Of course, when calculating the cumulative distribution function, one should use the mentioned relationship between the binomial and beta distributions. This method is certainly better than direct summation when n > 10.
In classical textbooks on statistics, to obtain the values of the binomial distribution, it is often recommended to use formulas based on limit theorems (such as the Moivre-Laplace formula). It should be noted that from a purely computational point of view the value of these theorems is close to zero, especially now, when there is a powerful computer on almost every table. The main disadvantage of the above approximations is their completely insufficient accuracy for the values of n typical for most applications. A no lesser disadvantage is the absence of any clear recommendations on the applicability of one or another approximation (in standard texts, only asymptotic formulations are given, they are not accompanied by accuracy estimates and, therefore, are of little use). I would say that both formulas are valid only for n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
I do not consider here the problem of finding quantiles: for discrete distributions, it is trivial, and in those problems where such distributions arise, as a rule, it is not relevant. If quantiles are still needed, I recommend reformulating the problem in such a way as to work with p-values (observed significances). Here is an example: when implementing some enumeration algorithms, at each step it is required to check the statistical hypothesis about a binomial random variable. According to the classical approach, at each step it is necessary to calculate the statistics of the criterion and compare its value with the boundary of the critical set. Since, however, the algorithm is enumerative, it is necessary to determine the boundary of the critical set each time anew (after all, the sample size changes from step to step), which unproductively increases time costs. The modern approach recommends calculating the observed significance and comparing it with the confidence probability, saving on the search for quantiles.
Therefore, the following codes do not calculate the inverse function, instead, the function rev_binomialDF is given, which calculates the probability p of success in a single trial given the number n of trials, the number m of successes in them, and the value y of the probability of getting these m successes. This uses the aforementioned relationship between the binomial and beta distributions.
In fact, this function allows you to get the boundaries of confidence intervals. Indeed, suppose we get m successes in n binomial trials. As is known, the left bound of the two-sided confidence interval for the parameter p with a confidence level is 0 if m = 0, and for is the solution of the equation  . Similarly, the right bound is 1 if m = n, and for is a solution to the equation
. Similarly, the right bound is 1 if m = n, and for is a solution to the equation  . This implies that in order to find the left boundary, we must solve for the equation
. This implies that in order to find the left boundary, we must solve for the equation  , and to search for the right one - the equation
, and to search for the right one - the equation  . They are solved in the functions binom_leftCI and binom_rightCI , which return the upper and lower bounds of the two-sided confidence interval, respectively.
. They are solved in the functions binom_leftCI and binom_rightCI , which return the upper and lower bounds of the two-sided confidence interval, respectively.
I want to note that if absolutely incredible accuracy is not needed, then for sufficiently large n, you can use the following approximation [B.L. van der Waerden, Mathematical statistics. M: IL, 1960, Ch. 2, sec. 7]:  , where g is the quantile of the normal distribution. The value of this approximation is that there are very simple approximations that allow you to calculate the quantiles of the normal distribution (see the text about calculating the normal distribution and the corresponding section of this reference). In my practice (mainly for n > 100), this approximation gave about 3-4 digits, which, as a rule, is quite enough.
, where g is the quantile of the normal distribution. The value of this approximation is that there are very simple approximations that allow you to calculate the quantiles of the normal distribution (see the text about calculating the normal distribution and the corresponding section of this reference). In my practice (mainly for n > 100), this approximation gave about 3-4 digits, which, as a rule, is quite enough.
Calculations with the following codes require the files betaDF.h , betaDF.cpp (see section on beta distribution), as well as logGamma.h , logGamma.cpp (see appendix A). You can also see an example of using functions.
binomialDF.h file
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(double trials, double successes, double p); /* * Let there be "trials" of independent observations * with probability "p" of success in each. * Compute the probability B(successes|trials,p) that the number * of successes is between 0 and "successes" (inclusive). */ double rev_binomialDF(double trials, double successes, double y); /* * Let the probability y of at least m successes * be known in trials of the Bernoulli scheme. The function finds the probability p * of success in a single trial. * * The following relation is used in calculations * * 1 - p = rev_Beta(trials-successes| successes+1, y). */ double binom_leftCI(double trials, double successes, double level); /* Let there be "trials" of independent observations * with probability "p" of success in each * and the number of successes is "successes". * The left bound of the two-sided confidence interval * is calculated with the significance level level. */ double binom_rightCI(double n, double successes, double level); /* Let there be "trials" of independent observations * with probability "p" of success in each * and the number of successes is "successes". * The right bound of the two-sided confidence interval * is calculated with the significance level level. */ #endif /* Ends #ifndef __BINOMIAL_H__ */ |
binomialDF.cpp file
| /***************************************************** **********/ /* Binomial Distribution */ /******************************** ***************************/ #include |
Consider the Binomial distribution, calculate its mathematical expectation, variance, mode. Using the MS EXCEL function BINOM.DIST(), we will plot the distribution function and probability density graphs. Let us estimate the distribution parameter p, the mathematical expectation of the distribution, and the standard deviation. Also consider the Bernoulli distribution.
Definition. Let them be held n tests, in each of which only 2 events can occur: the event "success" with a probability p or the event "failure" with the probability q =1-p (the so-called Bernoulli scheme,Bernoullitrials).
Probability of getting exactly x success in these n tests is equal to:
Number of successes in the sample x is a random variable that has Binomial distribution(English) Binomialdistribution) p and n – are parameters of this distribution.
Recall that in order to apply Bernoulli schemes and correspondingly binomial distribution, the following conditions must be met:
- each trial must have exactly two outcomes, conditionally called "success" and "failure".
- the result of each test should not depend on the results of previous tests (test independence).
- success rate p should be constant for all tests.
Binomial distribution in MS EXCEL
In MS EXCEL, starting from version 2010, for there is a BINOM.DIST() function, the English name is BINOM.DIST(), which allows you to calculate the probability that the sample will have exactly X"successes" (i.e. probability density function p(x), see formula above), and integral distribution function(probability that the sample will have x or less "successes", including 0).
Prior to MS EXCEL 2010, EXCEL had the BINOMDIST() function, which also allows you to calculate distribution function and probability density p(x). BINOMDIST() is left in MS EXCEL 2010 for compatibility.
The example file contains graphs probability distribution density and .

