სტატისტიკის გამოყენება ამ შენიშვნაში ნაჩვენები იქნება ჯვარედინი მაგალითით. ვთქვათ, თქვენ ხართ წარმოების მენეჯერი Perfect Parachute-ში. პარაშუტები მზადდება სინთეზური ბოჭკოებისგან, რომელსაც ოთხი სხვადასხვა მომწოდებელი აწვდის. პარაშუტის ერთ-ერთი მთავარი მახასიათებელი მისი სიძლიერეა. თქვენ უნდა დარწმუნდეთ, რომ ყველა მიწოდებულ ბოჭკოს აქვს იგივე სიმტკიცე. ამ კითხვაზე პასუხის გასაცემად აუცილებელია ექსპერიმენტის შემუშავება, რომელშიც სხვადასხვა მომწოდებლების სინთეტიკური ბოჭკოებისგან ნაქსოვი პარაშუტების სიძლიერე იზომება. ამ ექსპერიმენტის დროს მიღებული ინფორმაცია განსაზღვრავს, თუ რომელი მიმწოდებელი აწვდის ყველაზე გამძლე პარაშუტებს.
ბევრი აპლიკაცია დაკავშირებულია ექსპერიმენტებთან, რომლებშიც განიხილება ერთი ფაქტორის რამდენიმე ჯგუფი ან დონე. ზოგიერთ ფაქტორს, როგორიცაა კერამიკული სროლის ტემპერატურა, შეიძლება ჰქონდეს რამდენიმე რიცხვითი დონე (მაგ. 300°, 350°, 400° და 450°). სხვა ფაქტორებს, როგორიცაა საქონლის მდებარეობა სუპერმარკეტში, შეიძლება ჰქონდეს კატეგორიული დონე (მაგ., პირველი მიმწოდებელი, მეორე მიმწოდებელი, მესამე მიმწოდებელი, მეოთხე მიმწოდებელი). ცალმხრივი ექსპერიმენტები, რომლებშიც ექსპერიმენტული ერთეულები შემთხვევით ნაწილდება ჯგუფებად ან ფაქტორების დონეზე, ეწოდება სრულად რანდომიზებულს.
გამოყენებაფ- რამდენიმე მათემატიკური მოლოდინის განსხვავების შეფასების კრიტერიუმები
თუ ჯგუფებში ფაქტორის რიცხვითი გაზომვები უწყვეტია და დაკმაყოფილებულია დამატებითი პირობები, დისპერსიის ანალიზი (ANOVA - ანანალიზი ოვ ვარაანსი). დისპერსიის ანალიზს სრულად რანდომიზირებული დიზაინის გამოყენებით ეწოდება ცალმხრივი ANOVA. გარკვეული გაგებით, ტერმინი დისპერსიის ანალიზი არის შეცდომაში შემყვანი, რადგან ის ადარებს განსხვავებებს ჯგუფების საშუალო მნიშვნელობებს შორის და არა დისპერსიებს შორის. თუმცა, მათემატიკური მოლოდინების შედარება ხდება ზუსტად მონაცემთა ცვალებადობის ანალიზის საფუძველზე. ANOVA პროცედურაში გაზომვის შედეგების მთლიანი ვარიაცია იყოფა ჯგუფთაშორის და შიდაჯგუფად (ნახ. 1). ჯგუფშიდა ცვალებადობა აიხსნება ექსპერიმენტული შეცდომით, ხოლო ჯგუფთაშორისი ცვალებადობა ექსპერიმენტული პირობების ეფექტებით. სიმბოლო თანაღნიშნავს ჯგუფების რაოდენობას.
ბრინჯი. 1. ვარიაციის გამოყოფა სრულად რანდომიზებულ ექსპერიმენტში
ჩამოტვირთეთ შენიშვნა ფორმატში ან ფორმატში, მაგალითები ფორმატში
მოდი ვიჩვენოთ, რომ თანჯგუფები შედგენილია დამოუკიდებელი პოპულაციებიდან, რომლებსაც აქვთ ნორმალური განაწილება და იგივე ვარიაცია. ნულოვანი ჰიპოთეზა არის ის, რომ პოპულაციების მათემატიკური მოლოდინები იგივეა: H 0: μ 1 = μ 2 = ... = μ s. ალტერნატიული ჰიპოთეზა ამბობს, რომ ყველა მათემატიკური მოლოდინი არ არის ერთნაირი: H 1: ყველა μ j არ არის ერთნაირი ჯ= 1, 2, ..., s).
ნახ. 2 წარმოადგენს ჭეშმარიტ ნულოვანი ჰიპოთეზას ხუთი შედარებული ჯგუფის მათემატიკური მოლოდინების შესახებ, იმ პირობით, რომ ზოგად პოპულაციებს აქვთ ნორმალური განაწილება და იგივე ვარიაცია. ხუთი პოპულაცია, რომლებიც დაკავშირებულია სხვადასხვა ფაქტორების დონესთან, იდენტურია. მაშასადამე, ისინი ერთმანეთზეა გადანაწილებული, აქვთ ერთი და იგივე მათემატიკური მოლოდინი, ცვალებადობა და ფორმა.

ბრინჯი. 2. ხუთ პოპულაციას აქვს იგივე მათემატიკური მოლოდინი: μ 1 = μ 2 = μ 3 = μ 4 = μ 5
მეორეს მხრივ, დავუშვათ, რომ სინამდვილეში ნულოვანი ჰიპოთეზა მცდარია, ხოლო მეოთხე დონეს აქვს ყველაზე დიდი მათემატიკური მოლოდინი, პირველ დონეს აქვს ოდნავ დაბალი მათემატიკური მოლოდინი, ხოლო დანარჩენ დონეებს აქვთ იგივე და კიდევ უფრო მცირე მათემატიკური მოლოდინი (ნახ. 3). გაითვალისწინეთ, რომ საშუალო მნიშვნელობის გარდა, ხუთივე პოპულაცია იდენტურია (ანუ აქვს იგივე ცვალებადობა და ფორმა).

ბრინჯი. 3. ექსპერიმენტული პირობების ეფექტი შეინიშნება: μ 4 > μ 1 > μ 2 = μ 3 = μ 5
რამდენიმე ზოგადი პოპულაციის მათემატიკური მოლოდინების თანასწორობის ჰიპოთეზის შემოწმებისას, მთლიანი ვარიაცია იყოფა ორ ნაწილად: ჯგუფთაშორისი ცვალებადობა, ჯგუფებს შორის განსხვავებების გამო და შიდაჯგუფური ვარიაცია, იმავე ჯგუფს მიკუთვნებულ ელემენტებს შორის განსხვავებების გამო. მთლიანი ვარიაცია გამოიხატება კვადრატების ჯამურად (SST - კვადრატების ჯამი). ვინაიდან ნულოვანი ჰიპოთეზა არის ყველა მოლოდინი თანჯგუფები ერთმანეთის ტოლია, ჯამური ვარიაცია უდრის ინდივიდუალურ დაკვირვებებს შორის კვადრატული განსხვავებების ჯამს და ყველა ნიმუშისთვის გამოთვლილ საერთო საშუალოს (საშუალოების საშუალოს). სრული ვარიაცია:

სადაც ![]() - საერთო საშუალო, Xij - მე- უყურე ჯ- ჯგუფი ან დონე, nj- დაკვირვებების რაოდენობა ჯ- ჯგუფი, ნ- დაკვირვების საერთო რაოდენობა ყველა ჯგუფში (ე.ი. ნ = ნ 1
+ n 2 + … + nc), თან- შესწავლილი ჯგუფების ან დონეების რაოდენობა.
- საერთო საშუალო, Xij - მე- უყურე ჯ- ჯგუფი ან დონე, nj- დაკვირვებების რაოდენობა ჯ- ჯგუფი, ნ- დაკვირვების საერთო რაოდენობა ყველა ჯგუფში (ე.ი. ნ = ნ 1
+ n 2 + … + nc), თან- შესწავლილი ჯგუფების ან დონეების რაოდენობა.
ჯგუფთაშორისი ვარიაცია, რომელსაც ჩვეულებრივ უწოდებენ ჯგუფებს შორის კვადრატების ჯამს (SSA), უდრის კვადრატული განსხვავებების ჯამს თითოეული ჯგუფის სანიმუშო საშუალოს შორის ჯდა საერთო საშუალო გამრავლებული შესაბამისი ჯგუფის მოცულობაზე nj:

სადაც თან- შესწავლილი ჯგუფების ან დონეების რაოდენობა, nj- დაკვირვებების რაოდენობა ჯ- ჯგუფი, ჯ- ნიშნავს ჯ- ჯგუფი, - საერთო საშუალო.
შიდაჯგუფური ვარიაცია, რომელსაც ჩვეულებრივ უწოდებენ ჯგუფების შიგნით კვადრატების ჯამს (SSW), უდრის თითოეული ჯგუფის ელემენტებს შორის კვადრატული განსხვავებების ჯამს და ამ ჯგუფის საშუალო საშუალებებს შორის. ჯ:

სადაც Xიჯ - მე- ე ელემენტი ჯ- ჯგუფი, ჯ- ნიშნავს ჯ- ჯგუფი.
იმიტომ რომ შედარებულია თანფაქტორების დონეები, კვადრატთა ჯგუფთაშორისი ჯამი აქვს s - 1თავისუფლების ხარისხები. Ყოველი მათგანი თანდონეები აქვს nj – 1 თავისუფლების ხარისხი, ასე რომ, კვადრატების შიდაჯგუფური ჯამი აქვს ნ- თანთავისუფლების ხარისხი და

გარდა ამისა, კვადრატების ჯამური ჯამი აქვს ნ – 1 თავისუფლების ხარისხი, ყოველი დაკვირვების შემდეგ Xიჯყველაზე გამოთვლილ საერთო საშუალოსთან შედარებით ნდაკვირვებები. თუ თითოეული ეს ჯამი იყოფა თავისუფლების ხარისხების შესაბამის რაოდენობაზე, წარმოიქმნება დისპერსიის სამი ტიპი: ჯგუფთაშორისი(საშუალო კვადრატი - MSA-ს შორის), შიდაჯგუფი(საშუალო კვადრატი ფარგლებში - MSW) და სრული(საშუალო კვადრატი ჯამური - MST):
მიუხედავად იმისა, რომ დისპერსიული ანალიზის მთავარი მიზანია მათემატიკური მოლოდინების შედარება თანჯგუფები ექსპერიმენტული პირობების ეფექტის გამოსავლენად, მისი სახელწოდება განპირობებულია იმით, რომ ძირითადი ინსტრუმენტი არის სხვადასხვა ტიპის დისპერსიების ანალიზი. თუ ნულოვანი ჰიპოთეზა მართალია და მოსალოდნელ მნიშვნელობებს შორის თანჯგუფებში მნიშვნელოვანი განსხვავებები არ არის, სამივე ვარიაცია - MSA, MSW და MST - არის დისპერსიის შეფასება. σ2გაანალიზებული მონაცემების თანდაყოლილი. ანუ ნულოვანი ჰიპოთეზის შესამოწმებლად H 0: μ 1 = μ 2 = ... = μ sდა ალტერნატიული ჰიპოთეზა H 1: ყველა μ j არ არის ერთნაირი ჯ = 1, 2, …, თან), აუცილებელია სტატისტიკის გამოთვლა ფ-კრიტერიუმი, რომელიც არის ორი დისპერსიის თანაფარდობა, MSA და MSW. ტესტი ფ-სტატისტიკა ცვალებადობის ცვალებად ანალიზში

სტატისტიკა ფ- კრიტერიუმები ემორჩილება ფ- განაწილებასთან ერთად s - 1თავისუფლების ხარისხი მრიცხველში MSAდა n - თანთავისუფლების ხარისხი მნიშვნელში MSW. მოცემული მნიშვნელოვნების α დონისთვის, ნულოვანი ჰიპოთეზა უარყოფილია, თუ გამოითვლება ფ ფUთანდაყოლილი ფ- განაწილებასთან ერთად s - 1 n - თანთავისუფლების ხარისხი მნიშვნელში. ამრიგად, როგორც ნაჩვენებია ნახ. 4, გადაწყვეტილების წესი ჩამოყალიბებულია შემდეგნაირად: ნულოვანი ჰიპოთეზა H 0უარყოფილია თუ F > FU; წინააღმდეგ შემთხვევაში, ის არ არის უარყოფილი.

