Metoda iterației.În această metodă se face o comparație cu o anumită bază de date, unde pentru fiecare dintre obiecte există diferite opțiuni de modificare a afișajului. De exemplu, pentru recunoașterea optică a imaginii, puteți aplica metoda iterației la diferite unghiuri sau scări, decalaje, deformații etc. Pentru litere, puteți itera peste font sau proprietățile acestuia. În cazul recunoașterii modelelor de sunet, există o comparație cu unele modele cunoscute (un cuvânt rostit de multe persoane). În plus, se efectuează o analiză mai profundă a caracteristicilor imaginii. În cazul recunoașterii optice, aceasta poate fi definiția caracteristicilor geometrice. Proba de sunet în acest caz este supusă analizei de frecvență și amplitudine.
Următoarea metodă este utilizarea rețelelor neuronale artificiale(INS). Este nevoie fie de un număr mare de exemple ale sarcinii de recunoaștere, fie de o structură specială a rețelei neuronale care ține cont de specificul acestei sarcini. Dar, cu toate acestea, această metodă se caracterizează prin eficiență și productivitate ridicate.
Metode bazate pe estimări ale densităților de distribuție a valorilor caracteristicilor. Împrumutat din teoria clasică a deciziilor statistice, în care obiectele de studiu sunt considerate ca realizări ale unei variabile aleatoare multidimensionale distribuite în spațiul caracteristic după o anumită lege. Ele se bazează pe schema Bayesiană de luare a deciziilor, care face apel la probabilitățile inițiale ale obiectelor aparținând unei anumite clase și la densitățile de distribuție a caracteristicilor condiționate.
Grupul de metode bazat pe estimarea densităților de distribuție a valorilor caracteristicilor este direct legat de metodele de analiză discriminantă. Abordarea bayesiană a luării deciziilor este una dintre cele mai dezvoltate metode parametrice din statistica modernă, pentru care expresia analitică a legii distribuției (legea normală) este considerată cunoscută și doar un număr mic de parametri (vectori medii și matrice de covarianță). ) trebuie estimate. Principalele dificultăți în aplicarea acestei metode sunt considerate a fi necesitatea de a reține întregul eșantion de antrenament pentru a calcula estimările de densitate și sensibilitatea ridicată la eșantionul de antrenament.
Metode bazate pe ipoteze despre clasa funcțiilor de decizie.În acest grup, tipul funcției de decizie este considerat a fi cunoscut și este dată calitatea funcțională a acesteia. Pe baza acestei funcționale, aproximarea optimă a funcției de decizie se găsește din secvența de antrenament. Calitatea funcțională a regulii de decizie este de obicei asociată cu o eroare. Principalul avantaj al metodei este claritatea formulării matematice a problemei de recunoaștere. Posibilitatea extragerii de noi cunoștințe despre natura unui obiect, în special despre mecanismele de interacțiune a atributelor, este limitată aici fundamental de o structură dată de interacțiune, fixată în forma aleasă a funcțiilor de decizie.
Metoda de comparare a prototipurilor. Aceasta este cea mai ușoară metodă de recunoaștere extensivă din practică. Se aplică atunci când clasele recunoscute sunt afișate ca clase geometrice compacte. Apoi centrul grupării geometrice (sau obiectul cel mai apropiat de centru) este ales ca punct prototip.
Pentru a clasifica un obiect nedeterminat, se găsește prototipul cel mai apropiat de acesta, iar obiectul aparține aceleiași clase ca acesta. Evident, nu se formează imagini generalizate în această metodă. Diferite tipuri de distanțe pot fi folosite ca măsură.
Metoda k vecini cei mai apropiati. Metoda constă în faptul că, la clasificarea unui obiect necunoscut, se găsește un număr dat (k) al spațiului caracteristic cel mai apropiat din punct de vedere geometric al altor vecini cei mai apropiați cu apartenența deja cunoscută la o clasă. Decizia de a atribui un obiect necunoscut este luată prin analizarea informațiilor despre cei mai apropiați vecini ai săi. Necesitatea reducerii numărului de obiecte din eșantionul de antrenament (precedentele de diagnostic) este un dezavantaj al acestei metode, deoarece aceasta reduce reprezentativitatea eșantionului de antrenament.
Pe baza faptului că diferiți algoritmi de recunoaștere se comportă diferit pe același eșantion, se pune problema unei reguli de decizie sintetică care să folosească punctele forte ale tuturor algoritmilor. Pentru aceasta, există o metodă sintetică sau seturi de reguli de decizie care îmbină cele mai pozitive aspecte ale fiecăreia dintre metode.
În încheierea revizuirii metodelor de recunoaștere, prezentăm esența celor de mai sus într-un tabel rezumativ, adăugând câteva alte metode utilizate în practică.
Tabelul 1. Tabelul de clasificare al metodelor de recunoaștere, compararea domeniilor lor de aplicare și limitări
|
Clasificarea metodelor de recunoaștere |
Zona de aplicare |
Limitări (dezavantaje) |
|
|
Metode intensive de recunoaștere |
Metode bazate pe estimări de densitate |
Probleme cu o distribuție cunoscută (normală), necesitatea de a colecta statistici mari |
Necesitatea de a enumera întregul set de antrenament în timpul recunoașterii, sensibilitate ridicată la nereprezentativitatea setului de antrenament și artefacte |
|
Metode bazate pe ipoteze |
Clasele ar trebui să fie bine separabile |
Forma funcției de decizie trebuie cunoscută în prealabil. Imposibilitatea luării în considerare a noilor cunoștințe despre corelațiile dintre caracteristici |
|
|
Metode booleene |
Probleme de mică dimensiune |
La selectarea regulilor de decizie logică, este necesară o enumerare completă. Intensitate mare a muncii |
|
|
Metode lingvistice |
Sarcina de a determina gramatica pentru un anumit set de enunțuri (descrieri ale obiectelor) este dificil de formalizat. Probleme teoretice nerezolvate |
||
|
Metode extensive de recunoaștere |
Metoda de comparare a prototipurilor |
Probleme de dimensiuni reduse ale spațiului caracteristic |
Dependență ridicată a rezultatelor clasificării de metrică. Valoare optimă necunoscută |
|
k metoda vecinului apropiat |
Dependență ridicată a rezultatelor clasificării de metrică. Necesitatea unei enumerări complete a eșantionului de formare în timpul recunoașterii. Complexitatea computațională |
||
|
Algoritmi de calcul al notelor (ABO) |
Probleme de mică dimensiune în ceea ce privește numărul de clase și caracteristici |
Dependența rezultatelor clasificării de metrică. Necesitatea unei enumerări complete a eșantionului de formare în timpul recunoașterii. Complexitatea tehnică ridicată a metodei |
|
|
Regulile de decizie colectivă (CRC) este o metodă sintetică. |
Probleme de mică dimensiune în ceea ce privește numărul de clase și caracteristici |
Complexitatea tehnică foarte mare a metodei, numărul nerezolvat de probleme teoretice, atât în determinarea ariilor de competență ale anumitor metode, cât și în anumite metode în sine |
Cursul numărul 17.METODE DE RECUNOAȘTERE A MODELULUI
Există următoarele grupuri de metode de recunoaștere:
Metode ale funcției de proximitate
Metode cu funcții discriminante
Metode statistice de recunoaștere.
Metode lingvistice
metode euristice.
Primele trei grupe de metode sunt axate pe analiza caracteristicilor exprimate prin numere sau vectori cu componente numerice.
Grupul de metode lingvistice oferă recunoaștere a modelelor pe baza analizei structurii lor, care este descrisă de caracteristicile structurale corespunzătoare și relațiile dintre ele.
Grupul de metode euristice combină tehnicile caracteristice și procedurile logice utilizate de oameni în recunoașterea modelelor.
Metode ale funcției de proximitate
Metodele acestui grup se bazează pe utilizarea funcțiilor care evaluează măsura proximității dintre imaginea recognoscibilă cu vectorul X * = (X * 1 ,….,x*n), și imagini de referință ale diferitelor clase, reprezentate prin vectori x i = (x i 1 ,…, x i n), i= 1,…,N, Unde eu- numărul clasei de imagine.
Procedura de recunoaștere conform acestei metode constă în calcularea distanței dintre punctul imaginii recunoscute și fiecare dintre punctele reprezentând imaginea de referință, i.e. în calculul tuturor valorilor d i , i= 1,…,N. Imaginea aparține clasei pentru care valoarea d i are cea mai mică valoare dintre toate i= 1,…,N .
O funcție care mapează fiecare pereche de vectori x i, X * un număr real ca măsură a apropierii lor, i.e. determinarea distanței dintre ele poate fi destul de arbitrară. În matematică, o astfel de funcție se numește metrica spațiului. Trebuie să satisfacă următoarele axiome:
r(X y)=r(y,x);
r(X y) > 0 dacă X nu este egal yși r(X y)=0 dacă x=y;
r(X y) <=r(x,z)+r(z,y)
Aceste axiome sunt îndeplinite, în special, de următoarele funcții
un i= 1/2 , j=1,2,…n.
b i= suma, j=1,2,…n.
c i=abdominali max ( x i‑ x j *), j=1,2,…n.
Prima dintre acestea se numește norma euclidiană a spațiului vectorial. În consecință, spațiile în care funcția specificată este utilizată ca metrică se numesc spațiu euclidian.
Adesea, diferența pătratică medie a coordonatelor imaginii recunoscute este aleasă ca funcție de proximitate X *și standard x i, adică funcţie
d i = (1/n) suma( x i j‑ x j *) 2 , j=1,2,…n.
Valoare d i interpretat geometric ca pătratul distanței dintre punctele din spațiul caracteristic, raportat la dimensiunea spațiului.
Se dovedește adesea că diferitele caracteristici nu sunt la fel de importante în recunoaștere. Pentru a ține cont de această împrejurare la calcularea funcțiilor de proximitate ale diferenței de coordonate, caracteristicile corespunzătoare mai importante sunt înmulțite cu coeficienți mari, iar cele mai puțin importante cu coeficienți mai mici.
În acest caz d i = (1/n) suma wj (x i j‑ x j *) 2 , j=1,2,…n,
Unde wj- coeficienți de greutate.
Introducerea coeficienților de greutate este echivalentă cu scalarea axelor spațiului caracteristic și, în consecință, întinderea sau comprimarea spațiului în direcții separate.
Aceste deformări ale spațiului caracteristic urmăresc scopul unei astfel de plasări a punctelor de imagini de referință, care corespunde celei mai fiabile recunoașteri în condițiile unei dispersări semnificative de imagini din fiecare clasă în vecinătatea punctului imaginii de referință.
Grupurile de puncte de imagine apropiate unele de altele (clustere de imagini) în spațiul caracteristic se numesc clustere, iar problema identificării unor astfel de grupuri se numește problema grupării.
Sarcina de identificare a clusterelor este denumită sarcini de recunoaștere a modelelor nesupravegheate, de exemplu. la probleme de recunoaştere în lipsa unui exemplu de recunoaştere corectă.
Metode cu funcții discriminante
Ideea metodelor acestui grup este de a construi funcții care definesc limite în spațiul imaginilor, împărțind spațiul în regiuni corespunzătoare claselor de imagini. Cele mai simple și mai frecvent utilizate funcții de acest fel sunt funcțiile care depind liniar de valorile caracteristicilor. În spațiul caracteristic, ele corespund suprafețelor de separare sub formă de hiperplane. În cazul unui spațiu caracteristic bidimensional, o linie dreaptă acționează ca o funcție de separare.
Forma generală a funcției de decizie liniară este dată de formula
d(X)=w 1 X 1 + w 2 X 2 +…+w n x n +w n +1 = Wx+w n
Unde X- vector imagine, w=(w 1 , w 2 ,…w n) este vectorul coeficienților de greutate.
Când este împărțit în două clase X 1 și X 2 funcție discriminantă d(x) permite recunoașterea conform regulii:
X aparține X 1 dacă d(X)>0;
X aparține X 2 dacă d(X)<0.
În cazul în care un d(X)=0, atunci are loc cazul incertitudinii.
În cazul împărțirii în mai multe clase sunt introduse mai multe funcții. În acest caz, fiecare clasă de imagini este asociată cu o anumită combinație de semne de funcții discriminatorii.
De exemplu, dacă sunt introduse trei funcții discriminante, este posibilă următoarea variantă de selectare a claselor de imagini:
X aparține X 1 dacă d 1 (X)>0,d 2 (X)<0,d 3 (X)<0;
X aparține X 2 dacă d(X)<0,d 2 (X)>0,d 3 (X)<0;
X aparține X 3 dacă d(X)<0,d 2 (X)<0,d 3 (X)>0.
Se presupune că pentru alte combinaţii de valori d 1 (X),d 2 (X),d 3 (X) există un caz de incertitudine.
O variație a metodei funcțiilor discriminante este metoda funcțiilor decisive. În el, dacă este disponibil m se presupune că există clase m funcții d i(X), numit decisiv, astfel încât dacă X aparține X i, apoi d i(X) > dj(X) pentru toți j nu este egal i,acestea. funcţie decisivă d i(X) are valoarea maximă dintre toate funcțiile dj(X), j=1,...,n..
O ilustrare a unei astfel de metode poate fi un clasificator bazat pe o estimare a minimului distanței euclidiene în spațiul caracteristic dintre punctul de imagine și standard. Să o arătăm.
Distanța euclidiană dintre vectorul caracteristic al imaginii recognoscibile X iar vectorul imaginii de referință este determinat de formula || x i ‑ X|| = 1/2 , j=1,2,…n.
Vector X vor fi repartizate clasei i, pentru care valoarea || x i ‑ X *|| minim.
În loc de distanță, puteți compara pătratul distanței, de exemplu.
||x i ‑ X|| 2 = (x i ‑ X)(x i ‑ X) t = X X- 2X x i +x i x i
Din moment ce valoarea X X la fel pentru toată lumea i, minimul funcției || x i ‑ X|| 2 va coincide cu maximul funcţiei de decizie
d i(X) = 2X x i -x i x i.
acesta este X aparține X i, dacă d i(X) > dj(X) pentru toți j nu este egal i.
Acea. mașina de clasificare a distanței minime se bazează pe funcții de decizie liniare. Structura generală a unei astfel de mașini folosește funcții de decizie ale formei
d i (X)=w i 1 X 1 + w i 2 X 2 +…+w în x n +victorie +1
Poate fi reprezentat vizual prin diagrama bloc corespunzătoare.
Pentru o mașină care realizează clasificarea în funcție de distanța minimă, au loc egalitățile: w ij = -2x i j , victorie +1 = x i x i.
Recunoașterea echivalentă prin metoda funcțiilor discriminante poate fi efectuată dacă funcțiile discriminante sunt definite ca diferențe dij (X)=d i (X)‑d j (X).
Avantajul metodei funcțiilor discriminante este structura simplă a mașinii de recunoaștere, precum și posibilitatea implementării acesteia în principal prin blocuri de decizie predominant liniare.
Un alt avantaj important al metodei funcțiilor discriminante este posibilitatea antrenării automate a mașinii pentru recunoașterea corectă a unui eșantion dat (de antrenament) de modele.
În același timp, algoritmul de învățare automată se dovedește a fi foarte simplu în comparație cu alte metode de recunoaștere.
Din aceste motive, metoda funcțiilor discriminante a câștigat o mare popularitate și este adesea folosită în practică.
Proceduri de auto-învățare de recunoaștere a modelelor
Luați în considerare metode pentru construirea unei funcții discriminante dintr-un eșantion dat (de antrenament) așa cum sunt aplicate problemei împărțirii imaginilor în două clase. Dacă sunt date două seturi de imagini, aparținând respectiv claselor A și B, atunci se caută soluția problemei construirii unei funcții discriminante liniare sub forma unui vector de coeficienți de greutate. W=(w 1 ,w 2 ,...,w n,w n+1), care are proprietatea ca pentru orice imagine sunt conditiile
X aparține clasei A dacă >0, j=1,2,…n.
X aparține clasei B dacă<0, j=1,2,…n.
Dacă eșantionul de antrenament este N imagini ale ambelor clase, problema se reduce la găsirea unui vector w care să asigure validitatea sistemului de inegalități.Dacă eșantionul de antrenament este format din N imagini ale ambelor clase, problema se reduce la găsirea vectorului w, care asigură valabilitatea sistemului de inegalităţi
X 1 1 w i+X 21 w 2 +...+x n 1 w n+w n +1 >0;
X 1 2 w i+X 22 w 2 +...+x n 2 w n+w n +1 <0;
X 1 iw i+X 2i w 2 +...+x ni w n+w n +1 >0;