Binomial distribution has the designation B (n ; p) .
Note: For building integral distribution function perfect fit chart type Schedule, for distribution density – Histogram with grouping. For more information about building charts, read the article The main types of charts.
Note: For the convenience of writing formulas in the example file, Names for parameters have been created Binomial distribution: n and p.

The example file shows various probability calculations using MS EXCEL functions:
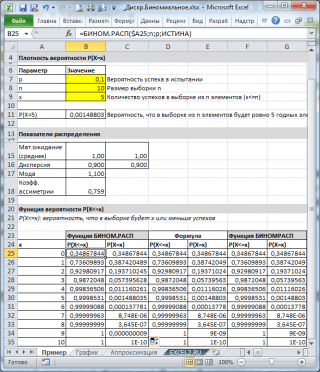
As seen in the picture above, it is assumed that:
- The infinite population from which the sample is made contains 10% (or 0.1) good elements (parameter p, third function argument = BINOM.DIST() )
- To calculate the probability that in a sample of 10 elements (parameter n, the second argument of the function) there will be exactly 5 valid elements (the first argument), you need to write the formula: =BINOM.DIST(5, 10, 0.1, FALSE)
- The last, fourth element is set = FALSE, i.e. function value is returned distribution density .
If the value of the fourth argument = TRUE, then the BINOM.DIST() function returns the value integral distribution function or simply distribution function. In this case, you can calculate the probability that the number of good items in the sample will be from a certain range, for example, 2 or less (including 0).
To do this, write the formula: = BINOM.DIST(2, 10, 0.1, TRUE)
Note: For a non-integer value of x, . For example, the following formulas will return the same value: =BINOM.DIST( 2 ; ten; 0.1; TRUE)=BINOM.DIST( 2,9 ; ten; 0.1; TRUE)
Note: In the example file probability density and distribution function also computed using the definition and the COMBIN() function.
Distribution indicators
AT example file on sheet Example there are formulas for calculating some distribution indicators:
- =n*p;
- (squared standard deviation) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
We derive the formula mathematical expectationBinomial distribution using Bernoulli scheme .
By definition, a random variable X in Bernoulli scheme(Bernoulli random variable) has distribution function :

