Paraan ng pag-ulit. Sa pamamaraang ito, ang isang paghahambing ay ginawa sa isang tiyak na database, kung saan para sa bawat isa sa mga bagay ay may iba't ibang mga pagpipilian para sa pagbabago ng display. Halimbawa, para sa optical image recognition, maaari mong ilapat ang paraan ng pag-iiba sa iba't ibang anggulo o kaliskis, offset, deformation, atbp. Para sa mga titik, maaari kang umulit sa font o sa mga katangian nito. Sa kaso ng sound pattern recognition, mayroong paghahambing sa ilang kilalang pattern (isang salitang binibigkas ng maraming tao). Dagdag pa, ang isang mas malalim na pagsusuri ng mga katangian ng imahe ay ginaganap. Sa kaso ng optical recognition, maaaring ito ang kahulugan ng mga geometric na katangian. Ang sound sample sa kasong ito ay sumasailalim sa frequency at amplitude analysis.
Ang susunod na paraan ay paggamit ng mga artipisyal na neural network(INS). Nangangailangan ito ng alinman sa isang malaking bilang ng mga halimbawa ng gawain sa pagkilala, o isang espesyal na istraktura ng neural network na isinasaalang-alang ang mga detalye ng gawaing ito. Ngunit, gayunpaman, ang pamamaraang ito ay nailalarawan sa pamamagitan ng mataas na kahusayan at pagiging produktibo.
Mga pamamaraan batay sa mga pagtatantya ng mga density ng pamamahagi ng mga halaga ng tampok. Hiniram mula sa klasikal na teorya ng mga desisyon sa istatistika, kung saan ang mga bagay ng pag-aaral ay itinuturing na mga pagsasakatuparan ng isang multidimensional na random na variable na ibinahagi sa feature space ayon sa ilang batas. Ang mga ito ay batay sa pamamaraan ng paggawa ng desisyon ng Bayesian, na umaapela sa mga paunang probabilidad ng mga bagay na kabilang sa isang partikular na klase at mga kondisyong densidad ng pamamahagi ng tampok.
Ang pangkat ng mga pamamaraan batay sa pagtatantya ng mga density ng pamamahagi ng mga halaga ng tampok ay direktang nauugnay sa mga pamamaraan ng pagsusuri ng diskriminasyon. Ang diskarte ng Bayesian sa paggawa ng desisyon ay isa sa mga pinaka-binuo na parametric na pamamaraan sa modernong istatistika, kung saan ang analytical expression ng batas sa pamamahagi (ang normal na batas) ay itinuturing na kilala at isang maliit na bilang lamang ng mga parameter (mean vectors at covariance matrice ) kailangang tantiyahin. Ang mga pangunahing kahirapan sa paglalapat ng pamamaraang ito ay itinuturing na ang pangangailangang alalahanin ang buong set ng pagsasanay upang kalkulahin ang mga pagtatantya ng density at mataas na sensitivity sa set ng pagsasanay.
Mga pamamaraan batay sa mga pagpapalagay tungkol sa klase ng mga function ng desisyon. Sa pangkat na ito, ang uri ng pagpapaandar ng pagpapasya ay itinuturing na kilala at ang kalidad ng pagganap nito ay ibinigay. Batay sa functional na ito, ang pinakamainam na approximation sa decision function ay makikita mula sa training sequence. Ang paggana ng kalidad ng panuntunan ng desisyon ay karaniwang nauugnay sa isang error. Ang pangunahing bentahe ng pamamaraan ay ang kalinawan ng matematikal na pagbabalangkas ng problema sa pagkilala. Ang posibilidad ng pagkuha ng mga bagong kaalaman tungkol sa likas na katangian ng isang bagay, sa partikular, kaalaman tungkol sa mga mekanismo ng pakikipag-ugnayan ng mga katangian, ay sa panimula ay limitado dito sa pamamagitan ng isang naibigay na istraktura ng pakikipag-ugnayan, na naayos sa napiling anyo ng mga pag-andar ng desisyon.
Paraan ng paghahambing ng prototype. Ito ang pinakamadaling paraan ng extensional recognition sa pagsasanay. Nalalapat ito kapag ang mga nakikilalang klase ay ipinapakita bilang mga compact na geometric na klase. Pagkatapos ang gitna ng geometric na pagpapangkat (o ang bagay na pinakamalapit sa gitna) ay pipiliin bilang prototype point.
Upang pag-uri-uriin ang isang hindi tiyak na bagay, ang prototype na pinakamalapit dito ay matatagpuan, at ang bagay ay kabilang sa parehong klase nito. Malinaw, walang pangkalahatang mga imahe na nabuo sa pamamaraang ito. Maaaring gamitin ang iba't ibang uri ng distansya bilang panukat.
Paraan ng k pinakamalapit na kapitbahay. Ang pamamaraan ay nakasalalay sa katotohanan na kapag nag-uuri ng isang hindi kilalang bagay, ang isang ibinigay na numero (k) ng geometrically na pinakamalapit na tampok na espasyo ng iba pang pinakamalapit na kapitbahay na may kilala nang kabilang sa isang klase ay matatagpuan. Ang desisyon na magtalaga ng hindi kilalang bagay ay ginawa sa pamamagitan ng pagsusuri ng impormasyon tungkol sa pinakamalapit na kapitbahay nito. Ang pangangailangan na bawasan ang bilang ng mga bagay sa sample ng pagsasanay (diagnostic precedents) ay isang kawalan ng pamamaraang ito, dahil binabawasan nito ang pagiging kinatawan ng sample ng pagsasanay.
Batay sa katotohanan na ang iba't ibang mga algorithm ng pagkilala ay kumikilos nang iba sa parehong sample, ang tanong ay bumangon sa isang synthetic na panuntunan sa pagpapasya na gagamit ng mga lakas ng lahat ng mga algorithm. Para dito, mayroong isang sintetikong pamamaraan o mga hanay ng mga panuntunan sa pagpapasya na pinagsasama ang pinakapositibong aspeto ng bawat isa sa mga pamamaraan.
Sa pagtatapos ng pagsusuri ng mga pamamaraan ng pagkilala, ipinakita namin ang kakanyahan ng nasa itaas sa isang talahanayan ng buod, pagdaragdag ng ilang iba pang mga pamamaraan na ginamit sa pagsasanay.
Talahanayan 1. Talaan ng pag-uuri ng mga pamamaraan ng pagkilala, paghahambing ng kanilang mga lugar ng aplikasyon at mga limitasyon
|
Pag-uuri ng mga pamamaraan ng pagkilala |
Lugar ng aplikasyon |
Mga Limitasyon (kakulangan) |
|
|
Mga pamamaraan ng masinsinang pagkilala |
Mga pamamaraan batay sa mga pagtatantya ng density |
Mga problema sa isang kilalang pamamahagi (normal), ang pangangailangan upang mangolekta ng malalaking istatistika |
Ang pangangailangang isa-isahin ang buong set ng pagsasanay sa panahon ng pagkilala, mataas na sensitivity sa hindi pagiging kinatawan ng set ng pagsasanay at mga artifact |
|
Mga pamamaraan batay sa pagpapalagay |
Ang mga klase ay dapat na maayos na mapaghihiwalay |
Dapat malaman nang maaga ang anyo ng pagpapasya. Ang imposibilidad ng pagsasaalang-alang ng mga bagong kaalaman tungkol sa mga ugnayan sa pagitan ng mga tampok |
|
|
Mga Paraan ng Boolean |
Mga problema sa maliit na sukat |
Kapag pumipili ng lohikal na mga panuntunan sa pagpapasya, ang isang kumpletong enumeration ay kinakailangan. Mataas na labor intensity |
|
|
Mga Paraang Pangwika |
Ang gawain ng pagtukoy ng gramatika para sa isang tiyak na hanay ng mga pahayag (mga paglalarawan ng mga bagay) ay mahirap gawing pormal. Hindi nalutas na mga teoretikal na problema |
||
|
Extension na paraan ng pagkilala |
Paraan ng paghahambing ng prototype |
Mga problema sa maliit na dimensyon ng feature space |
Mataas na pagtitiwala sa mga resulta ng pag-uuri sa sukatan. Hindi kilalang pinakamainam na sukatan |
|
k pinakamalapit na paraan ng kapitbahay |
Mataas na pagtitiwala sa mga resulta ng pag-uuri sa sukatan. Ang pangangailangan para sa isang kumpletong enumeration ng sample ng pagsasanay sa panahon ng pagkilala. Ang pagiging kumplikado ng computational |
||
|
Mga Algorithm ng Pagkalkula ng Marka (ABO) |
Mga problema ng maliit na dimensyon sa mga tuntunin ng bilang ng mga klase at tampok |
Pagdepende sa mga resulta ng pag-uuri sa sukatan. Ang pangangailangan para sa isang kumpletong enumeration ng sample ng pagsasanay sa panahon ng pagkilala. Mataas na teknikal na kumplikado ng pamamaraan |
|
|
Ang mga panuntunan ng kolektibong desisyon (CRC) ay isang sintetikong pamamaraan. |
Mga problema ng maliit na dimensyon sa mga tuntunin ng bilang ng mga klase at tampok |
Napakataas na teknikal na kumplikado ng pamamaraan, ang hindi nalutas na bilang ng mga teoretikal na problema, kapwa sa pagtukoy ng mga lugar ng kakayahan ng mga partikular na pamamaraan, at sa mga partikular na pamamaraan mismo. |
Lektura bilang 17.PARAAN NG PAGKILALA NG PATTERN
Mayroong mga sumusunod na grupo ng mga paraan ng pagkilala:
Mga Paraan ng Proximity Function
Mga Pamamaraan sa Pag-andar na may Diskriminasyon
Mga pamamaraan ng istatistika ng pagkilala.
Mga Paraang Pangwika
heuristic na pamamaraan.
Ang unang tatlong pangkat ng mga pamamaraan ay nakatuon sa pagsusuri ng mga tampok na ipinahayag ng mga numero o vector na may mga numerical na bahagi.
Ang pangkat ng mga pamamaraang pangwika ay nagbibigay ng pagkilala ng pattern batay sa pagsusuri ng kanilang istruktura, na inilalarawan ng kaukulang mga tampok na istruktura at mga relasyon sa pagitan nila.
Pinagsasama ng pangkat ng mga heuristic na pamamaraan ang mga katangiang pamamaraan at lohikal na pamamaraan na ginagamit ng mga tao sa pagkilala ng pattern.
Mga Paraan ng Proximity Function
Ang mga pamamaraan ng pangkat na ito ay batay sa paggamit ng mga function na sinusuri ang sukatan ng kalapitan sa pagitan ng nakikilalang imahe sa vector. x * = (x * 1 ,….,x*n), at mga reference na larawan ng iba't ibang klase, na kinakatawan ng mga vector x i = (x i 1 ,…, x i n), i= 1,…,N, saan ako- numero ng klase ng larawan.
Ang pamamaraan ng pagkilala ayon sa pamamaraang ito ay binubuo sa pagkalkula ng distansya sa pagitan ng punto ng kinikilalang imahe at bawat isa sa mga punto na kumakatawan sa reference na imahe, i.e. sa pagkalkula ng lahat ng mga halaga d i , i= 1,…,N. Ang imahe ay kabilang sa klase kung saan ang halaga d i may pinakamababang halaga sa lahat i= 1,…,N .
Isang function na nagmamapa sa bawat pares ng mga vector x i, x * isang tunay na numero bilang sukatan ng kanilang pagiging malapit, i.e. Ang pagtukoy sa distansya sa pagitan ng mga ito ay maaaring maging arbitrary. Sa matematika, ang naturang function ay tinatawag na space metric. Dapat itong matugunan ang mga sumusunod na axiom:
r(x,y)=r(y,x);
r(x,y) > 0 kung x hindi pantay y at r(x,y)=0 kung x=y;
r(x,y) <=r(x,z)+r(z,y)
Ang mga axiom na ito ay nasiyahan, sa partikular, sa pamamagitan ng mga sumusunod na function
a i= 1/2 , j=1,2,…n.
b i=sum, j=1,2,…n.
c i=max abs( x i‑ x j *), j=1,2,…n.
Ang una sa mga ito ay tinatawag na Euclidean norm ng isang vector space. Alinsunod dito, ang mga puwang kung saan ang tinukoy na function ay ginagamit bilang isang sukatan ay tinatawag na Euclidean space.
Kadalasan, pinipili ang root-mean-square na pagkakaiba ng mga coordinate ng kinikilalang larawan bilang proximity function. x * at pamantayan x i, ibig sabihin. function
d i = (1/n) kabuuan( x i j‑ x j *) 2 , j=1,2,…n.
Halaga d i geometrically interpreted bilang parisukat ng distansya sa pagitan ng mga punto sa tampok na espasyo, na nauugnay sa dimensyon ng espasyo.
Madalas lumalabas na ang iba't ibang mga tampok ay hindi pantay na mahalaga sa pagkilala. Upang isaalang-alang ang sitwasyong ito kapag kinakalkula ang mga proximity function ng pagkakaiba sa mga coordinate, ang mga kaukulang mas mahalagang tampok ay pinarami ng malalaking coefficient, at ang hindi gaanong mahalaga sa mga mas maliit.
Sa kasong ito d i = (1/n) kabuuan wj (x i j‑ x j *) 2 , j=1,2,…n,
saan wj- mga koepisyent ng timbang.
Ang pagpapakilala ng mga weight coefficient ay katumbas ng pag-scale sa mga axes ng feature space at, nang naaayon, pag-stretch o pag-compress ng space sa magkahiwalay na direksyon.
Ang mga pagpapapangit na ito ng tampok na espasyo ay nagsusumikap sa layunin ng naturang pag-aayos ng mga punto ng mga reference na imahe, na tumutugma sa pinaka maaasahang pagkilala sa ilalim ng mga kondisyon ng isang makabuluhang scatter ng mga larawan ng bawat klase sa paligid ng punto ng reference na imahe.
Ang mga pangkat ng mga larawan ay malapit sa isa't isa (mga kumpol ng mga larawan) sa espasyo ng tampok ay tinatawag na mga kumpol, at ang problema sa pagtukoy ng mga naturang grupo ay tinatawag na problema sa clustering.
Ang gawain ng pagtukoy ng mga kumpol ay tinutukoy bilang mga hindi pinangangasiwaang mga gawain sa pagkilala ng pattern, ibig sabihin. sa mga problema sa pagkilala sa kawalan ng isang halimbawa ng tamang pagkilala.
Mga Pamamaraan sa Pag-andar na may Diskriminasyon
Ang ideya ng mga pamamaraan ng pangkat na ito ay upang bumuo ng mga function na tumutukoy sa mga hangganan sa espasyo ng mga imahe, na naghahati sa espasyo sa mga rehiyon na naaayon sa mga klase ng mga imahe. Ang pinakasimpleng at madalas na ginagamit na mga function ng ganitong uri ay mga function na linearly umaasa sa mga halaga ng mga tampok. Sa feature space, tumutugma sila sa paghihiwalay ng mga ibabaw sa anyo ng mga hyperplane. Sa kaso ng isang two-dimensional na feature space, ang isang tuwid na linya ay gumaganap bilang isang separating function.
Ang pangkalahatang anyo ng linear decision function ay ibinibigay ng formula
d(x)=w 1 x 1 + w 2 x 2 +…+w n x n +w n +1 = Wx+w n
saan x- vector ng imahe, w=(w 1 , w 2 ,…w n) ay ang vector ng weight coefficients.
Kapag nahahati sa dalawang klase X 1 at X 2 discriminant function d(x) nagbibigay-daan sa pagkilala ayon sa panuntunan:
x nabibilang X 1 kung d(x)>0;
x nabibilang X 2 kung d(x)<0.
Kung ang d(x)=0, pagkatapos ay magaganap ang kaso ng kawalan ng katiyakan.
Sa kaso ng paghahati sa ilang mga klase, maraming mga pag-andar ang ipinakilala. Sa kasong ito, ang bawat klase ng mga imahe ay nauugnay sa isang tiyak na kumbinasyon ng mga palatandaan ng mga pag-andar na nagpapakita ng kaibhan.
Halimbawa, kung ang tatlong discriminant function ay ipinakilala, ang sumusunod na variant ng pagpili ng mga klase ng imahe ay posible:
x nabibilang X 1 kung d 1 (x)>0,d 2 (x)<0,d 3 (x)<0;
x nabibilang X 2 kung d(x)<0,d 2 (x)>0,d 3 (x)<0;
x nabibilang X 3 kung d(x)<0,d 2 (x)<0,d 3 (x)>0.
Ipinapalagay na para sa iba pang mga kumbinasyon ng mga halaga d 1 (x),d 2 (x),d 3 (x) mayroong isang kaso ng kawalan ng katiyakan.
Ang isang pagkakaiba-iba ng paraan ng discriminant functions ay ang paraan ng mapagpasyang function. Sa loob nito, kung magagamit m ipinapalagay na umiiral ang mga klase m mga function d i(x), tinatawag na mapagpasyahan, na kung x nabibilang X i, pagkatapos d i(x) > dj(x) para sa lahat j hindi pantay i, mga. mapagpasyang function d i(x) ay may pinakamataas na halaga sa lahat ng mga function dj(x), j=1,...,n..
Ang isang paglalarawan ng naturang pamamaraan ay maaaring isang classifier batay sa isang pagtatantya ng pinakamababa ng Euclidean na distansya sa tampok na espasyo sa pagitan ng punto ng imahe at ang pamantayan. Ipakita natin.
Euclidean na distansya sa pagitan ng feature vector ng nakikilalang larawan x at ang vector ng reference na imahe ay tinutukoy ng formula || x i ‑ x|| = 1/2 , j=1,2,…n.
Vector x itatalaga sa klase i, kung saan ang halaga || x i ‑ x *|| pinakamababa.
Sa halip na distansya, maaari mong ihambing ang parisukat ng distansya, i.e.
||x i ‑ x|| 2 = (x i ‑ x)(x i ‑ x) t = x x- 2x x i +x i x i
Dahil ang halaga x x pareho para sa lahat i, ang minimum ng function || x i ‑ x|| 2 ay mag-tutugma sa maximum ng function ng desisyon
d i(x) = 2x x i -x i x i.
i.e x nabibilang X i, kung d i(x) > dj(x) para sa lahat j hindi pantay i.
yun. ang minimum na distance classifying machine ay batay sa linear decision functions. Ang pangkalahatang istraktura ng naturang makina ay gumagamit ng mga function ng pagpapasya ng form
d i (x)=w i 1 x 1 + w i 2 x 2 +…+w sa x n +w i n +1
Maaari itong biswal na kinakatawan ng naaangkop na block diagram.
Para sa isang makina na nagsasagawa ng pag-uuri ayon sa pinakamababang distansya, ang mga pagkakapantay-pantay ay nagaganap: w ij = -2x i j , w i n +1 = x i x i.
Ang katumbas na pagkilala sa pamamagitan ng paraan ng mga discriminant function ay maaaring isagawa kung ang discriminant function ay tinukoy bilang mga pagkakaiba dij (x)=d i (x)‑d j (x).
Ang bentahe ng paraan ng mga discriminant function ay ang simpleng istraktura ng recognition machine, pati na rin ang posibilidad ng pagpapatupad nito pangunahin sa pamamagitan ng nakararami sa mga linear na bloke ng desisyon.
Ang isa pang mahalagang bentahe ng paraan ng mga discriminant function ay ang posibilidad ng awtomatikong pagsasanay ng makina para sa tamang pagkilala sa isang naibigay na (pagsasanay) na sample ng mga pattern.
Kasabay nito, ang awtomatikong pag-aaral ng algorithm ay naging napaka-simple kumpara sa iba pang mga paraan ng pagkilala.
Para sa mga kadahilanang ito, ang paraan ng mga discriminant function ay nakakuha ng malawak na katanyagan at kadalasang ginagamit sa pagsasanay.
Mga pamamaraan ng pagkilala sa sarili sa pag-aaral ng pattern
Isaalang-alang ang mga pamamaraan para sa pagbuo ng isang discriminant function mula sa isang ibinigay na sample (pagsasanay) bilang inilapat sa problema ng paghahati ng mga imahe sa dalawang klase. Kung ang dalawang hanay ng mga imahe ay ibinigay, ayon sa pagkakabanggit sa mga klase A at B, kung gayon ang solusyon sa problema ng pagbuo ng isang linear discriminant function ay hinahangad sa anyo ng isang vector ng mga koepisyent ng timbang. W=(w 1 ,w 2 ,...,w n,w n+1), na may pag-aari na para sa anumang larawan ang mga kundisyon
x kabilang sa klase A kung >0, j=1,2,…n.
x kabilang sa klase B kung<0, j=1,2,…n.
Kung ang sample ng pagsasanay ay N mga larawan ng parehong klase, ang problema ay nababawasan sa paghahanap ng isang vector w na nagsisiguro sa bisa ng sistema ng hindi pagkakapantay-pantay. Kung ang sample ng pagsasanay ay binubuo ng N mga imahe ng parehong mga klase, ang problema ay nabawasan sa paghahanap ng vector w, na nagsisiguro sa bisa ng sistema ng hindi pagkakapantay-pantay
