As mentioned earlier, examples of probability distributions continuous random variable X are:
- uniform probability distribution of a continuous random variable;
- exponential probability distribution of a continuous random variable;
- normal distribution probabilities of a continuous random variable.
Let us give the concept of uniform and exponential distribution laws, probability formulas and numerical characteristics of the considered functions.
| Index | Random distribution law | The exponential law of distribution |
|---|---|---|
| Definition | Uniform is called the probability distribution of a continuous random variable X, whose density remains constant on the interval and has the form | An exponential (exponential) is called the probability distribution of a continuous random variable X, which is described by a density having the form |
 where λ is a constant positive value |
||
| distribution function |  |
|
| Probability hitting the interval |  |
|
| Expected value | ||
| Dispersion |  |
|
| Standard deviation |  |
Examples of solving problems on the topic "Uniform and exponential laws of distribution"
Task 1.
Buses run strictly according to the schedule. Movement interval 7 min. Find: (a) the probability that a passenger arriving at a stop will wait for the next bus for less than two minutes; b) the probability that a passenger approaching the stop will wait for the next bus for at least three minutes; c) the mathematical expectation and standard deviation of the random variable X - the passenger's waiting time.
Solution. 1. By the condition of the problem, a continuous random variable X=(passenger waiting time) evenly distributed between the arrivals of two buses. The length of the distribution interval of the random variable X is equal to b-a=7, where a=0, b=7.
2. The waiting time will be less than two minutes if the random value X falls within the interval (5;7). The probability of falling into a given interval is found by the formula: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(5< Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
3. The waiting time will be at least three minutes (that is, from three to seven minutes) if the random value X falls within the interval (0; 4). The probability of falling into a given interval is found by the formula: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(0< Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
4. Mathematical expectation of a continuous, uniformly distributed random variable X - the passenger's waiting time, we find by the formula: M(X)=(a+b)/2. M (X) \u003d (0 + 7) / 2 \u003d 7/2 \u003d 3.5.
5. The standard deviation of a continuous, uniformly distributed random variable X - the passenger's waiting time, we find by the formula: σ(X)=√D=(b-a)/2√3. σ(X)=(7-0)/2√3=7/2√3≈2.02.
Task 2.
The exponential distribution is given for x ≥ 0 by the density f(x) = 5e – 5x. Required: a) write an expression for the distribution function; b) find the probability that, as a result of the test, X falls into the interval (1; 4); c) find the probability that as a result of the test X ≥ 2; d) calculate M(X), D(X), σ(X).
Solution. 1. Since, by condition, exponential distribution , then from the formula for the probability distribution density of the random variable X we obtain λ = 5. Then the distribution function will look like:
2. The probability that as a result of the test X falls into the interval (1; 4) will be found by the formula:
P(a< X < b) = e −λa − e −λb
.
P(1< X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. The probability that as a result of the test X ≥ 2 will be found by the formula: P(a< X < b) = e −λa − e −λb при a=2, b=∞.
Р(Х≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. We find for the exponential distribution:
- mathematical expectation according to the formula M(X) =1/λ = 1/5 = 0.2;
- dispersion according to the formula D (X) \u003d 1 / λ 2 \u003d 1/25 \u003d 0.04;
- standard deviation according to the formula σ(X) = 1/λ = 1/5 = 1.2.
This issue has long been studied in detail, and the method of polar coordinates, proposed by George Box, Mervyn Muller and George Marsaglia in 1958, was most widely used. This method allows you to get a pair of independent normally distributed random variables with mean 0 and variance 1 as follows:
Where Z 0 and Z 1 are the desired values, s \u003d u 2 + v 2, and u and v are random variables uniformly distributed on the segment (-1, 1), selected in such a way that the condition 0 is satisfied< s < 1.
Many use these formulas without even thinking, and many do not even suspect their existence, since they use ready-made implementations. But there are people who have questions: “Where did this formula come from? And why do you get a pair of values at once? In the following, I will try to give a clear answer to these questions.
To begin with, let me remind you what the probability density, the distribution function of a random variable and the inverse function are. Suppose there is some random variable, the distribution of which is given by the density function f(x), which has the following form:

This means that the probability that the value of this random variable will be in the interval (A, B) is equal to the area of the shaded area. And as a consequence, the area of the entire shaded area should be equal to unity, since in any case the value of the random variable will fall into the domain of the function f.
The distribution function of a random variable is an integral of the density function. And in this case, its approximate form will be as follows:

Here the meaning is that the value of the random variable will be less than A with probability B. And as a result, the function never decreases, and its values lie in the interval .
An inverse function is a function that returns the argument of the original function if you pass the value of the original function into it. For example, for the function x 2 the inverse will be the root extraction function, for sin (x) it is arcsin (x), etc.
Since most pseudo-random number generators give only a uniform distribution at the output, it often becomes necessary to convert it to some other one. In this case, to a normal Gaussian:

The basis of all methods for transforming a uniform distribution into any other distribution is the inverse transformation method. It works as follows. A function is found that is inverse to the function of the required distribution, and a random variable uniformly distributed on the segment (0, 1) is passed to it as an argument. At the output, we obtain a value with the required distribution. For clarity, here is the following picture.

Thus, a uniform segment is, as it were, smeared in accordance with the new distribution, being projected onto another axis through an inverse function. But the problem is that the integral of the density of the Gaussian distribution is not easy to calculate, so the above scientists had to cheat.
There is a chi-square distribution (Pearson distribution), which is the distribution of the sum of squares of k independent normal random variables. And in the case when k = 2, this distribution is exponential.

This means that if a point in a rectangular coordinate system has random X and Y coordinates distributed normally, then after converting these coordinates to the polar system (r, θ), the square of the radius (the distance from the origin to the point) will be distributed exponentially, since the square of the radius is the sum of the squares of the coordinates (according to the Pythagorean law). The distribution density of such points on the plane will look like this:


Since it is equal in all directions, the angle θ will have a uniform distribution in the range from 0 to 2π. The converse is also true: if you specify a point in the polar coordinate system using two independent random variables (the angle distributed uniformly and the radius distributed exponentially), then the rectangular coordinates of this point will be independent normal random variables. And the exponential distribution from the uniform distribution is already much easier to obtain, using the same inverse transformation method. This is the essence of the Box-Muller polar method.
Now let's get the formulas.
![]() (1)
(1)
To obtain r and θ, it is necessary to generate two random variables uniformly distributed on the segment (0, 1) (let's call them u and v), the distribution of one of which (let's say v) must be converted to exponential to obtain the radius. The exponential distribution function looks like this:
Its inverse function:
![]()
Since the uniform distribution is symmetrical, the transformation will work similarly with the function
![]()
It follows from the chi-square distribution formula that λ = 0.5. We substitute λ, v into this function and get the square of the radius, and then the radius itself:

We obtain the angle by stretching the unit segment to 2π:
Now we substitute r and θ into formulas (1) and get:
 (2)
(2)
These formulas are ready to use. X and Y will be independent and normally distributed with a variance of 1 and a mean of 0. To get a distribution with other characteristics, it is enough to multiply the result of the function by the standard deviation and add the mean.
But it is possible to get rid of trigonometric functions by specifying the angle not directly, but indirectly through the rectangular coordinates of a random point in a circle. Then, through these coordinates, it will be possible to calculate the length of the radius vector, and then find the cosine and sine by dividing x and y by it, respectively. How and why does it work?
We choose a random point from uniformly distributed in the circle of unit radius and denote the square of the length of the radius vector of this point by the letter s:

The choice is made by assigning random x and y rectangular coordinates uniformly distributed in the interval (-1, 1), and discarding points that do not belong to the circle, as well as the central point at which the angle of the radius vector is not defined. That is, the condition 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
We get the formulas, as at the beginning of the article. The disadvantage of this method is the rejection of points that are not included in the circle. That is, using only 78.5% of the generated random variables. On older computers, the lack of trigonometric functions was still a big advantage. Now, when one processor instruction simultaneously calculates sine and cosine in an instant, I think these methods can still compete.
Personally, I have two more questions:
- Why is the value of s evenly distributed?
- Why is the sum of squares of two normal random variables exponentially distributed?