This distribution is called Bernoulli distribution .
Note : Bernoulli distribution- special case Binomial distribution with parameter n=1.
Let's generate 3 arrays of 100 numbers with different probabilities of success: 0.1; 0.5 and 0.9. To do this, in the window Random number generation set the following parameters for each probability p:

Note: If you set the option Random scattering (Random seed), then you can choose a certain random set of generated numbers. For example, by setting this option =25, you can generate the same sets of random numbers on different computers (if, of course, other distribution parameters are the same). The option value can take integer values from 1 to 32,767. Option name Random scattering can confuse. It would be better to translate it as Set number with random numbers .
As a result, we will have 3 columns of 100 numbers, based on which, for example, we can estimate the probability of success p according to the formula: Number of successes/100(cm. example file sheet Generating Bernoulli).

Note: For Bernoulli distributions with p=0.5, you can use the formula =RANDBETWEEN(0;1) , which corresponds to .
Random number generation. Binomial distribution
Suppose there are 7 defective items in the sample. This means that it is "very likely" that the proportion of defective products has changed. p, which is a characteristic of our production process. Although this situation is “very likely”, there is a possibility (alpha risk, type 1 error, “false alarm”) that p remained unchanged, and the increased number of defective products was due to random sampling.
As can be seen in the figure below, 7 is the number of defective products that is acceptable for a process with p=0.21 at the same value Alpha. This illustrates that when the threshold of defective items in a sample is exceeded, p“probably” increased. The phrase "likely" means that there is only a 10% chance (100%-90%) that the deviation of the percentage of defective products above the threshold is due only to random causes.
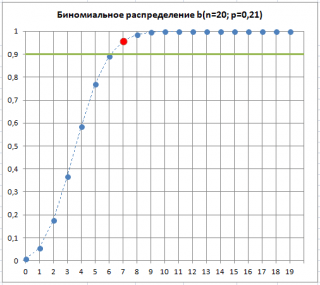
Thus, exceeding the threshold number of defective products in the sample may serve as a signal that the process has become upset and began to produce b about higher percentage of defective products.
Note: Prior to MS EXCEL 2010, EXCEL had a function CRITBINOM() , which is equivalent to BINOM.INV() . CRITBINOM() is left in MS EXCEL 2010 and higher for compatibility.
Relation of the Binomial distribution to other distributions
If the parameter nBinomial distribution tends to infinity and p tends to 0, then in this case Binomial distribution can be approximated. It is possible to formulate conditions when the approximation Poisson distribution works good:
- p(the less p and more n, the more accurate the approximation);
- p >0,9 (considering that q =1- p, calculations in this case must be performed using q(a X needs to be replaced with n - x). Therefore, the less q and more n, the more accurate the approximation).
At 0.110 Binomial distribution can be approximated.
In its turn, Binomial distribution can serve as a good approximation when the population size is N Hypergeometric distribution much larger than the sample size n (i.e., N>>n or n/N You can read more about the relationship of the above distributions in the article. Examples of approximation are also given there, and conditions are explained when it is possible and with what accuracy.
ADVICE: You can read about other distributions of MS EXCEL in the article .
The theory of probability is invisibly present in our lives. We do not pay attention to it, but every event in our life has one or another probability. Given the huge number of possible scenarios, it becomes necessary for us to determine the most likely and least likely of them. It is most convenient to analyze such probabilistic data graphically. Distribution can help us with this. Binomial is one of the easiest and most accurate.
Before moving directly to mathematics and probability theory, let's figure out who was the first to come up with this type of distribution and what is the history of the development of the mathematical apparatus for this concept.
Story
The concept of probability has been known since ancient times. However, ancient mathematicians did not attach much importance to it and were only able to lay the foundations for a theory that later became the theory of probability. They created some combinatorial methods that greatly helped those who later created and developed the theory itself.
In the second half of the seventeenth century, the formation of the basic concepts and methods of probability theory began. Definitions of random variables, methods for calculating the probability of simple and some complex independent and dependent events were introduced. Such an interest in random variables and probabilities was dictated by gambling: each person wanted to know what his chances of winning the game were.
The next step was the application of methods of mathematical analysis in probability theory. Eminent mathematicians such as Laplace, Gauss, Poisson and Bernoulli took up this task. It was they who advanced this area of mathematics to a new level. It was James Bernoulli who discovered the binomial distribution law. By the way, as we will later find out, on the basis of this discovery, several more were made, which made it possible to create the law of normal distribution and many others.
Now, before we begin to describe the binomial distribution, we will refresh a little in the memory of the concepts of probability theory, probably already forgotten from the school bench.
Fundamentals of Probability Theory
We will consider such systems, as a result of which only two outcomes are possible: "success" and "failure". This is easy to understand with an example: we toss a coin, guessing that tails will fall out. The probabilities of each of the possible events (tails - "success", heads - "not success") are equal to 50 percent with the coin perfectly balanced and there are no other factors that can affect the experiment.
It was the simplest event. But there are also complex systems in which sequential actions are performed, and the probabilities of the outcomes of these actions will differ. For example, consider the following system: in a box whose contents we cannot see, there are six absolutely identical balls, three pairs of blue, red and white colors. We have to get a few balls at random. Accordingly, by pulling out one of the white balls first, we will reduce by several times the probability that the next one we will also get a white ball. This happens because the number of objects in the system changes.
In the next section, we will look at more complex mathematical concepts that bring us close to what the words "normal distribution", "binomial distribution" and the like mean.