................................................
X 1 Nw i +x 2N w 2 +...+x nN w n +w n + 1>0;
Aici x i=(x i 1 ,x i 2 ,...,x i n ,x i n+ 1 ) - vectorul valorilor caracteristicilor imaginii din proba de antrenament, semnul > corespunde vectorilor imaginilor X aparținând clasei A și semnul< - векторам X aparținând clasei B.
Vectorul dorit w există dacă clasele A și B sunt separabile și nu există altfel. Valorile componentelor vectoriale w poate fi găsit fie în prealabil, în etapa premergătoare implementării hardware a SRO, fie direct de către SRO însuși în cursul funcționării sale. Ultima dintre aceste abordări oferă o mai mare flexibilitate și autonomie a SRO. Luați în considerare exemplul unui dispozitiv numit percentron. inventat în 1957 de omul de știință american Rosenblatt. O reprezentare schematică a percentronului, care asigură că imaginea este atribuită uneia dintre cele două clase, este prezentată în figura următoare.
Retină S Retină A Retină R
oh oh X 1
oh oh X 2
oh oh X 3
o(suma)-------> R(reacţie)
oh oh x i
oh oh x n
oh oh x n +1
Dispozitivul este format din elemente senzoriale retiniene S, care sunt conectate aleatoriu la elementele asociative ale retinei A. Fiecare element al celei de-a doua retine produce un semnal de ieșire numai dacă un număr suficient de elemente senzoriale conectate la intrarea sa se află într-o stare excitată. Răspunsul întregului sistem R este proporţională cu suma reacţiilor elementelor retinei asociative luate cu anumite greutăţi.
Indicând prin x i reacţie i al-lea element asociativ și prin w i- coeficientul greutăţii de reacţie i elementul asociativ, reacția sistemului poate fi scrisă ca R=sumă( w j x j), j=1,..,n. În cazul în care un R>0, atunci imaginea prezentată sistemului aparține clasei A, iar dacă R<0, то образ относится к классу B. Описание этой процедуры классификации соответствует рассмотренным нами раньше принципам классификации, и, очевидно, перцентронная модель распознавания образов представляет собой, за исключением сенсорной сетчатки, реализацию линейной дискриминантной функции. Принятый в перцентроне принцип формирования значений X 1 , X 2 ,...,x n corespunde unui anumit algoritm de formare a caracteristicilor pe baza semnalelor senzorilor primari.
În general, pot exista mai multe elemente R, care formează reacția perceptronului. În acest caz, se vorbește despre prezența retinei în perceptron R elemente de reacție.
Schema percentron poate fi extinsă și în cazul în care numărul de clase este mai mare de două, prin creșterea numărului de elemente retiniene R până la numărul de clase distincte și introducerea unui bloc pentru determinarea reacției maxime în conformitate cu schema prezentată în figura de mai sus. În acest caz, imaginea este atribuită clasei cu numărul i, dacă R i>Rj, pentru toți j.
Procesul de învățare a percentronului constă în selectarea valorilor coeficienților de greutate wj astfel încât semnalul de ieșire să corespundă clasei căreia îi aparține imaginea recunoscută.
Să luăm în considerare algoritmul de acțiune percentron folosind exemplul de recunoaștere a obiectelor din două clase: A și B. Obiectele clasei A trebuie să corespundă valorii R= +1, iar clasa B - valoarea R= -1.
Algoritmul de învățare este următorul.
Dacă altă imagine X aparține clasei A, dar R<0 (имеет место ошибка распознавания), тогда коэффициенты wj cu indici corespunzători valorilor xj>0, crește cu o anumită sumă dw, și restul coeficienților wj scade cu dw. În acest caz, valoarea reacției R primește o creștere față de valorile sale pozitive corespunzătoare clasificării corecte.
În cazul în care un X aparține clasei B, dar R>0 (există o eroare de recunoaștere), apoi coeficienții wj cu indici corespunzători xj<0, увеличивают на dw, și restul coeficienților wj redus cu aceeași sumă. În acest caz, valoarea reacției R este incrementat către valori negative corespunzătoare clasificării corecte.
Algoritmul introduce astfel o modificare a vectorului greutate w dacă și numai dacă imaginea prezentată la k-al-lea pas de antrenament, a fost clasificat incorect în timpul acestui pas și părăsește vectorul greutate w nicio modificare în cazul clasificării corecte. Dovada convergenței acestui algoritm este prezentată în [Too, Gonzalez]. Un astfel de antrenament va fi în cele din urmă (cu alegerea corectă dwși separabilitatea liniară a claselor de imagini) conduce la un vector w pentru o clasificare corectă.
Metode statistice de recunoaștere.
Metodele statistice se bazează pe minimizarea probabilității unei erori de clasificare. Probabilitatea P de clasificare incorectă a imaginii primite pentru recunoaștere, descrisă de vectorul caracteristic X, este determinat de formula
P = suma[ p(i)prob( D(X)+i | X clasă i)]
Unde m- numărul de clase,
p(i) = sonda ( X aparține clasei i) - probabilitate a priori de apartenență la o imagine arbitrară X la i-a clasa (frecvența de apariție a imaginilor i clasa a-a),
D(X) este o funcție care ia o decizie de clasificare (vectorul caracteristică X se potrivește cu numărul clasei i din set (1,2,..., m}),
prob( D(X) nu este egal i| X aparține clasei i) este probabilitatea evenimentului" D(X) nu este egal i„ când condiția de membru este îndeplinită X clasă i, adică probabilitatea de a lua o decizie eronată de către funcţie D(X) pentru o valoare dată X detinut de i- clasa a-a.
Se poate arăta că probabilitatea de clasificare greșită atinge un minim dacă D(X)=i dacă și numai dacă p(X|i)· p(i)>p(x|j)· p(j), pentru toți i+j, Unde p(x|i) - densitatea de distribuție a imaginilor i clasa a-a în spațiul de caracteristici.
Conform regulii de mai sus, punctul X aparține clasei care corespunde valorii maxime p(i) p(x|i), adică produsul probabilității (frecvenței) a priori de apariție a imaginilor i-a clasa și densitatea distribuției modelului i clasa a-a în spațiul de caracteristici. Regula de clasificare prezentată se numește bayesian, deoarece rezultă din binecunoscuta formulă Bayes în teoria probabilităţilor.
Exemplu. Să fie necesară recunoașterea semnalelor discrete la ieșirea unui canal de informații afectat de zgomot.
Fiecare semnal de intrare este 0 sau 1. Ca rezultat al transmiterii semnalului, la ieșirea canalului apare valoarea X, care este suprapus cu zgomotul gaussian cu medie zero și varianță b.
Pentru sinteza unui clasificator care realizează recunoașterea semnalului, vom folosi regula de clasificare bayesiană.
În clasa nr. 1 combinăm semnalele reprezentând unități, în clasa nr. 2 - semnale reprezentând zerouri. Să se știe dinainte că, în medie, din 1000 de semnale A semnalele sunt unităţi şi b semnale - zerouri. Apoi, valorile probabilităților a priori de apariție a semnalelor din clasa I și a II-a (unuri și, respectiv, zerouri), pot fi luate egale cu
p(1)=a/1000, p(2)=b/1000.
pentru că zgomotul este gaussian, i.e. respectă legea distribuției normale (Gauss), apoi densitatea distribuției imaginilor din prima clasă, în funcție de valoarea X, sau, care este aceeași, probabilitatea de a obține valoarea de ieșire X când semnalul 1 este aplicat la intrare, acesta este determinat de expresie
p(X¦1) =(2pib) -1/2 exp(-( X-1) 2 /(2b 2)),
iar densitatea distribuţiei în funcţie de valoare X imagini din clasa a doua, i.e. probabilitatea obţinerii valorii de ieşire X când se aplică un semnal 0 la intrare, acesta este determinat de expresie
p(X¦2)= (2pib) -1/2 exp(- X 2 /(2b 2)),
Aplicarea regulii de decizie bayesiană duce la concluzia că se transmite un semnal de clasa 2, adică. a trecut de zero dacă
p(2) p(X¦2) > p(1) p(X¦1)
sau, mai precis, dacă
b exp(- X 2 /(2b 2)) > A exp(-( X-1) 2 /(2b 2)),
Împărțind partea stângă a inegalității la partea dreaptă, obținem
(b/A)exp((1-2 X)/(2b 2)) >1,
de unde, după ce luăm logaritmul, aflăm
1-2X> 2b 2 ln(a/b)
X< 0.5 - б 2 ln(a/b)
Din inegalitatea rezultată rezultă că a=b, adică cu aceleași probabilități a priori de apariție a semnalelor 0 și 1, imaginii i se atribuie valoarea 0 atunci când X<0.5, а значение 1, когда X>0.5.
Dacă se știe dinainte că unul dintre semnale apare mai des, iar celălalt mai rar, adică. în cazul unor valori diferite Ași b, pragul de răspuns al clasificatorului este deplasat într-o parte sau cealaltă.
Deci la a/b=2,71 (corespunzător unei transmisii de 2,71 ori mai frecvente a celor) și b 2 =0,1, imaginii i se atribuie valoarea 0 dacă X<0.4, и значение 1, если X>0,4. Dacă nu există informații despre probabilitățile de distribuție a priori, atunci pot fi utilizate metode de recunoaștere statistică, care se bazează pe alte reguli de clasificare decât Bayesian.
Cu toate acestea, în practică, metodele bazate pe regulile lui Bayes sunt cele mai frecvente datorită eficienței lor mai mari și, de asemenea, datorită faptului că în majoritatea problemelor de recunoaștere a modelelor este posibil să se stabilească probabilități a priori pentru apariția imaginilor din fiecare clasă.
Metode lingvistice de recunoaștere a modelelor.
Metodele lingvistice de recunoaștere a modelelor se bazează pe analiza descrierii unei imagini idealizate, reprezentată ca un grafic sau un șir de simboluri, care este o frază sau o propoziție dintr-o anumită limbă.
Luați în considerare imaginile idealizate ale literelor obținute ca urmare a primei etape de recunoaștere lingvistică descrisă mai sus. Aceste imagini idealizate pot fi definite prin descrieri ale graficelor, reprezentate, de exemplu, sub formă de matrice de conexiune, așa cum sa făcut în exemplul de mai sus. Aceeași descriere poate fi reprezentată printr-o expresie formală a limbajului (expresie).
Exemplu. Să fie date trei imagini ale literei A obţinute ca rezultat al prelucrării preliminare a imaginii. Să desemnăm aceste imagini cu identificatorii A1, A2 și A3.
Pentru descrierea lingvistică a imaginilor prezentate, folosim PDL (Picture Description Language). Dicționarul de limbă PDL include următoarele caractere:
1. Numele celor mai simple imagini (primitive). După cum se aplică în cazul în cauză, primitivele și denumirile lor corespunzătoare sunt după cum urmează.
Imagini sub forma unei linii direcționate:
sus și stânga (le F t), la nord (nord)), sus și la dreapta (dreapta), la est (est)).
Nume: L, N, R, E.
2. Simboluri ale operaţiilor binare. (+,*,-) Sensul lor corespunde conexiunii secvențiale a primitivelor (+), conexiunii începuturilor și sfârșiturilor primitivelor (*), conexiunii numai a terminațiilor primitivelor (-).
3. Paranteze dreapta și stânga. ((,)) Parantezele vă permit să specificați ordinea în care operațiile vor fi efectuate într-o expresie.
Imaginile considerate A1, A2 și A3 sunt descrise în limbajul PDL, respectiv, prin următoarele expresii.
T(1)=R+((R-(L+N))*E-L
T(2)=(R+N)+((N+R)-L)*E-L
T(3)=(N+R)+(R-L)*E-(L+N)
După ce s-a construit descrierea lingvistică a imaginii, este necesar să analizăm, folosind o anumită procedură de recunoaștere, dacă imaginea dată aparține sau nu clasei care ne interesează (clasa literelor A), adică. indiferent dacă această imagine are sau nu o structură. Pentru a face acest lucru, în primul rând, este necesar să descriem clasa de imagini care au structura de interes pentru noi.
Evident, litera A conține întotdeauna următoarele elemente structurale: „piciorul” stâng, „piciorul” drept și capul. Să numim aceste elemente respectiv STL, STR, TR.
Apoi, în limbajul PDL, clasa de simbol A - SIMB A este descrisă prin expresie
SIMB A = STL + TR - STR
„Piciorul” stâng al STL este întotdeauna un lanț de elemente R și N, care pot fi scrise ca
STL ‑> R ¦ N ¦ (STL + R) ¦ (STL + N)
(STL este caracterul R sau N, sau un șir obținut prin adăugarea de caractere R sau N la șirul STL sursă)
„Piciorul” drept al STR este întotdeauna un lanț de elemente L și N, care poate fi scris după cum urmează, i.e.
STR ‑> L¦N¦ (STR + L)¦(STR + N)
Partea de cap a literei - TR este un contur închis, compus din elementul E și lanțuri precum STL și STR.
În limbajul PDL, structura TR este descrisă de expresie
TR ‑> (STL - STR) * E
În cele din urmă, obținem următoarea descriere a clasei de litere A:
SIMB A ‑> (STL + TR - STR),
STL ‑> R¦N¦ (STL + R)¦(STL + N)
STR ‑> L¦N¦ (STR + L)¦(STR + N)
TR ‑> (STL - STR) * E
Procedura de recunoaștere în acest caz poate fi implementată după cum urmează.
1. Se compară expresia corespunzătoare imaginii cu structura de referință STL + TR - STR.
2. Fiecare element al structurii STL, TR, STR, dacă este posibil, i.e. dacă descrierea imaginii este comparabilă cu standardul, se potrivește o subexpresie din expresia T(A). De exemplu,
pentru A1: STL=R, STR=L, TR=(R-(L+N))*E
pentru A2: STL = R + N, STR = L, TR = ((N + R) - L) * E
pentru A3: STL = N + R, STR = L + N, TR = (R - L) * E 3.
Expresiile STL, STR, TR sunt comparate cu structurile de referință corespunzătoare.
4. Dacă structura fiecărei expresii STL, STR, TR corespunde celei de referință, se concluzionează că imaginea aparține clasei de litere A. Dacă la oricare dintre etapele 2, 3, 4 apare o discrepanță între structura expresia analizată și se găsește referința, se ajunge la concluzia că imaginea nu aparține clasei SIMB A. Potrivirea structurii expresiei se poate face folosind limbajele algoritmice LISP, PLANER, PROLOG și alte limbaje similare de inteligență artificială.
În exemplul luat în considerare, toate șirurile STL sunt formate din N și R caractere, iar șirurile STR sunt formate din L și N caractere, ceea ce corespunde structurii date a acestor șiruri. Structura TR din imaginile luate în considerare corespunde și celei de referință, întrucât constă din „diferența” de șiruri de tip STL, STR, „înmulțite” cu simbolul E.
Astfel, ajungem la concluzia că imaginile luate în considerare aparțin clasei SIMB A.
Sinteza controlerului de acţionare electrică DC fuzzyîn mediul „MatLab”.
Sinteza unui controler fuzzy cu o singură intrare și o ieșire.
Problema este ca unitatea să urmărească cu acuratețe diferitele intrări. Dezvoltarea acțiunii de control este realizată de un controler fuzzy, în care se pot distinge structural următoarele blocuri funcționale: fuzzifier, rule block și defuzzifier.
Fig.4 Diagrama funcțională generalizată a unui sistem cu două variabile lingvistice.
 Fig.5 Diagrama schematică a unui controler fuzzy cu două variabile lingvistice.
Fig.5 Diagrama schematică a unui controler fuzzy cu două variabile lingvistice.
Algoritmul de control fuzzy în cazul general este o transformare a variabilelor de intrare ale controlerului fuzzy în variabilele sale de ieșire folosind următoarele proceduri interdependente:
1. transformarea variabilelor fizice de intrare obținute din senzorii de măsurare din obiectul de control în variabile lingvistice de intrare ale unui controler fuzzy;
2. prelucrarea enunţurilor logice, numite reguli lingvistice, privind variabilele lingvistice de intrare şi de ieşire ale controlorului;
3. transformarea variabilelor lingvistice de ieșire ale controlerului fuzzy în variabile de control fizic.
Să luăm mai întâi în considerare cel mai simplu caz, când sunt introduse doar două variabile lingvistice pentru a controla servomotor:
„unghi” - variabilă de intrare;
„acțiune de control” - variabilă de ieșire.
Vom sintetiza controlerul în mediul MatLab folosind caseta de instrumente Fuzzy Logic. Vă permite să creați sisteme fuzzy de inferență și clasificare în mediul MatLab, cu posibilitatea de a le integra în Simulink. Conceptul de bază al casetei de instrumente Fuzzy Logic este structura FIS - Fuzzy Inference System. Structura FIS conține toate datele necesare pentru implementarea mapării funcționale „intrări-ieșiri” bazată pe inferență logică fuzzy conform schemei prezentate în fig. 6.

