Today, XML is the industry standard for quickly and efficiently exchanging data between different solutions. However, there are many tasks where users need to represent XML data in a different form. In these cases, converter programs are needed. They bridge the gap between XML and popular table formats. If you need to convert XML data on a regular basis, then you definitely need to use Advanced XML Converter! With Advanced XML Converter you no longer need to write complex XML transformations and XSL stylesheets. Convert XML to HTML, CSV, DBF, XLS, SQL in an instant! Advanced XML Converter will help you convert to other formats such as HTML, CSV, DBF, XLS and SQL. As soon as the XML file is loaded and you press the "Convert" button, the program will produce fast and high-quality output to one of the tabular formats. To ensure correct output, Advanced XML Converter uses the hierarchical structure of the original XML file. You can select the data to be presented in the output file. You can also convert more than one file using batch run. With Advanced XML Converter you no longer need to write complex conversion or XSL transformation scripts. Converting XML to HTML, CSV, DBF, XLS, SQL is fast and intuitive!
| Download Advanced XML Converter | |
 |
|
You can extract all XML data or only data from specific tags with Advanced XML Converter. When viewing extracted data, you can quickly switch between different views (without new analysis and without reloading the data). You can set export options for each output format (such as HTML table styles and CSV delimiters for exported fields, and other options). Advanced XML Converter allows you to save all tables in one file or several files separately, as well as flexibly configure preview and output options.
The software does not require the installation of drivers or additional components as it is built on the Internet Explorer parser which is available on most systems. Advanced XML Converter does not require the .NET Framework or XML Schemas. The program does not require deep knowledge of the XML file structure and greatly facilitates the conversion of large amounts of XML data. As a user, you will be able to see the most complex XML documents in different view tables that are easy to read. This is very convenient for transferring information to databases or specialized systems that require a format close to plain text.
If you are looking for a fast system for converting XML data, Advanced XML Converter is the best choice! Affordable and easy to use program performs complex data transformations in minutes!
The latest version of Advanced XML Converter provides a simple, fast and highly efficient way to extract data from XML files and save it in popular HTML, DBF, CSV, Excel and SQL formats. |
|
With Advanced XML Converter you can: |
|
|
Probably you often need to convert an XML file or a folder with XML files into one or several DBF files. The problem is that XML structure, its hierarchy and nesting levels differ from file to file. In this article, we"ll take a detailed look on how to import an XML file of ANY structure to a flat DBF table.
A new feature called Import Custom XML was implemented in DBF Commander Professional version 2.7 (build 40). This command is available via the command line interface. The syntax is as follows:
dbfcommander.exe -icx
As you can see, there are four parameters:
- -icx– means Import Custom XML.
- <-attr> - use this parameter if you "d like to import tags with certain attributes.
DBF fields definition, or How to create a map-file
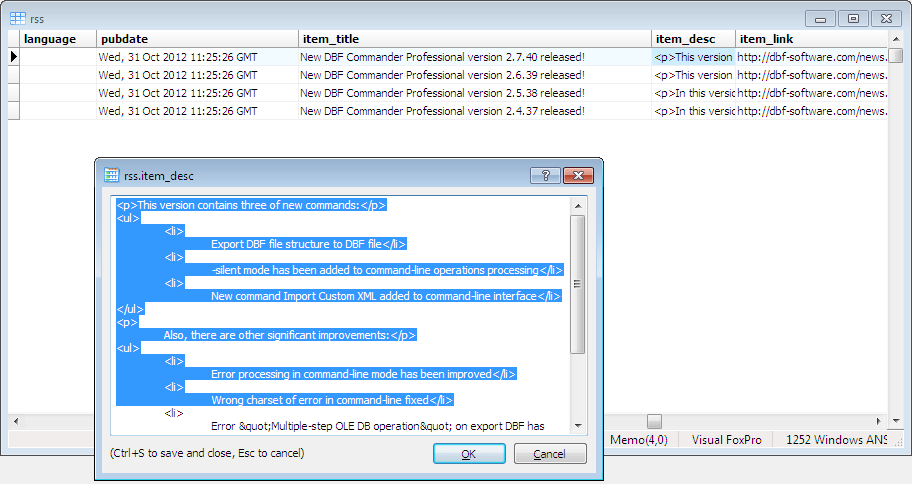
It is always better to learn something by using an example. In our situation, we need some well-known XML. Let's take an RSS news feed XML file (available ):
As you can see, there are four<item> elements nested in the<channel> element, which is itself nested in the top-level<rss> element. There are also elements of the same nesting level as the<item> elements:<generator>, <title>, <description>, etc.
Suppose that each<item> element should be represented as one row in the resulting DBF file. So our file will contain four records.
To create a map-file, first let's create the resulting DBF file. We need it because then we "ll be able to create a map-file in a few clicks. Launch DBF Commander Professional, click File -> New, and create a DBF file. In the case of the RSS XML file, the structure is as follows:

Click OK. The DBF file will be created, and now it can be used as a resulting file for our import from the XML process. You can use any available field types: character, Integer, Numeric, Date, etc.
To create a map-file based on the resulting file, click the Export Structure tool button (see the picture above). When the Save dialog opens, choose the path and filename, and then save the structure as a DBF file.
Matching XML tags to DBF fields
We have to do one more thing yet: define the XML tags that should be inserted in the fields of the resulting DBF file.
Open the DBF file you "ve just saved. Click File -> Structure and add a new field named" xmltagname"of the character type. You can add more fields in the map-file if you want to. For example, let "s add a field named" comment".Click OK to save the changes.
Now fill every row of the new" xmltagname"field with the XML nodes path (separated by " -> ") that should be inserted into the corresponding field in the DBF file:

It means that the value of the XML node<title> nested in the<channel> node which is nested in the top-level<rss>, will be inserted into the " title"field; the XML tag" rss -> channel -> description"will be inserted into the" desc"field, and so on.
In case of using" -attr" parameter, paths of the map-file must contain corresponding attributes as well, e.g.: " rss version="2.0" -> channel -> title".
Pay attention to the" item_desc"field. The XML tag" rss -> channel -> item -> description" contains the CDATA section with HTML markup. So its tag path should be finished with the " #cdata-section"string.
The last row that you can see in the picture above is the so-called " row-tag". This tag path allows DBF Commander to know which XML tag should be used as a new row in the resulting DBF file. In our case, it is" rss -> channel -> item".
Note that the value of the " name" field should be empty for the record containing the row-tag, so that the program can recognize the row-tag.
Well, that's all. Now we can run the import from XML to DBF itself. Execute the following command from the command line, or from a BAT file:
dbfcommander.exe -icx "D:\xml\rss.xml" "D:\dbf\" "D:\map-file.dbf"
As a result, we"ll get the new file" D:\dbf\rss.dbf"that contains the imported XML data:
You can download all the files used in this conversion from .
Send your good work in the knowledge base is simple. Use the form below
Students, graduate students, young scientists who use the knowledge base in their studies and work will be very grateful to you.
Hosted at http://www.allbest.ru/
Pridnestrovian State University named after T.G. Shevchenko
Institute of Engineering and Technology
Department of Information Technology and Automated Control of Production Processes
FINAL QUALIFICATION WORK
in the direction 230100 "Computer science and computer technology"
topic: "PROGRAM-CONVERTER OF DATABASES FROM DBF FILES TO XML FORMAT FILE"
Student Maksimov Dmitry Olegovich
Tiraspol, 2013
INTRODUCTION
1. RESEARCH AND ANALYSIS OF THE SUBJECT AREA
1.1 Description of the task
1.2 Justification of the relevance of the problem under study
1.3 Overview of methods for solving similar problems
1.4 Statement of the problem, system requirements, requirements for input data and output forms
2. DESIGN OF THE STRUCTURE AND ARCHITECTURE OF THE SOFTWARE PRODUCT
2.1 Choice of methods and means for implementation, its justification
2.2 Description of applied algorithms
2.3 Structure, architecture of the software product
2.4 Functional diagram, functional structure of the software product
3. IMPLEMENTATION AND TESTING OF THE SOFTWARE PRODUCT
3.1 Implementation description
3.2 Description of the user interface
3.3 Testing and evaluating the reliability of the software product
3.4 Cost calculation
3.5 Labor protection
CONCLUSION
LIST OF CONVENTIONS, SYMBOLS, UNITS AND TERMS
LIST OF USED LITERATURE
APPENDIX
INTRODUCTION
During the existence of computers, many operating systems have been developed. Now their number is measured in dozens and in various families there are file formats used only in a certain line of operating systems. If, for example, there are universal editors for images that open any file format containing images supported by operating systems, then, for example, there are no such editors for databases.
To work with each of the database formats, there is an individual database management system. There are a huge number of varieties of databases that differ in various criteria:
1) Classification by data model:
a) hierarchical;
b) network;
c) relational;
d) object and object-oriented;
e) object-relational, functional.
2) Classification by persistent storage environment:
a) in secondary memory, or traditional;
b) in RAM;
c) in tertiary memory.
3) Classification according to the degree of distribution:
a) centralized, or concentrated;
b) distributed.
4) Other types of database
a) spatial;
b) temporary;
c) space-time;
d) cyclic.
A large abundance of different databases does not allow you to directly transfer the contents of the database from one type to another. To solve this problem, there are converter programs that convert one database format to another. As a rule, converters exist only for the most common database formats, which does not allow you to directly convert some obsolete format to a modern one. Using two converters is not rational, so the best solution is to store databases in XML files as an intermediate step.
XML files and other file extensions based on the XML language have become very widespread, and almost every modern operating system supports this file format. XML files store a wide variety of data, from application settings to databases. XML-based files are used to exchange information on the Internet and between programs (which is what this markup language was originally conceived for). Since XML format files contain text data, they can be easily edited in any text editor, as well as set any user-friendly data encoding. In addition, there are a large number of XML document generators.
1 . RESEARCH AND ANALYSIS OF THE SUBJECT AREA
1.1 Description of the task
In the final qualifying work, it is required to implement a converter program that creates, based on the contents of the transferred dbf files, an XML format file according to a user-specified template. The number and structure of dbf files can be arbitrary, the output XML file must always be the same. Each dbf file has its own template, on the basis of which the program writes information to the XML file. It is necessary to implement the ability to create templates in two ways: using code and using a constructor. Templates created with code must select which data to write to the output file. This possibility is carried out with the help of special code commands developed specifically for this program. In the templates created using the constructor, it is required to implement a simple and convenient interface that will allow you to create custom templates, based on which the program writes information to an XML file.
1.2 Rationale for relevance problem under study
XML is a markup language recommended by the World Wide Web Consortium, which is actually a set of general syntax rules. XML is a text format designed for storing structured data (instead of existing database files), for exchanging information between programs, and for creating more specialized markup languages (for example, XHTML) on its basis.
An XML document is a database only in the most general sense of the word, that is, it is a collection of data. In this it is no different from many other files - in the end, all files consist of some kind of data. As a "database" format, XML has some advantages, such as being self-describing (markup describes the data). It is easy to make it handled by different software because the data is stored in Unicode, it stores the data in a tree or graph like structure. But it also has some drawbacks, for example, it is too verbose and relatively slow in accessing data due to the need to parse and convert text.
On the positive side, XML allows you to implement many of the things that can be found in conventional databases: storage (XML documents), schemas (DTD, XML Schema Language), query languages (XQuery, XPath, XQL, XML -QL, QUILT, etc.), APIs (SAX, DOM, JDOM), etc. The disadvantages include the lack of many features available in modern databases: storage economy, indexes, security, transactions and data integration, multi-user access, triggers, queries on many documents, etc.
Thus, while it is possible to use XML documents as a database in environments with little data, few users, and low performance requirements, it cannot be done in most business environments with many users and strong integration requirements. data and high performance requirements.
An example of a "database" that an XML document is suitable for is an .ini file - that is, a file that contains application configuration information. It's much easier to come up with a programming language with a small set of XML-based features and write a SAX application to interpret it than it is to write a parser for comma-separated files. In addition, XML allows you to nest data elements - this is quite difficult to do when separating data with commas. However, such files can hardly be called databases in the full sense of the word, since they are read and written linearly and only when the application is opened or closed.
The most interesting examples of datasets in which it is convenient to use an XML document as a database is a personal list of contacts (names, phone numbers, addresses, etc.). However, due to the low cost and ease of use of databases such as dBASE and Access, even in these cases there is little reason to use an XML document as the database. The only real advantage of XML is that data can be easily transferred from one application to another, but this advantage is not so important, since tools for serializing databases into XML format are already widespread.
Software development is relevant for the following reasons:
The dbf database format is outdated and does not meet modern requirements;
The XML format does not have strict requirements for content, the user can store data in any order and create tags with any name;
No converter program allows you to create your own XML file structure and write data from several dbf format files.
1.3 Overview of methods for solving similar problems
"White Town" makes it possible to convert dbf files to XML format. The program can convert dBase III, dBase IV, FoxPro, VFP and dBase Level 7 dbf files. The program supports command line interface. Thus, it can be launched from a .BAT or .LNK file after specifying the required parameters or according to a schedule from the Windows scheduler. The disadvantage of this software product is the inability to customize the output file format. The main application window is shown in Figure 1.1.
Figure 1.1 - The main window of the program "White Town"
"DBF Converter" is a versatile yet easy-to-use conversion program. This program has a wizard-like interface, but can also be used as a command line utility to process a group of files. "DBF Converter" supports all modern data exchange formats such as XML, CSV, TXT, HTML, RTF, PRG and others. Implemented the ability to convert DBF tables into SQL script, which can be imported into any SQL database.
In addition to simple transformations, "DBF Converter" allows you to manipulate data by selecting only certain columns and applying filters. Unlike the simplified filtering rules that are commonly found in other DBF applications, DBF Converter dynamically generates simple database entry forms. The ability to set advanced mask and rules on any field of a simple record is one of the most valuable features available in DBF Converter. The main disadvantage of this software is its cost of $29.95.
The main application window is shown in Figure 1.2.
Figure 1.2 - The main window of the program "DBF Converter"
"DBF View" is a free, compact and convenient program for working with DBF files. Does not require installation, works without additional drivers and libraries.
The main advantage is universality, fast and flexible linear search, which surpasses many SQL in speed.
Additional features:
Search by mask (pattern);
Editing, replacing, deleting, creating, adding data;
Sorting fields;
Multilingualism and creation of new dictionaries;
Import and export DBF, TXT, CSV, SQL, XML;
Recoding to DOS, Windows, translit and others;
Launch password;
Recording history.
The main disadvantage of this software is the inability to create templates when converting. The main window of the program is shown in Figure 1.3.
Figure 1.3 - The main window of the program "DBF View"
1.4 Problem statement, system requirements, requirements for output data and output forms
After studying the task, examining its relevance and analyzing the existing converter programs, a list of necessary requirements for the developed software was compiled.
The following functions must be implemented in the software product:
Reading the contents of dbf files;
Creating templates in one of two editors;
Template editing;
Selecting the order of converting dbf files;
Execution of templates;
Error logging;
Saving the results of the program in an XML file.
The software is written in Microsoft Visual Studio 2008 and requires to run:
Operating system of the Windows family of one of the versions: Windows Vista, Windows 7 or Windows 8;
Microsoft .NET Framework 4;
Visual FoxPro ODBC Drivers.
The minimum system requirements for the software product correspond to the minimum requirements for the operating system.
The input data can be dBase II, dBase III or dBase IV version dbf files.
The output files should be an XML format file with language version 1.x and support for any browser.
The path to the input and output files can be arbitrary.
2 . STRUCTURE AND ARCHITECTURE DESIGN OF SOFTWARE PRODUCT
2.1 Choice of methods and means for implementation, its justification
The integrated development environment Microsoft Visual Studio 2008 was chosen for the development of the software product.
Visual Studio 2008 - Released November 19, 2007, alongside .NET Framework 3.5. It is aimed at creating applications for the Windows Vista operating system (but also supports XP), Office 2007 and web applications. Includes LINQ, new versions of C#, and Visual Basic. The studio did not include Visual J#. One of its advantages is a completely Russian interface.
Visual Studio includes a source code editor with support for IntelliSense technology and the ability to easily refactor code. The built-in debugger can work as both a source-level debugger and a machine-level debugger. Other embeddable tools include a form editor to simplify the creation of an application's GUI, a web editor, a class designer, and a database schema designer. Visual Studio allows you to create and connect third-party add-ons (plugins) to extend functionality at almost every level, including adding support for source code version control systems (such as Subversion and Visual SourceSafe), adding new toolkits (for example, for editing and visual code design). in domain-specific programming languages or tools for other aspects of the software development process (for example, the Team Explorer client for working with Team Foundation Server).
All Visual Studio 2008 C#-based workbench features include:
The ability to formulate tasks in the language of object interaction;
High modularity of the program code;
Adaptability to the desire of users;
A high degree of program reusability;
A large number of linked libraries.
2. 2 Description of applied algorithms
In the development of this software, two main difficulties can be distinguished: building a recognizer for programmable templates and creating a programming model that would be used in templates created using the constructor.
1. Programmable patterns. Since the code used in templates is somewhat similar to the code used in programming languages, it is necessary that this recognizer takes over some functions of the code compiler, or rather its parsing functions. In the structure of the compiler, the parsing part consists of lexical, syntactic and semantic analysis. The lexical analyzer reads the program characters in the source language and constructs source language lexemes from them. The result of his work is a table of identifiers. The parser performs the extraction of syntactic constructions in the text of the source program, processed by the lexical analyzer. Brings the syntactic rules of the program into line with the grammar of the language. The parser is a text recognizer of the input language. The semantic analyzer checks the correctness of the text of the source program in terms of the meaning of the input language.
With the help of the code, the following features should be implemented: creating a loop, getting and displaying data on the number of rows and columns, getting the data type and column names, as well as getting the contents of the database cells. To do this, first of all, it is necessary to make a list of all possible states of the automaton. Possible states of the recognizer are presented in Table 2.1.
Table 2.1 - List of possible recognizer states
|
Status Index |
State |
Description |
|
|
Variable |
Cycle counter |
||
|
Service word denoting the beginning of a cycle |
|||
|
Service word denoting the exit condition of the loop |
|||
|
Functional word denoting that further reference will be to base columns |
|||
|
Functional word denoting that further reference will be to base strings |
|||
|
Quantity |
Functional word indicating the number of rows or columns, depending on what was the previous call |
||
|
Functional word denoting the output of the data type of the column to be accessed |
|||
|
Name |
Functional word denoting the output of the name of the column to which the appeal follows |
||
|
Special character separating service words |
|||
|
= (equal sign) |
A special character that indicates what value will be assigned to the variable when the loop starts. |
||
|
[ (open bracket) |
|||
|
] (close bracket) |
A special character indicating that a particular column or row was accessed |
||
|
Any integer |
Based on the compiled table, it is possible to construct a finite state machine of possible state transitions. Figure 2.1 shows a state machine.
Figure 2.1 - Finite state machine of possible transitions
On the basis of the constructed automaton, it is possible to construct a descending recognizer with a return (with the selection of alternatives). A descending backtracking recognizer is used to determine whether a string belongs to a grammar. It analyzes the current state, searches for a transition rule from the current state to the next one, if the next state matches, then the procedure is repeated for the next one. If the recognizer cannot find a transition rule from the current state to the next, then this chain does not belong to this grammar, that is, the code line is written with a logical error. If there are several transition options, then the recognizer remembers the state in which the alternative arose and returns to it if the chain does not belong to the grammar. Figure 2.2 shows a downward-facing resolver with a backtrack.
Figure 2.2 - Downward Resolver with Backtracking
During template analysis, an error log is kept that contains information about which template has an error, in which particular line of code and the type of error. Errors can be of the following types: unrecognized identifier (an attempt to use service words or special characters that are not provided for by the given code), violation of the logical meaning (the line of code did not pass the recognizer), an attempt to access a non-existent variable (accessing a variable to an uncreated variable or accessing a variable outside the loop), the beginning of the loop is not specified (the beginning and end of the loop must be specified in the form of opening and closing curly brackets).
2. Templates created using the constructor. One solution is the structure used in logical programming languages: apply condition filters to common input information, which in this case is the contents of a database table. Figure 2.3 shows the general structure of a database table.
Figure 2.3 - General structure of the database table
3. As an implementation, a solution was chosen using the "Truth Table". This table is a table with n+1 columns and m+1 rows, where n and m are the number of columns and rows in the input table. Each table cell stores a true or false value. Figure 2.4 shows the "Truth Table".
Figure 2.4 - "Truth table"
When a filter is applied, the true values are replaced with false, depending on what the filter was applied to. If the filter was applied to the contents of the cells, then the values will change for each cell specifically, and if to rows or columns, then only in an additional row or column.
When working with a database, the following entities can be distinguished: row index, column index, number of rows, number of columns, column type, column name, cell contents.
Conditions were also set out:<», «>”, “=”, “contains”, “matches”.
4. Selected entities and conditions are enough to display all possible data or impose all kinds of conditions. Figure 2.5 shows the "Truth Table" with filters applied.
Figure 2.5 - "Truth table" with filters applied
When outputting information to an XML file, the program determines what needs to be output, and then, using the "Truth Table", outputs only those values that correspond to the true value.
To create a template layout, the following types of tags were created: main, simple, global, block. The main one is a tag, there can be only one of this type in a document and it is required, it contains information about the XML document. Simple - tags of this type are the only way to display data and impose conditions on the "Truth Table". They consist of the following parts: title, source, and condition. Previously selected entities are used as a source and condition. If the tag has an empty name, its contents will not be displayed, but the condition for the "Truth Table" will be applied.
Global - tags of this type do not carry a logical load, they are just needed for output.
Block - tags of this type are necessary to combine the logic of simple tags, and everything that is written in the block tag will be displayed for each cell that satisfies the "Truth Table". The block tag itself is not displayed in the XML document.
2.3 Structure, architecture of the software product
Central to object-oriented programming is the development of a logical model of a system in the form of a class diagram. Class diagram (class diagram) serves to represent the static structure of the system model in the terminology of object-oriented programming classes. A class diagram can reflect, in particular, various relationships between individual entities of the subject area, such as objects and subsystems, as well as describe their internal structure and types of relationships.
Class (class) in this diagram is used to denote a set of objects that have the same structure, behavior and relationships with objects of other classes. Graphically, the class is depicted as a rectangle, which can be additionally divided by horizontal lines into sections or sections. These sections can contain the class name, attributes (variables), and operations (methods).
In addition to the internal structure or structure of classes, the corresponding diagram indicates the relationship between classes:
For this application, the classes described in Table 2.2 have been allocated.
Table 2.2 - Description of the classes used in the software product
The class diagram of the converter application is shown in Figure 2.6. From the diagram, you can see that the MyCode class is a variable of the Template class. The Template class contains the following fields: dt, lv, thisTemplate, mycode, fs, sr, sw, correct, masCode, masPerem, masPeremCount, masSost, masCodeLength. dt is a DataTable type variable containing information stored in the database; lv - a variable of the ListView type, an interface object into which error messages in templates are written; thisTemplate - a variable of type string, meaning the name of the template that is currently being processed; mycode - an array of the MyCode class that stores information about all code fragments found in this template; fs - a variable of the FileStream type, which determines which file the program will work with; sr - a variable of the StreamReader type, which determines from which file the information will be read; sw is a StreamWriter type variable that determines which file information will be written to; correct - a bool type variable indicating whether the current code fragment is processed correctly; masCode - an array of type string containing all found lines of code in the template; masCodeLength - an int variable indicating how many lines of code were found in the template; masPerem - two-dimensional array of string type containing the name and value of the created variables; masPeremCount - a variable of type int indicating how many variables have been created at the moment; masSost is an array of type int containing a list of machine states for the current line of code.
The class also contains the following methods: Connect, Search, Analize, Check, ExecuteCode. The Connect method connects to the template at the given path. The Search method finds code snippets in a template. The Analyze method determines the states for a line of code. The Check method is recursive, it determines the logical validity of a string. The ExecuteCode method executes the current template. For the described classes, you can make a class diagram. Figure 2.6 is a class diagram.
Figure 2.6 - Class diagram
2.4 Functional diagram, functional purpose of the software product
The software product has developed two possible options for processing information with unique algorithms.
If the user uses code templates, he must first specify the input files, then either create a new template or select an existing one. Next, the user specifies the directory and name of the output file and starts the conversion process. During this process, sections of code in the template are initially allocated, then lexemes are allocated in each of the sections, after which their logical meaning is determined and the template is executed. If errors occur at any of these stages, information about them is recorded in the error log. After executing all the templates, the user can use the output file.
If you use templates created using the constructor, then the user needs to specify the database that needs to be converted, then specify the directory of the output file, create a template and start the conversion process. The conversion itself consists of two parts: creating a truth table based on the template and executing the conversion according to the truth table. The output file can then be used by the user as intended.
In the second chapter of the final qualification work, development tools were chosen, namely Microsoft Visual Studio 2008, the main methods for implementing a software product were described, and its structure was also described. The functional diagram of the software product was also described.
The main points of consideration in the second chapter were:
The choice of methods and means for implementation, its justification;
Description of applied algorithms;
Structure, architecture of the software product;
Functional diagram, functional purpose of the software product.
3 . IMPLEMENTATIONAND TESTINGSOFTWARE PRODUCT
3.1 Implementation Description
One of the difficulties in implementing this software product is writing a recognizer algorithm. The whole algorithm is described by the methods: Search, Analize, Check, ExecuteCode.
The Search method reads the pattern and finds code fragments marked with "*" characters on both sides and writes them to the .
public voidSearch()
boolsign=false;
while (!sr.EndOfStream)
if ((c != "*") && (sign == true))
( s += c.ToString(); )
if ((c == "*") && (sign == false))
if ((c == "*") && (sign == true))
masCode = s;
masCodeLength++; )
s += c.ToString(); ))
mycode = new MyCode ;)
The Analize method splits a line of code into separate tokens and determines the state for each of them, if symbols or words that are not provided for by the language are used, or incorrect variable names are used, an appropriate error message is added to the error log. A complete list of used lexemes is presented in Table 2.1.
public void Analyze()
( string masIdent = new string;
int masIdentLength = 0;
bool sign = true;
for (int a = 0; a< masCodeLength; a++)
(correct=false;
masIdentLength = 0;
masCode[a] = masCode[a].Trim();
masCode[a] = masCode[a].ToLower();
for (int b = 0; b< masCode[a].Length; b++)
( c = masCode[a][b];
masIdentLength++; )
masIdent = ".";
masIdentLength++;
if ((c == " ") && (s != ""))
( masIdent = s;
masIdentLength++;
( masIdent = s;
masIdentLength++; )
mycode[a] = new MyCode("", null);
for (int z = 0; z< masIdentLength; z++)
mycode[a].code += masIdent[z] + " ";
masSost = new int;
In the previous part of the method, all found tokens were written to the masIdent array, then a loop is initialized in which the state is determined for all found tokens and written to the masSost array.
for (int b = 0; b< masIdentLength; b++)
if (masIdent[b] == "for")
else if (masIdent[b] == "before")
else if (masIdent[b] == "column")
else if (masIdent[b] == "string")
if (Char.IsLetter(masIdent[b]))
( bool f = true;
for (int d = 1; d< masIdent[b].Length; d++)
if (!Char.IsLetterOrDigit(masIdent[b][d]))
if (f == true) masSost[b] = 1; else
Adding an error entry to the error log if the ID found does not exist.
lv.Items.SubItems.Add("Unrecognized identifier " + masIdent[b]); )) else
lv.Items.SubItems.Add(mycode[a].code);
lv.Items.SubItems.Add("Unrecognized identifier " + masIdent[b]);))
mycode[a] = new MyCode(mycode[a].code, masSost);
Check(0, masSost, a); )
The Check method is based on the work of a descending resolver with a return: the current state is determined, if it is possible, then a transition is made to the next one. If it is not possible, then the state switches to an alternative one, if there is none, then an error message is added to the error log.
public void Check(int a, int s, int indc)
( if (masSost[a] == s)
( if ((s == 1) && (a == 0))
correct=true; ) else
if ((s == 2) && (a == 0)) s = 1; else
if (((s == 4) || (s == 5)) && (a == 0)) s = 8; else
if ((s == 1) && (a == 1)) s = 9; else
if ((s == 8) && (a == 1)) s = 6; else
if ((s == 10) && (a == 1)) s = 1; else
if ((s == 9) && (a == 2)) s = 12; else
if ((s == 6) && (a == 2))
( if (a == masSost.Length - 1)
correct=true; ) else
if (((s == 1) || (s == 12)) && (a == 2)) s = 11; else
if ((s == 12) && (a == 3)) s = 3; else
if ((s == 11) && (a == 3)) s = 8; else
if ((s == 3) && (a == 4)) s = 12; else
if ((s == 8) && (a == 4))
( if (masSost == 4)
if ((s == 6) && (a == 7))
( if (a == masSost.Length - 1)
correct=true; )
if (((s == 12) || (s == 1)) && (a == 7))
if ((s == 11) && (a == 8))
( if (a == masSost.Length - 1)
correct=true; )
If the array of input states passed the check by the resolver and all states matched, the correct variable is set to true, and if there is a mismatch somewhere, then the return is made and checked for an alternative state.
if (correct == false)
Check(a, s, indc); ) )
if ((s == 8) && (a == 1))
Check(a, s, indc); )
if ((s == 1) && (a == 2))
Check(a, s, indc);)
if ((s == 1) && (a == 7))
Check(a, s, indc); )
If the transition being made was not recognized, then the line of code being processed is considered logically invalid and an appropriate error entry is added to the error log.
if (correct == false)
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(masCode);
lv.Items.SubItems.Add("The logical meaning of the line is violated");
mycode.correct = false;
The ExecuteCode method writes the contents of the template to the output file by executing program lines. If a cycle is encountered, then a temporary file is created, into which the contents of the cycle are written, and until the cycle is completed, the contents of this file are executed. This is necessary to execute nested loops.
public void ExecuteCode(int NCode, bool cikcle, StreamReader sr, StreamWriter sw, int tempF)
while (!sr.EndOfStream)
c = Convert.ToChar(sr.Read());
The algorithm reads the input file character by character, if there is a closing curly brace, which means the end of the loop, and the variable cikcle is true, then this means that the method was nested and ends it.
if ((c == ")") && (cikcle == true))
If the read character was not "*", then this means that the character does not belong to code commands and it must simply be output.
If the character read was "*", the algorithm reads the next character, if it is "*", then this means that the user wanted to output this character to the output file.
( c = Convert.ToChar(sr.Read());
If the next character was not "*", then this means that all subsequent characters before "*" refer to code commands.
if (mycode.correct == true)
if (mycode.masSost == 1)
( bool create = false;
for (int a = 0; a< masPeremCount; a++)
( if (masPerem == mycode.code)
sw.Write(masPerem);
while (sr.Read() != "*")
If, in the code, the user tries to display a variable that has not been declared before, then an error entry is written to the error log and the far code is no longer executed.
if (create == false)
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add("Trying to display a non-existent variable");
mycode.code = ""; )
while (sr.Read() != "*")
if (mycode.masSost == 4)
(if (mycode.masSost == 6)
sw.Write(dt.Columns.Count.ToString());
while (sr.Read() != "*")
if (Convert.ToInt32(mycode.masValue)< dt.Columns.Count)
(if (mycode.masSost == 7)
sw.Write(dt.Columns.masValue)].DataType.Name);
sw.Write(dt.Columns.masValue)].ColumnName);)
If the user tries to access a column or row that does not exist, then the corresponding error entry is added to the error log.
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
mycode.code = ""; )
while (sr.Read() != "*")
( bool create = false;
for (int a = 0; a< masPeremCount; a++)
if (Convert.ToInt32(masPerem)< dt.Columns.Count)
(if (mycode.masSost == 13)
sw.Write(dt.Columns)].ColumnName);
sw.Write(dt.Columns)].DataType.Name);
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Index is out of scope");
mycode.code = ""; )
while (sr.Read() != "*")
if (create == false) (
If the user specifies a variable that does not exist as a column or row index, a corresponding error entry is added to the error log.
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Trying to access a non-existent variable");
while (sr.Read() != "*")
if (mycode.masSost == 5)
( int n1 = 0, n2 = 0, nn = 0;
if (mycode.masSost == 6)
( sw.Write(dt.Rows.Count.ToString());
while (sr.Read() != "*")
(if (mycode.masSost == 12)
( ( n1 = Convert.ToInt32(mycode.masValue);
if (mycode.masSost == 12)
( n2 = Convert.ToInt32(mycode.masValue);
( bool create = false;
for (int a = 0; a< masPeremCount; a++)
if (masPerem == mycode.masValue)
n2 = Convert.ToInt32(masPerem);
If a variable was used as a column or row index and its value exceeds the number of columns or rows in the table, respectively, then an entry about this error is added to the error log.
Else ( if (n1 >= dt.Rows.Count)
( if (mycode.code != "")
(lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Index " + n1 + " is out of range");))
if (n2 >= dt.Columns.Count)
( if (mycode.code != "")
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Index " + n2 + " is out of range"); ))
mycode.code = ""; )
while ((sr.Read() != "*") && (!sr.EndOfStream))
if (mycode.masSost == 2)
masPerem = mycode.masValue;
masPerem = mycode.masValue;
nk = masPeremCount;
masPeremCount++;
if (mycode.masSost == 12)
k = Convert.ToInt32(mycode.masValue); else
if (mycode.masSost == 4) k = dt.Columns.Count;
else k = dt.Rows.Count;
while (sr.Read() != "*") ( )
If the user declared a cycle and after that did not indicate its beginning without putting "(", this is regarded as an error and an entry about this is added to the error log.
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read());
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Cycle start not specified");
mycode.correct = false;
NCode++; ) else (
If the beginning of the loop is specified correctly, then the variable responsible for the depth of nesting of the loops is increased by one, the contents of the loop, up to the sign ")", are written to a temporary file, a duplicate of the arrays containing the values of the variables is created, and this recursive method is launched already for this temporary file.
Directory.CreateDirectory("Temp");
StreamWriter sw1=new StreamWriter("Temp\\Temp"+tempF.ToString()+".txt", false, Encoding.UTF8);
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read()); )
int cycleCount = 0;
while (c != ")")
if (sr.EndOfStream)
c = Convert.ToChar(sr.Read());
if ((c == ")") && (cickleCount != 0))
( cickleCount--;
c = Convert.ToChar(sr.Read()); ) )
StreamReader sr1 = new StreamReader("Temp\\Temp" + tempF.ToString() + ".txt", Encoding.UTF8);
int CickleCode = 0;
bool sign2 = false;
while (!sr1.EndOfStream)
( c = Convert.ToChar(sr1.Read());
if ((c != "*") && (sign2 == true))
( s1 += c.ToString(); )
if ((c == "*") && (sign2 == false))
if ((c == "*") && (sign2 == true))
( sign2 = false;
else s1 += c.ToString(); ) )
for (int a = Convert.ToInt32(mycode.masValue); a< k; a++)
( masPerem = a.ToString();
ExecuteCode(NCode + 1, true, new StreamReader("Temp\\Temp" + tempF.ToString() + ".txt", Encoding.UTF8), sw, tempF);)
After the loop ends, the temporary file is deleted, and the nesting depth of the loops is reduced by one.
masPerem = "";
masPerem = "";
NCode = CickleCode + 1;
File.Delete("Temp\\Temp" + tempF.ToString() + ".txt");
The algorithm for working with templates created using the constructor is described by the following methods: Execute, GetTruthTable, ExecuteTag.
The Execute method is called once when template processing starts. This method is external and other methods are called from it. Initially, the method creates an output file and a "Truth Table".
DataTable truthdt=new DataTable();
StreamWriter sw=new StreamWriter(textBox4.Text+"Output file.xml",false,Encoding.UTF8);
for (int a = 0; a<= dt.Columns.Count;a++)
truthdt.Columns.Add("",typeof(bool));
for (int a = 0; a<= dt.Rows.Count; a++)
( DataRow dr = truthdt.NewRow();
for (int b = 0; b< dr.ItemArray.Length; b++)
truthdt.Rows.Add(dr); )
After that, the loop begins to execute, highlighting each tag that determines its type, and depending on this, execute it.
while (!complete)
( tagind = GetTagIndex(Items);
if (mastag.type == types.global || mastag.type == types.main)
if (mastag.type == types.block)
if (Items >= itemscount)
complete=true; )
If the tag type is global or main, the contents of the tag are simply written to the file.
if (mastag.name != "")
sw.WriteLine(items);
If the tag type is block, then the list of all tags belonging to this fragment is written to a separate array, and it is also determined whether there are tags in this list that require string indexing to display values.
bool haveRow = false;
tag blocktag = new tag.indF - mastag.indS - 1];
for (int a = mastag.indS + 1, b = 0; a< mastag.indF; a++, b++)
( blocktag[b] = matag;
if (blocktag[b].type == types.simple)
if (blocktag[b].source == "row index" || blocktag[b].source == "cell content")
haveRow = true;)
After that, a "truth table" is created and all the conditions of the simple tags found in the list are applied to it.
truthdt=CreateTable(truthdt,dt);
for (int a = 0; a< blocktag.Length; a++)
if (blocktag[a].type == types.simple)
truthdt = GetTruthTable(dt, truthdt, blocktag[a]);
Further, depending on whether tags using string indexing were found, either only a column cycle is created, or cycles along columns and lines, in which all occurring tags are executed, except for block ones.
for (int a = 0; a< dt.Rows.Count; a++)
for (int b = 0; b< dt.Columns.Count; b++)
bool wasEx = false;
StreamWriter swt = new StreamWriter("temp.txt", false, Encoding.UTF8);
for (int c = 0; c< blocktag.Length; c++)
if (blocktag[c].type == types.global)
if (blocktag[c].name != "")
swt.WriteLine(items.indS + c + 1]);
if (blocktag[c].name != "")
wasEx=ExecuteTag(dt, truthdt, blocktag[c], a, b, swt); )
( StreamReader sr = new StreamReader("temp.txt", Encoding.UTF8);
sw.Write(sr.ReadToEnd());
File.Delete("temp.txt");
( for (int a=0;a for (int c = 0; c< blocktag.Length; c++) ( if (blocktag[c].type == types.global) if (blocktag[c].name != "") sw.WriteLine(items.indS + c + 1]); if (blocktag[c].type == types.simple) if (blocktag[c].name != "") ExecuteTag(dt, truthdt, blocktag[c], 0, a, sw); If the tag type is simple, then a new "Truth Table" is created for it and the tag is executed. if (mastag.type == types.simple) ( truthdt=CreateTable(truthdt,dt); DataTable tempdt = GetTruthTable(dt, truthdt, mastag); if(mastag.name!="") ExecuteTag(dt, tempdt, matag, 0, 0, sw); The GetTruthTable method applies conditions to the "Truth Table". As arguments, it takes a table with values from the database, an already created "Truth Table" and a tag, the condition of which needs to be processed. The ExecutTag method executes a simple tag. It takes as arguments a data table, a "truth table", a tag, a row index, a column index, and a file write stream. 3.2
Description of the user interface The main window of the program is divided into several parts: ".dbf", "Templates", ".xml" and the error log. In all parts, except for the log, there are elements responsible for selecting directories containing files or in which files must be saved. The error log is presented as a list of three columns: "pattern", "string", "error". The first column contains the name of the template in which the error was found. In the second, the line where the error occurred. Third, the type of error. Also on the form there are elements that do not belong to any of the groups. Some of them reflect the progress of the work, while the other starts the process itself. Figure 3.1 shows the main form - the main window of the program. Figure 3.1 - Main window of the program When working with templates, an additional program window opens, consisting of a field for the template name, an element that contains the template code, and buttons for saving the template and closing the window. Figure 3.2 shows a view of the additional program window (template editor). Figure 3.2 - Template editor window Also on the main form there is a control that opens the form for creating templates using the constructor. The constructor form contains the following controls: a list of already created tags, a field for entering the name of a new tag, a drop-down list for selecting a tag type, a drop-down list for selecting a tag source, a panel with elements for creating a tag condition, a field for defining a database file, a field for defining location of the output file, buttons for adding and deleting a tag, a button for starting processing. Figure 3.3 shows the template designer window. Figure 3.3 - Template constructor window As a result of the work of the software, XML files of various versions of the XML language were obtained. Databases of dbf format of versions dBase II, dBase III and dBase IV were used as input data. Converted files opened correctly with the following browsers: Internet Explorer 10, Mozilla Firefox 19, Google Chrome version 27.0.1453.93, Opera 12.15. In addition to browsers, files could be viewed and edited with any text editor. Based on the results obtained, it can be concluded that the XML files obtained during the operation of the program meet the requirements of the customer. 3.
3
Testing and evaluation of software product reliability When testing the software product, the following errors were identified: Indexing error to a database table cell; Loop variable output error; An error that occurs when the index of a row or column exceeds their number. 1. Indexing error to a database table cell. Occurs when the template contains a code of the form "*row[x].column[y]*", where x and y are numbers or variables. The problem was solved by adding an additional condition in the program code when processing similar strings in the template. 2. Loop variable output error. Occurs when a code of the form "*x*" is specified in the template, where x is a variable. The issue was resolved by changing the compilation of the identifier table. 3. An error that occurs if the index of a row or column exceeds their number. Occurs when the template contains a code like "*column[x].name*", where x is a number or a variable whose value exceeds the number of columns. The problem was solved by comparing the index value and the number of rows or columns, if the index exceeds, then an entry about this is added to the error log and the program continues to run. 3.
4
Cost calculation Businesses that constantly work with different database formats need to automate the process of converting from one database format to another. This will increase the productivity of workers, as well as reduce the requirements for their education. The software product, in addition to the software part, also consists of accompanying documentation, which are the result of the intellectual activity of the developers. In the structure of capital investments associated with automation of control, there are capital investments for the development of an automation project (pre-production costs) and capital investments for the implementation of the project (implementation costs): where K p - capital investments for design; К р - capital investments for project implementation. Calculation of capital investments for design. Capital investments for software design are determined by drawing up cost estimates and are determined by the formula: where K m - the cost of materials; K pr - wages of the main and additional with deductions in social insurance of engineering and technical personnel directly involved in the development of the project; K mash - the costs associated with the use of machine time for debugging the program; K c - payment for services to third parties, if the design is carried out with the involvement of third parties; K n - overhead costs of the design department. All calculations will be made in conventional units (c.u.), which corresponds to the cost of one US dollar in the Pridnestrovian Republican Bank at the time of software development. Material costs. Let's determine the cost estimate and calculate the cost of materials K m, which went to the development of software. The list of materials is determined by the theme of the thesis. They include the following: information carriers (paper, magnetic disks) and wearable objects of labor (pen, pencil, rubber band). The cost estimate for materials is presented in table 3.1. Table 3.1 - Estimated cost of materials Implementation of a converter program for creating an XML format file based on the transferred dbf files (according to a user-specified template). Create templates using code and using the constructor. Software product architecture design. thesis, added 06/27/2013 Development of a converter program that, based on the contents of the transferred dbf files, creates an XML file according to a user-specified template. Consider creating templates in two ways: using code and using a constructor. term paper, added 06/24/2013 Designing the user interface of a program that encrypts and decrypts files. Choice of data presentation format. List of procedures, macros and their purpose. Description of the functions used in the program, its testing and debugging. term paper, added 05/17/2013 Features of the "search engine" of duplicate files on the disk. Choice of programming environment. Development of a software product. Basic requirements for a program that searches for duplicate files on a disk. Show hidden files. term paper, added 03/28/2015 Characteristics of the work of the archiver - a computer program that compresses data into a single archive file for easier transmission, compact storage. Features of the archiving process - writing files and unzipping - opening files. abstract, added 03/26/2010 Development of a software product for exporting specifications from the PartList application. The choice of the method of transferring information to a file, the format for presentation. Converter development, user interface implementation. Rationale for the relevance of the development. thesis, added 09/25/2014 Software design. The scheme of the initial formation of the file directory, displaying the file directory, deleting files, sorting files by name, creation date and size using the direct selection method. Directory management in the file system. term paper, added 01/08/2014 Characteristics of wav and mp3 file formats. Building use case diagrams, developing a graphical interface and application architecture. Development of program operation algorithms: TrimWavFile method, TrimMp3, ChangeVolume, speedUpX1_2, speedDownX1_2. term paper, added 12/20/2013 An overview of the features of working with the Total Commander program. Create folders, copy files to a flash drive. Calling the context menu. Definition of the file structure. Renaming a group of files. Putting files in an archive. Splitting an archive into several parts. laboratory work, added 04/08/2014 Creation and verification of a model for the optimal placement of files in a computer network with a star-shaped, ring and arbitrary topology. The amount of data required to transfer files. Optimal distribution of files over computer network nodes. DBF is a database file, the ability to work with which was previously integrated into the Microsoft Office environment. Access and Excel applications worked with the format, later Access was removed from the package and became a separate program, and in Excel since 2007 DataBaseFile support was significantly limited. If you cannot open a DBF file directly in Excel, you must first convert it. However, although DBF is considered by many to be an obsolete format, it is still widely used in specialized programs in business, design, and engineering. Wherever you need to work with large amounts of information, their structuring and processing, query execution. For example, the 1C Enterprise software package is entirely based on database management. And given that a lot of office documentation and data goes to Excel, the issue of integrated work with these formats is relevant and in demand. In Excel 2003, it was possible to open and edit DBF, as well as save XLS documents in this format: IMPORTANT. Since 2007, you can open and view the database format in Excel, but you cannot make changes or save .xls documents in it. Standard program tools no longer provide for this possibility. However, there are special add-ons for the application that add such a function to it. In the network at various forums, programmers post their developments, you can find different options. The most popular add-on called XslToDBF can be downloaded from the developer's site http://basile-m.narod.ru/xlstodbf/download.html. The download is free, but if you wish, you can support the project by transferring any amount to your wallet or card. Installation and use: If you do not want to change anything in Office, do not trust add-ins and third-party applications, then you can offer a more time-consuming way to convert the XLS file to DBF: This method does not always work successfully, errors often occur in data processing and subsequent saving. And it is very long and uncomfortable. In order not to suffer yourself with office programs, many applications have been created that allow you to transfer data from one format to another. First, almost all powerful DBMS programs offer the ability to export to and load from XLS. Secondly, there are small utilities that specialize in converting. Here are some of them: In all these programs, the conversion comes down to the fact that you need to open the source file, and then execute the "Convert" or "Export" command. There are also free online conversion services. On such sites, it is proposed to send (upload) the source file, click "Convert", after which a link to the converted document will appear. How much you can trust such services, the decision is individual, at your own peril and risk. Thus, you can open DBF in Excel, but if its version is 2007 and newer, then nothing more can be done with it, just look. For editing, saving in XLS, there are special add-ons or programs, as well as for converting in the opposite direction. If you have experience of converting and working with DBF in different applications, please share your tips in the comments.Similar Documents
Excel problems when working with DBF
















Conversion