If a similar transformation is done for a normal random variable, then the density function of its square will turn out to be similar to a hyperbola. And the addition of two squares of normal random variables is already a much more complex process associated with double integration. And the fact that the result will be an exponential distribution, personally, it remains for me to check it with a practical method or accept it as an axiom. And for those who are interested, I suggest that you familiarize yourself with the topic closer, drawing knowledge from these books:
- Wentzel E.S. Probability theory
- Knut D.E. The Art of Programming Volume 2
In conclusion, I will give an example of the implementation of a normally distributed random number generator in JavaScript:
Function Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1.0; s = u * u + v * v; ) while (s > 1.0 || s == 0.0); var r = Math.sqrt(-2.0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + mean; ) ); ) g = new Gauss(); // create an object a = g.next(); // generate a pair of values and get the first one b = g.next(); // get the second c = g.next(); // generate a pair of values again and get the first one
The mean (mathematical expectation) and dev (standard deviation) parameters are optional. I draw your attention to the fact that the logarithm is natural.
A distribution is considered uniform if all values of a random variable (in the region of its existence, for example, in the interval) are equally probable. The distribution function for such a random variable has the form:
Distribution density: 
 1
1

Rice. Graphs of the distribution function (left) and distribution density (right).
Uniform distribution - concept and types. Classification and features of the category "Uniform distribution" 2017, 2018.
Basic discrete distributions of random variables Definition 1. Random variable Х, taking values 1, 2, …, n, has a uniform distribution if Pm = P(Х = m) = 1/n, m = 1, …, n. It's obvious that. Consider the following problem. There are N balls in an urn, of which M are white... .
Laws of distribution of continuous random variables Definition 5. A continuous random variable X, taking a value on the interval , has a uniform distribution if the distribution density has the form. (1) It is easy to verify that, . If a random variable... .
A distribution is considered uniform if all values of a random variable (in the region of its existence, for example, in the interval ) are equally probable. The distribution function for such a random variable has the form: Distribution density: F(x) f(x) 1 0 a b x 0 a b x ... .
Normal distribution laws Uniform, exponential and The probability density function of the uniform law is: (10.17) where a and b are given numbers, a< b; a и b – это параметры равномерного закона. Найдем функцию распределения F(x)... .
The uniform probability distribution is the simplest and can be either discrete or continuous. A discrete uniform distribution is such a distribution for which the probability of each of the values of CB is the same, that is: where N is the number ... .
Definition 16. A continuous random variable has a uniform distribution on the segment, if on this segment the distribution density of this random variable is constant, and outside it is equal to zero, that is, (45) The density graph for a uniform distribution is shown ...
As an example of a continuous random variable, consider a random variable X uniformly distributed over the interval (a; b). We say that the random variable X evenly distributed on the interval (a; b), if its distribution density is not constant on this interval:
From the normalization condition, we determine the value of the constant c . The area under the distribution density curve should be equal to one, but in our case it is the area of a rectangle with a base (b - α) and a height c (Fig. 1). 
Rice. 1 Uniform distribution density
From here we find the value of the constant c: ![]()
So, the density of a uniformly distributed random variable is equal to 
Let us now find the distribution function by the formula:
1) for ![]()
2) for
3) for 0+1+0=1.
In this way, 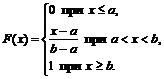
The distribution function is continuous and does not decrease (Fig. 2). 
Rice. 2 Distribution function of a uniformly distributed random variable
Let's find mathematical expectation of a uniformly distributed random variable according to the formula:
Uniform distribution variance is calculated by the formula and is equal to
Example #1. The scale division value of the measuring instrument is 0.2 . Instrument readings are rounded to the nearest whole division. Find the probability that an error will be made during the reading: a) less than 0.04; b) big 0.02
Solution. The rounding error is a random variable uniformly distributed over the interval between adjacent integer divisions. Consider the interval (0; 0.2) as such a division (Fig. a). Rounding can be carried out both towards the left border - 0, and towards the right - 0.2, which means that an error less than or equal to 0.04 can be made twice, which must be taken into account when calculating the probability: 