Elements of mathematical statistics
In statistics, which is one of the areas of application of the theory of probability, there are many examples where the data for analysis is not given explicitly. That is, not in numbers, but in the form of division according to characteristics, for example, according to gender. In order to apply a mathematical apparatus to such data and draw some conclusions from the results obtained, it is required to convert the initial data into a numerical format. As a rule, to implement this, a positive outcome is assigned a value of 1, and a negative one is assigned a value of 0. Thus, we obtain statistical data that can be analyzed using mathematical methods.
The next step in understanding what the binomial distribution of a random variable is is to determine the variance of the random variable and the mathematical expectation. We'll talk about this in the next section.

Expected value
In fact, understanding what mathematical expectation is is not difficult. Consider a system in which there are many different events with their own different probabilities. Mathematical expectation will be called a value equal to the sum of the products of the values of these events (in the mathematical form that we talked about in the last section) and the probability of their occurrence.
The mathematical expectation of the binomial distribution is calculated according to the same scheme: we take the value of a random variable, multiply it by the probability of a positive outcome, and then summarize the obtained data for all variables. It is very convenient to present these data graphically - this way the difference between the mathematical expectations of different values is better perceived.
In the next section, we will tell you a little about a different concept - the variance of a random variable. It is also closely related to such a concept as the binomial probability distribution, and is its characteristic.

Binomial distribution variance
This value is closely related to the previous one and also characterizes the distribution of statistical data. It represents the mean square of deviations of values from their mathematical expectation. That is, the variance of a random variable is the sum of the squared differences between the value of a random variable and its mathematical expectation, multiplied by the probability of this event.
In general, this is all we need to know about variance in order to understand what the binomial probability distribution is. Now let's move on to our main topic. Namely, what lies behind such a seemingly rather complicated phrase "binomial distribution law".

Binomial distribution
Let's first understand why this distribution is binomial. It comes from the word "binom". You may have heard of Newton's binomial - a formula that can be used to expand the sum of any two numbers a and b to any non-negative power of n.
As you probably already guessed, Newton's binomial formula and the binomial distribution formula are almost the same formulas. With the only exception that the second has an applied value for specific quantities, and the first is only a general mathematical tool, the applications of which in practice can be different.
Distribution formulas
The binomial distribution function can be written as the sum of the following terms:
(n!/(n-k)!k!)*p k *q n-k
Here n is the number of independent random experiments, p is the number of successful outcomes, q is the number of unsuccessful outcomes, k is the number of the experiment (it can take values from 0 to n),! - designation of a factorial, such a function of a number, the value of which is equal to the product of all the numbers going up to it (for example, for the number 4: 4!=1*2*3*4=24).
In addition, the binomial distribution function can be written as an incomplete beta function. However, this is already a more complex definition, which is used only when solving complex statistical problems.
The binomial distribution, examples of which we examined above, is one of the simplest types of distributions in probability theory. There is also a normal distribution, which is a type of binomial distribution. It is the most commonly used, and the easiest to calculate. There is also a Bernoulli distribution, a Poisson distribution, a conditional distribution. All of them characterize graphically the areas of probability of a particular process under different conditions.
In the next section, we will consider aspects related to the application of this mathematical apparatus in real life. At first glance, of course, it seems that this is another mathematical thing, which, as usual, does not find application in real life, and is generally not needed by anyone except mathematicians themselves. However, this is not the case. After all, all types of distributions and their graphical representations were created solely for practical purposes, and not as a whim of scientists.

