Iteračná metóda. Pri tejto metóde sa robí porovnanie s určitou databázou, kde pre každý z objektov existujú rôzne možnosti úpravy zobrazenia. Napríklad na optické rozpoznávanie obrazu môžete použiť metódu iterácie v rôznych uhloch alebo mierkach, posunoch, deformáciách atď. V prípade písmen môžete opakovať písmo alebo jeho vlastnosti. V prípade rozpoznávania zvukových vzorov existuje porovnanie s niektorými známymi vzormi (slovo, ktoré hovorí veľa ľudí). Ďalej sa vykonáva hlbšia analýza charakteristík obrazu. V prípade optického rozpoznávania to môže byť definícia geometrických charakteristík. Vzorka zvuku je v tomto prípade podrobená frekvenčnej a amplitúdovej analýze.
Ďalšia metóda je použitie umelých neurónových sietí(INS). Vyžaduje si to buď obrovské množstvo príkladov úlohy rozpoznávania, alebo špeciálnu štruktúru neurónovej siete, ktorá zohľadňuje špecifiká tejto úlohy. Táto metóda sa však vyznačuje vysokou účinnosťou a produktivitou.
Metódy založené na odhadoch distribučných hustôt hodnôt znakov. Vypožičané z klasickej teórie štatistického rozhodovania, v ktorej sa predmety skúmania považujú za realizácie viacrozmernej náhodnej premennej distribuovanej v priestore znakov podľa nejakého zákona. Sú založené na Bayesovej schéme rozhodovania, ktorá sa odvoláva na počiatočné pravdepodobnosti objektov patriacich do určitej triedy a hustoty distribúcie podmienených prvkov.
Skupina metód založených na odhade distribučných hustôt hodnôt znakov priamo súvisí s metódami diskriminačnej analýzy. Bayesovský prístup k rozhodovaniu je jednou z najrozvinutejších parametrických metód v modernej štatistike, pre ktorú sa analytické vyjadrenie distribučného zákona (normálny zákon) považuje za známe a len malý počet parametrov (stredné vektory a kovariančné matice ) je potrebné odhadnúť. Za hlavné ťažkosti pri aplikácii tejto metódy sa považuje potreba zapamätať si celý tréningový súbor na výpočet odhadov hustoty a vysoká citlivosť na tréningový súbor.
Metódy založené na predpokladoch o triede rozhodovacích funkcií. V tejto skupine sa typ rozhodovacej funkcie považuje za známy a je daná jej kvalitatívna funkcionalita. Na základe tohto funkcionálu sa z tréningovej sekvencie zistí optimálna aproximácia k rozhodovacej funkcii. Funkcionalita kvality rozhodovacieho pravidla je zvyčajne spojená s chybou. Hlavnou výhodou metódy je prehľadnosť matematickej formulácie rozpoznávacieho problému. Možnosť získavania nových poznatkov o povahe objektu, najmä poznatkov o mechanizmoch interakcie atribútov, je tu zásadne obmedzená danou štruktúrou interakcie, fixovanou vo zvolenej forme rozhodovacích funkcií.
Metóda porovnávania prototypov. Ide o najjednoduchšiu metódu rozšíreného rozpoznávania v praxi. Platí, keď sú rozpoznateľné triedy zobrazené ako kompaktné geometrické triedy. Potom sa ako prototypový bod vyberie stred geometrického zoskupenia (alebo objekt najbližšie k stredu).
Na klasifikáciu neurčitého objektu sa nájde prototyp, ktorý je mu najbližšie, a objekt patrí do rovnakej triedy ako on. Pri tejto metóde sa samozrejme nevytvárajú žiadne zovšeobecnené obrazy. Ako meradlo možno použiť rôzne typy vzdialeností.
Metóda k najbližších susedov. Metóda spočíva v tom, že pri klasifikácii neznámeho objektu sa nájde daný počet (k) geometricky najbližšieho priestorového priestoru ďalších najbližších susedov s už známou príslušnosťou k triede. Rozhodnutie o priradení neznámeho objektu sa robí analýzou informácií o jeho najbližších susedoch. Potreba znížiť počet objektov v trénovacej vzorke (diagnostické precedensy) je nevýhodou tejto metódy, pretože to znižuje reprezentatívnosť trénovacej vzorky.
Na základe skutočnosti, že rôzne rozpoznávacie algoritmy sa správajú odlišne na tej istej vzorke, vyvstáva otázka syntetického rozhodovacieho pravidla, ktoré by využívalo silné stránky všetkých algoritmov. Na tento účel existuje syntetická metóda alebo súbory rozhodovacích pravidiel, ktoré kombinujú najpozitívnejšie aspekty každej z metód.
Na záver prehľadu metód rozpoznávania uvádzame podstatu vyššie uvedeného v súhrnnej tabuľke a pridávame niektoré ďalšie metódy používané v praxi.
Tabuľka 1. Klasifikačná tabuľka metód rozpoznávania, porovnanie oblastí ich použitia a obmedzení
|
Klasifikácia metód rozpoznávania |
Oblasť použitia |
Obmedzenia (nevýhody) |
|
|
Intenzívne metódy rozpoznávania |
Metódy založené na odhadoch hustoty |
Problémy so známou distribúciou (normálna), potreba zbierať veľké štatistiky |
Potreba vyčísliť celý tréningový súbor pri rozpoznávaní, vysoká citlivosť na nereprezentatívnosť tréningového súboru a artefaktov |
|
Metódy založené na predpokladoch |
Triedy by mali byť dobre oddeliteľné |
Forma rozhodovacej funkcie musí byť známa vopred. Nemožnosť brať do úvahy nové poznatky o koreláciách medzi znakmi |
|
|
Booleovské metódy |
Problémy malých rozmerov |
Pri výbere logických rozhodovacích pravidiel je potrebný úplný zoznam. Vysoká pracovná náročnosť |
|
|
Lingvistické metódy |
Úloha určenia gramatiky pre určitú množinu výrokov (popisov objektov) je ťažko formalizovateľná. Nevyriešené teoretické problémy |
||
|
Rozširujúce metódy rozpoznávania |
Metóda porovnávania prototypov |
Problémy malého rozmeru priestoru prvkov |
Vysoká závislosť výsledkov klasifikácie od metriky. Neznáma optimálna metrika |
|
k metóda najbližšieho suseda |
Vysoká závislosť výsledkov klasifikácie od metriky. Potreba úplného vyčíslenia trénovacej vzorky počas rozpoznávania. Výpočtová zložitosť |
||
|
Algoritmy výpočtu známok (ABO) |
Problémy malého rozmeru z hľadiska počtu tried a vlastností |
Závislosť výsledkov klasifikácie na metrike. Potreba úplného vyčíslenia trénovacej vzorky počas rozpoznávania. Vysoká technická náročnosť metódy |
|
|
Pravidlá kolektívneho rozhodovania (CRC) sú syntetickou metódou. |
Problémy malého rozmeru z hľadiska počtu tried a vlastností |
Veľmi vysoká technická náročnosť metódy, nevyriešené množstvo teoretických problémov ako pri určovaní oblastí kompetencie jednotlivých metód, tak aj v samotných metódach. |
Prednáška číslo 17.METÓDY ROZPOZNÁVANIA VZORU
Existujú nasledujúce skupiny metód rozpoznávania:
Metódy funkcie priblíženia
Metódy diskriminačných funkcií
Štatistické metódy rozpoznávania.
Lingvistické metódy
heuristické metódy.
Prvé tri skupiny metód sú zamerané na analýzu znakov vyjadrených číslami alebo vektormi s číselnými zložkami.
Skupina lingvistických metód poskytuje rozpoznávanie vzorov na základe analýzy ich štruktúry, ktorá je popísaná zodpovedajúcimi štrukturálnymi znakmi a vzťahmi medzi nimi.
Skupina heuristických metód spája charakteristické techniky a logické postupy používané ľuďmi pri rozpoznávaní vzorov.
Metódy funkcie priblíženia
Metódy tejto skupiny sú založené na použití funkcií, ktoré vyhodnocujú mieru blízkosti medzi rozpoznateľným obrázkom s vektorom X * = (X * 1 ,….,x*n) a referenčné obrázky rôznych tried reprezentované vektormi x i = (x i 1 ,…, x i n), i= 1,…,N, kde ja-číslo triedy obrázka.
Postup rozpoznávania podľa tejto metódy spočíva vo výpočte vzdialenosti medzi bodom rozpoznaného obrazu a každým z bodov reprezentujúcich referenčný obraz, t.j. pri výpočte všetkých hodnôt d i , i= 1,…,N. Obrázok patrí do triedy, pre ktorú má hodnotu d i má zo všetkých najmenšiu hodnotu i= 1,…,N .
Funkcia, ktorá mapuje každý pár vektorov x i, X * reálne číslo ako miera ich blízkosti, t.j. určenie vzdialenosti medzi nimi môže byť celkom ľubovoľné. V matematike sa takáto funkcia nazýva priestorová metrika. Musí spĺňať nasledujúce axiómy:
r(x, y)=r(y,x);
r(x, y) > 0 ak X nerovná sa r a r(x, y)=0 ak x=y;
r(x, y) <=r(x,z)+r(z,y)
Tieto axiómy spĺňajú najmä nasledujúce funkcie
a i= 1/2 , j=1,2,…n.
b i=súčet, j=1,2,…n.
c i=max abs ( x i‑ x j *), j=1,2,…n.
Prvá z nich sa nazýva euklidovská norma vektorového priestoru. V súlade s tým sa priestory, v ktorých sa špecifikovaná funkcia používa ako metrika, nazývajú euklidovský priestor.
Často sa ako funkcia priblíženia vyberie odmocnina z rozdielu súradníc rozpoznaného obrazu X * a štandardné x i, t.j. funkciu
d i = (1/n) súčet( x i j‑ x j *) 2 , j=1,2,…n.
Hodnota d i geometricky interpretovaný ako druhá mocnina vzdialenosti medzi bodmi v priestore prvkov vo vzťahu k rozmeru priestoru.
Často sa ukazuje, že rôzne vlastnosti nie sú pri rozpoznávaní rovnako dôležité. Aby sa táto okolnosť zohľadnila pri výpočte funkcií priblíženia rozdielu v súradniciach, zodpovedajúce dôležitejšie vlastnosti sa vynásobia veľkými koeficientmi a menej dôležité menšími.
V tomto prípade d i = (1/n) súčet wj (x i j‑ x j *) 2 , j=1,2,…n,
kde wj- hmotnostné koeficienty.
Zavedenie váhových koeficientov je ekvivalentné zmenšovaniu osí priestoru znakov a podľa toho rozťahovaniu alebo stláčaniu priestoru v samostatných smeroch.
Tieto deformácie priestorového znaku sledujú cieľ takého umiestnenia bodov referenčných obrazov, ktoré zodpovedá najspoľahlivejšiemu rozpoznaniu za podmienok výrazného rozptylu obrazov každej triedy v blízkosti bodu referenčného obrazu.
Skupiny obrazových bodov blízko seba (zhluky obrazov) v priestore znakov sa nazývajú zhluky a problém identifikácie takýchto skupín sa nazýva problém zhlukovania.
Úloha identifikácie zhlukov sa označuje ako úlohy rozpoznávania vzorov bez dozoru, t.j. na problémy s rozpoznávaním pri absencii príkladu správneho rozpoznávania.
Metódy diskriminačných funkcií
Myšlienkou metód tejto skupiny je skonštruovať funkcie, ktoré definujú hranice v priestore obrázkov a rozdeľujú priestor na oblasti zodpovedajúce triedam obrázkov. Najjednoduchšie a najčastejšie používané funkcie tohto druhu sú funkcie, ktoré lineárne závisia od hodnôt vlastností. V priestore prvkov zodpovedajú oddeľujúcim plochám vo forme nadrovín. V prípade dvojrozmerného priestoru prvkov funguje priama čiara ako oddeľovacia funkcia.
Všeobecný tvar lineárnej rozhodovacej funkcie je daný vzorcom
d(X)=w 1 X 1 + w 2 X 2 +…+w n x n +w n +1 = Wx+w n
kde X- vektorový obrázok, w=(w 1 , w 2 ,…w n) je vektor váhových koeficientov.
Pri rozdelení do dvoch tried X 1 a X 2 diskriminačná funkcia d(x) umožňuje uznanie podľa pravidla:
X patrí X 1 ak d(X)>0;
X patrí X 2 ak d(X)<0.
Ak d(X)=0, potom nastáva prípad neistoty.
V prípade rozdelenia do viacerých tried sa zavádza niekoľko funkcií. V tomto prípade je každá trieda obrázkov spojená s určitou kombináciou znakov rozlišujúcich funkcií.
Napríklad, ak sú zavedené tri diskriminačné funkcie, potom je možný nasledujúci variant výberu tried obrázkov:
X patrí X 1 ak d 1 (X)>0,d 2 (X)<0,d 3 (X)<0;
X patrí X 2 ak d(X)<0,d 2 (X)>0,d 3 (X)<0;
X patrí X 3 ak d(X)<0,d 2 (X)<0,d 3 (X)>0.
Predpokladá sa, že pre iné kombinácie hodnôt d 1 (X),d 2 (X),d 3 (X) existuje prípad neistoty.
Obmenou metódy diskriminačných funkcií je metóda rozhodujúcich funkcií. V ňom, ak je k dispozícii m triedy sa predpokladá, že existujú m funkcie d i(X), nazývaný rozhodujúci, taký, že ak X patrí X i, potom d i(X) > dj(X) pre všetkých j nerovná sa i,tie. rozhodujúca funkcia d i(X) má maximálnu hodnotu spomedzi všetkých funkcií dj(X), j=1,...,n..
Ilustráciou takejto metódy môže byť klasifikátor založený na odhade minima euklidovskej vzdialenosti v priestore prvku medzi bodom obrazu a štandardom. Ukážme to.
Euklidovská vzdialenosť medzi príznakovým vektorom rozpoznateľného obrazu X a vektor referenčného obrázku je určený vzorcom || x i ‑ X|| = 1/2 , j=1,2,…n.
Vektor X bude pridelený do triedy i, pre ktoré je hodnota || x i ‑ X *|| minimálne.
Namiesto vzdialenosti môžete porovnávať druhú mocninu vzdialenosti, t.j.
||x i ‑ X|| 2 = (x i ‑ X)(x i ‑ X) t = X X- 2X x i +x i x i
Od hodnoty X X rovnako pre všetkých i, minimum funkcie || x i ‑ X|| 2 sa bude zhodovať s maximom rozhodovacej funkcie
d i(X) = 2X x i -x i x i.
to jest X patrí X i, ak d i(X) > dj(X) pre všetkých j nerovná sa i.
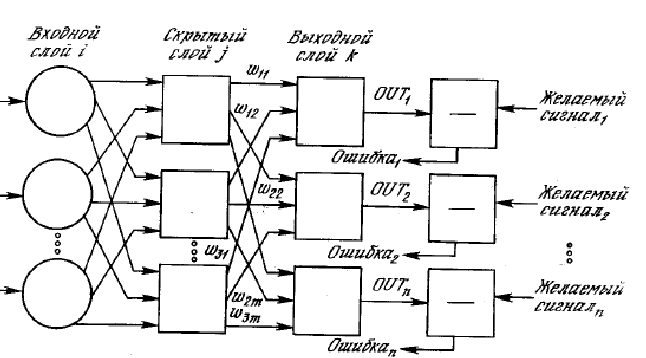
To. stroj na klasifikáciu minimálnej vzdialenosti je založený na lineárnych rozhodovacích funkciách. Všeobecná štruktúra takéhoto stroja využíva rozhodovacie funkcie formulára
d i (X)=w i 1 X 1 + w i 2 X 2 +…+w v x n +vyhrať +1
Dá sa vizuálne znázorniť príslušnou blokovou schémou.
Pre stroj, ktorý vykonáva klasifikáciu podľa minimálnej vzdialenosti, platia rovnosti: w ij = -2x i j , vyhrať +1 = x i x i.
Ekvivalentné rozpoznávanie metódou diskriminačných funkcií sa môže uskutočniť, ak sú diskriminačné funkcie definované ako rozdiely dij (X)=d i (X)‑dj (X).
Výhodou metódy diskriminačných funkcií je jednoduchá štruktúra rozpoznávacieho stroja, ako aj možnosť jeho implementácie najmä prostredníctvom prevažne lineárnych rozhodovacích blokov.
Ďalšou dôležitou výhodou metódy diskriminačných funkcií je možnosť automatického trénovania stroja na správne rozpoznanie danej (tréningovej) vzorky obrázkov.
Algoritmus automatického učenia sa zároveň ukazuje ako veľmi jednoduchý v porovnaní s inými metódami rozpoznávania.
Z týchto dôvodov si metóda diskriminačných funkcií získala veľkú obľubu a v praxi sa často používa.
Samoučiace sa postupy rozpoznávania vzorov
Zvážte metódy konštrukcie diskriminačnej funkcie z danej (tréningovej) vzorky aplikovanej na problém rozdelenia obrázkov do dvoch tried. Ak sú dané dve sady obrázkov, ktoré patria do tried A a B, potom sa riešenie problému konštrukcie lineárnej diskriminačnej funkcie hľadá vo forme vektora váhových koeficientov. W=(w 1 ,w 2 ,...,w n,w n+1), ktorý má tú vlastnosť, že pre akýkoľvek obrázok podmienky
X patrí do triedy A, ak >0, j=1,2,…n.
X patrí do triedy B, ak<0, j=1,2,…n.
Ak je tréningová vzorka N obrázkov oboch tried, problém sa redukuje na nájdenie vektora w, ktorý zabezpečí platnosť systému nerovností. N obrázkov oboch tried, problém sa redukuje na nájdenie vektora w, ktorý zabezpečuje platnosť systému nerovností
X 1 1 w i+X 21 w 2 +...+x n 1 w n+w n +1 >0;
X 1 2 w i+X 22 w 2 +...+x n 2 w n+w n +1 <0;
X 1 iw i+X 2i w 2 +...+x ni w n+w n +1 >0;
................................................
