Pertimbangkan distribusi chi-kuadrat. Menggunakan fungsi MS EXCELCHI2.DIST() kami akan membuat grafik fungsi distribusi dan kepadatan probabilitas, kami akan menjelaskan penerapan distribusi ini untuk keperluan statistik matematika.
Distribusi chi-kuadrat (X2, XI2, Bahasa inggrisChi- kuadratdistribusi) digunakan dalam berbagai metode statistik matematika:
- saat membangun;
- pada ;
- at (apakah data empiris konsisten dengan asumsi kita tentang fungsi distribusi teoritis atau tidak, ind. Goodness-of-fit)
- at (digunakan untuk menentukan hubungan antara dua variabel kategori, eng. Uji chi-kuadrat asosiasi).
Definisi: Jika x 1 , x 2 , …, x n adalah variabel acak bebas yang terdistribusi pada N(0;1), maka distribusi variabel acak Y=x 1 2 + x 2 2 +…+ x n 2 memiliki distribusi X 2 dengan n derajat kebebasan.
Distribusi X 2 tergantung pada satu parameter yang disebut derajat kebebasan (df, derajatdarikebebasan). Misalnya, ketika membangun jumlah derajat kebebasan sama dengan df=n-1, di mana n adalah ukurannya sampel.
Kepadatan distribusi X 2
dinyatakan dengan rumus:
Grafik Fungsi
Distribusi X 2 memiliki bentuk asimetris, sama dengan n, sama dengan 2n.
PADA contoh file pada lembar Grafik diberikan plot kepadatan distribusi probabilitas dan fungsi distribusi integral.

Properti yang berguna distribusi chi2
Misalkan x 1 , x 2 , …, x n adalah variabel acak bebas yang terdistribusi pada hukum biasa dengan parameter yang sama dan , dan X cf adalah rata-rata aritmatika nilai-nilai ini x.
Maka variabel acak kamu setara

Memiliki X 2 -distribusi dengan n-1 derajat kebebasan. Menggunakan definisi, ekspresi di atas dapat ditulis ulang sebagai berikut:

Karena itu, distribusi sampel statistik y, dengan contoh dari distribusi normal, Memiliki X 2 -distribusi dengan n-1 derajat kebebasan.
Kami akan membutuhkan properti ini untuk . Karena penyebaran hanya bisa menjadi bilangan positif, dan X 2 -distribusi digunakan untuk mengevaluasinya kamu d.b. >0, seperti yang dinyatakan dalam definisi.
Distribusi HI2 di MS EXCEL
Di MS EXCEL, mulai dari versi 2010, untuk X 2 -distribusi ada fungsi khusus CHISQ.DIST() , nama bahasa Inggrisnya adalah CHISQ.DIST(), yang memungkinkan Anda menghitung kepadatan probabilitas(lihat rumus di atas) dan (probabilitas bahwa variabel acak X memiliki XI2-distribusi, mengambil nilai kurang dari atau sama dengan x, P(X<= x}).
Catatan: Karena distribusi chi2 adalah kasus khusus, maka rumusnya =GAMMA.DIST(x,n/2,2,TRUE) untuk bilangan bulat positif n mengembalikan hasil yang sama dengan rumus =XI2.DIST(x, n, BENAR) atau =1-XI2.DIST.X(x;n) . Dan rumusnya =GAMMA.DIST(x,n/2,2,FALSE) mengembalikan hasil yang sama dengan rumus =XI2.DIST(x, n, SALAH), yaitu kepadatan probabilitas distribusi XI2.
Fungsi CH2.DIST.RT() kembali fungsi distribusi, lebih tepatnya, probabilitas tangan kanan, yaitu. P(X > x). Jelas bahwa kesetaraan
=CHI2.DIST.X(x;n)+ CHI2.DIST(x;n;TRUE)=1
karena suku pertama menghitung peluang P(X > x), dan suku kedua P(X<= x}.
Sebelum MS EXCEL 2010, EXCEL hanya memiliki fungsi HI2DIST(), yang memungkinkan Anda menghitung probabilitas tangan kanan, mis. P(X > x). Kemampuan fungsi MS EXCEL 2010 baru CHI2.DIST() dan CHI2.DIST.RT() tumpang tindih dengan kemampuan fungsi ini. Fungsi HI2DIST() dibiarkan di MS EXCEL 2010 untuk kompatibilitas.
CHI2.DIST() adalah satu-satunya fungsi yang mengembalikan kepadatan probabilitas distribusi chi2(argumen ketiga harus FALSE). Fungsi lainnya kembali fungsi distribusi integral, yaitu probabilitas bahwa variabel acak akan mengambil nilai dari rentang yang ditentukan: P(X<= x}.
Fungsi-fungsi MS EXCEL di atas diberikan dalam.
Contoh
Temukan probabilitas bahwa variabel acak X akan mengambil nilai kurang dari atau sama dengan yang diberikan x: P(X<= x}. Это можно сделать несколькими функциями:
CHI2.DIST(x, n, TRUE)
=1-CHI2.DIST.RP(x; n)
=1-CHI2DIST(x; n)
Fungsi XI2.DIST.X() mengembalikan probabilitas P(X > x), yang disebut probabilitas tangan kanan, jadi untuk menemukan P(X<= x}, необходимо вычесть ее результат от 1.
Mari kita cari probabilitas bahwa variabel acak X akan mengambil nilai yang lebih besar dari yang diberikan x: P(X > x). Ini dapat dilakukan dengan beberapa fungsi:
1-CHI2.DIST(x, n, TRUE)
=XI2.DIST.RP(x; n)
=CHI2DIST(x, n)
Fungsi distribusi chi2 terbalik
Fungsi invers digunakan untuk menghitung alfa- , yaitu untuk menghitung nilai x untuk probabilitas tertentu alfa, dan X harus memenuhi ekspresi P(X<= x}=alfa.
Fungsi CH2.INV() digunakan untuk menghitung interval kepercayaan dari varians distribusi normal.
Fungsi XI2.INV.RT() digunakan untuk menghitung , mis. jika tingkat signifikansi ditentukan sebagai argumen fungsi, misalnya, 0,05, maka fungsi tersebut akan mengembalikan nilai variabel acak x, yang P(X>x)=0,05. Sebagai perbandingan: fungsi XI2.INV() akan mengembalikan nilai variabel acak x, yang P(X<=x}=0,05.
Di MS EXCEL 2007 dan sebelumnya, alih-alih XI2.OBR.RT(), fungsi XI2OBR() digunakan.
Fungsi di atas dapat dipertukarkan, sebagai rumus berikut mengembalikan hasil yang sama:
=CHI.OBR(alfa,n)
=XI2.INV.RT(1-alfa;n)
\u003d XI2OBR (1-alfa; n)
Beberapa contoh perhitungan diberikan dalam contoh file pada lembar Fungsi.
Fungsi MS EXCEL menggunakan distribusi chi2
Di bawah ini adalah korespondensi antara nama fungsi Rusia dan Inggris:
HI2.DIST.PH() - ind. nama CHISQ.DIST.RT, mis. DISTRIBUSI CHI-SQuared Ekor Kanan, distribusi Chi-square (d) berekor kanan
XI2.OBR () - Bahasa Inggris. beri nama CHISQ.INV, mis. Distribusi CHI-Squared INVerse
HI2.PH.OBR() - Bahasa Inggris. beri nama CHISQ.INV.RT, mis. Distribusi CHI-SQuared INVerse Right Tail
HI2DIST() - ind. nama CHIDIST, fungsinya setara dengan CHISQ.DIST.RT
HI2OBR() - ind. nama CHIINV, yaitu Distribusi CHI-Squared INVerse
Estimasi parameter distribusi
Karena biasanya distribusi chi2 digunakan untuk keperluan statistik matematika (perhitungan) interval kepercayaan, pengujian hipotesis, dll.) dan hampir tidak pernah untuk membangun model nilai riil, maka untuk distribusi ini, pembahasan estimasi parameter distribusi tidak dilakukan di sini.
Perkiraan distribusi XI2 dengan distribusi normal
Dengan jumlah derajat kebebasan n>30 distribusi X 2 didekati dengan baik distribusi normal bersama rata-rata=n dan dispersi=2*n (lihat contoh lembar file Perkiraan).
Uji chi-kuadrat adalah metode universal untuk memeriksa kesesuaian antara hasil eksperimen dan model statistik yang digunakan.
Jarak Pearson X 2
Pyatnitsky A.M.
Universitas Kedokteran Negeri Rusia
Pada tahun 1900, Karl Pearson mengusulkan cara yang sederhana, serbaguna, dan efisien untuk menguji kesesuaian antara prediksi model dan data eksperimen. "Tes chi-kuadrat" miliknya adalah tes statistik yang paling penting dan paling umum digunakan. Sebagian besar masalah yang terkait dengan memperkirakan parameter model yang tidak diketahui dan memeriksa kesepakatan antara model dan data eksperimen dapat diselesaikan dengan bantuannya.
Biarkan ada model apriori ("pra-eksperimental") dari objek atau proses yang dipelajari (dalam statistik mereka berbicara tentang "hipotesis nol" H 0), dan hasil eksperimen dengan objek ini. Perlu diputuskan apakah modelnya memadai (apakah sesuai dengan kenyataan)? Bukankah hasil eksperimen itu bertentangan dengan gagasan kita tentang bagaimana realitas bekerja, atau dengan kata lain, haruskah H 0 ditolak? Seringkali tugas ini dapat direduksi menjadi membandingkan yang diamati (O i = Diamati ) dan diharapkan menurut model (E i = Diharapkan ) frekuensi rata-rata terjadinya peristiwa tertentu. Diyakini bahwa frekuensi yang diamati diperoleh dalam serangkaian N pengamatan independen (!) yang dilakukan di bawah kondisi konstan (!). Sebagai hasil dari setiap observasi, salah satu dari M event didaftarkan. Peristiwa-peristiwa ini tidak dapat terjadi secara bersamaan (tidak cocok berpasangan) dan salah satunya pasti terjadi (kombinasinya membentuk peristiwa yang andal). Totalitas semua pengamatan direduksi menjadi tabel (vektor) frekuensi (O i )=(O 1 ,… O M ), yang sepenuhnya menggambarkan hasil eksperimen. Nilai O2 =4 berarti kejadian nomor 2 terjadi sebanyak 4 kali. Jumlah frekuensi O 1 +… O M =N. Penting untuk membedakan antara dua kasus: N adalah tetap, tidak acak, N adalah variabel acak. Untuk jumlah percobaan N yang tetap, frekuensinya memiliki distribusi polinomial. Mari kita jelaskan skema umum ini dengan contoh sederhana.
Penerapan uji chi-kuadrat untuk menguji hipotesis sederhana.
Biarkan model (hipotesis nol H 0) bahwa dadu beraturan - semua wajah sering rontok sama dengan probabilitas p i =1/6, i =, M=6. Sebuah percobaan dilakukan, yang terdiri dari fakta bahwa tulang itu dilemparkan 60 kali (N = 60 tes independen dilakukan). Menurut model, kami berharap bahwa semua frekuensi yang diamati O i dari kejadian 1,2,... 6 poin harus mendekati nilai rata-ratanya E i =Np i =60∙(1/6)=10. Menurut H 0 vektor frekuensi tengah (E i )=(Np i )=(10, 10, 10, 10, 10, 10). (Hipotesis di mana frekuensi rata-rata diketahui sepenuhnya sebelum dimulainya percobaan disebut sederhana.) Jika vektor yang diamati (O i ) sama dengan (34,0,0,0,0,26) , maka segera jelas bahwa modelnya salah - tulang tidak bisa benar, karena hanya 1 dan 6 yang jatuh 60 kali.Probabilitas kejadian seperti itu untuk dadu yang benar dapat diabaikan: P = (2/6) 60 =2.4*10 -29 . Namun, munculnya perbedaan yang jelas antara model dan pengalaman merupakan pengecualian. Biarkan vektor frekuensi yang diamati (O i ) sama dengan (5, 15, 6, 14, 4, 16). Apakah ini setuju dengan H 0 ? Jadi, kita perlu membandingkan dua vektor frekuensi (E i ) dan (O i ). Pada saat yang sama, vektor frekuensi yang diharapkan (E i ) tidak acak, tetapi vektor frekuensi yang diamati (O i ) adalah acak - dalam percobaan berikutnya (dalam seri baru 60 lemparan) akan menjadi berbeda. Hal ini berguna untuk memperkenalkan interpretasi geometris dari masalah dan mengasumsikan bahwa dalam ruang frekuensi (dalam hal ini 6 dimensi) dua titik diberikan dengan koordinat (5, 15, 6, 14, 4, 16) dan (10, 10, 10, 10, 10, 10). Apakah mereka cukup jauh untuk dianggap tidak sesuai dengan H 0 ? Dengan kata lain, kita membutuhkan:
- belajar bagaimana mengukur jarak antara frekuensi (titik dalam ruang frekuensi),
- memiliki kriteria untuk jarak yang harus dianggap terlalu besar (“tidak mungkin”), yaitu, tidak konsisten dengan H 0 .
Kuadrat jarak Euclidean biasa adalah:
X 2 Euclid = S(O i -E i) 2 = (5-10) 2 + (15-10) 2 + (6-10) 2 + (14-10) 2 + (4-10) 2 + (16-10) 2
Selain itu, permukaan X 2 Euclid = const selalu bola jika kita memperbaiki nilai E i dan mengubah O i . Karl Pearson mencatat bahwa seseorang tidak boleh menggunakan jarak Euclidean dalam ruang frekuensi. Jadi, adalah salah untuk mengasumsikan bahwa titik (O =1030 dan E =1000) dan (O =40 dan E =10) berada pada jarak yang sama satu sama lain, meskipun dalam kedua kasus perbedaan O -E =30. Lagi pula, semakin besar frekuensi yang diharapkan, semakin besar penyimpangan dari itu harus dianggap mungkin. Oleh karena itu, titik (O =1030 dan E =1000) harus dianggap “dekat”, dan titik (O =40 dan E =10) “jauh” satu sama lain. Dapat ditunjukkan bahwa jika hipotesis H 0 benar, maka fluktuasi frekuensi O i relatif terhadap E i memiliki besar orde akar kuadrat(!) dari E i . Oleh karena itu, Pearson menyarankan bahwa ketika menghitung jarak, kuadratkan bukan selisih (O i -E i ), tetapi selisih yang dinormalisasi (O i -E i )/E i 1/2 . Jadi, berikut adalah rumus untuk menghitung jarak Pearson (sebenarnya itu adalah kuadrat jarak):
X 2 Pearson = S((O i -E i )/E i 1/2) 2 = S(O i -E i ) 2 /E i
Dalam contoh kami:
X 2 Pearson = (5-10) 2 /10+(15-10) 2 /10 +(6-10) 2 /10+(14-10) 2 /10+(4-10) 2 /10+( 16-10) 2 /10=15.4
Untuk dadu biasa, semua frekuensi yang diharapkan E i adalah sama, tetapi biasanya berbeda, sehingga permukaan di mana jarak Pearson konstan (X 2 Pearson = const) berubah menjadi ellipsoid, bukan bola.
Sekarang, setelah rumus untuk menghitung jarak dipilih, perlu untuk mengetahui jarak mana yang harus dianggap "tidak terlalu besar" (konsisten dengan H 0). Jadi, misalnya, apa yang dapat dikatakan tentang jarak yang kami hitung 15.4 ? Dalam berapa persentase kasus (atau dengan probabilitas berapa) jika kita bereksperimen dengan dadu biasa, kita akan mendapatkan jarak yang lebih besar dari 15,4? Jika persentase ini kecil<0.05), то H 0 надо отвергнуть. Иными словами требуется найти распределение длярасстояния Пирсона. Если все ожидаемые частоты E i не слишком малы (≥5), и верна H 0 , то нормированные разности (O i - E i )/E i 1/2 приближенно эквивалентны стандартным гауссовским случайным величинам: (O i - E i )/E i 1/2 ≈N (0,1). Это, например, означает, что в 95% случаев| (O i - E i )/E i 1/2 | < 1.96 ≈ 2 (правило “двух сигм”).
Penjelasan. Jumlah pengukuran O i yang masuk ke dalam sel tabel bernomor i memiliki distribusi binomial dengan parameter: m =Np i =E i ,σ =(Np i (1-pi )) 1/2 , di mana N adalah jumlah pengukuran (N " 1), p i adalah probabilitas untuk satu pengukuran jatuh ke dalam sel ini (ingat bahwa pengukuran independen dan dilakukan dalam kondisi konstan). Jika p i kecil, maka: (Np i ) 1/2 =E i dan distribusi binomial mendekati Poisson, dimana jumlah rata-rata pengamatan E i =λ, dan simpangan baku =λ 1/2 = E i 1/2. Untuk 5, distribusi Poisson mendekati normal N (m =E i =λ, =E i 1/2 =λ 1/2), dan nilai ternormalisasi (O i - E i )/E i 1 /2 N (0 ,satu).
Pearson mendefinisikan variabel acak 2 n – “chi-kuadrat dengan n derajat kebebasan”, sebagai jumlah kuadrat dari n r.v normal standar independen:
2 n = T 1 2 + T 2 2 + …+ T n 2 , dimana semuanya T i = N(0,1) - n. tentang. R. dengan. di.
Mari kita coba memahami secara visual arti dari variabel acak paling penting ini dalam statistik. Untuk melakukan ini, di bidang (untuk n = 2) atau di ruang angkasa (untuk n = 3) kami mewakili awan titik yang koordinatnya independen dan memiliki distribusi normal standarf T (x) ~exp (-x 2 /2 ). Pada sebuah bidang, menurut aturan “dua sigma”, yang diterapkan secara independen pada kedua koordinat, 90% (0,95*0,95≈0,90) dari titik-titik diapit oleh bujur sangkar (-2 f 2 2 (a) = exp(-a/2) = 0.5exp(-a/2). Dengan jumlah derajat kebebasan yang cukup besar n (n>30), distribusi chi-kuadrat mendekati distribusi normal: N (m = n; = (2n) ). Ini adalah konsekuensi dari "teorema limit pusat": jumlah dari kuantitas yang didistribusikan secara identik yang memiliki varians hingga mendekati hukum normal dengan peningkatan jumlah suku. Dalam praktiknya, harus diingat bahwa kuadrat rata-rata jarak sama dengan m (χ 2 n )=n , dan dispersinya 2 (χ 2 n )=2n . Dari sini mudah untuk menyimpulkan nilai chi-kuadrat mana yang harus dianggap terlalu kecil dan terlalu besar: sebagian besar distribusi terletak pada rentang dari n -2 ∙ (2n ) hingga n + 2 (2n ) . Jadi, jarak Pearson yang secara signifikan melebihi n +2∙ (2n ) harus dianggap sangat besar (tidak konsisten dengan H 0 ). Jika hasilnya mendekati n +2∙(2n) , maka Anda harus menggunakan tabel di mana Anda dapat mengetahui dengan tepat dalam proporsi kasus apa dan nilai chi-kuadrat yang besar mungkin muncul. Penting untuk mengetahui bagaimana memilih nilai yang tepat untuk jumlah derajat kebebasan (jumlah derajat kebebasan, disingkat n .d .f .). Tampaknya wajar untuk berpikir bahwa n sama dengan jumlah bit: n = M . Pearson menyarankan demikian dalam artikelnya. Dalam contoh dadu, ini berarti n = 6. Namun, beberapa tahun kemudian terbukti bahwa Pearson salah. Jumlah derajat kebebasan selalu lebih kecil dari jumlah digit, jika ada hubungan antara variabel acak O i. Untuk contoh dadu, jumlah O i adalah 60, dan hanya 5 frekuensi yang dapat diubah secara independen, jadi nilai yang benar adalah n=6-1=5. Untuk nilai n ini, kita mendapatkan n +2∙(2n) =5+2∙(10) =11.3. Karena 15.4>11.3, maka hipotesis H 0 – dadu benar, harus ditolak. Setelah mengklarifikasi kesalahan, tabel yang ada 2 harus dilengkapi, karena awalnya tidak ada kasus n = 1 di dalamnya, karena jumlah digit terkecil = 2. Sekarang ternyata mungkin ada kasus ketika jarak Pearson memiliki distribusi 2 n =1 . Contoh. Dengan 100 kali pelemparan sebuah koin, jumlah lambangnya adalah O 1 = 65, dan ekor O 2 = 35. Banyaknya angka M = 2. Jika koin simetris, maka frekuensi yang diharapkan adalah E 1 = 50, E 2 = 50. X 2 Pearson = S(O i -E i) 2 / E i \u003d (65-50) 2 / 50 + (35-50) 2 / 50 \u003d 2 * 225/50 \u003d 9. Nilai yang dihasilkan harus dibandingkan dengan nilai yang dapat diambil oleh variabel acak 2 n =1, yang didefinisikan sebagai kuadrat dari nilai normal standar 2 n =1 =T 1 2 9 ó
T 1 3 atau T 1 -3. Peluang kejadian tersebut sangat kecil P (χ 2 n =1 9) = 0,006. Oleh karena itu, koin tidak dapat dianggap simetris: H 0 harus ditolak. Fakta bahwa jumlah derajat kebebasan tidak dapat sama dengan jumlah bit dapat dilihat dari fakta bahwa jumlah frekuensi yang diamati selalu sama dengan jumlah yang diharapkan, misalnya O 1 + O 2 = 65 +35 = E 1 +E 2 =50+50=100. Oleh karena itu, titik acak dengan koordinat O 1 dan O 2 terletak pada garis lurus: O 1 + O 2 \u003d E 1 + E 2 \u003d 100 dan jarak ke pusat ternyata lebih kecil daripada jika pembatasan ini tidak di sana, dan mereka berada di seluruh pesawat. Memang, untuk dua variabel acak independen dengan harapan matematis E 1 =50, E 2 =50, jumlah realisasinya tidak harus selalu sama dengan 100 - misalnya, nilai O 1 =60, O 2 =55 akan dapat diterima. Penjelasan. Mari kita bandingkan hasil kriteria Pearson dengan M = 2 dengan apa yang diberikan rumus Moivre-Laplace ketika memperkirakan fluktuasi acak dalam frekuensi kemunculan suatu peristiwa =K /N memiliki probabilitas p dalam serangkaian N percobaan Bernoulli independen ( K adalah jumlah keberhasilan): 2 n =1 = S(O i -E i) 2 / E i \u003d (O 1 -E 1) 2 / E 1 + (O 2 -E 2) 2 / E 2 \u003d (Nν -Np) 2 / (Np) + ( N ( 1-ν )-N (1-p )) 2 /(N (1-p ))= =(Nν-Np) 2 (1/p + 1/(1-p))/N=(Nν-Np) 2 /(Np(1-p))=((K-Np)/(Npq) ) 2 = T2 Nilai T \u003d (K -Np) / (Npq) \u003d (K -m (K)) / (K) N (0,1) dengan (K) \u003d (Npq) ≥3. Kita melihat bahwa dalam kasus ini, hasil Pearson sama persis dengan yang diperoleh dengan menerapkan pendekatan normal pada distribusi binomial. Sejauh ini, kami telah mempertimbangkan hipotesis sederhana yang frekuensi rata-rata yang diharapkan E i sepenuhnya diketahui sebelumnya. Lihat di bawah untuk cara memilih jumlah derajat kebebasan yang tepat untuk hipotesis kompleks. Dalam contoh dengan dadu dan koin yang benar, frekuensi yang diharapkan dapat ditentukan sebelum (!) percobaan. Hipotesis semacam itu disebut "sederhana". Dalam praktiknya, "hipotesis kompleks" lebih umum. Pada saat yang sama, untuk menemukan frekuensi yang diharapkan E i, satu atau beberapa kuantitas (parameter model) harus diestimasi terlebih dahulu, dan ini hanya dapat dilakukan dengan menggunakan data eksperimen. Akibatnya, untuk "hipotesis kompleks", frekuensi yang diharapkan E i ternyata bergantung pada frekuensi yang diamati O i dan oleh karena itu menjadi variabel acak itu sendiri, berubah tergantung pada hasil percobaan. Dalam proses pemasangan parameter, jarak Pearson berkurang - parameter dipilih sedemikian rupa untuk meningkatkan kesepakatan antara model dan eksperimen. Oleh karena itu, jumlah derajat kebebasan harus dikurangi. Bagaimana cara mengevaluasi parameter model? Ada banyak metode estimasi yang berbeda - "metode kemungkinan maksimum", "metode momen", "metode substitusi". Namun, dimungkinkan untuk tidak melibatkan dana tambahan dan menemukan estimasi parameter dengan meminimalkan jarak Pearson. Di era pra-komputer, pendekatan ini jarang digunakan: tidak nyaman untuk perhitungan manual dan, sebagai suatu peraturan, tidak cocok untuk solusi analitis. Saat menghitung di komputer, minimalisasi numerik biasanya mudah dilakukan, dan keunggulan metode ini adalah universalitasnya. Jadi, menurut "metode minimisasi chi-kuadrat", kami memilih nilai parameter yang tidak diketahui sehingga jarak Pearson menjadi yang terkecil. (Omong-omong, dengan mempelajari perubahan jarak ini dengan pergeseran kecil relatif terhadap minimum yang ditemukan, seseorang dapat memperkirakan ukuran akurasi perkiraan: membangun interval kepercayaan.) Setelah parameter dan jarak minimum ini sendiri telah ditemukan, sekali lagi perlu untuk menjawab pertanyaan apakah itu cukup kecil. Urutan tindakan secara umum adalah sebagai berikut: P (χ 2 n > 2 crit)=1-α, di mana adalah "tingkat signifikansi" atau "ukuran pengujian" atau "Nilai kesalahan tipe I" (nilai tipikal = 0,05). Biasanya jumlah derajat kebebasan n dihitung dengan rumus n = (jumlah digit) – 1 – (jumlah parameter yang diestimasi) Jika X 2 > 2 crit, maka hipotesis H 0 ditolak, sebaliknya diterima. Dalam 100% kasus (yaitu, sangat jarang), cara memeriksa H 0 ini akan menyebabkan "kesalahan jenis pertama": hipotesis H 0 akan ditolak secara keliru. Contoh. Dalam penelitian 10 seri 100 benih, jumlah infestasi lalat mata hijau dihitung. Data yang diterima: O i = (16, 18, 11, 18, 21, 10, 20, 18, 17, 21); Di sini, vektor frekuensi yang diharapkan tidak diketahui sebelumnya. Jika data homogen dan diperoleh untuk distribusi binomial, maka satu parameter tidak diketahui - proporsi p benih yang terinfeksi. Perhatikan bahwa dalam tabel asli, sebenarnya, tidak ada 10 tetapi 20 frekuensi yang memenuhi 10 tautan: 16+84=100, ... 21+79=100. X 2 \u003d (16-100p) 2 / 100p + (84-100 (1-p)) 2 / (100 (1-p)) + ... + (21-100p) 2 /100p +(79-100(1-p)) 2 /(100(1-p)) Menggabungkan istilah berpasangan (seperti dalam contoh dengan koin), kita mendapatkan bentuk penulisan kriteria Pearson, yang biasanya langsung ditulis: X 2 \u003d (16-100p) 2 / (100p (1-p)) + ... + (21-100p) 2 / (100p (1-p)). Sekarang, jika kita menggunakan jarak Pearson minimum sebagai metode untuk menaksir p, maka kita perlu mencari p dimana X 2 = min. (Model mencoba, jika mungkin, untuk "menyesuaikan" dengan data eksperimen.) Kriteria Pearson adalah yang paling universal dari semua yang digunakan dalam statistik. Ini dapat diterapkan pada data satu dimensi dan multidimensi, fitur kuantitatif dan kualitatif. Namun, justru karena universalitas itulah seseorang harus berhati-hati agar tidak membuat kesalahan. 1. Pilihan peringkat. Estimasi Parameter. Penggunaan metode estimasi "buatan sendiri" yang tidak efisien dapat menyebabkan nilai jarak Pearson yang terlalu tinggi. Memilih jumlah derajat kebebasan yang tepat. Jika estimasi parameter dibuat bukan oleh frekuensi, tetapi langsung oleh data (misalnya, mean aritmatika diambil sebagai estimasi mean), maka jumlah pasti derajat kebebasan n tidak diketahui. Kami hanya tahu bahwa itu memenuhi ketidaksetaraan: (jumlah digit - 1 - jumlah parameter yang diperkirakan)< n
< (число разрядов – 1) Oleh karena itu, perlu untuk membandingkan X 2 dengan nilai kritis 2 crit yang dihitung pada seluruh rentang n . Bagaimana menginterpretasikan nilai chi-kuadrat yang sangat kecil? Haruskah sebuah koin dianggap simetris jika, setelah 10.000 kali pelemparan, ia memiliki 5.000 lambang? Sebelumnya, banyak ahli statistik percaya bahwa H 0 juga harus ditolak dalam kasus ini. Sekarang pendekatan lain diusulkan: untuk menerima H 0 , tetapi tundukkan data dan metode analisisnya untuk verifikasi tambahan. Ada dua kemungkinan: jarak Pearson yang terlalu kecil berarti bahwa peningkatan jumlah parameter model tidak disertai dengan penurunan jumlah derajat kebebasan yang tepat, atau data itu sendiri dipalsukan (mungkin secara tidak sengaja disesuaikan dengan hasil yang diharapkan). ). Contoh. Dua peneliti A dan B menghitung proporsi homozigot resesif aa pada generasi kedua dalam persilangan monohibrid AA * aa. Menurut hukum Mendel, proporsi ini adalah 0,25. Setiap peneliti melakukan 5 percobaan, dan 100 organisme dipelajari dalam setiap percobaan. Hasil A: 25, 24, 26, 25, 24. Kesimpulan Peneliti: Hukum Mendel valid (?). Hasil B: 29, 21, 23, 30, 19. Kesimpulan Peneliti: Hukum Mendel tidak valid (?). Namun, hukum Mendel bersifat statistik, dan analisis kuantitatif dari hasil membalikkan kesimpulan! Menggabungkan lima eksperimen menjadi satu, kita sampai pada distribusi chi-kuadrat dengan 5 derajat kebebasan (hipotesis sederhana sedang diuji): X 2 A = ((25-25) 2 +(24-25) 2 +(26-25) 2 +(25-25) 2 +(24-25) 2)/(100∙0.25∙0.75)=0.16 X 2 B = ((29-25) 2 +(21-25) 2 +(23-25) 2 +(30-25) 2 +(19-25) 2)/(100∙0.25∙0.75)=5,17 Nilai rata-rata m [χ 2 n =5 ]=5, simpangan baku [χ 2 n =5 ]=(2∙5) 1/2 =3,2. Oleh karena itu, tanpa mengacu pada tabel, jelas bahwa nilai X 2 B adalah tipikal, dan nilai X 2 A sangat kecil. Menurut tabel P (χ 2 n =5<0.16)<0.0001. Contoh ini adalah versi adaptasi dari kasus nyata yang terjadi pada tahun 1930-an (lihat karya Kolmogorov “On Another Proof of Mendel's Laws”). Anehnya, peneliti A mendukung genetika, sementara peneliti B menentangnya. Kebingungan notasi. Perlu untuk membedakan jarak Pearson, yang memerlukan kesepakatan tambahan dalam perhitungannya, dari konsep matematika variabel acak chi-kuadrat. Jarak Pearson dalam kondisi tertentu memiliki distribusi yang mendekati chi-kuadrat dengan n derajat kebebasan. Oleh karena itu, diinginkan untuk TIDAK menyatakan jarak Pearson dengan 2 n , tetapi menggunakan notasi yang serupa tetapi berbeda untuk X 2. . Kriteria Pearson tidak mahakuasa. Ada banyak sekali alternatif untuk H 0 , yang tidak dapat ia perhitungkan. Biarkan Anda menguji hipotesis bahwa fitur tersebut memiliki distribusi yang seragam, Anda memiliki 10 bit dan vektor frekuensi yang diamati adalah (130.125.121.118.116.115.114.113.111.110). Kriteria Pearson tidak dapat "memperhatikan" bahwa frekuensi menurun secara monoton dan H 0 tidak akan ditolak. Jika dilengkapi dengan kriteria deret, ya! Pertimbangkan aplikasinya diNONAUNGGULUji chi-kuadrat Pearson untuk menguji hipotesis sederhana. Setelah menerima data eksperimen (yaitu ketika ada beberapa Sampel) biasanya hukum distribusi dipilih yang paling menggambarkan variabel acak yang diwakili oleh yang diberikan contoh. Memeriksa seberapa baik data eksperimen dijelaskan oleh hukum distribusi teoretis yang dipilih dilakukan dengan menggunakan kriteria persetujuan. hipotesis nol, biasanya ada hipotesis bahwa distribusi variabel acak sama dengan beberapa hukum teoretis. Mari kita lihat dulu aplikasinya Uji kesesuaian Pearson X 2 (chi-kuadrat) dalam kaitannya dengan hipotesis sederhana (parameter dari distribusi teoritis diasumsikan diketahui). Kemudian - , ketika hanya bentuk distribusi yang ditentukan, dan parameter dari distribusi ini dan nilainya statistik X 2
diperkirakan/dihitung atas dasar yang sama sampel. Catatan: Dalam literatur berbahasa Inggris, prosedur aplikasi Tes kesesuaian Pearson X 2
punya nama Uji kesesuaian chi-kuadrat. Ingat prosedur untuk menguji hipotesis: Mari kita habiskan pengujian hipotesis untuk distribusi yang berbeda. Misalkan dua orang sedang bermain dadu. Setiap pemain memiliki set dadu mereka sendiri. Pemain bergiliran melempar 3 dadu sekaligus. Setiap putaran dimenangkan oleh orang yang menggulung lebih banyak angka enam sekaligus. Hasilnya dicatat. Salah satu pemain, setelah 100 putaran, memiliki kecurigaan bahwa tulang lawannya tidak simetris, karena. dia sering menang (sering melempar enam). Dia memutuskan untuk menganalisis seberapa besar kemungkinan hasil lawan seperti itu. Catatan: Karena 3 dadu, maka Anda dapat melempar 0 sekaligus; satu; 2 atau 3 enam, mis. variabel acak dapat mengambil 4 nilai. Dari teori probabilitas, kita mengetahui bahwa jika kubus-kubus tersebut simetris, maka probabilitas kejatuhan enam kubus memenuhi. Oleh karena itu, setelah 100 putaran, frekuensi enam dapat dihitung menggunakan rumus Rumus tersebut mengasumsikan bahwa sel A7
berisi jumlah yang sesuai dari enam yang dijatuhkan dalam satu putaran. Catatan: Perhitungan diberikan dalam contoh file pada lembar Diskrit. Untuk perbandingan diamati(Diamati) dan frekuensi teoritis(Diharapkan) nyaman digunakan. Dengan penyimpangan yang signifikan dari frekuensi yang diamati dari distribusi teoritis, hipotesis nol tentang distribusi variabel acak menurut hukum teoritis, harus ditolak. Artinya, jika dadu lawan tidak simetris, maka frekuensi yang diamati akan “berbeda nyata” dari distribusi binomial. Dalam kasus kami, pada pandangan pertama, frekuensinya cukup dekat dan sulit untuk menarik kesimpulan yang jelas tanpa perhitungan. Berlaku Uji kesesuaian Pearson X 2, sehingga alih-alih pernyataan subjektif "berbeda secara signifikan", yang dapat dibuat atas dasar perbandingan histogram, gunakan pernyataan yang benar secara matematis. Mari kita gunakan fakta bahwa hukum bilangan besar frekuensi yang diamati (Diamati) dengan meningkatnya volume sampel n cenderung ke probabilitas yang sesuai dengan hukum teoretis (dalam kasus kami, hukum binomial). Dalam kasus kami, ukuran sampel n adalah 100. Mari kita perkenalkan uji statistik, yang dilambangkan dengan X 2: di mana O l adalah frekuensi kejadian yang diamati di mana variabel acak telah mengambil nilai tertentu yang dapat diterima, E l adalah frekuensi teoretis yang sesuai (Diharapkan). L adalah jumlah nilai yang dapat diambil oleh variabel acak (dalam kasus kami sama dengan 4). Seperti yang dapat dilihat dari rumus, ini statistik adalah ukuran kedekatan frekuensi yang diamati dengan frekuensi teoretis, yaitu itu dapat digunakan untuk memperkirakan "jarak" antara frekuensi ini. Jika jumlah "jarak" ini "terlalu besar", maka frekuensi ini "berbeda secara substansial". Jelas bahwa jika kubus kita simetris (yaitu berlaku hukum binomial), maka kemungkinan jumlah "jarak" akan menjadi "terlalu besar" akan kecil. Untuk menghitung probabilitas ini, kita perlu mengetahui distribusinya statistik X2 ( statistik X2 dihitung berdasarkan random sampel, jadi itu adalah variabel acak dan, oleh karena itu, memiliki sendiri distribusi kemungkinan). Dari analog multidimensi Teorema integral Moivre-Laplace diketahui bahwa untuk n->∞ variabel acak kita X 2 asimtotik dengan L - 1 derajat kebebasan. Jadi jika dihitung nilai statistik X 2 (jumlah "jarak" antar frekuensi) akan lebih dari nilai batas tertentu, maka kita akan memiliki alasan untuk menolak hipotesis nol. Seperti dalam memeriksa hipotesis parametrik, nilai batas ditetapkan melalui tingkat signifikansi. Jika probabilitas bahwa statistik X 2 akan mengambil nilai kurang dari atau sama dengan yang dihitung ( p-berarti) akan lebih sedikit tingkat signifikansi, kemudian hipotesis nol dapat ditolak. Dalam kasus kami, nilai statistiknya adalah 22,757. Probabilitas bahwa statistik X 2 akan mengambil nilai lebih besar atau sama dengan 22,757 sangat kecil (0,000045) dan dapat dihitung dengan menggunakan rumus Catatan: Fungsi CH2.TEST() dirancang khusus untuk menguji hubungan antara dua variabel kategori (lihat ). Probabilitas 0,000045 secara signifikan lebih kecil dari biasanya tingkat signifikansi 0,05. Jadi, pemain memiliki banyak alasan untuk mencurigai lawannya tidak jujur ( hipotesis nol tentang kejujurannya ditolak). Saat diterapkan kriteria X 2 perawatan harus diambil untuk memastikan bahwa volume sampel n cukup besar, jika tidak, perkiraan distribusi akan menjadi tidak valid statistik X 2. Biasanya dianggap bahwa untuk ini cukup bahwa frekuensi yang diamati (Diamati) lebih besar dari 5. Jika ini tidak terjadi, maka frekuensi rendah digabungkan menjadi satu atau digabungkan ke frekuensi lain, dan probabilitas total ditetapkan ke nilai gabungan dan, karenanya, jumlah derajat kebebasan menurun X 2 -distribusi. Untuk meningkatkan kualitas aplikasi kriteria X 2(), perlu untuk mengurangi interval partisi (menaikkan L dan, karenanya, menambah jumlahnya derajat kebebasan), namun, hal ini dicegah dengan pembatasan jumlah pengamatan yang masuk ke dalam setiap interval (db>5). Tes kesesuaian Pearson X 2
dapat diterapkan dengan cara yang sama dalam kasus . Pertimbangkan beberapa contoh, terdiri dari 200 nilai. Hipotesis nol menyatakan bahwa Sampel terbuat dari . Catatan: Variabel acak dalam file sampel pada lembar Terus Menerus dihasilkan menggunakan rumus =NORM.ST.INV(RAND()). Oleh karena itu, nilai-nilai baru sampel dihasilkan setiap kali lembar dihitung ulang. Apakah kumpulan data yang tersedia memadai dapat dinilai secara visual. Seperti yang Anda lihat dari diagram, nilai sampel cukup cocok di sepanjang garis lurus. Namun, seperti untuk pengujian hipotesis berlaku Uji kesesuaian Pearson X 2 . Untuk melakukan ini, kami membagi rentang variasi variabel acak menjadi interval dengan langkah 0,5. Mari kita hitung frekuensi yang diamati dan frekuensi teoretis. Kami menghitung frekuensi yang diamati menggunakan fungsi FREQUENCY(), dan yang teoretis - menggunakan fungsi NORM.ST.DIST(). Catatan: Adapun kasus diskrit, perlu dipastikan bahwa Sampel cukup besar, dan lebih dari 5 nilai termasuk dalam interval. Hitung statistik X 2 dan bandingkan dengan nilai kritis untuk yang diberikan tingkat signifikansi(0,05). Karena kita membagi rentang variasi variabel acak menjadi 10 interval, maka jumlah derajat kebebasannya adalah 9. Nilai kritis dapat dihitung dengan rumus Grafik di atas menunjukkan bahwa nilai statistiknya adalah 8,19, yang jauh lebih tinggi kritis – hipotesis nol tidak ditolak. Di bawah ini yang mana Sampel diasumsikan nilai yang tidak mungkin, dan atas dasar kriteria Persetujuan Pearson X 2 hipotesis nol ditolak (terlepas dari kenyataan bahwa nilai acak dihasilkan menggunakan rumus =NORM.ST.INV(RAND()) menyediakan contoh dari distribusi normal standar). Hipotesis nol ditolak, meskipun secara visual datanya cukup mendekati garis lurus. Sebagai contoh, mari kita ambil juga contoh dari U(-3; 3). Dalam hal ini, bahkan dari grafik jelas bahwa hipotesis nol harus ditolak. Kriteria Persetujuan Pearson X 2 juga menegaskan bahwa hipotesis nol harus ditolak. Kementerian Pendidikan dan Ilmu Pengetahuan Federasi Rusia Badan Federal untuk Pendidikan kota Irkutsk Universitas Ekonomi dan Hukum Negeri Baikal Departemen Informatika dan Sibernetika Distribusi khi-kuadrat dan penerapannya Kolmykova Anna Andreevna mahasiswa tahun ke-2 grup IS-09-1 Untuk mengolah data yang diperoleh, kami menggunakan uji chi-kuadrat. Untuk melakukan ini, kami membuat tabel distribusi frekuensi empiris, yaitu. frekuensi yang kita amati: Secara teoritis, kami berharap frekuensi didistribusikan secara merata, yaitu. frekuensi akan didistribusikan secara proporsional antara anak laki-laki dan perempuan. Mari kita buat tabel frekuensi teoretis. Untuk melakukan ini, kalikan jumlah baris dengan jumlah kolom dan bagi jumlah yang dihasilkan dengan jumlah total (s). Tabel yang dihasilkan untuk perhitungan akan terlihat seperti ini: 2 \u003d (E - T)² / T n = (R - 1), di mana R adalah jumlah baris dalam tabel. Dalam kasus kami, chi-kuadrat = 4,21; n = 2. Menurut tabel nilai kritis kriteria, kami menemukan: pada n = 2 dan tingkat kesalahan 0,05, nilai kritis 2 = 5,99. Nilai yang dihasilkan lebih kecil dari nilai kritis yang berarti hipotesis nol diterima. Kesimpulan: guru tidak mementingkan jenis kelamin anak saat menuliskan ciri-cirinya. Tabel 1 Siswa dari hampir semua spesialisasi mempelajari bagian "teori probabilitas dan statistik matematika" di akhir kursus matematika yang lebih tinggi; pada kenyataannya, mereka hanya berkenalan dengan beberapa konsep dan hasil dasar, yang jelas tidak cukup untuk pekerjaan praktis. Siswa memenuhi beberapa metode penelitian matematika dalam kursus khusus (misalnya, seperti "Peramalan dan perencanaan teknis dan ekonomi", "Analisis teknis dan ekonomi", "Kontrol kualitas produk", "Pemasaran", "Pengendalian", "Metode matematika peramalan ", "Statistik", dll. - dalam kasus mahasiswa spesialisasi ekonomi), namun, presentasi dalam banyak kasus sangat disingkat dan resep. Akibatnya, pengetahuan ahli statistik terapan tidak mencukupi. Oleh karena itu, kursus "Statistik Terapan" di universitas teknik sangat penting, dan di universitas ekonomi - kursus "Ekonometrika", karena ekonometrika, seperti yang Anda tahu, adalah analisis statistik data ekonomi tertentu. 1. Orlov A.I. Statistik yang diterapkan. M.: Rumah penerbitan "Ujian", 2004. 2. Gmurman V.E. Teori Probabilitas dan Statistik Matematika. M.: Sekolah Tinggi, 1999. - 479p. 3. Ayvozyan S.A. Teori Probabilitas dan Statistik Terapan, v.1. M.: Unity, 2001. - 656s. 4. Khamitov G.P., Vedernikova T.I. Probabilitas dan statistik. Irkutsk: BSUEP, 2006 - 272p. 5. Ezhova L.N. ekonometrika. Irkutsk: BSUEP, 2002. - 314p. 6. Mosteller F. Lima puluh menghibur masalah probabilistik dengan solusi. M. : Nauka, 1975. - 111p. 7. Mosteller F. Probabilitas. M. : Mir, 1969. - 428s. 8. Yaglom A.M. Probabilitas dan informasi. M. : Nauka, 1973. - 511p. 9. Chistyakov V.P. Kursus probabilitas. M.: Nauka, 1982. - 256 hal. 10. Kremer N.Sh. Teori Probabilitas dan Statistik Matematika. M.: UNITI, 2000. - 543 hal. 11. Ensiklopedia matematika, v.1. M.: Ensiklopedia Soviet, 1976. - 655p. 12. http://psystat.at.ua/ - Statistik dalam psikologi dan pedagogi. Artikel uji Chi-kuadrat. Penggunaan kriteria ini didasarkan pada penggunaan ukuran (statistik) dari ketidaksesuaian antara teori F(x)
dan distribusi empiris F*
P (x)
, yang kira-kira mematuhi hukum distribusi
2
. Hipotesa H 0
Konsistensi distribusi diperiksa dengan menganalisis distribusi statistik ini. Penerapan kriteria membutuhkan konstruksi deret statistik. Jadi, biarkan sampel diwakili oleh baris statistik dengan jumlah digit M. Tingkat hit yang diamati dalam saya-
peringkat ke- n saya. Sesuai dengan hukum distribusi teoretis, frekuensi pukulan yang diharapkan dalam saya-digit ke- F saya. Selisih antara frekuensi yang diamati dan frekuensi yang diharapkan akan menjadi nilai ( n saya
– F saya). Untuk menemukan tingkat keseluruhan perbedaan antara F(x) dan F*
P (x) perlu untuk menghitung jumlah tertimbang dari perbedaan kuadrat untuk semua digit dari deret statistik nilai 2
dengan perbesaran tak terbatas n
memiliki 2 -distribusi (terdistribusi asimtotik sebagai 2). Distribusi ini tergantung pada jumlah derajat kebebasan k, yaitu jumlah nilai independen dari istilah dalam ekspresi (3.7). Jumlah derajat kebebasan sama dengan jumlah kamu dikurangi jumlah tautan linier yang dikenakan pada sampel. Satu koneksi ada karena fakta bahwa frekuensi apa pun dapat dihitung dari rangkaian frekuensi di sisanya M-1 digit. Selain itu, jika parameter distribusi tidak diketahui sebelumnya, maka ada batasan lain karena pemasangan distribusi ke sampel. Jika sampel menentukan S
parameter distribusi, maka jumlah derajat kebebasannya adalah k=
M
–
S–1.
Area penerimaan hipotesis H 0
ditentukan oleh kondisi
2
<
χ 2
(k;
sebuah)
, dimana 2
(k;
sebuah)
adalah titik kritis dari 2-distribusi dengan tingkat signifikansi sebuah. Peluang terjadinya kesalahan jenis pertama adalah sebuah, probabilitas kesalahan tipe II tidak dapat ditentukan dengan jelas, karena ada banyak sekali cara distribusi ketidakcocokan yang berbeda. Kekuatan tes tergantung pada jumlah digit dan ukuran sampel. Kriteria direkomendasikan untuk n>200, lamaran diperbolehkan di n>40, dalam kondisi seperti itulah kriteria tersebut konsisten (sebagai aturan, ia menolak hipotesis nol yang salah). Algoritma pemeriksaan kriteria 1. Bangun histogram dengan cara yang sama. 2. Berdasarkan bentuk histogramnya, ajukan hipotesis H 0: f(x)
= f 0 (x), H 1: f(x)
¹
f 0 (x), di mana f 0 (x) adalah densitas probabilitas dari hukum distribusi hipotetis (misalnya, seragam, eksponensial, normal). Komentar. Hipotesis hukum distribusi eksponensial dapat diajukan jika semua bilangan dalam sampel positif. 3. Hitung nilai kriteria menggunakan rumus di mana p saya- probabilitas teoretis mengenai variabel acak di saya- interval ke-th asalkan hipotesis H 0 benar. Rumus untuk perhitungan p saya dalam kasus eksponensial, hukum seragam dan normal, masing-masing, adalah sama. Hukum Eksponensial Di mana A 1
= 0, B m
= +¥. hukum seragam hukum biasa Di mana A 1 = -¥, B M = +¥. Perkataan. Setelah menghitung semua probabilitas p saya periksa apakah rasio kontrol terpenuhi Fungsi F( X) aneh. (+¥) = 1. 4. Dari tabel "Chi-square" dari Aplikasi, sebuah nilai dipilih
k
= M
- 1 - S. Di Sini S- jumlah parameter yang menjadi dasar hipotesis yang dipilih H 0 hukum distribusi. Nilai S untuk hukum seragam itu adalah 2, untuk eksponensial - 1, untuk normal - 2. 5. Jika Contoh3
.
1. Dengan menggunakan kriteria c 2, ajukan dan uji hipotesis tentang hukum distribusi variabel acak X, deret variasi, tabel interval dan histogram distribusi yang diberikan dalam contoh 1.2. Tingkat signifikansi a adalah 0,05. Keputusan
. Berdasarkan jenis histogram, kami berhipotesis bahwa variabel acak X didistribusikan menurut hukum normal: H 0: f(x)
= N(m, s); H 1: f(x)
¹
N(m, s). Nilai kriteria dihitung dengan rumus: Seperti disebutkan di atas, saat menguji hipotesis, lebih baik menggunakan histogram yang dapat disamakan. Pada kasus ini Probabilitas teoretis p saya kami menghitung dengan rumus (3.10). Pada saat yang sama, kami berasumsi bahwa p 1 = 0.5(F((-4.5245+1.7)/1.98)-F((-¥+1.7)/1.98) = 0.5(F(-1.427) -Ф(-¥)) = 0,5(-0,845+1) = 0,078. p 2 = 0.5(F((-3.8865+1.7)/1.98)-F((-4.5245+1.7)/1.98) = 0,5(F(-1,104)+0,845) = 0,5(-0,729+0,845) = 0,058. p 3
=
0,094; p 4
=
0,135; p 5
=
0,118; p 6
=
0,097; p 7
=
0,073; p 8
=
0,059; p 9
=
0,174; p 10 \u003d 0,5 (Ф ((+ + 1,7) / 1,98) - ((0,6932 + 1,7) / 1,98)) \u003d 0,114. Setelah itu, kami memeriksa pemenuhan hubungan kontrol 100 × (0,0062 + 0,0304 + 0,0004 + 0,0091 + 0,0028 + 0,0001 + 0,0100 + 0,0285 + 0,0315 + 0,0017) = 100 × 0,1207 = 12,07. Setelah itu, dari tabel "Chi - square" kami memilih nilai kritis Sebagai Menerapkan Uji Chi-Square untuk Menguji Hipotesis Kompleks
Poin Penting
Kasus diskrit
=BINOM.DIST(A7,3,1/6,FALSE)*100

=XI2.DIST.PX(22,757;4-1) atau
=XI2.TEST(Diamati; Diharapkan)
kasus terus menerus

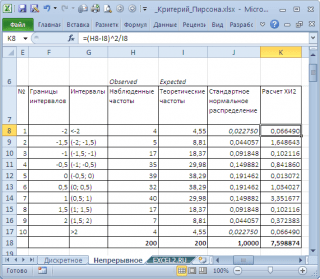
\u003d XI2.INV.RH (0,05; 9) atau
\u003d XI2.OBR (1-0,05; 9)

Lampiran
Titik distribusi kritis 2

Kesimpulan
Teori probabilitas dan statistik matematika memberikan pengetahuan dasar untuk statistik terapan dan ekonometrika.
Mereka diperlukan untuk spesialis untuk pekerjaan praktis.
Saya menganggap model probabilistik berkelanjutan dan mencoba menunjukkan kegunaannya dengan contoh.
Bibliografi
 ,
, frekuensi pukulan saya-interval;
frekuensi pukulan saya-interval; . (3.8)
. (3.8) . (3.10)
. (3.10)
 , di mana a adalah tingkat signifikansi yang diberikan (a = 0,05 atau a = 0,01), dan k- jumlah derajat kebebasan, ditentukan oleh rumus
, di mana a adalah tingkat signifikansi yang diberikan (a = 0,05 atau a = 0,01), dan k- jumlah derajat kebebasan, ditentukan oleh rumus , maka hipotesis H 0 ditolak. Jika tidak, tidak ada alasan untuk menolaknya: dengan probabilitas 1 - b itu benar, dan dengan probabilitas - b itu salah, tetapi nilai b tidak diketahui.
, maka hipotesis H 0 ditolak. Jika tidak, tidak ada alasan untuk menolaknya: dengan probabilitas 1 - b itu benar, dan dengan probabilitas - b itu salah, tetapi nilai b tidak diketahui. (3.11)
(3.11)


 .
. maka hipotesis H 0 diterima (tidak ada alasan untuk menolaknya).
maka hipotesis H 0 diterima (tidak ada alasan untuk menolaknya).