Application
By far the most important application of distributions is in statistics, where complex analysis of a multitude of data is needed. As practice shows, very many data arrays have approximately the same distributions of values: the critical regions of very low and very high values, as a rule, contain fewer elements than the average values.
Analysis of large data arrays is required not only in statistics. It is indispensable, for example, in physical chemistry. In this science, it is used to determine many quantities that are associated with random vibrations and movements of atoms and molecules.
In the next section, we will understand how important it is to apply statistical concepts such as binomial distribution of a random variable in everyday life for you and me.

Why do I need it?
Many people ask themselves this question when it comes to mathematics. And by the way, mathematics is not in vain called the queen of sciences. It is the basis of physics, chemistry, biology, economics, and in each of these sciences, some kind of distribution is also used: whether it is a discrete binomial distribution or a normal one, it does not matter. And if we take a closer look at the world around us, we will see that mathematics is used everywhere: in everyday life, at work, and even human relationships can be presented in the form of statistical data and analyzed (this, by the way, is done by those who work in special organizations involved in the collection of information).
Now let's talk a little about what to do if you need to know much more on this topic than what we have outlined in this article.
The information that we have given in this article is far from complete. There are many nuances as to what form the distribution might take. The binomial distribution, as we have already found out, is one of the main types on which all mathematical statistics and probability theory are based.
If you become interested, or in connection with your work you need to know much more on this topic, you will need to study the specialized literature. You should start with a university course in mathematical analysis and go there to the section on probability theory. Also knowledge in the field of series will be useful, because the binomial probability distribution is nothing more than a series of successive terms.
Conclusion
Before finishing the article, we would like to tell you one more interesting thing. It concerns directly the topic of our article and all mathematics in general.
Many people say that mathematics is a useless science, and nothing that they learned in school was useful to them. But knowledge is never superfluous, and if something is not useful to you in life, it means that you simply do not remember it. If you have knowledge, they can help you, but if you do not have them, then you cannot expect help from them.
So, we examined the concept of the binomial distribution and all the definitions associated with it and talked about how it is applied in our lives.
Chapter 7
Specific laws of distribution of random variables
Types of laws of distribution of discrete random variables
Let a discrete random variable take the values X 1 , X 2 , …, x n, … . The probabilities of these values can be calculated using various formulas, for example, using the basic theorems of probability theory, Bernoulli's formula, or some other formulas. For some of these formulas, the distribution law has its own name.
The most common laws of distribution of a discrete random variable are binomial, geometric, hypergeometric, Poisson's distribution law.
Binomial distribution law
Let it be produced n independent trials, in each of which an event may or may not occur BUT. The probability of the occurrence of this event in each single trial is constant, does not depend on the trial number and is equal to R=R(BUT). Hence the probability that the event will not occur BUT in each test is also constant and equal to q=1–R. Consider a random variable X equal to the number of occurrences of the event BUT in n tests. It is obvious that the values of this quantity are equal to
X 1 =0 - event BUT in n tests did not appear;
X 2 =1 – event BUT in n trials appeared once;
X 3 =2 - event BUT in n trials appeared twice;
…………………………………………………………..
x n +1 = n- event BUT in n tests appeared everything n once.
The probabilities of these values can be calculated using the Bernoulli formula (4.1):
where to=0, 1, 2, …,n .
Binomial distribution law X equal to the number of successes in n Bernoulli trials, with a probability of success R.
So, a discrete random variable has a binomial distribution (or is distributed according to the binomial law) if its possible values are 0, 1, 2, …, n, and the corresponding probabilities are calculated by formula (7.1).
The binomial distribution depends on two parameters R and n.
The distribution series of a random variable distributed according to the binomial law has the form:
| X | … | k | … | n | ||
| R | | … | … | |
Example 7.1 . Three independent shots are fired at the target. The probability of hitting each shot is 0.4. Random value X- the number of hits on the target. Construct its distribution series.
Decision. Possible values of a random variable X are X 1 =0; X 2 =1; X 3 =2; X 4=3. Find the corresponding probabilities using the Bernoulli formula. It is easy to show that the application of this formula here is fully justified. Note that the probability of not hitting the target with one shot will be equal to 1-0.4=0.6. Get

The distribution series has the following form:
| X | ||||
| R | 0,216 | 0,432 | 0,288 | 0,064 |
It is easy to check that the sum of all probabilities is equal to 1. The random variable itself X distributed according to the binomial law. ■
Let's find the mathematical expectation and variance of a random variable distributed according to the binomial law.
When solving example 6.5, it was shown that the mathematical expectation of the number of occurrences of an event BUT in n independent tests, if the probability of occurrence BUT in each test is constant and equal R, equals n· R
In this example, a random variable was used, distributed according to the binomial law. Therefore, the solution of Example 6.5 is, in fact, a proof of the following theorem.
Theorem 7.1. The mathematical expectation of a discrete random variable distributed according to the binomial law is equal to the product of the number of trials and the probability of "success", i.e. M(X)=n· R.
Theorem 7.2. The variance of a discrete random variable distributed according to the binomial law is equal to the product of the number of trials by the probability of "success" and the probability of "failure", i.e. D(X)=npq.
Skewness and kurtosis of a random variable distributed according to the binomial law are determined by the formulas
These formulas can be obtained using the concept of initial and central moments.
The binomial distribution law underlies many real situations. For large values n the binomial distribution can be approximated by other distributions, in particular the Poisson distribution.
Poisson distribution
Let there be n Bernoulli trials, with the number of trials n large enough. Previously, it was shown that in this case (if, in addition, the probability R events BUT very small) to find the probability that an event BUT to appear t once in the tests, you can use the Poisson formula (4.9). If the random variable X means the number of occurrences of the event BUT in n Bernoulli trials, then the probability that X will take on the meaning k can be calculated by the formula
 , (7.2)
, (7.2)
where λ = np.
Poisson distribution law is called the distribution of a discrete random variable X, for which the possible values are non-negative integers, and the probabilities p t these values are found by formula (7.2).
Value λ = np called parameter Poisson distribution.
A random variable distributed according to Poisson's law can take on an infinite number of values. Since for this distribution the probability R occurrence of an event in each trial is small, then this distribution is sometimes called the law of rare phenomena.
The distribution series of a random variable distributed according to the Poisson law has the form
| X | … | t | … | ||||
| R | … | … |
It is easy to verify that the sum of the probabilities of the second row is equal to 1. To do this, we need to remember that the function can be expanded in a Maclaurin series, which converges for any X. In this case we have
 . (7.3)
. (7.3)
As noted, Poisson's law in certain limiting cases replaces the binomial law. An example is a random variable X, the values of which are equal to the number of failures for a certain period of time with repeated use of a technical device. It is assumed that this device is of high reliability, i.e. the probability of failure in one application is very small.
In addition to such limiting cases, in practice there are random variables distributed according to the Poisson law, not related to the binomial distribution. For example, the Poisson distribution is often used when dealing with the number of events that occur in a period of time (the number of calls to the telephone exchange during the hour, the number of cars that arrived at the car wash during the day, the number of machine stops per week, etc. .). All these events must form the so-called flow of events, which is one of the basic concepts of queuing theory. Parameter λ characterizes the average intensity of the flow of events.
Example 7.2 . The faculty has 500 students. What is the probability that September 1st is the birthday of three students in this faculty?
Decision . Since the number of students n=500 is large enough and R– the probability of being born on the first of September to any of the students is , i.е. small enough, then we can assume that the random variable X– the number of students born on the first of September is distributed according to the Poisson law with the parameter λ = np= =1.36986. Then, according to formula (7.2), we obtain
Theorem 7.3. Let the random variable X distributed according to Poisson's law. Then its mathematical expectation and variance are equal to each other and equal to the value of the parameter λ , i.e. M(X) = D(X) = λ = np.
Proof. By the definition of mathematical expectation, using formula (7.3) and the distribution series of a random variable distributed according to the Poisson law, we obtain
Before finding the variance, we first find the mathematical expectation of the square of the considered random variable. We get

Hence, by the definition of dispersion, we obtain
The theorem has been proven.
Applying the concepts of initial and central moments, it can be shown that for a random variable distributed according to the Poisson law, the skewness and kurtosis coefficients are determined by the formulas
It is easy to understand that, since the semantic content of the parameter λ = np is positive, then a random variable distributed according to Poisson's law always has positive both skewness and kurtosis.
Not all phenomena are measured on a quantitative scale like 1, 2, 3 ... 100500 ... Not always a phenomenon can take on an infinite or a large number of different states. For example, a person's gender can be either M or F. The shooter either hits the target or misses. You can vote either “For” or “Against”, etc. etc. In other words, such data reflects the state of an alternative attribute - either “yes” (the event occurred) or “no” (the event did not occur). The coming event (positive outcome) is also called "success".
Experiments with such data are called Bernoulli scheme, in honor of the famous Swiss mathematician who found that with a large number of trials, the ratio of positive outcomes to the total number of trials tends to the probability of this event occurring.
Alternate Feature Variable
In order to use the mathematical apparatus in the analysis, the results of such observations should be written down in numerical form. To do this, a positive outcome is assigned the number 1, a negative one - 0. In other words, we are dealing with a variable that can only take two values: 0 or 1.
What benefit can be derived from this? In fact, no less than from ordinary data. So, it is easy to count the number of positive outcomes - it is enough to sum up all the values, i.e. all 1 (success). You can go further, but for this you need to introduce a couple of notations.
The first thing to note is that positive outcomes (which are equal to 1) have some probability of occurring. For example, getting heads on a coin toss is ½ or 0.5. This probability is traditionally denoted by the Latin letter p. Therefore, the probability of an alternative event occurring is 1-p, which is also denoted by q, i.e q = 1 – p. These designations can be visually systematized in the form of a variable distribution plate X.
We got a list of possible values and their probabilities. can be calculated expected value and dispersion. The expectation is the sum of the products of all possible values and their corresponding probabilities:
![]()
Let's calculate the expected value using the notation in the tables above.
It turns out that the mathematical expectation of an alternative sign is equal to the probability of this event - p.
Now let's define what the variance of an alternative feature is. Dispersion is the average square of deviations from the mathematical expectation. The general formula (for discrete data) is:
Hence the variance of the alternative feature:

It is easy to see that this dispersion has a maximum of 0.25 (at p=0.5).
Standard deviation - root of the variance:
The maximum value does not exceed 0.5.
As you can see, both the mathematical expectation and the variance of the alternative sign have a very compact form.
Binomial distribution of a random variable
Let's look at the situation from a different angle. Indeed, who cares that the average number of heads on a single toss is 0.5? It's even impossible to imagine. It is more interesting to raise the question of the number of heads for a given number of throws.
In other words, the researcher is often interested in the probability of a certain number of successful events occurring. This can be the number of defective products in the batch being checked (1 - defective, 0 - good) or the number of recoveries (1 - healthy, 0 - sick), etc. The number of such "successes" will be equal to the sum of all values of the variable X, i.e. the number of single outcomes.
Random value B is called binomial and takes values from 0 to n(at B= 0 - all parts are good, with B = n- all parts are defective). It is assumed that all values x independent of each other. Consider the main characteristics of a binomial variable, that is, we will establish its mathematical expectation, variance and distribution.
The expectation of a binomial variable is very easy to obtain. The mathematical expectation of the sum of values is the sum of the mathematical expectations of each added value, and it is the same for everyone, therefore:
For example, the expectation of the number of heads on 100 tosses is 100 × 0.5 = 50.
Now we derive the formula for the variance of the binomial variable. The variance of the sum of independent random variables is the sum of the variances. From here
Standard deviation, respectively
For 100 coin tosses, the standard deviation of the number of heads is
And finally, consider the distribution of the binomial quantity, i.e. the probability that the random variable B will take different values k, where 0≤k≤n. For a coin, this problem might sound like this: what is the probability of getting 40 heads in 100 tosses?
To understand the calculation method, let's imagine that the coin is tossed only 4 times. Either side can fall out each time. We ask ourselves: what is the probability of getting 2 heads out of 4 tosses. Each throw is independent of each other. This means that the probability of getting any combination will be equal to the product of the probabilities of a given outcome for each individual throw. Let O be heads and P be tails. Then, for example, one of the combinations that suit us may look like OOPP, that is:

The probability of such a combination is equal to the product of two probabilities of coming up heads and two more probabilities of not coming up heads (the reverse event calculated as 1-p), i.e. 0.5×0.5×(1-0.5)×(1-0.5)=0.0625. This is the probability of one of the combinations that suit us. But the question was about the total number of eagles, and not about any particular order. Then you need to add the probabilities of all combinations in which there are exactly 2 eagles. It is clear that they are all the same (the product does not change from changing the places of factors). Therefore, you need to calculate their number, and then multiply by the probability of any such combination. Let's count all combinations of 4 throws of 2 eagles: RROO, RORO, ROOR, ORRO, OROR, OORR. Only 6 options.