x 1 1 w i+x 21 w 2 +...+x n 1 w n+w n +1 >0;
x 1 2 w i+x 22 w 2 +...+x n 2 w n+w n +1 <0;
x 1 iw i+x 2i w 2 +...+x ni w n+w n +1 >0;
................................................
x 1 Nw i +x 2N w 2 +...+x nN w n +w n + 1>0;
dito x i=(x i 1 ,x i 2 ,...,x i n ,x i n+ 1 ) - ang vector ng mga halaga ng mga tampok ng imahe mula sa sample ng pagsasanay, ang > sign ay tumutugma sa mga vector ng mga imahe x kabilang sa klase A, at ang tanda< - векторам x kabilang sa klase B.
Ninanais na vector w umiiral kung ang mga klase A at B ay mapaghihiwalay at hindi umiiral kung hindi man. Mga halaga ng bahagi ng vector w ay matatagpuan alinman sa paunang, sa yugto bago ang pagpapatupad ng hardware ng FRO, o direkta ng FRO mismo sa kurso ng operasyon nito. Ang huli sa mga pamamaraang ito ay nagbibigay ng higit na kakayahang umangkop at awtonomiya ng SRO. Isaalang-alang ito sa halimbawa ng isang aparato na tinatawag na percentron. naimbento noong 1957 ng American scientist na si Rosenblatt. Ang isang eskematiko na representasyon ng percentron, na nagsisiguro na ang imahe ay itinalaga sa isa sa dalawang klase, ay ipinapakita sa sumusunod na figure.
Retina S Retina A Retina R
oh oh x 1
oh oh x 2
oh oh x 3
o(sum)-------> R(reaksyon)
oh oh x i
oh oh x n
oh oh x n +1
Ang aparato ay binubuo ng mga retinal sensory elements S, na random na konektado sa mga nag-uugnay na elemento ng retina A. Ang bawat elemento ng pangalawang retina ay gumagawa lamang ng isang output signal kung ang isang sapat na bilang ng mga sensory element na konektado sa input nito ay nasa isang excited na estado. Buong tugon ng system R ay proporsyonal sa kabuuan ng mga reaksyon ng mga elemento ng associative retina na kinuha na may ilang mga timbang.
Tinutukoy sa pamamagitan ng x i reaksyon i ika-uugnay na elemento at sa pamamagitan ng w i- koepisyent ng timbang ng reaksyon i ika-uugnay na elemento, ang reaksyon ng sistema ay maaaring isulat bilang R=sum( w j x j), j=1,..,n. Kung ang R>0, kung gayon ang imaheng ipinakita sa system ay kabilang sa klase A, at kung R<0, то образ относится к классу B. Описание этой процедуры классификации соответствует рассмотренным нами раньше принципам классификации, и, очевидно, перцентронная модель распознавания образов представляет собой, за исключением сенсорной сетчатки, реализацию линейной дискриминантной функции. Принятый в перцентроне принцип формирования значений x 1 , x 2 ,...,x n tumutugma sa isang tiyak na algorithm para sa pagbuo ng mga tampok batay sa mga signal ng mga pangunahing sensor.
Sa pangkalahatan, maaaring mayroong ilang mga elemento R, na bumubuo ng reaksyon ng perceptron. Sa kasong ito, ang isa ay nagsasalita ng pagkakaroon ng retina sa perceptron R mga elementong tumutugon.
Ang percentron scheme ay maaaring palawigin sa kaso kapag ang bilang ng mga klase ay higit sa dalawa, sa pamamagitan ng pagtaas ng bilang ng mga elemento ng retinal. R hanggang sa bilang ng mga nakikilalang klase at ang pagpapakilala ng isang bloke para sa pagtukoy ng maximum na reaksyon alinsunod sa pamamaraan na ipinakita sa figure sa itaas. Sa kasong ito, ang imahe ay itinalaga sa klase na may numero i, kung R i>Rj, para sa lahat j.
Ang proseso ng pag-aaral ng percentron ay binubuo sa pagpili ng mga halaga ng mga koepisyent ng timbang wj upang ang output signal ay tumutugma sa klase kung saan kabilang ang kinikilalang imahe.
Isaalang-alang natin ang algorithm ng pagkilos ng percentron gamit ang halimbawa ng pagkilala sa mga bagay ng dalawang klase: A at B. Ang mga bagay ng klase A ay dapat tumutugma sa halaga R= +1, at klase B - ang halaga R= -1.
Ang algorithm ng pag-aaral ay ang mga sumusunod.
Kung ibang larawan x kabilang sa klase A, ngunit R<0 (имеет место ошибка распознавания), тогда коэффициенты wj na may mga indeks na naaayon sa mga halaga xj>0, tumaas ng ilang halaga dw, at ang iba pang mga coefficient wj pagbaba ng dw. Sa kasong ito, ang halaga ng reaksyon R tumatanggap ng pagtaas patungo sa mga positibong halaga nito na tumutugma sa tamang pag-uuri.
Kung ang x kabilang sa klase B, ngunit R>0 (may error sa pagkilala), pagkatapos ay ang mga coefficient wj na may katumbas na mga indeks xj<0, увеличивают на dw, at ang iba pang mga coefficient wj nabawasan ng parehong halaga. Sa kasong ito, ang halaga ng reaksyon R ay nadaragdagan patungo sa mga negatibong halaga na tumutugma sa tamang pag-uuri.
Ang algorithm sa gayon ay nagpapakilala ng pagbabago sa weight vector w kung at kung ang imahe ay ipinakita sa k-th na hakbang sa pagsasanay, ay hindi wastong inuri sa hakbang na ito, at iniiwan ang weight vector w walang pagbabago sa kaso ng tamang pag-uuri. Ang patunay ng convergence ng algorithm na ito ay ipinakita sa [Too, Gonzalez]. Ang ganitong pagsasanay ay kalaunan (na may tamang pagpili dw at linear separability ng mga klase ng imahe) ay humahantong sa isang vector w para sa tamang pag-uuri.
Mga pamamaraan ng istatistika ng pagkilala.
Ang mga pamamaraan ng istatistika ay batay sa pagliit ng posibilidad ng isang error sa pag-uuri. Ang posibilidad na P ng maling pag-uuri ng larawang natanggap para sa pagkilala, na inilarawan ng feature vector x, ay tinutukoy ng formula
P = kabuuan [ p(i)prob( D(x)+i | x klase i)]
saan m- bilang ng mga klase,
p(i) = probe ( x nabibilang sa klase i) - isang priori na posibilidad na mapabilang sa isang arbitrary na imahe x sa i-th class (dalas ng paglitaw ng mga imahe i ika-klase),
D(x) ay isang function na gumagawa ng desisyon sa pag-uuri (ang feature vector x tumutugma sa numero ng klase i mula sa set (1,2,..., m}),
prob( D(x) hindi pantay i| x nabibilang sa klase i) ay ang posibilidad ng kaganapan " D(x) hindi pantay i" kapag natugunan ang kondisyon ng pagiging miyembro x klase i, ibig sabihin. ang posibilidad ng paggawa ng maling desisyon ng function D(x) para sa isang naibigay na halaga x pag-aari ni i-ika-klase.
Maaaring ipakita na ang posibilidad ng maling pag-uuri ay umabot sa pinakamababa kung D(x)=i kung at kung lamang p(x|i)· p(i)>p(x|j)· p(j), para sa lahat i+j, saan p(x|i) - density ng pamamahagi ng mga imahe i ika-klase sa feature space.
Ayon sa tuntunin sa itaas, ang punto x nabibilang sa klase na tumutugma sa pinakamataas na halaga p(i) p(x|i), ibig sabihin. ang produkto ng a priori probability (frequency) ng paglitaw ng mga imahe i-ika-klase at density ng pamamahagi ng pattern i ika-klase sa feature space. Ang ipinakita na tuntunin sa pag-uuri ay tinatawag na Bayesian, dahil ito ay sumusunod mula sa kilalang Bayes formula sa probability theory.
Halimbawa. Hayaang kailanganin na makilala ang mga discrete signal sa output ng isang channel ng impormasyon na apektado ng ingay.
Ang bawat input signal ay isang 0 o 1. Bilang resulta ng pagpapadala ng signal, ang output ng channel ay lilitaw ang halaga x, na pinatong ng Gaussian noise na may zero mean at variance b.
Para sa synthesis ng isang classifier na nagsasagawa ng pagkilala ng signal, gagamitin namin ang panuntunan sa pag-uuri ng Bayesian.
Sa klase No. 1 pinagsasama namin ang mga signal na kumakatawan sa mga unit, sa klase No. 2 - mga signal na kumakatawan sa mga zero. Ipaalam ito nang maaga na, sa karaniwan, sa bawat 1000 signal a ang mga signal ay mga yunit at b mga senyales - mga zero. Kung gayon ang mga halaga ng isang priori na posibilidad ng paglitaw ng mga signal ng ika-1 at ika-2 klase (mga isa at mga zero), ayon sa pagkakabanggit, ay maaaring kunin katumbas ng
p(1)=a/1000, p(2)=b/1000.
kasi ang ingay ay Gaussian, i.e. sumusunod sa normal (Gaussian) na batas sa pamamahagi, pagkatapos ay ang density ng pamamahagi ng mga larawan ng unang klase, depende sa halaga x, o, na pareho, ang posibilidad na makuha ang halaga ng output x kapag ang signal 1 ay inilapat sa input, ito ay tinutukoy ng expression
p(x¦1) =(2pib) -1/2 exp(-( x-1) 2 /(2b 2)),
at ang density ng pamamahagi depende sa halaga x mga larawan ng pangalawang klase, i.e. ang posibilidad na makuha ang halaga ng output x kapag ang isang signal 0 ay inilapat sa input, ito ay tinutukoy ng expression
p(x¦2)= (2pib) -1/2 exp(- x 2 /(2b 2)),
Ang aplikasyon ng panuntunan ng desisyon ng Bayesian ay humahantong sa konklusyon na ang isang signal ng klase 2 ay ipinadala, i.e. pumasa sa zero kung
p(2) p(x¦2) > p(1) p(x¦1)
o, mas partikular, kung
b exp(- x 2 /(2b 2)) > a exp(-( x-1) 2 /(2b 2)),
Ang paghahati sa kaliwang bahagi ng hindi pagkakapantay-pantay sa kanang bahagi, nakukuha natin
(b/a)exp((1-2 x)/(2b 2)) >1,
kung saan, pagkatapos kunin ang logarithm, makikita natin
1-2x> 2b 2 ln(a/b)
x< 0.5 - б 2 ln(a/b)
Ito ay sumusunod mula sa nagresultang hindi pagkakapantay-pantay na a=b, ibig sabihin. na may parehong priori probabilities ng paglitaw ng mga signal 0 at 1, ang imahe ay itinalaga ang halaga 0 kapag x<0.5, а значение 1, когда x>0.5.
Kung alam nang maaga na ang isa sa mga signal ay lumilitaw nang mas madalas, at ang iba ay mas madalas, i.e. sa kaso ng iba't ibang mga halaga a at b, ang threshold ng pagtugon ng classifier ay inilipat sa isang gilid o sa isa pa.
Kaya sa a/b=2.71 (naaayon sa 2.71 beses na mas madalas na paghahatid ng mga isa) at b 2 =0.1, ang imahe ay itinalaga ang halaga 0 kung x<0.4, и значение 1, если x>0.4. Kung walang impormasyon tungkol sa a priori distribution probabilities, maaaring gamitin ang statistical recognition method, na batay sa iba sa mga panuntunan sa pag-uuri ng Bayesian.
Gayunpaman, sa pagsasagawa, ang mga pamamaraan batay sa mga panuntunan ng Bayes ay pinaka-karaniwan dahil sa kanilang higit na kahusayan, at dahil din sa katotohanan na sa karamihan ng mga problema sa pagkilala ng pattern posible na magtakda ng isang priori probabilities para sa hitsura ng mga imahe ng bawat klase.
Mga pamamaraang pangwika ng pagkilala ng pattern.
Ang mga pamamaraan ng linguistic ng pagkilala ng pattern ay batay sa pagsusuri ng paglalarawan ng isang idealized na imahe, na kinakatawan bilang isang graph o isang string ng mga simbolo, na isang parirala o isang pangungusap ng isang tiyak na wika.
Isaalang-alang ang mga ideyal na larawan ng mga titik na nakuha bilang resulta ng unang yugto ng pagkilala sa wika na inilarawan sa itaas. Ang mga ideyal na imaheng ito ay maaaring tukuyin sa pamamagitan ng mga paglalarawan ng mga graph, na kinakatawan, halimbawa, sa anyo ng mga matrice ng koneksyon, tulad ng ginawa sa halimbawa sa itaas. Ang parehong paglalarawan ay maaaring katawanin ng isang pormal na parirala sa wika (expression).
Halimbawa. Hayaang bigyan ng tatlong larawan ng titik A na nakuha bilang resulta ng paunang pagproseso ng imahe. Italaga natin ang mga larawang ito na may mga identifier na A1, A2 at A3.
Para sa linguistic na paglalarawan ng mga ipinakitang larawan, ginagamit namin ang PDL (Picture Description Language). Kasama sa diksyunaryo ng wikang PDL ang mga sumusunod na character:
1. Mga pangalan ng pinakasimpleng larawan (primitives). Tulad ng inilapat sa kaso na isinasaalang-alang, ang mga primitive at ang kanilang kaukulang mga pangalan ay ang mga sumusunod.
Mga larawan sa anyo ng isang linyang nakadirekta:
pataas at umalis (le F t), sa hilaga (hilaga)), pataas at sa kanan (kanan), sa silangan (silangan)).
Mga Pangalan: L, N, R, E.
2. Mga simbolo ng binary operations. (+,*,-) Ang kanilang kahulugan ay tumutugma sa sunud-sunod na koneksyon ng primitives (+), ang koneksyon ng mga simula at pagtatapos ng primitives (*), ang koneksyon ng mga dulo lamang ng primitives (-).
3. Kanan at kaliwang bracket. ((,)) Binibigyang-daan ka ng mga panaklong na tukuyin ang pagkakasunud-sunod kung saan ang mga operasyon ay isasagawa sa isang expression.
Ang itinuturing na mga larawang A1, A2 at A3 ay inilalarawan sa wikang PDL, ayon sa pagkakabanggit, sa pamamagitan ng mga sumusunod na expression.
T(1)=R+((R-(L+N))*E-L
T(2)=(R+N)+((N+R)-L)*E-L
T(3)=(N+R)+(R-L)*E-(L+N)
Matapos mabuo ang linguistic na paglalarawan ng imahe, kinakailangan na pag-aralan, gamit ang ilang pamamaraan ng pagkilala, kung ang ibinigay na imahe ay kabilang sa klase ng interes sa amin (ang klase ng mga titik A), i.e. mayroon man o wala ang larawang ito. Upang gawin ito, una sa lahat, kinakailangan upang ilarawan ang klase ng mga imahe na may istraktura ng interes sa amin.
Malinaw, ang titik A ay palaging naglalaman ng mga sumusunod na elemento ng istruktura: ang kaliwang "binti", ang kanang "binti" at ang ulo. Pangalanan natin ang mga elementong ito ayon sa pagkakabanggit STL, STR, TR.
Pagkatapos, sa wikang PDL, ang klase ng simbolo A - SIMB A ay inilalarawan ng expression
SIMB A = STL + TR - STR
Ang kaliwang "binti" ng STL ay palaging isang kadena ng mga elemento R at N, na maaaring isulat bilang
STL ‑> R ¦ N ¦ (STL + R) ¦ (STL + N)
(Ang STL ay ang character na R o N, o isang string na nakuha sa pamamagitan ng pagdaragdag ng R o N character sa pinagmulang string ng STL)
Ang kanang "binti" ng STR ay palaging isang kadena ng mga elemento L at N, na maaaring isulat bilang mga sumusunod, i.e.
STR ‑> L¦N¦ (STR + L)¦(STR + N)
Ang ulong bahagi ng titik - TR ay isang saradong tabas, na binubuo ng elementong E at mga chain tulad ng STL at STR.
Sa wikang PDL, ang istraktura ng TR ay inilalarawan ng expression
TR ‑> (STL - STR) * E
Sa wakas, nakuha namin ang sumusunod na paglalarawan ng klase ng mga titik A:
SIMB A ‑> (STL + TR - STR),
STL ‑> R¦N¦ (STL + R)¦(STL + N)
STR ‑> L¦N¦ (STR + L)¦(STR + N)
TR ‑> (STL - STR) * E
Ang pamamaraan ng pagkilala sa kasong ito ay maaaring ipatupad bilang mga sumusunod.
1. Ang expression na naaayon sa imahe ay inihambing sa reference na istraktura STL + TR - STR.
2. Ang bawat elemento ng istraktura ng STL, TR, STR, kung maaari, i.e. kung ang paglalarawan ng larawan ay maihahambing sa pamantayan, ang ilang subexpression mula sa expression na T(A) ay itinutugma. Halimbawa,
para sa A1: STL=R, STR=L, TR=(R-(L+N))*E
para sa A2: STL = R + N, STR = L, TR = ((N + R) - L) * E
para sa A3: STL = N + R, STR = L + N, TR = (R - L) * E 3.
Ang mga expression ng STL, STR, TR ay inihambing sa kanilang mga kaukulang istruktura ng sanggunian.
4. Kung ang istraktura ng bawat STL, STR, TR expression ay tumutugma sa sanggunian, napagpasyahan na ang imahe ay kabilang sa klase ng mga titik A. Kung sa alinman sa mga yugto 2, 3, 4 ay may pagkakaiba sa pagitan ng istraktura ng nasuri na expression at ang sanggunian, napagpasyahan na ang imahe ay hindi kabilang sa klase ng SIMB A. Ang pagtutugma ng istraktura ng ekspresyon ay maaaring gawin gamit ang mga algorithmic na wika na LISP, PLANER, PROLOG at iba pang katulad na mga wika ng artificial intelligence.
Sa halimbawang isinasaalang-alang, ang lahat ng mga string ng STL ay binubuo ng mga N at R na mga character, at ang mga string ng STR ay binubuo ng mga L at N na mga character, na tumutugma sa ibinigay na istraktura ng mga string na ito. Ang istraktura ng TR sa mga isinasaalang-alang na mga imahe ay tumutugma din sa isang sanggunian, dahil binubuo ng "pagkakaiba" ng mga string ng uri ng STL, STR, "multiplied" ng simbolo E.
Kaya, dumating kami sa konklusyon na ang itinuturing na mga imahe ay kabilang sa klase SIMB A.
Synthesis ng fuzzy DC electric drive controllersa kapaligiran ng "MatLab".
Synthesis ng fuzzy controller na may isang input at output.
Ang problema ay ang pagkuha ng drive na sundin ang iba't ibang mga input nang tumpak. Ang pagbuo ng pagkilos ng kontrol ay isinasagawa ng isang malabo na controller, kung saan ang mga sumusunod na functional block ay maaaring makilala sa istruktura: fuzzifier, rule block at defuzzifier.
Fig.4 Generalized functional diagram ng isang system na may dalawang linguistic variable.
 Fig.5 Schematic diagram ng fuzzy controller na may dalawang linguistic variable.
Fig.5 Schematic diagram ng fuzzy controller na may dalawang linguistic variable.
Ang fuzzy control algorithm sa pangkalahatang kaso ay isang pagbabago ng mga input variable ng fuzzy controller sa mga output variable nito gamit ang mga sumusunod na magkakaugnay na pamamaraan:
1. pagbabago ng mga input na pisikal na variable na nakuha mula sa pagsukat ng mga sensor mula sa control object tungo sa input linguistic variable ng isang fuzzy controller;
2. pagpoproseso ng mga lohikal na pahayag, na tinatawag na linguistic rules, patungkol sa input at output linguistic variable ng controller;
3. pagbabago ng output linguistic variable ng fuzzy controller sa physical control variable.
Isaalang-alang muna natin ang pinakasimpleng kaso, kapag dalawang linguistic variable lamang ang ipinakilala upang kontrolin ang servo drive:
"anggulo" - input variable;
"control action" - variable ng output.
Si-synthesize namin ang controller sa MatLab environment gamit ang Fuzzy Logic toolbox. Binibigyang-daan ka nitong lumikha ng malabo na hinuha at malabo na mga sistema ng pag-uuri sa loob ng kapaligiran ng MatLab, na may posibilidad na isama ang mga ito sa Simulink. Ang pangunahing konsepto ng Fuzzy Logic Toolbox ay FIS-structure - Fuzzy Inference System. Ang FIS-structure ay naglalaman ng lahat ng kinakailangang data para sa pagpapatupad ng functional mapping na "inputs-outputs" batay sa malabo na lohikal na inference ayon sa scheme na ipinapakita sa fig. 6.

