Najbežnejšou formou štatistických ukazovateľov používaných v sociálno-ekonomickom výskume je priemerná hodnota, ktorá je zovšeobecnenou kvantitatívnou charakteristikou znaku štatistickej populácie. Priemerné hodnoty sú, ako to bolo, „reprezentantmi“ celej série pozorovaní. V mnohých prípadoch možno priemer určiť pomocou počiatočného pomeru priemeru (ISS) alebo jeho logického vzorca: . Napríklad na výpočet priemerných miezd zamestnancov podniku je potrebné vydeliť celkový mzdový fond počtom zamestnancov: Čitateľ počiatočného pomeru priemeru je jeho určujúcim ukazovateľom. Pre priemernú mzdu je takýmto určujúcim ukazovateľom mzdový fond. Pre každý ukazovateľ použitý v sociálno-ekonomickej analýze možno na výpočet priemeru zostaviť iba jeden skutočný referenčný pomer. Treba tiež dodať, že na presnejšie odhadnutie smerodajnej odchýlky pre malé vzorky (s počtom prvkov menším ako 30) by menovateľ výrazu pod koreňom nemal používať n, a n- 1.
Pojem a typy priemerov
Priemerná hodnota- ide o zovšeobecňujúci ukazovateľ štatistickej populácie, ktorý odstraňuje individuálne rozdiely v hodnotách štatistických veličín, čo vám umožňuje porovnávať rôzne populácie navzájom. Existovať 2 triedy priemerné hodnoty: výkonové a štrukturálne. Štrukturálne priemery sú móda a medián , ale najčastejšie sa používa výkonové priemery rôzne druhy.Výkonové priemery
Výkonové priemery môžu byť jednoduché a vážený.
Jednoduchý priemer sa vypočíta, keď existujú dve alebo viac nezoskupených štatistických hodnôt, usporiadaných v ľubovoľnom poradí podľa nasledujúceho všeobecného vzorca zákona o priemernej mocnine (pre rôzne hodnoty k (m)):
Vážený priemer sa vypočíta zo zoskupených štatistík pomocou nasledujúceho všeobecného vzorca:

Kde x - priemerná hodnota skúmaného javu; x i – i-tý variant spriemerovaného znaku ;
f i je váha i-tej možnosti.

kde X sú hodnoty jednotlivých štatistických hodnôt alebo stredy intervalov zoskupovania;
m - exponent, od ktorého hodnoty závisia tieto typy priemerov výkonu:
pri m = -1 harmonický priemer;
pre m = 0, geometrický priemer;
pre m = 1, aritmetický priemer;
pri m = 2, stredná odmocnina;
pri m = 3, priemer kubický.
Pomocou všeobecných vzorcov pre jednoduché a vážené priemery s rôznymi exponentmi m získame konkrétne vzorce každého typu, o ktorých budeme podrobnejšie diskutovať nižšie.
Aritmetický priemer
Aritmetický priemer - počiatočný moment prvého rádu, matematické očakávanie hodnôt náhodnej premennej s veľkým počtom pokusov;
Aritmetický priemer je najčastejšie používaná priemerná hodnota, ktorá sa získa dosadením m = 1 do všeobecného vzorca. Aritmetický priemer jednoduché má nasledujúci tvar:
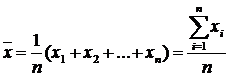 alebo
alebo ![]()
kde X sú hodnoty veličín, pre ktoré je potrebné vypočítať priemernú hodnotu; N je celkový počet hodnôt X (počet jednotiek v skúmanej populácii).
Napríklad študent zložil 4 skúšky a získal tieto známky: 3, 4, 4 a 5. Vypočítajte priemerné skóre pomocou jednoduchého aritmetického vzorca: (3+4+4+5)/4 = 16/4 = 4 . Aritmetický priemer vážený má nasledujúci tvar:
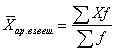
Kde f je počet hodnôt s rovnakou hodnotou X (frekvenciou). >Napríklad študent zložil 4 skúšky a získal tieto známky: 3, 4, 4 a 5. Vypočítajte priemerné skóre pomocou vzorca aritmetického váženého priemeru: (3*1 + 4*2 + 5*1)/4 = 16/4 = 4. Ak sú hodnoty X uvedené ako intervaly, potom sa na výpočty používajú stredy intervalov X, ktoré sú definované ako polovica súčtu hornej a dolnej hranice intervalu. A ak interval X nemá dolnú alebo hornú hranicu (otvorený interval), potom sa na jeho nájdenie použije rozsah (rozdiel medzi hornou a dolnou hranicou) susedného intervalu X. Napríklad podnik má 10 zamestnancov s praxou do 3 rokov, 20 zamestnancov s praxou od 3 do 5 rokov a 5 zamestnancov s praxou nad 5 rokov. Potom vypočítame priemernú dĺžku služby zamestnancov pomocou vzorca aritmetického váženého priemeru, pričom ako X vezmeme stred dĺžky servisných intervalov (2, 4 a 6 rokov): (2*10+4*20+6*5)/(10+20+5) = 3,71 roka.
Funkcia AVERAGE
Táto funkcia vypočíta priemer (aritmetický) svojich argumentov.
AVERAGE(číslo1; číslo2; ...)
Číslo1, číslo2, ... je 1 až 30 argumentov, pre ktoré sa vypočítava priemer.
Argumenty musia byť čísla alebo názvy, polia alebo odkazy obsahujúce čísla. Ak argument, ktorým je pole alebo odkaz, obsahuje texty, boolovské hodnoty alebo prázdne bunky, potom sa tieto hodnoty ignorujú; počítajú sa však bunky, ktoré obsahujú hodnoty null.
Funkcia AVERAGE
Vypočíta aritmetický priemer hodnôt uvedených v zozname argumentov. Okrem čísel sa na výpočte môžu podieľať aj textové a logické hodnoty, ako napríklad TRUE a FALSE.
AVERAGE(hodnota1; hodnota2;...)
Hodnota1, hodnota2,... sú 1 až 30 buniek, rozsahov buniek alebo hodnôt, pre ktoré sa vypočítava priemer.
Argumenty musia byť čísla, názvy, polia alebo odkazy. Polia a odkazy obsahujúce text sa interpretujú ako 0 (nula). Prázdny text ("") sa interpretuje ako 0 (nula). Argumenty obsahujúce hodnotu TRUE sú interpretované ako 1, Argumenty obsahujúce hodnotu FALSE sú interpretované ako 0 (nula).
Najčastejšie sa používa aritmetický priemer, ale niekedy sú potrebné aj iné typy priemerov. Pozrime sa na takéto prípady ďalej.
Priemerná harmonická
Harmonický priemer na určenie priemerného súčtu recipročných hodnôt;
Priemerná harmonická sa používa, keď pôvodné dáta neobsahujú frekvencie f pre jednotlivé hodnoty X, ale sú prezentované ako ich súčin Xf. Označením Xf=w vyjadríme f=w/X a nahradením týchto zápisov do vzorca váženého aritmetického priemeru dostaneme vzorec váženého harmonického priemeru:
Harmonický vážený priemer sa teda používa, keď sú frekvencie f neznáme, ale w=Xf je známe. V prípadoch, keď všetky w=1, teda jednotlivé hodnoty X sa vyskytujú 1-krát, použije sa harmonický jednoduchý priemerný vzorec:  alebo
alebo  Napríklad auto išlo z bodu A do bodu B rýchlosťou 90 km/h a späť rýchlosťou 110 km/h. Na určenie priemernej rýchlosti použijeme harmonický jednoduchý vzorec, pretože príklad udáva vzdialenosť w 1 \u003d w 2 (vzdialenosť z bodu A do bodu B je rovnaká ako z bodu B do A), ktorá sa rovná súčinu rýchlosti (X) a času (f). Priemerná rýchlosť = (1+1)/(1/90+1/110) = 99 km/h.
Napríklad auto išlo z bodu A do bodu B rýchlosťou 90 km/h a späť rýchlosťou 110 km/h. Na určenie priemernej rýchlosti použijeme harmonický jednoduchý vzorec, pretože príklad udáva vzdialenosť w 1 \u003d w 2 (vzdialenosť z bodu A do bodu B je rovnaká ako z bodu B do A), ktorá sa rovná súčinu rýchlosti (X) a času (f). Priemerná rýchlosť = (1+1)/(1/90+1/110) = 99 km/h.
Funkcia SRHARM
Vráti harmonický priemer množiny údajov. Harmonický priemer je prevrátená hodnota aritmetického priemeru prevrátených hodnôt.
SGARM(číslo1; číslo2; ...)
Číslo1, číslo2, ... je 1 až 30 argumentov, pre ktoré sa vypočítava priemer. Namiesto argumentov oddelených bodkočiarkou môžete použiť pole alebo odkaz na pole.
Harmonický priemer je vždy menší ako geometrický priemer, ktorý je vždy menší ako aritmetický priemer.
Geometrický priemer
Geometrická stredná hodnota na odhadovanie priemernej rýchlosti rastu náhodných premenných, zistenie hodnoty znaku v rovnakej vzdialenosti od minimálnych a maximálnych hodnôt;
Geometrický priemer používané pri určovaní priemerných relatívnych zmien. Geometrický priemer poskytuje najpresnejší priemerný výsledok, ak je úlohou nájsť takú hodnotu X, ktorá by bola rovnako vzdialená od maximálnych aj minimálnych hodnôt X. Napríklad v rokoch 2005 až 2008index inflácie v Rusku bolo: v roku 2005 - 1,109; v roku 2006 - 1 090; v roku 2007 - 1 119; v roku 2008 - 1 133. Pretože index inflácie je relatívna zmena (dynamický index), musíte vypočítať priemernú hodnotu pomocou geometrického priemeru: (1,109 * 1,090 * 1,119 * 1,133) ^ (1/4) = 1,1126, teda za obdobie od roku 2005 do roku 2008 rástli ceny ročne v priemere o 11,26 %. Chybný výpočet aritmetického priemeru by dal nesprávny výsledok 11,28 %.Funkcia SRGEOM
Vráti geometrický priemer poľa alebo rozsahu kladných čísel. Napríklad funkciu CAGEOM možno použiť na výpočet priemernej miery rastu, ak je uvedený zložený príjem s variabilnými sadzbami.
SGEOM(číslo1; číslo2; ...)
Číslo1, číslo2, ... je 1 až 30 argumentov, pre ktoré sa vypočítava geometrický priemer. Namiesto argumentov oddelených bodkočiarkou môžete použiť pole alebo odkaz na pole.
stredná odmocnina
Stredná odmocnina je počiatočný moment druhého rádu.
stredná odmocnina sa používa, keď počiatočné hodnoty X môžu byť kladné aj záporné, napríklad pri výpočte priemerných odchýlok.Priemerný kubický
Priemerný kubický je počiatočný moment tretieho rádu.
Priemerný kubický sa používa veľmi zriedkavo, napríklad pri výpočte indexov chudoby pre rozvojové krajiny (HPI-1) a pre rozvinuté krajiny (HPI-2), ktoré navrhuje a počíta OSN.Vo väčšine prípadov sú dáta sústredené okolo nejakého centrálneho bodu. Na opísanie akéhokoľvek súboru údajov teda stačí uviesť priemernú hodnotu. Zvážte postupne tri číselné charakteristiky, ktoré sa používajú na odhad strednej hodnoty rozdelenia: aritmetický priemer, medián a modus.
Priemerná
Aritmetický priemer (často označovaný jednoducho ako priemer) je najbežnejším odhadom priemeru rozdelenia. Je to výsledok vydelenia súčtu všetkých pozorovaných číselných hodnôt ich počtom. Pre ukážku čísel X 1, X 2, ..., Xn, priemer vzorky (označený symbolom ) sa rovná \u003d (X 1 + X 2 + ... + Xn) / n, alebo
kde je priemer vzorky, n- veľkosť vzorky, Xi– i-tý prvok vzorky.
Stiahnite si poznámku vo formáte alebo formáte, príklady vo formáte
Zvážte výpočet aritmetického priemeru päťročných priemerných ročných výnosov 15 veľmi rizikových podielových fondov (obrázok 1).

Ryža. 1. Priemerný ročný výnos 15 veľmi rizikových podielových fondov
Priemer vzorky sa vypočíta takto:

Ide o dobrý výnos, najmä v porovnaní s výnosom 3 – 4 %, ktorý vkladatelia bánk alebo družstevných bánk dostali za rovnaké časové obdobie. Ak zoradíte hodnoty výnosov, ľahko zistíte, že osem fondov má výnos nad priemerom a sedem pod priemerom. Aritmetický priemer funguje ako bilančný bod, takže nízkopríjmové fondy vyvažujú vysokopríjmové fondy. Všetky prvky vzorky sa podieľajú na výpočte priemeru. Žiadny z ostatných odhadcov distribučného priemeru túto vlastnosť nemá.
Kedy vypočítať aritmetický priemer. Keďže aritmetický priemer závisí od všetkých prvkov vzorky, prítomnosť extrémnych hodnôt výrazne ovplyvňuje výsledok. V takýchto situáciách môže aritmetický priemer skresliť význam číselných údajov. Preto pri popise súboru údajov obsahujúcich extrémne hodnoty je potrebné uviesť medián alebo aritmetický priemer a medián. Ak sa napríklad zo vzorky odstráni výnos fondu RS Emerging Growth, vzorový priemer výnosu 14 fondov sa zníži takmer o 1 % na 5,19 %.
Medián
Medián je stredná hodnota usporiadaného poľa čísel. Ak pole neobsahuje opakujúce sa čísla, polovica jeho prvkov bude menšia a polovica väčšia ako medián. Ak vzorka obsahuje extrémne hodnoty, je lepšie použiť na odhad priemeru skôr medián ako aritmetický priemer. Ak chcete vypočítať medián vzorky, musíte ju najskôr zoradiť.
Tento vzorec je nejednoznačný. Jeho výsledok závisí od toho, či je číslo párne alebo nepárne. n:
- Ak vzorka obsahuje nepárny počet položiek, medián je (n+1)/2- prvok.
- Ak vzorka obsahuje párny počet prvkov, medián leží medzi dvoma strednými prvkami vzorky a rovná sa aritmetickému priemeru vypočítanému pre tieto dva prvky.
Na výpočet mediánu pre vzorku 15 veľmi rizikových podielových fondov musíme najprv zoradiť nespracované údaje (obrázok 2). Potom bude medián oproti číslu stredného prvku vzorky; v našom príklade číslo 8. Excel má špeciálnu funkciu =MEDIAN(), ktorá pracuje aj s neusporiadanými poľami.

Ryža. 2. Medián 15 fondov
Medián je teda 6,5. To znamená, že polovica veľmi rizikových fondov nepresahuje 6,5, zatiaľ čo druhá polovica áno. Všimnite si, že medián 6,5 je o niečo väčší ako medián 6,08.
Ak zo vzorky odstránime ziskovosť fondu RS Emerging Growth, tak medián zostávajúcich 14 fondov klesne na 6,2 %, teda nie tak výrazne ako aritmetický priemer (obr. 3).

Ryža. 3. Medián 14 fondov
Móda
Termín prvýkrát zaviedol Pearson v roku 1894. Móda je číslo, ktoré sa vo vzorke vyskytuje najčastejšie (najmódnejšie). Móda dobre popisuje napríklad typickú reakciu vodičov na semafor, aby zastavili premávku. Klasickým príkladom využitia módy je výber veľkosti vyrábanej šarže topánok či farby tapety. Ak má distribúcia viacero režimov, potom sa hovorí, že je multimodálna alebo multimodálna (má dva alebo viac „vrcholov“). Multimodálna distribúcia poskytuje dôležité informácie o povahe skúmanej premennej. Napríklad v sociologických prieskumoch, ak premenná predstavuje preferenciu alebo postoj k niečomu, potom multimodalita môže znamenať, že existuje niekoľko výrazne odlišných názorov. Multimodalita je tiež indikátorom toho, že vzorka nie je homogénna a že pozorovania môžu byť generované dvoma alebo viacerými „prekrývajúcimi sa“ distribúciami. Na rozdiel od aritmetického priemeru odľahlé hodnoty neovplyvňujú režim. Pre priebežne distribuované náhodné premenné, akými sú priemerné ročné výnosy podielových fondov, režim niekedy vôbec neexistuje (alebo nedáva zmysel). Keďže tieto indikátory môžu nadobúdať rôzne hodnoty, opakujúce sa hodnoty sú extrémne zriedkavé.
Kvartily
Kvartily sú miery, ktoré sa najčastejšie používajú na vyhodnotenie distribúcie údajov pri popise vlastností veľkých numerických vzoriek. Zatiaľ čo medián rozdeľuje usporiadané pole na polovicu (50 % prvkov poľa je menších ako medián a 50 % je väčších), kvartily rozdeľujú usporiadaný súbor údajov na štyri časti. Hodnoty Q1, medián a Q3 sú 25., 50. a 75. percentil. Prvý kvartil Q 1 je číslo, ktoré rozdeľuje vzorku na dve časti: 25 % prvkov je menších ako prvý kvartil a 75 % je viac ako prvý kvartil.
Tretí kvartil Q 3 je číslo, ktoré tiež rozdeľuje vzorku na dve časti: 75 % prvkov je menej ako a 25 % je viac ako tretí kvartil.
Na výpočet kvartilov vo verziách Excelu pred rokom 2007 sa použila funkcia =QUARTILE(pole, časť). Počnúc Excelom 2010 platia dve funkcie:
- =QUARTILE.ON(pole, časť)
- =QUARTILE.EXC(pole; časť)
Tieto dve funkcie poskytujú mierne odlišné hodnoty (obrázok 4). Napríklad pri výpočte kvartilov pre vzorku obsahujúcu údaje o priemernom ročnom výnose 15 veľmi rizikových podielových fondov, Q 1 = 1,8 alebo -0,7 pre QUARTILE.INC a QUARTILE.EXC, v tomto poradí. Mimochodom, skôr použitá funkcia QUARTILE zodpovedá modernej funkcii QUARTILE.ON. Na výpočet kvartilov v Exceli pomocou vyššie uvedených vzorcov je možné ponechať pole údajov bez poradia.

Ryža. 4. Vypočítajte kvartily v Exceli
Ešte raz zdôraznime. Excel dokáže vypočítať kvartily pre jednorozmerné diskrétne série, obsahujúci hodnoty náhodnej premennej. Výpočet kvartilov pre frekvenčné rozdelenie je uvedený v časti nižšie.
geometrický priemer
Na rozdiel od aritmetického priemeru geometrický priemer meria, do akej miery sa premenná zmenila v priebehu času. Geometrický priemer je koreň n stupňa z produktu n hodnoty (v Exceli sa používa funkcia = CUGEOM):
G= (X 1 * X 2 * ... * X n) 1/n
Podobný parameter - geometrický priemer miery návratnosti - je určený vzorcom:
G \u003d [(1 + R 1) * (1 + R 2) * ... * (1 + R n)] 1 / n - 1,
kde RI- miera návratnosti i-té časové obdobie.
Predpokladajme napríklad, že počiatočná investícia je 100 000 USD. Do konca prvého roka klesne na 50 000 USD a do konca druhého roka sa vráti na pôvodných 100 000 USD. Miera návratnosti tejto investície počas dvoch ročné obdobie sa rovná 0, keďže počiatočná a konečná výška prostriedkov sa navzájom rovnajú. Aritmetický priemer ročnej miery návratnosti je však = (-0,5 + 1) / 2 = 0,25 alebo 25 %, pretože miera návratnosti v prvom roku R 1 = (50 000 - 100 000) / 100 000 = -0,5 a v druhom R 2 = (100 000 - 50 000) / 50 000 = 1. Zároveň geometrický priemer miery návratnosti za dva roky je: G = [(1–0,5) * (1 + 1 )] 1 /2 – 1 = ½ – 1 = 1 – 1 = 0. Geometrický priemer teda presnejšie vyjadruje zmenu (presnejšie absenciu zmeny) v objeme investícií za dvojročné obdobie ako aritmetický priemer.
Zaujímavosti. Po prvé, geometrický priemer bude vždy menší ako aritmetický priemer tých istých čísel. Okrem prípadu, keď sú všetky prevzaté čísla navzájom rovnaké. Po druhé, po zvážení vlastností pravouhlého trojuholníka je možné pochopiť, prečo sa priemer nazýva geometrický. Výška pravouhlého trojuholníka zníženého do prepony je priemerná úmernosť medzi priemetmi nôh na preponu a každá noha je priemerná úmernosť medzi preponou a jej priemetom na preponu (obr. 5). Toto poskytuje geometrický spôsob konštrukcie geometrického priemeru dvoch (dĺžok) segmentov: musíte zostaviť kruh zo súčtu týchto dvoch segmentov ako priemer, potom výšku, obnovenú od bodu ich spojenia po priesečník s kruh, poskytne požadovanú hodnotu:

Ryža. 5. Geometrický charakter geometrického priemeru (obrázok z Wikipédie)
Druhou dôležitou vlastnosťou číselných údajov je ich variácia charakterizujúce stupeň rozptylu údajov. Dve rôzne vzorky sa môžu líšiť v stredných hodnotách aj vo variáciách. Avšak, ako je znázornené na obr. 6 a 7, dve vzorky môžu mať rovnakú variáciu, ale rôzne priemery, alebo rovnakú strednú hodnotu a úplne odlišnú variáciu. Údaje zodpovedajúce polygónu B na obr. 7 sa menia oveľa menej ako údaje, z ktorých bol polygón A zostavený.

Ryža. 6. Dve symetrické distribúcie v tvare zvona s rovnakým rozptylom a rôznymi strednými hodnotami

Ryža. 7. Dve symetrické distribúcie v tvare zvona s rovnakými strednými hodnotami a rôznym rozptylom
Existuje päť odhadov variácií údajov:
- rozpätie,
- medzikvartilový rozsah,
- rozptyl,
- štandardná odchýlka,
- variačný koeficient.
rozsah
Rozsah je rozdiel medzi najväčším a najmenším prvkom vzorky:
Potiahnutie = XMax-XMin
Rozsah vzorky obsahujúcej priemerné ročné výnosy 15 veľmi rizikových podielových fondov možno vypočítať pomocou usporiadaného poľa (pozri obrázok 4): rozsah = 18,5 - (-6,1) = 24,6. To znamená, že rozdiel medzi najvyšším a najnižším priemerným ročným výnosom pre veľmi rizikové fondy je 24,6 %.
Rozsah meria celkové rozšírenie údajov. Hoci rozsah vzoriek je veľmi jednoduchým odhadom celkového rozptylu údajov, jeho slabinou je, že nezohľadňuje presne to, ako sú údaje rozdelené medzi minimálny a maximálny prvok. Tento efekt je dobre viditeľný na obr. 8, ktorý znázorňuje vzorky s rovnakým rozsahom. Stupnica B ukazuje, že ak vzorka obsahuje aspoň jednu extrémnu hodnotu, rozsah vzorky je veľmi nepresným odhadom rozptylu údajov.

Ryža. 8. Porovnanie troch vzoriek s rovnakým rozsahom; trojuholník symbolizuje podporu rovnováhy a jeho umiestnenie zodpovedá priemernej hodnote vzorky
Medzikvartilný rozsah
Interkvartil alebo priemerný rozsah je rozdiel medzi tretím a prvým kvartilom vzorky:
Medzikvartilový rozsah \u003d Q 3 – Q 1
Táto hodnota umožňuje odhadnúť rozšírenie 50% prvkov a nebrať do úvahy vplyv extrémnych prvkov. Interkvartilné rozpätie pre vzorku obsahujúcu údaje o priemerných ročných výnosoch 15 veľmi rizikových podielových fondov je možné vypočítať pomocou údajov na obr. 4 (napríklad pre funkciu QUARTILE.EXC): Interkvartilový rozsah = 9,8 - (-0,7) = 10,5. Interval medzi 9,8 a -0,7 sa často označuje ako stredná polovica.
Treba poznamenať, že hodnoty Q 1 a Q 3, a teda medzikvartilové rozpätie, nezávisia od prítomnosti odľahlých hodnôt, pretože ich výpočet nezohľadňuje žiadnu hodnotu, ktorá by bola menšia ako Q 1 alebo väčšia ako Q 3 . Celkové kvantitatívne charakteristiky, ako je medián, prvý a tretí kvartil a medzikvartilové rozpätie, ktoré nie sú ovplyvnené odľahlými hodnotami, sa nazývajú robustné ukazovatele.
Zatiaľ čo rozsah a medzikvartilový rozsah poskytujú odhad celkového a stredného rozptylu vzorky, ani jeden z týchto odhadov nezohľadňuje presne to, ako sú údaje rozdelené. Rozptyl a štandardná odchýlka bez tohto nedostatku. Tieto ukazovatele vám umožňujú posúdiť mieru kolísania údajov okolo priemeru. Ukážkový rozptyl je aproximáciou aritmetického priemeru vypočítaného zo štvorcových rozdielov medzi každým prvkom vzorky a priemerom vzorky. Pre vzorku X 1 , X 2 , ... X n je rozptyl vzorky (označený symbolom S 2 daný nasledujúcim vzorcom:

Vo všeobecnosti je rozptyl vzorky súčet štvorcových rozdielov medzi prvkami vzorky a priemerom vzorky, delený hodnotou rovnajúcou sa veľkosti vzorky mínus jedna:

kde - aritmetický priemer, n- veľkosť vzorky, X i - i- prvok vzorky X. V Exceli pred verziou 2007 sa na výpočet rozptylu vzorky používala funkcia =VAR(), od verzie 2010 sa používa funkcia =VAR.V().
Najpraktickejší a široko akceptovaný odhad rozptylu údajov je smerodajná odchýlka. Tento indikátor je označený symbolom S a rovná sa druhej odmocnine rozptylu vzorky:

V Exceli pred verziou 2007 sa na výpočet smerodajnej odchýlky používala funkcia =STDEV(), od verzie 2010 funkcia =STDEV.B(). Na výpočet týchto funkcií je možné zmeniť poradie dátového poľa.
Vzorový rozptyl ani vzorová smerodajná odchýlka nemôžu byť negatívne. Jediná situácia, v ktorej môžu byť ukazovatele S 2 a S nulové, je, ak sú všetky prvky vzorky rovnaké. V tomto úplne nepravdepodobnom prípade je rozsah a medzikvartilový rozsah tiež nulový.
Číselné údaje sú vo svojej podstate nestále. Každá premenná môže nadobúdať rôzne hodnoty. Napríklad rôzne podielové fondy majú rôznu mieru návratnosti a straty. Vzhľadom na variabilitu číselných údajov je veľmi dôležité študovať nielen odhady priemeru, ktoré sú sumatívneho charakteru, ale aj odhady rozptylu, ktoré charakterizujú rozptyl údajov.
Rozptyl a štandardná odchýlka nám umožňujú odhadnúť rozptyl údajov okolo priemeru, inými slovami, určiť, koľko prvkov vzorky je menších ako priemer a koľko väčších. Disperzia má niektoré cenné matematické vlastnosti. Jeho hodnota je však druhá mocnina mernej jednotky – štvorcové percento, štvorcový dolár, štvorcový palec atď. Prirodzeným odhadom rozptylu je preto štandardná odchýlka, ktorá sa vyjadruje v obvyklých merných jednotkách – percentách príjmu, dolároch alebo palcoch.
Smerodajná odchýlka vám umožňuje odhadnúť mieru fluktuácie prvkov vzorky okolo strednej hodnoty. Takmer vo všetkých situáciách sa väčšina pozorovaných hodnôt pohybuje v rozmedzí plus alebo mínus jednej štandardnej odchýlky od priemeru. Preto, keď poznáme aritmetický priemer prvkov vzorky a štandardnú odchýlku vzorky, je možné určiť interval, do ktorého patrí väčšina údajov.
Štandardná odchýlka výnosov 15 veľmi rizikových podielových fondov je 6,6 (obrázok 9). To znamená, že výnosnosť väčšiny fondov sa od priemernej hodnoty líši najviac o 6,6 % (t.j. pohybuje sa v rozmedzí od – S= 6,2 – 6,6 = –0,4 až + S= 12,8). V skutočnosti tento interval obsahuje päťročný priemerný ročný výnos 53,3 % (8 z 15) fondov.

Ryža. 9. Smerodajná odchýlka
Všimnite si, že v procese sčítania druhých mocnín rozdielov získavajú položky, ktoré sú ďalej od priemeru, väčšiu váhu ako položky, ktoré sú bližšie. Táto vlastnosť je hlavným dôvodom, prečo sa aritmetický priemer najčastejšie používa na odhad priemeru rozdelenia.
Variačný koeficient
Na rozdiel od predchádzajúcich odhadov rozptylu je variačný koeficient relatívnym odhadom. Vždy sa meria v percentách, nie v pôvodných dátových jednotkách. Variačný koeficient, označený symbolmi CV, meria rozptyl dát okolo priemeru. Variačný koeficient sa rovná štandardnej odchýlke vydelenej aritmetickým priemerom a vynásobenej 100 %:

kde S- štandardná odchýlka vzorky, - vzorový priemer.
Variačný koeficient vám umožňuje porovnať dve vzorky, ktorých prvky sú vyjadrené v rôznych jednotkách merania. Napríklad manažér poštovej doručovacej služby má v úmysle modernizovať vozový park kamiónov. Pri nakladaní balíkov je potrebné zvážiť dva typy obmedzení: hmotnosť (v librách) a objem (v kubických stopách) každého balíka. Predpokladajme, že vo vzorke 200 vriec je priemerná hmotnosť 26,0 libier, štandardná odchýlka hmotnosti je 3,9 libier, priemerný objem balenia je 8,8 kubických stôp a štandardná odchýlka objemu je 2,2 kubických stôp. Ako porovnať rozloženie hmotnosti a objemu balíkov?
Keďže merné jednotky hmotnosti a objemu sa navzájom líšia, manažér musí porovnať relatívny rozptyl týchto hodnôt. Hmotnostný variačný koeficient je CV W = 3,9 / 26,0 * 100 % = 15 % a objemový variačný koeficient CV V = 2,2 / 8,8 * 100 % = 25 %. Relatívny rozptyl objemov paketov je teda oveľa väčší ako relatívny rozptyl ich váh.
Distribučný formulár
Treťou dôležitou vlastnosťou vzorky je forma jej rozloženia. Toto rozdelenie môže byť symetrické alebo asymetrické. Na opísanie tvaru rozdelenia je potrebné vypočítať jeho priemer a medián. Ak sú tieto dve miery rovnaké, hovorí sa, že premenná je symetricky rozdelená. Ak je stredná hodnota premennej väčšia ako medián, jej rozdelenie má kladnú šikmosť (obr. 10). Ak je medián väčší ako priemer, distribúcia premennej je negatívne skreslená. Pozitívna šikmosť nastane, keď sa priemer zvýši na nezvyčajne vysoké hodnoty. Negatívna šikmosť nastáva, keď priemer klesá na nezvyčajne malé hodnoty. Premenná je symetricky rozdelená, ak nenadobúda žiadne extrémne hodnoty v žiadnom smere, takže veľké a malé hodnoty premennej sa navzájom rušia.

Ryža. 10. Tri typy rozvodov
Údaje zobrazené na stupnici A majú zápornú odchýlku. Tento obrázok ukazuje dlhý chvost a ľavé zošikmenie spôsobené nezvyčajne malými hodnotami. Tieto extrémne malé hodnoty posúvajú strednú hodnotu doľava a je menšia ako medián. Údaje zobrazené na stupnici B sú rozdelené symetricky. Ľavá a pravá polovica distribúcie sú ich zrkadlovými obrazmi. Veľké a malé hodnoty sa navzájom vyrovnávajú a priemer a medián sú rovnaké. Údaje uvedené na stupnici B majú kladnú odchýlku. Tento obrázok ukazuje dlhý chvost a skosenie doprava, spôsobené prítomnosťou nezvyčajne vysokých hodnôt. Tieto príliš veľké hodnoty posúvajú priemer doprava a ten je väčší ako medián.
V Exceli je možné získať popisné štatistiky pomocou doplnku Analytický balík. Prejdite si ponuku Údaje → Analýza dát, v okne, ktoré sa otvorí, vyberte riadok Deskriptívna štatistika a kliknite Dobre. V okne Deskriptívna štatistika určite uveďte vstupný interval(obr. 11). Ak chcete zobraziť popisnú štatistiku na rovnakom hárku ako pôvodné údaje, vyberte prepínač výstupný interval a zadajte bunku, do ktorej chcete umiestniť ľavý horný roh zobrazenej štatistiky (v našom príklade $C$1). Ak chcete vytlačiť údaje do nového hárka alebo do nového zošita, jednoducho vyberte príslušný prepínač. Začiarknite políčko vedľa Záverečná štatistika. Voliteľne si môžete vybrať aj vy Obtiažnosť,k-tý najmenší ak-tý najväčší.
Ak na zálohu Údaje v oblasti Analýza nevidíte ikonu Analýza dát, musíte najprv nainštalovať doplnok Analytický balík(pozri napríklad).

Ryža. 11. Popisná štatistika päťročných priemerných ročných výnosov fondov s veľmi vysokou mierou rizika, vypočítaná pomocou doplnku Analýza dát Excel programy
Excel vypočítava množstvo štatistík uvedených vyššie: priemer, medián, režim, štandardná odchýlka, rozptyl, rozsah ( interval), minimálna, maximálna a veľkosť vzorky ( skontrolovať). Okrem toho Excel pre nás vypočítava niektoré nové štatistiky: štandardnú chybu, špičatosť a šikmosť. štandardná chyba sa rovná štandardnej odchýlke vydelenej druhou odmocninou veľkosti vzorky. Asymetria charakterizuje odchýlku od symetrie rozdelenia a je funkciou, ktorá závisí od kocky rozdielov medzi prvkami vzorky a strednou hodnotou. Kurtóza je miera relatívnej koncentrácie údajov okolo priemeru verzus konce distribúcie a závisí od rozdielov medzi vzorkou a priemerom zvýšeným na štvrtú mocninu.
Výpočet deskriptívnej štatistiky pre všeobecnú populáciu
Priemer, rozptyl a tvar distribúcie diskutovaný vyššie sú charakteristiky založené na vzorke. Ak však súbor údajov obsahuje číselné merania celej populácie, potom je možné vypočítať jeho parametre. Tieto parametre zahŕňajú priemer, rozptyl a štandardnú odchýlku populácie.
Očakávaná hodnota sa rovná súčtu všetkých hodnôt bežnej populácie vydelenému objemom bežnej populácie:

kde µ - očakávaná hodnota, Xi- i-té premenné pozorovanie X, N- objem bežnej populácie. V Exceli sa na výpočet matematického očakávania používa rovnaká funkcia ako pre aritmetický priemer: =AVERAGE().
Rozptyl populácie rovný súčtu štvorcových rozdielov medzi prvkami bežnej populácie a mat. očakávanie delené veľkosťou populácie:

kde σ2 je rozptyl bežnej populácie. Excel pred verziou 2007 používa funkciu =VAR() na výpočet rozptylu populácie, počnúc verziou 2010 =VAR.G().
smerodajná odchýlka populácie sa rovná druhej odmocnine populačného rozptylu:

Excel pred verziou 2007 používa =STDEV() na výpočet štandardnej odchýlky populácie, počnúc verziou 2010 =STDEV.Y(). Všimnite si, že vzorce pre rozptyl populácie a štandardnú odchýlku sa líšia od vzorcov pre rozptyl vzorky a štandardnú odchýlku. Pri výpočte štatistických údajov vzorky S2 a S menovateľ zlomku je n - 1 a pri výpočte parametrov σ2 a σ - objem bežnej populácie N.
pravidlo palca
Vo väčšine situácií sa veľká časť pozorovaní sústreďuje okolo mediánu a vytvára zhluk. V súboroch údajov s kladným zošikmením sa tento zhluk nachádza naľavo (t. j. pod) od matematického očakávania a v súboroch so záporným zošikmením je tento zhluk umiestnený napravo (t. j. nad) od matematického očakávania. Symetrické údaje majú rovnaký priemer a medián a pozorovania sa zhlukujú okolo priemeru, čím sa vytvorí zvonovitá distribúcia. Ak distribúcia nemá výraznú šikmosť a údaje sú sústredené okolo určitého ťažiska, na odhad variability možno použiť orientačné pravidlo, ktoré hovorí: ak majú údaje zvonovité rozdelenie, potom približne 68 % pozorovaní sú v rámci jednej štandardnej odchýlky od matematického očakávania, približne 95 % pozorovaní je v rámci dvoch štandardných odchýlok od očakávanej hodnoty a 99,7 % pozorovaní je v rámci troch štandardných odchýlok od očakávanej hodnoty.
Štandardná odchýlka, ktorá je odhadom priemernej fluktuácie okolo matematického očakávania, teda pomáha pochopiť, ako sú pozorovania rozdelené, a identifikovať odľahlé hodnoty. Z praktického pravidla vyplýva, že pre zvonovité rozdelenia sa iba jedna hodnota z dvadsiatich líši od matematického očakávania o viac ako dve štandardné odchýlky. Preto hodnoty mimo intervalu u ± 2σ, možno považovať za odľahlé hodnoty. Okrem toho len tri z 1000 pozorovaní sa líšia od matematického očakávania o viac ako tri štandardné odchýlky. Teda hodnoty mimo intervalu u ± 3σ sú takmer vždy odľahlé. Pre distribúcie, ktoré sú veľmi zošikmené alebo nemajú zvonovitý tvar, možno použiť pravidlo Biename-Chebyshev.
Pred viac ako sto rokmi matematici Bienamay a Chebyshev nezávisle objavili užitočnú vlastnosť štandardnej odchýlky. Zistili, že pre akýkoľvek súbor údajov, bez ohľadu na tvar rozloženia, percento pozorovaní, ktoré ležia vo vzdialenosti nepresahujúcej kštandardné odchýlky od matematického očakávania, nie menej (1 – 1/ 2)*100%.
Napríklad, ak k= 2, Biename-Čebyševovo pravidlo hovorí, že aspoň (1 - (1/2) 2) x 100 % = 75 % pozorovaní musí ležať v intervale u ± 2σ. Toto pravidlo platí pre každého k presahujúce jednu. Biename-Čebyševovo pravidlo má veľmi všeobecný charakter a platí pre distribúcie akéhokoľvek druhu. Označuje minimálny počet pozorovaní, pričom vzdialenosť, od ktorej k matematickému očakávaniu nepresahuje danú hodnotu. Ak je však distribúcia v tvare zvona, základné pravidlo presnejšie odhadne koncentráciu údajov okolo priemeru.
Výpočet popisnej štatistiky pre distribúciu založenú na frekvencii
Ak pôvodné údaje nie sú k dispozícii, jediným zdrojom informácií sa stáva rozloženie frekvencie. V takýchto situáciách môžete vypočítať približné hodnoty kvantitatívnych ukazovateľov rozdelenia, ako je aritmetický priemer, štandardná odchýlka, kvartily.
Ak sú údaje vzorky prezentované ako frekvenčné rozdelenie, možno vypočítať približnú hodnotu aritmetického priemeru za predpokladu, že všetky hodnoty v rámci každej triedy sú sústredené v strede triedy:

kde - vzorový priemer, n- počet pozorovaní alebo veľkosť vzorky, s- počet tried v rozdelení frekvencií, mj- stredný bod j- trieda, fj- frekvencia zodpovedajúca j- trieda.
Na výpočet štandardnej odchýlky od distribúcie frekvencií sa tiež predpokladá, že všetky hodnoty v rámci každej triedy sú sústredené v strede triedy.

Aby sme pochopili, ako sa na základe frekvencií určujú kvartily série, uvažujme o výpočte dolného kvartilu na základe údajov za rok 2013 o rozdelení ruskej populácie podľa priemerného peňažného príjmu na obyvateľa (obr. 12).

Ryža. 12. Podiel obyvateľstva Ruska s peňažným príjmom na obyvateľa v priemere za mesiac, rubľov
Na výpočet prvého kvartilu série variácií intervalu môžete použiť vzorec:

kde Q1 je hodnota prvého kvartilu, xQ1 je spodná hranica intervalu obsahujúceho prvý kvartil (interval je určený akumulovanou frekvenciou, pričom prvý presahuje 25 %); i je hodnota intervalu; Σf je súčet frekvencií celej vzorky; pravdepodobne sa vždy rovná 100 %; SQ1–1 je kumulatívna frekvencia intervalu predchádzajúceho intervalu obsahujúcemu dolný kvartil; fQ1 je frekvencia intervalu obsahujúceho dolný kvartil. Vzorec pre tretí kvartil sa líši v tom, že na všetkých miestach musíte namiesto Q1 použiť Q3 a nahradiť ¾ namiesto ¼.
V našom príklade (obr. 12) je dolný kvartil v rozmedzí 7000,1 - 10 000, ktorého kumulatívna frekvencia je 26,4 %. Dolná hranica tohto intervalu je 7 000 rubľov, hodnota intervalu je 3 000 rubľov, akumulovaná frekvencia intervalu predchádzajúceho intervalu obsahujúceho dolný kvartil je 13,4 %, frekvencia intervalu obsahujúceho dolný kvartil je 13,0 %. Teda: Q1 \u003d 7000 + 3000 * (¼ * 100 - 13,4) / 13 \u003d 9677 rubľov.
Úskalia spojené s popisnou štatistikou
V tejto poznámke sme sa pozreli na to, ako opísať súbor údajov pomocou rôznych štatistík, ktoré odhadujú jeho priemer, rozptyl a distribúciu. Ďalším krokom je analýza a interpretácia údajov. Doteraz sme študovali objektívne vlastnosti údajov a teraz prejdeme k ich subjektívnej interpretácii. Na výskumníka číhajú dve chyby: nesprávne zvolený predmet analýzy a nesprávna interpretácia výsledkov.
Analýza výkonnosti 15 veľmi rizikových podielových fondov je pomerne nezaujatá. Dospel k úplne objektívnym záverom: všetky podielové fondy majú rozdielne výnosy, rozpätie výnosov fondov sa pohybuje od -6,1 do 18,5 a priemerný výnos je 6,08. Objektívnosť analýzy dát je zabezpečená správnou voľbou celkových kvantitatívnych ukazovateľov rozdelenia. Zvažovalo sa niekoľko metód odhadu priemeru a rozptylu údajov a boli uvedené ich výhody a nevýhody. Ako si vybrať správnu štatistiku, ktorá poskytuje objektívnu a nezaujatú analýzu? Ak je distribúcia údajov mierne skreslená, mal by sa medián zvoliť pred aritmetickým priemerom? Ktorý ukazovateľ presnejšie charakterizuje rozptyl údajov: smerodajná odchýlka alebo rozsah? Mala by byť uvedená kladná šikmosť rozdelenia?
Na druhej strane je interpretácia údajov subjektívnym procesom. Rôzni ľudia prichádzajú k rôznym záverom, interpretujúc rovnaké výsledky. Každý má svoj vlastný uhol pohľadu. Niekto považuje celkové priemerné ročné výnosy 15 fondov s veľmi vysokou mierou rizika za dobré a je celkom spokojný s dosiahnutým príjmom. Iní si môžu myslieť, že tieto fondy majú príliš nízke výnosy. Subjektivita by teda mala byť kompenzovaná čestnosťou, neutralitou a jasnosťou záverov.
Etické problémy
Analýza údajov je neoddeliteľne spojená s etickými otázkami. Mali by sme byť kritickí voči informáciám šíreným novinami, rádiom, televíziou a internetom. Postupom času sa naučíte byť skeptickí nielen k výsledkom, ale aj k cieľom, predmetu a objektivite výskumu. Slávny britský politik Benjamin Disraeli to povedal najlepšie: „Existujú tri druhy klamstiev: klamstvá, prekliate klamstvá a štatistiky.
Ako je uvedené v poznámke, pri výbere výsledkov, ktoré by sa mali prezentovať v správe, vznikajú etické problémy. Mali by sa zverejňovať pozitívne aj negatívne výsledky. Okrem toho pri vypracovaní správy alebo písomnej správy musia byť výsledky prezentované čestne, neutrálne a objektívne. Rozlišujte medzi zlými a nečestnými prezentáciami. Na to je potrebné určiť, aké boli úmysly rečníka. Niekedy rečník vynechá dôležité informácie z nevedomosti a niekedy aj zámerne (napríklad ak použije aritmetický priemer na odhadnutie priemeru jasne skreslených údajov, aby získal požadovaný výsledok). Nečestné je aj potláčanie výsledkov, ktoré nezodpovedajú pohľadu výskumníka.
Využívajú sa materiály z knihy Levin et al Štatistika pre manažérov. - M.: Williams, 2004. - s. 178–209
Funkcia QUARTILE bola zachovaná, aby bola v súlade so staršími verziami Excelu
Z analytického hľadiska a univerzálnej formy vyjadrenia štatistických ukazovateľov je najhodnotnejšia priemerná hodnota. Najbežnejší priemer - aritmetický priemer - má množstvo matematických vlastností, ktoré možno použiť pri jeho výpočte. Pri výpočte konkrétneho priemeru je zároveň vždy vhodné vychádzať z jeho logického vzorca, ktorým je pomer objemu atribútu k objemu populácie. Pre každý priemer existuje len jeden skutočný referenčný pomer, ktorý si v závislosti od dostupných údajov môže vyžadovať rôzne formy priemeru. Avšak vo všetkých prípadoch, kde z povahy spriemerovanej hodnoty vyplýva prítomnosť váh, nie je možné použiť ich nevážené vzorce namiesto vzorcov váženého priemeru.
Priemerná hodnota je najcharakteristickejšia hodnota atribútu pre populáciu a veľkosť atribútu populácie rovnomerne rozložená medzi jednotky populácie.
Charakteristika, pre ktorú sa vypočítava priemerná hodnota, sa nazýva spriemerované .
Priemerná hodnota je ukazovateľ vypočítaný porovnaním absolútnych alebo relatívnych hodnôt. Priemerná hodnota je
Priemerná hodnota odráža vplyv všetkých faktorov ovplyvňujúcich skúmaný jav a je pre ne výsledná. Inými slovami, splácanie individuálnych odchýlok a eliminovanie vplyvu prípadov, priemerná hodnota, ktorá odráža všeobecnú mieru výsledkov tejto akcie, pôsobí ako všeobecný vzorec skúmaného javu.
Podmienky použitia priemerov:
Ø homogenita skúmanej populácie. Ak niektoré prvky populácie podliehajúce vplyvu náhodného faktora majú výrazne odlišné hodnoty študovaného znaku od ostatných, potom tieto prvky ovplyvnia veľkosť priemeru pre túto populáciu. V tomto prípade priemer nebude vyjadrovať najtypickejšiu hodnotu znaku pre populáciu. Ak je skúmaný jav heterogénny, je potrebné ho rozdeliť do skupín obsahujúcich homogénne prvky. V tomto prípade sa vypočítajú skupinové priemery – skupinové priemery vyjadrujúce najcharakteristickejšiu hodnotu javu v každej skupine a následne sa vypočíta celková priemerná hodnota pre všetky prvky, charakterizujúca jav ako celok. Vypočíta sa ako priemer skupinových priemerov, vážený počtom prvkov populácie zahrnutých v každej skupine;
Ø dostatočný počet jednotiek v súhrne;
Ø maximálne a minimálne hodnoty znaku v skúmanej populácii.
Priemerná hodnota (ukazovateľ)- ide o zovšeobecnenú kvantitatívnu charakteristiku vlastnosti v systematickej populácii za špecifických podmienok miesta a času.
V štatistike sa používajú tieto formy (typy) priemerov, ktoré sa nazývajú výkonové a štrukturálne:
Ø aritmetický priemer(jednoduché a vážené);
![]() jednoduché
jednoduché
Priemerná(v matematike a štatistike) množiny čísel - súčet všetkých čísel delený ich počtom. Je to jedna z najbežnejších mier centrálnej tendencie.
Navrhli ho (spolu s geometrickým priemerom a harmonickým priemerom) pytagorejci.
Špeciálnymi prípadmi aritmetického priemeru sú priemer (všeobecnej populácie) a výberový priemer (vzoriek).
Úvod
Označte súbor údajov X = (X 1 , X 2 , …, X n), potom sa priemerná hodnota vzorky zvyčajne označuje vodorovnou čiarou nad premennou (x ¯ (\displaystyle (\bar (x))) , vyslovuje sa „ X s pomlčkou“).
Grécke písmeno μ sa používa na označenie aritmetického priemeru celej populácie. Pre náhodnú premennú, pre ktorú je definovaná stredná hodnota, je μ pravdepodobnostný priemer alebo matematické očakávanie náhodnej premennej. Ak je súbor X je súbor náhodných čísel s priemernou pravdepodobnosťou μ, potom pre ľubovoľnú vzorku X i z tejto kolekcie μ = E( X i) je očakávanie tejto vzorky.
V praxi je rozdiel medzi μ a x ¯ (\displaystyle (\bar (x))) v tom, že μ je typická premenná, pretože môžete vidieť vzorku a nie celú populáciu. Preto, ak je vzorka reprezentovaná náhodne (v zmysle teórie pravdepodobnosti), potom x ¯ (\displaystyle (\bar (x))) (ale nie μ) možno považovať za náhodnú premennú s rozdelením pravdepodobnosti na vzorke ( pravdepodobnostné rozdelenie priemeru).
Obe tieto množstvá sa vypočítajú rovnakým spôsobom:
X ¯ = 1 n ∑ i = 1 n x i = 1 n (x 1 + ⋯ + x n) . (\displaystyle (\bar (x))=(\frac (1)(n))\sum _(i=1)^(n)x_(i)=(\frac (1)(n))(x_ (1)+\cdots +x_(n)).)
Ak X je náhodná premenná, potom matematické očakávanie X možno považovať za aritmetický priemer hodnôt pri opakovaných meraniach veličiny X. Toto je prejav zákona veľkých čísel. Preto sa na odhad neznámeho matematického očakávania používa výberový priemer.
V elementárnej algebre je dokázané, že stred n+ 1 číslo nad priemerom nčísla vtedy a len vtedy, ak je nové číslo väčšie ako starý priemer, menšie vtedy a len vtedy, ak je nové číslo menšie ako priemer, a nemení sa vtedy a len vtedy, ak sa nové číslo rovná priemeru. Viac n, čím menší je rozdiel medzi novým a starým priemerom.
Všimnite si, že je k dispozícii niekoľko ďalších „priemerov“ vrátane mocninového priemeru, Kolmogorovovho priemeru, harmonického priemeru, aritmeticko-geometrického priemeru a rôznych vážených priemerov (napr. aritmeticky vážený priemer, geometricky vážený priemer, harmonický vážený priemer) .
Príklady
- Pre tri čísla ich musíte sčítať a deliť 3:
- Pre štyri čísla ich musíte sčítať a vydeliť 4:
Alebo jednoduchšie 5+5=10, 10:2. Pretože sme pridali 2 čísla, čo znamená, že koľko čísel sčítame, toľko vydelíme.
Spojitá náhodná premenná
Pre spojito rozloženú hodnotu f (x) (\displaystyle f(x)) je aritmetický priemer na intervale [ a ; b ] (\displaystyle ) je definovaný prostredníctvom určitého integrálu:
F (x) - [a; b ] = 1 b − a ∫ a b f (x) d x (\displaystyle (\overline (f(x)))_()=(\frac (1)(b-a))\int _(a)^(b) f(x)dx)
Niektoré problémy pri používaní priemeru
Nedostatok robustnosti
Hlavný článok: Robustnosť v štatistikeHoci sa aritmetický priemer často používa ako priemer alebo centrálne trendy, tento koncept sa nevzťahuje na robustnú štatistiku, čo znamená, že aritmetický priemer je výrazne ovplyvnený „veľkými odchýlkami“. Je pozoruhodné, že pre distribúcie s veľkou šikmosťou nemusí aritmetický priemer zodpovedať pojmu „priemer“ a hodnoty priemeru z robustných štatistík (napríklad medián) môžu lepšie popisovať centrálny trend.
Klasickým príkladom je výpočet priemerného príjmu. Aritmetický priemer môže byť nesprávne interpretovaný ako medián, čo môže viesť k záveru, že existuje viac ľudí s vyšším príjmom, ako v skutočnosti je. „Priemerný“ príjem sa interpretuje tak, že príjmy väčšiny ľudí sa k tomuto číslu približujú. Tento „priemerný“ (v zmysle aritmetického priemeru) príjem je vyšší ako príjem väčšiny ľudí, keďže vysoký príjem s veľkou odchýlkou od priemeru výrazne skresľuje aritmetický priemer (naproti tomu medián príjmu „vzdoruje“ taká šikmosť). Tento „priemerný“ príjem však nehovorí nič o počte ľudí v blízkosti mediánu príjmu (a nehovorí nič o počte ľudí v blízkosti modálneho príjmu). Ak sa však pojmy „priemer“ a „väčšina“ vezmú na ľahkú váhu, potom možno nesprávne vyvodiť záver, že väčšina ľudí má príjmy vyššie, ako v skutočnosti sú. Napríklad správa o „priemernom“ čistom príjme v Medine vo Washingtone, vypočítanom ako aritmetický priemer všetkých ročných čistých príjmov obyvateľov, poskytne prekvapivo vysoké číslo kvôli Billovi Gatesovi. Zvážte vzorku (1, 2, 2, 2, 3, 9). Aritmetický priemer je 3,17, ale päť zo šiestich hodnôt je pod týmto priemerom.
Zložené úročenie
Hlavný článok: ROIAk čísla množiť, ale nie zložiť, musíte použiť geometrický priemer, nie aritmetický priemer. Najčastejšie sa tento incident stáva pri výpočte návratnosti investície do financií.
Napríklad, ak akcie klesli o 10 % v prvom roku a vzrástli o 30 % v druhom roku, potom je nesprávne vypočítať „priemerný“ nárast za tieto dva roky ako aritmetický priemer (-10 % + 30 %) / 2 = 10 %; správny priemer je v tomto prípade daný zloženým ročným tempom rastu, z ktorého je ročný rast len cca 8,16653826392 % ≈ 8,2 %.
Dôvodom je, že percentá majú zakaždým nový počiatočný bod: 30 % je 30 % z čísla menšieho ako bola cena na začiatku prvého roka: ak akcia začínala na 30 dolároch a klesla o 10 %, má hodnotu 27 dolárov na začiatku druhého roka. Ak akcie vzrástli o 30 %, na konci druhého roka majú hodnotu 35,1 USD. Aritmetický priemer tohto rastu je 10 %, ale keďže akcie vzrástli len o 5,1 USD za 2 roky, priemerný nárast o 8,2 % dáva konečný výsledok 35,1 USD:
[30 USD (1 - 0,1) (1 + 0,3) = 30 USD (1 + 0,082) (1 + 0,082) = 35,1 USD]. Ak použijeme aritmetický priemer 10 % rovnakým spôsobom, nedostaneme skutočnú hodnotu: [30 $ (1 + 0,1) (1 + 0,1) = 36,3 $].
Zložený úrok na konci roka 2: 90 % * 130 % = 117 % , t. j. celkový nárast o 17 % a priemerný ročný zložený úrok je 117 % ≈ 108,2 % (\displaystyle (\sqrt (117\%)) \cca 108,2\%), čo znamená priemerný ročný nárast o 8,2%.
Pokyny
Hlavný článok: Štatistiky destináciíPri výpočte aritmetického priemeru nejakej premennej, ktorá sa cyklicky mení (napríklad fáza alebo uhol), je potrebné venovať osobitnú pozornosť. Napríklad priemer 1° a 359° by bol 1 ∘ + 359 ∘ 2 = (\displaystyle (\frac (1^(\circ )+359^(\circ ))(2))=) 180°. Toto číslo je nesprávne z dvoch dôvodov.
- Po prvé, uhlové miery sú definované iba pre rozsah od 0° do 360° (alebo od 0 do 2π, keď sa meria v radiánoch). Rovnaký pár čísel teda možno zapísať ako (1° a -1°) alebo ako (1° a 719°). Priemery každého páru sa budú líšiť: 1 ∘ + (− 1 ∘) 2 = 0 ∘ (\displaystyle (\frac (1^(\circ )+(-1^(\circ )))(2))= 0 ^(\circ )) , 1 ∘ + 719 ∘ 2 = 360 ∘ (\displaystyle (\frac (1^(\circ )+719^(\circ ))(2))=360^(\circ )) .
- Po druhé, v tomto prípade by hodnota 0° (ekvivalent 360°) bola geometricky najlepším priemerom, pretože čísla sa od 0° odchyľujú menej ako od akejkoľvek inej hodnoty (hodnota 0° má najmenší rozptyl). Porovnaj:
- číslo 1° sa od 0° líši len o 1°;
- číslo 1° sa od vypočítaného priemeru 180° odchyľuje o 179°.
Priemerná hodnota pre cyklickú premennú vypočítaná podľa vyššie uvedeného vzorca bude umelo posunutá vzhľadom na skutočný priemer do stredu číselného rozsahu. Z tohto dôvodu sa priemer počíta iným spôsobom, a to číslo s najmenším rozptylom (stredný bod) ako priemerná hodnota. Tiež namiesto odčítania sa používa modulo vzdialenosť (t.j. obvodová vzdialenosť). Napríklad modulárna vzdialenosť medzi 1° a 359° je 2°, nie 358° (na kruhu medzi 359° a 360°==0° - jeden stupeň, medzi 0° a 1° - tiež 1°, celkovo -2 °).
4.3. Priemerné hodnoty. Podstata a význam priemerov
Priemerná hodnota v štatistike sa nazýva zovšeobecňujúci ukazovateľ charakterizujúci typickú úroveň javu v špecifických podmienkach miesta a času, odrážajúci veľkosť rôzneho atribútu na jednotku kvalitatívne homogénnej populácie. V hospodárskej praxi sa používa široká škála ukazovateľov počítaných ako priemery.
Napríklad zovšeobecňujúci ukazovateľ príjmu pracovníkov v akciovej spoločnosti (AK) je priemerný príjem jedného pracovníka určený pomerom mzdového fondu a sociálnych odvodov za sledované obdobie (rok, štvrťrok, mesiac). ) k počtu pracovníkov v as.
Výpočet priemeru je jednou z bežných techník zovšeobecňovania; priemerný ukazovateľ odráža všeobecný, ktorý je typický (typický) pre všetky jednotky skúmanej populácie, pričom zároveň ignoruje rozdiely medzi jednotlivými jednotkami. V každom fenoméne a jeho vývoji existuje kombinácia šancu a potrebu. Pri výpočte priemerov sa vďaka fungovaniu zákona veľkých čísel náhodnosť navzájom ruší, vyrovnáva, takže môžete abstrahovať od nepodstatných čŕt javu, od kvantitatívnych hodnôt atribútu v každom konkrétnom prípade. V schopnosti abstrahovať od náhodnosti jednotlivých hodnôt, kolísaní spočíva vedecká hodnota priemerov ako sumarizovanie agregátne charakteristiky.
Tam, kde je potrebné zovšeobecnenie, vedie výpočet takýchto charakteristík k nahradeniu mnohých rôznych individuálnych hodnôt atribútu stredná ukazovateľ, ktorý charakterizuje súhrn javov, ktorý umožňuje identifikovať vzorce vlastné masovým spoločenským javom, ktoré sú v jednotlivých javoch nepostrehnuteľné.
Priemer odráža charakteristickú, typickú, reálnu úroveň skúmaných javov, charakterizuje tieto úrovne a ich zmeny v čase a priestore.
Priemer je súhrnná charakteristika zákonitostí procesu v podmienkach, v ktorých prebieha.
4.4. Druhy priemerov a metódy ich výpočtu
Výber typu priemeru je určený ekonomickým obsahom určitého ukazovateľa a východiskovými údajmi. V každom prípade sa použije jedna z priemerných hodnôt: aritmetika, garmonické, geometrické, kvadratické, kubické atď. Uvedené priemery patria do triedy moc stredná.
Okrem mocninných priemerov sa v štatistickej praxi používajú štrukturálne priemery, ktoré sa považujú za modus a medián.
Pozrime sa podrobnejšie na mocenské prostriedky.
Aritmetický priemer
Najbežnejším typom priemeru je priemer aritmetika. Používa sa v prípadoch, keď objem premenného atribútu pre celú populáciu je súčtom hodnôt atribútov jeho jednotlivých jednotiek. Sociálne javy sú charakterizované aditívnosťou (sčítaním) objemov premenlivého atribútu, to určuje rozsah aritmetického priemeru a vysvetľuje jeho prevahu ako zovšeobecňujúci ukazovateľ, napr.: celkový mzdový fond je súčtom miezd všetkých pracovníkov, hrubá úroda je súčet vyrobených produktov z celej osevnej plochy.
Ak chcete vypočítať aritmetický priemer, musíte vydeliť súčet všetkých hodnôt funkcií ich počtom.
Vo formulári sa použije aritmetický priemer jednoduchý priemer a vážený priemer. Jednoduchý priemer slúži ako počiatočná, definujúca forma.
jednoduchý aritmetický priemer sa rovná jednoduchému súčtu jednotlivých hodnôt spriemerovaného prvku, vydelenému celkovým počtom týchto hodnôt (používa sa v prípadoch, keď existujú nezoskupené jednotlivé hodnoty prvku):
kde  - jednotlivé hodnoty premennej (možnosti); m
- počet jednotiek obyvateľstva.
- jednotlivé hodnoty premennej (možnosti); m
- počet jednotiek obyvateľstva.
Ďalšie sčítacie limity vo vzorcoch nebudú uvedené. Napríklad je potrebné zistiť priemerný výkon jedného pracovníka (zámočníka), ak je známe, koľko dielov vyrobil každý z 15 pracovníkov, t.j. daný počet individuálnych hodnôt vlastnosti, ks:
21; 20; 20; 19; 21; 19; 18; 22; 19; 20; 21; 20; 18; 19; 20.
Jednoduchý aritmetický priemer sa vypočíta podľa vzorca (4.1), 1 ks:
Priemer možností, ktoré sa opakujú rôzny počet krát alebo o ktorých sa hovorí, že majú rôznu váhu, sa nazýva vážený. Váhy sú počty jednotiek v rôznych skupinách obyvateľstva (skupina kombinuje rovnaké možnosti).
Aritmetický vážený priemer- priemerné zoskupené hodnoty, - sa vypočíta podľa vzorca:
 , (4.2)
, (4.2)
kde  - váhy (frekvencia opakovania rovnakých znakov);
- váhy (frekvencia opakovania rovnakých znakov);
 -
súčet súčinov veľkosti znakov podľa ich frekvencií;
-
súčet súčinov veľkosti znakov podľa ich frekvencií;
 -
celkový počet jednotiek obyvateľstva.
-
celkový počet jednotiek obyvateľstva.
Techniku výpočtu aritmetického váženého priemeru ilustrujeme na príklade diskutovanom vyššie. Za týmto účelom zoskupíme počiatočné údaje a umiestnime ich do tabuľky. 4.1.
Tabuľka 4.1
Rozdelenie pracovníkov na vývoj dielov
Podľa vzorca (4.2) je aritmetický vážený priemer rovný, kusy:
V niektorých prípadoch môžu byť váhy reprezentované nie absolútnymi hodnotami, ale relatívnymi (v percentách alebo zlomkoch jednotky). Potom bude vzorec pre aritmetický vážený priemer vyzerať takto:

kde  - konkrétne, t.j. podiel každej frekvencie na celkovom súčte všetkých
- konkrétne, t.j. podiel každej frekvencie na celkovom súčte všetkých
Ak sa frekvencie počítajú v zlomkoch (koeficientoch), potom  = 1 a vzorec pre aritmeticky vážený priemer je:
= 1 a vzorec pre aritmeticky vážený priemer je:

Výpočet aritmetického váženého priemeru zo skupinových priemerov  vykonávané podľa vzorca:
vykonávané podľa vzorca:
 ,
,
kde f- počet jednotiek v každej skupine.
Výsledky výpočtu aritmetického priemeru skupinových priemerov sú uvedené v tabuľke. 4.2.
Tabuľka 4.2
Rozdelenie pracovníkov podľa priemernej dĺžky služby
V tomto príklade nie sú možnosťami jednotlivé údaje o dĺžke služby jednotlivých pracovníkov, ale priemery za každú dielňu. váhy f sú počty pracovníkov v obchodoch. Priemerná pracovná skúsenosť pracovníkov v celom podniku bude teda roky:
 .
.
Výpočet aritmetického priemeru v distribučnom rade
Ak sú hodnoty spriemerovaného atribútu uvedené ako intervaly („od - do“), t.j. intervalové distribučné série, potom pri výpočte aritmetickej strednej hodnoty sa stredy týchto intervalov berú ako hodnoty vlastností v skupinách, v dôsledku čoho sa vytvorí diskrétna séria. Zvážte nasledujúci príklad (tabuľka 4.3).
Prejdime z intervalového radu k diskrétnemu nahradením intervalových hodnôt ich priemernými hodnotami / (jednoduchý priemer
Tabuľka 4.3
Rozdelenie pracovníkov AO podľa výšky mesačných miezd
|
Skupiny pracovníkov pre |
Počet pracovníkov |
Stred intervalu |
|
|
mzdy, rub. |
os., f |
rub., X |
|
|
900 a viac |
|||
hodnoty otvorených intervalov (prvý a posledný) sú podmienene rovnaké ako priľahlé intervaly (druhý a predposledný).
Pri takomto výpočte priemeru je povolená určitá nepresnosť, pretože sa predpokladá rovnomerné rozloženie jednotiek atribútu v rámci skupiny. Chyba však bude tým menšia, čím užší je interval a čím viac jednotiek v intervale.
Po nájdení stredných bodov intervalov sa výpočty vykonajú rovnakým spôsobom ako v diskrétnom rade - možnosti sa vynásobia frekvenciami (váhmi) a súčet súčinov sa vydelí súčtom frekvencií (váh) , tisíc rubľov:
 .
.
Priemerná úroveň odmeňovania pracovníkov v JSC je teda 729 rubľov. za mesiac.
Výpočet aritmetického priemeru je často spojený s veľkým vynaložením času a práce. V niektorých prípadoch však možno postup výpočtu priemeru zjednodušiť a uľahčiť využitím jeho vlastností. Uveďme (bez dôkazu) niektoré základné vlastnosti aritmetického priemeru.
Nehnuteľnosť 1. Ak všetky jednotlivé charakteristické hodnoty (t.j. všetky možnosti) znížiť alebo zvýšiť ikrát, potom priemerná hodnota novej funkcie sa zodpovedajúcim spôsobom zníži alebo zvýši iraz.
Nehnuteľnosť 2. Ak sa znížia všetky varianty spriemerovanej funkciešiť alebo zvýšiť o číslo A, potom aritmetický priemervýrazne znížiť alebo zvýšiť o rovnaké číslo A.
Nehnuteľnosť 3. Ak sa znížia váhy všetkých spriemerovaných možností alebo zvýšiť na do krát sa aritmetický priemer nezmení.
Ako priemerné váhy môžete namiesto absolútnych ukazovateľov použiť špecifické váhy v celkovom súčte (podiely alebo percentá). To zjednodušuje výpočet priemeru.
Aby sa zjednodušili výpočty priemeru, sledujú cestu znižovania hodnôt možností a frekvencií. Najväčšie zjednodušenie sa dosiahne vtedy, keď ALE hodnota jednej z centrálnych možností s najvyššou frekvenciou sa vyberie ako / - hodnota intervalu (pre riadky s rovnakými intervalmi). Hodnota L sa nazýva pôvod, preto sa tento spôsob výpočtu priemeru nazýva „metóda počítania od podmienenej nuly“ resp. „metóda momentov“.
Predpokladajme, že všetky možnosti X najprv sa zníži o rovnaké číslo A a potom sa zníži i raz. Dostávame nový variačný distribučný rad nových variantov  .
.
Potom nové možnosti bude vyjadrené:
 ,
,
a ich nový aritmetický priemer  , -moment prvého poriadku- vzorec:
, -moment prvého poriadku- vzorec:
 .
.
Rovná sa priemeru pôvodných možností, najskôr znížených o ALE, a potom dovnútra i raz.
Na získanie skutočného priemeru potrebujete moment prvého rádu m 1 , vynásobte i a pridať ALE:
 .
.
Táto metóda výpočtu aritmetického priemeru z variačného radu sa nazýva „metóda momentov“. Táto metóda sa používa v radoch s rovnakými intervalmi.
Výpočet aritmetického priemeru metódou momentov ilustrujú údaje v tabuľke. 4.4.
Tabuľka 4.4
Rozdelenie malých podnikov v kraji podľa hodnoty fixných výrobných aktív (OPF) v roku 2000
|
Skupiny podnikov podľa nákladov na OPF, tisíc rubľov |
Počet podnikov f |
stredné intervaly, X |
|
|
|
14-16 16-18 18-20 20-22 22-24 |
||||


Nájdenie momentu prvej objednávky
 .
.
Potom za predpokladu, že A = 19 a viete to i= 2, vypočítajte X, tisíc rubľov.:
Typy priemerných hodnôt a metódy ich výpočtu
V štádiu štatistického spracovania je možné nastaviť rôzne výskumné úlohy, na riešenie ktorých je potrebné zvoliť vhodný priemer. V tomto prípade je potrebné riadiť sa nasledujúcim pravidlom: hodnoty, ktoré predstavujú čitateľa a menovateľa priemeru, musia spolu logicky súvisieť.
- výkonové priemery;
- štrukturálne priemery.
Predstavme si nasledujúci zápis:
Hodnoty, pre ktoré sa vypočítava priemer;
Priemer, kde vyššie uvedený riadok naznačuje, že dochádza k spriemerovaniu jednotlivých hodnôt;
Frekvencia (opakovateľnosť hodnôt jednotlivých vlastností).
Zo všeobecného vzorca mocninného priemeru sú odvodené rôzne priemery:
 (5.1)
(5.1)
pre k = 1 - aritmetický priemer; k = -1 - harmonický priemer; k = 0 - geometrický priemer; k = -2 - stredná odmocnina.
Priemery sú jednoduché alebo vážené. vážené priemery sa nazývajú veličiny, ktoré berú do úvahy, že niektoré varianty hodnôt atribútu môžu mať rôzne čísla, a preto je potrebné každý variant vynásobiť týmto číslom. Inými slovami, „váhy“ sú počty populačných jednotiek v rôznych skupinách, t.j. každá možnosť je „vážená“ svojou frekvenciou. Frekvencia f sa nazýva štatistická váha alebo vážený priemer.
Aritmetický priemer- najbežnejší typ média. Používa sa, keď sa výpočet vykonáva na nezoskupených štatistických údajoch, kde chcete získať priemerný súčet. Aritmetický priemer je taká priemerná hodnota znaku, po prijatí ktorej zostáva celkový objem znaku v populácii nezmenený.
Vzorec aritmetického priemeru ( jednoduché) má tvar
kde n je veľkosť populácie.
Napríklad priemerná mzda zamestnancov podniku sa vypočíta ako aritmetický priemer:

Určujúcimi ukazovateľmi sú tu mzdy každého zamestnanca a počet zamestnancov podniku. Pri výpočte priemeru zostala celková výška miezd rovnaká, ale rozdelená medzi všetkých pracovníkov takmer rovnako. Napríklad je potrebné vypočítať priemernú mzdu zamestnancov malej spoločnosti, kde je zamestnaných 8 ľudí:
Pri výpočte priemerov sa jednotlivé hodnoty spriemerovaného atribútu môžu opakovať, takže priemer sa počíta pomocou zoskupených údajov. V tomto prípade hovoríme o použití vážený aritmetický priemer, ktorý vyzerá
 (5.3)
(5.3)
Potrebujeme teda vypočítať priemernú cenu akcií akciovej spoločnosti na burze. Je známe, že transakcie sa uskutočnili do 5 dní (5 transakcií), počet akcií predaných za predajný kurz bol rozdelený takto:
1 - 800 ac. - 1010 rubľov
2 - 650 ac. - 990 rubľov.
3 - 700 ak. - 1015 rubľov.
4 - 550 ac. - 900 rubľov.
5 - 850 ak. - 1150 rubľov.
Počiatočný pomer na určenie priemernej ceny akcie je pomer celkového množstva transakcií (OSS) k počtu predaných akcií (KPA).
Na to, aby ste v Exceli našli priemernú hodnotu (či už číselnú, textovú, percentuálnu alebo inú), existuje veľa funkcií. A každý z nich má svoje vlastné vlastnosti a výhody. V tejto úlohe sa totiž dajú nastaviť určité podmienky.
Napríklad priemerné hodnoty série čísel v Exceli sa vypočítavajú pomocou štatistických funkcií. Môžete tiež ručne zadať svoj vlastný vzorec. Zvážme rôzne možnosti.
Ako nájsť aritmetický priemer čísel?
Ak chcete nájsť aritmetický priemer, sčítate všetky čísla v množine a vydelíte súčet číslom. Napríklad známky študenta z informatiky: 3, 4, 3, 5, 5. Čo platí za štvrťrok: 4. Aritmetický priemer sme našli pomocou vzorca: \u003d (3 + 4 + 3 + 5 + 5) / 5.
Ako to urobiť rýchlo pomocou funkcií Excelu? Zoberme si napríklad sériu náhodných čísel v reťazci:

Alebo: aktivujte bunku a jednoducho ručne zadajte vzorec: =AVERAGE(A1:A8).
Teraz sa pozrime, čo ešte funkcia AVERAGE dokáže.

Nájdite aritmetický priemer prvých dvoch a posledných troch čísel. Vzorec: = PRIEMER (A1:B1;F1:H1). výsledok:
Priemer podľa stavu
Podmienkou na zistenie aritmetického priemeru môže byť číselné kritérium alebo textové kritérium. Použijeme funkciu: =AVERAGEIF().
Nájdite aritmetický priemer čísel, ktoré sú väčšie alebo rovné 10.
Funkcia: =AVERAGEIF(A1:A8,">=10")
 Výsledok použitia funkcie AVERAGEIF pod podmienkou ">=10":
Výsledok použitia funkcie AVERAGEIF pod podmienkou ">=10": Tretí argument - "Priemerný rozsah" - je vynechaný. Po prvé, nevyžaduje sa. Po druhé, rozsah analyzovaný programom obsahuje LEN číselné hodnoty. V bunkách zadaných v prvom argumente sa vyhľadávanie vykoná podľa podmienky uvedenej v druhom argumente.
Pozor! Kritériá vyhľadávania je možné zadať v bunke. A vo vzorci urobiť odkaz na to.
Nájdite priemernú hodnotu čísel podľa textového kritéria. Napríklad priemerný predaj produktu „tabuľky“.

Funkcia bude vyzerať takto: =AVERAGEIF($A$2:$A$12;A7;$B$2:$B$12). Rozsah - stĺpec s názvami produktov. Kritériom vyhľadávania je odkaz na bunku so slovom „tabuľky“ (namiesto odkazu A7 môžete vložiť slovo „tabuľky“). Rozsah priemerovania - bunky, z ktorých sa budú brať údaje na výpočet priemernej hodnoty.
Ako výsledok výpočtu funkcie dostaneme nasledujúcu hodnotu:
Pozor! Pre textové kritérium (podmienku) musí byť špecifikovaný rozsah priemerovania.
Ako vypočítať váženú priemernú cenu v Exceli?

Ako poznáme váženú priemernú cenu?
Vzorec: =SÚČET (C2:C12,B2:B12)/SÚČET (C2:C12).

Pomocou vzorca SUMPRODUCT zistíme celkovú tržbu po predaji celého množstva tovaru. A funkcia SUM - sumarizuje množstvo tovaru. Vydelením celkových príjmov z predaja tovaru celkovým počtom jednotiek tovaru sme zistili váženú priemernú cenu. Tento ukazovateľ zohľadňuje „váhu“ každej ceny. Jeho podiel na celkovej mase hodnôt.
Smerodajná odchýlka: vzorec v Exceli
Rozlišujte medzi štandardnou odchýlkou pre všeobecnú populáciu a pre vzorku. V prvom prípade ide o koreň všeobecného rozptylu. V druhom z rozptylu vzorky.
Na výpočet tohto štatistického ukazovateľa sa zostaví vzorec rozptylu. Z nej sa odoberá koreň. Ale v Exceli je pripravená funkcia na nájdenie smerodajnej odchýlky.

Smerodajná odchýlka je spojená so škálou zdrojových údajov. Na obrazové znázornenie variácie analyzovaného rozsahu to nestačí. Na získanie relatívnej úrovne rozptylu v údajoch sa vypočíta variačný koeficient:
smerodajná odchýlka / aritmetický priemer
Vzorec v Exceli vyzerá takto:
STDEV (rozsah hodnôt) / AVERAGE (rozsah hodnôt).
Variačný koeficient sa vypočíta ako percento. Preto sme v bunke nastavili percentuálny formát.
