Tilastojen käyttö tässä huomautuksessa esitetään poikkileikkaavan esimerkin avulla. Oletetaan, että olet Perfect Parachuten tuotantopäällikkö. Laskuvarjot valmistetaan synteettisistä kuiduista, joita toimittaa neljä eri toimittajaa. Yksi laskuvarjon tärkeimmistä ominaisuuksista on sen vahvuus. Sinun on varmistettava, että kaikki toimitetut kuidut ovat yhtä vahvoja. Tähän kysymykseen vastaamiseksi on tarpeen suunnitella koe, jossa mitataan eri toimittajien synteettisistä kuiduista kudottujen laskuvarjojen lujuus. Tämän kokeen aikana saadut tiedot määräävät, mikä toimittaja tarjoaa kestävimmät laskuvarjot.
Monet sovellukset liittyvät kokeisiin, joissa tarkastellaan yhden tekijän useita ryhmiä tai tasoja. Joillakin tekijöillä, kuten keraamisen polttolämpötilalla, voi olla useita numeerisia tasoja (esim. 300°, 350°, 400° ja 450°). Muilla tekijöillä, kuten tavaroiden sijainnilla supermarketissa, voi olla kategorisia tasoja (esim. ensimmäinen toimittaja, toinen toimittaja, kolmas toimittaja, neljäs toimittaja). Yksitekijäkokeita, joissa kokeelliset yksiköt jaetaan satunnaisesti ryhmiin tai tekijätasoihin, kutsutaan täysin satunnaistetuiksi.
KäyttöF-kriteerit useiden matemaattisten odotusten erojen arvioimiseksi
Jos tekijän numeeriset mittaukset ryhmissä ovat jatkuvia ja jotkut lisäehdot täyttyvät, varianssianalyysi (ANOVA - An analyysi o f Va riance). Varianssianalyysiä käyttäen täysin satunnaistettuja malleja kutsutaan yksisuuntaiseksi ANOVAksi. Eräässä mielessä termi varianssianalyysi on harhaanjohtava, koska se vertaa eroja ryhmien keskiarvojen välillä, ei varianssien välillä. Matemaattisten odotusten vertailu tehdään kuitenkin juuri datan vaihteluanalyysin perusteella. ANOVA-menettelyssä mittaustulosten kokonaisvaihtelu jaetaan ryhmien väliseen ja ryhmän sisäiseen (kuva 1). Ryhmän sisäinen vaihtelu selittyy kokeellisella virheellä, kun taas ryhmien välinen vaihtelu selittyy koeolosuhteiden vaikutuksilla. Symboli Kanssa tarkoittaa ryhmien määrää.
Riisi. 1. Variaatioiden erottelu täysin satunnaistetussa kokeessa
Lataa muistiinpano muodossa tai muodossa, esimerkkejä muodossa
Teeskennetäänpä sitä Kanssa ryhmät vedetään itsenäisistä populaatioista, joilla on normaalijakauma ja sama varianssi. Nollahypoteesi on, että populaatioiden matemaattiset odotukset ovat samat: H 0: μ 1 = μ 2 = ... = μ s. Vaihtoehtoinen hypoteesi väittää, että kaikki matemaattiset odotukset eivät ole samoja: H 1: kaikki μ j eivät ole samoja j= 1, 2, …, s).
Kuvassa Kuva 2 esittää todellisen nollahypoteesin viiden vertailuryhmän matemaattisista odotuksista edellyttäen, että yleisillä populaatioilla on normaalijakauma ja sama varianssi. Viisi populaatiota, jotka liittyvät eri tekijätasoihin, ovat identtisiä. Siksi ne asettuvat päällekkäin, ja niillä on sama matemaattinen odotus, vaihtelu ja muoto.

Riisi. 2. Viidellä populaatiolla on sama matemaattinen odotus: μ 1 = μ 2 = μ 3 = μ 4 = μ 5
Toisaalta oletetaan, että itse asiassa nollahypoteesi on väärä ja neljännellä tasolla on suurin matemaattinen odotus, ensimmäisellä tasolla on hieman alhaisempi matemaattinen odotus ja muilla tasoilla on samat ja vielä pienemmät matemaattiset odotukset (kuva 1). 3). Huomaa, että keskiarvoa lukuun ottamatta kaikki viisi populaatiota ovat identtisiä (eli niillä on sama vaihtelevuus ja muoto).

Riisi. 3. Koeolosuhteiden vaikutus havaitaan: μ 4 > μ 1 > μ 2 = μ 3 = μ 5
Testattaessa hypoteesia usean yleisen populaation matemaattisten odotusten yhtäläisyydestä, kokonaisvariaatio jaetaan kahteen osaan: ryhmien väliseen vaihteluun ja ryhmän sisäiseen vaihteluun, joka johtuu samaan ryhmään kuuluvien elementtien välisistä eroista. Kokonaisvaihtelu ilmaistaan neliöiden kokonaissummana (SST - summa of squares total). Koska nollahypoteesi on, että kaikkien odotus Kanssa ryhmät ovat keskenään yhtä suuret, kokonaisvariaatio on yhtä suuri kuin yksittäisten havaintojen ja kaikille näytteille lasketun kokonaiskeskiarvon (keskiarvojen) välisten erojen neliöityjen summa. Täysi muunnelma:

missä ![]() - kokonaiskeskiarvo, Xij - i- katso sisään j- ryhmä tai taso, nj- havaintojen määrä j- ryhmä, n- havaintojen kokonaismäärä kaikissa ryhmissä (esim. n = n 1
+ n 2 + … + nc), Kanssa- tutkittujen ryhmien tai tasojen lukumäärä.
- kokonaiskeskiarvo, Xij - i- katso sisään j- ryhmä tai taso, nj- havaintojen määrä j- ryhmä, n- havaintojen kokonaismäärä kaikissa ryhmissä (esim. n = n 1
+ n 2 + … + nc), Kanssa- tutkittujen ryhmien tai tasojen lukumäärä.
Ryhmien välinen vaihtelu, jota yleensä kutsutaan ryhmien välisten neliöiden summaksi (SSA), on yhtä suuri kuin kunkin ryhmän otoskeskiarvon välisten neliöerojen summa. j ja kokonaiskeskiarvo kerrottuna vastaavan ryhmän tilavuudella nj:

missä Kanssa- opittujen ryhmien tai tasojen lukumäärä, nj- havaintojen määrä j- ryhmä, j- tarkoittaa j- ryhmä, - yleinen keskiarvo.
Ryhmän sisäinen vaihtelu, jota yleensä kutsutaan ryhmien neliöiden summaksi (SSW), on yhtä suuri kuin kunkin ryhmän elementtien ja tämän ryhmän otoskeskiarvon neliöerojen summa. j:

missä Xij - i-th elementti j- ryhmä, j- tarkoittaa j- ryhmä.
Koska niitä verrataan Kanssa tekijätasot, ryhmien välisellä neliösummalla on s - 1 vapauden asteet. Jokainen Kanssa tasoilla on nj – 1 vapausasteita, joten ryhmän sisäisellä neliösummalla on n- Kanssa vapausasteet ja

Lisäksi neliöiden kokonaissummalla on n – 1 vapausasteita jokaisen havainnon jälkeen Xij verrattuna kaiken kaikkiaan laskettuun kokonaiskeskiarvoon n havainnot. Jos kukin näistä summista jaetaan vastaavalla vapausasteiden lukumäärällä, syntyy kolmenlaista hajontaa: ryhmien välinen(keskiarvo - MSA), ryhmän sisäinen(keskineliö sisällä - MSW) ja saattaa loppuun(keskimääräinen neliösumma – MST):
Huolimatta siitä, että varianssianalyysin päätarkoitus on verrata matemaattisia odotuksia Kanssa ryhmiä paljastaakseen koeolosuhteiden vaikutuksen, sen nimi johtuu siitä, että päätyökalu on erityyppisten varianssien analyysi. Jos nollahypoteesi on totta, ja odotettujen arvojen välillä Kanssa ryhmissä ei ole merkittäviä eroja, kaikki kolme varianssia - MSA, MSW ja MST - ovat varianssiestimaatteja σ2 analysoituihin tietoihin. Joten testataksesi nollahypoteesia H 0: μ 1 = μ 2 = ... = μ s ja vaihtoehtoinen hypoteesi H 1: kaikki μ j eivät ole samoja j = 1, 2, …, Kanssa), on tarpeen laskea tilastot F-kriteeri, joka on kahden varianssin, MSA ja MSW, suhde. testata F-tilastot yksimuuttujavarianssianalyysissä

Tilastot F-kriteerit noudattavat F- jakelu kanssa s - 1 vapausasteet osoittajassa MSA ja n - kanssa vapausasteet nimittäjässä MSW. Tietylle merkitsevyystasolle α nollahypoteesi hylätään, jos lasketaan F FU luontainen F- jakelu kanssa s - 1 n - kanssa vapausasteet nimittäjässä. Siten, kuten kuvassa 1 on esitetty. 4, päätössääntö on muotoiltu seuraavasti: nollahypoteesi H 0 hylätty jos F > FU; muuten sitä ei hylätä.

