Obviamente, ao calcular a função de distribuição cumulativa, deve-se usar a relação mencionada entre as distribuições binomial e beta. Este método é certamente melhor do que a soma direta quando n > 10.
Nos livros clássicos de estatística, para obter os valores da distribuição binomial, muitas vezes é recomendável usar fórmulas baseadas em teoremas de limite (como a fórmula de Moivre-Laplace). Deve-se notar que do ponto de vista puramente computacional o valor desses teoremas é próximo de zero, especialmente agora, quando há um computador poderoso em quase todas as mesas. A principal desvantagem das aproximações acima é sua precisão completamente insuficiente para os valores de n típicos para a maioria das aplicações. Uma desvantagem não menor é a ausência de recomendações claras sobre a aplicabilidade de uma ou outra aproximação (em textos padrão, apenas formulações assintóticas são fornecidas, elas não são acompanhadas de estimativas de precisão e, portanto, são de pouca utilidade). Eu diria que ambas as fórmulas são válidas apenas para n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Não considero aqui o problema de encontrar quantis: para distribuições discretas, é trivial, e naqueles problemas em que tais distribuições surgem, via de regra, não é relevante. Se ainda forem necessários quantis, recomendo reformular o problema de forma a trabalhar com valores-p (significados observados). Aqui está um exemplo: ao implementar alguns algoritmos de enumeração, a cada passo é necessário verificar a hipótese estatística sobre a variável aleatória binomial. De acordo com a abordagem clássica, a cada passo é necessário calcular a estatística do critério e comparar seu valor com a fronteira do conjunto crítico. Como, no entanto, o algoritmo é enumerativo, é necessário determinar novamente o limite do conjunto crítico a cada vez (afinal, o tamanho da amostra muda de etapa para etapa), o que aumenta improdutivamente os custos de tempo. A abordagem moderna recomenda calcular a significância observada e compará-la com a probabilidade de confiança, economizando na busca por quantis.
Portanto, nos códigos abaixo, não há cálculo de função inversa, em vez disso, é dada a função rev_binomialDF, que calcula a probabilidade p de sucesso em uma única tentativa dado o número n de tentativas, o número m de sucessos nelas e o valor y da probabilidade de obter esses m sucessos. Isso usa a relação acima mencionada entre as distribuições binomial e beta.
Na verdade, esta função permite obter os limites dos intervalos de confiança. De fato, suponha que obtemos m sucessos em n tentativas binomiais. Como se sabe, o limite esquerdo do intervalo de confiança bilateral para o parâmetro p com um nível de confiança é 0 se m = 0, e for é a solução da equação  . Da mesma forma, o limite direito é 1 se m = n, e for é uma solução para a equação
. Da mesma forma, o limite direito é 1 se m = n, e for é uma solução para a equação  . Isso implica que, para encontrar o limite esquerdo, devemos resolver a equação
. Isso implica que, para encontrar o limite esquerdo, devemos resolver a equação  , e para procurar o correto - a equação
, e para procurar o correto - a equação  . Eles são resolvidos nas funções binom_leftCI e binom_rightCI , que retornam os limites superior e inferior do intervalo de confiança bilateral, respectivamente.
. Eles são resolvidos nas funções binom_leftCI e binom_rightCI , que retornam os limites superior e inferior do intervalo de confiança bilateral, respectivamente.
Quero observar que, se não for necessária uma precisão absolutamente incrível, então para n suficientemente grande, você pode usar a seguinte aproximação [B.L. van der Waerden, Estatística matemática. M: IL, 1960, cap. 2 segundos. 7]:  , onde g é o quantil da distribuição normal. O valor dessa aproximação é que existem aproximações muito simples que permitem calcular os quantis da distribuição normal (veja o texto sobre cálculo da distribuição normal e a seção correspondente desta referência). Na minha prática (principalmente para n > 100), essa aproximação deu cerca de 3-4 dígitos, o que, via de regra, é suficiente.
, onde g é o quantil da distribuição normal. O valor dessa aproximação é que existem aproximações muito simples que permitem calcular os quantis da distribuição normal (veja o texto sobre cálculo da distribuição normal e a seção correspondente desta referência). Na minha prática (principalmente para n > 100), essa aproximação deu cerca de 3-4 dígitos, o que, via de regra, é suficiente.
Os cálculos com os códigos a seguir requerem os arquivos betaDF.h , betaDF.cpp (consulte a seção sobre distribuição beta), bem como logGamma.h , logGamma.cpp (consulte o apêndice A). Você também pode ver um exemplo de uso de funções.
arquivo binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(duplas tentativas, duplos sucessos, duplo p); /* * Que haja "ensaios" de observações independentes * com probabilidade "p" de sucesso em cada um. * Calcular a probabilidade B(sucessos|tentativas,p) de que o número * de sucessos esteja entre 0 e "sucessos" (inclusive). */ double rev_binomialDF(tentativas duplas, sucessos duplos, y duplo); /* * Seja conhecida a probabilidade y de pelo menos m sucessos * nas tentativas do esquema de Bernoulli. A função encontra a probabilidade p * de sucesso em uma única tentativa. * * A seguinte relação é usada nos cálculos * * 1 - p = rev_Beta(tentativas-sucessos| sucessos+1, y). */ double binom_leftCI(ensaios duplos, sucessos duplos, nível duplo); /* Sejam "ensaios" de observações independentes * com probabilidade "p" de sucesso em cada * e o número de sucessos seja "sucessos". * O limite esquerdo do intervalo de confiança bilateral * é calculado com o nível de significância. */ double binom_rightCI(double n, double sucessos, double level); /* Sejam "ensaios" de observações independentes * com probabilidade "p" de sucesso em cada * e o número de sucessos seja "sucessos". * O limite direito do intervalo de confiança bilateral * é calculado com o nível de significância. */ #endif /* Termina #ifndef __BINOMIAL_H__ */ |
arquivo binomialDF.cpp
| /**************************************************** **** **********/ /* Distribuição Binomial */ /**************************** **** ****************************/ #include |
Considere a distribuição Binomial, calcule sua expectativa matemática, variância, moda. Usando a função BINOM.DIST() do MS EXCEL, vamos plotar a função de distribuição e os gráficos de densidade de probabilidade. Vamos estimar o parâmetro de distribuição p, a expectativa matemática da distribuição e o desvio padrão. Considere também a distribuição de Bernoulli.
Definição. Deixe-os ser mantidos n testes, em cada um dos quais apenas 2 eventos podem ocorrer: o evento "sucesso" com probabilidade p ou o evento "falha" com a probabilidade q =1-p (o chamado esquema de Bernoulli,Bernoulliensaios).
Probabilidade de obter exatamente x sucesso nestes n testes é igual a:
Número de sucessos na amostra x é uma variável aleatória que tem Distribuição binomial(Inglês) Binomialdistribuição) p e n – são parâmetros desta distribuição.
Lembre-se que para aplicar Esquemas de Bernoulli e correspondentemente distribuição binomial, as seguintes condições devem ser atendidas:
- cada tentativa deve ter exatamente dois resultados, chamados condicionalmente de "sucesso" e "fracasso".
- o resultado de cada teste não deve depender dos resultados de testes anteriores (independência do teste).
- taxa de sucesso p deve ser constante para todos os testes.
Distribuição binomial no MS EXCEL
No MS EXCEL, a partir da versão 2010, para existe uma função BINOM.DIST() , o nome em inglês é BINOM.DIST(), que permite calcular a probabilidade que a amostra terá exatamente X"sucessos" (ou seja, função densidade de probabilidade p(x), veja a fórmula acima), e função de distribuição integral(probabilidade de que a amostra tenha x ou menos "sucessos", incluindo 0).
Antes do MS EXCEL 2010, o EXCEL tinha a função DISTRBINOM(), que também permite calcular função de distribuição e densidade de probabilidade p(x). BINOMDIST() é deixado no MS EXCEL 2010 para compatibilidade.
O arquivo de exemplo contém gráficos densidade de distribuição de probabilidade e .

