Iterationsmethode. Bei dieser Methode wird ein Abgleich mit einer bestimmten Datenbank durchgeführt, wobei es für jedes der Objekte unterschiedliche Möglichkeiten gibt, die Darstellung zu modifizieren. Beispielsweise können Sie für die optische Bilderkennung das Iterationsverfahren bei verschiedenen Winkeln oder Maßstäben, Versätzen, Verformungen usw. anwenden. Bei Buchstaben können Sie über die Schriftart oder ihre Eigenschaften iterieren. Bei der Tonmustererkennung erfolgt ein Vergleich mit einigen bekannten Mustern (ein Wort, das von vielen Menschen gesprochen wird). Außerdem wird eine tiefere Analyse der Eigenschaften des Bildes durchgeführt. Bei der optischen Erkennung kann dies die Definition geometrischer Merkmale sein. Die Tonprobe wird dabei einer Frequenz- und Amplitudenanalyse unterzogen.
Die nächste Methode ist Einsatz künstlicher neuronaler Netze(INS). Es erfordert entweder eine große Anzahl von Beispielen der Erkennungsaufgabe oder eine spezielle neuronale Netzwerkstruktur, die die Besonderheiten dieser Aufgabe berücksichtigt. Dennoch zeichnet sich dieses Verfahren durch hohe Effizienz und Produktivität aus.
Methoden, die auf Schätzungen der Verteilungsdichten von Merkmalswerten basieren. Entlehnt von der klassischen Theorie statistischer Entscheidungen, in der die Untersuchungsobjekte als Realisierungen einer mehrdimensionalen Zufallsvariablen betrachtet werden, die gemäß einem Gesetz im Merkmalsraum verteilt sind. Sie basieren auf dem Bayes'schen Entscheidungsschema, das sich auf die Anfangswahrscheinlichkeiten von Objekten bezieht, die zu einer bestimmten Klasse gehören, und auf bedingte Merkmalsverteilungsdichten.
Die Gruppe der Methoden, die auf der Schätzung der Verteilungsdichten von Merkmalswerten basieren, steht in direktem Zusammenhang mit den Methoden der Diskriminanzanalyse. Der bayessche Ansatz zur Entscheidungsfindung ist eine der am weitesten entwickelten parametrischen Methoden in der modernen Statistik, für die der analytische Ausdruck des Verteilungsgesetzes (das Normalgesetz) als bekannt angesehen wird und nur eine kleine Anzahl von Parametern (Mittelwertvektoren und Kovarianzmatrizen). ) müssen geschätzt werden. Als Hauptschwierigkeiten bei der Anwendung dieser Methode gelten die Notwendigkeit, sich an die gesamte Trainingsstichprobe zu erinnern, um Dichteschätzungen zu berechnen, und die hohe Empfindlichkeit gegenüber der Trainingsstichprobe.
Methoden, die auf Annahmen über die Klasse der Entscheidungsfunktionen basieren. In dieser Gruppe gilt die Art der Entscheidungsfunktion als bekannt und ihr Gütefunktional ist gegeben. Basierend auf diesem Funktional wird die optimale Annäherung an die Entscheidungsfunktion aus der Trainingssequenz gefunden. Das Qualitätsfunktional der Entscheidungsregel ist normalerweise mit einem Fehler verbunden. Der Hauptvorteil des Verfahrens ist die Klarheit der mathematischen Formulierung des Erkennungsproblems. Die Möglichkeit, neues Wissen über die Beschaffenheit eines Objekts zu gewinnen, insbesondere Wissen über die Interaktionsmechanismen von Attributen, wird hier grundsätzlich durch eine gegebene Interaktionsstruktur, fixiert in der gewählten Form von Entscheidungsfunktionen, begrenzt.
Prototypische Vergleichsmethode. Dies ist in der Praxis die einfachste Methode der Erweiterungserkennung. Es gilt, wenn die erkennbaren Klassen als kompakte geometrische Klassen dargestellt werden. Dann wird das Zentrum der geometrischen Gruppierung (oder das dem Zentrum am nächsten liegende Objekt) als Prototyppunkt gewählt.
Um ein unbestimmtes Objekt zu klassifizieren, wird der Prototyp gefunden, der ihm am nächsten ist, und das Objekt gehört zu derselben Klasse wie es. Offensichtlich werden bei diesem Verfahren keine verallgemeinerten Bilder gebildet. Als Maß können verschiedene Arten von Distanzen verwendet werden.
Methode der k nächsten Nachbarn. Das Verfahren besteht darin, dass beim Klassifizieren eines unbekannten Objekts eine bestimmte Anzahl (k) des geometrisch nächsten Merkmalsraums anderer nächster Nachbarn mit bereits bekannter Zugehörigkeit zu einer Klasse gefunden wird. Die Entscheidung, ein unbekanntes Objekt zuzuordnen, wird durch Analysieren von Informationen über seine nächsten Nachbarn getroffen. Die Notwendigkeit, die Anzahl der Objekte in der Trainingsstichprobe (diagnostische Präzedenzfälle) zu reduzieren, ist ein Nachteil dieser Methode, da dies die Repräsentativität der Trainingsstichprobe verringert.
Ausgehend davon, dass sich verschiedene Erkennungsalgorithmen auf derselben Stichprobe unterschiedlich verhalten, stellt sich die Frage nach einer synthetischen Entscheidungsregel, die die Stärken aller Algorithmen nutzt. Dafür gibt es eine synthetische Methode oder Sätze von Entscheidungsregeln, die die positivsten Aspekte jeder der Methoden kombinieren.
Zum Abschluss der Überprüfung der Anerkennungsmethoden stellen wir die Essenz des Obigen in einer zusammenfassenden Tabelle dar und fügen einige andere in der Praxis verwendete Methoden hinzu.
Tabelle 1. Einordnungstabelle der Erkennungsverfahren, Vergleich ihrer Anwendungsbereiche und Grenzen
|
Klassifizierung von Erkennungsmethoden |
Anwendungsgebiet |
Einschränkungen (Nachteile) |
|
|
Intensive Erkennungsmethoden |
Methoden basierend auf Dichteschätzungen |
Probleme mit einer bekannten Verteilung (normal), die Notwendigkeit, große Statistiken zu sammeln |
Die Notwendigkeit, den gesamten Trainingssatz während der Erkennung aufzuzählen, hohe Empfindlichkeit gegenüber Nicht-Repräsentativität des Trainingssatzes und Artefakte |
|
Annahmebasierte Methoden |
Klassen sollten gut trennbar sein |
Die Form der Entscheidungsfunktion muss vorher bekannt sein. Die Unmöglichkeit, neue Erkenntnisse über Korrelationen zwischen Merkmalen zu berücksichtigen |
|
|
Boolesche Methoden |
Probleme kleiner Dimension |
Bei der Auswahl logischer Entscheidungsregeln ist eine vollständige Aufzählung erforderlich. Hohe Arbeitsintensität |
|
|
Linguistische Methoden |
Die Aufgabe, die Grammatik für einen bestimmten Satz von Aussagen (Beschreibungen von Objekten) zu bestimmen, ist schwer zu formalisieren. Ungelöste theoretische Probleme |
||
|
Erweiterungsmethoden der Anerkennung |
Prototypische Vergleichsmethode |
Probleme der kleinen Dimension des Merkmalsraums |
Hohe Abhängigkeit der Klassifikationsergebnisse von der Metrik. Unbekannte optimale Metrik |
|
k Nächste-Nachbar-Methode |
Hohe Abhängigkeit der Klassifikationsergebnisse von der Metrik. Die Notwendigkeit einer vollständigen Aufzählung des Trainingsmusters während der Erkennung. Rechenkomplexität |
||
|
Notenberechnungsalgorithmen (ABO) |
Probleme kleiner Dimension in Bezug auf die Anzahl der Klassen und Merkmale |
Abhängigkeit der Klassifizierungsergebnisse von der Metrik. Die Notwendigkeit einer vollständigen Aufzählung des Trainingsmusters während der Erkennung. Hoher technischer Aufwand des Verfahrens |
|
|
Collective Decision Rules (CRC) ist eine synthetische Methode. |
Probleme kleiner Dimension in Bezug auf die Anzahl der Klassen und Merkmale |
Sehr hoher technischer Aufwand der Methode, die ungelöste Anzahl theoretischer Probleme, sowohl bei der Bestimmung der Kompetenzbereiche bestimmter Methoden als auch bei den jeweiligen Methoden selbst |
Vortrag Nummer 17.MUSTERERKENNUNGSMETHODEN
Es gibt folgende Gruppen von Erkennungsverfahren:
Näherungsfunktionsmethoden
Diskriminanzfunktionsmethoden
Statistische Methoden der Anerkennung.
Linguistische Methoden
heuristische Methoden.
Die ersten drei Methodengruppen konzentrieren sich auf die Analyse von Merkmalen, die durch Zahlen oder Vektoren mit numerischen Komponenten ausgedrückt werden.
Die Gruppe der linguistischen Methoden bietet Mustererkennung auf der Grundlage der Analyse ihrer Struktur, die durch die entsprechenden Strukturmerkmale und Beziehungen zwischen ihnen beschrieben wird.
Die Gruppe der heuristischen Verfahren fasst die charakteristischen Techniken und logischen Verfahren des Menschen zur Mustererkennung zusammen.
Näherungsfunktionsmethoden
Die Verfahren dieser Gruppe basieren auf der Verwendung von Funktionen, die das Maß der Nähe zwischen dem erkennbaren Bild und dem Vektor auswerten x * = (x * 1 ,….,x*n) und Referenzbilder verschiedener Klassen, dargestellt durch Vektoren x ich = (x ich 1 ,…, x ich n), ich= 1,…,N, wo ich- Bildklassennummer.
Das Erkennungsverfahren gemäß diesem Verfahren besteht darin, den Abstand zwischen dem Punkt des erkannten Bildes und jedem der das Referenzbild darstellenden Punkte zu berechnen, d. h. bei der Berechnung aller Werte d ich , ich= 1,…,N. Das Bild gehört zu der Klasse, für die der Wert d ich hat den geringsten Wert von allen ich= 1,…,N .
Eine Funktion, die jedes Vektorpaar abbildet x ich, x * eine reelle Zahl als Maß für ihre Nähe, d.h. Die Bestimmung des Abstands zwischen ihnen kann ziemlich willkürlich sein. In der Mathematik wird eine solche Funktion Raummetrik genannt. Es muss die folgenden Axiome erfüllen:
r(x, y)=r(y,x);
r(x, y) > 0 wenn x nicht gleich j und r(x, y)=0 wenn x=y;
r(x, y) <=r(x, z)+r(z, y)
Diese Axiome werden insbesondere durch die folgenden Funktionen erfüllt
ein ich= 1/2 , j=1,2,…n.
b ich= Summe, j=1,2,…n.
c ich= max abs ( x ich‑ x j *), j=1,2,…n.
Die erste davon wird die euklidische Norm eines Vektorraums genannt. Dementsprechend werden die Räume, in denen die angegebene Funktion als Metrik verwendet wird, als euklidischer Raum bezeichnet.
Häufig wird als Näherungsfunktion die quadratische Mitteldifferenz der Koordinaten des erkannten Bildes gewählt x * und Standard x ich, d.h. Funktion
d ich = (1/n) Summe( x ich j‑ x j *) 2 , j=1,2,…n.
Wert d ich geometrisch interpretiert als das Quadrat des Abstands zwischen Punkten im Merkmalsraum, bezogen auf die Dimension des Raums.
Oft stellt sich heraus, dass unterschiedliche Merkmale bei der Wiedererkennung nicht gleich wichtig sind. Um diesen Umstand bei der Berechnung der Näherungsfunktionen der Koordinatendifferenz zu berücksichtigen, werden die entsprechenden wichtigeren Merkmale mit großen Koeffizienten multipliziert, die weniger wichtigen mit kleineren.
In diesem Fall d ich = (1/n) Summe W J (x ich j‑ x j *) 2 , j=1,2,…n,
wo W J- Gewichtskoeffizienten.
Die Einführung von Gewichtungskoeffizienten entspricht dem Skalieren der Achsen des Merkmalsraums und dementsprechend dem Dehnen oder Komprimieren des Raums in getrennten Richtungen.
Diese Deformationen des Merkmalsraums verfolgen das Ziel einer solchen Anordnung von Punkten von Referenzbildern, die einer möglichst zuverlässigen Erkennung unter Bedingungen einer signifikanten Streuung von Bildern jeder Klasse in der Nähe des Punktes des Referenzbildes entspricht.
Gruppen von nahe beieinander liegenden Bildpunkten (Bildcluster) im Merkmalsraum werden Cluster genannt, und das Problem, solche Gruppen zu identifizieren, wird Clustering-Problem genannt.
Die Aufgabe, Cluster zu identifizieren, wird als unüberwachte Mustererkennungsaufgabe bezeichnet, d. h. zu Erkennungsproblemen in Ermangelung eines Beispiels für eine korrekte Erkennung.
Diskriminanzfunktionsmethoden
Die Idee der Methoden dieser Gruppe besteht darin, Funktionen zu konstruieren, die Grenzen im Bildraum definieren und den Raum in Bereiche unterteilen, die Klassen von Bildern entsprechen. Die einfachsten und am häufigsten verwendeten Funktionen dieser Art sind Funktionen, die linear von den Werten von Merkmalen abhängen. Im Merkmalsraum entsprechen sie Trennflächen in Form von Hyperebenen. Bei einem zweidimensionalen Merkmalsraum wirkt eine Gerade als Trennfunktion.
Die allgemeine Form der linearen Entscheidungsfunktion ist durch die Formel gegeben
d(x)=w 1 x 1 + w 2 x 2 +…+w n x n +w n +1 = Wx+w n
wo x- Bildvektor, w=(w 1 , w 2 ,…w n) ist der Vektor der Gewichtskoeffizienten.
Bei Aufteilung in zwei Klassen X 1 und X 2 Diskriminanzfunktion d(x) erlaubt die Anerkennung gemäß der Regel:
x gehört X 1 wenn d(x)>0;
x gehört X 2 wenn d(x)<0.
Wenn ein d(x)=0, dann liegt der Unsicherheitsfall vor.
Bei der Aufteilung in mehrere Klassen werden mehrere Funktionen eingeführt. In diesem Fall ist jeder Klasse von Bildern eine bestimmte Kombination von Zeichen von Unterscheidungsfunktionen zugeordnet.
Führt man beispielsweise drei Diskriminanzfunktionen ein, so ist folgende Variante der Auswahl von Bildklassen möglich:
x gehört X 1 wenn d 1 (x)>0,d 2 (x)<0,d 3 (x)<0;
x gehört X 2 wenn d(x)<0,d 2 (x)>0,d 3 (x)<0;
x gehört X 3 wenn d(x)<0,d 2 (x)<0,d 3 (x)>0.
Dies wird für andere Kombinationen von Werten angenommen d 1 (x),d 2 (x),d 3 (x) liegt ein Unsicherheitsfall vor.
Eine Variation der Methode der Diskriminanzfunktionen ist die Methode der entscheidenden Funktionen. Darin ggf m Es wird davon ausgegangen, dass es Klassen gibt m Funktionen d ich(x), genannt entscheidend, so dass wenn x gehört X ich, dann d ich(x) > d j(x) für alle j nicht gleich ich,jene. entscheidende Funktion d ich(x) hat den maximalen Wert unter allen Funktionen d j(x), j=1,...,n..
Eine Veranschaulichung eines solchen Verfahrens kann ein Klassifikator sein, der auf einer Schätzung des Minimums des euklidischen Abstands im Merkmalsraum zwischen dem Bildpunkt und dem Standard basiert. Zeigen wir es.
Euklidischer Abstand zwischen dem Merkmalsvektor des erkennbaren Bildes x und der Vektor des Referenzbildes wird durch die Formel || bestimmt x ich ‑ x|| = 1/2 , j=1,2,…n.
Vektor x wird der Klasse zugeordnet ich, für die der Wert || x ich ‑ x *|| Minimum.
Anstelle der Entfernung können Sie auch das Quadrat der Entfernung vergleichen, d.h.
||x ich ‑ x|| 2 = (x ich ‑ x)(x ich ‑ x) t = x x- 2x x ich +x ich x ich
Da der Wert x x für alle gleich ich, das Minimum der Funktion || x ich ‑ x|| 2 fällt mit dem Maximum der Entscheidungsfunktion zusammen
d ich(x) = 2x x ich -x ich x ich.
also x gehört X ich, Wenn d ich(x) > d j(x) für alle j nicht gleich ich.
Dass. Die Mindestabstands-Klassifizierungsmaschine basiert auf linearen Entscheidungsfunktionen. Die allgemeine Struktur einer solchen Maschine verwendet Entscheidungsfunktionen der Form
d ich (x)=w ich 1 x 1 + w ich 2 x 2 +…+w in x n +gewinnen +1
Es kann durch das entsprechende Blockdiagramm visuell dargestellt werden.
Für eine Maschine, die eine Klassifizierung nach dem Mindestabstand durchführt, ergeben sich die Gleichsetzungen: wij = -2x ich j , gewinnen +1 = x ich x ich.
Eine äquivalente Erkennung nach der Methode der Diskriminanzfunktionen kann durchgeführt werden, wenn die Diskriminanzfunktionen als Differenzen definiert werden dij (x)=d ich (x)‑dj (x).
Der Vorteil der Methode der Diskriminanzfunktionen ist der einfache Aufbau der Erkennungsmaschine sowie die Möglichkeit ihrer Implementierung hauptsächlich durch überwiegend lineare Entscheidungsblöcke.
Ein weiterer wichtiger Vorteil der Methode der Diskriminanzfunktionen ist die Möglichkeit des automatischen Trainierens der Maschine für die korrekte Erkennung eines gegebenen (Trainings-)Musters von Bildern.
Gleichzeitig erweist sich der automatische Lernalgorithmus im Vergleich zu anderen Erkennungsverfahren als sehr einfach.
Aus diesen Gründen hat die Methode der Diskriminanzfunktionen große Popularität erlangt und wird in der Praxis häufig verwendet.
Selbstlernende Verfahren zur Mustererkennung
Betrachten Sie Methoden zum Konstruieren einer Diskriminanzfunktion aus einer gegebenen (Trainings-)Stichprobe, wie sie auf das Problem der Aufteilung von Bildern in zwei Klassen angewendet werden. Wenn zwei Sätze von Bildern gegeben sind, die jeweils zu den Klassen A und B gehören, dann wird die Lösung des Problems der Konstruktion einer linearen Diskriminanzfunktion in Form eines Vektors von Gewichtungskoeffizienten gesucht W=(w 1 ,w 2 ,...,w n,w n+1), die die Eigenschaft hat, dass für jedes Bild die Bedingungen gelten
x gehört zur Klasse A wenn >0, j=1,2,…n.
x gehört zur Klasse B, wenn<0, j=1,2,…n.
Wenn das Trainingsmuster ist N Abbildungen beider Klassen reduziert sich das Problem darauf, einen Vektor w zu finden, der die Gültigkeit des Ungleichungssystems sicherstellt N Bildern beider Klassen reduziert sich das Problem auf das Finden des Vektors w, die die Gültigkeit des Systems der Ungleichungen sicherstellt
x 1 1 w ich+x 21 w 2 +...+x n 1 w n+w n +1 >0;
x 1 2 w ich+x 22 w 2 +...+x n 2 w n+w n +1 <0;
x 1 ichw ich+x 2ich w 2 +...+x ni w n+w n +1 >0;
................................................
x 1 Nw ich + x 2N w 2 +...+x nN w n + w n + 1>0;
hier x ich=(x ich 1 , x i 2 ,...,x ich n ,x ich n+ 1 ) - der Vektor der Werte der Merkmale des Bildes aus dem Trainingsmuster, das Zeichen > entspricht den Vektoren der Bilder x Zugehörigkeit zur Klasse A, und das Zeichen< - векторам x zur Klasse B gehören.
Gewünschter Vektor w existiert, wenn die Klassen A und B trennbar sind, und existiert ansonsten nicht. Vektorkomponentenwerte w können entweder vorab in der Phase vor der Hardwareimplementierung der SRO oder direkt von der SRO selbst im Laufe ihres Betriebs gefunden werden. Der letzte dieser Ansätze bietet eine größere Flexibilität und Autonomie der SRO. Betrachten Sie es am Beispiel eines Geräts namens Percentron. 1957 vom amerikanischen Wissenschaftler Rosenblatt erfunden. Eine schematische Darstellung des Perzentrons, der dafür sorgt, dass das Bild einer der beiden Klassen zugeordnet wird, zeigt die folgende Abbildung.
Retina S Retina EIN Retina R
oh oh x 1
oh oh x 2
oh oh x 3
o(Summe)-------> R(Reaktion)
oh oh x ich
oh oh x n
oh oh x n +1
Das Gerät besteht aus retinalen sensorischen Elementen S, die zufällig mit den assoziativen Elementen der Netzhaut verbunden sind EIN. Jedes Element der zweiten Netzhaut erzeugt nur dann ein Ausgangssignal, wenn eine ausreichende Anzahl an seinem Eingang angeschlossener sensorischer Elemente in einem angeregten Zustand sind. Reaktion des gesamten Systems R ist proportional zur Summe der Reaktionen der Elemente der assoziativen Netzhaut, die mit bestimmten Gewichten genommen werden.
Bezeichnung durch x ich Reaktion ich assoziatives Element und durch w ich- Reaktionsgewichtskoeffizient ich assoziatives Element kann die Reaktion des Systems geschrieben werden als R=summe( w j x j), j=1,..,n. Wenn ein R>0, dann gehört das dem System präsentierte Bild zur Klasse A, und wenn R<0, то образ относится к классу B. Описание этой процедуры классификации соответствует рассмотренным нами раньше принципам классификации, и, очевидно, перцентронная модель распознавания образов представляет собой, за исключением сенсорной сетчатки, реализацию линейной дискриминантной функции. Принятый в перцентроне принцип формирования значений x 1 , x 2 ,...,x n entspricht einem bestimmten Algorithmus zur Bildung von Merkmalen basierend auf den Signalen der primären Sensoren.
Im Allgemeinen können mehrere Elemente vorhanden sein R, die die Reaktion des Perzeptrons bilden. Man spricht in diesem Fall vom Vorhandensein der Netzhaut im Perzeptron R reagierende Elemente.
Das Percentron-Schema kann auf den Fall erweitert werden, wenn die Anzahl der Klassen mehr als zwei beträgt, indem die Anzahl der Netzhautelemente erhöht wird R bis hin zur Anzahl der unterscheidbaren Klassen und der Einführung eines Blocks zur Bestimmung der maximalen Reaktion gemäß dem in obiger Abbildung dargestellten Schema. In diesem Fall wird das Bild der Klasse mit der Nummer zugeordnet ich, Wenn R ich>RJ, für alle j.
Der Lernprozess des Perzentrons besteht darin, die Werte der Gewichtskoeffizienten auszuwählen W J damit das Ausgangssignal der Klasse entspricht, zu der das erkannte Bild gehört.
Betrachten wir den Perzentron-Aktionsalgorithmus am Beispiel der Erkennung von Objekten zweier Klassen: A und B. Die Objekte der Klasse A müssen dem Wert entsprechen R= +1 und Klasse B - der Wert R= -1.
Der Lernalgorithmus ist wie folgt.
Wenn ein anderes Bild x gehört zur Klasse A, aber R<0 (имеет место ошибка распознавания), тогда коэффициенты W J mit Indizes, die Werten entsprechen xj>0, um einen gewissen Betrag erhöhen dw, und die restlichen Koeffizienten W J abnehmen um dw. In diesem Fall der Wert der Reaktion R erhält einen Zuwachs gegenüber seinen positiven Werten entsprechend der korrekten Einstufung.
Wenn ein x gehört zur Klasse B, aber R>0 (es liegt ein Erkennungsfehler vor), dann die Koeffizienten W J mit Indizes entsprechend xj<0, увеличивают на dw, und die restlichen Koeffizienten W J um den gleichen Betrag reduziert. In diesem Fall der Wert der Reaktion R zu negativen Werten hin inkrementiert, die der korrekten Klassifizierung entsprechen.
Der Algorithmus führt somit eine Änderung im Gewichtsvektor ein w wenn und nur wenn das Bild präsentiert wird k-ten Trainingsschritt, wurde bei diesem Schritt falsch klassifiziert und hinterlässt den Gewichtsvektor w keine Änderung bei korrekter Einstufung. Der Beweis der Konvergenz dieses Algorithmus wird in [Too, Gonzalez] präsentiert. Ein solches Training wird schließlich (bei richtiger Wahl dw und lineare Trennbarkeit von Bildklassen) führt zu einem Vektor w für die richtige Einstufung.
Statistische Methoden der Anerkennung.
Statistische Methoden basieren darauf, die Wahrscheinlichkeit eines Klassifikationsfehlers zu minimieren. Die Wahrscheinlichkeit P einer fehlerhaften Klassifikation des zur Erkennung empfangenen Bildes, beschrieben durch den Merkmalsvektor x, wird durch die Formel bestimmt
P = Summe[ p(ich) wahrscheinlich ( D(x)+ich | x Klasse ich)]
wo m- Anzahl der Klassen,
p(ich) = Sonde ( x gehört zur Klasse ich) - A-priori-Wahrscheinlichkeit der Zugehörigkeit zu einem beliebigen Bild x zu ich-te Klasse (Häufigkeit des Auftretens von Bildern ich Klasse),
D(x) ist eine Funktion, die eine Klassifizierungsentscheidung trifft (der Merkmalsvektor x entspricht der Klassennummer ich aus der Menge (1,2,..., m}),
prob( D(x) nicht gleich ich| x gehört zur Klasse ich) ist die Wahrscheinlichkeit des Ereignisses " D(x) nicht gleich ich“, wenn die Mitgliedschaftsbedingung erfüllt ist x Klasse ich, d.h. die Wahrscheinlichkeit, dass die Funktion eine fehlerhafte Entscheidung trifft D(x) für einen bestimmten Wert x gehört ich- Klasse.
Es kann gezeigt werden, dass die Wahrscheinlichkeit einer Fehlklassifikation ein Minimum erreicht, wenn D(x)=ich dann und nur dann, wenn p(x|ich)· p(ich)>p(x|j)· p(j), für alle i+j, wo p(x|i) - Verteilungsdichte von Bildern ich Klasse im Feature-Raum.
Nach obiger Regel ist der Punkt x gehört zu der Klasse, die dem Maximalwert entspricht p(ich) p(x|i), d. h. das Produkt der A-priori-Wahrscheinlichkeit (Häufigkeit) des Auftretens von Bildern ich-te Klasse und Musterverteilungsdichte ich Klasse im Feature-Raum. Die vorgestellte Klassifikationsregel heißt Bayesianisch, weil es folgt aus der bekannten Bayes-Formel in der Wahrscheinlichkeitstheorie.
Beispiel. Gegeben sei es, diskrete Signale am Ausgang eines mit Rauschen behafteten Informationskanals zu erkennen.
Jedes Eingangssignal ist eine 0 oder 1. Als Ergebnis der Signalübertragung erscheint am Ausgang des Kanals der Wert x, dem Gaußsches Rauschen mit Nullmittelwert und Varianz b überlagert ist.
Für die Synthese eines Klassifikators, der eine Signalerkennung durchführt, verwenden wir die Bayes'sche Klassifikationsregel.
In Klasse Nr. 1 kombinieren wir die Signale, die Einheiten darstellen, in Klasse Nr. 2 - Signale, die Nullen darstellen. Lassen Sie es im Voraus wissen, dass im Durchschnitt von 1000 Signalen a Signale sind Einheiten und b Signale - Nullen. Dann können die Werte der A-priori-Wahrscheinlichkeiten für das Auftreten von Signalen der 1. und 2. Klasse (Einsen bzw. Nullen) gleichgesetzt werden
p(1)=a/1000, p(2)=b/1000.
weil das Rauschen ist Gaußsch, d.h. gehorcht dem normalen (gaußschen) Verteilungsgesetz, dann ist die Verteilungsdichte von Bildern der ersten Klasse abhängig vom Wert x, oder, was dasselbe ist, die Wahrscheinlichkeit, den Ausgabewert zu erhalten x wenn Signal 1 am Eingang anliegt, wird es durch den Ausdruck bestimmt
p(x¦1) =(2pib) -1/2 exp(-( x-1) 2 /(2b 2)),
und die Verteilungsdichte abhängig vom Wert x Bilder der zweiten Klasse, d.h. die Wahrscheinlichkeit, den Ausgabewert zu erhalten x wenn am Eingang ein Signal 0 anliegt, wird es durch den Ausdruck bestimmt
p(x¦2)= (2pib) -1/2 exp(- x 2 /(2b 2)),
Die Anwendung der Bayes'schen Entscheidungsregel führt zu dem Schluss, dass ein Klasse-2-Signal übertragen wird, d.h. Null überschritten, wenn
p(2) p(x¦2) > p(1) p(x¦1)
oder genauer gesagt, wenn
b exp(- x 2 /(2b 2)) > a exp(-( x-1) 2 /(2b 2)),
Teilen wir die linke Seite der Ungleichung durch die rechte Seite, erhalten wir
(b/a)exp((1-2 x)/(2b 2)) >1,
woraus wir nach dem Logarithmieren finden
1-2x> 2b 2ln(a/b)
x< 0.5 - б 2 ln(a/b)
Aus der resultierenden Ungleichung folgt, dass a=b, d.h. bei gleichen a priori Auftrittswahrscheinlichkeiten der Signale 0 und 1 wird dem Bild der Wert 0 zugewiesen, wenn x<0.5, а значение 1, когда x>0.5.
Wenn im Voraus bekannt ist, dass eines der Signale öfter und das andere seltener auftritt, d.h. bei unterschiedlichen Werten a und b, wird die Ansprechschwelle des Klassifikators auf die eine oder andere Seite verschoben.
Also bei a/b= 2,71 (entspricht 2,71 mal häufigerer Übertragung von Einsen) und b 2 = 0,1, wird dem Bild der Wert 0 zugewiesen, wenn x<0.4, и значение 1, если x>0,4. Liegen keine Informationen über die A-priori-Verteilungswahrscheinlichkeiten vor, so können statistische Erkennungsverfahren verwendet werden, die auf anderen als Bayes'schen Klassifikationsregeln beruhen.
In der Praxis sind jedoch Verfahren auf der Grundlage von Bayes-Regeln aufgrund ihrer größeren Effizienz am gebräuchlichsten und auch aufgrund der Tatsache, dass es bei den meisten Mustererkennungsproblemen möglich ist, a priori Wahrscheinlichkeiten für das Auftreten von Bildern jeder Klasse festzulegen.
Sprachliche Methoden der Mustererkennung.
Linguistische Methoden der Mustererkennung basieren auf der Analyse der Beschreibung eines idealisierten Bildes, dargestellt als Graph oder eine Reihe von Symbolen, das eine Phrase oder ein Satz einer bestimmten Sprache ist.
Betrachten Sie die idealisierten Bilder von Buchstaben, die als Ergebnis der oben beschriebenen ersten Stufe der sprachlichen Erkennung erhalten werden. Diese idealisierten Bilder können durch Beschreibungen von Graphen definiert werden, die beispielsweise in Form von Verbindungsmatrizen dargestellt werden, wie dies im obigen Beispiel geschehen ist. Dieselbe Beschreibung kann durch eine formale Sprachphrase (Ausdruck) dargestellt werden.
Beispiel. Gegeben seien drei Bilder des Buchstabens A, die als Ergebnis einer vorläufigen Bildverarbeitung erhalten werden. Lassen Sie uns diese Bilder mit den Kennungen A1, A2 und A3 benennen.
Zur sprachlichen Beschreibung der präsentierten Bilder verwenden wir die PDL (Picture Description Language). Das PDL-Sprachwörterbuch enthält die folgenden Zeichen:
1. Namen der einfachsten Bilder (Primitive). Angewendet auf den betrachteten Fall sind die Grundelemente und ihre entsprechenden Namen wie folgt.
Bilder in Form einer Linie gerichtet:
hoch und links (le F t), nach Norden (Norden)), nach oben und nach rechts (rechts), nach Osten (Osten)).
Namen: L, N, R, E.
2. Symbole binärer Operationen. (+,*,-) Ihre Bedeutung entspricht der sequentiellen Verbindung von Primitiven (+), der Verbindung der Anfänge und Enden von Primitiven (*), der Verbindung nur der Enden von Primitiven (-).
3. Rechte und linke Klammern. ((,)) Mit runden Klammern können Sie die Reihenfolge angeben, in der Operationen in einem Ausdruck ausgeführt werden sollen.
Die betrachteten Bilder A1, A2 und A3 werden in der PDL-Sprache jeweils durch die folgenden Ausdrücke beschrieben.
T(1)=R+((R-(L+N))*E-L
T(2)=(R+N)+((N+R)-L)*E-L
T(3)=(N+R)+(R-L)*E-(L+N)
Nachdem die sprachliche Beschreibung des Bildes erstellt wurde, muss mithilfe eines Erkennungsverfahrens analysiert werden, ob das gegebene Bild zu der für uns interessanten Klasse (der Klasse der Buchstaben A) gehört, d.h. ob dieses Bild eine Struktur hat oder nicht. Dazu ist es zunächst notwendig, die Klasse von Bildern zu beschreiben, die die uns interessierende Struktur haben.
Offensichtlich enthält der Buchstabe A immer die folgenden Strukturelemente: das linke "Bein", das rechte "Bein" und den Kopf. Nennen wir diese Elemente jeweils STL, STR, TR.
Dann wird in der PDL-Sprache die Symbolklasse A – SIMB A durch den Ausdruck beschrieben
SIMB A = STL + TR - STR
Das linke "Bein" der STL ist immer eine Kette von Elementen R und N, die geschrieben werden kann als
STL ‑> R ¦ N ¦ (STL + R) ¦ (STL + N)
(STL ist das Zeichen R oder N oder eine Zeichenfolge, die durch Hinzufügen von R- oder N-Zeichen zur STL-Quellzeichenfolge erhalten wird.)
Der rechte "Zweig" von STR ist immer eine Kette der Elemente L und N, die wie folgt geschrieben werden kann, d.h.
STR ‑> L¦N¦ (STR + L)¦(STR + N)
Der Kopfteil des Buchstabens - TR ist eine geschlossene Kontur, die sich aus dem Element E und Ketten wie STL und STR zusammensetzt.
In der PDL-Sprache wird die TR-Struktur durch den Ausdruck beschrieben
TR ‑> (STL - STR) * E
Schließlich erhalten wir die folgende Beschreibung der Buchstabenklasse A:
SIMB A ‑> (STL + TR - STR),
STL ‑> R¦N¦ (STL + R)¦(STL + N)
STR ‑> L¦N¦ (STR + L)¦(STR + N)
TR ‑> (STL - STR) * E
Das Erkennungsverfahren kann in diesem Fall wie folgt implementiert werden.
1. Der dem Bild entsprechende Ausdruck wird mit der Referenzstruktur STL + TR - STR verglichen.
2. Jedes Element der Struktur STL, TR, STR, wenn möglich, d.h. wenn die Beschreibung des Bildes mit dem Standard vergleichbar ist, wird ein Teilausdruck des Ausdrucks T(A) abgeglichen. Zum Beispiel,
für A1: STL=R, STR=L, TR=(R-(L+N))*E
für A2: STL = R + N, STR = L, TR = ((N + R) - L) * E
für A3: STL = N + R, STR = L + N, TR = (R - L) * E 3.
STL-, STR-, TR-Ausdrücke werden mit ihren entsprechenden Referenzstrukturen verglichen.
4. Wenn die Struktur jedes STL-, STR-, TR-Ausdrucks der Referenz entspricht, wird gefolgert, dass das Bild zur Buchstabenklasse A gehört. Wenn in einer der Stufen 2, 3, 4 eine Diskrepanz zwischen der Struktur besteht Aus dem analysierten Ausdruck und der Referenz wird geschlossen, dass das Bild nicht zur SIMB-Klasse A gehört. Der Abgleich der Ausdrucksstruktur kann mit den algorithmischen Sprachen LISP, PLANER, PROLOG und anderen ähnlichen Sprachen für künstliche Intelligenz erfolgen.
Im betrachteten Beispiel bestehen alle STL-Strings aus N und R Zeichen und STR-Strings aus L und N Zeichen, was der gegebenen Struktur dieser Strings entspricht. Die TR-Struktur in den betrachteten Bildern entspricht auch der Referenz, da besteht aus "Differenz" von Zeichenketten vom Typ STL, STR, "multipliziert" mit dem Symbol E.
Somit kommen wir zu dem Schluss, dass die betrachteten Bilder zur Klasse gehören SIMB A.
Synthese eines Fuzzy-DC-Elektroantriebsreglersin der "MatLab"-Umgebung
Synthese eines Fuzzy-Reglers mit einem Ein- und Ausgang.
Das Problem besteht darin, den Antrieb dazu zu bringen, den verschiedenen Eingaben genau zu folgen. Die Entwicklung der Regelaktion erfolgt durch einen Fuzzy-Controller, bei dem folgende Funktionsblöcke strukturell unterschieden werden können: Fuzzifier, Regelblock und Defuzzifier.
Abb.4 Verallgemeinertes Funktionsdiagramm eines Systems mit zwei linguistischen Variablen.
 Abb.5 Schematische Darstellung eines Fuzzy-Reglers mit zwei linguistischen Variablen.
Abb.5 Schematische Darstellung eines Fuzzy-Reglers mit zwei linguistischen Variablen.
Der Fuzzy-Regelalgorithmus ist im allgemeinen Fall eine Transformation der Eingangsgrößen des Fuzzy-Reglers in seine Ausgangsgrößen mit folgenden zusammenhängenden Verfahren:
1. Transformation von von Messsensoren empfangenen physikalischen Eingangsgrößen des Regelobjekts in sprachliche Eingangsgrößen eines Fuzzy-Reglers;
2. Verarbeitung logischer Aussagen, sogenannter linguistischer Regeln, bezüglich der linguistischen Eingangs- und Ausgangsvariablen des Controllers;
3. Transformation der ausgegebenen linguistischen Größen des Fuzzy-Reglers in physikalische Regelgrößen.
Betrachten wir zunächst den einfachsten Fall, wenn nur zwei linguistische Variablen zur Steuerung des Servoantriebs eingeführt werden:
"Winkel" - Eingabevariable;
"control action" - Ausgangsvariable.
Wir werden den Controller in der MatLab-Umgebung mit der Fuzzy-Logic-Toolbox synthetisieren. Es ermöglicht die Erstellung von Fuzzy-Inferenz- und Fuzzy-Klassifizierungssystemen innerhalb der MatLab-Umgebung mit der Möglichkeit, sie in Simulink zu integrieren. Das Grundkonzept der Fuzzy Logic Toolbox ist die FIS-Struktur - Fuzzy Inference System. Die FIS-Struktur enthält alle notwendigen Daten für die Implementierung der funktionalen Abbildung "Eingänge-Ausgänge" auf der Grundlage einer Fuzzy-Logik-Inferenz gemäß dem in Fig. 10 gezeigten Schema. 6.

Abbildung 6. Fuzzy-Inferenz.
X - gestochen scharfer Vektor eingeben; - Vektor von Fuzzy-Mengen entsprechend dem Eingangsvektor X;
- das Ergebnis der logischen Inferenz in Form eines Vektors von Fuzzy-Sets; Y - Ausgabe eines scharfen Vektors.
Mit dem Fuzzy-Modul können Sie zwei Arten von Fuzzy-Systemen erstellen - Mamdani und Sugeno. In Systemen vom Mamdani-Typ besteht die Wissensbasis aus Regeln der Form „Wenn x 1 =niedrig und x 2 =mittel, dann y=hoch“. In Systemen vom Sugeno-Typ besteht die Wissensbasis aus Regeln der Form „Wenn x 1 =niedrig und x 2 =mittel, dann y=a 0 +a 1 x 1 +a 2 x 2 ". Der Hauptunterschied zwischen dem Mamdani- und dem Sugeno-System liegt also in den unterschiedlichen Möglichkeiten, die Werte der Ausgangsvariablen in den Regeln festzulegen, die die Wissensbasis bilden. In Systemen vom Mamdani-Typ werden die Werte der Ausgangsvariablen durch Fuzzy-Terme angegeben, in Systemen vom Sugeno-Typ - als lineare Kombination von Eingangsvariablen. In unserem Fall werden wir das Sugeno-System verwenden, weil es eignet sich besser für die Optimierung.
Um den Servoantrieb zu steuern, werden zwei linguistische Variablen eingeführt: "Fehler" (nach Position) und "Steueraktion". Der erste davon ist der Input, der zweite der Output. Lassen Sie uns einen Ausdruckssatz für die angegebenen Variablen definieren.
Die Hauptkomponenten der Fuzzy-Inferenz. Fuzzifier.
Für jede linguistische Variable definieren wir einen grundlegenden Begriffssatz der Form, der Fuzzy-Mengen enthält, die bezeichnet werden können: negativ hoch, negativ niedrig, Null, positiv niedrig, positiv hoch.
Lassen Sie uns zunächst subjektiv definieren, was mit den Begriffen "großer Fehler", "kleiner Fehler" usw. gemeint ist, indem die Zugehörigkeitsfunktionen für die entsprechenden Fuzzy-Mengen definiert werden. Hier kann man sich vorerst nur an der erforderlichen Genauigkeit, bekannten Parametern für die Klasse der Eingangssignale und gesundem Menschenverstand orientieren. Bisher konnte niemand einen starren Algorithmus zur Wahl der Parameter von Zugehörigkeitsfunktionen anbieten. In unserem Fall sieht die linguistische Variable "Fehler" so aus.
 Abb.7. Sprachvariable "Fehler".
Abb.7. Sprachvariable "Fehler".
Bequemer ist es, die linguistische Variable „Management“ in Form einer Tabelle darzustellen:
Tabelle 1
Regelblock.
Betrachten Sie die Reihenfolge der Definition mehrerer Regeln, die einige Situationen beschreiben:
Nehmen wir zum Beispiel an, dass der Ausgangswinkel gleich dem Eingangssignal ist (d. h. der Fehler ist Null). Offensichtlich ist dies die gewünschte Situation, und deshalb müssen wir nichts tun (die Steueraktion ist Null).
Betrachten Sie nun einen anderen Fall: Der Positionsfehler ist viel größer als Null. Natürlich müssen wir dies kompensieren, indem wir ein großes positives Steuersignal erzeugen.
Dass. Es wurden zwei Regeln aufgestellt, die formal wie folgt definiert werden können:
Wenn Fehler = null, dann Kontrollaktion = Null.
Wenn Fehler = groß positiv, dann Kontrollaktion = groß positiv.
 Abb.8. Kontrollbildung mit einem kleinen positiven Positionsfehler.
Abb.8. Kontrollbildung mit einem kleinen positiven Positionsfehler.
 Abb.9. Bildung der Kontrolle bei Nullfehler nach Position.
Abb.9. Bildung der Kontrolle bei Nullfehler nach Position.
Die folgende Tabelle zeigt alle Regeln, die allen Situationen für diesen einfachen Fall entsprechen.
Tabelle 2
Insgesamt können für einen Fuzzy-Regler mit n Eingängen und 1 Ausgang Steuerregeln bestimmt werden, wobei die Anzahl der Fuzzy-Sets für den i-ten Eingang ist, aber für die normale Funktion des Reglers nicht alle verwendet werden müssen mögliche Regeln, aber Sie kommen auch mit einer kleineren Anzahl davon aus. In unserem Fall werden alle 5 möglichen Regeln verwendet, um ein Fuzzy-Steuersignal zu bilden.
Defuzzifizierer.
Somit wird die resultierende Auswirkung U gemäß der Implementierung einer beliebigen Regel bestimmt. Wenn eine Situation auftritt, in der mehrere Regeln gleichzeitig ausgeführt werden, wird die resultierende Aktion U gemäß der folgenden Abhängigkeit gefunden:
 , wobei n die Anzahl der ausgelösten Regeln ist (Defuzzifizierung nach der Bereichszentrumsmethode), u n der physikalische Wert des Steuersignals ist, das jedem der Fuzzy-Mengen entspricht UBO, UMo, UZ, UMp, UBP. mUn(u) ist der Grad der Zugehörigkeit des Steuersignals u zur entsprechenden Fuzzy-Menge Un=( UBO, UMo, UZ, UMp, UBP). Es gibt auch andere Methoden der Defuzzifizierung, wenn die ausgegebene linguistische Variable proportional zur "starken" oder "schwachen" Regel selbst ist.
, wobei n die Anzahl der ausgelösten Regeln ist (Defuzzifizierung nach der Bereichszentrumsmethode), u n der physikalische Wert des Steuersignals ist, das jedem der Fuzzy-Mengen entspricht UBO, UMo, UZ, UMp, UBP. mUn(u) ist der Grad der Zugehörigkeit des Steuersignals u zur entsprechenden Fuzzy-Menge Un=( UBO, UMo, UZ, UMp, UBP). Es gibt auch andere Methoden der Defuzzifizierung, wenn die ausgegebene linguistische Variable proportional zur "starken" oder "schwachen" Regel selbst ist.
Lassen Sie uns die Steuerung des Elektroantriebs mit dem oben beschriebenen Fuzzy-Regler simulieren.
 Abb.10. Blockdiagramm des Systems in der Umgebungmatlab.
Abb.10. Blockdiagramm des Systems in der Umgebungmatlab.

Abb.11. Strukturdiagramm eines Fuzzy-Reglers in der Umgebungmatlab.

Abb.12. Transienter Prozess bei einem einstufigen Aufprall.

Reis. 13. Transienter Prozess unter harmonischer Eingabe für ein Modell mit einem Fuzzy-Controller, der eine linguistische Eingabevariable enthält.
Eine Analyse der Kennlinien eines Antriebs mit synthetisiertem Regelalgorithmus zeigt, dass diese bei weitem nicht optimal und schlechter sind als bei der Regelsynthese durch andere Methoden (zu viel Regelzeit bei Einzelschritteffekt und Fehler bei Oberschwingungseffekt). . Dies erklärt sich dadurch, dass die Parameter der Zugehörigkeitsfunktionen ziemlich willkürlich gewählt wurden und nur die Größe des Positionsfehlers als Reglereingang verwendet wurde. Von einer Optimalität des erhaltenen Reglers kann natürlich keine Rede sein. Damit stellt sich die Aufgabe, den Fuzzy-Regler zu optimieren, um möglichst hohe Regelgütekennzahlen zu erreichen. Jene. Die Aufgabe besteht darin, die Zielfunktion f(a 1 ,a 2 …a n) zu optimieren, wobei a 1 ,a 2 …a n die Koeffizienten sind, die Art und Eigenschaften des Fuzzy-Reglers bestimmen. Zur Optimierung des Fuzzy-Reglers verwenden wir den ANFIS-Baustein aus der Matlab-Umgebung. Eine der Möglichkeiten zur Verbesserung der Eigenschaften des Controllers kann auch darin bestehen, die Anzahl seiner Eingänge zu erhöhen. Dadurch wird der Regler flexibler und seine Leistung verbessert. Lassen Sie uns eine weitere linguistische Eingangsvariable hinzufügen - die Änderungsrate des Eingangssignals (seine Ableitung). Dementsprechend wird auch die Zahl der Regeln zunehmen. Dann hat der Schaltplan des Reglers die Form:

Abb.14 Schematische Darstellung eines Fuzzy-Reglers mit drei linguistischen Variablen.
Sei der Wert der Geschwindigkeit des Eingangssignals. Der Basistermsatz Tn ist definiert als:
Тn=("negativ (VO)", "null (Z)", "positiv (VR)").
Die Position der Zugehörigkeitsfunktionen für alle linguistischen Variablen ist in der Abbildung gezeigt.
Abb.15. Zugehörigkeitsfunktionen der linguistischen Variablen "Fehler".

Abb.16. Zugehörigkeitsfunktionen der linguistischen Variablen "Eingangssignalgeschwindigkeit".
Durch das Hinzufügen einer weiteren linguistischen Variablen erhöht sich die Anzahl der Regeln auf 3x5=15. Das Prinzip ihrer Zusammenstellung ist dem oben besprochenen völlig ähnlich. Alle sind in der folgenden Tabelle aufgeführt:
Tisch 3
| unscharfes Signal Management | Positionsfehler |
|||||
| Geschwindigkeit | ||||||
Zum Beispiel, wenn Wenn Fehler = Null und Eingangssignalableitung = groß positiv, dann Kontrollaktion = klein negativ.
 Abb.17. Kontrollbildung unter drei sprachlichen Variablen.
Abb.17. Kontrollbildung unter drei sprachlichen Variablen.
Durch die Zunahme der Anzahl der Eingänge und dementsprechend der Regeln selbst wird auch die Struktur des Fuzzy-Reglers komplizierter.
 Abb.18. Strukturdiagramm eines Fuzzy-Reglers mit zwei Eingängen.
Abb.18. Strukturdiagramm eines Fuzzy-Reglers mit zwei Eingängen.
Zeichnung hinzufügen

Abb.20. Transienter Prozess unter harmonischer Eingabe für ein Modell mit einem Fuzzy-Controller, der zwei linguistische Eingabevariablen enthält.

Reis. 21. Fehlersignal unter harmonischer Eingabe für ein Modell mit einem Fuzzy-Regler, der zwei linguistische Eingabevariablen enthält.
Lassen Sie uns den Betrieb eines Fuzzy-Controllers mit zwei Eingängen in der Matlab-Umgebung simulieren. Das Blockdiagramm des Modells ist genau das gleiche wie in Abb. 19. Aus dem Diagramm des transienten Prozesses für den harmonischen Eingang ist ersichtlich, dass die Genauigkeit des Systems erheblich zugenommen hat, aber gleichzeitig seine Oszillation zugenommen hat, insbesondere an Stellen, an denen die Ableitung der Ausgangskoordinate dazu tendiert Null. Es ist offensichtlich, dass die Gründe dafür, wie oben erwähnt, in der nicht optimalen Wahl von Parametern von Zugehörigkeitsfunktionen sowohl für Eingangs- als auch für Ausgangssprachvariablen liegen. Daher optimieren wir den Fuzzy-Regler mit dem ANFISedit-Block in der Matlab-Umgebung.
Fuzzy-Controller-Optimierung.
Betrachten Sie die Verwendung genetischer Algorithmen zur Fuzzy-Controller-Optimierung. Genetische Algorithmen sind adaptive Suchverfahren, die in den letzten Jahren häufig zur Lösung funktionaler Optimierungsprobleme eingesetzt werden. Sie basieren auf der Ähnlichkeit zu den genetischen Prozessen biologischer Organismen: Biologische Populationen entwickeln sich über mehrere Generationen, gehorchend den Gesetzen der natürlichen Auslese und nach dem von Charles Darwin entdeckten Prinzip des „Survival of the fittest“. Durch die Nachahmung dieses Prozesses sind genetische Algorithmen in der Lage, Lösungen für reale Probleme zu „entwickeln“, wenn sie entsprechend codiert sind.
Genetische Algorithmen arbeiten mit einer Reihe von "Individuen" - einer Population, von denen jedes eine mögliche Lösung für ein bestimmtes Problem darstellt. Jedes Individuum wird nach dem Maß seiner „Fitness“ danach beurteilt, wie „gut“ die Lösung des ihm entsprechenden Problems ist. Die fittesten Individuen sind in der Lage, Nachkommen durch "Kreuzung" mit anderen Individuen der Population zu "reproduzieren". Dies führt zur Entstehung neuer Individuen, die einige der von ihren Eltern geerbten Eigenschaften in sich vereinen. Die am wenigsten fitten Individuen reproduzieren sich mit geringerer Wahrscheinlichkeit, sodass die Eigenschaften, die sie besitzen, allmählich aus der Population verschwinden.
Auf diese Weise wird die gesamte neue Population machbarer Lösungen reproduziert, indem die besten Vertreter der vorherigen Generation ausgewählt, gekreuzt und viele neue Individuen gewonnen werden. Diese neue Generation enthält einen höheren Anteil an Eigenschaften, die die guten Mitglieder der vorherigen Generation besitzen. So werden von Generation zu Generation gute Eigenschaften in der gesamten Bevölkerung verteilt. Letztendlich wird sich die Bevölkerung der optimalen Lösung des Problems annähern.
Es gibt viele Möglichkeiten, die Idee der biologischen Evolution im Rahmen genetischer Algorithmen umzusetzen. Herkömmlich, kann in Form des folgenden Blockdiagramms dargestellt werden, das in Abbildung 22 gezeigt wird, wobei:
1. Initialisierung der Anfangspopulation - Generierung einer bestimmten Anzahl von Lösungen für das Problem, von denen aus der Optimierungsprozess beginnt;
2. Anwendung von Crossover- und Mutationsoperatoren;
3.  Stoppbedingungen – normalerweise wird der Optimierungsprozess fortgesetzt, bis eine Lösung für das Problem mit einer bestimmten Genauigkeit gefunden wird oder bis sich herausstellt, dass der Prozess konvergiert ist (d. h. es gab keine Verbesserung bei der Lösung des Problems im letzten N Generationen).
Stoppbedingungen – normalerweise wird der Optimierungsprozess fortgesetzt, bis eine Lösung für das Problem mit einer bestimmten Genauigkeit gefunden wird oder bis sich herausstellt, dass der Prozess konvergiert ist (d. h. es gab keine Verbesserung bei der Lösung des Problems im letzten N Generationen).
In der Matlab-Umgebung werden genetische Algorithmen durch eine separate Toolbox sowie durch das ANFIS-Paket repräsentiert. ANFIS ist eine Abkürzung für Adaptive-Network-Based Fuzzy Inference System – Adaptive Fuzzy Inference Network. ANFIS ist eine der ersten Varianten hybrider Neuro-Fuzzy-Netze – ein neuronales Netz einer besonderen Art der direkten Signalausbreitung. Die Architektur eines Neuro-Fuzzy-Netzwerks ist isomorph zu einer Fuzzy-Wissensbasis. In Neuro-Fuzzy-Netzen werden differenzierbare Implementierungen von Dreiecksnormen (Multiplikation und probabilistisches ODER) sowie glatte Zugehörigkeitsfunktionen verwendet. Dies ermöglicht die Verwendung schneller und genetischer Algorithmen zum Trainieren neuronaler Netze nach dem Backpropagation-Verfahren zur Konfiguration von Neuro-Fuzzy-Netzen. Die Architektur und Regeln für den Betrieb jeder Schicht des ANFIS-Netzwerks werden unten beschrieben.
ANFIS implementiert das Fuzzy-Inferenzsystem von Sugeno als fünfschichtiges neuronales Feed-Forward-Netzwerk. Der Zweck der Schichten ist wie folgt: Die erste Schicht sind die Terme der Eingabevariablen; die zweite Schicht - Antezedenzien (Pakete) von Fuzzy-Regeln; die dritte Ebene ist die Normalisierung des Erfüllungsgrades der Regeln; die vierte Schicht sind die Schlussfolgerungen der Regeln; die fünfte Schicht ist die Aggregation der nach verschiedenen Regeln erhaltenen Ergebnisse.
Die Netzwerkeingänge werden keiner separaten Schicht zugeordnet. Abbildung 23 zeigt ein ANFIS-Netz mit einer Eingangsvariablen („Fehler“) und fünf Fuzzy-Regeln. Für die sprachliche Bewertung der Eingangsgröße „Fehler“ werden 5 Begriffe verwendet.

Abb.23. StrukturANFIS-Netzwerke.
Lassen Sie uns die folgende Notation einführen, die für die weitere Darstellung notwendig ist:
Seien die Eingänge des Netzwerks;
y - Netzwerkausgang;
Fuzzy-Regel mit Ordnungszahl r;
m - Anzahl der Regeln;
Fuzzy-Term mit Zugehörigkeitsfunktion , verwendet zur sprachlichen Auswertung einer Variablen in der r-ten Regel (,);
Reelle Zahlen im Schluss der r-ten Regel (,).
Das ANFIS-Netzwerk funktioniert wie folgt.
Schicht 1 Jeder Knoten der ersten Schicht repräsentiert einen Term mit einer glockenförmigen Zugehörigkeitsfunktion. Die Eingänge des Netzwerks sind nur mit ihren Begriffen verbunden. Die Anzahl der Knoten in der ersten Schicht ist gleich der Summe der Kardinalitäten der Ausdruckssätze der Eingabevariablen. Die Ausgabe des Knotens ist der Grad der Zugehörigkeit des Werts der Eingangsvariablen zum entsprechenden Fuzzy-Term:
 ,
,
wobei a, b und c konfigurierbare Parameter der Zugehörigkeitsfunktion sind.
Schicht 2 Die Anzahl der Knoten in der zweiten Schicht ist m. Jeder Knoten dieser Schicht entspricht einer Fuzzy-Regel. Der Knoten der zweiten Schicht ist mit denjenigen Knoten der ersten Schicht verbunden, die die Vorläufer der entsprechenden Regel bilden. Daher kann jeder Knoten der zweiten Schicht 1 bis n Eingangssignale empfangen. Der Ausgang des Knotens ist der Ausführungsgrad der Regel, der als Produkt der Eingangssignale berechnet wird. Bezeichnen Sie die Ausgänge der Knoten dieser Schicht mit , .
Schicht 3 Die Anzahl der Knoten in der dritten Schicht ist ebenfalls m. Jeder Knoten dieser Schicht berechnet den relativen Erfüllungsgrad der Fuzzy-Regel:
Schicht 4 Die Anzahl der Knoten in der vierten Schicht ist ebenfalls m. Jeder Knoten ist mit einem Knoten der dritten Schicht sowie mit allen Eingängen des Netzwerks verbunden (Verbindungen zu den Eingängen sind in Fig. 18 nicht gezeigt). Der Knoten der vierten Schicht berechnet den Beitrag einer Fuzzy-Regel zur Netzwerkausgabe:
Schicht 5 Der einzelne Knoten dieser Schicht fasst die Beiträge aller Regeln zusammen:
![]() .
.
Typische Trainingsprozeduren für neuronale Netze können angewendet werden, um das ANFIS-Netz abzustimmen, da es nur differenzierbare Funktionen verwendet. Typischerweise wird eine Kombination aus Gradientenabstieg in Form von Backpropagation und kleinsten Quadraten verwendet. Der Backpropagation-Algorithmus passt die Parameter von Regelvorläufern an, d. h. Zugehörigkeitsfunktionen. Die Regelschlusskoeffizienten werden nach der Methode der kleinsten Quadrate geschätzt, da sie in linearer Beziehung zum Netzwerkausgang stehen. Jede Iteration des Abstimmungsverfahrens wird in zwei Schritten durchgeführt. In der ersten Stufe wird den Eingängen ein Trainingssample zugeführt und aus der Diskrepanz zwischen Soll- und Ist-Verhalten des Netzes mit der iterativen Methode der kleinsten Quadrate die optimalen Parameter der Knoten der vierten Schicht ermittelt. In der zweiten Stufe wird die Restdiskrepanz vom Netzwerkausgang zu den Eingängen übertragen und die Parameter der Knoten der ersten Schicht werden durch das Error-Backpropagation-Verfahren modifiziert. Gleichzeitig ändern sich die in der ersten Stufe gefundenen Regelschlusskoeffizienten nicht. Die iterative Abstimmungsprozedur wird fortgesetzt, bis der Rest einen vorbestimmten Wert überschreitet. Um Zugehörigkeitsfunktionen abzustimmen, können zusätzlich zu dem Fehler-Backpropagation-Verfahren andere Optimierungsalgorithmen verwendet werden, beispielsweise das Levenberg-Marquardt-Verfahren.

Abb.24. ANFISedit-Arbeitsbereich.
Versuchen wir nun, den Fuzzy-Regler für eine Einzelschrittaktion zu optimieren. Der gewünschte Einschwingvorgang ist ungefähr der folgende:

Abb.25. gewünschten Übergangsprozess.
Aus dem in Abb. Daraus folgt, dass der Motor die meiste Zeit mit voller Leistung laufen sollte, um die maximale Geschwindigkeit zu gewährleisten, und wenn er sich dem gewünschten Wert nähert, sollte er sanft langsamer werden. Geleitet von diesen einfachen Überlegungen, nehmen wir die folgende Stichprobe von Werten als Trainingswerte, die unten in Form einer Tabelle dargestellt werden:
Tabelle 4
| Fehlerwert | Managementwert |
| Fehlerwert | Managementwert |
| Fehlerwert | Managementwert |

Abb.26. Art des Trainingssets.
Das Training wird in 100 Schritten durchgeführt. Dies ist mehr als genug für die Konvergenz der verwendeten Methode.

Abb.27. Der Lernprozess eines neuronalen Netzes.
Beim Lernprozess werden die Parameter der Zugehörigkeitsfunktionen so gebildet, dass der Regler bei gegebenem Fehlerwert die notwendige Regelung erzeugt. Im Abschnitt zwischen den Knotenpunkten ist die Abhängigkeit der Regelung vom Fehler eine Interpolation der Tabellendaten. Das Interpolationsverfahren hängt davon ab, wie das neuronale Netzwerk trainiert wird. Tatsächlich kann das Fuzzy-Reglermodell nach dem Training als eine nichtlineare Funktion einer Variablen dargestellt werden, deren Graph unten dargestellt ist.

Abb.28. Diagramm der Abhängigkeit der Steuerung vom Fehler zur Position innerhalb des Reglers.
Nachdem wir die gefundenen Parameter der Zugehörigkeitsfunktionen gespeichert haben, simulieren wir das System mit einem optimierten Fuzzy-Regler.


Reis. 29. Transienter Prozess unter harmonischer Eingabe für ein Modell mit einem optimierten Fuzzy-Regler, der eine linguistische Eingangsvariable enthält.
Abb.30. Fehlersignal unter harmonischer Eingabe für ein Modell mit einem Fuzzy-Regler, der zwei linguistische Eingabevariablen enthält.
Aus den Graphen geht hervor, dass die Optimierung des Fuzzy-Reglers durch Training des neuronalen Netzes erfolgreich war. Deutlich verringerte Fluktuation und das Ausmaß des Fehlers. Daher ist der Einsatz eines neuronalen Netzes zur Optimierung von Reglern durchaus sinnvoll, deren Prinzip auf Fuzzy-Logik basiert. Allerdings kann auch ein optimierter Regler die Anforderungen an die Genauigkeit nicht erfüllen, so dass es ratsam ist, ein anderes Regelverfahren in Betracht zu ziehen, wenn der Fuzzy-Regler das Objekt nicht direkt regelt, sondern je nach Situation mehrere Regelgesetze kombiniert.
So, 29. März 2015
Derzeit gibt es viele Aufgaben, bei denen es erforderlich ist, abhängig vom Vorhandensein eines Objekts im Bild eine Entscheidung zu treffen oder es zu klassifizieren. Die Fähigkeit zu „erkennen“ gilt als die Haupteigenschaft biologischer Wesen, während Computersysteme diese Eigenschaft nicht vollständig besitzen.
Betrachten Sie die allgemeinen Elemente des Klassifizierungsmodells.
Klasse- eine Menge von Objekten, die gemeinsame Eigenschaften haben. Bei Objekten derselben Klasse wird das Vorhandensein von "Ähnlichkeit" angenommen. Für die Erkennungsaufgabe kann eine beliebige Anzahl von Klassen definiert werden, mehr als 1. Die Anzahl der Klassen wird durch die Zahl S bezeichnet. Jede Klasse hat ihre eigene identifizierende Klassenbezeichnung.
Einstufung- der Vorgang des Zuweisens von Klassenetiketten zu Objekten gemäß einer Beschreibung der Eigenschaften dieser Objekte. Ein Klassifikator ist ein Gerät, das eine Reihe von Merkmalen eines Objekts als Eingabe empfängt und als Ergebnis eine Klassenbezeichnung erzeugt.
Überprüfung- der Prozess des Abgleichens einer Objektinstanz mit einem einzelnen Objektmodell oder einer Klassenbeschreibung.
Unter Weg Wir werden den Namen des Bereichs im Raum der Attribute verstehen, in dem viele Objekte oder Phänomene der materiellen Welt angezeigt werden. Schild- eine quantitative Beschreibung einer bestimmten Eigenschaft des untersuchten Objekts oder Phänomens.
Feature-Raum dies ist ein N-dimensionaler Raum, der für eine gegebene Erkennungsaufgabe definiert ist, wobei N eine feste Anzahl von gemessenen Merkmalen für beliebige Objekte ist. Der dem Objekt des Erkennungsproblems entsprechende Vektor aus dem Merkmalsraum x ist ein N-dimensionaler Vektor mit Komponenten (x_1,x_2,…,x_N), die die Werte der Merkmale für das gegebene Objekt sind.
Mit anderen Worten, Mustererkennung kann definiert werden als die Zuordnung von Ausgangsdaten zu einer bestimmten Klasse, indem wesentliche Merkmale oder Eigenschaften, die diese Daten charakterisieren, aus der allgemeinen Masse irrelevanter Details extrahiert werden.
Beispiele für Klassifizierungsprobleme sind:
- Zeichenerkennung;
- Spracherkennung;
- Erstellen einer medizinischen Diagnose;
- Wettervorhersage;
- Gesichtserkennung
- Klassifizierung von Dokumenten usw.
Meistens ist das Quellmaterial das von der Kamera empfangene Bild. Die Aufgabe kann so formuliert werden, dass für jede Klasse im betrachteten Bild Merkmalsvektoren ermittelt werden. Der Prozess kann als Codierungsprozess angesehen werden, der darin besteht, jedem Merkmal aus dem Merkmalsraum für jede Klasse einen Wert zuzuweisen.
Betrachten wir 2 Klassen von Objekten: Erwachsene und Kinder. Als Merkmale können Sie Größe und Gewicht auswählen. Wie aus der Abbildung hervorgeht, bilden diese beiden Klassen zwei sich nicht überschneidende Mengen, was durch die gewählten Merkmale erklärt werden kann. Allerdings ist es nicht immer möglich, die richtigen gemessenen Parameter als Merkmale von Klassen auszuwählen. Beispielsweise sind die ausgewählten Parameter nicht dazu geeignet, nicht überlappende Klassen von Fußballspielern und Basketballspielern zu erstellen.
Die zweite Erkennungsaufgabe ist die Auswahl charakteristischer Merkmale oder Eigenschaften aus den Originalbildern. Diese Aufgabe kann der Vorverarbeitung zugeschrieben werden. Betrachten wir die Aufgabe der Spracherkennung, können wir Merkmale wie Vokale und Konsonanten unterscheiden. Das Attribut muss eine charakteristische Eigenschaft einer bestimmten Klasse sein, während es dieser Klasse gemeinsam ist. Zeichen, die die Unterschiede zwischen - Klassenzeichen charakterisieren. Merkmale, die allen Klassen gemeinsam sind, enthalten keine nützlichen Informationen und werden bei dem Erkennungsproblem nicht als Merkmale betrachtet. Die Auswahl von Merkmalen ist eine der wichtigen Aufgaben, die mit dem Aufbau eines Erkennungssystems verbunden sind.
Nachdem die Merkmale bestimmt sind, ist es notwendig, das optimale Entscheidungsverfahren für die Klassifizierung zu bestimmen. Stellen Sie sich ein Mustererkennungssystem vor, das dafür ausgelegt ist, verschiedene M-Klassen zu erkennen, die als m_1,m_2,…,m bezeichnet werden 3. Dann können wir annehmen, dass der Bildraum aus M Regionen besteht, die jeweils Punkte enthalten, die einem Bild aus einer Klasse entsprechen. Dann kann das Erkennungsproblem als Konstruktion von Grenzen betrachtet werden, die M Klassen auf der Grundlage der akzeptierten Messvektoren trennen.
Die Lösung des Problems der Bildvorverarbeitung, der Merkmalsextraktion und des Problems, die optimale Lösung und Klassifizierung zu erhalten, ist normalerweise mit der Notwendigkeit verbunden, eine Reihe von Parametern zu bewerten. Dies führt zu dem Problem der Parameterschätzung. Darüber hinaus ist es offensichtlich, dass die Merkmalsextraktion zusätzliche Informationen basierend auf der Art der Klassen verwenden kann.
Der Vergleich von Objekten kann anhand ihrer Darstellung in Form von Messvektoren erfolgen. Es ist praktisch, Messdaten als reelle Zahlen darzustellen. Dann kann die Ähnlichkeit der Merkmalsvektoren zweier Objekte mit der euklidischen Distanz beschrieben werden.

wobei d die Dimension des Merkmalsvektors ist.
Es gibt 3 Gruppen von Mustererkennungsverfahren:
- Probenvergleich. Diese Gruppe umfasst die Klassifizierung nach dem nächsten Mittelwert, die Klassifizierung nach der Entfernung zum nächsten Nachbarn. Auch Strukturerkennungsverfahren können in die Probenvergleichsgruppe aufgenommen werden.
- Statistische Methoden. Wie der Name schon sagt, verwenden statistische Methoden einige statistische Informationen, wenn sie ein Erkennungsproblem lösen. Das Verfahren bestimmt die Zugehörigkeit eines Objekts zu einer bestimmten Klasse anhand der Wahrscheinlichkeit, in manchen Fällen kommt es darauf an, die A-posteriori-Wahrscheinlichkeit eines Objekts zu bestimmen, das zu einer bestimmten Klasse gehört, sofern die Eigenschaften dieses Objekts das Passende angenommen haben Werte. Ein Beispiel ist das Bayessche Entscheidungsregelverfahren.
- Neuronale Netze. Eine separate Klasse von Erkennungsmethoden. Ein Unterscheidungsmerkmal von anderen ist die Fähigkeit zu lernen.
Klassifizierung nach dem nächsten Mittelwert
Beim klassischen Ansatz der Mustererkennung wird ein unbekanntes Objekt zur Klassifikation als Vektor elementarer Merkmale dargestellt. Ein merkmalsbasiertes Erkennungssystem kann auf verschiedene Arten entwickelt werden. Diese Vektoren können dem System als Ergebnis des Trainings im Voraus bekannt sein oder basierend auf einigen Modellen in Echtzeit vorhergesagt werden.
Ein einfacher Klassifizierungsalgorithmus besteht aus der Gruppierung von Klassenreferenzdaten unter Verwendung des Klassenerwartungsvektors (Mittelwert).

wobei x(i,j) das j-te Referenzmerkmal der Klasse i ist, n_j die Anzahl der Referenzvektoren der Klasse i ist.
Dann gehört das unbekannte Objekt zur Klasse i, wenn es viel näher am Erwartungsvektor der Klasse i liegt als an den Erwartungsvektoren anderer Klassen. Dieses Verfahren eignet sich für Probleme, bei denen die Punkte jeder Klasse kompakt und weit entfernt von den Punkten anderer Klassen liegen.

Schwierig wird es, wenn die Klassen beispielsweise etwas komplexer aufgebaut sind als in der Abbildung. In diesem Fall wird die Klasse 2 in zwei nicht überlappende Abschnitte unterteilt, die durch einen einzigen Durchschnittswert schlecht beschrieben werden. Außerdem ist Klasse 3 zu langgestreckt, Proben der 3. Klasse mit großen Werten von x_2-Koordinaten liegen näher am Durchschnittswert der 1. Klasse als der 3. Klasse.

Das beschriebene Problem kann in einigen Fällen durch eine Änderung der Entfernungsberechnung gelöst werden.
Wir werden die Eigenschaft der "Streuung" von Klassenwerten - σ_i entlang jeder Koordinatenrichtung i berücksichtigen. Die Standardabweichung ist gleich der Quadratwurzel der Varianz. Der skalierte euklidische Abstand zwischen dem Vektor x und dem Erwartungsvektor x_c ist

Diese Abstandsformel reduziert die Anzahl der Klassifizierungsfehler, aber in Wirklichkeit können die meisten Probleme nicht durch eine so einfache Klasse dargestellt werden.
Klassifizierung nach Entfernung zum nächsten Nachbarn
Ein weiterer Ansatz zur Klassifizierung besteht darin, einen unbekannten Merkmalsvektor x der Klasse zuzuordnen, der dieser Vektor am nächsten an einer separaten Stichprobe liegt. Diese Regel wird als Nächster-Nachbar-Regel bezeichnet. Die Klassifizierung des nächsten Nachbarn kann effizienter sein, selbst wenn die Klassen komplex sind oder wenn sich die Klassen überschneiden.
Dieser Ansatz erfordert keine Annahmen über die Verteilungsmodelle von Merkmalsvektoren im Raum. Der Algorithmus verwendet nur Informationen über bekannte Referenzproben. Das Lösungsverfahren basiert auf der Berechnung des Abstands x zu jeder Probe in der Datenbank und dem Finden des Mindestabstands. Die Vorteile dieser Vorgehensweise liegen auf der Hand:
- Sie können jederzeit neue Proben zur Datenbank hinzufügen;
- Baum- und Gitterdatenstrukturen reduzieren die Anzahl der berechneten Distanzen.
Außerdem wird die Lösung besser, wenn Sie in der Datenbank nicht nach einem nächsten Nachbarn suchen, sondern nach k. Dann liefert es für k > 1 die beste Stichprobe der Verteilung von Vektoren im d-dimensionalen Raum. Die effiziente Nutzung von k-Werten hängt jedoch davon ab, ob in jedem Bereich des Raums genug vorhanden ist. Bei mehr als zwei Klassen ist es schwieriger, die richtige Entscheidung zu treffen.
Literatur
- M.Castrillon, . O. Deniz, . D. Hernández und J. Lorenzo, „Ein Vergleich von Gesichts- und Gesichtsmerkmalsdetektoren basierend auf dem allgemeinen Objekterkennungsrahmen von Viola-Jones“, International Journal of Computer Vision, Nr. 22, S. 481-494, 2011.
- Y.-Q. Wang, „An Analysis of Viola-Jones Face Detection Algorithm“, IPOL Journal, 2013.
- L. Shapiro und D. Stockman, Computer Vision, Binom. Wissenslabor, 2006.
- Z. N. G., Erkennungsmethoden und ihre Anwendung, Sowjetischer Rundfunk, 1972.
- J. Tu, R. Gonzalez, Mathematische Prinzipien der Mustererkennung, Moskau: „Mir“ Moskau, 1974.
- Khan, H. Abdullah und M. Shamian Bin Zainal, "Effizienter Augen- und Munderkennungsalgorithmus unter Verwendung einer Kombination aus Viola Jones und Hautfarben-Pixelerkennung", International Journal of Engineering and Applied Sciences, Nr. Vol. 3, No. 3 Nr. 4, 2013.
- V. Gaede und O. Gunther, „Multidimensional Access Methods“, ACM Computing Surveys, S. 170-231, 1998.
Lebende Systeme, einschließlich des Menschen, sind seit ihrer Entstehung ständig mit der Aufgabe der Mustererkennung konfrontiert. Insbesondere die von den Sinnesorganen kommenden Informationen werden vom Gehirn verarbeitet, das wiederum die Informationen sortiert, für die Entscheidungsfindung sorgt und dann durch elektrochemische Impulse das notwendige Signal weiterleitet, beispielsweise an die Bewegungsorgane , die die notwendigen Maßnahmen umsetzen. Dann gibt es eine Veränderung in der Umgebung, und die oben genannten Phänomene treten erneut auf. Und wenn Sie schauen, dann wird jede Stufe von Anerkennung begleitet.
Mit der Entwicklung der Computertechnologie wurde es möglich, eine Reihe von Problemen zu lösen, die im Lebensprozess auftreten, um die Qualität des Ergebnisses zu erleichtern, zu beschleunigen und zu verbessern. Beispielsweise der Betrieb verschiedener Lebenserhaltungssysteme, die Mensch-Computer-Interaktion, das Aufkommen von Robotersystemen usw. Wir stellen jedoch fest, dass es derzeit nicht möglich ist, bei einigen Aufgaben (Erkennung von sich schnell bewegenden ähnlichen Objekten) ein zufriedenstellendes Ergebnis zu liefern , handschriftlicher Text).
Zweck der Arbeit: Untersuchung der Geschichte von Mustererkennungssystemen.
Geben Sie die qualitativen Veränderungen an, die auf dem Gebiet der Mustererkennung aufgetreten sind, sowohl theoretisch als auch technisch, und geben Sie die Gründe an.
Diskutieren Sie die Methoden und Prinzipien, die beim Rechnen verwendet werden;
Nennen Sie Beispiele für Perspektiven, die in naher Zukunft erwartet werden.
1. Was ist Mustererkennung?
Die ersten Studien mit Computertechnik folgten im Wesentlichen dem klassischen Schema der mathematischen Modellierung – mathematisches Modell, Algorithmus und Berechnung. Dies waren die Aufgaben der Modellierung der bei der Explosion von Atombomben ablaufenden Prozesse, der Berechnung ballistischer Flugbahnen, wirtschaftlicher und anderer Anwendungen. Allerdings gab es neben den klassischen Ideen dieser Reihe auch Methoden ganz anderer Natur, die, wie die Praxis bei der Lösung mancher Probleme gezeigt hat, oft bessere Ergebnisse lieferten als Lösungen, die auf überkomplizierten mathematischen Modellen beruhen. Ihre Idee war es, den Wunsch aufzugeben, ein erschöpfendes mathematisches Modell des Untersuchungsobjekts zu erstellen (außerdem war es oft praktisch unmöglich, adäquate Modelle zu konstruieren), und sich stattdessen mit der Antwort nur auf spezifische Fragen, die uns interessieren, zufrieden zu geben, und diese Antworten sollten anhand von Überlegungen gesucht werden, die einer breiten Klasse von Problemen gemeinsam sind. Forschungen dieser Art umfassten die Erkennung visueller Bilder, die Vorhersage von Erträgen, Flusspegeln, das Problem der Unterscheidung zwischen ölführenden und Grundwasserleitern anhand indirekter geophysikalischer Daten usw. Eine spezifische Antwort auf diese Aufgaben war in einer ziemlich einfachen Form erforderlich, wie z. zum Beispiel, ob ein Objekt zu einer der voreingestellten Klassen gehört. Und die Anfangsdaten dieser Aufgaben wurden in der Regel in Form von fragmentarischen Informationen über die untersuchten Objekte angegeben, beispielsweise in Form einer Reihe vorklassifizierter Objekte. Aus mathematischer Sicht bedeutet dies, dass die Mustererkennung (und diese Klasse von Problemen wurde in unserem Land benannt) eine weitreichende Verallgemeinerung der Idee der Funktionsextrapolation ist.
Die Bedeutung einer solchen Formulierung für die technischen Wissenschaften steht außer Frage und rechtfertigt zahlreiche Studien auf diesem Gebiet. Das Problem der Mustererkennung hat aber auch für die Naturwissenschaften einen breiteren Aspekt (es wäre allerdings seltsam, wenn etwas, das für künstliche kybernetische Systeme so wichtig ist, für natürliche nicht wichtig wäre). Der Kontext dieser Wissenschaft umfasste organisch die Fragen, die von alten Philosophen über die Natur unseres Wissens, unsere Fähigkeit, Bilder, Muster und Situationen der umgebenden Welt zu erkennen, gestellt wurden. Tatsächlich besteht praktisch kein Zweifel daran, dass die Mechanismen zur Erkennung der einfachsten Bilder, wie Bilder eines sich nähernden gefährlichen Raubtiers oder Nahrung, viel früher entstanden sind, als die elementare Sprache und der formale logische Apparat entstanden. Und zweifellos sind solche Mechanismen auch bei höheren Tieren ausreichend entwickelt, die in ihrer vitalen Aktivität auch dringend die Fähigkeit benötigen, ein ziemlich komplexes System von Zeichen der Natur zu unterscheiden. In der Natur sehen wir also, dass das Phänomen des Denkens und Bewusstseins eindeutig auf der Fähigkeit beruht, Muster zu erkennen, und der weitere Fortschritt der Intelligenzwissenschaft direkt mit der Tiefe des Verständnisses der grundlegenden Gesetze des Erkennens zusammenhängt. Um die Tatsache zu verstehen, dass die obigen Fragen weit über die Standarddefinition von Mustererkennung hinausgehen (in der englischen Literatur ist der Begriff überwachtes Lernen gebräuchlicher), ist es auch notwendig zu verstehen, dass sie tiefe Verbindungen zu dieser relativ engen (aber immer noch weit entfernten) Definition haben von erschöpft) Richtung.
Schon jetzt ist die Mustererkennung fest im Alltag angekommen und gehört zu den wichtigsten Kenntnissen eines modernen Ingenieurs. In der Medizin hilft die Mustererkennung Ärzten, genauere Diagnosen zu stellen, in Fabriken dient sie der Vorhersage von Mängeln in Warenchargen. Auch biometrische Personenidentifikationssysteme als algorithmischer Kern basieren auf den Ergebnissen dieser Disziplin. Die Weiterentwicklung der künstlichen Intelligenz, insbesondere das Design von Computern der fünften Generation, die in der Lage sind, direkter mit einer Person in natürlichen Sprachen für Menschen und durch Sprache zu kommunizieren, ist ohne Anerkennung undenkbar. Hier ist die Robotik, künstliche Steuerungssysteme, die Erkennungssysteme als lebensnotwendige Subsysteme enthalten, in greifbare Nähe gerückt.
Aus diesem Grund wurde der Entwicklung der Mustererkennung von Anfang an viel Aufmerksamkeit von Spezialisten verschiedener Profile gewidmet - Kybernetiker, Neurophysiologen, Psychologen, Mathematiker, Ökonomen usw. Vor allem aus diesem Grund speist sich die moderne Mustererkennung selbst aus den Ideen dieser Disziplinen. Ohne den Anspruch auf Vollständigkeit zu erheben (und es ist unmöglich, dies in einem kurzen Essay zu behaupten), werden wir die Geschichte der Mustererkennung und Schlüsselideen beschreiben.
Definitionen
Bevor wir zu den Hauptmethoden der Mustererkennung übergehen, geben wir einige notwendige Definitionen.
Die Erkennung von Bildern (Objekten, Signalen, Situationen, Phänomenen oder Prozessen) ist die Aufgabe, ein Objekt zu identifizieren oder eine seiner Eigenschaften anhand seines Bildes (optische Erkennung) oder Audioaufnahme (akustische Erkennung) und anderer Merkmale zu bestimmen.
Eines der grundlegenden ist das Konzept einer Menge, die keine spezifische Formulierung hat. In einem Computer wird eine Menge durch eine Menge sich nicht wiederholender Elemente des gleichen Typs dargestellt. Das Wort "sich nicht wiederholend" bedeutet, dass ein Element in der Menge entweder vorhanden ist oder nicht vorhanden ist. Die universelle Menge enthält alle möglichen Elemente für das zu lösende Problem, die leere Menge enthält keine.
Ein Bild ist eine Klassifikationsgruppierung im Klassifikationssystem, die eine bestimmte Gruppe von Objekten gemäß einem Attribut vereint (aussondert). Bilder haben eine charakteristische Eigenschaft, die sich darin manifestiert, dass die Kenntnis einer endlichen Anzahl von Phänomenen aus derselben Menge es ermöglicht, eine beliebig große Anzahl ihrer Vertreter zu erkennen. Bilder haben charakteristische objektive Eigenschaften in dem Sinne, dass verschiedene Menschen, die aus unterschiedlichem Beobachtungsmaterial lernen, dieselben Objekte meist gleich und unabhängig voneinander klassifizieren. In der klassischen Formulierung des Erkennungsproblems wird die universelle Menge in Teilbilder zerlegt. Jede Abbildung eines beliebigen Objekts auf die Wahrnehmungsorgane des Erkennungssystems, unabhängig von seiner Position relativ zu diesen Organen, wird gewöhnlich als Bild des Objekts bezeichnet, und Sätze solcher Bilder, die durch einige gemeinsame Eigenschaften vereint sind, sind Bilder.
Die Methode der Zuordnung eines Elements zu einem beliebigen Bild wird als Entscheidungsregel bezeichnet. Ein weiteres wichtiges Konzept sind Metriken, eine Möglichkeit, den Abstand zwischen Elementen einer universellen Menge zu bestimmen. Je kleiner dieser Abstand ist, desto ähnlicher sind die Objekte (Symbole, Geräusche usw.), die wir erkennen. Typischerweise werden die Elemente als Zahlensatz und die Metrik als Funktion angegeben. Die Effizienz des Programms hängt von der Wahl der Bilddarstellung und der Implementierung der Metrik ab, ein Erkennungsalgorithmus mit unterschiedlichen Metriken wird mit unterschiedlicher Häufigkeit Fehler machen.
Lernen wird gewöhnlich als der Prozess bezeichnet, in einem System eine bestimmte Reaktion auf Gruppen von externen identischen Signalen zu entwickeln, indem das externe Korrektursystem wiederholt beeinflusst wird. Eine solche externe Anpassung im Training wird üblicherweise als „Ermutigung“ und „Bestrafung“ bezeichnet. Der Mechanismus zur Generierung dieser Anpassung bestimmt fast vollständig den Lernalgorithmus. Selbstlernen unterscheidet sich vom Lernen dadurch, dass hier keine zusätzlichen Informationen über die Korrektheit der Reaktion auf das System gemeldet werden.
Anpassung ist ein Prozess der Änderung von Parametern und Struktur des Systems und möglicherweise auch von Steuerungsmaßnahmen auf der Grundlage aktueller Informationen, um einen bestimmten Zustand des Systems mit anfänglicher Unsicherheit und sich ändernden Betriebsbedingungen zu erreichen.
Lernen ist ein Prozess, durch den das System allmählich die Fähigkeit erwirbt, auf bestimmte äußere Einflüsse mit den erforderlichen Reaktionen zu reagieren, und Anpassung ist die Anpassung der Parameter und der Struktur des Systems, um die erforderliche Qualität zu erreichen Kontrolle unter Bedingungen ständiger Änderungen der äußeren Bedingungen.
Beispiele für Mustererkennungsaufgaben: - Buchstabenerkennung;
Generell lassen sich drei Methoden der Mustererkennung unterscheiden: Die Aufzählungsmethode. Dabei erfolgt ein Abgleich mit der Datenbank, wo für jeden Objekttyp alle möglichen Modifikationen der Anzeige dargestellt werden. Beispielsweise können Sie für die optische Bilderkennung die Methode anwenden, den Typ eines Objekts in verschiedenen Winkeln, Maßstäben, Verschiebungen, Verformungen usw. aufzuzählen. Bei Buchstaben müssen Sie über die Schriftart, die Schriftarteigenschaften usw. iterieren bei der Tonbilderkennung jeweils ein Vergleich mit einigen bekannten Mustern (z. B. ein von mehreren Personen gesprochenes Wort).
Der zweite Ansatz ist eine tiefere Analyse der Eigenschaften des Bildes. Bei der optischen Erkennung kann dies die Bestimmung verschiedener geometrischer Merkmale sein. Die Tonprobe wird in diesem Fall einer Frequenz-, Amplitudenanalyse usw. unterzogen.
Die nächste Methode ist die Verwendung künstlicher neuronaler Netze (KNN). Dieses Verfahren erfordert entweder eine große Anzahl von Beispielen der Erkennungsaufgabe während des Trainings oder eine spezielle neuronale Netzstruktur, die die Besonderheiten dieser Aufgabe berücksichtigt. Sie zeichnet sich jedoch durch höhere Effizienz und Produktivität aus.
4. Geschichte der Mustererkennung
Betrachten wir kurz den mathematischen Formalismus der Mustererkennung. Ein Objekt in der Mustererkennung wird durch eine Menge grundlegender Merkmale (Merkmale, Eigenschaften) beschrieben. Die Hauptmerkmale können unterschiedlicher Natur sein: Sie können einer geordneten Menge des reellen Linientyps oder einer diskreten Menge (die aber auch mit einer Struktur versehen sein kann) entnommen werden. Dieses Verständnis des Objekts steht sowohl im Einklang mit der Notwendigkeit praktischer Anwendungen der Mustererkennung als auch mit unserem Verständnis des Mechanismus der menschlichen Wahrnehmung eines Objekts. Tatsächlich glauben wir, dass, wenn eine Person ein Objekt beobachtet (misst), Informationen darüber durch eine begrenzte Anzahl von Sensoren (analysierten Kanälen) an das Gehirn gelangen und jeder Sensor mit der entsprechenden Eigenschaft des Objekts in Verbindung gebracht werden kann. Zusätzlich zu den Merkmalen, die unseren Messungen des Objekts entsprechen, gibt es auch ein ausgewähltes Merkmal oder eine Gruppe von Merkmalen, die wir Klassifikationsmerkmale nennen, und das Herausfinden ihrer Werte für einen bestimmten Vektor X ist die Aufgabe, die so natürlich ist und künstliche Erkennungssysteme durchführen.
Es ist klar, dass zur Ermittlung der Werte dieser Merkmale Informationen darüber erforderlich sind, in welcher Beziehung die bekannten Merkmale zu den klassifizierenden Merkmalen stehen. Informationen über diese Beziehung werden in Form von Präzedenzfällen gegeben, dh einer Reihe von Beschreibungen von Objekten mit bekannten Werten von Klassifizierungsmerkmalen. Und gemäß dieser Präzedenzfallinformation ist es erforderlich, eine Entscheidungsregel aufzubauen, die die willkürliche Beschreibung des Objekts auf den Wert seiner klassifizierenden Merkmale festlegt.
Dieses Problemverständnis der Mustererkennung hat sich in der Wissenschaft seit den 50er Jahren des letzten Jahrhunderts etabliert. Und dann ist aufgefallen, dass so eine Produktion gar nicht neu ist. Bewährte Methoden der statistischen Datenanalyse, die für viele praktische Aufgaben, wie beispielsweise die technische Diagnostik, aktiv genutzt wurden, standen vor einer solchen Formulierung und existierten bereits. Daher verliefen die ersten Schritte der Mustererkennung im Zeichen des statistischen Ansatzes, der das Hauptproblem diktierte.
Der statistische Ansatz basiert auf der Idee, dass der Anfangsraum von Objekten ein Wahrscheinlichkeitsraum ist und die Merkmale (Eigenschaften) von Objekten darauf gegebene Zufallsvariablen sind. Dann bestand die Aufgabe des Datenwissenschaftlers darin, aus einigen Überlegungen eine statistische Hypothese über die Verteilung von Merkmalen bzw. über die Abhängigkeit von klassifizierenden Merkmalen vom Rest aufzustellen. Die statistische Hypothese war in der Regel ein parametrisch spezifizierter Satz von Merkmalsverteilungsfunktionen. Eine typische und klassische statistische Hypothese ist die Hypothese der Normalverteilung dieser Verteilung (in der Statistik gibt es sehr viele Varianten solcher Hypothesen). Nach der Formulierung der Hypothese blieb es, diese Hypothese anhand von Präzedenzdaten zu testen. Diese Prüfung bestand darin, eine Verteilung aus dem anfänglich gegebenen Satz von Verteilungen (dem Parameter der Verteilungshypothese) auszuwählen und die Zuverlässigkeit (Konfidenzintervall) dieser Auswahl zu bewerten. Eigentlich war diese Verteilungsfunktion die Lösung des Problems, nur wurde das Objekt nicht eindeutig klassifiziert, sondern mit einigen Wahrscheinlichkeiten der Zugehörigkeit zu Klassen. Statistiker haben auch eine asymptotische Begründung für solche Methoden entwickelt. Solche Begründungen erfolgten nach folgendem Schema: Es wurde ein bestimmtes Gütefunktional der Verteilungswahl (Konfidenzintervall) festgestellt und es zeigte sich, dass mit zunehmender Präzedenzfallzahl unsere Wahl mit einer gegen 1 tendierenden Wahrscheinlichkeit richtig wurde Sinn dieses Funktionals (Konfidenzintervall tendiert gegen 0). Mit Blick auf die Zukunft können wir sagen, dass sich die statistische Betrachtung des Erkennungsproblems nicht nur in Bezug auf die entwickelten Algorithmen (zu denen Methoden der Cluster- und Diskriminanzanalyse, nichtparametrische Regression usw. gehören) als sehr fruchtbar erwiesen hat, sondern auch in der Folge von Vapnik eine tiefe statistische Theorie der Anerkennung zu schaffen.
Dennoch spricht vieles dafür, dass die Probleme der Mustererkennung nicht auf die Statistik reduziert werden. Jedes derartige Problem kann im Prinzip statistisch betrachtet werden, und die Ergebnisse seiner Lösung können statistisch interpretiert werden. Dazu muss lediglich angenommen werden, dass der Objektraum des Problems probabilistisch ist. Aus instrumentalistischer Sicht kann das Kriterium für den Erfolg der statistischen Interpretation eines bestimmten Erkennungsverfahrens aber nur das Vorhandensein einer Rechtfertigung für dieses Verfahren in der Sprache der Statistik als Teilgebiet der Mathematik sein. Rechtfertigung bedeutet hier die Entwicklung von Grundvoraussetzungen für die Problemstellung, die den Erfolg bei der Anwendung dieser Methode sicherstellen. Derzeit sind jedoch für die meisten Anerkennungsmethoden, einschließlich derjenigen, die direkt im Rahmen des statistischen Ansatzes entstanden sind, solche zufriedenstellenden Begründungen nicht gefunden worden. Darüber hinaus haben die derzeit am häufigsten verwendeten statistischen Algorithmen, wie Fishers lineare Diskriminante, Parzen-Fenster, EM-Algorithmus, nächste Nachbarn, ganz zu schweigen von Bayesian Belief Networks, eine stark ausgeprägte heuristische Natur und können andere Interpretationen als statistische haben. Und schließlich ist zu all dem noch hinzuzufügen, dass neben dem asymptotischen Verhalten von Erkennungsverfahren, dem Hauptthema der Statistik, die Praxis der Erkennung weit darüber hinausgehende Fragen nach der rechnerischen und strukturellen Komplexität von Verfahren aufwirft allein im Rahmen der Wahrscheinlichkeitstheorie.
Insgesamt sind entgegen den Bestrebungen der Statistiker, die Mustererkennung als Teilbereich der Statistik zu betrachten, ganz andere Vorstellungen in die Praxis und Ideologie der Erkennung eingedrungen. Einer davon wurde durch Forschungen auf dem Gebiet der visuellen Mustererkennung verursacht und basiert auf der folgenden Analogie.
Wie bereits erwähnt, lösen Menschen im Alltag ständig (oft unbewusst) die Probleme, verschiedene Situationen, auditive und visuelle Bilder zu erkennen. Eine solche Fähigkeit für Computer ist bestenfalls Zukunftsmusik. Einige Pioniere der Mustererkennung schlossen daraus, dass die Lösung dieser Probleme auf einem Computer ganz allgemein menschliche Denkprozesse simulieren sollte. Der berühmteste Versuch, sich dem Problem von dieser Seite zu nähern, war die berühmte Studie von F. Rosenblatt über Perceptrons.
Mitte der 50er Jahre schienen Neurophysiologen die physikalischen Prinzipien des Gehirns verstanden zu haben (in dem Buch „The New Mind of the King“ stellt der berühmte britische theoretische Physiker R. Penrose interessanterweise das neuronale Netzwerkmodell des Gehirns in Frage und untermauert die wesentliche Rolle der quantenmechanischen Effekte für ihre Funktionsweise, obwohl dieses Modell von Anfang an in Frage gestellt wurde.Auf der Grundlage dieser Entdeckungen entwickelte F. Rosenblatt ein Modell zum Erlernen des Erkennens visueller Muster, das er Perzeptron nannte.Rosenblatts Perzeptron ist die folgende Funktion (Abb. 1):
Abb. 1. Schematische Darstellung des Perzeptrons
Am Eingang erhält das Perzeptron einen Objektvektor, der in den Arbeiten von Rosenblatt ein binärer Vektor war, der zeigt, welche der Bildschirmpixel vom Bild verdunkelt werden und welche nicht. Ferner wird jedes der Zeichen dem Eingang des Neurons zugeführt, dessen Wirkung eine einfache Multiplikation mit einem bestimmten Gewicht des Neurons ist. Die Ergebnisse werden dem letzten Neuron zugeführt, das sie aufsummiert und die Gesamtmenge mit einem bestimmten Schwellenwert vergleicht. Abhängig von den Ergebnissen des Vergleichs wird das Eingabeobjekt X als notwendig erkannt oder nicht. Dann bestand die Aufgabe der Lernmustererkennung darin, die Gewichte von Neuronen und den Schwellenwert so auszuwählen, dass das Perzeptron auf vorhergehende visuelle Bilder richtige Antworten geben würde. Rosenblatt glaubte, dass die resultierende Funktion das gewünschte visuelle Bild gut erkennen würde, selbst wenn das Eingabeobjekt nicht zu den Präzedenzfällen gehörte. Aus bionischen Überlegungen hat er auch eine Methode zur Auswahl von Gewichten und eine Schwelle entwickelt, auf die wir nicht näher eingehen werden. Sagen wir einfach, sein Ansatz war bei einer Reihe von Erkennungsproblemen erfolgreich und hat zu einer ganzen Reihe von Forschungsarbeiten zu Lernalgorithmen auf der Grundlage neuronaler Netze geführt, von denen das Perzeptron ein Sonderfall ist.
Außerdem wurden verschiedene Verallgemeinerungen des Perzeptrons erfunden, die Funktion von Neuronen wurde kompliziert: Neuronen konnten nun nicht nur eingegebene Zahlen multiplizieren oder addieren und das Ergebnis mit Schwellenwerten vergleichen, sondern komplexere Funktionen auf sie anwenden. Abbildung 2 zeigt eine dieser neuronalen Komplikationen:

Reis. 2 Diagramm des neuronalen Netzes.
Darüber hinaus könnte die Topologie des neuronalen Netzes viel komplizierter sein als die von Rosenblatt betrachtete, zum Beispiel dies:
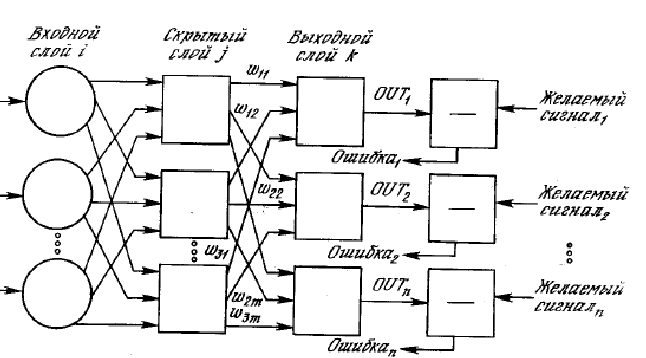
Reis. 3. Diagramm des neuronalen Netzwerks von Rosenblatt.
Komplikationen führten zu einer Zunahme der Anzahl einstellbarer Parameter während des Trainings, erhöhten aber gleichzeitig die Fähigkeit, sich auf sehr komplexe Muster einzustellen. Die Forschung auf diesem Gebiet geht jetzt in zwei eng verwandte Bereiche - sowohl verschiedene Netzwerktopologien als auch verschiedene Abstimmungsverfahren werden untersucht.
Neuronale Netze sind derzeit nicht nur ein Werkzeug zur Lösung von Mustererkennungsproblemen, sondern wurden auch in der Forschung zum assoziativen Gedächtnis und zur Bildkomprimierung eingesetzt. Obwohl sich diese Forschungsrichtung stark mit den Problemen der Mustererkennung überschneidet, ist sie ein eigenes Teilgebiet der Kybernetik. Für den Erkenner sind neuronale Netze im Moment nichts anderes als ein sehr spezifischer, parametrisch definierter Satz von Abbildungen, der in diesem Sinne keine wesentlichen Vorteile gegenüber vielen anderen ähnlichen Lernmodellen hat, die im Folgenden kurz aufgeführt werden.
Im Zusammenhang mit dieser Einschätzung der Rolle neuronaler Netze für die richtige Erkennung (also nicht für die Bionik, für die sie jetzt von größter Bedeutung sind) möchte ich Folgendes anmerken: Neuronale Netze sind ein äußerst komplexes Objekt für die Mathematik Analysen ermöglichen es uns bei richtiger Anwendung, sehr nicht triviale Gesetze in den Daten zu finden. Ihre Schwierigkeit bei der Analyse im allgemeinen Fall erklärt sich aus ihrer komplexen Struktur und den daraus resultierenden praktisch unerschöpflichen Möglichkeiten zur Verallgemeinerung verschiedenster Gesetzmäßigkeiten. Aber diese Vorteile sind, wie so oft, eine Fehlerquelle, die Möglichkeit der Nachschulung. Wie später diskutiert wird, ist eine solche zweifache Sicht auf die Aussichten eines beliebigen Lernmodells eines der Prinzipien des maschinellen Lernens.
Eine weitere beliebte Erkennungsrichtung sind logische Regeln und Entscheidungsbäume. Im Vergleich zu den oben genannten Erkennungsmethoden nutzen diese Methoden am aktivsten die Idee, unser Wissen über das Fachgebiet in Form der wahrscheinlich natürlichsten (auf einer bewussten Ebene) Strukturen auszudrücken - logischer Regeln. Eine elementare logische Regel bedeutet eine Aussage wie „wenn nicht klassifizierte Merkmale im Verhältnis X stehen, dann stehen die klassifizierten im Verhältnis Y“. Ein Beispiel für eine solche Regel in der medizinischen Diagnostik ist die folgende: Wenn der Patient über 60 Jahre alt ist und zuvor einen Herzinfarkt hatte, führen Sie die Operation nicht durch - das Risiko eines negativen Ergebnisses ist hoch.
Um nach logischen Regeln in den Daten zu suchen, sind zwei Dinge erforderlich: das Maß der „Informationsfähigkeit“ der Regel und der Raum der Regeln zu bestimmen. Und die Aufgabe, Regeln danach zu finden, wird zu einer Aufgabe der vollständigen oder teilweisen Aufzählung im Raum der Regeln, um die informativsten von ihnen zu finden. Die Definition der Informiertheit kann auf verschiedene Weise eingeführt werden, und wir werden nicht darauf eingehen, da dies auch ein Parameter des Modells ist. Der Suchraum ist standardmäßig definiert.
Nach dem Finden ausreichend aussagekräftiger Regeln beginnt die Phase des „Zusammenbaus“ der Regeln zum endgültigen Klassifikator. Ohne auf die hier auftretenden Probleme eingehend einzugehen (und davon gibt es eine beträchtliche Anzahl), listen wir 2 Hauptmethoden der „Montage“ auf. Der erste Typ ist eine lineare Liste. Der zweite Typ ist die gewichtete Abstimmung, wenn jeder Regel eine bestimmte Gewichtung zugewiesen wird und das Objekt vom Klassifizierer der Klasse zugewiesen wird, für die die größte Anzahl von Regeln gestimmt hat.
Tatsächlich werden die Regelaufbauphase und die „Zusammenbauphase“ zusammen durchgeführt, und beim Aufbau einer gewichteten Abstimmung oder Liste wird die Suche nach Regeln für Teile der Falldaten immer wieder aufgerufen, um eine bessere Übereinstimmung zwischen den Daten sicherzustellen das Model.
