Ako už bolo spomenuté, príklady rozdelenia pravdepodobnosti spojitá náhodná premenná X sú:
- rovnomerné rozdelenie pravdepodobnosti spojitej náhodnej premennej;
- exponenciálne rozdelenie pravdepodobnosti spojitej náhodnej premennej;
- normálne rozdelenie pravdepodobnosti spojitej náhodnej premennej.
Uveďme pojem zákonov rovnomerného a exponenciálneho rozdelenia, pravdepodobnostné vzorce a číselné charakteristiky uvažovaných funkcií.
| Indikátor | Zákon o náhodnom rozdelení | Exponenciálny zákon rozdelenia |
|---|---|---|
| Definícia | Uniforma je tzv rozdelenie pravdepodobnosti spojitej náhodnej premennej X, ktorej hustota zostáva na intervale konštantná a má tvar | Exponenciálny (exponenciálny) sa nazýva rozdelenie pravdepodobnosti spojitej náhodnej premennej X, ktorá je opísaná hustotou, ktorá má tvar |
 kde λ je konštantná kladná hodnota |
||
| distribučná funkcia |  |
|
| Pravdepodobnosť zasiahnutie intervalu |  |
|
| Očakávaná hodnota | ||
| Disperzia |  |
|
| Smerodajná odchýlka |  |
Príklady riešenia úloh na tému "Rovnomerné a exponenciálne zákony rozdelenia"
Úloha 1.
Autobusy jazdia presne podľa cestovného poriadku. Interval pohybu 7 min. Nájdite: (a) pravdepodobnosť, že cestujúci prichádzajúci na zastávku bude čakať na ďalší autobus menej ako dve minúty; b) pravdepodobnosť, že cestujúci blížiaci sa k zastávke bude čakať na nasledujúci autobus aspoň tri minúty; c) matematické očakávanie a smerodajná odchýlka náhodnej premennej X - čakacia doba cestujúceho.
rozhodnutie. 1. Podľa stavu problému spojitá náhodná premenná X=(čakacia doba cestujúceho) rovnomerne rozložené medzi príchodom dvoch autobusov. Dĺžka distribučného intervalu náhodnej premennej X sa rovná b-a=7, kde a=0, b=7.
2. Čakacia doba bude kratšia ako dve minúty, ak náhodná hodnota X spadá do intervalu (5;7). Pravdepodobnosť pádu do daného intervalu sa zistí podľa vzorca: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(5< Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
3. Čakacia doba bude minimálne tri minúty (teda od troch do siedmich minút), ak náhodná hodnota X spadá do intervalu (0; 4). Pravdepodobnosť pádu do daného intervalu sa zistí podľa vzorca: P(x 1<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(0< Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
4. Matematické očakávanie spojitej, rovnomerne rozloženej náhodnej premennej X - čakacej doby cestujúceho, zistíme podľa vzorca: M(X) = (a+b)/2. M (X) \u003d (0 + 7) / 2 \u003d 7/2 \u003d 3.5.
5. Smerodajnú odchýlku spojitej, rovnomerne rozloženej náhodnej premennej X - čakacej doby cestujúceho, zistíme podľa vzorca: σ(X)=√D=(b-a)/2√3. σ(X)=(7-0)/2√3=7/2√3≈2,02.
Úloha 2.
Exponenciálne rozdelenie je dané pre x ≥ 0 hustotou f(x) = 5e – 5x. Vyžaduje sa: a) napísať výraz pre distribučnú funkciu; b) nájdite pravdepodobnosť, že v dôsledku testu X spadne do intervalu (1; 4); c) nájdite pravdepodobnosť, že ako výsledok testu X ≥ 2; d) vypočítajte M(X), D(X), σ(X).
rozhodnutie. 1. Keďže podľa podmienok exponenciálne rozdelenie , potom zo vzorca pre hustotu rozdelenia pravdepodobnosti náhodnej premennej X dostaneme λ = 5. Potom bude funkcia rozdelenia vyzerať takto:
2. Pravdepodobnosť, že v dôsledku testu X spadne do intervalu (1; 4), zistíme podľa vzorca:
P(a< X < b) = e −λa − e −λb
.
P(1< X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. Pravdepodobnosť, že výsledkom testu bude X ≥ 2 podľa vzorca: P(a< X < b) = e −λa − e −λb при a=2, b=∞.
Р(Х≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. Pre exponenciálne rozdelenie nájdeme:
- matematické očakávanie podľa vzorca M(X) =1/λ = 1/5 = 0,2;
- disperzia podľa vzorca D (X) \u003d 1 / λ 2 \u003d 1/25 \u003d 0,04;
- smerodajná odchýlka podľa vzorca σ(X) = 1/λ = 1/5 = 1,2.
Táto problematika bola dlho podrobne študovaná a najviac sa používala metóda polárnych súradníc, ktorú navrhli George Box, Mervyn Muller a George Marsaglia v roku 1958. Táto metóda vám umožňuje získať pár nezávislých normálne rozdelených náhodných premenných so strednou hodnotou 0 a rozptylom 1 takto:
Kde Z 0 a Z 1 sú požadované hodnoty, s \u003d u 2 + v 2 a u a v sú náhodné premenné rovnomerne rozdelené na segmente (-1, 1), vybrané tak, že podmienka 0< s < 1.
Mnohí používajú tieto vzorce bez rozmýšľania a mnohí ani netušia o ich existencii, pretože používajú hotové implementácie. Ale sú ľudia, ktorí majú otázky: „Odkiaľ sa vzal tento vzorec? A prečo získate pár hodnôt naraz? V nasledujúcom texte sa pokúsim dať na tieto otázky jasnú odpoveď.
Na začiatok pripomeniem, čo je hustota pravdepodobnosti, distribučná funkcia náhodnej premennej a inverzná funkcia. Predpokladajme, že existuje nejaká náhodná premenná, ktorej rozdelenie je dané funkciou hustoty f(x), ktorá má nasledujúci tvar:

To znamená, že pravdepodobnosť, že hodnota tejto náhodnej premennej bude v intervale (A, B), sa rovná ploche vytieňovanej oblasti. V dôsledku toho sa plocha celej zatienenej oblasti musí rovnať jednote, pretože hodnota náhodnej premennej bude v každom prípade spadať do oblasti funkcie f.
Distribučná funkcia náhodnej premennej je integrálom funkcie hustoty. A v tomto prípade bude jeho približná podoba nasledovná:

Tu to znamená, že hodnota náhodnej premennej bude menšia ako A s pravdepodobnosťou B. V dôsledku toho funkcia nikdy neklesne a jej hodnoty ležia v intervale.
Inverzná funkcia je funkcia, ktorá vracia argument pôvodnej funkcie, ak do nej prenesiete hodnotu pôvodnej funkcie. Napríklad pre funkciu x 2 bude inverzná funkcia extrakcie koreňa, pre sin (x) je to arcsin (x) atď.
Pretože väčšina generátorov pseudonáhodných čísel dáva na výstupe iba rovnomerné rozdelenie, často je potrebné ho previesť na iné. V tomto prípade na normálny Gaussov:

Základom všetkých metód na transformáciu rovnomerného rozdelenia na akékoľvek iné rozdelenie je metóda inverznej transformácie. Funguje to nasledovne. Nájde sa funkcia, ktorá je inverzná k funkcii požadovaného rozdelenia a náhodná premenná rovnomerne rozložená na segmente (0, 1) sa jej odovzdá ako argument. Na výstupe získame hodnotu s požadovaným rozdelením. Pre prehľadnosť uvádzame nasledujúci obrázok.

Rovnomerný segment je teda akoby rozmazaný v súlade s novým rozdelením, pričom sa premieta na inú os prostredníctvom inverznej funkcie. Problém je však v tom, že integrál hustoty Gaussovho rozdelenia nie je ľahké vypočítať, takže vyššie uvedení vedci museli podvádzať.
Existuje chí-kvadrát rozdelenie (Pearsonovo rozdelenie), čo je rozdelenie súčtu druhých mocnín k nezávislých normálnych náhodných premenných. A v prípade, keď k = 2, je toto rozdelenie exponenciálne.

To znamená, že ak má bod v pravouhlom súradnicovom systéme náhodné súradnice X a Y rozložené normálne, potom po prevode týchto súradníc na polárny systém (r, θ) sa použije druhá mocnina polomeru (vzdialenosť od začiatku k bodu) budú rozdelené exponenciálne, pretože druhá mocnina polomeru je súčtom druhých mocnín súradníc (podľa Pytagorovho zákona). Hustota rozloženia takýchto bodov v rovine bude vyzerať takto:


Pretože je rovnaký vo všetkých smeroch, uhol θ bude mať rovnomerné rozloženie v rozsahu od 0 do 2π. Platí to aj naopak: ak určíte bod v polárnom súradnicovom systéme pomocou dvoch nezávislých náhodných premenných (uhol rozdelený rovnomerne a polomer rozložený exponenciálne), potom budú pravouhlé súradnice tohto bodu nezávislé normálne náhodné premenné. A exponenciálne rozdelenie z rovnomerného rozdelenia je už oveľa jednoduchšie získať pomocou rovnakej metódy inverznej transformácie. To je podstata Box-Mullerovej polárnej metódy.
Teraz poďme na vzorce.
![]() (1)
(1)
Na získanie r a θ je potrebné vygenerovať dve náhodné premenné rovnomerne rozdelené na segmente (0, 1) (nazvime ich u a v), pričom rozdelenie jednej z nich (povedzme v) je potrebné previesť na exponenciálne na získať polomer. Funkcia exponenciálneho rozdelenia vyzerá takto:
Jeho inverzná funkcia:
![]()
Keďže rovnomerné rozdelenie je symetrické, transformácia bude s funkciou fungovať podobne
![]()
Zo vzorca rozdelenia chí-kvadrát vyplýva, že λ = 0,5. Do tejto funkcie dosadíme λ, v a získame druhú mocninu polomeru a potom samotný polomer:

Uhol získame natiahnutím segmentu jednotky na 2π:
Teraz dosadíme r a θ do vzorcov (1) a dostaneme:
 (2)
(2)
Tieto vzorce sú pripravené na použitie. X a Y budú nezávislé a normálne rozdelené s rozptylom 1 a strednou hodnotou 0. Na získanie rozdelenia s inými charakteristikami stačí vynásobiť výsledok funkcie smerodajnou odchýlkou a pridať priemer.
Ale je možné sa zbaviť goniometrických funkcií zadaním uhla nie priamo, ale nepriamo cez pravouhlé súradnice náhodného bodu v kruhu. Potom pomocou týchto súradníc bude možné vypočítať dĺžku vektora polomeru a potom nájsť kosínus a sínus delením x a y nimi. Ako a prečo to funguje?
Vyberieme náhodný bod z rovnomerne rozmiestneného v kruhu jednotkového polomeru a druhú mocninu dĺžky vektora polomeru tohto bodu označíme písmenom s:

Voľba sa uskutočňuje priradením náhodných pravouhlých súradníc x a y rovnomerne rozložených v intervale (-1, 1) a vyradením bodov, ktoré nepatria do kruhu, ako aj stredového bodu, v ktorom je uhol vektora polomeru. nie je definované. Teda podmienka 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Dostaneme vzorce, ako na začiatku článku. Nevýhodou tejto metódy je odmietnutie bodov, ktoré nie sú zahrnuté v kruhu. To znamená, že s použitím iba 78,5 % vygenerovaných náhodných premenných. Na starších počítačoch bol nedostatok trigonometrických funkcií stále veľkou výhodou. Teraz, keď jedna inštrukcia procesora súčasne počíta sínus a kosínus v okamihu, myslím si, že tieto metódy môžu stále konkurovať.
Osobne mám ešte dve otázky:
- Prečo je hodnota s rovnomerne rozdelená?
- Prečo je súčet štvorcov dvoch normálnych náhodných premenných exponenciálne rozdelený?

Ak sa podobná transformácia vykoná pre normálnu náhodnú premennú, potom sa funkcia hustoty jej štvorca ukáže ako podobná hyperbole. A sčítanie dvoch štvorcov normálnych náhodných premenných je už oveľa zložitejší proces spojený s dvojitou integráciou. A to, že výsledkom bude exponenciálne rozdelenie, mi osobne zostáva overiť si to praktickou metódou alebo akceptovať ako axiómu. A pre tých, ktorí majú záujem, navrhujem, aby ste sa bližšie oboznámili s témou a čerpali poznatky z týchto kníh:
- Wentzel E.S. Teória pravdepodobnosti
- Knut D.E. Umenie programovania, zväzok 2
Na záver uvediem príklad implementácie normálne distribuovaného generátora náhodných čísel v JavaScripte:
Funkcia Gauss() ( var ready = nepravda; var sekunda = 0,0; this.next = function(mean, dev) ( mean = mean == nedefinované ? 0,0: mean; dev = dev == nedefinované ? 1,0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1,0; s = u * u + v * v; ) while (s > 1,0 || s == 0,0); var r = Math.sqrt(-2,0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + mean; ) ); ) g = new Gauss(); // vytvorenie objektu a = g.next(); // vygenerujte pár hodnôt a získajte prvú b = g.next(); // získame druhé c = g.next(); // znova vygenerujte pár hodnôt a získajte prvú
Parametre priemer (matematické očakávanie) a dev (štandardná odchýlka) sú voliteľné. Upozorňujem na skutočnosť, že logaritmus je prirodzený.
Rozdelenie sa považuje za rovnomerné, ak sú všetky hodnoty náhodnej premennej (v oblasti jej existencie, napríklad v intervale) rovnako pravdepodobné. Distribučná funkcia pre takúto náhodnú premennú má tvar:
Hustota distribúcie: 
 1
1

Ryža. Grafy distribučnej funkcie (vľavo) a hustoty distribúcie (vpravo).
Rovnomerné rozdelenie - pojem a typy. Klasifikácia a vlastnosti kategórie „Rovnomerná distribúcia“ 2017, 2018.
Základné diskrétne rozdelenia náhodných veličín Definícia 1. Náhodná premenná Х, nadobúdajúca hodnoty 1, 2, …, n, má rovnomerné rozdelenie, ak Pm = P(Х = m) = 1/n, m = 1, …, n . To je zrejmé. Zvážte nasledujúci problém: V urne je N loptičiek, z ktorých M je bielych... .
Zákony distribúcie spojitých náhodných veličín Definícia 5. Spojitá náhodná premenná X, ktorá má hodnotu na intervale , má rovnomerné rozdelenie, ak má hustota rozdelenia tvar. (1) Je ľahké overiť, že . Ak náhodná premenná... .
Rozdelenie sa považuje za rovnomerné, ak sú všetky hodnoty náhodnej premennej (v oblasti jej existencie, napríklad v intervale) rovnako pravdepodobné. Distribučná funkcia pre takúto náhodnú veličinu má tvar: Hustota rozdelenia: F(x) f(x) 1 0 a b x 0 a b x ... .
Zákony normálneho rozdelenia Rovnomerné, exponenciálne a Funkcia hustoty pravdepodobnosti rovnomerného zákona je: (10.17) kde a a b sú dané čísla, a< b; a и b – это параметры равномерного закона. Найдем функцию распределения F(x)... .
Rovnomerné rozdelenie pravdepodobnosti je najjednoduchšie a môže byť buď diskrétne alebo spojité. Diskrétne rovnomerné rozdelenie je také rozdelenie, pre ktoré je pravdepodobnosť každej z hodnôt CB rovnaká, to znamená: kde N je číslo ... .
Definícia 16. Spojitá náhodná premenná má rovnomerné rozdelenie na intervale, ak na tomto segmente je hustota rozdelenia tejto náhodnej premennej konštantná a mimo nej je rovná nule, to znamená (45) Graf hustoty pre rovnomerné rozdelenie je zobrazené...
Ako príklad spojitej náhodnej premennej uvažujme náhodnú premennú X rovnomerne rozloženú v intervale (a; b). Hovoríme, že náhodná premenná X rovnomerne rozložené na intervale (a; b), ak jeho hustota rozloženia nie je na tomto intervale konštantná:
Z normalizačnej podmienky určíme hodnotu konštanty c . Plocha pod krivkou hustoty rozloženia by sa mala rovnať jednej, ale v našom prípade je to plocha obdĺžnika so základňou (b - α) a výškou c (obr. 1). 
Ryža. 1 Rovnomerná hustota rozloženia
Odtiaľ nájdeme hodnotu konštanty c: ![]()
Hustota rovnomerne rozloženej náhodnej premennej sa teda rovná 
Teraz nájdime distribučnú funkciu podľa vzorca:
1) pre ![]()
2) pre
3) pre 0+1+0=1.
teda 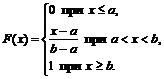
Distribučná funkcia je spojitá a neklesá (obr. 2). 
Ryža. 2 Distribučná funkcia rovnomerne rozloženej náhodnej premennej
Poďme nájsť matematické očakávanie rovnomerne rozloženej náhodnej premennej podľa vzorca:
Rozptyl rovnomerného rozdelenia sa vypočíta podľa vzorca a rovná sa
Príklad č. 1. Hodnota dielika stupnice meracieho prístroja je 0,2. Údaje prístroja sa zaokrúhľujú na najbližší celý dielik. Nájdite pravdepodobnosť, že počas čítania dôjde k chybe: a) menšia ako 0,04; b) veľká 0,02
rozhodnutie. Chyba zaokrúhľovania je náhodná premenná rovnomerne rozložená v intervale medzi susednými celočíselnými dielikmi. Za takéto delenie považujte interval (0; 0,2) (obr. a). Zaokrúhľovanie je možné vykonať smerom k ľavému okraju - 0 a smerom k pravému okraju - 0,2, čo znamená, že chyba menšia alebo rovná 0,04 môže byť vykonaná dvakrát, čo je potrebné vziať do úvahy pri výpočte pravdepodobnosti: 

P = 0,2 + 0,2 = 0,4
V druhom prípade môže chybová hodnota tiež presiahnuť 0,02 na oboch deliacich hraniciach, to znamená, že môže byť väčšia ako 0,02 alebo menšia ako 0,18. 
Potom pravdepodobnosť chyby, ako je táto:
Príklad č. 2. Predpokladalo sa, že stabilitu ekonomickej situácie v krajine (neexistencia vojen, prírodných katastrof atď.) za posledných 50 rokov možno posudzovať podľa charakteru rozloženia obyvateľstva podľa veku: v pokojnej situácii, to by malo byť uniforma. Ako výsledok štúdie boli pre jednu z krajín získané nasledujúce údaje.
Existuje dôvod domnievať sa, že v krajine bola nestabilná situácia?Rozhodovanie vykonávame pomocou kalkulačky Testovanie hypotéz. Tabuľka na výpočet ukazovateľov.
| skupiny | Stred intervalu, x i | Množstvo, fi | x i * f i | Kumulatívna frekvencia, S | |x - x cf |*f | (x - x sr) 2 *f | Frekvencia, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Vážený priemer
Variačné ukazovatele.
Absolútna miera variácie.
Rozsah variácie je rozdiel medzi maximálnymi a minimálnymi hodnotami atribútu primárnej série.
R = X max - X min
R = 70 - 0 = 70
Disperzia- charakterizuje mieru rozptylu okolo svojej strednej hodnoty (miera rozptylu, t. j. odchýlky od priemeru).
Smerodajná odchýlka.
Každá hodnota série sa líši od priemernej hodnoty 43 najviac o 23,92
Testovanie hypotéz o type distribúcie.
4. Testovanie hypotézy o Rovnomerné rozdelenie všeobecná populácia.
Aby bolo možné otestovať hypotézu o rovnomernom rozložení X, t.j. podľa zákona: f(x) = 1/(b-a) v intervale (a,b)
potrebné:
1. Odhadnite parametre a a b - konce intervalu, v ktorom boli pozorované možné hodnoty X, podľa vzorcov (znamienko * označuje odhady parametrov):
2. Nájdite hustotu pravdepodobnosti odhadovaného rozdelenia f(x) = 1/(b * - a *)
3. Nájdite teoretické frekvencie:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Porovnajte empirické a teoretické frekvencie pomocou Pearsonovho testu za predpokladu počtu stupňov voľnosti k = s-3, kde s je počet počiatočných intervalov vzorkovania; ak však bola vytvorená kombinácia malých frekvencií, a teda samotných intervalov, potom s je počet intervalov zostávajúcich po kombinácii.
rozhodnutie:
1. Nájdite odhady parametrov a * a b * rovnomerného rozdelenia pomocou vzorcov:
2. Nájdite hustotu predpokladaného rovnomerného rozdelenia:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Nájdite teoretické frekvencie:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
Zvyšné n s sa budú rovnať:
n s = n*f(x)(x i - x i-1)
| i | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i)2/n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4,0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3,5E-5 | 0.000199 |
| Celkom | 1 | 0.0532 |
Preto je kritická oblasť pre túto štatistiku vždy pravá: , ak je na tomto segmente hustota rozdelenia pravdepodobnosti náhodnej premennej konštantná, t.j. ak funkcia diferenciálneho rozdelenia f(x) má nasledujúci tvar:
![]()
Táto distribúcia sa niekedy nazýva zákon rovnomernej hustoty. O množstve, ktoré má na určitom segmente rovnomerné rozloženie, povieme, že je na tomto segmente rozložené rovnomerne.
Nájdite hodnotu konštanty c. Keďže oblasť ohraničená distribučnou krivkou a os oh, rovná sa teda 1
kde s=1/(b-a).
Teraz funkcia f(x)môže byť reprezentovaný ako

Zostrojme distribučnú funkciu
F(x ), pre ktoré nachádzame výraz F (x ) na intervale [ a , b]:


Grafy funkcií f (x) a F (x) vyzerajú takto:

Poďme nájsť číselné charakteristiky.
Pomocou vzorca na výpočet matematického očakávania NSW máme:

Matematické očakávanie náhodnej premennej rovnomerne rozloženej na intervale [a , b] sa zhoduje so stredom tohto segmentu.
Nájdite rozptyl rovnomerne rozloženej náhodnej premennej:
z čoho okamžite vyplýva, že štandardná odchýlka:
![]()
Nájdime teraz pravdepodobnosť, že hodnota náhodnej premennej s rovnomerným rozdelením spadá do intervalu(a, b), úplne patriaci do segmentu [a,b
]:

|
|

Geometricky je táto pravdepodobnosť oblasťou tieňovaného obdĺžnika. čísla a a
bvolal distribučných parametrov a jednoznačne definujú rovnomerné rozloženie.Príklad 1. Autobusy určitej trasy jazdia prísne podľa cestovného poriadku. Interval pohybu 5 minút. Nájdite pravdepodobnosť, že sa cestujúci priblížil k autobusovej zastávke. Bude čakať na ďalší autobus menej ako 3 minúty.
rozhodnutie:
ST - čakacia doba autobusu má rovnomerné rozloženie. Potom sa požadovaná pravdepodobnosť bude rovnať:
![]()
Príklad2. Hrana kocky x sa meria približne. A
Hranu kocky považujeme za náhodnú premennú rozloženú rovnomerne v intervale (
a,b), nájdite matematické očakávanie a rozptyl objemu kocky.rozhodnutie:
Objem kocky je náhodná premenná určená výrazom Y \u003d X 3. Potom matematické očakávanie je:
Rozptyl:
Online služba:
