверка проводится с помощью разбиения общей дисперсии (вариации) на части, одна из которых обусловлена случайной ошибкой (то есть внут-ришньогруповою изменчивостью), а вторая связана с различием средних значений. Если это различие значимо, нулевая гипотеза о существовании различия между средними значениями откидывается на определенном уровне значимости.
Дисперсионный однофакторный анализ
Дисперсионный однофакторный анализ используется в исследованиях изменения результативного признака под влиянием изменения условий или градаций фактора. Суть математических преобразований дисперсионной метода заключается в том, чтобы сопоставить дисперсии по факторам с дисперсией всех значений, полученных в эксперименте. Однофакторный анализ требует не менее трех градаций фактора и не менее двух испытаний в каждой градации. При проведении дисперсионного анализа необходимо проверить нормальность распределения исследуемой случайной величины и отсутствие различия дисперсий совокупностей. Это можно выполнить методами проверки статистических гипотез (см.раздел 5).
Предположим, что анализируется влияние фактора А на к уровнях А 1, ^ 4 2, а к. Например, в эксперименте это можно реализовать, если задействовать к выборок с различными градациями условий. На каждом уровне Ли (для каждой выборки) проведения п спостереженьх / 1, х / 2, х ш (см. Табл. 6.1).
Таблица 6.1
|
Номера наблюдений |
Уровни фактора А |
||
|
х 21 ooo |
|||
|
х первых |
х 2 И o |
||
|
х кп |
|||
|
Х2 o .. |
|||
Рассмотрим оценки различных дисперсий.
Дисперсия я 2 для уровня Аи (для определенной выборки) может быть записана как
Дисперсия я 0, характеризующий вариативность вне влияния фактора А
Общая дисперсия я всех пк наблюдений равна

Дисперсия я 2 А, характеризующий изменение средних х / под влиянием фактора А:
1 к _ =
к ~ 1 ¡= 1
Проверка влияния фактора А на смену средних может быть сведена к сравнению дисперсий я 2 А и я 2. Влияние фактора А считаться значимым на гальке
а если является значимым отношение 5 1я 2, то есть если
5 2 Л и ^> ^ а [к 1; к (п -1)], где к 1; к (п -1) - степени свободы ^ -распределение, 5 и я 7] - ^ -критерий Фишера. Пример 6.1. Двести предположение о том, что фактор скорости предъявления слов влияет на показатели их воспроизведения (данные в таблице рис. 8.1). Последовательность решения:
o Формулировка гипотез.
Н 0: фактор скорости не более выраженным, чем случайным; Н 1: фактор скорости более выраженным, чем случайным.
o Проверка предположений: исследуемый параметр нормальный распределение; выборки несвязанные одинаковых объемов; измерения по шкале отношений.
o Определение эмпирического критерия Г ЭМП базируется на сопоставлении квадратов сумм по столбцам с суммой квадратов всех эмпирических значений. Каждый столбец представляет выборку и соответствует определенной градации фактора скорости.
o Введенные обозначения:
п = 6 - количество наблюдений (строк)
к = 3 - количество факторов (столбиков)
пк = 6-3 = 18 - общее количество индивидуальных значений;
7 - индекс строк изменяется от 1 до п (7 = 1, 2, ..., п)
и - индекс столбиков изменяется от 1 до к (и = 1, 2, ..., к).
o Математические расчеты (см. рис 6.1 6.2):
i = 1 7 = 1 п м кп ^ и = 1)
Есть 1 = 6 2 + семь 2 + 6 2 + 5 2 + _ + 5 2 + 5 2 = 432; и 2 = - (34 2 + +29 2 + 23 2) = 421;
и 3 ^^ (34 + 29 + 23) 2 = 410,89; 3 o 6

