Statistical significance o p-significance level - ang pangunahing resulta ng pagsubok
istatistikal na hypothesis. nagsasalita teknikal na wika, ay ang posibilidad na makuha ang ibinigay
resulta sample na pag-aaral sa kondisyon na sa katunayan para sa heneral
set, ang null hypothesis ay totoo - ibig sabihin, walang relasyon. Sa madaling salita, ito
ang posibilidad na ang nakitang relasyon ay random at hindi isang pag-aari
pinagsama-samang. Eksakto istatistikal na kahalagahan, p-significance level ay
quantification pagiging maaasahan ng koneksyon: mas mababa ang posibilidad na ito, mas maaasahan ang koneksyon.
Ipagpalagay, kapag inihambing ang dalawang sample na ibig sabihin, nakuha ang halaga ng antas
istatistikal na kahalagahan p=0.05. Nangangahulugan ito na ang pagsubok sa istatistikal na hypothesis tungkol sa
Ang pagkakapantay-pantay ng mga paraan sa pangkalahatang populasyon ay nagpakita na kung ito ay totoo, kung gayon ang posibilidad
ang random na paglitaw ng mga nakitang pagkakaiba ay hindi hihigit sa 5%. Sa madaling salita, kung
dalawang sample ang paulit-ulit na kinuha mula sa parehong pangkalahatang populasyon, pagkatapos ay sa 1 ng
20 kaso ay magpapakita ng pareho o mas malaking pagkakaiba sa pagitan ng mga paraan ng mga sample na ito.
Ibig sabihin, mayroong 5% na pagkakataon na random ang mga nakitang pagkakaiba.
karakter, at hindi pag-aari ng pinagsama-samang.
Sa isang relasyon siyentipikong hypothesis ang antas ng statistical significance ay ang quantitative
tagapagpahiwatig ng antas ng kawalan ng tiwala sa konklusyon tungkol sa pagkakaroon ng isang koneksyon, na kinakalkula mula sa mga resulta
pumipili, empirical na pagsubok ng hypothesis na ito. Paano mas kaunting halaga p-level, mas mataas
istatistikal na kahalagahan ng resulta ng pag-aaral, na nagpapatunay sa siyentipikong hypothesis.
Kapaki-pakinabang na malaman kung ano ang nakakaimpluwensya sa antas ng kahalagahan. Antas ng kahalagahan, ang iba pang mga bagay ay pantay
sa itaas (mas mababang p-value) kung:
Ang magnitude ng koneksyon (pagkakaiba) ay mas malaki;
Ang pagkakaiba-iba ng (mga) katangian ay mas mababa;
Ang (mga) sample na laki ay mas malaki.
Unilateral Narito ang dalawang-tailed significance test
Kung ang layunin ng pag-aaral ay ipakita ang pagkakaiba sa pagitan ng mga parameter ng dalawang pangkalahatan
mga koleksyon na tumutugma sa iba't ibang natural na kondisyon nito ( kalagayan ng pamumuhay,
ang edad ng mga paksa, atbp.), madalas na hindi alam kung alin sa mga parameter na ito ang mas malaki, at
alin ang mas maliit.
Halimbawa, kung interesado ka sa pagkakaiba-iba ng mga resulta sa kontrol at
mga eksperimentong grupo, kung gayon, bilang panuntunan, walang tiwala sa tanda ng pagkakaiba sa pagitan ng mga pagkakaiba-iba o
ang mga karaniwang paglihis ng mga resulta kung saan tinatantya ang pagkakaiba-iba. Sa kasong ito
ang null hypothesis ay ang mga pagkakaiba ay pantay sa isa't isa, at ang layunin ng pag-aaral ay
patunayan ang kabaligtaran, i.e. may pagkakaiba sa pagitan ng mga pagkakaiba. Kasabay nito, pinapayagan iyon
ang pagkakaiba ay maaaring maging anumang tanda. Ang ganitong mga hypotheses ay tinatawag na dalawang panig.
Ngunit kung minsan ang gawain ay upang patunayan ang isang pagtaas o pagbaba sa isang parameter;
Halimbawa, average na resulta mas mataas sa experimental group kaysa sa control group. Kung saan
hindi na pinapayagan na ang pagkakaiba ay maaaring ibang tanda. Ang ganitong mga hypotheses ay tinatawag
Unilateral.
Ang mga pagsusulit sa kahalagahan na ginamit upang subukan ang dalawang panig na hypotheses ay tinatawag
Bilateral, at para sa unilateral - unilateral.
Ang tanong ay lumitaw kung alin sa mga pamantayan ang dapat piliin sa isang partikular na kaso. Sagot
Ang tanong na ito ay lampas sa pormal paraang istatistikal at ganap
Depende sa layunin ng pag-aaral. Sa anumang kaso ay hindi dapat pumili ng isa o ibang pamantayan
Pagsasagawa ng eksperimento batay sa pagsusuri ng pang-eksperimentong data, dahil maaari itong
humantong sa maling konklusyon. Kung, bago ang eksperimento, ipinapalagay na ang pagkakaiba
Ang mga inihambing na mga parameter ay maaaring parehong positibo at negatibo, sumusunod ito
Ang antas ng kahalagahan sa mga istatistika ay mahalagang tagapagpahiwatig, na sumasalamin sa antas ng kumpiyansa sa katumpakan, ang katotohanan ng natanggap (hinulaang) data. Ang konsepto ay malawakang ginagamit sa iba't ibang larangan: mula sa paghawak sosyolohikal na pananaliksik, sa istatistikal na pagsubok ng mga siyentipikong hypotheses.
