Ang pinakamatarik na paraan ng pagbaba ay isang variable na step gradient na paraan. Sa bawat pag-ulit, ang halaga ng hakbang na k ay pinili mula sa kondisyon ng minimum ng function na f(x) sa direksyon ng pagbaba, i.e.
Ang kundisyong ito ay nangangahulugan na ang paggalaw sa kahabaan ng antigradient ay nangyayari hangga't ang halaga ng function na f (x) ay bumababa. Mula sa isang matematikal na punto ng view, sa bawat pag-ulit, ito ay kinakailangan upang malutas ang problema ng one-dimensional minimization na may paggalang sa function.
()=f(x(k)-f(x(k)))
Ginagamit namin ang paraan ng ginintuang seksyon para dito.
Ang algorithm ng pinakamatarik na paraan ng pagbaba ay ang mga sumusunod.
Ang mga coordinate ng panimulang punto x (0) ay ibinibigay.
Sa puntong x (k) , k = 0, 1, 2, ..., ang halaga ng gradient f (x (k)) ay kinakalkula.
Ang laki ng hakbang k ay natutukoy sa pamamagitan ng one-dimensional minimization na may kinalaman sa function
()=f(x(k)-f(x(k))).
Ang mga coordinate ng point x (k) ay tinutukoy:
x i (k+1) = x i (k) - k f i (x (k)), i=1, …, n.
Ang kondisyon para sa paghinto ng umuulit na proseso ay nasuri:
||f(x(k+1))|| .
Kung ito ay nasiyahan, pagkatapos ay ang mga kalkulasyon ay hihinto. Kung hindi, ang paglipat sa hakbang 1. Ang geometric na interpretasyon ng pinakamatarik na paraan ng pagbaba ay ipinapakita sa fig. isa.


kanin. 2.1. Block diagram ng pinakamatarik na paraan ng pagbaba.
Pagpapatupad ng pamamaraan sa programa:
Ang pinakamatarik na paraan ng pagbaba.

kanin. 2.2. Pagpapatupad ng pinakamatarik na paraan ng pagbaba.
Konklusyon: Sa aming kaso, ang pamamaraan ay nagtagpo sa 7 pag-ulit. Ang Point A7 (0.6641; -1.3313) ay isang extremum point. Ang paraan ng conjugate direksyon. Para sa mga quadratic function, maaari kang lumikha ng gradient method, kung saan ang oras ng convergence ay magiging may hangganan at katumbas ng bilang ng mga variable n.
Tinatawag namin ang ilang direksyon at conjugate na may paggalang sa ilang positibong tiyak na Hess matrix H kung:
Pagkatapos i.e.. Kaya, sa yunit H, ang conjugate na direksyon ay nangangahulugan ng kanilang patayo. Sa pangkalahatang kaso, ang H ay hindi mahalaga. Sa pangkalahatang kaso, ang conjugation ay ang paglalapat ng Hess matrix sa isang vector - nangangahulugan ito ng pag-ikot ng vector na ito sa ilang anggulo, pagpapalawak o compression nito.

At ngayon ang isang vector ay orthogonal sa isang vector, ibig sabihin, ang conjugacy ay hindi ang orthogonality ng mga vectors, ngunit ang orthogonality ng isang rotated vectorat.i.i.


kanin. 2.3. Block diagram ng paraan ng mga direksyon ng conjugate.
Pagpapatupad ng pamamaraan sa programa: Ang paraan ng mga direksyon ng conjugate.

kanin. 2.4. Pagpapatupad ng paraan ng mga direksyon ng conjugate.

kanin. 2.5. Plot ng paraan ng conjugate directions.
Konklusyon: Ang puntong A3 (0.6666; -1.3333) ay natagpuan sa 3 pag-ulit at ito ang extremum point.
3. Pagsusuri ng mga pamamaraan para sa pagtukoy ng minimum, maximum na halaga ng function sa pagkakaroon ng mga paghihigpit
Alalahanin na ang pangkalahatang problema ng conditional optimization ay ganito ang hitsura
f(x) ® min, x О W,
kung saan ang W ay isang wastong subset ng R m . Ang isang subclass ng mga problema sa equality-type constraints ay nakikilala sa pamamagitan ng katotohanan na ang set ay ibinibigay sa pamamagitan ng constraints ng form
f i (x) = 0, kung saan f i: R m ®R (i = 1, …, k).
KayaW = (x О R m: f i (x) = 0, i = 1, …, k).
Magiging maginhawa para sa amin na isulat ang index na "0" para sa function na f. Kaya, ang problema sa pag-optimize na may mga hadlang sa uri ng pagkakapantay-pantay ay isinulat bilang
f 0 (x) ® min, (3.1)
f i (x) = 0, i = 1, …, k. (3.2)
Kung tinutukoy natin ngayon sa pamamagitan ng f isang function sa R m na may mga halaga sa R k , na ang notasyon ng coordinate ay may anyo na f(x) = (f 1 (x), …, f k (x)), pagkatapos ay (3.1)–( 3.2) ay maaari ding isulat sa form
f 0 (x) ® min, f(x) = Q.
Geometrically, ang problema sa equality type constraints ay ang problema sa paghahanap ng pinakamababang punto ng graph ng function f 0 sa manifold (tingnan ang Fig. 3.1).

Ang mga puntos na nakakatugon sa lahat ng mga paghihigpit (i.e., mga punto ng set ) ay karaniwang tinatawag na tinatanggap. Ang tinatanggap na puntong x* ay tinatawag na conditional minimum ng function f 0 sa ilalim ng mga hadlang f i (x) = 0, i = 1, ..., k (o isang solusyon sa problema (3.1)–(3.2)), kung para sa lahat ng tinatanggap na puntos x f 0 (x *) f 0 (x). (3.3)
Kung ang (3.3) ay nasiyahan lamang para sa tinatanggap na x na nakahiga sa ilang kapitbahayan V x * ng punto x*, kung gayon ang isa ay nagsasalita ng lokal na minimum na kondisyon. Ang mga konsepto ng conditional strict local at global minima ay tinukoy sa natural na paraan.
Pagbubuo ng problema
Hayaan ang function f(x) R n
Kailangan f(x) X = Rn

Diskarte sa paghahanap
x k
} , k = 0,1,...,
ganyan ![]() , k = 0.1,...
. Mga sequence point ( x k
) ay kinakalkula ayon sa panuntunan
, k = 0.1,...
. Mga sequence point ( x k
) ay kinakalkula ayon sa panuntunan
nasaan ang tuldok x 0 ay itinakda ng gumagamit; laki ng hakbang t k tinukoy para sa bawat halaga k mula sa kondisyon
Ang problema (3) ay maaaring malutas gamit ang kinakailangang minimum na kondisyon na sinusundan ng pagsuri sa sapat na minimum na kondisyon . Ang paraang ito ay maaaring gamitin para sa isang medyo simpleng function upang mabawasan, o para sa isang paunang pagtatantya ng isang medyo kumplikadong function. ![]() polinomyal P(tk)
(kadalasan ng ikalawa o ikatlong antas), at pagkatapos ay ang kundisyon ay papalitan ng kundisyon , at ang kundisyon ng kundisyon
polinomyal P(tk)
(kadalasan ng ikalawa o ikatlong antas), at pagkatapos ay ang kundisyon ay papalitan ng kundisyon , at ang kundisyon ng kundisyon 
Pagbuo ng pagkakasunod-sunod ( x k )
nagtatapos sa punto x k
, para saan , saan ε
ay isang binigay na maliit na positibong numero, o k ≥ M
, saan M
- ang naglilimita sa bilang ng mga pag-ulit, o may dalawang sabay na katuparan ng dalawang hindi pagkakapantay-pantay ![]() ,
, ![]() saan ε 2
ay isang maliit na positibong numero. Ang tanong ay kung ang isang punto x k
ituring bilang ang nahanap na pagtatantya ng nais na lokal na minimum na punto x *
, ay nalutas sa pamamagitan ng karagdagang pananaliksik.
saan ε 2
ay isang maliit na positibong numero. Ang tanong ay kung ang isang punto x k
ituring bilang ang nahanap na pagtatantya ng nais na lokal na minimum na punto x *
, ay nalutas sa pamamagitan ng karagdagang pananaliksik.
Geometric na interpretasyon ng pamamaraan para sa n=2 sa fig. apat.

Coordinate descent method
Pagbubuo ng problema
Hayaan ang function f(x) , bounded mula sa ibaba sa set R n at pagkakaroon ng tuluy-tuloy na partial derivatives sa lahat ng mga punto nito.
f(x) sa hanay ng mga tinatanggap na solusyon X = Rn , ibig sabihin. humanap ng puntong ganyan

Diskarte sa paghahanap
Ang diskarte para sa paglutas ng problema ay binubuo sa pagbuo ng isang pagkakasunod-sunod ng mga puntos ( x k
} , k = 0,1,...,
ganyan ![]() , k = 0.1,...
. Mga sequence point ( x k
) ay kinakalkula ng mga cycle ayon sa panuntunan
, k = 0.1,...
. Mga sequence point ( x k
) ay kinakalkula ng mga cycle ayon sa panuntunan
 (4)
(4)
saan j - numero ng ikot ng pagkalkula; j = 0,1,2,...; k - numero ng pag-ulit sa loob ng loop, k = 0,1,...,n - 1; e k +1 , k = 0,l,...,n - 1 -unit vector, (k+1) -th projection na kung saan ay katumbas ng 1; tuldok x 00 itinakda ng user, laki ng hakbang t k pinili mula sa kondisyon
 o
o  .
.
Kung ang napiling kundisyon sa kasalukuyang t k
ay hindi naisakatuparan, ang hakbang ay hinahati at ang punto  ay muling kinakalkula. Madaling makita iyon, para sa isang nakapirming j, sa isang pag-ulit na may numero k
isang point projection lang ang nagbabago x jk
, na mayroong numero k + 1
, at sa buong cycle na may numero j
, ibig sabihin. simula sa k = 0
at pagtatapos k=n-1
, lahat ng n projection ng point ay nagbabago x j0
. Pagkatapos ng puntong ito x jn
nagtalaga ng isang numero x j + 1.0
, at ito ay kinuha bilang panimulang punto para sa mga kalkulasyon sa j + 1
ikot. Ang pagkalkula ay nagtatapos sa punto x jk
kapag natugunan ang hindi bababa sa isa sa tatlong pamantayan sa pagtatapos ng bilang:
ay muling kinakalkula. Madaling makita iyon, para sa isang nakapirming j, sa isang pag-ulit na may numero k
isang point projection lang ang nagbabago x jk
, na mayroong numero k + 1
, at sa buong cycle na may numero j
, ibig sabihin. simula sa k = 0
at pagtatapos k=n-1
, lahat ng n projection ng point ay nagbabago x j0
. Pagkatapos ng puntong ito x jn
nagtalaga ng isang numero x j + 1.0
, at ito ay kinuha bilang panimulang punto para sa mga kalkulasyon sa j + 1
ikot. Ang pagkalkula ay nagtatapos sa punto x jk
kapag natugunan ang hindi bababa sa isa sa tatlong pamantayan sa pagtatapos ng bilang: ![]() , o , o dobleng katuparan ng mga hindi pagkakapantay - pantay .
, o , o dobleng katuparan ng mga hindi pagkakapantay - pantay .
Ang mga puntos na nakuha bilang resulta ng mga kalkulasyon ay maaaring isulat bilang mga elemento ng pagkakasunud-sunod (xl), saan l=n*j+k - serial number ng punto,
Ang geometric na interpretasyon ng pamamaraan para sa n = 2 ay ipinapakita sa fig. 5.

4. Paraan ng Frank-Wolfe .
Hayaang kailanganin upang mahanap ang pinakamataas na halaga ng concave function

Sa ilalim ng mga kondisyon

Ang isang katangian ng problemang ito ay ang sistema ng mga hadlang ay naglalaman lamang ng mga linear na hindi pagkakapantay-pantay. Ang tampok na ito ay ang batayan para sa pagpapalit ng non-linear na layunin na function ng isang linear na isa sa paligid ng puntong pinag-aaralan, dahil sa kung saan ang solusyon ng orihinal na problema ay nabawasan sa isang sunud-sunod na solusyon ng mga problema sa linear programming.
Ang proseso ng paghahanap ng solusyon sa problema ay nagsisimula sa pagtukoy ng isang punto na kabilang sa lugar ng mga tinatanggap na solusyon para sa
270
dachas. Hayaan itong maging punto X(k)
pagkatapos ay sa puntong ito ang gradient ng function (57) ay kinakalkula
At bumuo ng isang linear function

Pagkatapos ang pinakamataas na halaga ng function na ito ay matatagpuan sa ilalim ng mga hadlang (58) at (59). Hayaang matukoy ang solusyon sa problemang ito sa pamamagitan ng punto Z(k)
. Pagkatapos ay ang mga coordinate ng punto X(k+1)
:
saan λ k - ilang numero, na tinatawag na hakbang sa pagkalkula at natapos sa pagitan ng zero at isa (0<λ k < 1). Это число λ k kunin nang arbitraryo o matukoy
upang ang halaga ng function sa punto X (k + 1) f(X (k + 1)) depende sa λ k , ay ang maximum. Upang gawin ito, kailangan mong makahanap ng solusyon sa equation at piliin ang pinakamaliit na ugat nito. Kung ang halaga nito ay mas malaki kaysa sa isa, kung gayon λ k=1 . Matapos matukoy ang bilang λ k hanapin ang mga coordinate ng isang punto X(k+1) kalkulahin ang halaga ng layunin ng function sa loob nito at alamin ang pangangailangan na lumipat sa isang bagong punto X(k+2) . Kung may ganoong pangangailangan, pagkatapos ay kalkulahin sa punto X(k+1) gradient ng layunin ng function, pumunta sa kaukulang linear programming problem at hanapin ang solusyon nito. Tukuyin ang mga coordinate ng punto at X(k+2) at imbestigahan ang pangangailangan para sa karagdagang mga kalkulasyon. Pagkatapos ng isang tiyak na bilang ng mga hakbang, ang solusyon ng orihinal na problema ay nakuha nang may kinakailangang katumpakan.
Kaya, ang proseso ng paghahanap ng solusyon sa problema (57) - (59) ng pamamaraang Frank-Wolfe ay kinabibilangan ng mga sumusunod na hakbang:
1. Tukuyin ang paunang magagawang solusyon sa problema.
2. Hanapin ang gradient ng function (57) sa punto ng feasible solution.
3. Bumuo ng function (60) at hanapin ang pinakamataas na halaga nito sa ilalim ng mga kondisyon (58) at (59).
4. Tukuyin ang hakbang sa pagkalkula.
5. Gamit ang mga formula (61), ang mga bahagi ng isang bagong magagawang solusyon ay matatagpuan.
6. Suriin ang pangangailangan na lumipat sa susunod na katanggap-tanggap na solusyon. Kung kinakailangan, pumunta sa yugto 2, kung hindi, isang katanggap-tanggap na solusyon sa orihinal na problema ay matatagpuan.
Paraan ng mga function ng parusa.
Isaalang-alang ang problema sa pagtukoy ng pinakamataas na halaga ng isang malukong function
f (x 1, x 2, .... x n) sa ilalim ng mga kondisyon g i (x 1, x 2, .... x n) ≤ b i (i=l, m) , x j ≥ 0 (j=1, n) , saan g i (x 1, x 2, .... x n) ay mga convex function.
Sa halip na direktang lutasin ang problemang ito, hanapin ang maximum na halaga ng function F (x 1, x 2, ...., x n) \u003d f (x 1, x 2, ...., x n) +H(x 1, x 2, ...., x n) na siyang kabuuan ng layunin ng pag-andar ng problema, at ilang pag-andar
H(x 1, x 2, ...., x n), tinutukoy ng sistema ng mga hadlang at tinatawag function ng parusa. Ang pagpapaandar ng parusa ay maaaring itayo sa iba't ibang paraan. Gayunpaman, madalas itong kumukuha ng form
PERO a i > 0
- ilang pare-parehong numero na kumakatawan sa mga koepisyent ng timbang.
Gamit ang isang function ng parusa, ang isa ay sunud-sunod na gumagalaw mula sa isang punto patungo sa isa pa hanggang sa makuha ang isang katanggap-tanggap na solusyon. Sa kasong ito, ang mga coordinate ng susunod na punto ay matatagpuan sa pamamagitan ng formula
Ito ay sumusunod mula sa huling kaugnayan na kung ang nakaraang punto ay nasa lugar ng mga magagawang solusyon ng orihinal na problema, kung gayon ang pangalawang termino sa mga square bracket ay katumbas ng zero at ang paglipat sa susunod na punto ay tinutukoy lamang ng gradient ng ang layunin function. Kung ang ipinahiwatig na punto ay hindi nabibilang sa rehiyon ng mga magagawang solusyon, dahil sa terminong ito, sa kasunod na mga pag-ulit, ang isang pagbabalik sa rehiyon ng mga magagawang solusyon ay makakamit.
mga solusyon. Gayunpaman, mas kaunti a i
, mas mabilis na natagpuan ang isang katanggap-tanggap na solusyon, ngunit bumababa ang katumpakan ng pagpapasiya nito. Samakatuwid, ang proseso ng umuulit ay karaniwang nagsisimula sa medyo maliit na halaga a i
at, sa pagpapatuloy nito, ang mga halagang ito ay unti-unting tumataas.
Kaya, ang proseso ng paghahanap ng solusyon sa problema ng convex programming sa pamamagitan ng paraan ng pagpapaandar ng parusa ay kinabibilangan ng mga sumusunod na hakbang:
1. Tukuyin ang paunang magagawang solusyon.
2. Piliin ang hakbang sa pagkalkula.
3. Para sa lahat ng mga variable, ang mga partial derivatives ng layunin na function at mga function na tumutukoy sa lugar ng mga katanggap-tanggap na solusyon sa problema ay matatagpuan.
4. Sa pamamagitan ng formula (72) hanapin ang mga coordinate ng punto na tumutukoy sa isang posibleng bagong solusyon sa problema.
5. Suriin kung ang mga coordinate ng nahanap na punto ay nakakatugon sa sistema ng mga hadlang ng problema. Kung hindi, pagkatapos ay pumunta sa susunod na hakbang. Kung ang mga coordinate ng nahanap na punto ay tumutukoy ng isang magagawang solusyon sa problema, kung gayon ang pangangailangan na lumipat sa susunod na magagawang solusyon ay susuriin. Kung kinakailangan, pumunta sa yugto 2, kung hindi, isang katanggap-tanggap na solusyon sa orihinal na problema ay matatagpuan.
6. Magtakda ng mga timbang at pumunta sa hakbang 4.
Paraan ng Arrow-Hurwitz.
Kapag naghahanap ng solusyon sa mga problema sa nonlinear programming gamit ang paraan ng pagpapaandar ng parusa, pinili namin ang mga halaga a i , nang di-makatwiran, na humantong sa makabuluhang pagbabagu-bago sa liblib ng mga tinukoy na punto mula sa rehiyon ng mga magagawang solusyon. Ang kawalan na ito ay inalis sa pamamagitan ng paglutas ng problema sa pamamagitan ng pamamaraang Arrow-Hurwitz, ayon sa kung saan sa susunod na hakbang ng numero a i (k) kinakalkula ayon sa formula
Bilang mga paunang halaga a i (0) kumuha ng mga arbitrary na hindi negatibong numero.
HALIMBAWA NG SOLUSYON
Halimbawa 1.
Hanapin ang lokal na minimum ng isang function
Depinisyon ng punto x k
1. Itakda .
2. Ilagay k = 0 .
tatlumpu. Compute
40 . Compute ![]() . Lumipat tayo sa hakbang 5.
. Lumipat tayo sa hakbang 5.
limampu . Suriin natin ang kondisyon ![]() . Lumipat tayo sa hakbang 6.
. Lumipat tayo sa hakbang 6.
60 . Itakda natin t 0 \u003d 0.5 .
70. Compute
80. Ikumpara natin ![]() . Meron kami
. Meron kami ![]() . Konklusyon: kondisyon para sa k = 0
ay hindi ginaganap. Itakda natin t0 = 0.25
, magpatuloy tayo sa pag-uulit ng mga hakbang 7, 8.
. Konklusyon: kondisyon para sa k = 0
ay hindi ginaganap. Itakda natin t0 = 0.25
, magpatuloy tayo sa pag-uulit ng mga hakbang 7, 8.
701 . kalkulahin natin.
801 . Ikumpara natin f (x 1) at f (x 0) . Konklusyon: f(x1)< f (x 0) . Lumipat tayo sa hakbang 9.
90. Compute
Konklusyon: naniniwala kami k=1 at pumunta sa hakbang 3.
3 1 . Compute
4 1 . Compute ![]() . Lumipat tayo sa hakbang 5.
. Lumipat tayo sa hakbang 5.
5 1 . Suriin natin ang kondisyon k ≥ M: k = 1< 10 = M . Lumipat tayo sa hakbang 6.
6 1 . Itakda natin t 1 \u003d 0.25.
7 1 . Compute
![]()
8 1 . Ikumpara natin f (x 2) na may f (x 1) . Konklusyon: f (x 2)< f (х 1). Lumipat tayo sa hakbang 9.
9 1 . Compute
Konklusyon: naniniwala kami k = 2 at pumunta sa hakbang 3.
3 2 . Compute
4 2 . kalkulahin natin. Lumipat tayo sa hakbang 5.
5 2 . Suriin natin ang kondisyon k ≥ M : k = 2< 10 = М , pumunta sa hakbang 6.
6 2 . Itakda natin t2 =0,25 .
7 2 . Compute
![]()
8 2 . Ikumpara natin f (x 3) at f (x 2) . Konklusyon: f (x 3)< f (х 2) .Pumunta sa hakbang 9.
9 2 . Compute ![]()
Konklusyon: naniniwala kami k = 3 at pumunta sa hakbang 3.
3 3 . Compute
4 3 . kalkulahin natin. Lumipat tayo sa hakbang 5.
5 3 . Suriin natin ang kondisyon k ≥ M : k = 3<10 = М , pumunta sa hakbang 6.
6 3 . Itakda natin t 3 \u003d 0.25.
7 3 . Compute
![]()
8 3 . Ikumpara natin f (x 4) at f (x 3) : f (x 4)< f (х 3) .
9 3 . Compute ![]()
Ang mga kundisyon ay natutugunan sa k = 2.3 . Pagkalkula
tapos na. Nahanap ang punto
Sa fig. Ang 3 nakuhang puntos ay konektado sa pamamagitan ng isang tuldok na linya.

II. Pagsusuri ng Punto x 4 .
Function ![]() ay dalawang beses na naiba-iba, kaya sinusuri namin ang sapat na mga kondisyon para sa minimum sa punto x 4
. Upang gawin ito, sinusuri namin ang Hessian matrix.
ay dalawang beses na naiba-iba, kaya sinusuri namin ang sapat na mga kondisyon para sa minimum sa punto x 4
. Upang gawin ito, sinusuri namin ang Hessian matrix.
Ang matrix ay pare-pareho at positibong tiyak (i.e. . H > 0
), dahil pareho sa mga angular na menor de edad nito at positibo. Kaya ang punto ![]() ay ang nahanap na pagtatantya ng lokal na minimum na punto , at ang halaga
ay ang nahanap na pagtatantya ng lokal na minimum na punto , at ang halaga ![]() ay ang nahanap na pagtatantya ng halaga f(x*)=0
. Tandaan na ang kondisyon H > 0
, ay sabay na isang kundisyon para sa mahigpit na convexity ng function
ay ang nahanap na pagtatantya ng halaga f(x*)=0
. Tandaan na ang kondisyon H > 0
, ay sabay na isang kundisyon para sa mahigpit na convexity ng function ![]() . Samakatuwid, may nakitang mga pagtatantya ng pandaigdigang minimum na punto f(x)
at ang pinakamaliit na halaga nito sa R2
. ■
. Samakatuwid, may nakitang mga pagtatantya ng pandaigdigang minimum na punto f(x)
at ang pinakamaliit na halaga nito sa R2
. ■
Halimbawa 2
Hanapin ang lokal na minimum ng isang function
I. Pagpapasiya ng isang punto x k, kung saan natugunan ang hindi bababa sa isa sa mga pamantayan sa pagwawakas.
1. Itakda .
Hanapin ang gradient ng isang function sa isang arbitrary point
2. Ilagay k = 0 .
tatlumpu. Compute
40 . Compute ![]() . Lumipat tayo sa hakbang 5.
. Lumipat tayo sa hakbang 5.
limampu . Suriin natin ang kondisyon ![]() . Lumipat tayo sa hakbang 6.
. Lumipat tayo sa hakbang 6.
6°. Ang susunod na punto ay matatagpuan sa pamamagitan ng formula
Palitan natin ang nakuhang mga expression para sa mga coordinate sa
Hanapin ang minimum ng function f(t0) sa t0 gamit ang mga kinakailangang kondisyon para sa isang unconditional extremum:
![]()
Mula rito t0 =0.24
. kasi  , ang nahanap na halaga ng hakbang ay nagbibigay ng pinakamababa sa function f(t0)
sa t0
.
, ang nahanap na halaga ng hakbang ay nagbibigay ng pinakamababa sa function f(t0)
sa t0
.

Tukuyin natin ![]()
70. Hanapin natin
8°. Compute
![]()
![]()
Konklusyon: naniniwala kami k = 1 at pumunta sa hakbang 3.
3 1 . Compute
4 1 . Compute ![]()
5 1 . Suriin natin ang kondisyon k ≥ 1: k = 1< 10 = М.
6 1 . Tukuyin natin
7 1 . Hanapin natin ![]() :
:
8 1 . Compute
Naniniwala kami k = 2 at pumunta sa hakbang 3.
3 2 . Compute
4 2 . Compute
5 2 . Suriin natin ang kondisyon k ≥ M: k = 2< 10 = M .
6 2 . Tukuyin natin
7 2 . Hanapin natin ![]()
8 2 . Compute
Naniniwala kami k=3 at pumunta sa hakbang 3.
3 3 . Compute
4 3 . kalkulahin natin.
Tapos na ang kalkulasyon. Nahanap ang punto
II. Pagsusuri ng Punto x 3 .
Sa Halimbawa 1.1 (Kabanata 2 §1) ipinakita na ang function f(x) ay mahigpit na matambok at, samakatuwid, sa mga punto3 ay ang nahanap na pagtatantya ng pinakamababang punto sa buong mundo X* .
Halimbawa 3
Hanapin ang lokal na minimum ng isang function
![]()
I. Pagpapasiya ng isang punto x jk , kung saan natugunan ang hindi bababa sa isa sa mga pamantayan sa pagwawakas.
1. Itakda
Hanapin ang gradient ng isang function sa isang arbitrary point ![]()
2. Itakda j = 0.
tatlumpu. Suriin natin ang katuparan ng kondisyon
40 . Itakda natin k = 0.
limampu . Suriin natin ang katuparan ng kondisyon
60 . Compute
70. Suriin natin ang kondisyon ![]()
80. Itakda natin
90. Compute ![]() , saan
, saan
100 . Suriin natin ang kondisyon
Konklusyon: ipinapalagay namin at pumunta sa hakbang 9.
9 01 . Compute x 01 hakbang-hakbang
1001 . Suriin natin ang kondisyon ![]()
110 . Suriin natin ang mga kondisyon
Naniniwala kami k=1 at pumunta sa hakbang 5.
5 1 . Suriin natin ang kondisyon
6 1 . Compute
7 1 . Suriin natin ang kondisyon
8 1 . Itakda natin
9 1 . Compute
10 1 . Suriin natin ang kondisyon ![]() :
:
11 1 . Suriin natin ang mga kondisyon
Naniniwala kami k = 2 , pumunta sa hakbang 5.
5 2 . Suriin natin ang kondisyon. Itakda , pumunta sa hakbang 3.
3 1 . Suriin natin ang kondisyon
4 1 . Itakda natin k = 0.
5 2 . Suriin natin ang kondisyon
6 2 . Compute
7 2 . Suriin natin ang kondisyon
8 2 . Itakda natin
9 2 . Compute
10 2 . Suriin natin ang kondisyon ![]()
11 2 . Suriin natin ang mga kondisyon
Naniniwala kami k=1 at pumunta sa hakbang 5.
5 3 . Suriin natin ang kondisyon
6 3 . Compute
7 3 . Suriin natin ang mga kondisyon
8 3 . Itakda natin
9 3 . Compute
10 3 . Suriin natin ang kondisyon ![]()
11 3 . Suriin natin ang mga kondisyon
Itakda natin k = 2 at pumunta sa hakbang 5.
5 4 . Suriin natin ang kondisyon ![]()
Naniniwala kami j \u003d 2, x 20 \u003d x 12 at pumunta sa hakbang 3.
3 2 . Suriin natin ang kondisyon
4 2 . Itakda natin k=0 .
5 4 . Suriin natin ang kondisyon
6 4 . Compute
7 4 . Suriin natin ang kondisyon
8 4 . Itakda natin
9 4 . Compute
10 4 . Suriin natin ang kundisyon, pumunta sa hakbang 11.
11 4 . Suriin natin ang mga kondisyon
Ang mga kundisyon ay natutugunan sa dalawang magkasunod na cycle na may mga numero j = 2 at j -1= 1 . Nakumpleto ang pagkalkula, natagpuan ang punto
Sa fig. 6, ang mga nakuha na puntos ay konektado sa pamamagitan ng isang tuldok na linya.
Sa coordinate descent method, bumababa kami kasama ang isang putol na linya na binubuo ng mga line segment parallel sa coordinate axes.
II. Pagsusuri ng punto x21.
Halimbawa 1.1 ay nagpakita na ang function f(x)
ay mahigpit na matambok, may isang minimum, at samakatuwid ay isang punto ![]() ay ang nahanap na pagtatantya ng pandaigdigang minimum na punto.
ay ang nahanap na pagtatantya ng pandaigdigang minimum na punto.

