Наиболее распространенной формой статистических показателей, используемых в социально-экономических исследованиях, является средняя величина, представляющая собой обобщенную количественную характеристику признака статистической совокупности. Средние величины являются как бы «представителями» всего ряда наблюдений. Определить среднюю можно во многих случаях через исходное соотношение средней (ИСС) или ее логическую формулу: . Так, например, для расчета средней заработной платы работников предприятия необходимо общий фонд заработной платы разделить на число работников: Числитель исходного соотношения средней представляет собой ее определяющий показатель. Для средней заработной платы таким определяющим показателем является фонд заработной платы. Для каждого показателя, используемого в социально-экономическом анализе, можно составить только одно истинное исходное соотношение для расчета средней. Следует еще добавить, что для того, чтобы более точно оценить стандартное отклонение для малых выборок (с числом элементов менее 30), в знаменателе выражения под корнем надо использовать не n , а n- 1.
Понятие и виды средних величин
Средняя величина - это обобщающий показатель статистической совокупности, который погашает индивидуальные различия значений статистических величин, позволяя сравнивать разные совокупности между собой. Существует 2 класса средних величин: степенные и структурные. К структурным средним относятсямода имедиана , но наиболее часто применяютсястепенные средние различных видов.Степенные средние величины
Степенные средние могут быть простыми и взвешенными .
Простая средняя величина рассчитывается при наличии двух и более несгруппированных статистических величин, расположенных в произвольном порядке по следующей общей формуле средней степенной (при различной величине k (m)):
Взвешенная средняя величина рассчитывается по сгруппированным статистическим величинам с использованием следующей общей формулы:

Где x - средняя величина исследуемого явления; x i – i -й вариант усредняемого признака ;
f i – вес i -го варианта.

Где X – значения отдельных статистических величин или середин группировочных интервалов;
m - показатель степени, от значения которого зависят следующие виды степенных средних величин:
при m = -1 средняя гармоническая;
при m = 0 средняя геометрическая;
при m = 1 средняя арифметическая;
при m = 2 средняя квадратическая;
при m = 3 средняя кубическая.
Используя общие формулы простой и взвешенной средних при разных показателях степени m, получаем частные формулы каждого вида, которые будут далее подробно рассмотрены.
Средняя арифметическая
Средняя арифметическая – начальный момент первого порядка, математическое ожидание значений случайной величины при большом числе испытаний;
Средняя арифметическая - это самая часто используемая средняя величина, которая получается, если подставить в общую формулу m=1. Средняя арифметическая простая имеет следующий вид:
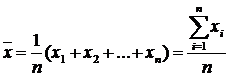 или
или
![]()
Где X - значения величин, для которых необходимо рассчитать среднее значение; N - общее количество значений X (число единиц в изучаемой совокупности).
Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Рассчитаем средний балл по формуле средней арифметической простой: (3+4+4+5)/4 = 16/4 = 4. Средняя арифметическая взвешенная имеет следующий вид:
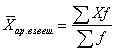
Где f - количество величин с одинаковым значением X (частота). >Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Рассчитаем средний балл по формуле средней арифметической взвешенной: (3*1 + 4*2 + 5*1)/4 = 16/4 = 4. Если значения X заданы в виде интервалов, то для расчетов используют середины интервалов X, которые определяются как полусумма верхней и нижней границ интервала. А если у интервала X отсутствует нижняя или верхняя граница (открытый интервал), то для ее нахождения применяют размах (разность между верхней и нижней границей) соседнего интервала X. Например, на предприятии 10 работников со стажем работы до 3 лет, 20 - со стажем от 3 до 5 лет, 5 работников - со стажем более 5 лет. Тогда рассчитаем средний стаж работников по формуле средней арифметической взвешенной, приняв в качестве X середины интервалов стажа (2, 4 и 6 лет): (2*10+4*20+6*5)/(10+20+5) = 3,71 года.
Функция СРЗНАЧ
Эта функция вычисляет среднее (арифметическое) своих аргументов.
СРЗНАЧ(число1; число2; ...)
Число1, число2, ... - это от 1 до 30 аргументов, для которых вычисляется среднее.
Аргументы должны быть числами или именами, массивами или ссылками, содержащими числа. Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако, ячейки, которые содержат нулевые значения, учитываются.
Функция СРЗНАЧА
Вычисляет среднее арифметическое значений, заданных в списке аргументов. Помимо чисел в расчете могут участвовать текст и логические значения, такие как ИСТИНА и ЛОЖЬ.
СРЗНАЧА(значение1,значение2,...)
Значение1, значение2,... - это от 1 до 30 ячеек, интервалов ячеек или значений, для которых вычисляется среднее.
Аргументы должны быть числами, именами, массивами или ссылками. Массивы и ссылки, содержащие текст, интерпретируются как 0 (ноль). Пустой текст ("") интерпретируется как 0 (ноль). Аргументы, содержащие значение ИСТИНА, интерпретируются как 1, Аргументы, содержащие значение ЛОЖЬ, интерпретируются как 0 (ноль).
Средняя арифметическая применяется чаще всего, но бывают случаи, когда необходимо применение других видов средних величин. Рассмотрим такие случаи далее.
Средняя гармоническая
Средняя гармоническая для определения средней суммы обратных величин;
Средняя гармоническая применяется, когда исходные данные не содержат частот f по отдельным значениям X, а представлены как их произведение Xf. Обозначив Xf=w, выразим f=w/X, и, подставив эти обозначения в формулу средней арифметической взвешенной, получим формулу средней гармонической взвешенной:
Таким
образом, средняя гармоническая взвешенная применяется тогда, когда неизвестны
частоты f, а известно w=Xf. В тех случаях, когда все w=1, то есть индивидуальные
значения X встречаются по 1 разу, применяется формула средней гармонической
простой:
 или
или
 Например, автомобиль ехал из пункта А в пункт Б со скоростью 90
км/ч, а обратно - со скоростью 110 км/ч. Для определения средней скорости
применим формулу средней гармонической простой, так как в примере дано
расстояние w 1 =w 2 (расстояние
из пункта А в пункт Б такое, же как и из Б в А), которое равно произведению
скорости (X) на время (f). Средняя скорость = (1+1)/(1/90+1/110) = 99 км/ч.
Например, автомобиль ехал из пункта А в пункт Б со скоростью 90
км/ч, а обратно - со скоростью 110 км/ч. Для определения средней скорости
применим формулу средней гармонической простой, так как в примере дано
расстояние w 1 =w 2 (расстояние
из пункта А в пункт Б такое, же как и из Б в А), которое равно произведению
скорости (X) на время (f). Средняя скорость = (1+1)/(1/90+1/110) = 99 км/ч.
Функция СРГАРМ
Возвращает среднее гармоническое множества данных. Среднее гармоническое - это величина, обратная к среднему арифметическому обратных величин.
СРГАРМ(число1;число2; ...)
Число1, число2, ... - это от 1 до 30 аргументов, для которых вычисляется среднее. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой.
Среднее гармоническое всегда меньше среднего геометрического, которое всегда меньше среднего арифметического.
Средняя геометрическая
Средняя геометрическая для оценки средних темпов роста случайной величин, нахождения значения признака, равноудаленного от минимального и максимального значения;
Средняя геометрическая применяется при определении средних относительных изменений. Геометрическая средняя величина дает наиболее точный результат осреднения, если задача стоит в нахождении такого значения X, который был бы равноудален как от максимального, так и от минимального значения X. Например, в период с 2005 по 2008 годы индекс инфляции в России составлял: в 2005 году - 1,109; в 2006 - 1,090; в 2007 - 1,119; в 2008 - 1,133. Так как индекс инфляции - это относительное изменение (индекс динамики), то рассчитывать среднее значение нужно по средней геометрической: (1,109*1,090*1,119*1,133)^(1/4) = 1,1126, то есть за период с 2005 по 2008 ежегодно цены росли в среднем на 11,26%. Ошибочный расчет по средней арифметической дал бы неверный результат 11,28%.Функция СРГЕОМ
Возвращает среднее геометрическое значений массива или интервала положительных чисел. Например, функцию СРГЕОМ можно использовать для вычисления средних темпов роста, если задан составной доход с переменными ставками.
СРГЕОМ (число1; число2; ...)
Число1, число2, ... - это от 1 до 30 аргументов, для которых вычисляется среднее геометрическое. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой.
Средняя квадратическая
Средняя квадратическая – начальный момент второго порядка.
Средняя квадратическая применяется в тех случая, когда исходные значения X могут быть как положительными, так и отрицательными, например при расчете средних отклонений.Средняя кубическая
Средняя кубическая – начальный момент третьего порядка.
Средняя кубическая применяется крайне редко, например, при расчете индексов нищеты населения для развивающихся стран (ИНН-1) и для развитых (ИНН-2), предложенных и рассчитываемых ООН.В большинстве случаев данные концентрируются вокруг некоей центральной точки. Таким образом, чтобы описать любой набор данных, достаточно указать средне значение. Рассмотрим последовательно три числовые характеристики, которые используются для оценки среднего значения распределения: среднее арифметическое, медиана и мода.
Среднее арифметическое
Среднее арифметическое (часто называемое просто средним) - наиболее распространенная оценка среднего значения распределения. Она является результатом деления суммы всех наблюдаемых числовых величин на их количество. Для выборки, состоящей из чисел Х 1 , Х 2 , …, Х n , выборочное среднее (обозначаемое символом ) равно = (Х 1 + Х 2 + … + Х n ) / n , или
где - выборочное среднее, n - объем выборки, X i – i-й элемент выборки.
Скачать заметку в формате или , примеры в формате
Рассмотрим вычисление среднего арифметического значения пятилетней среднегодовой доходности 15 взаимных фондов с очень высоким уровнем риска (рис. 1).