Distribuição binomial tem a designação B (n ; p) .
Observação: Para construção função de distribuição integral tipo de gráfico de ajuste perfeito Cronograma, por densidade de distribuição – Histograma com agrupamento. Para obter mais informações sobre como construir gráficos, leia o artigo Os principais tipos de gráficos.
Observação: Para a conveniência de escrever fórmulas no arquivo de exemplo, foram criados nomes para parâmetros Distribuição binomial: n e pág.

O arquivo de exemplo mostra vários cálculos de probabilidade usando as funções do MS EXCEL:
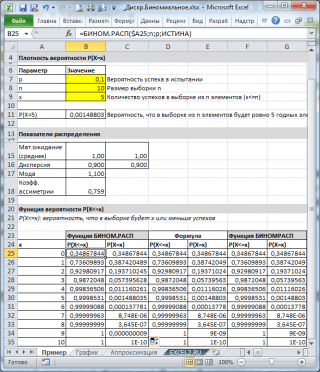
Como visto na imagem acima, supõe-se que:
- A população infinita da qual a amostra é feita contém 10% (ou 0,1) de bons elementos (parâmetro p, terceiro argumento da função = BINOM.DIST() )
- Para calcular a probabilidade de que em uma amostra de 10 elementos (parâmetro n, o segundo argumento da função) haverá exatamente 5 elementos válidos (o primeiro argumento), você precisa escrever a fórmula: =BINOM.DIST(5, 10, 0,1, FALSO)
- O último, quarto elemento é definido = FALSE, ou seja o valor da função é retornado densidade de distribuição .
Se o valor do quarto argumento = TRUE, a função BINOM.DIST() retorna o valor função de distribuição integral ou simplesmente função de distribuição. Nesse caso, você pode calcular a probabilidade de que o número de itens bons na amostra seja de um determinado intervalo, por exemplo, 2 ou menos (incluindo 0).
Para fazer isso, escreva a fórmula: = BINOM.DIST(2, 10, 0,1, VERDADEIRO)
Observação: Para um valor não inteiro de x, . Por exemplo, as fórmulas a seguir retornarão o mesmo valor: =BINOM.DIST( 2 ; dez; 0,1; VERDADE)=BINOM.DIST( 2,9 ; dez; 0,1; VERDADE)
Observação: No arquivo de exemplo densidade de probabilidade e função de distribuição também calculado usando a definição e a função COMBIN().
Indicadores de distribuição
NO arquivo de exemplo na planilha Exemplo existem fórmulas para calcular alguns indicadores de distribuição:
- =n*p;
- (desvio padrão quadrado) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*RAIZ(n*p*(1-p)).
Derivamos a fórmula expectativa matemáticaDistribuição binomial usando esquema de Bernoulli .
Por definição, uma variável aleatória X em esquema de Bernoulli(variável aleatória de Bernoulli) tem função de distribuição :

Essa distribuição é chamada Distribuição de Bernoulli .
Observação : Distribuição de Bernoulli- caso especial Distribuição binomial com parâmetro n=1.
Vamos gerar 3 arrays de 100 números com diferentes probabilidades de sucesso: 0,1; 0,5 e 0,9. Para isso, na janela Geração de números aleatórios defina os seguintes parâmetros para cada probabilidade p:

Observação: Se você definir a opção Dispersão aleatória (Semente aleatória), então você pode escolher um determinado conjunto aleatório de números gerados. Por exemplo, definindo esta opção =25, você pode gerar os mesmos conjuntos de números aleatórios em computadores diferentes (se, é claro, outros parâmetros de distribuição forem os mesmos). O valor da opção pode ter valores inteiros de 1 a 32.767. Nome da opção Dispersão aleatória pode confundir. Seria melhor traduzi-lo como Definir número com números aleatórios .
Como resultado, teremos 3 colunas de 100 números, com base nas quais, por exemplo, podemos estimar a probabilidade de sucesso p de acordo com a fórmula: Número de sucessos/100(cm. planilha de exemplo Gerando Bernoulli).

Observação: Por Distribuições de Bernoulli com p=0,5, você pode usar a fórmula =RANDBETWEEN(0;1) , que corresponde a .
Geração de números aleatórios. Distribuição binomial
Suponha que haja 7 itens defeituosos na amostra. Isso significa que é "muito provável" que a proporção de produtos defeituosos tenha mudado. p, que é uma característica do nosso processo de produção. Embora esta situação seja “muito provável”, existe a possibilidade (risco alfa, erro tipo 1, “alarme falso”) que p permaneceu inalterado, e o aumento do número de produtos defeituosos foi devido à amostragem aleatória.
Como pode ser visto na figura abaixo, 7 é o número de produtos defeituosos que é aceitável para um processo com p=0,21 no mesmo valor Alfa. Isso ilustra que quando o limite de itens defeituosos em uma amostra é excedido, p“provavelmente” aumentou. A frase "mais provável" significa que há apenas 10% de chance (100%-90%) de que o desvio da porcentagem de produtos defeituosos acima do limite seja devido apenas a causas aleatórias.
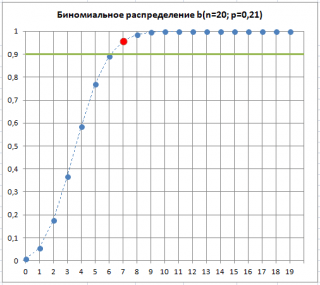
Assim, exceder o número limite de produtos defeituosos na amostra pode servir como um sinal de que o processo foi interrompido e começou a produzir b cerca de maior porcentagem de produtos defeituosos.
Observação: Antes do MS EXCEL 2010, o EXCEL tinha uma função CRITBINOM() , que é equivalente a BINOM.INV() . CRITBINOM() é deixado no MS EXCEL 2010 e superior para compatibilidade.
Relação da distribuição Binomial com outras distribuições
Se o parâmetro nDistribuição binomial tende ao infinito e p tende a 0, então neste caso Distribuição binomial pode ser aproximado. É possível formular condições quando a aproximação Distribuição de veneno funciona bem:
- p(quanto menos p e mais n, mais precisa a aproximação);
- p >0,9 (considerando que q =1- p, os cálculos neste caso devem ser realizados usando q(uma X precisa ser substituído por n - x). Portanto, quanto menos q e mais n, mais precisa será a aproximação).
Em 0,110 Distribuição binomial pode ser aproximado.
Por sua vez, Distribuição binomial pode servir como uma boa aproximação quando o tamanho da população é N Distribuição hipergeométrica muito maior do que o tamanho da amostra n (ou seja, N>>n ou n/N Você pode ler mais sobre a relação das distribuições acima no artigo. Exemplos de aproximação também são fornecidos lá, e as condições são explicadas quando é possível e com que precisão.
ADENDO: Você pode ler sobre outras distribuições do MS EXCEL no artigo.
A teoria da probabilidade está invisivelmente presente em nossas vidas. Não prestamos atenção a isso, mas cada evento em nossa vida tem uma ou outra probabilidade. Dado o grande número de cenários possíveis, torna-se necessário determinar o mais provável e o menos provável deles. É mais conveniente analisar esses dados probabilísticos graficamente. A distribuição pode nos ajudar com isso. Binomial é um dos mais fáceis e precisos.
Antes de passar diretamente para a matemática e a teoria das probabilidades, vamos descobrir quem foi o primeiro a apresentar esse tipo de distribuição e qual é a história do desenvolvimento do aparato matemático para esse conceito.
História
O conceito de probabilidade é conhecido desde os tempos antigos. No entanto, os matemáticos antigos não davam muita importância a isso e só foram capazes de lançar as bases para uma teoria que mais tarde se tornou a teoria da probabilidade. Eles criaram alguns métodos combinatórios que ajudaram muito aqueles que mais tarde criaram e desenvolveram a própria teoria.
Na segunda metade do século XVII, começou a formação dos conceitos e métodos básicos da teoria das probabilidades. Foram introduzidas definições de variáveis aleatórias, métodos para calcular a probabilidade de eventos independentes e dependentes simples e alguns complexos. Tal interesse por variáveis e probabilidades aleatórias era ditado pelo jogo: cada pessoa queria saber quais eram suas chances de ganhar o jogo.
O próximo passo foi a aplicação de métodos de análise matemática na teoria das probabilidades. Matemáticos eminentes como Laplace, Gauss, Poisson e Bernoulli assumiram essa tarefa. Foram eles que avançaram esta área da matemática para um novo nível. Foi James Bernoulli quem descobriu a lei de distribuição binomial. Aliás, como descobriremos mais tarde, com base nessa descoberta, várias outras foram feitas, o que possibilitou a criação da lei da distribuição normal e muitas outras.
Agora, antes de começarmos a descrever a distribuição binomial, vamos refrescar um pouco a memória dos conceitos da teoria das probabilidades, provavelmente já esquecidos do banco da escola.
Fundamentos da Teoria da Probabilidade
Consideraremos tais sistemas, como resultado dos quais apenas dois resultados são possíveis: "sucesso" e "fracasso". Isso é fácil de entender com um exemplo: jogamos uma moeda, adivinhando que sairá coroa. As probabilidades de cada um dos eventos possíveis (coroa - "sucesso", cara - "não sucesso") são iguais a 50% com a moeda perfeitamente equilibrada e não há outros fatores que possam afetar o experimento.
Foi o evento mais simples. Mas também existem sistemas complexos nos quais ações sequenciais são executadas, e as probabilidades dos resultados dessas ações serão diferentes. Por exemplo, considere o seguinte sistema: em uma caixa cujo conteúdo não podemos ver, há seis bolas absolutamente idênticas, três pares de cores azul, vermelho e branco. Temos que pegar algumas bolas ao acaso. Assim, ao retirar primeiro uma das bolas brancas, reduziremos várias vezes a probabilidade de que na próxima também obtenhamos uma bola branca. Isso acontece porque o número de objetos no sistema muda.
Na próxima seção, veremos conceitos matemáticos mais complexos que nos aproximam do que significam as palavras "distribuição normal", "distribuição binomial" e similares.

