Hoje, o XML é o padrão da indústria para troca rápida e eficiente de dados entre diferentes soluções. No entanto, há muitas tarefas em que os usuários precisam representar dados XML de uma forma diferente. Nesses casos, são necessários programas conversores. Eles preenchem a lacuna entre XML e formatos de tabela populares. Se você precisa converter dados XML regularmente, então você definitivamente precisa usar o Advanced XML Converter! Com o Advanced XML Converter, você não precisa mais escrever transformações XML complexas e folhas de estilo XSL. Converta XML para HTML, CSV, DBF, XLS, SQL em um instante! Advanced XML Converter irá ajudá-lo a converter para outros formatos como HTML, CSV, DBF, XLS e SQL. Assim que o arquivo XML for carregado e você pressionar o botão "Converter", o programa produzirá uma saída rápida e de alta qualidade para um dos formatos tabulares. Para garantir a saída correta, o Advanced XML Converter usa a estrutura hierárquica do arquivo XML original. Você pode selecionar os dados a serem apresentados no arquivo de saída. Você também pode converter mais de um arquivo usando a execução em lote. Com o Advanced XML Converter, você não precisa mais escrever scripts complexos de conversão ou transformação XSL. Converter XML para HTML, CSV, DBF, XLS, SQL é rápido e intuitivo!
| Baixe o Conversor XML Avançado | |
 |
|
Você pode extrair todos os dados XML ou apenas dados de tags específicas com o Advanced XML Converter. Ao visualizar os dados extraídos, você pode alternar rapidamente entre diferentes visualizações (sem novas análises e sem recarregar os dados). Você pode definir opções de exportação para cada formato de saída (como estilos de tabela HTML e delimitadores CSV para campos exportados e outras opções). Advanced XML Converter permite que você salve todas as tabelas em um arquivo ou vários arquivos separadamente, bem como configurar de forma flexível as opções de visualização e saída.
O software não requer a instalação de drivers ou componentes adicionais, pois é construído no analisador do Internet Explorer, disponível na maioria dos sistemas. Advanced XML Converter não requer o .NET Framework ou XML Schemas. O programa não requer profundo conhecimento da estrutura do arquivo XML e facilita muito a conversão de grandes quantidades de dados XML. Como usuário, você poderá ver os documentos XML mais complexos em diferentes tabelas de visualização fáceis de ler. Isso é muito conveniente para transferir informações para bancos de dados ou sistemas especializados que exigem um formato próximo ao texto simples.
Se você está procurando um sistema rápido para converter dados XML, o Advanced XML Converter é a melhor escolha! O programa acessível e fácil de usar realiza transformações complexas de dados em minutos!
A versão mais recente do Advanced XML Converter fornece uma maneira simples, rápida e altamente eficiente de extrair dados de arquivos XML e salvá-los em formatos populares de HTML, DBF, CSV, Excel e SQL. |
|
Com o Advanced XML Converter você pode: |
|
|
Provavelmente você muitas vezes precisa converter um XML arquivo ou uma pasta com XML arquivos em um ou vários DBF arquivos. O problema é que XML estrutura, sua hierarquia e níveis de aninhamento diferem de arquivo para arquivo. Neste artigo, veremos detalhadamente como importar um XML arquivo de QUALQUER estrutura para um flat DBF tabela.
Um novo recurso chamado Importar XML personalizado foi implementado em Profissional Comandante DBF versão 2.7 (compilação 40). Este comando está disponível através da interface de linha de comando. A sintaxe é a seguinte:
dbfcommander.exe -icx
Como você pode ver, existem quatro parâmetros:
- -icx- significa Importar XML personalizado.
- <-attr> - use este parâmetro se quiser importar tags com determinados atributos.
Definição de campos DBF ou Como criar um arquivo de mapa
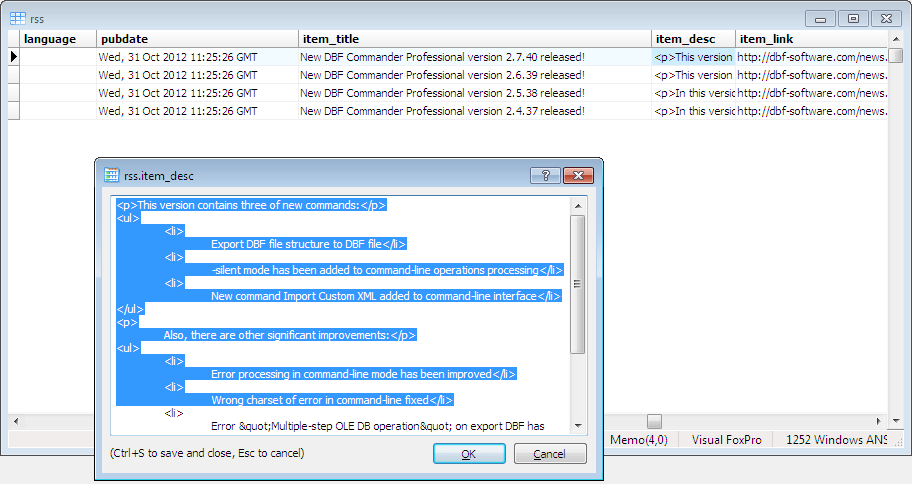
É sempre melhor aprender algo usando um exemplo. Em nossa situação, precisamos de alguns XML. Vamos dar um RSS feed de notícias XML arquivo (disponível):
Como você pode ver, são quatro<item> elementos aninhados no<canal> elemento, que está aninhado no nível superior<rss> elemento. Há também elementos do mesmo nível de aninhamento que o<item> elementos:<gerador>, <título>, <Descrição>, etc
Suponha que cada<item> elemento deve ser representado como uma linha no resultado DBF Arquivo. Portanto, nosso arquivo conterá quatro registros.
Para criar um arquivo de mapa, primeiro vamos criar o arquivo resultante DBF Arquivo. Precisamos dele porque assim poderemos criar um arquivo de mapa em poucos cliques. Profissional Comandante DBF, clique Arquivo -> Novo, e criar um DBF Arquivo. No caso do RSS XML arquivo, a estrutura é a seguinte:

Clique OK. o DBF arquivo será criado, e agora pode ser usado como arquivo resultante para nossa importação do XML processo. Você pode usar qualquer tipo de campo disponível: personagem, inteiro, Numérico, Encontro, etc
Para criar um arquivo de mapa com base no arquivo resultante, clique no Estrutura de exportação botão de ferramenta (veja a imagem acima). Quando a caixa de diálogo Salvar for aberta, escolha o caminho e o nome do arquivo e salve a estrutura como DBF Arquivo.
Correspondência de tags XML com campos DBF
Temos que fazer mais uma coisa ainda: definir o XML tags que devem ser inseridas nos campos do resultado DBF Arquivo.
Abra o DBF arquivo que você acabou de salvar. Clique em Arquivo -> Estrutura e adicione um novo campo chamado" xmltagname"do personagem modelo. Você pode adicionar mais campos no arquivo de mapa, se desejar. Por exemplo, vamos adicionar um campo chamado Comente".Clique OK para salvar as alterações.
Agora preencha todas as linhas do novo" xmltagname"campo com XML caminho de nós (separado por " -> ") que deve ser inserido no campo correspondente na DBF Arquivo:

Significa que o valor do XML nó<título> aninhado no<canal> nó que está aninhado no nível superior<rss>, será inserido no " título"campo; o XML marcação" rss -> canal -> descrição"será inserido no" descrição"campo, e assim por diante.
Em caso de uso" -attr", os caminhos do arquivo de mapa também devem conter os atributos correspondentes, por exemplo: " rss versão="2.0" -> canal -> título".
Prestar atenção à" item_desc"campo. O XML marcação" rss -> canal -> item -> descrição"contém o Seção CDATA com HTML marcação. Portanto, seu caminho de tag deve ser finalizado com o " #cdata-section"corda.
A última linha que você pode ver na imagem acima é a chamada " tag de linha". Este caminho de tag permite Comandante DBF saber qual XML deve ser usada como uma nova linha no resultado DBF Arquivo. No nosso caso, é" rss -> canal -> item".
Observe que o valor de " nome O campo " deve estar vazio para o registro que contém a marca-linha, para que o programa possa reconhecer a marca-linha.
Bem, isso é tudo. Agora podemos executar a importação de XML para DBF em si. Execute o seguinte comando na linha de comando ou em um BASTÃO Arquivo:
dbfcommander.exe -icx "D:\xml\rss.xml" "D:\dbf\" "D:\map-file.dbf"
Como resultado, obteremos o novo arquivo D:\dbf\rss.dbf"que contém os importados XML dados:
Você pode baixar todos os arquivos usados nesta conversão de .
Enviar seu bom trabalho na base de conhecimento é simples. Use o formulário abaixo
Estudantes, estudantes de pós-graduação, jovens cientistas que usam a base de conhecimento em seus estudos e trabalhos ficarão muito gratos a você.
Hospedado em http://www.allbest.ru/
Universidade Estadual Pridnestrovian em homenagem T.G. Shevchenko
Instituto de Engenharia e Tecnologia
Departamento de Tecnologia da Informação e Controle Automatizado de Processos Produtivos
TRABALHO DE QUALIFICAÇÃO FINAL
na direção 230100 "Ciência da computação e tecnologia da computação"
topic: "PROGRAMA-CONVERSOR DE BANCOS DE DADOS DE ARQUIVOS DBF PARA ARQUIVO DE FORMATO XML"
Aluno Maksimov Dmitry Olegovich
Tiraspol, 2013
INTRODUÇÃO
1. PESQUISA E ANÁLISE DA ÁREA ASSUNTO
1.1 Descrição da tarefa
1.2 Justificativa da relevância do problema em estudo
1.3 Visão geral dos métodos para resolver problemas semelhantes
1.4 Declaração do problema, requisitos do sistema, requisitos para dados de entrada e formulários de saída
2. DESENHO DA ESTRUTURA E ARQUITETURA DO PRODUTO DE SOFTWARE
2.1 Escolha dos métodos e meios de implementação, sua justificativa
2.2 Descrição dos algoritmos aplicados
2.3 Estrutura, arquitetura do produto de software
2.4 Diagrama funcional, estrutura funcional do produto de software
3. IMPLEMENTAÇÃO E TESTE DO PRODUTO DE SOFTWARE
3.1 Descrição da implementação
3.2 Descrição da interface do usuário
3.3 Testando e avaliando a confiabilidade do produto de software
3.4 Cálculo de custo
3.5 Proteção trabalhista
CONCLUSÃO
LISTA DE CONVENÇÕES, SÍMBOLOS, UNIDADES E TERMOS
LISTA DE LITERATURA USADA
APÊNDICE
INTRODUÇÃO
Durante a existência dos computadores, muitos sistemas operacionais foram desenvolvidos. Agora seu número é medido em dezenas e em várias famílias existem formatos de arquivo usados apenas em uma determinada linha de sistemas operacionais. Se, por exemplo, existem editores universais para imagens que abrem qualquer formato de arquivo contendo imagens de sistemas operacionais suportados, então, por exemplo, não existem tais editores para bancos de dados.
Para trabalhar com cada um dos formatos de banco de dados, existe um sistema de gerenciamento de banco de dados individual. Há um grande número de variedades de bancos de dados que diferem em vários critérios:
1) Classificação por modelo de dados:
a) hierárquica;
b) rede;
c) relacional;
d) orientada a objetos e orientada a objetos;
e) objeto-relacional, funcional.
2) Classificação por ambiente de armazenamento persistente:
a) em memória secundária, ou tradicional;
b) na RAM;
c) na memória terciária.
3) Classificação de acordo com o grau de distribuição:
a) centralizado ou concentrado;
b) distribuído.
4) Outros tipos de banco de dados
a) espacial;
b) temporária;
c) espaço-tempo;
e) cíclico.
Uma grande abundância de bancos de dados diferentes não permite que você transfira diretamente o conteúdo do banco de dados de um tipo para outro. Para resolver este problema, existem programas conversores que convertem um formato de banco de dados para outro. Como regra, os conversores existem apenas para os formatos de banco de dados mais comuns, o que não permite converter diretamente algum formato obsoleto em um moderno. Usar dois conversores não é racional, então a melhor solução é armazenar bancos de dados em arquivos XML como uma etapa intermediária.
Arquivos XML e arquivos de outras extensões baseadas na linguagem XML tornaram-se muito difundidos, quase qualquer sistema operacional moderno suporta esse formato de arquivo. Os arquivos XML armazenam uma ampla variedade de dados, desde configurações de aplicativos até bancos de dados. Arquivos baseados em XML são usados para trocar informações na Internet e entre programas (que é para o que essa linguagem de marcação foi originalmente concebida). Como os arquivos de formato XML contêm dados de texto, eles podem ser facilmente editados em qualquer editor de texto, bem como definir qualquer codificação de dados amigável. Além disso, há um grande número de geradores de documentos XML.
1 . PESQUISA E ANÁLISE DA ÁREA ASSUNTO
1.1 Descrição da tarefa
No trabalho de qualificação final, é necessário implementar um programa conversor que crie, com base no conteúdo dos arquivos dbf transferidos, um arquivo XML de acordo com um modelo especificado pelo usuário. O número e a estrutura dos arquivos dbf podem ser arbitrários, o arquivo XML de saída deve ser sempre o mesmo. Cada arquivo dbf tem seu próprio modelo, com base no qual o programa grava informações no arquivo XML. É necessário implementar a capacidade de criar modelos de duas maneiras: usando código e usando um construtor. Os modelos criados com código devem selecionar quais dados gravar no arquivo de saída. Esta possibilidade é realizada com a ajuda de comandos de código especiais desenvolvidos especificamente para este programa. Nos modelos criados usando o construtor, você precisa implementar uma interface simples e conveniente que permitirá criar modelos personalizados, com base nos quais o programa grava informações em um arquivo XML.
1.2 Justificativa da relevância problema em estudo
XML é uma linguagem de marcação recomendada pelo World Wide Web Consortium, que na verdade é um conjunto de regras gerais de sintaxe. XML é um formato de texto projetado para armazenar dados estruturados (em vez de arquivos de banco de dados existentes), para trocar informações entre programas e para criar linguagens de marcação mais especializadas (por exemplo, XHTML) com base nele.
Um documento XML é um banco de dados apenas no sentido mais geral da palavra, ou seja, é uma coleção de dados. Nisso não é diferente de muitos outros arquivos - no final, todos os arquivos consistem em algum tipo de dados. Como formato de "banco de dados", o XML tem algumas vantagens, como ser autodescritivo (a marcação descreve os dados). É fácil manuseá-lo por software diferente porque os dados são armazenados em Unicode, armazena os dados em uma árvore ou estrutura semelhante a um gráfico. Mas também tem algumas desvantagens, por exemplo, é muito detalhado e relativamente lento no acesso aos dados devido à necessidade de analisar e converter texto.
Do lado positivo, o XML permite implementar muitas das coisas que podem ser encontradas em bancos de dados convencionais: armazenamento (documentos XML), esquemas (DTD, XML Schema Language), linguagens de consulta (XQuery, XPath, XQL, XML - QL, QUILT, etc.), APIs (SAX, DOM, JDOM), etc. As desvantagens incluem a falta de muitos recursos disponíveis em bancos de dados modernos: economia de armazenamento, índices, segurança, transações e integridade de dados, acesso multiusuário, gatilhos, consultas em muitos documentos, etc.
Assim, embora seja possível usar documentos XML como banco de dados em ambientes com poucos dados, poucos usuários e requisitos de baixo desempenho, isso não pode ser feito na maioria dos ambientes de negócios com muitos usuários e fortes requisitos de integração, dados e requisitos de alto desempenho.
Um exemplo de "banco de dados" para o qual um documento XML é adequado é um arquivo .ini - ou seja, um arquivo que contém informações de configuração do aplicativo. É muito mais fácil criar uma linguagem de programação com um pequeno conjunto de recursos baseados em XML e escrever um aplicativo SAX para interpretá-lo do que escrever um analisador para arquivos separados por vírgula. Além disso, o XML permite aninhar elementos de dados - isso é bastante difícil de fazer ao separar dados com vírgulas. No entanto, tais arquivos dificilmente podem ser chamados de bancos de dados no sentido pleno da palavra, pois são lidos e escritos de forma linear e somente quando o aplicativo é aberto ou fechado.
Os exemplos mais interessantes de conjuntos de dados em que é conveniente usar um documento XML como banco de dados é uma lista pessoal de contatos (nomes, números de telefone, endereços etc.). No entanto, devido ao baixo custo e facilidade de uso de bancos de dados como dBASE e Access, mesmo nesses casos há pouca razão para usar um documento XML como banco de dados. O único benefício real do XML é que os dados podem ser facilmente transportados de um aplicativo para outro, mas esse benefício não é tão importante, pois já existem ferramentas difundidas para serializar bancos de dados no formato XML.
O desenvolvimento de software é relevante pelas seguintes razões:
O formato do banco de dados dbf está desatualizado e não atende aos requisitos modernos;
O formato XML não possui requisitos rígidos de conteúdo, o usuário pode armazenar os dados em qualquer ordem e criar tags com qualquer nome;
Nenhum programa conversor permite que você crie sua própria estrutura de arquivos XML e grave dados de vários arquivos de formato dbf.
1.3 Visão geral dos métodos para resolver problemas semelhantes
"White Town" torna possível converter arquivos dbf para o formato XML. O programa pode converter arquivos dbf dBase III, dBase IV, FoxPro, VFP e dBase Nível 7. O programa suporta interface de linha de comando. Assim, ele pode ser iniciado a partir de um arquivo .BAT ou .LNK após especificar os parâmetros necessários ou de acordo com um agendamento do agendador do Windows. A desvantagem deste produto de software é a incapacidade de personalizar o formato do arquivo de saída. A janela principal do aplicativo é mostrada na Figura 1.1.
Figura 1.1 - A janela principal do programa "White Town"
"DBF Converter" é um programa de conversão versátil e fácil de usar. Este programa possui uma interface semelhante a um assistente, mas também pode ser usado como um utilitário de linha de comando para processar um grupo de arquivos. "DBF Converter" suporta todos os formatos modernos de troca de dados, como XML, CSV, TXT, HTML, RTF, PRG e outros. Implementada a capacidade de converter tabelas DBF em script SQL, que pode ser importado para qualquer banco de dados SQL.
Além de transformações simples, "DBF Converter" permite manipular dados selecionando apenas determinadas colunas e aplicando filtros. Em contraste com as regras de filtragem simplificadas que normalmente são encontradas em outros aplicativos DBF, o "DBF Converter" compõe dinamicamente formulários simples de entrada de banco de dados. A capacidade de definir máscaras e regras avançadas em qualquer campo de um registro simples é um dos recursos mais valiosos disponíveis no DBF Converter. A principal desvantagem deste software é o seu custo de $ 29,95.
A janela principal do aplicativo é mostrada na Figura 1.2.
Figura 1.2 - A janela principal do programa "DBF Converter"
"DBF View" é um programa gratuito, compacto e conveniente para trabalhar com arquivos DBF. Não requer instalação, funciona sem drivers e bibliotecas adicionais.
A principal vantagem é a universalidade, busca linear rápida e flexível, que supera muitos SQL em velocidade.
Características adicionais:
Pesquisa por máscara (padrão);
Editar, substituir, excluir, criar, adicionar dados;
Campos de classificação;
Multilinguismo e criação de novos dicionários;
Importar e exportar DBF, TXT, CSV, SQL, XML;
Recodificação para DOS, Windows, translit e outros;
Lançar senha;
Gravando histórico.
A principal desvantagem deste software é a incapacidade de criar modelos ao converter. A janela principal do programa é mostrada na Figura 1.3.
Figura 1.3 - A janela principal do programa "DBF View"
1.4 Declaração do problema, requisitos do sistema, requisitos para dados de saída e formulários de saída
Após estudar a tarefa, examinar sua relevância e analisar os programas conversores existentes, foi compilada uma lista de requisitos necessários para o software desenvolvido.
As seguintes funções devem ser implementadas no produto de software:
Lendo o conteúdo de arquivos dbf;
Criação de templates em um dos dois editores;
Edição de modelos;
Selecionando a ordem de conversão de arquivos dbf;
Execução de templates;
Erro ao registrar;
Salvando os resultados do programa em um arquivo XML.
O software é escrito em Microsoft Visual Studio 2008 e requer a execução de:
Sistema operacional da família Windows de uma das versões: Windows Vista, Windows 7 ou Windows 8;
Microsoft .NET Framework 4;
Drivers ODBC do Visual FoxPro.
Os requisitos mínimos do sistema para o produto de software correspondem aos requisitos mínimos do sistema operacional.
Os dados de entrada podem ser arquivos dbf da versão dBase II, dBase III ou dBase IV.
Os arquivos de saída devem ser um arquivo de formato XML com versão de idioma 1.xe suporte para qualquer navegador.
O caminho para os arquivos de entrada e saída pode ser arbitrário.
2 . PROJETO DE ESTRUTURA E ARQUITETURA DO PRODUTO DE SOFTWARE
2.1 Escolha dos métodos e meios de implementação, sua justificativa
O ambiente de desenvolvimento integrado Microsoft Visual Studio 2008 foi escolhido para o desenvolvimento do produto de software.
Visual Studio 2008 - Lançado em 19 de novembro de 2007, juntamente com o .NET Framework 3.5. Destina-se a criar aplicativos para o sistema operacional Windows Vista (mas também suporta XP), Office 2007 e aplicativos da web. Inclui LINQ, novas versões de C# e Visual Basic. O estúdio não incluiu o Visual J#. Uma de suas vantagens é uma interface completamente russa.
O Visual Studio inclui um editor de código-fonte com suporte para a tecnologia IntelliSense e a capacidade de refatorar facilmente o código. O depurador interno pode funcionar como um depurador de nível de origem e um depurador de nível de máquina. Outras ferramentas incorporáveis incluem um editor de formulários para simplificar a criação da GUI de um aplicativo, um editor da Web, um designer de classe e um designer de esquema de banco de dados. O Visual Studio permite que você crie e conecte complementos de terceiros (plugins) para estender a funcionalidade em quase todos os níveis, incluindo a adição de suporte para sistemas de controle de versão de código-fonte (como Subversion e Visual SourceSafe), adicionando novos kits de ferramentas (por exemplo, para edição e design de código visual) em linguagens de programação específicas de domínio ou ferramentas para outros aspectos do processo de desenvolvimento de software (por exemplo, o cliente Team Explorer para trabalhar com o Team Foundation Server).
Todos os recursos de workbench baseados em C# do Visual Studio 2008 incluem:
A capacidade de formular tarefas na linguagem de interação de objetos;
Alta modularidade do código do programa;
Adaptabilidade ao desejo dos usuários;
Um alto grau de reutilização do programa;
Um grande número de bibliotecas vinculadas.
2. 2 Descrição dos algoritmos aplicados
No desenvolvimento deste software, duas dificuldades principais podem ser distinguidas: construir um reconhecedor para templates programáveis e criar um modelo de programação que seria utilizado em templates criados usando o construtor.
1. Padrões programáveis. Como o código usado nos templates é um pouco semelhante ao código usado nas linguagens de programação, é necessário que esse reconhecedor assuma algumas funções do compilador de código, ou melhor, suas funções de análise. Na estrutura do compilador, a parte de análise consiste em análise léxica, sintática e semântica. O analisador léxico lê os caracteres do programa no idioma de origem e constrói lexemas do idioma de origem a partir deles. O resultado de seu trabalho é uma tabela de identificadores. O parser realiza a extração de construções sintáticas no texto do programa fonte, processadas pelo analisador léxico. Alinha as regras sintáticas do programa com a gramática da linguagem. O analisador é um reconhecedor de texto do idioma de entrada. O analisador semântico verifica a exatidão do texto do programa fonte em termos do significado do idioma de entrada.
Com a ajuda do código, os seguintes recursos devem ser implementados: criação de um loop, obtenção e exibição de dados sobre o número de linhas e colunas, obtenção do tipo de dados e nomes das colunas, além de obter o conteúdo das células do banco de dados. Para fazer isso, em primeiro lugar, é necessário fazer uma lista de todos os estados possíveis do autômato. Os estados possíveis do reconhecedor são apresentados na Tabela 2.1.
Tabela 2.1 - Lista de possíveis estados do reconhecedor
|
Índice de status |
Estado |
Descrição |
|
|
Variável |
Contador de ciclos |
||
|
Palavra de serviço que indica o início de um ciclo |
|||
|
Palavra de serviço que denota a condição de saída do loop |
|||
|
Palavra funcional denotando que mais referência será para colunas de base |
|||
|
Palavra funcional denotando que uma referência adicional será para strings de base |
|||
|
Quantidade |
Palavra funcional que indica o número de linhas ou colunas, dependendo de qual foi a chamada anterior |
||
|
Palavra funcional que denota a saída do tipo de dados da coluna a ser acessada |
|||
|
Nome |
Palavra funcional que denota a saída do nome da coluna para a qual a apelação segue |
||
|
Caractere especial separando palavras de serviço |
|||
|
= (sinal de igual) |
Um caractere especial que indica qual valor será atribuído à variável quando o loop for iniciado. |
||
|
[(abra colchetes) |
|||
|
] (fechar colchete) |
Um caractere especial que indica que uma determinada coluna ou linha foi acessada |
||
|
Qualquer número inteiro |
Com base na tabela compilada, é possível construir uma máquina de estados finita de possíveis transições de estado. A Figura 2.1 mostra uma máquina de estados.
Figura 2.1 - Máquina de estados finitos de transições possíveis
Com base no autômato construído, é possível construir um reconhecedor descendente com retorno (com a seleção de alternativas). Um reconhecedor de retrocesso descendente é usado para determinar se uma string pertence a uma gramática. Ele analisa o estado atual, procura uma regra de transição do estado atual para o próximo, se o próximo estado corresponder, então o procedimento é repetido para o próximo. Se o reconhecedor não conseguir encontrar uma regra de transição do estado atual para o próximo, então esta cadeia não pertence a esta gramática, ou seja, a linha de código é escrita com um erro lógico. Se houver várias opções de transição, o reconhecedor se lembrará do estado em que a alternativa surgiu e retornará a ele se a cadeia não pertencer à gramática. A Figura 2.2 mostra um resolver voltado para baixo com um backtrack.
Figura 2.2 - Resolvedor descendente com retrocesso
Durante a análise do modelo, é mantido um log de erros que contém informações sobre qual modelo tem um erro, em qual linha de código específica e o tipo de erro. Os erros podem ser dos seguintes tipos: identificador não reconhecido (uma tentativa de usar palavras de serviço ou caracteres especiais que não são fornecidos pelo código fornecido), violação do sentido lógico (a linha de código não passou no reconhecedor), uma tentativa para acessar uma variável inexistente (acessar uma variável a uma variável não criada ou acessar uma variável fora do loop), o início do loop não é especificado (o início e o fim do loop devem ser especificados na forma de abertura e fechamento colchetes).
2. Modelos criados usando o construtor. Uma solução é a estrutura usada em linguagens de programação lógica: aplicar filtros de condição a informações de entrada comuns, que neste caso são o conteúdo de uma tabela de banco de dados. A Figura 2.3 mostra a estrutura geral de uma tabela de banco de dados.
Figura 2.3 - Estrutura geral da tabela do banco de dados
3. Como implementação, foi escolhida uma solução utilizando a "Truth Table". Esta tabela é uma tabela com n+1 colunas e m+1 linhas, onde n e m são o número de colunas e linhas na tabela de entrada. Cada célula da tabela armazena um valor verdadeiro ou falso. A Figura 2.4 mostra a "Tabela Verdade".
Figura 2.4 - "Tabela verdade"
Quando um filtro é aplicado, os valores verdadeiros são substituídos por falsos, dependendo do que o filtro foi aplicado. Se o filtro foi aplicado ao conteúdo das células, os valores serão alterados para cada célula especificamente e, se para linhas ou colunas, apenas em uma linha ou coluna adicional.
Ao trabalhar com um banco de dados, as seguintes entidades podem ser distinguidas: índice de linha, índice de coluna, número de linhas, número de colunas, tipo de coluna, nome da coluna, conteúdo da célula.
Também foram estabelecidas condições:<», «>”, “=”, “contém”, “corresponde”.
4. As entidades e condições selecionadas são suficientes para exibir todos os dados possíveis ou impor todos os tipos de condições. A Figura 2.5 mostra a "Tabela Verdade" com os filtros aplicados.
Figura 2.5 - "Tabela verdade" com filtros aplicados
Ao enviar informações para um arquivo XML, o programa determina o que precisa ser gerado e, em seguida, usando a "Tabela Verdade", emite apenas os valores que correspondem ao valor verdadeiro.
Para criar um layout de template, foram criados os seguintes tipos de tags: main, simple, global, block. A principal é uma tag, só pode haver uma desse tipo em um documento e ela é obrigatória, pois contém informações sobre o documento XML. Simples - tags desse tipo são a única maneira de exibir dados e impor condições na "Tabela de verdade". Eles consistem nas seguintes partes: título, fonte e condição. As entidades previamente selecionadas são usadas como fonte e condição. Se a tag estiver com o nome vazio, seu conteúdo não será exibido, mas será aplicada a condição da "Tabela Verdade".
Global - tags desse tipo não carregam uma carga lógica, são apenas necessárias para a saída.
Bloco - tags desse tipo são necessárias para combinar a lógica de tags simples, e tudo o que estiver escrito no tag do bloco será exibido para cada célula que satisfaça a "Tabela Verdade". A tag de bloco em si não é exibida no documento XML.
2.3 Estrutura, arquitetura do produto de software
Central para a programação orientada a objetos é o desenvolvimento de um modelo lógico de um sistema na forma de um diagrama de classes. O diagrama de classes (diagrama de classes) serve para representar a estrutura estática do modelo do sistema na terminologia das classes de programação orientadas a objetos. Um diagrama de classes pode refletir, em particular, vários relacionamentos entre entidades individuais da área de assunto, como objetos e subsistemas, bem como descrever sua estrutura interna e tipos de relacionamentos.
Classe (classe) neste diagrama é usada para denotar um conjunto de objetos que possuem a mesma estrutura, comportamento e relacionamentos com objetos de outras classes. Graficamente, a classe é representada como um retângulo, que também pode ser dividido por linhas horizontais em seções ou seções. Essas seções podem conter o nome da classe, atributos (variáveis) e operações (métodos).
Além da estrutura interna ou estrutura de classes, o diagrama correspondente indica o relacionamento entre as classes:
Para esta aplicação, foram alocadas as classes descritas na Tabela 2.2.
Tabela 2.2 - Descrição das classes utilizadas no produto de software
O diagrama de classes do aplicativo conversor é mostrado na Figura 2.6. No diagrama, você pode ver que a classe MyCode é uma variável da classe Template. A classe Template contém os seguintes campos: dt, lv, thisTemplate, mycode, fs, sr, sw, correct, masCode, masPerem, masPeremCount, masSost, masCodeLength. dt é uma variável do tipo DataTable que contém informações armazenadas no banco de dados; lv - uma variável do tipo ListView, um objeto de interface no qual as mensagens de erro nos modelos são gravadas; thisTemplate - uma variável do tipo string, ou seja, o nome do modelo que está sendo processado no momento; mycode - uma matriz da classe MyCode que armazena informações sobre todos os fragmentos de código encontrados neste modelo; fs - uma variável do tipo FileStream, que determina com qual arquivo o programa irá trabalhar; sr - uma variável do tipo StreamReader, que determina de qual arquivo a informação será lida; sw é uma variável do tipo StreamWriter que determina em quais informações do arquivo serão gravadas; correto - uma variável do tipo bool indicando se o fragmento de código atual é processado corretamente; masCode - um array do tipo string contendo todas as linhas de código encontradas no template; masCodeLength - uma variável int indicando quantas linhas de código foram encontradas no template; masPerem - array bidimensional do tipo string contendo o nome e o valor das variáveis criadas; masPeremCount - uma variável do tipo int indicando quantas variáveis foram criadas no momento; masSost é um array do tipo int contendo uma lista de estados de máquina para a linha de código atual.
A classe também contém os seguintes métodos: Connect, Search, Analyze, Check, ExecuteCode. O método Connect se conecta ao modelo no caminho fornecido. O método Search localiza trechos de código em um modelo. O método Analyze determina os estados de uma linha de código. O método Check é recursivo, ele determina a validade lógica de uma string. O método ExecuteCode executa o modelo atual. Para as classes descritas, você pode fazer um diagrama de classes. A Figura 2.6 é um diagrama de classes.
Figura 2.6 - Diagrama de classes
2.4 Diagrama funcional, propósito funcional do produto de software
O produto de software desenvolveu duas opções possíveis para processar informações com algoritmos exclusivos.
Se o usuário usa modelos de código, ele deve primeiro especificar os arquivos de entrada e, em seguida, criar um novo modelo ou selecionar um existente. Em seguida, o usuário especifica o diretório e o nome do arquivo de saída e inicia o processo de conversão. Durante este processo, as seções de código no modelo são inicialmente alocadas, em seguida, os lexemas são alocados em cada uma das seções, após o que seu significado lógico é determinado e o modelo é executado. Se ocorrerem erros em qualquer um desses estágios, as informações sobre eles serão registradas no log de erros. Após executar todos os templates, o usuário pode utilizar o arquivo de saída.
Se você usar modelos criados usando o construtor, o usuário precisará especificar o banco de dados que precisa ser convertido, especificar o diretório do arquivo de saída, criar um modelo e iniciar o processo de conversão. A conversão em si consiste em duas partes: criar uma tabela-verdade com base no modelo e executar a conversão de acordo com a tabela-verdade. O arquivo de saída pode então ser usado pelo usuário conforme pretendido.
No segundo capítulo do trabalho final de qualificação, foram escolhidas as ferramentas de desenvolvimento, nomeadamente o Microsoft Visual Studio 2008, foram descritos os principais métodos de implementação de um produto de software e descrita a sua estrutura. O diagrama funcional do produto de software também foi descrito.
Os principais pontos a serem considerados no segundo capítulo foram:
A escolha dos métodos e meios de implementação, sua justificação;
Descrição dos algoritmos aplicados;
Estrutura, arquitetura do produto de software;
Diagrama funcional, propósito funcional do produto de software.
3 . IMPLEMENTAÇÃOE TESTEPRODUTO DE SOFTWARE
3.1 Descrição da implementação
Uma das dificuldades na implementação deste produto de software é escrever um algoritmo de reconhecimento. Todo o algoritmo é descrito pelos métodos: Search, Analize, Check, ExecuteCode.
O método Search lê o padrão e encontra fragmentos de código marcados com caracteres "*" em ambos os lados e os grava no arquivo .
public voidSearch()
boolsign=false;
while (!sr.EndOfStream)
if ((c != "*") && (sinal == verdadeiro))
( s += c.ToString(); )
if ((c == "*") && (sinal == falso))
if ((c == "*") && (sinal == verdadeiro))
masCódigo = s;
masCódigoComprimento++; )
s += c.ToString(); ))
meucódigo = new MeuCódigo ;)
O método Analize divide uma linha de código em tokens separados e determina o estado de cada um deles, se forem usados símbolos ou palavras que não são fornecidos pela linguagem, ou nomes de variáveis incorretos forem usados, uma mensagem de erro apropriada é adicionada ao registro de erros. Uma lista completa de lexemas usados é apresentada na Tabela 2.1.
public void Analisar()
( string masIdent = nova string;
int masIdentLength = 0;
sinal bool = verdadeiro;
para (int a = 0; a< masCodeLength; a++)
(correto=falso;
masIdentLength = 0;
masCódigo[a] = masCódigo[a].Trim();
masCode[a] = masCode[a].ToLower();
para (int b = 0; b< masCode[a].Length; b++)
(c = masCódigo[a][b];
masIdentComprimento++; )
masIdent = ".";
masIdentComprimento++;
if ((c == " ") && (s != ""))
(masIdent = s;
masIdentComprimento++;
(masIdent = s;
masIdentComprimento++; )
meucódigo[a] = new MeuCódigo("", null);
para (int z = 0; z< masIdentLength; z++)
meucódigo[a].código += masIdent[z] + " ";
masSost = new int;
Na parte anterior do método, todos os tokens encontrados foram gravados no array masIdent, então um loop é inicializado no qual o estado é determinado para todos os tokens encontrados e gravados no array masSost.
para (int b = 0; b< masIdentLength; b++)
if (masIdent[b] == "para")
senão if (masIdent[b] == "antes")
else if (masIdent[b] == "coluna")
senão if (masIdent[b] == "string")
if (Char.IsLetter(masIdent[b]))
( bool f = verdadeiro;
para (int d = 1; d< masIdent[b].Length; d++)
if (!Char.IsLetterOrDigit(masIdent[b][d])))
if (f == verdadeiro) masSost[b] = 1; senão
Incluindo uma entrada de erro no log de erros se o ID encontrado não existir.
lv.Items.SubItems.Add("Identificador não reconhecido " + masIdent[b]); )) senão
lv.Items.SubItems.Add(mycode[a].code);
lv.Items.SubItems.Add("Identificador não reconhecido " + masIdent[b]);))
mycode[a] = new MyCode(mycode[a].code, masSost);
Check(0, masSost, a); )
O método Check é baseado no trabalho de um resolvedor descendente com um retorno: o estado atual é determinado, se possível, é feita uma transição para o próximo. Se não for possível, o estado muda para um alternativo, se não houver nenhum, uma mensagem de erro é adicionada ao log de erros.
public void Check(int a, int s, int indc)
( if (masSost[a] == s)
(se ((s == 1) && (a == 0))
correto=verdadeiro; ) senão
se ((s == 2) && (a == 0)) s = 1; senão
if (((s == 4) || (s == 5)) && (a == 0)) s = 8; senão
se ((s == 1) && (a == 1)) s = 9; senão
se ((s == 8) && (a == 1)) s = 6; senão
se ((s == 10) && (a == 1)) s = 1; senão
se ((s == 9) && (a == 2)) s = 12; senão
se ((s == 6) && (a == 2))
( if (a == masSost.Length - 1)
correto=verdadeiro; ) senão
if (((s == 1) || (s == 12)) && (a == 2)) s = 11; senão
se ((s == 12) && (a == 3)) s = 3; senão
se ((s == 11) && (a == 3)) s = 8; senão
se ((s == 3) && (a == 4)) s = 12; senão
se ((s == 8) && (a == 4))
( if (masSost == 4)
se ((s == 6) && (a == 7))
( if (a == masSost.Length - 1)
correto=verdadeiro; )
if (((s == 12) || (s == 1)) && (a == 7))
se ((s == 11) && (a == 8))
( if (a == masSost.Length - 1)
correto=verdadeiro; )
Se a matriz de estados de entrada for aprovada na verificação do resolvedor e todos os estados corresponderem, a variável correta será definida como verdadeira e, se houver uma incompatibilidade em algum lugar, o retorno será feito e verificado para um estado alternativo.
se (correto == falso)
Cheque(a, s, indc); ) )
se ((s == 8) && (a == 1))
Cheque(a, s, indc); )
se ((s == 1) && (a == 2))
Cheque(a, s, indc);)
se ((s == 1) && (a == 7))
Cheque(a, s, indc); )
Se a transição que está sendo feita não foi reconhecida, a linha de código que está sendo processada é considerada logicamente inválida e uma entrada de erro apropriada é adicionada ao log de erros.
se (correto == falso)
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(masCode);
lv.Items.SubItems.Add("O significado lógico da linha foi violado");
meucódigo.correto = false;
O método ExecuteCode grava o conteúdo do modelo no arquivo de saída executando as linhas do programa. Se um ciclo for encontrado, um arquivo temporário é criado, no qual o conteúdo do ciclo é gravado e, até que o ciclo seja concluído, o conteúdo desse arquivo é executado. Isso é necessário para executar loops aninhados.
public void ExecuteCode(int NCode, bool cikcle, StreamReader sr, StreamWriter sw, int tempF)
while (!sr.EndOfStream)
c = Convert.ToChar(sr.Read());
O algoritmo lê o arquivo de entrada caractere por caractere, se houver uma chave de fechamento, o que significa o fim do loop, e a variável cikcle for verdadeira, isso significa que o método foi aninhado e o finaliza.
if ((c == ")") && (ciclo == verdadeiro))
Se o caractere lido não for "*", isso significa que o caractere não pertence aos comandos de código e deve simplesmente ser gerado.
Se o caractere lido foi "*", o algoritmo lê o próximo caractere, se for "*", isso significa que o usuário queria enviar esse caractere para o arquivo de saída.
(c = Convert.ToChar(sr.Read());
Se o próximo caractere não for "*", isso significa que todos os caracteres subsequentes antes de "*" referem-se a comandos de código.
if (meucódigo.correto == verdadeiro)
if (meucódigo.masSost == 1)
( bool criar = false;
para (int a = 0; a< masPeremCount; a++)
( if (masPerem == meucódigo.código)
sw.Write(masPerem);
while (sr.Read() != "*")
Se, no código, o usuário tentar exibir uma variável que não foi declarada antes, uma entrada de erro será gravada no log de erros e o código remoto não será mais executado.
if (criar == falso)
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add("Tentando exibir uma variável inexistente");
meucódigo.código = ""; )
while (sr.Read() != "*")
if (meucódigo.masSost == 4)
(if (meucódigo.masSost == 6)
sw.Write(dt.Columns.Count.ToString());
while (sr.Read() != "*")
if (Convert.ToInt32(mycode.masValue)< dt.Columns.Count)
(if (meucódigo.masSost == 7)
sw.Write(dt.Columns.masValue)].DataType.Name);
sw.Write(dt.Columns.masValue)].ColumnName);)
Se o usuário tentar acessar uma coluna ou linha que não existe, a entrada de erro correspondente será adicionada ao log de erros.
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(meucódigo.código);
meucódigo.código = ""; )
while (sr.Read() != "*")
( bool criar = false;
para (int a = 0; a< masPeremCount; a++)
if (Convert.ToInt32(masPerem)< dt.Columns.Count)
(if (meucódigo.masSost == 13)
sw.Write(dt.Columns)].ColumnName);
sw.Write(dt.Columns)].DataType.Name);
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(meucódigo.código);
lv.Items.SubItems.Add("O índice está fora do escopo");
meucódigo.código = ""; )
while (sr.Read() != "*")
if (criar == falso) (
Se o usuário especificar uma variável inexistente como índice de coluna ou linha, uma entrada de erro correspondente será adicionada ao log de erros.
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(meucódigo.código);
lv.Items.SubItems.Add("Tentando acessar uma variável inexistente");
while (sr.Read() != "*")
if (meucódigo.masSost == 5)
(int n1 = 0, n2 = 0, nn = 0;
if (meucódigo.masSost == 6)
( sw.Write(dt.Rows.Count.ToString());
while (sr.Read() != "*")
(if (meucódigo.masSost == 12)
( ( n1 = Convert.ToInt32(mycode.masValue);
if (meucódigo.masSost == 12)
(n2 = Convert.ToInt32(mycode.masValue);
( bool criar = false;
para (int a = 0; a< masPeremCount; a++)
if (masPerem == meucódigo.masValue)
n2 = Convert.ToInt32(masPerem);
Se uma variável foi usada como índice de uma coluna ou linha e seu valor excede o número de colunas ou linhas da tabela, respectivamente, uma entrada sobre esse erro é adicionada ao log de erros.
Else ( if (n1 >= dt.Rows.Count)
( if (meucódigo.código != "")
(lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(meucódigo.código);
lv.Items.SubItems.Add("Index " + n1 + " está fora do intervalo");))
if (n2 >= dt.Columns.Count)
( if (meucódigo.código != "")
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(meucódigo.código);
lv.Items.SubItems.Add("Index " + n2 + " está fora do intervalo"); ))
meucódigo.código = ""; )
while ((sr.Read() != "*") && (!sr.EndOfStream))
if (meucódigo.masSost == 2)
masPerem = meucódigo.masValue;
masPerem = meucódigo.masValue;
nk = masPeremCount;
masPeremCount++;
if (meucódigo.masSost == 12)
k = Convert.ToInt32(mycode.masValue); senão
if (mycode.masSost == 4) k = dt.Columns.Count;
senão k = dt.Rows.Count;
while (sr.Read() != "*") ( )
Se o usuário declarou um ciclo e depois disso não indicou seu início sem colocar "(", isso é considerado um erro e uma entrada sobre isso é adicionada ao log de erros.
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read());
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(meucódigo.código);
lv.Items.SubItems.Add("Início do ciclo não especificado");
meucódigo.correto = false;
NCode++; ) senão (
Se o início do loop for especificado corretamente, a variável responsável pela profundidade do aninhamento dos loops será aumentada em um, o conteúdo do loop, até o sinal ")", será gravado em um arquivo temporário, uma duplicata dos arrays contendo os valores das variáveis é criado, e este método recursivo já é lançado para este arquivo temporário.
Directory.CreateDirectory("Temp");
StreamWriter sw1=new StreamWriter("Temp\\Temp"+tempF.ToString()+".txt", false, Encoding.UTF8);
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read()); )
int cicloContagem = 0;
enquanto (c != ")")
if (sr.EndOfStream)
c = Convert.ToChar(sr.Read());
if ((c == ")") && (cickleCount != 0))
(Contagem de cickles--;
c = Convert.ToChar(sr.Read()); ) )
StreamReader sr1 = new StreamReader("Temp\\Temp" + tempF.ToString() + ".txt", Encoding.UTF8);
int CickleCode = 0;
bool sinal2 = falso;
while (!sr1.EndOfStream)
(c = Convert.ToChar(sr1.Read());
if ((c != "*") && (sinal2 == verdadeiro))
( s1 += c.ToString(); )
if ((c == "*") && (sinal2 == falso))
if ((c == "*") && (sinal2 == verdadeiro))
( sinal2 = falso;
else s1 += c.ToString(); ) )
for (int a = Convert.ToInt32(mycode.masValue); a< k; a++)
( masPerem = a.ToString();
ExecuteCode(NCode + 1, true, new StreamReader("Temp\\Temp" + tempF.ToString() + ".txt", Encoding.UTF8), sw, tempF);)
Depois que o loop termina, o arquivo temporário é excluído e a profundidade de aninhamento dos loops é reduzida em um.
masPerem = "";
masPerem = "";
NCode = CickleCode + 1;
File.Delete("Temp\\Temp" + tempF.ToString() + ".txt");
O algoritmo para trabalhar com modelos criados usando o construtor é descrito pelos seguintes métodos: Execute, GetTruthTable, ExecuteTag.
O método Execute é chamado uma vez quando o processamento do modelo é iniciado. Este método é externo e outros métodos são chamados a partir dele. Inicialmente, o método cria um arquivo de saída e uma "Tabela Verdade".
DataTable truthdt=new DataTable();
StreamWriter sw=new StreamWriter(textBox4.Text+"Arquivo de saída.xml",false,Encoding.UTF8);
para (int a = 0; a<= dt.Columns.Count;a++)
verdadedt.Columns.Add("",typeof(bool));
para (int a = 0; a<= dt.Rows.Count; a++)
(DataRow dr = truthdt.NewRow();
para (int b = 0; b< dr.ItemArray.Length; b++)
verdadedt.Linhas.Add(dr); )
Depois disso, o loop começa a ser executado, destacando cada tag que determina seu tipo e, dependendo disso, execute-o.
enquanto (!completo)
( tagind = GetTagIndex(Itens);
if (mastag.type == types.global || mastag.type == types.main)
if (mastag.type == types.block)
if (Itens >= contagem de itens)
completo=verdadeiro; )
Se o tipo de tag for global ou main, o conteúdo da tag será simplesmente gravado no arquivo.
if (mastag.nome != "")
sw.WriteLine(itens);
Se o tipo de tag for block, a lista de todas as tags pertencentes a este fragmento será gravada em uma matriz separada e também será determinado se há tags nessa lista que exigem indexação de string para exibir valores.
bool temLinha = false;
tag blocktag = new tag.indF - mastag.indS - 1];
for (int a = mastag.indS + 1, b = 0; a< mastag.indF; a++, b++)
(blocotag[b] = matag;
if (blocktag[b].type == types.simple)
if (blocktag[b].source == "índice de linha" || blocktag[b].source == "conteúdo da célula")
terLinha = true ;)
Depois disso, uma "tabela verdade" é criada e todas as condições das tags simples encontradas na lista são aplicadas a ela.
verdadedt=CreateTable(truthdt,dt);
para (int a = 0; a< blocktag.Length; a++)
if (blocktag[a].type == types.simple)
verdadedt = GetTruthTable(dt, verdadedt, blocktag[a]);
Além disso, dependendo se tags usando indexação de strings foram encontradas, ou apenas um ciclo de coluna é criado ou ciclos ao longo de colunas e linhas, nas quais todas as tags encontradas são executadas, exceto as de bloco.
para (int a = 0; a< dt.Rows.Count; a++)
para (int b = 0; b< dt.Columns.Count; b++)
bool eraEx = false;
StreamWriter swt = new StreamWriter("temp.txt", false, Encoding.UTF8);
para (int c = 0; c< blocktag.Length; c++)
if (blocktag[c].type == types.global)
if (blocktag[c].name != "")
swt.WriteLine(items.indS + c + 1]);
if (blocktag[c].name != "")
wasEx=ExecuteTag(dt, truedt, blocktag[c], a, b, swt); )
( StreamReader sr = new StreamReader("temp.txt", Encoding.UTF8);
sw.Write(sr.ReadToEnd());
File.Delete("temp.txt");
( para (int a=0;a para (int c = 0; c< blocktag.Length; c++) ( if (blocktag[c].type == types.global) if (blocktag[c].name != "") sw.WriteLine(items.indS + c + 1]); if (blocktag[c].type == types.simple) if (blocktag[c].name != "") ExecuteTag(dt, truthdt, blocktag[c], 0, a, sw); Se o tipo de tag for simples, então uma nova "Truth Table" é criada para ele e a tag é executada. if (mastag.type == types.simple) (truthdt=CreateTable(truthdt,dt); DataTable tempdt = GetTruthTable(dt, truthdt, mastag); if(mastag.nome!="") ExecuteTag(dt, tempdt, matag, 0, 0, sw); O método GetTruthTable aplica condições à "Tabela de verdade". Como argumentos, ele pega uma tabela com valores do banco de dados, a já criada "Truth Table" e uma tag, cuja condição precisa ser processada. O método ExecutTag executa uma tag simples. Ele recebe como argumentos uma tabela de dados, uma "tabela verdade", uma tag, um índice de linha, um índice de coluna e um fluxo de gravação de arquivo. 3.2
Descrição da interface do usuário A janela principal do programa está dividida em várias partes: ".dbf", "Templates", ".xml" e o log de erros. Em todas as partes, exceto no log, existem elementos responsáveis por selecionar os diretórios que contêm arquivos ou nos quais os arquivos devem ser salvos. O log de erros é apresentado como uma lista de três colunas: "padrão", "string", "erro". A primeira coluna contém o nome do modelo no qual o erro foi encontrado. Na segunda, a linha onde ocorreu o erro. Terceiro, o tipo de erro. Também no formulário existem elementos que não pertencem a nenhum dos grupos. Alguns deles refletem o andamento da obra, enquanto outros iniciam o próprio processo. A Figura 3.1 mostra o formulário principal - a janela principal do programa. Figura 3.1 - Janela principal do programa Ao trabalhar com modelos, uma janela de programa adicional é aberta, consistindo em um campo para o nome do modelo, um elemento que contém o código do modelo e botões para salvar o modelo e fechar a janela. A Figura 3.2 mostra uma vista da janela do programa adicional (editor de modelos). Figura 3.2 - Janela do editor de modelos Também no formulário principal existe um controle que abre o formulário para criação de templates utilizando o construtor. O formulário do construtor contém os seguintes controles: uma lista de tags já criadas, um campo para inserir o nome de uma nova tag, uma lista suspensa para selecionar um tipo de tag, uma lista suspensa para selecionar uma origem de tag, um painel com elementos para criar uma condição de tag, um campo para definir um arquivo de banco de dados, um campo para definir a localização do arquivo de saída, botões para adicionar e excluir uma tag, um botão para iniciar o processamento. A Figura 3.3 mostra a janela do designer de templates. Figura 3.3 - Janela do construtor do modelo Como resultado do trabalho do software, foram obtidos arquivos XML de várias versões da linguagem XML. Bases de dados no formato dbf das versões dBase II, dBase III e dBase IV foram utilizadas como dados de entrada. Os arquivos convertidos foram abertos corretamente com os seguintes navegadores: Internet Explorer 10, Mozilla Firefox 19, Google Chrome versão 27.0.1453.93, Opera 12.15. Além dos navegadores, os arquivos podem ser visualizados e editados com qualquer editor de texto. Com base nos resultados obtidos, pode-se concluir que os arquivos XML obtidos durante a operação do programa atendem aos requisitos do cliente. 3.
3
Teste e avaliação da confiabilidade do produto de software Ao testar o produto de software, foram identificados os seguintes erros: Erro de indexação para uma célula da tabela de banco de dados; Erro de saída da variável de loop; Um erro que ocorre quando o índice de uma linha ou coluna excede seu número. 1. Erro de indexação em uma célula da tabela do banco de dados. Ocorre quando o modelo contém um código no formato "*row[x].column[y]*", onde xey são números ou variáveis. O problema foi resolvido adicionando uma condição adicional no código do programa ao processar strings semelhantes no modelo. 2. Erro de saída da variável de loop. Ocorre quando um código no formato "*x*" é especificado no modelo, onde x é uma variável. O problema foi resolvido alterando a compilação da tabela de identificadores. 3. Um erro que ocorre se o índice de uma linha ou coluna exceder seu número. Ocorre quando o modelo contém um código como "*column[x].name*", onde x é um número ou uma variável cujo valor excede o número de colunas. O problema foi resolvido comparando o valor do índice e o número de linhas ou colunas, se o índice exceder, uma entrada sobre isso será adicionada ao log de erros e o programa continuará sendo executado. 3.
4
Calculo de custo As empresas que trabalham constantemente com diferentes formatos de banco de dados precisam automatizar o processo de conversão de um formato de banco de dados para outro. Isso aumentará a produtividade dos trabalhadores, bem como reduzirá os requisitos para sua educação. O produto de software, além da parte de software, também consiste na documentação de acompanhamento, que é resultado da atividade intelectual dos desenvolvedores. Na estrutura de investimentos de capital associados à automação de controle, os investimentos de capital são alocados para o desenvolvimento de um projeto de automação (custos de pré-produção) e os investimentos de capital para a implantação do projeto (custos de implementação): onde K p - investimentos de capital para projeto; К р - investimentos de capital para implementação do projeto. Cálculo de investimentos de capital para design. Os investimentos de capital para o projeto de software são determinados pela elaboração de estimativas de custos e são determinados pela fórmula: onde K m - o custo dos materiais; K pr - salários básicos e adicionais com descontos no seguro social para engenheiros e técnicos diretamente envolvidos no desenvolvimento do projeto; K mash - os custos associados ao uso do tempo da máquina para depuração do programa; K c - pagamento de serviços a terceiros, se o projeto for realizado com o envolvimento de terceiros; K n - despesas gerais do departamento de design. Todos os cálculos serão feitos em unidades convencionais (u.c.), o que corresponde ao custo de um dólar americano no Pridnestrovian Republican Bank no momento do desenvolvimento do software. Custos de material. Vamos determinar a estimativa de custo e calcular o custo dos materiais K m, que foram para o desenvolvimento do software. A lista de materiais é determinada pelo tema da tese. Eles incluem o seguinte: suportes de informação (papel, discos magnéticos) e objetos de trabalho vestíveis (caneta, lápis, elástico). A estimativa de custo para materiais é apresentada na tabela 3.1. Tabela 3.1 - Custo estimado de materiais Implementação de um programa conversor para criar um arquivo de formato XML baseado nos arquivos dbf transferidos (de acordo com um modelo especificado pelo usuário). Crie modelos usando código e usando o construtor. Projeto de arquitetura de produto de software. tese, adicionada em 27/06/2013 Desenvolvimento de um programa conversor que, com base no conteúdo dos arquivos dbf transferidos, cria um arquivo XML de acordo com um modelo especificado pelo usuário. Considere criar modelos de duas maneiras: usando código e usando um construtor. trabalho de conclusão de curso, adicionado em 24/06/2013 Projetar a interface do usuário de um programa que criptografa e descriptografa arquivos. Escolha do formato de apresentação de dados. Lista de procedimentos, macros e sua finalidade. Descrição das funções utilizadas no programa, seus testes e depuração. trabalho de conclusão de curso, adicionado em 17/05/2013 Recursos do "motor de busca" de arquivos duplicados no disco. Escolha do ambiente de programação. Desenvolvimento de um produto de software. Requisitos básicos para um programa que procura arquivos duplicados em um disco. Mostrar arquivos ocultos. trabalho de conclusão de curso, adicionado em 28/03/2015 Características do trabalho do arquivador - um programa de computador que compacta dados em um único arquivo para facilitar a transmissão e o armazenamento compacto. Recursos do processo de arquivamento - gravação de arquivos e descompactação - abertura de arquivos. resumo, adicionado em 26/03/2010 Desenvolvimento de um produto de software para exportação de especificações do aplicativo PartList. A escolha do método de transferência de informações para um arquivo, o formato de apresentação. Desenvolvimento de conversores, implementação de interface de usuário. Justificativa para a relevância do desenvolvimento. tese, adicionada em 25/09/2014 Design de software. O esquema da formação inicial do diretório de arquivos, exibindo o diretório de arquivos, excluindo arquivos, classificando arquivos por nome, data de criação e tamanho usando o método de seleção direta. Gerenciamento de diretório no sistema de arquivos. trabalho de conclusão de curso, adicionado em 01/08/2014 Características dos formatos de arquivo wav e mp3. Construindo diagramas de casos de uso, desenvolvendo uma interface gráfica e arquitetura de aplicativos. Desenvolvimento de algoritmos de operação de programas: método TrimWavFile, TrimMp3, ChangeVolume, speedUpX1_2, speedDownX1_2. trabalho de conclusão de curso, adicionado em 20/12/2013 Uma visão geral dos recursos de trabalhar com o programa Total Commander. Crie pastas, copie arquivos para uma unidade flash. Chamando o menu de contexto. Definição da estrutura do arquivo. Renomeando um grupo de arquivos. Colocando arquivos em um arquivo. Dividir um arquivo em várias partes. trabalho de laboratório, adicionado em 04/08/2014 Criação e verificação de um modelo para a colocação ótima de arquivos em uma rede de computadores com topologia em forma de estrela, anel e arbitrária. A quantidade de dados necessária para transferir arquivos. Distribuição ideal de arquivos nos nós da rede de computadores. DBF é um arquivo de banco de dados, a capacidade de trabalhar com o qual foi anteriormente integrado ao ambiente Microsoft Office. Os aplicativos Access e Excel trabalharam com o formato, posteriormente o Access foi removido do pacote e se tornou um programa separado, e no Excel desde 2007 o suporte a DataBaseFile foi significativamente limitado. Se você não pode abrir um arquivo DBF diretamente no Excel, primeiro você deve convertê-lo. No entanto, embora o DBF seja considerado por muitos um formato obsoleto, ainda é amplamente utilizado em programas especializados na área de negócios, design e engenharia. Onde quer que você precise trabalhar com grandes quantidades de informações, sua estruturação e processamento, execução de consultas. Por exemplo, o pacote de software 1C Enterprise é inteiramente baseado em gerenciamento de banco de dados. E dado que muita documentação e dados de escritório vão para o Excel, a questão do trabalho integrado com estes formatos é relevante e procurada. No Excel 2003, era possível abrir e editar DBF, bem como salvar documentos XLS neste formato: IMPORTANTE. Desde 2007, você pode abrir e visualizar o formato do banco de dados no Excel, mas não pode fazer alterações ou salvar documentos .xls nele. As ferramentas de programa padrão não oferecem mais essa possibilidade. No entanto, existem complementos especiais para o aplicativo que adicionam essa função a ele. Na rede em vários fóruns, os programadores postam seus desenvolvimentos, você pode encontrar diferentes opções. O complemento mais popular chamado XslToDBF pode ser baixado do site do desenvolvedor http://basile-m.narod.ru/xlstodbf/download.html. O download é gratuito, mas se desejar, você pode apoiar o projeto transferindo qualquer valor para sua carteira ou cartão. Instalação e uso: Se você não deseja alterar nada no Office, não confia em suplementos e aplicativos de terceiros, pode oferecer uma maneira mais demorada de converter o arquivo XLS em DBF: Esse método nem sempre funciona com sucesso, geralmente ocorrem erros no processamento de dados e no salvamento subsequente. E é muito longo e desconfortável. Para não sofrer com os programas de escritório, foram criados muitos aplicativos que permitem transferir dados de um formato para outro. Primeiro, quase todos os programas DBMS poderosos oferecem a capacidade de exportar e carregar de XLS. Em segundo lugar, existem pequenos utilitários especializados em conversão. Aqui estão alguns deles: Em todos esses programas, a conversão se resume ao fato de que você precisa abrir o arquivo de origem e, em seguida, executar o comando "Converter" ou "Exportar". Existem também serviços de conversão online gratuitos. Nesses sites, propõe-se enviar (upload) o arquivo de origem, clicar em "Converter", após o qual aparecerá um link para o documento convertido. Quanto você pode confiar em tais serviços, a decisão é individual, por sua conta e risco. Assim, você pode abrir o DBF no Excel, mas se sua versão for 2007 e mais recente, nada mais pode ser feito com ele, basta olhar. Para editar, salvar em XLS, existem complementos ou programas especiais, bem como para converter na direção oposta. Se você tem experiência em converter e trabalhar com DBF em diferentes aplicativos, compartilhe suas dicas nos comentários.Documentos Semelhantes
Problemas do Excel ao trabalhar com DBF
















Conversão

