Die Verwendung von Statistiken in diesem Hinweis wird anhand eines Querschnittsbeispiels gezeigt. Angenommen, Sie sind Produktionsleiter bei Perfect Parachute. Fallschirme werden aus synthetischen Fasern hergestellt, die von vier verschiedenen Lieferanten geliefert werden. Eines der Hauptmerkmale eines Fallschirms ist seine Stärke. Es ist darauf zu achten, dass alle zugeführten Fasern die gleiche Stärke haben. Um diese Frage zu beantworten, ist es notwendig, ein Experiment zu konzipieren, bei dem die Festigkeit von Fallschirmen gemessen wird, die aus synthetischen Fasern verschiedener Lieferanten gewebt sind. Die während dieses Experiments gewonnenen Informationen werden bestimmen, welcher Anbieter die langlebigsten Fallschirme anbietet.
Viele Anwendungen beziehen sich auf Experimente, bei denen mehrere Gruppen oder Ebenen eines Faktors betrachtet werden. Einige Faktoren, wie z. B. die Brenntemperatur der Keramik, können mehrere Zahlenwerte haben (z. B. 300°, 350°, 400° und 450°). Andere Faktoren, wie etwa der Standort von Waren in einem Supermarkt, können kategoriale Ebenen haben (z. B. erster Lieferant, zweiter Lieferant, dritter Lieferant, vierter Lieferant). Ein-Faktor-Experimente, bei denen Versuchseinheiten zufällig Gruppen oder Faktorstufen zugeordnet werden, nennt man vollrandomisiert.
VerwendungszweckF-Kriterien zur Bewertung der Unterschiede zwischen mehreren mathematischen Erwartungen
Wenn numerische Messungen eines Faktors in Gruppen kontinuierlich sind und einige zusätzliche Bedingungen erfüllt sind, wird eine Varianzanalyse (ANOVA - Ein Analyse Ö f Va riechen). Die Varianzanalyse unter Verwendung vollständig randomisierter Designs wird als einfache ANOVA bezeichnet. In gewisser Weise ist der Begriff Varianzanalyse irreführend, da er die Unterschiede zwischen den Mittelwerten der Gruppen vergleicht, nicht zwischen den Varianzen. Der Vergleich der mathematischen Erwartungen erfolgt jedoch gerade auf der Grundlage der Analyse der Datenvariation. Beim ANOVA-Verfahren wird die Gesamtstreuung der Messergebnisse in Intergruppen und Intragruppen aufgeteilt (Abb. 1). Die Variation innerhalb der Gruppen wird durch experimentelle Fehler erklärt, während die Variation zwischen den Gruppen durch die Auswirkungen der experimentellen Bedingungen erklärt wird. Symbol Mit gibt die Anzahl der Gruppen an.
Reis. 1. Variationstrennung in einem vollständig randomisierten Experiment
Hinweis im Format oder herunterladen, Beispiele im Format
Stellen wir uns das vor Mit Gruppen werden aus unabhängigen Populationen gezogen, die eine Normalverteilung und dieselbe Varianz aufweisen. Die Nullhypothese lautet, dass die mathematischen Erwartungen der Populationen gleich sind: H 0: μ 1 = μ 2 = ... = μ s. Die alternative Hypothese besagt, dass nicht alle mathematischen Erwartungen gleich sind: H1: nicht alle μ j sind gleich j= 1, 2, …, s).
Auf Abb. Abbildung 2 stellt die wahre Nullhypothese über die mathematischen Erwartungen der fünf verglichenen Gruppen dar, vorausgesetzt, dass die Grundgesamtheiten eine Normalverteilung und die gleiche Varianz aufweisen. Die fünf Populationen, die mit unterschiedlichen Faktorniveaus assoziiert sind, sind identisch. Daher werden sie einander überlagert und haben die gleiche mathematische Erwartung, Variation und Form.

Reis. 2. Fünf Populationen haben dieselbe mathematische Erwartung: μ1 = μ2 = μ3 = μ4 = μ5
Nehmen wir andererseits an, dass die Nullhypothese tatsächlich falsch ist und die vierte Ebene die größte mathematische Erwartung hat, die erste Ebene eine etwas niedrigere mathematische Erwartung hat und die verbleibenden Ebenen die gleichen und sogar noch kleinere mathematische Erwartungen haben (Abb. 3). Beachten Sie, dass mit Ausnahme des Mittelwerts alle fünf Populationen identisch sind (d. h. dieselbe Variabilität und Form haben).

Reis. 3. Die Wirkung der Versuchsbedingungen wird beobachtet: μ4 > μ1 > μ2 = μ3 = μ5
Beim Testen der Hypothese der Gleichheit der mathematischen Erwartungen mehrerer allgemeiner Populationen wird die Gesamtvariation in zwei Teile unterteilt: Variation zwischen Gruppen aufgrund von Unterschieden zwischen Gruppen und Variation innerhalb von Gruppen aufgrund von Unterschieden zwischen Elementen, die derselben Gruppe angehören. Die Gesamtvariation wird als Gesamtsumme der Quadrate (SST – sum of squares total) ausgedrückt. Da die Nullhypothese lautet, dass die Erwartung aller Mit Gruppen einander gleich sind, ist die Gesamtvariation gleich der Summe der quadrierten Differenzen zwischen einzelnen Beobachtungen und dem für alle Stichproben berechneten Gesamtmittelwert (Mittelwert der Mittelwerte). Vollständige Variante:

wo ![]() - Gesamtdurchschnitt, Xij - ich-e zuschauen j-te Gruppe oder Ebene, NJ- Anzahl der Beobachtungen in j-te Gruppe, n- Gesamtzahl der Beobachtungen in allen Gruppen (d. h. n = n 1
+ n 2 + … + nc), Mit- Anzahl der studierten Gruppen oder Niveaus.
- Gesamtdurchschnitt, Xij - ich-e zuschauen j-te Gruppe oder Ebene, NJ- Anzahl der Beobachtungen in j-te Gruppe, n- Gesamtzahl der Beobachtungen in allen Gruppen (d. h. n = n 1
+ n 2 + … + nc), Mit- Anzahl der studierten Gruppen oder Niveaus.
Variation zwischen den Gruppen, normalerweise als Summe der Quadrate zwischen Gruppen (SSA) bezeichnet, ist gleich der Summe der quadrierten Differenzen zwischen dem Stichprobenmittelwert jeder Gruppe j und Gesamtdurchschnitt multipliziert mit dem Volumen der entsprechenden Gruppe NJ:

wo Mit- die Anzahl der unterrichteten Gruppen oder Niveaus, NJ- Anzahl der Beobachtungen in j-te Gruppe, j- mittlere Bedeutung j-te Gruppe, - allgemeiner Durchschnitt.
Variation innerhalb der Gruppe, üblicherweise Summe der Quadrate innerhalb von Gruppen (SSW) genannt, ist gleich der Summe der quadrierten Differenzen zwischen den Elementen jeder Gruppe und dem Stichprobenmittelwert dieser Gruppe j:

wo Xij - ich-tes Element j-te Gruppe, j- mittlere Bedeutung j-te Gruppe.
Weil sie verglichen werden Mit Faktorstufen, die Summe der Quadrate zwischen den Gruppen hat s - 1 Freiheitsgrade. Jeder von Mit Ebenen hat NJ – 1 Freiheitsgrade, also die gruppeninterne Summe der Quadrate hat n- Mit Freiheitsgrade u

Außerdem hat die Gesamtsumme der Quadrate n – 1 Freiheitsgrade, da jede Beobachtung Xij gegenüber dem über alles errechneten Gesamtdurchschnitt n Beobachtungen. Dividiert man jede dieser Summen durch die entsprechende Anzahl an Freiheitsgraden, ergeben sich drei Arten von Streuung: Intergruppe(mittleres Quadrat unter - MSA), konzernintern(mittleres Quadrat innerhalb - MSW) und Komplett(mittlere Quadratsumme - MST):
Obwohl der Hauptzweck der Varianzanalyse darin besteht, die mathematischen Erwartungen zu vergleichen Mit Gruppen, um die Wirkung experimenteller Bedingungen aufzudecken, ist sein Name darauf zurückzuführen, dass das Hauptwerkzeug die Analyse von Varianzen verschiedener Art ist. Wenn die Nullhypothese wahr ist, und zwischen den erwarteten Werten Mit Gruppen gibt es keine signifikanten Unterschiede, alle drei Varianzen – MSA, MSW und MST – sind Schätzungen der Varianz σ2 in den analysierten Daten enthalten. Also um die Nullhypothese zu testen H 0: μ 1 = μ 2 = ... = μ s und Alternativhypothese H1: nicht alle μ j sind gleich j = 1, 2, …, Mit), ist es notwendig, die Statistik zu berechnen F-Kriterium, das das Verhältnis zweier Varianzen ist, MSA und MSW. Prüfung F-Statistik in der univariaten Varianzanalyse

Statistiken F-Kriterien gehorcht F- Verteilung mit s - 1 Freiheitsgrade im Zähler MSA und n - mit Freiheitsgrade im Nenner MSW. Für ein gegebenes Signifikanzniveau α wird die Nullhypothese zurückgewiesen, wenn sie berechnet wird F FU inhärent F- Verteilung mit s - 1 n - mit Freiheitsgrade im Nenner. Somit, wie in Abb. 4 wird die Entscheidungsregel wie folgt formuliert: Nullhypothese H 0 abgelehnt, wenn F > FU; andernfalls wird es nicht zurückgewiesen.

Reis. 4. Kritischer Bereich der Varianzanalyse beim Testen einer Hypothese H 0
Wenn die Nullhypothese H 0 stimmt, berechnet F-Statistik ist nahe bei 1, da Zähler und Nenner Schätzungen desselben Werts sind - die Varianz σ 2, die den analysierten Daten innewohnt. Wenn die Nullhypothese H 0 falsch ist (und es gibt einen signifikanten Unterschied zwischen den Erwartungswerten verschiedener Gruppen), berechnet F-Statistik wird viel größer als eins sein, da ihr Zähler, MSA, zusätzlich zur natürlichen Variabilität der Daten, die Wirkung von experimentellen Bedingungen oder den Unterschied zwischen Gruppen schätzt, während der Nenner MSW nur die natürliche Variabilität der Daten schätzt. Somit ist das ANOVA-Verfahren F ist ein Test, bei dem bei gegebenem Signifikanzniveau α die Nullhypothese verworfen wird, wenn sie berechnet wird F- Statistiken sind größer als der obere kritische Wert FU inhärent F- Verteilung mit s - 1 Freiheitsgrade im Zähler und n - mit Freiheitsgrade im Nenner, wie in Abb. vier.
Um die einseitige Varianzanalyse zu veranschaulichen, kehren wir zu dem Szenario zurück, das am Anfang der Notiz skizziert wurde. Ziel des Experiments ist es festzustellen, ob Fallschirme, die aus synthetischen Fasern verschiedener Lieferanten gewebt sind, die gleiche Festigkeit aufweisen. Jede Gruppe hat fünf Fallschirme gewebt. Die Gruppen werden nach Lieferanten eingeteilt - Lieferant 1, Lieferant 2, Lieferant 3 und Lieferant 4. Die Festigkeit von Fallschirmen wird mit einem speziellen Gerät gemessen, das das Gewebe auf beiden Seiten auf Reißen prüft. Die Kraft, die erforderlich ist, um einen Fallschirm zu zerbrechen, wird auf einer speziellen Skala gemessen. Je höher die Bruchkraft, desto stärker der Fallschirm. Excel ermöglicht Analysen F-Statistiken mit einem Klick. Gehen Sie durch das Menü Daten → Datenanalyse, und wählen Sie die Zeile aus Einweganalyse der Varianz, füllen Sie das geöffnete Fenster aus (Abb. 5). Die Ergebnisse des Experiments (Gap-Stärke), einige deskriptive Statistiken und die Ergebnisse der Einweg-Varianzanalyse sind in den Fig. 6 und 7 gezeigt. 6.

Reis. 5. Fenster Einweg-ANOVA-Analysepaketübertreffen

Reis. Abb. 6. Festigkeitsindikatoren von Fallschirmen aus synthetischen Fasern, die von verschiedenen Lieferanten bezogen wurden, deskriptive Statistiken und Ergebnisse einer einseitigen Varianzanalyse
Eine Analyse von Abbildung 6 zeigt, dass es einen gewissen Unterschied zwischen den Mittelwerten der Stichprobe gibt. Die durchschnittliche Festigkeit der vom ersten Lieferanten erhaltenen Fasern beträgt 19,52, vom zweiten - 24,26, vom dritten - 22,84 und vom vierten - 21,16. Ist dieser Unterschied statistisch signifikant? Die Bruchkraftverteilung ist im Streudiagramm (Abb. 7) dargestellt. Es zeigt deutlich die Unterschiede sowohl zwischen Gruppen als auch innerhalb von ihnen. Wenn das Volumen jeder Gruppe größer wäre, könnten sie mit einem Stamm- und Blattdiagramm, einem Boxplot oder einem Normalverteilungsdiagramm analysiert werden.

Reis. 7. Kraftverteilungsdiagramm von Fallschirmen, die aus synthetischen Fasern gewebt wurden, die von vier Lieferanten bezogen wurden
Die Nullhypothese besagt, dass es keine signifikanten Unterschiede zwischen den mittleren Festigkeitswerten gibt: H 0: μ 1 = μ 2 = μ 3 = μ 4. Eine alternative Hypothese ist, dass es mindestens einen Lieferanten gibt, dessen durchschnittliche Faserstärke sich von anderen unterscheidet: H1: nicht alle μ j sind gleich ( j = 1, 2, …, Mit).
Gesamtdurchschnitt (siehe Abbildung 6) = MITTELWERT (D12:D15) = 21,945; Zur Bestimmung können Sie auch alle 20 Originalzahlen mitteln: \u003d AVERAGE (A3: D7). Varianzwerte werden berechnet Analysepaket und spiegeln sich in der Tabelle wider Varianzanalyse(siehe Abb. 6): SSA = 63,286, SSW = 97,504, SST = 160,790 (siehe Spalte SS Tische Varianzanalyse Abbildung 6). Mittelwerte werden berechnet, indem diese Quadratsummen durch die entsprechende Anzahl von Freiheitsgraden dividiert werden. Weil die Mit= 4 und n= 20 erhalten wir folgende Werte der Freiheitsgrade; für SSA: s - 1= 3; für SSW: n–c= 16; für SST: n - 1= 19 (siehe Spalte df). Also: MSA = SSA / ( c - 1)= 21,095; MSW=SSW/( n–c) = 6,094; MST = SST / ( n - 1) = 8,463 (siehe Spalte FRAU). F-Statistik = MSA / MSW = 3,462 (siehe Spalte F).
Oberer kritischer Wert FU, charakteristisch für F-Verteilung, wird bestimmt durch die Formel = F. OBR (0,95; 3; 16) = 3,239. Funktionsparameter =F.OBR(): α = 0,05, der Zähler hat drei Freiheitsgrade und der Nenner ist 16. Somit ist der berechnete F-Statistik gleich 3,462 überschreitet den oberen kritischen Wert FU= 3,239 wird die Nullhypothese verworfen (Abb. 8).

Reis. 8. Kritischer Bereich der Varianzanalyse bei einem Signifikanzniveau von 0,05, wenn der Zähler drei Freiheitsgrade hat und der Nenner -16 ist
R-Wert, d.h. die Wahrscheinlichkeit, dass unter einer wahren Nullhypothese F- Statistiken nicht weniger als 3,46, gleich 0,041 oder 4,1% (siehe Spalte p-Wert Tische Varianzanalyse Abbildung 6). Da dieser Wert das Signifikanzniveau α = 5 % nicht überschreitet, wird die Nullhypothese verworfen. Außerdem, R-Wert gibt an, dass die Wahrscheinlichkeit, einen solchen oder einen großen Unterschied zwischen den mathematischen Erwartungen der Allgemeinbevölkerung zu finden, sofern sie tatsächlich gleich sind, 4,1 % beträgt.
So. Es gibt einen Unterschied zwischen den vier Stichprobenmittelwerten. Die Nullhypothese war, dass alle mathematischen Erwartungen der vier Populationen gleich sind. Unter diesen Bedingungen wird ein Maß der Gesamtvariabilität (d. h. Gesamt-SST-Variation) der Stärke aller Fallschirme berechnet, indem die quadrierten Differenzen zwischen jeder Beobachtung summiert werden Xij und Gesamtdurchschnitt . Dann wurde die Gesamtvariation in zwei Komponenten aufgeteilt (siehe Abb. 1). Die erste Komponente war die Intergruppen-Variation in SSA und die zweite Komponente war die Intragruppen-Variation in SSW.
Was erklärt die Variabilität in den Daten? Mit anderen Worten, warum sind nicht alle Beobachtungen gleich? Ein Grund dafür ist, dass verschiedene Firmen Fasern mit unterschiedlichen Stärken liefern. Dies erklärt zum Teil, warum die Gruppen unterschiedliche Erwartungswerte haben: Je stärker die Wirkung der Versuchsbedingungen, desto größer die Differenz zwischen den Mittelwerten der Gruppen. Ein weiterer Grund für die Datenvariabilität ist die natürliche Variabilität jedes Prozesses, in diesem Fall der Herstellung von Fallschirmen. Selbst wenn alle Fasern vom selben Lieferanten gekauft würden, wäre ihre Stärke nicht gleich, wenn alle anderen Dinge gleich wären. Da dieser Effekt in jeder der Gruppen auftritt, wird er als Variation innerhalb der Gruppe bezeichnet.
Die Unterschiede zwischen den Stichprobenmittelwerten werden als Intergruppenvariation der SSA bezeichnet. Ein Teil der gruppeninternen Variation erklärt sich, wie bereits erwähnt, dadurch, dass die Daten zu unterschiedlichen Gruppen gehören. Aber selbst wenn die Gruppen genau gleich wären (d. h. die Nullhypothese wäre wahr), würde es immer noch Variationen zwischen den Gruppen geben. Der Grund dafür liegt in der natürlichen Variabilität des Fallschirmherstellungsprozesses. Da die Proben unterschiedlich sind, unterscheiden sich ihre Probenmittelwerte voneinander. Wenn die Nullhypothese wahr ist, sind daher sowohl die Variabilität zwischen den Gruppen als auch die Variabilität innerhalb der Gruppen Schätzungen der Populationsvariabilität. Wenn die Nullhypothese falsch ist, wird die Zwischengruppenhypothese größer sein. Diese Tatsache liegt zugrunde F-Kriterien für den Vergleich der Unterschiede zwischen den mathematischen Erwartungen mehrerer Gruppen.
Nachdem eine einfache ANOVA durchgeführt und ein signifikanter Unterschied zwischen Firmen festgestellt wurde, bleibt unbekannt, welcher der Lieferanten sich signifikant von den anderen unterscheidet. Wir wissen nur, dass die mathematischen Erwartungen der Bevölkerungen nicht gleich sind. Mit anderen Worten, mindestens eine der mathematischen Erwartungen unterscheidet sich signifikant von den anderen. Um festzustellen, welcher Anbieter sich von den anderen unterscheidet, können Sie verwenden Tukey-Verfahren, das einen paarweisen Vergleich zwischen Anbietern verwendet. Dieses Verfahren wurde von John Tukey entwickelt. Anschließend modifizierten er und C. Cramer dieses Verfahren unabhängig voneinander für Situationen, in denen sich die Stichprobengrößen voneinander unterscheiden.
Mehrfachvergleich: Tukey-Kramer-Verfahren
In unserem Szenario wurde eine Einweg-Varianzanalyse verwendet, um die Stärke von Fallschirmen zu vergleichen. Nachdem signifikante Unterschiede zwischen den mathematischen Erwartungen der vier Gruppen gefunden wurden, ist es notwendig zu bestimmen, welche Gruppen sich voneinander unterscheiden. Obwohl es mehrere Möglichkeiten gibt, dieses Problem zu lösen, beschreiben wir hier nur das Tukey-Kramer-Mehrfachvergleichsverfahren. Dieses Verfahren ist ein Beispiel für Post-hoc-Vergleichsverfahren, da die zu testende Hypothese nach der Datenanalyse formuliert wird. Mit dem Tukey-Kramer-Verfahren können Sie alle Gruppenpaare gleichzeitig vergleichen. In der ersten Stufe werden die Differenzen berechnet Xj - Xj ’ , wo j ≠j’ , zwischen mathematischen Erwartungen s(s – 1)/2 Gruppen. Kritische Spanne Das Tukey-Kramer-Verfahren wird nach folgender Formel berechnet:
wo Q U- der obere kritische Wert der Verteilung des studentisierten Bereichs, der hat Mit Freiheitsgrade im Zähler und n - Mit Freiheitsgrade im Nenner.
Sind die Stichprobenumfänge nicht gleich, wird der kritische Bereich für jedes mathematische Erwartungspaar separat berechnet. In der letzten Phase, jeder s(s – 1)/2 mathematischen Erwartungspaaren mit dem entsprechenden kritischen Bereich verglichen. Die Elemente eines Paares gelten als signifikant unterschiedlich, wenn der Betrag der Differenz | Xj - Xj ’ | zwischen ihnen den kritischen Bereich überschreitet.
Wenden wir das Tukey-Cramer-Verfahren auf das Problem der Stärke von Fallschirmen an. Da die Fallschirmfirma vier Lieferanten hat, sollten 4(4 – 1)/2 = 6 Paar Lieferanten getestet werden (Abbildung 9).

Reis. 9. Paarweise Vergleiche von Stichprobenmittelwerten
Da alle Gruppen das gleiche Volumen haben (also alle NJ = NJ ’ ), reicht es aus, nur einen kritischen Bereich zu berechnen. Dazu laut Tabelle ANOVA(Abb. 6) ermitteln wir den Wert von MSW = 6,094. Dann finden wir den Wert Q U bei α = 0,05, Mit= 4 (Anzahl der Freiheitsgrade im Zähler) und n- Mit= 20 – 4 = 16 (die Anzahl der Freiheitsgrade im Nenner). Leider habe ich die entsprechende Funktion in Excel nicht gefunden, also habe ich die Tabelle (Abb. 10) verwendet.

Reis. 10. Kritischer Wert des studentisierten Bereichs Q U
Wir bekommen:
Da nur 4,74 > 4,47 (siehe unterste Tabelle in Abbildung 9) ist, besteht ein statistisch signifikanter Unterschied zwischen Erst- und Zweitlieferant. Alle anderen Paare haben Stichprobenmittelwerte, die es uns nicht erlauben, über ihre Unterschiede zu sprechen. Folglich ist die durchschnittliche Festigkeit von Fallschirmen, die aus vom ersten Lieferanten gekauften Fasern gewebt sind, deutlich geringer als die des zweiten.
Notwendige Bedingungen für eine einseitige Varianzanalyse
Bei der Lösung des Problems der Festigkeit von Fallschirmen haben wir nicht geprüft, ob die Bedingungen erfüllt sind, unter denen man den Einfaktor anwenden kann F-Kriterium. Woher wissen Sie, ob Sie Single-Factor anwenden können? F-Kriterium bei der Analyse spezifischer experimenteller Daten? Einziger Faktor F Der -Test kann nur angewendet werden, wenn drei Grundannahmen erfüllt sind: Die experimentellen Daten müssen zufällig und unabhängig sein, eine Normalverteilung haben und ihre Varianzen müssen gleich sein.
Die erste Vermutung ist Zufälligkeit und Datenunabhängigkeit- sollte immer durchgeführt werden, da die Korrektheit jedes Experiments von der Zufälligkeit der Auswahl und / oder des Randomisierungsprozesses abhängt. Um die Ergebnisse nicht zu verfälschen, müssen die Daten extrahiert werden Mit Populationen zufällig und unabhängig voneinander. Ebenso sollten die Daten zufällig verteilt werden Mit Ebenen des für uns interessanten Faktors (Versuchsgruppen). Ein Verstoß gegen diese Bedingungen kann die Ergebnisse der Varianzanalyse ernsthaft verfälschen.
Die zweite Vermutung ist Normalität- bedeutet, dass die Daten aus normalverteilten Grundgesamtheiten stammen. Wie für t-Kriterium, Einweganalyse der Varianz basierend auf F-Kriterium ist relativ unempfindlich gegenüber der Verletzung dieser Bedingung. Wenn die Verteilung nicht zu weit von der Normalverteilung entfernt ist, das Signifikanzniveau F-Kriterium ändert sich wenig, insbesondere wenn die Stichprobengröße groß genug ist. Wenn die Bedingung der Normalverteilung ernsthaft verletzt wird, sollte sie angewendet werden.
Die dritte Vermutung ist Gleichmäßigkeit der Dispersion- bedeutet, dass die Varianzen jeder Grundgesamtheit gleich sind (d. h. σ 1 2 = σ 2 2 = … = σ j 2). Diese Annahme ermöglicht die Entscheidung, ob die Varianzen innerhalb der Gruppe getrennt oder zusammengelegt werden sollen. Wenn die Volumina der Gruppen gleich sind, hat die Bedingung der Homogenität der Varianz wenig Einfluss auf die Schlussfolgerungen, die mit verwendet werden F-Kriterien. Wenn die Stichprobenumfänge jedoch nicht gleich sind, kann ein Verstoß gegen die Bedingung der Varianzgleichheit die Ergebnisse der Varianzanalyse ernsthaft verfälschen. Daher sollte man sich bemühen sicherzustellen, dass die Stichprobengrößen gleich sind. Eine der Methoden zur Überprüfung der Annahme über die Homogenität der Varianz ist das Kriterium Levenay nachstehend beschrieben.
Wird von allen drei Bedingungen nur die Bedingung der Gleichmäßigkeit der Dispersion verletzt, so wird analog verfahren t-Kriterium mit separater Varianz (siehe Details). Wenn jedoch die Annahmen der Normalverteilung und der Varianzhomogenität gleichzeitig verletzt werden, ist es notwendig, die Daten zu normalisieren und die Unterschiede zwischen den Varianzen zu reduzieren oder ein nichtparametrisches Verfahren anzuwenden.
Leveneys Kriterium zur Überprüfung der Varianzhomogenität
Trotz der Tatsache, dass F- Das Kriterium ist relativ resistent gegen Verletzungen der Bedingung der Varianzgleichheit in Gruppen, ein grober Verstoß gegen diese Annahme wirkt sich erheblich auf das Signifikanzniveau und die Aussagekraft des Kriteriums aus. Vielleicht ist eines der mächtigsten das Kriterium Levenay. Um die Gleichheit der Varianzen zu überprüfen Mit Allgemeinbevölkerung werden wir die folgenden Hypothesen testen:
H 0: σ 1 2 = σ 2 2 = ... = σj 2
H1: nicht alle σ j 2 sind gleich ( j = 1, 2, …, Mit)
Der modifizierte Leveney-Test basiert auf der Behauptung, dass bei gleicher Variabilität in Gruppen eine Analyse der Varianz der absoluten Werte der Unterschiede zwischen Beobachtungen und Gruppenmedianen angewendet werden kann, um die Nullhypothese der Varianzgleichheit zu testen. Sie sollten also zuerst die Absolutwerte der Differenzen zwischen den Beobachtungen und den Medianen in jeder Gruppe berechnen und dann eine Einweg-Varianzanalyse der erhaltenen Absolutwerte der Differenzen durchführen. Um das Levenay-Kriterium zu veranschaulichen, kehren wir zu dem Szenario zurück, das am Anfang der Notiz skizziert wurde. Unter Verwendung der in Abb. 6 werden wir eine ähnliche Analyse durchführen, jedoch in Bezug auf die Module der Unterschiede in den Anfangsdaten und Medianen für jede Stichprobe separat (Abb. 11).
Mit der Varianzanalyse können Sie den Unterschied zwischen Datengruppen untersuchen, um festzustellen, ob diese Abweichungen zufällig sind oder durch bestimmte Umstände verursacht wurden. Wenn beispielsweise der Umsatz eines Unternehmens in einer der Regionen zurückgegangen ist, können Sie anhand der Varianzanalyse herausfinden, ob der Umsatzrückgang in dieser Region im Vergleich zu den anderen zufällig ist, und gegebenenfalls organisatorische Änderungen vornehmen. Wenn Sie ein Experiment unter verschiedenen Bedingungen durchführen, hilft die Varianzanalyse zu bestimmen, wie stark externe Faktoren die Messungen beeinflussen oder ob die Abweichungen zufällig sind. Wenn in der Produktion zur Verbesserung der Produktqualität die Art der Prozesse geändert wird, ermöglicht uns die Varianzanalyse, die Ergebnisse der Auswirkungen dieses Faktors zu bewerten.
Darauf Beispiel Wir zeigen, wie man ANOVA an experimentellen Daten durchführt.
Übung 1. Es gibt vier Rohstoffchargen für die Textilindustrie. Aus jeder Charge wurden fünf Proben ausgewählt und Tests durchgeführt, um die Größe der Bruchlast zu bestimmen. Die Testergebnisse sind in der Tabelle gezeigt.
71" height="29" bgcolor="white" style="border:.75pt einfarbig schwarz; vertikal ausrichten:oben;hintergrund:weiß">
Abb.1 |
 > Öffnen Sie eine Microsoft Excel-Tabelle. Klicken Sie auf die Beschriftung Sheet2, um zu einem anderen Arbeitsblatt zu wechseln.
> Öffnen Sie eine Microsoft Excel-Tabelle. Klicken Sie auf die Beschriftung Sheet2, um zu einem anderen Arbeitsblatt zu wechseln. > Geben Sie die in Abbildung 1 gezeigten ANOVA-Daten ein.
> Daten in Zahlenformat umwandeln. Wählen Sie dazu den Menübefehl Zelle formatieren. Das Zellenformatfenster erscheint auf dem Bildschirm (Abb. 2). Wählen Sie Numerisches Format und die eingegebenen Daten werden in das in Abb. 3
> Wählen Sie den Menübefehl Servicedatenanalyse (Extras * Datenanalyse). Das Fenster Datenanalyse (Datenanalyse) erscheint auf dem Bildschirm (Abb. 4).
> Klicken Sie in der Liste Analysewerkzeuge (Anova: Einzelfaktor) auf die Zeile Einzelfaktoranalyse der Varianz (Anova: Einzelfaktor).
> Klicken Sie auf OK, um das Fenster Datenanalyse (Datenanalyse) zu schließen. Das Fenster Einweg-Varianzanalyse erscheint auf dem Bildschirm zur Durchführung der Streuungsanalyse der Daten (Abb. 5).
https://pandia.ru/text/78/446/images/image006_46.jpg" width="311" height="214 src=">
|
> Installieren Kontrollkästchen-Tags in der ersten Zeile (Labels in Firts Rom) in der Gruppe Eingabesteuerelemente, wenn die erste Spalte des ausgewählten Datenbereichs Zeilennamen enthält.
> Im Eingabefeld Alpha Der (A1pha) Control Group Input ist standardmäßig auf einen Wert von 0,05 eingestellt, was sich auf die Fehlerwahrscheinlichkeit bei der Varianzanalyse bezieht.
> Wenn der Schalter Nev Worksheet Ply in der Controls-Gruppe Input options nicht gesetzt ist, stellen Sie ihn so ein, dass die Ergebnisse der Varianzanalyse auf einem neuen Worksheet platziert werden
> Klicken Sie auf OK, um das Fenster Anova: Single Factor zu schließen. Die Ergebnisse der Varianzanalyse erscheinen auf einem neuen Arbeitsblatt (Abb. 6).
|

Der Zellbereich A4:E6 enthält die Ergebnisse der deskriptiven Statistik. Zeile 4 enthält die Namen der Parameter, die Zeilen enthalten die nach Chargen berechneten Statistikwerte.
In Spalte Prüfen(Anzahl) sind die Anzahl der Messungen, in der Spalte Sum die Summe der Werte, in der Spalte Average (Avegage) die arithmetischen Mittelwerte, in der Spalte Variance (Varianse) die Streuung.
Die erhaltenen Ergebnisse zeigen, dass die höchste durchschnittliche Bruchlast in Charge Nr. 3 vorliegt und die größte Streuung der Bruchlast in Charge Nr. 1 vorliegt.
In einer Reihe von Zellen A11:G16 zeigt Informationen zur Signifikanz von Abweichungen zwischen Datengruppen an. Zeile 12 enthält die Namen der Varianzanalyseparameter, Zeile 13 - die Ergebnisse der gruppeninternen Verarbeitung, Zeile 14 - die Ergebnisse der gruppeninternen Verarbeitung und Zeile 16 - die Summe der Werte der beiden genannten Zeilen.
In Spalte SS (qi) sind die Variationswerte eingezeichnet, also die Quadratsummen über alle Abweichungen. Variation, wie Streuung, charakterisiert die Verbreitung von Daten. Aus der Tabelle ist ersichtlich, dass die gruppenübergreifende Streuung der Bruchlast deutlich höher ist als der Wert der gruppeninternen Streuung.
In Spalte df (k) die Werte der Anzahl der Freiheitsgrade werden gefunden. Diese Zahlen geben die Anzahl der unabhängigen Abweichungen an, über die die Varianz berechnet wird. Beispielsweise ist die Anzahl der Freiheitsgrade zwischen den Gruppen gleich der Differenz zwischen der Anzahl der Datengruppen und eins. Je größer die Zahl der Freiheitsgrade ist, desto höher ist die Zuverlässigkeit der Dispersionsparameter. Die Daten zu den Freiheitsgraden in der Tabelle zeigen, dass die Ergebnisse innerhalb der Gruppe zuverlässiger sind als die Parameter zwischen den Gruppen.
In Spalte FRAU (S2 ) sind die Streuungswerte eingezeichnet, die durch das Variationsverhältnis und die Anzahl der Freiheitsgrade bestimmt werden. Streuung charakterisiert den Grad der Streuung von Daten, hat aber im Gegensatz zur Größe der Variation keine direkte Tendenz, mit zunehmender Anzahl von Freiheitsgraden zuzunehmen. Die Tabelle zeigt, dass die Intergruppenvarianz viel größer ist als die Intragruppenvarianz.
In Spalte F gelegen, wert F- Statistiken, berechnet aus dem Verhältnis von Intergruppen- und Intragruppenvarianzen.
In Spalte Fkritisch(F crit) ist der F-kritische Wert eingezeichnet, berechnet aus der Anzahl der Freiheitsgrade und dem Wert von Alpha (A1pha). Verwendungskriterium für F-Statistik und F-kritischen Wert Fischer-Snedekora.
Wenn die F-Statistik größer als der F-kritische Wert ist, kann argumentiert werden, dass die Unterschiede zwischen Datengruppen nicht zufällig sind. also auf dem Signifikanzniveau α = 0,05 (bei einer Reliabilität von 0,95) wird die Nullhypothese verworfen und die Alternative akzeptiert: Der Unterschied zwischen den Rohstoffchargen hat einen erheblichen Einfluss auf die Größe der Bruchlast.
Die Spalte P-Wert enthält den Wahrscheinlichkeitswert, dass die Diskrepanz zwischen Gruppen zufällig ist. Da diese Wahrscheinlichkeit in der Tabelle sehr klein ist, ist die Abweichung zwischen den Gruppen nicht zufällig.
2. Lösen von Problemen der zweifachen Varianzanalyse ohne Wiederholungen
Microsoft Excel verfügt über die Funktion Anova: (Two-Factor Without Replication), mit der die Tatsache des Einflusses steuerbarer Faktoren identifiziert werden kann ABER und BEI auf einem effektiven Attribut basierend auf Beispieldaten und jeder Ebene von Faktoren ABER und BEI nur eine Probe passt. Um diese Funktion aufzurufen, wählen Sie den Befehl in der Menüleiste Service – Datenanalyse. Auf dem Bildschirm öffnet sich ein Fenster. Datenanalyse, in dem Sie einen Wert auswählen sollten Zweiweg-Varianzanalyse ohne Wiederholungen und klicken Sie auf die Schaltfläche OK. Als Ergebnis wird das in Abbildung 1 gezeigte Dialogfeld auf dem Bildschirm geöffnet.
78" height="42" bgcolor="white" style="border:.75pt einfarbig schwarz; vertikal ausrichten:oben;hintergrund:weiß">
3. Im Feld Alpha wird das akzeptierte Signifikanzniveau eingegeben. α , was der Wahrscheinlichkeit eines Fehlers erster Art entspricht.
4. Der Schalter in der Gruppe Ausgabeoptionen kann auf eine von drei Positionen eingestellt werden: Ausgabebereich, Neue Arbeitsblattlage oder Neue Arbeitsmappe.
Beispiel.
Zweiweg-Varianzanalyse ohne Wiederholungen(Anova: Two-Factor Without Replication) im folgenden Beispiel.

Auf dem Bild. Abbildung 2 zeigt den Ertrag (c/ha) von vier Weizensorten (vier Stufen von Faktor A), der mit fünf Arten von Düngemitteln (fünf Stufen von Faktor B) erzielt wurde. Die Daten wurden von 20 Parzellen gleicher Größe und ähnlicher Bodenbedeckung gewonnen. Muss definiert werden ob Sorte und Art des Düngers den Weizenertrag beeinflussen.
Zweiweg-Varianzanalyse ohne Wiederholungen sind in Abbildung 3 dargestellt.
 Wie aus den Ergebnissen ersichtlich, ist der errechnete Wert des F-Statistikwertes für Faktor A (Düngertyp) FABER=
l,67
, und der kritische Bereich wird durch das rechte Intervall (3.49; +∞) gebildet. Als FABER=
l,67
nicht in den kritischen Bereich fällt, gilt die HA-Hypothese: a
1
= a
2
+ = ja
annehmen, d.h. wir glauben das in diesem Experiment die Art des Düngers hatte keinen Einfluss auf den Ertrag.
Wie aus den Ergebnissen ersichtlich, ist der errechnete Wert des F-Statistikwertes für Faktor A (Düngertyp) FABER=
l,67
, und der kritische Bereich wird durch das rechte Intervall (3.49; +∞) gebildet. Als FABER=
l,67
nicht in den kritischen Bereich fällt, gilt die HA-Hypothese: a
1
= a
2
+ = ja
annehmen, d.h. wir glauben das in diesem Experiment die Art des Düngers hatte keinen Einfluss auf den Ertrag.
Als FBEI=2,03 fällt nicht in den kritischen Bereich, die Hypothese HB: b1 = b2 = ... = bm
auch akzeptieren, d.h. wir glauben daran Auch die Weizensorte hatte im Versuch keinen Einfluss auf den Ertrag.
2. Zweiweg-VarianzanalysecWiederholungen
Microsoft Excel verfügt über die Anova-Funktion: Two-Factor With Replication, die auch verwendet wird, um zu bestimmen, ob die kontrollierten Faktoren A und B ein Leistungsmerkmal basierend auf Stichprobendaten beeinflussen, jedoch entspricht jede Stufe eines der Faktoren A (oder B) mehr als einer Datenprobe.
Erwägen Sie die Verwendung der Funktion Zweiweg-Varianzanalyse mit Wiederholungen am nächsten Beispiel.
Beispiel 2. in der Tabelle. Abbildung 6 zeigt die tägliche Gewichtszunahme (g) von 18 für die Studie gesammelten Ferkeln in Abhängigkeit von der Haltung der Ferkel (Faktor A) und der Qualität ihrer Fütterung (Faktor B).
75" height="33" bgcolor="white" style="border:.75pt einfarbig schwarz; vertikal ausrichten:oben;hintergrund:weiß"> 

Dieses Dialogfeld legt die folgenden Optionen fest.
1. Geben Sie im Feld Eingabebereich einen Verweis auf den Zellbereich ein, der die analysierten Daten enthält. Wählen Sie Zellen aus G 4 Vor ich 13.
2. Definieren Sie im Feld Zeilen pro Stichprobe die Anzahl der Stichproben für jede Stufe eines der Faktoren. Jede Faktorstufe muss die gleiche Anzahl von Stichproben (Tabellenzeilen) enthalten. In unserem Fall beträgt die Anzahl der Zeilen drei.
3. Geben Sie im Feld Alpha den akzeptierten Wert des Signifikanzniveaus ein α , was gleich der Wahrscheinlichkeit eines Fehlers 1. Art ist.
4. Der Schalter in der Gruppe Ausgabeoptionen kann auf eine von drei Positionen eingestellt werden: Ausgabebereich (Ausgabeintervall), Neue Arbeitsblattlage (Neues Arbeitsblatt) oder Neue Arbeitsmappe (Neue Arbeitsmappe).
Ergebnisse der Zweiweg-Varianzanalyse unter Verwendung der Funktion Zweiweg-Varianzanalyse mit signifikanten Wiederholungen. Aufgrund der Tatsache, dass ![]() das Zusammenspiel dieser Faktoren ist unbedeutend (auf dem 5%-Niveau).
das Zusammenspiel dieser Faktoren ist unbedeutend (auf dem 5%-Niveau).
Hausaufgaben
1. Im Laufe von sechs Jahren wurden fünf verschiedene Technologien zum Anbau von Pflanzen eingesetzt. Versuchsdaten (in c/ha) sind in der Tabelle angegeben:
https://pandia.ru/text/78/446/images/image024_11.jpg" width="642" height="190 src=">
Es wird auf dem Signifikanzniveau α = 0,05 benötigt, um die Abhängigkeit der Produktion hochwertiger Fliesen von der Produktionslinie (Faktor A) festzustellen.
3. Über den Ertrag von vier Weizensorten auf den zugeteilten fünf Parzellen (Blöcken) liegen folgende Daten vor:
https://pandia.ru/text/78/446/images/image026_9.jpg" width="598" height="165 src=">
Es ist auf dem Signifikanzniveau α = 0,05 erforderlich, um den Einfluss von Technologien (Faktor A) und Unternehmen (Faktor B) auf die Arbeitsproduktivität zu ermitteln.
Um die Variabilität eines Merkmals unter dem Einfluss kontrollierter Variablen zu analysieren, wird die Dispersionsmethode verwendet.
Um die Beziehung zwischen Werten zu untersuchen - faktorielle Methode. Betrachten wir Analysewerkzeuge genauer: Fakultäts-, Streuungs- und Zwei-Faktoren-Streuungsmethoden zur Bewertung der Variabilität.
ANOVA in Excel
Bedingt lässt sich das Ziel des Dispersionsverfahrens wie folgt formulieren: aus der Gesamtvariabilität des Parameters 3 die jeweilige Variabilität zu isolieren:
- 1 - bestimmt durch die Wirkung jedes der untersuchten Werte;
- 2 - diktiert durch die Beziehung zwischen den untersuchten Werten;
- 3 - zufällig, diktiert von allen unerklärten Umständen.
In Microsoft Excel kann die Varianzanalyse mit dem Tool "Datenanalyse" (Registerkarte "Daten" - "Analyse") durchgeführt werden. Dies ist ein Tabellenkalkulations-Add-on. Wenn das Add-In nicht verfügbar ist, müssen Sie die „Excel-Optionen“ öffnen und die Einstellung für die Analyse aktivieren.
Die Arbeit beginnt mit der Gestaltung des Tisches. Regeln:
- Jede Spalte sollte die Werte eines untersuchten Faktors enthalten.
- Ordnen Sie die Spalten in aufsteigender/absteigender Reihenfolge des Werts des untersuchten Parameters an.
Betrachten Sie die Varianzanalyse in Excel anhand eines Beispiels.
Der Betriebspsychologe analysierte mit einer speziellen Technik die Strategie des Verhaltens von Mitarbeitern in einer Konfliktsituation. Es wird angenommen, dass das Verhalten durch das Bildungsniveau (1 - Sekundarstufe, 2 - Fachoberschule, 3 - Hochschulbildung) beeinflusst wird.
Geben Sie Daten in eine Excel-Tabelle ein:


Signifikante Parameter sind mit gelber Farbe gefüllt. Da der P-Wert zwischen den Gruppen größer als 1 ist, kann der Fisher-Test nicht als signifikant betrachtet werden. Folglich ist das Verhalten in einer Konfliktsituation nicht vom Bildungsniveau abhängig.
Faktorenanalyse in Excel: ein Beispiel
Die Faktorenanalyse ist eine multivariate Analyse von Beziehungen zwischen den Werten von Variablen. Mit dieser Methode können Sie die wichtigsten Aufgaben lösen:
- das gemessene Objekt umfassend beschreiben (darüber hinaus umfassend, kompakt);
- Identifizieren Sie verborgene Variablenwerte, die das Vorhandensein linearer statistischer Korrelationen bestimmen;
- Variablen klassifizieren (die Beziehung zwischen ihnen bestimmen);
- reduzieren Sie die Anzahl der benötigten Variablen.
Betrachten Sie das Beispiel der Faktorenanalyse. Angenommen, wir kennen die Verkäufe von Waren für die letzten 4 Monate. Es muss analysiert werden, welche Artikel nachgefragt werden und welche nicht.


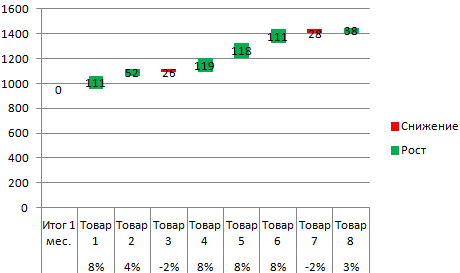
Jetzt können Sie deutlich sehen, welche Produktverkäufe das Hauptwachstum bringen.
Zwei-Wege-Varianzanalyse in Excel
Zeigt, wie zwei Faktoren die Wertänderung einer Zufallsvariablen beeinflussen. Betrachten Sie die bidirektionale Varianzanalyse in Excel anhand eines Beispiels.
Eine Aufgabe. Einer Gruppe von Männern und Frauen wurden Geräusche unterschiedlicher Lautstärke präsentiert: 1 - 10 dB, 2 - 30 dB, 3 - 50 dB. Die Reaktionszeit wurde in Millisekunden aufgezeichnet. Es muss festgestellt werden, ob das Geschlecht die Reaktion beeinflusst; Beeinflusst die Lautstärke die Reaktion?
Varianzanalyse
1. Das Konzept der Varianzanalyse
Varianzanalyse- Dies ist eine Analyse der Variabilität eines Merkmals unter dem Einfluss von kontrollierten variablen Faktoren. In der ausländischen Literatur wird die Varianzanalyse oft als ANOVA bezeichnet, was übersetzt Varianzanalyse (Varianzanalyse) bedeutet.
Die Aufgabe der Varianzanalyse besteht darin, die Variabilität einer anderen Art von der allgemeinen Variabilität des Merkmals zu isolieren:
a) Variabilität aufgrund der Wirkung jeder der untersuchten unabhängigen Variablen;
b) Variabilität aufgrund der Interaktion der untersuchten unabhängigen Variablen;
c) zufällige Variation aufgrund aller anderen unbekannten Variablen.
Die Variabilität aufgrund der Wirkung der untersuchten Variablen und ihrer Wechselwirkung korreliert mit zufälliger Variabilität. Ein Indikator für dieses Verhältnis ist der Fisher-F-Test.
Die Formel zur Berechnung des Kriteriums F enthält Schätzungen von Varianzen, dh der Verteilungsparameter eines Merkmals, daher ist das Kriterium F ein parametrisches Kriterium.
Je mehr die Variabilität des Merkmals auf die untersuchten Variablen (Faktoren) oder deren Zusammenspiel zurückzuführen ist, desto höher Erfahrungswerte des Kriteriums.
Null Die Hypothese in der Varianzanalyse besagt, dass die Durchschnittswerte des untersuchten effektiven Merkmals in allen Abstufungen gleich sind.
Alternative Die Hypothese besagt, dass die Durchschnittswerte des effektiven Attributs in verschiedenen Abstufungen des untersuchten Faktors unterschiedlich sind.
Die Varianzanalyse ermöglicht es uns, eine Änderung in einem Merkmal festzustellen, zeigt sie jedoch nicht an Richtung diese Veränderungen.
Beginnen wir die Varianzanalyse mit dem einfachsten Fall, wenn wir nur die Wirkung von untersuchen eines variabel (Einzelfaktor).
2. Einweg-Varianzanalyse für nicht verwandte Proben
2.1. Zweck der Methode
Die Methode der Einzelfaktor-Varianzanalyse wird in den Fällen verwendet, in denen Änderungen des effektiven Attributs unter dem Einfluss von sich ändernden Bedingungen oder Abstufungen eines beliebigen Faktors untersucht werden. Bei dieser Version des Verfahrens ist der Einfluss jeder der Abstufungen des Faktors verschiedene Stichprobe von Testpersonen. Es müssen mindestens drei Abstufungen des Faktors vorhanden sein. (Es kann zwei Abstufungen geben, aber in diesem Fall werden wir keine nichtlinearen Abhängigkeiten feststellen können und es erscheint sinnvoller, einfachere zu verwenden).
Eine nichtparametrische Variante dieser Analyseart ist der Kruskal-Wallis-H-Test.
Hypothesen
H 0: Unterschiede zwischen Faktornoten (unterschiedliche Bedingungen) sind nicht stärker ausgeprägt als zufällige Unterschiede innerhalb jeder Gruppe.
H 1: Unterschiede zwischen Faktorabstufungen (unterschiedliche Bedingungen) sind stärker ausgeprägt als zufällige Unterschiede innerhalb jeder Gruppe.
2.2. Einschränkungen der univariaten Varianzanalyse für unabhängige Stichproben
1. Univariate Varianzanalyse erfordert mindestens drei Abstufungen des Faktors und mindestens zwei Probanden in jeder Abstufung.
2. Das resultierende Merkmal muss in der Studienstichprobe normalverteilt sein.
Zwar wird in der Regel nicht angegeben, ob es sich um die Verteilung eines Merkmals in der gesamten untersuchten Stichprobe handelt oder in dem Teil davon, der den Streuungskomplex ausmacht.
3. Ein Beispiel für die Lösung des Problems durch die Methode der Einfaktor-Varianzanalyse für unabhängige Stichproben anhand des Beispiels:
Drei verschiedene Gruppen von sechs Probanden erhielten Listen mit zehn Wörtern. Wörter wurden der ersten Gruppe mit einer niedrigen Rate von 1 Wort pro 5 Sekunden präsentiert, der zweiten Gruppe mit einer durchschnittlichen Rate von 1 Wort pro 2 Sekunden und der dritten Gruppe mit einer hohen Rate von 1 Wort pro Sekunde. Es wurde vorhergesagt, dass die Wiedergabeleistung von der Geschwindigkeit der Wortpräsentation abhängt. Die Ergebnisse sind in der Tabelle dargestellt. eines.
Anzahl der wiedergegebenen Wörter Tabelle 1
|
Betreffnummer |
langsame Geschwindigkeit |
Durchschnittsgeschwindigkeit |
schnelle Geschwindigkeit |
|
Gesamtbetrag | |||
H 0: Unterschiede in der Wortlautstärke zwischen Gruppen sind nicht ausgeprägter als zufällige Unterschiede Innerhalb jede Gruppe.
H1: Unterschiede in der Wortlautstärke zwischen Gruppen sind ausgeprägter als zufällige Unterschiede Innerhalb jede Gruppe. Unter Verwendung der in der Tabelle dargestellten experimentellen Werte. 1 werden wir einige Werte ermitteln, die zur Berechnung des Kriteriums F benötigt werden.
Die Berechnung der Hauptgrößen für die einfache Varianzanalyse ist in der Tabelle dargestellt:
Tabelle 2
Tisch 3
Abfolge von Operationen in der einfachen ANOVA für nicht verbundene Proben

Die in dieser und den folgenden Tabellen häufig verwendete Bezeichnung SS ist eine Abkürzung für "Quadratsumme". Diese Abkürzung wird am häufigsten in übersetzten Quellen verwendet.
SS Tatsache bedeutet die Variabilität des Merkmals aufgrund der Wirkung des untersuchten Faktors;
SS gemeinsames- allgemeine Variabilität des Merkmals;
S CA- Variabilität aufgrund nicht berücksichtigter Faktoren, „zufälliger“ oder „Rest“-Variabilität.
FRAU- "Mean Square" oder die mathematische Erwartung der Summe der Quadrate, der Durchschnittswert der entsprechenden SS.
df - die Anzahl der Freiheitsgrade, die wir bei Betrachtung nichtparametrischer Kriterien mit dem griechischen Buchstaben bezeichnet haben v.
Fazit: H 0 wird abgelehnt. H 1 wird akzeptiert. Unterschiede in der Lautstärke der Wortwiedergabe zwischen den Gruppen sind ausgeprägter als zufällige Unterschiede innerhalb jeder Gruppe (α = 0,05). Die Geschwindigkeit der Präsentation von Wörtern beeinflusst also die Lautstärke ihrer Wiedergabe.
Ein Beispiel für die Lösung des Problems in Excel ist unten dargestellt:
Ausgangsdaten:

Mit dem Befehl: Tools->Data Analysis->One-Way Analysis of Variance erhalten wir folgende Ergebnisse:

ANOVA ist eine Reihe von statistischen Methoden, die entwickelt wurden, um Hypothesen über die Beziehung zwischen bestimmten Merkmalen und den untersuchten Faktoren zu testen, die keine quantitative Beschreibung haben, sowie um den Grad des Einflusses von Faktoren und ihrer Wechselwirkung festzustellen. In der Fachliteratur wird sie oft als ANOVA (vom englischen Namen Analysis of Variations) bezeichnet. Diese Methode wurde erstmals 1925 von R. Fischer entwickelt.
Arten und Kriterien der Varianzanalyse
Mit dieser Methode wird die Beziehung zwischen qualitativen (nominalen) Merkmalen und einer quantitativen (kontinuierlichen) Variablen untersucht. Tatsächlich testet es die Hypothese über die Gleichheit der arithmetischen Mittel mehrerer Stichproben. Daher kann es als parametrisches Kriterium zum gleichzeitigen Vergleich der Zentren mehrerer Proben betrachtet werden. Wenn Sie diese Methode für zwei Stichproben verwenden, sind die Ergebnisse der Varianzanalyse mit den Ergebnissen des Student-t-Tests identisch. Im Gegensatz zu anderen Kriterien ermöglicht Ihnen diese Studie jedoch, das Problem genauer zu untersuchen.
Die Varianzanalyse in der Statistik basiert auf dem Gesetz: Die Summe der quadratischen Abweichungen der kombinierten Stichprobe ist gleich der Summe der Quadrate der Abweichungen innerhalb der Gruppe und der Summe der Quadrate der Abweichungen zwischen den Gruppen. Für die Studie wird der Fisher-Test verwendet, um die Signifikanz der Differenz zwischen Intergruppen- und Intragruppen-Varianzen festzustellen. Notwendige Voraussetzungen hierfür sind jedoch die Normalverteilung der Verteilung und die Homoskedastizität (Varianzgleichheit) der Stichproben. Unterscheiden Sie zwischen eindimensionaler (einfaktorieller) Varianzanalyse und multivariater (multifaktorieller) Analyse. Der erste berücksichtigt die Abhängigkeit des untersuchten Werts von einem Attribut, der zweite - von vielen gleichzeitig, und ermöglicht es Ihnen auch, die Beziehung zwischen ihnen zu identifizieren.
Faktoren
Faktoren werden als kontrollierte Umstände bezeichnet, die das Endergebnis beeinflussen. Seine Verarbeitungsstufe oder -methode wird als Wert bezeichnet, der die spezifische Manifestation dieses Zustands charakterisiert. Diese Zahlen werden normalerweise in einer nominalen oder ordinalen Messskala angegeben. Oft werden Ausgabewerte auf quantitativen oder ordinalen Skalen gemessen. Dann besteht das Problem, die Ausgabedaten in einer Reihe von Beobachtungen zu gruppieren, die ungefähr den gleichen numerischen Werten entsprechen. Wenn die Anzahl der Gruppen zu groß ist, reicht die Anzahl der Beobachtungen in ihnen möglicherweise nicht aus, um zuverlässige Ergebnisse zu erhalten. Wird die Anzahl zu klein gewählt, kann dies zum Verlust wesentlicher Einflussmerkmale auf das System führen. Die spezifische Methode der Gruppierung von Daten hängt von Umfang und Art der Wertschwankung ab. Die Anzahl und Größe der Intervalle in der univariaten Analyse werden meistens durch das Prinzip gleicher Intervalle oder durch das Prinzip gleicher Häufigkeiten bestimmt.
Aufgaben der Ausbreitungsanalyse
Es gibt also Fälle, in denen Sie zwei oder mehr Proben vergleichen müssen. Dann ist es ratsam, die Varianzanalyse zu verwenden. Der Name der Methode weist darauf hin, dass die Schlussfolgerungen auf der Grundlage der Untersuchung der Komponenten der Varianz gezogen werden. Das Wesentliche der Studie ist, dass die Gesamtänderung des Indikators in Komponenten unterteilt wird, die der Wirkung jedes einzelnen Faktors entsprechen. Betrachten Sie eine Reihe von Problemen, die eine typische Varianzanalyse löst.
Beispiel 1
Die Werkstatt verfügt über eine Reihe von Werkzeugmaschinen - automatische Maschinen, die ein bestimmtes Teil herstellen. Die Größe jedes Teils ist ein zufälliger Wert, der von den Einstellungen jeder Maschine und zufälligen Abweichungen abhängt, die während des Herstellungsprozesses der Teile auftreten. Anhand der Abmessungen der Teile muss festgestellt werden, ob die Maschinen gleich aufgebaut sind.

Beispiel 2
Bei der Herstellung eines elektrischen Geräts werden verschiedene Arten von Isolierpapier verwendet: Kondensator, Elektro usw. Das Gerät kann mit verschiedenen Substanzen imprägniert werden: Epoxidharz, Lack, ML-2-Harz usw. Lecks können unter Vakuum bei beseitigt werden erhöhter Druck, wenn erhitzt. Es kann durch Eintauchen in Lack, unter einem kontinuierlichen Lackstrom usw. imprägniert werden. Das gesamte elektrische Gerät wird mit einer bestimmten Masse gegossen, von der es mehrere Möglichkeiten gibt. Qualitätsindikatoren sind die Spannungsfestigkeit der Isolierung, die Überhitzungstemperatur der Wicklung im Betriebszustand und einige andere. Während der Entwicklung des technologischen Prozesses zur Herstellung von Geräten muss festgestellt werden, wie sich jeder der aufgeführten Faktoren auf die Leistung des Geräts auswirkt.
Beispiel 3
Das Trolleybusdepot bedient mehrere Trolleybuslinien. Sie betreiben Trolleybusse verschiedener Typen, und 125 Inspektoren sammeln Fahrpreise. Die Verwaltung des Depots interessiert sich für die Frage: Wie kann man die wirtschaftliche Leistung jedes Controllers (Einnahmen) angesichts der verschiedenen Linien, verschiedenen Arten von Trolleybussen vergleichen? Wie kann die wirtschaftliche Machbarkeit des Starts von Oberleitungsbussen eines bestimmten Typs auf einer bestimmten Strecke bestimmt werden? Wie können angemessene Anforderungen für die Höhe der Einnahmen festgelegt werden, die der Schaffner auf jeder Strecke in verschiedenen Arten von Oberleitungsbussen erzielt?
Die Aufgabe bei der Auswahl einer Methode besteht darin, maximale Informationen über die Auswirkungen auf das Endergebnis jedes Faktors zu erhalten, die numerischen Merkmale einer solchen Auswirkung und ihre Zuverlässigkeit zu minimalen Kosten und in kürzester Zeit zu bestimmen. Methoden der Dispersionsanalyse ermöglichen es, solche Probleme zu lösen.
Univariate Analyse
Die Studie zielt darauf ab, das Ausmaß der Auswirkungen eines bestimmten Falls auf die zu analysierende Überprüfung zu bewerten. Eine weitere Aufgabe der univariaten Analyse kann darin bestehen, zwei oder mehr Umstände miteinander zu vergleichen, um den Unterschied in ihrem Einfluss auf die Erinnerung zu ermitteln. Wenn die Nullhypothese abgelehnt wird, besteht der nächste Schritt darin, Konfidenzintervalle für die erhaltenen Merkmale zu quantifizieren und zu bilden. Falls die Nullhypothese nicht abgelehnt werden kann, wird sie normalerweise akzeptiert und es wird eine Schlussfolgerung über die Art des Einflusses gezogen.
Die Einweg-Varianzanalyse kann zu einem nichtparametrischen Analogon der Kruskal-Wallis-Rangmethode werden. Er wurde 1952 von dem amerikanischen Mathematiker William Kruskal und dem Ökonomen Wilson Wallis entwickelt. Dieser Test soll die Nullhypothese testen, dass die Auswirkungen von Einflüssen auf die untersuchten Stichproben bei unbekannten, aber gleichen Mittelwerten gleich sind. In diesem Fall muss die Anzahl der Proben größer als zwei sein.

Das Jonkhier-Kriterium (Jonkhier-Terpstra) wurde 1952 unabhängig vom holländischen Mathematiker T. J. Terpstrom und 1954 vom britischen Psychologen E. R. Jonkhier vorgeschlagen. Es wird verwendet, wenn im Voraus bekannt ist, dass die verfügbaren Gruppen von Ergebnissen nach einer Zunahme der geordnet sind Einfluss des untersuchten Faktors, der auf einer ordinalen Skala gemessen wird.
M - das Bartlett-Kriterium, das 1937 vom britischen Statistiker Maurice Stevenson Bartlett vorgeschlagen wurde, wird verwendet, um die Nullhypothese über die Gleichheit der Varianzen mehrerer normaler Populationen zu testen, aus denen die untersuchten Stichproben entnommen werden, im allgemeinen Fall mit unterschiedlichen Größen ( die Anzahl jeder Probe muss mindestens vier betragen ).
G ist der Cochran-Test, der 1941 von dem Amerikaner William Gemmel Cochran entdeckt wurde. Er wird verwendet, um die Nullhypothese über die Gleichheit der Varianzen von Normalpopulationen für unabhängige Stichproben gleicher Größe zu testen.
Der nichtparametrische Levene-Test, der 1960 vom amerikanischen Mathematiker Howard Levene vorgeschlagen wurde, ist eine Alternative zum Bartlett-Test unter Bedingungen, bei denen nicht sicher ist, dass die untersuchten Stichproben einer Normalverteilung folgen.
1974 schlugen die amerikanischen Statistiker Morton B. Brown und Alan B. Forsyth einen Test vor (den Brown-Forsyth-Test), der sich etwas vom Levene-Test unterscheidet.
Zwei-Wege-Analyse
Die Zweiweg-Varianzanalyse wird für verknüpfte normalverteilte Stichproben verwendet. In der Praxis werden auch häufig komplexe Tabellen dieses Verfahrens verwendet, insbesondere solche, bei denen jede Zelle einen Datensatz (Wiederholungsmessungen) enthält, der festen Pegelwerten entspricht. Sind die für die Anwendung der zweifachen Varianzanalyse notwendigen Annahmen nicht erfüllt, wird der nichtparametrische Rangtest nach Friedman (Friedman, Kendall und Smith) verwendet, der Ende 1930 vom amerikanischen Ökonomen Milton Friedman entwickelt wurde. Dieses Kriterium ist unabhängig von der Art der Verteilung.
Es wird lediglich angenommen, dass die Verteilung der Größen gleich und stetig ist und dass sie selbst unabhängig voneinander sind. Beim Testen der Nullhypothese werden die Ausgabedaten in Form einer rechteckigen Matrix dargestellt, in der die Zeilen den Stufen von Faktor B und die Spalten den Stufen A entsprechen. Jede Zelle der Tabelle (Block) kann die sein Ergebnis von Messungen von Parametern an einem Objekt oder an einer Gruppe von Objekten mit konstanten Werten der Ebenen beider Faktoren . In diesem Fall werden die entsprechenden Daten als Durchschnittswerte eines bestimmten Parameters für alle Messungen oder Objekte der untersuchten Probe dargestellt. Um das Ausgabekriterium anzuwenden, ist es notwendig, von den direkten Ergebnissen der Messungen zu ihrem Rang überzugehen. Das Ranking wird für jede Zeile separat durchgeführt, das heißt, die Werte werden für jeden festen Wert geordnet.

Der Page-Test (L-Test), der 1963 vom amerikanischen Statistiker E. B. Page vorgeschlagen wurde, dient der Prüfung der Nullhypothese. Für große Stichproben wird die Page-Näherung verwendet. Sie gehorchen, vorbehaltlich der Realität der entsprechenden Nullhypothesen, der Standardnormalverteilung. Falls die Zeilen der Quelltabelle dieselben Werte haben, müssen die durchschnittlichen Ränge verwendet werden. In diesem Fall ist die Genauigkeit der Schlussfolgerungen umso schlechter, je größer die Anzahl solcher Zufälle ist.
Q - Cochran-Kriterium, vorgeschlagen von V. Cochran im Jahr 1937. Es wird in Fällen verwendet, in denen Gruppen homogener Probanden mehr als zwei Einflüssen ausgesetzt sind und für die zwei Optionen für die Überprüfung möglich sind - bedingt negativ (0) und bedingt positiv (1 ) . Die Nullhypothese besteht in der Gleichheit der Einflusseffekte. Die Zwei-Wege-Varianzanalyse ermöglicht es, das Vorhandensein von Verarbeitungseffekten zu bestimmen, ermöglicht es jedoch nicht, zu bestimmen, für welche Spalten dieser Effekt existiert. Bei der Lösung dieses Problems wird die Methode der multiplen Scheffe-Gleichungen für gekoppelte Proben verwendet.
Multivariate Analyse
Das Problem der multivariaten Varianzanalyse entsteht, wenn es gilt, den Einfluss von zwei oder mehr Bedingungen auf eine bestimmte Zufallsvariable zu bestimmen. Die Studie sieht das Vorhandensein einer abhängigen Zufallsvariablen vor, die auf einer Skala von Differenzen oder Verhältnissen gemessen wird, und mehrerer unabhängiger Variablen, von denen jede auf einer Namensskala oder in einer Rangskala ausgedrückt wird. Die Streuungsanalyse von Daten ist ein ziemlich entwickelter Zweig der mathematischen Statistik, der viele Optionen bietet. Das Konzept der Studie ist sowohl für univariate als auch für multivariate Studien üblich. Sein Wesen liegt darin, dass die Gesamtvarianz in Komponenten unterteilt wird, was einer bestimmten Gruppierung von Daten entspricht. Jede Gruppierung von Daten hat ihr eigenes Modell. Hier werden wir nur die wichtigsten Bestimmungen betrachten, die für das Verständnis und die praktische Anwendung seiner am häufigsten verwendeten Varianten notwendig sind.

Die Analyse der Varianz von Faktoren erfordert eine ziemlich sorgfältige Haltung bei der Erhebung und Präsentation von Eingabedaten und insbesondere bei der Interpretation der Ergebnisse. Im Gegensatz zum Einfaktor, dessen Ergebnisse bedingt in eine bestimmte Reihenfolge gebracht werden können, erfordern die Ergebnisse des Zweifaktors eine komplexere Darstellung. Eine noch schwierigere Situation entsteht, wenn drei, vier oder mehr Umstände vorliegen. Aus diesem Grund enthält das Modell selten mehr als drei (vier) Bedingungen. Ein Beispiel wäre das Auftreten von Resonanz bei einem bestimmten Wert von Kapazität und Induktivität des elektrischen Kreises; die Manifestation einer chemischen Reaktion mit einer bestimmten Gruppe von Elementen, aus denen das System aufgebaut ist; das Auftreten anomaler Effekte in komplexen Systemen unter einem bestimmten Zusammentreffen von Umständen. Das Vorhandensein von Wechselwirkungen kann das Modell des Systems radikal verändern und manchmal dazu führen, dass die Natur der Phänomene, mit denen sich der Experimentator befasst, neu überdacht wird.
Multivariate Varianzanalyse mit wiederholten Experimenten
Messdaten können oft nicht nach zwei, sondern nach mehr Faktoren gruppiert werden. Betrachtet man also die Varianzanalyse der Lebensdauer von Reifen für Trolleybusräder unter Berücksichtigung der Umstände (Hersteller und Strecke, auf der die Reifen betrieben werden), dann kann man als gesonderte Bedingung die Jahreszeit unterscheiden, in der die Reifen betrieben werden (nämlich: Winter- und Sommerbetrieb). Als Ergebnis haben wir das Problem der Drei-Faktoren-Methode.
Bei Vorliegen weiterer Bedingungen ist der Ansatz derselbe wie bei der Zwei-Wege-Analyse. In allen Fällen versucht das Modell zu vereinfachen. Das Phänomen der Wechselwirkung zweier Faktoren tritt nicht so oft auf, und die dreifache Wechselwirkung tritt nur in Ausnahmefällen auf. Nehmen Sie diejenigen Interaktionen auf, für die es vorherige Informationen und gute Gründe gibt, diese in das Modell einzubeziehen. Der Prozess, einzelne Faktoren zu isolieren und zu berücksichtigen, ist relativ einfach. Daher besteht häufig der Wunsch, weitere Umstände hervorzuheben. Davon sollte man sich nicht mitreißen lassen. Je mehr Bedingungen vorliegen, desto unzuverlässiger wird das Modell und desto größer ist die Fehlerwahrscheinlichkeit. Das Modell selbst, das eine große Anzahl unabhängiger Variablen enthält, wird ziemlich schwierig zu interpretieren und für die praktische Verwendung unbequem.
Allgemeine Idee der Varianzanalyse
Die Varianzanalyse in der Statistik ist eine Methode, um Beobachtungsergebnisse zu erhalten, die von verschiedenen gleichzeitigen Umständen abhängen, und deren Einfluss zu bewerten. Als Faktor wird eine Regelgröße bezeichnet, die der Art der Beeinflussung des Untersuchungsgegenstandes entspricht und in einem bestimmten Zeitraum einen bestimmten Wert annimmt. Sie können qualitativ und quantitativ sein. Niveaus quantitativer Bedingungen erhalten einen bestimmten Wert auf einer numerischen Skala. Beispiele sind Temperatur, Pressdruck, Stoffmenge. Qualitative Faktoren sind unterschiedliche Stoffe, unterschiedliche technologische Verfahren, Apparate, Füllstoffe. Ihre Ebenen entsprechen der Namensskala.

Zur Qualität gehören auch die Art des Verpackungsmaterials, die Lagerbedingungen der Darreichungsform. Es ist auch sinnvoll, den Mahlgrad von Rohstoffen, die fraktionierte Zusammensetzung von Granulaten, die einen quantitativen Wert haben, aber schwer zu regulieren sind, einzubeziehen, wenn eine quantitative Skala verwendet wird. Die Anzahl der Qualitätsfaktoren hängt von der Art der Darreichungsform sowie den physikalischen und technologischen Eigenschaften von Arzneistoffen ab. Beispielsweise können Tabletten aus kristallinen Substanzen durch direktes Verpressen erhalten werden. In diesem Fall genügt es, die Auswahl der Gleit- und Schmiermittel vorzunehmen.
Beispiele für Qualitätsfaktoren für verschiedene Arten von Darreichungsformen
- Tinkturen. Extraktionsmittelzusammensetzung, Art des Extraktors, Rohstoffaufbereitungsverfahren, Produktionsverfahren, Filtrationsverfahren.
- Extrakte (flüssig, dickflüssig, trocken). Die Zusammensetzung des Extraktionsmittels, das Extraktionsverfahren, die Anlagenart, das Verfahren zur Entfernung der Extraktionsmittel und Ballaststoffe.
- Tablets. Zusammensetzung aus Hilfsstoffen, Füllstoffen, Sprengmitteln, Bindemitteln, Gleit- und Gleitmitteln. Die Methode zur Herstellung von Tabletten, die Art der technologischen Ausrüstung. Art der Hülle und ihrer Bestandteile, Filmbildner, Pigmente, Farbstoffe, Weichmacher, Lösungsmittel.
- Injektionslösungen. Art des Lösungsmittels, Filtrationsverfahren, Art der Stabilisatoren und Konservierungsmittel, Sterilisationsbedingungen, Art der Ampullenabfüllung.
- Zäpfchen. Die Zusammensetzung der Zäpfchenbasis, das Verfahren zur Herstellung von Zäpfchen, Füllstoffen, Verpackung.
- Salben. Zusammensetzung der Basis, Strukturbestandteile, Herstellungsverfahren der Salbe, Art der Ausrüstung, Verpackung.
- Kapseln. Art des Hüllmaterials, Art der Kapselgewinnung, Art des Weichmachers, Konservierungsmittel, Farbstoff.
- Einreibungen. Herstellungsverfahren, Zusammensetzung, Art der Ausrüstung, Art des Emulgators.
- Aussetzungen. Art des Lösungsmittels, Art des Stabilisators, Dispergiermethode.
Beispiele für Qualitätsfaktoren und deren Niveaus, die im Herstellungsprozess von Tabletten untersucht wurden
- Backpulver. Kartoffelstärke, weißer Ton, eine Mischung aus Natriumbicarbonat mit Zitronensäure, basisches Magnesiumcarbonat.
- Bindungslösung. Wasser, Stärkepaste, Zuckersirup, Methylcelluloselösung, Hydroxypropylmethylcelluloselösung, Polyvinylpyrrolidonlösung, Polyvinylalkohollösung.
- Gleitsubstanz. Aerosil, Stärke, Talk.
- Füllstoff. Zucker, Glucose, Lactose, Natriumchlorid, Calciumphosphat.
- Schmiermittel. Stearinsäure, Polyethylenglycol, Paraffin.
Modelle der Streuungsanalyse bei der Untersuchung des Wettbewerbsniveaus des Staates
Eines der wichtigsten Kriterien für die Beurteilung des Zustands des Staates, das zur Beurteilung des Niveaus seines Wohlstands und seiner sozioökonomischen Entwicklung verwendet wird, ist die Wettbewerbsfähigkeit, dh eine Reihe von Eigenschaften, die der Volkswirtschaft innewohnen und die Fähigkeit bestimmen Staat, um mit anderen Ländern zu konkurrieren. Nachdem der Platz und die Rolle des Staates auf dem Weltmarkt bestimmt wurden, ist es möglich, eine klare Strategie zur Gewährleistung der wirtschaftlichen Sicherheit auf internationaler Ebene festzulegen, da dies der Schlüssel zu positiven Beziehungen zwischen Russland und allen Akteuren auf dem Weltmarkt ist: Investoren , Gläubiger, Landesregierungen.
Um das Niveau der Wettbewerbsfähigkeit von Staaten zu vergleichen, werden die Länder anhand komplexer Indizes eingestuft, die verschiedene gewichtete Indikatoren enthalten. Diese Indizes basieren auf Schlüsselfaktoren, die die wirtschaftliche, politische usw. Situation beeinflussen. Der Modellkomplex zur Untersuchung der Wettbewerbsfähigkeit des Staates sieht die Verwendung von Methoden der mehrdimensionalen statistischen Analyse vor (insbesondere Varianzanalyse (Statistik), ökonometrische Modellierung, Entscheidungsfindung) und umfasst die folgenden Hauptphasen:
- Bildung eines Systems von Indikatoren-Indikatoren.
- Auswertung und Prognose von Indikatoren der Wettbewerbsfähigkeit des Staates.
- Vergleich der Indikatoren-Indikatoren der Wettbewerbsfähigkeit der Staaten.
Betrachten wir nun den Inhalt der Modelle der einzelnen Stufen dieses Komplexes.
In der ersten Phase Unter Verwendung von Methoden des Expertenstudiums wird ein angemessener Satz von Wirtschaftsindikatoren-Indikatoren zur Bewertung der Wettbewerbsfähigkeit des Staates gebildet, wobei die Besonderheiten seiner Entwicklung auf der Grundlage internationaler Ratings und Daten aus statistischen Abteilungen berücksichtigt werden, die den Zustand des Systems widerspiegeln als Ganzes und seine Prozesse. Die Wahl dieser Indikatoren ist durch die Notwendigkeit gerechtfertigt, diejenigen auszuwählen, die es aus praktischer Sicht am besten ermöglichen, das Niveau des Staates, seine Investitionsattraktivität und die Möglichkeit einer relativen Lokalisierung bestehender potenzieller und tatsächlicher Bedrohungen zu bestimmen.

Die Hauptindikatoren der internationalen Ratingsysteme sind Indizes:
- Globale Wettbewerbsfähigkeit (GCC).
- Wirtschaftsfreiheit (IES).
- Menschliche Entwicklung (HDI).
- Wahrnehmung von Korruption (CPI).
- Interne und externe Bedrohungen (IVZZ).
- Potenzial für internationalen Einfluss (IPIP).
Zweite Phase sieht die Bewertung und Prognose von Indikatoren der Wettbewerbsfähigkeit des Staates nach internationalen Ratings für die untersuchten 139 Staaten der Welt vor.
Dritter Abschnitt sieht einen Vergleich der Bedingungen für die Wettbewerbsfähigkeit von Staaten mit den Methoden der Korrelations- und Regressionsanalyse vor.
Anhand der Ergebnisse der Studie kann die Art der Prozesse allgemein und für einzelne Komponenten der Wettbewerbsfähigkeit des Staates bestimmt werden; Testen Sie die Hypothese über den Einfluss von Faktoren und ihre Beziehung auf dem entsprechenden Signifikanzniveau.
Die Umsetzung der vorgeschlagenen Modelle wird es nicht nur ermöglichen, die aktuelle Situation des Niveaus der Wettbewerbsfähigkeit und der Investitionsattraktivität der Staaten zu bewerten, sondern auch die Mängel des Managements zu analysieren, Fehler oder falsche Entscheidungen zu vermeiden und die Entwicklung einer Krise zu verhindern im Staat.
