Statistical significance or p-significance level - the main test result
statistical hypothesis. talking technical language, is the probability of getting the given
result sample study provided that in fact for the general
set, the null hypothesis is true - that is, there is no relationship. In other words, this
the probability that the detected relationship is random and not a property
aggregates. Exactly statistical significance, p-significance level is
quantification reliability of the connection: the lower this probability, the more reliable the connection.
Suppose, when comparing two sample means, the value of the level was obtained
statistical significance p=0.05. This means that testing the statistical hypothesis about
equality of means in the general population showed that if it is true, then the probability
the random occurrence of the detected differences is no more than 5%. In other words, if
two samples were repeatedly drawn from the same general population, then in 1 of
20 cases would show the same or greater difference between the means of these samples.
That is, there is a 5% chance that the differences found are random.
character, and are not a property of the aggregate.
In a relationship scientific hypothesis the level of statistical significance is the quantitative
indicator of the degree of distrust in the conclusion about the presence of a connection, calculated from the results
selective, empirical testing of this hypothesis. How less value p-level, the higher
statistical significance of the result of the study, confirming the scientific hypothesis.
It is useful to know what influences the level of significance. Significance level, other things being equal
above (lower p-value) if:
The magnitude of the connection (difference) is greater;
The variability of the trait(s) is less;
The sample size(s) is larger.
Unilateral Here are two-tailed significance tests
If the purpose of the study is to reveal the difference between the parameters of the two general
collections that correspond to its various natural conditions ( living conditions,
the age of the subjects, etc.), it is often unknown which of these parameters will be greater, and
which one is smaller.
For example, if you are interested in the variability of results in the control and
experimental groups, then, as a rule, there is no confidence in the sign of the difference between the variances or
the standard deviations of the results against which variability is estimated. In this case
the null hypothesis is that the variances are equal to each other, and the goal of the study is
prove the opposite, i.e. there is a difference between the variances. At the same time, it is allowed that
the difference can be of any sign. Such hypotheses are called two-sided.
But sometimes the task is to prove an increase or decrease in a parameter;
for example, average result higher in the experimental group than in the control group. Wherein
it is no longer allowed that the difference can be of a different sign. Such hypotheses are called
Unilateral.
Significance tests used to test two-sided hypotheses are called
Bilateral, and for unilateral - unilateral.
The question arises as to which of the criteria should be chosen in a particular case. Answer
This question is beyond formal statistical methods and completely
Depends on the purpose of the study. In no case should one or another criterion be chosen after
Conducting an experiment based on the analysis of experimental data, since this can
lead to wrong conclusions. If, prior to the experiment, it is assumed that the difference
Compared parameters can be both positive and negative, it follows
The level of significance in statistics is important indicator, reflecting the degree of confidence in the accuracy, the truth of the received (predicted) data. The concept is widely used in various fields: from holding sociological research, to statistical testing of scientific hypotheses.
Definition
The level of statistical significance (or statistically significant result) shows what is the probability of random occurrence of the studied indicators. The overall statistical significance of the phenomenon is expressed by the p-value (p-level). In any experiment or observation, there is a possibility that the data obtained arose due to sampling errors. This is especially true for sociology.
That is, a value is statistically significant, whose probability of random occurrence is extremely small or tends to extremes. The extreme in this context is the degree of deviation of statistics from the null hypothesis (a hypothesis that is tested for consistency with the obtained sample data). AT scientific practice the significance level is selected before data collection and, as a rule, its coefficient is 0.05 (5%). For systems where it is critical exact values, this indicator can be 0.01 (1%) or less.

Background
The concept of significance level was introduced by the British statistician and geneticist Ronald Fisher in 1925 when he was developing a method for testing statistical hypotheses. When analyzing any process, there is a certain probability of certain phenomena. Difficulties arise when working with small (or not obvious) percentages of probabilities that fall under the concept of "measurement error".
When working with statistics that were not specific enough to be tested, scientists were faced with the problem of the null hypothesis, which “prevents” operating with small values. Fisher proposed for such systems to determine the probability of events at 5% (0.05) as a convenient sample cutoff that allows one to reject the null hypothesis in the calculations.

Introduction of a fixed coefficient
In 1933 Jerzy scientists Neumann and Egon Pearson in their papers recommended setting a certain significance level in advance (before data collection). Examples of the use of these rules are clearly visible during the elections. Suppose there are two candidates, one of which is very popular and the other is not well known. It is obvious that the first candidate will win the election, and the chances of the second tend to zero. Strive - but not equal: there is always the possibility of force majeure, sensational information, unexpected decisions that can change the predicted election results.
Neumann and Pearson agreed that Fisher's proposed significance level of 0.05 (denoted by the symbol α) is the most convenient. However, Fischer himself in 1956 opposed fixing this value. He believed that the level of α should be set in accordance with specific circumstances. For example, in particle physics it is 0.01.

p-value
The term p-value was first used by Brownlee in 1960. The p-level (p-value) is an indicator found in inverse relationship on the validity of the results. The highest p-value corresponds to the lowest level of confidence in the sampled relationship between variables.
This value reflects the probability of errors associated with the interpretation of the results. Assume p-value = 0.05 (1/20). It shows a five percent chance that the relationship between variables found in the sample is just a random feature of the sample. That is, if this dependence is absent, then with multiple similar experiments, on average, in every twentieth study, one can expect the same or greater dependence between variables. Often the p-level is considered as the "margin" of the error level.
By the way, p-value may not reflect real addiction between variables, but only shows some mean value within the assumptions. In particular, the final analysis of the data will also depend on the chosen values given coefficient. With p-level = 0.05 there will be some results, and with a coefficient equal to 0.01, others.

Testing statistical hypotheses
The level of statistical significance is especially important when testing hypotheses. For example, when calculating a two-sided test, the rejection area is divided equally at both ends of the sampling distribution (relative to the zero coordinate) and the truth of the obtained data is calculated.
Let's suppose that while monitoring a certain process (phenomenon), it turned out that new statistical information indicates small changes relative to previous values. At the same time, the discrepancies in the results are small, not obvious, but important for the study. The specialist faces a dilemma: do the changes really occur or are they sampling errors (measurement inaccuracy)?
In this case, either the null hypothesis is applied or rejected (everything is attributed to an error, or the change in the system is recognized as a fait accompli). The process of solving the problem is based on the ratio of the overall statistical significance (p-value) and the level of significance (α). If p-level< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Used values
The level of significance depends on the analyzed material. In practice, the following fixed values are used:
- α = 0.1 (or 10%);
- α = 0.05 (or 5%);
- α = 0.01 (or 1%);
- α = 0.001 (or 0.1%).
The more accurate the calculations are required, the smaller the coefficient α is used. Naturally, statistical forecasts in physics, chemistry, pharmaceuticals, and genetics require greater accuracy than in political science and sociology.

Significance thresholds in specific areas
In high-precision fields such as particle physics and manufacturing, statistical significance is often expressed as the ratio of the standard deviation (denoted by the sigma coefficient - σ) relative to normal distribution probabilities (Gaussian distribution). σ is a statistical indicator that determines the dispersion of values of a certain quantity relative to mathematical expectations. Used to plot the probability of events.
Depending on the field of knowledge, the coefficient σ varies greatly. For example, when predicting the existence of the Higgs boson, the parameter σ is equal to five (σ=5), which corresponds to the p-value=1/3.5 million. areas.
Efficiency
It must be taken into account that the coefficients α and p-value are not exact characteristics. Whatever the level of significance in the statistics of the phenomenon under study, it is not an unconditional basis for accepting the hypothesis. For example, the smaller the value of α, the greater the chance that the hypothesis being established is significant. However, there is a risk of error, which reduces the statistical power (significance) of the study.
Researchers who focus exclusively on statistical meaningful results may draw erroneous conclusions. At the same time, it is difficult to double-check their work, since they apply assumptions (which, in fact, are the values of α and p-value). Therefore, it is always recommended, along with the calculation of statistical significance, to determine another indicator - the magnitude of the statistical effect. Effect size is a quantitative measure of the strength of an effect.
