វិធីសាស្រ្តធ្វើម្តងទៀត។នៅក្នុងវិធីសាស្រ្តនេះ ការប្រៀបធៀបត្រូវបានធ្វើឡើងជាមួយនឹងមូលដ្ឋានទិន្នន័យជាក់លាក់ ដែលសម្រាប់វត្ថុនីមួយៗមានជម្រើសផ្សេងគ្នាសម្រាប់ការកែប្រែការបង្ហាញ។ ឧទាហរណ៍ សម្រាប់ការសម្គាល់រូបភាពអុបទិក អ្នកអាចអនុវត្តវិធីធ្វើឡើងវិញនៅមុំផ្សេងគ្នា ឬមាត្រដ្ឋាន អុហ្វសិត ការខូចទ្រង់ទ្រាយជាដើម។ សម្រាប់អក្សរ អ្នកអាចសរសេរឡើងវិញលើពុម្ពអក្សរ ឬលក្ខណៈសម្បត្តិរបស់វា។ នៅក្នុងករណីនៃការទទួលស្គាល់លំនាំសំឡេង មានការប្រៀបធៀបជាមួយនឹងគំរូដែលគេស្គាល់មួយចំនួន (ពាក្យដែលនិយាយដោយមនុស្សជាច្រើន)។ លើសពីនេះទៀតការវិភាគស៊ីជម្រៅអំពីលក្ខណៈនៃរូបភាពត្រូវបានអនុវត្ត។ នៅក្នុងករណីនៃការទទួលស្គាល់អុបទិកនេះអាចជានិយមន័យនៃលក្ខណៈធរណីមាត្រ។ សំណាកសំឡេងនៅក្នុងករណីនេះត្រូវបានធ្វើការវិភាគប្រេកង់ និងទំហំ។
វិធីសាស្រ្តបន្ទាប់គឺ ការប្រើប្រាស់បណ្តាញសរសៃប្រសាទសិប្បនិម្មិត(INS) ។ វាទាមទារនូវឧទាហរណ៍មួយចំនួនធំនៃភារកិច្ចទទួលស្គាល់ ឬរចនាសម្ព័ន្ធបណ្តាញសរសៃប្រសាទពិសេសដែលគិតគូរពីភាពជាក់លាក់នៃកិច្ចការនេះ។ ប៉ុន្តែទោះជាយ៉ាងណាក៏ដោយ វិធីសាស្ត្រនេះត្រូវបានកំណត់ដោយប្រសិទ្ធភាព និងផលិតភាពខ្ពស់។
វិធីសាស្រ្តផ្អែកលើការប៉ាន់ប្រមាណនៃដង់ស៊ីតេចែកចាយនៃតម្លៃលក្ខណៈពិសេស. ខ្ចីពីទ្រឹស្ដីបុរាណនៃការសម្រេចចិត្តស្ថិតិ ដែលវត្ថុនៃការសិក្សាត្រូវបានចាត់ទុកថាជាការសម្រេចបាននៃអថេរចៃដន្យពហុវិមាត្រដែលបានចែកចាយក្នុងចន្លោះលក្ខណៈពិសេសនេះបើយោងតាមច្បាប់មួយចំនួន។ ពួកវាផ្អែកលើគ្រោងការណ៍នៃការសម្រេចចិត្តរបស់ Bayesian ដែលអំពាវនាវដល់ប្រូបាប៊ីលីតេដំបូងនៃវត្ថុដែលជាកម្មសិទ្ធិរបស់ថ្នាក់ជាក់លាក់មួយ និងដង់ស៊ីតេនៃការចែកចាយមុខងារតាមលក្ខខណ្ឌ។
ក្រុមនៃវិធីសាស្រ្តដោយផ្អែកលើការប៉ាន់ប្រមាណនៃដង់ស៊ីតេចែកចាយនៃតម្លៃលក្ខណៈពិសេសគឺទាក់ទងដោយផ្ទាល់ទៅនឹងវិធីសាស្រ្តនៃការវិភាគរើសអើង។ វិធីសាស្រ្ត Bayesian ក្នុងការធ្វើសេចក្តីសម្រេច គឺជាវិធីសាស្រ្តមួយក្នុងចំនោមវិធីសាស្រ្តប៉ារ៉ាម៉ែត្រដែលបានអភិវឌ្ឍបំផុតនៅក្នុងស្ថិតិទំនើប ដែលការបញ្ចេញមតិវិភាគនៃច្បាប់ចែកចាយ (ច្បាប់ធម្មតា) ត្រូវបានគេចាត់ទុកថាត្រូវបានគេស្គាល់ ហើយមានតែប៉ារ៉ាម៉ែត្រមួយចំនួនតូចប៉ុណ្ណោះ (វ៉ិចទ័រមធ្យម និងម៉ាទ្រីសនៃភាពប្រែប្រួល។ ) ចាំបាច់ត្រូវប៉ាន់ស្មាន។ ការលំបាកចម្បងក្នុងការអនុវត្តវិធីសាស្រ្តនេះត្រូវបានចាត់ទុកថាជាតម្រូវការក្នុងការចងចាំគំរូបណ្តុះបណ្តាលទាំងមូលដើម្បីគណនាការប៉ាន់ប្រមាណដង់ស៊ីតេនិងភាពប្រែប្រួលខ្ពស់ចំពោះគំរូបណ្តុះបណ្តាល។
វិធីសាស្រ្តផ្អែកលើការសន្មត់អំពីថ្នាក់នៃមុខងារនៃការសម្រេចចិត្ត។នៅក្នុងក្រុមនេះ ប្រភេទនៃមុខងារការសម្រេចចិត្តត្រូវបានចាត់ទុកថាត្រូវបានគេស្គាល់ ហើយមុខងារគុណភាពរបស់វាត្រូវបានផ្តល់ឱ្យ។ ដោយផ្អែកលើមុខងារនេះ ការប៉ាន់ស្មានដ៏ល្អប្រសើរចំពោះមុខងារនៃការសម្រេចចិត្តត្រូវបានរកឃើញពីលំដាប់បណ្តុះបណ្តាល។ មុខងារនៃការគ្រប់គ្រងគុណភាពនៃការសម្រេចចិត្តជាធម្មតាត្រូវបានភ្ជាប់ជាមួយនឹងកំហុសមួយ។ អត្ថប្រយោជន៍ចម្បងនៃវិធីសាស្រ្តគឺភាពច្បាស់លាស់នៃរូបមន្តគណិតវិទ្យានៃបញ្ហាការទទួលស្គាល់។ លទ្ធភាពនៃការទាញយកចំណេះដឹងថ្មីអំពីធម្មជាតិនៃវត្ថុ ជាពិសេសចំណេះដឹងអំពីយន្តការនៃអន្តរកម្មនៃគុណលក្ខណៈ ត្រូវបានកំណត់ជាមូលដ្ឋាននៅទីនេះដោយរចនាសម្ព័ន្ធអន្តរកម្មដែលបានផ្តល់ឱ្យ ជួសជុលនៅក្នុងទម្រង់នៃមុខងារការសម្រេចចិត្តដែលបានជ្រើសរើស។
វិធីសាស្រ្តប្រៀបធៀបគំរូ។នេះគឺជាវិធីសាស្ត្រទទួលស្គាល់ផ្នែកបន្ថែមដែលងាយស្រួលបំផុតក្នុងការអនុវត្ត។ វាអនុវត្តនៅពេលដែលថ្នាក់ដែលអាចស្គាល់បានត្រូវបានបង្ហាញជាថ្នាក់ធរណីមាត្របង្រួម។ បន្ទាប់មកចំណុចកណ្តាលនៃក្រុមធរណីមាត្រ (ឬវត្ថុដែលនៅជិតកណ្តាលបំផុត) ត្រូវបានជ្រើសរើសជាចំណុចគំរូ។
ដើម្បីចាត់ថ្នាក់វត្ថុដែលមិនអាចកំណត់បាន គំរូដែលនៅជិតបំផុតត្រូវបានរកឃើញ ហើយវត្ថុនោះជាកម្មសិទ្ធិរបស់ថ្នាក់ដូចគ្នាជាមួយវា។ ជាក់ស្តែង គ្មានរូបភាពទូទៅត្រូវបានបង្កើតឡើងនៅក្នុងវិធីសាស្រ្តនេះទេ។ ប្រភេទផ្សេងៗនៃចម្ងាយអាចត្រូវបានប្រើជារង្វាស់។
វិធីសាស្រ្ត k អ្នកជិតខាង។វិធីសាស្រ្តគឺស្ថិតនៅក្នុងការពិតដែលថានៅពេលចាត់ថ្នាក់វត្ថុមិនស្គាល់ លេខដែលបានផ្តល់ឱ្យ (k) នៃលំហលក្ខណៈធរណីមាត្រដែលនៅជិតបំផុតនៃអ្នកជិតខាងដែលនៅជិតបំផុតដែលស្គាល់រួចហើយជាកម្មសិទ្ធិរបស់ថ្នាក់ត្រូវបានរកឃើញ។ ការសម្រេចចិត្តប្រគល់វត្ថុមិនស្គាល់មួយត្រូវបានធ្វើឡើងដោយការវិភាគព័ត៌មានអំពីអ្នកជិតខាងដែលនៅជិតបំផុត។ តម្រូវការកាត់បន្ថយចំនួនវត្ថុនៅក្នុងគំរូបណ្តុះបណ្តាល (គំរូរោគវិនិច្ឆ័យ) គឺជាគុណវិបត្តិនៃវិធីសាស្ត្រនេះ ព្រោះវាកាត់បន្ថយភាពតំណាងនៃគំរូបណ្តុះបណ្តាល។
ដោយផ្អែកលើការពិតដែលថាក្បួនដោះស្រាយការទទួលស្គាល់ផ្សេងគ្នាមានឥរិយាបទខុសគ្នានៅលើគំរូដូចគ្នា សំណួរកើតឡើងនៃច្បាប់នៃការសម្រេចចិត្តសំយោគដែលនឹងប្រើភាពខ្លាំងនៃក្បួនដោះស្រាយទាំងអស់។ ចំពោះបញ្ហានេះ មានវិធីសាស្រ្តសំយោគ ឬសំណុំនៃច្បាប់នៃការសម្រេចចិត្តដែលរួមបញ្ចូលគ្នានូវទិដ្ឋភាពវិជ្ជមានបំផុតនៃវិធីសាស្រ្តនីមួយៗ។
នៅក្នុងការសន្និដ្ឋាននៃការពិនិត្យឡើងវិញនៃវិធីសាស្រ្តនៃការទទួលស្គាល់ យើងបង្ហាញខ្លឹមសារនៃចំណុចខាងលើនៅក្នុងតារាងសង្ខេប ដោយបន្ថែមវិធីសាស្រ្តផ្សេងទៀតមួយចំនួនដែលប្រើក្នុងការអនុវត្ត។
តារាងទី 1. តារាងចំណាត់ថ្នាក់នៃវិធីសាស្រ្តនៃការទទួលស្គាល់ ការប្រៀបធៀបនៃផ្នែកនៃការអនុវត្ត និងដែនកំណត់របស់ពួកគេ។
|
ចំណាត់ថ្នាក់នៃវិធីសាស្រ្តទទួលស្គាល់ |
តំបន់ដាក់ពាក្យ |
ដែនកំណត់ (គុណវិបត្តិ) |
|
|
វិធីសាស្រ្តទទួលស្គាល់ខ្លាំង |
វិធីសាស្រ្តផ្អែកលើការប៉ាន់ស្មានដង់ស៊ីតេ |
បញ្ហាជាមួយនឹងការចែកចាយដែលគេស្គាល់ (ធម្មតា) តម្រូវការក្នុងការប្រមូលស្ថិតិធំ |
តម្រូវការក្នុងការរាប់បញ្ចូលសំណុំបណ្ដុះបណ្ដាលទាំងមូលកំឡុងពេលទទួលស្គាល់ ភាពប្រែប្រួលខ្ពស់ចំពោះភាពមិនតំណាងនៃឈុតបណ្ដុះបណ្ដាល និងវត្ថុបុរាណ |
|
វិធីសាស្រ្តផ្អែកលើការសន្មត់ |
ថ្នាក់គួរត្រូវបានបែងចែកយ៉ាងល្អ |
ទម្រង់នៃមុខងារនៃការសម្រេចចិត្តត្រូវតែដឹងជាមុន។ ភាពមិនអាចទៅរួចនៃការគិតគូរអំពីចំណេះដឹងថ្មីអំពីទំនាក់ទំនងរវាងលក្ខណៈពិសេស |
|
|
វិធីសាស្ត្រប៊ូលីន |
បញ្ហានៃទំហំតូច |
នៅពេលជ្រើសរើសច្បាប់នៃការសម្រេចចិត្តឡូជីខល ការរាប់បញ្ចូលពេញលេញគឺចាំបាច់។ អាំងតង់ស៊ីតេពលកម្មខ្ពស់។ |
|
|
វិធីសាស្រ្តភាសាវិទ្យា |
ភារកិច្ចនៃការកំណត់វេយ្យាករណ៍សម្រាប់សំណុំជាក់លាក់នៃសេចក្តីថ្លែងការណ៍ (ការពិពណ៌នាអំពីវត្ថុ) គឺពិបាកក្នុងការកំណត់ជាផ្លូវការ។ បញ្ហាទ្រឹស្តីដែលមិនអាចដោះស្រាយបាន។ |
||
|
វិធីសាស្រ្តបន្ថែមនៃការទទួលស្គាល់ |
វិធីសាស្រ្តប្រៀបធៀបគំរូ |
បញ្ហានៃទំហំតូចនៃទំហំមុខងារ |
ការពឹងផ្អែកខ្ពស់នៃលទ្ធផលចំណាត់ថ្នាក់លើម៉ែត្រ។ មិនស្គាល់ម៉ែត្រដ៏ប្រសើរបំផុត។ |
|
k វិធីសាស្រ្តអ្នកជិតខាងដែលនៅជិតបំផុត។ |
ការពឹងផ្អែកខ្ពស់នៃលទ្ធផលចំណាត់ថ្នាក់លើម៉ែត្រ។ តម្រូវការសម្រាប់ការរាប់បញ្ចូលពេញលេញនៃគំរូបណ្តុះបណ្តាលក្នុងអំឡុងពេលទទួលស្គាល់។ ភាពស្មុគស្មាញនៃការគណនា |
||
|
ក្បួនដោះស្រាយការគណនាថ្នាក់ (ABO) |
បញ្ហានៃវិមាត្រតូចនៅក្នុងលក្ខខណ្ឌនៃចំនួនថ្នាក់និងលក្ខណៈពិសេស |
ការពឹងផ្អែកលើលទ្ធផលនៃការចាត់ថ្នាក់លើម៉ែត្រ។ តម្រូវការសម្រាប់ការរាប់បញ្ចូលពេញលេញនៃគំរូបណ្តុះបណ្តាលក្នុងអំឡុងពេលទទួលស្គាល់។ ភាពស្មុគស្មាញបច្ចេកទេសខ្ពស់នៃវិធីសាស្រ្ត |
|
|
វិធាននៃការសម្រេចចិត្តរួម (CRC) គឺជាវិធីសាស្ត្រសំយោគ។ |
បញ្ហានៃវិមាត្រតូចនៅក្នុងលក្ខខណ្ឌនៃចំនួនថ្នាក់និងលក្ខណៈពិសេស |
ភាពស្មុគស្មាញបច្ចេកទេសខ្ពស់នៃវិធីសាស្រ្ត ចំនួនដែលមិនអាចដោះស្រាយបាននៃបញ្ហាទ្រឹស្តី ទាំងក្នុងការកំណត់ផ្នែកនៃសមត្ថកិច្ចនៃវិធីសាស្រ្តជាក់លាក់ និងវិធីសាស្រ្តជាក់លាក់ដោយខ្លួនឯង |
មេរៀនលេខ ១៧ ។វិធីសាស្រ្តទទួលស្គាល់លំនាំ
មានក្រុមដូចខាងក្រោមនៃវិធីសាស្រ្តទទួលស្គាល់:
វិធីសាស្រ្តមុខងារជិត
វិធីសាស្រ្តមុខងាររើសអើង
វិធីសាស្រ្តស្ថិតិនៃការទទួលស្គាល់។
វិធីសាស្រ្តភាសាវិទ្យា
វិធីសាស្រ្ត heuristic ។
វិធីសាស្រ្តបីក្រុមដំបូងគឺផ្តោតលើការវិភាគនៃលក្ខណៈដែលបង្ហាញដោយលេខ ឬវ៉ិចទ័រដែលមានធាតុផ្សំជាលេខ។
ក្រុមនៃវិធីសាស្រ្តភាសាផ្តល់នូវការទទួលស្គាល់លំនាំដោយផ្អែកលើការវិភាគនៃរចនាសម្ព័ន្ធរបស់ពួកគេដែលត្រូវបានពិពណ៌នាដោយលក្ខណៈពិសេសនៃរចនាសម្ព័ន្ធដែលត្រូវគ្នានិងទំនាក់ទំនងរវាងពួកគេ។
ក្រុមនៃវិធីសាស្រ្ត heuristic រួមបញ្ចូលគ្នានូវបច្ចេកទេសលក្ខណៈ និងនីតិវិធីឡូជីខលដែលប្រើដោយមនុស្សក្នុងការទទួលស្គាល់គំរូ។
វិធីសាស្រ្តមុខងារជិត
វិធីសាស្រ្តនៃក្រុមនេះគឺផ្អែកលើការប្រើប្រាស់មុខងារដែលវាយតម្លៃរង្វាស់នៃភាពជិតរវាងរូបភាពដែលអាចស្គាល់បានជាមួយវ៉ិចទ័រ x * = (x * 1 ,….,x*n) និងរូបភាពយោងនៃថ្នាក់ផ្សេងៗ តំណាងដោយវ៉ិចទ័រ x ខ្ញុំ = (x ខ្ញុំ 1 ,…, x ខ្ញុំ n), ខ្ញុំ= 1,…,នកន្លែងណា ខ្ញុំ-លេខថ្នាក់រូបភាព។
នីតិវិធីនៃការទទួលស្គាល់នេះបើយោងតាមវិធីសាស្រ្តនេះមាននៅក្នុងការគណនាចម្ងាយរវាងចំណុចនៃរូបភាពដែលបានទទួលស្គាល់និងគ្នានៃចំណុចតំណាងឱ្យរូបភាពយោង, i.e. ក្នុងការគណនាតម្លៃទាំងអស់។ ឃ ខ្ញុំ , ខ្ញុំ= 1,…,ន. រូបភាពជាកម្មសិទ្ធិរបស់ថ្នាក់ដែលតម្លៃ ឃ ខ្ញុំមានតម្លៃតិចបំផុតក្នុងចំណោមទាំងអស់។ ខ្ញុំ= 1,…,ន .
អនុគមន៍ដែលធ្វើផែនទីគូវ៉ិចទ័រនីមួយៗ x ខ្ញុំ, x *ចំនួនពិតជារង្វាស់នៃភាពស្និទ្ធស្នាលរបស់ពួកគេ i.e. ការកំណត់ចម្ងាយរវាងពួកវាអាចបំពានបាន។ នៅក្នុងគណិតវិទ្យា មុខងារបែបនេះត្រូវបានគេហៅថា មាត្រដ្ឋានលំហ។ វាត្រូវតែបំពេញ axioms ខាងក្រោម:
r(x,y)=r(y,x);
r(x,y) > 0 ប្រសិនបើ xមិនស្មើគ្នា yនិង r(x,y)=0 ប្រសិនបើ x=y;
r(x,y) <=r(x,z)+r(z,y)
axioms ទាំងនេះត្រូវបានពេញចិត្តជាពិសេសដោយមុខងារដូចខាងក្រោម
មួយ ខ្ញុំ= 1/2 , j=1,2,…ន.
b i= ផលបូក j=1,2,…ន.
c i= អតិបរមា abs ( x ខ្ញុំ‑ x j *), j=1,2,…ន.
ទីមួយនៃទាំងនេះត្រូវបានគេហៅថា Euclidean បទដ្ឋាននៃទំហំវ៉ិចទ័រ។ ដូច្នោះហើយ ចន្លោះដែលអនុគមន៍ដែលបានបញ្ជាក់ត្រូវបានប្រើជាម៉ែត្រ ត្រូវបានគេហៅថាលំហ Euclidean ។
ជាញឹកញាប់ ភាពខុសគ្នាជា root-mean-square នៃកូអរដោណេនៃរូបភាពដែលបានទទួលស្គាល់ត្រូវបានជ្រើសរើសជាមុខងារជិត x *និងស្តង់ដារ x ខ្ញុំ, i.e. មុខងារ
ឃ ខ្ញុំ = (1/ន) ផលបូក( x ខ្ញុំ j‑ x j *) 2 , j=1,2,…ន.
តម្លៃ ឃ ខ្ញុំធរណីមាត្របានបកស្រាយថាជាការ៉េនៃចំងាយរវាងចំនុចក្នុងលំហលក្ខណៈ ដែលទាក់ទងទៅនឹងវិមាត្រនៃលំហ។
ជារឿយៗវាប្រែថាលក្ខណៈពិសេសផ្សេងៗគ្នាមិនមានសារៈសំខាន់ដូចគ្នានៅក្នុងការទទួលស្គាល់។ ដើម្បីយកកាលៈទេសៈនេះទៅក្នុងគណនីនៅពេលគណនាមុខងារជិតនៃភាពខុសគ្នានៃកូអរដោណេ លក្ខណៈសំខាន់ៗដែលទាក់ទងគ្នាគឺត្រូវគុណនឹងមេគុណធំ ហើយសំខាន់តិចជាងដោយលេខតូចជាង។
ក្នុងករណីនេះ ឃ ខ្ញុំ = (1/ន) ផលបូក ច (x ខ្ញុំ j‑ x j *) 2 , j=1,2,…ន,
កន្លែងណា ច- មេគុណទម្ងន់។
ការណែនាំនៃមេគុណទម្ងន់គឺស្មើនឹងការធ្វើមាត្រដ្ឋានអ័ក្សនៃទំហំមុខងារ ហើយតាមនោះ ការលាតសន្ធឹង ឬបង្រួមលំហក្នុងទិសដៅដាច់ដោយឡែក។
ការខូចទ្រង់ទ្រាយនៃលំហលក្ខណៈទាំងនេះបន្តដល់គោលដៅនៃការរៀបចំចំណុចនៃរូបភាពយោង ដែលត្រូវនឹងការទទួលស្គាល់ដែលអាចទុកចិត្តបំផុតនៅក្រោមលក្ខខណ្ឌនៃការខ្ចាត់ខ្ចាយនៃរូបភាពសំខាន់ៗនៃថ្នាក់នីមួយៗនៅក្នុងតំបន់ជុំវិញចំណុចនៃរូបភាពយោង។
ក្រុមនៃចំណុចរូបភាពនៅជិតគ្នា (ចង្កោមរូបភាព) ក្នុងចន្លោះលក្ខណៈពិសេសត្រូវបានគេហៅថាចង្កោម ហើយបញ្ហានៃការកំណត់អត្តសញ្ញាណក្រុមបែបនេះត្រូវបានគេហៅថាបញ្ហាចង្កោម។
ភារកិច្ចនៃការកំណត់អត្តសញ្ញាណចង្កោមគឺត្រូវបានសំដៅថាជាភារកិច្ចសម្គាល់លំនាំដែលមិនមានការត្រួតពិនិត្យ ពោលគឺឧ។ ចំពោះបញ្ហានៃការទទួលស្គាល់ក្នុងករណីដែលគ្មានឧទាហរណ៍នៃការទទួលស្គាល់ត្រឹមត្រូវ។
វិធីសាស្រ្តមុខងាររើសអើង
គំនិតនៃវិធីសាស្រ្តនៃក្រុមនេះគឺដើម្បីបង្កើតមុខងារដែលកំណត់ព្រំដែននៅក្នុងចន្លោះនៃរូបភាពដោយបែងចែកចន្លោះទៅជាតំបន់ដែលត្រូវគ្នាទៅនឹងថ្នាក់នៃរូបភាព។ មុខងារសាមញ្ញបំផុត និងប្រើញឹកញាប់បំផុតនៃប្រភេទនេះគឺជាមុខងារដែលអាស្រ័យលីនេអ៊ែរលើតម្លៃនៃលក្ខណៈពិសេស។ នៅក្នុងលំហលក្ខណៈ ពួកវាត្រូវគ្នាទៅនឹងផ្ទៃដែលបំបែកចេញជាទម្រង់ hyperplanes ។ នៅក្នុងករណីនៃលំហលក្ខណៈពីរវិមាត្រ បន្ទាត់ត្រង់ដើរតួជាមុខងារបំបែក។
ទម្រង់ទូទៅនៃអនុគមន៍ការសម្រេចចិត្តលីនេអ៊ែរត្រូវបានផ្តល់ដោយរូបមន្ត
ឃ(x)=វ 1 x 1 + វ 2 x 2 +…+w n x n +w n +1 = Wx+w n
កន្លែងណា x- វ៉ិចទ័ររូបភាព w=(វ 1 , វ 2 ,…w n) គឺជាវ៉ិចទ័រនៃមេគុណទម្ងន់។
នៅពេលបែងចែកជាពីរថ្នាក់ X 1 និង X 2 មុខងាររើសអើង ឃ(x) អនុញ្ញាតឱ្យមានការទទួលស្គាល់ដោយយោងតាមច្បាប់៖
xជាកម្មសិទ្ធិ X 1 ប្រសិនបើ ឃ(x)>0;
xជាកម្មសិទ្ធិ X 2 ប្រសិនបើ ឃ(x)<0.
ប្រសិនបើ ក ឃ(x)=0 បន្ទាប់មកករណីនៃភាពមិនច្បាស់លាស់កើតឡើង។
នៅក្នុងករណីនៃការបំបែកទៅជាថ្នាក់ជាច្រើន មុខងារជាច្រើនត្រូវបានណែនាំ។ ក្នុងករណីនេះ ថ្នាក់នីមួយៗនៃរូបភាពត្រូវបានភ្ជាប់ជាមួយនឹងការរួមបញ្ចូលគ្នាជាក់លាក់នៃសញ្ញានៃមុខងាររើសអើង។
ឧទាហរណ៍ ប្រសិនបើមុខងាររើសអើងចំនួនបីត្រូវបានណែនាំ នោះវ៉ារ្យ៉ង់ខាងក្រោមនៃការជ្រើសរើសថ្នាក់រូបភាពគឺអាចធ្វើទៅបាន៖
xជាកម្មសិទ្ធិ X 1 ប្រសិនបើ ឃ 1 (x)>0,ឃ 2 (x)<0,ឃ 3 (x)<0;
xជាកម្មសិទ្ធិ X 2 ប្រសិនបើ ឃ(x)<0,ឃ 2 (x)>0,ឃ 3 (x)<0;
xជាកម្មសិទ្ធិ X 3 ប្រសិនបើ ឃ(x)<0,ឃ 2 (x)<0,ឃ 3 (x)>0.
វាត្រូវបានសន្មត់ថាសម្រាប់បន្សំផ្សេងទៀតនៃតម្លៃ ឃ 1 (x),ឃ 2 (x),ឃ 3 (x) មានករណីនៃភាពមិនប្រាកដប្រជា។
បំរែបំរួលនៃវិធីសាស្រ្តនៃមុខងាររើសអើង គឺជាវិធីសាស្ត្រនៃមុខងារសម្រេចចិត្ត។ នៅក្នុងវាប្រសិនបើមាន មថ្នាក់ត្រូវបានសន្មត់ថាមាន មមុខងារ ឃ ខ្ញុំ(x) ហៅថា សម្រេច, ដូចជាថា បើ xជាកម្មសិទ្ធិ X ខ្ញុំបន្ទាប់មក ឃ ខ្ញុំ(x) > ឌីជេ(x) សម្រាប់ទាំងអស់ jមិនស្មើគ្នា ខ្ញុំទាំងនោះ។ មុខងារសម្រេចចិត្ត ឃ ខ្ញុំ(x) មានតម្លៃអតិបរមាក្នុងចំណោមមុខងារទាំងអស់។ ឌីជេ(x), j=1,...,ន..
រូបភាពនៃវិធីសាស្រ្តបែបនេះអាចជាការចាត់ថ្នាក់ដោយផ្អែកលើការប៉ាន់ប្រមាណនៃអប្បបរមានៃចម្ងាយ Euclidean ក្នុងចន្លោះលក្ខណៈពិសេសរវាងចំណុចរូបភាព និងស្តង់ដារ។ សូមបង្ហាញវា។
ចម្ងាយ Euclidean រវាងវ៉ិចទ័រលក្ខណៈនៃរូបភាពដែលអាចស្គាល់បាន។ xហើយវ៉ិចទ័រនៃរូបភាពយោងត្រូវបានកំណត់ដោយរូបមន្ត || x ខ្ញុំ ‑ x|| = 1/2 , j=1,2,…ន.
វ៉ិចទ័រ xនឹងត្រូវបានចាត់តាំងទៅថ្នាក់ ខ្ញុំដែលតម្លៃ || x ខ្ញុំ ‑ x *|| អប្បបរមា។
ជំនួសឱ្យចម្ងាយ អ្នកអាចប្រៀបធៀបការ៉េនៃចម្ងាយ ឧ។
||x ខ្ញុំ ‑ x|| 2 = (x ខ្ញុំ ‑ x)(x ខ្ញុំ ‑ x) t = x x- 2x x ខ្ញុំ +x i x i
ចាប់តាំងពីតម្លៃ x xដូចគ្នាសម្រាប់មនុស្សគ្រប់គ្នា ខ្ញុំ, អប្បបរមានៃអនុគមន៍ || x ខ្ញុំ ‑ x|| 2 នឹងស្របគ្នាជាមួយនឹងអតិបរិមានៃមុខងារនៃការសម្រេចចិត្ត
ឃ ខ្ញុំ(x) = 2x x ខ្ញុំ -x i x i.
នោះគឺ xជាកម្មសិទ្ធិ X ខ្ញុំ, ប្រសិនបើ ឃ ខ្ញុំ(x) > ឌីជេ(x) សម្រាប់ទាំងអស់ jមិនស្មើគ្នា ខ្ញុំ.
នោះ។ ម៉ាស៊ីនចាត់ថ្នាក់ចម្ងាយអប្បបរមាគឺផ្អែកលើមុខងារសម្រេចចិត្តលីនេអ៊ែរ។ រចនាសម្ព័ន្ធទូទៅនៃម៉ាស៊ីនបែបនេះប្រើមុខងារសម្រេចចិត្តនៃទម្រង់
ឃ ខ្ញុំ (x)=w ខ្ញុំ 1 x 1 + w ខ្ញុំ 2 x 2 +…+w ក្នុង x n +w i n +1
វាអាចត្រូវបានតំណាងដោយមើលឃើញដោយដ្យាក្រាមប្លុកសមស្រប។
សម្រាប់ម៉ាស៊ីនដែលធ្វើចំណាត់ថ្នាក់តាមចម្ងាយអប្បបរមា សមភាពកើតឡើង៖ w ij = -2x ខ្ញុំ j , w i n +1 = x i x i.
ការទទួលស្គាល់សមមូលដោយវិធីសាស្ត្រនៃមុខងាររើសអើងអាចត្រូវបានអនុវត្ត ប្រសិនបើមុខងាររើសអើងត្រូវបានកំណត់ថាជាភាពខុសគ្នា ឌីជេ (x)=ឃ ខ្ញុំ (x)‑ឌីជេ (x).
អត្ថប្រយោជន៍នៃវិធីសាស្រ្តនៃមុខងាររើសអើងគឺរចនាសម្ព័ន្ធសាមញ្ញនៃម៉ាស៊ីនទទួលស្គាល់ ក៏ដូចជាលទ្ធភាពនៃការអនុវត្តរបស់វាជាចម្បងតាមរយៈប្លុកការសម្រេចចិត្តលីនេអ៊ែរលើសលុប។
អត្ថប្រយោជន៍សំខាន់មួយទៀតនៃវិធីសាស្រ្តនៃមុខងាររើសអើងគឺលទ្ធភាពនៃការបណ្តុះបណ្តាលដោយស្វ័យប្រវត្តិនៃម៉ាស៊ីនសម្រាប់ការទទួលស្គាល់ត្រឹមត្រូវនៃគំរូគំរូដែលបានផ្តល់ឱ្យ (ការបណ្តុះបណ្តាល) ។
ក្នុងពេលជាមួយគ្នានេះ ក្បួនដោះស្រាយការរៀនដោយស្វ័យប្រវត្តិប្រែទៅជាសាមញ្ញណាស់ក្នុងការប្រៀបធៀបជាមួយនឹងវិធីសាស្ត្រទទួលស្គាល់ផ្សេងទៀត។
សម្រាប់ហេតុផលទាំងនេះ វិធីសាស្រ្តនៃមុខងាររើសអើងបានទទួលនូវប្រជាប្រិយភាពយ៉ាងទូលំទូលាយ ហើយត្រូវបានគេប្រើជាញឹកញាប់នៅក្នុងការអនុវត្ត។
ការទទួលស្គាល់លំនាំ នីតិវិធីរៀនដោយខ្លួនឯង។
ពិចារណាអំពីវិធីសាស្រ្តសម្រាប់បង្កើតមុខងាររើសអើងសម្រាប់គំរូដែលបានផ្តល់ឱ្យ (ការបណ្តុះបណ្តាល) ដូចដែលបានអនុវត្តចំពោះបញ្ហានៃការបែងចែករូបភាពជាពីរថ្នាក់។ ប្រសិនបើសំណុំរូបភាពពីរត្រូវបានផ្តល់ឱ្យរៀងគ្នានៃថ្នាក់ A និង B នោះដំណោះស្រាយចំពោះបញ្ហានៃការបង្កើតមុខងាររើសអើងលីនេអ៊ែរត្រូវបានស្វែងរកក្នុងទម្រង់ជាវ៉ិចទ័រនៃមេគុណទម្ងន់ វ=(វ 1 ,វ 2 ,...,w n,w n+1) ដែលមានលក្ខណសម្បត្តិសម្រាប់រូបភាពណាមួយមានលក្ខខណ្ឌ
xជាកម្មសិទ្ធិរបស់ថ្នាក់ A ប្រសិនបើ > 0, j=1,2,…ន.
xជាកម្មសិទ្ធិរបស់ថ្នាក់ B ប្រសិនបើ<0, j=1,2,…ន.
ប្រសិនបើគំរូបណ្តុះបណ្តាលគឺ នរូបភាពនៃថ្នាក់ទាំងពីរ បញ្ហាត្រូវបានកាត់បន្ថយទៅការស្វែងរកវ៉ិចទ័រ w ដែលធានានូវសុពលភាពនៃប្រព័ន្ធវិសមភាព។ ប្រសិនបើគំរូបណ្តុះបណ្តាលមាន នរូបភាពនៃថ្នាក់ទាំងពីរ បញ្ហាត្រូវបានកាត់បន្ថយទៅការស្វែងរកវ៉ិចទ័រ វដែលធានានូវសុពលភាពនៃប្រព័ន្ធវិសមភាព
x 1 1 w ខ្ញុំ+x 21 វ 2 +...+x ន 1 w n+w n +1 >0;
x 1 2 w ខ្ញុំ+x 22 វ 2 +...+x ន 2 w n+w n +1 <0;
x 1 ខ្ញុំw ខ្ញុំ+x 2ខ្ញុំ វ 2 +...+x ni w n+w n +1 >0;
................................................
x 1 នw ខ្ញុំ + x 2ន វ 2 +...+x nN w n +w n + 1>0;