Kahulugan
Ang antas ng istatistikal na kahalagahan (o istatistikal na makabuluhang resulta) ay nagpapakita kung ano ang posibilidad ng random na paglitaw ng mga pinag-aralan na tagapagpahiwatig. Ang pangkalahatang istatistikal na kahalagahan ng phenomenon ay ipinahayag ng p-value (p-level). Sa anumang eksperimento o obserbasyon, may posibilidad na lumitaw ang data na nakuha dahil sa mga error sa sampling. Ito ay totoo lalo na para sa sosyolohiya.
Ibig sabihin, ang isang halaga ay makabuluhan ayon sa istatistika, na ang posibilidad ng random na paglitaw ay napakaliit o may posibilidad na sukdulan. Ang sukdulan sa kontekstong ito ay ang antas ng paglihis ng mga istatistika mula sa null hypothesis (isang hypothesis na nasubok para sa pagkakapare-pareho sa nakuhang sample na data). AT siyentipikong kasanayan ang antas ng kabuluhan ay pinili bago ang pangongolekta ng data at, bilang panuntunan, ang coefficient nito ay 0.05 (5%). Para sa mga sistema kung saan ito ay kritikal eksaktong mga halaga, ang indicator na ito ay maaaring 0.01 (1%) o mas mababa.

Background
Ang konsepto ng antas ng kahalagahan ay ipinakilala ng British statistician at geneticist na si Ronald Fisher noong 1925 nang siya ay bumuo ng isang paraan para sa pagsubok. istatistikal na hypotheses. Kapag sinusuri ang anumang proseso, mayroong isang tiyak na posibilidad ng ilang mga phenomena. Ang mga paghihirap ay lumitaw kapag nagtatrabaho sa maliit (o hindi halata) na mga porsyento ng mga probabilidad na nasa ilalim ng konsepto ng "error sa pagsukat".
Kapag nagtatrabaho sa mga istatistika na hindi sapat na tiyak upang masuri, ang mga siyentipiko ay nahaharap sa problema ng null hypothesis, na "pinipigilan" na gumana sa maliliit na halaga. Iminungkahi ni Fisher para sa mga naturang sistema na matukoy ang posibilidad ng mga kaganapan sa 5% (0.05) bilang isang maginhawang sample cutoff na nagpapahintulot sa isa na tanggihan ang null hypothesis sa mga kalkulasyon.

Pagpapakilala ng isang nakapirming koepisyent
Noong 1933 Mga siyentista ni Jerzy Inirerekomenda nina Neumann at Egon Pearson sa kanilang mga papel na magtakda ng isang tiyak na antas ng kahalagahan nang maaga (bago ang koleksyon ng data). Ang mga halimbawa ng paggamit ng mga panuntunang ito ay malinaw na nakikita sa panahon ng halalan. Kumbaga may dalawang kandidato, ang isa ay sikat na sikat at ang isa ay hindi kilala. Malinaw na ang unang kandidato ang mananalo sa halalan, at ang mga pagkakataon ng pangalawa ay malamang na zero. Magsikap - ngunit hindi pantay-pantay: palaging may posibilidad ng force majeure, kahindik-hindik na impormasyon, hindi inaasahang mga desisyon na maaaring magbago sa hinulaang resulta ng halalan.
Sina Neumann at Pearson ay sumang-ayon na ang iminungkahing antas ng kahalagahan ni Fisher na 0.05 (na tinutukoy ng simbolo na α) ay ang pinaka-maginhawa. Gayunpaman, si Fischer mismo noong 1956 ay sumalungat sa pag-aayos ng halagang ito. Naniniwala siya na ang antas ng α ay dapat itakda alinsunod sa mga tiyak na pangyayari. Halimbawa, sa pisika ng particle ito ay 0.01.

p-halaga
Ang terminong p-value ay unang ginamit ni Brownlee noong 1960. Ang p-level (p-value) ay isang indicator na makikita sa baliktad na relasyon sa bisa ng mga resulta. Ang pinakamataas na p-value ay tumutugma sa pinakamababang antas ng kumpiyansa sa sample na relasyon sa pagitan ng mga variable.
Sinasalamin ng value na ito ang posibilidad ng mga error na nauugnay sa interpretasyon ng mga resulta. Ipagpalagay na p-value = 0.05 (1/20). Nagpapakita ito ng limang porsyentong pagkakataon na ang ugnayan sa pagitan ng mga variable na matatagpuan sa sample ay isang random na tampok lamang ng sample. Iyon ay, kung wala ang pag-asa na ito, kung gayon sa maraming katulad na mga eksperimento, sa karaniwan, sa bawat ikadalawampung pag-aaral, maaaring asahan ng isa ang pareho o higit na pag-asa sa pagitan ng mga variable. Kadalasan ang p-level ay itinuturing na "margin" ng antas ng error.
Sa pamamagitan ng paraan, ang p-value ay maaaring hindi sumasalamin tunay na adiksyon sa pagitan ng mga variable, ngunit nagpapakita lamang ng ilang mean na halaga sa loob ng mga pagpapalagay. Sa partikular, ang huling pagsusuri ng data ay magdedepende rin sa mga napiling halaga ibinigay na koepisyent. Sa p-level = 0.05 magkakaroon ng ilang mga resulta, at may coefficient na katumbas ng 0.01, iba pa.

Pagsubok ng mga istatistikal na hypotheses
Ang antas ng istatistikal na kahalagahan ay lalong mahalaga kapag sinusubukan ang mga hypotheses. Halimbawa, kapag kinakalkula ang isang dalawang-panig na pagsubok, ang lugar ng pagtanggi ay nahahati nang pantay sa magkabilang dulo ng distribusyon ng sampling (na may kaugnayan sa zero coordinate) at kinakalkula ang katotohanan ng nakuhang data.
Ipagpalagay natin na habang sinusubaybayan ang isang tiyak na proseso (phenomenon), lumabas na ang bagong istatistikal na impormasyon ay nagpapahiwatig maliliit na pagbabago nauugnay sa mga nakaraang halaga. Kasabay nito, ang mga pagkakaiba sa mga resulta ay maliit, hindi halata, ngunit mahalaga para sa pag-aaral. Ang espesyalista ay nahaharap sa isang dilemma: ang mga pagbabago ba ay talagang nangyayari o sila ba ay nagsa-sample ng mga error (pagkakamali sa pagsukat)?
Sa kasong ito, alinman sa null hypothesis ay inilapat o tinanggihan (lahat ay iniuugnay sa isang error, o ang pagbabago sa system ay kinikilala bilang isang fait accompli). Ang proseso ng paglutas ng problema ay batay sa ratio ng kabuuang istatistikal na kahalagahan (p-value) at ang antas ng kahalagahan (α). Kung p-level< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Mga ginamit na halaga
Ang antas ng kahalagahan ay nakasalalay sa nasuri na materyal. Sa pagsasagawa, ang mga sumusunod na nakapirming halaga ay ginagamit:
- α = 0.1 (o 10%);
- α = 0.05 (o 5%);
- α = 0.01 (o 1%);
- α = 0.001 (o 0.1%).
Kung mas tumpak ang mga kalkulasyon ay kinakailangan, mas maliit ang coefficient α na ginagamit. Naturally, ang mga istatistikal na pagtataya sa physics, chemistry, pharmaceuticals, at genetics ay nangangailangan ng higit na katumpakan kaysa sa political science at sociology.

Mga threshold ng kahalagahan sa mga partikular na lugar
Sa mga patlang na may mataas na katumpakan tulad ng pisika ng butil at pagmamanupaktura, ang kahalagahang istatistika ay kadalasang ipinapahayag bilang ratio ng karaniwang paglihis (na tinutukoy ng sigma coefficient - σ) na may kaugnayan sa normal na pamamahagi probabilities (Gaussian distribution). Ang σ ay isang istatistikal na tagapagpahiwatig na tumutukoy sa pagpapakalat ng mga halaga ng isang tiyak na dami na nauugnay sa mga inaasahan sa matematika. Ginagamit upang iplano ang posibilidad ng mga pangyayari.
Depende sa larangan ng kaalaman, malaki ang pagkakaiba ng koepisyent σ. Halimbawa, kapag hinuhulaan ang pagkakaroon ng Higgs boson, ang parameter na σ ay katumbas ng lima (σ=5), na tumutugma sa p-value=1/3.5 milyon.
Kahusayan
Dapat itong isaalang-alang na ang mga coefficient α at p-value ay hindi eksaktong mga katangian. Anuman ang antas ng kahalagahan sa mga istatistika ng hindi pangkaraniwang bagay na pinag-aaralan, ito ay hindi isang walang kundisyong batayan para tanggapin ang hypothesis. Halimbawa, mas maliit ang halaga ng α, mas malaki ang pagkakataon na ang hypothesis na itinatag ay makabuluhan. Gayunpaman, may panganib ng pagkakamali, na nagpapababa sa istatistikal na kapangyarihan (kahalagahan) ng pag-aaral.
Mga mananaliksik na eksklusibong nakatuon sa istatistika makabuluhang resulta maaaring gumawa ng mga maling konklusyon. Kasabay nito, mahirap i-double-check ang kanilang trabaho, dahil inilalapat nila ang mga pagpapalagay (na, sa katunayan, ay ang mga halaga ng α at p-value). Samakatuwid, palaging inirerekomenda, kasama ang pagkalkula ng istatistikal na kahalagahan, upang matukoy ang isa pang tagapagpahiwatig - ang magnitude ng istatistikal na epekto. Ang laki ng epekto ay isang quantitative measure ng lakas ng isang epekto.
Ang mga istatistika ay matagal nang naging mahalagang bahagi ng buhay. Nahaharap ang mga tao sa lahat ng dako. Batay sa mga istatistika, ang mga konklusyon ay iginuhit tungkol sa kung saan at anong mga sakit ang karaniwan, kung ano ang higit na hinihiling sa isang partikular na rehiyon o sa isang tiyak na bahagi ng populasyon. Maging ang mga konstruksyon ay nakabatay sa mga programang pampulitika mga kandidato sa gobyerno. Ginagamit din ang mga ito ng mga retail chain kapag bumibili ng mga kalakal, at ang mga manufacturer ay ginagabayan ng data na ito sa kanilang mga panukala.
stats na naglalaro mahalagang papel sa buhay ng lipunan at nakakaapekto sa bawat indibidwal na miyembro nito, kahit sa maliliit na bagay. Halimbawa, kung sa pamamagitan ng , mas gusto ng karamihan sa mga tao madidilim na kulay sa mga damit sa isang partikular na lungsod o rehiyon, napakahirap na makahanap ng maliwanag na dilaw na kapote na may floral print sa mga lokal na outlet. Ngunit ano ang mga dami na bumubuo sa data na ito na may ganoong epekto? Halimbawa, ano ang "makabuluhang istatistika"? Ano nga ba ang ibig sabihin ng kahulugang ito?
Ano ito?
Ang mga istatistika bilang isang agham ay binubuo ng isang kumbinasyon iba't ibang laki at mga konsepto. Isa na rito ang konsepto ng "statistical significance". Ito ang pangalan ng halaga mga variable, ang posibilidad ng paglitaw ng iba pang mga tagapagpahiwatig kung saan ay bale-wala.
Halimbawa, 9 sa 10 tao ang nagsusuot ng rubber shoes sa kanilang mga paa habang lakad sa umaga para sa mga kabute sa kagubatan ng taglagas pagkatapos ng maulan na gabi. Ang posibilidad na sa isang punto 8 sa kanila ay nakasuot ng canvas moccasins ay bale-wala. Kaya, sa ito tiyak na halimbawa ang numero 9 ay isang halaga na tinatawag na "statistical significance".
Alinsunod dito, kung bubuo pa natin ang nasa itaas praktikal na halimbawa, ang mga tindahan ng sapatos ay bumibili sa pagtatapos panahon ng tag-init rubber boots sa mas maraming bilang kaysa sa ibang mga oras ng taon. Oo, ang halaga istatistikal na kahalagahan ay may epekto sa pang-araw-araw na buhay.
Siyempre, sa mga kumplikadong kalkulasyon, halimbawa, kapag hinuhulaan ang pagkalat ng mga virus, malaking numero mga variable. Ngunit ang pinakadiwa ng pagtukoy ng isang makabuluhang tagapagpahiwatig ng istatistikal na data ay magkatulad, anuman ang pagiging kumplikado ng mga kalkulasyon at ang bilang ng mga hindi pare-parehong halaga.
Paano ito kinakalkula?
Ginagamit kapag kinakalkula ang halaga ng indicator na "statistical significance" ng equation. Iyon ay, maaari itong maitalo na sa kasong ito ang lahat ay napagpasyahan ng matematika. ng karamihan simpleng opsyon ang computing ay isang chain mga operasyong matematikal, na kinabibilangan ng mga sumusunod na parameter:
- dalawang uri ng mga resulta na nakuha mula sa mga survey o ang pag-aaral ng layunin ng data, halimbawa, ang mga halaga kung saan ginawa ang mga pagbili, na tinutukoy ng a at b;
- tagapagpahiwatig para sa parehong mga grupo - n;
- ang halaga ng bahagi ng pinagsamang sample - p;
- ang konsepto ng "karaniwang error" - SE.
Ang susunod na hakbang ay upang matukoy ang pangkalahatang tagapagpahiwatig ng pagsubok - t, ang halaga nito ay inihambing sa bilang na 1.96. Ang 1.96 ay isang average na halaga na kumakatawan sa isang saklaw na 95% ayon sa t-distribution ng Mag-aaral.
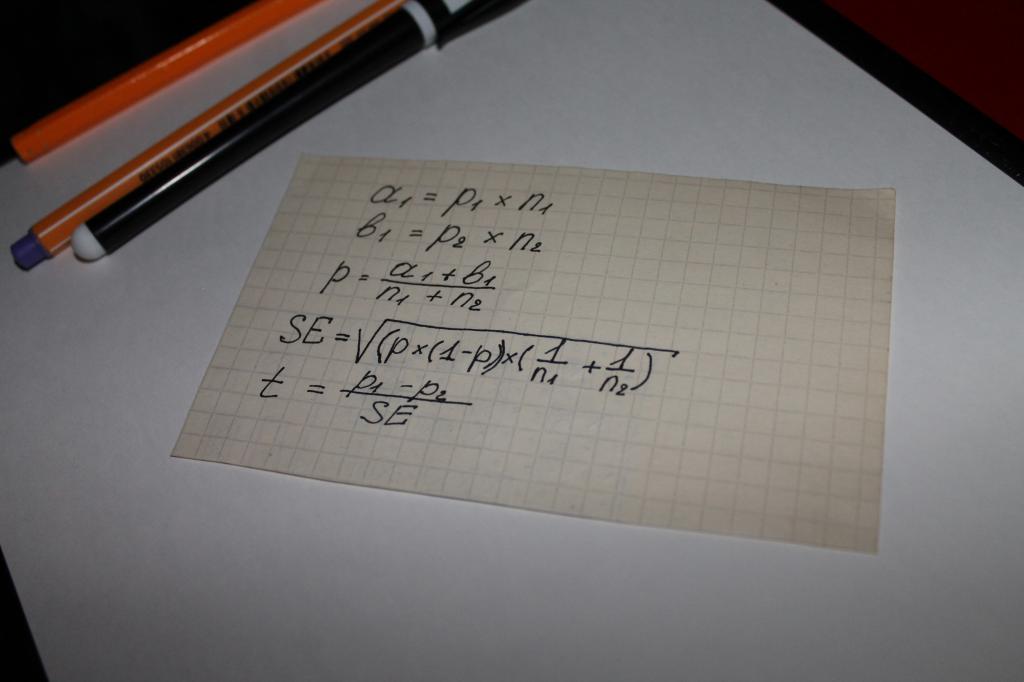
Ang tanong ay madalas na lumitaw kung ano ang pagkakaiba sa pagitan ng mga halaga ng n at p. Ang nuance na ito ay madaling linawin sa isang halimbawa. Kumbaga, ang istatistikal na kahalagahan ng katapatan sa anumang produkto o tatak ng mga lalaki at babae ay kalkulado.
Sa kasong ito, ang mga titik ay susundan ng mga sumusunod:
- n ay ang bilang ng mga sumasagot;
- p - ang bilang ng nasiyahan sa produkto.
Ang bilang ng mga nakapanayam na kababaihan sa kasong ito ay itatalaga bilang n1. Alinsunod dito, ang mga lalaki - n2. Ang parehong halaga ay magkakaroon ng mga numerong "1" at "2" sa simbolo p.
Ang paghahambing ng tagapagpahiwatig ng pagsubok sa mga average na halaga ng mga talahanayan ng pagkalkula ng Mag-aaral ay nagiging tinatawag na "statistical significance".
Ano ang ibig sabihin ng pagpapatunay?
