Wie bereits erwähnt, Beispiele für Wahrscheinlichkeitsverteilungen stetige Zufallsvariable X sind:
- gleichmäßige Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen;
- exponentielle Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen;
- Normalverteilung Wahrscheinlichkeiten einer kontinuierlichen Zufallsvariablen.
Lassen Sie uns das Konzept der gleichmäßigen und exponentiellen Verteilungsgesetze, Wahrscheinlichkeitsformeln und numerischen Eigenschaften der betrachteten Funktionen angeben.
| Index | Zufallsverteilungsgesetz | Das Exponentialgesetz der Verteilung |
|---|---|---|
| Definition | Uniform heißt die Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen X, deren Dichte auf dem Intervall konstant bleibt und die Form hat | Ein Exponential (Exponential) heißt die Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen X, die durch eine Dichte der Form beschrieben wird |
 wobei λ ein konstanter positiver Wert ist |
||
| Verteilungsfunktion |  |
|
| Wahrscheinlichkeit Intervall treffen |  |
|
| Erwarteter Wert | ||
| Streuung |  |
|
| Standardabweichung |  |
Beispiele zur Problemlösung zum Thema "Gleichmäßige und exponentielle Verteilungsgesetze"
Aufgabe 1.
Die Busse fahren streng nach Fahrplan. Bewegungsintervall 7 min. Finden Sie: (a) die Wahrscheinlichkeit, dass ein Fahrgast, der an einer Haltestelle ankommt, weniger als zwei Minuten auf den nächsten Bus wartet; b) die Wahrscheinlichkeit, dass ein Fahrgast, der sich der Haltestelle nähert, mindestens drei Minuten auf den nächsten Bus wartet; c) die mathematische Erwartung und die Standardabweichung der Zufallsvariablen X – die Wartezeit des Passagiers.
Lösung. 1. Durch die Bedingung des Problems, eine kontinuierliche Zufallsvariable X = (Passagierwartezeit) gleichmäßig verteilt zwischen der Ankunft von zwei Bussen. Die Länge des Verteilungsintervalls der Zufallsvariablen X ist gleich b-a=7, wobei a=0, b=7.
2. Die Wartezeit beträgt weniger als zwei Minuten, wenn der Zufallswert X in das Intervall (5;7) fällt. Die Wahrscheinlichkeit, in ein bestimmtes Intervall zu fallen, wird durch die Formel ermittelt: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(5< Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
3. Die Wartezeit beträgt mindestens drei Minuten (d. h. drei bis sieben Minuten), wenn der Zufallswert X in das Intervall (0; 4) fällt. Die Wahrscheinlichkeit, in ein bestimmtes Intervall zu fallen, wird durch die Formel ermittelt: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(0< Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
4. Mathematische Erwartung einer kontinuierlichen, gleichverteilten Zufallsvariablen X – die Wartezeit des Fahrgastes finden wir durch die Formel: M(X)=(a+b)/2. M (X) \u003d (0 + 7) / 2 \u003d 7/2 \u003d 3,5.
5. Die Standardabweichung einer kontinuierlichen, gleichverteilten Zufallsvariablen X - die Wartezeit des Fahrgastes finden wir nach der Formel: σ(X)=√D=(b-a)/2√3. σ(X)=(7-0)/2√3=7/2√3≈2.02.
Aufgabe 2.
Die Exponentialverteilung ist für x ≥ 0 durch die Dichte f(x) = 5e – 5x gegeben. Erforderlich: a) Schreiben Sie einen Ausdruck für die Verteilungsfunktion; b) finde die Wahrscheinlichkeit, dass X als Ergebnis des Tests in das Intervall (1; 4) fällt; c) Finden Sie die Wahrscheinlichkeit, dass als Ergebnis des Tests X ≥ 2; d) Berechnen Sie M(X), D(X), σ(X).
Lösung. 1. Da aufgrund der Bedingung Exponentialverteilung , dann erhalten wir aus der Formel für die Wahrder Zufallsvariablen X λ = 5. Dann sieht die Verteilungsfunktion so aus:
2. Die Wahrscheinlichkeit, dass X als Ergebnis des Tests in das Intervall (1; 4) fällt, wird durch die Formel ermittelt:
P (ein< X < b) = e −λa − e −λb
.
P(1< X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. Die Wahrscheinlichkeit, dass als Ergebnis des Tests X ≥ 2 durch die Formel gefunden wird: P(a< X < b) = e −λa − e −λb при a=2, b=∞.
Р(Х≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. Wir finden für die Exponentialverteilung:
- mathematischer Erwartungswert nach der Formel M(X) =1/λ = 1/5 = 0,2;
- Dispersion gemäß der Formel D (X) \u003d 1 / λ 2 \u003d 1/25 \u003d 0,04;
- Standardabweichung nach der Formel σ(X) = 1/λ = 1/5 = 1,2.
Dieses Problem wurde lange Zeit im Detail untersucht, und die Methode der Polarkoordinaten, die 1958 von George Box, Mervyn Muller und George Marsaglia vorgeschlagen wurde, wurde am weitesten verbreitet. Mit dieser Methode können Sie wie folgt ein Paar unabhängiger normalverteilter Zufallsvariablen mit dem Mittelwert 0 und der Varianz 1 erhalten:
Wobei Z 0 und Z 1 die gewünschten Werte sind, s \u003d u 2 + v 2 und u und v Zufallsvariablen sind, die gleichmäßig auf dem Segment (-1, 1) verteilt sind und so ausgewählt werden, dass die Bedingung 0 erfüllt ist< s < 1.
Viele verwenden diese Formeln, ohne darüber nachzudenken, und viele ahnen nicht einmal ihre Existenz, da sie vorgefertigte Implementierungen verwenden. Aber es gibt Leute, die Fragen haben: „Woher kommt diese Formel? Und warum bekommt man gleich ein Wertepaar? Im Folgenden werde ich versuchen, eine klare Antwort auf diese Fragen zu geben.
Lassen Sie mich zunächst daran erinnern, was die Wahrscheinlichkeitsdichte, die Verteilungsfunktion einer Zufallsvariablen und die Umkehrfunktion sind. Angenommen, es gibt eine Zufallsvariable, deren Verteilung durch die Dichtefunktion f(x) gegeben ist, die die folgende Form hat:

Dies bedeutet, dass die Wahrscheinlichkeit, dass der Wert dieser Zufallsvariablen im Intervall (A, B) liegt, gleich der Fläche des schraffierten Bereichs ist. Folglich sollte die Fläche des gesamten schattierten Bereichs gleich Eins sein, da der Wert der Zufallsvariablen in jedem Fall in den Bereich der Funktion f fällt.
Die Verteilungsfunktion einer Zufallsvariablen ist ein Integral der Dichtefunktion. Und in diesem Fall wird seine ungefähre Form wie folgt sein:

Hier ist die Bedeutung, dass der Wert der Zufallsvariablen mit Wahrscheinlichkeit B kleiner als A sein wird. Und als Ergebnis nimmt die Funktion nie ab und ihre Werte liegen im Intervall .
Eine Umkehrfunktion ist eine Funktion, die das Argument der ursprünglichen Funktion zurückgibt, wenn Sie den Wert der ursprünglichen Funktion übergeben. Zum Beispiel ist für die Funktion x 2 die Inverse die Wurzelziehfunktion, für sin (x) ist es arcsin (x) usw.
Da die meisten Pseudozufallszahlengeneratoren nur eine gleichmäßige Verteilung am Ausgang liefern, ist es oft notwendig, diese in eine andere umzuwandeln. In diesem Fall zu einem normalen Gaußschen:

Grundlage aller Verfahren zur Transformation einer Gleichverteilung in eine beliebige andere Verteilung ist die inverse Transformationsmethode. Es funktioniert wie folgt. Es wird eine Funktion gefunden, die invers zur Funktion der gesuchten Verteilung ist, und ihr als Argument eine Zufallsvariable übergeben, die gleichmäßig auf das Segment (0, 1) verteilt ist. Am Ausgang erhalten wir einen Wert mit der gewünschten Verteilung. Zur Verdeutlichung hier das folgende Bild.

Somit wird ein gleichförmiges Segment entsprechend der neuen Verteilung gleichsam verschmiert und durch eine Umkehrfunktion auf eine andere Achse projiziert. Aber das Problem ist, dass das Integral der Dichte der Gaußschen Verteilung nicht einfach zu berechnen ist, also mussten die oben genannten Wissenschaftler schummeln.
Es gibt eine Chi-Quadrat-Verteilung (Pearson-Verteilung), die die Verteilung der Summe der Quadrate von k unabhängigen normalen Zufallsvariablen ist. Und im Fall von k = 2 ist diese Verteilung exponentiell.