Statistics has long been an integral part of life. People face it everywhere. Based on statistics, conclusions are drawn about where and what diseases are common, what is more in demand in a particular region or among a certain segment of the population. Even constructions are based on political programs candidates for government. They are also used by retail chains when purchasing goods, and manufacturers are guided by these data in their proposals.
stats playing important role in the life of society and affects each of its individual members, even in small things. For example, if by , most people prefer dark colors in clothes in a particular city or region, it will be extremely difficult to find a bright yellow raincoat with a floral print in local outlets. But what are the quantities that make up these data that have such an impact? For example, what is “statistically significant”? What exactly is meant by this definition?
What's this?
Statistics as a science is made up of a combination different sizes and concepts. One of them is the concept of "statistical significance". This is the name of the value variables, the probability of occurrence of other indicators in which is negligible.
For example, 9 out of 10 people wear rubber shoes on their feet during morning walk for mushrooms in autumn forest after a rainy night. The probability that at some point 8 of them put on canvas moccasins is negligible. Thus, in this specific example the number 9 is a value that is called "statistical significance".
Accordingly, if we develop further the above practical example, shoe stores are buying by the end summer season rubber boots in greater numbers than at other times of the year. Yes, the value statistical significance has an impact on everyday life.
Of course, in complex calculations, for example, when predicting the spread of viruses, big number variables. But the very essence of determining a significant indicator of statistical data is similar, regardless of the complexity of the calculations and the number of non-constant values.
How is it calculated?
Used when calculating the value of the indicator "statistical significance" of the equation. That is, it can be argued that in this case everything is decided by mathematics. by the most simple option computing is a chain mathematical operations, which includes the following parameters:
- two types of results obtained from surveys or the study of objective data, for example, the amounts for which purchases are made, denoted by a and b;
- indicator for both groups - n;
- the value of the share of the combined sample - p;
- the concept of "standard error" - SE.
The next step is to determine the overall test indicator - t, its value is compared with the number 1.96. 1.96 is an average value representing a range of 95% according to Student's t-distribution.
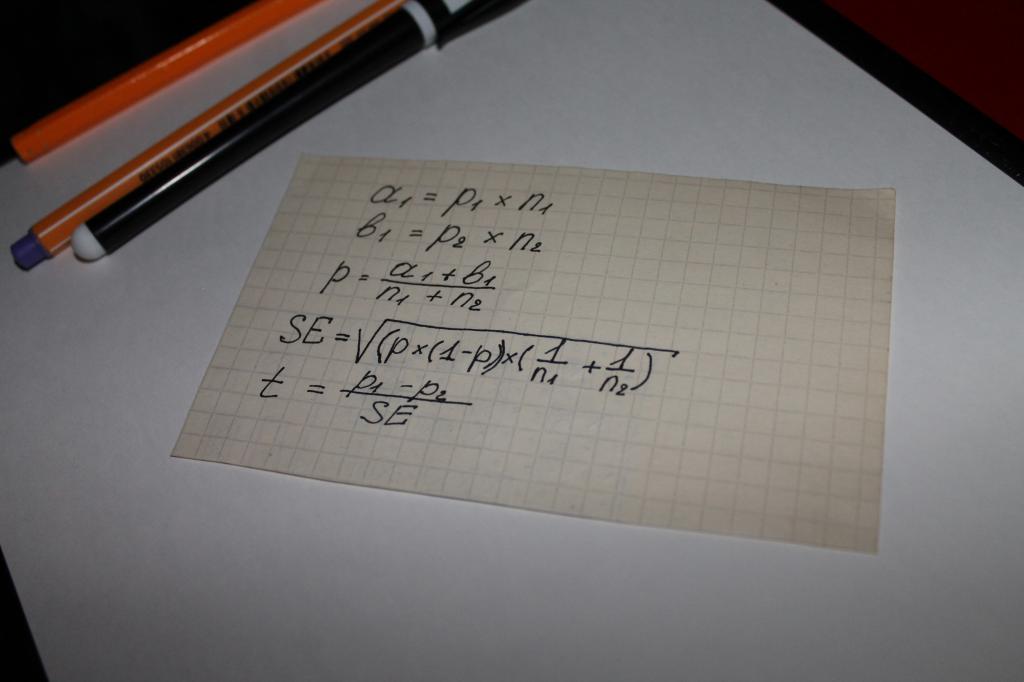
The question often arises as to what is the difference between the values of n and p. This nuance is easy to clarify with an example. Suppose, the statistical significance of loyalty to any product or brand of men and women is calculated.
In this case, the letters will be followed by the following:
- n is the number of respondents;
- p - the number of satisfied with the product.
The number of interviewed women in this case will be designated as n1. Accordingly, men - n2. The same value will have the numbers "1" and "2" at the symbol p.
Comparing the test indicator with the average values of Student's calculation tables becomes what is called "statistical significance".
What is meant by verification?
The results of any mathematical calculation can always be checked; this is taught to children even in primary school. It is logical to assume that since the statistical indicators are determined using a chain of calculations, then they are checked.
However, testing for statistical significance is not just math. Statistics deals with large quantity variables and various probabilities, which are not always amenable to calculation. That is, if we return to the example given at the beginning of the article with rubber shoes, then the logical construction of statistical data, which buyers of goods for stores will rely on, can be disrupted by dry and hot weather, which is not typical for autumn. As a result of this phenomenon, the number of people purchasing rubber boots will decrease and outlets will suffer losses. Anticipate a weather anomaly mathematical formula, of course, cannot. This moment is called - "mistake".

It is precisely the probability of such errors that the check of the level of calculated significance takes into account. It takes into account both calculated indicators and accepted levels of significance, as well as quantities conventionally called hypotheses.
What is a level of significance?
The concept of "level" is included in the main criteria for statistical significance. It is used in applied and practical statistics. This is a kind of quantity that takes into account the probability possible deviations or mistakes.
The level is based on the identification of differences in ready-made samples, it allows you to establish their significance or, conversely, randomness. This concept has not only digital meanings, but also their peculiar interpretations. They explain how the value should be understood, and the level itself is determined by comparing the result with the average index, this reveals the degree of reliability of the differences.

Thus, the concept of a level can be presented simply - it is an indicator of an acceptable, probable error or error in the conclusions drawn from the statistical data obtained.
What significance levels are used?
The statistical significance of the error probability coefficients in practice is based on three basic levels.
The first level is the threshold at which the value is 5%. That is, the probability of error does not exceed the significance level of 5%. This means that the confidence in the impeccability and infallibility of the conclusions made on the basis of statistical research data is 95%.
The second level is the 1% threshold. Accordingly, this figure means that one can be guided by the data obtained during statistical calculations with 99% confidence.
The third level is 0.1%. With this value, the probability of an error is equal to a fraction of a percent, that is, errors are practically eliminated.
What is a hypothesis in statistics?
Errors as a concept are divided into two areas regarding the acceptance or rejection of the null hypothesis. A hypothesis is a concept behind which, according to the definition, a set of other data or statements is hidden. That is the description probability distribution something related to the subject of statistical accounting.

There are two hypotheses in simple calculations - zero and alternative. The difference between them is that the null hypothesis is based on the idea that there are no fundamental differences between the samples involved in determining the statistical significance, and the alternative one is completely opposite to it. That is alternative hypothesis based on the presence of a significant difference in these samples.
What are the errors?
Errors as a concept in statistics are directly dependent on the acceptance of one or another hypothesis as true. They can be divided into two directions or types:
- the first type is due to the acceptance of the null hypothesis, which turned out to be incorrect;
- the second one is caused by following the alternative.

The first type of error is called false positive and is quite common in all areas where statistics are used. Accordingly, the error of the second type is called false negative.
Why is regression important in statistics?
The statistical significance of regression is that it can be used to establish how realistic the model calculated on the basis of the data is. various dependencies; allows you to identify the sufficiency or lack of factors for accounting and conclusions.
The regression value is determined by comparing the results with the data listed in the Fisher tables. Or using analysis of variance. Importance regression indicators have with complex statistical studies and calculations involving a large number of variables, random data and likely changes.
Statistical Significance
The results obtained using a certain research procedure are called statistically significant if the probability of their random occurrence is very small. This concept can be illustrated by the example of tossing a coin. Suppose a coin is flipped 30 times; It came up 17 times heads and 13 times it came up tails. is it meaningful Is this a deviation from the expected result (15 heads and 15 tails), or is this a coincidence? To answer this question, you can, for example, toss the same coin many times 30 times in a row, and at the same time note how many times the ratio of heads and tails, equal to 17:13, is repeated. Statistical analysis saves us from this tedious process. With its help, after the first 30 coin tosses, it is possible to estimate the possible number of random occurrences of 17 heads and 13 tails. Such an estimate is called a probabilistic statement.
AT scientific literature in industrial-organizational psychology probabilistic statement in mathematical form denoted by the expression R(probability)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (R< 0.01). This fact is important for understanding the literature, but should not be taken to mean that it is pointless to make observations that do not meet these standards. So-called non-significant research results (observations that can be obtained by chance more one or five times out of 100) can be very useful for identifying trends and as a guide to future research.
It should also be noted that not all psychologists agree with traditional standards and procedures (eg Cohen, 1994; Sauley & Bedeian, 1989). Issues related to measurements are themselves main theme the work of many researchers studying the accuracy of measurement methods and the prerequisites that underlie existing methods and standards, as well as developing new doctors and instruments. Perhaps sometime in the future, research in this power will lead to a change in the traditional standards for assessing statistical significance, and these changes will gain universal acceptance. (The Fifth Chapter of the American Psychological Association brings together psychologists who specialize in the study of assessments, measurements, and statistics.)
In research reports, a probabilistic statement such as R< 0.05, due to some statistics that is, a number that is obtained as a result of a certain set of mathematical computational procedures. Probabilistic confirmation is obtained by comparing these statistics with data from special tables that are published for this purpose. In industrial-organizational psychological research frequently encountered statistics such as r, F, t, r>(read "chi square") and R(read "multiple R"). In each case, the statistics (one number) obtained from the analysis of a series of observations can be compared with the numbers from the published table. After that, it is possible to formulate a probabilistic statement about the probability of randomly obtaining this number, that is, to draw a conclusion about the significance of the observations.
To understand the studies described in this book, it is enough to have a clear understanding of the concept of statistical significance and not necessarily know how the statistics mentioned above are calculated. However, it would be useful to discuss one assumption that underlies all of these procedures. This is the assumption that all observed variables are distributed approximately normal law. In addition, when reading reports on industrial-organizational psychological research, three more concepts often come up that play an important role - first, correlation and correlation, secondly, the determinant/ predictor variable and "ANOVA" ( analysis of variance), thirdly, a group of statistical methods under common name"meta-analysis".
Hypothesis testing is carried out using statistical analysis. Statistical significance is found using the P-value, which corresponds to the probability this event under the assumption that some statement (the null hypothesis) is true. If the P-value is less than a given level of statistical significance (usually 0.05), the experimenter can safely conclude that the null hypothesis is false and move on to consider the alternative hypothesis. Using Student's t-test, you can calculate the P-value and determine the significance for two data sets.
Steps
Part 1
Setting up an experiment- The null hypothesis (H 0) usually states that there is no difference between the two datasets. For example: those students who read the material before class do not get higher marks.
- The alternative hypothesis (H a) is the opposite of the null hypothesis and is a statement that needs to be confirmed with experimental data. For example: those students who read the material before class get higher marks.
-
Set the significance level to determine how much the distribution of the data must differ from the usual for it to be considered a significant result. Significance level (also called α (\displaystyle \alpha )-level) is the threshold you define for statistical significance. If the P-value is less than or equal to the significance level, the data is considered statistically significant.
- As a rule, the level of significance (value α (\displaystyle \alpha )) is taken equal to 0.05, in which case the probability of detecting a random difference between different data sets is only 5%.
- The higher the level of significance (and, accordingly, less p-value), the more reliable the results.
- If you want more reliable results, lower the P-value to 0.01. Typically, lower P-values are used in production when it is necessary to detect defects in products. In this case, high fidelity is required to ensure that all parts work as expected.
- For most hypotheses experiments, a significance level of 0.05 is sufficient.
-
Decide which criteria you will use: one-sided or two-sided. One of the assumptions in Student's t-test is that the data are normally distributed. The normal distribution is a bell-shaped curve with the maximum number results in the middle of the curve. Student's t-test is mathematical method data validation, which allows you to determine whether the data falls outside the normal distribution (more, less, or in the “tails” of the curve).
- If you are not sure if the data is above or below control group values, use a two-tailed test. This will allow you to determine the significance in both directions.
- If you know in which direction the data might fall outside the normal distribution, use a one-tailed test. In the example above, we expect students' grades to go up, so a one-tailed test can be used.
-
Determine the sample size using statistical power. The statistical power of a study is the probability that a given sample size will produce the expected result. A common power threshold (or β) is 80%. Power analysis without any prior data can be tricky because some information is required about the expected means in each data set and their standard deviations. Use the online power calculator to determine the optimal sample size for your data.
- Typically, researchers conduct a small pilot study that provides data for power analysis and determines the sample size needed for a larger and more complete study.
- If you do not have the opportunity to conduct a pilot study, try to estimate possible average values based on the literature data and the results of other people. This may help you determine the optimal sample size.
Part 2
Calculate standard deviation-
Write down the formula for the standard deviation. The standard deviation indicates how large the spread of the data is. It allows you to conclude how close the data obtained on a particular sample. At first glance, the formula seems rather complicated, but the explanations below will help you understand it. The formula has next view: s = √∑((x i – µ) 2 /(N – 1)).
- s - standard deviation;
- the ∑ sign indicates that all the data obtained in the sample should be added;
- x i corresponds to the i-th value, that is, a separate result obtained;
- µ is the average value for this group;
- N- total number data in the sample.
-
Find the average in each group. To calculate the standard deviation, you must first find the mean for each study group. The mean value is denoted Greek letterµ (mu). To find the average, simply add up all the resulting values and divide them by the amount of data (sample size).
- For example, to find average grade in the group of those students who study the material before classes, consider a small data set. For simplicity, we use a set of five points: 90, 91, 85, 83 and 94.
- Let's add all the values together: 90 + 91 + 85 + 83 + 94 = 443.
- Divide the sum by the number of values, N = 5: 443/5 = 88.6.
- Thus, the average value for this group is 88.6.
-
Subtract each value obtained from the average. The next step is to calculate the difference (x i - µ). To do this, subtract from the found medium size each received value. In our example, we need to find five differences:
- (90 - 88.6), (91 - 88.6), (85 - 88.6), (83 - 88.6) and (94 - 88.6).
- As a result, we get the following values: 1.4, 2.4, -3.6, -5.6 and 5.4.
-
Square each value obtained and add them together. Each of the quantities just found should be squared. All will disappear at this step. negative values. If after this step you have negative numbers, then you forgot to square them.
- For our example, we get 1.96, 5.76, 12.96, 31.36 and 29.16.
- We add the obtained values: 1.96 + 5.76 + 12.96 + 31.36 + 29.16 = 81.2.
-
Divide by the sample size minus 1. In the formula, the sum is divided by N - 1 due to the fact that we do not take into account general population, but we take for evaluation a sample of all students.
- Subtract: N - 1 = 5 - 1 = 4
- Divide: 81.2/4 = 20.3
-
Extract Square root. After dividing the sum by the sample size minus one, take the square root of the found value. This is the last step in calculating the standard deviation. There are statistical programs that, after entering the initial data, perform all the necessary calculations.
- In our example, the standard deviation of the marks of those students who read the material before class is s = √20.3 = 4.51.
Part 3
Determine Significance-
Calculate the variance between the two groups of data. Up to this step, we have considered the example for only one group of data. If you want to compare two groups, obviously you should take the data for both groups. Calculate the standard deviation for the second group of data and then find the variance between the two experimental groups. The dispersion is calculated using the following formula: s d = √((s 1 /N 1) + (s 2 /N 2)).
Define your hypothesis. The first step in evaluating statistical significance is to choose the question you want answered and formulate a hypothesis. A hypothesis is a statement about experimental data, their distribution and properties. For any experiment, there is both a null and an alternative hypothesis. Generally speaking, you will have to compare two sets of data to determine if they are similar or different.
