Dnes je XML priemyselným štandardom pre rýchlu a efektívnu výmenu údajov medzi rôznymi riešeniami. Existuje však veľa úloh, pri ktorých používatelia potrebujú reprezentovať údaje XML v inej forme. V týchto prípadoch sú potrebné programy prevodníka. Premosťujú priepasť medzi XML a populárnymi tabuľkovými formátmi. Ak potrebujete pravidelne prevádzať dáta XML, potom určite musíte použiť Advanced XML Converter! S Advanced XML Converter už nemusíte písať zložité XML transformácie a XSL štýly. Konvertujte XML na HTML, CSV, DBF, XLS, SQL v okamihu! Pokročilý XML Converter vám pomôže konvertovať do iných formátov, ako sú HTML, CSV, DBF, XLS a SQL. Hneď po načítaní súboru XML a stlačení tlačidla „Konvertovať“ program vytvorí rýchly a kvalitný výstup do jedného z tabuľkových formátov. Na zabezpečenie správneho výstupu používa Advanced XML Converter hierarchickú štruktúru pôvodného súboru XML. Môžete vybrať údaje, ktoré sa zobrazia vo výstupnom súbore. Môžete tiež previesť viac ako jeden súbor pomocou dávkového spustenia. S Advanced XML Converter už nemusíte písať zložité konverzné alebo XSL transformačné skripty. Konverzia XML do HTML, CSV, DBF, XLS, SQL je rýchla a intuitívna!
| Stiahnite si Advanced XML Converter | |
 |
|
Pomocou pokročilého prevodníka XML môžete extrahovať všetky údaje XML alebo iba údaje z konkrétnych značiek. Pri prezeraní extrahovaných údajov môžete rýchlo prepínať medzi rôznymi zobrazeniami (bez novej analýzy a bez opätovného načítania údajov). Môžete nastaviť možnosti exportu pre každý výstupný formát (ako sú štýly tabuliek HTML a oddeľovače CSV pre exportované polia a ďalšie možnosti). Pokročilý XML Converter umožňuje uložiť všetky tabuľky do jedného súboru alebo viacerých súborov samostatne, ako aj flexibilne konfigurovať možnosti náhľadu a výstupu.
Softvér nevyžaduje inštaláciu ovládačov alebo ďalších komponentov, pretože je postavený na analyzátore Internet Explorer, ktorý je dostupný na väčšine systémov. Advanced XML Converter nevyžaduje .NET Framework alebo XML Schemas. Program nevyžaduje hlboké znalosti o štruktúre súborov XML a výrazne uľahčuje konverziu veľkého množstva údajov XML. Ako používateľ budete môcť vidieť najzložitejšie dokumenty XML v rôznych prehľadových tabuľkách, ktoré sú ľahko čitateľné. To je veľmi výhodné na prenos informácií do databáz alebo špecializovaných systémov, ktoré vyžadujú formát blízky obyčajnému textu.
Ak hľadáte rýchly systém na konverziu dát XML, Advanced XML Converter je tou najlepšou voľbou! Cenovo dostupný a ľahko použiteľný program vykonáva komplexné transformácie údajov v priebehu niekoľkých minút!
Najnovšia verzia Advanced XML Converter poskytuje jednoduchý, rýchly a vysoko efektívny spôsob, ako extrahovať dáta zo súborov XML a uložiť ich v obľúbených formátoch HTML, DBF, CSV, Excel a SQL. |
|
S Advanced XML Converter môžete: |
|
|
Pravdepodobne často potrebujete previesť XML súbor alebo priečinok s XML súbory do jedného alebo viacerých DBF súbory. Problém je v tom XMLštruktúra, jej hierarchia a úrovne vnorenia sa líšia súbor od súboru. V tomto článku sa podrobne pozrieme na to, ako importovať súbor XML súbor AKEJKOĽVEK štruktúry do bytu DBF tabuľky.
Nová funkcia tzv Importovať vlastný XML bola realizovaná v r DBF Commander Professional verzia 2.7 (zostava 40). Tento príkaz je dostupný cez rozhranie príkazového riadku. Syntax je nasledovná:
dbfcommander.exe -icx
Ako vidíte, existujú štyri parametre:
- -icx– znamená Importovať vlastný XML.
- <-attr> - tento parameter použite, ak chcete importovať značky s určitými atribútmi.
Definícia polí DBF alebo Ako vytvoriť súbor mapy
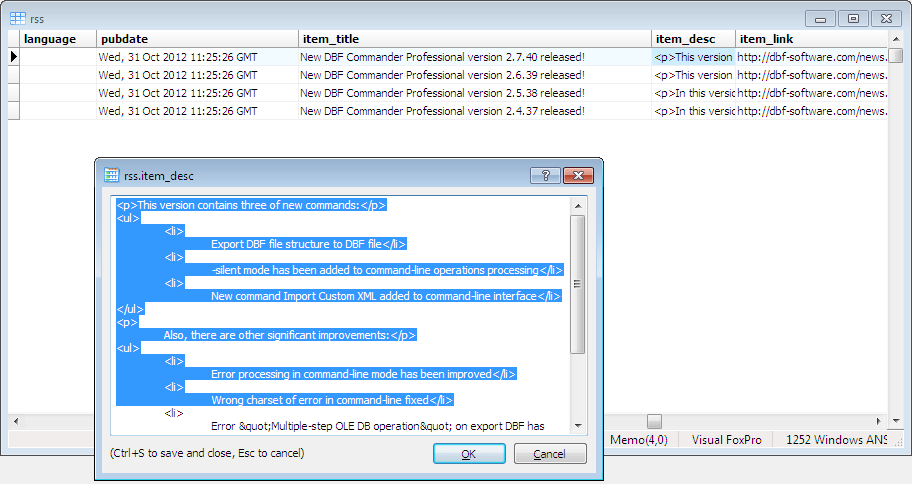
Vždy je lepšie sa niečo naučiť na príklade. V našej situácii potrebujeme nejaké známe XML. Vezmime si RSS spravodajský kanál XML súbor (k dispozícii):
Ako vidíte, sú štyri<položka> prvky vnorené v<kanál> prvok, ktorý je sám vnorený v najvyššej úrovni<rss> prvok. Existujú aj prvky rovnakej úrovne vnorenia ako<položka> prvky:<generátor>, <titul>, <popis> atď.
Predpokladajme, že každý<položka> prvok by mal byť vo výsledku reprezentovaný ako jeden riadok DBF súbor. Takže náš súbor bude obsahovať štyri záznamy.
Ak chcete vytvoriť súbor mapy, najprv vytvorte výsledný súbor DBF súbor. Potrebujeme to, pretože potom budeme môcť vytvoriť súbor mapy niekoľkými kliknutiami. Spustite DBF Commander Professional, kliknite Súbor -> Nový a vytvorte a DBF súbor. V prípade RSS XML súbor, štruktúra je nasledovná:

Kliknite OK. The DBF vytvorí sa súbor a teraz ho možno použiť ako výsledný súbor pre náš import z XML proces. Môžete použiť akékoľvek dostupné typy polí: charakter, Celé číslo, Numerický, Dátum, atď.
Ak chcete vytvoriť súbor mapy na základe výsledného súboru, kliknite na Exportná štruktúra tlačidlo nástroja (pozri obrázok vyššie). Keď sa otvorí dialógové okno Uložiť, vyberte cestu a názov súboru a potom uložte štruktúru ako a DBF súbor.
Priraďovanie značiek XML k poliam DBF
Musíme urobiť ešte jednu vec: definovať XML značky, ktoré by mali byť vložené do polí výsledného DBF súbor.
Otvor DBF súbor, ktorý ste práve uložili. Kliknite Súbor -> Štruktúra a pridajte nové pole s názvom" xmltagname"z charakter typu. Ak chcete, môžete do mapového súboru pridať ďalšie polia. Napríklad „pridajme pole s názvom“ komentovať". Kliknite OK pre uloženie zmien.
Teraz vyplňte každý riadok nového" xmltagname"pole s XML cesta uzlov (oddelená znakom " -> "), ktoré by sa malo vložiť do zodpovedajúceho poľa v DBF súbor:

Znamená to, že hodnota XML uzol<titul> vnorené v<kanál> uzol, ktorý je vnorený na najvyššej úrovni<rss>, bude vložený do " titul"pole; XML značka" rss -> kanál -> popis"bude vložené do" desc„pole a tak ďalej.
V prípade použitia" -attr"parameter, cesty k mapovému súboru musia obsahovať aj zodpovedajúce atribúty, napr.: " rss version="2.0" -> kanál -> názov".
Venujte pozornosť " item_desc"pole XML značka" rss -> kanál -> položka -> popis“ obsahuje sekcia CDATA s HTML značkovanie. Takže cesta k značke by mala byť ukončená znakom " #cdata-section"reťazec.
Posledný riadok, ktorý môžete vidieť na obrázku vyššie, je tzv. riadok-značka Táto cesta značky umožňuje veliteľ DBF vedieť ktorý XML tag by sa mal vo výsledku použiť ako nový riadok DBF súbor. V našom prípade je to" rss -> kanál -> položka".
Všimnite si, že hodnota " názov"" pole by malo byť prázdne pre záznam obsahujúci značku riadka, aby program mohol značku riadka rozpoznať.
To je všetko. Teraz môžeme spustiť import z XML do DBF sám. Vykonajte nasledujúci príkaz z príkazového riadku alebo z a BAT súbor:
dbfcommander.exe -icx "D:\xml\rss.xml" "D:\dbf\" "D:\mapový súbor.dbf"
Výsledkom je, že "získame nový súbor" D:\dbf\rss.dbf ktorý obsahuje dovezené XMLúdaje:
Všetky súbory použité v tejto konverzii si môžete stiahnuť z .
Odoslanie dobrej práce do databázy znalostí je jednoduché. Použite nižšie uvedený formulár
Študenti, postgraduálni študenti, mladí vedci, ktorí pri štúdiu a práci využívajú vedomostnú základňu, vám budú veľmi vďační.
Hostené na http://www.allbest.ru/
Podnesterská štátna univerzita pomenovaná po T.G. Ševčenko
Inžiniersky a technologický inštitút
Katedra informačných technológií a automatizovaného riadenia výrobných procesov
ZÁVEREČNÁ KVALIFIKAČNÁ PRÁCA
v smere 230100 "Informatika a výpočtová technika"
téma: "PROGRAMOVÝ KONVERTOR DATABÁZ ZO SÚBOROV DBF DO SÚBORU FORMÁTU XML"
Študent Maksimov Dmitrij Olegovič
Tiraspol, 2013
ÚVOD
1. VÝSKUM A ANALÝZA OBLASTI PREDMETU
1.1 Popis úlohy
1.2 Zdôvodnenie relevantnosti skúmaného problému
1.3 Prehľad metód riešenia podobných problémov
1.4 Vyjadrenie problému, systémové požiadavky, požiadavky na vstupné údaje a výstupné formuláre
2. NÁVRH ŠTRUKTÚRY A ARCHITEKTÚRY SOFTVÉROVÉHO PRODUKTU
2.1 Výber metód a prostriedkov na realizáciu, jej zdôvodnenie
2.2 Popis použitých algoritmov
2.3 Štruktúra, architektúra softvérového produktu
2.4 Funkčná schéma, funkčná štruktúra softvérového produktu
3. IMPLEMENTÁCIA A TESTOVANIE SOFTVÉROVÉHO PRODUKTU
3.1 Popis implementácie
3.2 Popis používateľského rozhrania
3.3 Testovanie a hodnotenie spoľahlivosti softvérového produktu
3.4 Kalkulácia nákladov
3.5 Ochrana práce
ZÁVER
ZOZNAM KONvencií, SYMBOLOV, JEDNOTIEK A POJMOV
ZOZNAM POUŽITEJ LITERATÚRY
DODATOK
ÚVOD
Počas existencie počítačov bolo vyvinutých mnoho operačných systémov. Teraz sa ich počet meria v desiatkach av rôznych rodinách existujú formáty súborov používané iba v určitom rade operačných systémov. Ak napríklad existujú univerzálne editory obrázkov, ktoré otvárajú akýkoľvek formát súborov obsahujúci obrázky podporované operačnými systémami, potom napríklad neexistujú žiadne takéto editory pre databázy.
Na prácu s každým z databázových formátov existuje individuálny systém správy databázy. Existuje veľké množstvo rôznych databáz, ktoré sa líšia v rôznych kritériách:
1) Klasifikácia podľa dátového modelu:
a) hierarchické;
b) sieť;
c) vzťahové;
d) objektovo a objektovo orientované;
e) vecno-vzťahové, funkčné.
2) Klasifikácia podľa perzistentného úložného prostredia:
a) v sekundárnej pamäti alebo tradičnej;
b) v RAM;
c) v terciárnej pamäti.
3) Klasifikácia podľa stupňa distribúcie:
a) centralizované alebo koncentrované;
b) distribuované.
4) Iné typy databáz
a) priestorové;
b) dočasné;
c) časopriestor;
d) cyklický.
Veľké množstvo rôznych databáz vám neumožňuje priamo prenášať obsah databázy z jedného typu na druhý. Na vyriešenie tohto problému existujú konvertorové programy, ktoré konvertujú jeden databázový formát do druhého. Spravidla existujú konvertory len pre najbežnejšie databázové formáty, čo neumožňuje priamo previesť niektorý zastaraný formát na moderný. Použitie dvoch konvertorov nie je racionálne, preto je najlepším riešením ukladanie databáz do súborov XML ako medzikrok.
Súbory XML a súbory iných rozšírení založených na jazyku XML sa veľmi rozšírili, takmer každý moderný operačný systém podporuje tento formát súborov. Súbory XML ukladajú širokú škálu údajov, od nastavení aplikácie až po databázy. Súbory založené na XML sa používajú na výmenu informácií na internete a medzi programami (na čo bol tento značkovací jazyk pôvodne vytvorený). Keďže súbory vo formáte XML obsahujú textové údaje, možno ich jednoducho upravovať v ľubovoľnom textovom editore, ako aj nastaviť ľubovoľné užívateľsky prívetivé kódovanie údajov. Okrem toho existuje veľké množstvo generátorov dokumentov XML.
1 . VÝSKUM A ANALÝZA OBLASTI PREDMETU
1.1 Popis úlohy
V záverečnej kvalifikačnej práci je potrebné implementovať konvertorový program, ktorý na základe obsahu prenesených dbf súborov vytvorí XML súbor podľa užívateľom zadanej šablóny. Počet a štruktúra dbf súborov môže byť ľubovoľná, výstupný XML súbor musí byť vždy rovnaký. Každý dbf súbor má svoju šablónu, na základe ktorej program zapisuje informácie do XML súboru. Je potrebné implementovať schopnosť vytvárať šablóny dvoma spôsobmi: pomocou kódu a pomocou konštruktora. Šablóny vytvorené pomocou kódu musia vybrať, ktoré údaje sa majú zapísať do výstupného súboru. Táto možnosť sa vykonáva pomocou špeciálnych kódových príkazov vyvinutých špeciálne pre tento program. V šablónach vytvorených pomocou konštruktora je potrebné implementovať jednoduché a pohodlné rozhranie, ktoré vám umožní vytvárať vlastné šablóny, na základe ktorých program zapisuje informácie do XML súboru.
1.2 Zdôvodnenie relevantnosti skúmaný problém
XML je značkovací jazyk odporúčaný konzorciom World Wide Web Consortium, čo je vlastne súbor všeobecných pravidiel syntaxe. XML je textový formát určený na ukladanie štruktúrovaných údajov (namiesto existujúcich databázových súborov), na výmenu informácií medzi programami a na vytváranie špecializovanejších značkovacích jazykov (napríklad XHTML) na jeho základe.
XML dokument je databázou len v najvšeobecnejšom zmysle slova, teda je to súbor údajov. V tomto sa nelíši od mnohých iných súborov - v konečnom dôsledku všetky súbory pozostávajú z nejakých údajov. Ako „databázový“ formát má XML určité výhody, ako napríklad samoopisný (značka popisuje údaje). Je ľahké, aby to spracoval iný softvér, pretože údaje sú uložené v kóde Unicode, ukladajú údaje v stromovej alebo grafovej štruktúre. Má však aj určité nevýhody, napríklad je príliš podrobný a relatívne pomalý v prístupe k údajom kvôli potrebe analýzy a konverzie textu.
Pozitívom je, že XML vám umožňuje implementovať veľa vecí, ktoré možno nájsť v konvenčných databázach: úložisko (XML dokumenty), schémy (DTD, XML Schema Language), dotazovacie jazyky (XQuery, XPath, XQL, XML - QL, QUILT atď.), API (SAX, DOM, JDOM) atď. Medzi nevýhody patrí nedostatok mnohých funkcií dostupných v moderných databázach: ekonomika ukladania, indexy, bezpečnosť, integrácia transakcií a údajov, prístup viacerých používateľov, spúšťače, dotazy na mnohé dokumenty atď.
Zatiaľ čo je teda možné použiť dokumenty XML ako databázu v prostrediach s malým množstvom údajov, malým počtom používateľov a nízkymi požiadavkami na výkon, vo väčšine podnikových prostredí s mnohými používateľmi a vysokými požiadavkami na integráciu to nemožno urobiť.
Príkladom „databázy“, pre ktorú je vhodný XML dokument, je súbor .ini – teda súbor, ktorý obsahuje informácie o konfigurácii aplikácie. Je oveľa jednoduchšie prísť s programovacím jazykom s malou sadou funkcií založených na XML a napísať aplikáciu SAX na jeho interpretáciu, ako písať syntaktický analyzátor súborov oddelených čiarkami. XML navyše umožňuje vnárať dátové prvky – to je pri oddeľovaní dát čiarkami dosť ťažké. Takéto súbory však možno len ťažko nazvať databázami v plnom zmysle slova, keďže sa čítajú a zapisujú lineárne a len pri otvorení alebo zatvorení aplikácie.
Najzaujímavejšie príklady datasetov, v ktorých je vhodné použiť XML dokument ako databázu, je osobný zoznam kontaktov (mená, telefónne čísla, adresy atď.). Avšak kvôli nízkym nákladom a jednoduchosti používania databáz, ako sú dBASE a Access, aj v týchto prípadoch nie je dôvod použiť ako databázu dokument XML. Jedinou skutočnou výhodou XML je, že údaje možno ľahko prenášať z jednej aplikácie do druhej, ale táto výhoda nie je až taká dôležitá, keďže nástroje na serializáciu databáz do formátu XML sú už rozšírené.
Vývoj softvéru je dôležitý z nasledujúcich dôvodov:
Databázový formát dbf je zastaraný a nespĺňa moderné požiadavky;
Formát XML nemá prísne požiadavky na obsah, používateľ môže ukladať dáta v ľubovoľnom poradí a vytvárať značky s ľubovoľným názvom;
Žiadny konvertorový program vám neumožňuje vytvoriť si vlastnú štruktúru súboru XML a zapisovať údaje z niekoľkých súborov vo formáte dbf.
1.3 Prehľad metód riešenia podobných problémov
"White Town" umožňuje konvertovať súbory dbf do formátu XML. Program dokáže konvertovať súbory dbf dBase III, dBase IV, FoxPro, VFP a dBase Level 7. Program podporuje rozhranie príkazového riadku. Dá sa teda spustiť zo súboru .BAT alebo .LNK po zadaní požadovaných parametrov alebo podľa plánu z plánovača Windows. Nevýhodou tohto softvérového produktu je nemožnosť prispôsobenia formátu výstupného súboru. Hlavné okno aplikácie je znázornené na obrázku 1.1.
Obrázok 1.1 - Hlavné okno programu "White Town"
"DBF Converter" je všestranný, ale ľahko použiteľný konverzný program. Tento program má rozhranie podobné sprievodcovi, ale dá sa použiť aj ako nástroj príkazového riadka na spracovanie skupiny súborov. "DBF Converter" podporuje všetky moderné formáty výmeny údajov, ako sú XML, CSV, TXT, HTML, RTF, PRG a ďalšie. Implementovaná možnosť konverzie DBF tabuliek do SQL skriptu, ktorý je možné importovať do akejkoľvek SQL databázy.
Okrem jednoduchých transformácií vám „DBF Converter“ umožňuje manipulovať s údajmi výberom iba určitých stĺpcov a použitím filtrov. Na rozdiel od zjednodušených pravidiel filtrovania, ktoré sa zvyčajne nachádzajú v iných DBF aplikáciách, "DBF Converter" dynamicky skladá jednoduché formuláre na zadávanie databáz. Schopnosť nastaviť rozšírenú masku a pravidlá na ľubovoľné pole jednoduchého záznamu je jednou z najcennejších funkcií dostupných v DBF Converter. Hlavnou nevýhodou tohto softvéru je jeho cena 29,95 USD.
Hlavné okno aplikácie je znázornené na obrázku 1.2.
Obrázok 1.2 - Hlavné okno programu "DBF Converter"
"DBF View" je bezplatný, kompaktný a pohodlný program na prácu so súbormi DBF. Nevyžaduje inštaláciu, funguje bez ďalších ovládačov a knižníc.
Hlavnou výhodou je univerzálnosť, rýchle a flexibilné lineárne vyhľadávanie, ktoré rýchlosťou prekonáva mnohé SQL.
Pridané vlastnosti:
Vyhľadávanie podľa masky (vzoru);
Úpravy, nahradzovanie, mazanie, vytváranie, pridávanie údajov;
Triediace polia;
Viacjazyčnosť a vytváranie nových slovníkov;
Import a export DBF, TXT, CSV, SQL, XML;
Prekódovanie do DOS, Windows, translit a iné;
Spúšťacie heslo;
História nahrávania.
Hlavnou nevýhodou tohto softvéru je nemožnosť vytvárať šablóny pri prevode. Hlavné okno programu je znázornené na obrázku 1.3.
Obrázok 1.3 - Hlavné okno programu "DBF View"
1.4 Problémové vyhlásenie, systémové požiadavky, požiadavky na výstupné dáta a výstupné formuláre
Po preštudovaní úlohy, preskúmaní jej relevantnosti a analýze existujúcich konvertorových programov bol zostavený zoznam potrebných požiadaviek na vyvinutý softvér.
V softvérovom produkte musia byť implementované nasledujúce funkcie:
Čítanie obsahu súborov dbf;
Vytváranie šablón v jednom z dvoch editorov;
Úprava šablóny;
Výber poradia konverzie súborov dbf;
Vykonávanie šablón;
Protokolovanie chýb;
Uloženie výsledkov programu do súboru XML.
Softvér je napísaný v Microsoft Visual Studio 2008 a vyžaduje spustenie:
Operačný systém rodiny Windows jednej z verzií: Windows Vista, Windows 7 alebo Windows 8;
Microsoft .NET Framework 4;
Ovládače Visual FoxPro ODBC.
Minimálne systémové požiadavky na softvérový produkt zodpovedajú minimálnym požiadavkám na operačný systém.
Vstupnými údajmi môžu byť súbory dbf verzie dBase II, dBase III alebo dBase IV.
Výstupné súbory by mali byť vo formáte XML s jazykovou verziou 1.xa podporou pre akýkoľvek prehliadač.
Cesta k vstupným a výstupným súborom môže byť ľubovoľná.
2 . ŠTRUKTÚRA A ARCHITEKTÚRA NÁVRH SOFTVÉROVÉHO PRODUKTU
2.1 Výber metód a prostriedkov na realizáciu, jej zdôvodnenie
Pre vývoj softvérového produktu bolo zvolené integrované vývojové prostredie Microsoft Visual Studio 2008.
Visual Studio 2008 – vydané 19. novembra 2007 spolu s .NET Framework 3.5. Je zameraný na tvorbu aplikácií pre operačný systém Windows Vista (podporuje však aj XP), Office 2007 a webové aplikácie. Zahŕňa LINQ, nové verzie C# a Visual Basic. Štúdio nezahŕňalo Visual J#. Jednou z jeho výhod je úplne ruské rozhranie.
Visual Studio obsahuje editor zdrojového kódu s podporou technológie IntelliSense a možnosťou jednoduchého refaktorovania kódu. Vstavaný debugger môže fungovať ako ladiaci nástroj na úrovni zdroja aj ako ladiaci nástroj na úrovni stroja. Medzi ďalšie nástroje na vloženie patrí editor formulárov na zjednodušenie vytvárania GUI aplikácie, webový editor, návrhár tried a návrhár schém databázy. Visual Studio vám umožňuje vytvárať a pripájať doplnky (pluginy) tretích strán na rozšírenie funkčnosti na takmer každej úrovni, vrátane pridania podpory pre systémy riadenia verzií zdrojového kódu (ako sú Subversion a Visual SourceSafe), pridávania nových sád nástrojov (napr. na úpravu a návrh vizuálneho kódu v programovacích jazykoch špecifických pre doménu alebo nástroje pre iné aspekty procesu vývoja softvéru (napríklad klient Team Explorer pre prácu s Team Foundation Server).
Všetky funkcie pracovného stola Visual Studio 2008 založeného na jazyku C# zahŕňajú:
Schopnosť formulovať úlohy v jazyku interakcie objektov;
Vysoká modularita programového kódu;
Prispôsobivosť želaniam používateľov;
Vysoký stupeň opätovnej použiteľnosti programu;
Veľký počet prepojených knižníc.
2. 2 Popis aplikovaných algoritmov
Pri vývoji tohto softvéru možno rozlíšiť dve hlavné ťažkosti: vytvorenie rozpoznávača pre programovateľné šablóny a vytvorenie programovacieho modelu, ktorý by sa použil v šablónach vytvorených pomocou konštruktora.
1. Programovateľné vzory. Keďže kód používaný v šablónach je do istej miery podobný kódu používanému v programovacích jazykoch, je potrebné, aby tento rozpoznávač prevzal niektoré funkcie kompilátora kódu, respektíve jeho parsovacie funkcie. V štruktúre kompilátora sa parsovacia časť skladá z lexikálnej, syntaktickej a sémantickej analýzy. Lexikálny analyzátor číta znaky programu v zdrojovom jazyku a vytvára z nich lexémy zdrojového jazyka. Výsledkom jeho práce je tabuľka identifikátorov. Syntaktický analyzátor vykonáva extrakciu syntaktických konštrukcií v texte zdrojového programu, ktorý spracováva lexikálny analyzátor. Zosúladí syntaktické pravidlá programu s gramatikou jazyka. Analyzátor je nástroj na rozpoznávanie textu vstupného jazyka. Sémantický analyzátor kontroluje správnosť textu zdrojového programu z hľadiska významu vstupného jazyka.
Pomocou kódu by sa mali implementovať nasledujúce funkcie: vytvorenie slučky, získanie a zobrazenie údajov o počte riadkov a stĺpcov, získanie typu údajov a názvov stĺpcov, ako aj získanie obsahu databázových buniek. K tomu je v prvom rade potrebné urobiť zoznam všetkých možných stavov automatu. Možné stavy rozpoznávača sú uvedené v tabuľke 2.1.
Tabuľka 2.1 - Zoznam možných stavov rozpoznávania
|
Index stavu |
Štát |
Popis |
|
|
Variabilné |
Počítadlo cyklov |
||
|
Servisné slovo označujúce začiatok cyklu |
|||
|
Servisné slovo označujúce stav ukončenia slučky |
|||
|
Funkčné slovo označujúce, že ďalší odkaz bude na základné stĺpce |
|||
|
Funkčné slovo označujúce, že ďalší odkaz bude na základné reťazce |
|||
|
množstvo |
Funkčné slovo označujúce počet riadkov alebo stĺpcov v závislosti od toho, aký bol predchádzajúci hovor |
||
|
Funkčné slovo označujúce výstup typu údajov stĺpca, ku ktorému sa má pristupovať |
|||
|
názov |
Funkčné slovo označujúce výstup názvu stĺpca, na ktorý nasleduje odvolanie |
||
|
Špeciálny znak oddeľujúci služobné slová |
|||
|
= (rovná sa) |
Špeciálny znak, ktorý označuje, aká hodnota bude priradená premennej pri spustení cyklu. |
||
|
[ (otvorená zátvorka) |
|||
|
] (tesná zátvorka) |
Špeciálny znak označujúci, že bol prístup ku konkrétnemu stĺpcu alebo riadku |
||
|
Akékoľvek celé číslo |
Na základe zostavenej tabuľky je možné zostrojiť konečný stavový automat možných stavových prechodov. Obrázok 2.1 zobrazuje stavový automat.
Obrázok 2.1 - Konečný automat možných prechodov
Na základe zostrojeného automatu je možné zostrojiť zostupný rozpoznávač s návratom (s výberom alternatív). Na určenie, či reťazec patrí do gramatiky, sa používa zostupný rozpoznávač spätného sledovania. Analyzuje aktuálny stav, hľadá prechodové pravidlo z aktuálneho stavu do nasledujúceho, ak sa nasledujúci stav zhoduje, postup sa opakuje pre ďalší. Ak rozpoznávač nemôže nájsť prechodové pravidlo z aktuálneho stavu do nasledujúceho, potom tento reťazec nepatrí do tejto gramatiky, to znamená, že riadok kódu je zapísaný s logickou chybou. Ak je viacero možností prechodu, tak si rozpoznávač zapamätá stav, v ktorom alternatíva vznikla a vráti sa k nemu, ak reťazec nepatrí do gramatiky. Obrázok 2.2 zobrazuje rezolver smerujúci nadol so spätnou dráhou.
Obrázok 2.2 - Downward Resolver s Backtracking
Počas analýzy šablóny sa uchováva protokol chýb, ktorý obsahuje informácie o tom, ktorá šablóna má chybu, v ktorom konkrétnom riadku kódu a type chyby. Chyby môžu byť nasledujúcich typov: nerozpoznaný identifikátor (pokus použiť servisné slová alebo špeciálne znaky, ktoré daný kód neposkytuje), porušenie logického významu (riadok kódu neprešiel rozpoznávačom), pokus pre prístup k neexistujúcej premennej (prístup k premennej k nevytvorenej premennej alebo prístup k premennej mimo cyklu), začiatok cyklu nie je určený (začiatok a koniec cyklu je potrebné zadať vo forme otvorenia a zatvorenia zložené zátvorky).
2. Šablóny vytvorené pomocou konštruktora. Jedným z riešení je štruktúra používaná v logických programovacích jazykoch: aplikujte filtre podmienok na bežné vstupné informácie, ktorými je v tomto prípade obsah databázovej tabuľky. Obrázok 2.3 zobrazuje všeobecnú štruktúru databázovej tabuľky.
Obrázok 2.3 - Všeobecná štruktúra databázovej tabuľky
3. Ako implementácia bolo zvolené riešenie pomocou "Tuth Table". Táto tabuľka je tabuľka s n+1 stĺpcami a m+1 riadkami, kde n a m sú počet stĺpcov a riadkov vo vstupnej tabuľke. Každá bunka tabuľky obsahuje hodnotu true alebo false. Obrázok 2.4 zobrazuje "Tabuľku pravdy".
Obrázok 2.4 - "Tabuľka pravdy"
Keď sa použije filter, skutočné hodnoty sa nahradia nepravdivými v závislosti od toho, na čo bol filter použitý. Ak bol filter aplikovaný na obsah buniek, hodnoty sa zmenia špecificky pre každú bunku, a ak na riadky alebo stĺpce, potom iba v ďalšom riadku alebo stĺpci.
Pri práci s databázou možno rozlíšiť nasledovné entity: index riadku, index stĺpca, počet riadkov, počet stĺpcov, typ stĺpca, názov stĺpca, obsah bunky.
Boli stanovené aj podmienky:<», «>"", "=", "obsahuje", "zhoduje sa".
4. Vybrané entity a podmienky stačia na zobrazenie všetkých možných údajov alebo na uloženie všetkých druhov podmienok. Obrázok 2.5 ukazuje „Tuth Table“ s použitými filtrami.
Obrázok 2.5 - "Tabuľka pravdy" s použitými filtrami
Pri výstupe informácií do súboru XML program určí, čo je potrebné vypísať, a potom pomocou „Tuth Table“ vypíše iba tie hodnoty, ktoré zodpovedajú skutočnej hodnote.
Na vytvorenie rozloženia šablóny boli vytvorené tieto typy značiek: main, simple, global, block. Hlavným je tag, tento typ môže byť v dokumente len jeden a je povinný, obsahuje informácie o XML dokumente. Jednoduché – tagy tohto typu sú jediným spôsobom, ako zobraziť údaje a klásť podmienky na „Tabuľku pravdy“. Pozostávajú z nasledujúcich častí: názov, zdroj a stav. Predtým vybrané entity sa používajú ako zdroj a podmienka. Ak má tag prázdny názov, jeho obsah sa nezobrazí, ale uplatní sa podmienka pre „Tabuľku pravdy“.
Globálne - značky tohto typu nenesú logickú záťaž, sú potrebné len na výstup.
Blok - tagy tohto typu sú potrebné na spojenie logiky jednoduchých tagov a všetko, čo je napísané v tagu bloku, sa zobrazí pre každú bunku, ktorá spĺňa "Tuth Table". Samotná značka bloku sa v dokumente XML nezobrazuje.
2.3 Štruktúra, architektúra softvérového produktu
Ústredným bodom objektovo orientovaného programovania je vývoj logického modelu systému vo forme diagramu tried. Diagram tried (class diagram) slúži na znázornenie statickej štruktúry modelu systému v terminológii tried objektovo orientovaného programovania. Diagram tried môže odrážať najmä rôzne vzťahy medzi jednotlivými entitami predmetnej oblasti, ako sú objekty a subsystémy, ako aj popisovať ich vnútornú štruktúru a typy vzťahov.
Trieda (trieda) v tomto diagrame sa používa na označenie množiny objektov, ktoré majú rovnakú štruktúru, správanie a vzťahy s objektmi iných tried. Graficky je trieda znázornená ako obdĺžnik, ktorý je navyše možné rozdeliť vodorovnými čiarami na sekcie alebo sekcie. Tieto časti môžu obsahovať názov triedy, atribúty (premenné) a operácie (metódy).
Okrem vnútornej štruktúry alebo štruktúry tried, zodpovedajúci diagram naznačuje vzťah medzi triedami:
Pre túto aplikáciu boli priradené triedy opísané v tabuľke 2.2.
Tabuľka 2.2 - Popis tried použitých v softvérovom produkte
Diagram tried aplikácie prevodníka je znázornený na obrázku 2.6. Z diagramu môžete vidieť, že trieda MyCode je premennou triedy Template. Trieda Template obsahuje nasledujúce polia: dt, lv, thisTemplate, mycode, fs, sr, sw, correct, masCode, masPerem, masPeremCount, masSost, masCodeLength. dt je premenná typu DataTable obsahujúca informácie uložené v databáze; lv - premenná typu ListView, objekt rozhrania, do ktorého sa zapisujú chybové hlásenia v šablónach; thisTemplate - premenná typu string, čo znamená názov šablóny, ktorá sa práve spracováva; mycode - pole triedy MyCode, ktoré ukladá informácie o všetkých fragmentoch kódu nájdených v tejto šablóne; fs - premenná typu FileStream, ktorá určuje, s ktorým súborom bude program pracovať; sr - premenná typu StreamReader, ktorá určuje, z ktorého súboru sa budú informácie čítať; sw je premenná typu StreamWriter, ktorá určuje, do ktorého súboru sa budú zapisovať informácie; správny - premenná typu bool, ktorá indikuje, či je aktuálny fragment kódu spracovaný správne; masCode - pole typu reťazec obsahujúce všetky nájdené riadky kódu v šablóne; masCodeLength - premenná typu int označujúca, koľko riadkov kódu sa našlo v šablóne; masPerem - dvojrozmerné pole typu reťazec obsahujúce názov a hodnotu vytvorených premenných; masPeremCount - premenná typu int označujúca, koľko premenných bolo momentálne vytvorených; masSost je pole typu int obsahujúce zoznam stavov stroja pre aktuálny riadok kódu.
Trieda obsahuje aj nasledujúce metódy: Connect, Search, Analize, Check, ExecuteCode. Metóda Connect sa pripojí k šablóne na danej ceste. Metóda vyhľadávania nájde útržky kódu v šablóne. Metóda Analyze určuje stavy pre riadok kódu. Metóda Check je rekurzívna, určuje logickú platnosť reťazca. Metóda ExecuteCode spustí aktuálnu šablónu. Pre popísané triedy môžete vytvoriť diagram tried. Obrázok 2.6 je diagram tried.
Obrázok 2.6 - Diagram tried
2.4 Funkčná schéma, funkčný účel softvérového produktu
Softvérový produkt vyvinul dve možné možnosti spracovania informácií pomocou jedinečných algoritmov.
Ak používateľ používa šablóny kódu, musí najprv špecifikovať vstupné súbory a potom buď vytvoriť novú šablónu, alebo vybrať existujúcu. Ďalej používateľ určí adresár a názov výstupného súboru a spustí proces konverzie. Počas tohto procesu sa najskôr pridelia sekcie kódu v šablóne, potom sa v každej sekcii pridelia lexémy, po ktorých sa určí ich logický význam a vykoná sa šablóna. Ak sa v ktorejkoľvek z týchto fáz vyskytnú chyby, informácie o nich sa zaznamenajú do protokolu chýb. Po vykonaní všetkých šablón môže používateľ použiť výstupný súbor.
Ak používate šablóny vytvorené pomocou konštruktora, používateľ musí zadať databázu, ktorú je potrebné skonvertovať, potom zadať adresár výstupného súboru, vytvoriť šablónu a spustiť proces prevodu. Samotný prevod pozostáva z dvoch častí: vytvorenie pravdivostnej tabuľky na základe šablóny a vykonanie prevodu podľa pravdivostnej tabuľky. Výstupný súbor môže potom používateľ použiť podľa plánu.
V druhej kapitole záverečnej kvalifikačnej práce boli zvolené vývojové nástroje a to Microsoft Visual Studio 2008, popísané hlavné metódy implementácie softvérového produktu a popísaná aj jeho štruktúra. Popísaná bola aj funkčná schéma softvérového produktu.
Hlavné body úvahy v druhej kapitole boli:
Výber metód a prostriedkov na realizáciu, jej opodstatnenie;
Popis aplikovaných algoritmov;
Štruktúra, architektúra softvérového produktu;
Funkčná schéma, funkčný účel softvérového produktu.
3 . IMPLEMENTÁCIAA TESTOVANIESOFTVÉROVÝ PRODUKT
3.1 Popis implementácie
Jednou z ťažkostí pri implementácii tohto softvérového produktu je písanie algoritmu rozpoznávania. Celý algoritmus je popísaný metódami: Search, Analize, Check, ExecuteCode.
Metóda Search prečíta vzor a nájde fragmenty kódu označené na oboch stranách znakmi „*“ a zapíše ich do súboru .
public voidSearch()
boolsign=false;
zatiaľ čo (!sr.EndOfStream)
if ((c != "*") && (znamienko == pravda))
( s += c.ToString(); )
if ((c == "*") && (znamienko == nepravda))
if ((c == "*") && (znamienko == true))
masCode = s;
masCodeLength++; )
s += c.ToString(); ))
mycode = nový MyCode ;)
Metóda Analize rozdelí riadok kódu na samostatné tokeny a určí stav každého z nich, ak sa použijú symboly alebo slová, ktoré jazyk neposkytuje, alebo sa použijú nesprávne názvy premenných, do súboru sa pridá príslušné chybové hlásenie. denník chýb. Kompletný zoznam použitých lexém je uvedený v tabuľke 2.1.
public void Analyze()
( string masIdent = nový reťazec;
int masIdentLength = 0;
boolov znak = true;
pre (int a = 0; a< masCodeLength; a++)
(správne=nepravda;
masIdentLength = 0;
masCode[a] = masCode[a].Trim();
masCode[a] = masCode[a].ToLower();
pre (int b = 0; b< masCode[a].Length; b++)
(c = masCode[a][b];
masIdentLength++; )
masIdent = ".";
masIdentLength++;
if ((c == " ") && (s != ""))
( masIdent = s;
masIdentLength++;
( masIdent = s;
masIdentLength++; )
mycode[a] = new MyCode("", null);
pre (int z = 0; z< masIdentLength; z++)
mycode[a].code += masIdent[z] + " ";
masSost = new int;
V predchádzajúcej časti metódy boli všetky nájdené tokeny zapísané do poľa masIdent, následne sa inicializuje cyklus, v ktorom sa určí stav pre všetky nájdené tokeny a zapíše sa do poľa masSost.
pre (int b = 0; b< masIdentLength; b++)
if (masIdent[b] == "pre")
else if (masIdent[b] == "predtým")
else if (masIdent[b] == "stĺpec")
else if (masIdent[b] == "reťazec")
if (Char.IsLetter(masIdent[b]))
( bool f = pravda;
pre (int d = 1; d< masIdent[b].Length; d++)
if (!Char.IsLetterOrDigit(masIdent[b][d]))
if (f == true) massSost[b] = 1; inak
Pridanie chybového záznamu do protokolu chýb, ak nájdené ID neexistuje.
lv.Items.SubItems.Add("Nerozpoznaný identifikátor " + masIdent[b]); )) inak
lv.Items.SubItems.Add(mycode[a].code);
lv.Items.SubItems.Add("Nerozpoznaný identifikátor " + masIdent[b]);))
mycode[a] = new MyCode(mycode[a].code, massSost);
Check(0, massSost, a); )
Metóda Check je založená na práci zostupného resolvera s návratom: určí sa aktuálny stav, ak je to možné, potom sa vykoná prechod na ďalší. Ak to nie je možné, potom sa stav prepne na alternatívny, ak žiadny nie je, do protokolu chýb sa pridá chybové hlásenie.
public void Check(int a, int s, int indc)
( if (masSost[a] == s)
( if ((s == 1) && (a == 0))
spravne=pravda; ) inak
if ((s == 2) && (a == 0)) s = 1; inak
if (((s == 4) || (s == 5)) && (a == 0)) s = 8; inak
if ((s == 1) && (a == 1)) s = 9; inak
if ((s == 8) && (a == 1)) s = 6; inak
if ((s == 10) && (a == 1)) s = 1; inak
if ((s == 9) && (a == 2)) s = 12; inak
if ((s == 6) && (a == 2))
( if (a == massSost.Length - 1)
spravne=pravda; ) inak
if (((s == 1) || (s == 12)) && (a == 2)) s = 11; inak
if ((s == 12) && (a == 3)) s = 3; inak
if ((s == 11) && (a == 3)) s = 8; inak
if ((s == 3) && (a == 4)) s = 12; inak
if ((s == 8) && (a == 4))
( if (masSost == 4)
if ((s == 6) && (a == 7))
( if (a == massSost.Length - 1)
spravne=pravda; )
if (((s == 12) || (s == 1)) && (a == 7))
if ((s == 11) && (a == 8))
( if (a == massSost.Length - 1)
spravne=pravda; )
Ak pole vstupných stavov prešlo kontrolou resolverom a všetky stavy sa zhodujú, správna premenná sa nastaví na hodnotu true a ak niekde dôjde k nesúladu, vykoná sa návrat a skontroluje sa alternatívny stav.
if (správne == nepravda)
Check(a, s, indc); ))
if ((s == 8) && (a == 1))
Check(a, s, indc); )
if ((s == 1) && (a == 2))
Kontrola (a, s, indc);)
if ((s == 1) && (a == 7))
Check(a, s, indc); )
Ak sa vykonávaný prechod nerozpoznal, spracovávaný riadok kódu sa považuje za logicky neplatný a do protokolu chýb sa pridá príslušná chybová položka.
if (správne == nepravda)
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(masCode);
lv.Items.SubItems.Add("Logický význam riadku je porušený");
mycode.correct = false;
Metóda ExecuteCode zapíše obsah šablóny do výstupného súboru spustením programových riadkov. Ak sa vyskytne cyklus, potom sa vytvorí dočasný súbor, do ktorého sa zapíše obsah cyklu a kým sa cyklus nedokončí, obsah tohto súboru sa vykoná. Toto je potrebné na vykonanie vnorených slučiek.
public void ExecuteCode (int NCode, bool cikcle, StreamReader sr, StreamWriter sw, int tempF)
zatiaľ čo (!sr.EndOfStream)
c = Convert.ToChar(sr.Read());
Algoritmus číta vstupný súbor znak po znaku, ak existuje uzatváracia zložená zátvorka, ktorá znamená koniec cyklu a premenná cikcle je true, znamená to, že metóda bola vnorená a ukončí ju.
if ((c == ")") && (cikcle == true))
Ak načítaný znak nebol "*", znamená to, že znak nepatrí do kódových príkazov a musí sa jednoducho vypísať.
Ak bol načítaný znak "*", algoritmus prečíta ďalší znak, ak je "*", potom to znamená, že používateľ chcel tento znak vypísať do výstupného súboru.
( c = Convert.ToChar(sr.Read());
Ak nasledujúci znak nebol „*“, znamená to, že všetky nasledujúce znaky pred „*“ sa vzťahujú na kódové príkazy.
if (mycode.correct == true)
if (mycode.masSost == 1)
( bool vytvoriť = false;
pre (int a = 0; a< masPeremCount; a++)
( if (masPerem == mycode.code)
sw.Write(masPerem);
while (sr.Read() != "*")
Ak sa v kóde používateľ pokúsi zobraziť premennú, ktorá predtým nebola deklarovaná, potom sa do protokolu chýb zapíše chybový záznam a vzdialený kód sa už nevykoná.
if (vytvoriť == nepravda)
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add("Pokúšam sa zobraziť neexistujúcu premennú");
mycode.code = ""; )
while (sr.Read() != "*")
if (mycode.masSost == 4)
(ak (mycode.masSost == 6)
sw.Write(dt.Columns.Count.ToString());
while (sr.Read() != "*")
if (Convert.ToInt32(mycode.masValue)< dt.Columns.Count)
(ak (mycode.masSost == 7)
sw.Write(dt.Columns.masValue)].DataType.Name);
sw.Write(dt.Columns.masValue)].ColumnName);)
Ak sa používateľ pokúsi o prístup k stĺpcu alebo riadku, ktorý neexistuje, do protokolu chýb sa pridá zodpovedajúca chybová položka.
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
mycode.code = ""; )
while (sr.Read() != "*")
( bool vytvoriť = false;
pre (int a = 0; a< masPeremCount; a++)
if (Convert.ToInt32(masPerem)< dt.Columns.Count)
(ak (mycode.masSost == 13)
sw.Write(dt.Columns)].Názov stĺpca);
sw.Write(dt.Columns)].DataType.Name);
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Index je mimo rozsahu");
mycode.code = ""; )
while (sr.Read() != "*")
if (vytvoriť == nepravda) (
Ak používateľ zadá neexistujúcu premennú ako index stĺpca alebo riadka, do protokolu chýb sa pridá zodpovedajúca chybová položka.
lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Pokúšam sa o prístup k neexistujúcej premennej");
while (sr.Read() != "*")
if (mycode.masSost == 5)
(int n1 = 0, n2 = 0, nn = 0;
if (mycode.masSost == 6)
( sw.Write(dt.Rows.Count.ToString());
while (sr.Read() != "*")
(ak (mycode.masSost == 12)
( ( n1 = Convert.ToInt32(mycode.masValue);
if (mycode.masSost == 12)
( n2 = Convert.ToInt32(mycode.masValue);
( bool vytvoriť = false;
pre (int a = 0; a< masPeremCount; a++)
if (masPerem == mycode.masValue)
n2 = Convert.ToInt32(masPerem);
Ak bola premenná použitá ako index stĺpca alebo riadka a jej hodnota presahuje počet stĺpcov alebo riadkov v tabuľke, potom sa do protokolu chýb pridá záznam o tejto chybe.
Else ( if (n1 >= dt.Rows.Count)
( if (mycode.code != "")
(lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Index " + n1 + " je mimo rozsahu");))
if (n2 >= dt.Columns.Count)
( if (mycode.code != "")
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Index " + n2 + " je mimo rozsahu"); ))
mycode.code = ""; )
while ((sr.Read() != "*") && (!sr.EndOfStream))
if (mycode.masSost == 2)
masPerem = mycode.masValue;
masPerem = mycode.masValue;
nk = masPeremCount;
masPeremCount++;
if (mycode.masSost == 12)
k = Convert.ToInt32(mycode.masValue); inak
if (mycode.masSost == 4) k = dt.Columns.Count;
else k = dt.Rows.Count;
while (sr.Read() != "*") ( )
Ak používateľ deklaroval cyklus a potom neuviedol jeho začiatok bez uvedenia „(“, považuje sa to za chybu a záznam o tom sa pridá do protokolu chýb.
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read());
( lv.Items.Add(thisTemplate, thisTemplate);
lv.Items.SubItems.Add(mycode.code);
lv.Items.SubItems.Add("Začiatok cyklu nie je špecifikovaný");
mycode.correct = false;
NCode++; ) inak (
Ak je začiatok slučky zadaný správne, potom sa premenná zodpovedná za hĺbku vnorenia slučiek zvýši o jednu, obsah slučky až po znamienko ")" sa zapíše do dočasného súboru, duplikátu z polí obsahujúcich hodnoty premenných sa vytvorí a táto rekurzívna metóda sa spustí už pre tento dočasný súbor.
Directory.CreateDirectory("Temp");
StreamWriter sw1=new StreamWriter("Temp\\Temp"+tempF.ToString()+.txt", false, Kódovanie.UTF8);
c = Convert.ToChar(sr.Read());
c = Convert.ToChar(sr.Read()); )
int cycleCount = 0;
zatiaľ čo (c != ")")
if (sr.EndOfStream)
c = Convert.ToChar(sr.Read());
if ((c == ")") && (cickleCount != 0))
( cickleCount--;
c = Convert.ToChar(sr.Read()); ))
StreamReader sr1 = new StreamReader("Temp\\Temp" + tempF.ToString() + ".txt", Kódovanie.UTF8);
int CickleCode = 0;
bool sign2 = false;
while (!sr1.EndOfStream)
( c = Convert.ToChar(sr1.Read());
if ((c != "*") && (znamienko2 == pravda))
( s1 += c.ToString(); )
if ((c == "*") && (znamienko2 == nepravda))
if ((c == "*") && (znamienko2 == pravda))
( znamienko2 = nepravda;
else s1 += c.ToString(); ))
for (int a = Convert.ToInt32(mycode.masValue); a< k; a++)
( masPerem = a.ToString();
ExecuteCode(NCode + 1, true, new StreamReader("Temp\\Temp" + tempF.ToString() + ".txt", Encoding.UTF8), sw, tempF);)
Po skončení cyklu sa dočasný súbor odstráni a hĺbka vnorenia slučiek sa zníži o jednu.
masPerem = "";
masPerem = "";
NCode = CickleCode + 1;
File.Delete("Temp\\Temp" + tempF.ToString() + ".txt");
Algoritmus pre prácu so šablónami vytvorenými pomocou konštruktora je popísaný nasledujúcimi metódami: Execute, GetTruthTable, ExecuteTag.
Metóda Execute sa volá raz, keď sa spustí spracovanie šablóny. Táto metóda je externá a z nej sa volajú ďalšie metódy. Na začiatku metóda vytvorí výstupný súbor a "Tuth Table".
DataTable truedt=new DataTable();
StreamWriter sw=new StreamWriter(textBox4.Text+"Výstupný súbor.xml",false,Kódovanie.UTF8);
pre (int a = 0; a<= dt.Columns.Count;a++)
truedt.Columns.Add("",typeof(bool));
pre (int a = 0; a<= dt.Rows.Count; a++)
( DataRow dr = truedt.NewRow();
pre (int b = 0; b< dr.ItemArray.Length; b++)
truedt.Rows.Add(dr); )
Potom sa cyklus začne vykonávať, pričom sa zvýrazní každá značka, ktorá určuje jej typ, a v závislosti od toho sa vykoná.
kým (!kompletné)
( tagind = GetTagIndex(Položky);
if (mastag.type == types.global || mastag.type == types.main)
if (mastag.type == types.block)
if (Položky >= počet položiek)
úplný=pravda; )
Ak je typ značky globálny alebo hlavný, obsah značky sa jednoducho zapíše do súboru.
if (mastag.name != "")
sw.WriteLine(položky);
Ak je typ značky block, potom sa zoznam všetkých značiek patriacich do tohto fragmentu zapíše do samostatného poľa a tiež sa určí, či sa v tomto zozname nachádzajú značky, ktoré vyžadujú indexovanie reťazcov na zobrazenie hodnôt.
bool haveRow = false;
tag blocktag = new tag.indF - mastag.indS - 1];
for (int a = matag.indS + 1, b = 0; a< mastag.indF; a++, b++)
( blocktag[b] = matag;
if (blocktag[b].type == types.simple)
if (blocktag[b].source == "index riadka" || blocktag[b].source == "obsah bunky")
haveRow = pravda ;)
Potom sa vytvorí "pravdivá tabuľka" a aplikujú sa na ňu všetky podmienky jednoduchých značiek nájdených v zozname.
truedt=CreateTable(truthdt,dt);
pre (int a = 0; a< blocktag.Length; a++)
if (blocktag[a].type == types.simple)
truedt = GetTruthTable(dt, truedt, blocktag[a]);
Ďalej, v závislosti od toho, či sa našli značky využívajúce indexovanie reťazcov, sa vytvorí buď len cyklus stĺpcov, alebo cykly pozdĺž stĺpcov a riadkov, v ktorých sa vykonajú všetky vyskytujúce sa značky okrem blokových.
pre (int a = 0; a< dt.Rows.Count; a++)
pre (int b = 0; b< dt.Columns.Count; b++)
bool wasEx = false;
StreamWriter swt = new StreamWriter("temp.txt", false, Kódovanie.UTF8);
pre (int c = 0; c< blocktag.Length; c++)
if (blocktag[c].type == types.global)
if (blocktag[c].name != "")
swt.WriteLine(items.indS + c + 1]);
if (blocktag[c].name != "")
wasEx=ExecuteTag(dt, truedt, blocktag[c], a, b, swt); )
( StreamReader sr = new StreamReader("temp.txt", Kódovanie.UTF8);
sw.Write(sr.ReadToEnd());
File.Delete("temp.txt");
(pre (int a=0;a pre (int c = 0; c< blocktag.Length; c++) ( if (blocktag[c].type == types.global) if (blocktag[c].name != "") sw.WriteLine(items.indS + c + 1]); if (blocktag[c].type == types.simple) if (blocktag[c].name != "") ExecuteTag(dt, truedt, blocktag[c], 0, a, sw); Ak je typ tagu jednoduchý, potom sa preň vytvorí nová „Tuth Table“ a tag sa spustí. if (mastag.type == types.simple) ( truedt=CreateTable(truthdt,dt); DataTable tempdt = GetTruthTable(dt, truedt, mastag); if(mastag.name!="") ExecuteTag(dt, tempdt, matag, 0, 0, sw); Metóda GetTruthTable aplikuje podmienky na "Tuth Table". Ako argumenty berie tabuľku s hodnotami z databázy, už vytvorenú „Tuth Table“ a značku, ktorej stav je potrebné spracovať. Metóda ExecutTag vykoná jednoduchú značku. Ako argumenty používa tabuľku s údajmi, „tabuľku pravdy“, značku, index riadku, index stĺpca a prúd zápisu súboru. 3.2
Popis používateľského rozhrania Hlavné okno programu je rozdelené na niekoľko častí: „.dbf“, „Šablóny“, „.xml“ a protokol chýb. Vo všetkých častiach, okrem logu, sú prvky zodpovedné za výber adresárov obsahujúcich súbory alebo do ktorých musia byť súbory uložené. Protokol chýb je prezentovaný ako zoznam troch stĺpcov: "vzor", "reťazec", "chyba". Prvý stĺpec obsahuje názov šablóny, v ktorej bola chyba nájdená. V druhom riadok, kde nastala chyba. Po tretie, typ chyby. Aj na formulári sú prvky, ktoré nepatria do žiadnej zo skupín. Niektoré z nich odrážajú postup práce, zatiaľ čo iné spúšťajú samotný proces. Na obrázku 3.1 je zobrazený hlavný formulár – hlavné okno programu. Obrázok 3.1 - Hlavné okno programu Pri práci so šablónami sa otvorí ďalšie okno programu pozostávajúce z poľa pre názov šablóny, prvku, ktorý obsahuje kód šablóny a tlačidiel na uloženie šablóny a zatvorenie okna. Obrázok 3.2 zobrazuje pohľad na dodatočné okno programu (editor šablón). Obrázok 3.2 - Okno editora šablón Na hlavnom formulári je tiež ovládací prvok, ktorý otvára formulár na vytváranie šablón pomocou konštruktora. Formulár konštruktora obsahuje tieto ovládacie prvky: zoznam už vytvorených značiek, pole na zadanie názvu novej značky, rozbaľovací zoznam na výber typu značky, rozbaľovací zoznam na výber zdroja značky, panel s prvkami na vytvorenie podmienky tagu, pole na definovanie databázového súboru, pole na definovanie umiestnenia výstupného súboru, tlačidlá na pridanie a odstránenie tagu, tlačidlo na spustenie spracovania. Obrázok 3.3 zobrazuje okno návrhára šablón. Obrázok 3.3 - Okno konštruktora šablón Výsledkom práce softvéru boli získané súbory XML rôznych verzií jazyka XML. Ako vstupné dáta boli použité databázy formátu dbf verzií dBase II, dBase III a dBase IV. Prevedené súbory sa správne otvorili v nasledujúcich prehliadačoch: Internet Explorer 10, Mozilla Firefox 19, Google Chrome verzia 27.0.1453.93, Opera 12.15. Okrem prehliadačov je možné súbory prezerať a upravovať pomocou ľubovoľného textového editora. Na základe získaných výsledkov možno usúdiť, že XML súbory získané počas prevádzky programu spĺňajú požiadavky zákazníka. 3.
3
Testovanie a hodnotenie spoľahlivosti softvérového produktu Pri testovaní softvérového produktu boli zistené nasledujúce chyby: Chyba indexovania do bunky databázovej tabuľky; Chyba výstupu premennej slučky; Chyba, ktorá nastane, keď index riadka alebo stĺpca prekročí ich počet. 1. Chyba indexovania do bunky databázovej tabuľky. Vyskytuje sa, keď šablóna obsahuje kód v tvare "*riadok[x].stĺpec[y]*", kde x a y sú čísla alebo premenné. Problém bol vyriešený pridaním ďalšej podmienky do programového kódu pri spracovaní podobných reťazcov v šablóne. 2. Chyba výstupu premennej slučky. Vyskytuje sa, keď je v šablóne zadaný kód v tvare "*x*", kde x je premenná. Problém bol vyriešený zmenou kompilácie tabuľky identifikátorov. 3. Chyba, ktorá nastane, ak index riadka alebo stĺpca prekročí ich počet. Vyskytuje sa, keď šablóna obsahuje kód ako "*stĺpec[x].názov*", kde x je číslo alebo premenná, ktorej hodnota presahuje počet stĺpcov. Problém bol vyriešený porovnaním hodnoty indexu a počtu riadkov alebo stĺpcov, ak index prekročí, potom sa do protokolu chýb pridá záznam a program pokračuje v práci. 3.
4
Kalkulácia nákladov Firmy, ktoré neustále pracujú s rôznymi databázovými formátmi, potrebujú automatizovať proces konverzie z jedného databázového formátu do druhého. Tým sa zvýši produktivita pracovníkov, ako aj znížia požiadavky na ich vzdelanie. Softvérový produkt okrem softvérovej časti tvorí aj sprievodná dokumentácia, ktorá je výsledkom duševnej činnosti vývojárov. V štruktúre kapitálových investícií spojených s automatizáciou riadenia sa nachádzajú kapitálové investície na vývoj projektu automatizácie (predvýrobné náklady) a kapitálové investície na realizáciu projektu (náklady na realizáciu): kde K p - kapitálové investície do dizajnu; К р - kapitálové investície na realizáciu projektu. Výpočet kapitálových investícií pre projektovanie. Kapitálové investície do návrhu softvéru sa určujú vypracovaním odhadov nákladov a určujú sa podľa vzorca: kde K m - náklady na materiál; K pr - základné a doplnkové mzdy so zrážkami v sociálnom poistení pre inžiniersky a technický personál priamo zapojený do vývoja projektu; K mash - náklady spojené s využitím strojového času na ladenie programu; K c - platba za služby tretím stranám, ak sa dizajn vykonáva so zapojením tretích strán; K n - režijné náklady projekčného oddelenia. Všetky výpočty budú robené v konvenčných jednotkách (c.u.), čo zodpovedá cene jedného amerického dolára v Podnesterskej republikánskej banke v čase vývoja softvéru. Materiálové náklady. Stanovme si odhad nákladov a vypočítajme náklady na materiál K m, ktorý išiel na vývoj softvéru. Zoznam materiálov je určený témou diplomovej práce. Patria sem: nosiče informácií (papier, magnetické disky) a nositeľné pracovné predmety (pero, ceruzka, gumička). Odhad nákladov na materiál je uvedený v tabuľke 3.1. Tabuľka 3.1 - Odhadované náklady na materiál Implementácia konvertorového programu na vytvorenie súboru vo formáte XML na základe prenesených súborov dbf (podľa užívateľom zadanej šablóny). Vytvorte šablóny pomocou kódu a pomocou konštruktora. Návrh architektúry softvérového produktu. práca, pridané 27.06.2013 Vývoj konvertorového programu, ktorý na základe obsahu prenesených dbf súborov vytvorí XML súbor podľa užívateľom zadanej šablóny. Zvážte vytvorenie šablón dvoma spôsobmi: pomocou kódu a pomocou konštruktora. semestrálna práca, pridaná 24.06.2013 Navrhovanie používateľského rozhrania programu, ktorý šifruje a dešifruje súbory. Výber formátu prezentácie údajov. Zoznam procedúr, makier a ich účel. Popis funkcií používaných v programe, jeho testovanie a ladenie. semestrálna práca, pridaná 17.05.2013 Funkcie „vyhľadávača“ duplicitných súborov na disku. Výber programovacieho prostredia. Vývoj softvérového produktu. Základné požiadavky na program, ktorý hľadá duplicitné súbory na disku. Zobraziť skryté súbory. semestrálna práca, pridaná 28.03.2015 Charakteristika práce archivátora - počítačový program, ktorý komprimuje dáta do jedného archívneho súboru pre jednoduchší prenos, kompaktné ukladanie. Vlastnosti procesu archivácie - zapisovanie súborov a rozbaľovanie - otváranie súborov. abstrakt, pridaný 26.03.2010 Vývoj softvérového produktu na export špecifikácií z aplikácie PartList. Výber spôsobu prenosu informácií do súboru, formátu prezentácie. Vývoj prevodníka, implementácia užívateľského rozhrania. Zdôvodnenie relevantnosti vývoja. práca, pridané 25.09.2014 Návrh softvéru. Schéma počiatočného vytvorenia adresára súborov, zobrazenie adresára súborov, mazanie súborov, triedenie súborov podľa názvu, dátumu vytvorenia a veľkosti metódou priameho výberu. Správa adresárov v súborovom systéme. semestrálna práca, pridaná 01.08.2014 Charakteristika formátov súborov wav a mp3. Vytváranie diagramov prípadov použitia, vývoj grafického rozhrania a aplikačnej architektúry. Vývoj algoritmov prevádzky programu: metóda TrimWavFile, TrimMp3, ChangeVolume, speedUpX1_2, speedDownX1_2. semestrálna práca, pridaná 20.12.2013 Prehľad funkcií práce s programom Total Commander. Vytvorte priečinky, skopírujte súbory na flash disk. Vyvolanie kontextového menu. Definícia štruktúry súboru. Premenovanie skupiny súborov. Ukladanie súborov do archívu. Rozdelenie archívu na niekoľko častí. laboratórne práce, doplnené 04.08.2014 Vytvorenie a overenie modelu optimálneho umiestnenia súborov v počítačovej sieti s hviezdicovou, prstencovou a ľubovoľnou topológiou. Množstvo údajov potrebných na prenos súborov. Optimálna distribúcia súborov cez uzly počítačovej siete. DBF je databázový súbor, s možnosťou práce bola predtým integrovaná do prostredia Microsoft Office. Aplikácie Access a Excel pracovali s formátom, neskôr bol Access z balíka odstránený a stal sa samostatným programom a v Exceli bola od roku 2007 výrazne obmedzená podpora DataBaseFile. Ak nemôžete otvoriť súbor DBF priamo v Exceli, musíte ho najskôr skonvertovať. Hoci DBF mnohí považujú za zastaraný formát, stále sa široko používa v špecializovaných programoch v oblasti obchodu, dizajnu a inžinierstva. Všade tam, kde potrebujete pracovať s veľkým množstvom informácií, ich štruktúrovanie a spracovanie, vykonávanie dotazov. Napríklad softvérový balík 1C Enterprise je úplne založený na správe databázy. A vzhľadom na to, že veľa kancelárskej dokumentácie a údajov ide do Excelu, otázka integrovanej práce s týmito formátmi je relevantná a žiadaná. V Exceli 2003 bolo možné otvárať a upravovať DBF, ako aj ukladať XLS dokumenty v tomto formáte: DÔLEŽITÉ Od roku 2007 môžete otvárať a zobrazovať databázový formát v Exceli, ale nemôžete v ňom vykonávať zmeny ani ukladať dokumenty vo formáte .xls. Štandardné programové nástroje už túto možnosť neposkytujú. Pre aplikáciu však existujú špeciálne doplnky, ktoré do nej pridávajú takúto funkciu. V sieti na rôznych fórach programátori uverejňujú svoj vývoj, môžete nájsť rôzne možnosti. Najpopulárnejší doplnok s názvom XslToDBF si môžete stiahnuť zo stránky vývojára http://basile-m.narod.ru/xlstodbf/download.html. Sťahovanie je bezplatné, ale ak chcete, môžete projekt podporiť prevodom ľubovoľnej sumy na vašu peňaženku alebo kartu. Inštalácia a použitie: Ak nechcete v Office nič meniť, neveríte doplnkom a aplikáciám tretích strán, potom môžete ponúknuť časovo náročnejší spôsob prevodu súboru XLS na DBF: Tento spôsob nie vždy funguje úspešne, často dochádza k chybám pri spracovaní údajov a následnom ukladaní. A je to veľmi dlhé a nepohodlné. Aby ste netrpeli kancelárskymi programami, vzniklo mnoho aplikácií, ktoré vám umožňujú prenášať dáta z jedného formátu do druhého. Po prvé, takmer všetky výkonné programy DBMS ponúkajú možnosť exportu a načítania z XLS. Po druhé, existujú malé spoločnosti, ktoré sa špecializujú na konverziu. Tu sú niektoré z nich: Vo všetkých týchto programoch konverzia spočíva v tom, že musíte otvoriť zdrojový súbor a potom spustiť príkaz „Konvertovať“ alebo „Exportovať“. Existujú aj bezplatné online konverzné služby. Na takýchto stránkach sa navrhuje odoslať (nahrať) zdrojový súbor, kliknúť na „Konvertovať“, po ktorom sa zobrazí odkaz na konvertovaný dokument. Do akej miery môžete takýmto službám dôverovať, rozhodnutie je individuálne, na vlastné nebezpečenstvo a riziko. DBF teda môžete otvoriť v Exceli, ale ak je jeho verzia 2007 a novšia, potom sa s tým nedá nič robiť, stačí sa pozrieť. Na úpravu, ukladanie do XLS existujú špeciálne doplnky alebo programy, ako aj na konverziu v opačnom smere. Ak máte skúsenosti s konverziou a prácou s DBF v rôznych aplikáciách, podeľte sa o svoje tipy v komentároch.Podobné dokumenty
Problémy s Excelom pri práci s DBF
















Konverzia