P = 0.2 + 0.2 = 0.4
For the second case, the error value can also exceed 0.02 on both division boundaries, that is, it can be either greater than 0.02 or less than 0.18. 
Then the probability of an error like this:
Example #2. It was assumed that the stability of the economic situation in the country (the absence of wars, natural disasters, etc.) over the past 50 years can be judged by the nature of the distribution of the population by age: in a calm situation, it should be uniform. As a result of the study, the following data were obtained for one of the countries.
Is there any reason to believe that there was an unstable situation in the country?We carry out the decision using the calculator Hypothesis testing. Table for calculating indicators.
| Groups | Interval middle, x i | Quantity, fi | x i * f i | Cumulative frequency, S | |x - x cf |*f | (x - x sr) 2 *f | Frequency, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
weighted average
Variation indicators.
Absolute Variation Rates.
The range of variation is the difference between the maximum and minimum values of the attribute of the primary series.
R = X max - X min
R=70 - 0=70
Dispersion- characterizes the measure of spread around its mean value (measure of dispersion, i.e. deviation from the mean).
Standard deviation.
Each value of the series differs from the average value of 43 by no more than 23.92
Testing hypotheses about the type of distribution.
4. Testing the hypothesis about uniform distribution the general population.
In order to test the hypothesis about the uniform distribution of X, i.e. according to the law: f(x) = 1/(b-a) in the interval (a,b)
necessary:
1. Estimate the parameters a and b - the ends of the interval in which the possible values of X were observed, according to the formulas (the * sign denotes the estimates of the parameters):
2. Find the probability density of the estimated distribution f(x) = 1/(b * - a *)
3. Find theoretical frequencies:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Compare the empirical and theoretical frequencies using the Pearson test, assuming the number of degrees of freedom k = s-3, where s is the number of initial sampling intervals; if, however, a combination of small frequencies, and therefore the intervals themselves, was made, then s is the number of intervals remaining after the combination.
Solution:
1. Find the estimates of the parameters a * and b * of the uniform distribution using the formulas:
2. Find the density of the assumed uniform distribution:
f(x) = 1/(b * - a *) = 1/(84.42 - 1.58) = 0.0121
3. Find the theoretical frequencies:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0.0121 (10-1.58) \u003d 0.1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0.0121 (84.42-70) \u003d 0.17
The remaining n s will be equal:
n s = n*f(x)(x i - x i-1)
| i | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Total | 1 | 0.0532 |
Therefore, the critical region for this statistic is always right-handed: . if on this segment the probability distribution density of the random variable is constant, i.e. if the differential distribution function f(x) has the following form:
![]()
This distribution is sometimes called law of uniform density. About a quantity that has a uniform distribution on a certain segment, we will say that it is distributed uniformly on this segment.
Find the value of the constant c. Since the area bounded by the distribution curve and the axis Oh, equals 1, then
where With=1/(b-a).
Now the function f(x)can be represented as

Let's construct the distribution function
F(x ), for which we find the expression F (x ) on the interval [ a , b]:


Graphs of functions f (x) and F (x) look like:

Let's find numerical characteristics.
Using the formula for calculating the mathematical expectation of the NSW, we have:

Thus, the mathematical expectation of a random variable uniformly distributed on the interval [a , b] coincides with the middle of this segment.
Find the variance of a uniformly distributed random variable:
from which it immediately follows that the standard deviation:
![]()
Let us now find the probability that the value of a random variable with a uniform distribution falls into the interval(a , b ) , belonging entirely to the segment [a,b
]:

|
|

Geometrically, this probability is the area of the shaded rectangle. Numbers a and
bcalled distribution parameters and uniquely define a uniform distribution.Example1. Buses of a certain route run strictly according to the schedule. Movement interval 5 minutes. Find the probability that the passenger approached the bus stop. Will wait for the next bus less than 3 minutes.
Solution:
ST - bus waiting time has a uniform distribution. Then the desired probability will be equal to:
![]()
Example2. The edge of the cube x is measured approximately. And
Considering the edge of the cube as a random variable distributed uniformly in the interval (
a,b), find the mathematical expectation and variance of the volume of the cube.Solution:
The volume of the cube is a random variable determined by the expression Y \u003d X 3. Then the mathematical expectation is:
Dispersion:
Online service:
