Bentuk indikator statistik yang paling umum digunakan dalam penelitian sosial ekonomi adalah nilai rata-rata, yang merupakan karakteristik kuantitatif umum dari suatu tanda populasi statistik. Nilai rata-rata, seolah-olah, adalah "perwakilan" dari seluruh rangkaian pengamatan. Dalam banyak kasus, rata-rata dapat ditentukan melalui rasio awal rata-rata (ISS) atau rumus logisnya: . Jadi, misalnya, untuk menghitung upah rata-rata karyawan suatu perusahaan, perlu membagi dana upah total dengan jumlah karyawan: Pembilang rasio awal rata-rata adalah indikator yang menentukan. Untuk upah rata-rata, indikator penentu tersebut adalah dana upah. Untuk setiap indikator yang digunakan dalam analisis sosial ekonomi, hanya satu rasio acuan yang benar yang dapat dikompilasi untuk menghitung rata-rata. Juga harus ditambahkan bahwa untuk lebih akurat memperkirakan simpangan baku untuk sampel kecil (dengan jumlah elemen kurang dari 30), penyebut dari ekspresi di bawah akar tidak boleh menggunakan n, sebuah n- 1.
Konsep dan jenis rata-rata
Nilai rata-rata- ini adalah indikator generalisasi populasi statistik, yang menghilangkan perbedaan individu dalam nilai kuantitas statistik, memungkinkan Anda untuk membandingkan populasi yang berbeda satu sama lain. Ada 2 kelas nilai rata-rata: kekuatan dan struktural. Rata-rata struktural adalah mode dan median , tapi yang paling umum digunakan rata-rata daya berbagai jenis.Rata-rata daya
Rata-rata daya dapat menjadi sederhana dan tertimbang.
Rata-rata sederhana dihitung ketika ada dua atau lebih nilai statistik yang tidak dikelompokkan, disusun dalam urutan arbitrer sesuai dengan rumus umum hukum pangkat rata-rata berikut (untuk nilai k (m) yang berbeda):
Rata-rata tertimbang dihitung dari statistik yang dikelompokkan menggunakan rumus umum berikut:

Dimana x - nilai rata-rata dari fenomena yang diteliti; x i – varian ke-i dari fitur rata-rata ;
f i adalah bobot opsi ke-i.

Dimana X adalah nilai nilai statistik individu atau titik tengah interval pengelompokan;
m - eksponen, yang nilainya bergantung pada jenis rata-rata daya berikut:
pada m = -1 rata-rata harmonik;
untuk m = 0, mean geometrik;
untuk m = 1, mean aritmatika;
pada m = 2, akar rata-rata kuadrat;
pada m = 3, kubik rata-rata.
Dengan menggunakan rumus umum untuk rata-rata sederhana dan rata-rata tertimbang dengan eksponen berbeda m, kita memperoleh rumus khusus dari setiap jenis, yang akan dibahas secara rinci di bawah ini.
Rata-rata aritmatika
Rata-rata aritmatika - momen awal orde pertama, ekspektasi matematis dari nilai-nilai variabel acak dengan sejumlah besar percobaan;
Rata-rata aritmatika adalah nilai rata-rata yang paling umum digunakan, yang diperoleh dengan mensubstitusi m = 1 ke dalam rumus umum. Rata-rata aritmatika sederhana memiliki bentuk sebagai berikut:
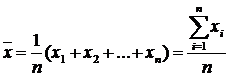 atau
atau ![]()
Di mana X adalah nilai kuantitas yang perlu untuk menghitung nilai rata-rata; N adalah jumlah total nilai X (jumlah satuan dalam populasi yang diteliti).
Misalnya, seorang siswa lulus 4 ujian dan menerima nilai berikut: 3, 4, 4 dan 5. Mari kita hitung skor rata-rata menggunakan rumus rata-rata aritmatika sederhana: (3+4+4+5)/4 = 16/4 = 4. Rata-rata aritmatika tertimbang memiliki bentuk sebagai berikut:
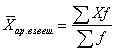
Dimana f adalah banyaknya nilai dengan nilai X (frekuensi) yang sama. >Misalnya, seorang siswa lulus 4 ujian dan mendapat nilai berikut: 3, 4, 4 dan 5. Hitung skor rata-rata menggunakan rumus rata-rata tertimbang aritmatika: (3*1 + 4*2 + 5*1)/4 = 16/4 = 4 . Jika nilai X diberikan sebagai interval, maka titik tengah interval X digunakan untuk perhitungan, yang didefinisikan sebagai setengah jumlah batas atas dan bawah interval. Dan jika interval X tidak memiliki batas bawah atau batas atas (interval terbuka), maka untuk menemukannya digunakan rentang (selisih antara batas atas dan bawah) dari interval X yang berdekatan. Misalnya, di perusahaan ada 10 karyawan dengan pengalaman kerja hingga 3 tahun, 20 - dengan pengalaman kerja 3 hingga 5 tahun, 5 karyawan - dengan pengalaman kerja lebih dari 5 tahun. Kemudian kami menghitung rata-rata lama masa kerja karyawan menggunakan rumus rata-rata tertimbang aritmatika, dengan mengambil X di tengah interval masa kerja (2, 4 dan 6 tahun): (2*10+4*20+6*5)/(10+20+5) = 3,71 tahun.
Fungsi RATA-RATA
Fungsi ini menghitung rata-rata (aritmatika) dari argumennya.
RATA-RATA(angka1, angka2, ...)
Number1, number2, ... adalah argumen 1 hingga 30 yang rata-ratanya dihitung.
Argumen harus berupa angka atau nama, larik atau referensi yang berisi angka. Jika argumen, yang berupa larik atau tautan, berisi teks, boolean, atau sel kosong, maka nilai tersebut diabaikan; namun, sel yang berisi nilai nol akan dihitung.
Fungsi RATA-RATA
Menghitung rata-rata aritmatika dari nilai yang diberikan dalam daftar argumen. Selain angka, teks dan nilai logika, seperti TRUE dan FALSE, dapat berpartisipasi dalam penghitungan.
RATA-RATA(nilai1, nilai2,...)
Nilai1, nilai2,... adalah 1 hingga 30 sel, rentang sel, atau nilai yang rata-ratanya dihitung.
Argumen harus berupa angka, nama, array, atau referensi. Array dan tautan yang berisi teks ditafsirkan sebagai 0 (nol). Teks kosong ("") diartikan sebagai 0 (nol). Argumen yang mengandung nilai TRUE ditafsirkan sebagai 1, Argumen yang mengandung nilai FALSE ditafsirkan sebagai 0 (nol).
Rata-rata aritmatika paling sering digunakan, tetapi ada kalanya jenis rata-rata lain diperlukan. Mari kita pertimbangkan kasus-kasus seperti itu lebih lanjut.
Harmonik rata-rata
Rata-rata harmonik untuk menentukan jumlah rata-rata timbal balik;
Harmonik rata-rata digunakan ketika data asli tidak mengandung frekuensi f untuk nilai individu X, tetapi disajikan sebagai produk Xf mereka. Dengan menyatakan Xf=w, kita nyatakan f=w/X, dan mensubstitusikan penunjukan ini ke dalam rumus rata-rata aritmatika berbobot, kita memperoleh rumus rata-rata harmonik berbobot:
Jadi, rata-rata tertimbang harmonik digunakan ketika frekuensi f tidak diketahui, tetapi w=Xf diketahui. Dalam kasus di mana semua w = 1, yaitu nilai individu X terjadi 1 kali, rumus rata-rata sederhana harmonik diterapkan:  atau
atau  Sebagai contoh, sebuah mobil bergerak dari titik A ke titik B dengan kecepatan 90 km/jam dan kembali dengan kecepatan 110 km/jam. Untuk menentukan kecepatan rata-rata, kami menerapkan rumus sederhana harmonik, karena contoh memberikan jarak w 1 \u003d w 2 (jarak dari titik A ke titik B sama dengan dari B ke A), yang sama dengan produk kecepatan (X) dan waktu (f). Kecepatan rata-rata = (1+1)/(1/90+1/110) = 99 km/jam.
Sebagai contoh, sebuah mobil bergerak dari titik A ke titik B dengan kecepatan 90 km/jam dan kembali dengan kecepatan 110 km/jam. Untuk menentukan kecepatan rata-rata, kami menerapkan rumus sederhana harmonik, karena contoh memberikan jarak w 1 \u003d w 2 (jarak dari titik A ke titik B sama dengan dari B ke A), yang sama dengan produk kecepatan (X) dan waktu (f). Kecepatan rata-rata = (1+1)/(1/90+1/110) = 99 km/jam.
fungsi SRHARM
Mengembalikan rata-rata harmonik dari kumpulan data. Rata-rata harmonik adalah kebalikan dari rata-rata aritmatika dari kebalikannya.
SGARM(nomor1, nomor2, ...)
Number1, number2, ... adalah argumen 1 hingga 30 yang rata-ratanya dihitung. Anda dapat menggunakan larik atau referensi larik alih-alih argumen yang dipisahkan titik koma.
Rata-rata harmonik selalu lebih kecil dari rata-rata geometrik, yang selalu lebih kecil dari rata-rata aritmatika.
Rata-rata geometris
Rata-rata geometrik untuk memperkirakan laju pertumbuhan rata-rata variabel acak, menemukan nilai fitur yang berjarak sama dari nilai minimum dan maksimum;
Rata-rata geometris digunakan dalam menentukan rata-rata perubahan relatif. Nilai rata-rata geometrik memberikan hasil rata-rata yang paling akurat jika tugasnya adalah menemukan nilai X seperti itu, yang berjarak sama dari nilai maksimum dan minimum X. Misalnya, antara tahun 2005 dan 2008indeks inflasi di Rusia adalah: pada 2005 - 1,109; pada tahun 2006 - 1.090; pada tahun 2007 - 1.119; pada tahun 2008 - 1.133. Karena indeks inflasi adalah perubahan relatif (indeks dinamis), maka Anda perlu menghitung nilai rata-rata menggunakan mean geometrik: (1,109 * 1,090 * 1,119 * 1,133) ^ (1/4) = 1,1126, yaitu untuk periode dari tahun 2005 hingga 2008 setiap tahun harga tumbuh rata-rata 11,26%. Perhitungan yang salah pada rata-rata aritmatika akan memberikan hasil yang salah sebesar 11,28%.Fungsi SRGEOM
Mengembalikan rata-rata geometrik larik atau rentang bilangan positif. Misalnya, fungsi CAGEOM dapat digunakan untuk menghitung tingkat pertumbuhan rata-rata jika pendapatan majemuk dengan tingkat variabel diberikan.
SRGEOM(nomor1; nomor2; ...)
Angka1, angka2, ... adalah argumen 1 hingga 30 yang rata-rata geometrisnya dihitung. Anda dapat menggunakan larik atau referensi larik alih-alih argumen yang dipisahkan titik koma.
akar rata-rata kuadrat
Akar kuadrat rata-rata adalah momen awal orde kedua.
akar rata-rata kuadrat digunakan ketika nilai awal X bisa positif dan negatif, misalnya, saat menghitung deviasi rata-rata.Kubik rata-rata
Kubik rata-rata adalah momen awal orde ketiga.
Kubik rata-rata sangat jarang digunakan, misalnya, ketika menghitung indeks kemiskinan untuk negara berkembang (HPI-1) dan untuk negara maju (HPI-2), diusulkan dan dihitung oleh PBB.Dalam kebanyakan kasus, data terkonsentrasi di sekitar beberapa titik pusat. Jadi, untuk menggambarkan kumpulan data apa pun, cukup dengan menunjukkan nilai rata-rata. Mari kita perhatikan berturut-turut tiga karakteristik numerik yang digunakan untuk memperkirakan nilai rata-rata dari distribusi: rata-rata aritmatika, median, dan modus.
Rata-rata
Rata-rata aritmatika (sering disebut hanya sebagai rata-rata) adalah perkiraan yang paling umum dari rata-rata distribusi. Ini adalah hasil dari membagi jumlah semua nilai numerik yang diamati dengan jumlah mereka. Untuk contoh bilangan X 1, X 2, ..., Xn, mean sampel (dilambangkan dengan simbol ) sama dengan \u003d (X 1 + X 2 + ... + Xn) / n, atau
di mana rata-rata sampel, n- ukuran sampel, Xsaya– elemen ke-i dari sampel.
Unduh catatan dalam atau format, contoh dalam format
Pertimbangkan untuk menghitung rata-rata aritmatika dari pengembalian tahunan rata-rata lima tahun dari 15 reksa dana berisiko sangat tinggi (Gambar 1).