ბრინჯი. 4. დისპერსიის ანალიზის კრიტიკული არეალი ჰიპოთეზის ტესტირებისას H 0
თუ ნულოვანი ჰიპოთეზა H 0მართალია, გამოთვლილი ფ- სტატისტიკა ახლოს არის 1-თან, ვინაიდან მისი მრიცხველი და მნიშვნელი არის იგივე მნიშვნელობის შეფასება - დისპერსიული σ 2, რომელიც თან ახლავს გაანალიზებულ მონაცემებს. თუ ნულოვანი ჰიპოთეზა H 0არის მცდარი (და არის მნიშვნელოვანი განსხვავება სხვადასხვა ჯგუფის მოლოდინების მნიშვნელობებს შორის), გამოთვლილი ფ- სტატისტიკა გაცილებით დიდი იქნება ერთზე, ვინაიდან მისი მრიცხველი, MSA, მონაცემების ბუნებრივი ცვალებადობის გარდა, აფასებს ექსპერიმენტული პირობების ეფექტს ან განსხვავებას ჯგუფებს შორის, ხოლო მნიშვნელი MSW აფასებს მხოლოდ მონაცემთა ბუნებრივ ცვალებადობას. ამრიგად, ANOVA პროცედურა არის ფარის ტესტი, რომელშიც მოცემულ მნიშვნელოვნების დონეზე α, ნულოვანი ჰიპოთეზა უარყოფილია, თუ გათვლილი ფ- სტატისტიკა აღემატება ზედა კრიტიკულ მნიშვნელობას ფUთანდაყოლილი ფ- განაწილებასთან ერთად s - 1თავისუფლების ხარისხი მრიცხველში და n - თანთავისუფლების ხარისხი მნიშვნელში, როგორც ნაჩვენებია ნახ. 4.
დისპერსიის ცალმხრივი ანალიზის საილუსტრაციოდ, დავუბრუნდეთ ჩანაწერის დასაწყისში გამოკვეთილ სცენარს. ექსპერიმენტის მიზანია დადგინდეს, აქვთ თუ არა სხვადასხვა მომწოდებლებისგან მიღებული სინთეტიკური ბოჭკოებისგან ნაქსოვი პარაშუტები ერთნაირი სიმტკიცე. თითოეულ ჯგუფს აქვს ნაქსოვი ხუთი პარაშუტი. ჯგუფები იყოფა მიმწოდებლის მიხედვით - მომწოდებელი 1, მიმწოდებელი 2, მომწოდებელი 3 და მიმწოდებელი 4. პარაშუტების სიძლიერე იზომება სპეციალური მოწყობილობის გამოყენებით, რომელიც ამოწმებს ქსოვილს ორივე მხრიდან გახლეჩვას. პარაშუტის გასატეხად საჭირო ძალა იზომება სპეციალური მასშტაბით. რაც უფრო მაღალია გატეხვის ძალა, მით უფრო ძლიერია პარაშუტი. Excel იძლევა ანალიზის საშუალებას ფ- სტატისტიკა ერთი დაწკაპუნებით. გაიარეთ მენიუ მონაცემები → Მონაცემთა ანალიზიდა აირჩიეთ ხაზი ცალმხრივი დისპერსიული ანალიზი, შეავსეთ გახსნილი ფანჯარა (სურ. 5). ექსპერიმენტის შედეგები (უფსკრული სიძლიერე), ზოგიერთი აღწერილობითი სტატისტიკა და ცალმხრივი დისპერსიის ანალიზის შედეგები ნაჩვენებია ნახ. 6.

ბრინჯი. 5. ფანჯარა ცალმხრივი ANOVA ანალიზის პაკეტი excel

ბრინჯი. სურ. 6. სხვადასხვა მომწოდებლებისგან მიღებული სინთეზური ბოჭკოებისგან ნაქსოვი პარაშუტების სიძლიერის ინდიკატორები, აღწერითი სტატისტიკა და ცალმხრივი დისპერსიული ანალიზის შედეგები
სურათი 6-ის ანალიზი აჩვენებს, რომ არსებობს გარკვეული განსხვავება ნიმუშის საშუალებებს შორის. პირველი მიმწოდებლისგან მიღებული ბოჭკოების საშუალო სიმტკიცე არის 19,52, მეორედან - 24,26, მესამედან - 22,84 და მეოთხედან - 21,16. არის ეს განსხვავება სტატისტიკურად მნიშვნელოვანი? რღვევის ძალის განაწილება ნაჩვენებია სკატერის დიაგრამაზე (ნახ. 7). ის ნათლად აჩვენებს განსხვავებებს როგორც ჯგუფებს შორის, ასევე მათ შიგნით. თუ თითოეული ჯგუფის მოცულობა უფრო დიდი იყო, მათი ანალიზი შეიძლებოდა ღეროსა და ფოთლის ნაკვეთის, ყუთის ნაკვეთის ან ნორმალური განაწილების ნაკვეთის გამოყენებით.

ბრინჯი. 7. ოთხი მიმწოდებლისგან მიღებული სინთეტიკური ბოჭკოებისგან ნაქსოვი პარაშუტების სიძლიერის გავრცელების სქემა
ნულოვანი ჰიპოთეზა ამბობს, რომ არ არსებობს მნიშვნელოვანი განსხვავებები საშუალო სიმტკიცის მნიშვნელობებს შორის: H 0: μ 1 = μ 2 = μ 3 = μ 4. ალტერნატიული ჰიპოთეზა არის ის, რომ არის მინიმუმ ერთი მიმწოდებელი, რომლის ბოჭკოს საშუალო სიძლიერე განსხვავდება სხვებისგან: H 1: ყველა μ j არ არის ერთნაირი ( ჯ = 1, 2, …, თან).
საერთო საშუალო (იხ. სურათი 6) = AVERAGE(D12:D15) = 21,945; დასადგენად, თქვენ ასევე შეგიძლიათ საშუალოდ 20-ვე ორიგინალური რიცხვი: \u003d AVERAGE (A3: D7). ვარიაციის მნიშვნელობები გამოითვლება საანალიზო პაკეტიდა აისახება ცხრილში დისპერსიის ანალიზი(იხ. ნახ. 6): SSA = 63.286, SSW = 97.504, SST = 160.790 (იხ. სვეტი SSმაგიდები დისპერსიის ანალიზისურათი 6). საშუალოები გამოითვლება კვადრატების ამ ჯამების გაყოფით თავისუფლების ხარისხების შესაბამის რაოდენობაზე. Იმდენად, რამდენადაც თან= 4 და ნ= 20, ჩვენ ვიღებთ თავისუფლების ხარისხების შემდეგ მნიშვნელობებს; SSA-სთვის: s - 1= 3; SSW-სთვის: n–c= 16; SST-სთვის: n - 1= 19 (იხ. სვეტი დფ). ამრიგად: MSA = SSA / ( გ - 1)= 21.095; MSW=SSW/( n–c) = 6.094; MST = SST / ( n - 1) = 8.463 (იხ. სვეტი ᲥᲐᲚᲑᲐᲢᲝᲜᲘ). ფ-სტატისტიკა = MSA / MSW = 3.462 (იხ. სვეტი ფ).
ზედა კრიტიკული მნიშვნელობა ფU, დამახასიათებელი ფ-განაწილება, განისაზღვრება ფორმულით = F. OBR (0.95; 3; 16) = 3.239. ფუნქციის პარამეტრები =F.OBR(): α = 0,05, მრიცხველს აქვს თავისუფლების სამი ხარისხი, ხოლო მნიშვნელი არის 16. ამრიგად, გამოთვლილი ფ-3.462-ის ტოლი სტატისტიკა აღემატება ზედა კრიტიკულ მნიშვნელობას ფU= 3.239, ნულოვანი ჰიპოთეზა უარყოფილია (ნახ. 8).

ბრინჯი. 8. დისპერსიის ანალიზის კრიტიკული არეალი მნიშვნელოვნების დონეზე 0,05, თუ მრიცხველს აქვს თავისუფლების სამი ხარისხი და მნიშვნელი არის -16
რ- ღირებულება, ე.ი. ალბათობა იმისა, რომ ჭეშმარიტი ნულოვანი ჰიპოთეზის მიხედვით ფ- სტატისტიკა არანაკლებ 3,46, ტოლია 0,041 ან 4,1% (იხ. სვეტი p-მნიშვნელობამაგიდები დისპერსიის ანალიზისურათი 6). ვინაიდან ეს მნიშვნელობა არ აღემატება მნიშვნელოვნების დონეს α = 5%, ნულოვანი ჰიპოთეზა უარყოფილია. გარდა ამისა, რ-მნიშვნელობა მიუთითებს იმაზე, რომ საერთო პოპულაციის მათემატიკურ მოლოდინებს შორის ასეთი ან დიდი სხვაობის პოვნის ალბათობა, იმ პირობით, რომ ისინი რეალურად იგივეა, არის 4,1%.
Ისე. არსებობს განსხვავება ოთხ ნიმუშს შორის. ნულოვანი ჰიპოთეზა იყო, რომ ოთხი პოპულაციის ყველა მათემატიკური მოლოდინი თანაბარია. ამ პირობებში, ყველა პარაშუტის სიძლიერის მთლიანი ცვალებადობის (ანუ მთლიანი SST ცვალებადობის) საზომი გამოითვლება თითოეულ დაკვირვებას შორის კვადრატული განსხვავებების შეჯამებით. Xijდა საერთო საშუალო . შემდეგ მთლიანი ვარიაცია დაიყო ორ კომპონენტად (იხ. სურ. 1). პირველი კომპონენტი იყო ჯგუფთაშორისი ვარიაცია SSA-ში და მეორე კომპონენტი იყო შიდაჯგუფური ვარიაცია SSW-ში.
რა ხსნის მონაცემთა ცვალებადობას? სხვა სიტყვებით რომ ვთქვათ, რატომ არ არის ყველა დაკვირვება ერთნაირი? ერთი მიზეზი არის ის, რომ სხვადასხვა ფირმა აწვდის ბოჭკოებს სხვადასხვა სიძლიერით. ეს ნაწილობრივ განმარტავს, თუ რატომ აქვთ ჯგუფებს განსხვავებული მოსალოდნელი მნიშვნელობები: რაც უფრო ძლიერია ექსპერიმენტული პირობების ეფექტი, მით მეტია განსხვავება ჯგუფების საშუალო მნიშვნელობებს შორის. მონაცემთა ცვალებადობის კიდევ ერთი მიზეზი არის ნებისმიერი პროცესის ბუნებრივი ცვალებადობა, ამ შემთხვევაში პარაშუტების წარმოება. მაშინაც კი, თუ ყველა ბოჭკო შეძენილი უნდა იყოს ერთი და იგივე მომწოდებლისგან, მათი სიძლიერე არ იქნება იგივე, ყველა დანარჩენი თანაბარი იქნება. ვინაიდან ეს ეფექტი ჩნდება თითოეულ ჯგუფში, მას უწოდებენ ჯგუფურ ვარიაციას.
ნიმუშების საშუალებებს შორის განსხვავებებს უწოდებენ SSA-ს ჯგუფთაშორის ვარიაციას. შიდაჯგუფური ვარიაციის ნაწილი, როგორც უკვე აღვნიშნეთ, აიხსნება იმით, რომ მონაცემები სხვადასხვა ჯგუფს მიეკუთვნება. თუმცა, მაშინაც კი, თუ ჯგუფები ზუსტად იგივე იქნებოდა (ანუ, ნულოვანი ჰიპოთეზა იქნება ჭეშმარიტი), მაინც იქნება ჯგუფთაშორისი ვარიაცია. ამის მიზეზი პარაშუტის წარმოების პროცესის ბუნებრივ ცვალებადობაშია. ვინაიდან ნიმუშები განსხვავებულია, მათი ნიმუშის საშუალებები განსხვავდება ერთმანეთისგან. მაშასადამე, თუ ნულოვანი ჰიპოთეზა ჭეშმარიტია, როგორც ჯგუფს შორის, ასევე ჯგუფურ ცვალებადობას წარმოადგენს პოპულაციის ცვალებადობის შეფასება. თუ ნულოვანი ჰიპოთეზა მცდარია, ჯგუფთა ჰიპოთეზა უფრო დიდი იქნება. სწორედ ეს ფაქტი უდევს საფუძვლად ფ-რამდენიმე ჯგუფის მათემატიკურ მოლოდინებს შორის განსხვავებების შედარების კრიტერიუმები.
ცალმხრივი ANOVA-ს განხორციელების და ფირმებს შორის მნიშვნელოვანი განსხვავებების აღმოჩენის შემდეგ, უცნობი რჩება რომელი მიმწოდებელი მნიშვნელოვნად განსხვავდება სხვებისგან. ჩვენ მხოლოდ ის ვიცით, რომ მოსახლეობის მათემატიკური მოლოდინები არ არის თანაბარი. სხვა სიტყვებით რომ ვთქვათ, მათემატიკური მოლოდინებიდან ერთი მაინც მნიშვნელოვნად განსხვავდება სხვებისგან. იმის დასადგენად, თუ რომელი პროვაიდერი განსხვავდება სხვებისგან, შეგიძლიათ გამოიყენოთ Tukey პროცედურა, რომელიც იყენებს პროვაიდერებს შორის წყვილ შედარებას. ეს პროცედურა შეიმუშავა ჯონ ტუკეიმ. შემდგომში მან და C. Cramer-მა დამოუკიდებლად შეცვალეს ეს პროცედურა იმ სიტუაციებისთვის, როდესაც ნიმუშის ზომები განსხვავდება ერთმანეთისგან.
მრავალჯერადი შედარება: ტუკი-კრამერის პროცედურა
ჩვენს სცენარში, პარაშუტების სიძლიერის შესადარებლად გამოიყენეს დისპერსიის ცალმხრივი ანალიზი. ოთხი ჯგუფის მათემატიკურ მოლოდინებს შორის მნიშვნელოვანი განსხვავებების აღმოჩენის შემდეგ, აუცილებელია განვსაზღვროთ რომელი ჯგუფები განსხვავდებიან ერთმანეთისგან. მიუხედავად იმისა, რომ ამ პრობლემის გადაჭრის რამდენიმე გზა არსებობს, ჩვენ მხოლოდ ტუკი-კრამერის მრავალჯერადი შედარების პროცედურას აღვწერთ. ეს მეთოდი არის პოსტ-ჰოკ შედარების პროცედურების მაგალითი, ვინაიდან შესამოწმებელი ჰიპოთეზა ჩამოყალიბებულია მონაცემთა ანალიზის შემდეგ. Tukey-Kramer პროცედურა საშუალებას გაძლევთ ერთდროულად შეადაროთ ჯგუფის ყველა წყვილი. პირველ ეტაპზე განსხვავებები გამოითვლება Xჯ - Xჯ ’ , სად j ≠ჯ’ , მათემატიკურ მოლოდინებს შორის s(s – 1)/2ჯგუფები. კრიტიკული დიაპაზონი Tukey-Kramer პროცედურა გამოითვლება ფორმულით:
სადაც Q U- სტუდენტური დიაპაზონის განაწილების ზედა კრიტიკული მნიშვნელობა, რომელსაც აქვს თანთავისუფლების ხარისხი მრიცხველში და ნ - თანთავისუფლების ხარისხი მნიშვნელში.
თუ ნიმუშის ზომები არ არის იგივე, კრიტიკული დიაპაზონი გამოითვლება მათემატიკური მოლოდინების თითოეული წყვილისთვის ცალ-ცალკე. ბოლო ეტაპზე თითოეული s(s – 1)/2მათემატიკური მოლოდინების წყვილი შედარებულია შესაბამის კრიტიკულ დიაპაზონთან. წყვილის ელემენტები მნიშვნელოვნად განსხვავებულად ითვლება, თუ განსხვავების მოდული | Xj - Xჯ ’ | მათ შორის აღემატება კრიტიკულ დიაპაზონს.
გამოვიყენოთ თუკი-კრამერის პროცედურა პარაშუტების სიძლიერის პრობლემაზე. ვინაიდან პარაშუტის კომპანიას ჰყავს ოთხი მომწოდებელი, უნდა შემოწმდეს 4(4 – 1)/2 = 6 წყვილი მომწოდებელი (სურათი 9).

ბრინჯი. 9. ნიმუშის საშუალებების წყვილი შედარება
ვინაიდან ყველა ჯგუფს აქვს იგივე მოცულობა (ანუ ყველა nj = nj ’ ), საკმარისია მხოლოდ ერთი კრიტიკული დიაპაზონის გამოთვლა. ამისათვის, ცხრილის მიხედვით ANOVA(ნახ. 6) ჩვენ განვსაზღვრავთ MSW = 6.094 მნიშვნელობას. შემდეგ ჩვენ ვიპოვით მნიშვნელობას Q Uα = 0.05-ზე, თან= 4 (თავისუფლების გრადუსების რაოდენობა მრიცხველში) და ნ- თან= 20 – 4 = 16 (თავისუფლების გრადუსების რაოდენობა მნიშვნელში). სამწუხაროდ, Excel-ში შესაბამისი ფუნქცია ვერ ვიპოვე და გამოვიყენე ცხრილი (ნახ. 10).

ბრინჯი. 10. სტუდენტური დიაპაზონის კრიტიკული მნიშვნელობა Q U
ჩვენ ვიღებთ:
ვინაიდან მხოლოდ 4.74 > 4.47 (იხ. ქვედა ცხრილი 9-ზე), სტატისტიკურად მნიშვნელოვანი განსხვავებაა პირველ და მეორე მიმწოდებელს შორის. ყველა სხვა წყვილს აქვს სანიმუშო საშუალებები, რაც არ გვაძლევს საშუალებას ვისაუბროთ მათ განსხვავებაზე. შესაბამისად, პირველი მიმწოდებლისგან შეძენილი ბოჭკოებისგან ნაქსოვი პარაშუტების საშუალო სიძლიერე მნიშვნელოვნად ნაკლებია მეორეზე.
ცალმხრივი დისპერსიული ანალიზისთვის აუცილებელი პირობები
პარაშუტების სიმტკიცის პრობლემის გადაჭრისას, ჩვენ არ შევამოწმეთ არის თუ არა დაკმაყოფილებული პირობები, რომლითაც შეიძლება ერთი ფაქტორის გამოყენება. ფ-კრიტერიუმი. როგორ იცით, შეგიძლიათ თუ არა ერთი ფაქტორის გამოყენება ფ-კრიტერიუმი კონკრეტული ექსპერიმენტული მონაცემების ანალიზში? ერთი ფაქტორი ფტესტის გამოყენება შესაძლებელია მხოლოდ იმ შემთხვევაში, თუ დაკმაყოფილებულია სამი ძირითადი დაშვება: ექსპერიმენტული მონაცემები უნდა იყოს შემთხვევითი და დამოუკიდებელი, ჰქონდეს ნორმალური განაწილება და მათი ვარიაციები უნდა იყოს იგივე.
პირველი ვარაუდი არის შემთხვევითობა და მონაცემთა დამოუკიდებლობა- ყოველთვის უნდა გაკეთდეს, რადგან ნებისმიერი ექსპერიმენტის სისწორე დამოკიდებულია არჩევანის შემთხვევითობაზე და/ან რანდომიზაციის პროცესზე. შედეგების დამახინჯების თავიდან ასაცილებლად, აუცილებელია მონაცემების ამოღება თანპოპულაციები შემთხვევით და ერთმანეთისგან დამოუკიდებლად. ანალოგიურად, მონაცემები შემთხვევით უნდა გადანაწილდეს თანჩვენთვის საინტერესო ფაქტორის დონეები (ექსპერიმენტული ჯგუფები). ამ პირობების დარღვევამ შეიძლება სერიოზულად დაამახინჯოს დისპერსიული ანალიზის შედეგები.
მეორე ვარაუდი არის ნორმალურობა- ნიშნავს, რომ მონაცემები აღებულია ნორმალურად განაწილებული პოპულაციებიდან. რაც შეეხება ტ-კრიტერიუმი, ცალმხრივი დისპერსიის ანალიზი ეფუძნება ფ- კრიტერიუმი შედარებით უგრძნობია ამ მდგომარეობის დარღვევის მიმართ. თუ განაწილება არ არის ძალიან შორს ნორმალურიდან, მნიშვნელოვნების დონე ფ-კრიტერიუმი ოდნავ იცვლება, განსაკუთრებით თუ ნიმუშის ზომა საკმარისად დიდია. თუ ნორმალური განაწილების მდგომარეობა სერიოზულად არის დარღვეული, ის უნდა იქნას გამოყენებული.
მესამე ვარაუდი არის დისპერსიის ერთგვაროვნება- ნიშნავს, რომ თითოეული ზოგადი პოპულაციის ვარიაციები ერთმანეთის ტოლია (ე.ი. σ 1 2 = σ 2 2 = … = σ j 2). ეს ვარაუდი საშუალებას აძლევს ადამიანს გადაწყვიტოს, განცალკევდეს თუ გააერთიანოს ჯგუფური დისპერსიები. თუ ჯგუფების მოცულობა ერთნაირია, დისპერსიის ჰომოგენურობის პირობა მცირე გავლენას ახდენს გამოყენებით მიღებულ დასკვნებზე ფ- კრიტერიუმები. თუმცა, თუ ნიმუშის ზომები არ არის იგივე, დისპერსიების თანასწორობის პირობის დარღვევამ შეიძლება სერიოზულად დაამახინჯოს დისპერსიული ანალიზის შედეგები. ამრიგად, უნდა ვცდილობთ უზრუნველყოთ, რომ ნიმუშის ზომები იგივეა. ვარიაციის ჰომოგენურობის შესახებ დაშვების შემოწმების ერთ-ერთი მეთოდი კრიტერიუმია ლევენეიაღწერილია ქვემოთ.
თუ სამივე პირობიდან ირღვევა მხოლოდ დისპერსიული მდგომარეობის ერთგვაროვნება, ანალოგიური პროცედურა ტ-კრიტერიუმი ცალკე დისპერსიის გამოყენებით (იხილეთ დეტალები). თუმცა, თუ ნორმალური განაწილებისა და ვარიაციის ერთგვაროვნების დაშვება ერთდროულად ირღვევა, საჭიროა მონაცემთა ნორმალიზება და განსხვავებათა შორის განსხვავებების შემცირება ან არაპარამეტრული პროცედურის გამოყენება.
ლევენის კრიტერიუმი დისპერსიის ჰომოგენურობის შესამოწმებლად
Მიუხედავად იმისა, რომ ფ- კრიტერიუმი შედარებით მდგრადია ჯგუფებში განსხვავებების თანასწორობის პირობის დარღვევის მიმართ, ამ დაშვების უხეში დარღვევა მნიშვნელოვნად აისახება კრიტერიუმის მნიშვნელოვნებისა და სიმძლავრის დონეზე. ალბათ ერთ-ერთი ყველაზე ძლიერი კრიტერიუმია ლევენეი. დისპერსიების ტოლობის შესამოწმებლად თანზოგადი პოპულაციების მიხედვით, ჩვენ შევამოწმებთ შემდეგ ჰიპოთეზებს:
H 0: σ 1 2 = σ 2 2 = ... = σჯ 2
H 1: Ყველა არა σ j 2იგივეა ( ჯ = 1, 2, …, თან)
შეცვლილი ლევენის ტესტი ემყარება იმ მტკიცებას, რომ თუ ჯგუფებში ცვალებადობა იგივეა, დაკვირვებებსა და ჯგუფურ მედიანებს შორის განსხვავებების აბსოლუტური მნიშვნელობების დისპერსიის ანალიზი შეიძლება გამოყენებულ იქნას ვარიაციების თანასწორობის ნულოვანი ჰიპოთეზის შესამოწმებლად. ასე რომ, ჯერ უნდა გამოთვალოთ თითოეულ ჯგუფში დაკვირვებებსა და მედიანებს შორის განსხვავებების აბსოლუტური მნიშვნელობები, შემდეგ კი განახორციელოთ დისპერსიის ცალმხრივი ანალიზი განსხვავებების მიღებულ აბსოლუტურ მნიშვნელობებზე. ლევენის კრიტერიუმის საილუსტრაციოდ, დავუბრუნდეთ ჩანაწერის დასაწყისში გამოკვეთილ სცენარს. ნახ. 6, ჩვენ განვახორციელებთ მსგავს ანალიზს, ოღონდ საწყის მონაცემებსა და მედიანაში განსხვავებების მოდულებთან მიმართებაში თითოეული ნიმუშისთვის ცალკე (ნახ. 11).
დისპერსიის ანალიზი საშუალებას გაძლევთ შეისწავლოთ განსხვავება მონაცემთა ჯგუფებს შორის, დაადგინოთ არის თუ არა ეს შეუსაბამობები შემთხვევითი თუ გამოწვეული კონკრეტული გარემოებებით. მაგალითად, თუ კომპანიის გაყიდვები ერთ-ერთ რეგიონში შემცირდა, მაშინ დისპერსიის ანალიზის გამოყენებით შეგიძლიათ გაარკვიოთ, შემთხვევითია თუ არა ბრუნვის კლება ამ რეგიონში დანარჩენებთან შედარებით და, საჭიროების შემთხვევაში, განახორციელოთ ორგანიზაციული ცვლილებები. სხვადასხვა პირობებში ექსპერიმენტის ჩატარებისას, დისპერსიის ანალიზი დაგვეხმარება იმის დადგენაში, თუ რამდენად გავლენას ახდენს გარე ფაქტორები გაზომვებზე, ან გადახრები შემთხვევითია. თუ წარმოებაში, პროდუქციის ხარისხის გასაუმჯობესებლად, იცვლება პროცესების რეჟიმი, მაშინ დისპერსიის ანალიზი საშუალებას გვაძლევს შევაფასოთ ამ ფაქტორის ზემოქმედების შედეგები.
ამაზე მაგალითიჩვენ ვაჩვენებთ, თუ როგორ უნდა შესრულდეს ANOVA ექსპერიმენტულ მონაცემებზე.
სავარჯიშო 1. ტექსტილის ინდუსტრიისთვის არის ნედლეულის ოთხი პარტია. თითოეული პარტიიდან შეირჩა ხუთი ნიმუში და ჩატარდა ტესტები მსხვრევის დატვირთვის სიდიდის დასადგენად. ტესტის შედეგები ნაჩვენებია ცხრილში.
71" height="29" bgcolor="white" style="border:.75pt solid black; vertical-align:top;background:white">
ნახ.1 |
 > გახსენით Microsoft Excel ელცხრილი. დააწკაპუნეთ Sheet2 ეტიკეტზე სხვა სამუშაო ფურცელზე გადასართავად.
> გახსენით Microsoft Excel ელცხრილი. დააწკაპუნეთ Sheet2 ეტიკეტზე სხვა სამუშაო ფურცელზე გადასართავად. > შეიყვანეთ ANOVA მონაცემები, რომლებიც ნაჩვენებია სურათზე 1.
> გადაიყვანეთ მონაცემები რიცხვის ფორმატში. ამისათვის აირჩიეთ მენიუს ბრძანება Format Cell. ეკრანზე გამოჩნდება უჯრედის ფორმატის ფანჯარა (ნახ. 2). აირჩიეთ რიცხვითი ფორმატი და შეყვანილი მონაცემები გარდაიქმნება ნახ. 3
> აირჩიეთ მენიუს ბრძანება Service Data Analysis (Tools * Data Analysis). ეკრანზე გამოჩნდება მონაცემთა ანალიზი (მონაცემთა ანალიზი) ფანჯარა (ნახ. 4).
> დააწკაპუნეთ ხაზზე ვარიანტობის ერთი ფაქტორიანი ანალიზი (Anova: Single Factor) ანალიზის ხელსაწყოების სიაში (Anova: Single Factor).
> დააწკაპუნეთ OK მონაცემთა ანალიზის (მონაცემთა ანალიზის) ფანჯრის დასახურად. დისპერსიის ცალმხრივი ანალიზის ფანჯარა გამოჩნდება ეკრანზე მონაცემთა დისპერსიის ანალიზის ჩასატარებლად (ნახ. 5).
https://pandia.ru/text/78/446/images/image006_46.jpg" width="311" height="214 src=">
|
> დააინსტალირეთ მონიშვნის ველი ტეგებიპირველ რიგში (Labels in First Rom) Input controls ჯგუფში, თუ არჩეული მონაცემთა დიაპაზონის პირველი სვეტი შეიცავს რიგების სახელებს.
> შეყვანის ველში ალფა(A1pha) საკონტროლო ჯგუფის შეყვანა ნაგულისხმევად არის 0.05 მნიშვნელობა, რაც დაკავშირებულია დისპერსიის ანალიზში შეცდომის ალბათობასთან.
> თუ Nev Worksheet Ply გადამრთველი არ არის დაყენებული Input options ჯგუფში, მაშინ დააყენეთ ისე, რომ დისპერსიის ანალიზის შედეგები განთავსდეს ახალ სამუშაო ფურცელზე.
> დააწკაპუნეთ OK, რათა დახუროთ Anova: Single Factor ფანჯარა. დისპერსიული ანალიზის შედეგები გამოჩნდება ახალ სამუშაო ფურცელზე (ნახ. 6).
|

A4:E6 უჯრედების დიაპაზონი შეიცავს აღწერითი სტატისტიკის შედეგებს. ხაზი 4 შეიცავს პარამეტრების სახელებს, ხაზები შეიცავს სტატისტიკურ მნიშვნელობებს, რომლებიც გამოითვლება სურათების მიხედვით.
სვეტში Ჩეკი(Count) არის გაზომვების რაოდენობა, Sum სვეტში - მნიშვნელობების ჯამი, სვეტში Average (Avegage) - საშუალო არითმეტიკული მნიშვნელობები, სვეტში Variance (Varianse) - დისპერსია.
მიღებული შედეგები აჩვენებს, რომ ყველაზე მაღალი საშუალო მსხვრევადი დატვირთვა არის პარტიაში #3, ხოლო მსხვრევადი დატვირთვის ყველაზე დიდი დისპერსია არის პარტიაში #1.
უჯრედების დიაპაზონში A11:გ16 აჩვენებს ინფორმაციას მონაცემთა ჯგუფებს შორის შეუსაბამობების მნიშვნელობის შესახებ. სტრიქონი 12 შეიცავს დისპერსიული პარამეტრების ანალიზის სახელებს, სტრიქონი 13 - ჯგუფთაშორისი დამუშავების შედეგები, სტრიქონი 14 - შიდაჯგუფური დამუშავების შედეგები და სტრიქონი 16 - აღნიშნული ორი ხაზის მნიშვნელობების ჯამი.
სვეტში SS (qi) განლაგებულია ვარიაციის მნიშვნელობები, ანუ კვადრატების ჯამები ყველა გადახრებზე. ვარიაცია, დისპერსიის მსგავსად, ახასიათებს მონაცემთა გავრცელებას. ცხრილიდან ჩანს, რომ რღვევის დატვირთვის ჯგუფთაშორისი გავრცელება მნიშვნელოვნად აღემატება შიდაჯგუფურ ვარიაციას.
სვეტში დფ (კ) ნაპოვნია თავისუფლების ხარისხების რიცხვების მნიშვნელობები. ეს რიცხვები მიუთითებს დამოუკიდებელი გადახრების რაოდენობაზე, რომლებზედაც გამოითვლება განსხვავება. მაგალითად, თავისუფლების ხარისხთა ჯგუფთაშორისი რაოდენობა უდრის სხვაობას მონაცემთა ჯგუფების რაოდენობასა და ერთს შორის. რაც უფრო მეტია თავისუფლების ხარისხი, მით უფრო მაღალია დისპერსიის პარამეტრების სანდოობა. ცხრილში მოცემული თავისუფლების ხარისხი აჩვენებს, რომ ჯგუფური შედეგები უფრო სანდოა, ვიდრე ჯგუფთა შორის პარამეტრები.
სვეტში ᲥᲐᲚᲑᲐᲢᲝᲜᲘ (ს2 ) განლაგებულია დისპერსიული მნიშვნელობები, რომლებიც განისაზღვრება ცვალებადობის თანაფარდობით და თავისუფლების ხარისხით. დისპერსია ახასიათებს მონაცემთა გაფანტვის ხარისხს, მაგრამ ვარიაციის სიდიდისგან განსხვავებით, მას არ აქვს პირდაპირი ტენდენცია გაზრდის თავისუფლების ხარისხების რაოდენობის ზრდასთან ერთად. ცხრილი გვიჩვენებს, რომ ჯგუფთაშორისი დისპერსია ბევრად უფრო დიდია, ვიდრე შიდაჯგუფური ვარიანსი.
სვეტში ფმდებარეობს, ღირებულება ფ- სტატისტიკა, გამოითვლება ჯგუფთაშორისი და შიდაჯგუფური დისპერსიების შეფარდებით.
სვეტში ფკრიტიკული(F კრიტი) მდებარეობს F- კრიტიკული მნიშვნელობა, რომელიც გამოითვლება თავისუფლების გრადუსების რიცხვიდან და ალფას მნიშვნელობიდან (A1pha). F-სტატისტიკური და F-კრიტიკული მნიშვნელობის გამოყენების კრიტერიუმი ფიშერი-სნედეკორა.
თუ F-სტატისტიკა მეტია F-კრიტიკულ მნიშვნელობაზე, მაშინ შეიძლება ითქვას, რომ მონაცემთა ჯგუფებს შორის განსხვავებები შემთხვევითი არ არის. ანუ მნიშვნელოვნების დონეზე α = 0,05 (სანდოობით 0,95) ნულოვანი ჰიპოთეზა უარყოფილია და ალტერნატივა მიიღება: ნედლეულის პარტიებს შორის განსხვავება მნიშვნელოვან გავლენას ახდენს დამტვრევის დატვირთვის სიდიდეზე.
P-მნიშვნელობის სვეტი შეიცავს ალბათობის მნიშვნელობას, რომ ჯგუფებს შორის შეუსაბამობა შემთხვევითია. ვინაიდან ეს ალბათობა ძალიან მცირეა ცხრილში, გადახრა ჯგუფებს შორის არ არის შემთხვევითი.
2. დისპერსიის ორმხრივი ანალიზის ამოცანების ამოხსნა გამეორებების გარეშე
Microsoft Excel-ს აქვს Anova: (ორი ფაქტორი რეპლიკაციის გარეშე) ფუნქცია, რომელიც გამოიყენება კონტროლირებადი ფაქტორების გავლენის ფაქტის დასადგენად. მაგრამ და AT ეფექტურ ატრიბუტზე, რომელიც დაფუძნებულია ნიმუშის მონაცემებზე და ფაქტორების თითოეულ დონეზე მაგრამ და AT მხოლოდ ერთი ნიმუში ემთხვევა. ამ ფუნქციის გამოსაძახებლად აირჩიეთ ბრძანება მენიუს ზოლში სერვისი – მონაცემთა ანალიზი. ეკრანზე გაიხსნება ფანჯარა. Მონაცემთა ანალიზი, რომელშიც უნდა აირჩიოთ მნიშვნელობა დისპერსიის ორმხრივი ანალიზი გამეორებების გარეშედა დააჭირეთ ღილაკს OK. შედეგად, დიალოგური ფანჯარა, რომელიც ნაჩვენებია სურათზე 1, გაიხსნება ეკრანზე.
78" height="42" bgcolor="white" style="border:.75pt solid black; vertical-align:top;background:white">
3. ალფა ველში შეყვანილია მნიშვნელობის მისაღები დონე. α , რაც შეესაბამება პირველი სახის შეცდომის ალბათობას.
4. გამომავალი პარამეტრების ჯგუფში გადამრთველი შეიძლება დაყენდეს სამ პოზიციაზე ერთ-ერთზე: გამომავალი დიაპაზონი, ახალი სამუშაო ფურცელი ან ახალი სამუშაო წიგნი.
მაგალითი.
დისპერსიის ორმხრივი ანალიზი გამეორებების გარეშე(Anova: Two-Factor Without Replication) შემდეგ მაგალითში.

სურათზე. სურათი 2 გვიჩვენებს ხორბლის ოთხი ჯიშის მოსავლიანობას (ც/ჰა) (ა ფაქტორის ოთხი დონე) მიღწეული ხუთი ტიპის სასუქით (ბ ფაქტორის ხუთი დონე). მონაცემები მიღებული იქნა 20 ერთნაირი ზომის და მსგავსი ნიადაგის საფარის ნაკვეთიდან. უნდა განისაზღვროსგავლენას ახდენს თუ არა სასუქის ჯიში და სახეობა ხორბლის მოსავლიანობაზე.
დისპერსიის ორმხრივი ანალიზი გამეორებების გარეშენაჩვენებია სურათზე 3.
 როგორც შედეგებიდან ჩანს, F- სტატისტიკური მნიშვნელობის გამოთვლილი მნიშვნელობა A ფაქტორისთვის (სასუქის ტიპი) ფმაგრამ=
ლ,67
, და კრიტიკული რეგიონი იქმნება მარჯვენა ინტერვალით (3.49; +∞). როგორც ფმაგრამ=
ლ,67
არ შედის კრიტიკულ რეგიონში, HA ჰიპოთეზა: ა
1
= ა
2
+ = აკ
მიღება, ანუ ჩვენ გვჯერა, რომ ამ ექსპერიმენტში სასუქის ტიპს არ ჰქონდა გავლენა მოსავლიანობაზე.
როგორც შედეგებიდან ჩანს, F- სტატისტიკური მნიშვნელობის გამოთვლილი მნიშვნელობა A ფაქტორისთვის (სასუქის ტიპი) ფმაგრამ=
ლ,67
, და კრიტიკული რეგიონი იქმნება მარჯვენა ინტერვალით (3.49; +∞). როგორც ფმაგრამ=
ლ,67
არ შედის კრიტიკულ რეგიონში, HA ჰიპოთეზა: ა
1
= ა
2
+ = აკ
მიღება, ანუ ჩვენ გვჯერა, რომ ამ ექსპერიმენტში სასუქის ტიპს არ ჰქონდა გავლენა მოსავლიანობაზე.
როგორც ფAT=2.03 არ ჯდება კრიტიკულ რეგიონში, ჰიპოთეზა HB: ბ1 = ბ2 = ... = ბმ
ასევე მივიღოთ, ანუ ჩვენ გვჯერა, რომ ამაში ექსპერიმენტში ხორბლის ჯიშმაც არ იმოქმედა მოსავლიანობაზე.
2. დისპერსიის ორმხრივი ანალიზიგგამეორებები
Microsoft Excel-ს აქვს Anova ფუნქცია: Two-Factor With Replication, რომელიც ასევე გამოიყენება იმის დასადგენად, მოქმედებს თუ არა კონტროლირებადი ფაქტორები A და B ეფექტურობის მახასიათებლებზე, ნიმუშის მონაცემების საფუძველზე. თუმცა, A (ან B) ფაქტორის თითოეული დონე შეესაბამება ერთზე მეტ მონაცემს.
განიხილეთ ფუნქციის გამოყენება დისპერსიის ორმხრივი ანალიზი გამეორებებითშემდეგ მაგალითზე.
მაგალითი 2. მაგიდაზე. სურათი 6 გვიჩვენებს კვლევისთვის შეგროვებული 18 გოჭის დღიური წონის მომატებას (გ), რაც დამოკიდებულია გოჭების შენახვის მეთოდზე (ფაქტორი A) და მათი კვების ხარისხზე (ფაქტორი B).
75" height="33" bgcolor="white" style="border:.75pt solid black; vertical-align:top;background:white"> 

ეს დიალოგური ფანჯარა ადგენს შემდეგ ვარიანტებს.
1. შეყვანის დიაპაზონის ველში შეიყვანეთ მითითება გაანალიზებული მონაცემების შემცველი უჯრედების დიაპაზონზე. აირჩიეთ უჯრედები გ 4 ადრე მე 13.
2. ველში Rows per sample, განსაზღვრეთ ნიმუშების რაოდენობა ერთ-ერთი ფაქტორის თითოეული დონისთვის. თითოეული ფაქტორის დონე უნდა შეიცავდეს ნიმუშების ერთსა და იმავე რაოდენობას (ცხრილის რიგები). ჩვენს შემთხვევაში, ხაზების რაოდენობა სამია.
3. Alpha ველში შეიყვანეთ მნიშვნელობის დონის მიღებული მნიშვნელობა α , რომელიც უდრის I ტიპის შეცდომის ალბათობას.
4. გამომავალი პარამეტრების ჯგუფში გადამრთველი შეიძლება დაყენდეს სამიდან ერთ პოზიციაზე: გამომავალი დიაპაზონი (გამომავალი ინტერვალი), New Worksheet Ply (ახალი სამუშაო ფურცელი) ან ახალი სამუშაო წიგნი (ახალი სამუშაო წიგნი).
ფუნქციის გამოყენებით დისპერსიის ორმხრივი ანალიზის შედეგები დისპერსიის ორმხრივი ანალიზი მნიშვნელოვანი გამეორებებით.Იმის გამო, რომ ![]() ამ ფაქტორების ურთიერთქმედება უმნიშვნელოა (5%-იან დონეზე).
ამ ფაქტორების ურთიერთქმედება უმნიშვნელოა (5%-იან დონეზე).
Საშინაო დავალება
1. ექვსი წლის განმავლობაში ხუთ სხვადასხვა ტექნოლოგიას იყენებდნენ მოსავლის მოსაყვანად. ექსპერიმენტული მონაცემები (ც/ჰა) მოცემულია ცხრილში:
https://pandia.ru/text/78/446/images/image024_11.jpg" width="642" height="190 src=">
საჭიროა მნიშვნელოვნების დონეზე α = 0,05, რათა დადგინდეს მაღალი ხარისხის ფილების წარმოების დამოკიდებულება საწარმოო ხაზზე (ფაქტორი A).
3. გამოყოფილ ხუთ მიწის ნაკვეთზე (ბლოკში) ოთხი ჯიშის ხორბლის მოსავლიანობის შესახებ ხელმისაწვდომია შემდეგი მონაცემები:
https://pandia.ru/text/78/446/images/image026_9.jpg" width="598" height="165 src=">
საჭიროა მნიშვნელოვნების დონეზე α = 0,05 ტექნოლოგიების (ფაქტორი A) და საწარმოების (ფაქტორი B) შრომის პროდუქტიულობაზე ზემოქმედების დადგენა.
კონტროლირებადი ცვლადების გავლენის ქვეშ მახასიათებლის ცვალებადობის გასაანალიზებლად გამოიყენება დისპერსიული მეთოდი.
მნიშვნელობებს შორის კავშირის შესწავლა - ფაქტორული მეთოდი. განვიხილოთ უფრო დეტალურად ანალიტიკური ინსტრუმენტები: ცვალებადობის შეფასების ფაქტორული, დისპერსიული და ორფაქტორიანი დისპერსიის მეთოდები.
ANOVA Excel-ში
პირობითად, დისპერსიული მეთოდის მიზანი შეიძლება ჩამოყალიბდეს შემდეგნაირად: გამოვყოთ მე-3 პარამეტრის მთლიანი ცვალებადობიდან კონკრეტული ცვალებადობა:
- 1 - განისაზღვრება თითოეული შესწავლილი მნიშვნელობის მოქმედებით;
- 2 - ნაკარნახევი შესწავლილ მნიშვნელობებს შორის დამოკიდებულებით;
- 3 - შემთხვევითი, ნაკარნახევი ყველა გაუთვალისწინებელი გარემოებით.
Microsoft Excel-ში დისპერსიის ანალიზი შეიძლება განხორციელდეს "მონაცემთა ანალიზის" ხელსაწყოს გამოყენებით (ჩანართი "მონაცემები" - "ანალიზი"). ეს არის ცხრილების დანამატი. თუ დანამატი მიუწვდომელია, თქვენ უნდა გახსნათ „Excel Options“ და ჩართოთ პარამეტრი ანალიზისთვის.
სამუშაო იწყება მაგიდის დიზაინით. წესები:
- თითოეული სვეტი უნდა შეიცავდეს ერთი შესწავლილი ფაქტორის მნიშვნელობებს.
- დაალაგეთ სვეტები შესასწავლი პარამეტრის მნიშვნელობის ზრდად/კლებადობით.
განვიხილოთ დისპერსიის ანალიზი Excel-ში მაგალითის გამოყენებით.
კომპანიის ფსიქოლოგმა სპეციალური ტექნიკის გამოყენებით გააანალიზა თანამშრომლების ქცევის სტრატეგია კონფლიქტურ სიტუაციაში. ვარაუდობენ, რომ ქცევაზე გავლენას ახდენს განათლების დონე (1 - საშუალო, 2 - საშუალო სპეციალიზებული, 3 - უმაღლესი განათლება).
შეიყვანეთ მონაცემები Excel-ის ცხრილებში:


მნიშვნელოვანი პარამეტრი ივსება ყვითელი ფერით. ვინაიდან P- მნიშვნელობა ჯგუფებს შორის 1-ზე მეტია, ფიშერის ტესტი არ შეიძლება ჩაითვალოს მნიშვნელოვანად. შესაბამისად, კონფლიქტურ სიტუაციაში ქცევა არ არის დამოკიდებული განათლების დონეზე.
ფაქტორების ანალიზი Excel-ში: მაგალითი
ფაქტორული ანალიზი არის ცვლადების მნიშვნელობებს შორის ურთიერთობების მრავალვარიანტული ანალიზი. ამ მეთოდის გამოყენებით შეგიძლიათ გადაჭრათ ყველაზე მნიშვნელოვანი ამოცანები:
- ამომწურავად აღწერეთ გაზომილი ობიექტი (უფრო მეტიც, ტევადობით, კომპაქტურად);
- ფარული ცვლადის მნიშვნელობების იდენტიფიცირება, რომლებიც განსაზღვრავენ ხაზოვანი სტატისტიკური კორელაციების არსებობას;
- ცვლადების კლასიფიკაცია (მათ შორის კავშირის დადგენა);
- შეამცირეთ საჭირო ცვლადების რაოდენობა.
განვიხილოთ ფაქტორული ანალიზის მაგალითი. დავუშვათ, რომ ჩვენ ვიცით ნებისმიერი საქონლის გაყიდვები ბოლო 4 თვის განმავლობაში. აუცილებელია გაანალიზდეს, რომელი ნივთებია მოთხოვნადი და რომელი არა.


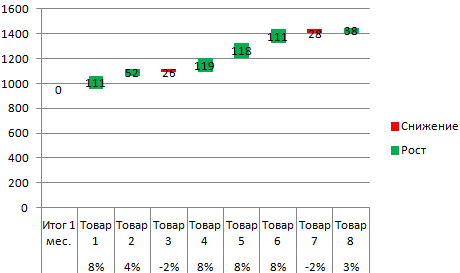
ახლა თქვენ ნათლად ხედავთ, რომელი პროდუქტის გაყიდვები იძლევა ძირითად ზრდას.
დისპერსიის ორმხრივი ანალიზი Excel-ში
გვიჩვენებს, თუ როგორ მოქმედებს ორი ფაქტორი შემთხვევითი ცვლადის მნიშვნელობის ცვლილებაზე. განვიხილოთ დისპერსიის ორმხრივი ანალიზი Excel-ში მაგალითის გამოყენებით.
დავალება. მამაკაცებისა და ქალების ჯგუფს წარუდგინეს სხვადასხვა მოცულობის ხმები: 1 - 10 dB, 2 - 30 dB, 3 - 50 dB. პასუხის დრო დაფიქსირდა მილიწამებში. აუცილებელია დადგინდეს, მოქმედებს თუ არა სქესი პასუხზე; მოქმედებს თუ არა ხმამაღალი რეაქციაზე?
დისპერსიის ანალიზი
1. ვარიაციის ანალიზის ცნება
დისპერსიის ანალიზი- ეს არის ნიშან-თვისების ცვალებადობის ანალიზი ნებისმიერი კონტროლირებადი ცვლადი ფაქტორების გავლენის ქვეშ. უცხოურ ლიტერატურაში დისპერსიის ანალიზს ხშირად მოიხსენიებენ როგორც ANOVA, რაც ითარგმნება როგორც დისპერსიის ანალიზი (Analysis of Variance).
დისპერსიული ანალიზის ამოცანამოიცავს სხვადასხვა სახის ცვალებადობის გამოყოფას მახასიათებლის ზოგადი ცვალებადობისგან:
ა) ცვალებადობა თითოეული შესწავლილი დამოუკიდებელი ცვლადის მოქმედებით;
ბ) ცვალებადობა შესწავლილი დამოუკიდებელი ცვლადების ურთიერთქმედების გამო;
გ) შემთხვევითი ცვალებადობა ყველა სხვა უცნობი ცვლადის გამო.
შესწავლილი ცვლადების მოქმედებით გამოწვეული ცვალებადობა და მათი ურთიერთქმედება კორელირებს შემთხვევით ცვალებადობასთან. ამ თანაფარდობის მაჩვენებელია ფიშერის F ტესტი.
F კრიტერიუმის გამოთვლის ფორმულა მოიცავს დისპერსიების შეფასებას, ანუ მახასიათებლის განაწილების პარამეტრებს, ამიტომ კრიტერიუმი F არის პარამეტრული კრიტერიუმი.
რაც უფრო მეტად არის თვისების ცვალებადობა განპირობებული შესწავლილი ცვლადებით (ფაქტორებით) ან მათი ურთიერთქმედებით, მით უფრო მაღალია კრიტერიუმის ემპირიული მნიშვნელობები.
Ნული ჰიპოთეზა დისპერსიის ანალიზში იტყვის, რომ შესწავლილი ეფექტური მახასიათებლის საშუალო მნიშვნელობები ყველა გრადაციაში ერთნაირია.
ალტერნატივა ჰიპოთეზაში ნათქვამია, რომ ეფექტური ატრიბუტის საშუალო მნიშვნელობები შესწავლილი ფაქტორის სხვადასხვა გრადაციაში განსხვავებულია.
დისპერსიის ანალიზი საშუალებას გვაძლევს განვაცხადოთ ცვლილება ნიშან-თვისებაში, მაგრამ არ მიუთითებს მიმართულებაეს ცვლილებები.
დისპერსიის ანალიზი დავიწყოთ უმარტივესი შემთხვევით, როდესაც ვსწავლობთ მხოლოდ მოქმედებას ერთიცვლადი (ერთი ფაქტორი).
2. ცალმხრივი დისპერსიის ანალიზი დაუკავშირებელი ნიმუშებისთვის
2.1. მეთოდის მიზანი
დისპერსიის ერთფაქტორიანი ანალიზის მეთოდი გამოიყენება იმ შემთხვევებში, როდესაც ეფექტური ატრიბუტის ცვლილებები შესწავლილია ცვალებადი პირობების ან რომელიმე ფაქტორის გრადაციის გავლენის ქვეშ. მეთოდის ამ ვერსიაში ფაქტორების თითოეული გრადაციის გავლენა არის სხვადასხვატესტის საგნების ნიმუში. ფაქტორის მინიმუმ სამი გრადაცია უნდა იყოს. (შეიძლება იყოს ორი გრადაცია, მაგრამ ამ შემთხვევაში ჩვენ ვერ დავადგინეთ არაწრფივი დამოკიდებულებები და უფრო გონივრული ჩანს უფრო მარტივის გამოყენება).
ამ ტიპის ანალიზის არაპარამეტრული ვარიანტია Kruskal-Wallis H ტესტი.
ჰიპოთეზები
H 0: განსხვავებები ფაქტორების კლასებს შორის (განსხვავებული პირობები) არ არის უფრო გამოხატული, ვიდრე შემთხვევითი განსხვავებები თითოეულ ჯგუფში.
H 1: განსხვავებები ფაქტორების გრადაციას შორის (სხვადასხვა პირობები) უფრო გამოხატულია, ვიდრე შემთხვევითი განსხვავებები თითოეულ ჯგუფში.
2.2. დისპერსიის ერთვარიანტული ანალიზის შეზღუდვები დაუკავშირებელი ნიმუშებისთვის
1. ვარიაციის უნივარიანტული ანალიზი მოითხოვს ფაქტორის მინიმუმ სამ გრადაციას და მინიმუმ ორ საგანს თითოეულ გრადაციაში.
2. შედეგიანი მახასიათებელი ნორმალურად უნდა იყოს განაწილებული საკვლევ ნიმუშში.
მართალია, ჩვეულებრივ არ არის მითითებული, ვსაუბრობთ მახასიათებლის განაწილებაზე მთელ გამოკითხულ ნიმუშში თუ მის იმ ნაწილში, რომელიც ქმნის დისპერსიულ კომპლექსს.
3. პრობლემის გადაჭრის მაგალითი დისპერსიის ერთფაქტორიანი ანალიზის მეთოდით დაუკავშირებელი ნიმუშებისთვის მაგალითის გამოყენებით:
ექვსი საგნისგან შემდგარმა სამმა სხვადასხვა ჯგუფმა მიიღო ათი სიტყვის სია. პირველ ჯგუფს სიტყვები წარუდგინეს დაბალი სიჩქარით 1 სიტყვა 5 წამში, მეორე ჯგუფს საშუალო სიჩქარით 1 სიტყვა 2 წამში, ხოლო მესამე ჯგუფს მაღალი სიჩქარით 1 სიტყვა წამში. იწინასწარმეტყველა, რომ რეპროდუცირების შესრულება დამოკიდებული იქნებოდა სიტყვების პრეზენტაციის სიჩქარეზე. შედეგები წარმოდგენილია ცხრილში. ერთი.
რეპროდუცირებული სიტყვების რაოდენობა ცხრილი 1
|
საგნის ნომერი |
დაბალი სიჩქარე |
საშუალო სიჩქარე |
მაღალი სიჩქარე |
|
მთლიანი რაოდენობა | |||
H 0: განსხვავებები სიტყვების მოცულობაში შორისჯგუფები არ არის უფრო გამოხატული, ვიდრე შემთხვევითი განსხვავებები შიგნითთითოეული ჯგუფი.
H1: განსხვავებები სიტყვების მოცულობაში შორისჯგუფები უფრო გამოხატულია, ვიდრე შემთხვევითი განსხვავებები შიგნითთითოეული ჯგუფი. ცხრილში წარმოდგენილი ექსპერიმენტული მნიშვნელობების გამოყენებით. 1, ჩვენ დავამყარებთ რამდენიმე მნიშვნელობას, რომელიც დაგჭირდებათ F კრიტერიუმის გამოსათვლელად.
ცალმხრივი დისპერსიული ანალიზისთვის ძირითადი რაოდენობების გამოთვლა მოცემულია ცხრილში:
ცხრილი 2
ცხრილი 3
ოპერაციების თანმიმდევრობა ცალმხრივი ANOVA-ში გათიშული ნიმუშებისთვის

ხშირად გამოყენებული ამ და მომდევნო ცხრილებში, აღნიშვნა SS არის აბრევიატურა "კვადრატების ჯამი". ეს აბრევიატურა ყველაზე ხშირად გამოიყენება თარგმნილ წყაროებში.
SS ფაქტინიშნავს ნიშან-თვისების ცვალებადობას, შესწავლილი ფაქტორის მოქმედების გამო;
SS საერთო- ნიშან-თვისების ზოგადი ცვალებადობა;
ს CA- ცვალებადობა გაუთვალისწინებელი ფაქტორების გამო, "შემთხვევითი" ან "ნარჩენი" ცვალებადობა.
ᲥᲐᲚᲑᲐᲢᲝᲜᲘ- "საშუალო კვადრატი", ან კვადრატების ჯამის მათემატიკური მოლოდინი, შესაბამისი SS-ის საშუალო მნიშვნელობა.
დფ - თავისუფლების ხარისხების რაოდენობა, რომელიც არაპარამეტრული კრიტერიუმების განხილვისას აღვნიშნეთ ბერძნული ასოებით. ვ.
დასკვნა: H 0 უარყოფილია. H 1 მიღებულია. ჯგუფებს შორის სიტყვების რეპროდუქციის მოცულობაში განსხვავებები უფრო გამოხატულია, ვიდრე შემთხვევითი განსხვავებები თითოეულ ჯგუფში (α=0.05). ასე რომ, სიტყვების წარმოდგენის სიჩქარე გავლენას ახდენს მათი რეპროდუქციის მოცულობაზე.
Excel-ში პრობლემის გადაჭრის მაგალითი მოცემულია ქვემოთ:
საწყისი მონაცემები:

ბრძანების გამოყენებით: Tools->Data Analysis->ცალმხრივი დისპერსიის ანალიზი, მივიღებთ შემდეგ შედეგებს:

ANOVA არის სტატისტიკური მეთოდების ნაკრები, რომელიც შექმნილია ჰიპოთეზების შესამოწმებლად გარკვეულ მახასიათებლებსა და შესწავლილ ფაქტორებს შორის ურთიერთობის შესახებ, რომლებსაც არ აქვთ რაოდენობრივი აღწერა, ასევე ფაქტორების გავლენის ხარისხისა და მათი ურთიერთქმედების დასადგენად. სპეციალიზებულ ლიტერატურაში მას ხშირად უწოდებენ ANOVA (ინგლისური სახელწოდებიდან Analysis of Variations). ეს მეთოდი პირველად რ.ფიშერმა 1925 წელს შეიმუშავა.
ვარიაციის ანალიზის ტიპები და კრიტერიუმები
ეს მეთოდი გამოიყენება ხარისხობრივ (ნომინალურ) მახასიათებლებსა და რაოდენობრივ (უწყვეტ) ცვლადს შორის კავშირის გამოსაკვლევად. ფაქტობრივად, ის ამოწმებს ჰიპოთეზას რამდენიმე ნიმუშის არითმეტიკული საშუალებების თანასწორობის შესახებ. ამრიგად, ის შეიძლება ჩაითვალოს პარამეტრულ კრიტერიუმად რამდენიმე ნიმუშის ცენტრის ერთდროულად შესადარებლად. თუ ამ მეთოდს გამოიყენებთ ორ ნიმუშზე, მაშინ დისპერსიული ანალიზის შედეგები იდენტური იქნება Student-ის t-ტესტის შედეგებისა. თუმცა, სხვა კრიტერიუმებისგან განსხვავებით, ეს კვლევა საშუალებას გაძლევთ უფრო დეტალურად შეისწავლოთ პრობლემა.
სტატისტიკის დისპერსიის ანალიზი ეფუძნება კანონს: გაერთიანებული ნიმუშის კვადრატული გადახრების ჯამი უდრის შიდაჯგუფური გადახრების კვადრატების ჯამს და ჯგუფთაშორისი გადახრების კვადრატების ჯამს. კვლევისთვის ფიშერის ტესტი გამოიყენება ჯგუფთაშორის და შიდაჯგუფურ დისპერსიებს შორის განსხვავების დასადგენად. თუმცა, ამისათვის აუცილებელი წინაპირობაა ნიმუშების განაწილების ნორმალურობა და ჰომოსკედასტურობა (ვარიანტების თანასწორობა). განასხვავებენ ცვალებადობის ერთგანზომილებიან (ერთფაქტორიან) და მრავალვარიანტულ (მულტიფაქტორულ) ანალიზს. პირველი განიხილავს შესწავლილი ღირებულების დამოკიდებულებას ერთ ატრიბუტზე, მეორე - ბევრზე ერთდროულად და ასევე საშუალებას გაძლევთ განსაზღვროთ მათ შორის ურთიერთობა.
ფაქტორები
ფაქტორებს ეწოდება კონტროლირებადი გარემოებები, რომლებიც გავლენას ახდენენ საბოლოო შედეგზე. მის დონეს ან დამუშავების მეთოდს ეწოდება მნიშვნელობა, რომელიც ახასიათებს ამ მდგომარეობის სპეციფიკურ გამოვლინებას. ეს მაჩვენებლები ჩვეულებრივ მოცემულია გაზომვის ნომინალური ან რიგითი მასშტაბით. ხშირად გამომავალი მნიშვნელობები იზომება რაოდენობრივი ან რიგითი მასშტაბებით. შემდეგ ჩნდება გამომავალი მონაცემების დაჯგუფების პრობლემა დაკვირვებების სერიაში, რომლებიც შეესაბამება დაახლოებით იგივე რიცხვით მნიშვნელობებს. თუ ჯგუფების რაოდენობა ძალიან დიდია, მაშინ მათში დაკვირვებების რაოდენობა შეიძლება არასაკმარისი იყოს სანდო შედეგების მისაღებად. თუ რიცხვი ძალიან მცირეა, ამან შეიძლება გამოიწვიოს სისტემაზე გავლენის არსებითი მახასიათებლების დაკარგვა. მონაცემთა დაჯგუფების კონკრეტული მეთოდი დამოკიდებულია მნიშვნელობების ცვალებადობის მოცულობასა და ბუნებაზე. უნივარიანტულ ანალიზში ინტერვალების რაოდენობა და ზომა ყველაზე ხშირად განისაზღვრება თანაბარი ინტერვალების პრინციპით ან თანაბარი სიხშირეების პრინციპით.
დისპერსიული ანალიზის ამოცანები
ასე რომ, არის შემთხვევები, როდესაც საჭიროა ორი ან მეტი ნიმუშის შედარება. სწორედ მაშინ არის მიზანშეწონილი დისპერსიული ანალიზის გამოყენება. მეთოდის სახელწოდება მიუთითებს იმაზე, რომ დასკვნები კეთდება დისპერსიის კომპონენტების შესწავლის საფუძველზე. კვლევის არსი იმაში მდგომარეობს, რომ ინდიკატორის საერთო ცვლილება იყოფა კომპონენტებად, რომლებიც შეესაბამება თითოეული ინდივიდუალური ფაქტორის მოქმედებას. განვიხილოთ მთელი რიგი პრობლემები, რომლებსაც ხსნის დისპერსიის ტიპიური ანალიზი.
მაგალითი 1
სახელოსნოში არის რამდენიმე ჩარხები - ავტომატური მანქანები, რომლებიც აწარმოებენ კონკრეტულ ნაწილს. თითოეული ნაწილის ზომა არის შემთხვევითი მნიშვნელობა, რომელიც დამოკიდებულია თითოეული მანქანის პარამეტრებზე და შემთხვევით გადახრებზე, რომლებიც ხდება ნაწილების წარმოების პროცესში. ნაწილების ზომების გაზომვებიდან უნდა დადგინდეს, არის თუ არა მანქანები დაყენებული ერთნაირად.

მაგალითი 2
ელექტრო აპარატის წარმოებისას გამოიყენება სხვადასხვა სახის საიზოლაციო ქაღალდი: კონდენსატორი, ელექტრო და ა.შ. აპარატის გაჟღენთვა შესაძლებელია სხვადასხვა ნივთიერებებით: ეპოქსიდური ფისოვანი, ლაქი, ML-2 რეზინი და ა.შ. გაჟონვის აღმოფხვრა შესაძლებელია ვაკუუმში. ამაღლებული წნევა გაცხელებისას. მისი გაჟღენთვა შესაძლებელია ლაქში ჩაძირვით, ლაქის უწყვეტი ნაკადის ქვეშ და ა.შ. ელექტრო აპარატი მთლიანობაში ივსება გარკვეული ნაერთით, რომლის რამდენიმე ვარიანტი არსებობს. ხარისხის მაჩვენებლებია იზოლაციის დიელექტრიკული სიძლიერე, გრაგნილის გადახურების ტემპერატურა სამუშაო რეჟიმში და მრავალი სხვა. მოწყობილობების წარმოების ტექნოლოგიური პროცესის განვითარებისას აუცილებელია განისაზღვროს, თუ როგორ მოქმედებს თითოეული ჩამოთვლილი ფაქტორი მოწყობილობის მუშაობაზე.
მაგალითი 3
ტროლეიბუსის დეპო ემსახურება ტროლეიბუსის რამდენიმე მარშრუტს. ისინი სხვადასხვა ტიპის ტროლეიბუსებს მართავენ და მგზავრობის საფასურს 125 ინსპექტორი აგროვებს. დეპოს ხელმძღვანელობას აინტერესებს კითხვა: როგორ შევადაროთ თითოეული კონტროლიორის (შემოსავლის) ეკონომიკური მაჩვენებლები სხვადასხვა მარშრუტების, სხვადასხვა ტიპის ტროლეიბუსების გათვალისწინებით? როგორ განვსაზღვროთ კონკრეტულ მარშრუტზე გარკვეული ტიპის ტროლეიბუსების გაშვების ეკონომიკური მიზანშეწონილობა? როგორ დავადგინოთ გონივრული მოთხოვნები შემოსავლის ოდენობაზე, რომელსაც კონდუქტორი მოაქვს თითოეულ მარშრუტზე სხვადასხვა ტიპის ტროლეიბუსებში?
მეთოდის არჩევის ამოცანაა, როგორ მივიღოთ მაქსიმალური ინფორმაცია თითოეული ფაქტორის საბოლოო შედეგზე ზემოქმედების შესახებ, განვსაზღვროთ ასეთი ზემოქმედების რიცხვითი მახასიათებლები, მათი სანდოობა მინიმალურ ფასად და უმოკლეს დროში. დისპერსიული ანალიზის მეთოდები ასეთი პრობლემების გადაჭრის საშუალებას იძლევა.
უნივარიანტული ანალიზი
კვლევა მიზნად ისახავს შეაფასოს კონკრეტული შემთხვევის გავლენის სიდიდე გაანალიზებულ მიმოხილვაზე. უნივარიატიული ანალიზის კიდევ ერთი ამოცანა შეიძლება იყოს ორი ან მეტი გარემოების ერთმანეთთან შედარება, რათა დადგინდეს მათი გავლენის განსხვავება გახსენებაზე. თუ ნულოვანი ჰიპოთეზა უარყოფილია, მაშინ შემდეგი ნაბიჯი არის მიღებული მახასიათებლების რაოდენობრივი განსაზღვრა და ნდობის ინტერვალების აგება. იმ შემთხვევაში, როდესაც ნულოვანი ჰიპოთეზის უარყოფა შეუძლებელია, ის ჩვეულებრივ მიიღება და კეთდება დასკვნა გავლენის ხასიათის შესახებ.
დისპერსიის ცალმხრივი ანალიზი შეიძლება გახდეს კრუსკალ-ვალისის რანგის მეთოდის არაპარამეტრული ანალოგი. იგი შეიმუშავეს ამერიკელმა მათემატიკოსმა უილიამ კრუსკალმა და ეკონომისტმა უილსონ უოლისმა 1952 წელს. ეს ტესტი გამიზნულია ნულოვანი ჰიპოთეზის შესამოწმებლად, რომ ზემოქმედების ეფექტი შესწავლილ ნიმუშებზე ტოლია უცნობი, მაგრამ თანაბარი საშუალო მნიშვნელობებით. ამ შემთხვევაში ნიმუშების რაოდენობა ორზე მეტი უნდა იყოს.

ჯონხიერის (Jonkhier-Terpstra) კრიტერიუმი დამოუკიდებლად შემოგვთავაზეს ჰოლანდიელმა მათემატიკოსმა ტ.ჯ. ტერპსტრომმა 1952 წელს და ბრიტანელი ფსიქოლოგმა ე. შესწავლილი ფაქტორის გავლენა, რომელიც იზომება რიგითი სკალით.
M - ბარტლეტის კრიტერიუმი, შემოთავაზებული ბრიტანელი სტატისტიკოსის მორის სტივენსონ ბარტლეტის მიერ 1937 წელს, გამოიყენება ნულოვანი ჰიპოთეზის შესამოწმებლად რამდენიმე ნორმალური ზოგადი პოპულაციის ვარიაციების თანასწორობის შესახებ, საიდანაც აღებულია შესწავლილი ნიმუშები, ზოგად შემთხვევაში, სხვადასხვა ზომის. (თითოეული ნიმუშის რაოდენობა უნდა იყოს მინიმუმ ოთხი).
G არის კოკრანის ტესტი, რომელიც აღმოაჩინა ამერიკელმა უილიამ გემელ კოხრანმა 1941 წელს. იგი გამოიყენება ნულოვანი ჰიპოთეზის შესამოწმებლად ნორმალური პოპულაციების დისპერსიების თანასწორობის შესახებ თანაბარი ზომის დამოუკიდებელი ნიმუშებისთვის.
არაპარამეტრული ლევენის ტესტი, რომელიც შემოთავაზებულია ამერიკელი მათემატიკოსის ჰოვარდ ლევენის მიერ 1960 წელს, არის ბარტლეტის ტესტის ალტერნატივა იმ პირობებში, როდესაც არ არის დარწმუნებული, რომ შესასწავლი ნიმუშები მიჰყვება ნორმალურ განაწილებას.
1974 წელს ამერიკელმა სტატისტიკოსებმა Morton B. Brown-მა და Alan B. Forsythe-მა შემოგვთავაზეს ტესტი (ბრაუნ-ფორსაიტის ტესტი), რომელიც გარკვეულწილად განსხვავდება ლევენის ტესტისგან.
ორმხრივი ანალიზი
დისპერსიის ორმხრივი ანალიზი გამოიყენება ნორმალურად განაწილებული ნიმუშებისთვის. პრაქტიკაში ხშირად გამოიყენება ამ მეთოდის რთული ცხრილები, კერძოდ ის, რომლებშიც თითოეული უჯრედი შეიცავს მონაცემთა ერთობლიობას (განმეორებითი გაზომვები), რომლებიც შეესაბამება ფიქსირებული დონის მნიშვნელობებს. თუ დისპერსიის ორმხრივი ანალიზის გამოსაყენებლად აუცილებელი დაშვებები არ არის დაკმაყოფილებული, მაშინ გამოიყენება ფრიდმანის არაპარამეტრული რანგის ტესტი (ფრიდმანი, კენდალი და სმიტი), რომელიც შემუშავებულია ამერიკელი ეკონომისტის მილტონ ფრიდმანის მიერ 1930 წლის ბოლოს. ეს კრიტერიუმი არ არის დამოკიდებული განაწილების ტიპზე.
მხოლოდ ვარაუდობენ, რომ რაოდენობების განაწილება ერთნაირი და უწყვეტია და რომ ისინი თავად არიან ერთმანეთისგან დამოუკიდებელი. ნულოვანი ჰიპოთეზის ტესტირებისას გამომავალი მონაცემები წარმოდგენილია მართკუთხა მატრიცის სახით, რომელშიც რიგები შეესაბამება B ფაქტორის დონეებს, ხოლო სვეტები A დონეებს. ცხრილის (ბლოკის) თითოეული უჯრედი შეიძლება იყოს პარამეტრების გაზომვის შედეგი ერთ ობიექტზე ან ობიექტთა ჯგუფზე ორივე ფაქტორის დონის მუდმივი მნიშვნელობებით. ამ შემთხვევაში, შესაბამისი მონაცემები წარმოდგენილია, როგორც გარკვეული პარამეტრის საშუალო მნიშვნელობები შესწავლილი ნიმუშის ყველა გაზომვისთვის ან ობიექტისთვის. გამომავალი კრიტერიუმის გამოსაყენებლად აუცილებელია გაზომვების პირდაპირი შედეგებიდან მათ რანგზე გადასვლა. რეიტინგი ხორციელდება თითოეული მწკრივისთვის ცალკე, ანუ მნიშვნელობები შეკვეთილია თითოეული ფიქსირებული მნიშვნელობისთვის.

პეიჯის ტესტი (L-ტესტი), შემოთავაზებული ამერიკელი სტატისტიკოსის E. B. Page-ის მიერ 1963 წელს, შექმნილია ნულოვანი ჰიპოთეზის შესამოწმებლად. დიდი ნიმუშებისთვის გამოიყენება გვერდის მიახლოება. ისინი, შესაბამისი ნულოვანი ჰიპოთეზების რეალობის გათვალისწინებით, ემორჩილებიან სტანდარტულ ნორმალურ განაწილებას. იმ შემთხვევაში, როდესაც წყაროს ცხრილის სტრიქონებს აქვთ იგივე მნიშვნელობები, აუცილებელია საშუალო რანგის გამოყენება. ამ შემთხვევაში, დასკვნების სიზუსტე უფრო უარესი იქნება, მით მეტია ასეთი დამთხვევების რაოდენობა.
Q - Cochran-ის კრიტერიუმი, შემოთავაზებული ვ. ) . ნულოვანი ჰიპოთეზა შედგება გავლენის ეფექტების თანასწორობისგან. დისპერსიის ორმხრივი ანალიზი შესაძლებელს ხდის გადამუშავების ეფექტების არსებობის დადგენას, მაგრამ არ იძლევა იმის დადგენას, თუ რომელი სვეტებისთვის არსებობს ეს ეფექტი. ამ პრობლემის გადაჭრისას გამოიყენება მრავალი შეფის განტოლების მეთოდი დაწყვილებული ნიმუშებისთვის.
მრავალვარიანტული ანალიზი
დისპერსიის მულტივარიანტული ანალიზის პრობლემა ჩნდება მაშინ, როდესაც აუცილებელია ორი ან მეტი პირობის გავლენის დადგენა გარკვეულ შემთხვევით ცვლადზე. კვლევა ითვალისწინებს ერთი დამოკიდებული შემთხვევითი ცვლადის არსებობას, რომელიც იზომება განსხვავებების ან თანაფარდობების შკალაზე, და რამდენიმე დამოუკიდებელი ცვლადის არსებობას, რომელთაგან თითოეული გამოხატულია სახელების სკალაზე ან რანგის სკალაში. მონაცემთა დისპერსიული ანალიზი არის მათემატიკური სტატისტიკის საკმაოდ განვითარებული ფილიალი, რომელსაც აქვს უამრავი ვარიანტი. კვლევის კონცეფცია საერთოა როგორც ერთვარიანტული, ასევე მრავალვარიანტული კვლევებისთვის. მისი არსი მდგომარეობს იმაში, რომ მთლიანი განსხვავება იყოფა კომპონენტებად, რაც შეესაბამება მონაცემების გარკვეულ დაჯგუფებას. მონაცემთა თითოეულ დაჯგუფებას აქვს საკუთარი მოდელი. აქ განვიხილავთ მხოლოდ ძირითად დებულებებს, რომლებიც აუცილებელია მისი ყველაზე ხშირად გამოყენებული ვარიანტების გასაგებად და პრაქტიკული გამოყენებისთვის.

დისპერსიის ფაქტორული ანალიზი მოითხოვს ფრთხილად ყურადღებას შეტანილი მონაცემების შეგროვებასა და პრეზენტაციაზე, განსაკუთრებით კი შედეგების ინტერპრეტაციაზე. ერთი ფაქტორისგან განსხვავებით, რომლის შედეგები პირობითად შეიძლება განთავსდეს გარკვეული თანმიმდევრობით, ორფაქტორიანი შედეგები მოითხოვს უფრო რთულ პრეზენტაციას. კიდევ უფრო რთული სიტუაცია იქმნება, როდესაც არსებობს სამი, ოთხი ან მეტი გარემოება. ამის გამო მოდელი იშვიათად მოიცავს სამზე (ოთხ) პირობას. მაგალითი იქნება რეზონანსის წარმოქმნა ელექტრული წრის ტევადობისა და ინდუქციურობის გარკვეულ მნიშვნელობაზე; ქიმიური რეაქციის გამოვლინება ელემენტების გარკვეულ კომპლექტთან, საიდანაც აგებულია სისტემა; კომპლექსურ სისტემებში ანომალიური ეფექტების გაჩენა გარემოებების გარკვეულ დამთხვევაში. ურთიერთქმედების არსებობამ შეიძლება რადიკალურად შეცვალოს სისტემის მოდელი და ზოგჯერ გამოიწვიოს იმ ფენომენების ბუნების გადახედვა, რომელთანაც ექსპერიმენტატორი საქმე აქვს.
დისპერსიის მრავალვარიანტული ანალიზი განმეორებითი ექსპერიმენტებით
გაზომვის მონაცემები ხშირად შეიძლება დაჯგუფდეს არა ორი, არამედ მეტი ფაქტორით. ასე რომ, თუ გავითვალისწინებთ ტროლეიბუსის ბორბლების საბურავების მომსახურების ვადის დისპერსიულ ანალიზს, გარემოებების გათვალისწინებით (მწარმოებელი და მარშრუტი, რომელზეც გამოიყენება საბურავები), მაშინ ცალკე პირობად შეგვიძლია გამოვყოთ სეზონი, რომლის დროსაც გამოიყენება საბურავები (კერძოდ: ზამთრის და ზაფხულის ექსპლუატაცია). შედეგად გვექნება სამფაქტორიანი მეთოდის პრობლემა.
მეტი პირობების არსებობისას, მიდგომა იგივეა, რაც ორმხრივ ანალიზში. ყველა შემთხვევაში მოდელი ცდილობს გამარტივებას. ორი ფაქტორის ურთიერთქმედების ფენომენი არც ისე ხშირად ჩნდება და სამმაგი ურთიერთქმედება მხოლოდ გამონაკლის შემთხვევებში ხდება. ჩართეთ ის ურთიერთქმედებები, რომლებზეც არსებობს წინა ინფორმაცია და კარგი მიზეზები მოდელში გასათვალისწინებლად. ინდივიდუალური ფაქტორების გამოყოფისა და მათი გათვალისწინების პროცესი შედარებით მარტივია. ამიტომ, ხშირად ჩნდება მეტი გარემოებების გამოკვეთის სურვილი. თქვენ არ უნდა გაიტაცოთ ამით. რაც უფრო მეტი პირობაა, მით უფრო ნაკლებად სანდო ხდება მოდელი და მით მეტია შეცდომის შანსი. თავად მოდელი, რომელიც მოიცავს დამოუკიდებელ ცვლადების დიდ რაოდენობას, ხდება საკმაოდ რთული ინტერპრეტაცია და პრაქტიკული გამოყენებისთვის მოუხერხებელი.
დისპერსიის ანალიზის ზოგადი იდეა
სტატისტიკის დისპერსიის ანალიზი არის დაკვირვების შედეგების მოპოვების მეთოდი, რომელიც დამოკიდებულია სხვადასხვა თანმხლებ გარემოებებზე და მათი გავლენის შეფასებაზე. კონტროლირებად ცვლადს, რომელიც შეესაბამება კვლევის ობიექტზე ზემოქმედების მეთოდს და დროის გარკვეულ პერიოდში გარკვეულ მნიშვნელობას იძენს, ფაქტორი ეწოდება. ისინი შეიძლება იყოს ხარისხობრივი და რაოდენობრივი. რაოდენობრივი პირობების დონეები იძენს გარკვეულ მნიშვნელობას რიცხვითი მასშტაბით. მაგალითებია ტემპერატურა, დაჭერით წნევა, ნივთიერების რაოდენობა. ხარისხობრივი ფაქტორებია სხვადასხვა ნივთიერებები, სხვადასხვა ტექნოლოგიური მეთოდები, აპარატები, შემავსებლები. მათი დონეები შეესაბამება სახელების მასშტაბს.

ხარისხში ასევე შედის შესაფუთი მასალის ტიპი, დოზირების ფორმის შენახვის პირობები. რაციონალურია აგრეთვე ნედლეულის დაფქვის ხარისხის, გრანულების ფრაქციული შემადგენლობის ჩართვა, რომლებსაც აქვთ რაოდენობრივი მნიშვნელობა, მაგრამ ძნელად დასარეგულირებელია, თუ რაოდენობრივი მასშტაბი გამოიყენება. ხარისხის ფაქტორების რაოდენობა დამოკიდებულია დოზირების ფორმის ტიპზე, აგრეთვე სამკურნალო ნივთიერებების ფიზიკურ და ტექნოლოგიურ თვისებებზე. მაგალითად, ტაბლეტების მიღება შესაძლებელია კრისტალური ნივთიერებებისგან პირდაპირი შეკუმშვით. ამ შემთხვევაში, საკმარისია მოცურების და საპოხი აგენტების შერჩევა.
ხარისხის ფაქტორების მაგალითები სხვადასხვა ტიპის დოზირების ფორმებისთვის
- ნაყენები.ექსტრაქტორის შემადგენლობა, ექსტრაქტორის ტიპი, ნედლეულის მომზადების მეთოდი, წარმოების მეთოდი, ფილტრაციის მეთოდი.
- ექსტრაქტები (თხევადი, სქელი, მშრალი).ექსტრაქტორის შემადგენლობა, ექსტრაქციის მეთოდი, ინსტალაციის ტიპი, ექსტრაქტორი და ბალასტური ნივთიერებების მოცილების მეთოდი.
- აბები.დამხმარე ნივთიერებების, შემავსებლების, დეზინტეგრატორების, შემკვრელების, ლუბრიკანტების და საპოხი მასალების შემადგენლობა. ტაბლეტების მიღების მეთოდი, ტექნოლოგიური აღჭურვილობის ტიპი. გარსის ტიპი და მისი კომპონენტები, ფირის შემქმნელი, პიგმენტები, საღებავები, პლასტიზატორები, გამხსნელები.
- საინექციო ხსნარები.გამხსნელის ტიპი, ფილტრაციის მეთოდი, სტაბილიზატორებისა და კონსერვანტების ბუნება, სტერილიზაციის პირობები, ამპულების შევსების მეთოდი.
- სუპოზიტორები.სუპოზიტორების ბაზის შემადგენლობა, სუპოზიტორების, შემავსებლის, შეფუთვის მიღების მეთოდი.
- მალამოები.ბაზის შემადგენლობა, სტრუქტურული კომპონენტები, მალამოს მომზადების მეთოდი, აღჭურვილობის ტიპი, შეფუთვა.
- კაფსულები.გარსის მასალის ტიპი, კაფსულების მიღების მეთოდი, პლასტიზატორის ტიპი, კონსერვანტი, საღებავი.
- ლინიმენტები.წარმოების მეთოდი, შემადგენლობა, აღჭურვილობის ტიპი, ემულგატორის ტიპი.
- შეჩერებები.გამხსნელის ტიპი, სტაბილიზატორის ტიპი, დისპერსიის მეთოდი.
ტაბლეტების წარმოების პროცესში შესწავლილი ხარისხის ფაქტორების მაგალითები და მათი დონეები
- Ფქვილი.კარტოფილის სახამებელი, თეთრი თიხა, ნატრიუმის ბიკარბონატის ნაზავი ლიმონმჟავასთან, ძირითადი მაგნიუმის კარბონატი.
- სავალდებულო ხსნარი.წყალი, სახამებლის პასტა, შაქრის სიროფი, მეთილცელულოზის ხსნარი, ჰიდროქსიპროპილ მეთილცელულოზის ხსნარი, პოლივინილპიროლიდონის ხსნარი, პოლივინილ სპირტის ხსნარი.
- მოცურების ნივთიერება.აეროსილი, სახამებელი, ტალკი.
- შემავსებელი.შაქარი, გლუკოზა, ლაქტოზა, ნატრიუმის ქლორიდი, კალციუმის ფოსფატი.
- ლუბრიკანტი.სტეარინის მჟავა, პოლიეთილენ გლიკოლი, პარაფინი.
დისპერსიული ანალიზის მოდელები სახელმწიფოს კონკურენტუნარიანობის დონის შესწავლაში
სახელმწიფოს მდგომარეობის შეფასების ერთ-ერთი ყველაზე მნიშვნელოვანი კრიტერიუმი, რომელიც გამოიყენება მისი კეთილდღეობისა და სოციალურ-ეკონომიკური განვითარების დონის შესაფასებლად, არის კონკურენტუნარიანობა, ანუ ეროვნული ეკონომიკის თანდაყოლილი თვისებების ერთობლიობა, რომელიც განსაზღვრავს სახელმწიფოს კონკურენცია გაუწიოს სხვა ქვეყნებს. მსოფლიო ბაზარზე სახელმწიფოს ადგილისა და როლის დადგენის შემდეგ, შესაძლებელია ჩამოყალიბდეს მკაფიო სტრატეგია ეკონომიკური უსაფრთხოების უზრუნველსაყოფად საერთაშორისო მასშტაბით, რადგან ეს არის პოზიტიური ურთიერთობების გასაღები რუსეთსა და მსოფლიო ბაზარზე ყველა მოთამაშეს შორის: ინვესტორებს შორის. , კრედიტორები, სახელმწიფო მთავრობები.
სახელმწიფოთა კონკურენტუნარიანობის დონის შესადარებლად, ქვეყნების რეიტინგები ხდება რთული ინდექსების გამოყენებით, რომლებიც მოიცავს სხვადასხვა შეწონილ მაჩვენებლებს. ეს მაჩვენებლები ეფუძნება ძირითად ფაქტორებს, რომლებიც გავლენას ახდენენ ეკონომიკურ, პოლიტიკურ და ა.შ. სახელმწიფოს კონკურენტუნარიანობის შესწავლის მოდელების კომპლექსი ითვალისწინებს მრავალგანზომილებიანი სტატისტიკური ანალიზის მეთოდების გამოყენებას (კერძოდ, ეს არის დისპერსიის ანალიზი (სტატისტიკა), ეკონომეტრიული მოდელირება, გადაწყვეტილების მიღება) და მოიცავს შემდეგ ძირითად ეტაპებს:
- ინდიკატორ-ინდიკატორების სისტემის ფორმირება.
- სახელმწიფოს კონკურენტუნარიანობის მაჩვენებლების შეფასება და პროგნოზირება.
- სახელმწიფოთა კონკურენტუნარიანობის ინდიკატორები-ინდიკატორების შედარება.
ახლა კი განვიხილოთ ამ კომპლექსის თითოეული ეტაპის მოდელების შინაარსი.
პირველ ეტაპზესაექსპერტო კვლევის მეთოდების გამოყენებით ყალიბდება სახელმწიფოს კონკურენტუნარიანობის შესაფასებლად ეკონომიკური მაჩვენებლების-ინდიკატორების გონივრული ნაკრები, მისი განვითარების სპეციფიკის გათვალისწინებით, საერთაშორისო რეიტინგებისა და სტატისტიკური დეპარტამენტების მონაცემების საფუძველზე, რომელიც ასახავს სისტემის მდგომარეობას. მთლიანობაში და მის პროცესებს. ამ ინდიკატორების არჩევანი გამართლებულია იმ ინდიკატორების შერჩევის აუცილებლობით, რომლებიც ყველაზე სრულად, პრაქტიკის თვალსაზრისით, საშუალებას იძლევა განისაზღვროს სახელმწიფოს დონე, მისი საინვესტიციო მიმზიდველობა და არსებული პოტენციური და ფაქტობრივი საფრთხეების შედარებითი ლოკალიზაციის შესაძლებლობა.

საერთაშორისო სარეიტინგო სისტემების ძირითადი მაჩვენებლები-ინდიკატორებია ინდექსები:
- გლობალური კონკურენტუნარიანობა (GCC).
- ეკონომიკური თავისუფლება (IES).
- ადამიანური განვითარება (HDI).
- კორუფციის აღქმა (CPI).
- შიდა და გარე საფრთხეები (IVZZ).
- საერთაშორისო გავლენის პოტენციალი (IPIP).
მეორე ფაზაითვალისწინებს სახელმწიფოს კონკურენტუნარიანობის მაჩვენებლების შეფასებას და პროგნოზირებას საერთაშორისო რეიტინგების მიხედვით შესწავლილი მსოფლიოს 139 სახელმწიფოსთვის.
მესამე ეტაპიითვალისწინებს სახელმწიფოთა კონკურენტუნარიანობის პირობების შედარებას კორელაციური და რეგრესული ანალიზის მეთოდების გამოყენებით.
კვლევის შედეგების გამოყენებით შესაძლებელია განისაზღვროს პროცესების ხასიათი ზოგადად და სახელმწიფოს კონკურენტუნარიანობის ცალკეული კომპონენტები; შეამოწმეთ ჰიპოთეზა ფაქტორების გავლენისა და მათი ურთიერთობის შესახებ მნიშვნელობის შესაბამის დონეზე.
შემოთავაზებული მოდელების დანერგვა საშუალებას მისცემს არა მხოლოდ შეაფასოს სახელმწიფოების კონკურენტუნარიანობის და საინვესტიციო მიმზიდველობის დონის არსებული მდგომარეობა, არამედ გააანალიზოს მენეჯმენტის ხარვეზები, თავიდან აიცილოს არასწორი გადაწყვეტილებების შეცდომები და თავიდან აიცილოს კრიზისის განვითარება. სახელმწიფოში.