នៅទីនេះ x ខ្ញុំ=(x ខ្ញុំ 1 , x អ៊ី 2 ,...,x i n ,x i n+ 1 ) - វ៉ិចទ័រនៃតម្លៃនៃលក្ខណៈពិសេសនៃរូបភាពពីគំរូការបណ្តុះបណ្តាល, សញ្ញា> ត្រូវនឹងវ៉ិចទ័រនៃរូបភាព xជាកម្មសិទ្ធិរបស់ថ្នាក់ A និងសញ្ញា< - векторам xជាកម្មសិទ្ធិរបស់ថ្នាក់ B ។
វ៉ិចទ័រដែលចង់បាន វមានប្រសិនបើថ្នាក់ A និង B អាចបំបែកបាន ហើយមិនមានទេ។ តម្លៃសមាសធាតុវ៉ិចទ័រ វអាចត្រូវបានរកឃើញជាមុន នៅដំណាក់កាលមុនការអនុវត្តផ្នែករឹងនៃ SRO ឬដោយផ្ទាល់ដោយ SRO ផ្ទាល់ក្នុងដំណើរការប្រតិបត្តិការរបស់វា។ វិធីសាស្រ្តចុងក្រោយនេះផ្តល់នូវភាពបត់បែនកាន់តែច្រើន និងស្វ័យភាពរបស់ SRO ។ ពិចារណាវានៅលើឧទាហរណ៍នៃឧបករណ៍ដែលហៅថាភាគរយរ៉ុន។ បង្កើតឡើងដោយអ្នកវិទ្យាសាស្ត្រអាមេរិក Rosenblatt ក្នុងឆ្នាំ 1957 ។ តំណាងគ្រោងការណ៍នៃភាគរយដែលធានាថារូបភាពត្រូវបានចាត់ឱ្យទៅថ្នាក់មួយក្នុងចំណោមថ្នាក់ពីរគឺត្រូវបានបង្ហាញក្នុងរូបខាងក្រោម។
រីទីណា សរីទីណា ករីទីណា រ
អូ អូ x 1
អូ អូ x 2
អូ អូ x 3
o(ផលបូក)--------> រ(ប្រតិកម្ម)
អូ អូ x ខ្ញុំ
អូ អូ x ន
អូ អូ x ន +1
ឧបករណ៍នេះមានធាតុរំញោចរីទីណា សដែលត្រូវបានភ្ជាប់ដោយចៃដន្យទៅនឹងធាតុផ្សំនៃរីទីណា ក. ធាតុនីមួយៗនៃរីទីណាទី 2 បង្កើតសញ្ញាទិន្នផលបានលុះត្រាតែចំនួនគ្រប់គ្រាន់នៃធាតុញ្ញាណដែលភ្ជាប់ទៅនឹងធាតុបញ្ចូលរបស់វាស្ថិតក្នុងស្ថានភាពរំភើប។ ការឆ្លើយតបប្រព័ន្ធទាំងមូល រគឺសមាមាត្រទៅនឹងផលបូកនៃប្រតិកម្មនៃធាតុនៃរីទីណាដែលភ្ជាប់ជាមួយនឹងទម្ងន់ជាក់លាក់។
បញ្ជាក់តាមរយៈ x ខ្ញុំប្រតិកម្ម ខ្ញុំ th associative element និងតាមរយៈ w ខ្ញុំ- មេគុណទម្ងន់ប្រតិកម្ម ខ្ញុំ th associative element ប្រតិកម្មនៃប្រព័ន្ធអាចត្រូវបានសរសេរជា រ=sum( w j x j), j=1,..,ន. ប្រសិនបើ ក រ>0 បន្ទាប់មករូបភាពដែលបង្ហាញទៅប្រព័ន្ធជាកម្មសិទ្ធិរបស់ថ្នាក់ A ហើយប្រសិនបើ រ<0, то образ относится к классу B. Описание этой процедуры классификации соответствует рассмотренным нами раньше принципам классификации, и, очевидно, перцентронная модель распознавания образов представляет собой, за исключением сенсорной сетчатки, реализацию линейной дискриминантной функции. Принятый в перцентроне принцип формирования значений x 1 , x 2 ,...,x នត្រូវគ្នាទៅនឹងក្បួនដោះស្រាយជាក់លាក់មួយសម្រាប់ការបង្កើតលក្ខណៈពិសេសដោយផ្អែកលើសញ្ញារបស់ឧបករណ៍ចាប់សញ្ញាបឋម។
ជាទូទៅវាអាចមានធាតុជាច្រើន។ រដែលបង្កើតជាប្រតិកម្មរបស់ perceptron ។ ក្នុងករណីនេះមនុស្សម្នាក់និយាយអំពីវត្តមានរបស់រីទីណានៅក្នុង perceptron រធាតុប្រតិកម្ម។
គ្រោងការណ៍ភាគរយអាចត្រូវបានពង្រីកទៅករណីនៅពេលដែលចំនួនថ្នាក់មានច្រើនជាងពីរ ដោយបង្កើនចំនួនធាតុរីទីណា។ ររហូតដល់ចំនួនថ្នាក់ដែលអាចបែងចែកបាន និងការណែនាំនៃប្លុកសម្រាប់កំណត់ប្រតិកម្មអតិបរមាដោយអនុលោមតាមគ្រោងការណ៍ដែលបានបង្ហាញក្នុងរូបភាពខាងលើ។ ក្នុងករណីនេះ រូបភាពត្រូវបានកំណត់ទៅថ្នាក់ដោយមានលេខ ខ្ញុំ, ប្រសិនបើ R i>Rj, សម្រាប់ទាំងអស់ j.
ដំណើរការសិក្សារបស់ភាគរយមានក្នុងការជ្រើសរើសតម្លៃនៃមេគុណទម្ងន់ ចដូច្នេះសញ្ញាលទ្ធផលត្រូវគ្នានឹងថ្នាក់ដែលរូបភាពដែលបានទទួលស្គាល់។
អនុញ្ញាតឱ្យយើងពិចារណាក្បួនដោះស្រាយសកម្មភាពភាគរយដោយប្រើឧទាហរណ៍នៃការទទួលស្គាល់វត្ថុនៃថ្នាក់ពីរ: A និង B. វត្ថុនៃថ្នាក់ A ត្រូវតែឆ្លើយតបទៅនឹងតម្លៃ រ= +1, និងថ្នាក់ B - តម្លៃ រ= -1.
ក្បួនដោះស្រាយការរៀនមានដូចខាងក្រោម។
ប្រសិនបើរូបភាពផ្សេងទៀត។ xជាកម្មសិទ្ធិរបស់ថ្នាក់ A ប៉ុន្តែ រ<0 (имеет место ошибка распознавания), тогда коэффициенты ចជាមួយនឹងសន្ទស្សន៍ដែលត្រូវគ្នានឹងតម្លៃ x j> 0 កើនឡើងដោយចំនួនមួយចំនួន dwនិងមេគុណដែលនៅសល់ ចថយចុះដោយ dw. ក្នុងករណីនេះតម្លៃនៃប្រតិកម្ម រទទួលបានការកើនឡើងឆ្ពោះទៅរកតម្លៃវិជ្ជមានរបស់វាដែលត្រូវនឹងចំណាត់ថ្នាក់ត្រឹមត្រូវ។
ប្រសិនបើ ក xជាកម្មសិទ្ធិរបស់ថ្នាក់ B ប៉ុន្តែ រ>0 (មានកំហុសក្នុងការទទួលស្គាល់) បន្ទាប់មកមេគុណ ចជាមួយនឹងសន្ទស្សន៍ដែលត្រូវគ្នា។ x j<0, увеличивают на dwនិងមេគុណដែលនៅសល់ ចកាត់បន្ថយដោយបរិមាណដូចគ្នា។ ក្នុងករណីនេះតម្លៃនៃប្រតិកម្ម រត្រូវបានបង្កើនឆ្ពោះទៅរកតម្លៃអវិជ្ជមានដែលត្រូវគ្នាទៅនឹងចំណាត់ថ្នាក់ត្រឹមត្រូវ។
ដូច្នេះក្បួនដោះស្រាយណែនាំការផ្លាស់ប្តូរវ៉ិចទ័រទម្ងន់ វប្រសិនបើនិងបានតែប្រសិនបើរូបភាពបង្ហាញទៅ k-th ជំហានហ្វឹកហាត់ ត្រូវបានចាត់ថ្នាក់មិនត្រឹមត្រូវក្នុងអំឡុងពេលជំហាននេះ ហើយទុកវ៉ិចទ័រទម្ងន់ វមិនមានការផ្លាស់ប្តូរក្នុងករណីមានចំណាត់ថ្នាក់ត្រឹមត្រូវ។ ភស្តុតាងនៃការបញ្ចូលគ្នានៃក្បួនដោះស្រាយនេះត្រូវបានបង្ហាញនៅក្នុង [Too, Gonzalez] ។ ការបណ្តុះបណ្តាលបែបនេះនឹងនៅទីបំផុត (ជាមួយនឹងជម្រើសត្រឹមត្រូវ។ dwនិងភាពបំបែកលីនេអ៊ែរនៃថ្នាក់រូបភាព) នាំទៅរកវ៉ិចទ័រ វសម្រាប់ការចាត់ថ្នាក់ត្រឹមត្រូវ។
វិធីសាស្រ្តស្ថិតិនៃការទទួលស្គាល់។
វិធីសាស្រ្តស្ថិតិគឺផ្អែកលើការបង្រួមអប្បបរមានៃប្រូបាប៊ីលីតេនៃកំហុសក្នុងការចាត់ថ្នាក់។ ប្រូបាប៊ីលីតេ P នៃការចាត់ថ្នាក់មិនត្រឹមត្រូវនៃរូបភាពដែលបានទទួលសម្រាប់ការទទួលស្គាល់ ពិពណ៌នាដោយវ៉ិចទ័រលក្ខណៈពិសេស x, ត្រូវបានកំណត់ដោយរូបមន្ត
P = ផលបូក[ ទំ(ខ្ញុំ) បញ្ហា ( ឃ(x)+ខ្ញុំ | xថ្នាក់ ខ្ញុំ)]
កន្លែងណា ម- ចំនួនថ្នាក់,
ទំ(ខ្ញុំ) = ស៊ើបអង្កេត ( xជាកម្មសិទ្ធិរបស់ថ្នាក់ ខ្ញុំ) - ប្រូបាប៊ីលីតេអាទិភាពនៃភាពជាកម្មសិទ្ធិរបស់រូបភាពបំពាន xទៅ ខ្ញុំ-th class (ភាពញឹកញាប់នៃការកើតឡើងនៃរូបភាព ខ្ញុំថ្នាក់),
ឃ(x) គឺជាមុខងារដែលធ្វើការសម្រេចចិត្តចាត់ថ្នាក់ (វ៉ិចទ័រលក្ខណៈ xត្រូវនឹងលេខថ្នាក់ ខ្ញុំពីសំណុំ (1,2, ..., ម}),
បញ្ហា( ឃ(x) មិនស្មើគ្នា ខ្ញុំ| xជាកម្មសិទ្ធិរបស់ថ្នាក់ ខ្ញុំ) គឺជាប្រូបាប៊ីលីតេនៃព្រឹត្តិការណ៍ " ឃ(x) មិនស្មើគ្នា ខ្ញុំ"នៅពេលដែលលក្ខខណ្ឌសមាជិកភាពត្រូវបានបំពេញ xថ្នាក់ ខ្ញុំ, i.e. ប្រូបាប៊ីលីតេនៃការសម្រេចចិត្តខុសដោយមុខងារ ឃ(x) សម្រាប់តម្លៃដែលបានផ្តល់ឱ្យ xជាកម្មសិទ្ធិរបស់ ខ្ញុំ- ថ្នាក់។
វាអាចត្រូវបានបង្ហាញថាប្រូបាប៊ីលីតេនៃការចាត់ថ្នាក់មិនត្រឹមត្រូវឈានដល់អប្បបរមាប្រសិនបើ ឃ(x)=ខ្ញុំប្រសិនបើ និងប្រសិនបើ ទំ(x|ខ្ញុំ)· ទំ(ខ្ញុំ)>ទំ(x|j)· ទំ(j), សម្រាប់ទាំងអស់ ខ្ញុំ+jកន្លែងណា ទំ(x|i) - ដង់ស៊ីតេនៃការចែកចាយរូបភាព ខ្ញុំថ្នាក់ទីនៅក្នុងចន្លោះលក្ខណៈពិសេស។
យោងតាមច្បាប់ខាងលើចំណុច xជាកម្មសិទ្ធិរបស់ថ្នាក់ដែលត្រូវគ្នានឹងតម្លៃអតិបរមា ទំ(ខ្ញុំ) ទំ(x|i), i.e. ផលិតផលនៃប្រូបាប៊ីលីតេអាទិភាព (ប្រេកង់) នៃរូបរាងនៃរូបភាព ខ្ញុំ- ថ្នាក់ និងដង់ស៊ីតេចែកចាយគំរូ ខ្ញុំថ្នាក់ទីនៅក្នុងចន្លោះលក្ខណៈពិសេស។ ច្បាប់ចំណាត់ថ្នាក់ដែលបានបង្ហាញត្រូវបានគេហៅថា Bayesian ដោយសារតែ វាធ្វើតាមរូបមន្ត Bayes ដ៏ល្បីល្បាញនៅក្នុងទ្រឹស្តីប្រូបាប៊ីលីតេ។
ឧទាហរណ៍។ អនុញ្ញាតឱ្យវាចាំបាច់ដើម្បីទទួលស្គាល់សញ្ញាដាច់ពីគ្នានៅឯលទ្ធផលនៃឆានែលព័ត៌មានដែលរងផលប៉ះពាល់ដោយសំលេងរំខាន។
សញ្ញាបញ្ចូលនីមួយៗគឺ 0 ឬ 1។ ជាលទ្ធផលនៃការបញ្ជូនសញ្ញា លទ្ធផលនៃឆានែលបង្ហាញតម្លៃ xដែលត្រូវបានបញ្ចូលដោយសំលេងរំខាន Gaussian ជាមួយនឹងសូន្យមធ្យម និងបំរែបំរួល ខ។
សម្រាប់ការសំយោគនៃអ្នកចាត់ថ្នាក់ដែលអនុវត្តការទទួលស្គាល់សញ្ញា យើងនឹងប្រើច្បាប់ចំណាត់ថ្នាក់ Bayesian ។
នៅក្នុងថ្នាក់ទី 1 យើងរួមបញ្ចូលគ្នានូវសញ្ញាតំណាងឱ្យឯកតានៅក្នុងថ្នាក់លេខ 2 - សញ្ញាតំណាងឱ្យសូន្យ។ អនុញ្ញាតឱ្យវាដឹងជាមុនថាជាមធ្យម ក្នុងចំណោមសញ្ញា 1000 កសញ្ញាគឺជាឯកតានិង ខសញ្ញា - សូន្យ។ បន្ទាប់មកតម្លៃនៃប្រូបាប៊ីលីតេអាទិភាពនៃការលេចឡើងនៃសញ្ញានៃថ្នាក់ទី 1 និងទី 2 (មួយនិងសូន្យ) រៀងគ្នាអាចត្រូវបានយកស្មើនឹង
p(1)=a/1000, p(2)=b/1000។
ដោយសារតែ សំលេងរំខានគឺ Gaussian, i.e. គោរពច្បាប់ចែកចាយធម្មតា (Gaussian) បន្ទាប់មកដង់ស៊ីតេនៃការចែកចាយរូបភាពនៃថ្នាក់ទីមួយ អាស្រ័យលើតម្លៃ xឬ ដែលដូចគ្នា ប្រូបាប៊ីលីតេនៃការទទួលបានតម្លៃលទ្ធផល xនៅពេលដែលសញ្ញា 1 ត្រូវបានអនុវត្តនៅការបញ្ចូលវាត្រូវបានកំណត់ដោយកន្សោម
ទំ(x¦1) =(2pib) -1/2 exp(-( x-1) 2 /(2b 2)),
និងដង់ស៊ីតេចែកចាយអាស្រ័យលើតម្លៃ xរូបភាពនៃថ្នាក់ទីពីរ, i.e. ប្រូបាប៊ីលីតេនៃការទទួលបានតម្លៃលទ្ធផល xនៅពេលដែលសញ្ញា 0 ត្រូវបានអនុវត្តនៅការបញ្ចូលវាត្រូវបានកំណត់ដោយកន្សោម
ទំ(x¦2)= (2pib) -1/2 exp(- x២/(២ខ២)),
ការអនុវត្តច្បាប់នៃការសម្រេចចិត្តរបស់ Bayesian នាំឱ្យមានការសន្និដ្ឋានថាសញ្ញាថ្នាក់ 2 ត្រូវបានបញ្ជូនពោលគឺឧ។ ឆ្លងកាត់សូន្យប្រសិនបើ
ទំ(2) ទំ(x¦២) > ទំ(1) ទំ(x¦1)
ឬជាពិសេសជាងនេះទៅទៀតប្រសិនបើ
ខ exp(- x២/(២ ប ២)) > ក exp(-( x-1) 2 /(2b 2)),
ការបែងចែកផ្នែកខាងឆ្វេងនៃវិសមភាពដោយផ្នែកខាងស្តាំយើងទទួលបាន
(ខ/ក exp((1-2 x)/(2b 2)) >1,
ពីណាមក បន្ទាប់ពីយកលោការីតមក យើងរកឃើញ
1-2x> 2b 2 ln(a/b)
x< 0.5 - б 2 ln(a/b)
វាកើតឡើងពីវិសមភាពលទ្ធផលនោះ។ a=b, i.e. ជាមួយនឹងប្រូបាប៊ីលីតេអាទិភាពដូចគ្នានៃការកើតឡើងនៃសញ្ញា 0 និង 1 រូបភាពត្រូវបានផ្តល់តម្លៃ 0 នៅពេល x<0.5, а значение 1, когда x>0.5.
ប្រសិនបើវាត្រូវបានគេដឹងជាមុនថាសញ្ញាមួយក្នុងចំណោមសញ្ញាលេចឡើងញឹកញាប់ជាងហើយមួយទៀតមិនសូវជាញឹកញាប់ i.e. ក្នុងករណីតម្លៃខុសគ្នា កនិង ខកម្រិតនៃការឆ្លើយតបរបស់អ្នកចាត់ថ្នាក់ត្រូវបានប្តូរទៅម្ខាង ឬម្ខាងទៀត។
ដូច្នេះនៅ ក/ខ=2.71 (ត្រូវគ្នាទៅនឹងការបញ្ជូនញឹកញាប់ជាង 2.71 ដង) និង b 2 = 0.1 រូបភាពត្រូវបានផ្តល់តម្លៃ 0 ប្រសិនបើ x<0.4, и значение 1, если x> 0.4 ។ ប្រសិនបើមិនមានព័ត៌មានអំពីប្រូបាប៊ីលីតេនៃការចែកចាយអាទិភាពទេនោះ វិធីសាស្ត្រនៃការទទួលស្គាល់ស្ថិតិអាចត្រូវបានប្រើ ដែលផ្អែកលើច្បាប់ផ្សេងពីចំណាត់ថ្នាក់ Bayesian ។
ទោះជាយ៉ាងណាក៏ដោយនៅក្នុងការអនុវត្ត វិធីសាស្រ្តដែលផ្អែកលើច្បាប់របស់ Bayes គឺជារឿងធម្មតាបំផុតដោយសារតែប្រសិទ្ធភាពកាន់តែច្រើនរបស់វា ហើយដោយសារតែបញ្ហានៃការទទួលស្គាល់គំរូភាគច្រើន វាអាចធ្វើទៅបានដើម្បីកំណត់ប្រូបាប៊ីលីតេអាទិភាពសម្រាប់រូបរាងនៃរូបភាពនៃថ្នាក់នីមួយៗ។
វិធីសាស្រ្តភាសានៃការទទួលស្គាល់គំរូ។
វិធីសាស្រ្តភាសានៃការទទួលស្គាល់លំនាំគឺផ្អែកលើការវិភាគលើការពិពណ៌នានៃរូបភាពដែលមានឧត្តមគតិ តំណាងជាក្រាហ្វ ឬខ្សែអក្សរនៃនិមិត្តសញ្ញា ដែលជាឃ្លា ឬប្រយោគនៃភាសាជាក់លាក់មួយ។
ពិចារណាអំពីរូបភាពនៃអក្សរដែលមានឧត្តមគតិដែលទទួលបានជាលទ្ធផលនៃដំណាក់កាលដំបូងនៃការទទួលស្គាល់ភាសាដែលបានពិពណ៌នាខាងលើ។ រូបភាពដែលមានឧត្តមគតិទាំងនេះអាចត្រូវបានកំណត់ដោយការពិពណ៌នានៃក្រាហ្វ តំណាង ជាឧទាហរណ៍ក្នុងទម្រង់ម៉ាទ្រីសនៃការតភ្ជាប់ ដូចដែលបានធ្វើនៅក្នុងឧទាហរណ៍ខាងលើ។ ការពិពណ៌នាដូចគ្នាអាចត្រូវបានតំណាងដោយឃ្លាភាសាផ្លូវការ (កន្សោម) ។
ឧទាហរណ៍។ អនុញ្ញាតឱ្យមានរូបភាពបីនៃអក្សរ A ដែលទទួលបានជាលទ្ធផលនៃការដំណើរការរូបភាពបឋម។ ចូរកំណត់រូបភាពទាំងនេះដោយមានសញ្ញាសម្គាល់ A1, A2 និង A3។
សម្រាប់ការពិពណ៌នាភាសានៃរូបភាពដែលបានបង្ហាញ យើងប្រើ PDL (ភាសាពិពណ៌នារូបភាព)។ វចនានុក្រមភាសា PDL រួមបញ្ចូលនិមិត្តសញ្ញាដូចខាងក្រោមៈ
1. ឈ្មោះរូបភាពសាមញ្ញបំផុត (បុព្វកាល)។ ដូចដែលបានអនុវត្តចំពោះករណីដែលកំពុងពិចារណា បុព្វបទ និងឈ្មោះដែលត្រូវគ្នាមានដូចខាងក្រោម។
រូបភាពក្នុងទម្រង់ជាបន្ទាត់ដឹកនាំ៖
ឡើងលើ និងឆ្វេង (លេ ច t) ទៅខាងជើង (ខាងជើង)) ឡើងលើ និងខាងស្តាំ (ស្តាំ) ទៅខាងកើត (ខាងកើត))។
ឈ្មោះ៖ L, N, R, E.
2. និមិត្តសញ្ញានៃប្រតិបត្តិការគោលពីរ។ (+,*,-) អត្ថន័យរបស់ពួកគេត្រូវគ្នាទៅនឹងការតភ្ជាប់តាមលំដាប់នៃបុព្វកាល (+) ការភ្ជាប់នៃការចាប់ផ្តើម និងការបញ្ចប់នៃបុព្វកាល (*) ការភ្ជាប់នៃតែការបញ្ចប់នៃបុព្វកាល (-)។
3. តង្កៀបខាងស្តាំនិងខាងឆ្វេង។ ((,)) វង់ក្រចកអនុញ្ញាតឱ្យអ្នកបញ្ជាក់លំដាប់ដែលប្រតិបត្តិការត្រូវអនុវត្តក្នុងកន្សោមមួយ។
រូបភាពដែលបានពិចារណា A1, A2 និង A3 ត្រូវបានពិពណ៌នាជាភាសា PDL រៀងគ្នាដោយកន្សោមខាងក្រោម។
T(1)=R+((R-(L+N))*E-L
T(2)=(R+N)+((N+R)-L)*E-L
T(3)=(N+R)+(R-L)*E-(L+N)
បន្ទាប់ពីការពិពណ៌នាភាសានៃរូបភាពត្រូវបានបង្កើតឡើង ចាំបាច់ត្រូវធ្វើការវិភាគ ដោយប្រើនីតិវិធីទទួលស្គាល់មួយចំនួន ថាតើរូបភាពដែលបានផ្តល់ឱ្យជាកម្មសិទ្ធិរបស់ថ្នាក់ដែលចាប់អារម្មណ៍ចំពោះយើង (ថ្នាក់អក្សរ A) ពោលគឺឧ។ ថាតើរូបភាពនេះមានរចនាសម្ព័ន្ធខ្លះឬអត់។ ដើម្បីធ្វើដូចនេះដំបូងបង្អស់វាចាំបាច់ក្នុងការពិពណ៌នាអំពីថ្នាក់នៃរូបភាពដែលមានរចនាសម្ព័ន្ធគួរឱ្យចាប់អារម្មណ៍ចំពោះយើង។
ជាក់ស្តែងអក្សរ A តែងតែមានធាតុរចនាសម្ព័ន្ធដូចខាងក្រោមៈ "ជើង" ខាងឆ្វេង "ជើង" និងក្បាល។ ចូរដាក់ឈ្មោះធាតុទាំងនេះតាមលំដាប់ STL, STR, TR ។
បន្ទាប់មកនៅក្នុងភាសា PDL និមិត្តសញ្ញាថ្នាក់ A - SIMB A ត្រូវបានពិពណ៌នាដោយកន្សោម
SIMB A = STL + TR - STR
"ជើង" ខាងឆ្វេងនៃ STL គឺតែងតែជាខ្សែសង្វាក់នៃធាតុ R និង N ដែលអាចសរសេរជា
STL ‑> R ¦ N ¦ (STL + R) ¦ (STL + N)
(STL គឺជាតួអក្សរ R ឬ N ឬខ្សែអក្សរដែលទទួលបានដោយការបន្ថែមតួអក្សរ R ឬ N ទៅខ្សែអក្សរ STL ប្រភព)
"ជើង" ខាងស្តាំនៃ STR គឺតែងតែជាខ្សែសង្វាក់នៃធាតុ L និង N ដែលអាចសរសេរដូចខាងក្រោម i.e.
STR --> L¦N¦ (STR + L)¦(STR + N)
ផ្នែកក្បាលនៃអក្សរ - TR គឺជាវណ្ឌវង្កបិទដែលផ្សំឡើងដោយធាតុ E និងច្រវាក់ដូចជា STL និង STR ។
នៅក្នុងភាសា PDL រចនាសម្ព័ន្ធ TR ត្រូវបានពិពណ៌នាដោយកន្សោម
TR -> (STL - STR) * អ៊ី
ជាចុងក្រោយ យើងទទួលបានសេចក្ដីពណ៌នាខាងក្រោមនៃថ្នាក់អក្សរ A៖
SIMB A --> (STL + TR - STR),
STL --> R¦N¦ (STL + R)¦(STL + N)
STR --> L¦N¦ (STR + L)¦(STR + N)
TR -> (STL - STR) * អ៊ី
នីតិវិធីនៃការទទួលស្គាល់ក្នុងករណីនេះអាចត្រូវបានអនុវត្តដូចខាងក្រោម។
1. កន្សោមដែលត្រូវនឹងរូបភាពត្រូវបានប្រៀបធៀបជាមួយនឹងរចនាសម្ព័ន្ធយោង STL + TR - STR ។
2. ធាតុនីមួយៗនៃរចនាសម្ព័ន្ធ STL, TR, STR ប្រសិនបើអាចធ្វើទៅបាន i.e. ប្រសិនបើការពិពណ៌នានៃរូបភាពគឺអាចប្រៀបធៀបបានជាមួយនឹងស្តង់ដារ នោះកន្សោមរងខ្លះពីកន្សោម T(A) ត្រូវបានផ្គូផ្គង។ ឧទាហរណ៍,
សម្រាប់ A1៖ STL=R, STR=L, TR=(R-(L+N))*E
សម្រាប់ A2: STL = R + N, STR = L, TR = ((N + R) - L) * E
សម្រាប់ A3: STL = N + R, STR = L + N, TR = (R - L) * E 3 ។
កន្សោម STL, STR, TR ត្រូវបានប្រៀបធៀបជាមួយនឹងរចនាសម្ព័ន្ធយោងដែលត្រូវគ្នា។
4. ប្រសិនបើរចនាសម្ព័ន្ធនៃកន្សោម STL, STR, TR នីមួយៗត្រូវគ្នានឹងសេចក្តីយោងមួយ វាត្រូវបានសន្និដ្ឋានថារូបភាពជាកម្មសិទ្ធិរបស់ថ្នាក់អក្សរ A. ប្រសិនបើនៅដំណាក់កាល 2, 3, 4 មានភាពមិនស្របគ្នារវាងរចនាសម្ព័ន្ធ នៃកន្សោមដែលបានវិភាគ និងឯកសារយោង វាត្រូវបានសន្និដ្ឋានថារូបភាពមិនមែនជារបស់ SIMB class A. ការផ្គូផ្គងរចនាសម្ព័ន្ធកន្សោមអាចត្រូវបានធ្វើដោយប្រើភាសាក្បួនដោះស្រាយ LISP, PLANER, PROLOG និងភាសាសិប្បនិម្មិតស្រដៀងគ្នាផ្សេងទៀត។
នៅក្នុងឧទាហរណ៍ដែលកំពុងពិចារណា ខ្សែអក្សរ STL ទាំងអស់ត្រូវបានបង្កើតឡើងដោយតួអក្សរ N និង R ហើយខ្សែអក្សរ STR ត្រូវបានបង្កើតឡើងដោយតួអក្សរ L និង N ដែលត្រូវនឹងរចនាសម្ព័ន្ធដែលបានផ្តល់ឱ្យនៃខ្សែទាំងនេះ។ រចនាសម្ព័ន្ធ TR នៅក្នុងរូបភាពដែលបានពិចារណាក៏ត្រូវគ្នាទៅនឹងឯកសារយោងមួយផងដែរ ចាប់តាំងពី មាន "ភាពខុសគ្នា" នៃខ្សែប្រភេទ STL, STR, "គុណ" ដោយនិមិត្តសញ្ញា E.
ដូច្នេះហើយ យើងឈានដល់ការសន្និដ្ឋានថារូបភាពដែលបានពិចារណាជាកម្មសិទ្ធិរបស់ថ្នាក់ ស៊ីមប៊ីក.
ការសំយោគឧបករណ៍បញ្ជាដ្រាយអគ្គិសនី DC ដែលមិនច្បាស់នៅក្នុងបរិយាកាស "MatLab"
ការសំយោគឧបករណ៍បញ្ជា fuzzy ជាមួយនឹងការបញ្ចូលនិងទិន្នផលមួយ។
បញ្ហាគឺការទទួលបានដ្រាយដើម្បីធ្វើតាមការបញ្ចូលផ្សេងៗបានត្រឹមត្រូវ។ ការអភិវឌ្ឍន៍នៃសកម្មភាពត្រួតពិនិត្យត្រូវបានអនុវត្តដោយឧបករណ៍បញ្ជា fuzzy ដែលក្នុងនោះប្លុកមុខងារខាងក្រោមអាចត្រូវបានសម្គាល់តាមរចនាសម្ព័ន្ធ: fuzzifier, rule block និង defuzzifier ។
Fig.4 ដ្យាក្រាមមុខងារទូទៅនៃប្រព័ន្ធដែលមានអថេរភាសាពីរ។
 Fig.5 ដ្យាក្រាមគំនូសតាងនៃឧបករណ៍បញ្ជា fuzzy ជាមួយអថេរភាសាពីរ។
Fig.5 ដ្យាក្រាមគំនូសតាងនៃឧបករណ៍បញ្ជា fuzzy ជាមួយអថេរភាសាពីរ។
ក្បួនដោះស្រាយវត្ថុបញ្ជា fuzzy ក្នុងករណីទូទៅគឺជាការបំប្លែងអថេរបញ្ចូលរបស់ឧបករណ៍បញ្ជា fuzzy ទៅជាអថេរលទ្ធផលរបស់វាដោយប្រើនីតិវិធីទាក់ទងគ្នាដូចខាងក្រោមៈ
1. ការបំប្លែងអថេររូបវន្តធាតុចូលដែលទទួលបានពីការវាស់ស្ទង់ឧបករណ៍ចាប់សញ្ញាពីវត្ថុបញ្ជាទៅជាអថេរភាសាបញ្ចូលរបស់ឧបករណ៍បញ្ជា fuzzy;
ដំណើរការនៃសេចក្តីថ្លែងការណ៍តក្កវិជ្ជា ហៅថា ក្បួនភាសា ទាក់ទងនឹងការបញ្ចូល និងទិន្នផលអថេរភាសារបស់ឧបករណ៍បញ្ជា។
3. ការបំប្លែងអថេរភាសាលទ្ធផលរបស់ឧបករណ៍បញ្ជា fuzzy ទៅជាអថេរគ្រប់គ្រងរូបវន្ត។
ចូរយើងពិចារណាជាដំបូងករណីសាមញ្ញបំផុត នៅពេលដែលមានតែអថេរភាសាពីរប៉ុណ្ណោះដែលត្រូវបានណែនាំដើម្បីគ្រប់គ្រង servo drive៖
"មុំ" - អថេរបញ្ចូល;
"សកម្មភាពត្រួតពិនិត្យ" - អថេរលទ្ធផល។
យើងនឹងសំយោគឧបករណ៍បញ្ជានៅក្នុងបរិស្ថាន MatLab ដោយប្រើប្រអប់ឧបករណ៍ Fuzzy Logic ។ វាអនុញ្ញាតឱ្យអ្នកបង្កើតការសន្និដ្ឋានមិនច្បាស់ និងប្រព័ន្ធចំណាត់ថ្នាក់មិនច្បាស់នៅក្នុងបរិស្ថាន MatLab ជាមួយនឹងលទ្ធភាពនៃការរួមបញ្ចូលពួកវាទៅក្នុង Simulink ។ គោលគំនិតជាមូលដ្ឋាននៃប្រអប់ឧបករណ៍ Fuzzy Logic គឺ FIS-structure - Fuzzy Inference System។ រចនាសម្ព័ន្ធ FIS មានទិន្នន័យចាំបាច់ទាំងអស់សម្រាប់ការអនុវត្តការគូសផែនទីមុខងារ "ធាតុចូល-លទ្ធផល" ដោយផ្អែកលើការសន្និដ្ឋានឡូជីខលមិនច្បាស់យោងទៅតាមគ្រោងការណ៍ដែលបានបង្ហាញក្នុងរូបភព។ ៦.

រូបភាពទី 6. ការសន្និដ្ឋានមិនច្បាស់។
X - បញ្ចូលវ៉ិចទ័រច្បាស់; - វ៉ិចទ័រនៃសំណុំ fuzzy ដែលត្រូវគ្នាទៅនឹងវ៉ិចទ័របញ្ចូល X;
- លទ្ធផលនៃការសន្និដ្ឋានឡូជីខលក្នុងទម្រង់ជាវ៉ិចទ័រនៃសំណុំស្រពិចស្រពិល; Y - លទ្ធផលវ៉ិចទ័រច្បាស់។
ម៉ូឌុល fuzzy អនុញ្ញាតឱ្យអ្នកបង្កើតប្រព័ន្ធ fuzzy ពីរប្រភេទ - Mamdani និង Sugeno ។ នៅក្នុងប្រព័ន្ធប្រភេទ Mamdani មូលដ្ឋានចំណេះដឹងមានច្បាប់នៃទម្រង់ "ប្រសិនបើ x 1 = ទាប និង x 2 = មធ្យម នោះ y = ខ្ពស់". នៅក្នុងប្រព័ន្ធប្រភេទ Sugeno មូលដ្ឋានចំណេះដឹងមានច្បាប់នៃទម្រង់ "ប្រសិនបើ x 1 = ទាប និង x 2 = មធ្យម នោះ y = a 0 +a 1 x 1 +a 2 x 2 ". ដូច្នេះភាពខុសគ្នាសំខាន់រវាងប្រព័ន្ធ Mamdani និង Sugeno ស្ថិតនៅក្នុងវិធីផ្សេងគ្នានៃការកំណត់តម្លៃនៃអថេរលទ្ធផលនៅក្នុងច្បាប់ដែលបង្កើតជាមូលដ្ឋានចំណេះដឹង។ នៅក្នុងប្រព័ន្ធប្រភេទ Mamdani តម្លៃនៃអថេរលទ្ធផលត្រូវបានផ្តល់ដោយពាក្យស្រពិចស្រពិល នៅក្នុងប្រព័ន្ធប្រភេទ Sugeno - ជាការរួមបញ្ចូលគ្នាលីនេអ៊ែរនៃអថេរបញ្ចូល។ ក្នុងករណីរបស់យើងយើងនឹងប្រើប្រព័ន្ធ Sugeno ពីព្រោះ វាផ្តល់ប្រាក់កម្ចីដោយខ្លួនវាល្អប្រសើរជាងមុនក្នុងការបង្កើនប្រសិទ្ធភាព។
ដើម្បីគ្រប់គ្រងដ្រាយ servo អថេរភាសាពីរត្រូវបានណែនាំ: "កំហុស" (តាមទីតាំង) និង "សកម្មភាពត្រួតពិនិត្យ" ។ ទីមួយនៃពួកគេគឺជាការបញ្ចូល, ទីពីរគឺជាទិន្នផល។ ចូរកំណត់ពាក្យកំណត់សម្រាប់អថេរដែលបានបញ្ជាក់។
សមាសធាតុសំខាន់នៃការសន្និដ្ឋានមិនច្បាស់។ ឧបករណ៍បំភាន់។
សម្រាប់អថេរភាសានីមួយៗ យើងកំណត់សំណុំពាក្យជាមូលដ្ឋាននៃទម្រង់ ដែលរួមមានសំណុំ fuzzy ដែលអាចត្រូវបានកំណត់៖ អវិជ្ជមានខ្ពស់ អវិជ្ជមានទាប សូន្យ ទាបវិជ្ជមាន ខ្ពស់វិជ្ជមាន។
ជាដំបូង ចូរយើងកំណត់ប្រធានបទដោយអត្ថន័យនៃពាក្យ "កំហុសធំ" "កំហុសតូច" ជាដើម ដោយកំណត់មុខងារសមាជិកភាពសម្រាប់សំណុំ fuzzy ដែលត្រូវគ្នា។ នៅទីនេះ សម្រាប់ពេលនេះ មនុស្សម្នាក់អាចត្រូវបានដឹកនាំដោយភាពត្រឹមត្រូវដែលត្រូវការ ប៉ារ៉ាម៉ែត្រដែលគេស្គាល់សម្រាប់ថ្នាក់នៃសញ្ញាបញ្ចូល និងសុភវិនិច្ឆ័យ។ រហូតមកដល់ពេលនេះ គ្មាននរណាម្នាក់អាចផ្តល់នូវក្បួនដោះស្រាយរឹងណាមួយសម្រាប់ការជ្រើសរើសប៉ារ៉ាម៉ែត្រនៃមុខងារសមាជិកភាពនោះទេ។ ក្នុងករណីរបស់យើង "កំហុស" អថេរភាសានឹងមើលទៅដូចនេះ។
 រូប ៧. អថេរភាសាវិទ្យា "កំហុស" ។
រូប ៧. អថេរភាសាវិទ្យា "កំហុស" ។
វាងាយស្រួលជាងក្នុងការតំណាងឱ្យអថេរភាសា "ការគ្រប់គ្រង" ក្នុងទម្រង់ជាតារាង៖
តារាងទី 1
ប្លុកច្បាប់.
ពិចារណាពីលំដាប់នៃការកំណត់ច្បាប់មួយចំនួនដែលពិពណ៌នាអំពីស្ថានភាពមួយចំនួន៖
ជាឧទាហរណ៍ ឧបមាថា មុំទិន្នផលគឺស្មើនឹងសញ្ញាបញ្ចូល (ឧ. កំហុសគឺសូន្យ)។ ជាក់ស្តែងនេះគឺជាស្ថានភាពដែលចង់បានហើយដូច្នេះយើងមិនចាំបាច់ធ្វើអ្វីទេ (សកម្មភាពត្រួតពិនិត្យគឺសូន្យ) ។
ឥឡូវពិចារណាករណីមួយទៀត៖ កំហុសទីតាំងគឺធំជាងសូន្យ។ តាមធម្មជាតិ យើងត្រូវតែទូទាត់សងសម្រាប់វាដោយបង្កើតសញ្ញាត្រួតពិនិត្យវិជ្ជមានដ៏ធំមួយ។
នោះ។ ច្បាប់ចំនួនពីរត្រូវបានគូរឡើង ដែលអាចកំណត់ជាផ្លូវការដូចខាងក្រោម៖
ប្រសិនបើ error = null, បន្ទាប់មកសកម្មភាពត្រួតពិនិត្យ = សូន្យ។
ប្រសិនបើកំហុស = វិជ្ជមានធំ, បន្ទាប់មកសកម្មភាពត្រួតពិនិត្យ = វិជ្ជមានធំ។
 រូប ៨. ការបង្កើតការគ្រប់គ្រងដោយមានកំហុសវិជ្ជមានតូចមួយនៅក្នុងទីតាំង។
រូប ៨. ការបង្កើតការគ្រប់គ្រងដោយមានកំហុសវិជ្ជមានតូចមួយនៅក្នុងទីតាំង។
 Fig.9 ។ ការបង្កើតការគ្រប់គ្រងនៅកំហុសសូន្យតាមទីតាំង។
Fig.9 ។ ការបង្កើតការគ្រប់គ្រងនៅកំហុសសូន្យតាមទីតាំង។
តារាងខាងក្រោមបង្ហាញពីច្បាប់ទាំងអស់ដែលត្រូវគ្នានឹងស្ថានភាពទាំងអស់សម្រាប់ករណីដ៏សាមញ្ញនេះ។
តារាង 2
សរុបមក សម្រាប់ឧបករណ៍បញ្ជា fuzzy ជាមួយ n inputs និង 1 output ច្បាប់គ្រប់គ្រងអាចត្រូវបានកំណត់ តើចំនួន fuzzy sets សម្រាប់ការបញ្ចូល i-th នៅឯណា ប៉ុន្តែសម្រាប់ដំណើរការធម្មតារបស់ controller វាមិនចាំបាច់ប្រើទាំងអស់ដែលអាចធ្វើទៅបានទេ។ ច្បាប់ ប៉ុន្តែអ្នកអាចទទួលបានដោយចំនួនតិចនៃពួកគេ។ ក្នុងករណីរបស់យើង ច្បាប់ដែលអាចមានទាំង 5 ត្រូវបានប្រើដើម្បីបង្កើតជាសញ្ញាត្រួតពិនិត្យមិនច្បាស់។
ឧបករណ៍បំលែងសំឡេង។
ដូច្នេះផលប៉ះពាល់ជាលទ្ធផល U នឹងត្រូវបានកំណត់យោងទៅតាមការអនុវត្តច្បាប់ណាមួយ។ ប្រសិនបើស្ថានភាពកើតឡើងនៅពេលដែលច្បាប់ជាច្រើនត្រូវបានប្រតិបត្តិក្នុងពេលតែមួយ នោះសកម្មភាពលទ្ធផល U ត្រូវបានរកឃើញដោយយោងទៅតាមទំនាក់ទំនងដូចខាងក្រោមៈ
 ដែលជាកន្លែងដែល n គឺជាចំនួននៃច្បាប់ដែលបានកេះ (ការបន្លំដោយវិធីសាស្ត្រកណ្តាលតំបន់) u nគឺជាតម្លៃរូបវន្តនៃសញ្ញាបញ្ជាដែលត្រូវគ្នានឹងសំណុំ fuzzy នីមួយៗ UBO, UMo, យូZ, UMp, UBទំ. មUn(u)គឺជាកម្រិតនៃភាពជាកម្មសិទ្ធិរបស់សញ្ញាបញ្ជា u ទៅនឹងសំណុំ fuzzy ដែលត្រូវគ្នា Un=( UBO, UMo, យូZ, UMp, UBទំ) វាក៏មានវិធីសាស្រ្តផ្សេងទៀតនៃការ defuzzification នៅពេលដែលអថេរភាសាលទ្ធផលគឺសមាមាត្រទៅនឹងច្បាប់ "ខ្លាំង" ឬ "ខ្សោយ" ខ្លួនឯង។
ដែលជាកន្លែងដែល n គឺជាចំនួននៃច្បាប់ដែលបានកេះ (ការបន្លំដោយវិធីសាស្ត្រកណ្តាលតំបន់) u nគឺជាតម្លៃរូបវន្តនៃសញ្ញាបញ្ជាដែលត្រូវគ្នានឹងសំណុំ fuzzy នីមួយៗ UBO, UMo, យូZ, UMp, UBទំ. មUn(u)គឺជាកម្រិតនៃភាពជាកម្មសិទ្ធិរបស់សញ្ញាបញ្ជា u ទៅនឹងសំណុំ fuzzy ដែលត្រូវគ្នា Un=( UBO, UMo, យូZ, UMp, UBទំ) វាក៏មានវិធីសាស្រ្តផ្សេងទៀតនៃការ defuzzification នៅពេលដែលអថេរភាសាលទ្ធផលគឺសមាមាត្រទៅនឹងច្បាប់ "ខ្លាំង" ឬ "ខ្សោយ" ខ្លួនឯង។
ចូរយើងធ្វើត្រាប់តាមដំណើរការនៃការគ្រប់គ្រងដ្រាយអគ្គីសនីដោយប្រើឧបករណ៍បញ្ជា fuzzy ដែលបានពិពណ៌នាខាងលើ។
 Fig.10 ។ ប្លុកដ្យាក្រាមនៃប្រព័ន្ធនៅក្នុងបរិស្ថានmatlab.
Fig.10 ។ ប្លុកដ្យាក្រាមនៃប្រព័ន្ធនៅក្នុងបរិស្ថានmatlab.

Fig.11 ។ ដ្យាក្រាមរចនាសម្ព័នរបស់ឧបករណ៍បញ្ជាមិនច្បាស់នៅក្នុងបរិស្ថានmatlab.

Fig.12 ។ ដំណើរការបណ្តោះអាសន្ននៅសកម្មភាពមួយជំហាន។

អង្ករ។ 13. ដំណើរការបណ្តោះអាសន្នក្រោមការបញ្ចូលអាម៉ូនិកសម្រាប់គំរូមួយដែលមានឧបករណ៍បញ្ជា fuzzy ដែលមានអថេរភាសាបញ្ចូលមួយ។
ការវិភាគអំពីលក្ខណៈនៃដ្រាយជាមួយនឹងក្បួនដោះស្រាយគ្រប់គ្រងសំយោគបង្ហាញថាពួកគេនៅឆ្ងាយពីភាពល្អប្រសើរបំផុត និងអាក្រក់ជាងនៅក្នុងករណីនៃការសំយោគវត្ថុបញ្ជាដោយវិធីសាស្រ្តផ្សេងទៀត (ពេលវេលាគ្រប់គ្រងច្រើនពេកជាមួយនឹងឥទ្ធិពលមួយជំហាន និងកំហុសជាមួយនឹងអាម៉ូនិកមួយ) . នេះត្រូវបានពន្យល់ដោយការពិតដែលថាប៉ារ៉ាម៉ែត្រនៃមុខងារសមាជិកភាពត្រូវបានជ្រើសរើសតាមអំពើចិត្ត ហើយមានតែទំហំនៃកំហុសទីតាំងប៉ុណ្ណោះដែលត្រូវបានប្រើជាការបញ្ចូលឧបករណ៍បញ្ជា។ តាមធម្មជាតិ មិនអាចមានការនិយាយអំពីភាពល្អប្រសើរណាមួយនៃឧបករណ៍បញ្ជាដែលទទួលបាននោះទេ។ ដូច្នេះ ភារកិច្ចនៃការបង្កើនប្រសិទ្ធភាពឧបករណ៍បញ្ជា fuzzy ក្លាយជាពាក់ព័ន្ធដើម្បីសម្រេចបាននូវសូចនាករខ្ពស់បំផុតដែលអាចធ្វើបាននៃគុណភាពត្រួតពិនិត្យ។ ទាំងនោះ។ ភារកិច្ចគឺដើម្បីបង្កើនប្រសិទ្ធភាពមុខងារគោលបំណង f (a 1 ,a 2 …a n) ដែល 1 ,a 2 …a n គឺជាមេគុណដែលកំណត់ប្រភេទ និងលក្ខណៈរបស់ឧបករណ៍បញ្ជា fuzzy ។ ដើម្បីបង្កើនប្រសិទ្ធភាពឧបករណ៍បញ្ជា fuzzy យើងប្រើប្លុក ANFIS ពីបរិស្ថាន Matlab ។ ដូចគ្នានេះផងដែរ វិធីមួយក្នុងចំណោមវិធីដើម្បីកែលម្អលក្ខណៈរបស់ឧបករណ៍បញ្ជាអាចជាការបង្កើនចំនួនធាតុចូលរបស់វា។ នេះនឹងធ្វើឱ្យនិយតករកាន់តែមានភាពបត់បែន និងកែលម្អដំណើរការរបស់វា។ ចូរបន្ថែមអថេរភាសាបញ្ចូលមួយបន្ថែមទៀត - អត្រានៃការផ្លាស់ប្តូរនៃសញ្ញាបញ្ចូល (ដេរីវេរបស់វា)។ ដូច្នោះហើយចំនួនច្បាប់ក៏នឹងកើនឡើងផងដែរ។ បន្ទាប់មកដ្យាក្រាមសៀគ្វីរបស់និយតករនឹងមានទម្រង់៖

Fig.14 ដ្យាក្រាមគំនូសតាងនៃឧបករណ៍បញ្ជា fuzzy ដែលមានអថេរភាសាចំនួនបី។
ចូរឱ្យតម្លៃនៃល្បឿននៃសញ្ញាបញ្ចូល។ សំណុំពាក្យមូលដ្ឋាន Tn ត្រូវបានកំណត់ជា៖
Тn = ("អវិជ្ជមាន (VO)", "សូន្យ (Z)", "វិជ្ជមាន (VR)") ។
ទីតាំងនៃមុខងារសមាជិកភាពសម្រាប់អថេរភាសាទាំងអស់ត្រូវបានបង្ហាញក្នុងរូប។
Fig.15 ។ មុខងារសមាជិកភាពនៃអថេរភាសា "កំហុស" ។

Fig.16 ។ មុខងារសមាជិកភាពនៃអថេរភាសា "ល្បឿនសញ្ញាបញ្ចូល".
ដោយសារតែការបន្ថែមអថេរភាសាមួយបន្ថែមទៀត ចំនួននៃច្បាប់នឹងកើនឡើងដល់ 3x5=15។ គោលការណ៍នៃការចងក្រងរបស់ពួកគេគឺស្រដៀងគ្នាទាំងស្រុងទៅនឹងអ្វីដែលបានពិភាក្សាខាងលើ។ ពួកវាទាំងអស់ត្រូវបានបង្ហាញក្នុងតារាងខាងក្រោម៖
តារាងទី 3
| សញ្ញាមិនច្បាស់ ការគ្រប់គ្រង | កំហុសទីតាំង |
|||||
| ល្បឿន | ||||||
ឧទាហរណ៍ប្រសិនបើ ប្រសិនបើកំហុស = សូន្យ និងសញ្ញាបញ្ចូល ដេរីវេ = វិជ្ជមានធំ, បន្ទាប់មកសកម្មភាពត្រួតពិនិត្យ = អវិជ្ជមានតូច។
 Fig.17 ។ ការបង្កើតការគ្រប់គ្រងក្រោមអថេរភាសាចំនួនបី។
Fig.17 ។ ការបង្កើតការគ្រប់គ្រងក្រោមអថេរភាសាចំនួនបី។
ដោយសារតែការកើនឡើងនៃចំនួនធាតុចូល ហើយយោងទៅតាមច្បាប់ខ្លួនឯង រចនាសម្ព័ន្ធរបស់ឧបករណ៍បញ្ជា fuzzy ក៏នឹងកាន់តែស្មុគស្មាញផងដែរ។
 រូប ១៨. ដ្យាក្រាមរចនាសម្ព័នរបស់ឧបករណ៍បញ្ជា fuzzy ជាមួយនឹងការបញ្ចូលពីរ។
រូប ១៨. ដ្យាក្រាមរចនាសម្ព័នរបស់ឧបករណ៍បញ្ជា fuzzy ជាមួយនឹងការបញ្ចូលពីរ។
បន្ថែមគំនូរ

Fig.20 ។ ដំណើរការបណ្តោះអាសន្នក្រោមការបញ្ចូលអាម៉ូនិកសម្រាប់គំរូមួយដែលមានឧបករណ៍បញ្ជា fuzzy ដែលមានអថេរភាសាបញ្ចូលពីរ។

អង្ករ។ 21. សញ្ញាកំហុសនៅក្រោមការបញ្ចូលអាម៉ូនិកសម្រាប់ម៉ូដែលដែលមានឧបករណ៍បញ្ជា fuzzy ដែលមានអថេរភាសាបញ្ចូលពីរ។
តោះក្លែងធ្វើប្រតិបត្តិការរបស់ឧបករណ៍បញ្ជាមិនច្បាស់ជាមួយនឹងការបញ្ចូលពីរនៅក្នុងបរិស្ថាន Matlab ។ ដ្យាក្រាមប្លុកនៃគំរូនឹងដូចគ្នាបេះបិទដូចក្នុងរូប។ 19. ពីក្រាហ្វនៃដំណើរការបណ្តោះអាសន្នសម្រាប់ការបញ្ចូលអាម៉ូនិក វាអាចត្រូវបានគេមើលឃើញថាភាពត្រឹមត្រូវនៃប្រព័ន្ធបានកើនឡើងយ៉ាងខ្លាំង ប៉ុន្តែនៅពេលជាមួយគ្នានោះ លំយោលរបស់វាបានកើនឡើង ជាពិសេសនៅកន្លែងដែលដេរីវេនៃកូអរដោណេទិន្នផលមានទំនោរទៅ សូន្យ វាច្បាស់ណាស់ថាហេតុផលសម្រាប់បញ្ហានេះ ដូចដែលបានរៀបរាប់ខាងលើគឺជាជម្រើសដែលមិនសមស្របបំផុតនៃប៉ារ៉ាម៉ែត្រនៃមុខងារសមាជិកភាព ទាំងសម្រាប់អថេរភាសាបញ្ចូល និងទិន្នផល។ ដូច្នេះហើយ យើងបង្កើនប្រសិទ្ធភាពឧបករណ៍បញ្ជាមិនច្បាស់ដោយប្រើប្លុក ANFISedit នៅក្នុងបរិស្ថាន Matlab ។
ការបង្កើនប្រសិទ្ធភាពឧបករណ៍បញ្ជាមិនច្បាស់។
ពិចារណាលើការប្រើប្រាស់ក្បួនដោះស្រាយហ្សែនសម្រាប់ការបង្កើនប្រសិទ្ធភាពឧបករណ៍បញ្ជា fuzzy ។ ក្បួនដោះស្រាយហ្សែនគឺជាវិធីសាស្រ្តស្វែងរកការសម្របខ្លួនដែលត្រូវបានប្រើជាញឹកញាប់ក្នុងប៉ុន្មានឆ្នាំថ្មីៗនេះដើម្បីដោះស្រាយបញ្ហាបង្កើនប្រសិទ្ធភាពមុខងារ។ ពួកវាផ្អែកលើភាពស្រដៀងគ្នាទៅនឹងដំណើរការហ្សែននៃសារពាង្គកាយជីវសាស្ត្រ៖ ប្រជាជនជីវសាស្រ្តមានការរីកចម្រើនជាច្រើនជំនាន់ ដោយគោរពច្បាប់នៃការជ្រើសរើសធម្មជាតិ និងយោងទៅតាមគោលការណ៍នៃ "ការរស់រានមានជីវិតរបស់សមបំផុត" ដែលត្រូវបានរកឃើញដោយ Charles Darwin ។ តាមរយៈការធ្វើត្រាប់តាមដំណើរការនេះ ក្បួនដោះស្រាយហ្សែនអាច "វិវត្ត" ដំណោះស្រាយចំពោះបញ្ហាក្នុងពិភពពិត ប្រសិនបើពួកគេត្រូវបានសរសេរកូដត្រឹមត្រូវ។
ក្បួនដោះស្រាយហ្សែនដំណើរការជាមួយសំណុំនៃ "បុគ្គល" - ចំនួនប្រជាជនដែលនីមួយៗតំណាងឱ្យដំណោះស្រាយដែលអាចកើតមានចំពោះបញ្ហាដែលបានផ្តល់ឱ្យ។ បុគ្គលម្នាក់ៗត្រូវបានវាយតម្លៃដោយរង្វាស់នៃ "កាយសម្បទា" របស់វាយោងទៅតាម "ល្អ" ដំណោះស្រាយនៃបញ្ហាដែលត្រូវនឹងវា។ បុគ្គលដែលស័ក្តិសមបំផុតអាច "បន្តពូជ" កូនចៅដោយ "ការបង្កាត់ពូជ" ជាមួយបុគ្គលផ្សេងទៀតនៅក្នុងចំនួនប្រជាជន។ នេះនាំឱ្យមានការលេចឡើងនៃបុគ្គលថ្មីដែលរួមបញ្ចូលគ្នានូវលក្ខណៈមួយចំនួនដែលបានទទួលមរតកពីឪពុកម្តាយរបស់ពួកគេ។ បុគ្គលដែលស័ក្តិសមតិចបំផុតទំនងជាមិនសូវបន្តពូជទេ ដូច្នេះលក្ខណៈដែលពួកគេមាននឹងបាត់បន្តិចម្តងៗពីចំនួនប្រជាជន។
នេះជារបៀបដែលប្រជាជនថ្មីទាំងមូលនៃដំណោះស្រាយដែលអាចធ្វើទៅបានត្រូវបានបង្កើតឡើងវិញ ជ្រើសរើសអ្នកតំណាងដ៏ល្អបំផុតនៃជំនាន់មុន ឆ្លងកាត់ពួកគេ និងទទួលបានបុគ្គលថ្មីៗជាច្រើន។ ជំនាន់ថ្មីនេះមានសមាមាត្រខ្ពស់ជាងនៃលក្ខណៈដែលសមាជិកល្អនៃជំនាន់មុនមាន។ ដូច្នេះពីមួយជំនាន់ទៅមួយជំនាន់ លក្ខណៈល្អត្រូវបានចែកចាយពាសពេញប្រជាជន។ នៅទីបំផុត ប្រជាជននឹងបង្រួបបង្រួមគ្នាទៅនឹងដំណោះស្រាយដ៏ប្រសើរបំផុតចំពោះបញ្ហា។
មានវិធីជាច្រើនដើម្បីអនុវត្តគំនិតនៃការវិវត្តន៍ជីវសាស្រ្តក្នុងក្របខ័ណ្ឌនៃក្បួនដោះស្រាយហ្សែន។ ប្រពៃណី អាចត្រូវបានតំណាងក្នុងទម្រង់នៃដ្យាក្រាមប្លុកខាងក្រោមដែលបង្ហាញក្នុងរូបភាពទី 22 ដែល៖
1. ការចាប់ផ្តើមនៃចំនួនប្រជាជនដំបូង - ការបង្កើតចំនួននៃដំណោះស្រាយចំពោះបញ្ហាដែលដំណើរការបង្កើនប្រសិទ្ធភាពចាប់ផ្តើម។
2. ការអនុវត្តនៃប្រតិបត្តិករឆ្លងកាត់ និងការផ្លាស់ប្តូរ;
3.  លក្ខខណ្ឌបញ្ឈប់ - ជាធម្មតា ដំណើរការបង្កើនប្រសិទ្ធភាពត្រូវបានបន្តរហូតដល់ដំណោះស្រាយចំពោះបញ្ហាជាមួយនឹងភាពត្រឹមត្រូវដែលបានផ្តល់ឱ្យត្រូវបានរកឃើញ ឬរហូតដល់វាត្រូវបានបង្ហាញថាដំណើរការបានបង្រួបបង្រួមគ្នា (ឧ. វាមិនមានភាពប្រសើរឡើងក្នុងដំណោះស្រាយនៃបញ្ហាក្នុងរយៈពេលចុងក្រោយនេះ។ N ជំនាន់) ។
លក្ខខណ្ឌបញ្ឈប់ - ជាធម្មតា ដំណើរការបង្កើនប្រសិទ្ធភាពត្រូវបានបន្តរហូតដល់ដំណោះស្រាយចំពោះបញ្ហាជាមួយនឹងភាពត្រឹមត្រូវដែលបានផ្តល់ឱ្យត្រូវបានរកឃើញ ឬរហូតដល់វាត្រូវបានបង្ហាញថាដំណើរការបានបង្រួបបង្រួមគ្នា (ឧ. វាមិនមានភាពប្រសើរឡើងក្នុងដំណោះស្រាយនៃបញ្ហាក្នុងរយៈពេលចុងក្រោយនេះ។ N ជំនាន់) ។
នៅក្នុងបរិស្ថាន Matlab ក្បួនដោះស្រាយហ្សែនត្រូវបានតំណាងដោយប្រអប់ឧបករណ៍ដាច់ដោយឡែក ក៏ដូចជាដោយកញ្ចប់ ANFIS ។ ANFIS គឺជាអក្សរកាត់សម្រាប់ Adaptive-Network-Based Fuzzy Inference System - Adaptive Fuzzy Inference Network។ ANFIS គឺជាវ៉ារ្យ៉ង់ទីមួយនៃបណ្តាញសរសៃប្រសាទកូនកាត់ - បណ្តាញសរសៃប្រសាទនៃប្រភេទពិសេសនៃការផ្សព្វផ្សាយសញ្ញាផ្ទាល់។ ស្ថាបត្យកម្មនៃបណ្តាញ neuro-fuzzy គឺ isomorphic ទៅមូលដ្ឋានចំណេះដឹងមិនច្បាស់។ ការអនុវត្តខុសគ្នានៃបទដ្ឋានត្រីកោណ (គុណ និងប្រូបាប៊ីលីក OR) ក៏ដូចជាមុខងារសមាជិកភាពរលូនត្រូវបានប្រើនៅក្នុងបណ្តាញសរសៃប្រសាទ។ នេះធ្វើឱ្យវាអាចប្រើក្បួនដោះស្រាយហ្សែនបានលឿន និងរហ័សសម្រាប់ការបណ្តុះបណ្តាលបណ្តាញសរសៃប្រសាទដោយផ្អែកលើវិធីសាស្ត្រនៃការបន្តពូជពង្សដើម្បីសម្រួលបណ្តាញសរសៃប្រសាទ។ ស្ថាបត្យកម្ម និងច្បាប់សម្រាប់ប្រតិបត្តិការនៃស្រទាប់នីមួយៗនៃបណ្តាញ ANFIS ត្រូវបានពិពណ៌នាខាងក្រោម។
ANFIS អនុវត្តប្រព័ន្ធការសន្និដ្ឋានមិនច្បាស់របស់ Sugeno ជាបណ្តាញសរសៃប្រសាទដែលបញ្ជូនបន្ត 5 ស្រទាប់។ គោលបំណងនៃស្រទាប់មានដូចខាងក្រោម: ស្រទាប់ទីមួយគឺជាលក្ខខណ្ឌនៃអថេរបញ្ចូល; ស្រទាប់ទីពីរ - មុន (ក្បាលដី) នៃច្បាប់មិនច្បាស់; ស្រទាប់ទីបីគឺជាការធ្វើឱ្យធម្មតានៃកម្រិតនៃការបំពេញនៃច្បាប់; ស្រទាប់ទីបួនគឺជាការសន្និដ្ឋាននៃច្បាប់; ស្រទាប់ទីប្រាំគឺជាការប្រមូលផ្តុំនៃលទ្ធផលដែលទទួលបានដោយយោងទៅតាមច្បាប់ផ្សេងៗគ្នា។
ការបញ្ចូលបណ្តាញមិនត្រូវបានបែងចែកទៅជាស្រទាប់ដាច់ដោយឡែកទេ។ រូបភាពទី 23 បង្ហាញបណ្តាញ ANFIS ដែលមានអថេរបញ្ចូលមួយ ("កំហុស") និងក្បួនមិនច្បាស់ប្រាំ។ សម្រាប់ការវាយតម្លៃភាសានៃអថេរបញ្ចូល "កំហុស" ពាក្យ 5 ត្រូវបានប្រើ។

Fig.23 ។ រចនាសម្ព័ន្ធANFIS- បណ្តាញ។
ចូរយើងណែនាំសញ្ញាណខាងក្រោម ដែលចាំបាច់សម្រាប់ការបង្ហាញបន្ថែម៖
អនុញ្ញាតឱ្យក្លាយជាធាតុចូលនៃបណ្តាញ;
y - លទ្ធផលបណ្តាញ;
ក្បួនមិនច្បាស់ជាមួយលេខលំដាប់ r;
m - ចំនួននៃច្បាប់;
ពាក្យស្រពិចស្រពិលជាមួយមុខងារសមាជិកភាព ប្រើសម្រាប់ការវាយតម្លៃភាសានៃអថេរក្នុងក្បួន r-th (,);
ចំនួនពិតនៅក្នុងការសន្និដ្ឋាននៃច្បាប់ rth (,) ។
ANFIS-network មានមុខងារដូចខាងក្រោម។
ស្រទាប់ 1ថ្នាំងនីមួយៗនៃស្រទាប់ទីមួយតំណាងឱ្យពាក្យមួយជាមួយនឹងមុខងារសមាជិកភាពរាងកណ្តឹង។ ធាតុបញ្ចូលនៃបណ្តាញត្រូវបានភ្ជាប់ទៅលក្ខខណ្ឌរបស់ពួកគេតែប៉ុណ្ណោះ។ ចំនួនថ្នាំងនៅក្នុងស្រទាប់ទីមួយគឺស្មើនឹងផលបូកនៃ cardinalities នៃសំណុំពាក្យនៃអថេរបញ្ចូល។ លទ្ធផលនៃ node គឺជាកម្រិតនៃកម្មសិទ្ធិនៃតម្លៃនៃ input variable ទៅនឹងពាក្យ fuzzy ដែលត្រូវគ្នា៖
 ,
,
ដែល a, b, និង c គឺជាប៉ារ៉ាម៉ែត្រកំណត់រចនាសម្ព័ន្ធមុខងារសមាជិកភាព។
ស្រទាប់ 2ចំនួនថ្នាំងនៅក្នុងស្រទាប់ទីពីរគឺ m ។ ថ្នាំងនីមួយៗនៃស្រទាប់នេះត្រូវគ្នាទៅនឹងច្បាប់ស្រពិចស្រពិលមួយ។ ថ្នាំងនៃស្រទាប់ទីពីរត្រូវបានភ្ជាប់ទៅថ្នាំងទាំងនោះនៃស្រទាប់ទីមួយដែលបង្កើតជាបុព្វបទនៃច្បាប់ដែលត្រូវគ្នា។ ដូច្នេះថ្នាំងនីមួយៗនៃស្រទាប់ទីពីរអាចទទួលសញ្ញាបញ្ចូលពី 1 ដល់ n ។ លទ្ធផលនៃថ្នាំងគឺជាកម្រិតនៃការប្រតិបត្តិនៃច្បាប់ដែលត្រូវបានគណនាជាផលិតផលនៃសញ្ញាបញ្ចូល។ សម្គាល់លទ្ធផលនៃថ្នាំងនៃស្រទាប់នេះដោយ , .
ស្រទាប់ទី 3ចំនួនថ្នាំងនៅក្នុងស្រទាប់ទីបីក៏ m ។ ថ្នាំងនីមួយៗនៃស្រទាប់នេះគណនាកម្រិតដែលទាក់ទងនៃការបំពេញច្បាប់មិនច្បាស់៖
ស្រទាប់ទី 4ចំនួនថ្នាំងនៅក្នុងស្រទាប់ទី 4 ក៏មាន m ។ ថ្នាំងនីមួយៗត្រូវបានភ្ជាប់ទៅថ្នាំងមួយនៃស្រទាប់ទីបី ក៏ដូចជាការបញ្ចូលទាំងអស់នៃបណ្តាញ (ការភ្ជាប់ទៅធាតុបញ្ចូលមិនត្រូវបានបង្ហាញក្នុងរូបភាពទី 18)។ ថ្នាំងនៃស្រទាប់ទី 4 គណនាការរួមចំណែកនៃច្បាប់ស្រពិចស្រពិលមួយចំពោះលទ្ធផលបណ្តាញ៖
ស្រទាប់ 5ថ្នាំងតែមួយនៃស្រទាប់នេះសង្ខេបការរួមចំណែកនៃច្បាប់ទាំងអស់៖
![]() .
.
នីតិវិធីបណ្តុះបណ្តាលបណ្តាញសរសៃប្រសាទធម្មតាអាចត្រូវបានអនុវត្តដើម្បីលៃតម្រូវបណ្តាញ ANFIS ព្រោះវាប្រើតែមុខងារផ្សេងគ្នាប៉ុណ្ណោះ។ ជាធម្មតា ការរួមបញ្ចូលគ្នានៃជម្រាលជម្រាលក្នុងទម្រង់នៃការបន្តពូជ និងការ៉េតិចបំផុតត្រូវបានប្រើ។ ក្បួនដោះស្រាយ backpropagation កែតម្រូវប៉ារ៉ាម៉ែត្រនៃ rule antecedents i.e. មុខងារសមាជិកភាព។ មេគុណការសន្និដ្ឋាននៃច្បាប់ត្រូវបានប៉ាន់ប្រមាណដោយវិធីសាស្ត្រការេតិចបំផុត ព្រោះវាជាប់ទាក់ទងនឹងលទ្ធផលបណ្តាញ។ ការធ្វើឡើងវិញម្តងៗនៃនីតិវិធីសម្រួលត្រូវបានអនុវត្តជាពីរជំហាន។ នៅដំណាក់កាលដំបូង គំរូបណ្តុះបណ្តាលមួយត្រូវបានផ្តល់អាហារដល់ធាតុចូល ហើយប៉ារ៉ាម៉ែត្រដ៏ល្អប្រសើរនៃថ្នាំងនៃស្រទាប់ទី 4 ត្រូវបានរកឃើញពីភាពមិនស្របគ្នារវាងឥរិយាបថដែលចង់បាន និងជាក់ស្តែងនៃបណ្តាញដោយប្រើវិធីសាស្ត្រការ៉េតិចបំផុតដដែលៗ។ នៅដំណាក់កាលទីពីរ ភាពខុសគ្នានៃសំណល់ត្រូវបានផ្ទេរពីទិន្នផលបណ្តាញទៅកាន់ធាតុបញ្ចូល ហើយប៉ារ៉ាម៉ែត្រនៃថ្នាំងនៃស្រទាប់ទីមួយត្រូវបានកែប្រែដោយវិធីសាស្ត្រ backpropagation កំហុស។ ទន្ទឹមនឹងនេះមេគុណសេចក្តីសន្និដ្ឋាននៃច្បាប់ដែលបានរកឃើញនៅដំណាក់កាលដំបូងមិនផ្លាស់ប្តូរទេ។ នីតិវិធីកែតម្រូវឡើងវិញបន្តរហូតដល់សំណល់លើសពីតម្លៃដែលបានកំណត់ទុកជាមុន។ ដើម្បីសម្រួលមុខងារសមាជិកភាព បន្ថែមពីលើវិធីសាស្ត្របង្កើតកំហុស ក្បួនដោះស្រាយបង្កើនប្រសិទ្ធភាពផ្សេងទៀតអាចត្រូវបានប្រើ ឧទាហរណ៍ វិធីសាស្ត្រ Levenberg-Marquardt ។

Fig.24 ។ ANFIS កែសម្រួលកន្លែងធ្វើការ។
ឥឡូវនេះសូមឱ្យយើងព្យាយាមបង្កើនប្រសិទ្ធភាពឧបករណ៍បញ្ជាមិនច្បាស់សម្រាប់សកម្មភាពមួយជំហាន។ ដំណើរការបណ្តោះអាសន្នដែលចង់បានគឺប្រហែលដូចខាងក្រោម៖

Fig.25 ។ ដំណើរការផ្លាស់ប្តូរដែលចង់បាន។
ពីក្រាហ្វដែលបង្ហាញក្នុងរូប។ វាធ្វើតាមដែលថាភាគច្រើននៃពេលវេលាម៉ាស៊ីនគួរតែដំណើរការដោយថាមពលពេញលេញដើម្បីធានាបាននូវល្បឿនអតិបរមា ហើយនៅពេលជិតដល់តម្លៃដែលចង់បាន វាគួរតែបន្ថយល្បឿនដោយរលូន។ ដោយបានដឹកនាំដោយការពិចារណាដ៏សាមញ្ញទាំងនេះ យើងនឹងយកគំរូនៃតម្លៃខាងក្រោមជាការបណ្តុះបណ្តាលមួយដែលបង្ហាញខាងក្រោមក្នុងទម្រង់ជាតារាង៖
តារាងទី 4
| តម្លៃកំហុស | តម្លៃគ្រប់គ្រង |
| តម្លៃកំហុស | តម្លៃគ្រប់គ្រង |
| តម្លៃកំហុស | តម្លៃគ្រប់គ្រង |

Fig.26 ។ ប្រភេទនៃគំរូបណ្តុះបណ្តាល។
ការបណ្តុះបណ្តាលនឹងត្រូវបានអនុវត្តនៅ 100 ជំហាន។ នេះគឺច្រើនជាងគ្រប់គ្រាន់សម្រាប់ការបញ្ចូលគ្នានៃវិធីសាស្រ្តដែលបានប្រើ។

Fig.27 ។ ដំណើរការនៃការរៀនបណ្តាញសរសៃប្រសាទ។
នៅក្នុងដំណើរការសិក្សា ប៉ារ៉ាម៉ែត្រនៃមុខងារសមាជិកភាពត្រូវបានបង្កើតឡើងតាមរបៀបដែលជាមួយនឹងតម្លៃកំហុសដែលបានផ្តល់ឱ្យ ឧបករណ៍បញ្ជាបង្កើតការត្រួតពិនិត្យចាំបាច់។ នៅក្នុងផ្នែករវាងចំនុច nodal ភាពអាស្រ័យនៃការគ្រប់គ្រងលើកំហុសគឺជា interpolation នៃទិន្នន័យតារាង។ វិធីសាស្រ្ត interpolation អាស្រ័យលើរបៀបដែលបណ្តាញសរសៃប្រសាទត្រូវបានបណ្តុះបណ្តាល។ ជាការពិត បន្ទាប់ពីការបណ្តុះបណ្តាល គំរូឧបករណ៍បញ្ជា fuzzy អាចត្រូវបានតំណាងថាជាមុខងារមិនមែនលីនេអ៊ែរនៃអថេរមួយ ក្រាហ្វដែលត្រូវបានបង្ហាញខាងក្រោម។

Fig.28 ។ គ្រោងនៃការពឹងផ្អែកនៃការគ្រប់គ្រងពីកំហុសទៅទីតាំងខាងក្នុងនិយតករ។
ដោយបានរក្សាទុកប៉ារ៉ាម៉ែត្រដែលបានរកឃើញនៃមុខងារសមាជិកភាព យើងក្លែងធ្វើប្រព័ន្ធជាមួយនឹងឧបករណ៍បញ្ជា fuzzy ដែលបានធ្វើឱ្យប្រសើរ។


អង្ករ។ 29. ដំណើរការបណ្តោះអាសន្នក្រោមការបញ្ចូលអាម៉ូនិកសម្រាប់គំរូជាមួយនឹងឧបករណ៍បញ្ជា fuzzy ដែលត្រូវបានធ្វើឱ្យប្រសើរដែលមានអថេរភាសាបញ្ចូលមួយ។
Fig.30 ។ សញ្ញាកំហុសនៅក្រោមការបញ្ចូលអាម៉ូនិកសម្រាប់ម៉ូដែលដែលមានឧបករណ៍បញ្ជា fuzzy ដែលមានអថេរភាសាបញ្ចូលពីរ។
វាធ្វើតាមពីក្រាហ្វដែលការបង្កើនប្រសិទ្ធភាពនៃឧបករណ៍បញ្ជា fuzzy ដោយការបណ្តុះបណ្តាលបណ្តាញសរសៃប្រសាទបានជោគជ័យ។ ការថយចុះគួរឱ្យកត់សម្គាល់នៃភាពប្រែប្រួលនិងទំហំនៃកំហុស។ ដូច្នេះ ការប្រើប្រាស់បណ្តាញសរសៃប្រសាទគឺសមហេតុផលណាស់សម្រាប់ការបង្កើនប្រសិទ្ធភាពឧបករណ៍បញ្ជា គោលការណ៍ដែលផ្អែកលើតក្កវិជ្ជាមិនច្បាស់។ ទោះបីជាយ៉ាងណាក៏ដោយ សូម្បីតែឧបករណ៍បញ្ជាដែលបង្កើនប្រសិទ្ធភាពក៏មិនអាចបំពេញតម្រូវការសម្រាប់ភាពត្រឹមត្រូវបានដែរ ដូច្នេះគួរពិចារណាវិធីសាស្ត្រត្រួតពិនិត្យមួយផ្សេងទៀត នៅពេលដែលឧបករណ៍បញ្ជាមិនច្បាស់មិនគ្រប់គ្រងវត្ថុដោយផ្ទាល់ ប៉ុន្តែរួមបញ្ចូលគ្នានូវច្បាប់គ្រប់គ្រងជាច្រើនអាស្រ័យលើស្ថានភាព។
ថ្ងៃអាទិត្យ ទី២៩ ខែមីនា ឆ្នាំ២០១៥
បច្ចុប្បន្ននេះ មានកិច្ចការជាច្រើនដែលតម្រូវឱ្យធ្វើការសម្រេចចិត្តមួយចំនួន អាស្រ័យលើវត្តមានរបស់វត្ថុក្នុងរូបភាព ឬដើម្បីចាត់ថ្នាក់វា។ សមត្ថភាពក្នុងការ "ទទួលស្គាល់" ត្រូវបានចាត់ទុកថាជាទ្រព្យសម្បត្តិសំខាន់នៃជីវសាស្រ្តខណៈពេលដែលប្រព័ន្ធកុំព្យូទ័រមិនមានកម្មសិទ្ធិពេញលេញនោះទេ។
ពិចារណាធាតុទូទៅនៃគំរូចំណាត់ថ្នាក់។
ថ្នាក់- សំណុំនៃវត្ថុដែលមានលក្ខណៈសម្បត្តិរួម។ សម្រាប់វត្ថុនៃថ្នាក់ដូចគ្នា វត្តមាននៃ "ភាពស្រដៀងគ្នា" ត្រូវបានសន្មត់។ សម្រាប់កិច្ចការទទួលស្គាល់ ចំនួនថ្នាក់តាមអំពើចិត្តអាចត្រូវបានកំណត់ច្រើនជាង 1. ចំនួនថ្នាក់ត្រូវបានតំណាងដោយលេខ S. ថ្នាក់នីមួយៗមានស្លាកថ្នាក់កំណត់អត្តសញ្ញាណរៀងខ្លួន។
ចំណាត់ថ្នាក់- ដំណើរការនៃការផ្តល់ class labels ទៅ objects យោងទៅតាមការពណ៌នាខ្លះនៃ properties នៃ objects ទាំងនេះ។ ឧបករណ៍ចាត់ថ្នាក់គឺជាឧបករណ៍ដែលទទួលសំណុំនៃលក្ខណៈពិសេសរបស់វត្ថុជាការបញ្ចូល និងបង្កើតស្លាកថ្នាក់ជាលទ្ធផល។
ការផ្ទៀងផ្ទាត់- ដំណើរការនៃការផ្គូផ្គងវត្ថុវត្ថុមួយជាមួយនឹងគំរូវត្ថុតែមួយ ឬការពិពណ៌នាថ្នាក់។
នៅក្រោម វិធីយើងនឹងយល់ពីឈ្មោះនៃតំបន់នៅក្នុងលំហនៃគុណលក្ខណៈ ដែលវត្ថុ ឬបាតុភូតជាច្រើននៃពិភពសម្ភារៈត្រូវបានបង្ហាញ។ សញ្ញា- ការពិពណ៌នាបរិមាណនៃទ្រព្យសម្បត្តិជាក់លាក់នៃវត្ថុ ឬបាតុភូតដែលកំពុងសិក្សា។
ចន្លោះលក្ខណៈពិសេសនេះគឺជាទំហំ N-dimensional ដែលបានកំណត់សម្រាប់ភារកិច្ចទទួលស្គាល់ដែលបានផ្តល់ឱ្យ ដែល N គឺជាចំនួនថេរនៃលក្ខណៈវាស់វែងសម្រាប់វត្ថុណាមួយ។ វ៉ិចទ័រពីទំហំលក្ខណៈ x ដែលត្រូវគ្នានឹងវត្ថុនៃបញ្ហាការទទួលស្គាល់គឺជាវ៉ិចទ័រវិមាត្រ N ដែលមានសមាសភាគ (x_1,x_2,…,x_N) ដែលជាតម្លៃនៃលក្ខណៈពិសេសសម្រាប់វត្ថុដែលបានផ្ដល់។
ម្យ៉ាងវិញទៀត ការទទួលស្គាល់លំនាំអាចត្រូវបានកំណត់ថាជាការចាត់ចែងទិន្នន័យដំបូងទៅថ្នាក់ជាក់លាក់មួយ ដោយទាញយកលក្ខណៈសំខាន់ៗ ឬលក្ខណៈសម្បត្តិដែលកំណត់លក្ខណៈទិន្នន័យនេះពីទំហំទូទៅនៃព័ត៌មានលម្អិតដែលមិនពាក់ព័ន្ធ។
ឧទាហរណ៍នៃបញ្ហាចំណាត់ថ្នាក់គឺ៖
- ការទទួលស្គាល់តួអក្សរ;
- ការទទួលស្គាល់ការនិយាយ;
- បង្កើតការធ្វើរោគវិនិច្ឆ័យវេជ្ជសាស្រ្ត;
- ការព្យាករណ៍អាកាសធាតុ;
- ការទទួលស្គាល់មុខ
- ការចាត់ថ្នាក់នៃឯកសារជាដើម។
ភាគច្រើនជាញឹកញាប់ សម្ភារៈប្រភពគឺជារូបភាពដែលទទួលបានពីកាមេរ៉ា។ ភារកិច្ចអាចត្រូវបានបង្កើតជាការទទួលបានលក្ខណៈពិសេសវ៉ិចទ័រសម្រាប់ថ្នាក់នីមួយៗនៅក្នុងរូបភាពដែលបានពិចារណា។ ដំណើរការអាចត្រូវបានមើលថាជាដំណើរការសរសេរកូដ ដែលមាននៅក្នុងការកំណត់តម្លៃទៅលក្ខណៈពិសេសនីមួយៗពីទំហំមុខងារសម្រាប់ថ្នាក់នីមួយៗ។
ប្រសិនបើយើងពិចារណា 2 ថ្នាក់នៃវត្ថុ: មនុស្សពេញវ័យនិងកុមារ។ ជាលក្ខណៈពិសេស អ្នកអាចជ្រើសរើសកម្ពស់ និងទម្ងន់បាន។ ដូចរូបខាងក្រោម ថ្នាក់ទាំងពីរនេះបង្កើតជាសំណុំមិនប្រសព្វគ្នាពីរ ដែលអាចត្រូវបានពន្យល់ដោយលក្ខណៈពិសេសដែលបានជ្រើសរើស។ ទោះយ៉ាងណាក៏ដោយ វាមិនតែងតែអាចជ្រើសរើសប៉ារ៉ាម៉ែត្រដែលបានវាស់វែងត្រឹមត្រូវជាលក្ខណៈនៃថ្នាក់នោះទេ។ ជាឧទាហរណ៍ ប៉ារ៉ាម៉ែត្រដែលបានជ្រើសរើសមិនស័ក្តិសមសម្រាប់ការបង្កើតថ្នាក់ដែលមិនត្រួតស៊ីគ្នានៃអ្នកលេងបាល់ទាត់ និងអ្នកលេងបាល់បោះនោះទេ។
កិច្ចការទី 2 នៃការទទួលស្គាល់គឺការជ្រើសរើសលក្ខណៈពិសេស ឬលក្ខណៈសម្បត្តិពីរូបភាពដើម។ ភារកិច្ចនេះអាចត្រូវបានកំណត់គុណលក្ខណៈដំណើរការមុន។ ប្រសិនបើយើងពិចារណាលើភារកិច្ចនៃការទទួលស្គាល់ការនិយាយ យើងអាចបែងចែកលក្ខណៈដូចជាស្រៈ និងព្យញ្ជនៈ។ គុណលក្ខណៈត្រូវតែជាលក្ខណៈលក្ខណៈនៃថ្នាក់ជាក់លាក់មួយ ខណៈពេលដែលវាជារឿងធម្មតាសម្រាប់ថ្នាក់នេះ។ សញ្ញាដែលកំណត់លក្ខណៈខុសគ្នារវាង - សញ្ញាអន្តរថ្នាក់។ លក្ខណៈពិសេសទូទៅសម្រាប់ថ្នាក់ទាំងអស់មិនផ្ទុកព័ត៌មានដែលមានប្រយោជន៍ និងមិនត្រូវបានចាត់ទុកថាជាលក្ខណៈពិសេសនៅក្នុងបញ្ហានៃការទទួលស្គាល់នោះទេ។ ជម្រើសនៃលក្ខណៈពិសេសគឺជាកិច្ចការសំខាន់មួយដែលត្រូវបានផ្សារភ្ជាប់ជាមួយនឹងការសាងសង់ប្រព័ន្ធទទួលស្គាល់។
បន្ទាប់ពីលក្ខណៈពិសេសត្រូវបានកំណត់វាចាំបាច់ដើម្បីកំណត់នីតិវិធីការសម្រេចចិត្តដ៏ល្អប្រសើរសម្រាប់ការចាត់ថ្នាក់។ ពិចារណាប្រព័ន្ធទទួលស្គាល់លំនាំដែលបានរចនាឡើងដើម្បីទទួលស្គាល់ថ្នាក់ M ផ្សេងៗ តំណាងថា m_1,m_2,…,m 3. បន្ទាប់មកយើងអាចសន្មត់ថាទំហំរូបភាពមានតំបន់ M ដែលនីមួយៗមានចំណុចដែលត្រូវគ្នានឹងរូបភាពពីថ្នាក់មួយ។ បន្ទាប់មកបញ្ហានៃការទទួលស្គាល់អាចត្រូវបានចាត់ទុកថាជាការសាងសង់ព្រំដែនបំបែកថ្នាក់ M ដោយផ្អែកលើវ៉ិចទ័ររង្វាស់ដែលបានទទួលយក។
ដំណោះស្រាយនៃបញ្ហានៃការដំណើរការរូបភាពជាមុន ការទាញយកលក្ខណៈពិសេស និងបញ្ហានៃការទទួលបានដំណោះស្រាយដ៏ល្អប្រសើរ និងការចាត់ថ្នាក់ជាធម្មតាត្រូវបានផ្សារភ្ជាប់ជាមួយនឹងតម្រូវការដើម្បីវាយតម្លៃប៉ារ៉ាម៉ែត្រមួយចំនួន។ នេះនាំឱ្យមានបញ្ហានៃការប៉ាន់ប្រមាណប៉ារ៉ាម៉ែត្រ។ លើសពីនេះ វាច្បាស់ណាស់ថាការទាញយកលក្ខណៈពិសេសអាចប្រើព័ត៌មានបន្ថែមដោយផ្អែកលើលក្ខណៈនៃថ្នាក់។
ការប្រៀបធៀបវត្ថុអាចត្រូវបានធ្វើឡើងនៅលើមូលដ្ឋាននៃការតំណាងរបស់ពួកគេនៅក្នុងទម្រង់នៃវ៉ិចទ័រវាស់វែង។ វាងាយស្រួលតំណាងឱ្យទិន្នន័យវាស់វែងជាចំនួនពិត។ បន្ទាប់មកភាពស្រដៀងគ្នានៃវ៉ិចទ័រលក្ខណៈនៃវត្ថុពីរអាចត្រូវបានពិពណ៌នាដោយប្រើចម្ងាយ Euclidean ។

ដែល d គឺជាវិមាត្រនៃវ៉ិចទ័រលក្ខណៈ។
មាន 3 ក្រុមនៃវិធីសាស្រ្តសម្គាល់គំរូ:
- ការប្រៀបធៀបគំរូ. ក្រុមនេះរួមបញ្ចូលការចាត់ថ្នាក់តាមមធ្យោបាយជិតបំផុត ចំណាត់ថ្នាក់តាមចម្ងាយទៅអ្នកជិតខាងដែលនៅជិតបំផុត។ វិធីសាស្ត្រទទួលស្គាល់រចនាសម្ព័ន្ធក៏អាចរួមបញ្ចូលក្នុងក្រុមប្រៀបធៀបគំរូផងដែរ។
- វិធីសាស្រ្តស្ថិតិ. ដូចដែលឈ្មោះបង្កប់ន័យ វិធីសាស្ត្រស្ថិតិប្រើព័ត៌មានស្ថិតិមួយចំនួននៅពេលដោះស្រាយបញ្ហាការទទួលស្គាល់។ វិធីសាស្ត្រកំណត់ពីកម្មសិទ្ធិរបស់វត្ថុទៅថ្នាក់ជាក់លាក់មួយដោយផ្អែកលើប្រូបាប៊ីលីតេ។ ក្នុងករណីខ្លះ វាកើតឡើងដើម្បីកំណត់ប្រូបាប៊ីលីតេក្រោយនៃវត្ថុដែលជាកម្មសិទ្ធិរបស់ថ្នាក់ជាក់លាក់មួយ ផ្តល់ថាលក្ខណៈនៃវត្ថុនេះបានយកសមស្រប។ តម្លៃ។ ឧទាហរណ៍មួយគឺវិធីសាស្រ្តនៃការសម្រេចចិត្តរបស់ Bayesian ។
- បណ្តាញសរសៃប្រសាទ. ថ្នាក់ដាច់ដោយឡែកនៃវិធីសាស្រ្តទទួលស្គាល់។ លក្ខណៈពិសេសប្លែកពីអ្នកដទៃគឺសមត្ថភាពក្នុងការរៀន។
ការចាត់ថ្នាក់តាមមធ្យោបាយជិតបំផុត។
នៅក្នុងវិធីសាស្រ្តបុរាណនៃការទទួលស្គាល់លំនាំដែលក្នុងនោះវត្ថុមិនស្គាល់សម្រាប់ការចាត់ថ្នាក់ត្រូវបានតំណាងជាវ៉ិចទ័រនៃលក្ខណៈបឋម។ ប្រព័ន្ធទទួលស្គាល់ផ្អែកលើលក្ខណៈពិសេសអាចត្រូវបានបង្កើតឡើងតាមវិធីផ្សេងៗ។ វ៉ិចទ័រទាំងនេះអាចដឹងដល់ប្រព័ន្ធជាមុន ដែលជាលទ្ធផលនៃការបណ្តុះបណ្តាល ឬព្យាករណ៍ក្នុងពេលវេលាជាក់ស្តែងដោយផ្អែកលើគំរូមួយចំនួន។
ក្បួនដោះស្រាយការចាត់ថ្នាក់សាមញ្ញមានទិន្នន័យយោងថ្នាក់ជាក្រុមដោយប្រើវ៉ិចទ័ររំពឹងថ្នាក់ (មធ្យម)។

ដែល x(i,j) គឺជាលក្ខណៈយោង j-th នៃថ្នាក់ i, n_j គឺជាចំនួនវ៉ិចទ័រយោងនៃថ្នាក់ i ។
បន្ទាប់មក វត្ថុមិនស្គាល់នឹងជាកម្មសិទ្ធិរបស់ថ្នាក់ i ប្រសិនបើវានៅជិតវ៉ិចទ័ររំពឹងទុកនៃថ្នាក់ i ជាងវ៉ិចទ័ររំពឹងទុកនៃថ្នាក់ផ្សេងទៀត។ វិធីសាស្រ្តនេះគឺសមរម្យសម្រាប់បញ្ហាដែលចំណុចនៃថ្នាក់នីមួយៗមានទីតាំងនៅបង្រួម និងឆ្ងាយពីចំណុចនៃថ្នាក់ផ្សេងទៀត។

ការលំបាកនឹងកើតឡើងប្រសិនបើថ្នាក់មានរចនាសម្ព័ន្ធស្មុគស្មាញបន្តិចឧទាហរណ៍ដូចក្នុងរូប។ ក្នុងករណីនេះ ថ្នាក់ទី 2 ត្រូវបានបែងចែកជាពីរផ្នែកដែលមិនត្រួតគ្នា ដែលត្រូវបានពិពណ៌នាមិនល្អដោយតម្លៃមធ្យមមួយ។ ផងដែរ ថ្នាក់ទី 3 គឺវែងពេក គំរូនៃថ្នាក់ទី 3 ដែលមានតម្លៃធំនៃកូអរដោនេ x_2 គឺនៅជិតតម្លៃមធ្យមនៃថ្នាក់ទី 1 ជាងថ្នាក់ទី 3 ។

បញ្ហាដែលបានពិពណ៌នានៅក្នុងករណីខ្លះអាចត្រូវបានដោះស្រាយដោយការផ្លាស់ប្តូរការគណនាចម្ងាយ។
យើងនឹងពិចារណាពីលក្ខណៈនៃ "ការខ្ចាត់ខ្ចាយ" នៃតម្លៃថ្នាក់ - σ_i តាមទិសដៅកូអរដោនេនីមួយៗ i ។ គម្លាតស្តង់ដារគឺស្មើនឹងឫសការ៉េនៃវ៉ារ្យង់។ ចម្ងាយ Euclidean ដែលបានធ្វើមាត្រដ្ឋានរវាងវ៉ិចទ័រ x និងវ៉ិចទ័ររំពឹងទុក x_c គឺ

រូបមន្តពីចម្ងាយនេះនឹងកាត់បន្ថយចំនួនកំហុសក្នុងចំណាត់ថ្នាក់ ប៉ុន្តែតាមពិត បញ្ហាភាគច្រើនមិនអាចតំណាងដោយថ្នាក់សាមញ្ញបែបនេះទេ។
ការចាត់ថ្នាក់តាមចម្ងាយទៅអ្នកជិតខាងដែលនៅជិតបំផុត។
វិធីសាស្រ្តមួយផ្សេងទៀតក្នុងការចាត់ថ្នាក់គឺត្រូវកំណត់វ៉ិចទ័រ x ដែលមិនស្គាល់ទៅថ្នាក់ដែលវ៉ិចទ័រនេះនៅជិតបំផុតទៅនឹងគំរូដាច់ដោយឡែកមួយ។ ច្បាប់នេះត្រូវបានគេហៅថាច្បាប់អ្នកជិតខាងដែលនៅជិតបំផុត។ ការចាត់ថ្នាក់អ្នកជិតខាងដែលនៅជិតបំផុតអាចមានប្រសិទ្ធភាពជាង សូម្បីតែនៅពេលដែលថ្នាក់ស្មុគស្មាញ ឬនៅពេលដែលថ្នាក់ជាន់គ្នាក៏ដោយ។
វិធីសាស្រ្តនេះមិនតម្រូវឱ្យមានការសន្មត់អំពីគំរូចែកចាយនៃវ៉ិចទ័រលក្ខណៈនៅក្នុងលំហទេ។ ក្បួនដោះស្រាយប្រើតែព័ត៌មានអំពីគំរូឯកសារយោងដែលគេស្គាល់ប៉ុណ្ណោះ។ វិធីសាស្រ្តដំណោះស្រាយគឺផ្អែកលើការគណនាចម្ងាយ x ទៅនឹងគំរូនីមួយៗក្នុងមូលដ្ឋានទិន្នន័យ និងស្វែងរកចម្ងាយអប្បបរមា។ អត្ថប្រយោជន៍នៃវិធីសាស្រ្តនេះគឺជាក់ស្តែង:
- នៅពេលណាមួយ អ្នកអាចបន្ថែមគំរូថ្មីទៅក្នុងមូលដ្ឋានទិន្នន័យ។
- រចនាសម្ព័ន្ធទិន្នន័យដើមឈើ និងក្រឡាចត្រង្គកាត់បន្ថយចំនួនចម្ងាយដែលបានគណនា។
លើសពីនេះ ដំណោះស្រាយនឹងកាន់តែប្រសើរ ប្រសិនបើអ្នករកមើលនៅក្នុងមូលដ្ឋានទិន្នន័យ មិនមែនសម្រាប់អ្នកជិតខាងដែលនៅជិតបំផុតនោះទេ ប៉ុន្តែសម្រាប់ k ។ បន្ទាប់មក សម្រាប់ k > 1 វាផ្តល់នូវគំរូដ៏ល្អបំផុតនៃការចែកចាយវ៉ិចទ័រនៅក្នុងលំហ d-dimensional ។ ទោះជាយ៉ាងណាក៏ដោយការប្រើប្រាស់ប្រកបដោយប្រសិទ្ធភាពនៃតម្លៃ k អាស្រ័យលើថាតើមានគ្រប់គ្រាន់នៅក្នុងតំបន់នីមួយៗនៃលំហ។ ប្រសិនបើមានច្រើនជាងពីរថ្នាក់ នោះវាពិបាកជាងក្នុងការសម្រេចចិត្តត្រឹមត្រូវ។
អក្សរសិល្ប៍
- M. Castrillon, ។ O. Deniz, . D. Hernández និង J. Lorenzo, “ការប្រៀបធៀបនៃឧបករណ៍ចាប់សញ្ញាមុខ និងផ្ទៃមុខ ដោយផ្អែកលើក្របខ័ណ្ឌការរកឃើញវត្ថុទូទៅ Viola-Jones” International Journal of Computer Vision, លេខ 22, ទំព័រ។ ៤៨១-៤៩៤ ឆ្នាំ ២០១១។
- Y.-Q. Wang, "ការវិភាគនៃក្បួនដោះស្រាយ Viola-Jones Face Detection Algorithm," IPOL Journal, 2013 ។
- L. Shapiro និង D. Stockman, ចក្ខុវិស័យកុំព្យូទ័រ, Binom ។ មន្ទីរពិសោធន៍ចំណេះដឹង ឆ្នាំ ២០០៦។
- Z. N. G. វិធីសាស្រ្តទទួលស្គាល់ និងកម្មវិធីរបស់ពួកគេ វិទ្យុសូវៀត ឆ្នាំ ១៩៧២។
- J. Tu, R. Gonzalez, Mathematical Principles of Pattern Recognition, Moscow: “Mir” Moscow, 1974 ។
- Khan, H. Abdullah និង M. Shamian Bin Zainal "ក្បួនដោះស្រាយការរកឃើញភ្នែក និងមាត់ប្រកបដោយប្រសិទ្ធភាព ដោយប្រើការរួមបញ្ចូលគ្នានៃ viola jones និងការរកឃើញភីកសែលពណ៌ស្បែក" International Journal of Engineering and Applied Sciences, no. Vol. លេខ 3 លេខ 4 ឆ្នាំ 2013 ។
- V. Gaede និង O. Gunther, "Multidimensional Access Methods," ACM Computing Surveys, ទំព័រ។ 170-231, 1998 ។
ប្រព័ន្ធនៃការរស់នៅ រួមទាំងមនុស្សផងដែរ ត្រូវបានប្រឈមមុខជានិច្ចជាមួយនឹងភារកិច្ចនៃការទទួលស្គាល់គំរូចាប់តាំងពីការចាប់ផ្តើមរបស់ពួកគេ។ ជាពិសេស ព័ត៌មានដែលចេញមកពីសរីរាង្គនៃអារម្មណ៍ត្រូវបានដំណើរការដោយខួរក្បាល ដែលនៅក្នុងវេនតម្រៀបព័ត៌មាន ធានាការសម្រេចចិត្ត ហើយបន្ទាប់មកដោយប្រើអេឡិចត្រូគីមី បញ្ជូនសញ្ញាចាំបាច់បន្ថែមទៀត ឧទាហរណ៍ ទៅកាន់សរីរាង្គនៃចលនា ដែល អនុវត្តសកម្មភាពចាំបាច់។ បន្ទាប់មកមានការផ្លាស់ប្តូរបរិយាកាស ហើយបាតុភូតខាងលើក៏កើតឡើងម្តងទៀត។ ហើយប្រសិនបើអ្នកមើលទៅបន្ទាប់មកដំណាក់កាលនីមួយៗត្រូវបានអមដោយការទទួលស្គាល់។
ជាមួយនឹងការអភិវឌ្ឍនៃបច្ចេកវិទ្យាកុំព្យូទ័រវាបានក្លាយជាអាចធ្វើទៅបានដើម្បីដោះស្រាយបញ្ហាមួយចំនួនដែលកើតឡើងនៅក្នុងដំណើរការនៃជីវិត, សម្របសម្រួល, បង្កើនល្បឿន, កែលម្អគុណភាពនៃលទ្ធផល។ ឧទាហរណ៍ ប្រតិបត្តិការនៃប្រព័ន្ធទ្រទ្រង់ជីវិតផ្សេងៗ អន្តរកម្មរវាងមនុស្ស និងកុំព្យូទ័រ ការលេចចេញនូវប្រព័ន្ធមនុស្សយន្ត។ អត្ថបទសរសេរដោយដៃ) ។
គោលបំណងនៃការងារ៖ ដើម្បីសិក្សាប្រវត្តិនៃប្រព័ន្ធទទួលស្គាល់គំរូ។
ចង្អុលបង្ហាញការផ្លាស់ប្តូរគុណភាពដែលបានកើតឡើងនៅក្នុងវាលនៃការទទួលស្គាល់លំនាំ, ទាំងទ្រឹស្តីនិងបច្ចេកទេស, បង្ហាញពីហេតុផល;
ពិភាក្សាអំពីវិធីសាស្រ្ត និងគោលការណ៍ដែលបានប្រើក្នុងការគណនា;
ផ្តល់ឧទាហរណ៍នៃការរំពឹងទុកដែលរំពឹងទុកនាពេលអនាគតដ៏ខ្លី។
1. តើការទទួលស្គាល់លំនាំគឺជាអ្វី?
ការស្រាវជ្រាវដំបូងជាមួយនឹងបច្ចេកវិទ្យាកុំព្យូទ័រជាមូលដ្ឋានបានអនុវត្តតាមគ្រោងការណ៍បុរាណនៃគំរូគណិតវិទ្យា - គំរូគណិតវិទ្យា ក្បួនដោះស្រាយ និងការគណនា។ ទាំងនេះគឺជាភារកិច្ចនៃគំរូនៃដំណើរការដែលកើតឡើងក្នុងអំឡុងពេលនៃការផ្ទុះគ្រាប់បែកបរមាណូ ការគណនាគន្លងផ្លោង សេដ្ឋកិច្ច និងកម្មវិធីផ្សេងៗទៀត។ ទោះជាយ៉ាងណាក៏ដោយ បន្ថែមពីលើគំនិតបុរាណនៃស៊េរីនេះ វាក៏មានវិធីសាស្រ្តដែលផ្អែកលើលក្ខណៈខុសគ្នាទាំងស្រុងផងដែរ ហើយដូចដែលការអនុវត្តនៃការដោះស្រាយបញ្ហាមួយចំនួនបានបង្ហាញ ពួកវាតែងតែផ្តល់លទ្ធផលប្រសើរជាងដំណោះស្រាយដោយផ្អែកលើគំរូគណិតវិទ្យាដែលស្មុគស្មាញ។ គំនិតរបស់ពួកគេគឺបោះបង់ចោលនូវបំណងប្រាថ្នាដើម្បីបង្កើតគំរូគណិតវិទ្យាដ៏ពេញលេញនៃវត្ថុដែលកំពុងសិក្សា (លើសពីនេះទៅទៀត ជារឿយៗវាមិនអាចទៅរួចទេក្នុងការសាងសង់គំរូគ្រប់គ្រាន់) ហើយជំនួសឱ្យការពេញចិត្តនឹងចម្លើយចំពោះតែសំណួរជាក់លាក់ដែលយើងចាប់អារម្មណ៍ និង ចម្លើយទាំងនេះគួរតែត្រូវបានស្វែងរកពីការពិចារណាទូទៅទៅថ្នាក់ធំទូលាយនៃបញ្ហា។ ការស្រាវជ្រាវប្រភេទនេះរួមមាន ការទទួលស្គាល់រូបភាពដែលមើលឃើញ ការព្យាករណ៍ទិន្នផល កម្រិតទឹកទន្លេ បញ្ហានៃការបែងចែករវាងការបង្ហូរប្រេង និងអាងទឹកដោយប្រើទិន្នន័យភូមិសាស្ត្រដោយប្រយោល។ល។ ចម្លើយជាក់លាក់មួយនៅក្នុងកិច្ចការទាំងនេះត្រូវបានទាមទារក្នុងទម្រង់សាមញ្ញដូចជា ឧទាហរណ៍ ថាតើវត្ថុមួយជាកម្មសិទ្ធិរបស់ថ្នាក់ដែលបានកំណត់ជាមុនឬអត់។ ហើយទិន្នន័យដំបូងនៃភារកិច្ចទាំងនេះជាក្បួនត្រូវបានផ្តល់ឱ្យក្នុងទម្រង់នៃព័ត៌មានបែកខ្ញែកអំពីវត្ថុដែលកំពុងសិក្សា ឧទាហរណ៍ក្នុងទម្រង់នៃសំណុំនៃវត្ថុដែលបានចាត់ថ្នាក់ជាមុន។ តាមទស្សនៈគណិតវិទ្យា នេះមានន័យថា ការទទួលស្គាល់លំនាំ (ហើយថ្នាក់នៃបញ្ហានេះត្រូវបានគេដាក់ឈ្មោះនៅក្នុងប្រទេសរបស់យើង) គឺជាការយល់ឃើញទូលំទូលាយនៃគំនិតនៃការបន្ថែមមុខងារ។
សារៈសំខាន់នៃការបង្កើតបែបនេះសម្រាប់វិទ្យាសាស្ត្របច្ចេកទេសគឺហួសពីការសង្ស័យ ហើយនេះបង្ហាញអំពីភាពត្រឹមត្រូវនៃការសិក្សាជាច្រើននៅក្នុងតំបន់នេះ។ ទោះជាយ៉ាងណាក៏ដោយ បញ្ហានៃការទទួលស្គាល់គំរូក៏មានទិដ្ឋភាពទូលំទូលាយសម្រាប់វិទ្យាសាស្ត្រធម្មជាតិផងដែរ (ទោះជាយ៉ាងណាក៏ដោយ វានឹងចម្លែកប្រសិនបើអ្វីដែលសំខាន់សម្រាប់ប្រព័ន្ធអ៊ីនធឺណេតសិប្បនិម្មិតនឹងមិនមានសារៈសំខាន់សម្រាប់ធម្មជាតិទេ)។ បរិបទនៃវិទ្យាសាស្ត្រនេះរួមបញ្ចូលនូវសំណួរដែលចោទឡើងដោយទស្សនវិទូបុរាណអំពីធម្មជាតិនៃចំណេះដឹងរបស់យើង សមត្ថភាពរបស់យើងក្នុងការទទួលស្គាល់រូបភាព គំរូ ស្ថានភាពនៃពិភពលោកជុំវិញយើង។ តាមពិតទៅ វាគ្មានការងឿងឆ្ងល់ទេថា យន្តការសម្រាប់ទទួលស្គាល់រូបភាពសាមញ្ញបំផុត ដូចជារូបភាពនៃសត្វមំសាសី ឬអាហារដ៏គ្រោះថ្នាក់ដែលជិតមកដល់នោះ ត្រូវបានបង្កើតឡើងលឿនជាងភាសាបឋម ហើយឧបករណ៍ឡូជីខលផ្លូវការបានកើតឡើង។ ហើយគ្មានការងឿងឆ្ងល់ទេថា យន្តការបែបនេះក៏ត្រូវបានអភិវឌ្ឍគ្រប់គ្រាន់នៅក្នុងសត្វខ្ពស់ៗផងដែរ ដែលក្នុងសកម្មភាពសំខាន់របស់វា ក៏ត្រូវការជាបន្ទាន់នូវសមត្ថភាពក្នុងការបែងចែកប្រព័ន្ធស្មុគស្មាញនៃសញ្ញានៃធម្មជាតិផងដែរ។ ដូច្នេះនៅក្នុងធម្មជាតិ យើងឃើញថាបាតុភូតនៃការគិត និងមនសិការគឺផ្អែកយ៉ាងច្បាស់លើសមត្ថភាពក្នុងការទទួលស្គាល់គំរូ ហើយការរីកចម្រើនបន្ថែមទៀតនៃវិទ្យាសាស្ត្របញ្ញាគឺទាក់ទងដោយផ្ទាល់ទៅនឹងជម្រៅនៃការយល់ដឹងអំពីច្បាប់ជាមូលដ្ឋាននៃការទទួលស្គាល់។ ការយល់ដឹងពីការពិតដែលថាសំណួរខាងលើហួសពីនិយមន័យស្តង់ដារនៃការទទួលស្គាល់គំរូ (ពាក្យថាការរៀនដែលត្រូវបានត្រួតពិនិត្យគឺជារឿងធម្មតាជាងនៅក្នុងអក្សរសិល្ប៍ភាសាអង់គ្លេស) វាក៏ចាំបាច់ផងដែរក្នុងការយល់ថាពួកគេមានទំនាក់ទំនងយ៉ាងស៊ីជម្រៅជាមួយនឹងភាពតូចចង្អៀតនេះ (ប៉ុន្តែនៅតែ ឆ្ងាយពីការហត់នឿយ) ទិសដៅ។
សូម្បីតែឥឡូវនេះ ការទទួលស្គាល់គំរូបានចូលយ៉ាងរឹងមាំក្នុងជីវិតប្រចាំថ្ងៃ ហើយជាចំណេះដឹងដ៏សំខាន់បំផុតមួយរបស់វិស្វករទំនើប។ នៅក្នុងឱសថ ការទទួលស្គាល់លំនាំជួយឱ្យវេជ្ជបណ្ឌិតធ្វើការវិនិច្ឆ័យបានត្រឹមត្រូវជាងមុន ហើយនៅក្នុងរោងចក្រ វាត្រូវបានប្រើប្រាស់ដើម្បីទស្សន៍ទាយពីពិការភាពនៅក្នុងបណ្តុំទំនិញ។ ប្រព័ន្ធកំណត់អត្តសញ្ញាណបុគ្គលជីវមាត្រជាស្នូលក្បួនដោះស្រាយរបស់ពួកគេក៏ផ្អែកលើលទ្ធផលនៃវិន័យនេះដែរ។ ការអភិវឌ្ឍន៍បន្ថែមទៀតនៃបញ្ញាសិប្បនិមិត្ត ជាពិសេសការរចនាកុំព្យូទ័រជំនាន់ទី 5 ដែលមានសមត្ថភាពទំនាក់ទំនងផ្ទាល់ជាមួយមនុស្សម្នាក់ជាភាសាធម្មជាតិសម្រាប់មនុស្ស និងតាមរយៈការនិយាយគឺមិនអាចគិតទុកជាមុនបានទេបើគ្មានការទទួលស្គាល់។ នៅទីនេះ មនុស្សយន្ត ប្រព័ន្ធគ្រប់គ្រងសិប្បនិម្មិតដែលមានប្រព័ន្ធទទួលស្គាល់ថាជាប្រព័ន្ធរងដ៏សំខាន់ គឺស្ថិតនៅក្នុងភាពងាយស្រួល។
នោះហើយជាមូលហេតុដែលការយកចិត្តទុកដាក់ជាច្រើនត្រូវបានផ្តោតលើការអភិវឌ្ឍន៍នៃការទទួលស្គាល់គំរូតាំងពីដំបូងដោយអ្នកឯកទេសនៃទម្រង់ផ្សេងៗគ្នា - cybernetics, neurophysiologist, psychologists, mathematicians, economists ។ល។ ភាគច្រើនសម្រាប់ហេតុផលនេះ ការទទួលស្គាល់គំរូសម័យទំនើបដោយខ្លួនវាផ្ទាល់លើគំនិតនៃវិញ្ញាសាទាំងនេះ។ ដោយគ្មានការអះអាងថាពេញលេញ (ហើយវាមិនអាចទៅរួចទេក្នុងការអះអាងវានៅក្នុងអត្ថបទខ្លីមួយ) យើងនឹងរៀបរាប់អំពីប្រវត្តិនៃការទទួលស្គាល់គំរូគំនិតសំខាន់ៗ។
និយមន័យ
មុននឹងបន្តទៅវិធីសាស្រ្តសំខាន់ៗនៃការទទួលស្គាល់គំរូ យើងផ្តល់និយមន័យចាំបាច់មួយចំនួន។
ការទទួលស្គាល់រូបភាព (វត្ថុ សញ្ញា ស្ថានភាព បាតុភូត ឬដំណើរការ) គឺជាភារកិច្ចនៃការកំណត់អត្តសញ្ញាណវត្ថុ ឬកំណត់លក្ខណៈសម្បត្តិណាមួយដោយរូបភាពរបស់វា (ការទទួលស្គាល់អុបទិក) ឬការថតសំឡេង (ការទទួលស្គាល់សូរស័ព្ទ) និងលក្ខណៈផ្សេងៗទៀត។
មូលដ្ឋានមួយក្នុងចំណោមមូលដ្ឋានគឺគំនិតនៃសំណុំដែលមិនមានទម្រង់ជាក់លាក់។ នៅក្នុងកុំព្យូទ័រ សំណុំមួយត្រូវបានតំណាងដោយសំណុំនៃធាតុដែលមិនកើតឡើងដដែលៗនៃប្រភេទដូចគ្នា។ ពាក្យថា មិនធ្វើដដែលៗ មានន័យថា ធាតុខ្លះក្នុងសំណុំ មានឬមិននៅទីនោះ។ សំណុំសកលរួមបញ្ចូលធាតុដែលអាចធ្វើបានទាំងអស់សម្រាប់បញ្ហាដែលកំពុងត្រូវបានដោះស្រាយ សំណុំទទេមិនមានទេ។
រូបភាពគឺជាការចាត់ថ្នាក់ជាក្រុមនៅក្នុងប្រព័ន្ធចាត់ថ្នាក់ដែលបង្រួបបង្រួម (ឯកវចនៈ) ក្រុមជាក់លាក់នៃវត្ថុតាមលក្ខណៈមួយចំនួន។ រូបភាពមានលក្ខណៈសម្បត្តិលក្ខណៈ ដែលបង្ហាញឱ្យឃើញដោយខ្លួនវាផ្ទាល់នៅក្នុងការពិតដែលថាការស្គាល់គ្នាជាមួយនឹងចំនួនកំណត់នៃបាតុភូតពីសំណុំដូចគ្នានេះធ្វើឱ្យវាអាចទទួលស្គាល់ចំនួនច្រើនតាមអំពើចិត្តនៃអ្នកតំណាងរបស់វា។ រូបភាពមានលក្ខណៈសម្បត្តិគោលបំណងលក្ខណៈក្នុងន័យថា មនុស្សផ្សេងគ្នាដែលរៀនពីសម្ភារៈសង្កេតផ្សេងៗគ្នា សម្រាប់ផ្នែកភាគច្រើនចាត់ថ្នាក់វត្ថុដូចគ្នាតាមរបៀបដូចគ្នា និងដោយឯករាជ្យពីគ្នាទៅវិញទៅមក។ នៅក្នុងរូបមន្តបុរាណនៃបញ្ហាការទទួលស្គាល់ សំណុំសកលត្រូវបានបែងចែកទៅជាផ្នែក - រូបភាព។ ការគូសផែនទីនីមួយៗនៃវត្ថុណាមួយទៅកាន់សរីរាង្គដែលយល់ឃើញនៃប្រព័ន្ធទទួលស្គាល់ ដោយមិនគិតពីទីតាំងរបស់វាទាក់ទងទៅនឹងសរីរាង្គទាំងនេះ ជាធម្មតាត្រូវបានគេហៅថារូបភាពនៃវត្ថុ ហើយសំណុំនៃរូបភាពដែលរួបរួមដោយលក្ខណៈសម្បត្តិទូទៅមួយចំនួនគឺជារូបភាព។
វិធីសាស្រ្តនៃការកំណត់ធាតុមួយទៅរូបភាពណាមួយត្រូវបានគេហៅថាច្បាប់នៃការសម្រេចចិត្ត។ គោលគំនិតសំខាន់មួយទៀតគឺម៉ែត្រ ដែលជាវិធីដើម្បីកំណត់ចម្ងាយរវាងធាតុនៃសំណុំសកល។ ចម្ងាយនេះកាន់តែតូច វត្ថុ (និមិត្តសញ្ញា សំឡេង។ល។) ដែលយើងស្គាល់កាន់តែស្រដៀងគ្នា។ ជាធម្មតា ធាតុត្រូវបានបញ្ជាក់ជាសំណុំលេខ ហើយម៉ែត្រត្រូវបានបញ្ជាក់ជាអនុគមន៍។ ប្រសិទ្ធភាពនៃកម្មវិធីអាស្រ័យលើជម្រើសនៃការតំណាងរូបភាព និងការអនុវត្តម៉ែត្រ ក្បួនដោះស្រាយការទទួលស្គាល់មួយជាមួយនឹងម៉ែត្រផ្សេងគ្នានឹងធ្វើឱ្យមានកំហុសជាមួយនឹងប្រេកង់ខុសៗគ្នា។
ការរៀនជាធម្មតាត្រូវបានគេហៅថាដំណើរការនៃការអភិវឌ្ឍនៅក្នុងប្រព័ន្ធមួយចំនួនដែលជាប្រតិកម្មជាក់លាក់មួយចំពោះក្រុមនៃសញ្ញាដូចគ្នាបេះបិទខាងក្រៅដោយឥទ្ធិពលម្តងហើយម្តងទៀតនៃប្រព័ន្ធកែតម្រូវខាងក្រៅ។ ការកែតម្រូវខាងក្រៅបែបនេះក្នុងការបណ្តុះបណ្តាលជាធម្មតាត្រូវបានគេហៅថា "ការលើកទឹកចិត្ត" និង "ការដាក់ទណ្ឌកម្ម" ។ យន្តការសម្រាប់បង្កើតការកែតម្រូវនេះស្ទើរតែទាំងស្រុងកំណត់នូវក្បួនដោះស្រាយការរៀនសូត្រ។ ការរៀនដោយខ្លួនឯងខុសពីការរៀនដែលនៅទីនេះ ព័ត៌មានបន្ថែមអំពីភាពត្រឹមត្រូវនៃប្រតិកម្មទៅនឹងប្រព័ន្ធមិនត្រូវបានរាយការណ៍ទេ។
ការសម្របខ្លួនគឺជាដំណើរការនៃការផ្លាស់ប្តូរប៉ារ៉ាម៉ែត្រ និងរចនាសម្ព័ន្ធនៃប្រព័ន្ធ ហើយក៏អាចគ្រប់គ្រងសកម្មភាពផងដែរ ដោយផ្អែកលើព័ត៌មានបច្ចុប្បន្ន ដើម្បីសម្រេចបាននូវស្ថានភាពជាក់លាក់នៃប្រព័ន្ធជាមួយនឹងភាពមិនច្បាស់លាស់ដំបូង និងការផ្លាស់ប្តូរលក្ខខណ្ឌប្រតិបត្តិការ។
ការរៀនសូត្រគឺជាដំណើរការមួយ ជាលទ្ធផលដែលប្រព័ន្ធទទួលបានបន្តិចម្តងៗនូវសមត្ថភាពក្នុងការឆ្លើយតបជាមួយនឹងប្រតិកម្មចាំបាច់ចំពោះសំណុំមួយចំនួននៃឥទ្ធិពលខាងក្រៅ ហើយការបន្សាំគឺជាការកែតម្រូវនៃប៉ារ៉ាម៉ែត្រ និងរចនាសម្ព័ន្ធនៃប្រព័ន្ធ ដើម្បីសម្រេចបាននូវគុណភាពដែលត្រូវការនៃ ការគ្រប់គ្រងនៅក្នុងលក្ខខណ្ឌនៃការផ្លាស់ប្តូរជាបន្តបន្ទាប់នៅក្នុងលក្ខខណ្ឌខាងក្រៅ។
ឧទាហរណ៍នៃភារកិច្ចទទួលស្គាល់លំនាំ៖ - ការទទួលស្គាល់អក្សរ;
ជាទូទៅវិធីសាស្រ្តបីនៃការទទួលស្គាល់គំរូអាចត្រូវបានសម្គាល់: វិធីសាស្ត្ររាប់បញ្ចូល។ ក្នុងករណីនេះ ការប្រៀបធៀបត្រូវបានធ្វើឡើងជាមួយនឹងមូលដ្ឋានទិន្នន័យ ដែលសម្រាប់ប្រភេទនីមួយៗនៃវត្ថុនីមួយៗ ការកែប្រែដែលអាចកើតមាននៃការបង្ហាញត្រូវបានបង្ហាញ។ ឧទាហរណ៍ សម្រាប់ការទទួលស្គាល់រូបភាពអុបទិក អ្នកអាចអនុវត្តវិធីសាស្រ្តនៃការរាប់បញ្ចូលប្រភេទនៃវត្ថុនៅមុំផ្សេងគ្នា មាត្រដ្ឋាន ការផ្លាស់ទីលំនៅ ការខូចទ្រង់ទ្រាយ។ លំនាំដែលគេស្គាល់ (ឧទាហរណ៍ ពាក្យដែលនិយាយដោយមនុស្សជាច្រើន)។
វិធីសាស្រ្តទីពីរគឺការវិភាគស៊ីជម្រៅអំពីលក្ខណៈនៃរូបភាព។ នៅក្នុងករណីនៃការទទួលស្គាល់អុបទិក នេះអាចជាការកំណត់នៃលក្ខណៈធរណីមាត្រផ្សេងៗ។ សំណាកសំឡេងនៅក្នុងករណីនេះត្រូវបានទទួលរងនូវប្រេកង់ ការវិភាគទំហំ។ល។
វិធីសាស្រ្តបន្ទាប់គឺការប្រើប្រាស់បណ្តាញសរសៃប្រសាទសិប្បនិម្មិត (ANN) ។ វិធីសាស្រ្តនេះតម្រូវឱ្យមានឧទាហរណ៍មួយចំនួនធំនៃភារកិច្ចទទួលស្គាល់ក្នុងអំឡុងពេលបណ្តុះបណ្តាល ឬរចនាសម្ព័ន្ធបណ្តាញសរសៃប្រសាទពិសេសដែលគិតគូរពីភាពជាក់លាក់នៃកិច្ចការនេះ។ ទោះជាយ៉ាងណាក៏ដោយ វាត្រូវបានសម្គាល់ដោយប្រសិទ្ធភាព និងផលិតភាពខ្ពស់ជាងមុន។
4. ប្រវត្តិនៃការទទួលស្គាល់លំនាំ
ចូរយើងពិចារណាដោយសង្ខេបអំពីទម្រង់គណិតវិទ្យានៃការទទួលស្គាល់គំរូ។ វត្ថុមួយនៅក្នុងការទទួលស្គាល់លំនាំត្រូវបានពិពណ៌នាដោយសំណុំនៃលក្ខណៈមូលដ្ឋាន (លក្ខណៈពិសេស លក្ខណៈសម្បត្តិ) ។ លក្ខណៈសំខាន់ៗអាចមានលក្ខណៈខុសគ្នា៖ ពួកគេអាចយកចេញពីសំណុំតាមលំដាប់នៃប្រភេទបន្ទាត់ពិត ឬពីសំណុំដាច់ពីគ្នា (ដែលទោះជាយ៉ាងណាក៏អាចត្រូវបានផ្តល់ដោយរចនាសម្ព័ន្ធផងដែរ)។ ការយល់ដឹងអំពីវត្ថុនេះគឺស្របទាំងតម្រូវការសម្រាប់ការអនុវត្តជាក់ស្តែងនៃការទទួលស្គាល់គំរូ និងជាមួយនឹងការយល់ដឹងរបស់យើងអំពីយន្តការនៃការយល់ឃើញរបស់មនុស្សចំពោះវត្ថុមួយ។ ជាការពិតណាស់ យើងជឿថា នៅពេលដែលមនុស្សម្នាក់សង្កេត (វាស់) វត្ថុមួយ ព័ត៌មានអំពីវាកើតឡើងតាមរយៈឧបករណ៍ចាប់សញ្ញាចំនួនកំណត់ (បណ្តាញវិភាគ) ទៅកាន់ខួរក្បាល ហើយឧបករណ៍ចាប់សញ្ញានីមួយៗអាចត្រូវបានផ្សារភ្ជាប់ជាមួយនឹងលក្ខណៈដែលត្រូវគ្នានៃវត្ថុ។ បន្ថែមពីលើលក្ខណៈពិសេសដែលត្រូវនឹងការវាស់វែងរបស់យើងនៃវត្ថុនោះ វាក៏មានលក្ខណៈពិសេសដែលបានជ្រើសរើស ឬក្រុមនៃលក្ខណៈពិសេសផងដែរ ដែលយើងហៅថាលក្ខណៈចាត់ថ្នាក់ ហើយការស្វែងរកតម្លៃរបស់វាសម្រាប់វ៉ិចទ័រ X ដែលបានផ្តល់គឺជាកិច្ចការដែលធម្មជាតិ និងប្រព័ន្ធទទួលស្គាល់សិប្បនិម្មិតអនុវត្ត។
វាច្បាស់ណាស់ថាដើម្បីបង្កើតតម្លៃនៃលក្ខណៈពិសេសទាំងនេះវាចាំបាច់ដើម្បីឱ្យមានព័ត៌មានអំពីរបៀបដែលលក្ខណៈពិសេសដែលគេស្គាល់ទាក់ទងនឹងការចាត់ថ្នាក់។ ព័ត៌មានអំពីទំនាក់ទំនងនេះត្រូវបានផ្តល់ឱ្យក្នុងទម្រង់នៃបុព្វបទ នោះគឺជាសំណុំនៃការពិពណ៌នាអំពីវត្ថុដែលមានតម្លៃដែលគេស្គាល់នៃលក្ខណៈចាត់ថ្នាក់។ ហើយយោងទៅតាមព័ត៌មានមុននេះ វាត្រូវបានទាមទារដើម្បីបង្កើតច្បាប់នៃការសម្រេចចិត្តដែលនឹងកំណត់ការពិពណ៌នាតាមអំពើចិត្តនៃវត្ថុនៃតម្លៃនៃលក្ខណៈនៃការចាត់ថ្នាក់របស់វា។
ការយល់ដឹងអំពីបញ្ហានៃការទទួលស្គាល់គំរូនេះត្រូវបានបង្កើតឡើងនៅក្នុងវិទ្យាសាស្ត្រតាំងពីទសវត្សរ៍ឆ្នាំ 1950 ។ ហើយបន្ទាប់មកគេសង្កេតឃើញថាការផលិតបែបនេះមិនមែនជារឿងថ្មីទេ។ វិធីសាស្រ្តដែលបង្ហាញឱ្យឃើញយ៉ាងល្អនៃការវិភាគទិន្នន័យស្ថិតិ ដែលត្រូវបានប្រើយ៉ាងសកម្មសម្រាប់កិច្ចការជាក់ស្តែងជាច្រើន ដូចជាឧទាហរណ៍ ការវិនិច្ឆ័យបច្ចេកទេស ត្រូវប្រឈមមុខនឹងការបង្កើតបែបនោះ ហើយមានរួចហើយ។ ដូច្នេះជំហានដំបូងនៃការទទួលស្គាល់គំរូបានឆ្លងកាត់ក្រោមសញ្ញានៃវិធីសាស្រ្តស្ថិតិ ដែលកំណត់បញ្ហាចម្បង។
វិធីសាស្រ្តស្ថិតិគឺផ្អែកលើគំនិតដែលថាលំហដំបូងនៃវត្ថុគឺជាលំហប្រូបាប៊ីលីស្ត ហើយលក្ខណៈពិសេស (លក្ខណៈ) នៃវត្ថុគឺជាអថេរចៃដន្យដែលបានផ្តល់ឱ្យនៅលើវា។ បន្ទាប់មក ភារកិច្ចរបស់អ្នកវិទ្យាសាស្ត្រទិន្នន័យគឺត្រូវដាក់ចេញនូវសម្មតិកម្មស្ថិតិអំពីការចែកចាយនៃលក្ខណៈពិសេស ឬជាជាងអំពីការពឹងផ្អែកនៃការបែងចែកលក្ខណៈនៅលើអ្វីដែលនៅសល់ពីការពិចារណាមួយចំនួន។ សម្មតិកម្មស្ថិតិ ជាក្បួនគឺជាសំណុំនៃមុខងារចែកចាយលក្ខណៈដែលបានបញ្ជាក់ដោយប៉ារ៉ាម៉ែត្រ។ សម្មតិកម្មស្ថិតិធម្មតា និងបុរាណគឺជាសម្មតិកម្មនៃភាពធម្មតានៃការចែកចាយនេះ (មានសម្មតិកម្មបែបនេះជាច្រើននៅក្នុងស្ថិតិ)។ បន្ទាប់ពីបង្កើតសម្មតិកម្ម វានៅតែត្រូវសាកល្បងសម្មតិកម្មនេះលើទិន្នន័យមុននេះ។ ការត្រួតពិនិត្យនេះមាននៅក្នុងការជ្រើសរើសការចែកចាយមួយចំនួនពីសំណុំនៃការចែកចាយដែលបានផ្តល់ឱ្យដំបូង (ប៉ារ៉ាម៉ែត្រសម្មតិកម្មការចែកចាយ) និងការវាយតម្លៃភាពអាចជឿជាក់បាន (ចន្លោះពេលទំនុកចិត្ត) នៃជម្រើសនេះ។ តាមពិត មុខងារចែកចាយនេះគឺជាចំលើយចំពោះបញ្ហា មានតែវត្ថុប៉ុណ្ណោះដែលត្រូវបានចាត់ថ្នាក់មិនមែនដោយឡែកទេ ប៉ុន្តែជាមួយនឹងប្រូបាប៊ីលីតេមួយចំនួននៃកម្មសិទ្ធិរបស់ថ្នាក់។ អ្នកស្ថិតិក៏បានបង្កើតយុត្តិកម្ម asymptotic សម្រាប់វិធីសាស្រ្តបែបនេះ។ យុត្តិកម្មបែបនេះត្រូវបានធ្វើឡើងតាមគ្រោងការណ៍ខាងក្រោម៖ មុខងារគុណភាពជាក់លាក់នៃជម្រើសនៃការចែកចាយ (ចន្លោះពេលទំនុកចិត្ត) ត្រូវបានបង្កើតឡើង ហើយវាត្រូវបានបង្ហាញថាជាមួយនឹងការកើនឡើងនៃចំនួនគំរូ ជម្រើសរបស់យើងជាមួយនឹងប្រូបាប៊ីលីតេដែលមានទំនោរទៅ 1 បានក្លាយជាត្រឹមត្រូវនៅក្នុង អារម្មណ៍នៃមុខងារនេះ (ចន្លោះពេលទំនុកចិត្តមានទំនោរទៅ 0) ។ សម្លឹងទៅមុខ យើងអាចនិយាយបានថា ទិដ្ឋភាពស្ថិតិនៃបញ្ហាការទទួលស្គាល់បានប្រែទៅជាមានផ្លែផ្កាមិនត្រឹមតែនៅក្នុងលក្ខខណ្ឌនៃក្បួនដោះស្រាយដែលបានអភិវឌ្ឍទេ (ដែលរួមមានវិធីសាស្រ្តនៃការវិភាគចង្កោម និងការបែងចែក ការតំរែតំរង់ដែលមិនមែនជាប៉ារ៉ាម៉ែត្រ។ ដើម្បីបង្កើតទ្រឹស្តីស្ថិតិស៊ីជម្រៅនៃការទទួលស្គាល់។
ទោះជាយ៉ាងណាក៏ដោយ មានអំណះអំណាងយ៉ាងមុតមាំក្នុងការពេញចិត្តចំពោះការពិតដែលថាបញ្ហានៃការទទួលស្គាល់គំរូមិនត្រូវបានកាត់បន្ថយទៅជាស្ថិតិទេ។ ជាគោលការណ៍បញ្ហាណាមួយអាចត្រូវបានពិចារណាតាមទស្សនៈស្ថិតិ ហើយលទ្ធផលនៃដំណោះស្រាយរបស់វាអាចត្រូវបានបកស្រាយតាមស្ថិតិ។ ដើម្បីធ្វើដូចនេះវាគ្រាន់តែជាការចាំបាច់ក្នុងការសន្មតថាចន្លោះនៃវត្ថុនៃបញ្ហាគឺប្រហែល។ ប៉ុន្តែតាមទស្សនៈនៃឧបករណ៍និយម លក្ខណៈវិនិច្ឆ័យសម្រាប់ភាពជោគជ័យនៃការបកស្រាយស្ថិតិនៃវិធីសាស្រ្តទទួលស្គាល់ជាក់លាក់មួយអាចគ្រាន់តែជាអត្ថិភាពនៃយុត្តិកម្មសម្រាប់វិធីសាស្រ្តនេះនៅក្នុងភាសានៃស្ថិតិដែលជាសាខានៃគណិតវិទ្យា។ យុត្តិកម្មនៅទីនេះមានន័យថាការអភិវឌ្ឍន៍តម្រូវការមូលដ្ឋានសម្រាប់បញ្ហាដែលធានានូវភាពជោគជ័យក្នុងការអនុវត្តវិធីសាស្ត្រនេះ។ ទោះបីជាយ៉ាងណាក៏ដោយ នៅពេលនេះ សម្រាប់វិធីសាស្រ្តទទួលស្គាល់ភាគច្រើន រួមទាំងវិធីសាស្ត្រដែលកើតឡើងដោយផ្ទាល់នៅក្នុងក្របខ័ណ្ឌនៃវិធីសាស្រ្តស្ថិតិនោះ យុត្តិកម្មដ៏គួរឱ្យពេញចិត្តបែបនេះមិនត្រូវបានរកឃើញទេ។ លើសពីនេះទៀត ក្បួនដោះស្រាយស្ថិតិដែលប្រើជាទូទៅបំផុតនៅពេលនេះ ដូចជាការរើសអើងលីនេអ៊ែររបស់ Fisher, Parzen window, EM algorithm, អ្នកជិតខាងដែលនៅជិតបំផុត ដែលមិននិយាយអំពីបណ្តាញជំនឿ Bayesian មានលក្ខណៈ heuristic បញ្ចេញសំឡេងខ្លាំង ហើយអាចមានការបកស្រាយខុសពីស្ថិតិ។ ហើយជាចុងក្រោយ ចំពោះចំណុចទាំងអស់ខាងលើ វាគួរតែត្រូវបានបន្ថែមថា បន្ថែមពីលើឥរិយាបទ asymptotic នៃវិធីសាស្រ្តទទួលស្គាល់ ដែលជាបញ្ហាចម្បងនៃស្ថិតិ ការអនុវត្តនៃការទទួលស្គាល់បានលើកឡើងនូវសំណួរអំពីភាពស្មុគស្មាញនៃការគណនា និងរចនាសម្ព័ន្ធនៃវិធីសាស្រ្តដែលហួសពី គ្រោងការណ៍នៃទ្រឹស្តីប្រូបាប៊ីលីតេតែម្នាក់ឯង។
សរុបមក ផ្ទុយទៅនឹងសេចក្តីប្រាថ្នារបស់អ្នកស្ថិតិដើម្បីពិចារណាការទទួលស្គាល់គំរូជាផ្នែកនៃស្ថិតិ គំនិតខុសគ្នាទាំងស្រុងចូលទៅក្នុងការអនុវត្ត និងមនោគមវិជ្ជានៃការទទួលស្គាល់។ មួយក្នុងចំនោមពួកគេត្រូវបានបង្កឡើងដោយការស្រាវជ្រាវនៅក្នុងវិស័យនៃការទទួលស្គាល់គំរូដែលមើលឃើញហើយត្រូវបានផ្អែកលើភាពស្រដៀងគ្នាខាងក្រោម។
ដូចដែលបានកត់សម្គាល់រួចមកហើយនៅក្នុងជីវិតប្រចាំថ្ងៃមនុស្សតែងតែដោះស្រាយបញ្ហា (ជាញឹកញាប់ដោយមិនដឹងខ្លួន) បញ្ហានៃការទទួលស្គាល់ស្ថានភាពផ្សេងៗ auditory និងរូបភាពដែលមើលឃើញ។ សមត្ថភាពបែបនេះសម្រាប់កុំព្យូទ័រគឺល្អបំផុត គឺជាបញ្ហានៃអនាគត។ ពីនេះ អ្នកត្រួសត្រាយមួយចំនួននៃការទទួលស្គាល់គំរូបានសន្និដ្ឋានថា ដំណោះស្រាយនៃបញ្ហាទាំងនេះនៅលើកុំព្យូទ័រគួរតែក្លែងធ្វើដំណើរការនៃការគិតរបស់មនុស្ស។ ការប៉ុនប៉ងដ៏ល្បីល្បាញបំផុតដើម្បីចូលទៅជិតបញ្ហាពីខាងនេះគឺការសិក្សាដ៏ល្បីល្បាញរបស់ F. Rosenblatt លើ perceptrons ។
នៅពាក់កណ្តាលទសវត្សរ៍ទី 50 វាហាក់ដូចជាអ្នកជំនាញខាងសរសៃប្រសាទបានយល់ពីគោលការណ៍រាងកាយនៃខួរក្បាល (នៅក្នុងសៀវភៅ "គំនិតថ្មីនៃស្តេច" ដែលជាអ្នកទ្រឹស្តីរូបវិទូជនជាតិអង់គ្លេសដ៏ល្បីល្បាញ R. Penrose បានសួរសំណួរអំពីគំរូបណ្តាញសរសៃប្រសាទនៃខួរក្បាលដោយបញ្ជាក់យ៉ាងច្បាស់លាស់។ តួនាទីសំខាន់នៃឥទ្ធិពលមេកានិចកង់ទិចក្នុងដំណើរការរបស់វា ទោះបីជាយ៉ាងណាក៏ដោយ គំរូនេះត្រូវបានចោទសួរតាំងពីដំបូងមក។ ដោយផ្អែកលើរបកគំហើញទាំងនេះ F. Rosenblatt បានបង្កើតគំរូសម្រាប់រៀនស្គាល់គំរូដែលមើលឃើញ ដែលគាត់ហៅថា perceptron។ ការយល់ដឹងរបស់ Rosenblatt គឺជាមុខងារខាងក្រោម (រូបភាពទី 1)៖
រូបទី 1. គ្រោងការណ៍នៃ Perceptron
នៅឯការបញ្ចូល perceptron ទទួលបានវ៉ិចទ័រវត្ថុដែលនៅក្នុងស្នាដៃរបស់ Rosenblatt គឺជាវ៉ិចទ័រគោលពីរដែលបង្ហាញថាភីកសែលអេក្រង់មួយណាត្រូវបានងងឹតដោយរូបភាព ហើយមួយណាមិនមែនទេ។ លើសពីនេះ សញ្ញានីមួយៗត្រូវបានផ្តល់អាហារដល់ការបញ្ចូលនៃណឺរ៉ូន ដែលជាសកម្មភាពនៃការគុណសាមញ្ញដោយទម្ងន់ជាក់លាក់នៃណឺរ៉ូន។ លទ្ធផលត្រូវបានផ្តល់អាហារដល់ណឺរ៉ូនចុងក្រោយ ដែលបន្ថែមពួកវា និងប្រៀបធៀបចំនួនសរុបជាមួយនឹងកម្រិតជាក់លាក់មួយ។ អាស្រ័យលើលទ្ធផលនៃការប្រៀបធៀប វត្ថុបញ្ចូល X ត្រូវបានទទួលស្គាល់ថាចាំបាច់ឬអត់។ បន្ទាប់មក ភារកិច្ចនៃការរៀនទទួលស្គាល់លំនាំគឺជ្រើសរើសទម្ងន់នៃណឺរ៉ូន និងតម្លៃកម្រិត ដើម្បីឱ្យ perceptron ផ្តល់ចម្លើយត្រឹមត្រូវលើរូបភាពដែលមើលឃើញពីមុន។ Rosenblatt ជឿថាមុខងារលទ្ធផលនឹងល្អក្នុងការទទួលស្គាល់រូបភាពដែលចង់បាន ទោះបីជាវត្ថុបញ្ចូលមិនមែនជាគំរូមុនក៏ដោយ។ ពីការពិចារណាបែប bionic គាត់ក៏បានបង្កើតនូវវិធីសាស្រ្តមួយសម្រាប់ជ្រើសរើសទម្ងន់ និងកម្រិតមួយដែលយើងនឹងមិនរស់នៅ។ ចូរនិយាយថាវិធីសាស្រ្តរបស់គាត់បានជោគជ័យនៅក្នុងបញ្ហានៃការទទួលស្គាល់មួយចំនួន ហើយបានផ្តល់នូវការស្រាវជ្រាវទាំងមូលលើក្បួនដោះស្រាយការរៀនដោយផ្អែកលើបណ្តាញសរសៃប្រសាទ ដែល perceptron គឺជាករណីពិសេសមួយ។
លើសពីនេះ ភាពទូទៅផ្សេងៗនៃ perceptron ត្រូវបានបង្កើតឡើង មុខងារនៃណឺរ៉ូនមានភាពស្មុគស្មាញ៖ ឥឡូវនេះ ណឺរ៉ូនមិនត្រឹមតែអាចគុណលេខបញ្ចូល ឬបន្ថែមពួកវា ហើយប្រៀបធៀបលទ្ធផលជាមួយនឹងកម្រិតកំណត់ប៉ុណ្ណោះទេ ប៉ុន្តែអនុវត្តមុខងារស្មុគស្មាញបន្ថែមទៀតចំពោះពួកគេ។ រូបភាពទី 2 បង្ហាញពីផលវិបាកនៃសរសៃប្រសាទទាំងនេះ៖

អង្ករ។ 2 ដ្យាក្រាមនៃបណ្តាញសរសៃប្រសាទ។
លើសពីនេះទៀត topology នៃបណ្តាញសរសៃប្រសាទអាចមានភាពស្មុគស្មាញជាងការពិចារណាដោយ Rosenblatt ឧទាហរណ៍នេះ:
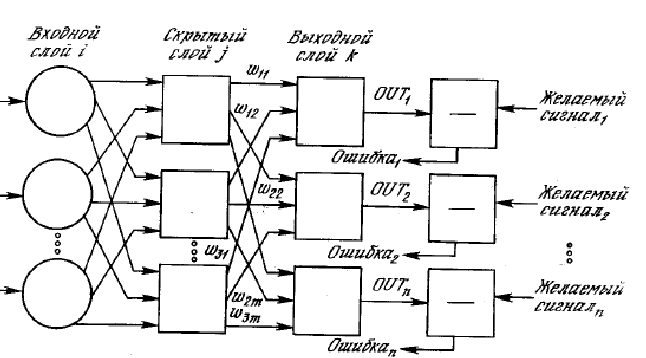
អង្ករ។ 3. ដ្យាក្រាមនៃបណ្តាញសរសៃប្រសាទរបស់ Rosenblatt ។
ភាពស្មុគស្មាញបាននាំឱ្យមានការកើនឡើងនៃចំនួនប៉ារ៉ាម៉ែត្រដែលអាចលៃតម្រូវបានក្នុងអំឡុងពេលហ្វឹកហាត់ប៉ុន្តែក្នុងពេលតែមួយបានបង្កើនសមត្ថភាពក្នុងការលៃតម្រូវទៅនឹងគំរូស្មុគស្មាញបំផុត។ ការស្រាវជ្រាវនៅក្នុងតំបន់នេះឥឡូវនេះកំពុងដំណើរការលើផ្នែកពីរដែលទាក់ទងគ្នាយ៉ាងជិតស្និទ្ធ - ទាំងប្រព័ន្ធបណ្តាញផ្សេងៗ និងវិធីសាស្ត្រកែតម្រូវផ្សេងៗកំពុងត្រូវបានសិក្សា។
បច្ចុប្បន្នបណ្តាញសរសៃប្រសាទមិនត្រឹមតែជាឧបករណ៍សម្រាប់ដោះស្រាយបញ្ហាការទទួលស្គាល់គំរូប៉ុណ្ណោះទេ ប៉ុន្តែត្រូវបានប្រើប្រាស់ក្នុងការស្រាវជ្រាវលើអង្គចងចាំដែលពាក់ព័ន្ធ និងការបង្រួមរូបភាព។ ទោះបីជាបន្ទាត់នៃការស្រាវជ្រាវនេះត្រួតលើគ្នាយ៉ាងខ្លាំងជាមួយនឹងបញ្ហានៃការទទួលស្គាល់គំរូក៏ដោយ វាគឺជាផ្នែកដាច់ដោយឡែកនៃ cybernetics ។ សម្រាប់អ្នកទទួលស្គាល់នៅពេលនេះ បណ្តាញប្រសាទគឺគ្មានអ្វីក្រៅពីសំណុំផែនទីដែលបានកំណត់តាមលក្ខណៈជាក់លាក់ជាក់លាក់នោះទេ ដែលក្នុងន័យនេះមិនមានអត្ថប្រយោជន៍សំខាន់ណាមួយលើគំរូសិក្សាស្រដៀងគ្នាជាច្រើនទៀតដែលនឹងត្រូវបានរាយបញ្ជីដោយសង្ខេបខាងក្រោម។
នៅក្នុងការតភ្ជាប់ជាមួយនឹងការវាយតម្លៃនៃតួនាទីនៃបណ្តាញសរសៃប្រសាទសម្រាប់ការទទួលស្គាល់ត្រឹមត្រូវ (នោះគឺមិនមែនសម្រាប់ bionics ដែលពួកគេមានសារៈសំខាន់បំផុតឥឡូវនេះ) ខ្ញុំចង់កត់សម្គាល់ដូចខាងក្រោម: បណ្តាញសរសៃប្រសាទដែលជាវត្ថុស្មុគស្មាញបំផុតសម្រាប់គណិតវិទ្យា។ ការវិភាគ ជាមួយនឹងការប្រើប្រាស់ត្រឹមត្រូវ អនុញ្ញាតឱ្យយើងរកឃើញច្បាប់ដែលមិនសំខាន់នៅក្នុងទិន្នន័យ។ ការលំបាករបស់ពួកគេសម្រាប់ការវិភាគនៅក្នុងករណីទូទៅត្រូវបានពន្យល់ដោយរចនាសម្ព័ន្ធស្មុគ្រស្មាញរបស់ពួកគេ ហើយជាលទ្ធផល លទ្ធភាពដែលមិនអាចខ្វះបានសម្រាប់ការធ្វើឱ្យមានភាពទៀងទាត់ជាច្រើនប្រភេទ។ ប៉ុន្តែគុណសម្បត្តិទាំងនេះ ដូចដែលកើតមានជាញឹកញាប់ គឺជាប្រភពនៃកំហុសដែលអាចកើតមាន លទ្ធភាពនៃការបណ្តុះបណ្តាលឡើងវិញ។ ដូចដែលនឹងត្រូវបានពិភាក្សានៅពេលក្រោយ ទិដ្ឋភាពពីរយ៉ាងនៃការរំពឹងទុកនៃគំរូសិក្សាណាមួយគឺជាគោលការណ៍មួយនៃការរៀនម៉ាស៊ីន។
ទិសដៅដ៏ពេញនិយមមួយទៀតក្នុងការទទួលស្គាល់គឺច្បាប់ឡូជីខល និងដើមឈើការសម្រេចចិត្ត។ នៅក្នុងការប្រៀបធៀបជាមួយនឹងវិធីសាស្រ្តនៃការទទួលស្គាល់ខាងលើ វិធីសាស្រ្តទាំងនេះភាគច្រើនប្រើយ៉ាងសកម្មនូវគំនិតនៃការបញ្ចេញចំណេះដឹងរបស់យើងអំពីប្រធានបទក្នុងទម្រង់នៃរចនាសម្ព័ន្ធប្រហែលជាធម្មជាតិបំផុត (នៅលើកម្រិតដឹងខ្លួន) - ក្បួនឡូជីខល។ ក្បួនឡូជីខលបឋមមានន័យថាសេចក្តីថ្លែងការណ៍ដូចជា "ប្រសិនបើលក្ខណៈពិសេសដែលមិនបានចាត់ថ្នាក់ស្ថិតនៅក្នុងសមាមាត្រ X នោះធាតុដែលបានចាត់ថ្នាក់គឺនៅក្នុងសមាមាត្រ Y" ។ ឧទាហរណ៏នៃច្បាប់បែបនេះក្នុងការធ្វើរោគវិនិច្ឆ័យវេជ្ជសាស្រ្តមានដូចខាងក្រោម: ប្រសិនបើអ្នកជំងឺមានអាយុលើសពី 60 ឆ្នាំហើយគាត់ធ្លាប់មានគាំងបេះដូងពីមុនមកនោះកុំធ្វើការវះកាត់ - ហានិភ័យនៃលទ្ធផលអវិជ្ជមានគឺខ្ពស់។
ដើម្បីស្វែងរកក្បួនឡូជីខលនៅក្នុងទិន្នន័យ 2 យ៉ាងគឺចាំបាច់: ដើម្បីកំណត់រង្វាស់នៃ "ព័ត៌មាន" នៃច្បាប់ និងចន្លោះនៃច្បាប់។ ហើយភារកិច្ចនៃការស្វែងរកច្បាប់បន្ទាប់ពីនោះប្រែទៅជាភារកិច្ចនៃការរាប់បញ្ចូលពេញលេញឬដោយផ្នែកនៅក្នុងចន្លោះនៃច្បាប់ដើម្បីស្វែងរកព័ត៌មានច្រើនបំផុត។ និយមន័យនៃខ្លឹមសារព័ត៌មានអាចត្រូវបានណែនាំតាមវិធីផ្សេងៗគ្នា ហើយយើងនឹងមិនពឹងផ្អែកលើរឿងនេះទេ ដោយពិចារណាថានេះក៏ជាប៉ារ៉ាម៉ែត្រមួយចំនួននៃគំរូផងដែរ។ ចន្លោះស្វែងរកត្រូវបានកំណត់តាមវិធីស្តង់ដារ។
បន្ទាប់ពីបានរកឃើញច្បាប់ដែលមានព័ត៌មានគ្រប់គ្រាន់ ដំណាក់កាលនៃ "ការផ្គុំ" ក្បួនទៅក្នុងចំណាត់ថ្នាក់ចុងក្រោយចាប់ផ្តើម។ ដោយមិនពិភាក្សាស៊ីជម្រៅអំពីបញ្ហាដែលកើតឡើងនៅទីនេះ (ហើយវាមានចំនួនច្រើនសន្ធឹកសន្ធាប់) យើងរាយបញ្ជីវិធីសាស្រ្តសំខាន់ចំនួន 2 នៃ "ការជួបប្រជុំគ្នា" ។ ប្រភេទទីមួយគឺបញ្ជីលីនេអ៊ែរ។ ប្រភេទទីពីរគឺការបោះឆ្នោតដែលមានទម្ងន់ នៅពេលដែលទម្ងន់ជាក់លាក់មួយត្រូវបានចាត់ចែងទៅច្បាប់នីមួយៗ ហើយវត្ថុត្រូវបានចាត់ថ្នាក់ដោយអ្នកចាត់ថ្នាក់ទៅថ្នាក់ដែលច្បាប់ចំនួនច្រើនបំផុតបានបោះឆ្នោត។
ជាការពិត ដំណាក់កាលបង្កើតច្បាប់ និងដំណាក់កាល "ការជួបប្រជុំគ្នា" ត្រូវបានអនុវត្តរួមគ្នា ហើយនៅពេលបង្កើតការបោះឆ្នោតដែលមានទម្ងន់ ឬបញ្ជី ការស្វែងរកច្បាប់លើផ្នែកខ្លះនៃទិន្នន័យករណីត្រូវបានហៅម្តងហើយម្តងទៀត ដើម្បីធានាឱ្យមានភាពសមស្របរវាងទិន្នន័យ និង ម៉ូដែល។