Larawan 6. Malabo na hinuha.
X - input malulutong na vector; - vector ng fuzzy set na tumutugma sa input vector X;
- ang resulta ng lohikal na inference sa anyo ng isang vector ng fuzzy set; Y - output ng malulutong na vector.
Binibigyang-daan ka ng fuzzy module na bumuo ng mga fuzzy system ng dalawang uri - Mamdani at Sugeno. Sa mga sistemang uri ng Mamdani, ang base ng kaalaman ay binubuo ng mga patakaran ng form "Kung x 1 = mababa at x 2 = katamtaman, kung gayon y = mataas". Sa mga sistemang uri ng Sugeno, ang base ng kaalaman ay binubuo ng mga patakaran ng form “Kung x 1 =mababa at x 2 =medium, kung gayon y=a 0 +a 1 x 1 +a 2 x 2 ". Kaya, ang pangunahing pagkakaiba sa pagitan ng mga sistema ng Mamdani at Sugeno ay nakasalalay sa iba't ibang paraan ng pagtatakda ng mga halaga ng output variable sa mga patakaran na bumubuo sa base ng kaalaman. Sa mga sistema ng uri ng Mamdani, ang mga halaga ng variable ng output ay ibinibigay ng mga malabo na termino, sa mga sistema ng uri ng Sugeno - bilang isang linear na kumbinasyon ng mga variable ng input. Sa aming kaso, gagamitin namin ang sistema ng Sugeno, dahil ito ay nagpapahiram ng mas mahusay sa pag-optimize.
Upang kontrolin ang servo drive, dalawang linguistic variable ang ipinakilala: "error" (ayon sa posisyon) at "control action". Ang una sa kanila ay ang input, ang pangalawa ay ang output. Tukuyin natin ang isang term-set para sa mga tinukoy na variable.
Ang mga pangunahing bahagi ng malabo na hinuha. Fuzzifier.
Para sa bawat linguistic variable, tinutukoy namin ang isang pangunahing term-set ng form, na kinabibilangan ng mga fuzzy set na maaaring italaga: negatibong mataas, negatibong mababa, zero, positibong mababa, positibong mataas.
Una sa lahat, subjective na tukuyin natin kung ano ang ibig sabihin ng mga terminong "malaking error", "maliit na error", atbp., na tumutukoy sa mga function ng membership para sa kaukulang fuzzy set. Dito, sa ngayon, ang isa ay maaari lamang magabayan ng kinakailangang katumpakan, mga kilalang parameter para sa klase ng mga signal ng input, at sentido komun. Sa ngayon, walang nakapag-alok ng anumang mahigpit na algorithm para sa pagpili ng mga parameter ng mga function ng membership. Sa aming kaso, ang linguistic variable na "error" ay magiging ganito.
 Fig.7. Lingguwistika variable na "error".
Fig.7. Lingguwistika variable na "error".
Ito ay mas maginhawa upang kumatawan sa linguistic variable na "pamamahala" sa anyo ng isang talahanayan:
Talahanayan 1
Block ng panuntunan.
Isaalang-alang ang pagkakasunud-sunod ng pagtukoy ng ilang panuntunan na naglalarawan sa ilang sitwasyon:
Ipagpalagay, halimbawa, na ang anggulo ng output ay katumbas ng input signal (i.e., ang error ay zero). Malinaw, ito ang nais na sitwasyon, at samakatuwid ay wala tayong kailangang gawin (ang kontrol na aksyon ay zero).
Ngayon isaalang-alang ang isa pang kaso: ang error sa posisyon ay mas malaki kaysa sa zero. Natural, dapat nating bayaran ito sa pamamagitan ng pagbuo ng malaking positibong signal ng kontrol.
yun. dalawang panuntunan ang ginawa, na maaaring pormal na tukuyin tulad ng sumusunod:
kung error = null, pagkatapos pagkilos ng kontrol = zero.
kung error = malaking positibo, pagkatapos pagkilos ng kontrol = malaking positibo.
 Fig.8. Pagbubuo ng kontrol na may maliit na positibong error sa posisyon.
Fig.8. Pagbubuo ng kontrol na may maliit na positibong error sa posisyon.
 Fig.9. Pagbubuo ng kontrol sa zero error sa pamamagitan ng posisyon.
Fig.9. Pagbubuo ng kontrol sa zero error sa pamamagitan ng posisyon.
Ang talahanayan sa ibaba ay nagpapakita ng lahat ng mga patakaran na naaayon sa lahat ng mga sitwasyon para sa simpleng kaso na ito.
talahanayan 2
Sa kabuuan, para sa isang malabo na controller na may n input at 1 output, ang mga panuntunan sa kontrol ay maaaring matukoy, kung saan ang bilang ng mga fuzzy set para sa i-th input, ngunit para sa normal na paggana ng controller ay hindi kinakailangang gamitin ang lahat ng posible. mga panuntunan, ngunit maaari kang makayanan sa mas maliit na bilang ng mga ito. Sa aming kaso, lahat ng 5 posibleng panuntunan ay ginagamit upang bumuo ng malabo na signal ng kontrol.
Defuzzifier.
Kaya, ang magreresultang epekto U ay matutukoy ayon sa pagpapatupad ng anumang panuntunan. Kung ang isang sitwasyon ay lumitaw kapag ang ilang mga patakaran ay naisakatuparan nang sabay-sabay, ang resultang aksyon na U ay matatagpuan ayon sa sumusunod na pag-asa:
 , kung saan ang n ay ang bilang ng mga na-trigger na panuntunan (defuzzification sa pamamagitan ng area center method), ikaw n ay ang pisikal na halaga ng control signal na naaayon sa bawat fuzzy set UBO, UMo, UZ, Ump, UBP. mhindi(u) ay ang antas ng pagmamay-ari ng control signal u sa kaukulang fuzzy set Un=( UBO, UMo, UZ, Ump, UBP). Mayroon ding iba pang mga paraan ng defuzzification, kapag ang output linguistic variable ay proporsyonal sa "malakas" o "mahina" na panuntunan mismo.
, kung saan ang n ay ang bilang ng mga na-trigger na panuntunan (defuzzification sa pamamagitan ng area center method), ikaw n ay ang pisikal na halaga ng control signal na naaayon sa bawat fuzzy set UBO, UMo, UZ, Ump, UBP. mhindi(u) ay ang antas ng pagmamay-ari ng control signal u sa kaukulang fuzzy set Un=( UBO, UMo, UZ, Ump, UBP). Mayroon ding iba pang mga paraan ng defuzzification, kapag ang output linguistic variable ay proporsyonal sa "malakas" o "mahina" na panuntunan mismo.
Gayahin natin ang proseso ng pagkontrol sa electric drive gamit ang fuzzy controller na inilarawan sa itaas.
 Fig.10. Block diagram ng system sa kapaligiranmatlab.
Fig.10. Block diagram ng system sa kapaligiranmatlab.

Fig.11. Structural diagram ng fuzzy controller sa kapaligiranmatlab.

Fig.12. Lumilipas na proseso sa isang hakbang na pagkilos.

kanin. 13. Lumilipas na proseso sa ilalim ng harmonic input para sa isang modelo na may malabo na controller na naglalaman ng isang input linguistic variable.
Ang isang pagsusuri ng mga katangian ng isang drive na may synthesized control algorithm ay nagpapakita na ang mga ito ay malayo sa pinakamainam at mas masahol pa kaysa sa kaso ng control synthesis sa pamamagitan ng iba pang mga pamamaraan (masyadong maraming oras ng kontrol na may isang solong hakbang na epekto at isang error na may isang harmonic) . Ito ay ipinaliwanag sa pamamagitan ng ang katunayan na ang mga parameter ng mga function ng pagiging miyembro ay pinili nang arbitraryo, at tanging ang laki ng error sa posisyon ang ginamit bilang mga input ng controller. Naturally, hindi maaaring pag-usapan ang anumang pagiging mahusay ng nakuha na controller. Samakatuwid, ang gawain ng pag-optimize ng fuzzy controller ay nagiging may kaugnayan upang makamit ang pinakamataas na posibleng mga tagapagpahiwatig ng kalidad ng kontrol. Yung. ang gawain ay i-optimize ang layunin ng function f(a 1 ,a 2 …a n), kung saan ang a 1 ,a 2 …a n ay ang mga coefficient na tumutukoy sa uri at katangian ng fuzzy controller. Upang i-optimize ang malabo na controller, ginagamit namin ang ANFIS block mula sa kapaligiran ng Matlab. Gayundin, ang isa sa mga paraan upang mapabuti ang mga katangian ng controller ay maaaring dagdagan ang bilang ng mga input nito. Gagawin nitong mas flexible ang regulator at mapapabuti nito ang pagganap nito. Magdagdag pa tayo ng isa pang input linguistic variable - ang rate ng pagbabago ng input signal (derivative nito). Alinsunod dito, tataas din ang bilang ng mga patakaran. Pagkatapos ang circuit diagram ng regulator ay kukuha ng form:

Fig.14 Schematic diagram ng fuzzy controller na may tatlong linguistic variable.
Hayaan ang halaga ng bilis ng input signal. Ang batayang term-set na Tn ay tinukoy bilang:
Тn=("negatibo (VO)", "zero (Z)", "positibo (VR)").
Ang lokasyon ng membership function para sa lahat ng linguistic variable ay ipinapakita sa figure.
Fig.15. Mga function ng membership ng linguistic variable na "error".

Fig.16. Mga function ng membership ng linguistic variable na "input signal speed".
Dahil sa pagdaragdag ng isa pang linguistic variable, ang bilang ng mga panuntunan ay tataas sa 3x5=15. Ang prinsipyo ng kanilang compilation ay ganap na katulad ng tinalakay sa itaas. Ang lahat ng mga ito ay ipinapakita sa sumusunod na talahanayan:
Talahanayan 3
| malabo na signal pamamahala | Error sa posisyon |
|||||
| Bilis | ||||||
Halimbawa, kung kung error = zero at input signal derivative = malaking positibo, pagkatapos kontrol na aksyon = maliit na negatibo.
 Fig.17. Pagbuo ng kontrol sa ilalim ng tatlong variable na linguistic.
Fig.17. Pagbuo ng kontrol sa ilalim ng tatlong variable na linguistic.
Dahil sa pagtaas ng bilang ng mga input at, nang naaayon, ang mga panuntunan mismo, ang istraktura ng fuzzy controller ay magiging mas kumplikado din.
 Fig.18. Structural diagram ng fuzzy controller na may dalawang input.
Fig.18. Structural diagram ng fuzzy controller na may dalawang input.
Magdagdag ng pagguhit

Fig.20. Lumilipas na proseso sa ilalim ng harmonic input para sa isang modelo na may fuzzy controller na naglalaman ng dalawang input linguistic variable.

kanin. 21. Error signal sa ilalim ng harmonic input para sa isang modelo na may fuzzy controller na naglalaman ng dalawang input linguistic variable.
Gayahin natin ang pagpapatakbo ng fuzzy controller na may dalawang input sa kapaligiran ng Matlab. Ang block diagram ng modelo ay magiging eksaktong kapareho ng sa Fig. 19. Mula sa graph ng transient na proseso para sa harmonic input, makikita na ang katumpakan ng system ay tumaas nang malaki, ngunit sa parehong oras ang oscillation nito ay tumaas, lalo na sa mga lugar kung saan ang derivative ng output coordinate ay may posibilidad na sero. Malinaw na ang mga dahilan para dito, tulad ng nabanggit sa itaas, ay ang hindi pinakamainam na pagpili ng mga parameter ng mga function ng membership, kapwa para sa input at output na mga variable na linguistic. Samakatuwid, ino-optimize namin ang fuzzy controller gamit ang ANFISedit block sa kapaligiran ng Matlab.
Malabo na pag-optimize ng controller.
Isaalang-alang ang paggamit ng mga genetic algorithm para sa fuzzy controller optimization. Ang mga genetic algorithm ay mga adaptive na paraan ng paghahanap na kadalasang ginagamit sa mga nakaraang taon upang malutas ang mga problema sa functional optimization. Ang mga ito ay batay sa pagkakatulad sa mga prosesong genetic ng mga biyolohikal na organismo: ang mga biyolohikal na populasyon ay umuunlad sa ilang henerasyon, sumusunod sa mga batas ng natural na pagpili at ayon sa prinsipyo ng "survival of the fittest", na natuklasan ni Charles Darwin. Sa pamamagitan ng paggaya sa prosesong ito, nagagawa ng mga genetic algorithm na "magbago" ng mga solusyon sa mga problema sa totoong mundo kung naaangkop ang mga ito sa pagkaka-code.
Ang mga genetic algorithm ay gumagana sa isang hanay ng mga "indibidwal" - isang populasyon, na ang bawat isa ay kumakatawan sa isang posibleng solusyon sa isang partikular na problema. Ang bawat indibidwal ay sinusuri sa pamamagitan ng sukatan ng kanyang "kaangkupan" ayon sa kung gaano "kahusay" ang solusyon ng problemang kaugnay nito. Ang pinakakarapat-dapat na mga indibidwal ay maaaring "magparami" ng mga supling sa pamamagitan ng "cross-breeding" sa ibang mga indibidwal sa populasyon. Ito ay humahantong sa paglitaw ng mga bagong indibidwal na pinagsama ang ilan sa mga katangiang minana mula sa kanilang mga magulang. Ang mga hindi gaanong angkop na indibidwal ay mas malamang na magparami, kaya ang mga katangiang taglay nila ay unti-unting mawawala sa populasyon.
Ito ay kung paano muling ginawa ang buong bagong populasyon ng mga magagawang solusyon, pagpili ng pinakamahusay na mga kinatawan ng nakaraang henerasyon, pagtawid sa kanila at pagkuha ng maraming mga bagong indibidwal. Ang bagong henerasyong ito ay naglalaman ng mas mataas na ratio ng mga katangian na taglay ng mabubuting miyembro ng nakaraang henerasyon. Kaya, mula sa henerasyon hanggang sa henerasyon, ang mga magagandang katangian ay ipinamamahagi sa buong populasyon. Sa huli, ang populasyon ay magsasama-sama sa pinakamainam na solusyon sa problema.
Mayroong maraming mga paraan upang ipatupad ang ideya ng biological evolution sa loob ng balangkas ng genetic algorithm. Tradisyonal, ay maaaring katawanin sa anyo ng sumusunod na block diagram na ipinapakita sa Figure 22, kung saan:
1. Pagsisimula ng paunang populasyon - pagbuo ng isang naibigay na bilang ng mga solusyon sa problema, kung saan nagsisimula ang proseso ng pag-optimize;
2. Application ng crossover at mutation operator;
3.  Mga kundisyon sa paghinto - kadalasan, ang proseso ng pag-optimize ay nagpapatuloy hanggang sa matagpuan ang isang solusyon sa problema na may partikular na katumpakan, o hanggang sa maihayag na ang proseso ay nagtagpo (ibig sabihin, walang pagpapabuti sa solusyon ng problema sa nakalipas na mga taon. N henerasyon).
Mga kundisyon sa paghinto - kadalasan, ang proseso ng pag-optimize ay nagpapatuloy hanggang sa matagpuan ang isang solusyon sa problema na may partikular na katumpakan, o hanggang sa maihayag na ang proseso ay nagtagpo (ibig sabihin, walang pagpapabuti sa solusyon ng problema sa nakalipas na mga taon. N henerasyon).
Sa kapaligiran ng Matlab, ang mga genetic algorithm ay kinakatawan ng isang hiwalay na toolbox, pati na rin ng ANFIS package. Ang ANFIS ay isang abbreviation para sa Adaptive-Network-Based Fuzzy Inference System - Adaptive Fuzzy Inference Network. Ang ANFIS ay isa sa mga unang variant ng hybrid neuro-fuzzy network - isang neural network ng isang espesyal na uri ng direktang pagpapalaganap ng signal. Ang arkitektura ng isang neuro-fuzzy network ay isomorphic sa isang malabo na base ng kaalaman. Naiiba ang mga pagpapatupad ng mga triangular na pamantayan (multiplikasyon at probabilistic OR) pati na rin ang maayos na mga function ng membership ay ginagamit sa mga neuro-fuzzy na network. Ginagawa nitong posible na gumamit ng mabilis at genetic na mga algorithm para sa pagsasanay ng mga neural network batay sa paraan ng backpropagation upang ibagay ang mga neuro-fuzzy na network. Ang arkitektura at mga panuntunan para sa pagpapatakbo ng bawat layer ng ANFIS network ay inilarawan sa ibaba.
Ipinapatupad ng ANFIS ang fuzzy inference system ng Sugeno bilang isang limang-layer na feed-forward neural network. Ang layunin ng mga layer ay ang mga sumusunod: ang unang layer ay ang mga tuntunin ng input variable; ang pangalawang layer - antecedents (parcels) ng fuzzy rules; ang ikatlong layer ay ang normalisasyon ng antas ng katuparan ng mga patakaran; ang ikaapat na layer ay ang mga konklusyon ng mga patakaran; ang ikalimang layer ay ang pagsasama-sama ng resulta na nakuha ayon sa iba't ibang mga patakaran.
Ang mga input ng network ay hindi inilalaan sa isang hiwalay na layer. Ipinapakita ng Figure 23 ang isang network ng ANFIS na may isang input variable ("error") at limang malabo na panuntunan. Para sa linguistic na pagsusuri ng input variable na "error" 5 termino ang ginamit.

Fig.23. IstrukturaANFIS-mga network.
Ipakilala natin ang sumusunod na notasyon, kinakailangan para sa karagdagang presentasyon:
Hayaan ang mga input ng network;
y - output ng network;
Malabo na panuntunan na may ordinal na bilang r;
m - bilang ng mga patakaran;
Fuzzy term na may membership function , na ginagamit para sa linguistic na pagsusuri ng isang variable sa r-th na panuntunan (,);
Mga tunay na numero sa pagtatapos ng rth rule (,).
Ang ANFIS-network ay gumagana tulad ng sumusunod.
Layer 1 Ang bawat node ng unang layer ay kumakatawan sa isang termino na may hugis ng kampanang membership function. Ang mga input ng network ay konektado lamang sa kanilang mga termino. Ang bilang ng mga node sa unang layer ay katumbas ng kabuuan ng mga cardinality ng mga term set ng input variable. Ang output ng node ay ang antas ng pag-aari ng halaga ng input variable sa kaukulang fuzzy term:
 ,
,
kung saan ang a, b, at c ay mga parameter na maaaring i-configure ng function ng membership.
Layer 2 Ang bilang ng mga node sa pangalawang layer ay m. Ang bawat node ng layer na ito ay tumutugma sa isang malabo na panuntunan. Ang node ng pangalawang layer ay konektado sa mga node ng unang layer na bumubuo sa mga antecedent ng kaukulang panuntunan. Samakatuwid, ang bawat node ng pangalawang layer ay maaaring makatanggap mula 1 hanggang n input signal. Ang output ng node ay ang antas ng pagpapatupad ng panuntunan, na kinakalkula bilang produkto ng mga input signal. Tukuyin ang mga output ng mga node ng layer na ito sa pamamagitan ng , .
Layer 3 Ang bilang ng mga node sa ikatlong layer ay m din. Ang bawat node ng layer na ito ay kinakalkula ang relatibong antas ng katuparan ng fuzzy na panuntunan:
Layer 4 Ang bilang ng mga node sa ikaapat na layer ay m din. Ang bawat node ay konektado sa isang node ng ikatlong layer gayundin sa lahat ng mga input ng network (ang mga koneksyon sa mga input ay hindi ipinapakita sa Fig. 18). Kinakalkula ng node ng ikaapat na layer ang kontribusyon ng isang malabo na panuntunan sa output ng network:
Layer 5 Ang nag-iisang node ng layer na ito ay nagbubuod sa mga kontribusyon ng lahat ng mga panuntunan:
![]() .
.
Maaaring ilapat ang mga karaniwang pamamaraan ng pagsasanay sa neural network upang ibagay ang network ng ANFIS, dahil gumagamit lang ito ng mga function na naiba-iba. Kadalasan, ginagamit ang kumbinasyon ng gradient descent sa anyo ng backpropagation at least squares. Inaayos ng backpropagation algorithm ang mga parameter ng mga nauna sa panuntunan, i.e. mga function ng membership. Ang mga koepisyent ng konklusyon ng panuntunan ay tinatantya ng pinakamababang paraan ng mga parisukat, dahil ang mga ito ay linear na nauugnay sa output ng network. Ang bawat pag-ulit ng pamamaraan ng pag-tune ay isinasagawa sa dalawang hakbang. Sa unang yugto, ang isang sample ng pagsasanay ay ibinibigay sa mga input, at ang pinakamainam na mga parameter ng mga node ng ikaapat na layer ay matatagpuan mula sa pagkakaiba sa pagitan ng nais at aktwal na pag-uugali ng network gamit ang iterative least squares method. Sa ikalawang yugto, ang natitirang pagkakaiba ay inililipat mula sa output ng network sa mga input, at ang mga parameter ng mga node ng unang layer ay binago ng paraan ng backpropagation ng error. Kasabay nito, ang mga koepisyent ng konklusyon ng panuntunan na natagpuan sa unang yugto ay hindi nagbabago. Ang proseso ng umuulit na pag-tune ay nagpapatuloy hanggang ang nalalabi ay lumampas sa isang paunang natukoy na halaga. Upang ibagay ang mga function ng membership, bilang karagdagan sa paraan ng backpropagation ng error, maaaring gamitin ang iba pang mga algorithm sa pag-optimize, halimbawa, ang pamamaraang Levenberg-Marquardt.

Fig.24. ANFISedit workspace.
Subukan natin ngayon na i-optimize ang fuzzy controller para sa isang hakbang na aksyon. Ang gustong lumilipas na proseso ay humigit-kumulang sa sumusunod:

Fig.25. nais na proseso ng paglipat.
Mula sa graph na ipinapakita sa Fig. ito ay sumusunod na karamihan sa mga oras na ang makina ay dapat tumakbo sa buong lakas upang matiyak ang pinakamataas na bilis, at kapag papalapit sa nais na halaga, dapat itong bumagal nang maayos. Ginagabayan ng mga simpleng pagsasaalang-alang na ito, kukunin namin ang sumusunod na sample ng mga halaga bilang isang pagsasanay, na ipinakita sa ibaba sa anyo ng isang talahanayan:
Talahanayan 4
| Halaga ng error | Halaga ng pamamahala |
| Halaga ng error | Halaga ng pamamahala |
| Halaga ng error | Halaga ng pamamahala |

Fig.26. Uri ng set ng pagsasanay.
Ang pagsasanay ay isasagawa sa 100 hakbang. Ito ay higit pa sa sapat para sa convergence ng paraan na ginamit.

Fig.27. Ang proseso ng pag-aaral ng isang neural network.
Sa proseso ng pag-aaral, ang mga parameter ng mga function ng pagiging miyembro ay nabuo sa paraang, na may ibinigay na halaga ng error, ang controller ay lumilikha ng kinakailangang kontrol. Sa seksyon sa pagitan ng mga nodal point, ang pagtitiwala ng kontrol sa error ay isang interpolation ng data ng talahanayan. Ang paraan ng interpolation ay depende sa kung paano sinanay ang neural network. Sa katunayan, pagkatapos ng pagsasanay, ang malabo na modelo ng controller ay maaaring katawanin bilang isang non-linear na function ng isang variable, ang graph kung saan ay ipinakita sa ibaba.

Fig.28. Plot ng pag-asa ng kontrol mula sa error hanggang sa posisyon sa loob ng regulator.
Ang pagkakaroon ng nai-save ang mga nahanap na parameter ng mga function ng membership, ginagaya namin ang system gamit ang isang naka-optimize na fuzzy controller.


kanin. 29. Lumilipas na proseso sa ilalim ng harmonic input para sa isang modelo na may na-optimize na fuzzy controller na naglalaman ng isang input linguistic variable.
Fig.30. Error signal sa ilalim ng harmonic input para sa isang modelo na may fuzzy controller na naglalaman ng dalawang input linguistic variable.
Ito ay sumusunod mula sa mga graph na ang pag-optimize ng fuzzy controller sa pamamagitan ng pagsasanay sa neural network ay matagumpay. Makabuluhang nabawasan ang pagbabagu-bago at ang laki ng error. Samakatuwid, ang paggamit ng isang neural network ay lubos na makatwiran para sa pag-optimize ng mga controller, ang prinsipyo nito ay batay sa malabo na lohika. Gayunpaman, kahit na ang isang naka-optimize na controller ay hindi maaaring matugunan ang mga kinakailangan para sa katumpakan, kaya ipinapayong isaalang-alang ang isa pang paraan ng kontrol, kapag ang malabo na controller ay hindi direktang kinokontrol ang bagay, ngunit pinagsasama ang ilang mga batas sa kontrol depende sa sitwasyon.
Linggo, Mar 29, 2015
Sa kasalukuyan, maraming mga gawain kung saan kinakailangan na gumawa ng ilang desisyon depende sa pagkakaroon ng isang bagay sa imahe o upang pag-uri-uriin ito. Ang kakayahang "kilalanin" ay itinuturing na pangunahing pag-aari ng mga biyolohikal na nilalang, habang ang mga computer system ay hindi ganap na nagtataglay ng ari-arian na ito.
Isaalang-alang ang mga pangkalahatang elemento ng modelo ng pag-uuri.
Klase- isang set ng mga bagay na may mga karaniwang katangian. Para sa mga bagay ng parehong klase, ang pagkakaroon ng "pagkakatulad" ay ipinapalagay. Para sa gawain sa pagkilala, maaaring tukuyin ang isang di-makatwirang bilang ng mga klase, higit sa 1. Ang bilang ng mga klase ay tinutukoy ng bilang na S. Ang bawat klase ay may sariling pagkilala sa label ng klase.
Pag-uuri- ang proseso ng pagtatalaga ng mga label ng klase sa mga bagay, ayon sa ilang paglalarawan ng mga katangian ng mga bagay na ito. Ang classifier ay isang device na tumatanggap ng set ng mga feature ng isang object bilang input at gumagawa ng class label bilang resulta.
Pagpapatunay- ang proseso ng pagtutugma ng isang object instance sa isang object model o class description.
Sa ilalim paraan mauunawaan natin ang pangalan ng lugar sa espasyo ng mga katangian, kung saan ipinapakita ang maraming bagay o phenomena ng materyal na mundo. tanda- isang quantitative na paglalarawan ng isang partikular na katangian ng bagay o phenomenon na pinag-aaralan.
tampok na espasyo ito ay isang N-dimensional na espasyo na tinukoy para sa isang naibigay na gawain sa pagkilala, kung saan ang N ay isang nakapirming bilang ng mga nasusukat na tampok para sa anumang mga bagay. Ang vector mula sa feature space x na tumutugma sa object ng problema sa pagkilala ay isang N-dimensional vector na may mga bahagi (x_1,x_2,…,x_N), na siyang mga value ng mga feature para sa ibinigay na object.
Sa madaling salita, ang pagkilala ng pattern ay maaaring tukuyin bilang pagtatalaga ng paunang data sa isang partikular na klase sa pamamagitan ng pagkuha ng mga mahahalagang tampok o katangian na nagpapakilala sa data na ito mula sa pangkalahatang masa ng mga hindi nauugnay na detalye.
Ang mga halimbawa ng mga problema sa pag-uuri ay:
- pagkilala sa karakter;
- pagkilala sa pagsasalita;
- pagtatatag ng medikal na diagnosis;
- Ulat panahon;
- pagkilala sa mukha
- pag-uuri ng mga dokumento, atbp.
Kadalasan, ang pinagmulang materyal ay ang larawang natanggap mula sa camera. Ang gawain ay maaaring buuin bilang pagkuha ng mga feature vector para sa bawat klase sa isinasaalang-alang na imahe. Maaaring tingnan ang proseso bilang isang proseso ng coding, na binubuo sa pagtatalaga ng halaga sa bawat feature mula sa feature space para sa bawat klase.
Kung isasaalang-alang natin ang 2 klase ng mga bagay: matatanda at bata. Bilang mga tampok, maaari kang pumili ng taas at timbang. Tulad ng sumusunod mula sa figure, ang dalawang klase na ito ay bumubuo ng dalawang di-intersecting set, na maaaring ipaliwanag ng mga napiling tampok. Gayunpaman, hindi laging posible na piliin ang mga tamang sinusukat na parameter bilang mga tampok ng mga klase. Halimbawa, ang mga napiling parameter ay hindi angkop para sa paglikha ng mga hindi magkakapatong na klase ng mga manlalaro ng football at basketball player.
Ang pangalawang gawain ng pagkilala ay ang pagpili ng mga katangian o katangian mula sa orihinal na mga imahe. Ang gawaing ito ay maaaring maiugnay sa preprocessing. Kung isasaalang-alang natin ang gawain ng pagkilala sa pagsasalita, maaari nating makilala ang mga katangian tulad ng mga patinig at katinig. Ang katangian ay dapat na isang katangian ng isang partikular na klase, habang ito ay karaniwan sa klase na ito. Mga palatandaan na nagpapakilala sa mga pagkakaiba sa pagitan ng - mga palatandaan ng interclass. Ang mga feature na karaniwan sa lahat ng klase ay hindi nagdadala ng kapaki-pakinabang na impormasyon at hindi itinuturing na mga feature sa problema sa pagkilala. Ang pagpili ng mga tampok ay isa sa mga mahahalagang gawain na nauugnay sa pagtatayo ng isang sistema ng pagkilala.
Matapos matukoy ang mga tampok, kinakailangan upang matukoy ang pinakamainam na pamamaraan ng pagpapasya para sa pag-uuri. Isaalang-alang ang isang sistema ng pagkilala ng pattern na idinisenyo upang makilala ang iba't ibang klase ng M, na tinutukoy bilang m_1,m_2,…,m 3. Pagkatapos ay maaari nating ipagpalagay na ang espasyo ng imahe ay binubuo ng mga rehiyon ng M, bawat isa ay naglalaman ng mga puntos na tumutugma sa isang imahe mula sa isang klase. Kung gayon ang problema sa pagkilala ay maaaring ituring bilang ang pagtatayo ng mga hangganan na naghihiwalay sa mga klase ng M batay sa tinatanggap na mga vector ng pagsukat.
Ang solusyon sa problema ng preprocessing ng imahe, pagkuha ng tampok at ang problema sa pagkuha ng pinakamainam na solusyon at pag-uuri ay kadalasang nauugnay sa pangangailangan na suriin ang isang bilang ng mga parameter. Ito ay humahantong sa problema ng pagtatantya ng parameter. Bilang karagdagan, malinaw na ang feature extraction ay maaaring gumamit ng karagdagang impormasyon batay sa likas na katangian ng mga klase.
Ang paghahambing ng mga bagay ay maaaring gawin batay sa kanilang representasyon sa anyo ng mga vector ng pagsukat. Ito ay maginhawa upang kumatawan sa data ng pagsukat bilang mga tunay na numero. Pagkatapos ay ang pagkakatulad ng mga feature vector ng dalawang bagay ay maaaring ilarawan gamit ang Euclidean distance.

kung saan ang d ay ang dimensyon ng feature vector.
Mayroong 3 pangkat ng mga pamamaraan ng pagkilala ng pattern:
- Halimbawang paghahambing. Kasama sa pangkat na ito ang pag-uuri ayon sa pinakamalapit na mean, pag-uuri ayon sa distansya sa pinakamalapit na kapitbahay. Ang mga paraan ng pagkilala sa istruktura ay maaari ding isama sa sample na pangkat ng paghahambing.
- Paraang istatistikal. Gaya ng ipinahihiwatig ng pangalan, ang mga pamamaraan ng istatistika ay gumagamit ng ilang istatistikal na impormasyon kapag nilulutas ang isang problema sa pagkilala. Tinutukoy ng pamamaraan ang pag-aari ng isang bagay sa isang partikular na klase batay sa probabilidad. Sa ilang mga kaso, bumababa ito sa pagtukoy ng posterior probability ng isang bagay na kabilang sa isang partikular na klase, sa kondisyon na ang mga katangian ng bagay na ito ay nakakuha ng naaangkop na mga halaga. Ang isang halimbawa ay ang pamamaraan ng panuntunan ng desisyon ng Bayesian.
- Mga neural network. Isang hiwalay na klase ng mga paraan ng pagkilala. Ang isang natatanging tampok mula sa iba ay ang kakayahang matuto.
Pag-uuri ayon sa pinakamalapit na mean
Sa klasikal na diskarte ng pagkilala ng pattern, kung saan ang isang hindi kilalang bagay para sa pag-uuri ay kinakatawan bilang isang vector ng mga elementarya na tampok. Ang isang feature-based na recognition system ay maaaring mabuo sa iba't ibang paraan. Ang mga vector na ito ay maaaring malaman ng system nang maaga bilang isang resulta ng pagsasanay o hinulaang sa real time batay sa ilang mga modelo.
Ang isang simpleng algorithm ng pag-uuri ay binubuo ng pagpapangkat ng data ng sangguniang klase gamit ang vector ng inaasahan ng klase (mean).

kung saan ang x(i,j) ay ang j-th reference feature ng class i, n_j ay ang bilang ng reference vectors ng class i.
Kung gayon ang hindi kilalang bagay ay mapabilang sa klase i kung ito ay mas malapit sa expectation vector ng class i kaysa sa expectation vectors ng ibang mga klase. Ang pamamaraang ito ay angkop para sa mga problema kung saan ang mga punto ng bawat klase ay matatagpuan nang compact at malayo sa mga punto ng iba pang mga klase.

Ang mga paghihirap ay lilitaw kung ang mga klase ay may bahagyang mas kumplikadong istraktura, halimbawa, tulad ng sa figure. Sa kasong ito, ang klase 2 ay nahahati sa dalawang hindi magkakapatong na seksyon, na hindi maganda ang paglalarawan ng isang average na halaga. Gayundin, ang klase 3 ay masyadong pinahaba, ang mga sample ng 3rd class na may malalaking halaga ng x_2 coordinates ay mas malapit sa average na halaga ng 1st class kaysa sa 3rd class.

Ang inilarawan na problema sa ilang mga kaso ay maaaring malutas sa pamamagitan ng pagbabago ng pagkalkula ng distansya.
Isasaalang-alang namin ang katangian ng "scatter" ng mga halaga ng klase - σ_i, kasama ang bawat direksyon ng coordinate i. Ang standard deviation ay katumbas ng square root ng variance. Ang naka-scale na Euclidean na distansya sa pagitan ng vector x at ng inaasahang vector x_c ay

Ang formula ng distansya na ito ay magbabawas sa bilang ng mga error sa pag-uuri, ngunit sa katotohanan, ang karamihan sa mga problema ay hindi maaaring katawanin ng ganoong simpleng klase.
Pag-uuri ayon sa distansya sa pinakamalapit na kapitbahay
Ang isa pang diskarte sa pag-uuri ay ang magtalaga ng hindi kilalang feature vector x sa klase kung saan ang vector na ito ay pinakamalapit sa isang hiwalay na sample. Ang panuntunang ito ay tinatawag na pinakamalapit na tuntunin sa kapitbahay. Ang pinakamalapit na pag-uuri ng kapitbahay ay maaaring maging mas mahusay kahit na ang mga klase ay kumplikado o kapag ang mga klase ay nagsasapawan.
Ang diskarte na ito ay hindi nangangailangan ng mga pagpapalagay tungkol sa mga modelo ng pamamahagi ng mga feature vector sa espasyo. Ang algorithm ay gumagamit lamang ng impormasyon tungkol sa mga kilalang reference sample. Ang paraan ng solusyon ay batay sa pagkalkula ng distansya x sa bawat sample sa database at paghahanap ng pinakamababang distansya. Ang mga pakinabang ng pamamaraang ito ay halata:
- sa anumang oras maaari kang magdagdag ng mga bagong sample sa database;
- binabawasan ng mga istruktura ng data ng puno at grid ang bilang ng mga nakalkulang distansya.
Bilang karagdagan, ang solusyon ay magiging mas mahusay kung titingnan mo sa database hindi para sa isang pinakamalapit na kapitbahay, ngunit para sa k. Pagkatapos, para sa k > 1, nagbibigay ito ng pinakamahusay na sample ng pamamahagi ng mga vector sa d-dimensional na espasyo. Gayunpaman, ang mahusay na paggamit ng mga halaga ng k ay nakasalalay sa kung mayroong sapat sa bawat rehiyon ng espasyo. Kung mayroong higit sa dalawang klase, kung gayon ito ay mas mahirap na gumawa ng tamang desisyon.
Panitikan
- M. Castrillon,. O. Deniz, . D. Hernández at J. Lorenzo, "Isang paghahambing ng mga face at facial feature detector batay sa Viola-Jones general object detection framework," International Journal of Computer Vision, blg. 22, pp. 481-494, 2011.
- Y.-Q. Wang, "Isang Pagsusuri ng Viola-Jones Face Detection Algorithm," IPOL Journal, 2013.
- L. Shapiro at D. Stockman, Computer vision, Binom. Knowledge Lab, 2006.
- Z. N. G., Mga pamamaraan ng pagkilala at ang kanilang aplikasyon, radyo ng Sobyet, 1972.
- J. Tu, R. Gonzalez, Mathematical Principles of Pattern Recognition, Moscow: "Mir" Moscow, 1974.
- Khan, H. Abdullah at M. Shamian Bin Zainal, "Mahusay na algorithm sa pagtuklas ng mga mata at bibig gamit ang kumbinasyon ng viola jones at pagtukoy ng pixel ng kulay ng balat" International Journal of Engineering and Applied Sciences, no. Vol. 3 no 4, 2013.
- V. Gaede at O. Gunther, "Multidimensional Access Methods," ACM Computing Surveys, pp. 170-231, 1998.
Ang mga nabubuhay na sistema, kabilang ang mga tao, ay patuloy na nahaharap sa gawain ng pagkilala sa pattern mula noong sila ay nagsimula. Sa partikular, ang impormasyon na nagmumula sa mga organo ng pandama ay pinoproseso ng utak, na, sa turn, ay nag-uuri ng impormasyon, tinitiyak ang paggawa ng desisyon, at pagkatapos, gamit ang mga electrochemical impulses, nagpapadala pa ng kinakailangang signal, halimbawa, sa mga organo ng paggalaw. , na nagpapatupad ng mga kinakailangang aksyon. Pagkatapos ay mayroong pagbabago sa kapaligiran, at ang mga phenomena sa itaas ay naganap muli. At kung titingnan mo, kung gayon ang bawat yugto ay sinamahan ng pagkilala.
Sa pag-unlad ng teknolohiya ng computer, naging posible na malutas ang isang bilang ng mga problema na lumitaw sa proseso ng buhay, upang mapadali, mapabilis, mapabuti ang kalidad ng resulta. Halimbawa, ang pagpapatakbo ng iba't ibang mga sistema ng suporta sa buhay, pakikipag-ugnayan ng tao-computer, ang paglitaw ng mga robotic system, atbp. Gayunpaman, tandaan namin na kasalukuyang hindi posible na magbigay ng isang kasiya-siyang resulta sa ilang mga gawain (pagkilala sa mabilis na gumagalaw na mga katulad na bagay , sulat-kamay na teksto).
Layunin ng gawain: pag-aralan ang kasaysayan ng mga sistema ng pagkilala ng pattern.
Ipahiwatig ang mga pagbabago sa husay na naganap sa larangan ng pagkilala sa pattern, parehong teoretikal at teknikal, na nagpapahiwatig ng mga dahilan;
Talakayin ang mga pamamaraan at prinsipyong ginamit sa pag-compute;
Magbigay ng mga halimbawa ng mga prospect na inaasahan sa malapit na hinaharap.
1. Ano ang pattern recognition?
Ang unang pananaliksik sa teknolohiya ng computer ay karaniwang sumunod sa klasikal na pamamaraan ng pagmomodelo ng matematika - modelo ng matematika, algorithm at pagkalkula. Ito ang mga gawain ng pagmomodelo ng mga prosesong nagaganap sa panahon ng mga pagsabog ng atomic bomb, pagkalkula ng mga ballistic na trajectory, pang-ekonomiya at iba pang mga aplikasyon. Gayunpaman, bilang karagdagan sa mga klasikal na ideya ng seryeng ito, mayroon ding mga pamamaraan na nakabatay sa isang ganap na naiibang kalikasan, at tulad ng ipinakita ng kasanayan sa paglutas ng ilang mga problema, madalas silang nagbibigay ng mas mahusay na mga resulta kaysa sa mga solusyon batay sa sobrang kumplikadong mga modelo ng matematika. Ang kanilang ideya ay upang talikuran ang pagnanais na lumikha ng isang kumpletong modelo ng matematika ng bagay na pinag-aaralan (bukod dito, kadalasan ay halos imposible na makabuo ng sapat na mga modelo), at sa halip ay masiyahan sa sagot lamang sa mga partikular na tanong na interesado tayo, at ang mga sagot na ito ay dapat hanapin mula sa mga pagsasaalang-alang na karaniwan sa isang malawak na uri ng mga problema. Kasama sa pananaliksik sa ganitong uri ang pagkilala sa mga visual na imahe, pagtataya ng mga ani, mga antas ng ilog, ang problema sa pagkilala sa pagitan ng oil-bearing at aquifers gamit ang hindi direktang geophysical data, atbp. Ang isang tiyak na sagot sa mga gawaing ito ay kinakailangan sa medyo simpleng anyo, tulad ng, halimbawa, kung ang isang bagay ay kabilang sa isa sa mga pre-fixed na klase. At ang paunang data ng mga gawaing ito, bilang panuntunan, ay ibinigay sa anyo ng fragmentary na impormasyon tungkol sa mga bagay na pinag-aaralan, halimbawa, sa anyo ng isang hanay ng mga pre-classified na bagay. Mula sa isang matematikal na pananaw, nangangahulugan ito na ang pagkilala sa pattern (at ang klase ng mga problemang ito ay pinangalanan sa ating bansa) ay isang malawak na paglalahat ng ideya ng extrapolation ng function.
Ang kahalagahan ng naturang pormulasyon para sa mga teknikal na agham ay walang pag-aalinlangan, at ito mismo ay nagbibigay-katwiran sa maraming pag-aaral sa lugar na ito. Gayunpaman, ang problema sa pagkilala ng pattern ay mayroon ding mas malawak na aspeto para sa natural na agham (gayunpaman, magiging kakaiba kung ang isang bagay na napakahalaga para sa mga artipisyal na cybernetic system ay hindi magiging mahalaga para sa mga natural). Ang konteksto ng agham na ito ay organikong kasama ang mga tanong na ibinibigay ng mga sinaunang pilosopo tungkol sa kalikasan ng ating kaalaman, ang ating kakayahang makilala ang mga imahe, pattern, sitwasyon ng mundo sa ating paligid. Sa katunayan, halos walang alinlangan na ang mga mekanismo para sa pagkilala sa pinakasimpleng mga imahe, tulad ng mga larawan ng isang paparating na mapanganib na mandaragit o pagkain, ay nabuo nang mas maaga kaysa sa elementarya na wika at ang pormal na lohikal na kagamitan ay lumitaw. At walang alinlangan na ang mga naturang mekanismo ay sapat din na binuo sa mas mataas na mga hayop, na, sa kanilang mahahalagang aktibidad, ay nangangailangan din ng kagyat na kakayahang makilala ang isang medyo kumplikadong sistema ng mga palatandaan ng kalikasan. Kaya, sa kalikasan, nakikita natin na ang kababalaghan ng pag-iisip at kamalayan ay malinaw na nakabatay sa kakayahang makilala ang mga pattern, at ang karagdagang pag-unlad ng agham ng katalinuhan ay direktang nauugnay sa lalim ng pag-unawa sa mga pangunahing batas ng pagkilala. Ang pag-unawa sa katotohanan na ang mga tanong sa itaas ay higit pa sa karaniwang kahulugan ng pattern recognition (sa panitikang Ingles, ang terminong pinangangasiwaang pag-aaral ay mas karaniwan), kinakailangan ding maunawaan na mayroon silang malalim na koneksyon sa medyo makitid na ito (ngunit malayo pa rin. mula sa naubos) direksyon.
Kahit na ngayon, ang pagkilala ng pattern ay matatag na pumasok sa pang-araw-araw na buhay at isa sa pinakamahalagang kaalaman ng isang modernong inhinyero. Sa medisina, ang pattern recognition ay nakakatulong sa mga doktor na gumawa ng mas tumpak na mga diagnosis; sa mga pabrika, ginagamit ito upang mahulaan ang mga depekto sa mga batch ng mga produkto. Ang biometric personal identification system bilang kanilang algorithmic core ay nakabatay din sa mga resulta ng disiplinang ito. Ang karagdagang pag-unlad ng artificial intelligence, lalo na ang disenyo ng ikalimang henerasyon na mga computer na may kakayahang mas direktang komunikasyon sa isang tao sa natural na mga wika para sa mga tao at sa pamamagitan ng pagsasalita, ay hindi maiisip nang walang pagkilala. Dito, madaling maabot ang robotics, mga artificial control system na naglalaman ng mga recognition system bilang mahahalagang subsystem.
Iyon ang dahilan kung bakit maraming pansin ang naibigay sa pagbuo ng pagkilala sa pattern mula sa simula ng mga espesyalista ng iba't ibang mga profile - cybernetics, neurophysiologist, psychologist, mathematician, ekonomista, atbp. Higit sa lahat para sa kadahilanang ito, ang modernong pagkilala sa pattern mismo ay kumakain sa mga ideya ng mga disiplinang ito. Nang hindi inaangkin na kumpleto (at imposibleng angkinin ito sa isang maikling sanaysay), ilalarawan namin ang kasaysayan ng pagkilala ng pattern, mga pangunahing ideya.
Mga Kahulugan
Bago magpatuloy sa mga pangunahing pamamaraan ng pagkilala ng pattern, nagbibigay kami ng ilang kinakailangang mga kahulugan.
Ang pagkilala sa mga imahe (mga bagay, signal, sitwasyon, phenomena o proseso) ay ang gawain ng pagtukoy ng isang bagay o pagtukoy ng alinman sa mga katangian nito sa pamamagitan ng imahe nito (optical recognition) o audio recording (acoustic recognition) at iba pang mga katangian.
Ang isa sa mga pangunahing ay ang konsepto ng isang set na walang tiyak na pagbabalangkas. Sa isang computer, ang isang set ay kinakatawan ng isang set ng mga hindi umuulit na elemento ng parehong uri. Ang salitang "hindi umuulit" ay nangangahulugan na ang ilang elemento sa set ay naroroon o wala. Kasama sa unibersal na hanay ang lahat ng posibleng elemento para sa problemang nilulutas, ang walang laman na hanay ay hindi naglalaman ng anuman.
Ang imahe ay isang pagpapangkat ng klasipikasyon sa sistema ng pag-uuri na pinag-iisa (iisa-isa) ang isang partikular na pangkat ng mga bagay ayon sa ilang katangian. Ang mga imahe ay may katangian na pag-aari, na nagpapakita ng sarili sa katotohanan na ang kakilala sa isang may hangganan na bilang ng mga phenomena mula sa parehong hanay ay ginagawang posible na makilala ang isang di-makatwirang malaking bilang ng mga kinatawan nito. Ang mga imahe ay may mga katangian ng layunin na katangian sa kahulugan na ang iba't ibang mga tao na natututo mula sa iba't ibang materyal sa pagmamasid, sa karamihan, ay nag-uuri ng parehong mga bagay sa parehong paraan at independyente sa bawat isa. Sa klasikal na pagbabalangkas ng problema sa pagkilala, ang unibersal na hanay ay nahahati sa mga bahagi-mga imahe. Ang bawat pagmamapa ng anumang bagay sa nakikitang mga organo ng sistema ng pagkilala, anuman ang posisyon nito na nauugnay sa mga organo na ito, ay karaniwang tinatawag na isang imahe ng bagay, at ang mga hanay ng naturang mga imahe, na pinagsama ng ilang karaniwang mga katangian, ay mga imahe.
Ang paraan ng pagtatalaga ng isang elemento sa anumang imahe ay tinatawag na panuntunan ng desisyon. Ang isa pang mahalagang konsepto ay ang mga sukatan, isang paraan upang matukoy ang distansya sa pagitan ng mga elemento ng isang unibersal na hanay. Kung mas maliit ang distansyang ito, mas magkakatulad ang mga bagay (mga simbolo, tunog, atbp.) na ating kinikilala. Karaniwan, ang mga elemento ay tinukoy bilang isang hanay ng mga numero, at ang sukatan ay tinukoy bilang isang function. Ang kahusayan ng programa ay nakasalalay sa pagpili ng representasyon ng mga imahe at ang pagpapatupad ng sukatan, ang isang algorithm ng pagkilala na may iba't ibang sukatan ay magkakamali sa iba't ibang mga frequency.
Ang pagkatuto ay karaniwang tinatawag na proseso ng pagbuo sa ilang sistema ng isang partikular na reaksyon sa mga grupo ng panlabas na magkaparehong signal sa pamamagitan ng paulit-ulit na pag-impluwensya sa panlabas na sistema ng pagwawasto. Ang ganitong panlabas na pagsasaayos sa pagsasanay ay karaniwang tinatawag na "pagpapalakas ng loob" at "kaparusahan". Ang mekanismo para sa pagbuo ng pagsasaayos na ito ay halos ganap na tinutukoy ang algorithm ng pag-aaral. Ang pag-aaral sa sarili ay naiiba sa pag-aaral na dito ay hindi naiulat ang karagdagang impormasyon tungkol sa kawastuhan ng reaksyon sa system.
Ang adaptasyon ay isang proseso ng pagbabago ng mga parameter at istraktura ng system, at posibleng kontrolin din ang mga aksyon, batay sa kasalukuyang impormasyon upang makamit ang isang tiyak na estado ng system na may paunang kawalan ng katiyakan at pagbabago ng mga kondisyon ng operating.
Ang pag-aaral ay isang proseso, bilang isang resulta kung saan ang sistema ay unti-unting nakakakuha ng kakayahang tumugon sa mga kinakailangang reaksyon sa ilang mga hanay ng mga panlabas na impluwensya, at ang pagbagay ay ang pagsasaayos ng mga parameter at istraktura ng system upang makamit ang kinakailangang kalidad ng kontrol sa mga kondisyon ng patuloy na pagbabago sa mga panlabas na kondisyon.
Mga halimbawa ng mga gawain sa pagkilala ng pattern: - Pagkilala ng titik;
Sa pangkalahatan, tatlong paraan ng pagkilala ng pattern ang maaaring makilala: Ang paraan ng enumeration. Sa kasong ito, ang isang paghahambing ay ginawa sa database, kung saan para sa bawat uri ng bagay ang lahat ng posibleng pagbabago ng display ay ipinakita. Halimbawa, para sa optical image recognition, maaari mong ilapat ang paraan ng pag-enumerate ng uri ng isang bagay sa iba't ibang anggulo, kaliskis, displacement, deformation, atbp. Para sa mga titik, kailangan mong umulit sa font, mga katangian ng font, atbp. Sa kaso ng sound image recognition, ayon sa pagkakabanggit, isang paghahambing sa ilang kilalang pattern (halimbawa, isang salitang binibigkas ng ilang tao).
Ang pangalawang diskarte ay isang mas malalim na pagsusuri ng mga katangian ng imahe. Sa kaso ng optical recognition, maaaring ito ang pagpapasiya ng iba't ibang geometric na katangian. Ang sound sample sa kasong ito ay sumasailalim sa frequency, amplitude analysis, atbp.
Ang susunod na paraan ay ang paggamit ng mga artificial neural network (ANN). Ang pamamaraang ito ay nangangailangan ng alinman sa isang malaking bilang ng mga halimbawa ng gawain sa pagkilala sa panahon ng pagsasanay, o isang espesyal na istraktura ng neural network na isinasaalang-alang ang mga detalye ng gawaing ito. Gayunpaman, ito ay nakikilala sa pamamagitan ng mas mataas na kahusayan at pagiging produktibo.
4. Kasaysayan ng pattern recognition
Isaalang-alang natin sa madaling sabi ang mathematical formalism ng pattern recognition. Ang isang bagay sa pagkilala ng pattern ay inilalarawan ng isang hanay ng mga pangunahing katangian (mga tampok, katangian). Ang mga pangunahing katangian ay maaaring magkaiba: maaari silang makuha mula sa isang nakaayos na hanay ng tunay na uri ng linya, o mula sa isang discrete set (na, gayunpaman, ay maaari ding pagkalooban ng isang istraktura). Ang pag-unawa sa bagay na ito ay pare-pareho sa pangangailangan para sa mga praktikal na aplikasyon ng pattern recognition at sa ating pag-unawa sa mekanismo ng pang-unawa ng tao sa isang bagay. Sa katunayan, naniniwala kami na kapag ang isang tao ay nagmamasid (nagsusukat) ng isang bagay, ang impormasyon tungkol dito ay dumarating sa pamamagitan ng isang tiyak na bilang ng mga sensor (na-analyze na mga channel) sa utak, at ang bawat sensor ay maaaring iugnay sa kaukulang katangian ng bagay. Bilang karagdagan sa mga tampok na tumutugma sa aming mga sukat ng bagay, mayroon ding isang napiling tampok, o isang pangkat ng mga tampok, na tinatawag naming pag-uuri ng mga tampok, at ang paghahanap ng kanilang mga halaga para sa isang naibigay na vector X ay ang gawain na natural. at gumaganap ang mga sistema ng artipisyal na pagkilala.
Malinaw na upang maitaguyod ang mga halaga ng mga tampok na ito, kinakailangan na magkaroon ng impormasyon tungkol sa kung paano nauugnay ang mga kilalang tampok sa mga pag-uuri. Ang impormasyon tungkol sa relasyon na ito ay ibinibigay sa anyo ng mga nauna, iyon ay, isang hanay ng mga paglalarawan ng mga bagay na may mga kilalang halaga ng pag-uuri ng mga tampok. At ayon sa precedent na impormasyong ito, kinakailangan na bumuo ng isang panuntunan sa pagpapasya na magtatakda ng di-makatwirang paglalarawan ng bagay ng halaga ng mga tampok ng pag-uuri nito.
Ang pag-unawa sa problema ng pagkilala ng pattern ay itinatag sa agham mula noong 50s ng huling siglo. At pagkatapos ay napansin na ang naturang produksyon ay hindi naman bago. Ang mga mahusay na napatunayang pamamaraan ng pagtatasa ng data ng istatistika, na aktibong ginagamit para sa maraming praktikal na mga gawain, tulad ng, halimbawa, mga teknikal na diagnostic, ay nahaharap sa naturang pagbabalangkas at umiiral na. Samakatuwid, ang mga unang hakbang ng pagkilala ng pattern ay ipinasa sa ilalim ng tanda ng istatistikal na diskarte, na nagdidikta sa pangunahing problema.
Ang diskarte sa istatistika ay batay sa ideya na ang paunang espasyo ng mga bagay ay isang probabilistikong espasyo, at ang mga tampok (mga katangian) ng mga bagay ay mga random na variable na ibinigay dito. Pagkatapos ang gawain ng data scientist ay maglagay ng isang istatistikal na hypothesis tungkol sa pamamahagi ng mga tampok, o sa halip tungkol sa pag-asa ng pag-uuri ng mga tampok sa iba, mula sa ilang mga pagsasaalang-alang. Ang istatistikal na hypothesis, bilang panuntunan, ay isang parametrically na tinukoy na hanay ng mga function ng pamamahagi ng tampok. Ang isang tipikal at klasikal na istatistikal na hypothesis ay ang hypothesis ng normalidad ng distribusyon na ito (mayroong napakaraming uri ng naturang hypothesis sa mga istatistika). Matapos bumalangkas ng hypothesis, nanatili itong subukan ang hypothesis na ito sa precedent data. Ang tseke na ito ay binubuo sa pagpili ng ilang distribusyon mula sa unang ibinigay na hanay ng mga distribusyon (ang distribution hypothesis parameter) at pagtatasa ng pagiging maaasahan (confidence interval) ng pagpipiliang ito. Sa totoo lang, ang pagpapaandar na ito ng pamamahagi ay ang sagot sa problema, tanging ang bagay ay inuri hindi natatangi, ngunit may ilang mga posibilidad na kabilang sa mga klase. Ang mga istatistika ay nakabuo din ng isang asymptotic na katwiran para sa mga naturang pamamaraan. Ang ganitong mga katwiran ay ginawa ayon sa sumusunod na pamamaraan: ang isang tiyak na kalidad ng pagganap ng pagpili ng pamamahagi (pagtitiwala sa pagitan) ay itinatag at ipinakita na sa pagtaas ng bilang ng mga nauna, ang aming pagpili na may posibilidad na may posibilidad na 1 ay naging tama sa ang kahulugan ng functional na ito (confidence interval tending to 0). Sa hinaharap, maaari nating sabihin na ang istatistikal na pananaw ng problema sa pagkilala ay naging napakabunga hindi lamang sa mga tuntunin ng binuo na mga algorithm (na kinabibilangan ng mga pamamaraan ng cluster at discriminant analysis, nonparametric regression, atbp.), ngunit kasunod na pinangunahan ng Vapnik upang lumikha ng malalim na istatistikal na teorya ng pagkilala.
Gayunpaman, mayroong isang malakas na argumento na pabor sa katotohanan na ang mga problema sa pagkilala ng pattern ay hindi nabawasan sa mga istatistika. Anumang ganoong problema, sa prinsipyo, ay maaaring isaalang-alang mula sa istatistikal na pananaw, at ang mga resulta ng solusyon nito ay maaaring bigyang-kahulugan sa istatistika. Upang gawin ito, kinakailangan lamang na ipagpalagay na ang espasyo ng mga bagay ng problema ay probabilistiko. Ngunit mula sa punto ng view ng instrumentalism, ang pamantayan para sa tagumpay ng istatistikal na interpretasyon ng isang tiyak na paraan ng pagkilala ay maaari lamang maging katwiran ng pamamaraang ito sa wika ng mga istatistika bilang isang sangay ng matematika. Ang pagbibigay-katwiran dito ay nangangahulugan ng pagbuo ng mga pangunahing kinakailangan para sa problema na nagsisiguro ng tagumpay sa paglalapat ng pamamaraang ito. Gayunpaman, sa ngayon, para sa karamihan ng mga pamamaraan ng pagkilala, kabilang ang mga direktang lumitaw sa loob ng balangkas ng istatistikal na diskarte, ang mga naturang kasiya-siyang katwiran ay hindi natagpuan. Bilang karagdagan, ang pinakakaraniwang ginagamit na mga istatistikal na algorithm sa ngayon, tulad ng linear discriminant ni Fisher, Parzen window, EM algorithm, mga pinakamalapit na kapitbahay, bukod pa sa mga network ng paniniwala ng Bayesian, ay may malakas na binibigkas na heuristic na katangian at maaaring may mga interpretasyong iba sa mga istatistikal. At sa wakas, sa lahat ng nasa itaas, dapat itong idagdag na bilang karagdagan sa asymptotic na pag-uugali ng mga pamamaraan ng pagkilala, na siyang pangunahing isyu ng mga istatistika, ang pagsasagawa ng pagkilala ay nagtataas ng mga katanungan tungkol sa computational at structural complexity ng mga pamamaraan na higit pa. ang balangkas ng probability theory lamang.
Sa kabuuan, salungat sa mga adhikain ng mga istatistika na isaalang-alang ang pagkilala ng pattern bilang isang seksyon ng mga istatistika, ganap na magkakaibang mga ideya ang pumasok sa kasanayan at ideolohiya ng pagkilala. Ang isa sa mga ito ay sanhi ng pananaliksik sa larangan ng visual pattern recognition at batay sa sumusunod na pagkakatulad.
Tulad ng nabanggit na, sa pang-araw-araw na buhay ang mga tao ay patuloy na nalulutas (madalas na hindi sinasadya) ang mga problema ng pagkilala sa iba't ibang mga sitwasyon, pandinig at visual na mga imahe. Ang gayong kakayahan para sa mga computer ay, sa pinakamaganda, isang bagay sa hinaharap. Mula dito, napagpasyahan ng ilang mga pioneer ng pattern recognition na ang solusyon sa mga problemang ito sa isang computer ay dapat, sa pangkalahatan, gayahin ang mga proseso ng pag-iisip ng tao. Ang pinakatanyag na pagtatangka na lapitan ang problema mula sa panig na ito ay ang sikat na pag-aaral ni F. Rosenblatt sa mga perceptron.
Noong kalagitnaan ng 50s, tila naunawaan ng mga neurophysiologist ang mga pisikal na prinsipyo ng utak (sa aklat na "The New Mind of the King", ang sikat na British theoretical physicist na si R. Penrose ay kawili-wiling nagtatanong sa modelo ng neural network ng utak, na nagpapatunay. ang mahalagang papel ng quantum mechanical effects sa paggana nito ; bagaman, gayunpaman, ang modelong ito ay kinuwestiyon sa simula pa lamang. Batay sa mga pagtuklas na ito, si F. Rosenblatt ay bumuo ng isang modelo para sa pag-aaral na makilala ang mga visual na pattern, na tinawag niyang perceptron. Rosenblatt's perceptron ay ang sumusunod na function (Fig. 1):
Fig 1. Schematic ng Perceptron
Sa input, ang perceptron ay tumatanggap ng object vector, na sa mga gawa ni Rosenblatt ay isang binary vector na nagpapakita kung alin sa mga pixel ng screen ang na-black out ng imahe at alin ang hindi. Dagdag pa, ang bawat isa sa mga palatandaan ay pinapakain sa input ng neuron, ang pagkilos nito ay isang simpleng multiplikasyon sa isang tiyak na bigat ng neuron. Ang mga resulta ay ibinibigay sa huling neuron, na nagdaragdag sa kanila at inihahambing ang kabuuang halaga sa isang tiyak na threshold. Depende sa mga resulta ng paghahambing, ang input object X ay kinikilala kung kinakailangan o hindi. Pagkatapos ang gawain ng pag-aaral ng pattern recognition ay ang piliin ang mga timbang ng mga neuron at ang halaga ng threshold upang ang perceptron ay makapagbigay ng mga tamang sagot sa mga naunang visual na imahe. Naniniwala si Rosenblatt na ang resultang function ay magiging mahusay sa pagkilala sa nais na visual na imahe kahit na ang input object ay wala sa mga nauna. Mula sa mga pagsasaalang-alang ng bionic, nakaisip din siya ng isang paraan para sa pagpili ng mga timbang at isang threshold, na hindi natin tatalakayin. Sabihin na lang natin na ang kanyang diskarte ay matagumpay sa isang bilang ng mga problema sa pagkilala at nagbunga ng isang buong linya ng pananaliksik sa pag-aaral ng mga algorithm batay sa mga neural network, kung saan ang perceptron ay isang espesyal na kaso.
Dagdag pa, ang iba't ibang mga generalization ng perceptron ay naimbento, ang pag-andar ng mga neuron ay kumplikado: ngayon ang mga neuron ay hindi lamang maaaring magparami ng mga numero ng input o idagdag ang mga ito at ihambing ang resulta sa mga threshold, ngunit maglapat ng mas kumplikadong mga pag-andar sa kanila. Ipinapakita ng Figure 2 ang isa sa mga komplikasyon ng neuron na ito:

kanin. 2 Diagram ng neural network.
Bilang karagdagan, ang topology ng neural network ay maaaring maging mas kumplikado kaysa sa isa na isinasaalang-alang ni Rosenblatt, halimbawa, ito:
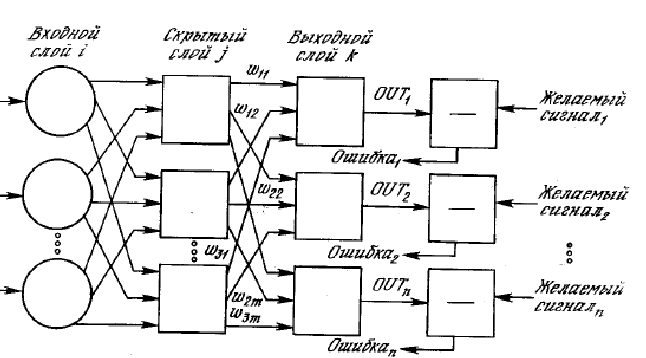
kanin. 3. Diagram ng neural network ni Rosenblatt.
Ang mga komplikasyon ay humantong sa isang pagtaas sa bilang ng mga adjustable na mga parameter sa panahon ng pagsasanay, ngunit sa parehong oras ay nadagdagan ang kakayahang mag-tune sa napaka kumplikadong mga pattern. Ang pananaliksik sa lugar na ito ay nagpapatuloy na ngayon sa dalawang malapit na magkakaugnay na lugar - parehong pinag-aaralan ang iba't ibang mga topolohiya ng network at iba't ibang paraan ng pag-tune.
Ang mga neural network ay kasalukuyang hindi lamang isang tool para sa paglutas ng mga problema sa pagkilala ng pattern, ngunit ginamit sa pananaliksik sa nauugnay na memorya at compression ng imahe. Bagama't ang linya ng pananaliksik na ito ay mahigpit na nagsasapawan sa mga problema sa pagkilala sa pattern, ito ay isang hiwalay na seksyon ng cybernetics. Para sa kinikilala sa ngayon, ang mga neural network ay hindi hihigit sa isang napaka-espesipiko, parametrically na tinukoy na hanay ng mga pagmamapa, na sa ganitong kahulugan ay walang anumang makabuluhang pakinabang sa maraming iba pang katulad na mga modelo ng pag-aaral na maililista sa ibaba.
Kaugnay ng pagtatasa na ito ng papel ng mga neural network para sa wastong pagkilala (iyon ay, hindi para sa bionics, kung saan ang mga ito ay pinakamahalaga ngayon), nais kong tandaan ang mga sumusunod: mga neural network, na isang lubhang kumplikadong bagay para sa matematika. Ang pagsusuri, sa wastong paggamit ng mga ito, ay nagbibigay-daan sa amin na makahanap ng mga napaka-di-trivial na batas sa data. Ang kanilang kahirapan para sa pagsusuri, sa pangkalahatang kaso, ay ipinaliwanag ng kanilang kumplikadong istraktura at, bilang isang resulta, halos hindi mauubos na mga posibilidad para sa pangkalahatan ng isang malawak na iba't ibang mga regularidad. Ngunit ang mga pakinabang na ito, tulad ng madalas na nangyayari, ay isang mapagkukunan ng mga potensyal na pagkakamali, ang posibilidad ng muling pagsasanay. Tulad ng tatalakayin sa ibang pagkakataon, ang gayong dalawang beses na pagtingin sa mga prospect ng anumang modelo ng pag-aaral ay isa sa mga prinsipyo ng machine learning.
Ang isa pang tanyag na direksyon sa pagkilala ay ang mga lohikal na panuntunan at mga puno ng desisyon. Kung ihahambing sa nabanggit na mga pamamaraan ng pagkilala, ang mga pamamaraang ito ay pinaka-aktibong gumagamit ng ideya ng pagpapahayag ng aming kaalaman tungkol sa paksa sa anyo ng marahil ang pinaka natural (sa antas ng kamalayan) - mga lohikal na panuntunan. Ang isang elementarya na lohikal na panuntunan ay nangangahulugang isang pahayag tulad ng "kung ang hindi na-classify na mga tampok ay nasa ratio X, kung gayon ang mga inuri ay nasa ratio na Y". Ang isang halimbawa ng naturang panuntunan sa mga medikal na diagnostic ay ang mga sumusunod: kung ang edad ng pasyente ay higit sa 60 taong gulang at siya ay dati nang inatake sa puso, kung gayon huwag isagawa ang operasyon - ang panganib ng isang negatibong resulta ay mataas.
Upang maghanap ng mga lohikal na panuntunan sa data, 2 bagay ang kailangan: upang matukoy ang sukat ng "kaalaman" ng panuntunan at ang espasyo ng mga panuntunan. At ang gawain ng paghahanap ng mga panuntunan pagkatapos nito ay nagiging isang gawain ng kumpleto o bahagyang enumeration sa espasyo ng mga panuntunan upang mahanap ang pinaka-kaalaman sa mga ito. Ang kahulugan ng nilalaman ng impormasyon ay maaaring ipakilala sa iba't ibang paraan, at hindi namin ito tatalakayin, kung isasaalang-alang na ito rin ay ilang parameter ng modelo. Ang espasyo sa paghahanap ay tinukoy sa karaniwang paraan.
Matapos makahanap ng sapat na kaalamang mga panuntunan, magsisimula ang yugto ng "pagsasama-sama" ng mga panuntunan sa panghuling classifier. Nang hindi tinatalakay nang malalim ang mga problema na lumitaw dito (at mayroong isang malaking bilang ng mga ito), naglilista kami ng 2 pangunahing pamamaraan ng "pagpupulong". Ang unang uri ay isang linear na listahan. Ang pangalawang uri ay may timbang na pagboto, kapag ang isang tiyak na timbang ay itinalaga sa bawat panuntunan, at tinutukoy ng classifier ang bagay sa klase kung saan bumoto ang pinakamalaking bilang ng mga panuntunan.
Sa katunayan, ang yugto ng pagbuo ng panuntunan at ang yugto ng "assembly" ay isinagawa nang magkasama at, kapag gumagawa ng may timbang na boto o listahan, paulit-ulit na tinatawag ang paghahanap para sa mga panuntunan sa mga bahagi ng data ng kaso upang matiyak na mas angkop sa pagitan ng data at ang modelo.