Sa lahat ng mga pamamaraan ng gradient sa itaas, ang pagkakasunud-sunod ng mga puntos ( x k ) converges sa isang nakatigil na punto ng function f(x) sa ilalim ng medyo pangkalahatang mga proposisyon tungkol sa mga katangian ng function na ito. Sa partikular, ang teorama ay totoo:
Teorama. Kung ang function na f (x) ay bounded mula sa ibaba, ang gradient nito ay natutugunan ang Lipschitz condition () at ang pagpili ng value t n ginawa ng isa sa mga pamamaraan na inilarawan sa itaas, pagkatapos ay anuman ang panimulang punto x 0 :
![]() sa .
sa .
Sa praktikal na pagpapatupad ng scheme
![]() k=1, 2, …n.
k=1, 2, …n.
hihinto ang mga pag-ulit kung para sa lahat i , i = 1, 2, ..., n , mga kondisyon ng uri
 ,
,
kung saan ang ilang ibinigay na numero na nagpapakilala sa katumpakan ng paghahanap ng pinakamababa.
Sa ilalim ng mga kondisyon ng theorem, tinitiyak ng gradient method ang convergence sa function o sa pinakamababang lower bound (kung ang function f(x) ay walang minimum; kanin. 7), o sa halaga ng function sa ilang nakatigil na punto, na siyang limitasyon ng sequence (x hanggang ). Madaling makabuo ng mga halimbawa kapag ang isang saddle ay natanto sa puntong ito, at hindi isang minimum. Sa pagsasagawa, ang mga pamamaraan ng gradient descent ay kumpiyansa na lumalampas sa mga saddle point at nakakahanap ng minima ng layunin ng function (sa pangkalahatang kaso, lokal na minima).

KONGKLUSYON
Ang mga halimbawa ng mga pamamaraan ng gradient ng walang limitasyong pag-optimize ay isinasaalang-alang sa itaas. Bilang resulta ng gawaing ginawa, ang mga sumusunod na konklusyon ay maaaring iguguhit:
1. Higit pa o hindi gaanong kumplikadong mga problema sa paghahanap ng isang extremum sa pagkakaroon ng mga paghihigpit ay nangangailangan ng mga espesyal na diskarte at pamamaraan.
2. Maraming mga algorithm para sa paglutas ng mga problema sa mga paghihigpit ay kinabibilangan ng pag-minimize nang walang mga paghihigpit bilang isang tiyak na yugto.
3. Ang iba't ibang paraan ng pagbaba ay naiiba sa bawat isa sa paraan ng pagpili ng direksyon ng pagbaba at ang haba ng hakbang sa direksyong iyon.
4. Sa ngayon ay walang ganoong teorya na magsasaalang-alang sa anumang mga tampok ng mga function na naglalarawan sa pagbabalangkas ng problema. Ang kagustuhan ay dapat ibigay sa mga pamamaraan na mas madaling pamahalaan sa proseso ng paglutas ng problema.
Ang tunay na inilapat na mga problema sa pag-optimize ay napakasalimuot. Ang mga makabagong pamamaraan ng pag-optimize ay hindi palaging nakakayanan ang paglutas ng mga tunay na problema nang walang tulong ng tao.
BIBLIOGRAPIYA
1. Kosorukov O.A. Pananaliksik sa Operasyon: Isang Teksbuk. 2003
2. Pantleev A.V. Mga paraan ng pag-optimize sa mga halimbawa at gawain: aklat-aralin. Benepisyo. 2005
3. Shishkin E.V. Pananaliksik sa pagpapatakbo: aklat-aralin. 2006
4. Akulich I.L. Mathematical programming sa mga halimbawa at gawain. 1986
5. Wentzel E.S. Pananaliksik sa pagpapatakbo. 1980
6. Venttsel E.S., Ovcharov L.A. Teorya ng probabilidad at mga aplikasyon nito sa engineering. 1988
©2015-2019 site
Lahat ng karapatan ay pag-aari ng kanilang mga may-akda. Hindi inaangkin ng site na ito ang pagiging may-akda, ngunit nagbibigay ng libreng paggamit.
Petsa ng paggawa ng page: 2017-07-02
Fig.3. Geometric na interpretasyon ng pinakamatarik na paraan ng pagbaba. Sa bawat hakbang, ito ay pinili upang ang susunod na pag-ulit ay ang pinakamababang punto ng function sa ray L.
Ang variant na ito ng gradient na paraan ay batay sa pagpili ng hakbang mula sa sumusunod na pagsasaalang-alang. Mula sa punto ay lilipat tayo sa direksyon ng antigradient hanggang sa maabot natin ang minimum ng function f sa direksyong ito, ibig sabihin, sa ray:
Sa madaling salita, ay pinili upang ang susunod na pag-ulit ay ang pinakamababang punto ng function f sa ray L (tingnan ang Fig. 3). Ang variant na ito ng gradient method ay tinatawag na steepest descent method. Tandaan, sa pamamagitan ng paraan, na sa paraang ito ang mga direksyon ng mga katabing hakbang ay orthogonal.
Ang pinakamatarik na paraan ng pagbaba ay nangangailangan ng paglutas ng isang one-dimensional na problema sa pag-optimize sa bawat hakbang. Ipinapakita ng pagsasanay na ang pamamaraang ito ay madalas na nangangailangan ng mas kaunting mga operasyon kaysa sa gradient na paraan na may pare-parehong hakbang.
Sa pangkalahatang sitwasyon, gayunpaman, ang teoretikal na rate ng convergence ng steepest descent method ay hindi mas mataas kaysa sa rate ng convergence ng gradient method na may pare-pareho (pinakamainam) na hakbang.
Mga halimbawang numero
Paraan ng Constant Step Gradient Descent
Upang pag-aralan ang convergence ng gradient descent method na may pare-parehong hakbang, napili ang function:
Mula sa nakuha na mga resulta, maaari nating tapusin na ang pamamaraan ay nag-iiba kung ang dalas ay masyadong malaki, at dahan-dahang nagtatagpo kung ang dalas ay masyadong maliit, at ang katumpakan ay mas malala. Kinakailangang piliin ang hakbang na pinakamalaki sa mga kung saan nagtatagpo ang pamamaraan.
Gradient method na may step splitting
Upang pag-aralan ang convergence ng gradient descent method na may step splitting (2), ang sumusunod na function ay pinili:
Ang paunang pagtatantya ay ang punto (10,10).
Ihinto ang ginamit na pamantayan:
Ang mga resulta ng eksperimento ay ipinapakita sa talahanayan:
|
Ibig sabihin parameter |
Halaga ng parameter |
Halaga ng parameter |
Nakamit ang katumpakan |
Bilang ng mga pag-ulit |
Mula sa mga resulta na nakuha, maaari nating tapusin na ang pinakamainam na pagpili ng mga parameter ay: , bagaman ang pamamaraan ay hindi masyadong sensitibo sa pagpili ng mga parameter.
Pinakamatarik na Paraan ng Pagbaba
Upang pag-aralan ang convergence ng steepest descent method, ang sumusunod na function ay pinili:
Ang paunang pagtatantya ay ang punto (10,10). Ihinto ang ginamit na pamantayan:
Ang pamamaraan ng ginintuang seksyon ay ginamit upang malutas ang mga problema sa pag-optimize ng one-dimensional.
Ang pamamaraan ay nakakuha ng katumpakan ng 6e-8 sa 9 na pag-ulit.
Mula dito maaari nating tapusin na ang pinakamatarik na pamamaraan ng paglusong ay nagtatagpo nang mas mabilis kaysa sa pamamaraan ng gradient ng paghahati ng hakbang at ang paraan ng patuloy na pamamaraan ng pagbaba ng gradient ng hakbang.
Ang kawalan ng pinakamatarik na paraan ng pagbaba ay ang pangangailangang lutasin ang isang problema sa pag-optimize ng one-dimensional.
Kapag nagprograma ng mga pamamaraan ng gradient descent, dapat maging maingat ang isa sa pagpili ng mga parameter, lalo
- · Paraan ng gradient descent na may pare-parehong hakbang: ang hakbang ay dapat piliin na mas mababa sa 0.01, kung hindi, ang pamamaraan ay magkakaiba (ang pamamaraan ay maaaring mag-iba kahit sa hakbang na ito, depende sa function na pinag-aaralan).
- · Gradient method na may step splitting ay hindi masyadong sensitibo sa pagpili ng mga parameter. Isa sa mga pagpipiliang mapagpipilian:
- · Pinakamatarik na paraan ng pagbaba: Bilang isang one-dimensional na paraan ng pag-optimize, ang ginintuang paraan ng seksyon (kapag naaangkop) ay maaaring gamitin.
Ang conjugate gradient na paraan ay isang umuulit na pamamaraan para sa walang limitasyong pag-optimize sa multidimensional na espasyo. Ang pangunahing bentahe ng pamamaraan ay ang paglutas ng quadratic optimization na problema sa isang may hangganan na bilang ng mga hakbang. Samakatuwid, ang conjugate gradient method para sa pag-optimize ng quadratic functional ay unang inilarawan, ang mga umuulit na formula ay hinango, at ang mga pagtatantya ng convergence rate ay ibinigay. Pagkatapos nito, ipinapakita kung paano ang paraan ng conjugate ay pangkalahatan upang ma-optimize ang isang arbitrary na functional, ang iba't ibang mga bersyon ng pamamaraan ay isinasaalang-alang, at ang convergence ay tinatalakay.
Pahayag ng problema sa pag-optimize
Hayaang maibigay ang isang set at isang layunin na function (objective function) ang tinukoy sa set na ito. Ang problema sa pag-optimize ay upang mahanap ang eksaktong upper o lower bound ng layunin function sa set. Ang hanay ng mga punto kung saan naabot ang mas mababang hangganan ng layunin ng function ay tinutukoy.
Kung, kung gayon ang problema sa pag-optimize ay tinatawag na unconstrained. Kung, kung gayon ang problema sa pag-optimize ay tinatawag na napilitan.
Conjugate gradient method para sa isang quadratic functional
Pahayag ng pamamaraan
Isaalang-alang ang sumusunod na problema sa pag-optimize:
Dito, ay isang simetriko positive-definite matrix ng laki. Ang ganitong problema sa pag-optimize ay tinatawag na quadratic. Pansinin, iyon. Ang extremum na kondisyon ng isang function ay katumbas ng system Ang function ay umabot sa lower bound nito sa isang puntong tinukoy ng equation. Kaya, ang problema sa pag-optimize na ito ay nabawasan sa paglutas ng isang sistema ng mga linear na equation. Ang ideya ng conjugate gradient na paraan ay ang mga sumusunod: Hayaan ang maging batayan ng c. Pagkatapos, para sa anumang punto, ang vector ay pinalawak sa mga tuntunin ng batayan Kaya, maaari itong kinakatawan bilang
Ang bawat susunod na approximation ay kinakalkula ng formula:
Kahulugan. Dalawang vector at tinatawag na conjugate na may kinalaman sa isang simetriko matrix B kung
Ilarawan natin ang paraan ng pagbuo ng batayan sa conjugate gradient method. Bilang paunang pagtatantya, pipili tayo ng arbitrary vector. Sa bawat pag-ulit, ang mga sumusunod na patakaran ay pinili:
Ang mga base vector ay kinakalkula ng mga formula:
Ang mga coefficient ay pinili upang ang mga vectors at ay conjugate na may paggalang sa A.
Kung tinutukoy natin ng, pagkatapos ng ilang mga pagpapasimple ay nakuha natin ang mga huling formula na ginamit sa aplikasyon ng conjugate gradient na paraan sa pagsasanay:
Ang sumusunod na theorem ay totoo para sa conjugate gradient method: Theorem Let, kung saan ay isang simetriko positibong tiyak na matrix ng laki. Pagkatapos ang conjugate gradient method ay nagtatagpo nang hindi hihigit sa mga hakbang at ang mga sumusunod na relasyon ay nagtataglay:
Pamamaraan Convergence
Kung ang lahat ng mga kalkulasyon ay eksakto, at ang paunang data ay eksakto, kung gayon ang pamamaraan ay nagtatagpo sa solusyon ng system nang hindi hihigit sa mga pag-ulit, kung saan ang dimensyon ng system. Ang isang mas pinong pagsusuri ay nagpapakita na ang bilang ng mga pag-ulit ay hindi lalampas, kung saan ang bilang ng iba't ibang eigenvalues ng matrix A. Upang matantya ang rate ng convergence, ang sumusunod (sa halip magaspang) pagtatantya ay totoo:
Pinapayagan nito ang pagtatantya ng rate ng convergence kung ang mga pagtatantya para sa maximum at minimum na mga eigenvalues ng matrix ay kilala. Sa pagsasagawa, ang sumusunod na pamantayan sa paghinto ay kadalasang ginagamit:
Computational complexity
Ang mga operasyon ay isinasagawa sa bawat pag-ulit ng pamamaraan. Ang bilang ng mga operasyon na ito ay kinakailangan upang kalkulahin ang produkto - ito ang pinakamatagal na pamamaraan sa bawat pag-ulit. Ang natitirang mga kalkulasyon ay nangangailangan ng mga operasyong O(n). Ang kabuuang computational complexity ng pamamaraan ay hindi lalampas - dahil ang bilang ng mga pag-ulit ay hindi hihigit sa n.
Halimbawa ng numero
Inilapat namin ang conjugate gradient method upang malutas ang system, kung saan ang C gamit ang conjugate gradient method, ang solusyon ng system na ito ay nakuha sa dalawang pag-ulit. Matrix eigenvalues - 5, 5, -5 - dalawa sa kanila ay naiiba, samakatuwid, ayon sa teoretikal na pagtatantya, ang bilang ng mga pag-ulit ay hindi maaaring lumampas sa dalawa
Ang conjugate gradient method ay isa sa mga pinaka-epektibong pamamaraan para sa paglutas ng SLAE na may positibong tiyak na matrix. Ang pamamaraan ay ginagarantiyahan ang convergence sa isang may hangganan na bilang ng mga hakbang, at ang kinakailangang katumpakan ay maaaring makamit nang mas maaga. Ang pangunahing problema ay na, dahil sa akumulasyon ng mga pagkakamali, ang orthogonality ng batayan ng hangin ay maaaring lumabag, na nagpapalala sa convergence
Conjugate gradient method sa pangkalahatan
Isaalang-alang natin ngayon ang isang pagbabago ng conjugate gradient method para sa kaso kapag ang minimized functional ay hindi quadratic: Ating lutasin ang problema:
Isang patuloy na naiba-iba na function. Upang baguhin ang conjugate gradient na paraan upang malutas ang problemang ito, kinakailangan upang makakuha ng para sa mga formula na hindi kasama ang matrix A:
maaaring kalkulahin gamit ang isa sa tatlong mga formula:
1. - Paraan ng Fletcher-Reeves
- 2. - Paraang Polak-Ribi`ere
Kung ang function ay parisukat at mahigpit na matambok, ang lahat ng tatlong mga formula ay nagbibigay ng parehong resulta. Kung ay isang arbitrary na function, ang bawat isa sa mga formula ay tumutugma sa sarili nitong pagbabago ng conjugate gradient method. Ang ikatlong formula ay bihirang ginagamit dahil nangangailangan ito ng function at pagkalkula ng Hessian ng function sa bawat hakbang ng pamamaraan.
Kung ang function ay hindi quadratic, ang conjugate gradient method ay maaaring hindi magtagpo sa isang may hangganang bilang ng mga hakbang. Bilang karagdagan, ang eksaktong pagkalkula sa bawat hakbang ay posible lamang sa mga bihirang kaso. Samakatuwid, ang akumulasyon ng mga error ay humahantong sa katotohanan na ang mga vectors ay hindi na nagpapahiwatig ng direksyon ng pagbaba ng pag-andar. Pagkatapos ay sa ilang hakbang ay inaakala nila. Ang hanay ng lahat ng mga numero kung saan ito ay tinatanggap ay ituturing bilang. Ang mga numero ay tinatawag na mga oras ng pag-update ng pamamaraan. Sa pagsasagawa, madalas na pinipili ng isa kung saan ang sukat ng espasyo.
Pamamaraan Convergence
Para sa pamamaraang Fletcher-Reeves, mayroong convergence theorem na nagpapataw ng hindi masyadong mahigpit na mga kundisyon sa pinapaliit na function: Theorem. Hayaang matugunan ang mga sumusunod na kondisyon:
Limitado ang set
Natutugunan ng derivative ang kondisyon ng Lipschitz na may pare-pareho sa ilang kapitbahayan
set M: .
Ang convergence ay napatunayan para sa Polak-Reiber na pamamaraan sa ilalim ng pagpapalagay na isang mahigpit na convex function. Sa pangkalahatang kaso, imposibleng patunayan ang convergence ng Polak-Reiber method. Sa kabaligtaran, ang sumusunod na theorem ay totoo: Theorem. Ipagpalagay na sa pamamaraang Polak-Reiber ang mga halaga sa bawat hakbang ay eksaktong kinakalkula. Pagkatapos ay mayroong isang function, at isang paunang approximation, tulad na.
Gayunpaman, ang paraan ng Polak-Reiber ay mas gumagana sa pagsasanay. Ang pinakakaraniwang pamantayan sa paghinto sa pagsasanay: Ang pamantayan ng gradient ay nagiging mas mababa sa isang tiyak na threshold Ang halaga ng function sa panahon ng m sunud-sunod na mga pag-ulit ay halos hindi nagbago
Computational complexity
Sa bawat pag-ulit ng mga pamamaraan ng Polack-Reiber o Fletcher-Reeves, ang function at ang gradient nito ay kinakalkula nang isang beses, at ang problema ng one-dimensional na pag-optimize ay malulutas. Kaya, ang pagiging kumplikado ng isang hakbang ng conjugate gradient na paraan ay kapareho ng pagkakasunud-sunod ng pagiging kumplikado ng hakbang ng pinakamatarik na paraan ng pagbaba. Sa pagsasagawa, ang conjugate gradient method ay nagpapakita ng pinakamahusay na convergence rate.
Hahanapin namin ang minimum ng function sa pamamagitan ng paraan ng conjugate gradients
Ang minimum ng function na ito ay katumbas ng 1 at naabot sa punto (5, 4). Ihambing natin ang mga pamamaraan ng Polack-Reiber at Fletcher-Reeves sa halimbawa ng function na ito. Ang mga pag-ulit sa parehong mga pamamaraan ay humihinto kapag ang parisukat ng gradient norm ay nagiging mas maliit sa kasalukuyang hakbang. Ang paraan ng ginintuang seksyon ay ginagamit para sa pagpili.
|
Paraan ng Fletcher-Reeves |
Paraan ng Polack-Reiber |
|||||
|
Bilang ng mga pag-ulit |
Nakahanap ng solusyon |
Halaga ng function |
Bilang ng mga pag-ulit |
Nakahanap ng solusyon |
Halaga ng function |
|
|
(5.01382198,3.9697932) |
(5.03942877,4.00003512) |
|||||
|
(5.01056482,3.99018026) |
(4.9915894,3.99999044) |
|||||
|
(4.9979991,4.00186173) |
(5.00336181,4.0000018) |
|||||
|
(4.99898277,4.00094645) |
(4.99846808,3.99999918) |
|||||
|
(4.99974658,4.0002358) |
(4.99955034,3.99999976) |
Dalawang bersyon ng conjugate gradient method ang ipinatupad: para sa pagliit ng isang quadratic functional, at para sa pagliit ng isang arbitrary function. Sa unang kaso, ang pamamaraan ay ipinatupad ng vector function
Ang mga pamamaraan ng gradient descent ay isang medyo makapangyarihang tool para sa paglutas ng mga problema sa pag-optimize. Ang pangunahing kawalan ng mga pamamaraan ay ang limitadong lugar ng kakayahang magamit. Ang conjugate gradient method ay gumagamit lamang ng impormasyon tungkol sa linear na bahagi ng pagtaas sa isang punto, tulad ng sa gradient descent method. Kasabay nito, ang conjugate gradient method ay nagbibigay-daan sa paglutas ng mga quadratic na problema sa isang may hangganang bilang ng mga hakbang. Sa maraming iba pang mga problema, ang conjugate gradient na paraan ay higit pa sa gradient descent method. Ang convergence ng gradient method ay mahalagang nakadepende sa kung gaano katumpak ang one-dimensional na problema sa pag-optimize ay nalutas. Ang mga posibleng loop ng pamamaraan ay naayos na may mga update. Gayunpaman, kung ang pamamaraan ay tumama sa lokal na minimum ng function, malamang na hindi ito makakalabas dito.
Anotasyon: Sa panayam na ito, ang mga pamamaraan ng multi-parameter na pag-optimize bilang ang pinakamatarik na paraan ng pagbaba at ang paraan ng Davidon-Fletcher-Powell ay malawakang saklaw. Bilang karagdagan, ang isang paghahambing na pagsusuri ng mga pamamaraan sa itaas ay isinasagawa upang matukoy ang pinaka-epektibo, ang kanilang mga pakinabang at kawalan ay natukoy; at isinasaalang-alang din ang mga problema ng multivariate optimization, tulad ng paraan ng mga bangin at ang paraan ng multi-extremality.
1. Paraan ng pinakamatarik na pagbaba
Ang kakanyahan ng pamamaraang ito ay sa tulong ng naunang nabanggit coordinate descent method Ang isang paghahanap ay isinasagawa mula sa isang naibigay na punto sa isang direksyon na kahanay sa isa sa mga axes, hanggang sa isang minimum na punto sa direksyon na ito. Isinasagawa ang paghahanap sa direksyong parallel sa kabilang axis, at iba pa. Ang mga direksyon, siyempre, ay naayos. Tila makatwirang subukang baguhin ang pamamaraang ito sa paraang sa bawat yugto ang paghahanap para sa pinakamababang punto ay isinasagawa kasama ang "pinakamahusay" na direksyon. Hindi malinaw kung aling direksyon ang "pinakamahusay", ngunit ito ay kilala na direksyon ng gradient ay ang direksyon ng pinakamabilis na pagtaas ng function. Samakatuwid, ang kabaligtaran na direksyon ay ang direksyon ng pinakamabilis na pagbaba ng function. Maaaring bigyang-katwiran ang ari-arian na ito bilang mga sumusunod.
Ipagpalagay natin na lumilipat tayo mula sa punto x patungo sa susunod na punto x + hd , kung saan ang d ay ilang direksyon at h ay isang hakbang na may kaunting haba. Samakatuwid, ang paggalaw ay ginawa mula sa punto (x 1, x 2, ..., x n) hanggang sa punto (x 1 + zx 1, x 2 + zx 2, ..., x n + zx n), saan
Ang pagbabago sa mga halaga ng function ay tinutukoy ng mga relasyon
| (1.3) |
Hanggang sa unang order zx i , at ang mga partial derivatives ay kinakalkula sa puntong x . Paano dapat piliin ang mga direksyon d i na nakakatugon sa equation (1.2) upang makuha ang pinakamalaking pagbabago sa function na df ? Ito ay kung saan ang problema ng pag-maximize na may isang hadlang arises. Inilapat namin ang paraan ng mga multiplier ng Lagrange, sa tulong kung saan tinukoy namin ang function
Ang halaga ng df na nagbibigay-kasiyahan sa hadlang (1.2) ay umabot sa pinakamataas nito kapag ang function
Naabot ang maximum. Ang hinango nito
Dahil dito,
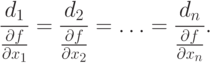 |
(1.6) |
Pagkatapos ang di ~ df/dx i at ang direksyon d ay kahanay sa direksyon V/(x) sa puntong x.
Sa ganitong paraan, pinakamalaking lokal na pagtaas Ang function para sa isang naibigay na maliit na hakbang h ay nangyayari kapag ang d ay ang direksyon na Vf(x) o g(x) . Samakatuwid, ang direksyon ng pinakamatarik na pagbaba ay ang direksyon
Sa isang mas simpleng anyo, ang equation (1.3) ay maaaring isulat bilang mga sumusunod:
Nasaan ang anggulo sa pagitan ng mga vectors Vf(x) at dx . Para sa isang ibinigay na halaga ng dx, pinaliit namin ang df sa pamamagitan ng pagpili , upang ang direksyon ng dx ay pareho sa direksyon ng -Vf(x) .
Magkomento. direksyon ng gradient patayo sa anumang punto sa linya ng pare-parehong antas, dahil ang pag-andar ay pare-pareho sa linyang ito. Kaya, kung ang (d 1 , d 2 , ..., d n) ay isang maliit na hakbang sa linya ng antas, kung gayon
At samakatuwid
 |
(1.8) |
Halimbawa 6.8.3-1. Hanapin ang minimum ng function Q(x, y) gamit ang GDS method.
Hayaan ang Q(x,y) = x 2 +2y 2 ; x 0 = 2; y 0 = 1.
Suriin natin ang sapat na mga kondisyon para sa pagkakaroon ng minimum:
![]()
Gawin natin ang isang pag-ulit ayon sa algorithm.
1. Q(x0,y0) = 6.
2.
Kapag x \u003d x 0 at y \u003d y 0, ![]()
3. Hakbang l k \u003d l 0 \u003d 0.5
Kaya 4< 8, следовательно, условие сходимости не выполняется и требуется, уменьшив шаг (l=l /2), повторять п.п.3-4 до выполнения условия сходимости. То есть, полученный шаг используется для нахождения следующей точки траектории спуска.
Ang kakanyahan ng pamamaraan ay ang mga sumusunod. Mula sa napiling punto (x 0 ,y 0) ang pagbaba ay isinasagawa sa direksyon ng anti-gradient hanggang sa maabot ang pinakamababang halaga ng layunin ng function na Q(x, y) kasama ang sinag (Larawan 6.8.4- 1). Sa nahanap na punto, ang sinag ay humipo sa antas ng linya. Pagkatapos, mula sa puntong ito, ang pagbaba ay isinasagawa sa direksyon ng anti-gradient (patayo sa linya ng antas) hanggang sa ang kaukulang sinag ay hawakan ang linya ng antas na dumadaan dito sa isang bagong punto, at iba pa.

Ipahayag natin ang layuning function na Q(x, y) sa mga tuntunin ng hakbang l. Kasabay nito, kinakatawan namin ang layunin ng function sa isang tiyak na hakbang bilang isang function ng isang variable, i.e. laki ng hakbang
Ang laki ng hakbang sa bawat pag-ulit ay tinutukoy mula sa pinakamababang kundisyon:
Min( (l)) l k = l*(x k , y k), l >0.
Kaya, sa bawat pag-ulit, ang pagpili ng hakbang l k ay nagpapahiwatig ng solusyon ng isang one-dimensional na problema sa pag-optimize. Ayon sa paraan ng paglutas ng problemang ito, mayroong:
· analytical method (NSA);
· Numerical na paraan (NCh).
Sa paraan ng NSA, ang halaga ng hakbang ay nakuha mula sa kundisyon , at sa pamamaraang LSS, ang halaga l k ay makikita sa isang segment na may ibinigay na katumpakan gamit ang isa sa mga one-dimensional na paraan ng pag-optimize.
Halimbawa 6.8.4-1. Hanapin ang pinakamababa ng function Q(x,y)=x 2 + 2y 2 na may katumpakan na e=0.1, sa ilalim ng mga unang kundisyon: x 0 =2; y 0 =1.
Gawin natin ang isang pag-ulit ayon sa pamamaraan NSA.
=(x-2lx) 2 +2(y-4ly) 2 = x 2 -4lx 2 +4l 2 x 2 +2y 2 -16ly 2 +32l 2 y 2 .
Mula sa kundisyon ¢(l)=0 makikita natin ang halaga l*: ![]()
Ang resultang function na l=l(x,y) ay nagpapahintulot sa iyo na mahanap ang halaga ng l. Para sa x=2 at y=1 mayroon tayong l=0.3333.
Kalkulahin ang mga halaga ng mga coordinate ng susunod na punto:

Suriin natin ang katuparan ng pamantayan ng pagwawakas ng pag-ulit para sa k=1:

Dahil |2*0.6666|>0.1 at |-0.3333*4|>0.1 , ang mga kondisyon para sa pagwawakas ng proseso ng pag-ulit ay hindi natutugunan, ibig sabihin. hindi nahanap ang minimum. Samakatuwid, dapat mong kalkulahin ang bagong halaga ng l sa x=x 1 at y=y 1 at makuha ang mga coordinate ng susunod na descent point. Magpapatuloy ang mga kalkulasyon hanggang sa matugunan ang mga kondisyon ng pagtatapos ng pagbaba.
Ang pagkakaiba sa pagitan ng numerical NN method at ang analytical ay ang paghahanap para sa value ng l sa bawat pag-ulit ay ginagawa ng isa sa mga numerical na pamamaraan ng one-dimensional optimization (halimbawa, ang dichotomy method o ang golden section method). Sa kasong ito, ang hanay ng mga tinatanggap na halaga ng l - ay nagsisilbing isang agwat ng kawalan ng katiyakan.