Figura 6. Inferență neclară.
X - vector clar de intrare; - vector de mulţimi fuzzy corespunzător vectorului de intrare X;
- rezultatul inferenței logice sub forma unui vector de mulțimi fuzzy; Y - vector crisp de ieșire.
Modulul fuzzy vă permite să construiți sisteme fuzzy de două tipuri - Mamdani și Sugeno. În sistemele de tip Mamdani, baza de cunoștințe este formată din reguli de formă „Dacă x 1 = scăzut și x 2 = mediu, atunci y = ridicat”. În sistemele de tip Sugeno, baza de cunoștințe constă din reguli de formă „Dacă x 1 = scăzut și x 2 = mediu, atunci y = a 0 + a 1 x 1 + a 2 x 2 ". Astfel, principala diferență dintre sistemele Mamdani și Sugeno constă în diferitele moduri de setare a valorilor variabilei de ieșire în regulile care formează baza de cunoștințe. În sistemele de tip Mamdani, valorile variabilei de ieșire sunt date prin termeni fuzzy, în sistemele de tip Sugeno - ca o combinație liniară de variabile de intrare. În cazul nostru, vom folosi sistemul Sugeno, deoarece se pretează mai bine la optimizare.
Pentru controlul servomotorului sunt introduse două variabile lingvistice: „eroare” (prin poziție) și „acțiune de control”. Primul dintre ele este intrarea, al doilea este ieșirea. Să definim un set de termeni pentru variabilele specificate.
Principalele componente ale inferenței fuzzy. Fuzzifier.
Pentru fiecare variabilă lingvistică, definim un set de termeni de bază al formei, care include seturi fuzzy care pot fi desemnate: negativ mare, negativ scăzut, zero, pozitiv scăzut, pozitiv ridicat.
În primul rând, să definim subiectiv ce se înțelege prin termenii „eroare mare”, „eroare mică”, etc., definind funcțiile de membru pentru mulțimile fuzzy corespunzătoare. Aici, deocamdată, cineva poate fi ghidat doar de precizia necesară, de parametri cunoscuți pentru clasa de semnale de intrare și de bun simț. Până acum, nimeni nu a fost capabil să ofere vreun algoritm rigid pentru alegerea parametrilor funcțiilor de membru. În cazul nostru, variabila lingvistică „eroare” va arăta astfel.
 Fig.7. Variabila lingvistică „eroare”.
Fig.7. Variabila lingvistică „eroare”.
Este mai convenabil să reprezentați variabila lingvistică „management” sub forma unui tabel:
tabelul 1
Blocarea regulilor.
Luați în considerare succesiunea definirii mai multor reguli care descriu unele situații:
Să presupunem, de exemplu, că unghiul de ieșire este egal cu semnalul de intrare (adică, eroarea este zero). Evident, aceasta este situația dorită și, prin urmare, nu trebuie să facem nimic (acțiunea de control este zero).
Acum luați în considerare un alt caz: eroarea de poziție este mult mai mare decât zero. Desigur, trebuie să o compensăm prin generarea unui semnal mare de control pozitiv.
Acea. au fost elaborate două reguli, care pot fi definite formal după cum urmează:
dacă eroare = nul, apoi actiune de control = zero.
dacă eroare = mare pozitiv, apoi actiune de control = mare pozitiv.
 Fig.8. Formarea controlului cu o mică eroare pozitivă în poziție.
Fig.8. Formarea controlului cu o mică eroare pozitivă în poziție.
 Fig.9. Formarea controlului la eroare zero după poziție.
Fig.9. Formarea controlului la eroare zero după poziție.
Tabelul de mai jos prezintă toate regulile corespunzătoare tuturor situațiilor pentru acest caz simplu.
masa 2
În total, pentru un controler fuzzy cu n intrări și 1 ieșire, pot fi determinate reguli de control, unde este numărul de seturi fuzzy pentru intrarea i-a, dar pentru funcționarea normală a controlerului nu este necesar să se utilizeze toate posibilele reguli, dar te poți descurca cu un număr mai mic dintre ele. În cazul nostru, toate cele 5 reguli posibile sunt folosite pentru a forma un semnal de control neclar.
Defuzzifier.
Astfel, impactul rezultat U va fi determinat în funcție de implementarea oricărei reguli. Dacă apare o situație când sunt executate mai multe reguli simultan, atunci acțiunea rezultată U se găsește în funcție de următoarea dependență:
 , unde n este numărul de reguli declanșate (defuzzificare prin metoda centrului zonei), u n este valoarea fizică a semnalului de control corespunzător fiecăruia dintre seturile fuzzy UBO, UMo, UZ, UMp, UBP. mUn(u) este gradul de apartenență a semnalului de control u la mulțimea fuzzy corespunzătoare Un=( UBO, UMo, UZ, UMp, UBP). Există și alte metode de defuzificare, când variabila lingvistică de ieșire este proporțională cu regula „puternică” sau „slabă” în sine.
, unde n este numărul de reguli declanșate (defuzzificare prin metoda centrului zonei), u n este valoarea fizică a semnalului de control corespunzător fiecăruia dintre seturile fuzzy UBO, UMo, UZ, UMp, UBP. mUn(u) este gradul de apartenență a semnalului de control u la mulțimea fuzzy corespunzătoare Un=( UBO, UMo, UZ, UMp, UBP). Există și alte metode de defuzificare, când variabila lingvistică de ieșire este proporțională cu regula „puternică” sau „slabă” în sine.
Să simulăm procesul de control al acționării electrice folosind controlerul fuzzy descris mai sus.
 Fig.10. Schema bloc a sistemului din mediumatlab.
Fig.10. Schema bloc a sistemului din mediumatlab.

Fig.11. Diagrama structurală a unui controler fuzzy în mediumatlab.

Fig.12. Proces tranzitoriu într-o singură acțiune.

Orez. 13. Proces tranzitoriu sub intrare armonică pentru un model cu un controler fuzzy care conține o variabilă lingvistică de intrare.
O analiză a caracteristicilor unui drive cu un algoritm de control sintetizat arată că acestea sunt departe de a fi optime și mai proaste decât în cazul sintezei controlului prin alte metode (prea mult timp de control cu un efect de un singur pas și o eroare cu unul armonic) . Acest lucru se explică prin faptul că parametrii funcțiilor de membru au fost aleși destul de arbitrar și doar amploarea erorii de poziție a fost folosită ca intrări ale controlerului. Desigur, nu se poate vorbi de vreo optimitate a controlerului obținut. Prin urmare, sarcina de optimizare a controlerului fuzzy devine relevantă pentru a obține cei mai înalți indicatori posibili ai calității controlului. Acestea. sarcina este de a optimiza funcția obiectiv f(a 1 ,a 2 …a n), unde a 1 ,a 2 …a n sunt coeficienții care determină tipul și caracteristicile controlerului fuzzy. Pentru a optimiza controlerul fuzzy, folosim blocul ANFIS din mediul Matlab. De asemenea, una dintre modalitățile de îmbunătățire a caracteristicilor controlerului poate fi creșterea numărului de intrări ale acestuia. Acest lucru va face regulatorul mai flexibil și va îmbunătăți performanța acestuia. Să mai adăugăm o variabilă lingvistică de intrare - rata de modificare a semnalului de intrare (derivata sa). În consecință, și numărul de reguli va crește. Apoi schema de circuit a regulatorului va lua forma:

Fig.14 Diagrama schematică a unui controler fuzzy cu trei variabile lingvistice.
Fie valoarea vitezei semnalului de intrare. Setul de termeni de bază Tn este definit ca:
Тn=(„negativ (VO)”, „zero (Z)”, „pozitiv (VR)”).
Locația funcțiilor de apartenență pentru toate variabilele lingvistice este prezentată în figură.
Fig.15. Funcții de apartenență ale variabilei lingvistice „eroare”.

Fig.16. Funcții de apartenență ale variabilei lingvistice „viteza semnalului de intrare”.
Datorită adăugării unei variabile lingvistice, numărul de reguli va crește la 3x5=15. Principiul compilarii lor este complet similar cu cel discutat mai sus. Toate acestea sunt prezentate în următorul tabel:
Tabelul 3
| semnal neclar management | Eroare de poziție |
|||||
| Viteză | ||||||
De exemplu, dacă dacă eroare = zero și derivată a semnalului de intrare = pozitiv mare, apoi actiune de control = mic negativ.
 Fig.17. Formarea controlului sub trei variabile lingvistice.
Fig.17. Formarea controlului sub trei variabile lingvistice.
Datorită creșterii numărului de intrări și, în consecință, a regulilor în sine, structura controlerului fuzzy va deveni, de asemenea, mai complicată.
 Fig.18. Diagrama structurală a unui controler fuzzy cu două intrări.
Fig.18. Diagrama structurală a unui controler fuzzy cu două intrări.
Adăugați desen

Fig.20. Proces tranzitoriu sub intrare armonică pentru un model cu un controler fuzzy care conține două variabile lingvistice de intrare.

Orez. 21. Semnal de eroare la intrarea armonică pentru un model cu un controler fuzzy care conține două variabile lingvistice de intrare.
Să simulăm funcționarea unui controler fuzzy cu două intrări în mediul Matlab. Diagrama bloc a modelului va fi exact aceeași ca în Fig. 19. Din graficul procesului tranzitoriu pentru intrarea armonică, se poate observa că acuratețea sistemului a crescut semnificativ, dar în același timp oscilația acestuia a crescut, mai ales în locurile în care derivata coordonatei de ieșire tinde să zero. Este evident că motivul pentru aceasta, așa cum sa menționat mai sus, este alegerea neoptimală a parametrilor funcțiilor de membru, atât pentru variabilele lingvistice de intrare cât și de ieșire. Prin urmare, optimizăm controlerul fuzzy utilizând blocul ANFISedit în mediul Matlab.
Optimizarea controlerului fuzzy.
Luați în considerare utilizarea algoritmilor genetici pentru optimizarea controlerului fuzzy. Algoritmii genetici sunt metode de căutare adaptive care sunt adesea folosite în ultimii ani pentru a rezolva problemele de optimizare funcțională. Ele se bazează pe asemănarea cu procesele genetice ale organismelor biologice: populațiile biologice se dezvoltă pe parcursul mai multor generații, respectând legile selecției naturale și conform principiului „supraviețuirii celui mai potrivit”, descoperit de Charles Darwin. Imitând acest proces, algoritmii genetici sunt capabili să „evolueze” soluții la problemele din lumea reală dacă sunt codați corespunzător.
Algoritmii genetici lucrează cu un set de „indivizi” - o populație, fiecare dintre acestea reprezentând o posibilă soluție la o problemă dată. Fiecare individ este evaluat prin măsura „aptitudinii” sale în funcție de cât de „bună” este soluția problemei care îi corespunde. Cei mai apți indivizi sunt capabili să „reproducă” descendenți prin „încrucișare” cu alți indivizi din populație. Acest lucru duce la apariția unor noi indivizi care combină unele dintre caracteristicile moștenite de la părinți. Indivizii cel mai puțin apți sunt mai puțin probabil să se reproducă, astfel încât trăsăturile pe care le posedă vor dispărea treptat din populație.
Așa se reproduce întreaga nouă populație de soluții fezabile, alegând cei mai buni reprezentanți ai generației precedente, încrucișându-i și obținând o mulțime de indivizi noi. Această nouă generație conține un raport mai mare de caracteristici pe care le posedă membrii buni ai generației precedente. Astfel, din generație în generație, caracteristicile bune sunt distribuite în întreaga populație. În cele din urmă, populația va converge către soluția optimă a problemei.
Există multe modalități de implementare a ideii de evoluție biologică în cadrul algoritmilor genetici. Tradițional, poate fi reprezentat sub forma următoarei diagrame bloc prezentată în Figura 22, unde:
1. Initializarea populatiei initiale - generarea unui numar dat de solutii la problema, de la care incepe procesul de optimizare;
2. Aplicarea operatorilor de încrucișare și mutație;
3.  Condiții de oprire - de obicei, procesul de optimizare este continuat până când se găsește o soluție a problemei cu o precizie dată sau până când se dezvăluie că procesul a convergit (adică nu a existat nicio îmbunătățire a soluționării problemei în ultima perioadă). N generații).
Condiții de oprire - de obicei, procesul de optimizare este continuat până când se găsește o soluție a problemei cu o precizie dată sau până când se dezvăluie că procesul a convergit (adică nu a existat nicio îmbunătățire a soluționării problemei în ultima perioadă). N generații).
În mediul Matlab, algoritmii genetici sunt reprezentați de o cutie de instrumente separată, precum și de pachetul ANFIS. ANFIS este o abreviere pentru Adaptive-Network-Based Fuzzy Inference System - Adaptive Fuzzy Inference Network. ANFIS este una dintre primele variante de rețele hibride neuro-fuzzy - o rețea neuronală de tip special de propagare directă a semnalului. Arhitectura unei rețele neuro-fuzzy este izomorfă cu o bază de cunoștințe neclară. Implementările diferențiabile ale normelor triunghiulare (înmulțirea și OR probabilistic), precum și funcțiile de membru netedă sunt utilizate în rețelele neuro-fuzzy. Acest lucru face posibilă utilizarea algoritmilor rapidi și genetici pentru antrenarea rețelelor neuronale bazate pe metoda de backpropagation pentru a regla rețelele neuro-fuzzy. Arhitectura și regulile de funcționare a fiecărui nivel al rețelei ANFIS sunt descrise mai jos.
ANFIS implementează sistemul de inferență fuzzy al lui Sugeno ca o rețea neuronală feed-forward cu cinci straturi. Scopul straturilor este următorul: primul strat reprezintă termenii variabilelor de intrare; al doilea strat - antecedente (parcele) de reguli fuzzy; al treilea strat este normalizarea gradului de îndeplinire a regulilor; al patrulea strat este concluziile regulilor; al cincilea strat este agregarea rezultatului obţinut după diferite reguli.
Intrările de rețea nu sunt alocate unui nivel separat. Figura 23 prezintă o rețea ANFIS cu o variabilă de intrare („eroare”) și cinci reguli neclare. Pentru evaluarea lingvistică a variabilei de intrare „eroare” se folosesc 5 termeni.

Fig.23. StructuraANFIS-rețele.
Să introducem următoarea notație, necesară pentru prezentarea ulterioară:
Fie intrările rețelei;
y - ieșire din rețea;
Regula fuzzy cu numărul ordinal r;
m - numărul de reguli;
Termen neclar cu funcție de apartenență , folosit pentru evaluarea lingvistică a unei variabile din regula r-a (,);
Numerele reale în concluzia regulii a r-a (,).
Rețeaua ANFIS funcționează după cum urmează.
Stratul 1 Fiecare nod al primului strat reprezintă un termen cu o funcție de membru în formă de clopot. Intrările rețelei sunt conectate numai la termenii lor. Numărul de noduri din primul strat este egal cu suma cardinalităților seturi de termeni de variabile de intrare. Ieșirea nodului este gradul de apartenență a valorii variabilei de intrare la termenul fuzzy corespunzător:
 ,
,
unde a, b și c sunt parametri configurabili pentru funcția de membru.
Stratul 2 Numărul de noduri din al doilea strat este m. Fiecare nod al acestui strat corespunde unei reguli fuzzy. Nodul celui de-al doilea strat este conectat la acele noduri ale primului strat care formează antecedentele regulii corespunzătoare. Prin urmare, fiecare nod al celui de-al doilea strat poate primi de la 1 la n semnale de intrare. Ieșirea nodului este gradul de execuție al regulii, care este calculat ca produsul semnalelor de intrare. Notați ieșirile nodurilor acestui strat prin , .
Stratul 3 Numărul de noduri din al treilea strat este de asemenea m. Fiecare nod al acestui strat calculează gradul relativ de îndeplinire a regulii fuzzy:
Stratul 4 Numărul de noduri din al patrulea strat este de asemenea m. Fiecare nod este conectat la un nod al celui de-al treilea strat, precum și la toate intrările rețelei (conexiunile la intrări nu sunt prezentate în Fig. 18). Nodul celui de-al patrulea strat calculează contribuția unei reguli fuzzy la ieșirea rețelei:
Stratul 5 Unicul nod al acestui strat rezumă contribuțiile tuturor regulilor:
![]() .
.
Procedurile tipice de antrenament ale rețelei neuronale pot fi aplicate pentru a regla rețeaua ANFIS, deoarece utilizează numai funcții diferențiabile. În mod obișnuit, se utilizează o combinație de coborâre a gradientului sub formă de retropropagare și cele mai mici pătrate. Algoritmul de backpropagation ajustează parametrii antecedentelor de regulă, i.e. funcții de membru. Coeficienții de concluzie ale regulii sunt estimați prin metoda celor mai mici pătrate, deoarece sunt legați liniar de ieșirea rețelei. Fiecare iterație a procedurii de reglare este efectuată în doi pași. În prima etapă, un eșantion de antrenament este alimentat intrărilor, iar parametrii optimi ai nodurilor celui de-al patrulea strat se găsesc din discrepanța dintre comportamentul dorit și cel real al rețelei folosind metoda iterativă a celor mai mici pătrate. În a doua etapă, discrepanța reziduală este transferată de la ieșirea rețelei la intrări, iar parametrii nodurilor primului strat sunt modificați prin metoda de retropropagare a erorii. În același timp, coeficienții de concluzie a regulii găsiți în prima etapă nu se modifică. Procedura de reglare iterativă continuă până când reziduul depășește o valoare predeterminată. Pentru a regla funcțiile de membru, pe lângă metoda de backpropagation a erorilor, pot fi utilizați și alți algoritmi de optimizare, de exemplu, metoda Levenberg-Marquardt.

Fig.24. ANFISedit spațiu de lucru.
Să încercăm acum să optimizăm controlerul fuzzy pentru o acțiune cu un singur pas. Procesul tranzitoriu dorit este aproximativ următorul:

Fig.25. procesul de tranziție dorit.
Din graficul prezentat în Fig. rezultă că de cele mai multe ori motorul ar trebui să funcționeze la putere maximă pentru a asigura viteza maximă, iar când se apropie de valoarea dorită să încetinească lin. Ghidați de aceste considerații simple, vom lua următorul eșantion de valori ca unul de antrenament, prezentat mai jos sub forma unui tabel:
Tabelul 4
| Valoarea erorii | Valoarea managementului |
| Valoarea erorii | Valoarea managementului |
| Valoarea erorii | Valoarea managementului |

Fig.26. Tip de set de antrenament.
Antrenamentul se va desfășura în 100 de pași. Acest lucru este mai mult decât suficient pentru convergența metodei utilizate.

Fig.27. Procesul de învățare a unei rețele neuronale.
În procesul de învățare, parametrii funcțiilor de membru sunt formați în așa fel încât, cu o valoare de eroare dată, controlerul să creeze controlul necesar. În secțiunea dintre punctele nodale, dependența controlului de eroare este o interpolare a datelor din tabel. Metoda de interpolare depinde de modul în care este antrenată rețeaua neuronală. De fapt, după antrenament, modelul controlerului fuzzy poate fi reprezentat ca o funcție neliniară a unei variabile, al cărei grafic este prezentat mai jos.

Fig.28. Graficul dependenței controlului de la eroare la poziția în interiorul regulatorului.
După ce au salvat parametrii găsiți ai funcțiilor de membru, simulăm sistemul cu un controler fuzzy optimizat.


