Hydrogen bonds are formed between the amino group of one base and the carbonyl group of another, as well as between the amide and imine nitrogen atoms. For example, two hydrogen bonds form between adenine and thymine, and these heterocyclic bases form a complementary pair. This means that the adenine base of one chain will correspond to the thymine base of the other chain. Another pair of complementary bases is guanine and cytosine, between which three hydrogen bonds occur.
The areas occupied by pairs of complementary bases are approximately the same.
The complementarity of the bases underlies the patterns formulated by E. Chargaff (Chargaff's rules):
1. - the number of purine bases is equal to the number of pyrimidine bases;
2. - the amount of adenine is equal to the amount of thymine; the amount of guanine is equal to the amount of cytosine;
3. - the sum of adenine and cytosine is equal to the sum of guanine and thymine
(A / T \u003d C / G \u003d 1).
Double-stranded DNA with complementary polynucleotide chains provides the possibility of self-doubling (replication) of the molecule. This complex process can be represented as follows: before doubling, the hydrogen bonds are broken and the two chains unwind and diverge. Each strand then serves as a template for the formation of a complementary strand thereon. After replication, two daughter DNA molecules are formed, in each of which one helix is taken from the parent DNA, and the other (complementary) is synthesized anew.
The DNA double helix has several shapes depending on the degree of hydration of the molecule. The forms differ in the location of the plane of base pairs in relation to the axis of the helix, to each other, according to the variant of the twisting of the helix (to the right, to the left) and other features.
Between the chains there are two "furrows" - large and small. In these grooves, proteins can specifically interact with certain atoms. nucleic acids, recognize specific nucleotide sequences without disturbing complementary interactions double helix. It has been established that, due to such interactions, regulatory proteins can control gene expression.


Forms of the secondary structure of the DNA molecule
Secondary structure of RNA
An RNA molecule is built from a single polynucleotide chain. The number of nucleotides can range from 75 to several thousand, and molecular mass will change in the range from 25 thousand to several million.
The RNA polypeptide chain does not have a strictly defined structure. It can fold on itself and form separate two-stranded sections with hydrogen bonds between purine and pyrimidine bases. Hydrogen bonds in RNA do not obey strict rules like vDNA.
tRNA has been studied in detail. The tRNA molecule has a secondary structure, which consists of four helical sections, three, four single-stranded loops. This structure is called a "cloverleaf".
On the right is the largest human DNA helix built from people on the beach in Varna (Bulgaria), which was included in the Guinness Book of Records on April 23, 2016
Deoxyribonucleic acid. General information
DNA (deoxyribonucleic acid) - a kind of life blueprint, complex code, which contains data on hereditary information. This complex macromolecule is capable of storing and transmitting hereditary genetic information from generation to generation. DNA determines such properties of any living organism as heredity and variability. The information encoded in it determines the entire development program of any living organism. Genetically embedded factors predetermine the entire course of life of both a person and any other organism. Artificial or natural influence external environment can only slightly affect the overall severity of individual genetic traits or affect the development of programmed processes.
Deoxyribonucleic acid(DNA) is a macromolecule (one of the three main ones, the other two are RNA and proteins), which provides storage, transmission from generation to generation and implementation of the genetic program for the development and functioning of living organisms. DNA contains information about the structure various kinds RNA and proteins.
In eukaryotic cells (animals, plants, and fungi), DNA is found in the cell nucleus as part of chromosomes, as well as in some cell organelles (mitochondria and plastids). In the cells of prokaryotic organisms (bacteria and archaea), a circular or linear DNA molecule, the so-called nucleoid, is attached from the inside to cell membrane. They and lower eukaryotes (for example, yeast) also have small autonomous, mostly circular DNA molecules called plasmids.
FROM chemical point DNA is a long polymer molecule made up of repeating units called nucleotides. Each nucleotide is made up of a nitrogenous base, a sugar (deoxyribose), and a phosphate group. The bonds between nucleotides in a chain are formed by deoxyribose ( FROM) and phosphate ( F) groups (phosphodiester bonds).

Rice. 2. Nuclertide consists of a nitrogenous base, sugar (deoxyribose) and a phosphate group
In the overwhelming majority of cases (except for some viruses containing single-stranded DNA), the DNA macromolecule consists of two chains oriented by nitrogenous bases to each other. This double-stranded molecule is twisted in a helix.
There are four types of nitrogenous bases found in DNA (adenine, guanine, thymine, and cytosine). The nitrogenous bases of one of the chains are connected to the nitrogenous bases of the other chain by hydrogen bonds according to the principle of complementarity: adenine combines only with thymine ( A-T), guanine - only with cytosine ( G-C). It is these pairs that make up the "rungs" of the helical "ladder" of DNA (see: Fig. 2, 3 and 4).

Rice. 2. Nitrogenous bases
The sequence of nucleotides allows you to "encode" information about various types RNA, the most important of which are information or template (mRNA), ribosomal (rRNA) and transport (tRNA). All these types of RNA are synthesized on the DNA template by copying the DNA sequence into the RNA sequence synthesized during transcription and take part in protein biosynthesis (translation process). In addition to coding sequences, cell DNA contains sequences that perform regulatory and structural functions.