Therefore, the desired probability of getting 2 heads after 4 throws is 6×0.0625=0.375.
However, counting in this way is tedious. Already for 10 coins, it will be very difficult to get the total number of options by brute force. Therefore, smart people invented a formula a long time ago, with the help of which they calculate the number of different combinations of n elements by k, where n is the total number of elements, k is the number of elements whose arrangement options are calculated. Combination formula of n elements by k is:
![]()
Similar things take place in the combinatorics section. I send everyone who wants to improve their knowledge there. Hence, by the way, the name of the binomial distribution (the formula above is the coefficient in the expansion of the Newton binomial).
The formula for determining the probability can be easily generalized to any number n and k. As a result, the binomial distribution formula has the following form.
Multiply the number of matching combinations by the probability of one of them.
For practical use, it is enough to simply know the formula for the binomial distribution. And you may not even know - below is how to determine the probability using Excel. But it's better to know.
Let's use this formula to calculate the probability of getting 40 heads in 100 tosses:
Or just 1.08%. For comparison, the probability of the mathematical expectation of this experiment, that is, 50 heads, is 7.96%. The maximum probability of a binomial value belongs to the value corresponding to the mathematical expectation.
Calculating probabilities of binomial distribution in Excel
If you use only paper and a calculator, then the calculations using the binomial distribution formula, despite the absence of integrals, are quite difficult. For example, a value of 100! - has more than 150 characters. Previously, and even now, approximate formulas were used to calculate such quantities. At the moment, it is advisable to use special software, such as MS Excel. Thus, any user (even a humanist by education) can easily calculate the probability of the value of a binomially distributed random variable.
To consolidate the material, we will use Excel for the time being as a regular calculator, i.e. Let's make a step-by-step calculation using the binomial distribution formula. Let's calculate, for example, the probability of getting 50 heads. Below is a picture with the calculation steps and the final result.

As you can see, the intermediate results have such a scale that they do not fit in a cell, although simple functions of the type are used everywhere: FACTOR (factorial calculation), POWER (raising a number to a power), as well as multiplication and division operators. Moreover, this calculation is rather cumbersome, in any case it is not compact, since many cells involved. And yes, it's hard to figure it out.
In general, Excel provides a ready-made function for calculating the probabilities of the binomial distribution. The function is called BINOM.DIST.

Number of successes is the number of successful trials. We have 50 of them.
Number of trials - number of throws: 100 times.
Probability of Success – the probability of getting heads on one toss is 0.5.
Integral - either 1 or 0 is indicated. If 0, then the probability is calculated P(B=k); if 1, then the binomial distribution function is calculated, i.e. sum of all probabilities from B=0 before B=k inclusive.
We press OK and we get the same result as above, only everything was calculated by one function.

Very comfortably. For the sake of experiment, instead of the last parameter 0, we put 1. We get 0.5398. This means that in 100 coin tosses, the probability of getting heads between 0 and 50 is almost 54%. And at first it seemed that it should be 50%. In general, calculations are made easily and quickly.
A real analyst must understand how the function behaves (what is its distribution), so let's calculate the probabilities for all values from 0 to 100. That is, let's ask ourselves: what is the probability that not a single eagle will fall out, that 1 eagle will fall, 2, 3 , 50, 90 or 100. The calculation is shown in the following picture. The blue line is the binomial distribution itself, the red dot is the probability for a specific number of successes k.

One might ask, isn't the binomial distribution similar to... Yes, very similar. Even De Moivre (in 1733) said that with large samples the binomial distribution approaches (I don’t know what it was called then), but no one listened to him. Only Gauss, and then Laplace, 60-70 years later, rediscovered and carefully studied the normal distribution law. The graph above clearly shows that the maximum probability falls on the mathematical expectation, and as it deviates from it, it sharply decreases. Just like normal law.
The binomial distribution is of great practical importance, it occurs quite often. Using Excel, calculations are carried out easily and quickly.