Orez. 29. Proces tranzitoriu sub intrare armonică pentru un model cu un controler fuzzy optimizat care conține o variabilă lingvistică de intrare.
Fig.30. Semnal de eroare la intrarea armonică pentru un model cu un controler fuzzy care conține două variabile lingvistice de intrare.
Din grafice rezultă că optimizarea controlerului fuzzy prin antrenarea rețelei neuronale a avut succes. Scăderea semnificativă a fluctuației și a mărimii erorii. Prin urmare, utilizarea unei rețele neuronale este destul de rezonabilă pentru optimizarea controlerelor, al căror principiu se bazează pe logica fuzzy. Cu toate acestea, nici un controler optimizat nu poate satisface cerințele de acuratețe, așa că este indicat să se ia în considerare o altă metodă de control, atunci când controlerul fuzzy nu controlează în mod direct obiectul, ci combină mai multe legi de control în funcție de situație.
Duminica, 29 martie 2015
În prezent, există multe sarcini în care se cere să se ia o decizie în funcție de prezența unui obiect în imagine sau să-l clasifice. Abilitatea de a „recunoaște” este considerată principala proprietate a ființelor biologice, în timp ce sistemele informatice nu posedă pe deplin această proprietate.
Luați în considerare elementele generale ale modelului de clasificare.
Clasă- un set de obiecte care au proprietăți comune. Pentru obiectele din aceeași clasă, se presupune prezența „asemănării”. Un număr arbitrar de clase poate fi definit pentru sarcina de recunoaștere, mai mult de 1. Numărul de clase este notat cu numărul S. Fiecare clasă are propria etichetă de identificare a clasei.
Clasificare- procesul de atribuire a etichetelor de clasă obiectelor, conform unei descrieri a proprietăților acestor obiecte. Un clasificator este un dispozitiv care primește un set de caracteristici ale unui obiect ca intrare și ca rezultat produce o etichetă de clasă.
Verificare- procesul de potrivire a unei instanțe de obiect cu un singur model de obiect sau descriere de clasă.
Sub cale vom înțelege denumirea zonei în spațiul atributelor, în care sunt afișate multe obiecte sau fenomene ale lumii materiale. semn- o descriere cantitativă a unei anumite proprietăți a obiectului sau fenomenului studiat.
caracteristică spațiu acesta este un spațiu N-dimensional definit pentru o anumită sarcină de recunoaștere, unde N este un număr fix de caracteristici măsurate pentru orice obiect. Vectorul din spațiul caracteristic x corespunzător obiectului problemei de recunoaștere este un vector N-dimensional cu componente (x_1,x_2,…,x_N), care sunt valorile caracteristicilor pentru obiectul dat.
Cu alte cuvinte, recunoașterea modelelor poate fi definită ca atribuirea datelor inițiale unei anumite clase prin extragerea trăsăturilor sau proprietăților esențiale care caracterizează aceste date din masa generală de detalii irelevante.
Exemple de probleme de clasificare sunt:
- recunoașterea caracterelor;
- recunoaștere a vorbirii;
- stabilirea unui diagnostic medical;
- Prognoza meteo;
- recunoaștere facială
- clasificarea documentelor etc.
Cel mai adesea, materialul sursă este imaginea primită de la cameră. Sarcina poate fi formulată ca obținerea de vectori caracteristici pentru fiecare clasă din imaginea considerată. Procesul poate fi privit ca un proces de codare, care constă în atribuirea unei valori fiecărei caracteristici din spațiul de caracteristici pentru fiecare clasă.
Dacă luăm în considerare 2 clase de obiecte: adulți și copii. Ca caracteristici, puteți alege înălțimea și greutatea. După cum reiese din figură, aceste două clase formează două mulțimi care nu se intersectează, care pot fi explicate prin caracteristicile alese. Cu toate acestea, nu este întotdeauna posibil să alegeți parametrii măsurați corecti ca caracteristici ale claselor. De exemplu, parametrii selectați nu sunt potriviți pentru crearea unor clase care nu se suprapun de jucători de fotbal și baschetbalist.
A doua sarcină de recunoaștere este selectarea trăsăturilor sau proprietăților caracteristice din imaginile originale. Această sarcină poate fi atribuită preprocesării. Dacă luăm în considerare sarcina recunoașterii vorbirii, putem distinge trăsături precum vocalele și consoanele. Atributul trebuie să fie o proprietate caracteristică a unei anumite clase, fiind în același timp comun acestei clase. Semne care caracterizează diferențele dintre - semne interclase. Caracteristicile comune tuturor claselor nu conțin informații utile și nu sunt considerate caracteristici în problema recunoașterii. Alegerea caracteristicilor este una dintre sarcinile importante asociate cu construirea unui sistem de recunoaștere.
După ce caracteristicile sunt determinate, este necesar să se determine procedura optimă de decizie pentru clasificare. Luați în considerare un sistem de recunoaștere a modelelor conceput pentru a recunoaște diferite clase M, notate ca m_1,m_2,...,m 3. Atunci putem presupune că spațiul imaginii este format din M regiuni, fiecare conținând puncte corespunzătoare unei imagini dintr-o clasă. Atunci problema recunoașterii poate fi considerată ca construcția granițelor care separă M clase pe baza vectorilor de măsurare acceptați.
Rezolvarea problemei preprocesării imaginii, extragerii caracteristicilor și a problemei obținerii soluției și clasificării optime este de obicei asociată cu necesitatea evaluării unui număr de parametri. Aceasta duce la problema estimării parametrilor. În plus, este evident că extragerea caracteristicilor poate folosi informații suplimentare bazate pe natura claselor.
Compararea obiectelor se poate face pe baza reprezentării lor sub formă de vectori de măsură. Este convenabil să reprezentați datele de măsurare ca numere reale. Apoi, asemănarea vectorilor caracteristici a două obiecte poate fi descrisă folosind distanța euclidiană.

unde d este dimensiunea vectorului caracteristic.
Există 3 grupuri de metode de recunoaștere a modelelor:
- Comparație de probă. Acest grup include clasificarea după cea mai apropiată medie, clasificarea după distanța până la cel mai apropiat vecin. Metodele de recunoaștere structurală pot fi incluse și în grupul de comparație al eșantionului.
- Metode statistice. După cum sugerează și numele, metodele statistice folosesc unele informații statistice atunci când rezolvă o problemă de recunoaștere. Metoda determină apartenența unui obiect la o anumită clasă pe baza probabilității.În unele cazuri, aceasta se rezumă la determinarea probabilității a posteriori ca un obiect să aparțină unei anumite clase, cu condiția ca trăsăturile acestui obiect să fi luat valorile. Un exemplu este metoda Bayesiană a regulilor de decizie.
- Rețele neuronale. O clasă separată de metode de recunoaștere. O trăsătură distinctivă față de ceilalți este capacitatea de a învăța.
Clasificare după cea mai apropiată medie
În abordarea clasică a recunoașterii modelelor, în care un obiect necunoscut pentru clasificare este reprezentat ca un vector de trăsături elementare. Un sistem de recunoaștere bazat pe caracteristici poate fi dezvoltat în diferite moduri. Acești vectori pot fi cunoscuți de sistem în prealabil ca urmare a antrenamentului sau prevăzuți în timp real pe baza unor modele.
Un algoritm simplu de clasificare constă în gruparea datelor de referință de clasă folosind vectorul așteptării clasei (media).

unde x(i,j) este j-a caracteristică de referință a clasei i, n_j este numărul de vectori de referință ai clasei i.
Atunci obiectul necunoscut va aparține clasei i dacă este mult mai aproape de vectorul de așteptare al clasei i decât de vectorii de așteptare ai altor clase. Această metodă este potrivită pentru problemele în care punctele fiecărei clase sunt situate compact și departe de punctele altor clase.

Dificultăți vor apărea dacă clasele au o structură puțin mai complexă, de exemplu, ca în figură. În acest caz, clasa 2 este împărțită în două secțiuni care nu se suprapun, care sunt slab descrise de o singură valoare medie. De asemenea, clasa 3 este prea alungită, eșantioanele din clasa a 3-a cu valori mari ale coordonatelor x_2 sunt mai aproape de valoarea medie a clasei 1 decât a clasei a 3-a.

Problema descrisă în unele cazuri poate fi rezolvată prin modificarea calculului distanței.
Vom lua în considerare caracteristica „împrăștierii” valorilor clasei - σ_i, de-a lungul fiecărei direcții de coordonate i. Abaterea standard este egală cu rădăcina pătrată a varianței. Distanța euclidiană scalată dintre vectorul x și vectorul de așteptare x_c este

Această formulă de distanță va reduce numărul de erori de clasificare, dar, în realitate, majoritatea problemelor nu pot fi reprezentate de o clasă atât de simplă.
Clasificare după distanță până la cel mai apropiat vecin
O altă abordare a clasificării este de a atribui un vector caracteristic necunoscut x clasei de care acest vector este cel mai apropiat de un eșantion separat. Această regulă se numește regula vecinului cel mai apropiat. Clasificarea celui mai apropiat vecin poate fi mai eficientă chiar și atunci când clasele sunt complexe sau când clasele se suprapun.
Această abordare nu necesită ipoteze despre modelele de distribuție a vectorilor caracteristici în spațiu. Algoritmul folosește numai informații despre mostrele de referință cunoscute. Metoda soluției se bazează pe calcularea distanței x până la fiecare probă din baza de date și găsirea distanței minime. Avantajele acestei abordări sunt evidente:
- oricând puteți adăuga noi mostre în baza de date;
- structurile de date arbore și grilă reduc numărul de distanțe calculate.
În plus, soluția va fi mai bună dacă căutați în baza de date nu un vecin cel mai apropiat, ci k. Apoi, pentru k > 1, oferă cel mai bun eșantion al distribuției vectorilor în spațiul d-dimensional. Cu toate acestea, utilizarea eficientă a valorilor k depinde de faptul dacă există suficient în fiecare regiune a spațiului. Dacă există mai mult de două clase, atunci este mai dificil să iei decizia corectă.
Literatură
- M. Castrillon, . O. Deniz, . D. Hernández și J. Lorenzo, „A comparison of face and facial feature detectors based on the Viola-Jones general object detection framework”, International Journal of Computer Vision, nr.22, pp. 481-494, 2011.
- Y.-Q. Wang, „O analiză a algoritmului de detectare a feței Viola-Jones”, Jurnalul IPOL, 2013.
- L. Shapiro și D. Stockman, Computer vision, Binom. Laboratorul de cunoștințe, 2006.
- Z. N. G., Metode de recunoaștere și aplicarea lor, Radio sovietică, 1972.
- J. Tu, R. Gonzalez, Principii matematice ale recunoașterii modelelor, Moscova: „Mir” Moscova, 1974.
- Khan, H. Abdullah și M. Shamian Bin Zainal, „Algoritm eficient de detectare a ochilor și a gurii folosind combinația de viola jones și detectarea pixelilor de culoare a pielii” Jurnalul Internațional de Inginerie și Științe Aplicate, nr. 3 nr 4, 2013.
- V. Gaede și O. Gunther, „Multidimensional Access Methods”, ACM Computing Surveys, pp. 170-231, 1998.
Sistemele vii, inclusiv oamenii, s-au confruntat în mod constant cu sarcina de a recunoaște modelele încă de la începuturile lor. În special, informația care vine de la organele de simț este procesată de creier, care la rândul său sortează informațiile, asigură luarea deciziilor și apoi, folosind impulsuri electrochimice, transmite semnalul necesar în continuare, de exemplu, către organele de mișcare, care implementeaza actiunile necesare. Apoi are loc o schimbare a mediului, iar fenomenele de mai sus apar din nou. Și dacă te uiți, atunci fiecare etapă este însoțită de recunoaștere.
Odată cu dezvoltarea tehnologiei informatice, a devenit posibil să se rezolve o serie de probleme care apar în procesul vieții, pentru a facilita, accelera, îmbunătăți calitatea rezultatului. De exemplu, funcționarea diferitelor sisteme de susținere a vieții, interacțiunea om-calculator, apariția sistemelor robotizate etc. Cu toate acestea, observăm că în prezent nu este posibil să se ofere un rezultat satisfăcător în unele sarcini (recunoașterea obiectelor similare cu mișcare rapidă). , text scris de mână).
Scopul lucrării: studierea istoriei sistemelor de recunoaștere a modelelor.
Indicați modificările calitative intervenite în domeniul recunoașterii modelelor, atât teoretice, cât și tehnice, indicând motivele;
Discutați metodele și principiile utilizate în calcul;
Dați exemple de perspective care sunt așteptate în viitorul apropiat.
1. Ce este recunoașterea modelelor?
Prima cercetare cu tehnologia computerizată a urmat practic schema clasică de modelare matematică – model matematic, algoritm și calcul. Acestea au fost sarcinile de modelare a proceselor care au loc în timpul exploziilor bombelor atomice, calcularea traiectoriilor balistice, aplicații economice și de altă natură. Totuși, pe lângă ideile clasice ale acestei serii, au existat și metode bazate pe o cu totul altă natură și, așa cum a arătat practica rezolvării unor probleme, acestea au dat adesea rezultate mai bune decât soluțiile bazate pe modele matematice prea complicate. Ideea lor a fost să renunțe la dorința de a crea un model matematic exhaustiv al obiectului studiat (mai mult, de multe ori era practic imposibil să se construiască modele adecvate), și în schimb să se mulțumească cu răspunsul doar la întrebări specifice care ne interesează și aceste răspunsuri ar trebui căutate din considerente comune unei clase largi de probleme. Cercetările de acest fel au inclus recunoașterea imaginilor vizuale, prognozarea randamentelor, nivelurile râurilor, problema distingerii dintre acvifere și petrol, folosind date geofizice indirecte etc. Un răspuns specific la aceste sarcini era necesar într-o formă destul de simplă, cum ar fi: de exemplu, dacă un obiect aparține uneia dintre clasele prefixate. Și datele inițiale ale acestor sarcini, de regulă, au fost date sub formă de informații fragmentare despre obiectele studiate, de exemplu, sub forma unui set de obiecte preclasificate. Din punct de vedere matematic, aceasta înseamnă că recunoașterea modelelor (și această clasă de probleme a fost numită în țara noastră) este o generalizare de anvergură a ideii de extrapolare a funcției.
Importanța unei astfel de formulări pentru științele tehnice este fără îndoială, iar acest lucru în sine justifică numeroase studii în acest domeniu. Cu toate acestea, problema recunoașterii modelelor are și un aspect mai larg pentru știința naturii (cu toate acestea, ar fi ciudat dacă ceva atât de important pentru sistemele cibernetice artificiale nu ar fi important pentru cele naturale). Contextul acestei științe includea în mod organic întrebările puse de filosofii antici despre natura cunoștințelor noastre, capacitatea noastră de a recunoaște imagini, tipare, situații din lumea înconjurătoare. De fapt, practic nu există nicio îndoială că mecanismele de recunoaștere a celor mai simple imagini, cum ar fi imaginile unui prădător periculos sau hrană care se apropie, s-au format mult mai devreme decât a apărut limbajul elementar și aparatul logic formal. Și nu există nicio îndoială că astfel de mecanisme sunt suficient de dezvoltate și la animalele superioare, care, în activitatea lor vitală, au nevoie urgentă și de capacitatea de a distinge un sistem destul de complex de semne ale naturii. Astfel, în natură, vedem că fenomenul gândirii și conștiinței se bazează în mod clar pe capacitatea de a recunoaște tipare, iar progresul ulterioar al științei inteligenței este direct legat de profunzimea înțelegerii legilor fundamentale ale recunoașterii. Înțelegând faptul că întrebările de mai sus depășesc cu mult definiția standard a recunoașterii modelelor (termenul de învățare supervizată este mai frecvent în literatura de limba engleză), este, de asemenea, necesar să înțelegem că ele au legături profunde cu acest lucru relativ îngust (dar totuși departe de epuizat) direcţie.
Chiar și acum, recunoașterea modelelor a intrat ferm în viața de zi cu zi și este una dintre cele mai vitale cunoștințe ale unui inginer modern. În medicină, recunoașterea modelelor ajută medicii să facă diagnostice mai precise; în fabrici, este folosită pentru a prezice defectele loturii de mărfuri. Sistemele biometrice de identificare personală ca nucleu algoritmic se bazează, de asemenea, pe rezultatele acestei discipline. Dezvoltarea ulterioară a inteligenței artificiale, în special proiectarea computerelor de generația a cincea capabile să comunice mai direct cu o persoană în limbi naturale pentru oameni și prin vorbire, este de neconceput fără recunoaștere. Aici, robotica, sistemele de control artificial care conțin sisteme de recunoaștere ca subsisteme vitale, sunt la îndemână.
De aceea, s-a acordat multă atenție dezvoltării recunoașterii modelelor de la bun început de către specialiști de diferite profiluri - cibernetică, neurofiziologi, psihologi, matematicieni, economiști etc. În mare parte din acest motiv, recunoașterea modernă a modelelor în sine se hrănește cu ideile acestor discipline. Fără a pretinde că este complet (și este imposibil să o pretindem într-un scurt eseu), vom descrie istoria recunoașterii modelelor, idei cheie.
Definiții
Înainte de a trece la principalele metode de recunoaștere a modelelor, dăm câteva definiții necesare.
Recunoașterea imaginilor (obiecte, semnale, situații, fenomene sau procese) este sarcina de a identifica un obiect sau de a determina oricare dintre proprietățile acestuia prin imagine (recunoaștere optică) sau înregistrare audio (recunoaștere acustică) și alte caracteristici.
Una dintre cele de bază este conceptul de set care nu are o formulare specifică. Într-un computer, un set este reprezentat de un set de elemente nerepetate de același tip. Cuvântul „nerepetă” înseamnă că un element din set fie este acolo, fie nu este acolo. Multimea universala cuprinde toate elementele posibile pentru problema rezolvata, multimea goala nu contine niciuna.
O imagine este o grupare de clasificare în sistemul de clasificare care unește (separează) un anumit grup de obiecte în funcție de un anumit atribut. Imaginile au o proprietate caracteristică, care se manifestă prin faptul că cunoașterea unui număr finit de fenomene din același set face posibilă recunoașterea unui număr arbitrar de mare a reprezentanților săi. Imaginile au proprietăți obiective caracteristice, în sensul că diferiți oameni care învață din material de observație diferit, în cea mai mare parte, clasifică aceleași obiecte în același mod și independent unul de celălalt. În formularea clasică a problemei recunoașterii, mulțimea universală este împărțită în părți-imagini. Fiecare mapare a oricărui obiect la organele de percepție ale sistemului de recunoaștere, indiferent de poziția sa față de aceste organe, este de obicei numită o imagine a obiectului, iar seturile de astfel de imagini, unite prin unele proprietăți comune, sunt imagini.
Metoda de atribuire a unui element oricărei imagini se numește regulă de decizie. Un alt concept important este metrica, o modalitate de a determina distanța dintre elementele unui set universal. Cu cât această distanță este mai mică, cu atât sunt mai asemănătoare obiectele (simboluri, sunete etc.) pe care le recunoaștem. De obicei, elementele sunt specificate ca un set de numere, iar metrica este specificată ca o funcție. Eficiența programului depinde de alegerea reprezentării imaginilor și de implementarea metricii, un algoritm de recunoaștere cu metrici diferite va face greșeli cu frecvențe diferite.
Învățarea este de obicei numită proces de dezvoltare într-un sistem a unei anumite reacții la grupuri de semnale externe identice prin influențarea în mod repetat a sistemului extern de corecție. O astfel de ajustare externă în antrenament este de obicei numită „încurajare” și „pedeapsă”. Mecanismul de generare a acestei ajustări determină aproape complet algoritmul de învățare. Auto-învățarea diferă de învățare prin aceea că aici nu sunt raportate informații suplimentare despre corectitudinea reacției la sistem.
Adaptarea este un proces de modificare a parametrilor și structurii sistemului, eventual și a acțiunilor de control, pe baza informațiilor curente, pentru a atinge o anumită stare a sistemului cu incertitudine inițială și condiții de funcționare în schimbare.
Învățarea este un proces, în urma căruia sistemul dobândește treptat capacitatea de a răspunde cu reacțiile necesare la anumite seturi de influențe externe, iar adaptarea este ajustarea parametrilor și structurii sistemului pentru a atinge calitatea necesară a controlul în condiţii de schimbări continue ale condiţiilor externe.
Exemple de sarcini de recunoaștere a modelelor: - Recunoașterea literelor;
În general, se pot distinge trei metode de recunoaștere a modelelor: Metoda de enumerare. În acest caz se face o comparație cu baza de date, unde pentru fiecare tip de obiect sunt prezentate toate modificările posibile ale afișajului. De exemplu, pentru recunoașterea optică a imaginii, puteți aplica metoda de sortare a tipului unui obiect în diferite unghiuri, scări, deplasări, deformații etc. Pentru litere, trebuie să sortați prin font, proprietățile fontului etc. În cazul recunoașterii imaginii sunetului, respectiv, o comparație cu unele modele cunoscute (de exemplu, un cuvânt rostit de mai multe persoane).
A doua abordare este o analiză mai profundă a caracteristicilor imaginii. În cazul recunoașterii optice, aceasta poate fi determinarea diferitelor caracteristici geometrice. Proba de sunet în acest caz este supusă analizei de frecvență, amplitudine etc.
Următoarea metodă este utilizarea rețelelor neuronale artificiale (ANN). Această metodă necesită fie un număr mare de exemple ale sarcinii de recunoaștere în timpul antrenamentului, fie o structură specială a rețelei neuronale care ține cont de specificul acestei sarcini. Cu toate acestea, se distinge prin eficiență și productivitate mai ridicate.
4. Istoricul recunoașterii modelelor
Să luăm în considerare pe scurt formalismul matematic al recunoașterii modelelor. Un obiect în recunoaștere a modelelor este descris de un set de caracteristici de bază (trăsături, proprietăți). Principalele caracteristici pot fi de natură diferită: pot fi preluate dintr-o mulțime ordonată de tip linie reală, sau dintr-o mulțime discretă (care, însă, poate fi înzestrată și cu o structură). Această înțelegere a obiectului este în concordanță atât cu nevoia de aplicații practice ale recunoașterii modelelor, cât și cu înțelegerea noastră a mecanismului de percepție umană a unui obiect. Într-adevăr, credem că atunci când un obiect este observat (măsurat) de către o persoană, informațiile despre acesta vin printr-un număr finit de senzori (canale analizate) către creier, iar fiecare senzor poate fi asociat cu caracteristica corespunzătoare a obiectului. Pe lângă caracteristicile care corespund măsurătorilor noastre ale obiectului, există și o caracteristică selectată, sau un grup de caracteristici, pe care le numim caracteristici de clasificare, iar aflarea valorilor acestora pentru un anumit vector X este sarcina naturală. iar sistemele de recunoaștere artificială funcționează.
Este clar că pentru a stabili valorile acestor caracteristici, este necesar să existe informații despre modul în care caracteristicile cunoscute sunt legate de cele clasificatoare. Informațiile despre această relație sunt date sub formă de precedente, adică un set de descrieri ale obiectelor cu valori cunoscute ale caracteristicilor de clasificare. Și conform acestei informații precedente, este necesar să se construiască o regulă de decizie care să stabilească descrierea arbitrară a obiectului valorii caracteristicilor sale de clasificare.
Această înțelegere a problemei recunoașterii modelelor a fost stabilită în știință încă din anii 50 ai secolului trecut. Și atunci s-a observat că o astfel de producție nu este deloc nouă. Metodele bine dovedite de analiză a datelor statistice, care au fost utilizate în mod activ pentru multe sarcini practice, cum ar fi, de exemplu, diagnosticarea tehnică, s-au confruntat cu o astfel de formulare și existau deja. Prin urmare, primii pași ai recunoașterii modelelor au trecut sub semnul abordării statistice, care a dictat problema principală.
Abordarea statistică se bazează pe ideea că spațiul inițial al obiectelor este un spațiu probabilistic, iar trăsăturile (caracteristicile) obiectelor sunt variabile aleatorii date pe acesta. Apoi, sarcina cercetătorului de date a fost să propună o ipoteză statistică despre distribuția caracteristicilor, sau mai degrabă despre dependența caracteristicilor de clasificare față de restul, din unele considerații. Ipoteza statistică, de regulă, a fost un set parametric de funcții de distribuție a caracteristicilor. O ipoteză statistică tipică și clasică este ipoteza normalității acestei distribuții (există foarte multe varietăți de astfel de ipoteze în statistică). După formularea ipotezei, a rămas de testat această ipoteză pe date precedente. Această verificare a constat în alegerea unei distribuții din setul de distribuții dat inițial (parametrul ipotezei distribuției) și evaluarea fiabilității (intervalul de încredere) a acestei alegeri. De fapt, această funcție de distribuție a fost răspunsul la problemă, doar obiectul a fost clasificat nu în mod unic, ci cu unele probabilități de apartenență la clase. Statisticienii au dezvoltat, de asemenea, o justificare asimptotică pentru astfel de metode. Asemenea justificări au fost făcute după următoarea schemă: s-a stabilit o anumită funcționalitate a calității alegerii distribuției (interval de încredere) și s-a demonstrat că odată cu creșterea numărului de precedente, alegerea noastră cu o probabilitate care tinde spre 1 a devenit corectă în sensul acestui funcțional (interval de încredere tinde spre 0). Privind în perspectivă, putem spune că viziunea statistică a problemei recunoașterii s-a dovedit a fi foarte fructuoasă nu numai în ceea ce privește algoritmii dezvoltați (care includ metode de analiză cluster și discriminantă, regresie neparametrică etc.), dar și ulterior a condus Vapnik pentru a crea o teorie statistică profundă a recunoașterii .
Cu toate acestea, există un argument puternic în favoarea faptului că problemele de recunoaștere a modelelor nu se reduc la statistici. Orice astfel de problemă, în principiu, poate fi considerată din punct de vedere statistic, iar rezultatele rezolvării acesteia pot fi interpretate statistic. Pentru a face acest lucru, este necesar doar să presupunem că spațiul obiectelor problemei este probabilistic. Dar din punct de vedere al instrumentalismului, criteriul succesului unei interpretări statistice a unei anumite metode de recunoaștere nu poate fi decât existența unei fundamentari a acestei metode în limbajul statisticii ca ramură a matematicii. Justificarea înseamnă aici dezvoltarea cerințelor de bază pentru problema care asigură succesul aplicării acestei metode. Cu toate acestea, în momentul de față, pentru majoritatea metodelor de recunoaștere, inclusiv cele care au apărut direct în cadrul abordării statistice, astfel de justificări satisfăcătoare nu au fost găsite. În plus, algoritmii statistici cei mai des utilizați în acest moment, precum discriminantul liniar al lui Fisher, fereastra Parzen, algoritmul EM, cei mai apropiați vecini, ca să nu mai vorbim de rețelele de credințe bayesiene, au o natură euristică puternic pronunțată și pot avea interpretări diferite de cele statistice. Și, în sfârșit, la toate cele de mai sus, trebuie adăugat că, pe lângă comportamentul asimptotic al metodelor de recunoaștere, care este principala problemă a statisticii, practica recunoașterii ridică întrebări de complexitate computațională și structurală a metodelor care depășesc cu mult numai cadrul teoriei probabilităților.
În total, spre deosebire de aspirațiile statisticienilor de a considera recunoașterea modelelor ca o secțiune a statisticii, ideile complet diferite au intrat în practica și ideologia recunoașterii. Una dintre ele a fost cauzată de cercetări în domeniul recunoașterii modelelor vizuale și se bazează pe următoarea analogie.
După cum sa menționat deja, în viața de zi cu zi oamenii rezolvă în mod constant (adesea în mod inconștient) problemele de recunoaștere a diferitelor situații, imagini auditive și vizuale. O astfel de capacitate pentru computere este, în cel mai bun caz, o chestiune de viitor. Din aceasta, unii pionieri ai recunoașterii modelelor au ajuns la concluzia că rezolvarea acestor probleme pe computer ar trebui, în termeni generali, să simuleze procesele gândirii umane. Cea mai faimoasă încercare de a aborda problema din această parte a fost faimosul studiu al lui F. Rosenblatt asupra perceptronilor.
Până la mijlocul anilor 1950, se părea că neurofiziologii au înțeles principiile fizice ale creierului (în cartea „The New Mind of the King”, celebrul fizician teoretician britanic R. Penrose pune la îndoială interesant modelul rețelei neuronale a creierului, argumentând rolul esențial al efectelor mecanicii cuantice în funcționarea sa, deși, totuși, acest model a fost pus la îndoială încă de la început.Pe baza acestor descoperiri, F. Rosenblatt a dezvoltat un model pentru învățarea recunoașterii tiparelor vizuale, pe care l-a numit perceptronul lui Rosenblatt. este următoarea funcție (Fig. 1):
Fig 1. Schema Perceptronului
La intrare, perceptronul primește un vector obiect, care în lucrările lui Rosenblatt a fost un vector binar care arată care dintre pixelii ecranului este înnegrit de imagine și care nu. Mai mult, fiecare dintre semne este alimentat de intrarea neuronului, a cărui acțiune este o simplă multiplicare cu o anumită greutate a neuronului. Rezultatele sunt transmise ultimului neuron, care le adună și compară suma totală cu un anumit prag. În funcție de rezultatele comparației, obiectul de intrare X este recunoscut ca fiind necesar sau nu. Apoi, sarcina de a învăța recunoașterea modelelor a fost de a selecta greutățile neuronilor și valoarea pragului, astfel încât perceptronul să ofere răspunsuri corecte asupra imaginilor vizuale precedente. Rosenblatt credea că funcția rezultată ar fi bună la recunoașterea imaginii vizuale dorite chiar dacă obiectul de intrare nu se numără printre precedente. Din considerente bionice, a venit și cu o metodă de selectare a greutăților și a unui prag, asupra cărora nu ne vom opri. Să spunem doar că abordarea sa a avut succes într-o serie de probleme de recunoaștere și a dat naștere unei întregi arii de cercetare a algoritmilor de învățare bazați pe rețele neuronale, dintre care perceptronul este un caz special.
Mai mult, au fost inventate diverse generalizări ale perceptronului, funcția neuronilor a fost complicată: acum neuronii nu puteau doar să înmulțească numerele de intrare sau să le adauge și să compare rezultatul cu praguri, ci să le aplice funcții mai complexe. Figura 2 prezintă una dintre aceste complicații neuronale:

Orez. 2 Diagrama rețelei neuronale.
În plus, topologia rețelei neuronale ar putea fi mult mai complicată decât cea considerată de Rosenblatt, de exemplu, aceasta:
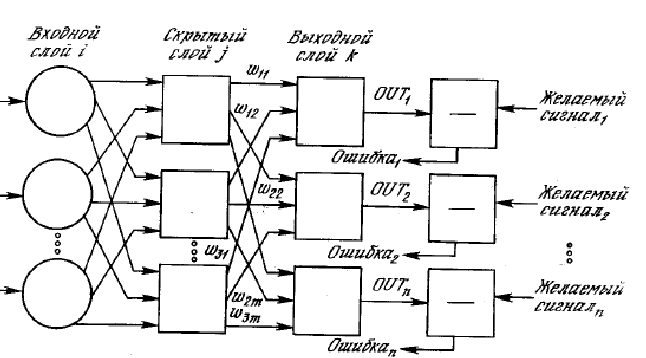
Orez. 3. Diagrama rețelei neuronale Rosenblatt.
Complicațiile au condus la o creștere a numărului de parametri ajustabili în timpul antrenamentului, dar, în același timp, au crescut capacitatea de a se adapta la tipare foarte complexe. Cercetările în acest domeniu se desfășoară acum în două domenii strâns legate - sunt studiate atât diverse topologii de rețea, cât și diferite metode de reglare.
Rețelele neuronale nu sunt în prezent doar un instrument pentru rezolvarea problemelor de recunoaștere a modelelor, ci au fost folosite în cercetările privind memoria asociativă și compresia imaginilor. Deși această linie de cercetare se suprapune puternic cu problemele de recunoaștere a modelelor, este o secțiune separată a ciberneticii. Pentru recunoaștere în acest moment, rețelele neuronale nu sunt altceva decât un set de mapări foarte specific, definit parametric, care în acest sens nu are avantaje semnificative față de multe alte modele de învățare similare care vor fi enumerate pe scurt mai jos.
În legătură cu această evaluare a rolului rețelelor neuronale pentru recunoașterea corectă (adică nu pentru bionică, pentru care acum sunt de o importanță capitală), aș dori să remarc următoarele: rețelele neuronale, fiind un obiect extrem de complex pentru matematică. analiza, cu utilizarea lor corectă, ne permit să găsim legi foarte nebanale în date. Dificultatea lor de analiză, în cazul general, se explică prin structura lor complexă și, ca urmare, posibilități practic inepuizabile de generalizare a unei game largi de regularități. Dar aceste avantaje, așa cum se întâmplă adesea, sunt o sursă de potențiale erori, posibilitatea de recalificare. După cum va fi discutat mai târziu, o astfel de viziune dublă a perspectivelor oricărui model de învățare este unul dintre principiile învățării automate.
O altă direcție populară în recunoaștere este regulile logice și arborii de decizie. În comparație cu metodele de recunoaștere menționate mai sus, aceste metode folosesc cel mai activ ideea de a ne exprima cunoștințele despre domeniul subiectului sub forma probabil cele mai naturale (la nivel conștient) structuri - reguli logice. O regulă logică elementară înseamnă o afirmație de genul „dacă caracteristicile neclasificate sunt în raportul X, atunci cele clasificate sunt în raportul Y”. Un exemplu de astfel de regulă în diagnosticul medical este următorul: dacă vârsta pacientului este de peste 60 de ani și a avut anterior un atac de cord, atunci nu efectuați operația - riscul unui rezultat negativ este mare.
Pentru a căuta reguli logice în date, sunt necesare 2 lucruri: pentru a determina măsura „informativității” regulii și spațiul regulilor. Iar sarcina de a găsi reguli după aceea se transformă într-o sarcină de enumerare completă sau parțială în spațiul regulilor pentru a găsi cele mai informative dintre ele. Definiția conținutului informațional poate fi introdusă într-o varietate de moduri și nu ne vom opri asupra acestui lucru, având în vedere că acesta este și un parametru al modelului. Spațiul de căutare este definit în mod standard.
După găsirea unor reguli suficient de informative, începe faza de „asamblare” a regulilor în clasificatorul final. Fără a discuta în profunzime problemele care apar aici (și există un număr considerabil de ele), enumeram 2 metode principale de „asamblare”. Primul tip este o listă liniară. Al doilea tip este votul ponderat, când fiecărei reguli i se atribuie o anumită pondere, iar clasificatorul referă obiectul la clasa pentru care a votat cel mai mare număr de reguli.
De fapt, faza de construire a regulilor și faza de „adunare” se desfășoară împreună și, la construirea unui vot sau a unei liste ponderate, căutarea regulilor pe părți ale datelor din caz este apelată din nou și din nou pentru a asigura o mai bună potrivire între date și modelul.