Beras. 1. Rata-rata pengembalian tahunan pada 15 reksa dana berisiko sangat tinggi
Rata-rata sampel dihitung sebagai berikut:

Ini adalah pengembalian yang baik, terutama jika dibandingkan dengan pengembalian 3-4% yang diterima oleh deposan bank atau serikat kredit selama periode waktu yang sama. Jika Anda mengurutkan nilai pengembalian, mudah untuk melihat bahwa delapan dana memiliki pengembalian di atas, dan tujuh - di bawah rata-rata. Rata-rata aritmatika bertindak sebagai titik keseimbangan, sehingga dana berpenghasilan rendah mengimbangi dana berpenghasilan tinggi. Semua elemen sampel terlibat dalam perhitungan rata-rata. Tak satu pun dari estimator lain dari distribusi rata-rata memiliki properti ini.
Kapan menghitung rata-rata aritmatika. Karena rata-rata aritmatika tergantung pada semua elemen sampel, keberadaan nilai ekstrem secara signifikan mempengaruhi hasil. Dalam situasi seperti itu, rata-rata aritmatika dapat mendistorsi makna data numerik. Oleh karena itu, ketika menggambarkan kumpulan data yang berisi nilai-nilai ekstrim, perlu untuk menunjukkan median atau rata-rata aritmatika dan median. Misalnya, jika pengembalian dana RS Emerging Growth dihapus dari sampel, rata-rata sampel pengembalian dana 14 berkurang hampir 1% menjadi 5,19%.
median
Median adalah nilai tengah dari deretan angka yang diurutkan. Jika array tidak mengandung angka berulang, maka setengah dari elemennya akan kurang dari dan setengah lebih dari median. Jika sampel mengandung nilai ekstrim, lebih baik menggunakan median daripada mean aritmatika untuk memperkirakan mean. Untuk menghitung median sampel, terlebih dahulu harus diurutkan.
Formula ini ambigu. Hasilnya tergantung pada apakah bilangan itu genap atau ganjil. n:
- Jika sampel berisi jumlah item ganjil, mediannya adalah (n+1)/2 elemen -th.
- Jika sampel mengandung jumlah elemen yang genap, median terletak di antara dua elemen tengah sampel dan sama dengan rata-rata aritmatika yang dihitung untuk dua elemen ini.
Untuk menghitung median untuk sampel 15 reksa dana berisiko sangat tinggi, pertama-tama kita perlu mengurutkan data mentahnya (Gambar 2). Maka median akan berlawanan dengan jumlah elemen tengah sampel; dalam contoh kita nomor 8. Excel memiliki fungsi khusus =MEDIAN() yang bekerja dengan array yang tidak berurutan juga.

Beras. 2. Median 15 dana
Jadi, mediannya adalah 6,5. Ini berarti bahwa setengah dari dana berisiko sangat tinggi tidak melebihi 6,5, sedangkan setengah lainnya melakukannya. Perhatikan bahwa median 6,5 sedikit lebih besar dari median 6,08.
Jika kita menghapus profitabilitas dana RS Emerging Growth dari sampel, maka median dari 14 dana yang tersisa akan turun menjadi 6,2%, yaitu, tidak sepenting rata-rata aritmatika (Gbr. 3).

Beras. 3. Median 14 dana
Mode
Istilah tersebut pertama kali diperkenalkan oleh Pearson pada tahun 1894. Fashion adalah angka yang paling sering muncul dalam sampel (paling fashionable). Fashion menggambarkan dengan baik, misalnya, reaksi khas pengemudi terhadap sinyal lalu lintas untuk menghentikan lalu lintas. Contoh klasik penggunaan mode adalah pilihan ukuran batch sepatu yang diproduksi atau warna wallpaper. Jika suatu distribusi memiliki beberapa mode, maka dikatakan multimodal atau multimodal (memiliki dua atau lebih "puncak"). Distribusi multimodal memberikan informasi penting tentang sifat variabel yang diteliti. Misalnya, dalam survei sosiologis, jika suatu variabel mewakili preferensi atau sikap terhadap sesuatu, maka multimodalitas dapat berarti bahwa ada beberapa pendapat yang sangat berbeda. Multimodalitas juga merupakan indikator bahwa sampel tidak homogen dan bahwa pengamatan dapat dihasilkan oleh dua atau lebih distribusi "tumpang tindih". Berbeda dengan mean aritmatika, outlier tidak mempengaruhi mode. Untuk variabel acak yang terdistribusi terus menerus, seperti rata-rata pengembalian tahunan reksa dana, modus terkadang tidak ada sama sekali (atau tidak masuk akal). Karena indikator ini dapat mengambil berbagai nilai, nilai berulang sangat jarang.
Kuartil
Kuartil adalah ukuran yang paling umum digunakan untuk mengevaluasi distribusi data ketika menggambarkan sifat sampel numerik besar. Sementara median membagi larik terurut menjadi dua (50% elemen larik lebih kecil dari median dan 50% lebih besar), kuartil memecah kumpulan data terurut menjadi empat bagian. Nilai Q 1 , median dan Q 3 berturut-turut adalah persentil ke-25, ke-50 dan ke-75. Kuartil pertama Q 1 adalah bilangan yang membagi sampel menjadi dua bagian: 25% elemennya kurang dari, dan 75% lebih dari kuartil pertama.
Kuartil ketiga Q 3 adalah bilangan yang juga membagi sampel menjadi dua bagian: 75% elemennya kurang dari, dan 25% lebih dari kuartil ketiga.
Untuk menghitung kuartil di versi Excel sebelum 2007, fungsi =QUARTILE(array, part) digunakan. Dimulai dengan Excel 2010, dua fungsi berlaku:
- =QUARTILE.ON(array, bagian)
- =QUARTILE.EXC(array, bagian)
Kedua fungsi ini memberikan nilai yang sedikit berbeda (Gambar 4). Misalnya, ketika menghitung kuartil sampel yang berisi data tentang pengembalian tahunan rata-rata dari 15 reksa dana berisiko sangat tinggi, Q 1 = 1,8 atau -0,7 untuk QUARTILE.INC dan QUARTILE.EXC, masing-masing. Omong-omong, fungsi QUARTILE yang digunakan sebelumnya sesuai dengan fungsi QUARTILE.ON modern. Untuk menghitung kuartil di Excel menggunakan rumus di atas, larik data dapat dibiarkan tidak berurutan.