X 1 Nw i +x 2N w 2 +...+x nN w n +w n + 1>0;
tu x i=(x i 1 ,x i 2 ,...,x i n ,x i n+ 1 ) - vektor hodnôt vlastností obrázka z tréningovej vzorky, znak > zodpovedá vektorom obrázkov X patriace do triedy A, a znak< - векторам X patriace do triedy B.
Požadovaný vektor w existuje, ak sú triedy A a B oddeliteľné a inak neexistuje. Hodnoty vektorového komponentu w možno nájsť buď vopred, v štádiu predchádzajúcej hardvérovej implementácii SRO, alebo priamo SRO v priebehu jej prevádzky. Posledný z týchto prístupov poskytuje väčšiu flexibilitu a autonómiu SRO. Zvážte to na príklade zariadenia s názvom percentron. vynašiel v roku 1957 americký vedec Rosenblatt. Schematické znázornenie percentrónu, ktoré zabezpečuje priradenie obrázku do jednej z dvoch tried, je na nasledujúcom obrázku.
Retina S Retina A Retina R
oh oh X 1
oh oh X 2
oh oh X 3
o (súčet)--------> R(reakcia)
oh oh x i
oh oh x n
oh oh x n +1
Zariadenie pozostáva zo senzorických prvkov sietnice S, ktoré sú náhodne spojené s asociatívnymi prvkami sietnice A. Každý prvok druhej sietnice produkuje výstupný signál iba vtedy, ak je dostatočný počet senzorických prvkov pripojených na jeho vstup v excitovanom stave. Odozva celého systému R je úmerná súčtu reakcií prvkov asociatívnej sietnice braných s určitými váhami.
Označenie cez x i reakciu i asociatívny prvok a cez w i- koeficient reakčnej hmotnosti i asociatívny prvok, reakciu systému možno zapísať ako R=sum( w j x j), j=1,..,n. Ak R>0, potom obraz prezentovaný systému patrí do triedy A, a ak R<0, то образ относится к классу B. Описание этой процедуры классификации соответствует рассмотренным нами раньше принципам классификации, и, очевидно, перцентронная модель распознавания образов представляет собой, за исключением сенсорной сетчатки, реализацию линейной дискриминантной функции. Принятый в перцентроне принцип формирования значений X 1 , X 2 ,...,x n zodpovedá určitému algoritmu na vytváranie znakov na základe signálov primárnych snímačov.
Vo všeobecnosti môže existovať niekoľko prvkov R, ktoré tvoria reakciu perceptrónu. V tomto prípade sa hovorí o prítomnosti sietnice v perceptróne R reagujúce prvky.
Schéma percentrónu môže byť rozšírená na prípad, keď je počet tried väčší ako dve, zvýšením počtu prvkov sietnice R až po počet rozlíšiteľných tried a zavedenie bloku na určenie maximálnej reakcie v súlade so schémou uvedenou na vyššie uvedenom obrázku. V tomto prípade je obrázok priradený triede s číslom i, ak RI>Rj, pre všetkých j.
Proces učenia percentrónu spočíva vo výbere hodnôt váhových koeficientov wj aby výstupný signál zodpovedal triede, do ktorej rozpoznaný obraz patrí.
Uvažujme o akčnom algoritme percentrón na príklade rozpoznávania objektov dvoch tried: A a B. Objekty triedy A musia zodpovedať hodnote R= +1 a trieda B - hodnota R= -1.
Algoritmus učenia je nasledujúci.
Ak iný obrázok X patrí do triedy A, ale R<0 (имеет место ошибка распознавания), тогда коэффициенты wj s indexmi zodpovedajúcimi hodnotám x j>0, zvýšiť o určitú sumu dw a zvyšok koeficientov wj znížiť o dw. V tomto prípade hodnota reakcie R dostane prírastok k svojim kladným hodnotám zodpovedajúcim správnej klasifikácii.
Ak X patrí do triedy B, ale R>0 (vyskytla sa chyba rozpoznávania), potom koeficienty wj s indexmi zodpovedajúcimi x j<0, увеличивают на dw a zvyšok koeficientov wj znížená o rovnakú sumu. V tomto prípade hodnota reakcie R sa zvyšuje smerom k záporným hodnotám zodpovedajúcim správnej klasifikácii.
Algoritmus teda zavádza zmenu vo vektore hmotnosti w vtedy a len vtedy, ak je obraz prezentovaný k-th tréningový krok, bol počas tohto kroku nesprávne klasifikovaný a opúšťa vektor hmotnosti wžiadna zmena v prípade správnej klasifikácie. Dôkaz konvergencie tohto algoritmu je uvedený v [Too, Gonzalez]. Takéto školenie nakoniec bude (pri správnom výbere dw a lineárna oddeliteľnosť tried obrázkov) vedie k vektoru w pre správnu klasifikáciu.
Štatistické metódy rozpoznávania.
Štatistické metódy sú založené na minimalizácii pravdepodobnosti klasifikačnej chyby. Pravdepodobnosť P nesprávnej klasifikácie obrazu prijatého na rozpoznanie, opísaná znakovým vektorom X, sa určuje podľa vzorca
P = súčet[ p(i)prob( D(X)+i | X trieda i)]
kde m- počet tried,
p(i) = sonda ( X patrí do triedy i) - a priori pravdepodobnosť príslušnosti k ľubovoľnému obrázku X do i-th class (frekvencia výskytu obrázkov i trieda),
D(X) je funkcia, ktorá rozhoduje o klasifikácii (vektor znakov X zodpovedá číslu triedy i zo sady (1,2,..., m}),
problém( D(X) nerovná sa i| X patrí do triedy i) je pravdepodobnosť udalosti" D(X) nerovná sa i“ keď je splnená podmienka členstva X trieda i, t.j. pravdepodobnosť, že funkcia urobí chybné rozhodnutie D(X) pre danú hodnotu X vo vlastníctve i- trieda.
Dá sa ukázať, že pravdepodobnosť nesprávneho zaradenia dosahuje minimum, ak D(X)=i ak a len vtedy p(X|i)· p(i)>p(x|j)· p(j), pre všetkých i+j, kde p(x|i) - hustota distribúcie obrázkov i triedy v priestore funkcií.
Podľa vyššie uvedeného pravidla bod X patrí do triedy, ktorá zodpovedá maximálnej hodnote p(i) p(x|i), t.j. súčin apriórnej pravdepodobnosti (frekvencie) výskytu obrazov i-tej triedy a hustoty distribúcie vzorov i triedy v priestore funkcií. Prezentované klasifikačné pravidlo sa nazýva Bayesovské, pretože vyplýva to zo známeho Bayesovho vzorca v teórii pravdepodobnosti.
Príklad. Nech je potrebné rozpoznať diskrétne signály na výstupe informačného kanála ovplyvneného šumom.
Každý vstupný signál je 0 alebo 1. V dôsledku prenosu signálu sa na výstupe kanála zobrazí hodnota X, ktorý je superponovaný s Gaussovým šumom s nulovým priemerom a rozptylom b.
Na syntézu klasifikátora, ktorý vykonáva rozpoznávanie signálu, použijeme Bayesovské klasifikačné pravidlo.
V triede č. 1 kombinujeme signály predstavujúce jednotky, v triede č. 2 - signály predstavujúce nuly. Vopred nech je známe, že v priemere z každých 1000 signálov a signály sú jednotky a b signály - nuly. Potom sa hodnoty a priori pravdepodobnosti výskytu signálov 1. a 2. triedy (jednotky a nuly), v tomto poradí, môžu rovnať
p(1)=a/1000, p(2)=b/1000.
Pretože šum je Gaussovský, t.j. dodržiava zákon normálneho (Gaussovho) rozdelenia, potom hustota rozloženia obrázkov prvej triedy v závislosti od hodnoty X, alebo, ktorá je rovnaká, pravdepodobnosť získania výstupnej hodnoty X keď je na vstup privedený signál 1, je určený výrazom
p(X¦1) =(2pib) -1/2 exp(-( X-1) 2 /(2b 2)),
a hustota distribúcie v závislosti od hodnoty X obrazy druhej triedy, t.j. pravdepodobnosť získania výstupnej hodnoty X keď je na vstup privedený signál 0, je určený výrazom
p(X¦2)= (2pib) -1/2 exp(- X 2 /(2b 2)),
Aplikácia Bayesovho rozhodovacieho pravidla vedie k záveru, že sa prenáša signál triedy 2, t.j. prešiel nulou, ak
p(2) p(X¦2) > p(1) p(X¦1)
alebo konkrétnejšie, ak
b exp(- X 2 /(2b 2)) > a exp(-( X-1) 2 /(2b 2)),
Vydelením ľavej strany nerovnosti pravou stranou dostaneme
(b/a)exp((1-2 X)/(2b 2)) >1,
odkiaľ po logaritmovaní zistíme
1-2X> 2b 2 ln(a/b)
X< 0.5 - б 2 ln(a/b)
Z výslednej nerovnosti vyplýva, že a=b, t.j. pri rovnakej apriórnej pravdepodobnosti výskytu signálov 0 a 1 je obrázku priradená hodnota 0, keď X<0.5, а значение 1, когда X>0.5.
Ak je vopred známe, že jeden zo signálov sa objavuje častejšie, a druhý menej často, t.j. v prípade rozdielnych hodnôt a a b prah odozvy klasifikátora sa posunie na jednu alebo druhú stranu.
Takže pri a/b=2,71 (zodpovedá 2,71-krát častejšiemu prenosu jednotiek) a b 2 =0,1, obrázku sa priradí hodnota 0, ak X<0.4, и значение 1, если X>0,4. Ak neexistujú žiadne informácie o pravdepodobnostiach apriórneho rozdelenia, potom možno použiť metódy štatistického rozpoznávania, ktoré sú založené na iných ako Bayesovských pravidlách klasifikácie.
V praxi sú však metódy založené na Bayesových pravidlách najbežnejšie kvôli ich väčšej účinnosti a tiež kvôli tomu, že vo väčšine problémov s rozpoznávaním vzorov je možné nastaviť a priori pravdepodobnosti vzhľadu obrázkov každej triedy.
Lingvistické metódy rozpoznávania vzorov.
Lingvistické metódy rozpoznávania vzorov sú založené na analýze popisu idealizovaného obrazu, reprezentovaného ako graf alebo reťazec symbolov, čo je fráza alebo veta určitého jazyka.
Zvážte idealizované obrázky písmen získané ako výsledok prvej fázy jazykového rozpoznávania opísaného vyššie. Tieto idealizované obrazy je možné definovať pomocou opisov grafov, reprezentovaných napríklad vo forme spojovacích matíc, ako to bolo urobené vo vyššie uvedenom príklade. Rovnaký opis môže byť reprezentovaný formálnou jazykovou frázou (výrazom).
Príklad. Uveďme tri obrázky písmena A, získané ako výsledok predbežného spracovania obrázkov. Označme tieto obrázky identifikátormi A1, A2 a A3.
Na lingvistický popis prezentovaných obrázkov používame PDL (Picture Description Language). Slovník jazyka PDL obsahuje nasledujúce znaky:
1. Názvy najjednoduchších obrázkov (primitív). Primitívy a ich zodpovedajúce názvy sú v tomto prípade uvedené nižšie.
Obrázky vo forme riadenej čiary:
hore a doľava (le F t), na sever (sever)), hore a doprava (vpravo), na východ (východ)).
Mená: L, N, R, E.
2. Symboly binárnych operácií. (+,*,-) Ich význam zodpovedá postupnému spájaniu primitív (+), spájaniu začiatkov a koncov primitív (*), spájaniu iba koncoviek primitív (-).
3. Pravá a ľavá zátvorka. ((,)) Zátvorky umožňujú určiť poradie, v ktorom sa majú operácie vykonávať vo výraze.
Uvažované obrázky A1, A2 a A3 sú v jazyku PDL popísané nasledujúcimi výrazmi.
T(1)=R+((R-(L+N))*E-L
T(2)=(R+N)+((N+R)-L)*E-L
T(3)=(N+R)+(R-L)*E-(L+N)
Po vybudovaní lingvistického popisu obrazu je potrebné pomocou nejakého rozpoznávacieho postupu analyzovať, či daný obraz patrí do pre nás zaujímavej triedy (trieda písmen A), t.j. či tento obrázok má alebo nemá nejakú štruktúru. Na tento účel je potrebné najskôr opísať triedu obrázkov, ktoré majú štruktúru, ktorá nás zaujíma.
Je zrejmé, že písmeno A vždy obsahuje nasledujúce konštrukčné prvky: ľavú "nohu", pravú "nohu" a hlavu. Nazvime tieto prvky STL, STR, TR.
Potom je v jazyku PDL trieda symbolov A - SIMB A opísaná výrazom
SIMB A = STL + TR - STR
Ľavá „noha“ STL je vždy reťazec prvkov R a N, ktoré možno písať ako
STL ‑> R ¦ N ¦ (STL + R) ¦ (STL + N)
(STL je znak R alebo N alebo reťazec získaný pridaním znakov R alebo N do zdrojového reťazca STL)
Pravou „nohou“ STR je vždy reťazec prvkov L a N, ktorý možno zapísať nasledovne, t.j.
STR ‑> L¦N¦ (STR + L)¦ (STR + N)
Hlavová časť písmena - TR je uzavretý obrys, zložený z prvku E a reťazí ako STL a STR.
V jazyku PDL je štruktúra TR opísaná výrazom
TR -> (STL - STR) * E
Nakoniec dostaneme nasledujúci popis triedy písmen A:
SIMB A -> (STL + TR - STR),
STL ‑> R¦N¦ (STL + R)¦ (STL + N)
STR ‑> L¦N¦ (STR + L)¦ (STR + N)
TR -> (STL - STR) * E
Postup uznávania sa v tomto prípade môže uskutočniť nasledovne.
1. Výraz zodpovedajúci obrázku sa porovná s referenčnou štruktúrou STL + TR - STR.
2. Každý prvok štruktúry STL, TR, STR, pokiaľ je to možné, t.j. ak je popis obrázka porovnateľný so štandardom, zhoduje sa nejaký podvýraz z výrazu T(A). Napríklad,
pre A1: STL=R, STR=L, TR=(R-(L+N))*E
pre A2: STL = R + N, STR = L, TR = ((N + R) - L) * E
pre A3: STL = N + R, STR = L + N, TR = (R - L) * E 3.
Výrazy STL, STR, TR sa porovnávajú s ich zodpovedajúcimi referenčnými štruktúrami.
4. Ak štruktúra každého výrazu STL, STR, TR zodpovedá referenčnému výrazu, dochádza k záveru, že obrázok patrí do triedy písmen A. Ak v niektorom zo štádií 2, 3, 4 existuje nesúlad medzi štruktúrou z analyzovaného výrazu a odkazu sa dospelo k záveru, že obrázok nepatrí do SIMB triedy A. Porovnanie štruktúry výrazov je možné vykonať pomocou algoritmických jazykov LISP, PLANER, PROLOG a iných podobných jazykov umelej inteligencie.
V uvažovanom príklade sú všetky reťazce STL tvorené znakmi N a R a reťazce STR sú tvorené znakmi L a N, čo zodpovedá danej štruktúre týchto reťazcov. Štruktúra TR na uvažovaných obrázkoch tiež zodpovedá referenčnej, keďže pozostáva z "rozdielu" reťazcov typu STL, STR, "vynásobeného" symbolom E.
Dostávame sa teda k záveru, že uvažované obrázky patria do triedy SIMB A.
Syntéza fuzzy jednosmerného regulátora elektrického pohonuv prostredí "MatLab".
Syntéza fuzzy regulátora s jedným vstupom a výstupom.
Problém je prinútiť disk, aby presne sledoval rôzne vstupy. Vývoj riadiacej akcie je realizovaný fuzzy regulátorom, v ktorom možno štrukturálne rozlíšiť nasledovné funkčné bloky: fuzzifier, rule block a defuzzifier.
Obr.4 Zovšeobecnený funkčný diagram systému s dvoma jazykovými premennými.
 Obr.5 Schematický diagram fuzzy regulátora s dvoma lingvistickými premennými.
Obr.5 Schematický diagram fuzzy regulátora s dvoma lingvistickými premennými.
Algoritmus fuzzy riadenia je vo všeobecnom prípade transformáciou vstupných premenných fuzzy regulátora na jeho výstupné premenné pomocou nasledujúcich vzájomne súvisiacich postupov:
1. transformácia vstupných fyzikálnych veličín získaných z meracích senzorov z riadiaceho objektu na vstupné lingvistické premenné fuzzy regulátora;
2. spracovanie logických príkazov, nazývaných lingvistické pravidlá, týkajúce sa vstupných a výstupných lingvistických premenných kontrolóra;
3. transformácia výstupných lingvistických premenných fuzzy regulátora na fyzikálne riadiace premenné.
Uvažujme najskôr o najjednoduchšom prípade, keď sú na ovládanie servopohonu zavedené iba dve jazykové premenné:
"uhol" - vstupná premenná;
"riadiaca akcia" - výstupná premenná.
Ovládač syntetizujeme v prostredí MatLab pomocou toolboxu Fuzzy Logic. Umožňuje vytvárať fuzzy inferencie a fuzzy klasifikačné systémy v prostredí MatLab s možnosťou ich integrácie do Simulinku. Základným konceptom Fuzzy Logic Toolbox je štruktúra FIS – Fuzzy Inference System. Štruktúra FIS obsahuje všetky potrebné údaje na implementáciu funkčného mapovania "vstupy-výstupy" na základe fuzzy logickej inferencie podľa schémy znázornenej na obr. 6.

Obrázok 6. Fuzzy inferencia.
X - vstupný ostrý vektor; - vektor fuzzy množín zodpovedajúci vstupnému vektoru X;
- výsledok logickej inferencie vo forme vektora fuzzy množín Y - výstupný ostrý vektor.
Fuzzy modul umožňuje zostaviť fuzzy systémy dvoch typov – Mamdani a Sugeno. V systémoch typu Mamdani pozostáva báza znalostí z pravidiel formy „Ak x 1 = nízke a x 2 = stredné, potom y = vysoké“. V systémoch typu Sugeno pozostáva báza znalostí z pravidiel formy "Ak x 1 = nízke a x 2 = stredné, potom y = a 0 + a 1 x 1 + a 2 x 2 ". Hlavný rozdiel medzi systémami Mamdani a Sugeno teda spočíva v rôznych spôsoboch nastavenia hodnôt výstupnej premennej v pravidlách, ktoré tvoria vedomostnú základňu. V systémoch typu Mamdani sú hodnoty výstupnej premennej dané fuzzy pojmami, v systémoch typu Sugeno - ako lineárna kombinácia vstupných premenných. V našom prípade použijeme systém Sugeno, pretože hodí sa lepšie na optimalizáciu.
Na riadenie servopohonu sú zavedené dve jazykové premenné: "chyba" (podľa polohy) a "riadiaca činnosť". Prvý z nich je vstup, druhý je výstup. Definujme množinu termínov pre špecifikované premenné.
Hlavné zložky fuzzy inferencie. Fuzzifier.
Pre každú lingvistickú premennú definujeme základnú množinu pojmov formulára, ktorá zahŕňa fuzzy množiny, ktoré možno označiť: záporná vysoká, záporná nízka, nula, kladná nízka, kladná vysoká.
Najprv si subjektívne definujme, čo sa rozumie pod pojmami „veľká chyba“, „malá chyba“ atď., pričom definujme funkcie príslušnosti pre zodpovedajúce fuzzy množiny. Tu sa zatiaľ možno riadiť len požadovanou presnosťou, známymi parametrami pre triedu vstupných signálov a zdravým rozumom. Zatiaľ nikto nedokázal ponúknuť žiadny rigidný algoritmus na výber parametrov funkcií členstva. V našom prípade bude jazyková premenná „chyba“ vyzerať takto.
 Obr.7. Jazyková premenná „chyba“.
Obr.7. Jazyková premenná „chyba“.
Je vhodnejšie reprezentovať jazykovú premennú „manažment“ vo forme tabuľky:
stôl 1
Blok pravidiel.
Zvážte postupnosť definovania niekoľkých pravidiel, ktoré popisujú niektoré situácie:
Predpokladajme napríklad, že výstupný uhol sa rovná vstupnému signálu (t.j. chyba je nulová). Je zrejmé, že ide o želanú situáciu, a preto nemusíme robiť nič (kontrolná akcia je nulová).
Teraz zvážte iný prípad: chyba polohy je oveľa väčšia ako nula. Prirodzene, musíme to kompenzovať generovaním veľkého pozitívneho riadiaceho signálu.
To. boli vypracované dve pravidlá, ktoré možno formálne definovať takto:
ak chyba = null, potom kontrolná činnosť = nula.
ak chyba = veľké pozitívum, potom kontrolná akcia = veľká pozitívna.
 Obr.8. Vytvorenie kontroly s malou kladnou chybou v polohe.
Obr.8. Vytvorenie kontroly s malou kladnou chybou v polohe.
 Obr.9. Tvorba kontroly pri nulovej chybe polohy.
Obr.9. Tvorba kontroly pri nulovej chybe polohy.
V tabuľke nižšie sú uvedené všetky pravidlá zodpovedajúce všetkým situáciám pre tento jednoduchý prípad.
tabuľka 2
Celkovo možno pre fuzzy regulátor s n vstupmi a 1 výstupom určiť pravidlá riadenia, kde je počet fuzzy množín pre i-tý vstup, ale pre normálnu funkciu regulátora nie je potrebné použiť všetky možné pravidlá, ale vystačíte si s menším počtom z nich. V našom prípade sa na vytvorenie fuzzy riadiaceho signálu používa všetkých 5 možných pravidiel.
Defuzzifier.
Výsledný vplyv U bude teda určený podľa implementácie akéhokoľvek pravidla. Ak nastane situácia, keď sa vykoná niekoľko pravidiel naraz, potom sa výsledná akcia U nájde podľa nasledujúceho vzťahu:
 , kde n je počet spustených pravidiel (defuzzifikácia metódou centra oblasti), u n je fyzikálna hodnota riadiaceho signálu zodpovedajúceho každej z fuzzy množín UBO, UMo, UZ, UMp, UBP. mUn(u) je miera príslušnosti riadiaceho signálu u k zodpovedajúcej fuzzy množine Un=( UBO, UMo, UZ, UMp, UBP). Existujú aj iné metódy defuzzifikácie, kedy je výstupná lingvistická premenná úmerná samotnému „silnému“ alebo „slabému“ pravidlu.
, kde n je počet spustených pravidiel (defuzzifikácia metódou centra oblasti), u n je fyzikálna hodnota riadiaceho signálu zodpovedajúceho každej z fuzzy množín UBO, UMo, UZ, UMp, UBP. mUn(u) je miera príslušnosti riadiaceho signálu u k zodpovedajúcej fuzzy množine Un=( UBO, UMo, UZ, UMp, UBP). Existujú aj iné metódy defuzzifikácie, kedy je výstupná lingvistická premenná úmerná samotnému „silnému“ alebo „slabému“ pravidlu.
Simulujme proces riadenia elektrického pohonu pomocou vyššie opísaného fuzzy regulátora.
 Obr.10. Bloková schéma systému v prostredímatlab.
Obr.10. Bloková schéma systému v prostredímatlab.

Obr.11. Štrukturálny diagram fuzzy regulátora v prostredímatlab.

Obr.12. Prechodný proces s dopadom na jeden krok.

Ryža. 13. Prechodný proces pod harmonickým vstupom pre model s fuzzy regulátorom obsahujúcim jednu vstupnú lingvistickú premennú.
Analýza charakteristík pohonu so syntetizovaným riadiacim algoritmom ukazuje, že nie sú ani zďaleka optimálne a horšie ako v prípade syntézy riadenia inými metódami (príliš dlhý čas riadenia s efektom jedného kroku a chyba s harmonickým) . Vysvetľuje sa to tým, že parametre funkcií členstva boli zvolené celkom svojvoľne a ako vstupy regulátora bola použitá iba veľkosť chyby polohy. Prirodzene, o nejakej optimalite získaného regulátora nemôže byť ani reči. Preto sa úloha optimalizácie fuzzy regulátora stáva aktuálnou, aby sa dosiahli čo najvyššie ukazovatele kvality riadenia. Tie. úlohou je optimalizovať účelovú funkciu f(a 1 ,a 2 …a n), kde a 1 ,a 2 …a n sú koeficienty určujúce typ a charakteristiky fuzzy regulátora. Na optimalizáciu fuzzy regulátora používame blok ANFIS z prostredia Matlab. Jedným zo spôsobov, ako zlepšiť vlastnosti regulátora, môže byť aj zvýšenie počtu jeho vstupov. Regulátor tak bude flexibilnejší a zlepší sa jeho výkon. Pridajme ešte jednu vstupnú lingvistickú premennú – rýchlosť zmeny vstupného signálu (jeho derivácie). V súlade s tým sa zvýši aj počet pravidiel. Potom bude mať schéma zapojenia regulátora tvar:

Obr.14 Schematický diagram fuzzy regulátora s tromi lingvistickými premennými.
Nech je hodnota rýchlosti vstupného signálu. Základná množina termínov Tn je definovaná ako:
Тn=("negatívny (VO)", "nula (Z)", "pozitívny (VR)").
Umiestnenie funkcií príslušnosti pre všetky jazykové premenné je znázornené na obrázku.
Obr.15. Členské funkcie jazykovej premennej „chyba“.

Obr.16. Členské funkcie lingvistickej premennej "rýchlosť vstupného signálu".
Vďaka pridaniu ďalšej lingvistickej premennej sa počet pravidiel zvýši na 3x5=15. Princíp ich zostavovania je úplne podobný tomu, ktorý je uvedený vyššie. Všetky sú uvedené v nasledujúcej tabuľke:
Tabuľka 3
| fuzzy signál zvládanie | Chyba polohy |
|||||
| Rýchlosť | ||||||
Napríklad, ak ak chyba = nula a derivácia vstupného signálu = veľká kladná, potom kontrolná akcia = malý negatívny.
 Obr.17. Formovanie kontroly pod tromi jazykovými premennými.
Obr.17. Formovanie kontroly pod tromi jazykovými premennými.
V dôsledku nárastu počtu vstupov a teda aj samotných pravidiel sa skomplikuje aj štruktúra fuzzy regulátora.
 Obr.18. Štrukturálny diagram fuzzy regulátora s dvoma vstupmi.
Obr.18. Štrukturálny diagram fuzzy regulátora s dvoma vstupmi.
Pridajte kresbu

Obr.20. Prechodný proces pod harmonickým vstupom pre model s fuzzy regulátorom obsahujúcim dve vstupné lingvistické premenné.

Ryža. 21. Chybový signál pod harmonickým vstupom pre model s fuzzy regulátorom obsahujúcim dve vstupné lingvistické premenné.
Simulujme činnosť fuzzy regulátora s dvoma vstupmi v prostredí Matlab. Bloková schéma modelu bude úplne rovnaká ako na obr. 19. Z grafu prechodového procesu pre harmonický vstup je vidieť, že presnosť sústavy sa výrazne zvýšila, no zároveň sa zvýšila jej oscilácia, najmä v miestach, kde má derivácia výstupnej súradnice tendenciu k nula. Je zrejmé, že dôvodom je, ako už bolo spomenuté vyššie, neoptimálny výber parametrov funkcií príslušnosti, a to pre vstupné aj výstupné lingvistické premenné. Preto optimalizujeme fuzzy regulátor pomocou bloku ANFISedit v prostredí Matlab.
Fuzzy optimalizácia ovládača.
Zvážte použitie genetických algoritmov na optimalizáciu fuzzy regulátorov. Genetické algoritmy sú adaptívne metódy vyhľadávania, ktoré sa v posledných rokoch často používajú na riešenie problémov funkčnej optimalizácie. Sú založené na podobnosti s genetickými procesmi biologických organizmov: biologické populácie sa vyvíjajú počas niekoľkých generácií, v súlade so zákonmi prirodzeného výberu a podľa princípu „prežitia najschopnejších“, ktorý objavil Charles Darwin. Napodobňovaním tohto procesu sú genetické algoritmy schopné „vyvíjať“ riešenia skutočných problémov, ak sú vhodne zakódované.
Genetické algoritmy pracujú s množinou „jednotlivcov“ – populáciou, z ktorých každý predstavuje možné riešenie daného problému. Každý jednotlivec je hodnotený mierou jeho „fitness“ podľa toho, ako „dobré“ je riešenie jemu zodpovedajúceho problému. Najzdatnejšie jedince sú schopné „rozmnožiť“ potomstvo „krížením“ s inými jedincami v populácii. To vedie k vzniku nových jedincov, ktorí kombinujú niektoré vlastnosti zdedené od svojich rodičov. Najmenej zdatní jedinci majú menšiu pravdepodobnosť, že sa rozmnožia, takže vlastnosti, ktoré majú, postupne z populácie miznú.
Takto sa reprodukuje celá nová populácia realizovateľných riešení, pričom sa vyberajú tí najlepší predstavitelia predchádzajúcej generácie, krížia sa a získavajú sa množstvo nových jedincov. Táto nová generácia obsahuje vyšší pomer vlastností, ktoré majú dobrí členovia predchádzajúcej generácie. Z generácie na generáciu sú teda dobré vlastnosti distribuované v celej populácii. V konečnom dôsledku sa populácia priblíži k optimálnemu riešeniu problému.
Existuje mnoho spôsobov, ako implementovať myšlienku biologickej evolúcie v rámci genetických algoritmov. Tradičný môže byť znázornený vo forme nasledujúceho blokového diagramu znázorneného na obrázku 22, kde:
1. Inicializácia počiatočnej populácie - generovanie daného počtu riešení problému, od ktorého sa začína proces optimalizácie;
2. Aplikácia operátorov kríženia a mutácie;
3.  Podmienky zastavenia - proces optimalizácie zvyčajne pokračuje, kým sa nenájde riešenie problému s danou presnosťou, alebo kým sa nezistí, že proces konvergoval (t. j. nedošlo k žiadnemu zlepšeniu riešenia problému za posledné obdobie). N generácií).
Podmienky zastavenia - proces optimalizácie zvyčajne pokračuje, kým sa nenájde riešenie problému s danou presnosťou, alebo kým sa nezistí, že proces konvergoval (t. j. nedošlo k žiadnemu zlepšeniu riešenia problému za posledné obdobie). N generácií).
V prostredí Matlab sú genetické algoritmy reprezentované samostatným súborom nástrojov, ako aj balíkom ANFIS. ANFIS je skratka pre Adaptive-Network-Based Fuzzy Inference System - Adaptive Fuzzy Inference Network. ANFIS je jedným z prvých variantov hybridných neuro-fuzzy sietí - neurónová sieť špeciálneho typu priameho šírenia signálu. Architektúra neuro-fuzzy siete je izomorfná s fuzzy bázou znalostí. V neuro-fuzzy sieťach sa používajú diferencovateľné implementácie trojuholníkových noriem (násobenie a pravdepodobnostné OR), ako aj funkcie hladkého členstva. To umožňuje použiť rýchle a genetické algoritmy na trénovanie neurónových sietí založených na metóde spätného šírenia na ladenie neuro-fuzzy sietí. Architektúra a pravidlá prevádzky každej vrstvy siete ANFIS sú popísané nižšie.
ANFIS implementuje Sugenov fuzzy inferenčný systém ako päťvrstvovú doprednú neurónovú sieť. Účel vrstiev je nasledovný: prvá vrstva sú členy vstupných premenných; druhá vrstva - predchodcovia (parcely) fuzzy pravidiel; treťou vrstvou je normalizácia stupňa plnenia pravidiel; štvrtou vrstvou sú závery pravidiel; piata vrstva je agregácia výsledku získaného podľa rôznych pravidiel.
Sieťové vstupy nie sú pridelené samostatnej vrstve. Obrázok 23 zobrazuje sieť ANFIS s jednou vstupnou premennou („chyba“) a piatimi fuzzy pravidlami. Na lingvistické vyhodnotenie vstupnej premennej "chyba" sa používa 5 pojmov.

Obr.23. ŠtruktúraANFIS- siete.
Uveďme si nasledujúci zápis potrebný pre ďalšiu prezentáciu:
Dovoliť sú vstupy siete;
y - sieťový výstup;
Fuzzy pravidlo s radovou číslovkou r;
m - počet pravidiel;
Fuzzy term s funkciou príslušnosti , používaný na lingvistické vyhodnotenie premennej v r-tom pravidle (,);
Reálne čísla v závere r-tého pravidla (,).
Sieť ANFIS funguje nasledovne.
Vrstva 1 Každý uzol prvej vrstvy predstavuje jeden člen s funkciou členstva v tvare zvona. Vstupy siete sú pripojené len na ich podmienky. Počet uzlov v prvej vrstve sa rovná súčtu mohutností množín termínov vstupných premenných. Výstupom uzla je miera príslušnosti hodnoty vstupnej premennej k zodpovedajúcemu fuzzy členu:
 ,
,
kde a, b a c sú parametre konfigurovateľné funkciou členstva.
Vrstva 2 Počet uzlov v druhej vrstve je m. Každý uzol tejto vrstvy zodpovedá jednému fuzzy pravidlu. Uzol druhej vrstvy je spojený s tými uzlami prvej vrstvy, ktoré tvoria predchodcu zodpovedajúceho pravidla. Preto môže každý uzol druhej vrstvy prijímať od 1 do n vstupných signálov. Výstupom uzla je stupeň vykonania pravidla, ktorý sa vypočíta ako súčin vstupných signálov. Označte výstupy uzlov tejto vrstvy , .
Vrstva 3 Počet uzlov v tretej vrstve je tiež m. Každý uzol tejto vrstvy vypočítava relatívny stupeň splnenia fuzzy pravidla:
Vrstva 4 Počet uzlov vo štvrtej vrstve je tiež m. Každý uzol je pripojený k jednému uzlu tretej vrstvy ako aj všetkým vstupom siete (prepojenia na vstupy nie sú na obr. 18). Uzol štvrtej vrstvy vypočítava príspevok jedného fuzzy pravidla k sieťovému výstupu:
Vrstva 5 Jediný uzol tejto vrstvy sumarizuje príspevky všetkých pravidiel:
![]() .
.
Na vyladenie siete ANFIS je možné použiť typické tréningové postupy neurónovej siete, pretože používa iba diferencovateľné funkcie. Typicky sa používa kombinácia zostupu gradientu vo forme spätného šírenia a najmenších štvorcov. Algoritmus spätného šírenia upravuje parametre predchodcov pravidiel, t.j. členské funkcie. Záverové koeficienty pravidiel sa odhadujú metódou najmenších štvorcov, pretože sú lineárne spojené s výstupom siete. Každá iterácia postupu ladenia sa vykonáva v dvoch krokoch. V prvej fáze sa na vstupy privedie trénovacia vzorka a z nezrovnalosti medzi požadovaným a skutočným správaním siete sa pomocou iteračnej metódy najmenších štvorcov zistia optimálne parametre uzlov štvrtej vrstvy. V druhej fáze sa zvyškový nesúlad prenesie z výstupu siete na vstupy a parametre uzlov prvej vrstvy sa upravia metódou spätného šírenia chýb. V tomto prípade sa koeficienty záverov pravidiel zistené v prvej fáze nemenia. Postup iteratívneho ladenia pokračuje, kým zvyšková hodnota neprekročí vopred stanovenú hodnotu. Na vyladenie funkcií príslušnosti možno okrem metódy spätného šírenia chýb použiť aj iné optimalizačné algoritmy, napríklad metódu Levenberg-Marquardt.

Obr.24. Pracovný priestor ANFISedit.
Skúsme teraz optimalizovať fuzzy regulátor pre jednokrokovú akciu. Požadovaný prechodný proces je približne nasledujúci:

Obr.25. požadovaný proces prechodu.
Z grafu znázorneného na obr. z toho vyplýva, že väčšinu času by mal motor bežať na plný výkon, aby si zabezpečil maximálne otáčky a pri priblížení sa k požadovanej hodnote by mal plynulo spomaľovať. Na základe týchto jednoduchých úvah vezmeme nasledujúcu vzorku hodnôt ako tréningovú, ktorá je uvedená nižšie vo forme tabuľky:
Tabuľka 4
| Chybová hodnota | Hodnota manažmentu |
| Chybová hodnota | Hodnota manažmentu |
| Chybová hodnota | Hodnota manažmentu |

Obr.26. Typ tréningovej vzorky.
Školenie bude prebiehať v 100 krokoch. Na konvergenciu použitej metódy je to viac než dosť.

Obr.27. Proces učenia sa neurónovej siete.
V procese učenia sa parametre funkcií členstva tvoria tak, že pri danej chybovej hodnote regulátor vytvorí potrebnú kontrolu. V úseku medzi uzlovými bodmi je závislosť kontroly od chyby interpoláciou údajov tabuľky. Interpolačná metóda závisí od toho, ako je neurónová sieť trénovaná. V skutočnosti, po tréningu, model fuzzy regulátora môže byť reprezentovaný ako nelineárna funkcia jednej premennej, ktorej graf je uvedený nižšie.

Obr.28. Graf závislosti riadenia od chyby k polohe vo vnútri regulátora.
Po uložení zistených parametrov funkcií príslušnosti simulujeme systém s optimalizovaným fuzzy regulátorom.