Das bedeutet, dass, wenn ein Punkt in einem rechtwinkligen Koordinatensystem zufällige X- und Y-Koordinaten hat, die normal verteilt sind, nach der Umwandlung dieser Koordinaten in das Polarsystem (r, θ) das Quadrat des Radius (der Abstand vom Ursprung zum Punkt) exponentiell verteilt, da das Quadrat des Radius die Summe der Quadrate der Koordinaten ist (nach dem Gesetz des Pythagoras). Die Verteilungsdichte solcher Punkte in der Ebene sieht folgendermaßen aus:


Da er in allen Richtungen gleich ist, hat der Winkel θ eine gleichmäßige Verteilung im Bereich von 0 bis 2π. Umgekehrt gilt auch: Wenn Sie einen Punkt im Polarkoordinatensystem durch zwei unabhängige Zufallsvariablen (den Winkel gleichmäßig verteilt und den Radius exponentiell verteilt) angeben, dann sind die rechtwinkligen Koordinaten dieses Punktes unabhängige normale Zufallsvariablen. Und es ist bereits viel einfacher, mit derselben inversen Transformationsmethode aus einer Gleichverteilung eine Exponentialverteilung zu erhalten. Dies ist die Essenz der polaren Box-Muller-Methode.
Kommen wir nun zu den Formeln.
![]() (1)
(1)
Um r und θ zu erhalten, ist es notwendig, zwei Zufallsvariablen zu erzeugen, die gleichmäßig auf dem Segment (0, 1) verteilt sind (nennen wir sie u und v), wobei die Verteilung einer davon (sagen wir v) in exponentiell umgewandelt werden muss Radius erhalten. Die Exponentialverteilungsfunktion sieht so aus:
Seine Umkehrfunktion:
![]()
Da die Gleichverteilung symmetrisch ist, funktioniert die Transformation ähnlich mit der Funktion
![]()
Aus der Chi-Quadrat-Verteilungsformel folgt, dass λ = 0,5. Wir setzen λ, v in diese Funktion ein und erhalten das Quadrat des Radius und dann den Radius selbst:

Wir erhalten den Winkel, indem wir das Einheitssegment auf 2π strecken:
Jetzt setzen wir r und θ in die Formeln (1) ein und erhalten:
 (2)
(2)
Diese Formeln sind gebrauchsfertig. X und Y sind unabhängig und normalverteilt mit einer Varianz von 1 und einem Mittelwert von 0. Um eine Verteilung mit anderen Merkmalen zu erhalten, reicht es aus, das Ergebnis der Funktion mit der Standardabweichung zu multiplizieren und den Mittelwert zu addieren.
Aber es ist möglich, trigonometrische Funktionen loszuwerden, indem man den Winkel nicht direkt angibt, sondern indirekt durch die rechtwinkligen Koordinaten eines beliebigen Punktes in einem Kreis. Dann ist es durch diese Koordinaten möglich, die Länge des Radiusvektors zu berechnen und dann den Kosinus und den Sinus zu finden, indem man x bzw. y durch ihn dividiert. Wie und warum funktioniert es?
Wir wählen einen zufällig im Kreis gleichmäßig verteilten Punkt mit Einheitsradius aus und bezeichnen das Quadrat der Länge des Radiusvektors dieses Punktes mit dem Buchstaben s:

Die Auswahl erfolgt durch Zuweisung zufälliger x- und y-Rechteckkoordinaten, die gleichmäßig im Intervall (-1, 1) verteilt sind, und Verwerfen von Punkten, die nicht zum Kreis gehören, sowie des Mittelpunkts, an dem der Winkel des Radiusvektors liegt nicht definiert. Das heißt, die Bedingung 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Wir erhalten die Formeln wie am Anfang des Artikels. Der Nachteil dieser Methode ist die Ablehnung von Punkten, die nicht im Kreis enthalten sind. Das heißt, es werden nur 78,5 % der generierten Zufallsvariablen verwendet. Auf älteren Computern war das Fehlen trigonometrischer Funktionen noch ein großer Vorteil. Wenn jetzt ein Prozessorbefehl gleichzeitig Sinus und Cosinus in einem Augenblick berechnet, denke ich, dass diese Methoden immer noch konkurrieren können.
Ich persönlich habe noch zwei Fragen:
- Warum ist der Wert von s gleichmäßig verteilt?
- Warum ist die Summe der Quadrate zweier normaler Zufallsvariablen exponentiell verteilt?

Wenn eine ähnliche Transformation für eine normale Zufallsvariable durchgeführt wird, wird sich die Dichtefunktion ihres Quadrats als ähnlich einer Hyperbel herausstellen. Und die Addition von zwei Quadraten normaler Zufallsvariablen ist bereits ein viel komplexerer Vorgang, der mit der doppelten Integration verbunden ist. Und die Tatsache, dass das Ergebnis eine Exponentialverteilung sein wird, bleibt mir persönlich, es mit einer praktischen Methode zu überprüfen oder es als Axiom zu akzeptieren. Und für Interessierte schlage ich vor, sich näher mit dem Thema vertraut zu machen und Wissen aus diesen Büchern zu ziehen:
- Wentzel E.S. Wahrscheinlichkeitstheorie
- Knut D.E. Die Kunst des Programmierens Band 2
Abschließend gebe ich ein Beispiel für die Implementierung eines normalverteilten Zufallszahlengenerators in JavaScript:
Funktion Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1.0; s = u * u + v * v; ) while (s > 1.0 || s == 0.0); var r = Math.sqrt(-2.0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + mean; ) ); ) g = new Gauss(); // Objekt erstellen a = g.next(); // erzeuge ein Wertepaar und erhalte den ersten b = g.next(); // zweites bekommen c = g.next(); // erzeuge wieder ein Wertepaar und erhalte den ersten
Die Parameter mean (mathematische Erwartung) und dev (Standardabweichung) sind optional. Ich mache Sie darauf aufmerksam, dass der Logarithmus natürlich ist.
Eine Verteilung gilt als gleichmäßig, wenn alle Werte einer Zufallsvariablen (im Bereich ihrer Existenz, beispielsweise im Intervall) gleich wahrscheinlich sind. Die Verteilungsfunktion für eine solche Zufallsvariable hat die Form:
Verteilungsdichte: 
 1
1