Riisi. 4. Varianssianalyysin kriittinen alue hypoteesia testattaessa H 0
Jos nollahypoteesi H 0 on totta, laskettu F-tilasto on lähellä 1:tä, koska sen osoittaja ja nimittäjä ovat saman arvon arvioita - analysoidulle tiedolle ominaista varianssia σ 2. Jos nollahypoteesi H 0 on väärä (ja eri ryhmien odotusarvojen välillä on merkittävä ero), laskettu F-tilasto tulee olemaan paljon suurempi kuin yksi, koska sen osoittaja, MSA, arvioi aineiston luonnollisen vaihtelun lisäksi koeolosuhteiden vaikutuksen tai ryhmien välisen eron, kun taas nimittäjä MSW arvioi vain aineiston luonnollisen vaihtelun. Siten ANOVA-menettely on F on testi, jossa tietyllä merkitsevyystasolla α nollahypoteesi hylätään, jos laskettu F- tilastot ovat suurempia kuin ylempi kriittinen arvo FU luontainen F- jakelu kanssa s - 1 vapausasteet osoittajassa ja n - kanssa vapausasteet nimittäjässä, kuten kuvasta näkyy. neljä.
Yksisuuntaisen varianssianalyysin havainnollistamiseksi palataan huomautuksen alussa esitettyyn skenaarioon. Kokeen tarkoituksena on selvittää, ovatko eri toimittajilta saaduista synteettisistä kuiduista kudotut laskuvarjot yhtä lujia. Jokaisella ryhmällä on viisi laskuvarjoa. Ryhmät on jaettu toimittajan mukaan - Toimittaja 1, Toimittaja 2, Toimittaja 3 ja Toimittaja 4. Laskuvarjojen lujuus mitataan erikoislaitteella, joka testaa kankaan repeytymistä molemmilta puolilta. Laskuvarjon murtamiseen tarvittava voima mitataan erityisellä asteikolla. Mitä suurempi murtovoima, sitä vahvempi laskuvarjo. Excel mahdollistaa analysoinnin F- Tilastot yhdellä napsautuksella. Käy valikon läpi Data → Tietojen analysointi ja valitse rivi Yksisuuntainen varianssianalyysi, täytä avautunut ikkuna (kuva 5). Kokeen tulokset (raon lujuus), joitain kuvaavia tilastoja ja yksisuuntaisen varianssianalyysin tulokset on esitetty kuvioissa 1-3. 6.

Riisi. 5. Ikkuna Yksisuuntainen ANOVA-analyysipaketti excel

Riisi. Kuva 6. Eri toimittajilta hankituista synteettikuiduista kudottujen laskuvarjojen lujuusindikaattorit, kuvaavat tilastot ja yksisuuntaisen varianssianalyysin tulokset
Kuvan 6 analyysi osoittaa, että näytevälineiden välillä on jonkin verran eroa. Ensimmäiseltä toimittajalta saatujen kuitujen keskimääräinen lujuus on 19,52, toiselta - 24,26, kolmannelta - 22,84 ja neljänneltä - 21,16. Onko tämä ero tilastollisesti merkittävä? Murtovoiman jakautuminen on esitetty sirontakaaviossa (kuva 7). Se osoittaa selvästi erot sekä ryhmien välillä että niiden sisällä. Jos kunkin ryhmän tilavuus olisi suurempi, ne voitaisiin analysoida käyttämällä varsi- ja lehtikuvaajaa, laatikkokuvaajaa tai normaalijakauman kuvaajaa.

Riisi. 7. Neljältä toimittajalta hankituista synteettikuiduista kudottujen laskuvarjojen lujuuden leviämiskaavio
Nollahypoteesi väittää, että keskimääräisten lujuusarvojen välillä ei ole merkittäviä eroja: H 0: μ 1 = μ 2 = μ 3 = μ 4. Vaihtoehtoinen hypoteesi on, että on ainakin yksi toimittaja, jonka keskimääräinen kuidun lujuus eroaa muista: H 1: kaikki μ j eivät ole samoja ( j = 1, 2, …, Kanssa).
Kokonaiskeskiarvo (katso kuva 6) = KESKIARVO(D12:D15) = 21,945; määrittääksesi voit myös laskea kaikkien 20 alkuperäisen luvun keskiarvon: \u003d AVERAGE (A3: D7). Varianssiarvot lasketaan Analyysipaketti ja ne näkyvät taulukossa Varianssianalyysi(katso kuva 6): SSA = 63,286, SSW = 97,504, SST = 160,790 (katso sarake SS taulukoita Varianssianalyysi kuva 6). Keskiarvot lasketaan jakamalla nämä neliösummat sopivalla määrällä vapausasteita. Koska Kanssa= 4 ja n= 20, saamme seuraavat vapausasteiden arvot; SSA:lle: s - 1= 3; SSW:lle: n–c= 16; SST:lle: n - 1= 19 (katso sarake df). Siten: MSA = SSA / ( c - 1)= 21,095; MSW=SSW/( n–c) = 6,094; MST = SST / ( n - 1) = 8,463 (katso sarake NEITI). F-tilastot = MSA / MSW = 3,462 (katso sarake F).
Ylempi kriittinen arvo FU, ominaisuus F-jakauma, määritetään kaavalla = F. OBR (0,95; 3; 16) = 3,239. Funktioparametrit =F.OBR(): α = 0,05, osoittajalla on kolme vapausastetta ja nimittäjä on 16. Näin ollen laskettu F-tilasto, joka on 3,462, ylittää ylemmän kriittisen arvon FU= 3,239, nollahypoteesi hylätään (kuva 8).

Riisi. 8. Varianssianalyysin kriittinen alue merkitsevyystasolla 0,05, jos osoittajalla on kolme vapausastetta ja nimittäjä on -16
R-arvo, ts. todennäköisyys, että todellisessa nollahypoteesissa F- tilastot vähintään 3,46, mikä vastaa 0,041 tai 4,1 % (katso sarake p-arvo taulukoita Varianssianalyysi kuva 6). Koska tämä arvo ei ylitä merkitsevyystasoa α = 5%, nollahypoteesi hylätään. Lisäksi, R-arvo osoittaa, että todennäköisyys löytää tällainen tai suuri ero yleisten populaatioiden matemaattisten odotusten välillä, mikäli ne ovat todella samat, on 4,1 %.
Niin. Neljän näytteen keskiarvon välillä on ero. Nollahypoteesi oli, että kaikki neljän populaation matemaattiset odotukset ovat samat. Näissä olosuhteissa lasketaan kaikkien laskuvarjojen lujuuden kokonaisvaihtelun (eli SST-vaihtelun) mitta laskemalla yhteen kunkin havainnon väliset erot. Xij ja kokonaiskeskiarvo . Sitten kokonaisvaihtelu jaettiin kahteen komponenttiin (katso kuva 1). Ensimmäinen komponentti oli ryhmien välinen vaihtelu SSA:ssa ja toinen komponentti oli ryhmän sisäinen vaihtelu SSW:ssä.
Mikä selittää tietojen vaihtelun? Toisin sanoen, miksi kaikki havainnot eivät ole samoja? Yksi syy on se, että eri yritykset toimittavat erivahvuisia kuituja. Tämä osittain selittää, miksi ryhmillä on erilaiset odotusarvot: mitä voimakkaampi koeolosuhteiden vaikutus on, sitä suurempi ero ryhmien keskiarvojen välillä on. Toinen syy tietojen vaihteluun on minkä tahansa prosessin, tässä tapauksessa laskuvarjojen tuotannon, luonnollinen vaihtelu. Vaikka kaikki kuidut ostettaisiin samalta toimittajalta, niiden lujuus ei olisi sama, kun kaikki muut asiat olisivat samat. Koska tämä vaikutus esiintyy jokaisessa ryhmässä, sitä kutsutaan ryhmän sisäiseksi variaatioksi.
Näytteen keskiarvojen välisiä eroja kutsutaan SSA:n ryhmien väliseksi variaatioksi. Osa ryhmän sisäisestä vaihtelusta, kuten jo mainittiin, selittyy sillä, että tiedot kuuluvat eri ryhmiin. Kuitenkin, vaikka ryhmät olisivat täsmälleen samat (eli nollahypoteesi olisi totta), ryhmien välistä vaihtelua olisi silti. Syynä tähän on laskuvarjon valmistusprosessin luonnollinen vaihtelu. Koska näytteet ovat erilaisia, niiden näytekeinot eroavat toisistaan. Siksi, jos nollahypoteesi pitää paikkansa, sekä ryhmien välinen että ryhmän sisäinen vaihtelu ovat populaation vaihtelun arvioita. Jos nollahypoteesi on väärä, ryhmien välinen hypoteesi on suurempi. Tämä tosiasia on taustalla F-kriteerit useiden ryhmien matemaattisten odotusten välisten erojen vertailuun.
Yksisuuntaisen ANOVA-analyysin ja yritysten välisen merkittävän eron löytämisen jälkeen jää epäselväksi, mikä toimittajista eroaa merkittävästi muista. Tiedämme vain, että populaatioiden matemaattiset odotukset eivät ole samat. Toisin sanoen ainakin yksi matemaattisista odotuksista poikkeaa merkittävästi muista. Voit määrittää, mikä palveluntarjoaja eroaa muista, käyttämällä Tukey-menettely, joka käyttää palveluntarjoajien välistä parivertailua. Tämän menetelmän on kehittänyt John Tukey. Myöhemmin hän ja C. Cramer muuttivat tätä menettelyä itsenäisesti tilanteisiin, joissa näytteiden koot eroavat toisistaan.
Useita vertailuja: Tukey-Kramer-menettely
Skenaariossamme käytettiin yksisuuntaista varianssianalyysiä laskuvarjojen lujuuden vertailuun. Kun neljän ryhmän matemaattisten odotusten välillä on havaittu merkittäviä eroja, on tarpeen määrittää, mitkä ryhmät eroavat toisistaan. Vaikka tämän ongelman ratkaisemiseksi on useita tapoja, kuvataan vain Tukey-Kramer-monivertailumenettely. Tämä menetelmä on esimerkki post hoc -vertailumenettelyistä, koska testattava hypoteesi muotoillaan data-analyysin jälkeen. Tukey-Kramer-menettelyn avulla voit verrata samanaikaisesti kaikkia ryhmäpareja. Ensimmäisessä vaiheessa lasketaan erot Xj – Xj ’ , missä j ≠j’ , matemaattisten odotusten välillä s(s – 1)/2 ryhmiä. Kriittinen jänneväli Tukey-Kramer-menettely lasketaan kaavalla:
missä Q U- opiskelija-alueen jakauman ylempi kriittinen arvo, jolla on Kanssa vapausasteet osoittajassa ja n - Kanssa vapausasteet nimittäjässä.
Jos otoskoot eivät ole samat, kriittinen alue lasketaan kullekin matemaattiselle odotusparille erikseen. Viimeisessä vaiheessa jokainen s(s – 1)/2 matemaattisten odotusten paria verrataan vastaavaan kriittiseen vaihteluväliin. Parin elementtien katsotaan olevan merkittävästi erilaisia, jos eron moduuli | Xj – Xj ’ | niiden välillä ylittää kriittisen alueen.
Sovelletaan Tukey-Cramer-menettelyä laskuvarjojen lujuuden ongelmaan. Koska laskuvarjoyhtiöllä on neljä toimittajaa, tulee testata 4(4 – 1)/2 = 6 toimittajaparia (kuva 9).

Riisi. 9. Näytteen keskiarvojen pareittainen vertailu
Koska kaikilla ryhmillä on sama tilavuus (eli kaikilla nj = nj ’ ), riittää vain yhden kriittisen alueen laskeminen. Voit tehdä tämän taulukon mukaan ANOVA(Kuva 6) määritetään arvo MSW = 6,094. Sitten löydämme arvon Q U kun α = 0,05, Kanssa= 4 (vapausasteiden lukumäärä osoittajassa) ja n- Kanssa= 20 – 4 = 16 (vapausasteiden lukumäärä nimittäjässä). Valitettavasti en löytänyt vastaavaa funktiota Excelistä, joten käytin taulukkoa (kuva 10).

Riisi. 10. Opiskelija-alueen kriittinen arvo Q U
Saamme:
Koska vain 4,74 > 4,47 (katso alataulukko kuvassa 9), ensimmäisen ja toisen toimittajan välillä on tilastollisesti merkitsevä ero. Kaikilla muilla pareilla on näytekeinot, jotka eivät salli meidän puhua niiden erosta. Tästä johtuen ensimmäiseltä toimittajalta ostetuista kuiduista kudottujen laskuvarjojen keskimääräinen lujuus on huomattavasti pienempi kuin toiselta toimittajalta.
Yksisuuntaisen varianssianalyysin välttämättömät ehdot
Ratkaiseessamme laskuvarjojen lujuuden ongelmaa emme tarkastaneet, täyttyvätkö ehdot, joilla yksikerrointa voidaan käyttää F-kriteeri. Mistä tiedät, voitko soveltaa yksikerrointa F-kriteeri tietyn kokeellisen tiedon analysoinnissa? Yksi tekijä F-testiä voidaan soveltaa vain, jos kolme perusoletusta täyttyvät: kokeellisen datan on oltava satunnaista ja riippumatonta, normaalijakaumaa ja niiden varianssien on oltava samat.
Ensimmäinen arvaus on satunnaisuus ja tietojen riippumattomuus- tulisi aina tehdä, koska minkä tahansa kokeen oikeellisuus riippuu valinnan satunnaisuudesta ja/tai satunnaistusprosessista. Tulosten vääristymisen välttämiseksi tiedot on poimittava Kanssa populaatiot satunnaisesti ja toisistaan riippumatta. Vastaavasti tiedot tulisi jakaa satunnaisesti Kanssa meitä kiinnostavan tekijän tasot (kokeelliset ryhmät). Näiden ehtojen rikkominen voi vakavasti vääristää varianssianalyysin tuloksia.
Toinen arvaus on normaalia- tarkoittaa, että tiedot on otettu normaalisti jakautuneista populaatioista. Mitä tulee t-kriteeri, yksisuuntainen varianssianalyysi perustuu F-kriteeri on suhteellisen epäherkkä tämän ehdon rikkomiselle. Jos jakauma ei ole liian kaukana normaalista, merkitsevyystaso F-kriteeri muuttuu vähän, varsinkin jos otoskoko on riittävän suuri. Jos normaalijakauman ehtoa rikotaan vakavasti, sitä tulee soveltaa.
Kolmas arvaus on dispersion tasaisuus- tarkoittaa, että kunkin yleisen populaation varianssit ovat keskenään yhtä suuret (eli σ 1 2 = σ 2 2 = … = σ j 2). Tämän oletuksen avulla voidaan päättää, erotetaanko vai yhdistetäänkö ryhmän sisäiset varianssit. Jos ryhmien tilavuudet ovat samat, varianssin homogeenisuuden ehto ei juurikaan vaikuta päätelmiin, jotka saadaan käyttämällä F-kriteeri. Jos otoskoot eivät kuitenkaan ole samat, varianssien yhtäläisyyden ehdon rikkominen voi vääristää vakavasti varianssianalyysin tuloksia. Siksi on pyrittävä varmistamaan, että otoskoot ovat samat. Yksi menetelmistä varianssin homogeenisuutta koskevan oletuksen tarkistamiseksi on kriteeri Levenay kuvailtu alla.
Jos kaikista kolmesta ehdosta vain dispersioehdon tasaisuus rikotaan, menettely on analoginen t-kriteeri käyttäen erillistä varianssia (katso yksityiskohdat). Kuitenkin, jos normaalijakauman ja varianssin homogeenisuuden oletuksia rikotaan samanaikaisesti, on tiedot normalisoitava ja varianssien välisiä eroja pienennettävä tai sovelletaan ei-parametrista menettelyä.
Leveneyn kriteeri varianssin homogeenisuuden tarkistamiseksi
Siitä huolimatta F- kriteeri on suhteellisen vastustuskykyinen ryhmien varianssien yhtäläisyyden ehdon rikkomiselle, tämän oletuksen törkeä rikkominen vaikuttaa merkittävästi kriteerin merkitystasoon ja voimakkuuteen. Ehkä yksi tehokkaimmista on kriteeri Levenay. Varianssien yhtäläisyyden tarkistamiseksi Kanssa yleisiä populaatioita, testaamme seuraavat hypoteesit:
H 0: σ 1 2 = σ 2 2 = ... = σj 2
H 1: Ei kaikki σ j 2 ovat samat ( j = 1, 2, …, Kanssa)
Modifioitu Leveneyn testi perustuu väitteeseen, että jos vaihtelu ryhmissä on sama, voidaan havaintojen ja ryhmän mediaanien välisten erojen absoluuttisten arvojen varianssin analyysillä testata varianssien yhtäläisyyden nollahypoteesia. Joten ensin sinun tulee laskea havaintojen ja mediaanien välisten erojen absoluuttiset arvot kussakin ryhmässä ja tehdä sitten yksisuuntainen varianssianalyysi saaduista erojen absoluuttisista arvoista. Levenayn kriteerin havainnollistamiseksi palataan muistiinpanon alussa esitettyyn skenaarioon. Käyttämällä kuvassa esitettyjä tietoja. Kuvassa 6 suoritamme samanlaisen analyysin, mutta lähtötietojen ja mediaanien erojen moduulien suhteen kullekin näytteelle erikseen (kuva 11).
Varianssianalyysin avulla voit tutkia tietoryhmien välisiä eroja ja määrittää, ovatko nämä erot satunnaisia vai johtuvatko ne tietyistä olosuhteista. Esimerkiksi jos yrityksen myynti jollain alueella on laskenut, niin varianssianalyysin avulla voit selvittää, onko liikevaihdon lasku tällä alueella sattumaa muihin verrattuna, ja tarvittaessa tehdä organisaatiomuutoksia. Eri olosuhteissa suoritettaessa varianssianalyysi auttaa määrittämään, kuinka paljon ulkoiset tekijät vaikuttavat mittauksiin tai poikkeamat ovat satunnaisia. Jos tuotannossa tuotteiden laadun parantamiseksi muutetaan prosessien muotoa, niin varianssianalyysin avulla voimme arvioida tämän tekijän vaikutuksen tuloksia.
Tällä esimerkki näytämme, kuinka ANOVA suoritetaan kokeellisille tiedoille.
Harjoitus 1. Tekstiiliteollisuuden raaka-aineita on neljä erää. Jokaisesta erästä valittiin viisi näytettä ja suoritettiin testejä murtokuorman suuruuden määrittämiseksi. Testitulokset näkyvät taulukossa.
71" height="29" bgcolor="white" style="border:.75pt yksivärinen musta; vertical-align:top;background:white">
Kuva 1 |
 > Avaa Microsoft Excel -laskentataulukko. Napsauta Sheet2-tunnistetta vaihtaaksesi toiseen laskentataulukkoon.
> Avaa Microsoft Excel -laskentataulukko. Napsauta Sheet2-tunnistetta vaihtaaksesi toiseen laskentataulukkoon. > Syötä kuvassa 1 näkyvät ANOVA-tiedot.
> Muunna tiedot numeromuotoon. Voit tehdä tämän valitsemalla Muotoile solu -valikosta. Näyttöön tulee solumuotoikkuna (kuva 2). Valitse Numeerinen muoto ja syötetyt tiedot muunnetaan kuvan 1 mukaiseen muotoon. 3
> Valitse valikon komento Service Data Analysis (Työkalut * Data Analysis). Data Analysis (Data Analysis) -ikkuna tulee näyttöön (kuva 4).
> Napsauta riviä Yhden tekijän varianssianalyysi (Anova: Single Factor) Analyysityökalut (Anova: Single Factor) -luettelossa.
> Napsauta OK sulkeaksesi Data Analysis (Data Analysis) -ikkunan. Yksisuuntainen varianssianalyysi -ikkuna ilmestyy näytölle tietojen dispersioanalyysin suorittamista varten (kuva 5).
https://pandia.ru/text/78/446/images/image006_46.jpg" width="311" height="214 src=">
|
> Asenna Valintaruutu Tunnisteet ensimmäisellä rivillä (Labels in Firts Rom) Input controls -ryhmässä, jos valitun tietoalueen ensimmäinen sarake sisältää rivien nimiä.
> Syöttökentässä Alpha Ohjausryhmän (A1pha) tulon oletusarvo on 0,05, joka liittyy varianssianalyysin virhetodennäköisyyteen.
> Jos Nev Worksheet Ply -kytkintä ei ole asetettu ohjausobjektien Input options -ryhmässä, aseta se niin, että varianssianalyysin tulokset sijoitetaan uudelle laskentataulukolle
> Napsauta OK sulkeaksesi Anova: Single Factor -ikkunan. Varianssianalyysin tulokset näkyvät uudella laskentataulukolla (kuva 6).
|

Solualue A4:E6 sisältää kuvaavien tilastojen tulokset. Rivi 4 sisältää parametrien nimet, rivit sisältävät eräkohtaisesti lasketut tilastoarvot.
Sarakkeessa Tarkistaa(Count) ovat mittausten lukumäärä, sarakkeessa Sum - arvojen summa, sarakkeessa Average (Avegage) - aritmeettiset keskiarvot, sarakkeessa Variance (Varianse) - dispersio.
Saadut tulokset osoittavat, että suurin keskimääräinen murtokuorma on erässä #3 ja suurin murtokuorman hajonta erässä #1.
Useissa soluissa A11:G16 näyttää tietoa tietoryhmien välisten erojen merkityksestä. Rivi 12 sisältää varianssiparametrien analyysin nimet, rivi 13 - ryhmien välisen käsittelyn tulokset, rivi 14 - ryhmän sisäisen käsittelyn tulokset ja rivi 16 - kahden mainitun rivin arvojen summan.
Sarakkeessa SS (qi) vaihteluarvot sijaitsevat, eli kaikkien poikkeamien neliösummat. Variaatio, kuten hajonta, luonnehtii tiedon leviämistä. Taulukosta voidaan nähdä, että murtokuorman ryhmien välinen hajonta on merkittävästi suurempi kuin ryhmän sisäinen vaihtelu.
Sarakkeessa df (k) vapausasteiden lukujen arvot löytyvät. Nämä luvut osoittavat riippumattomien poikkeamien lukumäärän, joiden osalta varianssi lasketaan. Esimerkiksi ryhmien välinen vapausasteiden lukumäärä on yhtä suuri kuin dataryhmien lukumäärän ja yhden erotus. Mitä suurempi vapausasteiden lukumäärä on, sitä suurempi on dispersioparametrien luotettavuus. Taulukon vapausasteet osoittavat, että ryhmän sisäiset tulokset ovat luotettavampia kuin ryhmien väliset parametrit.
Sarakkeessa NEITI (S2 ) dispersioarvot sijaitsevat, jotka määräytyvät vaihtelusuhteen ja vapausasteiden lukumäärän mukaan. Dispersio luonnehtii datan sironta-astetta, mutta toisin kuin variaation suuruus, sillä ei ole suoraa taipumusta kasvaa vapausasteiden lukumäärän kasvaessa. Taulukko osoittaa, että ryhmien välinen varianssi on paljon suurempi kuin ryhmän sisäinen varianssi.
Sarakkeessa F sijainti, arvo F- tilastot, joka lasketaan ryhmien välisten ja ryhmien sisäisten varianssien suhteella.
Sarakkeessa Fkriittinen(F crit) F-kriittinen arvo paikantuu laskettuna vapausasteiden lukumäärästä ja Alfa (A1pha) arvosta. F-tilastollinen ja F-kriittisen arvon käyttökriteeri Fisher-Snedekora.
Jos F-tilasto on suurempi kuin F-kriittinen arvo, voidaan väittää, että tietoryhmien väliset erot eivät ole satunnaisia. eli merkitsevyystasolla α = 0,05 (luotettavuudella 0,95) nollahypoteesi hylätään ja vaihtoehto hyväksytään: raaka-aineerien erolla on merkittävä vaikutus murtokuorman suuruuteen.
P-arvosarake sisältää todennäköisyysarvon, että ryhmien välinen ero on satunnainen. Koska tämä todennäköisyys on taulukossa hyvin pieni, ryhmien välinen poikkeama ei ole satunnainen.
2. Kaksisuuntaisen varianssianalyysin tehtävien ratkaiseminen ilman toistoja
Microsoft Excelissä on Anova: (Two-Factor Without Replication) -toiminto, jonka avulla voidaan tunnistaa hallittavien tekijöiden vaikutus. MUTTA ja AT tehokkaalla attribuutilla, joka perustuu näytetietoihin ja jokaiseen tekijätasoon MUTTA ja AT vain yksi näyte vastaa. Kutsu tämä toiminto valitsemalla komento valikkoriviltä Palvelu – Tietojen analysointi. Näytölle avautuu ikkuna. Tietojen analysointi, josta sinun tulee valita arvo Kaksisuuntainen varianssianalyysi ilman toistoja ja napsauta OK-painiketta. Tämän seurauksena kuvassa 1 näkyvä valintaikkuna avautuu näytölle.
78" height="42" bgcolor="white" style="border:.75pt yksivärinen musta; vertical-align:top;background:white">
3. Alfa-kenttään syötetään hyväksytty merkitystaso. α , joka vastaa ensimmäisen tyyppisen virheen todennäköisyyttä.
4. Tulostusasetukset-ryhmän kytkin voidaan asettaa johonkin kolmesta asennosta: Tulostusalue, Uusi työarkin kerros tai Uusi työkirja.
Esimerkki.
Kaksisuuntainen varianssianalyysi ilman toistoja(Anova: Two-Factor Without Replication) seuraavassa esimerkissä.

Kuvan päällä. Kuvassa 2 on esitetty neljän vehnälajikkeen (neljä tekijä A:n tasoa) sato (c/ha), joka on saavutettu viidellä lannoitteella (viisi tekijä B:tä). Tiedot saatiin 20 samankokoiselta ja samanlaiselta maapeiteeltä. Tarve määritellä vaikuttaako lajike ja lannoitetyyppi vehnän satoon.
Kaksisuuntainen varianssianalyysi ilman toistoja on esitetty kuvassa 3.
 Kuten tuloksista voidaan nähdä, tekijän A (lannoitetyyppi) F-tilastoarvon laskettu arvo FMUTTA=
l,67
, ja kriittisen alueen muodostaa oikeanpuoleinen väli (3.49; +∞). Koska FMUTTA=
l,67
ei kuulu kriittiseen alueeseen, HA-hypoteesi: a
1
= a
2
+ = ak
hyväksyä, eli uskomme, että tässä kokeessa lannoitetyypillä ei ollut vaikutusta satoon.
Kuten tuloksista voidaan nähdä, tekijän A (lannoitetyyppi) F-tilastoarvon laskettu arvo FMUTTA=
l,67
, ja kriittisen alueen muodostaa oikeanpuoleinen väli (3.49; +∞). Koska FMUTTA=
l,67
ei kuulu kriittiseen alueeseen, HA-hypoteesi: a
1
= a
2
+ = ak
hyväksyä, eli uskomme, että tässä kokeessa lannoitetyypillä ei ollut vaikutusta satoon.
Koska FAT=2.03 ei kuulu kriittiseen alueeseen, hypoteesiin HB: b1 = b2 = ... = bm
myös hyväksyä, eli uskomme siihen Kokeessa vehnälajike ei myöskään vaikuttanut satoon.
2. Kaksisuuntainen varianssianalyysictoistoja
Microsoft Excelissä on Anova-toiminto: Two-Factor With Replication, jota käytetään myös määrittämään, vaikuttavatko kontrolloidut tekijät A ja B suorituskykyominaisuuteen näytetietojen perusteella, kuitenkin yhden tekijän A (tai B) kukin taso vastaa useampaa kuin yhtä datanäytettä.
Harkitse toiminnon käyttöä Kaksisuuntainen varianssianalyysi toistoilla seuraavassa esimerkissä.
Esimerkki 2. pöydässä. Kuvassa 6 on esitetty tutkimukseen kerätyn 18 porsaan päivittäinen painonnousu (g) riippuen porsaiden pitotavasta (tekijä A) ja ruokinnan laadusta (tekijä B).
75" height="33" bgcolor="white" style="border:.75pt yksivärinen musta; vertical-align:top;background:white"> 