Ryža. 29. Prechodný proces pod harmonickým vstupom pre model s optimalizovaným fuzzy regulátorom obsahujúcim jednu vstupnú lingvistickú premennú.
Obr.30. Chybový signál pod harmonickým vstupom pre model s fuzzy regulátorom obsahujúcim dve vstupné lingvistické premenné.
Z grafov vyplýva, že optimalizácia fuzzy regulátora trénovaním neurónovej siete bola úspešná. Výrazne sa znížila fluktuácia a veľkosť chyby. Preto je použitie neurónovej siete celkom rozumné na optimalizáciu regulátorov, ktorých princíp je založený na fuzzy logike. Ani optimalizovaný regulátor však nedokáže uspokojiť požiadavky na presnosť, preto je vhodné uvažovať o inom spôsobe riadenia, kedy fuzzy regulátor neriadi objekt priamo, ale kombinuje viaceré zákonitosti riadenia v závislosti od situácie.
Nedeľa, 29. marec 2015
V súčasnosti existuje veľa úloh, pri ktorých je potrebné urobiť nejaké rozhodnutie v závislosti od prítomnosti objektu na obrázku alebo ho klasifikovať. Schopnosť „rozpoznať“ sa považuje za hlavnú vlastnosť biologických bytostí, zatiaľ čo počítačové systémy túto vlastnosť úplne nevlastnia.
Zvážte všeobecné prvky klasifikačného modelu.
Trieda- súbor predmetov, ktoré majú spoločné vlastnosti. Pre objekty rovnakej triedy sa predpokladá prítomnosť „podobnosti“. Pre úlohu rozpoznávania je možné definovať ľubovoľný počet tried, viac ako 1. Počet tried je označený číslom S. Každá trieda má svoj vlastný identifikačný štítok triedy.
Klasifikácia- proces priraďovania označení tried k objektom, podľa nejakého popisu vlastností týchto objektov. Klasifikátor je zariadenie, ktoré prijíma množinu vlastností objektu ako vstup a ako výsledok vytvára označenie triedy.
Overenie- proces porovnávania inštancie objektu s jedným objektovým modelom alebo popisom triedy.
Pod spôsobom názov oblasti budeme chápať v priestore atribútov, v ktorom sú zobrazené mnohé predmety či javy hmotného sveta. znamenie- kvantitatívny popis konkrétnej vlastnosti skúmaného objektu alebo javu.
priestor funkcií toto je N-rozmerný priestor definovaný pre danú úlohu rozpoznávania, kde N je pevný počet meraných prvkov pre ľubovoľné objekty. Vektor z priestoru znakov x zodpovedajúci objektu rozpoznávacieho problému je N-rozmerný vektor so zložkami (x_1,x_2,…,x_N), čo sú hodnoty vlastností pre daný objekt.
Inými slovami, rozpoznávanie vzorov možno definovať ako priradenie počiatočných údajov k určitej triede extrahovaním základných znakov alebo vlastností, ktoré charakterizujú tieto údaje zo všeobecného množstva irelevantných detailov.
Príklady klasifikačných problémov sú:
- rozpoznávanie znakov;
- rozpoznávanie reči;
- stanovenie lekárskej diagnózy;
- predpoveď počasia;
- rozpoznávanie tváre
- triedenie dokumentov a pod.
Zdrojovým materiálom je najčastejšie obraz prijatý z fotoaparátu. Úlohu možno formulovať ako získanie vektorov vlastností pre každú triedu v uvažovanom obrázku. Proces možno považovať za proces kódovania, ktorý spočíva v priradení hodnoty každému prvku z priestoru prvkov pre každú triedu.
Ak vezmeme do úvahy 2 triedy objektov: dospelých a detí. Ako vlastnosti si môžete vybrať výšku a hmotnosť. Ako vyplýva z obrázku, tieto dve triedy tvoria dve nepretínajúce sa množiny, čo možno vysvetliť zvolenými znakmi. Nie vždy je však možné zvoliť správne namerané parametre ako znaky tried. Zvolené parametre napríklad nie sú vhodné na vytváranie neprekrývajúcich sa tried futbalistov a basketbalistov.
Druhou úlohou rozpoznávania je výber charakteristických znakov alebo vlastností z pôvodných obrázkov. Túto úlohu možno pripísať predbežnému spracovaniu. Ak vezmeme do úvahy úlohu rozpoznávania reči, môžeme rozlíšiť také znaky, ako sú samohlásky a spoluhlásky. Atribút musí byť charakteristickou vlastnosťou konkrétnej triedy, pričom musí byť pre túto triedu spoločný. Znaky, ktoré charakterizujú rozdiely medzi - medzitriednymi znakmi. Funkcie spoločné pre všetky triedy nenesú užitočné informácie a nepovažujú sa za vlastnosti v probléme rozpoznávania. Výber vlastností je jednou z dôležitých úloh spojených s konštrukciou rozpoznávacieho systému.
Po určení znakov je potrebné určiť optimálny rozhodovací postup pre klasifikáciu. Zvážte systém rozpoznávania vzorov navrhnutý tak, aby rozpoznával rôzne triedy M, označované ako m_1,m_2,…,m 3. Potom môžeme predpokladať, že priestor obrazu pozostáva z M oblastí, z ktorých každá obsahuje body zodpovedajúce obrázku z jednej triedy. Potom sa problém rozpoznávania môže považovať za konštrukciu hraníc oddeľujúcich M triedy na základe akceptovaných meracích vektorov.
Riešenie problému predspracovania obrazu, extrakcie znakov a problém získania optimálneho riešenia a klasifikácie je zvyčajne spojený s potrebou vyhodnocovania množstva parametrov. To vedie k problému odhadu parametrov. Okrem toho je zrejmé, že extrakcia funkcií môže využívať ďalšie informácie založené na povahe tried.
Porovnanie objektov je možné vykonať na základe ich reprezentácie vo forme meracích vektorov. Je vhodné reprezentovať namerané údaje ako reálne čísla. Potom možno podobnosť vektorov príznakov dvoch objektov opísať pomocou euklidovskej vzdialenosti.

kde d je rozmer charakteristického vektora.
Existujú 3 skupiny metód rozpoznávania vzorov:
- Ukážkové porovnanie. Táto skupina zahŕňa klasifikáciu podľa najbližšieho priemeru, klasifikáciu podľa vzdialenosti k najbližšiemu susedovi. Do porovnávacej skupiny vzoriek možno zahrnúť aj metódy štrukturálneho rozpoznávania.
- Štatistické metódy. Ako už názov napovedá, štatistické metódy využívajú niektoré štatistické informácie pri riešení problému rozpoznávania. Metóda určuje príslušnosť objektu k určitej triede na základe pravdepodobnosti. V niektorých prípadoch ide o určenie aposteriórnej pravdepodobnosti objektu patriaceho do určitej triedy za predpokladu, že vlastnosti tohto objektu nadobudli primeranú hodnotu. hodnoty. Príkladom je metóda Bayesovho rozhodovacieho pravidla.
- Neurálne siete. Samostatná trieda metód rozpoznávania. Charakteristickým znakom od ostatných je schopnosť učiť sa.
Klasifikácia podľa najbližšieho priemeru
V klasickom prístupe rozpoznávania vzorov, v ktorom je neznámy objekt na klasifikáciu reprezentovaný ako vektor elementárnych znakov. Systém rozpoznávania založený na vlastnostiach možno vyvinúť rôznymi spôsobmi. Tieto vektory môžu byť systému známe vopred ako výsledok školenia alebo predpovedané v reálnom čase na základe niektorých modelov.
Jednoduchý klasifikačný algoritmus pozostáva zo zoskupenia referenčných údajov triedy pomocou vektora očakávania triedy (priemer).

kde x(i,j) je j-tý referenčný znak triedy i, n_j je počet referenčných vektorov triedy i.
Potom bude neznámy objekt patriť do triedy i, ak je oveľa bližšie k vektoru očakávania triedy i ako k vektorom očakávania iných tried. Táto metóda je vhodná pre problémy, v ktorých sú body každej triedy umiestnené kompaktne a ďaleko od bodov iných tried.

Ťažkosti nastanú, ak majú triedy o niečo zložitejšiu štruktúru, napríklad ako na obrázku. V tomto prípade je trieda 2 rozdelená na dve neprekrývajúce sa časti, ktoré sú zle opísané jednou priemernou hodnotou. Trieda 3 je tiež príliš pretiahnutá, vzorky 3. triedy s veľkými hodnotami súradníc x_2 sú bližšie k priemernej hodnote 1. triedy ako 3. triedy.

Opísaný problém možno v niektorých prípadoch vyriešiť zmenou výpočtu vzdialenosti.
Budeme brať do úvahy charakteristiku „rozptylu“ hodnôt triedy - σ_i pozdĺž každého smeru súradníc i. Smerodajná odchýlka sa rovná druhej odmocnine rozptylu. Škálovaná euklidovská vzdialenosť medzi vektorom x a očakávaným vektorom x_c je

Tento vzorec vzdialenosti zníži počet klasifikačných chýb, ale v skutočnosti väčšina problémov nemôže byť reprezentovaná takouto jednoduchou triedou.
Klasifikácia podľa vzdialenosti k najbližšiemu susedovi
Ďalším prístupom ku klasifikácii je priradenie neznámeho znakového vektora x triede, ktorej je tento vektor najbližšie k samostatnej vzorke. Toto pravidlo sa nazýva pravidlo najbližšieho suseda. Klasifikácia najbližšieho suseda môže byť efektívnejšia, aj keď sú triedy zložité alebo keď sa triedy prekrývajú.
Tento prístup nevyžaduje predpoklady o distribučných modeloch vektorov znakov v priestore. Algoritmus používa iba informácie o známych referenčných vzorkách. Metóda riešenia je založená na výpočte vzdialenosti x ku každej vzorke v databáze a nájdení minimálnej vzdialenosti. Výhody tohto prístupu sú zrejmé:
- kedykoľvek môžete do databázy pridať nové vzorky;
- stromové a mriežkové dátové štruktúry znižujú počet vypočítaných vzdialeností.
Navyše, riešenie bude lepšie, ak si v databáze pozriete nie jedného najbližšieho suseda, ale k. Potom pre k > 1 poskytuje najlepšiu vzorku rozloženia vektorov v d-rozmernom priestore. Efektívne využitie hodnôt k však závisí od toho, či je v každej oblasti priestoru dostatok. Ak existuje viac ako dve triedy, potom je ťažšie urobiť správne rozhodnutie.
Literatúra
- M. Castrillon, . O. Deniz, . D. Hernández a J. Lorenzo, „Porovnanie detektorov tváre a tvárových prvkov na základe všeobecného rámca detekcie objektov Viola-Jones“, International Journal of Computer Vision, číslo 22, str. 481-494, 2011.
- Y.-Q. Wang, "Analýza algoritmu detekcie tváre Viola-Jones", IPOL Journal, 2013.
- L. Shapiro a D. Stockman, Počítačové videnie, Binom. Knowledge Lab, 2006.
- Z. N. G., Metódy rozpoznávania a ich aplikácia, Sovietsky rozhlas, 1972.
- J. Tu, R. Gonzalez, Matematické princípy rozpoznávania vzorov, Moskva: „Mir“ Moskva, 1974.
- Khan, H. Abdullah a M. Shamian Bin Zainal, "Efektívny algoritmus detekcie očí a úst s použitím kombinácie detekcie pixelov podľa farby violy a kože" International Journal of Engineering and Applied Sciences, č. 3 č. 4, 2013.
- V. Gaede a O. Gunther, "Multidimenzionální prístupové metódy," ACM Computing Surveys, str. 170-231, 1998.
Živé systémy, vrátane ľudí, sa od svojho vzniku neustále stretávajú s úlohou rozpoznávania vzorov. Predovšetkým informácie prichádzajúce zo zmyslových orgánov spracováva mozog, ktorý informácie triedi, zabezpečuje rozhodovanie a následne pomocou elektrochemických impulzov prenáša potrebný signál ďalej, napríklad do pohybových orgánov. , ktoré vykonávajú potrebné úkony. Potom dôjde k zmene prostredia a opäť nastanú vyššie uvedené javy. A ak sa pozriete, každá fáza je sprevádzaná uznaním.
S rozvojom výpočtovej techniky bolo možné vyriešiť množstvo problémov, ktoré vznikajú v procese života, uľahčiť, urýchliť a zlepšiť kvalitu výsledku. Napríklad prevádzka rôznych systémov na podporu života, interakcia človeka s počítačom, vznik robotických systémov atď. Poznamenávame však, že v súčasnosti nie je možné poskytnúť uspokojivý výsledok pri niektorých úlohách (rozpoznanie rýchlo sa pohybujúcich podobných objektov , ručne písaný text).
Účel práce: študovať históriu systémov rozpoznávania vzorov.
Uveďte kvalitatívne zmeny, ktoré sa vyskytli v oblasti rozpoznávania vzorov, teoretické aj technické, s uvedením dôvodov;
Diskutujte o metódach a princípoch používaných vo výpočtovej technike;
Uveďte príklady perspektív, ktoré sa očakávajú v blízkej budúcnosti.
1. Čo je rozpoznávanie vzorov?
Prvý výskum s výpočtovou technikou vychádzal v podstate z klasickej schémy matematického modelovania - matematický model, algoritmus a výpočet. Boli to úlohy modelovania procesov vyskytujúcich sa pri výbuchoch atómových bômb, výpočtu balistických trajektórií, ekonomických a iných aplikácií. Okrem klasických myšlienok tejto série však existovali aj metódy založené na úplne inom charaktere a ako ukázala prax riešenia niektorých problémov, často dávali lepšie výsledky ako riešenia založené na príliš komplikovaných matematických modeloch. Ich myšlienkou bolo opustiť túžbu vytvoriť vyčerpávajúci matematický model skúmaného objektu (navyše často bolo prakticky nemožné skonštruovať adekvátne modely) a namiesto toho sa uspokojiť s odpoveďou len na konkrétne otázky, ktoré nás zaujímajú a tieto odpovede by sa mali hľadať v úvahách spoločných pre širokú triedu problémov. Výskum tohto druhu zahŕňal rozpoznávanie vizuálnych obrazov, predpovedanie výnosov, hladiny riek, problém rozlíšenia medzi ropou a zvodnenými vrstvami pomocou nepriamych geofyzikálnych údajov atď. V týchto úlohách bola potrebná konkrétna odpoveď v pomerne jednoduchej forme, ako napr. napríklad, či objekt patrí do jednej z vopred stanovených tried. A počiatočné údaje o týchto úlohách boli spravidla uvedené vo forme fragmentárnych informácií o skúmaných objektoch, napríklad vo forme súboru vopred klasifikovaných objektov. Z matematického hľadiska to znamená, že rozpoznávanie vzorov (a táto trieda problémov bola v našej krajine pomenovaná) je ďalekosiahlym zovšeobecnením myšlienky extrapolácie funkcií.
Význam takejto formulácie pre technické vedy je nepochybný a to samo osebe odôvodňuje početné štúdie v tejto oblasti. Problém rozpoznávania vzorov má však pre prírodné vedy aj širší aspekt (bolo by však zvláštne, keby niečo také dôležité pre umelé kybernetické systémy nebolo dôležité pre prírodné). Kontext tejto vedy organicky zahŕňal otázky starovekých filozofov o povahe nášho poznania, našej schopnosti rozpoznávať obrazy, vzory, situácie sveta okolo nás. V skutočnosti prakticky niet pochýb o tom, že mechanizmy na rozpoznávanie tých najjednoduchších obrazov, ako sú obrazy blížiaceho sa nebezpečného predátora alebo potravy, sa sformovali oveľa skôr, ako vznikol elementárny jazyk a formálny logický aparát. A niet pochýb o tom, že takéto mechanizmy sú dostatočne vyvinuté aj u vyšších zvierat, ktoré vo svojej životnej činnosti tiež naliehavo potrebujú schopnosť rozlíšiť pomerne zložitý systém znakov prírody. V prírode teda vidíme, že fenomén myslenia a vedomia je jednoznačne založený na schopnosti rozpoznávať vzorce a ďalší pokrok vedy o inteligencii priamo súvisí s hĺbkou pochopenia základných zákonov rozpoznávania. Pochopenie skutočnosti, že vyššie uvedené otázky ďaleko presahujú štandardnú definíciu rozpoznávania vzorov (v anglickej literatúre je bežnejší termín supervised learning), je tiež potrebné pochopiť, že majú hlboké súvislosti s týmto relatívne úzkym (ale stále ďaleko). z vyčerpaného) smeru.
Aj teraz sa rozpoznávanie vzorov pevne zapísalo do každodenného života a je jednou z najdôležitejších znalostí moderného inžiniera. V medicíne rozpoznávanie vzorov pomáha lekárom robiť presnejšie diagnózy, v továrňach sa používa na predpovedanie chýb v sériách tovaru. Z výsledkov tejto disciplíny vychádzajú aj biometrické osobné identifikačné systémy ako ich algoritmické jadro. Ďalší vývoj umelej inteligencie, najmä návrh počítačov piatej generácie schopných priamejšej komunikácie s človekom v prirodzených jazykoch pre ľudí a prostredníctvom reči, je nemysliteľný bez rozpoznania. Tu je robotika, umelé riadiace systémy obsahujúce rozpoznávacie systémy ako životne dôležité podsystémy, na dosah.
Preto rozvoju rozpoznávania vzorov už od začiatku venovali veľkú pozornosť odborníci rôznych profilov – kybernetici, neurofyziológovia, psychológovia, matematici, ekonómovia atď. Z veľkej časti z tohto dôvodu sa samotné moderné rozpoznávanie vzorov napája na myšlienky týchto disciplín. Bez nároku na úplnosť (a nie je možné to tvrdiť v krátkej eseji), popíšeme históriu rozpoznávania vzorov, kľúčové myšlienky.
Definície
Predtým, ako pristúpime k hlavným metódam rozpoznávania vzorov, uvádzame niekoľko potrebných definícií.
Rozpoznávanie obrazov (predmetov, signálov, situácií, javov alebo procesov) je úlohou identifikovať predmet alebo určiť niektorú z jeho vlastností podľa jeho obrazu (optické rozpoznávanie) alebo zvukového záznamu (akustické rozpoznávanie) a iných charakteristík.
Jedným zo základných je koncept súboru, ktorý nemá konkrétnu formuláciu. V počítači je množina reprezentovaná množinou neopakujúcich sa prvkov rovnakého typu. Slovo "neopakujúce sa" znamená, že nejaký prvok v množine buď je alebo tam nie je. Univerzálna sada obsahuje všetky možné prvky pre riešený problém, prázdna sada neobsahuje žiadne.
Obrázok je klasifikačné zoskupenie v klasifikačnom systéme, ktoré zjednocuje (vyčleňuje) určitú skupinu objektov podľa nejakého atribútu. Obrazy majú charakteristickú vlastnosť, ktorá sa prejavuje v tom, že oboznámenie sa s konečným počtom javov z tej istej množiny umožňuje rozpoznať ľubovoľne veľký počet jej zástupcov. Obrázky majú charakteristické objektívne vlastnosti v tom zmysle, že rôzni ľudia, ktorí sa učia z rôznych pozorovacích materiálov, väčšinou klasifikujú rovnaké objekty rovnakým spôsobom a nezávisle od seba. Pri klasickej formulácii rozpoznávacieho problému je univerzálna množina rozdelená na časti-obrazy. Každé mapovanie akéhokoľvek objektu na vnímacie orgány rozpoznávacieho systému, bez ohľadu na jeho polohu voči týmto orgánom, sa zvyčajne nazýva obrazom objektu a súbory takýchto obrazov, spojené niektorými spoločnými vlastnosťami, sú obrazy.
Spôsob priradenia prvku k ľubovoľnému obrázku sa nazýva rozhodovacie pravidlo. Ďalším dôležitým pojmom je metrika, spôsob určenia vzdialenosti medzi prvkami univerzálneho súboru. Čím je táto vzdialenosť menšia, tým sú si predmety (symboly, zvuky atď.), ktoré rozpoznávame, podobnejšie. Prvky sú zvyčajne špecifikované ako množina čísel a metrika je špecifikovaná ako funkcia. Účinnosť programu závisí od výberu reprezentácie obrázkov a implementácie metriky, jeden rozpoznávací algoritmus s rôznymi metrikami bude robiť chyby s rôznymi frekvenciami.
Učenie sa zvyčajne nazýva proces vývoja v nejakom systéme konkrétnej reakcie na skupiny vonkajších identických signálov opakovaným ovplyvňovaním vonkajšieho korekčného systému. Takáto vonkajšia úprava v tréningu sa zvyčajne nazýva „povzbudenie“ a „trest“. Mechanizmus generovania tejto úpravy takmer úplne určuje algoritmus učenia. Samoučenie sa od učenia líši tým, že sa tu neuvádzajú dodatočné informácie o správnosti reakcie na systém.
Adaptácia je proces zmeny parametrov a štruktúry systému, prípadne aj kontrolných akcií, na základe aktuálnych informácií s cieľom dosiahnuť určitý stav systému s počiatočnou neistotou a meniacimi sa prevádzkovými podmienkami.
Učenie je proces, v dôsledku ktorého systém postupne získava schopnosť reagovať potrebnými reakciami na určité súbory vonkajších vplyvov a adaptácia je úprava parametrov a štruktúry systému za účelom dosiahnutia požadovanej kvality kontrola v podmienkach nepretržitých zmien vonkajších podmienok.
Príklady úloh rozpoznávania vzorov: - Rozpoznávanie písmen;
Vo všeobecnosti možno rozlíšiť tri spôsoby rozpoznávania vzorov: Metóda enumerácie. V tomto prípade sa vykoná porovnanie s databázou, kde sú pre každý typ objektu prezentované všetky možné úpravy zobrazenia. Napríklad pre optické rozpoznávanie obrazu môžete použiť metódu enumerácie typu objektu v rôznych uhloch, mierkach, posunoch, deformáciách atď. Pre písmená musíte iterovať písmo, vlastnosti písma atď. prípad rozpoznávania zvukového obrazu, respektíve porovnanie s niektorými známymi vzormi (napríklad slovom, ktoré hovorí viacero ľudí).
Druhým prístupom je hlbšia analýza charakteristík obrazu. V prípade optického rozpoznávania to môže byť určenie rôznych geometrických charakteristík. Vzorka zvuku je v tomto prípade podrobená frekvenčnej, amplitúdovej analýze atď.
Ďalšou metódou je použitie umelých neurónových sietí (ANN). Táto metóda vyžaduje buď veľké množstvo príkladov úlohy rozpoznávania počas tréningu, alebo špeciálnu štruktúru neurónovej siete, ktorá zohľadňuje špecifiká tejto úlohy. Vyznačuje sa však vyššou účinnosťou a produktivitou.
4. História rozpoznávania vzorov
Pozrime sa stručne na matematický formalizmus rozpoznávania vzorov. Objekt pri rozpoznávaní vzorov je opísaný súborom základných charakteristík (vlastností, vlastností). Hlavné charakteristiky môžu byť rôzneho charakteru: môžu byť prevzaté z usporiadanej množiny typu reálnej čiary, alebo z diskrétnej množiny (ktorá však môže byť vybavená aj štruktúrou). Toto chápanie objektu je v súlade s potrebou praktických aplikácií rozpoznávania vzorov, ako aj s naším chápaním mechanizmu ľudského vnímania objektu. Skutočne veríme, že keď človek pozoruje (meria) objekt, informácie o ňom prichádzajú cez konečný počet senzorov (analyzovaných kanálov) do mozgu a každý senzor môže byť spojený s príslušnou charakteristikou objektu. Okrem znakov, ktoré zodpovedajú našim meraniam objektu, existuje aj vybraný znak alebo skupina znakov, ktoré nazývame klasifikačné znaky a zistiť ich hodnoty pre daný vektor X je úloha, ktorá je prirodzená a systémy umelého rozpoznávania.
Je zrejmé, že na stanovenie hodnôt týchto vlastností je potrebné mať informácie o tom, ako známe vlastnosti súvisia s klasifikačnými. Informácie o tomto vzťahu sú uvedené vo forme precedensov, to znamená súboru popisov objektov so známymi hodnotami klasifikačných znakov. A podľa týchto precedensných informácií je potrebné vybudovať rozhodovacie pravidlo, ktoré určí svojvoľný popis predmetu hodnoty jeho klasifikačných znakov.
Toto chápanie problému rozpoznávania vzorov je vo vede zavedené od 50. rokov minulého storočia. A potom sa zistilo, že takáto produkcia nie je vôbec nová. Takejto formulácii čelili a už existovali osvedčené metódy štatistickej analýzy údajov, ktoré sa aktívne využívali pri mnohých praktických úlohách, ako je napríklad technická diagnostika. Preto prvé kroky rozpoznávania vzorov prešli pod znakom štatistického prístupu, ktorý diktoval hlavný problém.
Štatistický prístup je založený na myšlienke, že počiatočný priestor objektov je pravdepodobnostný priestor a znaky (charakteristiky) objektov sú na ňom dané náhodné premenné. Úlohou dátového vedca bolo potom z niektorých úvah predložiť štatistickú hypotézu o rozdelení znakov, alebo skôr o závislosti klasifikačných znakov od ostatných. Štatistická hypotéza bola spravidla parametricky špecifikovaná množina funkcií distribúcie funkcií. Typickou a klasickou štatistickou hypotézou je hypotéza normality tohto rozdelenia (takýchto hypotéz je v štatistike veľmi veľa). Po sformulovaní hypotézy zostávalo túto hypotézu otestovať na precedensných údajoch. Táto kontrola spočívala vo výbere nejakého rozdelenia z pôvodne daného súboru rozdelení (parameter hypotézy rozdelenia) a posúdení spoľahlivosti (intervalu spoľahlivosti) tohto výberu. V skutočnosti bola táto distribučná funkcia odpoveďou na problém, len objekt nebol klasifikovaný jednoznačne, ale s určitou pravdepodobnosťou, že patrí do tried. Štatistici tiež vyvinuli asymptotické odôvodnenie takýchto metód. Takéto zdôvodnenia boli urobené podľa nasledujúcej schémy: bola stanovená určitá kvalitatívna funkcionalita výberu rozdelenia (interval spoľahlivosti) a ukázalo sa, že s nárastom počtu precedensov sa náš výber s pravdepodobnosťou smerujúcou k 1 stal správnym v r. zmysel tohto funkcionálu (interval spoľahlivosti má tendenciu k 0). Pri pohľade do budúcnosti môžeme povedať, že štatistický pohľad na problém rozpoznávania sa ukázal ako veľmi plodný nielen z hľadiska vyvinutých algoritmov (ktoré zahŕňajú metódy klastrovej a diskriminačnej analýzy, neparametrickú regresiu atď.), ale následne viedol Vapnika k vytvoriť hlbokú štatistickú teóriu rozpoznávania.
Napriek tomu existuje silný argument v prospech skutočnosti, že problémy rozpoznávania vzorov sa neobmedzujú na štatistiku. Každý takýto problém možno v zásade posudzovať zo štatistického hľadiska a výsledky jeho riešenia možno štatisticky interpretovať. Na to je potrebné iba predpokladať, že priestor objektov problému je pravdepodobnostný. Ale z hľadiska inštrumentalizmu môže byť kritériom úspešnosti štatistickej interpretácie určitej metódy rozpoznávania len existencia opodstatnenia tejto metódy v jazyku štatistiky ako odvetvia matematiky. Odôvodnenie tu znamená vypracovanie základných požiadaviek na problém, ktoré zabezpečia úspech pri uplatňovaní tejto metódy. V súčasnosti sa však pre väčšinu metód rozpoznávania, vrátane tých, ktoré vznikli priamo v rámci štatistického prístupu, nenašli takéto uspokojivé zdôvodnenia. Okrem toho, v súčasnosti najčastejšie používané štatistické algoritmy, ako je Fisherov lineárny diskriminant, Parzenovo okno, EM algoritmus, najbližší susedia, nehovoriac o Bayesovských sieťach viery, majú silne výraznú heuristickú povahu a môžu mať odlišné interpretácie od štatistických. A na záver k vyššie uvedenému treba dodať, že okrem asymptotického správania metód rozpoznávania, ktoré je hlavnou témou štatistiky, prax rozpoznávania vyvoláva otázky výpočtovej a štrukturálnej zložitosti metód, ktoré ďaleko presahujú rámec samotný rámec teórie pravdepodobnosti.
Celkovo, v rozpore s ašpiráciami štatistikov považovať rozpoznávanie vzorov za časť štatistiky, do praxe a ideológie uznávania vstúpili úplne iné myšlienky. Jeden z nich bol spôsobený výskumom v oblasti vizuálneho rozpoznávania vzorov a je založený na nasledujúcej analógii.
Ako už bolo uvedené, v každodennom živote ľudia neustále riešia (často nevedome) problémy s rozpoznávaním rôznych situácií, sluchových a vizuálnych obrazov. Takáto schopnosť pre počítače je prinajlepšom otázkou budúcnosti. Z toho niektorí priekopníci rozpoznávania vzorov usúdili, že riešenie týchto problémov na počítači by malo vo všeobecnosti simulovať procesy ľudského myslenia. Najznámejším pokusom priblížiť problém z tejto strany bola slávna štúdia F. Rosenblatta o perceptrónoch.
V polovici 50-tych rokov sa zdalo, že neurofyziológovia pochopili fyzikálne princípy mozgu (slávny britský teoretický fyzik R. Penrose v knihe „The New Mind of the King“ zaujímavo spochybňuje model neurónovej siete mozgu, čo potvrdzuje podstatnú úlohu kvantových mechanických efektov v jeho fungovaní; hoci tento model bol od začiatku spochybňovaný. Na základe týchto objavov F. Rosenblatt vyvinul model na učenie sa rozpoznávať zrakové vzorce, ktorý nazval perceptrón. Rosenblattov perceptrón je nasledujúca funkcia (obr. 1):
Obr. 1. Schéma perceptrónu
Na vstupe prijíma perceptrón objektový vektor, ktorý bol v dielach Rosenblatta binárnym vektorom, ktorý ukazuje, ktorý z pixelov obrazovky je zatemnený obrazom a ktorý nie. Ďalej je každý zo znakov privádzaný na vstup neurónu, ktorého pôsobením je jednoduché násobenie určitou hmotnosťou neurónu. Výsledky sú privádzané do posledného neurónu, ktorý ich sčítava a porovnáva celkové množstvo s určitým prahom. V závislosti od výsledkov porovnania sa vstupný objekt X rozpozná ako potrebný alebo nie. Potom bolo úlohou učenia sa rozpoznávania vzorov vybrať váhy neurónov a prahovú hodnotu tak, aby perceptrón dával správne odpovede na predchádzajúce vizuálne obrázky. Rosenblatt veril, že výsledná funkcia bude dobrá pri rozpoznávaní požadovaného vizuálneho obrazu, aj keď vstupný objekt nepatrí medzi precedensy. Z bionických úvah prišiel aj na metódu výberu váh a prah, nad ktorou sa nebudeme zdržiavať. Povedzme, že jeho prístup bol úspešný v mnohých problémoch s rozpoznávaním a dal podnet na celý rad výskumov algoritmov učenia založených na neurónových sieťach, z ktorých špeciálnym prípadom je perceptrón.
Ďalej boli vynájdené rôzne zovšeobecnenia perceptrónu, funkcia neurónov bola komplikovaná: teraz neuróny mohli nielen násobiť vstupné čísla alebo ich sčítať a porovnávať výsledok s prahmi, ale aplikovať na ne zložitejšie funkcie. Obrázok 2 ukazuje jednu z týchto komplikácií neurónov:

Ryža. 2 Schéma neurónovej siete.
Okrem toho by topológia neurónovej siete mohla byť oveľa komplikovanejšia ako tá, ktorú zvažoval Rosenblatt, napríklad toto:
Ryža. 3. Schéma Rosenblattovej neurónovej siete.
Komplikácie viedli k zvýšeniu počtu nastaviteľných parametrov počas tréningu, no zároveň sa zvýšila schopnosť naladiť sa na veľmi zložité vzory. Výskum v tejto oblasti teraz prebieha v dvoch úzko súvisiacich oblastiach – skúmajú sa rôzne topológie sietí a rôzne metódy ladenia.
Neurónové siete sú v súčasnosti nielen nástrojom na riešenie problémov s rozpoznávaním vzorov, ale využívajú sa aj pri výskume asociatívnej pamäte a kompresie obrazu. Hoci sa táto línia výskumu výrazne prekrýva s problémami rozpoznávania vzorov, ide o samostatnú časť kybernetiky. Pre rozpoznávača v súčasnosti nie sú neurónové siete ničím iným ako veľmi špecifickou, parametricky definovanou množinou zobrazení, ktorá v tomto zmysle nemá žiadne významné výhody oproti mnohým iným podobným modelom učenia, ktoré budú stručne uvedené nižšie.
V súvislosti s týmto hodnotením úlohy neurónových sietí pre správne rozpoznávanie (teda nie pre bioniku, pre ktorú majú teraz prvoradý význam), by som rád poznamenal nasledovné: neurónové siete sú mimoriadne zložitým objektom pre matematické analýzy nám pri správnom použití umožňujú nájsť v dátach veľmi netriviálne zákony. Ich náročnosť na analýzu sa vo všeobecnosti vysvetľuje ich zložitou štruktúrou a v dôsledku toho prakticky nevyčerpateľnými možnosťami zovšeobecnenia širokej škály zákonitostí. Ale tieto výhody, ako sa často stáva, sú zdrojom potenciálnych chýb, možnosťou preškolenia. Ako bude diskutované neskôr, takýto dvojitý pohľad na vyhliadky akéhokoľvek modelu učenia je jedným z princípov strojového učenia.
Ďalším populárnym smerom v rozpoznávaní sú logické pravidlá a rozhodovacie stromy. V porovnaní s vyššie uvedenými metódami rozpoznávania tieto metódy najaktívnejšie využívajú myšlienku vyjadrenia našich vedomostí o predmetnej oblasti vo forme pravdepodobne najprirodzenejších (na vedomej úrovni) štruktúr - logických pravidiel. Elementárne logické pravidlo znamená výrok typu „ak sú nezaradené znaky v pomere X, potom klasifikované sú v pomere Y“. Príklad takéhoto pravidla v lekárskej diagnostike je nasledujúci: ak je vek pacienta starší ako 60 rokov a predtým mal srdcový infarkt, potom operáciu nevykonávajte - riziko negatívneho výsledku je vysoké.
Na hľadanie logických pravidiel v dátach sú potrebné 2 veci: určiť mieru „informatívnosti“ pravidla a priestor pravidiel. A úloha nájsť pravidlá sa potom zmení na úlohu úplného alebo čiastočného vymenovania v priestore pravidiel s cieľom nájsť z nich čo najinformatívnejšie. Definíciu informačného obsahu je možné zaviesť rôznymi spôsobmi a nebudeme sa tým zaoberať, keďže ide tiež o určitý parameter modelu. Vyhľadávací priestor je definovaný štandardným spôsobom.
Po nájdení dostatočne informatívnych pravidiel nastáva fáza „skladania“ pravidiel do výsledného klasifikátora. Bez toho, aby sme do hĺbky rozoberali problémy, ktoré tu vznikajú (a je ich značné množstvo), uvádzame 2 hlavné metódy „montáže“. Prvým typom je lineárny zoznam. Druhým typom je vážené hlasovanie, kedy je každému pravidlu priradená určitá váha a objekt je klasifikátorom priradený triede, za ktorú hlasovalo najviac pravidiel.
V skutočnosti sa fáza vytvárania pravidiel a fáza „zhromažďovania“ vykonávajú spoločne a pri zostavovaní váženého hlasovania alebo zoznamu sa znova a znova vyvoláva vyhľadávanie pravidiel o častiach údajov prípadu, aby sa zabezpečilo lepšie prispôsobenie údajov a model.