Rice. 3. DNA replication
Location of basic combinations chemical compounds DNA and quantitative ratios between these combinations provide encoding of hereditary information.
Education new DNA (replication)
- The process of replication: the unwinding of the DNA double helix - the synthesis of complementary strands by DNA polymerase - the formation of two DNA molecules from one.
- The double helix "unzips" into two branches when enzymes break the bond between the base pairs of chemical compounds.
- Each branch is a new DNA element. New base pairs are connected in the same sequence as in the parent branch.
Upon completion of the duplication, two independent helices are formed, created from the chemical compounds of the parent DNA and having the same genetic code with it. In this way, DNA is able to rip through information from cell to cell.
More detailed information:
STRUCTURE OF NUCLEIC ACIDS

Rice. four . Nitrogenous bases: adenine, guanine, cytosine, thymine
Deoxyribonucleic acid(DNA) refers to nucleic acids. Nucleic acids is a class of irregular biopolymers whose monomers are nucleotides.
Nucleotides consist of nitrogenous base, connected to a five-carbon carbohydrate (pentose) - deoxyribose(in the case of DNA) or ribose(in the case of RNA) that binds to the remainder phosphoric acid(H 2 PO 3 -).
Nitrogenous bases There are two types: pyrimidine bases - uracil (only in RNA), cytosine and thymine, purine bases - adenine and guanine.

Rice. 5. Types of nitrogenous bases: pyrimidine and purine
The carbon atoms in a pentose molecule are numbered from 1 to 5. Phosphate combines with the third and fifth carbon atoms. This is how nucleic acids are linked together to form a chain of nucleic acids. Thus, we can isolate the 3' and 5' ends of the DNA strand:

Rice. 6. Isolation isolate the 3' and 5' ends of the DNA strand
Two strands of DNA form double helix. These chains in a spiral are oriented in opposite directions. AT different chains DNA nitrogenous bases are linked together by hydrogen bonds. Adenine always combines with thymine, and cytosine always combines with guanine. It is called complementarity rule.
Complementarity rule:
| A-T G-C |
For example, if we are given a DNA strand that has the sequence
3'-ATGTCCTAGCTGCTCG - 5',
then the second chain will be complementary to it and directed to opposite direction- from 5'-end to 3'-end:
5'- TACAGGATCGACGAGC- 3'.

Rice. 7. The direction of the chains of the DNA molecule and the connection of nitrogenous bases using hydrogen bonds
REPLICATION
DNA replication is the process of duplicating a DNA molecule by matrix synthesis. Replication takes place semi-conservative mechanism. This means that the double helix of DNA unwinds and a new chain is completed on each of its chains according to the principle of complementarity. The daughter DNA molecule thus contains one strand from the parent molecule and one newly synthesized. Replication occurs in the 3' to 5' direction of the parent strand.

Rice. 8. Replication (doubling) of the DNA molecule
DNA synthesis- this is not such a complicated process as it might seem at first glance. If you think about it, then first you need to figure out what synthesis is. It is the process of bringing something together. The formation of a new DNA molecule takes place in several stages:
- DNA topoisomerase, located in front of the replication fork, cuts the DNA in order to facilitate its unwinding and unwinding.
- DNA helicase, following topoisomerase, affects the process of "unwinding" the DNA helix.
- DNA-binding proteins carry out the binding of DNA strands, and also carry out their stabilization, preventing them from sticking to each other.
- DNA polymerase synthesizes the leading strand of the daughter DNA.

Rice. 9. Schematic representation of the replication process, numbers indicate: (1) Lag strand, (2) Leading strand, (3) DNA polymerase (Polα), (4) DNA ligase, (5) RNA primer, (6) Primase , (7) Okazaki fragment, (8) DNA polymerase (Polδ), (9) Helicase, (10) Single-stranded DNA binding proteins, (11) Topoisomerase
RNA structure
Ribonucleic acid(RNA) is one of the three main macromolecules (the other two are DNA and proteins) that are found in the cells of all living organisms.
Just like DNA, RNA is made up of a long chain in which each link is called a nucleotide. Each nucleotide is made up of a nitrogenous base, a ribose sugar, and a phosphate group. However, unlike DNA, RNA usually has one rather than two strands. Pentose in RNA is represented by ribose, not deoxyribose (ribose has an additional hydroxyl group on the second carbohydrate atom). Finally, DNA differs from RNA in the composition of nitrogenous bases: instead of thymine ( T) uracil is present in RNA ( U) , which is also complementary to adenine.
The sequence of nucleotides allows RNA to encode genetic information. All cellular organisms use RNA (mRNA) to program protein synthesis.
Cellular RNAs are formed in a process called transcription , that is, the synthesis of RNA on a DNA template, carried out by special enzymes - RNA polymerases.
Messenger RNAs (mRNAs) then take part in a process called broadcast, those. protein synthesis on the mRNA template with the participation of ribosomes. Other RNAs undergo chemical modifications after transcription, and after the formation of secondary and tertiary structures perform functions depending on the type of RNA.