Tämä valintaikkuna määrittää seuraavat asetukset.
1. Kirjoita Input Range -kenttään viittaus analysoidut tiedot sisältävään solualueeseen. Valitse solut kohteesta G 4 ennen minä 13.
2. Määritä Rivit per näyte -kentässä näytteiden määrä yhden tekijän kullekin tasolle. Jokaisella tekijätasolla on oltava sama määrä näytteitä (taulukon rivejä). Meidän tapauksessamme rivien lukumäärä on kolme.
3. Kirjoita Alfa-kenttään merkitsevyystason hyväksytty arvo α , joka on yhtä suuri kuin tyypin I virheen todennäköisyys.
4. Tulostusasetukset-ryhmän kytkin voidaan asettaa johonkin kolmesta asennosta: Tulostusalue (Tulosten aikaväli), Uusi laskentataulukkokerros (uusi laskentataulukko) tai Uusi työkirja (uusi työkirja).
Kaksisuuntaisen varianssianalyysin tulokset funktiota käyttämällä Kaksisuuntainen varianssianalyysi, jossa on merkittäviä toistoja. Johtuen siitä, että ![]() näiden tekijöiden vuorovaikutus on merkityksetön (5 %:n tasolla).
näiden tekijöiden vuorovaikutus on merkityksetön (5 %:n tasolla).
Kotitehtävät
1. Kuuden vuoden aikana viljeltiin viittä erilaista teknologiaa. Koetiedot (c/ha) on annettu taulukossa:
https://pandia.ru/text/78/446/images/image024_11.jpg" width="642" height="190 src=">
Merkitystasolla α = 0,05 vaaditaan korkealaatuisten laattojen tuotannon riippuvuus tuotantolinjasta (tekijä A).
3. Saatavilla on seuraavat tiedot neljän vehnälajikkeen sadosta myönnetyltä viideltä tontilta (lohkolta):
https://pandia.ru/text/78/446/images/image026_9.jpg" width="598" height="165 src=">
Merkittävyystasolla α = 0,05 vaaditaan teknologioiden (tekijä A) ja yritysten (tekijä B) vaikutus työn tuottavuuteen.
Ominaisuuden vaihtelevuuden analysoimiseksi kontrolloitujen muuttujien vaikutuksen alaisena käytetään dispersiomenetelmää.
Arvojen välisen suhteen tutkiminen - tekijämenetelmä. Tarkastellaanpa tarkemmin analyyttisiä työkaluja: tekijä-, dispersio- ja kaksitekijädispersiomenetelmiä vaihtelevuuden arvioimiseksi.
ANOVA Excelissä
Ehdollisesti dispersiomenetelmän tavoite voidaan muotoilla seuraavasti: eristää parametrin 3 kokonaisvaihtelusta erityinen vaihtelu:
- 1 - määräytyy kunkin tutkitun arvon vaikutuksesta;
- 2 - tutkittujen arvojen välisen suhteen sanelema;
- 3 - satunnainen, kaikkien huomioimattomien olosuhteiden sanelema.
Microsoft Excelissä varianssianalyysi voidaan suorittaa käyttämällä "Data Analysis" -työkalua (välilehti "Data" - "Analysis"). Tämä on laskentataulukon lisäosa. Jos apuohjelma ei ole saatavilla, sinun on avattava "Excel-asetukset" ja otettava asetus käyttöön analysointia varten.
Työ alkaa pöydän suunnittelusta. Säännöt:
- Jokaisen sarakkeen tulee sisältää yhden tutkittavan tekijän arvot.
- Järjestä sarakkeet nousevaan/laskevaan järjestykseen tutkittavan parametrin arvon mukaan.
Harkitse varianssianalyysiä Excelissä esimerkin avulla.
Yrityksen psykologi analysoi erityistekniikalla työntekijöiden käyttäytymisstrategiaa konfliktitilanteessa. Oletetaan, että koulutustaso (1 - keskiasteen, 2 - keskiasteen erikoistunut, 3 - korkea-asteen koulutus) vaikuttaa käyttäytymiseen.
Syötä tiedot Excel-laskentataulukkoon:


Merkittävä parametri on täytetty keltaisella värillä. Koska ryhmien välinen P-arvo on suurempi kuin 1, Fisherin testiä ei voida pitää merkittävänä. Näin ollen käyttäytyminen konfliktitilanteessa ei riipu koulutustasosta.
Tekijäanalyysi Excelissä: esimerkki
Tekijäanalyysi on monimuuttujaanalyysi muuttujien arvojen välisistä suhteista. Tällä menetelmällä voit ratkaista tärkeimmät tehtävät:
- kuvaile mitattava kohde kattavasti (lisäksi kapasiteetin, tiiviisti);
- tunnistaa piilotetut muuttujaarvot, jotka määrittävät lineaaristen tilastollisten korrelaatioiden olemassaolon;
- luokitella muuttujat (määrittää niiden välinen suhde);
- vähentää tarvittavien muuttujien määrää.
Harkitse esimerkkiä tekijäanalyysistä. Oletetaan, että tiedämme minkä tahansa tavaran myynnin viimeisten 4 kuukauden ajalta. On tarpeen analysoida, mitkä tuotteet ovat kysyttyjä ja mitkä eivät.


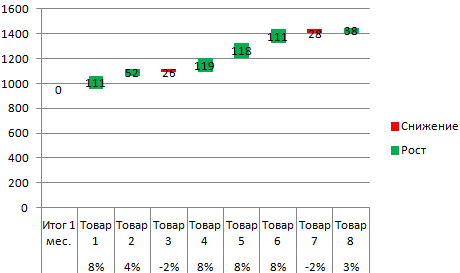
Nyt näkee selvästi, mikä tuotemyynti tuottaa pääkasvun.
Kaksisuuntainen varianssianalyysi Excelissä
Näyttää kuinka kaksi tekijää vaikuttaa satunnaismuuttujan arvon muutokseen. Harkitse kaksisuuntaista varianssianalyysiä Excelissä esimerkin avulla.
Tehtävä. Ryhmä miehiä ja naisia esiteltiin eri äänenvoimakkuuksilla: 1 - 10 dB, 2 - 30 dB, 3 - 50 dB. Vastausaika tallennettiin millisekunteina. On tarpeen määrittää, vaikuttaako sukupuoli vasteeseen; Vaikuttaako äänenvoimakkuus vasteeseen?
Varianssianalyysi
1. Varianssianalyysin käsite
Varianssianalyysi- Tämä on analyysi piirteen vaihtelevuudesta minkä tahansa kontrolloidun muuttujan vaikutuksen alaisena. Ulkomaisessa kirjallisuudessa varianssianalyysistä käytetään usein nimitystä ANOVA, joka tarkoittaa varianssianalyysiä (Variance-analyysi).
Varianssianalyysin tehtävä koostuu erilaisen vaihtelun eristämisestä ominaisuuden yleisestä vaihtelevuudesta:
a) kunkin tutkitun riippumattoman muuttujan vaikutuksesta johtuva vaihtelu;
b) tutkittujen riippumattomien muuttujien vuorovaikutuksesta johtuva vaihtelevuus;
c) kaikista muista tuntemattomista muuttujista johtuva satunnaisvaihtelu.
Tutkittujen muuttujien vaikutuksesta ja niiden vuorovaikutuksesta johtuva vaihtelevuus korreloi satunnaisvaihtelun kanssa. Tämän suhteen indikaattori on Fisherin F-testi.
Kriteerin F laskentakaava sisältää varianssien estimaatit eli piirteen jakautumisparametrit, joten kriteeri F on parametrinen kriteeri.
Mitä enemmän ominaisuuden vaihtelevuus johtuu tutkituista muuttujista (tekijöistä) tai niiden vuorovaikutuksesta, sitä korkeampi kriteerin empiiriset arvot.
Nolla varianssianalyysin hypoteesi sanoo, että tutkitun tehollisen ominaisuuden keskiarvot kaikissa asteikoissa ovat samat.
Vaihtoehtoinen hypoteesi väittää, että tehokkaan attribuutin keskiarvot tutkitun tekijän eri asteikoissa ovat erilaisia.
Varianssianalyysin avulla voimme todeta ominaisuuden muutoksen, mutta se ei osoita suunta näitä muutoksia.
Aloitetaan varianssianalyysi yksinkertaisimmasta tapauksesta, kun tutkitaan vain:n toimintaa yksi muuttuja (yksi tekijä).
2. Yksisuuntainen varianssianalyysi toisiinsa liittyville näytteille
2.1. Menetelmän tarkoitus
Yksimuuttujavarianssianalyysimenetelmää käytetään tapauksissa, joissa tehollisen attribuutin muutoksia tutkitaan muuttuvien olosuhteiden tai minkä tahansa tekijän gradaatioiden vaikutuksesta. Tässä menetelmän versiossa tekijän kunkin asteikon vaikutus on eri näyte koehenkilöistä. Tekijän asteikolla on oltava vähintään kolme astetta. (Asteasteita voi olla kaksi, mutta tässä tapauksessa emme pysty muodostamaan epälineaarisia riippuvuuksia ja näyttää järkevämmältä käyttää yksinkertaisempia).
Tämän tyyppisen analyysin ei-parametrinen muunnos on Kruskal-Wallis H -testi.
Hypoteesit
H 0: Erot tekijäluokkien (eri olosuhteet) välillä eivät ole selvempiä kuin satunnaiset erot kunkin ryhmän sisällä.
H 1: Erot tekijägradaatioiden välillä (eri olosuhteet) ovat selvempiä kuin satunnaiset erot kunkin ryhmän sisällä.
2.2. Yksimuuttujavarianssianalyysin rajoitukset riippumattomille näytteille
1. Yksimuuttujavarianssianalyysi vaatii vähintään kolme tekijän asteitusta ja vähintään kaksi kohdetta kussakin asteikossa.
2. Tuloksena olevan piirteen on jakaantuttava normaalisti tutkimusnäytteessä.
Yleensä ei tosin kerrota, puhutaanko piirteen jakautumisesta koko tutkitussa otoksessa vai siinä osassa sitä, joka muodostaa dispersiokompleksin.
3. Esimerkki ongelman ratkaisemisesta riippumattomien näytteiden yksitekijävarianssianalyysimenetelmällä käyttämällä esimerkkiä:
Kolme eri kuuden aiheen ryhmää sai kymmenen sanan luettelot. Sanat esiteltiin ensimmäiselle ryhmälle alhaisella nopeudella 1 sana 5 sekunnissa, toiselle ryhmälle keskimäärin 1 sana 2 sekunnissa ja kolmannelle ryhmälle suurella nopeudella 1 sana sekunnissa. Jäljennyksen suorituskyvyn ennustettiin riippuvan sanan esitysnopeudesta. Tulokset on esitetty taulukossa. yksi.
Toistettujen sanojen määrä pöytä 1
|
aiheen numero |
alhainen nopeus |
keskinopeus |
suuri nopeus |
|
kokonaismäärä | |||
H 0: Erot sanan määrässä välillä ryhmät eivät ole selvempiä kuin satunnaiset erot sisällä jokainen ryhmä.
H1: Erot sanojen määrässä välillä ryhmät ovat selvempiä kuin satunnaiset erot sisällä jokainen ryhmä. Käyttämällä taulukossa esitettyjä kokeellisia arvoja. 1, määritämme joitain arvoja, joita tarvitaan kriteerin F laskemiseen.
Yksisuuntaisen varianssianalyysin pääsuureiden laskenta on esitetty taulukossa:
taulukko 2
Taulukko 3
Toimintojärjestys irrotettujen näytteiden yksisuuntaisessa ANOVAssa

Tässä ja myöhemmissä taulukoissa usein käytetty nimitys SS on lyhenne sanoista "neliöiden summa". Tätä lyhennettä käytetään useimmiten käännetyissä lähteissä.
SS tosiasia tarkoittaa ominaisuuden vaihtelevuutta tutkitun tekijän vaikutuksesta;
SS yleinen- piirteen yleinen vaihtelevuus;
S CA- huomioimattomista tekijöistä johtuva vaihtelu, "satunnainen" tai "jäännös" vaihtelu.
NEITI- "keskineliö" tai neliöiden summan matemaattinen odotus, vastaavan SS:n keskiarvo.
df - vapausasteiden lukumäärä, jonka merkitsimme kreikkalaisella kirjaimella, kun otetaan huomioon ei-parametriset kriteerit v.
Johtopäätös: H 0 hylätään. H 1 hyväksytään. Erot sanantoiston volyymissa ryhmien välillä ovat selvempiä kuin satunnaiset erot kunkin ryhmän sisällä (α=0,05). Joten sanojen esitysnopeus vaikuttaa niiden toiston määrään.
Alla on esimerkki ongelman ratkaisemisesta Excelissä:
Alkutiedot:

Käyttämällä komentoa: Työkalut->Tietojen analyysi->Yksisuuntainen varianssianalyysi, saamme seuraavat tulokset:

Varianssianalyysi on joukko tilastollisia menetelmiä, jotka on suunniteltu testaamaan hypoteeseja tiettyjen piirteiden ja tutkittujen tekijöiden välisestä suhteesta, joilla ei ole kvantitatiivista kuvausta, sekä selvittää tekijöiden ja niiden vuorovaikutuksen vaikutusaste. Erikoiskirjallisuudessa sitä kutsutaan usein ANOVAksi (englanninkielisestä nimestä Analysis of Variations). Tämän menetelmän kehitti ensimmäisenä R. Fischer vuonna 1925.
Varianssianalyysin tyypit ja kriteerit
Tätä menetelmää käytetään laadullisten (nimellisten) ominaisuuksien ja kvantitatiivisen (jatkuvan) muuttujan välisen suhteen tutkimiseen. Itse asiassa se testaa hypoteesia useiden näytteiden aritmeettisten keskiarvojen yhtäläisyydestä. Näin ollen sitä voidaan pitää parametrisena kriteerinä useiden näytteiden keskipisteiden vertaamisessa kerralla. Jos käytät tätä menetelmää kahdelle näytteelle, varianssianalyysin tulokset ovat identtiset Studentin t-testin tulosten kanssa. Kuitenkin toisin kuin muut kriteerit, tämä tutkimus antaa sinun tutkia ongelmaa yksityiskohtaisemmin.
Tilastojen varianssianalyysi perustuu lakiin: yhdistetyn otoksen neliöpoikkeamien summa on yhtä suuri kuin ryhmän sisäisten poikkeamien neliöiden summa ja ryhmien välisten poikkeamien neliöiden summa. Tutkimuksessa käytetään Fisherin testiä ryhmien välisten ja ryhmien sisäisten varianssien välisen eron merkityksen selvittämiseen. Tätä varten tarvitaan kuitenkin jakauman normaalius ja näytteiden homoskedastisuus (varianssien tasaisuus). Erota yksiulotteinen (yksi tekijä) varianssianalyysi ja monimuuttuja (monitekijä). Ensimmäinen ottaa huomioon tutkittavan arvon riippuvuuden yhdestä attribuutista, toinen - useista kerralla, ja antaa sinun myös tunnistaa niiden välisen suhteen.
tekijät
Tekijöitä kutsutaan kontrolloiduiksi olosuhteiksi, jotka vaikuttavat lopputulokseen. Sen tasoa tai käsittelytapaa kutsutaan arvoksi, joka luonnehtii tämän tilan erityistä ilmentymää. Nämä luvut annetaan yleensä nimellis- tai järjestysmitta-asteikolla. Usein lähtöarvot mitataan kvantitatiivisilla tai järjestysasteikoilla. Sitten on ongelmana tulostietojen ryhmittely havaintojen sarjaan, jotka vastaavat suunnilleen samoja numeerisia arvoja. Jos ryhmien määrä on liian suuri, niissä olevien havaintojen määrä saattaa olla riittämätön luotettavien tulosten saamiseksi. Jos luku otetaan liian pieneksi, tämä voi johtaa järjestelmän vaikuttavien olennaisten ominaisuuksien menettämiseen. Tietty tietojen ryhmittelytapa riippuu arvojen vaihtelun määrästä ja luonteesta. Intervallien lukumäärä ja koko yksimuuttujaanalyysissä määräytyvät useimmiten yhtäläisten intervallien periaatteella tai yhtäläisten taajuuksien periaatteella.
Dispersioanalyysin tehtävät
Joten on tapauksia, joissa sinun on verrattava kahta tai useampaa näytettä. Silloin on suositeltavaa käyttää varianssianalyysiä. Menetelmän nimi kertoo, että johtopäätökset tehdään varianssin komponenttien tutkimuksen perusteella. Tutkimuksen ydin on, että indikaattorin kokonaismuutos jaetaan komponentteihin, jotka vastaavat kunkin yksittäisen tekijän toimintaa. Harkitse useita ongelmia, jotka tyypillinen varianssianalyysi ratkaisee.
Esimerkki 1
Pajalla on useita työstökoneita - automaattisia koneita, jotka tuottavat tietyn osan. Kunkin osan koko on satunnainen arvo, joka riippuu kunkin koneen asetuksista ja satunnaisista poikkeamista osien valmistusprosessin aikana. Osien mittojen perusteella on tarpeen määrittää, onko koneet asennettu samalla tavalla.