Рис. 6.1. Результаты Рис. 6.2. Расчетные формулы
дисперсионного анализа однофакторного дисперсионного анализа
o Критическое значение ^ кр можно получить с помощью функции
РРАСПОБР () для уровня значимости для а = 0,05 (0,01) и числа степеней свободы к 1 = 3-1 = 2 и к (п -1) = 3 (6-1) = 15. Г 0и05 ~ 3,68 и Г 0и01 ~ 6,36.
o Принятие решения. Поскольку ¥ ГМП> Р 0? 01 (6,89> 6,36), нулевая гипотеза Н 0 отклоняется на уровне значимости 0,01.
o Формулировка выводов. Различия в объеме воспроизведения слов (фактор скорости) более выраженными, чем случайным. Эту зависимость можно представить графически на рис. 6.3.

Рис. 6.3. Зависимость среднего объема воспроизведенных слов от скорости предъявления
Расчеты однофакторной модели можно провести с помощью пакета "Анализ данных" раздел "Однофакторный дисперсионный анализ" (рис. 6.4).

Рис. 6.4. Меню пакета "Анализ данных" После введения соответствующих параметров (рис. 6.5) можно получить результаты однофакторного дисперсионного анализа (рис. 6.6).

Рис. 6.5. Диалоговое окно

Рис. 6.6. Результаты однофакторного дисперсионного анализа (а = 0,05)
Компьютерный пакет "Анализ данных" выполняет расчеты основных статистик (суммы, средние, дисперсии, значение эмпирических и теоретических критериев и т.п.), что дает основания исследователю для статистических выводов.
Дисперсионный анализ есть совокупность статистических методов, предназначенных для проверки гипотез о связи между определенными признаками и исследуемыми факторами, которые не имеют количественного описания, а также для установления степени влияния факторов и их взаимодействия. В специальной литературе его часто называют ANOVA (от англоязычного названия Analysis of Variations). Впервые этот метод был разработан Р. Фишером в 1925 г.
Виды и критерии дисперсионного анализа
Этот метод используется для исследования связи между качественными (номинальными) признаками и количественной (непрерывной) переменной. По сути, он осуществляет тестирование гипотезы о равенстве средних арифметических нескольких выборок. Таким образом, его можно рассматривать как параметрический критерий для сравнения центров сразу нескольких выборок. Если использовать этот метод для двух выборок, то результаты дисперсионного анализа будут идентичны результатам t-критерия Стьюдента. Однако, в отличие от других критериев, это исследование позволяет изучить проблему более детально.
Дисперсионный анализ в статистике базируется на законе: сумма квадратов отклонений объединенной выборки равна сумме квадратов внутригрупповых отклонений и сумме квадратов межгрупповых отклонений. Для исследования используется критерий Фишера для установления значимости различия межгрупповых дисперсий от внутригрупповых. Однако для этого необходимыми предпосылками являются нормальность распределения и гомоскедастичность (равенство дисперсий) выборок. Различают одномерный (однофакторный) дисперсионный анализ и многомерный (многофакторный). Первый рассматривает зависимость исследуемой величины от одного признака, второй - сразу от многих, а также позволяет выявить связь между ними.
Факторы
Факторами называют контролируемые обстоятельства, что влияют на конечный результат. Его уровнем или способом обработки называют значение, которое характеризует конкретное проявление этого условия. Эти цифры обычно подают в номинальной или порядковой шкале измерений. Часто выходные значения измеряют в количественных или порядковых шкалах. Тогда возникает проблема группировки выходных данных в ряде наблюдений, что соответствуют примерно одинаковым числовым значениям. Если количество групп взять чрезмерно большим, то количество наблюдений в них может оказаться недостаточным для получения надежных результатов. Если брать число чрезмерно малым, это может привести к потере существенных особенностей влияния на систему. Конкретный способ группировки данных зависит от объема и характера варьирования значений. Количество и размеры интервалов при однофакторном анализе чаще всего определяют по принципу равных промежутков или по принципу равных частот.
Задачи дисперсионного анализа
Итак, существуют случаи, когда нужно сравнить две или больше выборок. Именно тогда и целесообразно применение дисперсионного анализа. Название метода указывает на то, что выводы делают на основе исследования составляющих дисперсии. Суть изучения состоит в том, что общее изменение показателя разбивают на составляющие части, которые соответствуют действию каждого отдельно взятого фактора. Рассмотрим ряд задач, которые решает типичный дисперсионный анализ.
Пример 1
В цехе есть ряд станков - автоматов, которые изготавливают определенную деталь. Размер каждой детали - это случайная величина, которая зависит от настройки каждого станка и случайных отклонений, возникающих в процессе изготовления деталей. Нужно по данным измерений размеров деталей определить, одинаково ли настроены станки.

Пример 2
Во время изготовления электрического аппарата используют различные типы изоляционной бумаги: конденсаторную, электротехническую и др. Аппарат можно пропитать различными веществами: эпоксидной смолой, лаком, смолой МЛ-2 и др. Утечки можно устранять под вакуумом при повышенном давлении, при нагреве. Пропитывать можно методом погружения в лак, под непрерывной струей лака и т. п. Электрический аппарат в целом заливают определенным компаундом, вариантов которого есть несколько. Показателями качества являются электрическая прочность изоляции, температура перегрева обмотки в рабочем режиме и ряд других. Во время отработки технологического процесса изготовления аппаратов надо определить, как влияет каждый из перечисленных факторов на показатели аппарата.
Пример 3
Троллейбусное депо обслуживает несколько троллейбусных маршрутов. На них работают троллейбусы различных типов, и оплату за проезд собирают 125 контролеров. Руководство депо интересует вопрос: как сравнить экономические показатели работы каждого контролера (выручку) учитывая различные маршруты, различные типы троллейбусов? Как определить экономическую целесообразность выпуска троллейбусов определенного типа на тот или другой маршрут? Как установить обоснованные требования к величине выручки, которую приносит кондуктор, на каждом маршруте в различных типах троллейбусов?
Задача по выбору метода состоит в том, как получить максимум информации относительно влияния на конечный результат каждого фактора, определить числовые характеристики такого влияния, их надежность при минимальных затратах и за максимально короткое время. Решить такие задачи позволяют методы дисперсионного анализа.
Однофакторный анализ
Исследование своей целью ставит оценку величины влияния конкретного случая на анализируемый отзыв. Другой задачей однофакторного анализа может быть сравнение двух или нескольких обстоятельств друг с другом с целью определения разницы их влияния на отзыв. Если нулевую гипотезу отвергают, то следующим этапом будет количественное оценивание и построение доверительных интервалов для полученных характеристик. В случае, когда нулевая гипотеза не может быть отброшенной, обычно ее принимают и делают вывод о сущности влияния.
Однофакторный дисперсионный анализ может стать непараметрическим аналогом рангового метода Краскела-Уоллиса. Он разработан американскими математиком Уильямом Краскелом и экономистом Вильсоном Уоллисом в 1952 г. Этот критерий назначен для проверки нулевой гипотезы о равенстве эффектов влияния на исследуемые выборки с неизвестными, но равными средними величинами. При этом количество выборок должно быть больше двух.

Критерий Джонкхиера (Джонкхиера-Терпстра) был предложен независимо друг от друга нидерландским математиком Т. Дж. Терпстром в 1952 г. и британским психологом Е. Р. Джонкхиером в 1954 г. Его применяют тогда, когда заранее известно, что имеющиеся группы результатов упорядочены по росту влияния исследуемого фактора, который измеряют в порядковой шкале.
М - критерий Бартлетта, предложенный британским статистиком Маурисом Стивенсоном Бартлеттом в 1937 г., применяют для проверки нулевой гипотезы о равенстве дисперсий нескольких нормальных генеральных совокупностей, с которых взяты исследуемые выборки, в общем случае имеющие различные объемы (число каждой выборки должно быть не меньше четырех).
G - критерий Кохрена, который открыл американец Вильям Геммел Кохрен в 1941 г. Его используют для проверки нулевой гипотезы о равенстве дисперсий нормальных генеральных совокупностей по независимым выборкам равного объема.
Непараметрический критерий Левене, предложенный американским математиком Ховардом Левене в 1960 г., является альтернативой критерия Бартлетта в условиях, когда нет уверенности в том, что исследуемые выборки подчиняются нормальному распределению.
В 1974 г. американские статистики Мортон Б. Браун и Алан Б. Форсайт предложили тест (критерий Брауна-Форсайта), который несколько отличается от критерия Левене.
Двухфакторный анализ
Двухфакторный дисперсионный анализ применяют для связанных нормально распределенных выборок. На практике часто используют и сложные таблицы этого метода, в частности те, в которых каждая ячейка содержит набор данных (повторные измерения), соответствующих фиксированным значениям уровней. Если предположения, необходимые для применения двухфакторного дисперсионного анализа, не выполняются, то используют непараметрический ранговый критерий Фридмана (Фридмана, Кендалла и Смита), разработанный американским экономистом Милтоном Фридманом в конце 1930 г. Этот критерий не зависит от типа распределения.
Предполагается только, что распределение величин является одинаковым и непрерывным, а сами они независимы одна от другой. При проверке нулевой гипотезы выходные данные подают в форме прямоугольной матрицы, в которой строки соответствуют уровням фактора В, а столбцы - уровням А. Каждая ячейка таблицы (блока) может быть результатом измерений параметров на одном объекте или на группе объектов при постоянных значениях уровней обоих факторов. В этом случае соответствующие данные подают как средние значения определенного параметра по всем измерениям или объектам исследуемой выборки. Для применения критерия выходных данных необходимо перейти от непосредственных результатов измерений к их рангу. Ранжирование осуществляют по каждой строке отдельно, то есть величины упорядочивают для каждого фиксированного значения.

Критерий Пейджа (L-критерий), предложенный американским статистиком Е. Б. Пейджем в 1963 г., предназначен для проверки нулевой гипотезы. Для больших выборок применяют аппроксимацию Пейджа. Они при условии реальности соответствующих нулевых гипотез подчиняются стандартному нормальному распределению. В случае, когда в строках исходной таблицы есть одинаковые значения, необходимо использовать средние ранги. При этом точность выводов будет тем хуже, чем больше будет количеств таких совпадений.
Q - критерий Кохрена, предложенный В. Кохреном в 1937 г. Его используют в случаях, когда группы однородных субъектов подвергаются воздействиям, количество которых превышает два и для которых возможны два варианта отзывов - условно-отрицательный (0) и условно-положительный (1). Нулевая гипотеза состоит из равенства эффектов влияния. Двухфакторный дисперсионный анализ дает возможность определить существование эффектов обработки, однако не дает возможности установить, для каких именно столбцов существует этот эффект. При решении данной проблемы применяют метод множественных уравнений Шеффе для связанных выборок.
Многофакторный анализ
Задача многофакторного дисперсионного анализа возникает тогда, когда нужно определить влияние двух или большего количества условий на определенную случайную величину. Исследование предусматривает наличие одной зависимой случайной величины, измеренной в шкале разницы или отношений, и нескольких независимых величин, каждая из которых выражена в шкале наименований или в ранговой. Дисперсионный анализ данных является достаточно развитым разделом математической статистики, который имеет массу вариантов. Концепция исследования общая как для однофакторного, так и для многофакторного. Сущность ее состоит в том, что общую дисперсию разбивают на составляющие, что соответствует определенной группировке данных. Каждой группировке данных соответствует своя модель. Здесь мы рассмотрим только основные положения, нужные для понимания и практического использования наиболее применяемых его вариантов.

Дисперсионный анализ факторов требует достаточно внимательного отношения к сбору и подаче входных данных, а особенно к интерпретации результатов. В отличие от однофакторного, результаты которого можно условно разместить в определенной последовательности, результаты двухфакторного требуют более сложного представления. Еще сложнее ситуация возникает, когда есть три, четыре или больше обстоятельств. Из-за этого в модель достаточно редко включают больше трех (четырех) условий. Примером может быть возникновение резонанса при определенной величине емкости и индуктивности электрического круга; проявление химической реакции при определенной совокупности элементов, из которых построена система; возникновение аномальных эффектов в сложных системах при определенном совпадении обстоятельств. Наличие взаимодействия может в корне изменить модель системы и иногда привести к переосмыслению природы явлений, с которыми имеет дело экспериментатор.
Многофакторный дисперсионный анализ с повторными опытами
Данные измерений достаточно часто можно группировать не по двум, а по большему количеству факторов. Так, если рассматривать дисперсионный анализ срока службы покрышек колес троллейбуса с учетом обстоятельств (завод-производитель и маршрут, на котором эксплуатируются покрышки), то можно выделить как отдельное условие сезон, во время которого эксплуатируются покрышки (а именно: зимняя и летняя эксплуатация). В результате будем иметь задачу трехфакторного метода.
При наличии большего количества условий подход такой же, как и в двухфакторном анализе. Во всех случаях модель пытаются упростить. Явление взаимодействия двух факторов проявляется не так часто, а тройное взаимодействие бывает только в исключительных случаях. Включают то взаимодействие, для которого есть предыдущая информация и серьезные основания, чтобы ее учесть в модели. Процесс выделения отдельных факторов и их учета относительно простой. Поэтому часто возникает желание выделить больше обстоятельств. Этим не следует увлекаться. Чем больше условий, тем менее надежной становится модель и тем больше вероятность ошибки. Сама модель, в которую входит большое количество независимых переменных, становится достаточно сложной для интерпретации и неудобной для практического использования.
Общая идея дисперсионного анализа
Дисперсионный анализ в статистике - это метод получения результатов наблюдений, зависимых от различных одновременно действующих обстоятельств, и оценки их влияния. Управляемую переменную величину, которая соответствует способу воздействия на объект исследования и в некоторый период времени приобретает определенное значение, называют фактором. Они могут быть качественными и количественными. Уровни количественных условий приобретают определенное значение на числовой шкале. Примерами являются температура, давление прессования, количество вещества. Качественные факторы - это разные вещества, разные технологические способы, аппараты, наполнители. Их уровням соответствует шкала наименований.

К качественным можно отнести также вид упаковочного материала, условия хранения лекарственной формы. Сюда же рационально отнести степень измельчения сырья, фракционный состав гранул, имеющих количественное значение, однако плохо поддающихся регулированию, если использовать количественную шкалу. Число качественных факторов зависит от вида лекарственной формы, а также физических и технологических свойств лекарственных веществ. Например, из кристаллических веществ можно получать таблетки прямым прессованием. В этом случае достаточно провести выбор скользящих и смазывающих веществ.
Примеры качественных факторов для различных видов лекарственных форм
- Настойки. Состав экстрагента, тип экстрактора, способ подготовки сырья, способ получения, способ фильтрации.
- Экстракты (жидкие, густые, сухие). Состав экстрагента, способ экстракции, тип установки, способ удаления экстрагента и балластных веществ.
- Таблетки. Состав вспомогательных веществ, наполнители, разрыхлители, связующие, смазывающие и скользящие вещества. Способ получения таблеток, вид технологического оборудования. Вид оболочки и ее компонентов, пленкообразователи, пигменты, красители, пластификаторы, растворители.
- Инъекционные растворы. Вид растворителя, способ фильтрации, природа стабилизаторов и консервантов, условия стерилизации, способ заполнения ампул.
- Суппозитории. Состав суппозиторной основы, способ получения суппозиториев, наполнителей, упаковки.
- Мази. Состав основы, структурные компоненты, способ приготовления мази, вид оборудования, упаковка.
- Капсулы. Вид оболочечного материала, способ получения капсул, тип пластификатора, консерванта, красителя.
- Линименты. Способ получения, состав, тип оборудования, тип эмульгатора.
- Суспензии. Вид растворителя, вид стабилизатора, метод диспергирования.
Примеры качественных факторов и их уровней, изучаемых в процессе изготовления таблеток
- Разрыхлитель. Крахмал картофельный, глина белая, смесь натрия гидрокарбоната с кислотой лимонной, магния карбонат основной.
- Связывающий раствор. Вода, крахмальный клейстер, сахарный сироп, раствор метилцеллюлозы, раствор оксипропилметилцеллюлозы, раствор поливинилпирролидона, раствор поливинилового спирта.
- Скользящая вещество. Аэросил, крахмал, тальк.
- Наполнитель. Сахар, глюкоза, лактоза, натрия хлорид, фосфат кальция.
- Смазывающее вещество. Стеариновая кислота, полиэтиленгликоль, парафин.
Модели дисперсионного анализа в исследовании уровня конкурентоспособности государства
Одним из важнейших критериев оценки состояния государства, по которым проводится оценка уровня его благосостояния и социально-экономического развития, является конкурентоспособность, то есть совокупность свойств, присущих национальной экономике, которые определяют способность государства конкурировать с другими странами. Определив место и роль государства на мировом рынке, можно установить четкую стратегию обеспечения экономической безопасности в международных масштабах, ведь она является залогом положительных взаимоотношений России со всеми игроками мирового рынка: инвесторами, кредиторами, правительствами государств.
Для сравнения уровня конкурентоспособности государств проводится ранжирование стран с помощью комплексных индексов, которые включают различные взвешенные показатели. В основу этих индексов заложены ключевые факторы, влияющие на экономическое, политическое и т. п. положение. Комплекс моделей исследования конкурентоспособности государства предусматривает использование методов многомерного статистического анализа (в частности, это дисперсионный анализ (статистика), эконометрическое моделирование, принятие решений) и включает следующие основные этапы:
- Формирование системы показателей-индикаторов.
- Оценку и прогнозирование индикаторов конкурентоспособности государства.
- Сравнение показателей-индикаторов конкурентоспособности государств.
А теперь рассмотрим содержание моделей каждого из этапов данного комплекса.
На первом этапе с помощью методов экспертного изучения формируется обоснованный комплекс экономических показателей-индикаторов оценки конкурентоспособности государства с учетом специфики ее развития на основе международных рейтингов и данных статистических отделов, отражающих состояние системы в целом и ее процессов. Выбор этих показателей обоснован необходимостью отобрать те из них, которые наиболее полно с точки зрения практики позволяют определить уровень государства, его инвестиционную привлекательность и возможности относительной локализации существующих потенциальных и реально действующих угроз.

Основные показатели-индикаторы международных рейтинг-систем - это индексы:
- Глобальной конкурентоспособности (ИГК).
- Экономической свободы (ИЭС).
- Развития человеческого потенциала (ИРЧП).
- Восприятия коррупции (ИВК).
- Внутренних и внешних угроз (ИВЗЗ).
- Потенциала международного влияния (ИПМВ).
Второй этап предусматривает оценку и прогнозирование индикаторов конкурентоспособности государства по международным рейтингам для исследуемых 139 государств мира.
Третий этап предусматривает сравнение условий конкурентоспособности государств при помощи методов корреляционно-регрессионного анализа.
Используя результаты исследования можно определить характер протекания процессов в целом и по отдельным составляющим конкурентоспособности государства; проверить гипотезу о влиянии факторов и их взаимосвязи при соответствующем уровне значимости.
Реализация предложенного комплекса моделей позволит не только оценить сложившуюся ситуацию уровня конкурентоспособности и инвестиционной привлекательности государств, но и проанализировать недостатки управления, предупредить ошибки неправильных решений, не допустить развития кризиса в государстве.