Рис. 1. Среднегодовая доходность 15 взаимных фондов с очень высоким уровнем риска
Выборочное среднее вычисляется следующим образом:

Это хороший доход, особенно по сравнению с 3–4% дохода, который получили вкладчики банков или кредитных союзов за тот же период времени. Если упорядочить значения доходности, то легко заметить, что восемь фондов имеют доходность выше, а семь - ниже среднего значения. Среднее арифметическое играет роль точки равновесия, так что фонды с низкими доходами уравновешивают фонды с высокими доходами. В вычислении среднего задействованы все элементы выборки. Ни одна из других оценок среднего значения распределения не обладает этим свойством.
Когда следует вычислять среднее арифметическое. Поскольку среднее арифметическое зависит от всех элементов выборки, наличие экстремальных значений значительно влияет на результат. В таких ситуациях среднее арифметическое может исказить смысл числовых данных. Следовательно, описывая набор данных, содержащий экстремальные значения, необходимо указывать медиану либо среднее арифметическое и медиану. Например, если удалить из выборки доходность фонда RS Emerging Growth, выборочное среднее доходности 14 фондов уменьшится почти на 1% и составит 5,19%.
Медиана
Медиана представляет собой срединное значение упорядоченного массива чисел. Если массив не содержит повторяющихся чисел, то половина его элементов окажется меньше, а половина - больше медианы. Если выборка содержит экстремальные значения, для оценки среднего значения лучше использовать не среднее арифметическое, а медиану. Чтобы вычислить медиану выборки, ее сначала необходимо упорядочить.
Эта формула неоднозначна. Ее результат зависит от четности или нечетности числа n :
- Если выборка содержит нечетное количество элементов, медиана равна (n+1)/2 -му элементу.
- Если выборка содержит четное количество элементов, медиана лежит между двумя средними элементами выборки и равна среднему арифметическому, вычисленному по этим двум элементам.
Чтобы вычислить медиану выборки, содержащей данные о доходности 15 взаимных фондов с очень высокий уровнем риска, сначала необходимо упорядочить исходные данные (рис. 2). Тогда медиана будет напротив номера среднего элемента выборки; в нашем примере №8. В Excel есть специальная функция =МЕДИАНА(), которая работает и с неупорядоченными массивами тоже.

Рис. 2. Медиана 15 фондов
Таким образом, медиана равна 6,5. Это означает, что доходность одной половины фондов с очень высоким уровнем риска не превышает 6,5, а доходность второй половины - превышает ее. Обратите внимание на то, что медиана, равная 6,5, ненамного больше среднего значения, равного 6,08.
Если удалить из выборки доходность фонда RS Emerging Growth, то медиана оставшихся 14 фондов уменьшится до 6,2%, то есть не так значительно, как среднее арифметическое (рис. 3).

Рис. 3. Медиана 14 фондов
Мода
Термин был впервые введен Пирсоном в 1894 г. Мода - это число, которое чаще других встречается в выборке (наиболее модное). Мода хорошо описывает, например, типичную реакцию водителей на сигнал светофора о прекращении движения. Классический пример использования моды - выбор размера выпускаемой партии обуви или цвета обоев. Если распределение имеет несколько мод, то говорят, что оно мультимодально или многомодально (имеет два или более «пика»). Мультимодальность распределения дает важную информацию о природе исследуемой переменной. Например, в социологических опросах, если переменная представляет собой предпочтение или отношение к чему-то, то мультимодальность может означать, что существуют несколько определенно различных мнений. Мультимодальность также служит индикатором того, что выборка не является однородной и наблюдения, возможно, порождены двумя или более «наложенными» распределениями. В отличие от среднего арифметического, выбросы на моду не влияют. Для непрерывно распределенных случайных величин, например, для показателей среднегодовой доходности взаимных фондов, мода иногда вообще не существует (или не имеет смысла). Поскольку эти показатели могут принимать самые разные значения, повторяющиеся величины встречаются крайне редко.
Квартили
Квартили - это показатели, которые чаще всего используются для оценки распределения данных при описании свойств больших числовых выборок. В то время как медиана разделяет упорядоченный массив пополам (50% элементов массива меньше медианы и 50% - больше), квартили разбивают упорядоченный набор данных на четыре части. Величины Q 1 , медиана и Q 3 являются 25-м, 50-м и 75-м перцентилем соответственно. Первый квартиль Q 1 - это число, разделяющее выборку на две части: 25% элементов меньше, а 75% - больше первого квартиля.
Третий квартиль Q 3 - это число, разделяющее выборку также на две части: 75% элементов меньше, а 25% - больше третьего квартиля.
Для расчета квартилей в версиях Excel до 2007 г. использовалась функция =КВАРТИЛЬ(массив;часть). Начиная с версии Excel2010 применяются две функции:
- =КВАРТИЛЬ.ВКЛ(массив;часть)
- =КВАРТИЛЬ.ИСКЛ(массив;часть)
Эти две функции дают немного различные значения (рис. 4). Например, при вычислении квартилей выборки, содержащей данные о среднегодовой доходности 15 взаимных фондов с очень высоким уровнем риска Q 1 = 1,8 или –0,7 для КВАРТИЛЬ.ВКЛ и КВАРТИЛЬ.ИСКЛ, соответственно. Кстати функция КВАРТИЛЬ, использовавшаяся ранее соответствует современной функции КВАРТИЛЬ.ВКЛ. Для расчета квартилей в Excel с помощью вышеприведенных формул массив данных можно не упорядочивать.

Рис. 4. Вычисление квартилей в Excel
Подчеркнем еще раз. Excel умеет рассчитывать квартили для одномерного дискретного ряда , содержащего значения случайной величины. Расчет квартилей для распределения на основе частот приведен ниже в разделе .
Среднее геометрическое
В отличие от среднего арифметического среднее геометрическое позволяет оценить степень изменения переменной с течением времени. Среднее геометрическое - это корень n -й степени из произведения n величин (в Excel используется функция =СРГЕОМ):
G = (X 1 * X 2 * … * X n) 1/n
Похожий параметр – среднее геометрическое значение нормы прибыли – определяется формулой:
G = [(1 + R 1) * (1 + R 2) * … * (1 + R n)] 1/n – 1,
где R i – норма прибыли за i -й период времени.
Например, предположим, что объем вложенных средств в исходный момент времени равен 100 000 долл. К концу первого года он падает до уровня 50 000 долл., а к концу второго года восстанавливается до исходной отметки 100 000 долл. Норма прибыли этой инвестиции за двухлетний период равна 0, поскольку первоначальный и финальный объем средств равны между собой. Однако среднее арифметическое годовых норм прибыли равно = (–0,5 + 1) / 2 = 0,25 или 25%, поскольку норма прибыли в первый год R 1 = (50 000 – 100 000) / 100 000 = –0,5, а во второй R 2 = (100 000 – 50 000) / 50 000 = 1. В то же время, среднее геометрическое значение нормы прибыли за два года равно: G = [(1–0,5) * (1+1)] 1/2 – 1 = ½ – 1 = 1 – 1 = 0. Таким образом, среднее геометрическое точнее отражает изменение (точнее, отсутствие изменений) объема инвестиций за двухлетний период, чем среднее арифметическое.
Интересные факты. Во-первых, среднее геометрическое всегда будет меньше среднего арифметического тех же чисел. За исключением случая, когда все взятые числа равны друг другу. Во-вторых, рассмотрев свойства прямоугольного треугольника, можно понять, почему среднее называется геометрическим. Высота прямоугольного треугольника, опущенная на гипотенузу, есть среднее пропорциональное между проекциями катетов на гипотенузу, а каждый катет есть среднее пропорциональное между гипотенузой и его проекцией на гипотенузу (рис. 5). Это даёт геометрический способ построения среднего геометрического двух (длин) отрезков: нужно построить окружность на сумме этих двух отрезков как на диаметре, тогда высота, восставленная из точки их соединения до пересечения с окружностью, даст искомую величину:

Рис. 5. Геометрическая природа среднего геометрического (рисунок из Википедии)
Второе важное свойство числовых данных - их вариация , характеризующая степень дисперсии данных. Две разные выборки могут отличаться как средними значениями, так и вариациями. Однако, как показано на рис. 6 и 7, две выборки могут иметь одинаковые вариации, но разные средние значения, либо одинаковые средние значения и совершенно разные вариации. Данные, которым соответствует полигон В на рис. 7, изменяются намного меньше, чем данные, по которым построен полигон А.

Рис. 6. Два симметричных распределения колоколообразной формы с одинаковым разбросом и разными средними значениями

Рис. 7. Два симметричных распределения колоколообразной формы с одинаковыми средними значениями и разным разбросом
Существует пять оценок вариации данных:
- размах,
- межквартильный размах,
- дисперсия,
- стандартное отклонение,
- коэффициент вариации.
Размах
Размахом называется разность между наибольшим и наименьшим элементами выборки:
Размах = Х Max – Х Min
Размах выборки, содержащей данные о среднегодовой доходности 15 взаимных фондов с очень высоким уровнем риска, можно вычислить, используя упорядоченный массив (см. рис. 4): Размах = 18,5 – (–6,1) = 24,6. Это значит, что разница между наибольшей и наименьшей среднегодовой доходностью фондов с очень высоким уровнем риска равна 24,6% .
Размах позволяет измерить общий разброс данных. Хотя размах выборки является весьма простой оценкой общего разброса данных, его слабость заключается в том, что он никак не учитывает, как именно распределены данные между минимальным и максимальным элементами. Этот эффект хорошо прослеживается на рис. 8, который иллюстрирует выборки, имеющие одинаковый размах. Шкала В демонстрирует, что если выборка содержит хотя бы одно экстремальное значение, размах выборки оказывается весьма неточной оценкой разброса данных.

Рис. 8. Сравнение трех выборок, имеющих одинаковый размах; треугольник символизирует опору весов, и его расположение соответствует среднему значению выборки
Межквартильный размах
Межквартильный, или средний, размах - это разность между третьим и первым квартилями выборки:
Межквартильный размах = Q 3 – Q 1
Эта величина позволяет оценить разброс 50% элементов и не учитывать влияние экстремальных элементов. Межквартильный размах выборки, содержащей данные о среднегодовой доходности 15 взаимных фондов с очень высоким уровнем риска, можно вычислить, используя данные на рис. 4 (например, для функции КВАРТИЛЬ.ИСКЛ): Межквартильный размах = 9,8 – (–0,7) = 10,5. Интервал, ограниченный числами 9,8 и –0,7, часто называют средней половиной.
Следует отметить, что величины Q 1 и Q 3 , а значит, и межквартильный размах, не зависят от наличия выбросов, поскольку при их вычислении не учитывается ни одна величина, которая была бы меньше Q 1 или больше Q 3 . Суммарные количественные характеристики, такие как медиана, первый и третий квартили, а также межквартильный размах, на которые не влияют выбросы, называются устойчивыми показателями.
Хотя размах и межквартильный размах позволяют оценить общий и средний разброс выборки соответственно, ни одна из этих оценок не учитывает, как именно распределены данные. Дисперсия и стандартное отклонение лишены этого недостатка. Эти показатели позволяют оценить степень колебания данных вокруг среднего значения. Выборочная дисперсия является приближением среднего арифметического, вычисленного на основе квадратов разностей между каждым элементом выборки и выборочным средним. Для выборки Х 1 , Х 2 , … Х n выборочная дисперсия (обозначаемая символом S 2 задается следующей формулой:

В общем случае выборочная дисперсия - это сумма квадратов разностей между элементами выборки и выборочным средним, деленная на величину, равную объему выборки минус один:

где - арифметическое среднее, n - объем выборки, X i - i -й элемент выборки X . В Excel до версии 2007 для расчета выборочной дисперсии использовалась функция =ДИСП(), с версии 2010 используется функция =ДИСП.В().
Наиболее практичной и широко распространенной оценкой разброса данных является стандартное выборочное отклонение . Этот показатель обозначается символом S и равен квадратному корню из выборочной дисперсии:

В Excel до версии 2007 для расчета стандартного выборочного отклонения использовалась функция =СТАНДОТКЛОН(), с версии 2010 используется функция =СТАНДОТКЛОН.В(). Для расчета этих функций массив данных может быть неупорядоченным.
Ни выборочная дисперсия, ни стандартное выборочное отклонение не могут быть отрицательными. Единственная ситуация, в которой показатели S 2 и S могут быть нулевыми, - если все элементы выборки равны между собой. В этом совершенно невероятном случае размах и межквартильный размах также равны нулю.
Числовые данные по своей природе изменчивы. Любая переменная может принимать множество разных значений. Например, разные взаимные фонды имеют разные показатели доходности и убытков. Вследствие изменчивости числовых данных очень важно изучать не только оценки среднего значения, которые по своей природе являются суммарными, но и оценки дисперсии, характеризующие разброс данных.
Дисперсия и стандартное отклонение позволяют оценить разброс данных вокруг среднего значения, иначе говоря, определить, сколько элементов выборки меньше среднего, а сколько - больше. Дисперсия обладает некоторыми ценными математическими свойствами. Однако ее величина представляет собой квадрат единицы измерения - квадратный процент, квадратный доллар, квадратный дюйм и т.п. Следовательно, естественной оценкой дисперсии является стандартное отклонение, которое выражается в обычных единицах измерений - процентах дохода, долларах или дюймах.
Стандартное отклонение позволяет оценить величину колебаний элементов выборки вокруг среднего значения. Практически во всех ситуациях основное количество наблюдаемых величин лежит в интервале плюс-минус одно стандартное отклонение от среднего значения. Следовательно, зная среднее арифметическое элементов выборки и стандартное выборочное отклонение, можно определить интервал, которому принадлежит основная масса данных.
Стандартное отклонение доходности 15 взаимных фондов с очень высоким уровнем риска равно 6,6 (рис. 9). Это значит, что доходность основной массы фондов отличается от среднего значения не более чем на 6,6% (т.е. колеблется в интервале от – S = 6,2 – 6,6 = –0,4 до + S = 12,8). Фактически в этом интервале лежит пятилетняя среднегодовая доходность 53,3% (8 из 15) фондов.

Рис. 9. Стандартное выборочное отклонение
Обратите внимание на то, что в процессе суммирования квадратов разностей элементы выборки, лежащие дальше от среднего значения, приобретают больший вес, чем элементы, лежащие ближе. Это свойство является основной причиной того, что для оценки среднего значения распределения чаще всего используется среднее арифметическое значение.
Коэффициент вариации
В отличие от предыдущих оценок разброса, коэффициент вариации является относительной оценкой. Он всегда измеряется в процентах, а не в единицах измерения исходных данных. Коэффициент вариации, обозначаемый символами CV, измеряет рассеивание данных относительно среднего значения. Коэффициент вариации равен стандартному отклонению, деленному на среднее арифметическое и умноженному на 100%:

где S - стандартное выборочное отклонение, - выборочное среднее.
Коэффициент вариации позволяет сравнить две выборки, элементы которых выражаются в разных единицах измерения. Например, управляющий службы доставки корреспонденции намеревается обновить парк грузовиков. При погрузке пакетов следует учитывать два вида ограничений: вес (в фунтах) и объем (в кубических футах) каждого пакета. Предположим, что в выборке, содержащей 200 пакетов, средний вес равен 26,0 фунтов, стандартное отклонение веса 3,9 фунтов, средний объем пакета 8,8 кубических футов, а стандартное отклонение объема 2,2 кубических фута. Как сравнить разброс веса и объема пакетов?
Поскольку единицы измерения веса и объема отличаются друг от друга, управляющий должен сравнить относительный разброс этих величин. Коэффициент вариации веса равен CV W = 3,9 / 26,0 * 100% = 15%, а коэффициент вариации объема CV V = 2,2 / 8,8 * 100% = 25% . Таким образом, относительный разброс объема пакетов намного больше относительного разброса их веса.
Форма распределения
Третье важное свойство выборки - форма ее распределения. Это распределение может быть симметричным или асимметричным. Чтобы описать форму распределения, необходимо вычислить его среднее значение и медиану. Если эти два показателя совпадают, переменная считается симметрично распределенной. Если среднее значение переменной больше медианы, ее распределение имеет положительную асимметрию (рис. 10). Если медиана больше среднего значения, распределение переменной имеет отрицательную асимметрию. Положительная асимметрия возникает, когда среднее значение увеличивается до необычайно высоких значений. Отрицательная асимметрия возникает, когда среднее значение уменьшается до необычайно малых значений. Переменная является симметрично распределенной, если она не принимает никаких экстремальных значений ни в одном из направлений, так что большие и малые значения переменной уравновешивают друг друга.

Рис. 10. Три вида распределений
Данные, изображенные на шкале А, имеют отрицательную асимметрию. На этом рисунке виден длинный хвост и перекос влево, вызванные наличием необычно малых значений. Эти крайне малые величины смещают среднее значение влево, и оно становится меньше медианы. Данные, изображенные на шкале Б, распределены симметрично. Левая и правая половины распределения являются своими зеркальными отражениями. Большие и малые величины уравновешивают друг друга, а среднее значение и медиана равны между собой. Данные, изображенные на шкале В, имеют положительную асимметрию. На этом рисунке виден длинный хвост и перекос вправо, вызванные наличием необычайно высоких значений. Эти слишком большие величины смещают среднее значение вправо, и оно становится больше медианы.
В Excel описательные статистики можно получить с помощью надстройки Пакет анализа . Пройдите по меню Данные → Анализ данных , в открывшемся окне выберите строку Описательная статистика и кликните Ok . В окне Описательная статистика обязательно укажите Входной интервал (рис. 11). Если вы хотите увидеть описательные статистики на том же листе, что и исходные данные, выберите переключатель Выходной интервал и укажите ячейку, куда следует поместить левый верхний угол выводимых статистик (в нашем примере $C$1). Если вы хотите вывести данные на новый лист или в новую книгу, достаточно просто выбрать соответствующий переключатель. Поставьте галочку напротив Итоговая статистика . По желанию также можно выбрать Уровень сложности, k-й наименьший и k-й наибольший .
Если на вкладе Данные в области Анализ у вас не отображается пиктограмма Анализ данных , нужно предварительно установить надстройку Пакет анализа (см., например, ).

Рис. 11. Описательные статистики пятилетней среднегодовой доходности фондов с очень высоким уровнями риска, вычисленные с помощью надстройки Анализ данных программы Excel
Excel вычисляет целый ряд статистик, рассмотренных выше: среднее, медиану, моду, стандартное отклонение, дисперсию, размах (интервал ), минимум, максимум и объем выборки (счет ). Кроме того, Excel вычисляет некоторые новые для нас статистики: стандартную ошибку, эксцесс и асимметричность. Стандартная ошибка равна стандартному отклонению, деленному на квадратный корень объема выборки. Асимметричность характеризует отклонение от симметричности распределения и является функцией, зависящей от куба разностей между элементами выборки и средним значением. Эксцесс представляет собой меру относительной концентрации данных вокруг среднего значения по сравнению с хвостами распределения и зависит от разностей между элементами выборки и средним значением, возведенных в четвертую степень.
Вычисление описательных статистик для генеральной совокупности
Среднее значение, разброс и форма распределения, рассмотренные выше, представляют собой характеристики, определяемые по выборке. Однако, если набор данных содержит числовые измерения всей генеральной совокупности, можно вычислить ее параметры. К числу таких параметров относятся математическое ожидание, дисперсия и стандартное отклонение генеральной совокупности.
Математическое ожидание равно сумме всех значений генеральной совокупности, деленной на объем генеральной совокупности:

где µ - математическое ожидание, X i - i -е наблюдение переменной X , N - объем генеральной совокупности. В Excel для вычисления математического ожидания используется та же функция, что и для среднего арифметического: =СРЗНАЧ().
Дисперсия генеральной совокупности равна сумме квадратов разностей между элементами генеральной совокупности и мат. ожиданием, деленной на объем генеральной совокупности:

где σ 2 – дисперсия генеральной совокупности. В Excel до версии 2007 для вычисления дисперсии генеральной совокупности используется функция =ДИСПР(), начиная с версии 2010 =ДИСП.Г().
Стандартное отклонение генеральной совокупности равно квадратному корню, извлеченному из дисперсии генеральной совокупности:

В Excel до версии 2007 для вычисления стандартного отклонения генеральной совокупности используется функция =СТАНДОТКЛОНП(), начиная с версии 2010 =СТАНДОТКЛОН.Г(). Обратите внимание на то, что формулы для дисперсии и стандартного отклонения генеральной совокупности отличаются от формул для вычисления выборочной дисперсии и стандартного отклонения. При вычислении выборочных статистик S 2 и S знаменатель дроби равен n – 1 , а при вычислении параметров σ 2 и σ - объему генеральной совокупности N .
Эмпирическое правило
В большинстве ситуаций крупная доля наблюдений концентрируется вокруг медианы, образуя кластер. В наборах данных, имеющих положительную асимметрию, этот кластер расположен левее (т.е. ниже) математического ожидания, а в наборах, имеющих отрицательную асимметрию, этот кластер расположен правее (т.е. выше) математического ожидания. У симметричных данных математическое ожидание и медиана совпадают, а наблюдения концентрируются вокруг математического ожидания, формируя колоколообразное распределение. Если распределение не имеет ярко выраженной асимметрии, а данные концентрируются вокруг некоего центра тяжести, для оценки изменчивости можно применять эмпирическое правило, которое гласит: если данные имеют колоколообразное распределение, то приблизительно 68% наблюдений отстоят от математического ожидания не более чем на одно стандартное отклонение, приблизительно 95% наблюдений отстоят от математического ожидания не более чем на два стандартных отклонения и 99,7% наблюдений отстоят от математического ожидания не более чем на три стандартных отклонения.
Таким образом, стандартное отклонение, представляющее собой оценку среднего колебания вокруг математического ожидания, помогает понять, как распределены наблюдения, и идентифицировать выбросы. Из эмпирического правила следует, что для колоколообразных распределений лишь одно значение из двадцати отличается от математического ожидания больше, чем на два стандартных отклонения. Следовательно, значения, лежащие за пределами интервала µ ± 2σ , можно считать выбросами. Кроме того, только три из 1000 наблюдений отличаются от математического ожидания больше чем на три стандартных отклонения. Таким образом, значения, лежащие за пределами интервала µ ± 3σ практически всегда являются выбросами. Для распределений, имеющих сильную асимметрию или не имеющих колоколообразной формы, можно применять эмпирическое правило Бьенамэ-Чебышева.
Более ста лет назад математики Бьенамэ и Чебышев независимо друг от друга открыли полезное свойство стандартного отклонения. Они обнаружили, что для любого набора данных, независимо от формы распределения, процент наблюдений, лежащих на расстоянии не превышающем k стандартных отклонений от математического ожидания, не меньше (1 – 1/ k 2)*100% .
Например, если k = 2, правило Бьенамэ-Чебышева гласит, что как минимум (1 – (1/2) 2) х 100% = 75% наблюдений должно лежать в интервале µ ± 2σ . Это правило справедливо для любого k , превышающего единицу. Правило Бьенамэ-Чебышева носит весьма общий характер и справедливо для распределений любого вида. Оно указывает минимальное количество наблюдений, расстояние от которых до математического ожидания не превышает заданной величины. Однако, если распределение имеет колоколообразную форму, эмпирическое правило более точно оценивает концентрацию данных вокруг математического ожидания.
Вычисление описательных статистик для распределения на основе частот
Если исходные данные недоступны, единственным источником информации становится распределение частот. В таких ситуациях можно вычислить приближенные значения количественных показателей распределения, таких как среднее арифметическое, стандартное отклонение, квартили.
Если выборочные данные представлены в виде распределения частот, приближенное значение среднего арифметического можно вычислить, предполагая, что все значения внутри каждого класса сосредоточены в средней точке класса:

где - выборочное среднее, n - количество наблюдений, или объем выборки, с - количество классов в распределении частот, m j - средняя точка j -гo класса, f j - частота, соответствующая j -му классу.
Для вычисления стандартного отклонения по распределению частот также предполагается, что все значения внутри каждого класса сосредоточены в средней точке класса.

Чтобы понять, как определяются квартили ряда на основе частот, рассмотрим расчет нижнего квартиля на основе данных за 2013 г. о распределении населения России по величине среднедушевых денежных доходов (рис. 12).

Рис. 12. Доля населения России со среднедушевыми денежными доходами в среднем за месяц, рублей
Для расчета первого квартиля интервального вариационного ряда можно воспользоваться формулой:

где Q1 – величина первого квартиля, хQ1 – нижняя граница интервала, содержащего первый квартиль (интервал определяется по накопленной частоте, первой превышающей 25%); i – величина интервала; Σf – сумма частот всей выборки; наверное, всегда равна 100%; SQ1–1 – накопленная частота интервала, предшествующего интервалу, содержащему нижний квартиль; fQ1 – частота интервала, содержащего нижний квартиль. Формула для третьего квартиля отличается тем, что во всех местах вместо Q1 нужно использовать Q3, а вместо ¼ подставить ¾.
В нашем примере (рис. 12) нижний квартиль находится в интервале 7000,1 – 10 000, накопленная частота которого равна 26,4%. Нижняя граница этого интервала – 7000 руб., величина интервала – 3000 руб., накопленная частота интервала, предшествующего интервалу, содержащему нижний квартиль – 13,4%, частота интервала, содержащего нижний квартиль – 13,0%. Таким образом: Q1 = 7000 + 3000 * (¼ * 100 – 13,4) / 13 = 9677 руб.
Ловушки, связанные с описательными статистиками
В этой заметке мы рассмотрели, как описать набор данных с помощью различных статистик, оценивающих его среднее значение, разброс и вид распределения. Следующим этапом является анализ и интерпретация данных. До сих пор мы изучали объективные свойства данных, а теперь переходим к их субъективной трактовке. Исследователя подстерегают две ошибки: неверно выбранный предмет анализа и неправильная интерпретация результатов.
Анализ доходности 15 взаимных фондов с очень высоким уровнем риска является вполне беспристрастным. Он привел к совершенно объективным выводам: все взаимные фонды имеют разную доходность, разброс доходности фондов колеблется от –6,1 до 18,5, а средняя доходность равна 6,08. Объективность анализа данных обеспечивается правильным выбором суммарных количественных показателей распределения. Было рассмотрено несколько способов оценки среднего значения и разброса данных, указаны их преимущества и недостатки. Как же выбрать правильную статистику, обеспечивающую объективный и беспристрастный анализ? Если распределение данных имеет небольшую асимметрию, следует ли выбирать медиану, а не среднее арифметическое? Какой показатель более точно характеризует разброс данных: стандартное отклонение или размах? Следует ли указывать на положительную асимметрию распределения?
С другой стороны, интерпретация данных является субъективным процессом. Разные люди приходят к разным выводам, истолковывая одни и те же результаты. У каждого своя точка зрения. Кто-то считает суммарные показатели среднегодовой доходности 15 фондов с очень высоким уровнем риска хорошими и вполне доволен полученным доходом. Другим может показаться, что эти фонды имеют слишком низкую доходность. Таким образом, субъективность следует компенсировать честностью, нейтральностью и ясностью выводов.
Этические проблемы
Анализ данных неразрывно связан с этическими вопросами. Следует критически относиться к информации, распространяемой газетами, радио, телевидением и Интерентом. Со временем вы научитесь скептически относиться не только к результатам, но и к целям, предмету и объективности исследований. Лучше всего об этом сказал известный британский политик Бенджамин Дизраэли: «Существуют три вида лжи: ложь, наглая ложь и статистика».
Как было отмечено в заметке этические проблемы возникают при выборе результатов, которые следует привести в отчете. Следует публиковать как положительные, так и отрицательные результаты. Кроме того, делая доклад или письменный отчет, результаты необходимо излагать честно, нейтрально и объективно. Следует различать неудачную и нечестную презентации. Для этого необходимо определить, каковы были намерения докладчика. Иногда важную информацию докладчик пропускает по невежеству, а иногда - умышленно (например, если он применяет среднее арифметическое для оценки среднего значения явно асимметричных данных, чтобы получить желаемый результат). Нечестно также замалчивать результаты, которые не соответствуют точке зрения исследователя.
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 178–209
Функция КВАРТИЛЬ оставлена для совмещения с более ранними версиями Excel
Средняя величина является наиболее ценной с аналитической точки зрения и универсальной формой выражения статистических показателей. Наиболее распространенная средняя - средняя арифметическая - обладает рядом математических свойств, которые могут быть использованы при ее расчете. В то же время при исчислении конкретной средней всегда целесообразно опираться на ее логическую формулу, представляющую собой отношение объема признака к объему совокупности. Для каждой средней существует только одно истинное исходное соотношение, для реализации которого, в зависимости от имеющихся данных, могут потребоваться различные формы средних. Однако во всех случаях, когда характер осредняемой величины подразумевает наличие весов, нельзя вместо взвешенных формул средних использовать их невзвешенные формулы.
Средняя величина - это наиболее характерное для совокупности значение признака и распределенный равными долями между единицами совокупности размер признака совокупности.
Признак, для которого рассчитывается средняя величина, носит название осредняемый .
Средняя величина - показатель, рассчитываемый сопоставлением абсолютных или относительных величин. Среднюю величину обозначают
Средняя величина отражает влияние всех факторов, влияющих на исследуемое явление, и является для них равнодействующей. Другими словами, погашая индивидуальные отклонения и устраняя влияние случаев, средняя величина, отражая общую меру результатов этого действия, выступает общей закономерностью изучаемого явления.
Условия применения средних величин:
Ø однородность исследуемой совокупности. Если некоторые подверженные влиянию случайного фактора элементы совокупности имеют значительно отличающиеся от остальных величины изучаемого признака, то данные элементы повлияют на размер средней для данной совокупности. В этом случае средняя не будет выражать наиболее типичную для совокупности величину признака. Если исследуемое явление неоднородно, требуется его разбивка на содержащие однородные элементы группы. В данном случае рассчитывают средние по группам - групповые средние, выражающие наиболее характерную величину явления в каждой группе, а затем рассчитывается общая средняя величина для всех элементов, характеризующая явление в целом. Она рассчитывается как средняя из групповых средних, взвешенных по числу включенных в каждую группу элементов совокупности;
Ø достаточное количество единиц в совокупности;
Ø максимальное и минимальное значения признака в изучаемой совокупности.
Средняя величина (показатель) – это обобщенная количественная характеристика признака в систематической совокупности в конкретных условиях места и времени .
В статистике применяется следующие формы (виды) средних величин, называемых степенными и структурными:
Ø средняя арифметическая (простая и взвешенная);
![]() простая
простая
Сре́днее арифмети́ческое (в математике и статистике) множества чисел - сумма всех чисел, делённая на их количество. Является одной из наиболее распространённых мер центральной тенденции.
Предложена (наряду со средним геометрическим и средним гармоническим) ещё пифагорейцами.
Частными случаями среднего арифметического являются среднее (генеральной совокупности) и выборочное среднее (выборки).
Введение
Обозначим множество данных X = (x 1 , x 2 , …, x n ), тогда выборочное среднее обычно обозначается горизонтальной чертой над переменной (x ¯ {\displaystyle {\bar {x}}} , произносится «x с чертой»).
Для обозначения среднего арифметического всей совокупности используется греческая буква μ. Для случайной величины, для которой определено среднее значение, μ есть вероятностное среднее или математическое ожидание случайной величины. Если множество X является совокупностью случайных чисел с вероятностным средним μ, тогда для любой выборки x i из этой совокупности μ = E{x i } есть математическое ожидание этой выборки.
На практике разница между μ и x ¯ {\displaystyle {\bar {x}}} в том, что μ является типичной переменной, потому что видеть можно скорее выборку, а не всю генеральную совокупность. Поэтому, если выборку представлять случайным образом (в терминах теории вероятностей), тогда x ¯ {\displaystyle {\bar {x}}} (но не μ) можно трактовать как случайную переменную, имеющую распределение вероятностей на выборке (вероятностное распределение среднего).
Обе эти величины вычисляются одним и тем же способом:
X ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + ⋯ + x n) . {\displaystyle {\bar {x}}={\frac {1}{n}}\sum _{i=1}^{n}x_{i}={\frac {1}{n}}(x_{1}+\cdots +x_{n}).}
Если X - случайная переменная, тогда математическое ожидание X можно рассматривать как среднее арифметическое значений в повторяющихся измерениях величины X . Это является проявлением закона больших чисел. Поэтому выборочное среднее используется для оценки неизвестного математического ожидания.
В элементарной алгебре доказано, что среднее n + 1 чисел больше среднего n чисел тогда и только тогда, когда новое число больше чем старое среднее, меньше тогда и только тогда, когда новое число меньше среднего, и не меняется тогда и только тогда, когда новое число равно среднему. Чем больше n , тем меньше различие между новым и старым средними значениями.
Заметим, что имеется несколько других «средних» значений, в том числе среднее степенное, среднее Колмогорова, гармоническое среднее, арифметико-геометрическое среднее и различные средне-взвешенные величины (например, среднее арифметическое взвешенное, среднее геометрическое взвешенное, среднее гармоническое взвешенное).
Примеры
- Для трёх чисел необходимо сложить их и разделить на 3:
- Для четырёх чисел необходимо сложить их и разделить на 4:
Или проще 5+5=10, 10:2. Потому что мы складывали 2 числа, а значит, сколько чисел складываем, на столько и делим.
Непрерывная случайная величина
Для непрерывно распределённой величины f (x) {\displaystyle f(x)} среднее арифметическое на отрезке [ a ; b ] {\displaystyle } определяется через определённый интеграл:
F (x) ¯ [ a ; b ] = 1 b − a ∫ a b f (x) d x {\displaystyle {\overline {f(x)}}_{}={\frac {1}{b-a}}\int _{a}^{b}f(x)dx}
Некоторые проблемы применения среднего
Отсутствие робастности
Основная статья: Робастность в статистикеХотя среднее арифметическое часто используется в качестве средних значений или центральных тенденций, это понятие не относится к робастной статистике, что означает, что среднее арифметическое подвержено сильному влиянию «больших отклонений». Примечательно, что для распределений с большим коэффициентом асимметрии среднее арифметическое может не соответствовать понятию «среднего», а значения среднего из робастной статистики (например, медиана) может лучше описывать центральную тенденцию.
Классическим примером является подсчёт среднего дохода. Арифметическое среднее может быть неправильно истолковано в качестве медианы, из-за чего может быть сделан вывод, что людей с большим доходом больше, чем на самом деле. «Средний» доход истолковывается таким образом, что доходы большинства людей находятся вблизи этого числа. Этот «средний» (в смысле среднего арифметического) доход является выше, чем доходы большинства людей, так как высокий доход с большим отклонением от среднего делает сильный перекос среднего арифметического (в отличие от этого, средний доход по медиане «сопротивляется» такому перекосу). Однако, этот «средний» доход ничего не говорит о количестве людей вблизи медианного дохода (и не говорит ничего о количестве людей вблизи модального дохода). Тем не менее, если легкомысленно отнестись к понятиям «среднего» и «большинство народа», то можно сделать неверный вывод о том, что большинство людей имеют доходы выше, чем они есть на самом деле. Например, отчёт о «среднем» чистом доходе в Медине, штат Вашингтон, подсчитанный как среднее арифметическое всех ежегодных чистых доходов жителей, даст на удивление большое число из-за Билла Гейтса. Рассмотрим выборку (1, 2, 2, 2, 3, 9). Среднее арифметическое равно 3.17, но пять значений из шести ниже этого среднего.
Сложный процент
Основная статья: Окупаемость инвестицийЕсли числа перемножать , а не складывать , нужно использовать среднее геометрическое, а не среднее арифметическое. Наиболее часто этот казус случается при расчёте окупаемости инвестиций в финансах.
Например, если акции в первый год упали на 10 %, а во второй год выросли на 30 %, тогда некорректно вычислять «среднее» увеличение за эти два года как среднее арифметическое (−10 % + 30 %) / 2 = 10 %; правильное среднее значение в этом случае дают совокупные ежегодные темпы роста, по которым годовой рост получается только около 8,16653826392 % ≈ 8,2 %.
Причина этого в том, что проценты имеют каждый раз новую стартовую точку: 30 % - это 30 % от меньшего, чем цена в начале первого года, числа: если акции в начале стоили $30 и упали на 10 %, они в начале второго года стоят $27. Если акции выросли на 30 %, они в конце второго года стоят $35.1. Арифметическое среднее этого роста 10 %, но поскольку акции выросли за 2 года всего на $5.1, средний рост в 8,2 % даёт конечный результат $35.1:
[$30 (1 - 0.1) (1 + 0.3) = $30 (1 + 0.082) (1 + 0.082) = $35.1]. Если же использовать таким же образом среднее арифметическое значение 10 %, мы не получим фактическое значение: [$30 (1 + 0.1) (1 + 0.1) = $36.3].
Сложный процент в конце 2 года: 90 % * 130 % = 117 % , то есть общий прирост 17 %, а среднегодовой сложный процент 117 % ≈ 108.2 % {\displaystyle {\sqrt {117\%}}\approx 108.2\%} , то есть среднегодовой прирост 8,2 %.
Направления
Основная статья: Статистика направленийПри расчёте среднего арифметического значений некоторой переменной, изменяющейся циклически (например, фаза или угол), следует проявлять особую осторожность. Например, среднее чисел 1° и 359° будет равно 1 ∘ + 359 ∘ 2 = {\displaystyle {\frac {1^{\circ }+359^{\circ }}{2}}=} 180°. Это число неверно по двум причинам.
- Во-первых, угловые меры определены только для диапазона от 0° до 360° (или от 0 до 2π при измерении в радианах). Таким образом, ту же пару чисел можно было бы записать как (1° и −1°) или как (1° и 719°). Средние значения каждой из пар будут отличаться: 1 ∘ + (− 1 ∘) 2 = 0 ∘ {\displaystyle {\frac {1^{\circ }+(-1^{\circ })}{2}}=0^{\circ }} , 1 ∘ + 719 ∘ 2 = 360 ∘ {\displaystyle {\frac {1^{\circ }+719^{\circ }}{2}}=360^{\circ }} .
- Во-вторых, в данном случае, значение 0° (эквивалентное 360°) будет геометрически лучшим средним значеним, так как числа отклоняются от 0° меньше, чем от какого-либо другого значения (у значения 0° наименьшая дисперсия). Сравните:
- число 1° отклоняется от 0° всего на 1°;
- число 1° отклоняется от вычисленного среднего, равного 180°, на 179°.
Среднее значение для циклической переменной, рассчитанное по приведённой формуле, будет искусственно сдвинуто относительно настоящего среднего к середине числового диапазона. Из-за этого среднее рассчитывается другим способом, а именно, в качестве среднего значения выбирается число с наименьшей дисперсией (центральная точка). Также вместо вычитания используется модульное расстояние (то есть, расстояние по окружности). Например, модульное расстояние между 1° и 359° равно 2°, а не 358° (на окружности между 359° и 360°==0° - один градус, между 0° и 1° - тоже 1°, в сумме - 2°).
4.3. Средние величины. Сущность и значение средних величин
Средней величиной в статистике называется обобщающий показатель, характеризующий типичный уровень явления в конкретных условиях места и времени, отражающий величину варьирующего признака в расчете на единицу качественно однородной совокупности. В экономической практике используется широкий круг показателей, вычисленных в виде средних величин.
Например, обобщающим показателем доходов рабочих акционерного общества (АО) служит средний доход одного рабочего, определяемый отношением фонда заработной платы и выплат социального характера за рассматриваемый период (год, квартал, месяц) к численности рабочих АО.
Вычисление среднего - один из распространенных приемов обобщения; средний показатель отражает то общее, что характерно (типично) для всех единиц изучаемой совокупности, в то же время он игнорирует различия отдельных единиц. В каждом явлении и его развитии имеет место сочетание случайности и необходимости. При исчислении средних в силу действия закона больших чисел случайности взаимопогашаются, уравновешиваются, поэтому можно абстрагироваться от несущественных особенностей явления, от количественных значений признака в каждом конкретном случае. В способности абстрагироваться от случайности отдельных значений, колебаний и заключена научная ценность средних как обобщающих характеристик совокупностей.
Там, где возникает потребность обобщения, расчет таких характеристик приводит к замене множества различных индивидуальных значений признака средним показателем, характеризующим всю совокупность явлений, что позволяет выявить закономерности, присущие массовым общественным явлениям, незаметные в единичных явлениях.
Средняя отражает характерный, типичный, реальный уровень изучаемых явлений, характеризует эти уровни и их изменения во времени и в пространстве.
Средняя - это сводная характеристика закономерностей процесса в тех условиях, в которых он протекает.
4.4. Виды средних и способы их вычисления
Выбор вида средней определяется экономическим содержанием определенного показателя и исходных данных. В каждом конкретном случае применяется, одна из средних величин: арифметическая, гар моническая, геометрическая, квадратическая, кубическая и т.д. Перечисленные средние относятся к классу степенных средних.
Помимо степенных средних в статистической практике используются средние структурные, в качестве которых рассматриваются мода и медиана.
Остановимся подробнее на степенных средних.
Средняя арифметическая
Наиболее распространенным видом средних является средняя арифметическая. Она применяется в тех случаях, когда объем варьирующего признака для всей совокупности является суммой значений признаков отдельных ее единиц. Для общественных явлений характерна аддитивность (суммарность) объемов варьирующего признака, этим определяется область применения средней арифметической и объясняется ее распространенность как обобщающего показателя, например: общий фонд заработной платы - это сумма заработных плат всех работников, валовый сбор урожая - сумма произведенной продукции со всей посевной площади.
Чтобы исчислить среднюю арифметическую, нужно сумму всех значений признаков разделить на их число.
Средняя арифметическая применяется в форме простой средней и взвешенной средней. Исходной, определяющей формой служит простая средняя.
Средняя арифметическая простая равна простой сумме отдельных значений осредняемого признака, деленной на общее число этих значений (она применяется в тех случаях, когда имеются несгруппированные индивидуальные значения признака):
где  - индивидуальные значения варьирующего (варианты);м
- число единиц совокупности.
- индивидуальные значения варьирующего (варианты);м
- число единиц совокупности.
Далее пределы суммирования в формулах указываться не будут. Например, требуется найти среднюю выработку одного рабочего (слесаря), если известно, сколько деталей изготовил каждый из 15 рабочих, т.е. дан ряд индивидуальных значений признака, шт.:
21; 20; 20; 19; 21; 19; 18; 22; 19; 20; 21; 20; 18; 19; 20.
Средняя арифметическая простая рассчитывается по формуле (4.1),1 шт.:
Средняя из вариантов, которые повторяются различное число раз, или, как говорят, имеют различный вес, называется взвешенной. В качестве весов выступают численности единиц в разных группах совокупности (в группу объединяют одинаковые варианты).
Средняя арифметическая взвешенная - средняя сгруппированных величин , - вычисляется по формуле:
 , (4.2)
, (4.2)
где  - веса (частоты повторения одинаковых признаков);
- веса (частоты повторения одинаковых признаков);
 -
сумма произведений величины признаков на их частоты;
-
сумма произведений величины признаков на их частоты;
 -
общая численность единиц совокупности.
-
общая численность единиц совокупности.
Технику вычисления средней арифметической взвешенной проиллюстрируем на рассмотренном выше примере. Для этого сгруппируем исходные данные и поместим их в табл. 4.1.
Таблица 4.1
Распределение рабочих по выработке деталей
По формуле (4.2) средняя арифметическая взвешенная равна, шт.:
В отдельных случаях веса могут быть представлены не абсолютными величинами, а относительными (в процентах или долях единицы). Тогда формула средней арифметической взвешенной будет иметь вид:

где  - частность, т.е. доля каждой частоты в общей сумме всех
- частность, т.е. доля каждой частоты в общей сумме всех
Если частоты подсчитывают в долях (коэффициентах), то  = 1,и формула средней арифметически взвешенной имеет вид:
= 1,и формула средней арифметически взвешенной имеет вид:

Вычисление средней арифметической взвешенной из групповых средних  осуществляется по формуле:
осуществляется по формуле:
 ,
,
где f -число единиц в каждой группе.
Результаты вычисления средней арифметической из групповых средних представлены в табл. 4.2.
Таблица 4.2
Распределение рабочих по среднему стажу работы
В этом примере вариантами являются не индивидуальные данные о стаже работы отдельных рабочих, а средние по каждому цеху . Весами f являются численности рабочих в цехах. Отсюда средний стаж работы рабочих по всему предприятию составит, лет:
 .
.
Расчет средней арифметической в рядах распределения
Если значения осредняемого признака заданы в виде интервалов («от - до»), т.е. интервальных рядов распределения, то при расчете средней арифметической величины в качестве значений признаков в группах принимают середины этих интервалов, в результате чего образуется дискретный ряд. Рассмотрим следующий пример (табл. 4.3).
От интервального ряда перейдем к дискретному путем замены интервальных значений их средними значениями/(простая средняя
Таблица 4.3
Распределение рабочих АО по уровню ежемесячной оплаты труда
|
Группы рабочих по |
Число рабочих, |
Середина интервала, |
|
|
оплате труда, руб. |
чел., f |
руб., х |
|
|
900 и более |
|||
величины открытых интервалов (первый и последний) условно приравниваются к интервалам, примыкающим к ним (второй и предпоследний).
При таком исчислении средней допускается некоторая неточность, поскольку делается предположение о равномерности распределения единиц признака внутри группы. Однако ошибка будет тем меньше, чем уже интервал и чем больше единиц в интервале.
После того как найдены середины интервалов, вычисления делают так же, как и в дискретном ряду, - варианты умножают на частоты (веса) и сумму произведений делят на сумму частот (весов), тыс. руб.:
 .
.
Итак, средний уровень оплаты труда рабочих АО составляет 729 руб. в месяц.
Вычисление средней арифметической часто сопряжено с большими затратами времени и труда. Однако в ряде случаев процедуру расчета средней можно упростить и облегчить, если воспользоваться ее свойствами. Приведем (без доказательства) некоторые основные свойства средней арифметической.
Свойство 1. Если все индивидуальные значения признака (т.е. все варианты) уменьшить или увеличить в i раз, то среднее значение нового признака соответственно уменьшится или увеличится в i раз.
Свойство 2. Если все варианты осредняемого признака умень шить или увеличить на число А, то средняя арифметическая соответ ственно уменьшится или увеличится на это же число А.
Свойство 3. Если веса всех осредняемых вариантов уменьшить или увеличить в к раз, то средняя арифметическая не изменится.
В качестве весов средней вместо абсолютных показателей можно использовать удельные веса в общем итоге (доли или проценты). Тем самым достигается упрощение расчетов средней.
Для упрощения расчетов средней идут по пути уменьшения значений вариантов и частот. Наибольшее упрощение достигается, когда в качестве А выбирается значение одного из центральных вариантов, обладающего наибольшей частотой, в качестве / - величина интервала (для рядов с одинаковыми интервалами). Величина Л называется началом отсчета, поэтому такой метод вычисления средней называется «способом отсчета от условного нуля» или «способом моментов».
Допустим, что все варианты х
сначала уменьшены на одно и то же число А, а затем уменьшены в i
раз. Получим новый вариационный ряд распределения новых вариантов  .
.
Тогда новые варианты будут выражаться:
 ,
,
а их новая средняя арифметическая  , -момент первого порядка
-формулой:
, -момент первого порядка
-формулой:
 .
.
Она равна средней из первоначальных вариантов, уменьшенной сначала на А, а затем в i раз.
Для получения действительной средней надо момент первого порядка m 1 , умножить на i и прибавить А:
 .
.
Данный способ вычисления средней арифметической из вариационного ряда называют «способом моментов». Применяется этот способ в рядах с равными интервалами.
Расчет средней арифметической по способу моментов иллюстрируется данными табл. 4.4.
Таблица 4.4
Распределение малых предприятий региона по стоимости основных производственных фондов (ОПФ) в 2000 г.
|
Группы предприятий по стоимости ОПФ, тыс. руб. |
Число предприятий,f |
Середины интервалов, x |
|
|
|
14-16 16-18 18-20 20-22 22-24 |
||||


Находим момент первого порядка
 .
.
Затем, принимая А = 19 и зная, что i = 2, вычисляем х, тыс. руб.:
Виды средних величин и методы их расчета
На этапе статистической обработки могут быть поставлены самые различные задачи исследования, для решения которых нужно выбрать соответствующую среднюю. При этом необходимо руководствоваться следующим правилом: величины, которые представляют собой числитель и знаменатель средней, должны быть логически связаны между собой.
- степенные средние ;
- структурные средние .
Введем следующие условные обозначения:
Величины, для которых исчисляется средняя;
Средняя, где черта сверху свидетельствует о том, что имеет место осреднение индивидуальных значений;
Частота (повторяемость индивидуальных значений признака).
Различные средние выводятся из общей формулы степенной средней:
 (5.1)
(5.1)
при k = 1 - средняя арифметическая; k = -1 - средняя гармоническая; k = 0 - средняя геометрическая; k = -2 - средняя квадратическая.
Средние величины бывают простые и взвешенные. Взвешенными средними называют величины, которые учитывают, что некоторые варианты значений признака могут иметь различную численность, в связи с чем каждый вариант приходится умножать на эту численность. Иными словами, «весами» выступают числа единиц совокупности в разных группах, т.е. каждый вариант «взвешивают» по своей частоте. Частоту f называют статистическим весом или весом средней .
Средняя арифметическая - самый распространенный вид средней. Она используется, когда расчет осуществляется по несгруппированным статистическим данным, где нужно получить среднее слагаемое. Средняя арифметическая - это такое среднее значение признака, при получении которого сохраняется неизменным общий объем признака в совокупности.
Формула средней арифметической (простой ) имеет вид
где n - численность совокупности.
Например, средняя заработная плата работников предприятия вычисляется как средняя арифметическая:

Определяющими показателями здесь являются заработная плата каждого работника и число работников предприятия. При вычислении средней общая сумма заработной платы осталась прежней, но распределенной как бы между всеми работниками поровну. К примеру, необходимо вычислить среднюю заработную плату работников небольшой фирмы, где заняты 8 человек:
При расчете средних величин отдельные значения признака, который осредняется, могут повторяться, поэтому расчет средней величины производится по сгруппированным данным. В этом случае речь идет об использовании средней арифметической взвешенной , которая имеет вид
 (5.3)
(5.3)
Так, нам необходимо рассчитать средний курс акций какого-то акционерного общества на торгах фондовой биржи. Известно, что сделки осуществлялись в течение 5 дней (5 сделок), количество проданных акций по курсу продаж распределилось следующим образом:
1 - 800 ак. - 1010 руб.
2 - 650 ак. - 990 руб.
3 - 700 ак. - 1015 руб.
4 - 550 ак. - 900 руб.
5 - 850 ак. - 1150 руб.
Исходным соотношением для определения среднего курса стоимости акций является отношение общей суммы сделок (ОСС) к количеству проданных акций (КПА).
Для того чтобы найти среднее значение в Excel (при том неважно числовое, текстовое, процентное или другое значение) существует много функций. И каждая из них обладает своими особенностями и преимуществами. Ведь в данной задаче могут быть поставлены определенные условия.
Например, средние значения ряда чисел в Excel считают с помощью статистических функций. Можно также вручную ввести собственную формулу. Рассмотрим различные варианты.
Как найти среднее арифметическое чисел?
Чтобы найти среднее арифметическое, необходимо сложить все числа в наборе и разделить сумму на количество. Например, оценки школьника по информатике: 3, 4, 3, 5, 5. Что выходит за четверть: 4. Мы нашли среднее арифметическое по формуле: =(3+4+3+5+5)/5.
Как это быстро сделать с помощью функций Excel? Возьмем для примера ряд случайных чисел в строке:

Или: сделаем активной ячейку и просто вручную впишем формулу: =СРЗНАЧ(A1:A8).
Теперь посмотрим, что еще умеет функция СРЗНАЧ.

Найдем среднее арифметическое двух первых и трех последних чисел. Формула: =СРЗНАЧ(A1:B1;F1:H1). Результат:
Среднее значение по условию
Условием для нахождения среднего арифметического может быть числовой критерий или текстовый. Будем использовать функцию: =СРЗНАЧЕСЛИ().
Найти среднее арифметическое чисел, которые больше или равны 10.
Функция: =СРЗНАЧЕСЛИ(A1:A8;">=10")
 Результат использования функции СРЗНАЧЕСЛИ по условию ">=10":
Результат использования функции СРЗНАЧЕСЛИ по условию ">=10":
Третий аргумент – «Диапазон усреднения» - опущен. Во-первых, он не обязателен. Во-вторых, анализируемый программой диапазон содержит ТОЛЬКО числовые значения. В ячейках, указанных в первом аргументе, и будет производиться поиск по прописанному во втором аргументе условию.
Внимание! Критерий поиска можно указать в ячейке. А в формуле сделать на нее ссылку.
Найдем среднее значение чисел по текстовому критерию. Например, средние продажи товара «столы».

Функция будет выглядеть так: =СРЗНАЧЕСЛИ($A$2:$A$12;A7;$B$2:$B$12). Диапазон – столбец с наименованиями товаров. Критерий поиска – ссылка на ячейку со словом «столы» (можно вместо ссылки A7 вставить само слово "столы"). Диапазон усреднения – те ячейки, из которых будут браться данные для расчета среднего значения.
В результате вычисления функции получаем следующее значение:
Внимание! Для текстового критерия (условия) диапазон усреднения указывать обязательно.
Как посчитать средневзвешенную цену в Excel?

Как мы узнали средневзвешенную цену?
Формула: =СУММПРОИЗВ(C2:C12;B2:B12)/СУММ(C2:C12).

С помощью формулы СУММПРОИЗВ мы узнаем общую выручку после реализации всего количества товара. А функция СУММ - сумирует количесвто товара. Поделив общую выручку от реализации товара на общее количество единиц товара, мы нашли средневзвешенную цену. Этот показатель учитывает «вес» каждой цены. Ее долю в общей массе значений.
Среднее квадратическое отклонение: формула в Excel
Различают среднеквадратическое отклонение по генеральной совокупности и по выборке. В первом случае это корень из генеральной дисперсии. Во втором – из выборочной дисперсии.
Для расчета этого статистического показателя составляется формула дисперсии. Из нее извлекается корень. Но в Excel существует готовая функция для нахождения среднеквадратического отклонения.

Среднеквадратическое отклонение имеет привязку к масштабу исходных данных. Для образного представления о вариации анализируемого диапазона этого недостаточно. Чтобы получить относительный уровень разброса данных, рассчитывается коэффициент вариации:
среднеквадратическое отклонение / среднее арифметическое значение
Формула в Excel выглядит следующим образом:
СТАНДОТКЛОНП (диапазон значений) / СРЗНАЧ (диапазон значений).
Коэффициент вариации считается в процентах. Поэтому в ячейке устанавливаем процентный формат.