Esimerkki 2
Sähkölaitteen valmistuksessa käytetään erilaisia eristyspapereita: kondensaattori-, sähkö- jne. Laite voidaan kyllästää erilaisilla aineilla: epoksihartsilla, lakalla, ML-2-hartsilla jne. Vuodot voidaan poistaa tyhjiössä klo. kohonnut paine kuumennettaessa. Se voidaan kyllästää upottamalla lakkaan, jatkuvan lakkavirran alla jne. Sähkölaite kokonaisuudessaan kaadetaan tietyllä yhdisteellä, jota on useita vaihtoehtoja. Laatuindikaattoreita ovat eristyksen dielektrisyys, käämin ylikuumenemislämpötila käyttötilassa ja monet muut. Laitteiden valmistusprosessin kehittämisen aikana on tarpeen määrittää, kuinka kukin luetelluista tekijöistä vaikuttaa laitteen suorituskykyyn.
Esimerkki 3
Johdinautovarikko palvelee useita johdinautoreittejä. He kuljettavat erityyppisiä johdinautoja ja 125 tarkastajaa kerää hintoja. Varaston johtoa kiinnostaa kysymys: kuinka vertailla kunkin lennonjohtajan taloudellista suorituskykyä (tuloa) eri reitit, erityyppiset johdinautot huomioon ottaen? Kuinka määrittää taloudellinen kannattavuus tietyntyyppisten johdinautojen käynnistämiseksi tietyllä reitillä? Kuinka asettaa kohtuulliset vaatimukset konduktöörin kullekin reitille erityyppisissä johdinautoissa tuomalle tulolle?
Menetelmän valinnan tehtävänä on saada mahdollisimman paljon tietoa kunkin tekijän vaikutuksesta lopputulokseen, määrittää vaikutuksen numeeriset ominaisuudet, niiden luotettavuus mahdollisimman pienin kustannuksin ja mahdollisimman lyhyessä ajassa. Dispersioanalyysimenetelmät mahdollistavat tällaisten ongelmien ratkaisemisen.
Yksimuuttuja-analyysi
Tutkimuksen tavoitteena on arvioida yksittäisen tapauksen vaikutusta analysoitavaan tarkasteluun. Yksimuuttuja-analyysin toinen tehtävä voi olla kahden tai useamman tilanteen vertaaminen toisiinsa, jotta voidaan määrittää ero niiden vaikutuksessa takaisinkutsuun. Jos nollahypoteesi hylätään, seuraava vaihe on kvantifioida ja rakentaa luottamusvälit saaduille ominaisuuksille. Siinä tapauksessa, että nollahypoteesia ei voida hylätä, se yleensä hyväksytään ja tehdään johtopäätös vaikutuksen luonteesta.
Yksisuuntaisesta varianssianalyysistä voi tulla ei-parametrinen analogi Kruskal-Wallis rank -menetelmälle. Sen kehittivät amerikkalainen matemaatikko William Kruskal ja taloustieteilijä Wilson Wallis vuonna 1952. Tämän testin tarkoituksena on testata nollahypoteesia, jonka mukaan vaikutuksen vaikutukset tutkittuihin näytteisiin ovat yhtä suuret kuin tuntemattomat mutta samat keskiarvot. Tässä tapauksessa näytteiden lukumäärän on oltava enemmän kuin kaksi.

Jonkhier-kriteerin (Jonkhier-Terpstra) ehdottivat itsenäisesti hollantilainen matemaatikko T. J. Terpstrom vuonna 1952 ja brittiläinen psykologi E. R. Jonkhier vuonna 1954. Sitä käytetään, kun tiedetään etukäteen, että käytettävissä olevat tulosryhmät ovat järjestyneet tulosten kasvun mukaan. tutkittavan tekijän vaikutus, joka mitataan järjestysasteikolla.
M - Bartlett-kriteeriä, jonka brittiläinen tilastotieteilijä Maurice Stevenson Bartlett ehdotti vuonna 1937, käytetään testaamaan nollahypoteesia useiden normaalien populaatioiden varianssien yhtäläisyydestä, joista tutkitut näytteet on yleensä otettu erikokoisina ( kunkin näytteen lukumäärän on oltava vähintään neljä).
G on Cochranin testi, jonka amerikkalainen William Gemmel Cochran löysi vuonna 1941. Sitä käytetään testaamaan nollahypoteesia normaalipopulaatioiden varianssien yhtäläisyydestä samankokoisille riippumattomille näytteille.
Amerikkalaisen matemaatikon Howard Levenen vuonna 1960 ehdottama ei-parametrinen Levene-testi on vaihtoehto Bartlett-testille olosuhteissa, joissa ei ole varmuutta siitä, että tutkittavat näytteet noudattavat normaalijakaumaa.
Vuonna 1974 amerikkalaiset tilastotieteilijät Morton B. Brown ja Alan B. Forsythe ehdottivat testiä (Brown-Forsythin testi), joka on hieman erilainen kuin Levene-testi.
Kaksisuuntainen analyysi
Kaksisuuntaista varianssianalyysiä käytetään linkitetyille normaalijakautuneille näytteille. Käytännössä käytetään usein tämän menetelmän monimutkaisia taulukoita, erityisesti sellaisia, joissa jokainen solu sisältää kiinteitä tasoarvoja vastaavan datajoukon (toistuvia mittauksia). Jos kaksisuuntaisen varianssianalyysin soveltamiseen tarvittavat oletukset eivät täyty, käytetään ei-parametrista Friedman-arvotestiä (Friedman, Kendall ja Smith), jonka amerikkalainen taloustieteilijä Milton Friedman on kehittänyt vuoden 1930 lopussa. kriteeri ei riipu jakelutyypistä.
Oletetaan vain, että suureiden jakauma on sama ja jatkuva ja että ne itse ovat toisistaan riippumattomia. Nollahypoteesia testattaessa lähtötiedot esitetään suorakaiteen muotoisena matriisina, jossa rivit vastaavat tekijän B tasoja ja sarakkeet tasoja A. Taulukon (lohkon) jokainen solu voi olla tulos parametrien mittauksista yhdestä kohteesta tai objektiryhmästä molempien tekijöiden tasojen vakioarvoilla. Tässä tapauksessa vastaavat tiedot esitetään tietyn parametrin keskiarvoina kaikille tutkittavan näytteen mittauksille tai kohteille. Tuotoskriteerin soveltamiseksi on siirryttävä suorista mittaustuloksista niiden arvoon. Järjestys suoritetaan jokaiselle riville erikseen, eli arvot tilataan jokaiselle kiinteälle arvolle.

Amerikkalaisen tilastotieteilijän E. B. Pagen vuonna 1963 ehdottama Page testi (L-testi) on suunniteltu testaamaan nollahypoteesia. Suurille näytteille käytetään sivun approksimaatiota. Vastaavien nollahypoteesien todellisuudesta riippuen ne noudattavat normaalia normaalijakaumaa. Siinä tapauksessa, että lähdetaulukon riveillä on samat arvot, on käytettävä keskimääräisiä arvoja. Tässä tapauksessa päätelmien tarkkuus on sitä huonompi, mitä suurempi on tällaisten yhteensattumien määrä.
Q - Cochranin kriteeri, jonka V. Cochran ehdotti vuonna 1937. Sitä käytetään tapauksissa, joissa homogeenisten koehenkilöiden ryhmät ovat alttiina useammalle kuin kahdelle vaikutukselle ja joissa on kaksi vastausvaihtoehtoa - ehdollisesti negatiivinen (0) ja ehdollisesti positiivinen (1) . Nollahypoteesi koostuu vaikutusvaikutusten yhtäläisyydestä. Kaksisuuntainen varianssianalyysi mahdollistaa prosessointivaikutusten olemassaolon määrittämisen, mutta sen avulla ei voida määrittää, missä sarakkeissa tämä vaikutus on olemassa. Tätä ongelmaa ratkaistaessa käytetään useiden Scheffen yhtälöiden menetelmää kytketyille näytteille.
Monimuuttuja-analyysi
Monimuuttujavarianssianalyysin ongelma syntyy, kun on tarpeen määrittää kahden tai useamman ehdon vaikutus tiettyyn satunnaismuuttujaan. Tutkimuksessa otetaan huomioon yksi riippuvainen satunnaismuuttuja, joka mitataan ero- tai suhdeasteikolla, ja useita riippumattomia muuttujia, joista jokainen ilmaistaan nimiasteikolla tai asteikolla. Tietojen dispersioanalyysi on melko kehittynyt matemaattisen tilaston haara, jolla on paljon vaihtoehtoja. Tutkimuksen käsite on yhteinen sekä yksimuuttuja- että monimuuttujatutkimuksille. Sen olemus on siinä, että kokonaisvarianssi on jaettu komponentteihin, mikä vastaa tiettyä dataryhmää. Jokaisella dataryhmällä on oma mallinsa. Tässä tarkastellaan vain tärkeimpiä säännöksiä, jotka ovat välttämättömiä sen eniten käytettyjen muunnelmien ymmärtämiseksi ja käytännölliseksi käyttämiseksi.