Elementos de estatística matemática
Em estatística, que é uma das áreas de aplicação da teoria da probabilidade, há muitos exemplos em que os dados para análise não são fornecidos explicitamente. Ou seja, não em números, mas na forma de divisão de acordo com características, por exemplo, de acordo com o gênero. Para aplicar um aparato matemático a tais dados e tirar algumas conclusões dos resultados obtidos, é necessário converter os dados iniciais em um formato numérico. Via de regra, para implementar isso, um resultado positivo recebe o valor 1 e um negativo recebe o valor 0. Assim, obtemos dados estatísticos que podem ser analisados usando métodos matemáticos.
O próximo passo para entender o que é a distribuição binomial de uma variável aleatória é determinar a variância da variável aleatória e a expectativa matemática. Falaremos sobre isso na próxima seção.

Valor esperado
De fato, entender o que é expectativa matemática não é difícil. Considere um sistema no qual existem muitos eventos diferentes com suas próprias probabilidades diferentes. A expectativa matemática será chamada de valor igual à soma dos produtos dos valores desses eventos (na forma matemática de que falamos na última seção) e a probabilidade de sua ocorrência.
A expectativa matemática da distribuição binomial é calculada de acordo com o mesmo esquema: pegamos o valor de uma variável aleatória, multiplicamos pela probabilidade de um resultado positivo e depois resumimos os dados obtidos para todas as variáveis. É muito conveniente apresentar esses dados graficamente - assim a diferença entre as expectativas matemáticas de diferentes valores é melhor percebida.
Na próxima seção, falaremos um pouco sobre um conceito diferente - a variância de uma variável aleatória. Também está intimamente relacionado a um conceito como a distribuição de probabilidade binomial, e é sua característica.

Variação da distribuição binomial
Esse valor está intimamente relacionado ao anterior e também caracteriza a distribuição dos dados estatísticos. Ele representa o quadrado médio dos desvios de valores de sua expectativa matemática. Ou seja, a variância de uma variável aleatória é a soma das diferenças quadradas entre o valor de uma variável aleatória e sua expectativa matemática, multiplicada pela probabilidade desse evento.
Em geral, isso é tudo o que precisamos saber sobre variância para entender o que é a distribuição de probabilidade binomial. Agora vamos para o nosso tópico principal. Ou seja, o que está por trás de uma frase aparentemente bastante complicada "lei de distribuição binomial".

Distribuição binomial
Vamos primeiro entender por que essa distribuição é binomial. Vem da palavra "binom". Você já deve ter ouvido falar do binômio de Newton - uma fórmula que pode ser usada para expandir a soma de quaisquer dois números a e b para qualquer potência não negativa de n.
Como você provavelmente já adivinhou, a fórmula binomial de Newton e a fórmula de distribuição binomial são quase as mesmas fórmulas. Com a única exceção de que o segundo tem um valor aplicado para quantidades específicas, e o primeiro é apenas uma ferramenta matemática geral, cujas aplicações na prática podem ser diferentes.
Fórmulas de distribuição
A função de distribuição binomial pode ser escrita como a soma dos seguintes termos:
(n!/(n-k)!k!)*p k *q n-k
Aqui n é o número de experimentos aleatórios independentes, p é o número de resultados bem sucedidos, q é o número de resultados malsucedidos, k é o número do experimento (pode levar valores de 0 a n),! - designação de um fatorial, tal função de um número, cujo valor é igual ao produto de todos os números que vão até ele (por exemplo, para o número 4: 4!=1*2*3*4= 24).
Além disso, a função de distribuição binomial pode ser escrita como uma função beta incompleta. No entanto, esta já é uma definição mais complexa, que é usada apenas na resolução de problemas estatísticos complexos.
A distribuição binomial, cujos exemplos examinamos acima, é um dos tipos mais simples de distribuição na teoria da probabilidade. Há também uma distribuição normal, que é um tipo de distribuição binomial. É o mais comumente usado e o mais fácil de calcular. Há também uma distribuição de Bernoulli, uma distribuição de Poisson, uma distribuição condicional. Todos eles caracterizam graficamente as áreas de probabilidade de um determinado processo sob diferentes condições.
Na próxima seção, consideraremos aspectos relacionados à aplicação desse aparato matemático na vida real. À primeira vista, é claro, parece que isso é outra coisa matemática, que, como sempre, não encontra aplicação na vida real e geralmente não é necessária a ninguém, exceto aos próprios matemáticos. No entanto, este não é o caso. Afinal, todos os tipos de distribuições e suas representações gráficas foram criadas apenas para fins práticos, e não por capricho dos cientistas.

Inscrição
De longe, a aplicação mais importante das distribuições é na estatística, onde é necessária uma análise complexa de uma infinidade de dados. Como mostra a prática, muitos arrays de dados têm aproximadamente as mesmas distribuições de valores: as regiões críticas de valores muito baixos e muito altos, como regra, contêm menos elementos do que os valores médios.
A análise de grandes matrizes de dados é necessária não apenas em estatísticas. É indispensável, por exemplo, em físico-química. Nesta ciência, é usado para determinar muitas quantidades que estão associadas a vibrações e movimentos aleatórios de átomos e moléculas.
Na próxima seção, entenderemos como é importante aplicar conceitos estatísticos como distribuição de uma variável aleatória na vida cotidiana para você e para mim.

Por que eu preciso disso?
Muitas pessoas se fazem essa pergunta quando se trata de matemática. E a propósito, a matemática não é em vão chamada de rainha das ciências. É a base da física, da química, da biologia, da economia, e em cada uma dessas ciências também se usa algum tipo de distribuição: seja uma distribuição binomial discreta ou uma normal, não importa. E se olharmos mais de perto o mundo ao nosso redor, veremos que a matemática é usada em todos os lugares: na vida cotidiana, no trabalho e até nas relações humanas podem ser apresentadas na forma de dados estatísticos e analisadas (isso, diga-se de passagem, , é feito por aqueles que trabalham em organizações especiais envolvidas na coleta de informações).
Agora vamos falar um pouco sobre o que fazer se você precisar saber muito mais sobre esse assunto do que o que descrevemos neste artigo.
As informações que fornecemos neste artigo estão longe de ser completas. Há muitas nuances quanto à forma que a distribuição pode tomar. A distribuição binomial, como já descobrimos, é um dos principais tipos em que se baseiam todas as estatísticas matemáticas e a teoria das probabilidades.
Se você se interessar, ou em relação ao seu trabalho, você precisa saber muito mais sobre esse assunto, precisará estudar a literatura especializada. Você deve começar com um curso universitário em análise matemática e ir até a seção sobre teoria das probabilidades. Também o conhecimento no campo das séries será útil, pois a distribuição de probabilidade binomial nada mais é do que uma série de termos sucessivos.
Conclusão
Antes de terminar o artigo, gostaríamos de contar mais uma coisa interessante. Diz respeito diretamente ao tema do nosso artigo e a toda a matemática em geral.
Muitas pessoas dizem que a matemática é uma ciência inútil, e nada do que aprenderam na escola foi útil para elas. Mas o conhecimento nunca é supérfluo, e se algo não é útil para você na vida, significa que você simplesmente não se lembra. Se você tiver conhecimento, eles podem ajudá-lo, mas se você não os tiver, não poderá esperar ajuda deles.
Assim, examinamos o conceito de distribuição binomial e todas as definições associadas a ela e conversamos sobre como ela é aplicada em nossas vidas.
Capítulo 7
Leis específicas de distribuição de variáveis aleatórias
Tipos de leis de distribuição de variáveis aleatórias discretas
Deixe uma variável aleatória discreta tomar os valores X 1 , X 2 , …, xn, … . As probabilidades desses valores podem ser calculadas usando várias fórmulas, por exemplo, usando os teoremas básicos da teoria das probabilidades, a fórmula de Bernoulli ou algumas outras fórmulas. Para algumas dessas fórmulas, a lei de distribuição tem seu próprio nome.
As leis mais comuns de distribuição de uma variável aleatória discreta são binomial, geométrica, hipergeométrica, lei de distribuição de Poisson.
Lei de distribuição binomial
Que seja produzido n ensaios independentes, em cada um dos quais um evento pode ou não ocorrer MAS. A probabilidade de ocorrência deste evento em cada tentativa é constante, não depende do número da tentativa e é igual a R=R(MAS). Portanto, a probabilidade de o evento não ocorrer MAS em cada teste também é constante e igual a q=1–R. Considere uma variável aleatória X igual ao número de ocorrências do evento MAS dentro n testes. É óbvio que os valores dessa quantidade são iguais a
X 1 =0 - evento MAS dentro n testes não apareceram;
X 2 = 1 - evento MAS dentro n os ensaios apareceram uma vez;
X 3 =2 - evento MAS dentro n ensaios apareceram duas vezes;
…………………………………………………………..
xn +1 = n- evento MAS dentro n testes apareceu tudo n uma vez.
As probabilidades desses valores podem ser calculadas usando a fórmula de Bernoulli (4.1):
Onde para=0, 1, 2, …,n .
Lei de distribuição binomial X igual ao número de sucessos em n Ensaios de Bernoulli, com probabilidade de sucesso R.
Assim, uma variável aleatória discreta tem uma distribuição binomial (ou é distribuída de acordo com a lei binomial) se seus valores possíveis são 0, 1, 2, …, n, e as probabilidades correspondentes são calculadas pela fórmula (7.1).
A distribuição binomial depende de dois parâmetros R e n.
A série de distribuição de uma variável aleatória distribuída de acordo com a lei binomial tem a forma:
| X | … | k | … | n | ||
| R | | … | … | |
Exemplo 7.1 . Três tiros independentes são disparados no alvo. A probabilidade de acertar cada tiro é 0,4. Valor aleatório X- o número de acertos no alvo. Construa sua série de distribuição.
Solução. Valores possíveis de uma variável aleatória X são X 1 =0; X 2 =1; X 3 =2; X 4=3. Encontre as probabilidades correspondentes usando a fórmula de Bernoulli. É fácil mostrar que a aplicação desta fórmula aqui é plenamente justificada. Observe que a probabilidade de não acertar o alvo com um tiro será igual a 1-0,4=0,6. Pegue

A série de distribuição tem a seguinte forma:
| X | ||||
| R | 0,216 | 0,432 | 0,288 | 0,064 |
É fácil verificar que a soma de todas as probabilidades é igual a 1. A própria variável aleatória X distribuídos de acordo com a lei binomial. ■
Vamos encontrar a esperança matemática e a variância de uma variável aleatória distribuída de acordo com a lei binomial.
Ao resolver o exemplo 6.5, foi mostrado que a expectativa matemática do número de ocorrências de um evento MAS dentro n testes independentes, se a probabilidade de ocorrência MAS em cada teste é constante e igual R, é igual a n· R
Neste exemplo, foi utilizada uma variável aleatória, distribuída de acordo com a lei binomial. Portanto, a solução do Exemplo 6.5 é, de fato, uma prova do seguinte teorema.
Teorema 7.1. A expectativa matemática de uma variável aleatória discreta distribuída de acordo com a lei binomial é igual ao produto do número de tentativas e a probabilidade de "sucesso", ou seja, M(X)=n· R.
Teorema 7.2. A variância de uma variável aleatória discreta distribuída de acordo com a lei binomial é igual ao produto do número de tentativas pela probabilidade de "sucesso" e a probabilidade de "fracasso", ou seja, D(X)=npq.
A assimetria e a curtose de uma variável aleatória distribuída de acordo com a lei binomial são determinadas pelas fórmulas
Essas fórmulas podem ser obtidas usando o conceito de momentos iniciais e centrais.
A lei de distribuição binomial está subjacente a muitas situações reais. Para grandes valores n a distribuição binomial pode ser aproximada por outras distribuições, em particular a distribuição de Poisson.
Distribuição de veneno
Deixe estar n Ensaios de Bernoulli, com o número de ensaios n grande o suficiente. Anteriormente, foi mostrado que neste caso (se, além disso, a probabilidade R desenvolvimentos MAS muito pequena) para encontrar a probabilidade de que um evento MAS aparecer t uma vez nos testes, você pode usar a fórmula de Poisson (4.9). Se a variável aleatória X significa o número de ocorrências do evento MAS dentro n tentativas de Bernoulli, então a probabilidade de que X vai assumir o significado k pode ser calculado pela fórmula
 , (7.2)
, (7.2)
Onde λ = nº.
lei de distribuição de Poissoné chamada de distribuição de uma variável aleatória discreta X, para os quais os valores possíveis são inteiros não negativos, e as probabilidades p t esses valores são encontrados pela fórmula (7.2).
Valor λ = nº chamado parâmetro Distribuição de veneno.
Uma variável aleatória distribuída de acordo com a lei de Poisson pode assumir um número infinito de valores. Uma vez que para esta distribuição a probabilidade R ocorrência de um evento em cada tentativa é pequena, então essa distribuição é às vezes chamada de lei dos fenômenos raros.
A série de distribuição de uma variável aleatória distribuída de acordo com a lei de Poisson tem a forma
| X | … | t | … | ||||
| R | … | … |
É fácil verificar que a soma das probabilidades da segunda linha é igual a 1. Para isso, precisamos lembrar que a função pode ser expandida em uma série de Maclaurin, que converge para qualquer X. Neste caso temos
 . (7.3)
. (7.3)
Como observado, a lei de Poisson em certos casos limites substitui a lei binomial. Um exemplo é uma variável aleatória X, cujos valores são iguais ao número de falhas por um determinado período de tempo com o uso repetido de um dispositivo técnico. Supõe-se que este dispositivo seja de alta confiabilidade, ou seja, a probabilidade de falha em um aplicativo é muito pequena.
Além desses casos limites, na prática existem variáveis aleatórias distribuídas de acordo com a lei de Poisson, não relacionadas à distribuição binomial. Por exemplo, a distribuição de Poisson é frequentemente usada para lidar com o número de eventos que ocorrem em um período de tempo (o número de chamadas para a central telefônica durante a hora, o número de carros que chegaram ao lava-jato durante o dia, o número de paradas de máquina por semana, etc.). Todos esses eventos devem formar o chamado fluxo de eventos, que é um dos conceitos básicos da teoria das filas. Parâmetro λ caracteriza a intensidade média do fluxo de eventos.
Exemplo 7.2 . A faculdade tem 500 alunos. Qual é a probabilidade de que 1º de setembro seja o aniversário de três alunos desta faculdade?
Solução . Uma vez que o número de alunos n= 500 é grande o suficiente e R– a probabilidade de nascer no dia primeiro de setembro para qualquer um dos alunos é , ou seja. suficientemente pequeno, então podemos assumir que a variável aleatória X– o número de alunos nascidos em primeiro de setembro é distribuído de acordo com a lei de Poisson com o parâmetro λ = np= = 1,36986. Então, de acordo com a fórmula (7.2), obtemos
Teorema 7.3. Deixe a variável aleatória X distribuído de acordo com a lei de Poisson. Então sua expectativa matemática e variância são iguais entre si e iguais ao valor do parâmetro λ , ou seja M(X) = D(X) = λ = np.
Prova. Pela definição de esperança matemática, usando a fórmula (7.3) e a série de distribuição de uma variável aleatória distribuída de acordo com a lei de Poisson, obtemos
Antes de encontrar a variância, primeiro encontramos a esperança matemática do quadrado da variável aleatória considerada. Nós temos

Assim, pela definição de dispersão, obtemos
O teorema foi provado.
Aplicando os conceitos de momentos iniciais e centrais, pode-se mostrar que para uma variável aleatória distribuída de acordo com a lei de Poisson, os coeficientes de assimetria e curtose são determinados pelas fórmulas
É fácil entender que, uma vez que o conteúdo semântico do parâmetro λ = npé positivo, então uma variável aleatória distribuída de acordo com a lei de Poisson sempre tem assimetria e curtose positivas.
Nem todos os fenômenos são medidos em uma escala quantitativa como 1, 2, 3 ... 100500 ... Nem sempre um fenômeno pode assumir um infinito ou um grande número de estados diferentes. Por exemplo, o sexo de uma pessoa pode ser M ou F. O atirador acerta o alvo ou erra. Você pode votar “a favor” ou “contra”, etc. etc. Em outras palavras, esses dados refletem o estado de um atributo alternativo - "sim" (o evento ocorreu) ou "não" (o evento não ocorreu). O próximo evento (resultado positivo) também é chamado de "sucesso".
Experimentos com esses dados são chamados esquema de Bernoulli, em homenagem ao famoso matemático suíço que descobriu que, com um grande número de tentativas, a razão de resultados positivos para o número total de tentativas tende à probabilidade desse evento ocorrer.
Variável de recurso alternativo
Para usar o aparato matemático na análise, os resultados de tais observações devem ser anotados em forma numérica. Para fazer isso, um resultado positivo recebe o número 1, um negativo - 0. Em outras palavras, estamos lidando com uma variável que só pode assumir dois valores: 0 ou 1.
Que benefício pode ser obtido com isso? Na verdade, nada menos do que a partir de dados comuns. Assim, é fácil contar o número de resultados positivos - basta somar todos os valores, ou seja, todos 1 (sucesso). Você pode ir mais longe, mas para isso você precisa introduzir algumas notações.
A primeira coisa a notar é que resultados positivos (que são iguais a 1) têm alguma probabilidade de ocorrer. Por exemplo, obter cara no lançamento de uma moeda é ½ ou 0,5. Esta probabilidade é tradicionalmente denotada pela letra latina p. Portanto, a probabilidade de ocorrência de um evento alternativo é 1-p, que também é denotado por q, isso é q = 1 – p. Essas designações podem ser sistematizadas visualmente na forma de uma placa de distribuição variável X.
Conseguimos uma lista de valores possíveis e suas probabilidades. pode ser calculado valor esperado e dispersão. A expectativa é a soma dos produtos de todos os valores possíveis e suas probabilidades correspondentes:
![]()
Vamos calcular o valor esperado usando a notação nas tabelas acima.
Acontece que a expectativa matemática de um sinal alternativo é igual à probabilidade desse evento - p.
Agora vamos definir qual é a variância de um recurso alternativo. A dispersão é o quadrado médio dos desvios da expectativa matemática. A fórmula geral (para dados discretos) é:
Daí a variância do recurso alternativo:

É fácil ver que esta dispersão tem um máximo de 0,25 (no p=0,5).
Desvio padrão - raiz da variação:
O valor máximo não excede 0,5.
Como você pode ver, tanto a expectativa matemática quanto a variância do sinal alternativo têm uma forma muito compacta.
Distribuição binomial de uma variável aleatória
Vejamos a situação de um ângulo diferente. De fato, quem se importa que a perda média de caras em um lance seja de 0,5? É até impossível imaginar. É mais interessante levantar a questão do número de caras para um determinado número de lances.
Em outras palavras, o pesquisador geralmente está interessado na probabilidade de um certo número de eventos bem-sucedidos ocorrerem. Este pode ser o número de produtos defeituosos no lote testado (1 - defeituoso, 0 - bom) ou o número de recuperações (1 - saudável, 0 - doente), etc. O número de tais "sucessos" será igual à soma de todos os valores da variável X, ou seja o número de resultados únicos.
Valor aleatório Bé chamado de binomial e assume valores de 0 a n(no B= 0 - todas as peças estão boas, com B = n- todas as peças estão com defeito). Suponha que todos os valores x independentes um do outro. Considere as principais características da variável binomial, ou seja, estabeleceremos sua expectativa matemática, variância e distribuição.
A expectativa de uma variável binomial é muito fácil de obter. A expectativa matemática da soma dos valoresé a soma das expectativas matemáticas de cada valor agregado, e é a mesma para todos, portanto:
Por exemplo, a expectativa do número de caras em 100 lançamentos é 100 × 0,5 = 50.
Agora derivamos a fórmula para a variância da variável binomial. A variância da soma das variáveis aleatórias independentes é a soma das variâncias. Daqui
Desvio padrão, respectivamente
Para 100 lançamentos de moedas, o desvio padrão do número de caras é
E, finalmente, considere a distribuição da quantidade binomial, ou seja, a probabilidade de que a variável aleatória B terá valores diferentes k, Onde 0≤k≤n. Para uma moeda, esse problema pode soar assim: qual é a probabilidade de obter 40 caras em 100 lançamentos?
Para entender o método de cálculo, vamos imaginar que a moeda seja lançada apenas 4 vezes. Qualquer um dos lados pode cair a cada vez. Perguntamo-nos: qual é a probabilidade de obter 2 caras em 4 lançamentos. Cada lance é independente um do outro. Isso significa que a probabilidade de obter qualquer combinação será igual ao produto das probabilidades de um determinado resultado para cada lance individual. Sejam O cara e P coroa. Então, por exemplo, uma das combinações que nos convém pode parecer OOPP, ou seja:

A probabilidade de tal combinação é igual ao produto de duas probabilidades de dar cara e mais duas probabilidades de não dar cara (o evento inverso calculado como 1-p), ou seja, 0,5×0,5×(1-0,5)×(1-0,5)=0,0625. Esta é a probabilidade de uma das combinações que nos convém. Mas a questão era sobre o número total de águias, e não sobre qualquer ordem em particular. Então você precisa adicionar as probabilidades de todas as combinações em que existem exatamente 2 águias. É claro que eles são todos iguais (o produto não muda ao mudar os lugares dos fatores). Portanto, você precisa calcular o número deles e depois multiplicar pela probabilidade de qualquer combinação. Vamos contar todas as combinações de 4 arremessos de 2 águias: RROO, RORO, ROOR, ORR, OROR, OORR. Apenas 6 opções.

Portanto, a probabilidade desejada de obter 2 caras após 4 lançamentos é 6×0,0625=0,375.
No entanto, contar dessa maneira é tedioso. Já para 10 moedas, será muito difícil obter o número total de opções por força bruta. Portanto, pessoas inteligentes inventaram uma fórmula há muito tempo, com a ajuda da qual calculam o número de diferentes combinações de n elementos por k, Onde né o número total de elementos, ké o número de elementos cujas opções de arranjo são calculadas. Fórmula de combinação de n elementos por ké:
![]()
Coisas semelhantes acontecem na seção de combinatória. Eu envio todos que querem melhorar seus conhecimentos para lá. Daí, aliás, o nome da distribuição binomial (a fórmula acima é o coeficiente na expansão do binômio de Newton).
A fórmula para determinar a probabilidade pode ser facilmente generalizada para qualquer número n e k. Como resultado, a fórmula de distribuição binomial tem a seguinte forma.
Multiplique o número de combinações correspondentes pela probabilidade de uma delas.
Para uso prático, basta conhecer a fórmula da distribuição binomial. E você pode nem saber - abaixo está como determinar a probabilidade usando o Excel. Mas é melhor saber.
Vamos usar esta fórmula para calcular a probabilidade de obter 40 caras em 100 lançamentos:
Ou apenas 1,08%. Para efeito de comparação, a probabilidade da expectativa matemática desse experimento, ou seja, 50 caras, é de 7,96%. A probabilidade máxima de um valor binomial pertence ao valor correspondente à expectativa matemática.
Calculando probabilidades de distribuição binomial no Excel
Se você usar apenas papel e uma calculadora, os cálculos usando a fórmula de distribuição binomial, apesar da ausência de integrais, serão bastante difíceis. Por exemplo, um valor de 100! - tem mais de 150 caracteres. Anteriormente, e mesmo agora, fórmulas aproximadas eram usadas para calcular tais quantidades. No momento, é aconselhável usar um software especial, como o MS Excel. Assim, qualquer usuário (mesmo um humanista por formação) pode calcular facilmente a probabilidade do valor de uma variável aleatória binomialmente distribuída.
Para consolidar o material, usaremos o Excel por enquanto como uma calculadora comum, ou seja, Vamos fazer um cálculo passo a passo usando a fórmula de distribuição binomial. Vamos calcular, por exemplo, a probabilidade de obter 50 caras. Abaixo segue uma foto com as etapas de cálculo e o resultado final.

Como você pode ver, os resultados intermediários têm uma escala tal que não cabem em uma célula, embora funções simples do tipo sejam usadas em todos os lugares: FACTOR (cálculo fatorial), POWER (elevando um número a uma potência), bem como operadores de multiplicação e divisão. Além disso, este cálculo é bastante complicado, em qualquer caso, não é compacto, pois muitas células envolvidas. E sim, é difícil descobrir isso.
Em geral, o Excel fornece uma função pronta para calcular as probabilidades da distribuição binomial. A função é chamada BINOM.DIST.

Número de sucessos é o número de tentativas bem-sucedidas. Temos 50 deles.
Número de testes - número de lances: 100 vezes.
Probabilidade de sucesso – a probabilidade de obter cara em um lance é 0,5.
Integrante - é indicado 1 ou 0. Se 0, então a probabilidade é calculada P(B=k); se 1, então a função de distribuição binomial é calculada, ou seja, soma de todas as probabilidades de B = 0 antes da B = k inclusivo.
Pressionamos OK e obtemos o mesmo resultado acima, apenas tudo foi calculado por uma função.

Muito confortavelmente. Por uma questão de experiência, em vez do último parâmetro 0, colocamos 1. Obtemos 0,5398. Isso significa que em 100 lançamentos de moedas, a probabilidade de obter cara entre 0 e 50 é de quase 54%. E a princípio parecia que deveria ser de 50%. Em geral, os cálculos são feitos de forma fácil e rápida.
Um analista real deve entender como a função se comporta (qual é sua distribuição), então vamos calcular as probabilidades para todos os valores de 0 a 100. Ou seja, vamos nos perguntar: qual é a probabilidade de que nem uma única águia caia , que 1 águia cairá, 2, 3 , 50, 90 ou 100. O cálculo é mostrado na figura a seguir. A linha azul é a própria distribuição binomial, o ponto vermelho é a probabilidade de um número específico de sucessos k.

Pode-se perguntar, a distribuição binomial não é semelhante a... Sim, muito semelhante. Até De Moivre (em 1733) disse que com grandes amostras a distribuição binomial se aproxima (não sei como se chamava na época), mas ninguém o ouviu. Apenas Gauss, e depois Laplace, 60-70 anos depois, redescobriram e estudaram cuidadosamente a lei da distribuição normal. O gráfico acima mostra claramente que a probabilidade máxima recai sobre a expectativa matemática e, à medida que se desvia dela, diminui drasticamente. Assim como a lei normal.
A distribuição binomial é de grande importância prática, ocorre com bastante frequência. Usando o Excel, os cálculos são realizados de forma fácil e rápida.
