सामाजिक-आर्थिक अनुसंधान में उपयोग किए जाने वाले सांख्यिकीय संकेतकों का सबसे सामान्य रूप औसत मूल्य है, जो एक सांख्यिकीय आबादी के संकेत की सामान्यीकृत मात्रात्मक विशेषता है। औसत मूल्य हैं, जैसा कि वे थे, टिप्पणियों की पूरी श्रृंखला के "प्रतिनिधि"। कई मामलों में, औसत औसत (आईएसएस) के प्रारंभिक अनुपात या इसके तार्किक सूत्र के माध्यम से निर्धारित किया जा सकता है:। इसलिए, उदाहरण के लिए, किसी उद्यम के कर्मचारियों के औसत वेतन की गणना करने के लिए, कुल वेतन निधि को कर्मचारियों की संख्या से विभाजित करना आवश्यक है: औसत के प्रारंभिक अनुपात का अंश इसका परिभाषित संकेतक है। औसत वेतन के लिए, ऐसा निर्धारण संकेतक मजदूरी निधि है। सामाजिक-आर्थिक विश्लेषण में उपयोग किए जाने वाले प्रत्येक संकेतक के लिए, औसत की गणना के लिए केवल एक सही संदर्भ अनुपात संकलित किया जा सकता है। यह भी जोड़ा जाना चाहिए कि छोटे नमूनों (30 से कम तत्वों की संख्या के साथ) के लिए मानक विचलन का अधिक सटीक अनुमान लगाने के लिए, रूट के तहत अभिव्यक्ति के हर का उपयोग नहीं करना चाहिए एन, ए एन- 1.
औसत की अवधारणा और प्रकार
औसत मूल्य- यह सांख्यिकीय जनसंख्या का एक सामान्यीकरण संकेतक है, जो सांख्यिकीय मात्राओं के मूल्यों में व्यक्तिगत अंतर को समाप्त करता है, जिससे आप एक दूसरे के साथ विभिन्न आबादी की तुलना कर सकते हैं। अस्तित्व 2 वर्गऔसत मूल्य: शक्ति और संरचनात्मक। संरचनात्मक औसत हैं पहनावा और मंझला , लेकिन सबसे अधिक इस्तेमाल किया जाने वाला बिजली औसतविभिन्न प्रकार के।बिजली औसत
शक्ति औसत हो सकता है सरलऔर भारित.
एक साधारण औसत की गणना तब की जाती है जब दो या दो से अधिक अवर्गीकृत सांख्यिकीय मान होते हैं, जो औसत शक्ति कानून के निम्नलिखित सामान्य सूत्र (k (m) के विभिन्न मूल्यों के लिए) के अनुसार एक मनमाना क्रम में व्यवस्थित होते हैं:
भारित औसत की गणना निम्न सामान्य सूत्र का उपयोग करके समूहीकृत आँकड़ों से की जाती है:

जहां x - अध्ययन के तहत घटना का औसत मूल्य; x i - औसत फीचर का i-th संस्करण;
f i, i-वें विकल्प का भार है।

जहां एक्स व्यक्तिगत सांख्यिकीय मूल्यों के मूल्य या समूह अंतराल के मध्य बिंदु हैं;
मी - घातांक, जिसके मूल्य पर निम्न प्रकार की शक्ति औसत निर्भर करती है:
एम = -1 हार्मोनिक माध्य पर;
एम = 0 के लिए, ज्यामितीय माध्य;
एम = 1 के लिए, समांतर माध्य;
m = 2 पर, मूल माध्य वर्ग;
एम = 3 पर, औसत घन।
विभिन्न घातांक m के साथ सरल और भारित औसत के लिए सामान्य सूत्रों का उपयोग करके, हम प्रत्येक प्रकार के विशेष सूत्र प्राप्त करते हैं, जिनकी चर्चा नीचे विस्तार से की जाएगी।
अंकगणित औसत
अंकगणित माध्य - पहले क्रम का प्रारंभिक क्षण, बड़ी संख्या में परीक्षणों के साथ एक यादृच्छिक चर के मूल्यों की गणितीय अपेक्षा;
अंकगणितीय माध्य सबसे अधिक उपयोग किया जाने वाला औसत मान है, जो सामान्य सूत्र में m = 1 को प्रतिस्थापित करके प्राप्त किया जाता है। अंकगणित औसत सरलनिम्नलिखित रूप है:
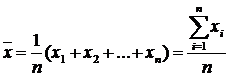 या
या ![]()
जहां एक्स उन मात्राओं के मूल्य हैं जिनके लिए औसत मूल्य की गणना करना आवश्यक है; N, X मानों की कुल संख्या है (अध्ययन की गई जनसंख्या में इकाइयों की संख्या)।
उदाहरण के लिए, एक छात्र ने 4 परीक्षा उत्तीर्ण की और निम्नलिखित ग्रेड प्राप्त किए: 3, 4, 4 और 5। आइए साधारण अंकगणितीय माध्य सूत्र का उपयोग करके औसत स्कोर की गणना करें: (3+4+4+5)/4 = 16/4 = 4.अंकगणित औसत भारितनिम्नलिखित रूप है:
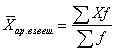
जहाँ f समान X मान (आवृत्ति) वाले मानों की संख्या है। > उदाहरण के लिए, एक छात्र ने 4 परीक्षा उत्तीर्ण की और निम्नलिखित ग्रेड प्राप्त किए: 3, 4, 4 और 5। अंकगणितीय भारित औसत सूत्र का उपयोग करके औसत स्कोर की गणना करें: (3 * 1 + 4 * 2 + 5 * 1) / 4 = 16/4 = 4।यदि एक्स मान अंतराल के रूप में दिए गए हैं, तो एक्स अंतराल के मध्य बिंदु गणना के लिए उपयोग किए जाते हैं, जिन्हें अंतराल की ऊपरी और निचली सीमाओं के आधे योग के रूप में परिभाषित किया जाता है। और यदि अंतराल X में निचली या ऊपरी सीमा (खुला अंतराल) नहीं है, तो इसे खोजने के लिए, आसन्न अंतराल X की सीमा (ऊपरी और निचली सीमाओं के बीच का अंतर) का उपयोग किया जाता है। उदाहरण के लिए, उद्यम में 3 साल तक के कार्य अनुभव वाले 10 कर्मचारी हैं, 20 - 3 से 5 साल के कार्य अनुभव के साथ, 5 कर्मचारी - 5 साल से अधिक के कार्य अनुभव के साथ। फिर हम अंकगणितीय भारित औसत सूत्र का उपयोग करके कर्मचारियों की सेवा की औसत लंबाई की गणना करते हैं, जो कि सेवा अंतराल (2, 4 और 6 वर्ष) की लंबाई के बीच में X के रूप में लेते हैं: (2*10+4*20+6*5)/(10+20+5) = 3.71 वर्ष।
औसत समारोह
यह फ़ंक्शन अपने तर्कों के औसत (अंकगणित) की गणना करता है।
औसत(नंबर1, नंबर2,...)
संख्या 1, संख्या 2, ... 1 से 30 तर्क हैं जिनके लिए औसत की गणना की जाती है।
तर्क संख्या या नाम, सरणियाँ या संख्या वाले संदर्भ होने चाहिए। यदि तर्क, जो एक सरणी या लिंक है, में टेक्स्ट, बूलियन या खाली सेल हैं, तो उन मानों को अनदेखा कर दिया जाता है; हालांकि, शून्य मान वाले कक्षों की गणना की जाती है।
औसत समारोह
तर्क सूची में दिए गए मानों के अंकगणितीय माध्य की गणना करता है। संख्याओं के अतिरिक्त, पाठ और तार्किक मान, जैसे TRUE और FALSE, गणना में भाग ले सकते हैं।
औसत (मान 1, मान 2,...)
Value1, value2,... 1 से 30 सेल, सेल रेंज या वे मान हैं जिनके लिए औसत की गणना की जाती है।
तर्क संख्या, नाम, सरणियाँ या संदर्भ होने चाहिए। टेक्स्ट वाले ऐरे और लिंक की व्याख्या 0 (शून्य) के रूप में की जाती है। खाली टेक्स्ट ("") की व्याख्या 0 (शून्य) के रूप में की जाती है। TRUE मान वाले तर्कों की व्याख्या 1 के रूप में की जाती है, FALSE मान वाले तर्कों की व्याख्या 0 (शून्य) के रूप में की जाती है।
अंकगणित माध्य का सबसे अधिक बार उपयोग किया जाता है, लेकिन ऐसे समय होते हैं जब अन्य प्रकार के औसत की आवश्यकता होती है। आइए आगे ऐसे मामलों पर विचार करें।
औसत हार्मोनिक
पारस्परिक का औसत योग निर्धारित करने के लिए हार्मोनिक माध्य;
औसत हार्मोनिकइसका उपयोग तब किया जाता है जब मूल डेटा में X के अलग-अलग मानों के लिए फ़्रीक्वेंसी f नहीं होती है, लेकिन उन्हें उनके उत्पाद Xf के रूप में प्रस्तुत किया जाता है। Xf=w को निरूपित करते हुए, हम f=w/X व्यक्त करते हैं, और इन पदनामों को भारित अंकगणितीय माध्य सूत्र में प्रतिस्थापित करते हुए, हम भारित हार्मोनिक माध्य सूत्र प्राप्त करते हैं:
इस प्रकार, हार्मोनिक भारित औसत का उपयोग तब किया जाता है जब आवृत्तियाँ f अज्ञात होती हैं, लेकिन w=Xf ज्ञात होता है। ऐसे मामलों में जहां सभी w=1, अर्थात्, X के व्यक्तिगत मान 1 बार आते हैं, हार्मोनिक सरल माध्य सूत्र लागू किया जाता है:  या
या  उदाहरण के लिए, एक कार बिंदु A से बिंदु B तक 90 किमी/घंटा की गति से और वापस 110 किमी/घंटा की गति से यात्रा कर रही थी। औसत गति निर्धारित करने के लिए, हम हार्मोनिक सरल सूत्र लागू करते हैं, क्योंकि उदाहरण दूरी w 1 \u003d w 2 देता है (बिंदु A से बिंदु B की दूरी B से A के समान है), जो उत्पाद के बराबर है गति (एक्स) और समय (एफ)। औसत गति = (1+1)/(1/90+1/110) = 99 किमी/घंटा।
उदाहरण के लिए, एक कार बिंदु A से बिंदु B तक 90 किमी/घंटा की गति से और वापस 110 किमी/घंटा की गति से यात्रा कर रही थी। औसत गति निर्धारित करने के लिए, हम हार्मोनिक सरल सूत्र लागू करते हैं, क्योंकि उदाहरण दूरी w 1 \u003d w 2 देता है (बिंदु A से बिंदु B की दूरी B से A के समान है), जो उत्पाद के बराबर है गति (एक्स) और समय (एफ)। औसत गति = (1+1)/(1/90+1/110) = 99 किमी/घंटा।
श्रम समारोह
डेटा सेट का हार्मोनिक माध्य लौटाता है। हार्मोनिक माध्य व्युत्क्रम के अंकगणितीय माध्य का व्युत्क्रम है।
एसजीएआरएम (नंबर 1, नंबर 2, ...)
संख्या 1, संख्या 2, ... 1 से 30 तर्क हैं जिनके लिए औसत की गणना की जाती है। आप अर्धविराम से अलग किए गए तर्कों के बजाय किसी सरणी या सरणी संदर्भ का उपयोग कर सकते हैं।
हार्मोनिक माध्य हमेशा ज्यामितीय माध्य से कम होता है, जो हमेशा अंकगणित माध्य से कम होता है।
जियोमेट्रिक माध्य
यादृच्छिक चर की औसत वृद्धि दर का अनुमान लगाने के लिए ज्यामितीय माध्य, न्यूनतम और अधिकतम मानों से समान दूरी पर एक विशेषता का मान ज्ञात करना;
जियोमेट्रिक माध्यऔसत सापेक्ष परिवर्तनों को निर्धारित करने में उपयोग किया जाता है। ज्यामितीय माध्य मान सबसे सटीक औसत परिणाम देता है यदि कार्य X का ऐसा मान ज्ञात करना है, जो X के अधिकतम और न्यूनतम दोनों मानों से समान दूरी पर होगा। उदाहरण के लिए, 2005 और 2008 के बीचमुद्रास्फीति सूचकांक रूस में था: 2005 में - 1.109; 2006 में - 1,090; 2007 में - 1,119; 2008 में - 1,133। चूंकि मुद्रास्फीति सूचकांक एक सापेक्ष परिवर्तन (गतिशील सूचकांक) है, तो आपको ज्यामितीय माध्य का उपयोग करके औसत मूल्य की गणना करने की आवश्यकता है: (1.109 * 1.090 * 1.119 * 1.133) ^ (1/4) = 1.1126, अर्थात अवधि के लिए 2005 से 2008 तक सालाना कीमतों में औसतन 11.26% की वृद्धि हुई। अंकगणित माध्य पर एक गलत गणना 11.28% का गलत परिणाम देगी।SRGEOM फ़ंक्शन
किसी सरणी या धनात्मक संख्याओं की श्रेणी का ज्यामितीय माध्य लौटाता है। उदाहरण के लिए, CAGEOM फ़ंक्शन का उपयोग औसत वृद्धि दर की गणना के लिए किया जा सकता है यदि परिवर्तनीय दरों के साथ चक्रवृद्धि आय दी गई हो।
SRGEOM(नंबर1;नंबर2;...)
संख्या 1, संख्या 2, ... 1 से 30 तर्क हैं जिनके लिए ज्यामितीय माध्य की गणना की जाती है। आप अर्धविराम से अलग किए गए तर्कों के बजाय किसी सरणी या सरणी संदर्भ का उपयोग कर सकते हैं।
वर्गमूल औसत का वर्ग
मूल माध्य वर्ग दूसरे क्रम का प्रारंभिक क्षण है।
वर्गमूल औसत का वर्गका उपयोग तब किया जाता है जब एक्स के प्रारंभिक मान सकारात्मक और नकारात्मक दोनों हो सकते हैं, उदाहरण के लिए, औसत विचलन की गणना करते समय।औसत घन
औसत घन तीसरे क्रम का प्रारंभिक क्षण है।
औसत घनबहुत कम ही प्रयोग किया जाता है, उदाहरण के लिए, विकासशील देशों (HPI-1) और विकसित देशों (HPI-2) के लिए गरीबी सूचकांकों की गणना करते समय, संयुक्त राष्ट्र द्वारा प्रस्तावित और गणना की जाती है।ज्यादातर मामलों में, डेटा किसी केंद्रीय बिंदु के आसपास केंद्रित होता है। इस प्रकार, किसी भी डेटा सेट का वर्णन करने के लिए, औसत मूल्य को इंगित करना पर्याप्त है। क्रमिक रूप से तीन संख्यात्मक विशेषताओं पर विचार करें जिनका उपयोग वितरण के औसत मूल्य का अनुमान लगाने के लिए किया जाता है: अंकगणितीय माध्य, माध्यिका और बहुलक।
औसत
अंकगणितीय माध्य (जिसे अक्सर केवल माध्य के रूप में संदर्भित किया जाता है) वितरण के माध्य का सबसे सामान्य अनुमान है। यह सभी देखे गए संख्यात्मक मानों के योग को उनकी संख्या से विभाजित करने का परिणाम है। संख्याओं के नमूने के लिए एक्स 1, एक्स 2, ..., एक्सएन, नमूना माध्य (प्रतीक द्वारा निरूपित) ) बराबर \u003d (एक्स 1 + एक्स 2 + ... + एक्सएन) / एन, या
नमूना माध्य कहाँ है, एन- नमूने का आकार, एक्समैं- नमूने का i-वें तत्व।
नोट या प्रारूप में डाउनलोड करें, प्रारूप में उदाहरण
15 अति-जोखिम वाले म्युचुअल फंडों के पांच साल के औसत वार्षिक रिटर्न के अंकगणितीय औसत की गणना करने पर विचार करें (चित्र 1)।