Varianssitekijäanalyysi vaatii huolellista huomiota syöttötietojen keräämiseen ja esittämiseen sekä erityisesti tulosten tulkintaan. Toisin kuin yksitekijä, jonka tulokset voidaan ehdollisesti asettaa tiettyyn järjestykseen, kaksitekijän tulokset vaativat monimutkaisempaa esitystä. Vielä vaikeampi tilanne syntyy, kun olosuhteita on kolme, neljä tai enemmän. Tästä johtuen malli sisältää harvoin enemmän kuin kolme (neljä) ehtoa. Esimerkkinä voisi olla resonanssin esiintyminen tietyllä sähköympyrän kapasitanssin ja induktanssin arvolla; kemiallisen reaktion ilmentymä tietyn elementtijoukon kanssa, josta järjestelmä on rakennettu; poikkeavien vaikutusten esiintyminen monimutkaisissa järjestelmissä tietyissä olosuhteiden sattuessa. Vuorovaikutuksen läsnäolo voi muuttaa järjestelmän mallia radikaalisti ja joskus johtaa kokeilun kohteena olevien ilmiöiden luonteen uudelleen ajattelemiseen.
Monimuuttuja varianssianalyysi toistuvilla kokeilla
Mittaustiedot voidaan usein ryhmitellä kahden, vaan useamman tekijän mukaan. Joten jos tarkastellaan johdinauton pyörien renkaiden käyttöiän hajonta-analyysiä, ottaen huomioon olosuhteet (valmistaja ja renkaiden käyttöreitti), voimme erottaa erillisenä ehtona kauden, jolloin renkaat ovat käytetty (eli: talvi- ja kesäkäyttö). Tämän seurauksena meillä on kolmitekijämenetelmän ongelma.
Jos ehtoja on enemmän, lähestymistapa on sama kuin kaksisuuntaisessa analyysissä. Kaikissa tapauksissa malli yrittää yksinkertaistaa. Kahden tekijän vuorovaikutusilmiö ei esiinny niin usein, ja kolmoisvuorovaikutusta esiintyy vain poikkeustapauksissa. Sisällytä ne vuorovaikutukset, joista on aiempaa tietoa ja hyviä syitä ottaa se huomioon mallissa. Yksittäisten tekijöiden eristäminen ja huomioon ottaminen on suhteellisen yksinkertaista. Siksi usein halutaan korostaa enemmän olosuhteita. Sinun ei pitäisi hukata tähän. Mitä enemmän ehtoja, sitä vähemmän luotettava malli tulee ja sitä suurempi on virheen mahdollisuus. Itse mallista, joka sisältää suuren määrän riippumattomia muuttujia, tulee melko vaikeasti tulkittava ja hankala käytännön käytössä.
Yleisidea varianssianalyysistä
Tilastojen varianssianalyysi on tapa saada havainnointituloksia, jotka riippuvat erilaisista samanaikaisista olosuhteista ja arvioida niiden vaikutusta. Ohjattua muuttujaa, joka vastaa menetelmää, jolla vaikutetaan tutkimuskohteeseen ja joka saa tietyn arvon tietyssä ajassa, kutsutaan tekijäksi. Ne voivat olla laadullisia ja määrällisiä. Kvantitatiivisten olosuhteiden tasot saavat tietyn arvon numeerisella asteikolla. Esimerkkejä ovat lämpötila, puristuspaine, aineen määrä. Laadullisia tekijöitä ovat erilaiset aineet, erilaiset teknologiset menetelmät, laitteet, täyteaineet. Niiden tasot vastaavat nimien asteikkoa.

Laatuun kuuluu myös pakkausmateriaalin tyyppi, annosmuodon säilytysolosuhteet. On myös järkevää ottaa mukaan raaka-aineiden jauhatusaste, rakeiden fraktiokoostumus, joilla on määrällinen arvo, mutta joita on vaikea säädellä, jos käytetään kvantitatiivista asteikkoa. Laatutekijöiden lukumäärä riippuu annosmuodon tyypistä sekä lääkeaineiden fysikaalisista ja teknologisista ominaisuuksista. Esimerkiksi tabletteja voidaan saada kiteisistä aineista suoraan puristamalla. Tässä tapauksessa riittää liuku- ja voiteluaineiden valinta.
Esimerkkejä eri tyyppisten annosmuotojen laatutekijöistä
- Tinktuurat. Uuttoaineen koostumus, uuttolaitteen tyyppi, raaka-aineen valmistusmenetelmä, valmistusmenetelmä, suodatusmenetelmä.
- Uutteet (nestemäiset, paksut, kuivat). Uuttoaineen koostumus, uuttomenetelmä, asennuksen tyyppi, uuttoaineen ja painolastiaineiden poistomenetelmä.
- Tabletit. Apuaineiden, täyteaineiden, hajotusaineiden, sideaineiden, voiteluaineiden ja voiteluaineiden koostumus. Tablettien hankintamenetelmä, teknisten laitteiden tyyppi. Kuoren tyyppi ja sen komponentit, kalvonmuodostajat, pigmentit, värit, pehmittimet, liuottimet.
- injektioliuokset. Liuottimen tyyppi, suodatusmenetelmä, stabilointi- ja säilöntäaineiden luonne, sterilointiolosuhteet, ampullien täyttötapa.
- Peräpuikot. Peräpuikkopohjan koostumus, peräpuikkojen, täyteaineiden, pakkausten hankintamenetelmä.
- Voiteet. Pohjan koostumus, rakenneosat, voiteen valmistusmenetelmä, laitetyyppi, pakkaus.
- Kapselit. Kuorimateriaalin tyyppi, kapselien valmistusmenetelmä, pehmittimen tyyppi, säilöntäaine, väriaine.
- Linimentit. Valmistusmenetelmä, koostumus, laitetyyppi, emulgointiaineen tyyppi.
- Jousitukset. Liuottimen tyyppi, stabilointiaineen tyyppi, dispersiomenetelmä.
Esimerkkejä tablettien valmistusprosessissa tutkituista laatutekijöistä ja niiden tasoista
- Leivinjauhe. Perunatärkkelys, valkoinen savi, natriumbikarbonaatin ja sitruunahapon seos, emäksinen magnesiumkarbonaatti.
- sitova ratkaisu. Vesi, tärkkelystahna, sokerisiirappi, metyyliselluloosaliuos,aliuos, polyvinyylipyrrolidoniliuos, polyvinyylialkoholiliuos.
- liukuva aine. Aerosil, tärkkelys, talkki.
- Täyteaine. Sokeri, glukoosi, laktoosi, natriumkloridi, kalsiumfosfaatti.
- Voiteluaine. Steariinihappo, polyetyleeniglykoli, parafiini.
Hajautusanalyysin mallit valtion kilpailukykytason tutkimuksessa
Yksi tärkeimmistä valtion tilan arviointikriteereistä, jonka mukaan sen hyvinvoinnin ja sosioekonomisen kehityksen tasoa arvioidaan, on kilpailukyky, eli joukko kansantaloudelle luontaisia ominaisuuksia, jotka määräävät valtion kyvyn. valtio kilpailemaan muiden maiden kanssa. Valtion paikan ja roolin määrittämisen jälkeen on mahdollista luoda selkeä strategia taloudellisen turvallisuuden takaamiseksi kansainvälisessä mittakaavassa, koska se on avain myönteisiin suhteisiin Venäjän ja kaikkien maailmanmarkkinoiden toimijoiden: sijoittajien välillä. , velkojat, osavaltioiden hallitukset.
Valtioiden kilpailukyvyn vertailua varten maat luokitellaan monimutkaisilla indekseillä, jotka sisältävät erilaisia painotettuja indikaattoreita. Nämä indeksit perustuvat avaintekijöihin, jotka vaikuttavat taloudelliseen, poliittiseen jne. tilanteeseen. Valtion kilpailukyvyn tutkimiseen tarkoitettu mallikokonaisuus mahdollistaa monimuuttujatilastoanalyysin menetelmien käytön (erityisesti tämä on varianssianalyysi (tilastot), ekonometrinen mallinnus, päätöksenteko) ja sisältää seuraavat päävaiheet:
- Indikaattori-indikaattorijärjestelmän muodostaminen.
- Valtion kilpailukyvyn tunnuslukujen arviointi ja ennustaminen.
- Valtioiden kilpailukyvyn indikaattoreiden-indikaattoreiden vertailu.
Ja nyt tarkastellaan tämän kompleksin kunkin vaiheen mallien sisältöä.
Ensimmäisessä vaiheessa asiantuntijatutkimusmenetelmien avulla muodostetaan kohtuullinen joukko taloudellisia indikaattoreita-indikaattoreita valtion kilpailukyvyn arvioimiseksi ottaen huomioon sen kehityksen erityispiirteet kansainvälisten arvioiden ja tilastoosastojen tietojen perusteella, mikä kuvastaa valtion tilaa. järjestelmä kokonaisuudessaan ja sen prosessit. Näiden indikaattoreiden valintaa perustelee tarve valita ne, jotka käytännössä mahdollistavat täydellisesti valtion tason, investointien houkuttelevuuden ja olemassa olevien mahdollisten ja todellisten uhkien suhteellisen paikallistamisen mahdollisuuden.

Kansainvälisten luokitusjärjestelmien tärkeimmät indikaattorit-indikaattorit ovat indeksit:
- Global Competitiveness (GCC).
- Taloudellinen vapaus (IES).
- Ihmisen kehitys (HDI).
- Käsitykset korruptiosta (CPI).
- Sisäiset ja ulkoiset uhat (IVZZ).
- Kansainvälisen vaikutuksen mahdollisuus (IPIP).
Toinen vaihe osavaltion kilpailukykyä mittaavien tunnuslukujen arvioinnin ja ennustamisen kansainvälisten luokituksen mukaan tutkituille 139 maailman osavaltiolle.
Kolmas vaihe tarjoaa valtioiden kilpailukyvyn edellytysten vertailun käyttämällä korrelaatio- ja regressioanalyysimenetelmiä.
Tutkimuksen tulosten avulla on mahdollista määrittää prosessien luonne yleisesti ja yksittäisten valtion kilpailukyvyn komponenttien osalta; testaa hypoteesia tekijöiden vaikutuksesta ja niiden suhteesta sopivalla merkitsevyystasolla.
Ehdotetun mallisarjan käyttöönoton avulla voidaan arvioida valtioiden kilpailukykytason ja investointien houkuttelevuuden nykytilannetta, mutta myös analysoida johtamisen puutteita, estää väärien päätösten virheet ja estää kriisin kehittymisen. osavaltiossa.