Beras. 4. Hitung kuartil di Excel
Mari kita tekankan lagi. Excel dapat menghitung kuartil untuk univariat seri diskrit, yang berisi nilai-nilai variabel acak. Perhitungan kuartil untuk distribusi berbasis frekuensi diberikan pada bagian di bawah ini.
rata-rata geometris
Berbeda dengan mean aritmatika, mean geometrik mengukur seberapa banyak variabel telah berubah dari waktu ke waktu. Rata-rata geometrik adalah akarnya n derajat dari produk n nilai (di Excel, fungsi = CUGEOM digunakan):
G= (X 1 * X 2 * ... * X n) 1/n
Parameter serupa - rata-rata geometrik dari tingkat pengembalian - ditentukan oleh rumus:
G \u003d [(1 + R 1) * (1 + R 2) * ... * (1 + R n)] 1 / n - 1,
di mana R i- tingkat pengembalian saya- periode waktu.
Misalnya, misalkan investasi awal adalah $100.000. Pada akhir tahun pertama, turun menjadi $50.000, dan pada akhir tahun kedua, ia pulih ke $100.000 semula. Tingkat pengembalian investasi ini selama dua tahun. periode tahun sama dengan 0, karena jumlah awal dan akhir dana sama satu sama lain. Namun, rata-rata aritmatika tingkat pengembalian tahunan adalah = (-0,5 + 1) / 2 = 0,25 atau 25%, karena tingkat pengembalian pada tahun pertama R 1 = (50.000 - 100.000) / 100.000 = -0,5 , dan pada detik kedua R 2 = (100.000 - 50.000) / 50.000 = 1. Pada saat yang sama, rata-rata geometrik tingkat pengembalian selama dua tahun adalah: G = [(1–0,5) * (1 + 1 )] 1 /2 – 1 = – 1 = 1 – 1 = 0. Dengan demikian, mean geometrik lebih akurat mencerminkan perubahan (lebih tepatnya, tidak adanya perubahan) dalam volume investasi selama dua tahun daripada mean aritmatika.
Fakta Menarik. Pertama, mean geometrik akan selalu lebih kecil dari mean aritmatika dari bilangan yang sama. Kecuali untuk kasus ketika semua angka yang diambil sama satu sama lain. Kedua, setelah mempertimbangkan sifat-sifat segitiga siku-siku, orang dapat memahami mengapa mean disebut geometris. Ketinggian segitiga siku-siku, diturunkan ke sisi miring, adalah rata-rata proporsional antara proyeksi kaki pada sisi miring, dan setiap kaki adalah proporsional rata-rata antara sisi miring dan proyeksi pada sisi miring (Gbr. 5). Ini memberikan cara geometris untuk membangun rata-rata geometris dari dua (panjang) segmen: Anda perlu membuat lingkaran pada jumlah dari dua segmen ini sebagai diameter, kemudian tingginya, dipulihkan dari titik koneksi mereka ke persimpangan dengan lingkaran, akan memberikan nilai yang diinginkan:

Beras. 5. Sifat geometris mean geometrik (gambar dari Wikipedia)
Sifat penting kedua dari data numerik adalah variasi mencirikan derajat penyebaran data. Dua sampel yang berbeda dapat berbeda baik dalam nilai rata-rata maupun dalam variasi. Namun, seperti yang ditunjukkan pada gambar. 6 dan 7, dua sampel dapat memiliki variasi yang sama tetapi rata-rata berbeda, atau rata-rata yang sama dan variasi yang sama sekali berbeda. Data yang sesuai dengan poligon B pada Gambar. 7 berubah jauh lebih sedikit daripada data dari mana poligon A dibangun.

Beras. 6. Dua distribusi berbentuk lonceng simetris dengan sebaran yang sama dan nilai rata-rata yang berbeda

Beras. 7. Dua distribusi berbentuk lonceng simetris dengan nilai rata-rata yang sama dan sebaran yang berbeda
Ada lima perkiraan variasi data:
- menjangkau,
- jarak interkuartil,
- penyebaran,
- simpangan baku,
- koefisien variasi.
cakupan
Rentang adalah perbedaan antara elemen terbesar dan terkecil dari sampel:
Gesek = XMax-Xmin
Rentang sampel yang berisi pengembalian tahunan rata-rata dari 15 reksa dana berisiko sangat tinggi dapat dihitung dengan menggunakan susunan berurutan (lihat Gambar 4): kisaran = 18,5 - (-6.1) = 24,6. Artinya, selisih rata-rata pengembalian tahunan tertinggi dan terendah untuk dana dengan risiko sangat tinggi adalah 24,6%.
Rentang mengukur keseluruhan penyebaran data. Meskipun rentang sampel adalah perkiraan yang sangat sederhana dari total penyebaran data, kelemahannya adalah tidak memperhitungkan secara tepat bagaimana data didistribusikan antara elemen minimum dan maksimum. Efek ini terlihat baik pada Gambar. 8 yang menggambarkan sampel memiliki kisaran yang sama. Skala B menunjukkan bahwa jika sampel mengandung setidaknya satu nilai ekstrim, rentang sampel adalah perkiraan yang sangat tidak akurat dari sebaran data.

Beras. 8. Perbandingan tiga sampel dengan rentang yang sama; segitiga melambangkan dukungan keseimbangan, dan lokasinya sesuai dengan nilai rata-rata sampel
Jarak interkuartil
Interkuartil, atau mean, jangkauan adalah perbedaan antara kuartil ketiga dan pertama sampel:
Rentang interkuartil \u003d Q 3 - Q 1
Nilai ini memungkinkan untuk memperkirakan penyebaran 50% elemen dan tidak memperhitungkan pengaruh elemen ekstrim. Rentang interkuartil untuk sampel yang berisi data pengembalian tahunan rata-rata dari 15 reksa dana berisiko sangat tinggi dapat dihitung dengan menggunakan data pada Gambar. 4 (misalnya, untuk fungsi QUARTILE.EXC): Rentang antarkuartil = 9,8 - (-0,7) = 10,5. Interval antara 9,8 dan -0,7 sering disebut sebagai paruh tengah.
Perlu dicatat bahwa nilai Q 1 dan Q 3, dan karenanya rentang interkuartil, tidak bergantung pada keberadaan outlier, karena perhitungannya tidak memperhitungkan nilai apa pun yang lebih kecil dari Q 1 atau lebih besar dari Q 3 . Karakteristik kuantitatif total, seperti median, kuartil pertama dan ketiga, dan rentang antarkuartil, yang tidak dipengaruhi oleh outlier, disebut indikator kuat.
Sementara rentang dan rentang interkuartil masing-masing memberikan perkiraan total dan rata-rata sebaran sampel, tidak satu pun dari perkiraan ini yang memperhitungkan dengan tepat bagaimana data didistribusikan. Varians dan simpangan baku bebas dari kekurangan ini. Indikator-indikator ini memungkinkan Anda untuk menilai tingkat fluktuasi data di sekitar mean. Varians sampel adalah perkiraan rata-rata aritmatika yang dihitung dari selisih kuadrat antara setiap elemen sampel dan rata-rata sampel. Untuk sampel X 1 , X 2 , ... X n varians sampel (dilambangkan dengan simbol S 2 diberikan oleh rumus berikut:

Secara umum, varians sampel adalah jumlah selisih kuadrat antara elemen sampel dan rata-rata sampel, dibagi dengan nilai yang sama dengan ukuran sampel dikurangi satu:

di mana - rata-rata aritmatika, n- ukuran sampel, X saya - saya-elemen sampel ke- X. Di Excel sebelum versi 2007, fungsi =VAR() digunakan untuk menghitung varians sampel, sejak versi 2010, fungsi =VAR.V() digunakan.
Perkiraan penyebaran data yang paling praktis dan diterima secara luas adalah simpangan baku. Indikator ini dilambangkan dengan simbol S dan sama dengan akar kuadrat dari varians sampel:

Di Excel sebelum versi 2007, fungsi =STDEV() digunakan untuk menghitung simpangan baku, dari versi 2010 fungsi =STDEV.V() digunakan. Untuk menghitung fungsi-fungsi ini, array data dapat diurutkan.
Baik varians sampel maupun deviasi standar sampel tidak boleh negatif. Satu-satunya situasi di mana indikator S 2 dan S bisa menjadi nol adalah jika semua elemen sampel adalah sama. Dalam kasus yang sama sekali tidak mungkin ini, jangkauan dan jangkauan antarkuartil juga nol.
Data numerik pada dasarnya tidak stabil. Setiap variabel dapat mengambil banyak nilai yang berbeda. Misalnya, reksa dana yang berbeda memiliki tingkat pengembalian dan kerugian yang berbeda. Karena variabilitas data numerik, sangat penting untuk mempelajari tidak hanya perkiraan rata-rata, yang bersifat sumatif, tetapi juga perkiraan varians, yang menjadi ciri penyebaran data.
Varians dan deviasi standar memungkinkan kita untuk memperkirakan penyebaran data di sekitar mean, dengan kata lain, untuk menentukan berapa banyak elemen sampel yang lebih kecil dari mean, dan berapa banyak yang lebih besar. Dispersi memiliki beberapa sifat matematika yang berharga. Namun, nilainya adalah kuadrat dari satuan ukuran - persentase persegi, dolar persegi, inci persegi, dll. Oleh karena itu, perkiraan alami varians adalah standar deviasi, yang dinyatakan dalam unit pengukuran biasa - persen pendapatan, dolar atau inci.
Deviasi standar memungkinkan Anda untuk memperkirakan jumlah fluktuasi elemen sampel di sekitar nilai rata-rata. Di hampir semua situasi, sebagian besar nilai yang diamati terletak dalam plus atau minus satu standar deviasi dari mean. Oleh karena itu, dengan mengetahui rata-rata aritmatika dari elemen sampel dan standar deviasi sampel, adalah mungkin untuk menentukan interval di mana sebagian besar data berada.
Standar deviasi pengembalian 15 reksa dana berisiko sangat tinggi adalah 6,6 (Gambar 9). Ini berarti bahwa profitabilitas sebagian besar dana berbeda dari nilai rata-rata tidak lebih dari 6,6% (yaitu, berfluktuasi dalam kisaran dari - S= 6,2 – 6,6 = –0,4 hingga + S= 12.8). Faktanya, interval ini mengandung pengembalian tahunan rata-rata lima tahun sebesar 53,3% (8 dari 15) dana.

Beras. 9. Standar deviasi
Perhatikan bahwa dalam proses menjumlahkan perbedaan kuadrat, item yang lebih jauh dari rata-rata mendapatkan bobot lebih banyak daripada item yang lebih dekat. Properti ini adalah alasan utama mengapa rata-rata aritmatika paling sering digunakan untuk memperkirakan rata-rata suatu distribusi.
Koefisien variasi
Tidak seperti perkiraan pencar sebelumnya, koefisien variasi adalah perkiraan relatif. Itu selalu diukur sebagai persentase, bukan dalam unit data asli. Koefisien variasi, dilambangkan dengan simbol CV, mengukur penyebaran data di sekitar mean. Koefisien variasi sama dengan simpangan baku dibagi rata-rata aritmatika dan dikalikan 100%:

di mana S- standar deviasi sampel, - rata-rata sampel.
Koefisien variasi memungkinkan Anda untuk membandingkan dua sampel, yang elemen-elemennya dinyatakan dalam satuan pengukuran yang berbeda. Misalnya, manajer layanan pengiriman surat bermaksud untuk meningkatkan armada truk. Saat memuat paket, ada dua jenis batasan yang perlu dipertimbangkan: berat (dalam pound) dan volume (dalam kaki kubik) setiap paket. Asumsikan bahwa dalam sampel 200 kantong, berat rata-ratanya adalah 26,0 pon, simpangan baku beratnya adalah 3,9 pon, volume rata-rata paket adalah 8,8 kaki kubik, dan simpangan baku volumenya adalah 2,2 kaki kubik. Bagaimana membandingkan penyebaran berat dan volume paket?
Karena unit pengukuran untuk berat dan volume berbeda satu sama lain, manajer harus membandingkan penyebaran relatif dari nilai-nilai ini. Koefisien variasi berat adalah CV W = 3,9 / 26,0 * 100% = 15%, dan koefisien variasi volume CV V = 2,2 / 8,8 * 100% = 25% . Jadi, hamburan relatif volume paket jauh lebih besar daripada hamburan relatif bobotnya.
Formulir distribusi
Properti penting ketiga dari sampel adalah bentuk distribusinya. Distribusi ini bisa simetris atau asimetris. Untuk menggambarkan bentuk suatu distribusi, perlu dihitung mean dan mediannya. Jika kedua ukuran ini sama, maka variabel tersebut dikatakan terdistribusi secara simetris. Jika nilai rata-rata suatu variabel lebih besar dari median, distribusinya memiliki skewness positif (Gbr. 10). Jika median lebih besar dari mean, distribusi variabel condong negatif. Kemiringan positif terjadi ketika rata-rata meningkat ke nilai yang sangat tinggi. Kemiringan negatif terjadi ketika rata-rata menurun ke nilai yang sangat kecil. Sebuah variabel terdistribusi secara simetris jika tidak mengambil nilai ekstrim di kedua arah, sehingga nilai besar dan kecil dari variabel saling meniadakan.

Beras. 10. Tiga jenis distribusi
Data yang digambarkan pada skala A memiliki skewness negatif. Gambar ini menunjukkan ekor yang panjang dan kemiringan ke kiri yang disebabkan oleh nilai-nilai yang sangat kecil. Nilai yang sangat kecil ini menggeser nilai rata-rata ke kiri, dan menjadi kurang dari median. Data yang ditampilkan pada skala B terdistribusi secara simetris. Bagian kiri dan kanan distribusi adalah bayangan cerminnya. Nilai besar dan kecil saling seimbang, dan mean dan median adalah sama. Data yang ditampilkan pada skala B memiliki kemiringan positif. Angka ini menunjukkan ekor yang panjang dan miring ke kanan, yang disebabkan oleh adanya nilai yang luar biasa tinggi. Nilai yang terlalu besar ini menggeser mean ke kanan, dan menjadi lebih besar dari median.
Di Excel, statistik deskriptif dapat diperoleh dengan menggunakan add-in Paket analisis. Pergi melalui menu Data → Analisis data, di jendela yang terbuka, pilih baris Statistik deskriptif dan klik Oke. Di jendela Statistik deskriptif pastikan untuk menunjukkan interval masukan(Gbr. 11). Jika Anda ingin melihat statistik deskriptif pada lembar yang sama dengan data asli, pilih tombol radio interval keluaran dan tentukan sel tempat Anda ingin menempatkan sudut kiri atas statistik yang ditampilkan (dalam contoh kita, $C$1). Jika Anda ingin mengeluarkan data ke lembar baru atau ke buku kerja baru, cukup pilih tombol radio yang sesuai. Centang kotak di sebelah Statistik akhir. Secara opsional, Anda juga dapat memilih Tingkat kesulitan,k-th terkecil danterbesar ke-k.
Jika di deposito Data di daerah Analisis Anda tidak melihat ikonnya Analisis data, Anda harus menginstal add-on terlebih dahulu Paket analisis(lihat, misalnya,).

Beras. 11. Statistik deskriptif pengembalian dana tahunan rata-rata lima tahun dengan tingkat risiko yang sangat tinggi, dihitung dengan menggunakan add-on Analisis data program excel
Excel menghitung sejumlah statistik yang dibahas di atas: mean, median, mode, standar deviasi, varians, range ( selang), minimum, maksimum, dan ukuran sampel ( memeriksa). Selain itu, Excel menghitung beberapa statistik baru untuk kami: kesalahan standar, kurtosis, dan kemiringan. kesalahan standar sama dengan simpangan baku dibagi dengan akar kuadrat dari ukuran sampel. asimetri mencirikan penyimpangan dari simetri distribusi dan merupakan fungsi yang bergantung pada pangkat tiga perbedaan antara elemen sampel dan nilai rata-rata. Kurtosis adalah ukuran konsentrasi relatif data di sekitar mean versus ekor distribusi, dan tergantung pada perbedaan antara sampel dan mean yang dipangkatkan ke empat.
Perhitungan statistik deskriptif untuk populasi umum
Mean, hamburan, dan bentuk distribusi yang dibahas di atas adalah karakteristik berbasis sampel. Namun, jika dataset berisi pengukuran numerik dari seluruh populasi, maka parameternya dapat dihitung. Parameter ini meliputi mean, varians, dan standar deviasi dari populasi.
Nilai yang diharapkan sama dengan jumlah semua nilai populasi umum dibagi dengan volume populasi umum:

di mana µ - nilai yang diharapkan, Xsaya- saya-pengamatan variabel ke-th X, N- volume populasi umum. Di Excel, untuk menghitung ekspektasi matematis, fungsi yang sama digunakan untuk mean aritmatika: =AVERAGE().
Varian populasi sama dengan jumlah selisih kuadrat antara elemen populasi umum dan mat. harapan dibagi dengan ukuran populasi:

di mana 2 adalah varians dari populasi umum. Excel sebelum versi 2007 menggunakan fungsi =VAR() untuk menghitung varians populasi, dimulai dengan versi 2010 =VAR.G().
simpangan baku populasi sama dengan akar kuadrat dari varians populasi:

Excel sebelum versi 2007 menggunakan =STDEV() untuk menghitung simpangan baku populasi, dimulai dengan versi 2010 =STDEV.Y(). Perhatikan bahwa rumus varians populasi dan simpangan baku berbeda dengan rumus varians sampel dan simpangan baku. Saat menghitung statistik sampel S2 dan S penyebut pecahan adalah n - 1, dan saat menghitung parameter 2 dan σ - volume populasi umum N.
aturan praktis
Dalam kebanyakan situasi, sebagian besar pengamatan terkonsentrasi di sekitar median, membentuk sebuah cluster. Dalam kumpulan data dengan skewness positif, cluster ini terletak di sebelah kiri (yaitu, di bawah) ekspektasi matematis, dan di set dengan skewness negatif, cluster ini terletak di sebelah kanan (yaitu, di atas) dari ekspektasi matematis. Data simetris memiliki mean dan median yang sama, dan pengamatan mengelompok di sekitar mean, membentuk distribusi berbentuk lonceng. Jika distribusi tidak memiliki kemiringan yang jelas, dan data terkonsentrasi di sekitar pusat gravitasi tertentu, aturan praktis dapat digunakan untuk memperkirakan variabilitas, yang mengatakan: jika data memiliki distribusi berbentuk lonceng, maka sekitar 68% dari pengamatan berada dalam satu standar deviasi dari harapan matematis, Sekitar 95% dari pengamatan berada dalam dua standar deviasi dari nilai yang diharapkan, dan 99,7% dari pengamatan berada dalam tiga standar deviasi dari nilai yang diharapkan.
Dengan demikian, standar deviasi, yang merupakan perkiraan fluktuasi rata-rata di sekitar ekspektasi matematis, membantu untuk memahami bagaimana pengamatan didistribusikan dan untuk mengidentifikasi outlier. Ini mengikuti dari aturan praktis bahwa untuk distribusi berbentuk lonceng, hanya satu nilai dalam dua puluh berbeda dari ekspektasi matematis lebih dari dua standar deviasi. Oleh karena itu, nilai di luar interval ± 2σ, dapat dianggap outlier. Selain itu, hanya tiga dari 1000 pengamatan yang berbeda dari ekspektasi matematis lebih dari tiga standar deviasi. Jadi, nilai di luar interval ± 3σ hampir selalu outlier. Untuk distribusi yang sangat miring atau tidak berbentuk lonceng, aturan praktis Biename-Chebyshev dapat diterapkan.
Lebih dari seratus tahun yang lalu, matematikawan Bienamay dan Chebyshev secara independen menemukan properti yang berguna dari standar deviasi. Mereka menemukan bahwa untuk kumpulan data apa pun, terlepas dari bentuk distribusinya, persentase pengamatan yang terletak pada jarak yang tidak melebihi k standar deviasi dari ekspektasi matematis, tidak kurang (1 – 1/ 2)*100%.
Misalnya, jika k= 2, aturan Biename-Chebyshev menyatakan bahwa setidaknya (1 - (1/2) 2) x 100% = 75% dari pengamatan harus terletak pada interval ± 2σ. Aturan ini berlaku untuk semua k melebihi satu. Aturan Biename-Chebyshev bersifat sangat umum dan berlaku untuk distribusi apa pun. Ini menunjukkan jumlah minimum pengamatan, jarak dari mana ke harapan matematis tidak melebihi nilai yang diberikan. Namun, jika distribusi berbentuk lonceng, aturan praktis memperkirakan konsentrasi data di sekitar rata-rata lebih akurat.
Menghitung statistik deskriptif untuk distribusi berbasis frekuensi
Jika data asli tidak tersedia, distribusi frekuensi menjadi satu-satunya sumber informasi. Dalam situasi seperti itu, Anda dapat menghitung nilai perkiraan indikator kuantitatif distribusi, seperti rata-rata aritmatika, standar deviasi, kuartil.
Jika data sampel disajikan sebagai distribusi frekuensi, nilai perkiraan rata-rata aritmatika dapat dihitung, dengan asumsi bahwa semua nilai dalam setiap kelas terkonsentrasi di titik tengah kelas:

di mana - rata-rata sampel, n- jumlah pengamatan, atau ukuran sampel, dengan- jumlah kelas dalam distribusi frekuensi, mj- titik tengah j-kelas, fj- frekuensi yang sesuai dengan j-kelas.
Untuk menghitung simpangan baku dari distribusi frekuensi, diasumsikan juga bahwa semua nilai dalam setiap kelas terkonsentrasi di titik tengah kelas.

Untuk memahami bagaimana kuartil deret ditentukan berdasarkan frekuensi, mari kita pertimbangkan perhitungan kuartil bawah berdasarkan data untuk tahun 2013 tentang distribusi populasi Rusia menurut rata-rata pendapatan tunai per kapita (Gbr. 12).

Beras. 12. Bagian populasi Rusia dengan pendapatan moneter per kapita rata-rata per bulan, rubel
Untuk menghitung kuartil pertama dari deret variasi interval, Anda dapat menggunakan rumus:

di mana Q1 adalah nilai kuartil pertama, xQ1 adalah batas bawah interval yang berisi kuartil pertama (interval ditentukan oleh frekuensi akumulasi, yang pertama melebihi 25%); i adalah nilai interval; f adalah jumlah frekuensi seluruh sampel; mungkin selalu sama dengan 100%; SQ1-1 adalah frekuensi kumulatif dari interval sebelum interval yang berisi kuartil bawah; fQ1 adalah frekuensi interval yang mengandung kuartil bawah. Rumus untuk kuartil ketiga berbeda dengan rumus di semua tempat, alih-alih Q1, Anda perlu menggunakan Q3, dan substitusikan alih-alih .
Dalam contoh kita (Gbr. 12), kuartil bawah berada dalam kisaran 7000,1 - 10.000, frekuensi kumulatifnya adalah 26,4%. Batas bawah interval ini adalah 7000 rubel, nilai interval adalah 3000 rubel, frekuensi akumulasi interval sebelum interval yang berisi kuartil bawah adalah 13,4%, frekuensi interval yang berisi kuartil bawah adalah 13,0%. Jadi: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13,4) / 13 \u003d 9677 rubel.
Jebakan yang terkait dengan statistik deskriptif
Dalam catatan ini, kami melihat cara mendeskripsikan kumpulan data menggunakan berbagai statistik yang memperkirakan rata-rata, sebaran, dan distribusinya. Langkah selanjutnya adalah menganalisis dan menginterpretasikan data. Sejauh ini, kita telah mempelajari sifat objektif data, dan sekarang kita beralih ke interpretasi subjektifnya. Dua kesalahan menunggu peneliti: subjek analisis yang dipilih secara tidak benar dan interpretasi hasil yang salah.
Analisis kinerja 15 reksa dana berisiko sangat tinggi cukup tidak bias. Dia membawa kesimpulan yang sepenuhnya objektif: semua reksa dana memiliki pengembalian yang berbeda, penyebaran pengembalian dana berkisar dari -6.1 hingga 18.5, dan pengembalian rata-rata adalah 6,08. Objektivitas analisis data dipastikan dengan pilihan yang benar dari indikator kuantitatif total distribusi. Beberapa metode untuk memperkirakan rata-rata dan sebaran data dipertimbangkan, dan kelebihan dan kekurangannya ditunjukkan. Bagaimana memilih statistik yang tepat yang memberikan analisis yang objektif dan tidak bias? Jika distribusi data sedikit miring, haruskah median dipilih daripada mean aritmatika? Indikator mana yang lebih akurat mencirikan penyebaran data: standar deviasi atau rentang? Haruskah kemiringan positif dari distribusi ditunjukkan?
Di sisi lain, interpretasi data adalah proses subjektif. Orang yang berbeda sampai pada kesimpulan yang berbeda, menafsirkan hasil yang sama. Setiap orang memiliki sudut pandangnya masing-masing. Seseorang menganggap total pengembalian tahunan rata-rata 15 dana dengan tingkat risiko yang sangat tinggi adalah baik dan cukup puas dengan pendapatan yang diterima. Orang lain mungkin berpikir bahwa dana ini memiliki pengembalian yang terlalu rendah. Dengan demikian, subjektivitas harus diimbangi dengan kejujuran, netralitas, dan kejelasan kesimpulan.
Masalah Etis
Analisis data terkait erat dengan masalah etika. Seseorang harus kritis terhadap informasi yang disebarluaskan oleh surat kabar, radio, televisi, dan Internet. Seiring waktu, Anda akan belajar untuk bersikap skeptis tidak hanya tentang hasil, tetapi juga tentang tujuan, subjek, dan objektivitas penelitian. Politisi Inggris yang terkenal Benjamin Disraeli mengatakan yang terbaik: "Ada tiga jenis kebohongan: kebohongan, kebohongan terkutuk dan statistik."
Sebagaimana dicatat dalam catatan, masalah etika muncul ketika memilih hasil yang harus disajikan dalam laporan. Hasil positif dan negatif harus dipublikasikan. Selain itu, dalam membuat laporan atau laporan tertulis, hasilnya harus disajikan secara jujur, netral dan objektif. Bedakan antara presentasi yang buruk dan tidak jujur. Untuk melakukan ini, perlu untuk menentukan apa niat pembicara. Kadang-kadang pembicara menghilangkan informasi penting karena ketidaktahuan, dan kadang-kadang dengan sengaja (misalnya, jika ia menggunakan rata-rata aritmatika untuk memperkirakan rata-rata data yang miring dengan jelas untuk mendapatkan hasil yang diinginkan). Juga tidak jujur untuk menekan hasil yang tidak sesuai dengan sudut pandang peneliti.
Bahan dari buku Levin et al.Statistik untuk manajer digunakan. - M.: Williams, 2004. - hal. 178–209
Fungsi QUARTILE dipertahankan untuk menyelaraskan dengan versi Excel sebelumnya
Nilai rata-rata adalah yang paling berharga dari sudut pandang analitis dan bentuk universal dari ekspresi indikator statistik. Rata-rata yang paling umum - rata-rata aritmatika - memiliki sejumlah sifat matematika yang dapat digunakan dalam perhitungannya. Pada saat yang sama, ketika menghitung rata-rata tertentu, selalu disarankan untuk mengandalkan rumus logisnya, yang merupakan rasio volume atribut dengan volume populasi. Untuk setiap mean, hanya ada satu rasio referensi yang benar, yang, tergantung pada data yang tersedia, mungkin memerlukan bentuk mean yang berbeda. Namun, dalam semua kasus di mana sifat nilai rata-rata menyiratkan adanya bobot, tidak mungkin untuk menggunakan rumus tidak berbobotnya alih-alih rumus rata-rata tertimbang.
Nilai rata-rata adalah nilai yang paling khas dari atribut untuk populasi dan ukuran atribut populasi yang didistribusikan dalam bagian yang sama antara unit-unit populasi.
Karakteristik yang nilai rata-ratanya dihitung disebut rata-rata .
Nilai rata-rata adalah indikator yang dihitung dengan membandingkan nilai absolut atau relatif. Nilai rata-ratanya adalah
Nilai rata-rata mencerminkan pengaruh semua faktor yang mempengaruhi fenomena yang diteliti, dan merupakan resultan bagi mereka. Dengan kata lain, membayar penyimpangan individu dan menghilangkan pengaruh kasus, nilai rata-rata, yang mencerminkan ukuran umum dari hasil tindakan ini, bertindak sebagai pola umum dari fenomena yang diteliti.
Ketentuan penggunaan rata-rata:
homogenitas populasi yang diteliti. Jika beberapa elemen populasi yang dipengaruhi faktor acak memiliki nilai yang berbeda secara signifikan dari sifat yang dipelajari dari yang lain, maka elemen-elemen ini akan mempengaruhi ukuran rata-rata untuk populasi ini. Dalam hal ini, rata-rata tidak akan mengungkapkan nilai paling khas dari fitur untuk populasi. Jika fenomena yang diteliti bersifat heterogen, maka perlu dipecah menjadi kelompok-kelompok yang mengandung unsur-unsur homogen. Dalam hal ini, rata-rata kelompok dihitung - rata-rata kelompok yang menyatakan nilai paling karakteristik dari fenomena di setiap kelompok, dan kemudian nilai rata-rata keseluruhan untuk semua elemen dihitung, yang mencirikan fenomena secara keseluruhan. Dihitung sebagai rata-rata dari rata-rata kelompok, dibobot dengan jumlah elemen populasi yang termasuk dalam setiap kelompok;
jumlah unit yang cukup dalam agregat;
nilai maksimum dan minimum sifat dalam populasi yang diteliti.
Nilai rata-rata (indikator)- ini adalah karakteristik kuantitatif umum dari suatu sifat dalam populasi sistematis di bawah kondisi tempat dan waktu tertentu.
Dalam statistik, bentuk (tipe) rata-rata berikut digunakan, yang disebut kekuatan dan struktural:
Ø rata-rata aritmatika(sederhana dan berbobot);
![]() sederhana
sederhana
Rata-rata(dalam matematika dan statistik) kumpulan angka - jumlah semua angka dibagi dengan jumlahnya. Ini adalah salah satu ukuran tendensi sentral yang paling umum.
Itu diusulkan (bersama dengan rata-rata geometris dan rata-rata harmonik) oleh Pythagoras.
Kasus khusus dari mean aritmatika adalah mean (dari populasi umum) dan mean sampel (dari sampel).
pengantar
Tunjukkan kumpulan data X = (x 1 , x 2 , …, x n), maka mean sampel biasanya dilambangkan dengan bilah horizontal di atas variabel (x (\displaystyle (\bar (x))) , diucapkan " x dengan tanda hubung").
Huruf Yunani digunakan untuk menunjukkan mean aritmatika dari seluruh populasi. Untuk variabel acak yang nilai rata-ratanya ditentukan, adalah probabilitas berarti atau ekspektasi matematis dari variabel acak. Jika himpunan X adalah kumpulan bilangan acak dengan rata-rata probabilitas , maka untuk setiap sampel x saya dari koleksi ini = E( x saya) adalah harapan dari sampel ini.
Dalam praktiknya, perbedaan antara dan x (\displaystyle (\bar (x))) adalah bahwa adalah variabel tipikal karena Anda dapat melihat sampel daripada seluruh populasi. Oleh karena itu, jika sampel direpresentasikan secara acak (dalam istilah teori probabilitas), maka x (\displaystyle (\bar (x))) (tetapi bukan ) dapat diperlakukan sebagai variabel acak yang memiliki distribusi probabilitas pada sampel ( distribusi probabilitas rata-rata).
Kedua besaran ini dihitung dengan cara yang sama:
X = 1 n i = 1 n x i = 1 n (x 1 + + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\cdots +x_(n)).)
Jika sebuah X adalah variabel acak, maka ekspektasi matematis X dapat dianggap sebagai rata-rata aritmatika dari nilai-nilai dalam pengukuran kuantitas yang berulang X. Ini adalah manifestasi dari hukum bilangan besar. Oleh karena itu, mean sampel digunakan untuk memperkirakan ekspektasi matematis yang tidak diketahui.
Dalam aljabar dasar, terbukti bahwa mean n+ 1 angka di atas rata-rata n angka jika dan hanya jika angka baru lebih besar dari rata-rata lama, kurang jika dan hanya jika angka baru lebih kecil dari rata-rata, dan tidak berubah jika dan hanya jika angka baru sama dengan rata-rata. Lebih n, semakin kecil perbedaan antara rata-rata baru dan lama.
Perhatikan bahwa ada beberapa "sarana" lain yang tersedia, termasuk mean hukum pangkat, mean Kolmogorov, mean harmonik, mean aritmatika-geometris, dan berbagai mean bobot (misalnya, mean bobot aritmatika, mean bobot geometrik, mean bobot harmonik) .
Contoh
- Untuk tiga angka, Anda perlu menambahkannya dan membaginya dengan 3:
- Untuk empat angka, Anda perlu menambahkannya dan membaginya dengan 4:
Atau lebih mudah 5+5=10, 10:2. Karena kita menambahkan 2 angka, artinya berapa banyak angka yang kita tambahkan, kita bagi sebanyak itu.
Variabel acak kontinu
Untuk nilai terdistribusi kontinu f (x) (\displaystyle f(x)) mean aritmatika pada interval [ a ; b ] (\displaystyle ) didefinisikan melalui integral tertentu:
F (x) [ a ; b ] = 1 b a a b f (x) d x (\displaystyle (\overline (f(x)))_()=(\frac (1)(b-a))\int _(a)^(b) f(x)dx)
Beberapa masalah menggunakan rata-rata
Kurangnya ketangguhan
Artikel utama: Ketangguhan dalam statistikMeskipun rata-rata aritmatika sering digunakan sebagai sarana atau tren sentral, konsep ini tidak berlaku untuk statistik yang kuat, yang berarti bahwa rata-rata aritmatika sangat dipengaruhi oleh "deviasi besar". Patut dicatat bahwa untuk distribusi dengan kemiringan besar, rata-rata aritmatika mungkin tidak sesuai dengan konsep "rata-rata", dan nilai rata-rata dari statistik yang kuat (misalnya, median) dapat menggambarkan tren pusat dengan lebih baik.
Contoh klasiknya adalah perhitungan pendapatan rata-rata. Rata-rata aritmatika dapat disalahartikan sebagai median, yang dapat mengarah pada kesimpulan bahwa ada lebih banyak orang dengan pendapatan lebih dari yang sebenarnya. Pendapatan "rata-rata" ditafsirkan sedemikian rupa sehingga pendapatan sebagian besar orang mendekati angka ini. Pendapatan "rata-rata" ini (dalam arti rata-rata aritmatika) lebih tinggi daripada pendapatan kebanyakan orang, karena pendapatan tinggi dengan penyimpangan besar dari rata-rata membuat rata-rata aritmatika sangat miring (sebaliknya, pendapatan median "menolak" kemiringan seperti itu). Namun, pendapatan "rata-rata" ini tidak mengatakan apa-apa tentang jumlah orang yang mendekati pendapatan rata-rata (dan tidak mengatakan apa-apa tentang jumlah orang yang mendekati pendapatan modal). Namun, jika konsep "rata-rata" dan "mayoritas" dianggap enteng, maka orang dapat salah menyimpulkan bahwa kebanyakan orang memiliki pendapatan lebih tinggi dari yang sebenarnya. Misalnya, laporan tentang pendapatan bersih "rata-rata" di Medina, Washington, yang dihitung sebagai rata-rata aritmatika dari semua pendapatan bersih tahunan penduduk, akan memberikan angka yang sangat tinggi karena Bill Gates. Perhatikan sampel (1, 2, 2, 2, 3, 9). Rata-rata aritmatika adalah 3,17, tetapi lima dari enam nilai berada di bawah rata-rata ini.
Bunga majemuk
Artikel utama: ROIJika angka berkembang biak, tapi tidak melipat, Anda perlu menggunakan mean geometrik, bukan mean aritmatika. Paling sering, kejadian ini terjadi ketika menghitung laba atas investasi di bidang keuangan.
Misalnya, jika saham turun 10% di tahun pertama dan naik 30% di tahun kedua, maka salah menghitung kenaikan "rata-rata" selama dua tahun ini sebagai mean aritmatika (−10% + 30%) / 2 = 10%; rata-rata yang benar dalam hal ini diberikan oleh tingkat pertumbuhan tahunan majemuk, dari mana pertumbuhan tahunan hanya sekitar 8,16653826392% 8,2%.
Alasan untuk ini adalah bahwa persentase memiliki titik awal baru setiap kali: 30% adalah 30% dari angka yang kurang dari harga pada awal tahun pertama: jika saham mulai dari $30 dan turun 10%, nilainya $27 pada awal tahun kedua. Jika stok naik 30%, nilainya $35,1 pada akhir tahun kedua. Rata-rata aritmatika dari pertumbuhan ini adalah 10%, tetapi karena stok hanya tumbuh sebesar $5,1 dalam 2 tahun, peningkatan rata-rata 8,2% memberikan hasil akhir sebesar $35,1:
[$30 (1 - 0,1) (1 + 0,3) = $30 (1 + 0,082) (1 + 0,082) = $35,1]. Jika kita menggunakan rata-rata aritmatika 10% dengan cara yang sama, kita tidak akan mendapatkan nilai sebenarnya: [$30 (1 + 0,1) (1 + 0,1) = $36,3].
Bunga majemuk pada akhir tahun 2: 90% * 130% = 117% , yaitu total kenaikan 17%, dan rata-rata bunga majemuk tahunan adalah 117% 108,2% (\displaystyle (\sqrt (117\%)) \kira-kira 108,2\%) , yaitu, peningkatan tahunan rata-rata 8,2%.
Petunjuk arah
Artikel utama: Statistik tujuanSaat menghitung rata-rata aritmatika dari beberapa variabel yang berubah secara siklis (misalnya, fase atau sudut), perhatian khusus harus diberikan. Misalnya, rata-rata dari 1° dan 359° adalah 1 + 359 2 = (\displaystyle (\frac (1^(\circ )+359^(\circ ))(2))=) 180°. Jumlah ini salah karena dua alasan.
- Pertama, ukuran sudut hanya ditentukan untuk rentang dari 0° hingga 360° (atau dari 0 hingga 2π bila diukur dalam radian). Jadi, pasangan bilangan yang sama dapat ditulis sebagai (1° dan 1°) atau sebagai (1° dan 719°). Rata-rata setiap pasangan akan berbeda: 1 + (− 1 ) 2 = 0 (\displaystyle (\frac (1^(\circ )+(-1^(\circ )))(2))= 0 ^(\circ )) , 1 + 719 2 = 360 (\displaystyle (\frac (1^(\circ )+719^(\circ ))(2))=360^(\circ )) .
- Kedua, dalam hal ini, nilai 0° (setara dengan 360°) akan menjadi rata-rata terbaik secara geometris, karena angka-angka tersebut menyimpang kurang dari 0° daripada nilai lainnya (nilai 0° memiliki varians terkecil). Membandingkan:
- angka 1° menyimpang dari 0° hanya sebesar 1°;
- angka 1° menyimpang dari rata-rata yang dihitung 180° sebesar 179°.
Nilai rata-rata untuk variabel siklik, dihitung menurut rumus di atas, akan digeser secara artifisial relatif terhadap rata-rata nyata ke tengah rentang numerik. Karena itu, rata-rata dihitung dengan cara yang berbeda, yaitu, angka dengan varians terkecil (titik tengah) dipilih sebagai nilai rata-rata. Juga, alih-alih mengurangkan, jarak modulo (yaitu, jarak keliling) digunakan. Misalnya, jarak modular antara 1° dan 359° adalah 2°, bukan 358° (pada lingkaran antara 359° dan 360°==0° - satu derajat, antara 0° dan 1° - juga 1°, secara total - 2 °).
4.3. Nilai rata-rata. Esensi dan makna rata-rata
Nilai rata-rata dalam statistik, indikator generalisasi disebut, yang mencirikan tingkat khas suatu fenomena dalam kondisi tempat dan waktu tertentu, yang mencerminkan besarnya atribut yang bervariasi per unit populasi yang homogen secara kualitatif. Dalam praktik ekonomi, berbagai indikator digunakan, dihitung sebagai rata-rata.
Misalnya, indikator generalisasi pendapatan pekerja di perusahaan saham gabungan (JSC) adalah pendapatan rata-rata satu pekerja, ditentukan oleh rasio dana upah dan pembayaran sosial untuk periode yang ditinjau (tahun, kuartal, bulan). ) dengan jumlah pekerja di JSC.
Menghitung rata-rata adalah salah satu teknik generalisasi yang umum; indikator rata-rata mencerminkan umum yang khas (tipikal) untuk semua unit populasi yang diteliti, sementara pada saat yang sama mengabaikan perbedaan antar unit individu. Dalam setiap fenomena dan perkembangannya ada kombinasi peluang dan membutuhkan. Saat menghitung rata-rata, karena pengoperasian hukum bilangan besar, keacakan membatalkan satu sama lain, menyeimbangkan, sehingga Anda dapat mengabstraksi dari fitur-fitur yang tidak signifikan dari fenomena tersebut, dari nilai kuantitatif atribut dalam setiap kasus tertentu. Dalam kemampuan untuk mengabstraksi dari keacakan nilai individu, fluktuasi terletak pada nilai ilmiah rata-rata sebagai meringkas karakteristik agregat.
Di mana ada kebutuhan untuk generalisasi, perhitungan karakteristik tersebut mengarah pada penggantian banyak nilai individu yang berbeda dari atribut medium indikator yang mencirikan totalitas fenomena, yang memungkinkan untuk mengidentifikasi pola-pola yang melekat dalam fenomena sosial massal, tidak terlihat dalam fenomena tunggal.
Rata-rata mencerminkan karakteristik, khas, tingkat nyata dari fenomena yang dipelajari, mencirikan tingkat ini dan perubahannya dalam ruang dan waktu.
Rata-rata adalah karakteristik ringkasan keteraturan proses di bawah kondisi di mana ia berlangsung.
4.4. Jenis rata-rata dan metode untuk menghitungnya
Pilihan jenis rata-rata ditentukan oleh kandungan ekonomi dari indikator tertentu dan data awal. Dalam setiap kasus, salah satu nilai rata-rata diterapkan: aritmatika, garmonik, geometris, kuadrat, kubik dll. Rata-rata yang terdaftar milik kelas kekuatan medium.
Selain rata-rata kekuatan hukum, dalam praktik statistik, rata-rata struktural digunakan, yang dianggap sebagai modus dan median.
Mari kita membahas lebih detail tentang sarana kekuasaan.
Rata-rata aritmatika
Jenis rata-rata yang paling umum adalah rata-rata hitung. Ini digunakan dalam kasus di mana volume atribut variabel untuk seluruh populasi adalah jumlah dari nilai atribut unit individualnya. Fenomena sosial dicirikan oleh penambahan (penjumlahan) volume atribut yang bervariasi, ini menentukan ruang lingkup rata-rata aritmatika dan menjelaskan prevalensinya sebagai indikator generalisasi, misalnya: dana upah total adalah jumlah dari upah semua pekerja, panen kotor adalah jumlah produk manufaktur dari seluruh area penaburan.
Untuk menghitung rata-rata aritmatika, Anda perlu membagi jumlah semua nilai fitur dengan jumlahnya.
Rata-rata aritmatika diterapkan dalam bentuk rata-rata sederhana dan rata-rata tertimbang. Rata-rata sederhana berfungsi sebagai bentuk awal yang menentukan.
rata-rata aritmatika sederhana sama dengan jumlah sederhana dari nilai individu dari fitur rata-rata, dibagi dengan jumlah total nilai ini (digunakan dalam kasus di mana ada nilai individu yang tidak dikelompokkan dari fitur):
di mana  - nilai individu dari variabel (opsi); m
- jumlah unit populasi.
- nilai individu dari variabel (opsi); m
- jumlah unit populasi.
Batas penjumlahan lebih lanjut dalam rumus tidak akan ditunjukkan. Misalnya, diperlukan untuk mencari keluaran rata-rata seorang pekerja (tukang kunci), jika diketahui berapa suku cadang yang diproduksi masing-masing dari 15 pekerja, yaitu diberikan sejumlah nilai individu dari sifat, pcs.:
21; 20; 20; 19; 21; 19; 18; 22; 19; 20; 21; 20; 18; 19; 20.
Rata-rata aritmatika sederhana dihitung dengan rumus (4.1), 1 pc.:
Rata-rata opsi yang diulang beberapa kali, atau dikatakan memiliki bobot yang berbeda, disebut tertimbang. Bobot adalah jumlah unit dalam kelompok populasi yang berbeda (kelompok menggabungkan opsi yang sama).
Rata-rata tertimbang aritmatika- nilai rata-rata yang dikelompokkan, - dihitung dengan rumus:
 , (4.2)
, (4.2)
di mana  - bobot (frekuensi pengulangan fitur yang sama);
- bobot (frekuensi pengulangan fitur yang sama);
 -
jumlah produk dari besarnya fitur dengan frekuensinya;
-
jumlah produk dari besarnya fitur dengan frekuensinya;
 -
jumlah unit populasi.
-
jumlah unit populasi.
Kami akan mengilustrasikan teknik untuk menghitung rata-rata tertimbang aritmatika menggunakan contoh yang dibahas di atas. Untuk melakukan ini, kami mengelompokkan data awal dan menempatkannya di tabel. 4.1.
Tabel 4.1
Distribusi pekerja untuk pengembangan suku cadang
Menurut rumus (4.2), rata-rata tertimbang aritmatika adalah sama, potongan:
Dalam beberapa kasus, bobot dapat direpresentasikan bukan dengan nilai absolut, tetapi dengan nilai relatif (dalam persentase atau pecahan dari suatu unit). Maka rumus untuk rata-rata tertimbang aritmatika akan terlihat seperti:

di mana  - khusus, mis. bagian dari setiap frekuensi dalam jumlah total semua
- khusus, mis. bagian dari setiap frekuensi dalam jumlah total semua
Jika frekuensi dihitung dalam pecahan (koefisien), maka  = 1, dan rumus untuk rata-rata tertimbang secara aritmatika adalah:
= 1, dan rumus untuk rata-rata tertimbang secara aritmatika adalah:

Perhitungan rata-rata tertimbang aritmatika dari rata-rata kelompok  dilakukan dengan rumus :
dilakukan dengan rumus :
 ,
,
di mana f-jumlah unit di setiap grup.
Hasil penghitungan mean aritmatika mean grup disajikan pada Tabel. 4.2.
Tabel 4.2
Distribusi pekerja menurut rata-rata lama kerja
Dalam contoh ini, pilihannya bukanlah data individu tentang masa kerja pekerja individu, tetapi rata-rata untuk setiap bengkel. timbangan f adalah jumlah pekerja di toko-toko. Oleh karena itu, pengalaman kerja rata-rata pekerja di seluruh perusahaan adalah, tahun:
 .
.
Perhitungan mean aritmatika dalam deret distribusi
Jika nilai atribut rata-rata diberikan sebagai interval ("dari - ke"), mis. deret distribusi interval, kemudian ketika menghitung nilai rata-rata aritmatika, titik tengah interval ini diambil sebagai nilai fitur dalam grup, sebagai akibatnya deret diskrit terbentuk. Perhatikan contoh berikut (Tabel 4.3).
Mari kita beralih dari deret interval ke deret diskrit dengan mengganti nilai interval dengan nilai rata-ratanya / (rata-rata sederhana
Tabel 4.3
Distribusi pekerja AO berdasarkan tingkat upah bulanan
|
Kelompok pekerja untuk |
Jumlah pekerja |
Pertengahan interval |
|
|
upah, gosok. |
pribadi, f |
menggosok., X |
|
|
900 dan lebih banyak lagi |
|||
nilai interval terbuka (pertama dan terakhir) secara kondisional disamakan dengan interval yang berdampingan dengannya (kedua dan kedua dari belakang).
Dengan perhitungan rata-rata seperti itu, beberapa ketidakakuratan diperbolehkan, karena asumsi dibuat tentang distribusi unit atribut yang seragam dalam grup. Namun, kesalahannya akan semakin kecil, semakin sempit intervalnya dan semakin banyak unit dalam intervalnya.
Setelah titik tengah interval ditemukan, perhitungan dilakukan dengan cara yang sama seperti dalam seri diskrit - opsi dikalikan dengan frekuensi (bobot) dan jumlah produk dibagi dengan jumlah frekuensi (bobot) , ribu rubel:
 .
.
Jadi, tingkat rata-rata remunerasi pekerja di JSC adalah 729 rubel. per bulan.
Perhitungan mean aritmatika sering dikaitkan dengan pengeluaran waktu dan tenaga yang besar. Namun, dalam beberapa kasus, prosedur untuk menghitung rata-rata dapat disederhanakan dan difasilitasi dengan menggunakan propertinya. Mari kita sajikan (tanpa bukti) beberapa sifat dasar mean aritmatika.
Properti 1. Jika semua nilai karakteristik individu (mis. semua opsi) berkurang atau bertambah sayakali, maka nilai rata-ratanya fitur baru akan berkurang atau bertambah sesuai dengan sayasekali.
Properti 2. Jika semua varian fitur rata-rata dikurangijahit atau tambah dengan angka A, maka mean aritmatikaberkurang atau bertambah secara signifikan dengan angka yang sama A.
Properti 3. Jika bobot semua opsi rata-rata dikurangi atau meningkat menjadi ke kali, rata-rata aritmatika tidak akan berubah.
Sebagai bobot rata-rata, alih-alih indikator absolut, Anda dapat menggunakan bobot spesifik dalam total (bagian atau persentase). Ini menyederhanakan perhitungan rata-rata.
Untuk menyederhanakan perhitungan rata-rata, mereka mengikuti jalur pengurangan nilai opsi dan frekuensi. Penyederhanaan terbesar dicapai ketika TETAPI nilai salah satu opsi pusat dengan frekuensi tertinggi dipilih sebagai / - nilai interval (untuk baris dengan interval yang sama). Nilai L disebut asal, sehingga cara menghitung rata-rata ini disebut “metode menghitung dari nol bersyarat” atau "metode momen".
Mari kita asumsikan bahwa semua opsi X pertama dikurangi dengan nomor yang sama A, dan kemudian dikurangi menjadi saya sekali. Kami mendapatkan rangkaian distribusi variasi baru dari varian baru  .
.
Kemudian pilihan baru akan diungkapkan:
 ,
,
dan mean aritmatika baru mereka  , -momen orde pertama- rumus:
, -momen orde pertama- rumus:
 .
.
Ini sama dengan rata-rata dari opsi asli, pertama dikurangi dengan TETAPI, dan kemudian di saya sekali.
Untuk mendapatkan rata-rata yang sebenarnya, Anda memerlukan momen urutan pertama m 1 , kalikan dengan saya dan tambahkan TETAPI:
 .
.
Metode menghitung rata-rata aritmatika dari deret variasi ini disebut "metode momen". Metode ini diterapkan dalam baris dengan interval yang sama.
Perhitungan mean aritmatika dengan metode momen diilustrasikan oleh data pada Tabel. 4.4.
Tabel 4.4
Distribusi usaha kecil di wilayah dengan nilai aset produksi tetap (OPF) pada tahun 2000
|
Grup perusahaan berdasarkan biaya OPF, ribuan rubel |
Jumlah perusahaan f |
interval tengah, x |
|
|
|
14-16 16-18 18-20 20-22 22-24 |
||||


Menemukan momen orde pertama
 .
.
Kemudian, dengan asumsi A = 19 dan mengetahui bahwa saya= 2, hitung X, ribu rubel.:
Jenis nilai rata-rata dan metode perhitungannya
Pada tahap pemrosesan statistik, berbagai tugas penelitian dapat ditetapkan, untuk solusinya perlu memilih rata-rata yang sesuai. Dalam hal ini, perlu dipandu oleh aturan berikut: nilai-nilai yang mewakili pembilang dan penyebut rata-rata harus secara logis terkait satu sama lain.
- rata-rata daya;
- rata-rata struktural.
Mari kita perkenalkan notasi berikut:
Nilai yang rata-ratanya dihitung;
Rata-rata, di mana garis di atas menunjukkan bahwa rata-rata nilai individu terjadi;
Frekuensi (pengulangan nilai sifat individu).
Berbagai sarana diturunkan dari rumus daya rata-rata umum:
 (5.1)
(5.1)
untuk k = 1 - rata-rata aritmatika; k = -1 - rata-rata harmonik; k = 0 - rata-rata geometrik; k = -2 - akar rata-rata kuadrat.
Rata-rata baik sederhana atau tertimbang. rata-rata tertimbang disebut besaran yang memperhitungkan bahwa beberapa varian nilai atribut mungkin memiliki angka yang berbeda, dan oleh karena itu setiap varian harus dikalikan dengan angka ini. Dengan kata lain, "bobot" adalah jumlah unit populasi dalam kelompok yang berbeda, mis. setiap opsi "ditimbang" berdasarkan frekuensinya. Frekuensi f disebut bobot statistik atau berat rata-rata.
Rata-rata aritmatika- jenis media yang paling umum. Ini digunakan ketika perhitungan dilakukan pada data statistik yang tidak dikelompokkan, di mana Anda ingin mendapatkan jumlah rata-rata. Rata-rata aritmatika adalah nilai rata-rata dari suatu fitur, setelah diterima di mana total volume fitur dalam populasi tetap tidak berubah.
Rumus rata-rata aritmatika ( sederhana) memiliki bentuk
dimana n adalah ukuran populasi.
Misalnya, gaji rata-rata karyawan suatu perusahaan dihitung sebagai rata-rata aritmatika:

Indikator penentu di sini adalah upah setiap karyawan dan jumlah karyawan perusahaan. Ketika menghitung rata-rata, jumlah total upah tetap sama, tetapi didistribusikan, seolah-olah, sama di antara semua pekerja. Misalnya, perlu untuk menghitung gaji rata-rata karyawan sebuah perusahaan kecil di mana 8 orang bekerja:
Saat menghitung rata-rata, nilai individu dari atribut yang dirata-ratakan dapat diulang, sehingga rata-rata dihitung menggunakan data yang dikelompokkan. Dalam hal ini, kita berbicara tentang menggunakan rata-rata aritmatika tertimbang, yang terlihat seperti
 (5.3)
(5.3)
Jadi, kita perlu menghitung rata-rata harga saham perusahaan saham gabungan di bursa. Diketahui bahwa transaksi dilakukan dalam waktu 5 hari (5 transaksi), jumlah saham yang dijual dengan kurs penjualan dibagikan sebagai berikut:
1 - 800 ac. - 1010 rubel
2 - 650 ac. - 990 gosok.
3 - 700 k. - 1015 rubel.
4 - 550 ac. - 900 gosok.
5 - 850 ak. - 1150 rubel.
Rasio awal untuk menentukan harga saham rata-rata adalah rasio antara jumlah total transaksi (OSS) dengan jumlah saham yang dijual (KPA).
Untuk menemukan nilai rata-rata di Excel (apakah itu numerik, tekstual, persentase atau nilai lainnya), ada banyak fungsi. Dan masing-masing memiliki karakteristik dan kelebihannya sendiri. Bagaimanapun, kondisi tertentu dapat diatur dalam tugas ini.
Misalnya, nilai rata-rata serangkaian angka di Excel dihitung menggunakan fungsi statistik. Anda juga dapat memasukkan rumus Anda sendiri secara manual. Mari kita pertimbangkan berbagai opsi.
Bagaimana menemukan rata-rata aritmatika angka?
Untuk menemukan mean aritmatika, Anda menambahkan semua angka dalam himpunan dan membagi jumlahnya dengan angka tersebut. Misalnya, nilai siswa dalam ilmu komputer: 3, 4, 3, 5, 5. Apa yang berlaku untuk seperempat: 4. Kami menemukan rata-rata aritmatika menggunakan rumus: \u003d (3 + 4 + 3 + 5 + 5) / 5.
Bagaimana melakukannya dengan cepat menggunakan fungsi Excel? Ambil contoh serangkaian angka acak dalam sebuah string:

Atau: aktifkan sel dan cukup masukkan rumus secara manual: =AVERAGE(A1:A8).
Sekarang mari kita lihat apa lagi yang bisa dilakukan fungsi AVERAGE.

Temukan rata-rata aritmatika dari dua angka pertama dan tiga angka terakhir. Rumus: =AVERAGE(A1:B1;F1:H1). Hasil:
Rata-rata berdasarkan kondisi
Kondisi untuk menemukan mean aritmatika dapat berupa kriteria numerik atau kriteria teks. Kami akan menggunakan fungsi: =AVERAGEIF().
Temukan rata-rata aritmatika dari angka yang lebih besar dari atau sama dengan 10.
Fungsi: =AVERAGEIF(A1:A8,">=10")
 Hasil penggunaan fungsi AVERAGEIF pada kondisi ">=10":
Hasil penggunaan fungsi AVERAGEIF pada kondisi ">=10": Argumen ketiga - "Rentang rata-rata" - dihilangkan. Pertama, tidak wajib. Kedua, rentang yang diuraikan oleh program HANYA berisi nilai numerik. Dalam sel yang ditentukan dalam argumen pertama, pencarian akan dilakukan sesuai dengan kondisi yang ditentukan dalam argumen kedua.
Perhatian! Kriteria pencarian dapat ditentukan dalam sel. Dan dalam rumus untuk membuat referensi untuk itu.
Mari kita cari nilai rata-rata angka dengan kriteria teks. Misalnya, penjualan rata-rata produk "meja".

Fungsinya akan terlihat seperti ini: =AVERAGEIF($A$2:$A$12;A7;$B$2:$B$12). Rentang - kolom dengan nama produk. Kriteria pencarian adalah tautan ke sel dengan kata "tabel" (Anda dapat menyisipkan kata "tabel" alih-alih tautan A7). Rentang rata-rata - sel-sel dari mana data akan diambil untuk menghitung nilai rata-rata.
Sebagai hasil dari menghitung fungsi, kami memperoleh nilai berikut:
Perhatian! Untuk kriteria teks (kondisi), rentang rata-rata harus ditentukan.
Bagaimana cara menghitung harga rata-rata tertimbang di Excel?

Bagaimana kita mengetahui harga rata-rata tertimbang?
Rumus: =SUMPRODUCT(C2:C12,B2:B12)/SUM(C2:C12).

Dengan menggunakan rumus SUMPRODUCT, kita mengetahui total pendapatan setelah penjualan seluruh kuantitas barang. Dan fungsi SUM - meringkas jumlah barang. Dengan membagi total pendapatan dari penjualan barang dengan jumlah total unit barang, kami menemukan harga rata-rata tertimbang. Indikator ini memperhitungkan "bobot" dari setiap harga. Bagiannya dalam total massa nilai.
Standar deviasi: rumus di Excel
Bedakan antara simpangan baku untuk populasi umum dan untuk sampel. Dalam kasus pertama, ini adalah akar dari varians umum. Yang kedua, dari varians sampel.
Untuk menghitung indikator statistik ini, rumus dispersi disusun. Akar diambil darinya. Tetapi di Excel ada fungsi yang sudah jadi untuk menemukan standar deviasi.

Standar deviasi terkait dengan skala sumber data. Ini tidak cukup untuk representasi figuratif dari variasi rentang yang dianalisis. Untuk mendapatkan tingkat hamburan relatif dalam data, koefisien variasi dihitung:
simpangan baku / mean aritmatika
Rumus di Excel terlihat seperti ini:
STDEV (rentang nilai) / RATA-RATA (rentang nilai).
Koefisien variasi dihitung sebagai persentase. Oleh karena itu, kami mengatur format persentase di dalam sel.