Ang mga resulta ng anumang pagkalkula ng matematika ay maaaring palaging suriin; ito ay itinuro sa mga bata kahit na sa mababang Paaralan. Ito ay lohikal na ipagpalagay na dahil ang mga istatistikal na tagapagpahiwatig ay tinutukoy gamit ang isang hanay ng mga kalkulasyon, pagkatapos ay sinusuri ang mga ito.
Gayunpaman, ang pagsubok para sa istatistikal na kahalagahan ay hindi lamang matematika. Ang mga istatistika ay tumatalakay sa malaking dami mga variable at iba't ibang probabilities, na hindi palaging pumapayag sa pagkalkula. Iyon ay, kung babalik tayo sa halimbawang ibinigay sa simula ng artikulo na may sapatos na goma, kung gayon ang lohikal na pagtatayo ng istatistikal na data, na aasahan ng mga mamimili ng mga kalakal para sa mga tindahan, ay maaaring magambala ng tuyo at mainit na panahon, na hindi karaniwan para sa taglagas. Bilang resulta ng hindi pangkaraniwang bagay na ito, ang bilang ng mga tao na bibili ng rubber boots ay bababa at ang mga outlet ay magdaranas ng pagkalugi. Asahan ang anomalya ng panahon mathematical formula, syempre, hindi pwede. Ang sandaling ito ay tinatawag na - "pagkakamali".

Tiyak na ang posibilidad ng naturang mga pagkakamali na isinasaalang-alang ng pagsusuri ng antas ng kinakalkula na kahalagahan. Isinasaalang-alang nito ang parehong mga kalkuladong tagapagpahiwatig at tinatanggap na mga antas ng kahalagahan, pati na rin ang mga dami na karaniwang tinatawag na hypotheses.
Ano ang antas ng kahalagahan?
Ang konsepto ng "antas" ay kasama sa pangunahing pamantayan para sa istatistikal na kahalagahan. Ginagamit ito sa mga inilapat at praktikal na istatistika. Ito ay isang uri ng dami na isinasaalang-alang ang posibilidad posibleng mga paglihis o mga pagkakamali.
Ang antas ay batay sa pagkakakilanlan ng mga pagkakaiba sa mga yari na sample, pinapayagan ka nitong maitatag ang kanilang kahalagahan o, sa kabaligtaran, randomness. Ang konseptong ito ay hindi lamang mga digital na kahulugan, kundi pati na rin ang kanilang mga kakaibang interpretasyon. Ipinaliwanag nila kung paano dapat maunawaan ang halaga, at ang antas mismo ay tinutukoy sa pamamagitan ng paghahambing ng resulta sa average na index, ipinapakita nito ang antas ng pagiging maaasahan ng mga pagkakaiba.

Kaya, ang konsepto ng isang antas ay maaaring iharap nang simple - ito ay isang tagapagpahiwatig ng isang katanggap-tanggap, malamang na pagkakamali o pagkakamali sa mga konklusyon na nakuha mula sa istatistikal na data na nakuha.
Anong mga antas ng kahalagahan ang ginagamit?
Ang istatistikal na kahalagahan ng error probability coefficients sa pagsasanay ay batay sa tatlong pangunahing antas.
Ang unang antas ay ang threshold kung saan ang halaga ay 5%. Iyon ay, ang posibilidad ng pagkakamali ay hindi lalampas sa antas ng kahalagahan na 5%. Nangangahulugan ito na ang kumpiyansa sa impeccability at infallibility ng mga konklusyon na ginawa batay sa istatistikal na data ng pananaliksik ay 95%.
Ang pangalawang antas ay ang 1% na threshold. Alinsunod dito, ang figure na ito ay nangangahulugan na ang isa ay maaaring magabayan ng data na nakuha sa panahon ng mga kalkulasyon ng istatistika na may 99% na kumpiyansa.
Ang ikatlong antas ay 0.1%. Sa halagang ito, ang posibilidad ng isang error ay katumbas ng isang bahagi ng isang porsyento, iyon ay, ang mga error ay halos tinanggal.
Ano ang hypothesis sa istatistika?
Ang mga error bilang isang konsepto ay nahahati sa dalawang lugar tungkol sa pagtanggap o pagtanggi sa null hypothesis. Ang hypothesis ay isang konsepto sa likod kung saan, ayon sa kahulugan, isang set ng iba pang data o mga pahayag ay nakatago. Iyon ang paglalarawan pamamahagi ng posibilidad isang bagay na may kaugnayan sa paksa ng statistical accounting.

Mayroong dalawang hypotheses sa mga simpleng kalkulasyon - zero at alternatibo. Ang pagkakaiba sa pagitan ng mga ito ay ang null hypothesis ay batay sa ideya na walang mga pangunahing pagkakaiba sa pagitan ng mga sample na kasangkot sa pagtukoy ng istatistikal na kahalagahan, at ang kahalili ay ganap na kabaligtaran dito. I.e alternatibong hypothesis batay sa pagkakaroon ng makabuluhang pagkakaiba sa mga sample na ito.
Ano ang mga pagkakamali?
Ang mga error bilang isang konsepto sa mga istatistika ay direktang umaasa sa pagtanggap ng isa o ibang hypothesis bilang totoo. Maaari silang nahahati sa dalawang direksyon o uri:
- ang unang uri ay dahil sa pagtanggap ng null hypothesis, na naging hindi tama;
- ang pangalawa ay sanhi ng pagsunod sa alternatibo.

Ang unang uri ng error ay tinatawag na false positive at medyo karaniwan sa lahat ng lugar kung saan ginagamit ang mga istatistika. Alinsunod dito, ang error ng pangalawang uri ay tinatawag na maling negatibo.
Bakit mahalaga ang regression sa mga istatistika?
Ang istatistikal na kahalagahan ng regression ay maaari itong magamit upang maitaguyod kung gaano katotoo ang modelo na kinakalkula batay sa data. iba't ibang dependencies; nagbibigay-daan sa iyo upang matukoy ang kasapatan o kakulangan ng mga kadahilanan para sa accounting at mga konklusyon.
Natutukoy ang halaga ng regression sa pamamagitan ng paghahambing ng mga resulta sa data na nakalista sa mga talahanayan ng Fisher. O gamit ang pagsusuri ng pagkakaiba. Kahalagahan ang mga tagapagpahiwatig ng pagbabalik ay may kumplikado istatistikal na pag-aaral at mga kalkulasyon na kinasasangkutan malaking bilang ng mga variable, random na data at malamang na mga pagbabago.
Istatistikong Kahalagahan
Ang mga resulta na nakuha gamit ang isang tiyak na pamamaraan ng pananaliksik ay tinatawag makabuluhang istatistika kung ang posibilidad ng kanilang random na paglitaw ay napakaliit. Ang konseptong ito ay maaaring ilarawan sa pamamagitan ng halimbawa ng paghagis ng barya. Ipagpalagay na ang isang barya ay binaligtad ng 30 beses; Umakyat ito ng 17 beses na ulo at 13 beses na nakabuntot. Ginagawa ba ito makabuluhan Ito ba ay isang paglihis mula sa inaasahang resulta (15 ulo at 15 buntot), o ito ba ay isang pagkakataon? Upang masagot ang tanong na ito, maaari mong, halimbawa, ihagis ang parehong barya ng maraming beses nang 30 beses sa isang hilera, at sa parehong oras tandaan kung gaano karaming beses ang ratio ng mga ulo at buntot, katumbas ng 17:13, ay paulit-ulit. Ang pagtatasa ng istatistika ay nagliligtas sa atin mula sa nakakapagod na prosesong ito. Sa tulong nito, pagkatapos ng unang 30 coin tosses, posibleng matantya ang posibleng bilang ng random na paglitaw ng 17 ulo at 13 buntot. Ang nasabing pagtatantya ay tinatawag na probabilistikong pahayag.
AT siyentipikong panitikan sa industrial-organizational psychology probabilistic statement sa anyong matematikal tinutukoy ng ekspresyon R(probability)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (R< 0.01). Ang katotohanang ito ay mahalaga para sa pag-unawa sa panitikan, ngunit hindi dapat ituring na walang kabuluhan na gumawa ng mga obserbasyon na hindi nakakatugon sa mga pamantayang ito. Ang tinatawag na hindi makabuluhang mga resulta ng pananaliksik (mga obserbasyon na maaaring makuha sa pamamagitan ng pagkakataon higit pa isa o limang beses sa 100) ay maaaring maging lubhang kapaki-pakinabang para sa pagtukoy ng mga uso at bilang gabay sa hinaharap na pananaliksik.
Dapat ding tandaan na hindi lahat ng psychologist ay sumasang-ayon sa mga tradisyonal na pamantayan at pamamaraan (hal. Cohen, 1994; Saley & Bedeian, 1989). Ang mga isyung nauugnay sa mga sukat ay ang kanilang mga sarili Pangunahing tema ang gawain ng maraming mananaliksik na pinag-aaralan ang katumpakan ng mga pamamaraan ng pagsukat at ang mga kinakailangan na pinagbabatayan umiiral na mga pamamaraan at mga pamantayan, gayundin ang pagbuo ng mga bagong doktor at instrumento. Marahil sa hinaharap, ang pagsasaliksik sa kapangyarihang ito ay hahantong sa pagbabago sa mga tradisyonal na pamantayan para sa pagtatasa ng istatistikal na kahalagahan, at ang mga pagbabagong ito ay magkakaroon ng pangkalahatang pagtanggap. (Ang Ikalimang Kabanata ng American Psychological Association ay nagsasama-sama ng mga psychologist na dalubhasa sa pag-aaral ng mga pagtatantya, mga sukat, at mga istatistika.)
Sa mga ulat ng pananaliksik, isang probabilistikong pahayag tulad ng R< 0.05, dahil sa ilan mga istatistika iyon ay, isang numero na nakuha bilang resulta ng isang tiyak na hanay ng mga pamamaraan sa pagkalkula ng matematika. Ang probabilistikong kumpirmasyon ay nakukuha sa pamamagitan ng paghahambing ng mga istatistikang ito sa data mula sa mga espesyal na talahanayan na na-publish para sa layuning ito. Sa industriyal-organisasyon sikolohikal na pananaliksik madalas na nakatagpo ng mga istatistika tulad ng r, F, t, r>(basahin ang "chi square") at R(basahin ang "maramihan R"). Sa bawat kaso, ang mga istatistika (isang numero) na nakuha mula sa pagsusuri ng isang serye ng mga obserbasyon ay maihahambing sa mga numero mula sa nai-publish na talahanayan. Pagkatapos nito, posible na magbalangkas ng isang probabilistikong pahayag tungkol sa posibilidad na random na makuha ang numerong ito, iyon ay, upang makagawa ng konklusyon tungkol sa kahalagahan ng mga obserbasyon.
Upang maunawaan ang mga pag-aaral na inilarawan sa aklat na ito, sapat na magkaroon ng malinaw na pag-unawa sa konsepto ng istatistikal na kahalagahan at hindi kinakailangang malaman kung paano kinakalkula ang mga istatistika na binanggit sa itaas. Gayunpaman, magiging kapaki-pakinabang na talakayin ang isang pagpapalagay na sumasailalim sa lahat ng mga pamamaraang ito. Ito ang pagpapalagay na ang lahat ng naobserbahang mga variable ay halos ibinahagi normal na batas. Bilang karagdagan, kapag nagbabasa ng mga ulat sa pang-industriya-organisasyon na sikolohikal na pananaliksik, tatlong higit pang mga konsepto ang madalas na lumalabas na may mahalagang papel - una, ugnayan at ugnayan, pangalawa, ang determinant/ predictor variable at "ANOVA" ( pagsusuri ng pagkakaiba-iba), pangatlo, isang pangkat ng mga istatistikal na pamamaraan sa ilalim karaniwang pangalan"meta-analysis".
Isinasagawa ang pagsusuri ng hypothesis gamit ang statistical analysis. Ang statistic significance ay matatagpuan gamit ang P-value, na tumutugma sa probabilidad ang kaganapang ito sa ilalim ng pagpapalagay na ang ilang pahayag (ang null hypothesis) ay totoo. Kung ang P-value ay mas mababa sa isang naibigay na antas ng istatistikal na kahalagahan (karaniwan ay 0.05), ligtas na mahihinuha ng eksperimento na ang null hypothesis ay mali at magpatuloy upang isaalang-alang ang alternatibong hypothesis. Gamit ang t-test ng Mag-aaral, maaari mong kalkulahin ang P-value at matukoy ang kahalagahan para sa dalawang set ng data.
Mga hakbang
Bahagi 1
Pagse-set up ng isang eksperimento- Ang null hypothesis (H 0) ay karaniwang nagsasaad na walang pagkakaiba sa pagitan ng dalawang dataset. Halimbawa: ang mga mag-aaral na nagbabasa ng materyal bago ang klase ay hindi nakakakuha ng mas mataas na marka.
- Ang alternatibong hypothesis (H a) ay ang kabaligtaran ng null hypothesis at isang pahayag na kailangang kumpirmahin gamit ang pang-eksperimentong data. Halimbawa: ang mga mag-aaral na nagbabasa ng materyal bago ang klase ay nakakakuha ng mas mataas na marka.
-
Itakda ang antas ng kahalagahan upang matukoy kung gaano kalaki ang pagkakaiba ng distribusyon ng data mula sa karaniwan para ito ay maituturing na isang makabuluhang resulta. Antas ng kahalagahan (tinatawag ding α (\displaystyle \alpha )-level) ay ang threshold na iyong tinukoy para sa istatistikal na kahalagahan. Kung ang P-value ay mas mababa sa o katumbas ng antas ng kahalagahan, ang data ay itinuturing na makabuluhang istatistika.
- Bilang isang tuntunin, ang antas ng kahalagahan (halaga α (\displaystyle \alpha )) ay kinuha katumbas ng 0.05, kung saan ang posibilidad ng pag-detect ng random na pagkakaiba sa pagitan ng iba't ibang set ng data ay 5% lamang.
- Mas mataas ang antas ng kahalagahan (at, nang naaayon, mas kaunting p-value), mas maaasahan ang mga resulta.
- Kung gusto mo ng mas maaasahang resulta, ibaba ang P-value sa 0.01. Kadalasan, ang mas mababang P-values ay ginagamit sa produksyon kapag kinakailangan upang makita ang mga depekto sa mga produkto. Sa kasong ito, kinakailangan ang mataas na katapatan upang matiyak na gumagana ang lahat ng bahagi tulad ng inaasahan.
- Para sa karamihan ng mga eksperimento ng hypotheses, sapat na ang antas ng kahalagahan na 0.05.
-
Magpasya kung aling pamantayan ang iyong gagamitin: isang panig o dalawang panig. Ang isa sa mga pagpapalagay sa t-test ng Mag-aaral ay ang data ay normal na ipinamamahagi. Ang normal na distribusyon ay hugis kampana na kurba na may ang maximum na bilang resulta sa gitna ng kurba. Ang t-test ng mag-aaral ay pamamaraan ng matematika pagpapatunay ng data, na nagbibigay-daan sa iyong matukoy kung ang data ay nasa labas ng normal na distribusyon (higit pa, mas kaunti, o sa "mga buntot" ng curve).
- Kung hindi ka sigurado kung nasa itaas o ibaba ang data pangkat ng kontrol value, gumamit ng two-tailed test. Ito ay magbibigay-daan sa iyo upang matukoy ang kahalagahan sa parehong direksyon.
- Kung alam mo kung saang direksyon maaaring mahulog ang data sa labas ng normal na distribution, gumamit ng one-tailed test. Sa halimbawa sa itaas, inaasahan naming tataas ang mga marka ng mga mag-aaral, kaya maaaring gumamit ng one-tailed test.
-
Tukuyin ang sample size gamit ang statistical power. Ang istatistikal na kapangyarihan ng isang pag-aaral ay ang posibilidad na ang isang ibinigay na laki ng sample ay makakapagdulot ng inaasahang resulta. Ang karaniwang power threshold (o β) ay 80%. Ang pagsusuri ng kapangyarihan nang walang anumang naunang data ay maaaring nakakalito dahil ang ilang impormasyon ay kinakailangan tungkol sa mga inaasahang paraan sa bawat set ng data at ang kanilang mga karaniwang paglihis. Gamitin ang online na power calculator para matukoy ang pinakamainam na laki ng sample para sa iyong data.
- Karaniwan, ang mga mananaliksik ay nagsasagawa ng isang maliit na pilot study na nagbibigay ng data para sa power analysis at tinutukoy ang sample size na kailangan para sa mas malaki at mas kumpletong pag-aaral.
- Kung wala kang pagkakataon na magsagawa ng isang pilot na pag-aaral, subukang tantyahin ang mga posibleng average na halaga batay sa data ng literatura at mga resulta ng ibang tao. Maaari itong makatulong sa iyo na matukoy ang pinakamainam na laki ng sample.
Bahagi 2
Kalkulahin karaniwang lihis-
Isulat ang formula para sa standard deviation. Ang standard deviation ay nagpapahiwatig kung gaano kalaki ang pagkalat ng data. Pinapayagan ka nitong tapusin kung gaano kalapit ang data na nakuha sa isang partikular na sample. Sa unang tingin, ang formula ay tila kumplikado, ngunit ang mga paliwanag sa ibaba ay makakatulong sa iyo na maunawaan ito. Ang formula ay may susunod na view: s = √∑((x i – µ) 2 /(N – 1)).
- s - karaniwang paglihis;
- ang ∑ sign ay nagpapahiwatig na ang lahat ng data na nakuha sa sample ay dapat idagdag;
- Ang x i ay tumutugma sa i-th na halaga, iyon ay, isang hiwalay na resulta na nakuha;
- µ ay ang average na halaga para sa pangkat na ito;
- N- kabuuang bilang data sa sample.
-
Hanapin ang average sa bawat pangkat. Upang kalkulahin ang karaniwang paglihis, kailangan mo munang hanapin ang mean para sa bawat pangkat ng pag-aaral. Ang ibig sabihin ng halaga ay tinutukoy liham ng Griyegoµ (mu). Upang mahanap ang average, idagdag lamang ang lahat ng mga resultang halaga at hatiin ang mga ito sa dami ng data (sample size).
- Halimbawa, upang mahanap average na grado sa grupo ng mga mag-aaral na nag-aaral ng materyal bago ang klase, isaalang-alang ang isang maliit na set ng data. Para sa pagiging simple, gumagamit kami ng isang set ng limang puntos: 90, 91, 85, 83 at 94.
- Idagdag natin ang lahat ng mga halaga nang magkasama: 90 + 91 + 85 + 83 + 94 = 443.
- Hatiin ang kabuuan sa bilang ng mga halaga, N = 5: 443/5 = 88.6.
- Kaya, ang average na halaga para sa pangkat na ito ay 88.6.
-
Ibawas ang bawat halaga na nakuha mula sa average. Susunod na hakbang ay upang kalkulahin ang pagkakaiba (x i - µ). Upang gawin ito, ibawas mula sa nahanap katamtamang laki bawat natanggap na halaga. Sa aming halimbawa, kailangan naming makahanap ng limang pagkakaiba:
- (90 - 88.6), (91 - 88.6), (85 - 88.6), (83 - 88.6) at (94 - 88.6).
- Bilang resulta, nakukuha namin ang mga sumusunod na halaga: 1.4, 2.4, -3.6, -5.6 at 5.4.
-
Square bawat halaga na nakuha at idagdag ang mga ito nang sama-sama. Dapat na kuwadrado ang bawat dami ng kakahanap lang. Mawawala ang lahat sa hakbang na ito. mga negatibong halaga. Kung pagkatapos ng hakbang na ito ay mayroon ka mga negatibong numero, pagkatapos ay nakalimutan mong parisukat ang mga ito.
- Para sa aming halimbawa, nakakakuha kami ng 1.96, 5.76, 12.96, 31.36 at 29.16.
- Idinaragdag namin ang mga nakuhang halaga: 1.96 + 5.76 + 12.96 + 31.36 + 29.16 = 81.2.
-
Hatiin sa sample size na minus 1. Sa formula, ang kabuuan ay nahahati sa N - 1 dahil sa hindi namin isinasaalang-alang pangkalahatang populasyon, ngunit kumukuha kami para sa pagsusuri ng isang sample ng lahat ng mga mag-aaral.
- Ibawas: N - 1 = 5 - 1 = 4
- Hatiin: 81.2/4 = 20.3
-
I-extract Kuwadrado na ugat. Pagkatapos hatiin ang kabuuan sa laki ng sample na binawasan ng isa, kunin ang square root ng nahanap na halaga. Ito ang huling hakbang sa pagkalkula ng standard deviation. Mayroong mga programa sa istatistika na, pagkatapos na ipasok ang paunang data, gawin ang lahat ng kinakailangang mga kalkulasyon.
- Sa aming halimbawa, ang standard deviation ng mga marka ng mga mag-aaral na nagbabasa ng materyal bago ang klase ay s = √20.3 = 4.51.
Bahagi 3
Tukuyin ang Kahalagahan-
Kalkulahin ang pagkakaiba sa pagitan ng dalawang pangkat ng data. Hanggang sa hakbang na ito, isinasaalang-alang namin ang halimbawa para lamang sa isang pangkat ng data. Kung gusto mong paghambingin ang dalawang grupo, malinaw na dapat mong kunin ang data para sa parehong grupo. Kalkulahin ang standard deviation para sa pangalawang pangkat ng data at pagkatapos ay hanapin ang pagkakaiba sa pagitan ng dalawa mga eksperimentong grupo. Ang dispersion ay kinakalkula gamit ang sumusunod na formula: s d = √((s 1 /N 1) + (s 2 /N 2)).
Tukuyin ang iyong hypothesis. Ang unang hakbang sa pagsusuri ng istatistikal na kahalagahan ay ang piliin ang tanong na gusto mong masagot at bumuo ng hypothesis. Ang hypothesis ay isang pahayag tungkol sa pang-eksperimentong data, ang kanilang pamamahagi at mga katangian. Para sa anumang eksperimento, mayroong parehong null at alternatibong hypothesis. Sa pangkalahatan, kakailanganin mong paghambingin ang dalawang set ng data upang matukoy kung magkapareho o magkaiba ang mga ito.