चावल। 1. 15 अति-जोखिम वाले म्युचुअल फंडों पर औसत वार्षिक रिटर्न
नमूना माध्य की गणना निम्नानुसार की जाती है:

यह एक अच्छा रिटर्न है, खासकर जब बैंक या क्रेडिट यूनियन जमाकर्ताओं को उसी समय अवधि में प्राप्त होने वाले 3-4% रिटर्न की तुलना में। यदि आप रिटर्न वैल्यू को सॉर्ट करते हैं, तो यह देखना आसान है कि आठ फंडों का रिटर्न ऊपर है, और सात - औसत से नीचे है। अंकगणित माध्य एक संतुलन बिंदु के रूप में कार्य करता है, ताकि निम्न-आय वाले फंड उच्च-आय वाले फंडों को संतुलित कर सकें। नमूने के सभी तत्व औसत की गणना में शामिल होते हैं। वितरण माध्य के किसी अन्य अनुमानक के पास यह गुण नहीं है।
अंकगणित माध्य की गणना कब करें।चूंकि अंकगणित माध्य नमूने के सभी तत्वों पर निर्भर करता है, चरम मूल्यों की उपस्थिति परिणाम को महत्वपूर्ण रूप से प्रभावित करती है। ऐसी स्थितियों में, अंकगणितीय माध्य संख्यात्मक डेटा के अर्थ को विकृत कर सकता है। इसलिए, चरम मूल्यों वाले डेटा सेट का वर्णन करते समय, माध्यिका या अंकगणितीय माध्य और माध्यिका को इंगित करना आवश्यक है। उदाहरण के लिए, अगर आरएस इमर्जिंग ग्रोथ फंड के रिटर्न को सैंपल से हटा दिया जाए, तो 14 फंड्स के रिटर्न का सैंपल एवरेज लगभग 1% घटकर 5.19% रह जाता है।
मंझला
माध्यिका संख्याओं के क्रमबद्ध सरणी का मध्य मान है। यदि सरणी में दोहराई जाने वाली संख्याएँ नहीं हैं, तो इसके आधे तत्व माध्यिका से कम और आधे से अधिक होंगे। यदि नमूने में चरम मान हैं, तो माध्य का अनुमान लगाने के लिए अंकगणितीय माध्य के बजाय माध्यिका का उपयोग करना बेहतर है। एक नमूने के माध्यिका की गणना करने के लिए, इसे पहले क्रमबद्ध किया जाना चाहिए।
यह सूत्र अस्पष्ट है। इसका परिणाम इस बात पर निर्भर करता है कि संख्या सम है या विषम। एन:
- यदि नमूने में विषम संख्या में आइटम हैं, तो माध्यिका है (एन+1)/2-वें तत्व।
- यदि नमूने में तत्वों की एक सम संख्या है, तो माध्यिका नमूने के दो मध्य तत्वों के बीच स्थित है और इन दो तत्वों पर गणना किए गए अंकगणितीय माध्य के बराबर है।
15 अति-जोखिम वाले म्युचुअल फंडों के नमूने के लिए माध्यिका की गणना करने के लिए, हमें पहले कच्चे डेटा (चित्र 2) को क्रमबद्ध करने की आवश्यकता है। तब माध्यिका नमूने के मध्य तत्व की संख्या के विपरीत होगी; हमारे उदाहरण संख्या 8 में। एक्सेल का एक विशेष कार्य =MEDIAN() है जो अनियंत्रित सरणियों के साथ भी काम करता है।

चावल। 2. मेडियन 15 फंड
अत: माध्यिका 6.5 है। इसका मतलब है कि बहुत अधिक जोखिम वाले फंडों में से आधे 6.5 से अधिक नहीं होते हैं, जबकि अन्य आधे ऐसा करते हैं। ध्यान दें कि 6.5 की माध्यिका 6.08 की माध्यिका से थोड़ी बड़ी है।
यदि हम नमूने से आरएस इमर्जिंग ग्रोथ फंड की लाभप्रदता को हटा दें, तो शेष 14 फंडों का माध्य घटकर 6.2% हो जाएगा, यानी अंकगणितीय माध्य (चित्र 3) जितना महत्वपूर्ण नहीं है।

चावल। 3. माध्य 14 निधि
पहनावा
यह शब्द पहली बार 1894 में पियर्सन द्वारा पेश किया गया था। फैशन वह संख्या है जो नमूने में सबसे अधिक बार होती है (सबसे फैशनेबल)। फैशन अच्छी तरह से वर्णन करता है, उदाहरण के लिए, ट्रैफ़िक को रोकने के लिए ट्रैफ़िक सिग्नल पर ड्राइवरों की विशिष्ट प्रतिक्रिया। फैशन के उपयोग का एक उत्कृष्ट उदाहरण जूते के उत्पादित बैच के आकार या वॉलपेपर के रंग का चुनाव है। यदि किसी वितरण में कई मोड हैं, तो इसे मल्टीमॉडल या मल्टीमॉडल (दो या अधिक "चोटी" हैं) कहा जाता है। बहुविध वितरण अध्ययनाधीन चर की प्रकृति के बारे में महत्वपूर्ण जानकारी प्रदान करता है। उदाहरण के लिए, समाजशास्त्रीय सर्वेक्षणों में, यदि कोई चर किसी चीज़ के प्रति वरीयता या दृष्टिकोण का प्रतिनिधित्व करता है, तो बहुविधता का अर्थ यह हो सकता है कि कई अलग-अलग राय हैं। बहुविधता भी एक संकेतक है कि नमूना सजातीय नहीं है और अवलोकन दो या दो से अधिक "अतिव्यापी" वितरण द्वारा उत्पन्न हो सकते हैं। अंकगणितीय माध्य के विपरीत, बाह्य कारक बहुलक को प्रभावित नहीं करते हैं। लगातार वितरित यादृच्छिक चर के लिए, जैसे कि म्यूचुअल फंड का औसत वार्षिक रिटर्न, कभी-कभी मोड बिल्कुल भी मौजूद नहीं होता है (या इसका कोई मतलब नहीं है)। चूंकि ये संकेतक कई प्रकार के मूल्यों को ले सकते हैं, इसलिए दोहराए जाने वाले मान अत्यंत दुर्लभ हैं।
चतुर्थक
चतुर्थक वे उपाय हैं जिनका उपयोग आमतौर पर बड़े संख्यात्मक नमूनों के गुणों का वर्णन करते समय डेटा के वितरण का मूल्यांकन करने के लिए किया जाता है। जबकि माध्यिका क्रमबद्ध सरणी को आधे में विभाजित करती है (50% सरणी तत्व माध्यिका से कम हैं और 50% अधिक हैं), चतुर्थक आदेशित डेटासेट को चार भागों में तोड़ते हैं। Q 1, माध्यिका और Q 3 मान क्रमशः 25वें, 50वें और 75वें प्रतिशतक हैं। प्रथम चतुर्थक Q 1 एक संख्या है जो नमूने को दो भागों में विभाजित करती है: 25% तत्व इससे कम हैं, और 75% पहले चतुर्थक से अधिक हैं।
तीसरी चतुर्थक Q 3 एक संख्या है जो नमूने को दो भागों में विभाजित करती है: 75% तत्व इससे कम हैं, और 25% तीसरे चतुर्थक से अधिक हैं।
2007 से पहले एक्सेल के संस्करणों में चतुर्थक की गणना करने के लिए, फ़ंक्शन =QUARTILE(array, part) का उपयोग किया गया था। एक्सेल 2010 से शुरू होकर, दो कार्य लागू होते हैं:
- = QUARTILE.ON (सरणी, भाग)
- = QUARTILE.EXC (सरणी, भाग)
ये दो फ़ंक्शन थोड़े अलग मान देते हैं (चित्र 4)। उदाहरण के लिए, 15 अति-जोखिम वाले म्युचुअल फंडों के औसत वार्षिक रिटर्न पर डेटा वाले नमूने के चतुर्थक की गणना करते समय, QUARTILE.INC और QUARTILE.EXC के लिए क्रमशः Q 1 = 1.8 या -0.7। वैसे, पहले इस्तेमाल किया जाने वाला QUARTILE फंक्शन आधुनिक QUARTILE.ON फंक्शन से मेल खाता है। उपरोक्त सूत्रों का उपयोग करके एक्सेल में चतुर्थक की गणना करने के लिए, डेटा सरणी को अनियंत्रित छोड़ा जा सकता है।

चावल। 4. एक्सेल में चतुर्थक की गणना करें
आइए फिर से जोर दें। एक्सेल यूनीवेरिएट के लिए चतुर्थक की गणना कर सकता है असतत श्रृंखला, जिसमें एक यादृच्छिक चर के मान होते हैं। आवृत्ति-आधारित वितरण के लिए चतुर्थक की गणना नीचे अनुभाग में दी गई है।
जियोमेट्रिक माध्य
अंकगणित माध्य के विपरीत, ज्यामितीय माध्य मापता है कि समय के साथ एक चर कितना बदल गया है। ज्यामितीय माध्य मूल है एनउत्पाद से वें डिग्री एनमान (एक्सेल में, फ़ंक्शन = CUGEOM का उपयोग किया जाता है):
जी= (एक्स 1 * एक्स 2 * ... * एक्स एन) 1/एन
एक समान पैरामीटर - वापसी की दर का ज्यामितीय माध्य - सूत्र द्वारा निर्धारित किया जाता है:
जी \u003d [(1 + आर 1) * (1 + आर 2) * ... * (1 + आर एन)] 1 / एन -1,
कहाँ पे आर आई- प्रतिफल दर मैं- समय की अवधि।
उदाहरण के लिए, मान लीजिए कि प्रारंभिक निवेश $100,000 है। पहले वर्ष के अंत तक, यह $50,000 तक गिर जाता है, और दूसरे वर्ष के अंत तक, यह मूल $100,000 तक वापस आ जाता है। इस निवेश पर दो से अधिक की वापसी की दर- वर्ष की अवधि 0 के बराबर है, क्योंकि प्रारंभिक और अंतिम राशि एक दूसरे के बराबर है। हालांकि, रिटर्न की वार्षिक दरों का अंकगणितीय औसत = (-0.5 + 1)/2 = 0.25 या 25% है, क्योंकि पहले वर्ष में रिटर्न की दर R 1 = (50,000 - 100,000) / 100,000 = -0.5, और दूसरे आर में 2 = (100,000 - 50,000) / 50,000 = 1. वहीं, दो साल के लिए रिटर्न की दर का ज्यामितीय माध्य है: जी = [(1–0.5) * (1 + 1 )] 1 /2 - 1 = ½ - 1 = 1 - 1 = 0। इस प्रकार, ज्यामितीय माध्य अंकगणितीय माध्य की तुलना में द्विवार्षिक पर निवेश की मात्रा में परिवर्तन (अधिक सटीक, परिवर्तन की अनुपस्थिति) को अधिक सटीक रूप से दर्शाता है।
रोचक तथ्य।सबसे पहले, ज्यामितीय माध्य हमेशा समान संख्याओं के अंकगणितीय माध्य से कम होगा। उस स्थिति को छोड़कर जब सभी ली गई संख्याएँ एक दूसरे के बराबर हों। दूसरे, एक समकोण त्रिभुज के गुणों पर विचार करने के बाद, कोई समझ सकता है कि माध्य को ज्यामितीय क्यों कहा जाता है। एक समकोण त्रिभुज की ऊंचाई, कर्ण तक कम, कर्ण पर पैरों के अनुमानों के बीच औसत आनुपातिक है, और प्रत्येक पैर कर्ण और कर्ण पर इसके प्रक्षेपण के बीच औसत आनुपातिक है (चित्र 5)। यह दो (लंबाई) खंडों के ज्यामितीय माध्य के निर्माण का एक ज्यामितीय तरीका देता है: आपको व्यास के रूप में इन दो खंडों के योग पर एक सर्कल बनाने की आवश्यकता है, फिर ऊंचाई, उनके कनेक्शन के बिंदु से चौराहे तक बहाल की जाती है सर्कल, वांछित मूल्य देगा:

चावल। 5. ज्यामितीय माध्य की ज्यामितीय प्रकृति (विकिपीडिया से चित्र)
संख्यात्मक आँकड़ों का दूसरा महत्वपूर्ण गुण है उनका उतार-चढ़ावडेटा के फैलाव की डिग्री की विशेषता। दो अलग-अलग नमूने माध्य मान और भिन्नता दोनों में भिन्न हो सकते हैं। हालांकि, जैसा चित्र में दिखाया गया है। 6 और 7, दो नमूनों में एक ही भिन्नता हो सकती है लेकिन अलग-अलग साधन, या एक ही माध्य और पूरी तरह से भिन्न भिन्नता हो सकती है। अंजीर में बहुभुज बी के अनुरूप डेटा। 7 उस डेटा से बहुत कम बदलता है जिससे बहुभुज A बनाया गया था।

चावल। 6. समान प्रसार और भिन्न माध्य मानों के साथ दो सममित घंटी के आकार का वितरण

चावल। 7. समान माध्य मान और भिन्न प्रकीर्णन के साथ दो सममित घंटी के आकार का वितरण
डेटा भिन्नता के पांच अनुमान हैं:
- अवधि,
- अन्तःचतुर्थक श्रेणी,
- फैलाव,
- मानक विचलन,
- भिन्नता का गुणांक।
दायरा
रेंज नमूने के सबसे बड़े और सबसे छोटे तत्वों के बीच का अंतर है:
स्वाइप = एक्समैक्स एक्समिनट
15 अति-जोखिम वाले म्युचुअल फंडों के औसत वार्षिक रिटर्न वाले नमूने की श्रेणी की गणना एक ऑर्डर किए गए सरणी का उपयोग करके की जा सकती है (चित्र 4 देखें): रेंज = 18.5 - (-6.1) = 24.6। इसका मतलब है कि बहुत अधिक जोखिम वाले फंड के लिए उच्चतम और निम्नतम औसत वार्षिक रिटर्न के बीच का अंतर 24.6% है।
सीमा डेटा के समग्र प्रसार को मापती है। यद्यपि नमूना श्रेणी डेटा के कुल प्रसार का एक बहुत ही सरल अनुमान है, इसकी कमजोरी यह है कि यह ध्यान नहीं देता है कि न्यूनतम और अधिकतम तत्वों के बीच डेटा कैसे वितरित किया जाता है। यह प्रभाव अंजीर में अच्छी तरह से देखा जाता है। 8 जो समान श्रेणी वाले नमूनों को दिखाता है। बी स्केल से पता चलता है कि यदि नमूने में कम से कम एक चरम मान है, तो नमूना श्रेणी डेटा के बिखराव का एक बहुत ही गलत अनुमान है।

चावल। 8. समान श्रेणी वाले तीन नमूनों की तुलना; त्रिभुज संतुलन के समर्थन का प्रतीक है, और इसका स्थान नमूने के औसत मूल्य से मेल खाता है
अन्तःचतुर्थक श्रेणी
इंटरक्वेर्टाइल, या माध्य, रेंज नमूने के तीसरे और पहले चतुर्थक के बीच का अंतर है:
इंटरक्वेर्टाइल रेंज \u003d क्यू 3 - क्यू 1
यह मान 50% तत्वों के प्रसार का अनुमान लगाना और चरम तत्वों के प्रभाव को ध्यान में नहीं रखना संभव बनाता है। 15 उच्च जोखिम वाले म्यूचुअल फंड के औसत वार्षिक रिटर्न पर डेटा वाले नमूने के लिए इंटरक्वेर्टाइल रेंज की गणना अंजीर में डेटा का उपयोग करके की जा सकती है। 4 (उदाहरण के लिए, QUARTILE.EXC फ़ंक्शन के लिए): इंटरक्वेर्टाइल रेंज = 9.8 - (-0.7) = 10.5। 9.8 और -0.7 के बीच के अंतराल को अक्सर मध्य आधा कहा जाता है।
यह ध्यान दिया जाना चाहिए कि क्यू 1 और क्यू 3 मान, और इसलिए इंटरक्वेर्टाइल रेंज, आउटलेर्स की उपस्थिति पर निर्भर नहीं करते हैं, क्योंकि उनकी गणना किसी भी मूल्य को ध्यान में नहीं रखती है जो क्यू 1 से कम या क्यू 3 से अधिक होगी। . कुल मात्रात्मक विशेषताएँ, जैसे कि माध्यिका, प्रथम और तृतीय चतुर्थक, और अंतःचतुर्थक श्रेणी, जो बाह्य कारकों से प्रभावित नहीं होती हैं, प्रबल संकेतक कहलाती हैं।
जबकि रेंज और इंटरक्वेर्टाइल रेंज क्रमशः नमूने के कुल और औसत बिखराव का अनुमान प्रदान करते हैं, इनमें से कोई भी अनुमान इस बात को ध्यान में नहीं रखता है कि डेटा कैसे वितरित किया जाता है। प्रसरण और मानक विचलनइस कमी से मुक्त। ये संकेतक आपको माध्य के आसपास डेटा के उतार-चढ़ाव की डिग्री का आकलन करने की अनुमति देते हैं। नमूना विचरणप्रत्येक नमूना तत्व और नमूना माध्य के बीच वर्ग अंतर से गणना किए गए अंकगणितीय माध्य का एक अनुमान है। X 1 , X 2 , ... X n के नमूने के लिए नमूना विचरण (प्रतीक S 2 द्वारा निरूपित निम्न सूत्र द्वारा दिया गया है:

सामान्य तौर पर, नमूना विचरण नमूना तत्वों और नमूना माध्य के बीच वर्ग अंतर का योग होता है, जो नमूना आकार शून्य से एक के बराबर मान से विभाजित होता है:

कहाँ पे - अंकगणित औसत, एन- नमूने का आकार, एक्स मैं - मैं-वें नमूना तत्व एक्स. संस्करण 2007 से पहले एक्सेल में, फ़ंक्शन =VAR() का उपयोग नमूना विचरण की गणना के लिए किया गया था, संस्करण 2010 के बाद से, फ़ंक्शन =VAR.V() का उपयोग किया जाता है।
डेटा स्कैटर का सबसे व्यावहारिक और व्यापक रूप से स्वीकृत अनुमान है मानक विचलन. यह सूचक प्रतीक एस द्वारा दर्शाया गया है और नमूना विचरण के वर्गमूल के बराबर है:

संस्करण 2007 से पहले एक्सेल में, मानक विचलन की गणना के लिए =STDEV() फ़ंक्शन का उपयोग किया गया था, संस्करण 2010 से =STDEV.B() फ़ंक्शन का उपयोग किया जाता है। इन कार्यों की गणना करने के लिए, डेटा सरणी को अनियंत्रित किया जा सकता है।
न तो नमूना विचरण और न ही नमूना मानक विचलन नकारात्मक हो सकता है। एकमात्र स्थिति जिसमें संकेतक S 2 और S शून्य हो सकते हैं यदि नमूने के सभी तत्व समान हों। इस पूरी तरह से असंभव मामले में, रेंज और इंटरक्वेर्टाइल रेंज भी शून्य है।
संख्यात्मक डेटा स्वाभाविक रूप से अस्थिर है। कोई भी चर कई अलग-अलग मान ले सकता है। उदाहरण के लिए, अलग-अलग म्यूचुअल फंड में रिटर्न और नुकसान की अलग-अलग दरें होती हैं। संख्यात्मक डेटा की परिवर्तनशीलता के कारण, न केवल माध्य के अनुमानों का अध्ययन करना बहुत महत्वपूर्ण है, जो प्रकृति में योगात्मक हैं, बल्कि विचरण के अनुमान भी हैं, जो डेटा के बिखराव की विशेषता रखते हैं।
विचरण और मानक विचलन हमें माध्य के चारों ओर डेटा के प्रसार का अनुमान लगाने की अनुमति देते हैं, दूसरे शब्दों में, यह निर्धारित करने के लिए कि नमूने के कितने तत्व माध्य से कम हैं, और कितने अधिक हैं। फैलाव में कुछ मूल्यवान गणितीय गुण हैं। हालाँकि, इसका मान माप की एक इकाई का वर्ग है - एक वर्ग प्रतिशत, एक वर्ग डॉलर, एक वर्ग इंच, आदि। इसलिए, भिन्नता का एक प्राकृतिक अनुमान मानक विचलन है, जिसे माप की सामान्य इकाइयों में व्यक्त किया जाता है - आय का प्रतिशत, डॉलर या इंच।
मानक विचलन आपको औसत मूल्य के आसपास नमूना तत्वों के उतार-चढ़ाव की मात्रा का अनुमान लगाने की अनुमति देता है। लगभग सभी स्थितियों में, अधिकांश देखे गए मान माध्य से प्लस या माइनस एक मानक विचलन के भीतर होते हैं। इसलिए, नमूना तत्वों के अंकगणितीय माध्य और मानक नमूना विचलन को जानकर, उस अंतराल को निर्धारित करना संभव है जिससे डेटा का बड़ा हिस्सा संबंधित है।
15 अति-जोखिम वाले म्युचुअल फंडों पर रिटर्न का मानक विचलन 6.6 है (चित्र 9)। इसका मतलब यह है कि बड़ी मात्रा में फंड की लाभप्रदता औसत मूल्य से 6.6% से अधिक नहीं होती है (यानी, यह सीमा से उतार-चढ़ाव करती है - एस= 6.2 - 6.6 = -0.4 से + एस= 12.8)। वास्तव में, इस अंतराल में पांच साल का औसत वार्षिक रिटर्न 53.3% (15 में से 8) फंड होता है।

चावल। 9. मानक विचलन
ध्यान दें कि चुकता अंतरों के योग की प्रक्रिया में, जो आइटम माध्य से अधिक दूर होते हैं, वे निकट की वस्तुओं की तुलना में अधिक वजन प्राप्त करते हैं। यह गुण मुख्य कारण है कि वितरण के माध्य का अनुमान लगाने के लिए अंकगणितीय माध्य का सबसे अधिक उपयोग किया जाता है।
भिन्नता का गुणांक
पिछले बिखराव अनुमानों के विपरीत, भिन्नता का गुणांक एक सापेक्ष अनुमान है। इसे हमेशा प्रतिशत के रूप में मापा जाता है, मूल डेटा इकाइयों में नहीं। भिन्नता का गुणांक, प्रतीकों CV द्वारा निरूपित, माध्य के आसपास डेटा के बिखराव को मापता है। भिन्नता का गुणांक अंकगणित माध्य से विभाजित मानक विचलन के बराबर है और 100% से गुणा किया जाता है:

कहाँ पे एस- मानक नमूना विचलन, - नमूना माध्य।
भिन्नता का गुणांक आपको दो नमूनों की तुलना करने की अनुमति देता है, जिनमें से तत्व माप की विभिन्न इकाइयों में व्यक्त किए जाते हैं। उदाहरण के लिए, मेल डिलीवरी सेवा का प्रबंधक ट्रकों के बेड़े को अपग्रेड करना चाहता है। पैकेज लोड करते समय, विचार करने के लिए दो प्रकार के प्रतिबंध हैं: प्रत्येक पैकेज का वजन (पाउंड में) और मात्रा (घन फीट में)। मान लें कि 200 बैग के नमूने में, औसत वजन 26.0 पाउंड है, वजन का मानक विचलन 3.9 पाउंड है, औसत पैकेज वॉल्यूम 8.8 क्यूबिक फीट है, और वॉल्यूम का मानक विचलन 2.2 क्यूबिक फीट है। वजन के फैलाव और पैकेजों के आयतन की तुलना कैसे करें?
चूंकि वजन और आयतन के लिए माप की इकाइयाँ एक दूसरे से भिन्न होती हैं, प्रबंधक को इन मूल्यों के सापेक्ष प्रसार की तुलना करनी चाहिए। वजन भिन्नता गुणांक CV W = 3.9 / 26.0 * 100% = 15% है, और मात्रा भिन्नता गुणांक CV V = 2.2 / 8.8 * 100% = 25% है। इस प्रकार, पैकेट के आयतन का आपेक्षिक प्रकीर्णन उनके भार के सापेक्ष प्रकीर्णन की तुलना में बहुत अधिक होता है।
वितरण प्रपत्र
नमूने की तीसरी महत्वपूर्ण संपत्ति इसके वितरण का रूप है। यह वितरण सममित या असममित हो सकता है। वितरण के आकार का वर्णन करने के लिए, इसके माध्य और माध्यिका की गणना करना आवश्यक है। यदि ये दोनों माप समान हैं, तो चर को सममित रूप से वितरित कहा जाता है। यदि किसी चर का माध्य मान माध्यिका से अधिक है, तो उसके बंटन में धनात्मक विषमता होती है (चित्र 10)। यदि माध्यिका माध्य से अधिक है, तो चर का वितरण ऋणात्मक रूप से विषम है। सकारात्मक विषमता तब होती है जब माध्य असामान्य रूप से उच्च मूल्यों तक बढ़ जाता है। नकारात्मक तिरछापन तब होता है जब माध्य असामान्य रूप से छोटे मानों तक घट जाता है। एक चर सममित रूप से वितरित किया जाता है यदि यह किसी भी दिशा में किसी भी चरम मान को नहीं लेता है, जैसे कि चर के बड़े और छोटे मान एक दूसरे को रद्द कर देते हैं।

चावल। 10. तीन प्रकार के वितरण
ए पैमाने पर दर्शाए गए डेटा में नकारात्मक तिरछापन है। यह आंकड़ा असामान्य रूप से छोटे मूल्यों के कारण एक लंबी पूंछ और बाएं तिरछा दिखाता है। ये अत्यंत छोटे मान माध्य मान को बाईं ओर स्थानांतरित करते हैं, और यह माध्यिका से कम हो जाता है। स्केल बी पर दिखाया गया डेटा सममित रूप से वितरित किया जाता है। वितरण के बाएँ और दाएँ भाग उनके दर्पण प्रतिबिम्ब हैं। बड़े और छोटे मूल्य एक दूसरे को संतुलित करते हैं, और माध्य और माध्य समान होते हैं। स्केल बी पर दिखाए गए डेटा में सकारात्मक विषमता है। यह आंकड़ा असामान्य रूप से उच्च मूल्यों की उपस्थिति के कारण एक लंबी पूंछ और दाईं ओर तिरछा दिखाता है। ये बहुत बड़े मान माध्य को दाईं ओर स्थानांतरित करते हैं, और यह माध्यिका से बड़ा हो जाता है।
एक्सेल में, वर्णनात्मक आँकड़े ऐड-इन का उपयोग करके प्राप्त किए जा सकते हैं विश्लेषण पैकेज. मेनू के माध्यम से जाओ जानकारी → डेटा विश्लेषण, खुलने वाली विंडो में, लाइन का चयन करें वर्णनात्मक आँकड़ेऔर क्लिक करें ठीक है. खिड़की में वर्णनात्मक आँकड़ेइंगित करना सुनिश्चित करें इनपुट अंतराल(चित्र 11)। यदि आप मूल डेटा के समान शीट पर वर्णनात्मक आंकड़े देखना चाहते हैं, तो रेडियो बटन का चयन करें आउटपुट अंतरालऔर उस सेल को निर्दिष्ट करें जहां आप प्रदर्शित आँकड़ों के ऊपरी बाएँ कोने को रखना चाहते हैं (हमारे उदाहरण में, $C$1)। यदि आप डेटा को किसी नई शीट या नई कार्यपुस्तिका में आउटपुट करना चाहते हैं, तो बस उपयुक्त रेडियो बटन का चयन करें। के बगल में स्थित बॉक्स को चेक करें अंतिम आंकड़े. वैकल्पिक रूप से, आप भी चुन सकते हैं कठिनाई स्तर,k-वें सबसे छोटा औरके-वें सबसे बड़ा.
अगर जमा पर जानकारीक्षेत्र में विश्लेषणआप आइकन नहीं देखते हैं डेटा विश्लेषण, आपको पहले ऐड-ऑन स्थापित करना होगा विश्लेषण पैकेज(देखें, उदाहरण के लिए,)।

चावल। 11. ऐड-ऑन का उपयोग करके गणना की गई बहुत उच्च स्तर के जोखिम वाले फंड के पांच साल के औसत वार्षिक रिटर्न के वर्णनात्मक आंकड़े डेटा विश्लेषणएक्सेल प्रोग्राम
एक्सेल ऊपर चर्चा किए गए कई आँकड़ों की गणना करता है: माध्य, माध्यिका, मोड, मानक विचलन, विचरण, श्रेणी ( मध्यान्तर), न्यूनतम, अधिकतम और नमूना आकार ( जाँच करना) इसके अलावा, एक्सेल हमारे लिए कुछ नए आँकड़ों की गणना करता है: मानक त्रुटि, कुर्टोसिस और तिरछापन। मानक त्रुटिनमूना आकार के वर्गमूल द्वारा विभाजित मानक विचलन के बराबर होता है। विषमतावितरण की समरूपता से विचलन की विशेषता है और यह एक ऐसा कार्य है जो नमूने के तत्वों और माध्य मान के बीच अंतर के घन पर निर्भर करता है। कर्टोसिस माध्य बनाम वितरण की पूंछ के आसपास डेटा की सापेक्ष एकाग्रता का एक उपाय है, और नमूना और चौथी शक्ति तक उठाए गए माध्य के बीच के अंतर पर निर्भर करता है।
सामान्य जनसंख्या के लिए वर्णनात्मक आँकड़ों की गणना
ऊपर चर्चा किए गए वितरण का माध्य, बिखराव और आकार नमूना-आधारित विशेषताएं हैं। हालाँकि, यदि डेटासेट में संपूर्ण जनसंख्या का संख्यात्मक माप शामिल है, तो इसके मापदंडों की गणना की जा सकती है। इन मापदंडों में जनसंख्या का माध्य, विचरण और मानक विचलन शामिल हैं।
अपेक्षित मूल्यसामान्य जनसंख्या की मात्रा से विभाजित सामान्य जनसंख्या के सभी मूल्यों के योग के बराबर है:

कहाँ पे µ - अपेक्षित मूल्य, एक्समैं- मैं-वें चर अवलोकन एक्स, एन- सामान्य जनसंख्या की मात्रा। एक्सेल में, गणितीय अपेक्षा की गणना करने के लिए, समान फ़ंक्शन का उपयोग अंकगणित माध्य के लिए किया जाता है: = औसत ()।
जनसंख्या भिन्नतासामान्य जनसंख्या और चटाई के तत्वों के बीच वर्ग अंतर के योग के बराबर। जनसंख्या के आकार से विभाजित अपेक्षा:

कहाँ पे 2सामान्य जनसंख्या का अंतर है। संस्करण 2007 से पहले का एक्सेल जनसंख्या विचरण की गणना के लिए =VAR() फ़ंक्शन का उपयोग करता है, जो संस्करण 2010 =VAR.G() से शुरू होता है।
जनसंख्या मानक विचलनजनसंख्या प्रसरण के वर्गमूल के बराबर है:

संस्करण 2007 से पहले का एक्सेल जनसंख्या मानक विचलन की गणना करने के लिए =STDEV() का उपयोग करता है, जो संस्करण 2010 =STDEV.Y() से शुरू होता है। ध्यान दें कि जनसंख्या विचरण और मानक विचलन के सूत्र नमूना विचरण और मानक विचलन के सूत्रों से भिन्न होते हैं। नमूना आंकड़ों की गणना करते समय एस 2और एसभिन्न का हर है एन - 1, और मापदंडों की गणना करते समय 2और σ - सामान्य जनसंख्या की मात्रा एन.
अंगूठे का नियम
ज्यादातर स्थितियों में, प्रेक्षणों का एक बड़ा हिस्सा माध्यिका के चारों ओर केंद्रित होता है, जिससे एक समूह बनता है। सकारात्मक तिरछापन वाले डेटा सेट में, यह क्लस्टर गणितीय अपेक्षा के बाईं ओर (यानी, नीचे) स्थित है, और नकारात्मक विषमता वाले सेट में, यह क्लस्टर गणितीय अपेक्षा के दाईं ओर (यानी, ऊपर) स्थित है। सममित डेटा का माध्य और माध्यिका समान होता है, और प्रेक्षण माध्य के चारों ओर क्लस्टर होते हैं, जो घंटी के आकार का वितरण बनाते हैं। यदि वितरण में एक स्पष्ट तिरछापन नहीं है, और डेटा गुरुत्वाकर्षण के एक निश्चित केंद्र के आसपास केंद्रित है, तो परिवर्तनशीलता का अनुमान लगाने के लिए अंगूठे के एक नियम का उपयोग किया जा सकता है, जो कहता है: यदि डेटा में घंटी के आकार का वितरण है, तो लगभग 68% अवलोकनों की संख्या गणितीय अपेक्षा के एक मानक विचलन के भीतर है, लगभग 95% अवलोकन अपेक्षित मूल्य के दो मानक विचलन के भीतर हैं, और 99.7% अवलोकन अपेक्षित मूल्य के तीन मानक विचलन के भीतर हैं।
इस प्रकार, मानक विचलन, जो गणितीय अपेक्षा के आसपास औसत उतार-चढ़ाव का एक अनुमान है, यह समझने में मदद करता है कि टिप्पणियों को कैसे वितरित किया जाता है और आउटलेर्स की पहचान करने में मदद करता है। यह अंगूठे के नियम से निम्नानुसार है कि घंटी के आकार के वितरण के लिए, बीस में केवल एक मान गणितीय अपेक्षा से दो से अधिक मानक विचलन से भिन्न होता है। इसलिए, अंतराल के बाहर के मान μ ± 2σ, आउटलेयर माना जा सकता है। इसके अलावा, 1000 में से केवल तीन अवलोकन गणितीय अपेक्षा से तीन से अधिक मानक विचलन से भिन्न होते हैं। इस प्रकार, अंतराल के बाहर के मान μ ± 3σलगभग हमेशा आउटलेयर होते हैं। उन वितरणों के लिए जो अत्यधिक तिरछे हैं या घंटी के आकार के नहीं हैं, अंगूठे का बिनेम-चेबीशेव नियम लागू किया जा सकता है।
सौ साल से भी अधिक समय पहले, गणितज्ञ बिएनमे और चेबीशेव ने स्वतंत्र रूप से मानक विचलन की एक उपयोगी संपत्ति की खोज की थी। उन्होंने पाया कि किसी भी डेटा सेट के लिए, वितरण के आकार की परवाह किए बिना, अवलोकनों का प्रतिशत जो दूरी पर स्थित है, से अधिक नहीं है कगणितीय अपेक्षा से मानक विचलन, कम नहीं (1 – 1/ 2)*100%.
उदाहरण के लिए, यदि क= 2, बायनेम-चेबीशेव नियम कहता है कि कम से कम (1 - (1/2) 2) x 100% = 75% प्रेक्षण अंतराल में होने चाहिए μ ± 2σ. यह नियम किसी के लिए भी सही है कएक से अधिक। बायनेम-चेबीशेव नियम एक बहुत ही सामान्य प्रकृति का है और किसी भी प्रकार के वितरण के लिए मान्य है। यह टिप्पणियों की न्यूनतम संख्या को इंगित करता है, जिससे गणितीय अपेक्षा की दूरी किसी दिए गए मान से अधिक नहीं होती है। हालांकि, यदि वितरण घंटी के आकार का है, तो अंगूठे का नियम अधिक सटीक रूप से माध्य के आसपास डेटा की एकाग्रता का अनुमान लगाता है।
आवृत्ति-आधारित वितरण के लिए वर्णनात्मक आंकड़ों की गणना
यदि मूल डेटा उपलब्ध नहीं है, तो बारंबारता वितरण सूचना का एकमात्र स्रोत बन जाता है। ऐसी स्थितियों में, आप वितरण के मात्रात्मक संकेतकों के अनुमानित मूल्यों की गणना कर सकते हैं, जैसे अंकगणित माध्य, मानक विचलन, चतुर्थक।
यदि नमूना डेटा को आवृत्ति वितरण के रूप में प्रस्तुत किया जाता है, तो अंकगणित माध्य के अनुमानित मूल्य की गणना की जा सकती है, यह मानते हुए कि प्रत्येक वर्ग के भीतर सभी मान वर्ग के मध्य बिंदु पर केंद्रित हैं:

कहाँ पे - नमूना माध्य, एन- अवलोकनों की संख्या, या नमूना आकार, साथ- बारंबारता बंटन में वर्गों की संख्या, एमजे- मध्य बिंदु जे-वीं कक्षा, एफजे- आवृत्ति के अनुरूप जे-वीं कक्षा।
आवृत्ति वितरण से मानक विचलन की गणना करने के लिए, यह भी माना जाता है कि प्रत्येक वर्ग के भीतर सभी मान वर्ग के मध्य बिंदु पर केंद्रित होते हैं।

यह समझने के लिए कि आवृत्तियों के आधार पर श्रृंखला के चतुर्थक कैसे निर्धारित किए जाते हैं, आइए हम प्रति व्यक्ति नकद आय (छवि 12) के औसत से रूसी आबादी के वितरण पर 2013 के आंकड़ों के आधार पर निम्न चतुर्थक की गणना पर विचार करें।

चावल। 12. प्रति माह प्रति व्यक्ति मौद्रिक आय के साथ रूस की जनसंख्या का हिस्सा, रूबल
अंतराल भिन्नता श्रृंखला के पहले चतुर्थक की गणना करने के लिए, आप सूत्र का उपयोग कर सकते हैं:

जहां Q1 पहले चतुर्थक का मान है, xQ1 पहले चतुर्थक वाले अंतराल की निचली सीमा है (अंतराल संचित आवृत्ति द्वारा निर्धारित किया जाता है, पहले 25% से अधिक); i अंतराल का मान है; f पूरे नमूने की आवृत्तियों का योग है; शायद हमेशा 100% के बराबर; SQ1–1 निचले चतुर्थक वाले अंतराल से पहले के अंतराल की संचयी आवृत्ति है; fQ1 निम्न चतुर्थक वाले अंतराल की आवृत्ति है। तीसरे चतुर्थक का सूत्र सभी जगहों पर अलग है, Q1 के बजाय, आपको Q3 का उपयोग करने की आवश्यकता है, और के बजाय को प्रतिस्थापित करना होगा।
हमारे उदाहरण (चित्र 12) में, निचला चतुर्थक 7000.1 - 10,000 की सीमा में है, जिसकी संचयी आवृत्ति 26.4% है। इस अंतराल की निचली सीमा 7000 रूबल है, अंतराल का मूल्य 3000 रूबल है, निचले चतुर्थक वाले अंतराल से पहले के अंतराल की संचित आवृत्ति 13.4% है, निचले चतुर्थक वाले अंतराल की आवृत्ति 13.0% है। इस प्रकार: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13.4) / 13 \u003d 9677 रूबल।
वर्णनात्मक आँकड़ों से जुड़े नुकसान
इस नोट में, हमने देखा कि विभिन्न आँकड़ों का उपयोग करके डेटासेट का वर्णन कैसे किया जाता है जो इसके माध्य, बिखराव और वितरण का अनुमान लगाते हैं। अगला कदम डेटा का विश्लेषण और व्याख्या करना है। अब तक, हमने डेटा के वस्तुनिष्ठ गुणों का अध्ययन किया है, और अब हम उनकी व्यक्तिपरक व्याख्या की ओर मुड़ते हैं। शोधकर्ता की प्रतीक्षा में दो गलतियाँ होती हैं: विश्लेषण का गलत ढंग से चुना गया विषय और परिणामों की गलत व्याख्या।
15 अति-जोखिम वाले म्युचुअल फंडों के प्रदर्शन का विश्लेषण काफी निष्पक्ष है। उन्होंने पूरी तरह से उद्देश्यपूर्ण निष्कर्ष निकाला: सभी म्यूचुअल फंडों के अलग-अलग रिटर्न होते हैं, फंड रिटर्न का फैलाव -6.1 से 18.5 तक होता है, और औसत रिटर्न 6.08 होता है। डेटा विश्लेषण की निष्पक्षता वितरण के कुल मात्रात्मक संकेतकों के सही विकल्प द्वारा सुनिश्चित की जाती है। आँकड़ों के माध्य और प्रकीर्णन का अनुमान लगाने के लिए कई विधियों पर विचार किया गया और उनके फायदे और नुकसान का संकेत दिया गया। एक उद्देश्य और निष्पक्ष विश्लेषण प्रदान करने वाले सही आँकड़े कैसे चुनें? यदि डेटा वितरण थोड़ा विषम है, तो क्या माध्यिका को अंकगणितीय माध्य पर चुना जाना चाहिए? कौन सा संकेतक डेटा के प्रसार को अधिक सटीक रूप से दर्शाता है: मानक विचलन या सीमा? क्या वितरण की सकारात्मक विषमता का संकेत दिया जाना चाहिए?
दूसरी ओर, डेटा व्याख्या एक व्यक्तिपरक प्रक्रिया है। अलग-अलग लोग एक ही परिणाम की व्याख्या करते हुए अलग-अलग निष्कर्ष पर आते हैं। हर किसी का अपना नजरिया होता है। कोई बहुत उच्च स्तर के जोखिम वाले 15 फंडों के कुल औसत वार्षिक रिटर्न को अच्छा मानता है और प्राप्त आय से काफी संतुष्ट है। अन्य लोग सोच सकते हैं कि इन फंडों में बहुत कम रिटर्न है। इस प्रकार, ईमानदारी, तटस्थता और निष्कर्षों की स्पष्टता से व्यक्तिपरकता की भरपाई की जानी चाहिए।
नैतिक मुद्दों
डेटा विश्लेषण नैतिक मुद्दों से अटूट रूप से जुड़ा हुआ है। समाचार पत्रों, रेडियो, टेलीविजन और इंटरनेट द्वारा प्रसारित सूचनाओं की आलोचना करनी चाहिए। समय के साथ, आप न केवल परिणामों के बारे में, बल्कि अनुसंधान के लक्ष्यों, विषय और निष्पक्षता के बारे में भी संदेह करना सीखेंगे। प्रसिद्ध ब्रिटिश राजनेता बेंजामिन डिसरायली ने इसे सबसे अच्छा कहा: "झूठ तीन प्रकार के होते हैं: झूठ, शापित झूठ और आंकड़े।"
जैसा कि नोट में उल्लेख किया गया है, रिपोर्ट में प्रस्तुत किए जाने वाले परिणामों को चुनते समय नैतिक मुद्दे उत्पन्न होते हैं। सकारात्मक और नकारात्मक दोनों परिणाम प्रकाशित किए जाने चाहिए। इसके अलावा, रिपोर्ट या लिखित रिपोर्ट बनाते समय, परिणाम ईमानदारी से, निष्पक्ष और निष्पक्ष रूप से प्रस्तुत किए जाने चाहिए। खराब और बेईमान प्रस्तुतियों के बीच भेद। ऐसा करने के लिए, यह निर्धारित करना आवश्यक है कि स्पीकर के इरादे क्या थे। कभी-कभी वक्ता महत्वपूर्ण जानकारी को अज्ञानता के कारण छोड़ देता है, और कभी-कभी जानबूझकर (उदाहरण के लिए, यदि वह वांछित परिणाम प्राप्त करने के लिए स्पष्ट रूप से विषम डेटा के माध्य का अनुमान लगाने के लिए अंकगणितीय माध्य का उपयोग करता है)। उन परिणामों को दबाना भी बेईमानी है जो शोधकर्ता के दृष्टिकोण से मेल नहीं खाते।
लेविन एट अल पुस्तक से सामग्री प्रबंधकों के लिए सांख्यिकी का उपयोग किया जाता है। - एम .: विलियम्स, 2004. - पी। 178–209
QUARTILE फ़ंक्शन को Excel के पुराने संस्करणों के साथ संरेखित करने के लिए बनाए रखा गया है
विश्लेषणात्मक दृष्टिकोण से औसत मूल्य सबसे मूल्यवान है और सांख्यिकीय संकेतकों की अभिव्यक्ति का एक सार्वभौमिक रूप है। सबसे सामान्य औसत - अंकगणितीय औसत - में कई गणितीय गुण होते हैं जिनका उपयोग इसकी गणना में किया जा सकता है। उसी समय, एक विशिष्ट औसत की गणना करते समय, हमेशा इसके तार्किक सूत्र पर भरोसा करने की सलाह दी जाती है, जो कि जनसंख्या की मात्रा के लिए विशेषता की मात्रा का अनुपात है। प्रत्येक माध्य के लिए, केवल एक वास्तविक संदर्भ अनुपात होता है, जिसे उपलब्ध आंकड़ों के आधार पर विभिन्न प्रकार के साधनों की आवश्यकता हो सकती है। हालांकि, सभी मामलों में जहां औसत मूल्य की प्रकृति वजन की उपस्थिति का तात्पर्य है, भारित औसत सूत्रों के बजाय उनके भारित सूत्रों का उपयोग करना असंभव है।
औसत मूल्य जनसंख्या के लिए विशेषता का सबसे विशिष्ट मूल्य है और जनसंख्या की इकाइयों के बीच समान शेयरों में वितरित जनसंख्या की विशेषता का आकार।
वह विशेषता जिसके लिए औसत मान की गणना की जाती है, कहलाती है औसतन .
औसत मूल्य एक संकेतक है जिसकी गणना निरपेक्ष या सापेक्ष मूल्यों की तुलना करके की जाती है। औसत मूल्य है
औसत मूल्य अध्ययन के तहत घटना को प्रभावित करने वाले सभी कारकों के प्रभाव को दर्शाता है, और उनके लिए परिणामी है। दूसरे शब्दों में, व्यक्तिगत विचलन को चुकाना और मामलों के प्रभाव को समाप्त करना, औसत मूल्य, इस क्रिया के परिणामों के सामान्य माप को दर्शाता है, अध्ययन के तहत घटना के सामान्य पैटर्न के रूप में कार्य करता है।
औसत के उपयोग के लिए शर्तें:
अध्ययन की गई जनसंख्या की एकरूपता। यदि यादृच्छिक कारक के प्रभाव के अधीन जनसंख्या के कुछ तत्वों में अध्ययन किए गए गुण के बाकी हिस्सों से काफी भिन्न मूल्य हैं, तो ये तत्व इस आबादी के औसत के आकार को प्रभावित करेंगे। इस मामले में, औसत जनसंख्या के लिए विशेषता के सबसे विशिष्ट मूल्य को व्यक्त नहीं करेगा। यदि अध्ययन की जा रही घटना विषमांगी है, तो उसे सजातीय तत्वों वाले समूहों में विभाजित करना आवश्यक है। इस मामले में, समूह औसत की गणना की जाती है - समूह औसत प्रत्येक समूह में घटना के सबसे विशिष्ट मूल्य को व्यक्त करता है, और फिर सभी तत्वों के लिए समग्र औसत मूल्य की गणना की जाती है, जो कि घटना को समग्र रूप से दर्शाती है। इसकी गणना समूह के औसत के रूप में की जाती है, प्रत्येक समूह में शामिल जनसंख्या तत्वों की संख्या से भारित;
समुच्चय में पर्याप्त संख्या में इकाइयाँ;
अध्ययन की गई जनसंख्या में विशेषता के अधिकतम और न्यूनतम मूल्य।
औसत मूल्य (संकेतक)- यह स्थान और समय की विशिष्ट परिस्थितियों में एक व्यवस्थित आबादी में एक विशेषता की सामान्यीकृत मात्रात्मक विशेषता है.
आँकड़ों में, औसत के निम्नलिखित रूपों (प्रकारों) का उपयोग किया जाता है, जिन्हें शक्ति और संरचनात्मक कहा जाता है:
Ø अंकगणित औसत(सरल और भारित);
![]() सरल
सरल
औसत(गणित और सांख्यिकी में) संख्याओं का समूह - सभी संख्याओं का योग उनकी संख्या से विभाजित होता है। यह केंद्रीय प्रवृत्ति के सबसे सामान्य उपायों में से एक है।
यह पाइथागोरस द्वारा प्रस्तावित किया गया था (ज्यामितीय माध्य और हार्मोनिक माध्य के साथ)।
अंकगणित माध्य के विशेष मामले माध्य (सामान्य जनसंख्या का) और नमूना माध्य (नमूनों का) हैं।
परिचय
डेटा के सेट को निरूपित करें एक्स = (एक्स 1 , एक्स 2 , …, एक्स एन), तो नमूना माध्य को आमतौर पर चर (x (\displaystyle (\bar (x))) के ऊपर एक क्षैतिज पट्टी द्वारा निरूपित किया जाता है, उच्चारित " एक्सएक डैश के साथ")।
ग्रीक अक्षर μ का प्रयोग संपूर्ण जनसंख्या के अंकगणितीय माध्य को दर्शाने के लिए किया जाता है। एक यादृच्छिक चर के लिए जिसके लिए एक माध्य मान परिभाषित किया गया है, μ is प्रायिकता माध्यया एक यादृच्छिक चर की गणितीय अपेक्षा। अगर सेट एक्सप्रायिकता माध्य μ के साथ यादृच्छिक संख्याओं का एक सेट है, तो किसी भी नमूने के लिए एक्स मैंइस संग्रह से μ = E( एक्स मैं) इस नमूने की अपेक्षा है।
व्यवहार में, μ और x (\displaystyle (\bar (x))) के बीच का अंतर यह है कि μ एक सामान्य चर है क्योंकि आप पूरी आबादी के बजाय नमूना देख सकते हैं। इसलिए, यदि नमूने को यादृच्छिक रूप से (प्रायिकता सिद्धांत के संदर्भ में) दर्शाया जाता है, तो x ¯ (\displaystyle (\bar (x))) (लेकिन μ नहीं) को एक यादृच्छिक चर के रूप में माना जा सकता है जिसमें नमूने पर संभाव्यता वितरण होता है ( माध्य का संभाव्यता वितरण)।
इन दोनों राशियों की गणना एक ही तरह से की जाती है:
एक्स ¯ = 1 एन ∑ आई = 1 एन एक्स आई = 1 एन (एक्स 1 + ⋯ + एक्स एन)। (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\cdots +x_(n))।)
यदि एक एक्सएक यादृच्छिक चर है, तो गणितीय अपेक्षा एक्समात्रा के बार-बार माप में मूल्यों के अंकगणितीय माध्य के रूप में माना जा सकता है एक्स. यह बड़ी संख्या के कानून की अभिव्यक्ति है। इसलिए, अज्ञात गणितीय अपेक्षा का अनुमान लगाने के लिए नमूना माध्य का उपयोग किया जाता है।
प्रारंभिक बीजगणित में, यह सिद्ध होता है कि माध्य एन+ 1 संख्या औसत से ऊपर एनसंख्याएँ यदि और केवल यदि नई संख्या पुराने औसत से अधिक है, कम और केवल यदि नई संख्या औसत से कम है, और यदि और केवल यदि नई संख्या औसत के बराबर है तो नहीं बदलती है। अधिक एन, नए और पुराने औसत के बीच का अंतर जितना छोटा होगा।
ध्यान दें कि कई अन्य "साधन" उपलब्ध हैं, जिनमें पावर-लॉ माध्य, कोलमोगोरोव माध्य, हार्मोनिक माध्य, अंकगणित-ज्यामितीय माध्य और विभिन्न भारित साधन (जैसे, अंकगणित-भारित माध्य, ज्यामितीय-भारित माध्य, हार्मोनिक-भारित माध्य) शामिल हैं। .
उदाहरण
- तीन संख्याओं के लिए, आपको उन्हें जोड़ना होगा और 3 से भाग देना होगा:
- चार संख्याओं के लिए, आपको उन्हें जोड़ना होगा और 4 से भाग देना होगा:
या आसान 5+5=10, 10:2। क्योंकि हमने 2 संख्याएँ जोड़ी हैं, जिसका अर्थ है कि हम कितनी संख्याएँ जोड़ते हैं, हम उससे विभाजित करते हैं।
सतत यादृच्छिक चर
निरंतर वितरित मान के लिए f (x) (\displaystyle f(x)) अंतराल पर अंकगणितीय माध्य [ a ; b ] (\displaystyle ) को एक निश्चित समाकलन द्वारा परिभाषित किया गया है:
एफ (एक्स) ¯ [ए; b ] = 1 b - a a b f (x) d x (\displaystyle (\overline (f(x)))_()=(\frac (1)(b-a))\int _(a)^(b) एफ (एक्स) डीएक्स)
औसत का उपयोग करने की कुछ समस्याएं
मजबूती की कमी
मुख्य लेख: आंकड़ों में मजबूतीयद्यपि अंकगणित माध्य को अक्सर साधन या केंद्रीय प्रवृत्तियों के रूप में उपयोग किया जाता है, यह अवधारणा मजबूत आंकड़ों पर लागू नहीं होती है, जिसका अर्थ है कि अंकगणितीय माध्य "बड़े विचलन" से बहुत अधिक प्रभावित होता है। यह उल्लेखनीय है कि बड़े विषमता वाले वितरण के लिए, अंकगणितीय माध्य "औसत" की अवधारणा के अनुरूप नहीं हो सकता है, और मजबूत आँकड़ों से माध्य के मान (उदाहरण के लिए, माध्यिका) केंद्रीय प्रवृत्ति का बेहतर वर्णन कर सकते हैं।
क्लासिक उदाहरण औसत आय की गणना है। अंकगणितीय माध्य को माध्यिका के रूप में गलत समझा जा सकता है, जिससे यह निष्कर्ष निकाला जा सकता है कि वास्तव में जितने लोग हैं, उससे अधिक आय वाले लोग हैं। "माध्य" आय की व्याख्या इस तरह से की जाती है कि अधिकांश लोगों की आय इस संख्या के करीब होती है। यह "औसत" (अंकगणितीय माध्य के अर्थ में) आय अधिकांश लोगों की आय से अधिक है, क्योंकि औसत से एक बड़े विचलन के साथ उच्च आय अंकगणितीय माध्य को अत्यधिक विषम बना देती है (इसके विपरीत, औसत आय "प्रतिरोध" करती है। ऐसा तिरछा)। हालांकि, यह "औसत" आय औसत आय के पास लोगों की संख्या के बारे में कुछ नहीं कहती है (और मोडल आय के पास लोगों की संख्या के बारे में कुछ नहीं कहती है)। हालांकि, अगर "औसत" और "बहुमत" की अवधारणाओं को हल्के में लिया जाता है, तो कोई गलत तरीके से निष्कर्ष निकाल सकता है कि ज्यादातर लोगों की आय वास्तव में उनकी तुलना में अधिक है। उदाहरण के लिए, मदीना, वाशिंगटन में "औसत" शुद्ध आय पर एक रिपोर्ट, जो निवासियों की सभी वार्षिक शुद्ध आय के अंकगणितीय औसत के रूप में गणना की जाती है, बिल गेट्स के कारण आश्चर्यजनक रूप से उच्च संख्या देगी। नमूने (1, 2, 2, 2, 3, 9) पर विचार करें। अंकगणितीय माध्य 3.17 है, लेकिन छह में से पांच मान इस माध्य से नीचे हैं।
चक्रवृद्धि ब्याज
मुख्य लेख: लागत पर लाभअगर संख्या गुणा, लेकिन नहीं तह करना, आपको ज्यामितीय माध्य का उपयोग करने की आवश्यकता है, न कि अंकगणितीय माध्य का। वित्त में निवेश पर प्रतिफल की गणना करते समय अक्सर यह घटना होती है।
उदाहरण के लिए, यदि स्टॉक पहले वर्ष में 10% गिर गया और दूसरे वर्ष में 30% बढ़ गया, तो इन दो वर्षों में "औसत" वृद्धि की गणना अंकगणितीय माध्य (−10% + 30%) / 2 के रूप में करना गलत है। = 10%; इस मामले में सही औसत चक्रवृद्धि वार्षिक वृद्धि दर द्वारा दिया गया है, जिसमें से वार्षिक वृद्धि केवल 8.16653826392% 8.2% है।
इसका कारण यह है कि प्रतिशत का हर बार एक नया प्रारंभिक बिंदु होता है: 30% 30% है पहले वर्ष की शुरुआत में कीमत से कम संख्या से:यदि स्टॉक 30 डॉलर से शुरू हुआ और 10% गिर गया, तो दूसरे वर्ष की शुरुआत में इसका मूल्य 27 डॉलर है। यदि स्टॉक 30% ऊपर है, तो दूसरे वर्ष के अंत में इसका मूल्य $35.1 है। इस वृद्धि का अंकगणितीय औसत 10% है, लेकिन चूंकि 2 वर्षों में स्टॉक केवल $5.1 बढ़ा है, 8.2% की औसत वृद्धि $35.1 का अंतिम परिणाम देती है:
[$30 (1 - 0.1) (1 + 0.3) = $30 (1 + 0.082) (1 + 0.082) = $35.1]। यदि हम उसी तरह से 10% के अंकगणितीय माध्य का उपयोग करते हैं, तो हमें वास्तविक मूल्य नहीं मिलेगा: [$30 (1 + 0.1) (1 + 0.1) = 36.3]।
वर्ष के अंत में चक्रवृद्धि ब्याज 2: 90% * 130% = 117% , यानी कुल 17% की वृद्धि, और औसत वार्षिक चक्रवृद्धि ब्याज 117% ≈ 108.2% (\displaystyle (\sqrt (117\%)) \लगभग 108.2\%) , यानी 8.2% की औसत वार्षिक वृद्धि।
दिशा-निर्देश
मुख्य लेख: गंतव्य आँकड़ेकिसी चर के अंकगणितीय माध्य की गणना करते समय जो चक्रीय रूप से बदलता है (उदाहरण के लिए, चरण या कोण), विशेष ध्यान रखा जाना चाहिए। उदाहरण के लिए, 1° और 359° का औसत 1 ∘ + 359 ∘ 2 = (\displaystyle (\frac (1^(\circ )+359^(\circ ))(2))=) 180° होगा। यह संख्या दो कारणों से गलत है।
- सबसे पहले, कोणीय उपायों को केवल 0° से 360° (या 0 से 2π जब रेडियन में मापा जाता है) की सीमा के लिए परिभाषित किया जाता है। इस प्रकार, संख्याओं के समान युग्म को (1° और -1°) या (1° और 719°) के रूप में लिखा जा सकता है। प्रत्येक जोड़ी का औसत अलग होगा: 1 ∘ + (− 1 ∘) 2 = 0 ∘ (\displaystyle (\frac (1^(\circ )+(-1^(\circ )))(2))= 0 ^(\circ )) , 1 + 719 ∘ 2 = 360 ∘ (\displaystyle (\frac (1^(\circ )+719^(\circ ))(2))=360^(\circ )) .
- दूसरा, इस मामले में, 0° (360° के बराबर) का मान ज्यामितीय रूप से सबसे अच्छा माध्य होगा, क्योंकि संख्याएं किसी भी अन्य मान की तुलना में 0° से कम विचलन करती हैं (मान 0° में सबसे छोटा विचरण होता है)। तुलना करना:
- संख्या 1° 0° से केवल 1° विचलित होती है;
- संख्या 1° 180° के परिकलित औसत से 179° का विचलन करती है।
उपरोक्त सूत्र के अनुसार गणना किए गए चक्रीय चर के लिए औसत मान को वास्तविक औसत के सापेक्ष संख्यात्मक श्रेणी के मध्य में कृत्रिम रूप से स्थानांतरित कर दिया जाएगा। इस वजह से, औसत की गणना एक अलग तरीके से की जाती है, अर्थात्, सबसे छोटे विचरण (केंद्र बिंदु) वाली संख्या को औसत मान के रूप में चुना जाता है। साथ ही, घटाने के बजाय, मोडुलो दूरी (यानी, परिधि दूरी) का उपयोग किया जाता है। उदाहरण के लिए, 1° और 359° के बीच मॉड्यूलर दूरी 2° है, न कि 358° (359° और 360°==0° के बीच के वृत्त पर - एक डिग्री, 0° और 1° के बीच - कुल मिलाकर 1° भी। - 2 डिग्री)।
4.3. औसत मान। औसत का सार और अर्थ
औसत मूल्यआँकड़ों में, एक सामान्यीकरण संकेतक कहा जाता है, जो स्थान और समय की विशिष्ट परिस्थितियों में एक घटना के विशिष्ट स्तर को दर्शाता है, जो गुणात्मक रूप से सजातीय जनसंख्या की प्रति इकाई भिन्न विशेषता के परिमाण को दर्शाता है। आर्थिक व्यवहार में, संकेतकों की एक विस्तृत श्रृंखला का उपयोग किया जाता है, जिसकी गणना औसत के रूप में की जाती है।
उदाहरण के लिए, एक संयुक्त स्टॉक कंपनी (JSC) में श्रमिकों की आय का एक सामान्य संकेतक एक कर्मचारी की औसत आय है, जो समीक्षाधीन अवधि (वर्ष, तिमाही, महीने) के लिए वेतन निधि और सामाजिक भुगतान के अनुपात से निर्धारित होता है। ) जेएससी में श्रमिकों की संख्या के लिए।
औसत की गणना करना एक सामान्य सामान्यीकरण तकनीक है; औसत संकेतक उस सामान्य को दर्शाता है जो अध्ययन की गई आबादी की सभी इकाइयों के लिए विशिष्ट (विशिष्ट) है, जबकि साथ ही यह व्यक्तिगत इकाइयों के बीच के अंतरों की उपेक्षा करता है। हर घटना और उसके विकास में एक संयोजन होता है मोकाऔर जरुरत।औसत की गणना करते समय, बड़ी संख्या के कानून के संचालन के कारण, यादृच्छिकता एक दूसरे को रद्द कर देती है, संतुलित हो जाती है, इसलिए आप प्रत्येक विशिष्ट मामले में विशेषता के मात्रात्मक मूल्यों से घटना की तुच्छ विशेषताओं से सार कर सकते हैं। व्यक्तिगत मूल्यों की यादृच्छिकता से अमूर्त करने की क्षमता में, उतार-चढ़ाव औसत का वैज्ञानिक मूल्य है: सारांशसमग्र विशेषताएं।
जहां सामान्यीकरण की आवश्यकता होती है, ऐसी विशेषताओं की गणना विशेषता के कई अलग-अलग व्यक्तिगत मूल्यों के प्रतिस्थापन की ओर ले जाती है मध्यमएक संकेतक जो घटनाओं की समग्रता की विशेषता है, जो सामूहिक सामाजिक घटनाओं में निहित पैटर्न की पहचान करना संभव बनाता है, एकल घटना में अगोचर।
औसत अध्ययन की गई घटनाओं की विशेषता, विशिष्ट, वास्तविक स्तर को दर्शाता है, इन स्तरों और समय और स्थान में उनके परिवर्तनों की विशेषता है।
औसत प्रक्रिया की नियमितताओं का एक सारांश विशेषता है जिसमें यह आगे बढ़ने की स्थिति में होता है।
4.4. औसत के प्रकार और उनकी गणना के तरीके
औसत के प्रकार का चुनाव एक निश्चित संकेतक की आर्थिक सामग्री और प्रारंभिक डेटा द्वारा निर्धारित किया जाता है। प्रत्येक मामले में, औसत मूल्यों में से एक लागू होता है: अंकगणित, गारोमोनिक, ज्यामितीय, द्विघात, घनआदि। सूचीबद्ध औसत वर्ग के हैं शक्तिमध्यम।
पावर-लॉ औसत के अलावा, सांख्यिकीय अभ्यास में, संरचनात्मक औसत का उपयोग किया जाता है, जिसे मोड और माध्य माना जाता है।
आइए हम शक्ति साधनों पर अधिक विस्तार से ध्यान दें।
अंकगणित औसत
औसत का सबसे सामान्य प्रकार है औसत अंकगणित।इसका उपयोग उन मामलों में किया जाता है जहां पूरी आबादी के लिए एक चर विशेषता का आयतन इसकी व्यक्तिगत इकाइयों की विशेषताओं के मूल्यों का योग होता है। सामाजिक घटनाओं को एक अलग विशेषता के संस्करणों के योग (योग) की विशेषता है, यह अंकगणितीय माध्य के दायरे को निर्धारित करता है और एक सामान्य संकेतक के रूप में इसकी व्यापकता की व्याख्या करता है, उदाहरण के लिए: कुल मजदूरी निधि सभी की मजदूरी का योग है श्रमिकों, सकल फसल पूरे बुवाई क्षेत्र से निर्मित उत्पादों का योग है।
अंकगणित माध्य की गणना करने के लिए, आपको सभी विशेषता मानों के योग को उनकी संख्या से विभाजित करने की आवश्यकता है।
अंकगणित माध्य को रूप में लागू किया जाता है साधारण औसत और भारित औसत।साधारण औसत प्रारंभिक, परिभाषित रूप के रूप में कार्य करता है।
सरल अंकगणित माध्यइन मूल्यों की कुल संख्या से विभाजित औसत विशेषता के व्यक्तिगत मूल्यों के साधारण योग के बराबर है (इसका उपयोग उन मामलों में किया जाता है जहां सुविधा के अवर्गीकृत व्यक्तिगत मूल्य होते हैं):
कहाँ पे  - चर के व्यक्तिगत मूल्य (विकल्प); एम
- जनसंख्या इकाइयों की संख्या।
- चर के व्यक्तिगत मूल्य (विकल्प); एम
- जनसंख्या इकाइयों की संख्या।
सूत्रों में आगे की योग सीमा का संकेत नहीं दिया जाएगा। उदाहरण के लिए, एक श्रमिक (ताला बनाने वाला) का औसत उत्पादन ज्ञात करना आवश्यक है, यदि यह ज्ञात हो कि प्रत्येक 15 श्रमिकों में से कितने भागों का उत्पादन किया गया है, अर्थात। विशेषता, पीसी के कई व्यक्तिगत मूल्यों को देखते हुए:
21; 20; 20; 19; 21; 19; 18; 22; 19; 20; 21; 20; 18; 19; 20.
सरल अंकगणितीय माध्य की गणना सूत्र (4.1), 1 पीसी द्वारा की जाती है।
विकल्पों का औसत जो अलग-अलग संख्या में दोहराया जाता है, या कहा जाता है कि अलग-अलग भार हैं, उसे कहा जाता है भारित।भार विभिन्न जनसंख्या समूहों में इकाइयों की संख्या है (समूह समान विकल्पों को जोड़ता है)।
अंकगणित भारित औसत- औसत समूहीकृत मान , - की गणना सूत्र द्वारा की जाती है:
 , (4.2)
, (4.2)
कहाँ पे  - वजन (समान सुविधाओं की पुनरावृत्ति की आवृत्ति);
- वजन (समान सुविधाओं की पुनरावृत्ति की आवृत्ति);
 -
उनकी आवृत्तियों द्वारा सुविधाओं के परिमाण के उत्पादों का योग;
-
उनकी आवृत्तियों द्वारा सुविधाओं के परिमाण के उत्पादों का योग;
 -
जनसंख्या इकाइयों की कुल संख्या।
-
जनसंख्या इकाइयों की कुल संख्या।
हम ऊपर चर्चा किए गए उदाहरण का उपयोग करके अंकगणितीय भारित औसत की गणना के लिए तकनीक का वर्णन करेंगे। ऐसा करने के लिए, हम प्रारंभिक डेटा को समूहित करते हैं और उन्हें तालिका में रखते हैं। 4.1.
तालिका 4.1
भागों के विकास के लिए श्रमिकों का वितरण
सूत्र (4.2) के अनुसार, अंकगणितीय भारित औसत बराबर है, टुकड़े:
कुछ मामलों में, वज़न को निरपेक्ष मानों द्वारा नहीं, बल्कि सापेक्ष (प्रतिशत या इकाई के अंशों में) द्वारा दर्शाया जा सकता है। तब अंकगणितीय भारित औसत का सूत्र इस प्रकार दिखेगा:

कहाँ पे  - विशेष, अर्थात्। सभी के कुल योग में प्रत्येक आवृत्ति का हिस्सा
- विशेष, अर्थात्। सभी के कुल योग में प्रत्येक आवृत्ति का हिस्सा
यदि आवृत्तियों को भिन्नों (गुणांक) में गिना जाता है, तो  = 1, और अंकगणितीय रूप से भारित औसत का सूत्र है:
= 1, और अंकगणितीय रूप से भारित औसत का सूत्र है:

समूह औसत से अंकगणितीय भारित औसत की गणना  सूत्र के अनुसार किया जाता है:
सूत्र के अनुसार किया जाता है:
 ,
,
कहाँ पे एफ-प्रत्येक समूह में इकाइयों की संख्या।
समूह माध्य के अंकगणितीय माध्य की गणना के परिणाम तालिका में प्रस्तुत किए गए हैं। 4.2.
तालिका 4.2
सेवा की औसत लंबाई के आधार पर श्रमिकों का वितरण
इस उदाहरण में, विकल्प व्यक्तिगत श्रमिकों की सेवा की लंबाई पर व्यक्तिगत डेटा नहीं हैं, बल्कि प्रत्येक कार्यशाला के लिए औसत हैं। तराजू एफदुकानों में श्रमिकों की संख्या है। इसलिए, पूरे उद्यम में श्रमिकों का औसत कार्य अनुभव होगा, वर्ष:
 .
.
वितरण श्रृंखला में अंकगणितीय माध्य की गणना
यदि औसत विशेषता के मान अंतराल ("से - से") के रूप में दिए गए हैं, अर्थात। अंतराल वितरण श्रृंखला, फिर अंकगणितीय माध्य मान की गणना करते समय, इन अंतरालों के मध्य बिंदुओं को समूहों में सुविधाओं के मूल्यों के रूप में लिया जाता है, जिसके परिणामस्वरूप एक असतत श्रृंखला बनती है। निम्नलिखित उदाहरण पर विचार करें (सारणी 4.3)।
आइए अंतराल मानों को उनके औसत मान / (साधारण औसत) के साथ बदलकर एक अंतराल श्रृंखला से एक असतत श्रृंखला में चलते हैं
तालिका 4.3
मासिक वेतन के स्तर से एओ श्रमिकों का वितरण
|
के लिए श्रमिकों के समूह |
श्रमिकों की संख्या |
अंतराल के बीच |
|
|
मजदूरी, रगड़। |
पर्स।, एफ |
रगड़ना।, एक्स |
|
|
900 और अधिक |
|||
खुले अंतराल (प्रथम और अंतिम) के मान सशर्त रूप से उनसे सटे अंतराल (दूसरे और अंतिम) के बराबर होते हैं।
औसत की इस तरह की गणना के साथ, कुछ अशुद्धि की अनुमति है, क्योंकि समूह के भीतर विशेषता की इकाइयों के समान वितरण के बारे में एक धारणा बनाई गई है। हालाँकि, त्रुटि जितनी छोटी होगी, अंतराल उतना ही संकरा होगा और अंतराल में जितनी अधिक इकाइयाँ होंगी।
अंतराल के मध्य बिंदु पाए जाने के बाद, गणना उसी तरह से की जाती है जैसे असतत श्रृंखला में - विकल्पों को आवृत्तियों (वजन) से गुणा किया जाता है और उत्पादों के योग को आवृत्तियों (वजन) के योग से विभाजित किया जाता है। , हजार रूबल:
 .
.
तो, जेएससी में श्रमिकों के पारिश्रमिक का औसत स्तर 729 रूबल है। प्रति माह।
अंकगणितीय माध्य की गणना अक्सर समय और श्रम के बड़े व्यय से जुड़ी होती है। हालांकि, कुछ मामलों में, औसत की गणना करने की प्रक्रिया को इसके गुणों का उपयोग करके सरल और सुविधाजनक बनाया जा सकता है। आइए हम (बिना प्रमाण के) समांतर माध्य के कुछ मूल गुण प्रस्तुत करते हैं।
संपत्ति 1. यदि सभी व्यक्तिगत विशेषता मान (अर्थात। सभी विकल्प) में कमी या वृद्धि मैंबार, फिर औसत मूल्य एक नई सुविधा में तदनुसार कमी या वृद्धि होगी मैंएक बार।
संपत्ति 2. अगर एवरेज फीचर के सभी वेरिएंट कम कर दिए जाते हैंसंख्या A से सीना या बढ़ाना, तो अंकगणितीय माध्यसमान संख्या A से काफी कमी या वृद्धि।
संपत्ति 3. यदि सभी औसत विकल्पों का भार कम कर दिया जाता है या बढ़ाने के लिए को समय, अंकगणितीय माध्य नहीं बदलेगा।
औसत भार के रूप में, निरपेक्ष संकेतकों के बजाय, आप समग्र कुल (शेयर या प्रतिशत) में विशिष्ट भार का उपयोग कर सकते हैं। यह औसत की गणना को सरल करता है।
औसत की गणना को सरल बनाने के लिए, वे विकल्पों और आवृत्तियों के मूल्यों को कम करने के मार्ग का अनुसरण करते हैं। सबसे बड़ा सरलीकरण तब प्राप्त होता है जब लेकिनउच्चतम आवृत्ति वाले केंद्रीय विकल्पों में से एक का मान / - अंतराल के मान (समान अंतराल वाली पंक्तियों के लिए) के रूप में चुना जाता है। L के मान को मूल कहा जाता है, इसलिए औसत की गणना करने की इस पद्धति को "सशर्त शून्य से गिनने की विधि" या "क्षणों की विधि"।
आइए मान लें कि सभी विकल्प एक्सपहले समान संख्या A से घटाया गया, और फिर में घटाया गया मैंएक बार। हमें नए वेरिएंट की एक नई विविधता वितरण श्रृंखला मिलती है  .
.
फिर नए विकल्पव्यक्त किया जाएगा:
 ,
,
और उनका नया अंकगणित माध्य  , -पहला आदेश क्षण- सूत्र:
, -पहला आदेश क्षण- सूत्र:
 .
.
यह मूल विकल्पों के औसत के बराबर है, पहले घटाकर लेकिन,और फिर में मैंएक बार।
वास्तविक औसत प्राप्त करने के लिए, आपको पहले आदेश का एक क्षण चाहिए एम 1 , से गुणा करो मैंऔर जोड़ लेकिन:
 .
.
एक परिवर्तनशील श्रृंखला से अंकगणितीय माध्य की गणना करने की इस पद्धति को कहा जाता है "क्षणों की विधि"।यह विधि समान अंतराल वाली पंक्तियों में लागू की जाती है।
आघूर्णों की विधि द्वारा अंकगणितीय माध्य की गणना तालिका में दिए गए डेटा द्वारा सचित्र है। 4.4.
तालिका 4.4
2000 में अचल उत्पादन परिसंपत्तियों (ओपीएफ) के मूल्य से क्षेत्र में छोटे उद्यमों का वितरण
|
ओपीएफ की लागत से उद्यमों के समूह, हजार रूबल |
उद्यमों की संख्या एफ |
मध्य अंतराल, एक्स |
|
|
|
14-16 16-18 18-20 20-22 22-24 |
||||


पहले आदेश का क्षण ढूँढना
 .
.
फिर, A = 19 मानकर और यह जानते हुए कि मैं= 2, गणना एक्स,हजार रूबल।:
औसत मूल्यों के प्रकार और उनकी गणना के तरीके
सांख्यिकीय प्रसंस्करण के चरण में, विभिन्न प्रकार के शोध कार्य निर्धारित किए जा सकते हैं, जिनके समाधान के लिए उपयुक्त औसत चुनना आवश्यक है। इस मामले में, निम्नलिखित नियम द्वारा निर्देशित होना आवश्यक है: औसत के अंश और हर का प्रतिनिधित्व करने वाले मान तार्किक रूप से एक दूसरे से संबंधित होने चाहिए।
- बिजली औसत;
- संरचनात्मक औसत.
आइए निम्नलिखित संकेतन का परिचय दें:
वे मान जिनके लिए औसत की गणना की जाती है;
औसत, जहां ऊपर की रेखा इंगित करती है कि व्यक्तिगत मूल्यों का औसत होता है;
आवृत्ति (व्यक्तिगत विशेषता मूल्यों की दोहराव)।
विभिन्न साधन सामान्य शक्ति माध्य सूत्र से प्राप्त होते हैं:
 (5.1)
(5.1)
k = 1 के लिए - अंकगणितीय माध्य; के = -1 - हार्मोनिक माध्य; के = 0 - ज्यामितीय माध्य; k = -2 - मूल माध्य वर्ग।
औसत या तो सरल या भारित होते हैं। भारित औसतवे मात्राएँ कहलाती हैं जो इस बात को ध्यान में रखती हैं कि विशेषता के मूल्यों के कुछ प्रकारों में भिन्न संख्याएँ हो सकती हैं, और इसलिए प्रत्येक संस्करण को इस संख्या से गुणा करना पड़ता है। दूसरे शब्दों में, "वजन" विभिन्न समूहों में जनसंख्या इकाइयों की संख्या है, अर्थात। प्रत्येक विकल्प इसकी आवृत्ति से "भारित" होता है। आवृत्ति f कहा जाता है सांख्यिकीय भारया वजन औसत.
अंकगणित औसत- माध्यम का सबसे आम प्रकार। इसका उपयोग तब किया जाता है जब गणना अवर्गीकृत सांख्यिकीय डेटा पर की जाती है, जहां आप औसत सारांश प्राप्त करना चाहते हैं। अंकगणित माध्य किसी विशेषता का ऐसा औसत मान है, जिसके प्राप्त होने पर जनसंख्या में विशेषता का कुल आयतन अपरिवर्तित रहता है।
अंकगणित माध्य सूत्र ( सरल) का रूप है
जहाँ n जनसंख्या का आकार है।
उदाहरण के लिए, किसी उद्यम के कर्मचारियों के औसत वेतन की गणना अंकगणितीय औसत के रूप में की जाती है:

यहां निर्धारण संकेतक प्रत्येक कर्मचारी की मजदूरी और उद्यम के कर्मचारियों की संख्या हैं। औसत की गणना करते समय, मजदूरी की कुल राशि समान रही, लेकिन सभी श्रमिकों के बीच समान रूप से वितरित की गई। उदाहरण के लिए, एक छोटी कंपनी के कर्मचारियों के औसत वेतन की गणना करना आवश्यक है जहां 8 लोग कार्यरत हैं:
औसत की गणना करते समय, औसत की विशेषता के व्यक्तिगत मूल्यों को दोहराया जा सकता है, इसलिए औसत की गणना समूहीकृत डेटा का उपयोग करके की जाती है। इस मामले में, हम उपयोग करने के बारे में बात कर रहे हैं अंकगणित माध्य भारित, जो दिखता है
 (5.3)
(5.3)
इसलिए, हमें स्टॉक एक्सचेंज में एक संयुक्त स्टॉक कंपनी के औसत शेयर मूल्य की गणना करने की आवश्यकता है। यह ज्ञात है कि लेनदेन 5 दिनों (5 लेनदेन) के भीतर किया गया था, बिक्री दर पर बेचे गए शेयरों की संख्या निम्नानुसार वितरित की गई थी:
1 - 800 ए.सी. - 1010 रूबल
2 - 650 ए.सी. - 990 रगड़।
3 - 700 एके। - 1015 रूबल।
4 - 550 ए.सी. - 900 रगड़।
5 - 850 एके। - 1150 रूबल।
औसत शेयर मूल्य निर्धारित करने के लिए प्रारंभिक अनुपात लेनदेन की कुल राशि (ओएसएस) और बेचे गए शेयरों की संख्या (केपीए) का अनुपात है।
एक्सेल में औसत मूल्य (चाहे वह संख्यात्मक, पाठ्य, प्रतिशत या अन्य मान हो) खोजने के लिए, कई कार्य हैं। और उनमें से प्रत्येक की अपनी विशेषताएं और फायदे हैं। आखिरकार, इस कार्य में कुछ शर्तें निर्धारित की जा सकती हैं।
उदाहरण के लिए, एक्सेल में संख्याओं की एक श्रृंखला के औसत मूल्यों की गणना सांख्यिकीय कार्यों का उपयोग करके की जाती है। आप मैन्युअल रूप से अपना स्वयं का सूत्र भी दर्ज कर सकते हैं। आइए विभिन्न विकल्पों पर विचार करें।
संख्याओं का अंकगणितीय माध्य कैसे ज्ञात करें?
समांतर माध्य ज्ञात करने के लिए, आप समुच्चय में सभी संख्याओं को जोड़ते हैं और योग को संख्या से विभाजित करते हैं। उदाहरण के लिए, कंप्यूटर विज्ञान में एक छात्र का ग्रेड: 3, 4, 3, 5, 5. / 5.
एक्सेल फ़ंक्शंस का उपयोग करके इसे जल्दी से कैसे करें? उदाहरण के लिए एक स्ट्रिंग में यादृच्छिक संख्याओं की एक श्रृंखला लें:

या: सेल को सक्रिय बनाएं और बस मैन्युअल रूप से सूत्र दर्ज करें: =AVERAGE(A1:A8)।
अब देखते हैं कि AVERAGE फ़ंक्शन और क्या कर सकता है।

पहले दो और अंतिम तीन संख्याओं का समांतर माध्य ज्ञात कीजिए। सूत्र: = औसत (A1:B1;F1:H1)। नतीजा:
स्थिति के अनुसार औसत
अंकगणित माध्य खोजने की शर्त एक संख्यात्मक मानदंड या एक पाठ हो सकती है। हम फ़ंक्शन का उपयोग करेंगे: =AVERAGEIF ()।
उन संख्याओं का समांतर माध्य ज्ञात कीजिए जो 10 से अधिक या उसके बराबर हों।
समारोह: = औसत (A1:A8,">=10")
 ">=10" शर्त पर AVERAGEIF फ़ंक्शन का उपयोग करने का परिणाम:
">=10" शर्त पर AVERAGEIF फ़ंक्शन का उपयोग करने का परिणाम: तीसरा तर्क - "औसत श्रेणी" - छोड़ा गया है। सबसे पहले, इसकी आवश्यकता नहीं है। दूसरे, प्रोग्राम द्वारा पार्स की गई श्रेणी में केवल संख्यात्मक मान होते हैं। पहले तर्क में निर्दिष्ट कोशिकाओं में, दूसरे तर्क में निर्दिष्ट शर्त के अनुसार खोज की जाएगी।
ध्यान! खोज मानदंड एक सेल में निर्दिष्ट किया जा सकता है। और इसका संदर्भ देने के सूत्र में।
आइए पाठ मानदंड द्वारा संख्याओं का औसत मान ज्ञात करें। उदाहरण के लिए, उत्पाद "टेबल" की औसत बिक्री।

फ़ंक्शन इस तरह दिखेगा: =AVERAGEIF($A$2:$A$12;A7;$B$2:$B$12)। रेंज - उत्पाद के नाम वाला एक कॉलम। खोज मानदंड "टेबल" शब्द के साथ एक सेल का लिंक है (आप लिंक ए 7 के बजाय "टेबल" शब्द डाल सकते हैं)। औसत सीमा - वे सेल जिनसे औसत मूल्य की गणना करने के लिए डेटा लिया जाएगा।
फ़ंक्शन की गणना के परिणामस्वरूप, हम निम्नलिखित मान प्राप्त करते हैं:
ध्यान! टेक्स्ट मानदंड (शर्त) के लिए, औसत श्रेणी निर्दिष्ट की जानी चाहिए।
एक्सेल में भारित औसत मूल्य की गणना कैसे करें?

हम भारित औसत मूल्य कैसे जानते हैं?
सूत्र: = SUMPRODUCT(C2:C12,B2:B12)/SUM(C2:C12)।

SUMPRODUCT सूत्र का उपयोग करके, हम माल की पूरी मात्रा की बिक्री के बाद कुल राजस्व का पता लगाते हैं। और SUM फ़ंक्शन - माल की मात्रा का योग करता है। माल की बिक्री से कुल राजस्व को माल की कुल इकाइयों की संख्या से विभाजित करके, हमने भारित औसत मूल्य पाया। यह संकेतक प्रत्येक मूल्य के "वजन" को ध्यान में रखता है। मूल्यों के कुल द्रव्यमान में इसका हिस्सा।
मानक विचलन: एक्सेल में सूत्र
सामान्य जनसंख्या और नमूने के लिए मानक विचलन के बीच अंतर करें। पहले मामले में, यह सामान्य विचरण का मूल है। दूसरे में, नमूना विचरण से।
इस सांख्यिकीय संकेतक की गणना करने के लिए, एक फैलाव सूत्र संकलित किया जाता है। इसकी जड़ ली जाती है। लेकिन एक्सेल में मानक विचलन खोजने के लिए एक तैयार कार्य है।

मानक विचलन स्रोत डेटा के पैमाने से जुड़ा हुआ है। यह विश्लेषण की गई सीमा की भिन्नता के आलंकारिक प्रतिनिधित्व के लिए पर्याप्त नहीं है। डेटा में बिखराव का सापेक्ष स्तर प्राप्त करने के लिए, भिन्नता के गुणांक की गणना की जाती है:
मानक विचलन / अंकगणित माध्य
एक्सेल में सूत्र इस तरह दिखता है:
STDEV (मानों की श्रेणी) / औसत (मानों की श्रेणी)।
भिन्नता के गुणांक की गणना प्रतिशत के रूप में की जाती है। इसलिए, हम सेल में प्रतिशत प्रारूप निर्धारित करते हैं।