Reis. Diagramme der Verteilungsfunktion (links) und der Verteilungsdichte (rechts).
Gleichverteilung - Konzept und Typen. Klassifizierung und Merkmale der Kategorie "Gleichverteilung" 2017, 2018.
Grundlegende diskrete Verteilungen von Zufallsvariablen Definition 1. Die Zufallsvariable Х, die die Werte 1, 2, …, n annimmt, ist gleichmäßig verteilt, wenn Pm = P(Х = m) = 1/n, m = 1, …, n . Es ist klar, dass. Betrachten Sie folgendes Problem: In einer Urne befinden sich N Kugeln, von denen M weiß sind... .
Verteilungsgesetze stetiger Zufallsvariablen Definition 5. Eine stetige Zufallsvariable X, die einen Wert im Intervall annimmt, ist gleichmäßig verteilt, wenn die Verteilungsdichte die Form hat. (1) Es ist leicht zu verifizieren, dass . Wenn eine Zufallsvariable... .
Eine Verteilung gilt als gleichmäßig, wenn alle Werte einer Zufallsvariablen (im Bereich ihrer Existenz, beispielsweise im Intervall) gleich wahrscheinlich sind. Die Verteilungsfunktion für eine solche Zufallsvariable hat die Form: Verteilungsdichte: F(x) f(x) 1 0 a b x 0 a b x ... .
Normalverteilungsgesetze Uniform, Exponential und Die Wdes Uniformgesetzes ist: (10.17) wobei a und b gegebene Zahlen sind, a< b; a и b – это параметры равномерного закона. Найдем функцию распределения F(x)... .
Die gleichmäßige Wahrscheinlichkeitsverteilung ist die einfachste und kann entweder diskret oder kontinuierlich sein. Eine diskrete Gleichverteilung ist eine solche Verteilung, bei der die Wahrscheinlichkeit für jeden der Werte von CB gleich ist, das heißt: wobei N die Zahl ... ist.
Definition 16. Eine kontinuierliche Zufallsvariable ist auf dem Segment gleichmäßig verteilt, wenn auf diesem Segment die Verteilungsdichte dieser Zufallsvariablen konstant ist und außerhalb gleich Null ist, dh (45) Der Dichtegraph für eine gleichmäßige Verteilung wird gezeigt ...
Als Beispiel für eine stetige Zufallsvariable betrachte man eine gleichmäßig über das Intervall (a; b) verteilte Zufallsvariable X. Wir sagen, dass die Zufallsvariable X gleichmäßig verteilt auf dem Intervall (a; b), wenn seine Verteilungsdichte auf diesem Intervall nicht konstant ist:
Aus der Normierungsbedingung bestimmen wir den Wert der Konstanten c . Die Fläche unter der Verteilungsdichtekurve sollte gleich eins sein, aber in unserem Fall ist es die Fläche eines Rechtecks mit einer Basis (b - α) und einer Höhe c (Abb. 1). 
Reis. 1 Einheitliche Verteilungsdichte
Von hier aus finden wir den Wert der Konstante c: ![]()
Die Dichte einer gleichverteilten Zufallsvariablen ist also gleich 
Lassen Sie uns nun die Verteilungsfunktion durch die Formel finden:
1) für ![]()
2) für
3) für 0+1+0=1.
Auf diese Weise, 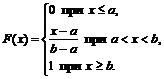
Die Verteilungsfunktion ist stetig und nimmt nicht ab (Abb. 2). 
Reis. 2 Verteilungsfunktion einer gleichverteilten Zufallsvariablen
Lass uns finden mathematische Erwartung einer gleichverteilten Zufallsvariablen nach der formel:
Varianz der gleichmäßigen Verteilung wird durch die Formel berechnet und ist gleich
Beispiel 1. Der Skalenteilwert des Messgeräts beträgt 0,2 . Instrumentenablesungen werden auf die nächste ganze Teilung gerundet. Finden Sie die Wahrscheinlichkeit, dass beim Lesen ein Fehler gemacht wird: a) weniger als 0,04; b) groß 0,02
Lösung. Der Rundungsfehler ist eine Zufallsvariable, die gleichmäßig über das Intervall zwischen benachbarten ganzzahligen Teilungen verteilt ist. Betrachten Sie das Intervall (0; 0,2) als eine solche Teilung (Abb. a). Die Rundung kann sowohl nach links - 0 als auch nach rechts - 0,2 erfolgen, was bedeutet, dass ein Fehler kleiner oder gleich 0,04 zweimal gemacht werden kann, was bei der Berechnung der Wahrscheinlichkeit berücksichtigt werden muss: 

P = 0,2 + 0,2 = 0,4
Für den zweiten Fall kann der Fehlerwert auch an beiden Teilungsgrenzen größer als 0,02 sein, also entweder größer als 0,02 oder kleiner als 0,18 sein. 
Dann ist die Wahrscheinlichkeit eines Fehlers wie folgt:
Beispiel #2. Es wurde angenommen, dass die Stabilität der wirtschaftlichen Situation im Land (das Fehlen von Kriegen, Naturkatastrophen usw.) in den letzten 50 Jahren anhand der Art der Altersverteilung der Bevölkerung beurteilt werden kann: in einer ruhigen Situation, es sollte sein Uniform. Als Ergebnis der Studie wurden für eines der Länder die folgenden Daten erhalten.
Gibt es Grund zu der Annahme, dass es im Land eine instabile Situation gab?Die Entscheidung führen wir mit Hilfe des Rechners Hypothesentest durch. Tabelle zur Berechnung von Indikatoren.
| Gruppen | Intervall Mitte, x i | Menge, z | x ich * f ich | Kumulative Häufigkeit, S | |x - x cf |*f | (x - x sr) 2 *f | Frequenz, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
gewichteter Durchschnitt
Variationsindikatoren.
Absolute Variationsraten.
Die Variationsbreite ist die Differenz zwischen den maximalen und minimalen Werten des Attributs der Primärreihe.
R = Xmax - Xmin
R=70 - 0=70
Streuung- charakterisiert das Streuungsmaß um seinen Mittelwert (Streuungsmaß, also Abweichung vom Mittelwert).
Standardabweichung.
Jeder Wert der Reihe weicht vom Mittelwert von 43 um nicht mehr als 23,92 ab
Testen von Hypothesen über die Art der Verteilung.
4. Testen der Hypothese über gleichmäßige Verteilung die allgemeine Bevölkerung.
Um die Hypothese einer Gleichverteilung von X zu testen, d.h. nach dem Gesetz: f(x) = 1/(b-a) im Intervall (a,b)
notwendig:
1. Schätzen Sie die Parameter a und b - die Enden des Intervalls, in dem die möglichen Werte von X beobachtet wurden, gemäß den Formeln (das *-Zeichen bezeichnet die Schätzungen der Parameter):
2. Finden Sie die Wahrscheinlichkeitsdichte der geschätzten Verteilung f(x) = 1/(b * - a *)
3. Finden Sie theoretische Frequenzen:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Vergleichen Sie die empirischen und theoretischen Häufigkeiten unter Verwendung des Pearson-Tests, wobei die Anzahl der Freiheitsgrade k = s-3 angenommen wird, wobei s die Anzahl der anfänglichen Abtastintervalle ist; Wenn jedoch eine Kombination kleiner Frequenzen und damit der Intervalle selbst vorgenommen wurde, ist s die Anzahl der nach der Kombination verbleibenden Intervalle.
Lösung:
1. Finden Sie die Schätzungen der Parameter a * und b * der Gleichverteilung mit den Formeln:
2. Finden Sie die Dichte der angenommenen Gleichverteilung:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Finde die theoretischen Frequenzen:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
Die restlichen n s sind gleich:
n s = n*f(x)(xi - x i-1)
| ich | n ich | n*i | n ich - n * ich | (n ich - n* ich) 2 | (n ich - n * ich) 2 /n * ich |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Gesamt | 1 | 0.0532 |
Daher ist der kritische Bereich für diese Statistik immer rechtshändig: . wenn auf diesem Segment die Wahrder Zufallsvariablen konstant ist, d.h. wenn die differentielle Verteilungsfunktion ist f(x) hat folgende Form:
![]()
Diese Verteilung wird manchmal als Gesetz der gleichmäßigen Dichte. Über eine Menge, die auf einem bestimmten Segment gleichmäßig verteilt ist, werden wir sagen, dass sie auf diesem Segment gleichmäßig verteilt ist.
Finden Sie den Wert der Konstanten c. Da die Fläche durch die Verteilungskurve und die Achse begrenzt ist Oh, gleich 1, dann
wo Mit=1/(b-a).
Jetzt die Funktion f(x)darstellen kann als

Konstruieren wir die Verteilungsfunktion
F(x ), wofür wir den Ausdruck finden F (x ) auf dem Intervall [ ein, b]:


Graphen der Funktionen f (x) und F (x) sehen so aus:

Lassen Sie uns numerische Merkmale finden.
Unter Verwendung der Formel zur Berechnung der mathematischen Erwartung des NSW haben wir:

Somit ist die mathematische Erwartung einer gleichmäßig auf das Intervall [ein, b] fällt mit der Mitte dieses Segments zusammen.
Finden Sie die Varianz einer gleichverteilten Zufallsvariablen:
woraus unmittelbar folgt, dass die Standardabweichung:
![]()
Finden wir nun die Wahrscheinlichkeit dafür, dass der Wert einer Zufallsvariablen mit einer Gleichverteilung in das Intervall fällt(a, b), vollständig dem Segment [a,b
]:

|
|

Geometrisch ist diese Wahrscheinlichkeit die Fläche des schraffierten Rechtecks. Zahlen a und
bgenannt Verteilungsparameter und eindeutig eine Gleichverteilung definieren.Beispiel 1. Busse einer bestimmten Route fahren streng nach Fahrplan. Bewegungsintervall 5 Minuten. Bestimmen Sie die Wahrscheinlichkeit, dass sich der Fahrgast der Bushaltestelle näherte. Warten auf den nächsten Bus weniger als 3 Minuten.
Lösung:
ST - Buswartezeit hat eine gleichmäßige Verteilung. Dann ist die gesuchte Wahrscheinlichkeit gleich:
![]()
Beispiel2. Die Kante des Würfels x wird ungefähr gemessen. Und
Betrachtet man die Kante des Würfels als gleichmäßig verteilte Zufallsvariable im Intervall (
a,b), finden Sie den mathematischen Erwartungswert und die Varianz des Volumens des Würfels.Lösung:
Das Volumen des Würfels ist eine Zufallsvariable, die durch den Ausdruck Y \u003d X 3 bestimmt wird. Dann lautet die mathematische Erwartung:
Streuung:
Onlineservice:
