Average(in mathematics and statistics) sets of numbers - the sum of all numbers divided by their number. It is one of the most common measures of central tendency.
It was proposed (along with the geometric mean and harmonic mean) by the Pythagoreans.
Special cases of the arithmetic mean are the mean (of the general population) and the sample mean (of samples).
Introduction
Denote the set of data X = (x 1 , x 2 , …, x n), then the sample mean is usually denoted by a horizontal bar over the variable (x ¯ (\displaystyle (\bar (x))) , pronounced " x with a dash").
The Greek letter μ is used to denote the arithmetic mean of the entire population. For a random variable for which a mean value is defined, μ is probability mean or the mathematical expectation of a random variable. If the set X is a collection of random numbers with a probability mean μ, then for any sample x i from this collection μ = E( x i) is the expectation of this sample.
In practice, the difference between μ and x ¯ (\displaystyle (\bar (x))) is that μ is a typical variable because you can see the sample rather than the entire population. Therefore, if the sample is represented randomly (in terms of probability theory), then x ¯ (\displaystyle (\bar (x))) (but not μ) can be treated as a random variable having a probability distribution on the sample (probability distribution of the mean).
Both of these quantities are calculated in the same way:
X ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + ⋯ + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\cdots +x_(n)).)
If a X is a random variable, then the mathematical expectation X can be considered as the arithmetic mean of the values in repeated measurements of the quantity X. This is a manifestation of the law of large numbers. Therefore, the sample mean is used to estimate the unknown mathematical expectation.
In elementary algebra, it is proved that the mean n+ 1 numbers above average n numbers if and only if the new number is greater than the old average, less if and only if the new number is less than the average, and does not change if and only if the new number is equal to the average. The more n, the smaller the difference between the new and old averages.
Note that there are several other "means" available, including power-law mean, Kolmogorov mean, harmonic mean, arithmetic-geometric mean, and various weighted means (e.g., arithmetic-weighted mean, geometric-weighted mean, harmonic-weighted mean).
Examples
- For three numbers, you need to add them and divide by 3:
- For four numbers, you need to add them and divide by 4:
Or easier 5+5=10, 10:2. Because we added 2 numbers, which means that how many numbers we add, we divide by that much.
Continuous random variable
For a continuously distributed value f (x) (\displaystyle f(x)) the arithmetic mean on the interval [ a ; b ] (\displaystyle ) is defined via a definite integral:
F (x) ¯ [ a ; b ] = 1 b − a ∫ a b f (x) d x (\displaystyle (\overline (f(x)))_()=(\frac (1)(b-a))\int _(a)^(b) f(x)dx)
Some problems of using the average
Lack of robustness
Main article: Robustness in statisticsAlthough the arithmetic mean is often used as means or central trends, this concept does not apply to robust statistics, which means that the arithmetic mean is heavily influenced by "large deviations". It is noteworthy that for distributions with a large skewness, the arithmetic mean may not correspond to the concept of “average”, and the values of the mean from robust statistics (for example, the median) may better describe the central trend.
The classic example is the calculation of the average income. The arithmetic mean can be misinterpreted as a median, which can lead to the conclusion that there are more people with more income than there really are. "Mean" income is interpreted in such a way that most people's incomes are close to this number. This "average" (in the sense of the arithmetic mean) income is higher than the income of most people, since a high income with a large deviation from the average makes the arithmetic mean strongly skewed (in contrast, the median income "resists" such a skew). However, this "average" income says nothing about the number of people near the median income (and says nothing about the number of people near the modal income). However, if the concepts of "average" and "majority" are taken lightly, then one can incorrectly conclude that most people have incomes higher than they actually are. For example, a report on the "average" net income in Medina, Washington, calculated as the arithmetic average of all annual net incomes of residents, will give a surprisingly high number due to Bill Gates. Consider the sample (1, 2, 2, 2, 3, 9). The arithmetic mean is 3.17, but five of the six values are below this mean.
Compound interest
Main article: ROIIf numbers multiply, but not fold, you need to use the geometric mean, not the arithmetic mean. Most often, this incident happens when calculating the return on investment in finance.
For example, if stocks fell 10% in the first year and rose 30% in the second year, then it is incorrect to calculate the "average" increase over these two years as the arithmetic mean (−10% + 30%) / 2 = 10%; the correct average in this case is given by the compound annual growth rate, from which the annual growth is only about 8.16653826392% ≈ 8.2%.
The reason for this is that percentages have a new starting point each time: 30% is 30% from a number less than the price at the beginning of the first year: if the stock started at $30 and fell 10%, it is worth $27 at the start of the second year. If the stock is up 30%, it is worth $35.1 at the end of the second year. The arithmetic average of this growth is 10%, but since the stock has only grown by $5.1 in 2 years, an average increase of 8.2% gives a final result of $35.1:
[$30 (1 - 0.1) (1 + 0.3) = $30 (1 + 0.082) (1 + 0.082) = $35.1]. If we use the arithmetic mean of 10% in the same way, we will not get the actual value: [$30 (1 + 0.1) (1 + 0.1) = $36.3].
Compound interest at the end of year 2: 90% * 130% = 117% , i.e. a total increase of 17%, and the average annual compound interest is 117% ≈ 108.2% (\displaystyle (\sqrt (117\%))\approx 108.2\%) , that is, an average annual increase of 8.2%.
Directions
Main article: Destination statisticsWhen calculating the arithmetic mean of some variable that changes cyclically (for example, phase or angle), special care should be taken. For example, the average of 1° and 359° would be 1 ∘ + 359 ∘ 2 = (\displaystyle (\frac (1^(\circ )+359^(\circ ))(2))=) 180°. This number is incorrect for two reasons.
- First, angular measures are only defined for the range from 0° to 360° (or from 0 to 2π when measured in radians). Thus, the same pair of numbers could be written as (1° and −1°) or as (1° and 719°). The averages of each pair will be different: 1 ∘ + (− 1 ∘) 2 = 0 ∘ (\displaystyle (\frac (1^(\circ )+(-1^(\circ )))(2))=0 ^(\circ )) , 1 ∘ + 719 ∘ 2 = 360 ∘ (\displaystyle (\frac (1^(\circ )+719^(\circ ))(2))=360^(\circ )) .
- Second, in this case, a value of 0° (equivalent to 360°) would be the geometrically best mean, since the numbers deviate less from 0° than from any other value (value 0° has the smallest variance). Compare:
- the number 1° deviates from 0° by only 1°;
- the number 1° deviates from the calculated average of 180° by 179°.
The average value for a cyclic variable, calculated according to the above formula, will be artificially shifted relative to the real average to the middle of the numerical range. Because of this, the average is calculated in a different way, namely, the number with the smallest variance (center point) is chosen as the average value. Also, instead of subtracting, modulo distance (i.e., circumferential distance) is used. For example, the modular distance between 1° and 359° is 2°, not 358° (on a circle between 359° and 360°==0° - one degree, between 0° and 1° - also 1°, in total - 2 °).
Types of average values and methods for their calculation
At the stage of statistical processing, a variety of research tasks can be set, for the solution of which it is necessary to choose the appropriate average. In this case, it is necessary to be guided by the following rule: the values \u200b\u200bthat represent the numerator and denominator of the average must be logically related to each other.
- power averages;
- structural averages.
Let us introduce the following notation:
The values for which the average is calculated;
Average, where the line above indicates that the averaging of individual values takes place;
Frequency (repeatability of individual trait values).
Various means are derived from the general power mean formula:
 (5.1)
(5.1)
for k = 1 - arithmetic mean; k = -1 - harmonic mean; k = 0 - geometric mean; k = -2 - root mean square.
Averages are either simple or weighted. weighted averages are called quantities that take into account that some variants of the values of the attribute may have different numbers, and therefore each variant has to be multiplied by this number. In other words, the "weights" are the numbers of population units in different groups, i.e. each option is "weighted" by its frequency. The frequency f is called statistical weight or weighing average.
Arithmetic mean- the most common type of medium. It is used when the calculation is carried out on ungrouped statistical data, where you want to get the average summand. The arithmetic mean is such an average value of a feature, upon receipt of which the total volume of the feature in the population remains unchanged.
The arithmetic mean formula ( simple) has the form
where n is the population size.
For example, the average salary of employees of an enterprise is calculated as the arithmetic average:

The determining indicators here are the wages of each employee and the number of employees of the enterprise. When calculating the average, the total amount of wages remained the same, but distributed, as it were, equally among all workers. For example, it is necessary to calculate the average salary of employees of a small company where 8 people are employed:
When calculating averages, individual values of the attribute that is averaged can be repeated, so the average is calculated using grouped data. In this case, we are talking about using arithmetic mean weighted, which looks like
 (5.3)
(5.3)
So, we need to calculate the average share price of a joint-stock company at the stock exchange. It is known that transactions were carried out within 5 days (5 transactions), the number of shares sold at the sales rate was distributed as follows:
1 - 800 ac. - 1010 rubles
2 - 650 ac. - 990 rub.
3 - 700 ak. - 1015 rubles.
4 - 550 ac. - 900 rub.
5 - 850 ak. - 1150 rubles.
The initial ratio for determining the average share price is the ratio of the total amount of transactions (TCA) to the number of shares sold (KPA):
OSS = 1010 800+990 650+1015 700+900 550+1150 850= 3 634 500;
CPA = 800+650+700+550+850=3550.
In this case, the average share price was equal to
![]()
It is necessary to know the properties of the arithmetic mean, which is very important both for its use and for its calculation. There are three main properties that most of all led to the widespread use of the arithmetic mean in statistical and economic calculations.
Property one (zero): the sum of positive deviations of individual values of a trait from its mean value is equal to the sum of negative deviations. This is a very important property, since it shows that any deviations (both with + and with -) due to random causes will be mutually canceled.
Proof:

Property two (minimum): the sum of the squared deviations of the individual values of the trait from the arithmetic mean is less than from any other number (a), i.e. is the minimum number.
Proof.
Compose the sum of the squared deviations from the variable a:
 (5.4)
(5.4)
To find the extremum of this function, it is necessary to equate its derivative with respect to a to zero:

From here we get:

 (5.5)
(5.5)
Therefore, the extremum of the sum of squared deviations is reached at . This extremum is the minimum, since the function cannot have a maximum.
Property three: the arithmetic mean of a constant is equal to this constant: at a = const.
In addition to these three most important properties of the arithmetic mean, there are so-called design properties, which are gradually losing their significance due to the use of electronic computers:
- if the individual value of the attribute of each unit is multiplied or divided by a constant number, then the arithmetic mean will increase or decrease by the same amount;
- the arithmetic mean will not change if the weight (frequency) of each feature value is divided by a constant number;
- if the individual values of the attribute of each unit are reduced or increased by the same amount, then the arithmetic mean will decrease or increase by the same amount.
Average harmonic. This average is called the reciprocal arithmetic average, since this value is used when k = -1.
Simple harmonic mean is used when the weights of the characteristic values are the same. Its formula can be derived from the base formula by substituting k = -1:
For example, we need to calculate the average speed of two cars that have traveled the same path, but at different speeds: the first at 100 km/h, the second at 90 km/h. Using the harmonic mean method, we calculate the average speed:

In statistical practice, harmonic weighted is more often used, the formula of which has the form
This formula is used in cases where the weights (or volumes of phenomena) for each attribute are not equal. In the original ratio, the numerator is known to calculate the average, but the denominator is unknown.
For example, when calculating the average price, we must use the ratio of the amount sold to the number of units sold. We do not know the number of units sold (we are talking about different goods), but we know the sums of sales of these different goods. Suppose you want to find out the average price of goods sold:
We get

![]()
Geometric mean. Most often, the geometric mean finds its application in determining the average growth rate (average growth rates), when the individual values of the trait are presented as relative values. It is also used if it is necessary to find the average between the minimum and maximum values of a characteristic (for example, between 100 and 1000000). There are formulas for simple and weighted geometric mean.
For a simple geometric mean
For the weighted geometric mean
RMS. The main scope of its application is the measurement of the variation of a trait in the population (calculation of the standard deviation).
Simple root mean square formula
Weighted Root Mean Square Formula
 (5.11)
(5.11)
As a result, we can say that the successful solution of the problems of statistical research depends on the correct choice of the type of average value in each specific case. The choice of the average assumes the following sequence:
a) the establishment of a generalizing indicator of the population;
b) determination of a mathematical ratio of values for a given generalizing indicator;
c) replacement of individual values by average values;
d) calculation of the average using the corresponding equation.
Mean values and variation
average value- this is a generalizing indicator that characterizes a qualitatively homogeneous population according to a certain quantitative attribute. For example, the average age of persons convicted of theft.
In judicial statistics, averages are used to characterize:
Average terms of consideration of cases of this category;
Medium size claim;
The average number of defendants per case;
Average amount of damage;
Average workload of judges, etc.
The average value is always named and has the same dimension as the attribute of a separate unit of the population. Each average value characterizes the studied population according to any one varying attribute, therefore, behind any average, there is a series of distribution of units of this population according to the studied attribute. The choice of the type of average is determined by the content of the indicator and the initial data for calculating the average.
All types of averages used in statistical studies fall into two categories:
1) power averages;
2) structural averages.
The first category of averages includes: arithmetic mean, harmonic mean, geometric mean and root mean square . The second category is fashion and median. Moreover, each of the listed types of power averages can have two forms: simple and weighted . The simple form of the mean is used to obtain the mean of the trait under study when the calculation is based on ungrouped statistics, or when each variant occurs only once in the population. Weighted averages are called values that take into account that the options for the values of a feature can have different numbers, and therefore each option has to be multiplied by the corresponding frequency. In other words, each option is "weighed" by its frequency. The frequency is called the statistical weight.
simple arithmetic mean- the most common type of medium. It is equal to the sum of individual characteristic values divided by the total number of these values:
 ,
,
where x 1 ,x 2 , … ,x N are the individual values of the variable trait (options), and N is the number of population units.
Arithmetic weighted average used when the data is presented in the form of distribution series or groupings. It is calculated as the sum of the products of the options and their corresponding frequencies, divided by the sum of the frequencies of all options:
where x i- meaning i–th variants of the feature; fi– frequency i-th options.
Thus, each variant value is weighted by its frequency, which is why the frequencies are sometimes called statistical weights.
Comment. When it comes to the arithmetic mean without specifying its type, the simple arithmetic mean is meant.
Table 12
Solution. For the calculation, we use the formula of the arithmetic weighted average:
Thus, on average, there are two defendants per criminal case.
If the calculation of the average value is carried out according to data grouped in the form of interval distribution series, then first you need to determine the median values of each interval x "i, then calculate the average value using the weighted arithmetic mean formula, in which x" i is substituted instead of x i.
Example. Data on the age of criminals convicted of theft are presented in the table:
Table 13
Determine the average age of criminals convicted of theft.
Solution. In order to determine the average age of criminals based on the interval variation series, you must first find the median values of the intervals. Since an interval series with open first and last intervals is given, the values of these intervals are taken equal to the values of adjacent closed intervals. In our case, the value of the first and last intervals are 10.
![]()
![]()
![]()
![]()
Now we find the average age of criminals using the weighted arithmetic mean formula:
Thus, the average age of offenders convicted of theft is approximately 27 years.
Average harmonic simple is the reciprocal of the arithmetic mean of the reciprocal values of the feature:
where 1/ x i are the reciprocal values of the variants, and N is the number of population units.
Example. In order to determine the average annual workload for judges of a district court when considering criminal cases, a survey was conducted on the workload of 5 judges of this court. The average time spent on one criminal case for each of the surveyed judges turned out to be equal (in days): 6, 0, 5, 6, 6, 3, 4, 9, 5, 4. Find the average costs for one criminal case and the average annual workload on the judges of this district court when considering criminal cases.
Solution. To determine the average time spent on one criminal case, we use the harmonic simple formula:

To simplify the calculations in the example, let's take the number of days in a year equal to 365, including weekends (this does not affect the calculation method, and when calculating a similar indicator in practice, it is necessary to substitute the number of working days in a particular year instead of 365 days). Then the average annual workload for judges of this district court when considering criminal cases will be: 365 (days): 5.56 ≈ 65.6 (cases).
If we used the simple arithmetic mean formula to determine the average time spent on one criminal case, we would get:
365 (days): 5.64 ≈ 64.7 (cases), i.e. the average workload for judges was less.
Let's check the validity of this approach. To do this, we use data on the time spent on one criminal case for each judge and calculate the number of criminal cases considered by each of them per year.
We get accordingly:
365(days) : 6 ≈ 61 (case), 365(days) : 5.6 ≈ 65.2 (case), 365(days) : 6.3 ≈ 58 (case),
365(days) : 4.9 ≈ 74.5 (cases), 365(days) : 5.4 ≈ 68 (cases).
Now we calculate the average annual workload for judges of this district court when considering criminal cases:
Those. the average annual load is the same as when using the harmonic mean.
Thus, the use of the arithmetic mean in this case is illegal.
In cases where the variants of a feature are known, their volumetric values (the product of the variants by the frequency), but the frequencies themselves are unknown, the harmonic weighted average formula is applied:
 ,
,
where x i are the values of the trait variants, and w i are the volumetric values of the variants ( w i = x i f i).
Example. Data on the price of a unit of the same type of goods produced by various institutions of the penitentiary system, and on the volume of its implementation are given in table 14.
Table 14
Find the average selling price of the product.
Solution. When calculating the average price, we must use the ratio of the amount sold to the number of units sold. We do not know the number of sold units, but we know the amount of sales of goods. Therefore, to find the average price of goods sold, we use the harmonic weighted average formula. We get

If you use the arithmetic mean formula here, you can get an average price that will be unrealistic:
![]()
Geometric mean is calculated by extracting the root of degree N from the product of all values of the feature options:
where x 1 ,x 2 , … ,x N are the individual values of the variable trait (options), and
N is the number of population units.
This type of average is used to calculate the average growth rates of time series.
root mean square is used to calculate the standard deviation, which is an indicator of variation, and will be discussed below.
To determine the structure of the population, special averages are used, which include median and fashion , or the so-called structural averages. If the arithmetic mean is calculated based on the use of all variants of the attribute values, then the median and mode characterize the value of the variant that occupies a certain average position in the ranked (ordered) series. The ordering of units of the statistical population can be carried out in ascending or descending order of the variants of the trait under study.
Median (Me) is the value that corresponds to the variant in the middle of the ranked series. Thus, the median is that variant of the ranked series, on both sides of which in this series there should be an equal number of population units.
To find the median, you first need to determine its serial number in the ranked series using the formula:
where N is the volume of the series (the number of population units).
If the series consists of an odd number of members, then the median is equal to the variant with the number N Me . If the series consists of an even number of members, then the median is defined as the arithmetic mean of two adjacent options located in the middle.
Example. Given a ranked series 1, 2, 3, 3, 6, 7, 9, 9, 10. The volume of the series is N = 9, which means N Me = (9 + 1) / 2 = 5. Therefore, Me = 6, i.e. . fifth option. If a row is given 1, 5, 7, 9, 11, 14, 15, 16, i.e. series with an even number of members (N = 8), then N Me = (8 + 1) / 2 = 4.5. So the median is equal to half the sum of the fourth and fifth options, i.e. Me = (9 + 11) / 2 = 10.
In a discrete variation series, the median is determined by the accumulated frequencies. Variant frequencies, starting with the first one, are summed until the median number is exceeded. The value of the last summed options will be the median.
Example. Find the median number of defendants per criminal case using the data in Table 12.
Solution. In this case, the volume of the variation series is N = 154, therefore, N Me = (154 + 1) / 2 = 77.5. Summing up the frequencies of the first and second options, we get: 75 + 43 = 118, i.e. we have surpassed the median number. So Me = 2.
In the interval variation series of the distribution, first indicate the interval in which the median will be located. He is called median . This is the first interval whose cumulative frequency exceeds half the volume of the interval variation series. Then the numerical value of the median is determined by the formula:

where x Me is the lower limit of the median interval; i is the value of the median interval; S Me-1 is the cumulative frequency of the interval that precedes the median; f Me is the frequency of the median interval.
Example. Find the median age of offenders convicted of theft, based on the statistics presented in Table 13.
Solution. Statistical data is represented by an interval variation series, which means that we first determine the median interval. The volume of the population N = 162, therefore, the median interval is the interval 18-28, because this is the first interval, the accumulated frequency of which (15 + 90 = 105) exceeds half the volume (162: 2 = 81) of the interval variation series. Now the numerical value of the median is determined by the above formula:

Thus, half of those convicted of theft are under 25 years old.
Fashion (Mo) name the value of the attribute, which is most often found in units of the population. Fashion is used to identify the value of the trait that has the greatest distribution. For a discrete series, the mode will be the variant with the highest frequency. For example, for a discrete series presented in Table 3 Mo= 1, since this value of the options corresponds to the highest frequency - 75. To determine the mode of the interval series, first determine modal interval (interval having the highest frequency). Then, within this interval, the value of the feature is found, which can be a mode.
Its value is found by the formula:
where x Mo is the lower limit of the modal interval; i is the value of the modal interval; f Mo is the frequency of the modal interval; f Mo-1 is the frequency of the interval preceding the modal; f Mo+1 is the frequency of the interval following the modal.
Example. Find the age mode of criminals convicted of theft, data on which are presented in table 13.
Solution. The highest frequency corresponds to the interval 18-28, therefore, the mode must be in this interval. Its value is determined by the above formula:
Thus, the largest number of criminals convicted of theft is 24 years old.
The average value gives a generalizing characteristic of the totality of the phenomenon under study. However, two populations with the same mean values may differ significantly from each other in terms of the degree of fluctuation (variation) in the value of the studied trait. For example, in one court the following terms of imprisonment were assigned: 3, 3, 3, 4, 5, 5, 5, 12, 12, 15 years, and in another - 5, 5, 6, 6, 7, 7, 7 , 8, 8, 8 years old. In both cases, the arithmetic mean is 6.7 years. However, these aggregates differ significantly from each other in the spread of individual values of the assigned term of imprisonment relative to the average value.
And for the first court, where this variation is quite large, the average term of imprisonment does not reflect the whole population well. Thus, if the individual values of the attribute differ little from each other, then the arithmetic mean will be a fairly indicative characteristic of the properties of this population. Otherwise, the arithmetic mean will be an unreliable characteristic of this population and its application in practice is ineffective. Therefore, it is necessary to take into account the variation in the values of the studied trait.
Variation- these are differences in the values of a trait in different units of a given population in the same period or point in time. The term "variation" is of Latin origin - variatio, which means difference, change, fluctuation. It arises as a result of the fact that the individual values of the attribute are formed under the combined influence of various factors (conditions), which are combined in different ways in each individual case. To measure the variation of a trait, various absolute and relative indicators are used.
The main indicators of variation include the following:
1) range of variation;
2) average linear deviation;
3) dispersion;
4) standard deviation;
5) coefficient of variation.
Let's briefly dwell on each of them.
Span variation R is the most accessible absolute indicator in terms of ease of calculation, which is defined as the difference between the largest and smallest values of the attribute for the units of this population:
![]()
The range of variation (range of fluctuations) is an important indicator of the variability of a feature, but it makes it possible to see only extreme deviations, which limits its scope. For a more accurate characterization of the variation of a trait based on its fluctuation, other indicators are used.
Average linear deviation represents the arithmetic mean of the absolute values of the deviations of the individual values of the trait from the mean and is determined by the formulas:
1) for ungrouped data
2) for variation series
![]()
However, the most widely used measure of variation is dispersion . It characterizes the measure of the spread of the values of the studied trait relative to its average value. The variance is defined as the average of the deviations squared.
simple variance for ungrouped data:
![]() .
.
Weighted variance for the variation series:
![]()
Comment. In practice, it is better to use the following formulas to calculate the variance:
For a simple variance
![]() .
.
For weighted variance
![]()
Standard deviation is the square root of the variance:
The standard deviation is a measure of the reliability of the mean. The smaller the standard deviation, the more homogeneous the population and the better the arithmetic mean reflects the entire population.
The dispersion measures considered above (range of variation, variance, standard deviation) are absolute indicators, by which it is not always possible to judge the degree of fluctuation of a trait. In some problems, it is necessary to use relative scattering indices, one of which is the coefficient of variation.
The coefficient of variation- expressed as a percentage of the ratio of the standard deviation to the arithmetic mean:
The coefficient of variation is used not only for a comparative assessment of the variation of different traits or the same trait in different populations, but also to characterize the homogeneity of the population. The statistical population is considered quantitatively homogeneous if the coefficient of variation does not exceed 33% (for distributions close to the normal distribution).
Example. There is the following data on the terms of imprisonment of 50 convicts delivered to serve the sentence imposed by the court in a correctional institution of the penitentiary system: 5, 4, 2, 1, 6, 3, 4, 3, 2, 2, 5, 6, 4, 3 , 10, 5, 4, 1, 2, 3, 3, 4, 1, 6, 5, 3, 4, 3, 5, 12, 4, 3, 2, 4, 6, 4, 4, 3, 1 , 5, 4, 3, 12, 6, 7, 3, 4, 5, 5, 3.
1. Construct a distribution series by terms of imprisonment.
2. Find the mean, variance and standard deviation.
3. Calculate the coefficient of variation and draw a conclusion about the homogeneity or heterogeneity of the studied population.
Solution. To construct a discrete distribution series, it is necessary to determine the variants and frequencies. The option in this problem is the term of imprisonment, and the frequency is the number of individual options. Having calculated the frequencies, we obtain the following discrete distribution series:
Find the mean and variance. Since the statistical data are represented by a discrete variational series, we will use the formulas of the arithmetic weighted average and variance to calculate them. We get:
= ![]() = 4,1;
= 4,1;
![]() =
= ![]() 5,21.
5,21.
Now we calculate the standard deviation:
![]()
We find the coefficient of variation:
![]()
Consequently, the statistical population is quantitatively heterogeneous.
simple arithmetic mean
Average values
Average values are widely used in statistics.
average value- this is a generalizing indicator in which the expression of the action of general conditions, patterns of development of the phenomenon under study is found.
Statistical averages are calculated on the basis of mass data of a correctly statistically organized observation (continuous and sample). However, the statistical average will be objective and typical if it is calculated from mass data for a qualitatively homogeneous population (mass phenomena). For example, if we calculate the average salary in joint-stock companies and state-owned enterprises, and extend the result to the entire population, then the average is fictitious, since it is calculated on a heterogeneous population, and such an average loses all meaning.
With the help of the average, there is, as it were, a smoothing of differences in the magnitude of the feature that arise for one reason or another in individual units of observation.
For example, the average output of an individual seller depends on many factors: qualifications, length of service, age, form of service, health, and so on. The average output reflects the general characteristics of the entire population.
The average value is measured in the same units as the feature itself.
Each average value characterizes the studied population according to any one attribute. In order to get a complete and comprehensive picture of the population under study in terms of a number of essential features, it is necessary to have a system of average values that can describe the phenomenon from different angles.
There are different types of averages:
arithmetic mean;
average harmonic;
geometric mean;
root mean square;
average cubic.
The averages of all the types listed above, in turn, are divided into simple (unweighted) and weighted.
Consider the types of averages that are used in statistics.
The simple arithmetic mean (unweighted) is equal to the sum of the individual values of the characteristic, divided by the number of these values.
Separate values of a feature are called variants and are denoted by х i (  ); the number of population units is denoted by n, the average value of the feature - by
); the number of population units is denoted by n, the average value of the feature - by  . Therefore, the simple arithmetic mean is:
. Therefore, the simple arithmetic mean is:
 or
or 
Example 1 Table 1
Data on the production of products A by workers per shift
In this example, the variable attribute is the release of products per shift.
The numerical values of the attribute (16, 17, etc.) are called variants. Let us determine the average output of products by the workers of this group:
 PCS.
PCS.
A simple arithmetic mean is used in cases where there are individual values of a characteristic, i.e. the data is not grouped. If the data is presented in the form of distribution series or groupings, then the average is calculated differently.
Arithmetic weighted average
The arithmetic weighted average is equal to the sum of the products of each individual value of the attribute (option) by the corresponding frequency, divided by the sum of all frequencies.
The number of identical feature values in the distribution series is called frequency or weight and is denoted by f i .
In accordance with this, the arithmetic weighted average looks like this:
 or
or 
It can be seen from the formula that the average depends not only on the values of the attribute, but also on their frequencies, i.e. on the composition of the population, on its structure.
Example 2 table 2
Worker wage data
According to the data of the discrete distribution series, it can be seen that the same values of the attribute (options) are repeated several times. So, variant x 1 occurs in the aggregate 2 times, and variant x 2 - 6 times, etc.
Calculate the average wage per worker:
The wage fund for each group of workers is equal to the product of options and frequency (  ), and the sum of these products gives the total wage fund of all workers (
), and the sum of these products gives the total wage fund of all workers (  ).
).
If the calculation were performed using the simple arithmetic average formula, the average earnings would be 3,000 rubles. (). Comparing the obtained result with the initial data, it is obvious that the average wage should be significantly higher (more than half of the workers receive wages above 3,000 rubles). Therefore, the calculation of the simple arithmetic mean in such cases will be erroneous.
Statistical material as a result of processing can be presented not only in the form of discrete distribution series, but also in the form of interval variation series with closed or open intervals.
Consider the calculation of the arithmetic mean for such series.
The average is:
MeanMean- numerical characteristic of a set of numbers or functions; - some number enclosed between the smallest and largest of their values.
|
Basic information
The starting point for the formation of the theory of averages was the study of proportions by the school of Pythagoras. At the same time, no strict distinction was made between the concepts of average and proportion. A significant impetus to the development of the theory of proportions from an arithmetic point of view was given by Greek mathematicians - Nicomachus of Geras (late I - early II century AD) and Pappus of Alexandria (III century AD). The first stage in the development of the concept of average is the stage when the average began to be considered the central member of a continuous proportion. But the concept of the mean as the central value of the progression does not make it possible to derive the concept of the mean with respect to a sequence of n terms, regardless of the order in which they follow each other. For this purpose it is necessary to resort to a formal generalization of averages. The next stage is the transition from continuous proportions to progressions - arithmetic, geometric and harmonic.
In the history of statistics, for the first time, the widespread use of averages is associated with the name of the English scientist W. Petty. W. Petty was one of the first who tried to give the average value a statistical meaning, linking it with economic categories. But Petty did not produce a description of the concept of the average value, its allocation. A. Quetelet is considered to be the founder of the theory of averages. He was one of the first to consistently develop the theory of averages, trying to bring a mathematical basis for it. A. Quetelet singled out two types of averages - actual averages and arithmetic averages. Properly averages represent a thing, a number, really existing. Actually averages or statistical averages should be derived from phenomena of the same quality, identical in their internal significance. Arithmetic averages are numbers that give the closest possible idea of many numbers, different, albeit homogeneous.
Each type of average can be either a simple average or a weighted average. The correctness of the choice of the average form follows from the material nature of the object of study. Simple average formulas are used if the individual values of the averaged feature do not repeat. When, in practical studies, individual values of the trait under study occur several times in units of the population under study, then the frequency of repetition of individual trait values is present in the calculation formulas of power averages. In this case, they are called weighted average formulas.
Wikimedia Foundation. 2010.
The average value is a generalizing indicator that characterizes the typical level of the phenomenon. It expresses the value of the attribute, related to the unit of the population.
The average value is:
1) the most typical value of the attribute for the population;
2) the volume of the sign of the population, distributed equally among the units of the population.
The characteristic for which the average value is calculated is called “averaged” in statistics.
The average always generalizes the quantitative variation of the trait, i.e. in average values, individual differences in the units of the population due to random circumstances are canceled out. In contrast to the average, the absolute value that characterizes the level of a feature of an individual unit of the population does not allow comparing the values of the feature for units belonging to different populations. So, if you need to compare the levels of remuneration of workers at two enterprises, then you cannot compare two employees of different enterprises on this basis. The wages of the workers selected for comparison may not be typical for these enterprises. If we compare the size of wage funds at the enterprises under consideration, then the number of employees is not taken into account and, therefore, it is impossible to determine where the level of wages is higher. Ultimately, only averages can be compared, i.e. How much does one worker earn on average in each company? Thus, there is a need to calculate the average value as a generalizing characteristic of the population.
It is important to note that in the process of averaging, the aggregate value of the attribute levels or its final value (in the case of calculating average levels in a time series) must remain unchanged. In other words, when calculating the average value, the volume of the trait under study should not be distorted, and the expressions made when calculating the average must necessarily make sense.
Calculating the average is one common generalization technique; the average indicator denies the general that is typical (typical) for all units of the studied population, at the same time it ignores the differences between individual units. In every phenomenon and its development there is a combination of chance and necessity. When calculating averages, due to the operation of the law of large numbers, randomness cancels each other out, balances out, therefore it is possible to abstract from the insignificant features of the phenomenon, from the quantitative values of the attribute in each specific case. In the ability to abstract from the randomness of individual values, fluctuations, lies the scientific value of averages as generalizing characteristics of aggregates.
In order for the average to be truly typifying, it must be calculated taking into account certain principles.
Let us dwell on some general principles for the application of averages.
1. The average should be determined for populations consisting of qualitatively homogeneous units.
2. The average should be calculated for a population consisting of a sufficiently large number of units.
3. The average should be calculated for the population, the units of which are in a normal, natural state.
4. The average should be calculated taking into account the economic content of the indicator under study.
5.2. Types of averages and methods for calculating them
Let us now consider the types of averages, the features of their calculation and areas of application. Average values are divided into two large classes: power averages, structural averages.
Power-law averages include the most well-known and commonly used types, such as geometric mean, arithmetic mean, and mean square.
The mode and median are considered as structural averages.
Let us dwell on power averages. Power averages, depending on the presentation of the initial data, can be simple and weighted. simple average is calculated from ungrouped data and has the following general form:
 ,
,
where X i is the variant (value) of the averaged feature;
n is the number of options.
Weighted average is calculated by grouped data and has a general form
 ,
,
where X i is the variant (value) of the averaged feature or the middle value of the interval in which the variant is measured;
m is the exponent of the mean;
f i - frequency showing how many times the i-e value of the averaged feature occurs.
If we calculate all types of averages for the same initial data, then their values will not be the same. Here the rule of majorance of averages applies: with an increase in the exponent m, the corresponding average value also increases:
In statistical practice, more often than other types of weighted averages, arithmetic and harmonic weighted averages are used.
Types of Power Means
|
Type of power |
Index |
Calculation formula |
|
|
Simple |
weighted |
||
|
harmonic |
|||
|
Geometric |
|
|
|
|
Arithmetic |
|||
|
quadratic |
|||
|
cubic |
|||


The harmonic mean has a more complex structure than the arithmetic mean. The harmonic mean is used for calculations when the weights are not the units of the population - the carriers of the trait, but the products of these units and the values of the trait (i.e. m = Xf). The average harmonic downtime should be used in cases of determining, for example, the average costs of labor, time, materials per unit of production, per part for two (three, four, etc.) enterprises, workers engaged in the manufacture of the same type of product , the same part, product.
The main requirement for the formula for calculating the average value is that all stages of the calculation have a real meaningful justification; the resulting average value should replace the individual values of the attribute for each object without breaking the connection between individual and summary indicators. In other words, the average value should be calculated in such a way that when each individual value of the averaged indicator is replaced by its average value, some final summary indicator, connected in one way or another with the averaged one, remains unchanged. This result is called determining since the nature of its relationship with individual values determines the specific formula for calculating the average value. Let's show this rule on the example of the geometric mean.
Geometric mean formula
most often used when calculating the average value of individual relative values of the dynamics.
The geometric mean is used if a sequence of chain relative values of dynamics is given, indicating, for example, an increase in production compared to the level of the previous year: i 1 , i 2 , i 3 ,…, i n . Obviously, the volume of production in the last year is determined by its initial level (q 0) and subsequent growth over the years:
q n =q 0 × i 1 × i 2 ×…×i n .
Taking q n as a defining indicator and replacing the individual values of the dynamics indicators with average ones, we arrive at the relation
From here
![]()
A special type of average values - structural averages - is used to study the internal structure of the series of distribution of attribute values, as well as to estimate the average value (power type), if, according to the available statistical data, its calculation cannot be performed (for example, if there were no data in the considered example). and on the volume of production, and on the amount of costs by groups of enterprises).
Indicators are most often used as structural averages. fashion - the most frequently repeated feature value - and median - the value of a feature that divides the ordered sequence of its values into two parts equal in number. As a result, in one half of the population units, the value of the attribute does not exceed the median level, and in the other half it is not less than it.
If the feature under study has discrete values, then there are no particular difficulties in calculating the mode and median. If the data on the values of the attribute X are presented in the form of ordered intervals of its change (interval series), the calculation of the mode and median becomes somewhat more complicated. Since the median value divides the entire population into two parts equal in number, it ends up in one of the intervals of the feature X. Using interpolation, the median value is found in this median interval:
 ,
,
where X Me is the lower limit of the median interval;
h Me is its value;
(Sum m) / 2 - half of the total number of observations or half of the volume of the indicator that is used as a weighting in the formulas for calculating the average value (in absolute or relative terms);
S Me-1 is the sum of observations (or the volume of the weighting feature) accumulated before the start of the median interval;
m Me is the number of observations or the volume of the weighting feature in the median interval (also in absolute or relative terms).
When calculating the modal value of a feature according to the data of the interval series, it is necessary to pay attention to the fact that the intervals are the same, since the indicator of the frequency of feature values X depends on this. For an interval series with equal intervals, the mode value is determined as
,
where X Mo is the lower value of the modal interval;
m Mo is the number of observations or the volume of the weighting feature in the modal interval (in absolute or relative terms);
m Mo-1 - the same for the interval preceding the modal;
m Mo+1 - the same for the interval following the modal;
h is the value of the interval of change of the trait in groups.
TASK 1
The following data are available for the group of industrial enterprises for the reporting year
|
№ enterprises |
Production volume, million rubles |
Average number of employees, pers. |
Profit, thousand rubles |
|
|
197,7 |
10,0 |
13,5 |
||
|
22,8 |
1500 |
136,2 |
||
|
465,5 |
18,4 |
1412 |
97,6 |
|
|
296,2 |
12,6 |
1200 |
44,4 |
|
|
584,1 |
22,0 |
1485 |
146,0 |
|
|
480,0 |
119,0 |
1420 |
110,4 |
|
|
57805 |
21,6 |
1390 |
138,7 |
|
|
204,7 |
30,6 |
|||
|
466,8 |
19,4 |
1375 |
111,8 |
|
|
292,2 |
113,6 |
1200 |
49,6 |
|
|
423,1 |
17,6 |
1365 |
105,8 |
|
|
192,6 |
30,7 |
|||
|
360,5 |
14,0 |
1290 |
64,8 |
|
|
280,3 |
10,2 |
33,3 |
It is required to perform a grouping of enterprises for the exchange of products, taking the following intervals:
from 400 to 600 million rubles
For each group and for all together, determine the number of enterprises, the volume of production, the average number of employees, the average output per employee. The grouping results should be presented in the form of a statistical table. Formulate a conclusion.
SOLUTION
Let's make a grouping of enterprises for the exchange of products, the calculation of the number of enterprises, the volume of production, the average number of employees according to the formula of a simple average. The results of grouping and calculations are summarized in a table.
Groups by production volume
№
enterprises
Production volume, million rubles
Average annual cost of fixed assets, million rubles
average sleep
juicy number of employees, pers.
Profit, thousand rubles
Average output per worker
1 group
up to 200 million rubles
1,8,12
197,7
204,7
192,6
10,0
9,4
8,8
900
817
13,5
30,6
30,7
28,2
2567
74,8
0,23
Average level
198,3
24,9
2 group
from 200 to 400 million rubles
4,10,13,14
196,2
292,2
360,5
280,3
12,6
113,6
14,0
10,2
1200
1200
1290
44,4
49,6
64,8
33,3
1129,2
150,4
4590
192,1
0,25
Average level
282,3
37,6
1530
64,0
3 group
from 400 to
600 million
2,3,5,6,7,9,11
592
465,5
584,1
480,0
578,5
466,8
423,1
22,8
18,4
22,0
119,0
21,6
19,4
17,6
1500
1412
1485
1420
1390
1375
1365
136,2
97,6
146,0
110,4
138,7
111,8
105,8
3590
240,8
9974
846,5
0,36
Average level
512,9
34,4
1421
120,9
Total in aggregate
5314,2
419,4
17131
1113,4
0,31
Aggregate average
379,6
59,9
1223,6
79,5
Conclusion. Thus, in the aggregate under consideration, the largest number of enterprises in terms of output fell into the third group - seven, or half of the enterprises. The value of the average annual value of fixed assets is also in this group, as well as the large value of the average number of employees - 9974 people, the enterprises of the first group are the least profitable.
TASK 2
We have the following data on the enterprises of the company
Number of the enterprise belonging to the company
I quarter
II quarter
Output, thousand rubles
Worked by working man-days
Average output per worker per day, rub.
59390,13
up to 200 million rubles
from 200 to 400 million rubles
Most of all in eq. In practice, one has to use the arithmetic mean, which can be calculated as the simple and weighted arithmetic mean.
Arithmetic mean (CA)-n the most common type of medium. It is used in cases where the volume of a variable attribute for the entire population is the sum of the values of the attributes of its individual units. Social phenomena are characterized by the additivity (summation) of the volumes of the varying attribute, this determines the scope of the SA and explains its prevalence as a generalizing indicator, for example: the general salary fund is the sum of the salary of all employees.
To calculate SA, you need to divide the sum of all feature values by their number. SA is used in 2 forms.
Consider first the simple arithmetic mean.
1-CA simple (initial, defining form) is equal to the simple sum of the individual values of the averaged feature, divided by the total number of these values (used when there are ungrouped index values of the feature):
The calculations made can be summarized in the following formula:
 (1)
(1)
where  - the average value of the variable attribute, i.e., the simple arithmetic mean;
- the average value of the variable attribute, i.e., the simple arithmetic mean;
 means summation, i.e., the addition of individual features;
means summation, i.e., the addition of individual features;
x- individual values of a variable attribute, which are called variants;
n - number of population units
Example1, it is required to find the average output of one worker (locksmith), if it is known how many parts each of the 15 workers produced, i.e. given a number of ind. trait values, pcs.: 21; twenty; twenty; 19; 21; 19; eighteen; 22; 19; twenty; 21; twenty; eighteen; 19; twenty.
SA simple is calculated by the formula (1), pcs.:
Example2. Let us calculate SA based on conditional data for 20 stores that are part of a trading company (Table 1). Table 1
Distribution of shops of the trading company "Vesna" by trading area, sq. M
|
store number |
store number | ||
To calculate the average store area (  ) it is necessary to add up the areas of all stores and divide the result by the number of stores:
) it is necessary to add up the areas of all stores and divide the result by the number of stores:

Thus, the average store area for this group of trade enterprises is 71 sq.m.
Therefore, in order to determine the SA is simple, it is necessary to divide the sum of all values of a given attribute by the number of units that have this attribute.
2
where f 1
,
f 2
,
… ,f n
–
weight (frequency of repetition of the same features); is the sum of the products of the magnitude of features and their frequencies; is the total number of population units.![]() (2)
(2)
Where X- options;
f- frequency (weight).
SA weighted is the quotient of dividing the sum of the products of the variants and their corresponding frequencies by the sum of all frequencies. Frequencies ( f) appearing in the SA formula are usually called scales, as a result of which the SA calculated taking into account the weights is called the weighted SA.
We will illustrate the technique for calculating weighted SA using the example 1 considered above. To do this, we group the initial data and place them in Table.
The average of the grouped data is determined as follows: first, the variants are multiplied by the frequencies, then the products are added and the resulting sum is divided by the sum of the frequencies.
According to formula (2), the weighted SA is, pcs.: ![]()

P

Distribution of Vesna stores by retail space, sq. m
Thus, the result is the same. However, this will already be the arithmetic weighted average.
In the previous example, we computed the arithmetic average, provided that the absolute frequencies (number of stores) are known. However, in some cases there are no absolute frequencies, but relative frequencies are known, or, as they are commonly called, frequencies that show the proportion or the proportion of frequencies in the entire population.
When calculating SA weighted use frequencies allows you to simplify calculations when the frequency is expressed in large, multi-digit numbers. The calculation is made in the same way, however, since the average value is increased by 100 times, the result should be divided by 100.
Then the formula for the arithmetic weighted average will look like:
where d– frequency, i.e. the share of each frequency in the total sum of all frequencies.
(3)In our example 2, we first determine the share of stores by groups in the total number of stores of the company "Spring". So, for the first group, the specific gravity corresponds to 10%  . We get the following data Table3
. We get the following data Table3
Signs of units of statistical aggregates are different in their meaning, for example, the wages of workers of one profession of an enterprise are not the same for the same period of time, market prices for the same products are different, crop yields in the farms of the region, etc. Therefore, in order to determine the value of a feature characteristic of the entire population of units under study, average values are calculated.
average value –
it is a generalizing characteristic of the set of individual values of some quantitative trait.
The population studied by a quantitative attribute consists of individual values; they are influenced by both general causes and individual conditions. In the average value, the deviations characteristic of the individual values are canceled out. The average, being a function of a set of individual values, represents the entire set with one value and reflects the common thing that is inherent in all its units.
The average calculated for populations consisting of qualitatively homogeneous units is called typical average. For example, you can calculate the average monthly salary of an employee of one or another professional group (miner, doctor, librarian). Of course, the levels of monthly wages of miners, due to the difference in their qualifications, length of service, hours worked per month and many other factors, differ from each other, and from the level of average wages. However, the average level reflects the main factors that affect the level of wages, and mutually offset the differences that arise due to the individual characteristics of the employee. The average wage reflects the typical level of wages for this type of worker. Obtaining a typical average should be preceded by an analysis of how this population is qualitatively homogeneous. If the population consists of separate parts, it should be divided into typical groups (average temperature in the hospital).
Average values used as characteristics for heterogeneous populations are called system averages. For example, the average value of the gross domestic product (GDP) per capita, the average consumption of various groups of goods per person and other similar values representing the general characteristics of the state as a single economic system.
The average should be calculated for populations consisting of a sufficiently large number of units. Compliance with this condition is necessary in order for the law of large numbers to come into force, as a result of which random deviations of individual values from the general trend cancel each other out.
Types of averages and methods for calculating them
The choice of the type of average is determined by the economic content of a certain indicator and the initial data. However, any average value should be calculated so that when it replaces each variant of the averaged feature, the final, generalizing, or, as it is commonly called, defining indicator, which is related to the average. For example, when replacing the actual speeds on separate sections of the path, their average speed should not change the total distance traveled by the vehicle in the same time; when replacing the actual wages of individual employees of the enterprise with the average wage, the wage fund should not change. Consequently, in each specific case, depending on the nature of the available data, there is only one true average value of the indicator that is adequate to the properties and essence of the socio-economic phenomenon under study.
The most commonly used are the arithmetic mean, harmonic mean, geometric mean, mean square, and mean cubic.
The listed averages belong to the class power average and are combined by the general formula:
,
where is the average value of the studied trait;
m is the exponent of the mean;
– current value (variant) of the averaged feature;
n is the number of features.
Depending on the value of the exponent m, the following types of power averages are distinguished:
at m = -1 – mean harmonic ;
at m = 0 – geometric mean ;
at m = 1 – arithmetic mean;
at m = 2 – root mean square ;
at m = 3 - average cubic.
When using the same initial data, the larger the exponent m in the above formula, the larger the value of the average value:
.
This property of power-law means to increase with an increase in the exponent of the defining function is called the rule of majorance of means.
Each of the marked averages can take two forms: simple and weighted.
The simple form of the middle applies when the average is calculated on primary (ungrouped) data. weighted form– when calculating the average for secondary (grouped) data.
Arithmetic mean
The arithmetic mean is used when the volume of the population is the sum of all individual values of the varying attribute. It should be noted that if the type of average is not indicated, the arithmetic average is assumed. Its logical formula is: ![]()
simple arithmetic mean calculated by ungrouped data
according to the formula: ![]() or ,
or ,
where are the individual values of the feature;
j is the serial number of the unit of observation, which is characterized by the value ;
N is the number of observation units (set size).
Example. In the lecture “Summary and grouping of statistical data”, the results of observing the work experience of a team of 10 people were considered. Calculate the average work experience of the workers of the brigade. 5, 3, 5, 4, 3, 4, 5, 4, 2, 4.
According to the formula of the arithmetic mean simple, one also calculates chronological averages, if the time intervals for which the characteristic values are presented are equal.
Example. The volume of products sold for the first quarter amounted to 47 den. units, for the second 54, for the third 65 and for the fourth 58 den. units The average quarterly turnover is (47+54+65+58)/4 = 56 den. units
If momentary indicators are given in the chronological series, then when calculating the average, they are replaced by half-sums of values at the beginning and end of the period.
If there are more than two moments and the intervals between them are equal, then the average is calculated using the formula for the average chronological
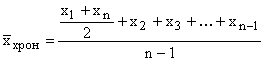 ,
,
where n is the number of time points
When the data is grouped by attribute values
(i.e., a discrete variational distribution series is constructed) with weighted arithmetic mean is calculated using either frequencies , or frequencies of observation of specific values of the feature , the number of which (k) is significantly less than the number of observations (N) .
,
,
where k is the number of groups of the variation series,
i is the number of the group of the variation series.
Since , and , we obtain the formulas used for practical calculations:
and
Example. Let's calculate the average length of service of the working teams for the grouped series.
a) using frequencies:
b) using frequencies:
When the data is grouped by intervals
, i.e. are presented in the form of interval distribution series; when calculating the arithmetic mean, the middle of the interval is taken as the value of the feature, based on the assumption of a uniform distribution of population units in this interval. The calculation is carried out according to the formulas:
and
where is the middle of the interval: ,
where and are the lower and upper boundaries of the intervals (provided that the upper boundary of this interval coincides with the lower boundary of the next interval).
Example. Let us calculate the arithmetic mean of the interval variation series constructed from the results of a study of the annual wages of 30 workers (see the lecture "Summary and grouping of statistical data").
Table 1 - Interval variation series of distribution.
Intervals, UAH |
Frequency, pers. |
frequency, |
The middle of the interval |
||
600-700 |
3 |
0,10 |
(600+700):2=650 |
1950 |
65 |
![]() UAH or
UAH or ![]() UAH
UAH
The arithmetic means calculated on the basis of the initial data and interval variation series may not coincide due to the uneven distribution of the attribute values within the intervals. In this case, for a more accurate calculation of the arithmetic weighted average, one should use not the middle of the intervals, but the arithmetic simple averages calculated for each group ( group averages). The average calculated from group means using a weighted calculation formula is called general average.
The arithmetic mean has a number of properties.
1. The sum of deviations of the variant from the mean is zero:
.
2. If all values of the option increase or decrease by the value A, then the average value increases or decreases by the same value A: ![]()
3. If each option is increased or decreased by B times, then the average value will also increase or decrease by the same number of times:
or ![]()
4. The sum of the products of the variant by the frequencies is equal to the product of the average value by the sum of the frequencies: ![]()
5. If all frequencies are divided or multiplied by any number, then the arithmetic mean will not change: 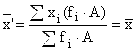
6) if in all intervals the frequencies are equal to each other, then the arithmetic weighted average is equal to the simple arithmetic average: ![]() ,
,
where k is the number of groups in the variation series.
Using the properties of the average allows you to simplify its calculation.
Suppose that all options (x) are first reduced by the same number A, and then reduced by a factor of B. The greatest simplification is achieved when the value of the middle of the interval with the highest frequency is chosen as A, and the value of the interval as B (for rows with equal intervals). The quantity A is called the origin, so this method of calculating the average is called way b ohm reference from conditional zero or way of moments.
After such a transformation, we obtain a new variational distribution series, the variants of which are equal to . Their arithmetic mean, called moment of the first order, is expressed by the formula and according to the second and third properties, the arithmetic mean is equal to the mean of the original version, reduced first by A, and then by B times, i.e. .
For getting real average(middle of the original row) you need to multiply the moment of the first order by B and add A: 
The calculation of the arithmetic mean by the method of moments is illustrated by the data in Table. 2.
Table 2 - Distribution of employees of the enterprise shop by length of service
Work experience, years |
Amount of workers |
Interval midpoint |
|||
0 – 5 |
12 |
2,5 |
15 |
3 |
36 |
Finding the moment of the first order ![]() . Then, knowing that A = 17.5, and B = 5, we calculate the average work experience of the shop workers:
. Then, knowing that A = 17.5, and B = 5, we calculate the average work experience of the shop workers:
years
Average harmonic
As shown above, the arithmetic mean is used to calculate the average value of a feature in cases where its variants x and their frequencies f are known.
If the statistical information does not contain frequencies f for individual options x of the population, but is presented as their product , the formula is applied average harmonic weighted. To calculate the average, denote , whence . Substituting these expressions into the weighted arithmetic mean formula, we obtain the weighted harmonic mean formula:  ,
,
where is the volume (weight) of the indicator attribute values in the interval with number i (i=1,2, …, k).
Thus, the harmonic mean is used in cases where it is not the options themselves that are subject to summation, but their reciprocals: ![]() .
.
In cases where the weight of each option is equal to one, i.e. individual values of the inverse feature occur once, apply simple harmonic mean: ,
,
where are individual variants of the inverse trait that occur once;
N is the number of options.
If there are harmonic averages for two parts of the population with a number of and, then the total average for the entire population is calculated by the formula: 
and called weighted harmonic mean of the group means.
Example. Three deals were made during the first hour of trading on the currency exchange. Data on the amount of hryvnia sales and the hryvnia exchange rate against the US dollar are given in Table. 3 (columns 2 and 3). Determine the average exchange rate of the hryvnia against the US dollar for the first hour of trading.
Table 3 - Data on the course of trading on the currency exchange
The average dollar exchange rate is determined by the ratio of the amount of hryvnias sold in the course of all transactions to the amount of dollars acquired as a result of the same transactions. The total amount of the hryvnia sale is known from column 2 of the table, and the amount of dollars purchased in each transaction is determined by dividing the hryvnia sale amount by its exchange rate (column 4). A total of $22 million was purchased during three transactions. This means that the average hryvnia exchange rate for one dollar was 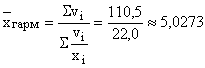 .
.
The resulting value is real, because his substitution of the actual hryvnia exchange rates in transactions will not change the total amount of sales of the hryvnia, which acts as defining indicator: mln. UAH
If the arithmetic mean was used for the calculation, i.e. ![]() hryvnia, then at the exchange rate for the purchase of 22 million dollars. UAH 110.66 million would have to be spent, which is not true.
hryvnia, then at the exchange rate for the purchase of 22 million dollars. UAH 110.66 million would have to be spent, which is not true.
Geometric mean
The geometric mean is used to analyze the dynamics of phenomena and allows you to determine the average growth rate. When calculating the geometric mean, the individual values of the trait are relative indicators of dynamics, built in the form of chain values, as the ratio of each level to the previous one.
The geometric simple mean is calculated by the formula: 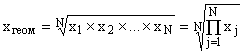 ,
,
where is the sign of the product,
N is the number of averaged values.
Example. The number of registered crimes over 4 years increased by 1.57 times, including for the 1st - by 1.08 times, for the 2nd - by 1.1 times, for the 3rd - by 1.18 and for the 4th - 1.12 times. Then the average annual growth rate of the number of crimes is: , i.e. The number of registered crimes has grown by an average of 12% annually.
1,8
-0,8
0,2
1,0
1,4
1
3
4
1
1
3,24
0,64
0,04
1
1,96
3,24
1,92
0,16
1
1,96
To calculate the mean square weighted, we determine and enter in the table and. Then the average value of deviations of the length of products from a given norm is equal to: 
The arithmetic mean in this case would be unsuitable, because as a result, we would get zero deviation.
The use of the root mean square will be discussed later in the exponents of variation.
In the process of studying mathematics, students get acquainted with the concept of the arithmetic mean. In the future, in statistics and some other sciences, students are faced with the calculation of others. What can they be and how do they differ from each other?
meaning and difference
Not always accurate indicators give an understanding of the situation. In order to assess this or that situation, it is sometimes necessary to analyze a huge number of figures. And then averages come to the rescue. They allow you to assess the situation in general.
Since school days, many adults remember the existence of the arithmetic mean. It is very easy to calculate - the sum of a sequence of n terms is divisible by n. That is, if you need to calculate the arithmetic mean in the sequence of values 27, 22, 34 and 37, then you need to solve the expression (27 + 22 + 34 + 37) / 4, since 4 values \u200b\u200bare used in the calculations. In this case, the desired value will be equal to 30.
Often, as part of the school course, the geometric mean is also studied. The calculation of this value is based on extracting the root of the nth degree from the product of n terms. If we take the same numbers: 27, 22, 34 and 37, then the result of the calculations will be 29.4.
The harmonic mean in a general education school is usually not the subject of study. However, it is used quite often. This value is the reciprocal of the arithmetic mean and is calculated as a quotient of n - the number of values and the sum 1/a 1 +1/a 2 +...+1/a n . If we again take the same for calculation, then the harmonic will be 29.6.

Weighted Average: Features
However, all of the above values may not be used everywhere. For example, in statistics, when calculating some, the "weight" of each number used in calculations plays an important role. The results are more revealing and correct because they take into account more information. This group of values is collectively referred to as the "weighted average". They are not passed at school, so it is worth dwelling on them in more detail.
First of all, it is worth explaining what is meant by the "weight" of a particular value. The easiest way to explain this is with a concrete example. The body temperature of each patient is measured twice a day in the hospital. Of the 100 patients in different departments of the hospital, 44 will have a normal temperature - 36.6 degrees. Another 30 will have an increased value - 37.2, 14 - 38, 7 - 38.5, 3 - 39, and the remaining two - 40. And if we take the arithmetic mean, then this value in general for the hospital will be over 38 degrees! But almost half of the patients have absolutely And here it would be more correct to use the weighted average, and the "weight" of each value will be the number of people. In this case, the result of the calculation will be 37.25 degrees. The difference is obvious.
In the case of weighted average calculations, the "weight" can be taken as the number of shipments, the number of people working on a given day, in general, anything that can be measured and affect the final result.

Varieties
The weighted average corresponds to the arithmetic average discussed at the beginning of the article. However, the first value, as already mentioned, also takes into account the weight of each number used in the calculations. In addition, there are also weighted geometric and harmonic values.
There is another interesting variety used in series of numbers. This is a weighted moving average. It is on its basis that trends are calculated. In addition to the values themselves and their weight, periodicity is also used there. And when calculating the average value at some point in time, values for previous time periods are also taken into account.
Calculating all these values is not that difficult, but in practice, only the usual weighted average is usually used.
Calculation methods
In the age of computerization, there is no need to manually calculate the weighted average. However, it would be useful to know the calculation formula so that you can check and, if necessary, correct the results obtained.
It will be easiest to consider the calculation on a specific example.
It is necessary to find out what is the average wage at this enterprise, taking into account the number of workers receiving a particular salary.
So, the calculation of the weighted average is carried out using the following formula:
x = (a 1 *w 1 +a 2 *w 2 +...+a n *w n)/(w 1 +w 2 +...+w n)
For example, the calculation would be:
x = (32*20+33*35+34*14+40*6)/(20+35+14+6) = (640+1155+476+240)/75 = 33.48
Obviously, there is no particular difficulty in manually calculating the weighted average. The formula for calculating this value in one of the most popular applications with formulas - Excel - looks like the SUMPRODUCT (series of numbers; series of weights) / SUM (series of weights) function.