Rice. 10. The difference between DNA and RNA in terms of the nitrogenous base: instead of thymine (T), RNA contains uracil (U), which is also complementary to adenine.
TRANSCRIPTION
This is the process of RNA synthesis on a DNA template. DNA unwinds at one of the sites. One of the chains contains information that needs to be copied onto the RNA molecule - this chain is called coding. The second strand of DNA, which is complementary to the coding strand, is called the template strand. In the process of transcription on the template chain in the 3'-5' direction (along the DNA chain), an RNA chain complementary to it is synthesized. Thus, an RNA copy of the coding strand is created.
![]()
Rice. 11. Schematic representation of transcription
For example, if we are given the sequence of the coding strand
3'-ATGTCCTAGCTGCTCG - 5',
then, according to the rule of complementarity, the matrix chain will carry the sequence
5'- TACAGGATCGACGAGC- 3',
and the RNA synthesized from it is the sequence
BROADCAST
Consider the mechanism protein synthesis on the RNA matrix, as well as the genetic code and its properties. Also, for clarity, at the link below, we recommend watching a short video about the processes of transcription and translation occurring in a living cell:

Rice. 12. Process of protein synthesis: DNA codes for RNA, RNA codes for protein
GENETIC CODE
Genetic code - a method of encoding the amino acid sequence of proteins using a sequence of nucleotides. Each amino acid is encoded by a sequence of three nucleotides - a codon or a triplet.
Genetic code common to most pro- and eukaryotes. The table lists all 64 codons and lists the corresponding amino acids. The base order is from the 5" to the 3" end of the mRNA.
Table 1. Standard genetic code
|
1st nie |
2nd base |
3rd nie |
|||||||
|
U |
C |
A |
G |
||||||
|
U |
U U U |
(Phe/F) |
U C U |
(Ser/S) |
U A U |
(Tyr/Y) |
U G U |
(Cys/C) |
U |
|
U U C |
U C C |
U A C |
U G C |
C |
|||||
|
U U A |
(Leu/L) |
U C A |
U A A |
Stop codon** |
U G A |
Stop codon** |
A |
||
|
U U G |
U C G |
U A G |
Stop codon** |
U G G |
(Trp/W) |
G |
|||
|
C |
C U U |
C C U |
(Pro/P) |
C A U |
(His/H) |
C G U |
(Arg/R) |
U |
|
|
C U C |
C C C |
C A C |
C G C |
C |
|||||
|
C U A |
C C A |
C A A |
(Gln/Q) |
CGA |
A |
||||
|
C U G |
C C G |
C A G |
C G G |
G |
|||||
|
A |
A U U |
(Ile/I) |
A C U |
(Thr/T) |
A A U |
(Asn/N) |
A G U |
(Ser/S) |
U |
|
A U C |
A C C |
A A C |
A G C |
C |
|||||
|
A U A |
A C A |
A A A |
(Lys/K) |
A G A |
A |
||||
|
A U G |
(Met/M) |
A C G |
A A G |
A G G |
G |
||||
|
G |
G U U |
(Val/V) |
G C U |
(Ala/A) |
G A U |
(Asp/D) |
G G U |
(Gly/G) |
U |
|
G U C |
G C C |
G A C |
G G C |
C |
|||||
|
G U A |
G C A |
G A A |
(Glu/E) |
G G A |
A |
||||
|
G U G |
G C G |
G A G |
G G G |
G |
|||||
Among the triplets, there are 4 special sequences that act as "punctuation marks":
- *Triplet AUG, also encoding methionine, is called start codon. This codon begins the synthesis of a protein molecule. Thus, during protein synthesis, the first amino acid in the sequence will always be methionine.
- **Triplets UAA, UAG and UGA called stop codons and do not code for any amino acids. At these sequences, protein synthesis stops.
Properties of the genetic code
1. Tripletity. Each amino acid is encoded by a sequence of three nucleotides - a triplet or codon.
2. Continuity. There are no additional nucleotides between the triplets, information is read continuously.
3. Non-overlapping. One nucleotide cannot be part of two triplets at the same time.
4. Uniqueness. One codon can code for only one amino acid.

5. Degeneracy. One amino acid can be encoded by several different codons.

6. Versatility. The genetic code is the same for all living organisms.
Example. We are given the sequence of the coding strand:
3’- CCGATTGCACGTCGATCGTATA- 5’.
The matrix chain will have the sequence:
5’- GGCTAACGTGCAGCTAGCATAT- 3’.
Now we “synthesize” informational RNA from this chain:
3’- CCGAUUGCACGUCGAUCGUAUA- 5’.
Protein synthesis goes in the direction 5' → 3', therefore, we need to flip the sequence in order to "read" the genetic code:
5’- AUAUGCUAGCUGCACGUUAGCC- 3’.
Now find the start codon AUG:
5’- AU AUG CUAGCUGCACGUUAGCC- 3’.
Divide the sequence into triplets:
sounds like this: information from DNA is transferred to RNA (transcription), from RNA to protein (translation). DNA can also be duplicated by replication, and a process is also possible reverse transcription, when DNA is synthesized from the RNA template, but such a process is mainly characteristic of viruses.

Rice. 13. Central dogma of molecular biology
GENOM: GENES AND CHROMOSOMES
(general concepts)
Genome - the totality of all the genes of an organism; its complete chromosome set.
The term "genome" was proposed by G. Winkler in 1920 to describe the totality of genes contained in the haploid set of chromosomes of organisms of one species. The original meaning of this term indicated that the concept of the genome, in contrast to the genotype, is genetic characteristic the species as a whole, not the individual. With development molecular genetics the meaning of the term has changed. It is known that DNA, which is the carrier of genetic information in most organisms and, therefore, forms the basis of the genome, includes not only genes in modern sense this word. Most of The DNA of eukaryotic cells is represented by non-coding (“redundant”) nucleotide sequences that do not contain information about proteins and nucleic acids. Thus, the main part of the genome of any organism is the entire DNA of its haploid set of chromosomes.
Genes are segments of DNA molecules that code for polypeptides and RNA molecules.
Per last century our understanding of genes has changed dramatically. Previously, a genome was a region of a chromosome that encodes or determines one trait or phenotypic(visible) property, such as eye color.
In 1940, George Beadle and Edward Tatham proposed molecular definition gene. Scientists processed fungus spores Neurospora crassa x-rays and other agents that cause changes in the DNA sequence ( mutations), and found mutant strains of the fungus that lost some specific enzymes, which in some cases led to a violation of the whole metabolic pathway. Beadle and Tatham came to the conclusion that a gene is a section of genetic material that defines or codes for a single enzyme. This is how the hypothesis "one gene, one enzyme". This concept was later extended to the definition "one gene - one polypeptide", since many genes encode proteins that are not enzymes, and a polypeptide can be a subunit of a complex protein complex.
On fig. 14 shows a diagram of how DNA triplets determine a polypeptide, the amino acid sequence of a protein, mediated by mRNA. One of the DNA strands plays the role of a template for the synthesis of mRNA, the nucleotide triplets (codons) of which are complementary to the DNA triplets. In some bacteria and many eukaryotes, coding sequences are interrupted by non-coding regions (called introns).
Contemporary biochemical definition gene even more specifically. Genes are all sections of DNA that encode the primary sequence of end products, which include polypeptides or RNA that have a structural or catalytic function.
Along with genes, DNA also contains other sequences that perform exclusively regulatory function. Regulatory sequences may mark the beginning or end of genes, affect transcription, or indicate the site of initiation of replication or recombination. Some genes can be expressed in different ways, with the same piece of DNA serving as a template for the formation of different products.
We can roughly calculate minimum gene size coding for the intermediate protein. Each amino acid in a polypeptide chain is encoded by a sequence of three nucleotides; the sequences of these triplets (codons) correspond to the chain of amino acids in the polypeptide encoded by the given gene. A polypeptide chain of 350 amino acid residues middle length) corresponds to a sequence of 1050 b.p. ( bp). However, many eukaryotic genes and some prokaryotic genes are interrupted by DNA segments that do not carry information about the protein, and therefore turn out to be much longer than a simple calculation shows.
How many genes are on one chromosome?
 Rice. 15. View of chromosomes in prokaryotic (left) and eukaryotic cells. Histones are a broad class of nuclear proteins that perform two main functions: they are involved in the packaging of DNA strands in the nucleus and in the epigenetic regulation of nuclear processes such as transcription, replication, and repair.
Rice. 15. View of chromosomes in prokaryotic (left) and eukaryotic cells. Histones are a broad class of nuclear proteins that perform two main functions: they are involved in the packaging of DNA strands in the nucleus and in the epigenetic regulation of nuclear processes such as transcription, replication, and repair.
As you know, bacterial cells have a chromosome in the form of a DNA strand, packed into a compact structure - a nucleoid. prokaryotic chromosome Escherichia coli, whose genome is completely decoded, is a circular DNA molecule (in fact, it is not right circle, but rather a loop without beginning or end), consisting of 4,639,675 b.p. This sequence contains approximately 4300 protein genes and another 157 genes for stable RNA molecules. AT human genome approximately 3.1 billion base pairs corresponding to almost 29,000 genes located on 24 different chromosomes.
Prokaryotes (Bacteria).
 Bacterium E. coli has one double-stranded circular DNA molecule. It consists of 4,639,675 b.p. and reaches a length of approximately 1.7 mm, which exceeds the length of the cell itself E. coli about 850 times. In addition to the large circular chromosome as part of the nucleoid, many bacteria contain one or more small circular DNA molecules that are freely located in the cytosol. These extrachromosomal elements are called plasmids(Fig. 16).
Bacterium E. coli has one double-stranded circular DNA molecule. It consists of 4,639,675 b.p. and reaches a length of approximately 1.7 mm, which exceeds the length of the cell itself E. coli about 850 times. In addition to the large circular chromosome as part of the nucleoid, many bacteria contain one or more small circular DNA molecules that are freely located in the cytosol. These extrachromosomal elements are called plasmids(Fig. 16).
Most plasmids consist of only a few thousand base pairs, some contain more than 10,000 bp. They carry genetic information and replicate with the formation of daughter plasmids that fall into daughter cells during the division of the parent cell. Plasmids are found not only in bacteria, but also in yeast and other fungi. In many cases, plasmids offer no advantage to the host cells and their only job is to reproduce independently. However, some plasmids carry genes useful to the host. For example, genes contained in plasmids can confer resistance to antibacterial agents in bacterial cells. Plasmids carrying the geneβ-lactamases confer resistance to β-lactam antibiotics such as penicillin and amoxicillin. Plasmids can pass from antibiotic-resistant cells to other cells of the same or different bacterial species, causing those cells to also become resistant. Intensive use of antibiotics is a powerful selective factor that promotes the spread of plasmids encoding antibiotic resistance (as well as transposons that encode similar genes) among pathogenic bacteria, and leads to the emergence of bacterial strains with resistance to several antibiotics. Doctors are beginning to understand the dangers of widespread use of antibiotics and prescribe them only when absolutely necessary. For similar reasons, the widespread use of antibiotics for the treatment of farm animals is limited.
See also: Ravin N.V., Shestakov S.V. Genome of prokaryotes // Vavilov Journal of Genetics and Breeding, 2013. V. 17. No. 4/2. pp. 972-984.
Eukaryotes.
Table 2. DNA, genes and chromosomes of some organisms
|
shared DNA, b.s. |
Number of chromosomes* |
Approximate number of genes |
|
|
Escherichia coli(bacterium) |
4 639 675 |
4 435 |
|
|
Saccharomyces cerevisiae(yeast) |
12 080 000 |
16** |
5 860 |
|
Caenorhabditis elegans(nematode) |
90 269 800 |
12*** |
23 000 |
|
Arabidopsis thaliana(plant) |
119 186 200 |
33 000 |
|
|
Drosophila melanogaster(fruit fly) |
120 367 260 |
20 000 |
|
|
Oryza sativa(rice) |
480 000 000 |
57 000 |
|
|
Mus muscle(mouse) |
2 634 266 500 |
27 000 |
|
|
Homo sapiens(human) |
3 070 128 600 |
29 000 |
Note. Information is constantly updated; For more up-to-date information, refer to individual genomic project websites.
* For all eukaryotes, except yeast, the diploid set of chromosomes is given. diploid kit chromosomes (from Greek diploos - double and eidos - view) - a double set of chromosomes (2n), each of which has a homologous one.
**Haploid set. Wild strains of yeast typically have eight (octaploid) or more sets of these chromosomes.
***For females with two X chromosomes. Males have an X chromosome, but no Y, i.e. only 11 chromosomes.
A yeast cell, one of the smallest eukaryotes, has 2.6 times more DNA than a cell E. coli(Table 2). fruit fly cells Drosophila, classical object genetic research, contain 35 times more DNA, and human cells contain about 700 times more DNA than cells E. coli. Many plants and amphibians contain even more DNA. The genetic material of eukaryotic cells is organized in the form of chromosomes. Diploid set of chromosomes (2 n) depends on the type of organism (Table 2).
For example, in a human somatic cell there are 46 chromosomes ( rice. 17). Each chromosome in a eukaryotic cell, as shown in Fig. 17, a, contains one very large double-stranded DNA molecule. Twenty-four human chromosomes (22 paired chromosomes and two sex chromosomes X and Y) differ in length by more than 25 times. Each eukaryotic chromosome contains a specific set of genes.

Rice. 17. eukaryotic chromosomes.a- a pair of connected and condensed sister chromatids from the human chromosome. In this form, eukaryotic chromosomes remain after replication and in metaphase during mitosis. b- a complete set of chromosomes from a leukocyte of one of the authors of the book. Each normal human somatic cell contains 46 chromosomes.
If you connect the DNA molecules of the human genome (22 chromosomes and chromosomes X and Y or X and X) to each other, you get a sequence about one meter long. Note: In all mammals and other heterogametic male organisms, females have two X chromosomes (XX) and males have one X chromosome and one Y chromosome (XY).
Most human cells, so the total DNA length of such cells is about 2m. An adult human has about 10 14 cells, so the total length of all DNA molecules is 2・10 11 km. For comparison, the circumference of the Earth is 4・10 4 km, and the distance from the Earth to the Sun is 1.5・10 8 km. That's how amazingly compactly packaged DNA is in our cells!
In eukaryotic cells, there are other organelles containing DNA - these are mitochondria and chloroplasts. Many hypotheses have been put forward regarding the origin of mitochondrial and chloroplast DNA. The generally accepted point of view today is that they are the rudiments of the chromosomes of ancient bacteria that penetrated into the cytoplasm of the host cells and became the precursors of these organelles. Mitochondrial DNA codes for mitochondrial tRNA and rRNA, as well as several mitochondrial proteins. More than 95% of mitochondrial proteins are encoded by nuclear DNA.
STRUCTURE OF GENES
Consider the structure of the gene in prokaryotes and eukaryotes, their similarities and differences. Despite the fact that a gene is a section of DNA that codes for only one protein or RNA, in addition to the directly coding part, it also includes regulatory and other structural elements having different structure in prokaryotes and eukaryotes.
coding sequence- the main structural and functional unit of the gene, it is in it that the triplets of nucleotides encodingamino acid sequence. It starts with a start codon and ends with a stop codon.
Before and after the coding sequence are untranslated 5' and 3' sequences. They perform regulatory and auxiliary functions, for example, ensure the landing of the ribosome on mRNA.
Untranslated and coding sequences make up the unit of transcription - the transcribed DNA region, that is, the DNA region from which mRNA is synthesized.
Terminator A non-transcribed region of DNA at the end of a gene where RNA synthesis stops.
At the beginning of the gene is regulatory area, which includes promoter and operator.
promoter- the sequence with which the polymerase binds during transcription initiation. Operator- this is the area to which special proteins can bind - repressors, which can reduce the activity of RNA synthesis from this gene - in other words, reduce it expression.
The structure of genes in prokaryotes
The general plan for the structure of genes in prokaryotes and eukaryotes does not differ - both contain a regulatory region with a promoter and operator, a transcription unit with coding and non-translated sequences, and a terminator. However, the organization of genes in prokaryotes and eukaryotes is different.

Rice. 18. Scheme of the structure of the gene in prokaryotes (bacteria) -the image is enlarged
At the beginning and at the end of the operon, there are common regulatory regions for several structural genes. From the transcribed region of the operon, one mRNA molecule is read, which contains several coding sequences, each of which has its own start and stop codon. From each of these areasone protein is synthesized. In this way, Several protein molecules are synthesized from one i-RNA molecule.
Prokaryotes combine several genes into a single functional unit -operon. The work of the operon can be regulated by other genes, which can be noticeably removed from the operon itself - regulators. The protein translated from this gene is called repressor. It binds to the operator of the operon, regulating the expression of all the genes contained in it at once.
Prokaryotes are also characterized by the phenomenon transcription and translation conjugations.
![]()
Rice. 19 The phenomenon of conjugation of transcription and translation in prokaryotes - the image is enlarged
In a reaction catalyzed by reverse transcriptase.
cDNA is often used to clone eukaryotic genes in prokaryotes. Complementary DNA is also produced by retroviruses (HIV-1, HIV-2, Simian Immunodeficiency Virus) and then integrated into host DNA to form a provirus.
Often, eukaryotic genes can be expressed in prokaryotic cells. In the most simple case, the method involves inserting eukaryotic DNA into the prokaryotic genome, then transcribing the DNA into mRNA, and then translating the mRNA into proteins. Prokaryotic cells do not have intron-cutting enzymes, and therefore introns must be cut from eukaryotic DNA prior to insertion into the prokaryotic genome. DNA complementary to mature mRNA is thus called complementary DNA - cDNA(cDNA). For successful expression of proteins encoded in eukaryotic cDNA in prokaryotes, regulatory elements of prokaryotic genes (eg, promoters) are also required.
One of the methods for obtaining the necessary gene (DNA molecule), which will be subject to replication (cloning) with the release of a significant number of replicas, is the construction of complementary DNA (cDNA) on mRNA. This method requires the use of reverse transcriptase, an enzyme that is present in some RNA-containing viruses and provides DNA synthesis on an RNA template.
The method is widely used to obtain cDNA and includes the isolation of mRNA from the total tissue mRNA, which encodes the translation of a specific protein (for example, interferon, insulin) with further synthesis on this mRNA as a template of the necessary cDNA using reverse transcriptase.
The gene that was obtained using the above procedure (cDNA) must be introduced into the bacterial cell in such a way that it integrates into its genome. For this, they form recombinant DNA, which consists of cDNA and a special DNA molecule that rules as a conductor, or vector, capable of penetrating the recipient into the cell. Viruses or plasmids are used as vectors for cDNA. Plasmids are small circular DNA molecules that are separate from the nucleoid. bacterial cell, contain several genes important for the function of the entire cell (for example, antibiotic resistance genes and can replicate independently of the main genome (DNA) of the cell. Biologically important and practically useful for genetic engineering The properties of plasmids are their ability to transfer from one cell to another by the mechanism of transformation or conjugation, as well as the ability to be included in the bacterial chromosome and replicate along with it.
Watson and Crick showed that the formation of hydrogen bonds and a regular double helix is possible only when the larger purine base adenine (A) in one chain has a smaller pyrimidine base thymine (T) as its partner in the other chain, and guanine (G) associated with cytosine (C). This pattern can be represented as follows: Correspondence A "T and G" C is called the rule of complementarity, and the chains themselves complementary. According to this rule, the content of adenine in DNA is always equal to the content of thymine, and the amount of guanine is always equal to the amount of cytosine. It should be noted that two strands of DNA, differing chemically, carry the same information, because due to complementarity, one strand uniquely defines the other.The structure of RNA is less ordered. It is usually a single-stranded molecule, although the RNA of some viruses consists of two strands. But even such RNA is more flexible than DNA. Some sections in the RNA molecule are mutually complementary and, when the chain is bent, pair, forming double-stranded structures (hairpins). First of all, this applies to transfer RNAs (tRNAs). Some bases in tRNA undergo modification after the synthesis of the molecule. For example, sometimes methyl groups are attached to them.
FUNCTION OF NUCLEIC ACIDS One of the main functions of nucleic acids is the determination of protein synthesis. Information about the structure of proteins, encoded in the nucleotide sequence of DNA, must be transmitted from one generation to another, and therefore its unmistakable copying is necessary, i.e. synthesis of exactly the same DNA molecule (replication).Replication and transcription. From a chemical point of view, nucleic acid synthesis is polymerization, i.e. sequential connection of building blocks. Such blocks are nucleoside triphosphates; The reaction can be represented as follows: The energy required for synthesis is released when pyrophosphate is cleaved off, and special enzymes, DNA polymerases, catalyze the reaction.
The energy required for synthesis is released when pyrophosphate is cleaved off, and special enzymes, DNA polymerases, catalyze the reaction. As a result of such a synthetic process, we would get a polymer with a random base sequence. However, most polymerases only work in the presence of a pre-existing nucleic acid, a template that dictates which nucleotide will be attached to the end of the chain. This nucleotide must be complementary to the corresponding template nucleotide, so that the new strand is complementary to the original. Using then the complementary strand as a matrix, we get exact copy original.
DNA consists of two mutually complementary strands. During replication, they diverge, and each of them serves as a template for the synthesis of a new strand:
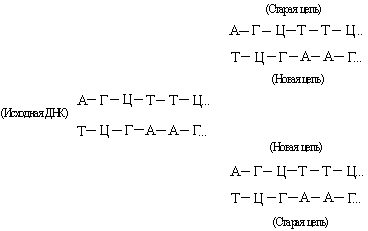 This forms two new double helixes with the same base sequence as the original DNA. Sometimes the replication process "fails" and mutations occur (see also
HEREDITY).
As a result of DNA transcription, cellular RNAs (mRNA, rRNA and tRNA) are formed:
This forms two new double helixes with the same base sequence as the original DNA. Sometimes the replication process "fails" and mutations occur (see also
HEREDITY).
As a result of DNA transcription, cellular RNAs (mRNA, rRNA and tRNA) are formed: They are complementary to one of the DNA strands and are a copy of the other strand, except that uracil takes the place of thymine. In this way, many RNA copies of one of the DNA strands can be obtained.In a normal cell, information is transmitted only in the direction of DNA.® DNA and DNA ® RNA. However, other processes are possible in virus-infected cells: RNA® RNA and RNA ® DNA. The genetic material of many viruses is represented by an RNA molecule, usually single-stranded. Having entered the host cell, this RNA replicates to form a complementary molecule, on which, in turn, many copies of the original viral RNA are synthesized:
They are complementary to one of the DNA strands and are a copy of the other strand, except that uracil takes the place of thymine. In this way, many RNA copies of one of the DNA strands can be obtained.In a normal cell, information is transmitted only in the direction of DNA.® DNA and DNA ® RNA. However, other processes are possible in virus-infected cells: RNA® RNA and RNA ® DNA. The genetic material of many viruses is represented by an RNA molecule, usually single-stranded. Having entered the host cell, this RNA replicates to form a complementary molecule, on which, in turn, many copies of the original viral RNA are synthesized: Viral RNA can be transcribed by an enzyme-
reverse transcriptase-
in DNA, which is sometimes included in the chromosomal DNA of the host cell. Now this DNA carries viral genes, and after transcription, viral RNA can appear in the cell. Thus, after long time, during which no virus is found in the cell, it will reappear in it without re-infection. Viruses whose genetic material is incorporated into the chromosome of the host cell are often the cause of cancer.
Viral RNA can be transcribed by an enzyme-
reverse transcriptase-
in DNA, which is sometimes included in the chromosomal DNA of the host cell. Now this DNA carries viral genes, and after transcription, viral RNA can appear in the cell. Thus, after long time, during which no virus is found in the cell, it will reappear in it without re-infection. Viruses whose genetic material is incorporated into the chromosome of the host cell are often the cause of cancer.
After the discovery of the principle of molecular organization of such a substance as DNA in 1953, began to develop molecular biology. Further, in the process of research, scientists found out how DNA is recombined, its composition, and how our human genome is arranged.
Every day on molecular level are happening the most complex processes. How is the DNA molecule arranged, what does it consist of? What role do DNA molecules play in a cell? Let's talk in detail about all the processes occurring inside the double chain.
What is hereditary information?
So how did it all start? Back in 1868 found in the nuclei of bacteria. And in 1928, N. Koltsov put forward the theory that it is in DNA that all genetic information about a living organism is encrypted. Then J. Watson and F. Crick found a model for the now well-known DNA helix in 1953, for which they deserved recognition and an award - the Nobel Prize.
What is DNA anyway? This substance consists of 2 combined threads, more precisely spirals. A section of such a chain with certain information is called a gene.

DNA stores all the information about what kind of proteins will be formed and in what order. The DNA macromolecule is material carrier incredibly voluminous information, which is recorded in a strict sequence of individual building blocks - nucleotides. There are 4 nucleotides in total, they complement each other chemically and geometrically. This principle of complementation, or complementarity, in science will be described later. This rule plays key role in encoding and decoding genetic information.
Since the DNA strand is incredibly long, there are no repetitions in this sequence. Every living being has its own unique DNA strand.
Functions of DNA
The functions include the storage of hereditary information and its transmission to offspring. Without this function, the genome of a species could not be preserved and developed over millennia. Organisms that have undergone major gene mutations are more likely to not survive or lose their ability to produce offspring. So there is a natural protection against the degeneration of the species.

Another essential important function— implementation of the stored information. The cell cannot make any vital protein without the instructions that are stored in the double strand.
Composition of nucleic acids
Now it is already reliably known what the nucleotides themselves, the building blocks of DNA, consist of. They include 3 substances:
- Orthophosphoric acid.
- nitrogenous base. Pyrimidine bases - which have only one ring. These include thymine and cytosine. Purine bases containing 2 rings. These are guanine and adenine.
- Sucrose. DNA contains deoxyribose, RNA contains ribose.
The number of nucleotides is always equal to the number of nitrogenous bases. In special laboratories, the nucleotide is cleaved and isolated from it nitrogenous base. So they study the individual properties of these nucleotides and possible mutations in them.
Levels of organization of hereditary information
There are 3 levels of organization: gene, chromosomal and genomic. All the information needed for the synthesis of a new protein is contained in a small section of the chain - the gene. That is, the gene is considered the lowest and simplest level of encoding information.

Genes, in turn, are assembled into chromosomes. Thanks to such an organization of the carrier of hereditary material, groups of traits alternate according to certain laws and are transmitted from one generation to another. It should be noted that there are incredibly many genes in the body, but information is not lost, even when it is recombined many times.
There are several types of genes:
- on functional purpose 2 types are distinguished: structural and regulatory sequences;
- according to the influence on the processes occurring in the cell, they distinguish: supervital, lethal, conditionally lethal genes, as well as mutator and antimutator genes.
Genes are located along the chromosome linear order. In chromosomes, information is not randomly focused, there is a certain order. There is even a map showing positions, or gene loci. For example, it is known that data on the color of the eyes of a child is encrypted in chromosome number 18.
What is a genome? This is the name of the entire set of nucleotide sequences in the cell of the body. The genome characterizes whole view, not a single individual.
What is the human genetic code?
The fact is that all the huge potential human development laid down at the time of conception. All hereditary information that is necessary for the development of the zygote and the growth of the child after birth is encrypted in the genes. Sections of DNA are the most basic carriers of hereditary information.

Humans have 46 chromosomes, or 22 somatic pairs plus one sex-determining chromosome from each parent. This diploid set of chromosomes encodes the entire physical appearance of a person, his mental and physical abilities and predisposition to diseases. Somatic chromosomes are outwardly indistinguishable, but they carry different information, since one of them is from the father, the other is from the mother.
The male code differs from the female code in the last pair of chromosomes - XY. The female diploid set is the last pair, XX. Males get one X chromosome from their biological mother, and then it is passed on to their daughters. The sex Y chromosome is passed on to sons.
Human chromosomes vary greatly in size. For example, the smallest pair of chromosomes is #17. And the biggest pair is 1 and 3.
The diameter of the double helix in humans is only 2 nm. The DNA is so tightly coiled that it fits in the small nucleus of the cell, although it will be up to 2 meters long if unwound. The length of the helix is hundreds of millions of nucleotides.
How is the genetic code transmitted?
So, what role do DNA molecules play in a cell during division? Genes - carriers of hereditary information - are inside every cell of the body. In order to pass on their code to a daughter organism, many creatures divide their DNA into 2 identical helices. This is called replication. In the process of replication, DNA unwinds and special "machines" complete each chain. After the genetic helix bifurcates, the nucleus and all organelles begin to divide, and then the whole cell.
But a person has a different process of gene transfer - sexual. The signs of the father and mother are mixed, the new genetic code contains information from both parents.
Storage and transmission of hereditary information is possible due to complex organization strands of DNA. After all, as we said, the structure of proteins is encrypted in genes. Once created at the time of conception, this code will copy itself throughout life. The karyotype (personal set of chromosomes) does not change during the renewal of organ cells. The transmission of information is carried out with the help of sex gametes - male and female.
Only viruses containing a single strand of RNA are unable to transmit their information to their offspring. Therefore, in order to reproduce, they need human or animal cells.
Implementation of hereditary information
In the nucleus of a cell, there are constant important processes. All information recorded in chromosomes is used to build proteins from amino acids. But the DNA strand never leaves the nucleus, so another person's help is needed here. important connection= RNA. Just RNA is able to penetrate the nuclear membrane and interact with the DNA chain.
Through the interaction of DNA and 3 types of RNA, all encoded information is realized. At what level is the implementation of hereditary information? All interactions occur at the nucleotide level. Messenger RNA copies a segment of the DNA chain and brings this copy to the ribosome. Here begins the synthesis of the nucleotides of a new molecule.
In order for the mRNA to copy the necessary part of the chain, the helix unfolds and then, upon completion of the recoding process, is restored again. Moreover, this process can occur simultaneously on 2 sides of 1 chromosome.
The principle of complementarity
They consist of 4 nucleotides - these are adenine (A), guanine (G), cytosine (C), thymine (T). They are connected by hydrogen bonds according to the rule of complementarity. The works of E. Chargaff helped to establish this rule, since the scientist noticed some patterns in the behavior of these substances. E. Chargaff discovered that the molar ratio of adenine to thymine is equal to one. And in the same way, the ratio of guanine to cytosine is always equal to one.
Based on his work, geneticists have formed a rule for the interaction of nucleotides. The rule of complementarity states that adenine combines only with thymine, and guanine with cytosine. During the decoding of the helix and the synthesis of a new protein in the ribosome, this alternation rule helps to quickly find the necessary amino acid that is attached to the transfer RNA.
RNA and its types
What is hereditary information? nucleotides in the DNA double strand. What is RNA? What is her job? RNA, or ribonucleic acid, helps extract information from DNA, decode it, and, based on the principle of complementarity, create required by cells proteins.
In total, 3 types of RNA are isolated. Each of them performs strictly its function.
- Informational (mRNA), or it is also called matrix. It goes right into the center of the cell, into the nucleus. It finds in one of the chromosomes the necessary genetic material for building a protein and copies one of the sides of the double chain. Copying occurs again according to the principle of complementarity.
- Transport- this is small molecule, which has nucleotide decoders on one side, and amino acids corresponding to the main code on the other side. The task of tRNA is to deliver it to the "workshop", that is, to the ribosome, where it synthesizes the necessary amino acid.
- rRNA is ribosomal. It controls the amount of protein that is produced. Consists of 2 parts - amino acid and peptide site.
The only difference when decoding is that RNA does not have thymine. Instead of thymine, uracil is present here. But then, in the process of protein synthesis, with tRNA, it still correctly establishes all the amino acids. If there are any failures in the decoding of information, then a mutation occurs.
Repair of a damaged DNA molecule
The process of repairing a damaged double strand is called reparation. During the repair process, damaged genes are removed.

Then the required sequence of elements is exactly reproduced and crashes back into the same place on the chain from where it was extracted. All this happens thanks to special chemicals- enzymes.
Why do mutations occur?
Why do some genes begin to mutate and cease to fulfill their function - the storage of vital hereditary information? This is due to a decoding error. For example, if adenine is accidentally replaced with thymine.
There are also chromosomal and genomic mutations. Chromosomal mutations occur if sections of hereditary information fall out, double, or are generally transferred and integrated into another chromosome.

Genomic mutations are the most serious. Their cause is a change in the number of chromosomes. That is, when instead of a pair - a diploid set, a triploid set is present in the karyotype.
Most famous example a triploid mutation is Down syndrome, in which the personal set of chromosomes is 47. In such children, 3 chromosomes are formed in place of the 21st pair.
There is also such a mutation as polyploidy. But polyploidy is found only in plants.
