Statistische Signifikanz oder p-Signifikanzniveau - das Haupttestergebnis
statistische Hypothese. reden Fachsprache, ist die Wahrscheinlichkeit, das Gegebene zu erhalten
Ergebnis Beispielstudie vorausgesetzt, dass in der Tat für die allgemeine
gesetzt ist, ist die Nullhypothese wahr - das heißt, es gibt keine Beziehung. Mit anderen Worten, dies
die Wahrscheinlichkeit, dass die erkannte Beziehung zufällig und keine Eigenschaft ist
Aggregate. Genau statistische Signifikanz, p-Signifikanzniveau ist
Quantifizierung Zuverlässigkeit der Verbindung: Je niedriger diese Wahrscheinlichkeit, desto zuverlässiger die Verbindung.
Angenommen, beim Vergleich zweier Stichprobenmittelwerte wurde der Wert des Niveaus erhalten
statistische Signifikanz p = 0,05. Dies bedeutet, dass die statistische Hypothese etwa getestet wird
Gleichheit der Mittel in der allgemeinen Bevölkerung zeigte, dass, wenn es wahr ist, dann die Wahrscheinlichkeit
das zufällige Auftreten der festgestellten Unterschiede nicht mehr als 5 % beträgt. Mit anderen Worten, wenn
zwei Proben wurden wiederholt aus derselben Allgemeinbevölkerung gezogen, dann in 1 von
20 Fälle würden den gleichen oder größeren Unterschied zwischen den Mittelwerten dieser Stichproben zeigen.
Das heißt, es besteht eine Wahrscheinlichkeit von 5 %, dass die gefundenen Unterschiede zufällig sind.
Charakter und sind keine Eigenschaft des Aggregats.
Gegenüber wissenschaftliche Hypothese das statistische Signifikanzniveau ist das quantitative
Indikator für den Grad des Misstrauens in die Schlussfolgerung über das Vorhandensein eines Zusammenhangs, berechnet aus den Ergebnissen
selektive, empirische Überprüfung dieser Hypothese. Wie weniger Wert p-Level, desto höher
statistische Signifikanz des Ergebnisses der Studie, Bestätigung der wissenschaftlichen Hypothese.
Es ist nützlich zu wissen, was das Signifikanzniveau beeinflusst. Signifikanzniveau, unter sonst gleichen Bedingungen
oben (unterer p-Wert), wenn:
Die Größe der Verbindung (Differenz) ist größer;
Die Variabilität der Eigenschaft(en) ist geringer;
Die Stichprobengröße(n) ist größer.
Einseitig Hier sind zweiseitige Signifikanztests
Wenn der Zweck der Studie darin besteht, den Unterschied zwischen den Parametern der beiden allgemeinen aufzudecken
Sammlungen, die seinen verschiedenen natürlichen Bedingungen entsprechen ( Lebensbedingungen,
das Alter der Probanden usw.), ist oft nicht bekannt, welcher dieser Parameter größer sein wird, und
welcher ist kleiner.
Wenn Sie sich zum Beispiel für die Variabilität der Ergebnisse in der Kontrolle interessieren und
Experimentalgruppen, dann besteht in der Regel kein Vertrauen in das Vorzeichen der Differenz zwischen den Varianzen oder
die Standardabweichungen der Ergebnisse, anhand derer die Streuung geschätzt wird. In diesem Fall
Die Nullhypothese lautet, dass die Varianzen gleich sind, und das Ziel der Studie ist
beweise das Gegenteil, d.h. Es gibt einen Unterschied zwischen den Varianzen. Dabei ist es erlaubt
der Unterschied kann beliebig sein. Solche Hypothesen nennt man zweiseitig.
Aber manchmal besteht die Aufgabe darin, eine Zunahme oder Abnahme eines Parameters nachzuweisen;
Zum Beispiel, durchschnittliches Ergebnis in der Versuchsgruppe höher als in der Kontrollgruppe. Dabei
es ist nicht mehr zulässig, dass die Differenz ein anderes Vorzeichen haben kann. Solche Hypothesen werden genannt
Einseitig.
Signifikanztests, die zum Testen zweiseitiger Hypothesen verwendet werden, werden als bezeichnet
Bilateral und für einseitig - einseitig.
Es stellt sich die Frage, welches der Kriterien im konkreten Fall zu wählen ist. Antworten
Diese Frage ist mehr als formal statistische Methoden und vollständig
Hängt vom Zweck der Studie ab. Auf keinen Fall sollte das eine oder andere Kriterium nachgewählt werden
Durchführung eines Experiments auf der Grundlage der Analyse experimenteller Daten, da dies möglich ist
zu falschen Schlussfolgerungen führen. Wenn vor dem Experiment angenommen wird, dass die Differenz
Daraus folgt, dass verglichene Parameter sowohl positiv als auch negativ sein können
Das Signifikanzniveau in der Statistik ist wichtiger Indikator, die den Grad des Vertrauens in die Genauigkeit, die Wahrheit der empfangenen (vorhergesagten) Daten widerspiegelt. Das Konzept ist weit verbreitet in verschiedene Gebiete: vom Halten soziologische Forschung, zur statistischen Überprüfung wissenschaftlicher Hypothesen.
Definition
Das Niveau der statistischen Signifikanz (oder statistisch signifikantes Ergebnis) zeigt, wie hoch die Wahrscheinlichkeit des zufälligen Auftretens der untersuchten Indikatoren ist. Die statistische Gesamtsignifikanz des Phänomens wird durch den p-Wert (p-Level) ausgedrückt. Bei jedem Experiment oder jeder Beobachtung besteht die Möglichkeit, dass die erhaltenen Daten aufgrund von Stichprobenfehlern entstanden sind. Dies gilt insbesondere für die Soziologie.
Das heißt, ein Wert ist statistisch signifikant, dessen Wahrscheinlichkeit des zufälligen Auftretens äußerst gering ist oder zu Extremen tendiert. Das Extrem ist in diesem Zusammenhang der Grad der Abweichung der Statistik von der Nullhypothese (einer Hypothese, die auf Konsistenz mit den erhaltenen Stichprobendaten getestet wird). BEIM wissenschaftliche Praxis das Signifikanzniveau wird vor der Datenerhebung ausgewählt und sein Koeffizient beträgt in der Regel 0,05 (5 %). Für Systeme, wo es kritisch ist genaue Werte, dieser Indikator kann 0,01 (1%) oder weniger betragen.

Hintergrund
Das Konzept des Signifikanzniveaus wurde 1925 von dem britischen Statistiker und Genetiker Ronald Fisher eingeführt, als er eine Testmethode entwickelte Statistische Hypothesen. Bei der Analyse eines Prozesses gibt es eine gewisse Wahrscheinlichkeit für bestimmte Phänomene. Schwierigkeiten treten auf, wenn mit kleinen (oder nicht offensichtlichen) Prozentsätzen von Wahrscheinlichkeiten gearbeitet wird, die unter den Begriff „Messfehler“ fallen.
Bei der Arbeit mit Statistiken, die nicht spezifisch genug waren, um getestet zu werden, standen Wissenschaftler vor dem Problem der Nullhypothese, die das Arbeiten mit kleinen Werten „verhindert“. Fisher schlug für solche Systeme vor, die Wahrscheinlichkeit von Ereignissen bei 5 % (0,05) als bequemen Stichprobengrenzwert zu bestimmen, der es einem ermöglicht, die Nullhypothese in den Berechnungen abzulehnen.

Einführung eines festen Koeffizienten
1933 Jerzy Wissenschaftler Neumann und Egon Pearson empfahlen in ihren Arbeiten, vorab (vor der Datenerhebung) ein bestimmtes Signifikanzniveau festzulegen. Beispiele für die Anwendung dieser Regeln sind während der Wahlen deutlich sichtbar. Angenommen, es gibt zwei Kandidaten, von denen einer sehr beliebt und der andere nicht sehr bekannt ist. Es ist offensichtlich, dass der erste Kandidat die Wahl gewinnen wird, und die Chancen des zweiten tendieren gegen Null. Streben – aber nicht gleich: Es besteht immer die Möglichkeit höherer Gewalt, sensationeller Informationen, unerwarteter Entscheidungen, die die prognostizierten Wahlergebnisse verändern können.
Neumann und Pearson stimmten darin überein, dass das von Fisher vorgeschlagene Signifikanzniveau von 0,05 (gekennzeichnet durch das Symbol α) das bequemste ist. Fischer selbst widersetzte sich jedoch 1956 einer Festlegung dieses Wertes. Er glaubte, dass das Niveau von α in Übereinstimmung mit spezifischen Umständen festgelegt werden sollte. In der Teilchenphysik ist er beispielsweise 0,01.

p-Wert
Der Begriff p-Wert wurde erstmals 1960 von Brownlee verwendet. Der p-Wert (p-Wert) ist ein Indikator, der in gefunden wird umgekehrte Beziehungüber die Aussagekraft der Ergebnisse. Der höchste p-Wert entspricht dem niedrigsten Konfidenzniveau in der Stichprobenbeziehung zwischen Variablen.
Dieser Wert spiegelt die Wahrscheinlichkeit von Fehlern wider, die mit der Interpretation der Ergebnisse verbunden sind. Angenommen p-Wert = 0,05 (1/20). Es zeigt eine Wahrscheinlichkeit von fünf Prozent, dass die Beziehung zwischen den in der Stichprobe gefundenen Variablen nur ein zufälliges Merkmal der Stichprobe ist. Das heißt, wenn diese Abhängigkeit nicht vorhanden ist, kann man bei wiederholten ähnlichen Experimenten im Durchschnitt in jeder zwanzigsten Studie die gleiche oder größere Abhängigkeit zwischen den Variablen erwarten. Oft wird der p-Pegel als "Grenze" des Fehlerpegels betrachtet.
Übrigens spiegelt der p-Wert möglicherweise nicht wider echte Sucht zwischen den Variablen, zeigt aber nur einen gewissen Mittelwert innerhalb der Annahmen. Insbesondere die endgültige Analyse der Daten wird auch von den gewählten Werten abhängen angegebenen Koeffizienten. Bei p-Level = 0,05 gibt es einige Ergebnisse, bei einem Koeffizienten von 0,01 andere.

Testen statistischer Hypothesen
Das Niveau der statistischen Signifikanz ist besonders wichtig, wenn Hypothesen getestet werden. Wenn Sie beispielsweise einen zweiseitigen Test berechnen, wird der Ablehnungsbereich an beiden Enden der Stichprobenverteilung (relativ zur Nullkoordinate) gleichmäßig aufgeteilt und die Wahrheit der erhaltenen Daten berechnet.
Nehmen wir an, dass sich bei der Überwachung eines bestimmten Prozesses (Phänomens) herausstellt, dass neue statistische Informationen darauf hindeuten Kleine Veränderungen relativ zu früheren Werten. Gleichzeitig sind die Abweichungen in den Ergebnissen klein, nicht offensichtlich, aber wichtig für die Studie. Der Fachmann steht vor einem Dilemma: Treten die Veränderungen wirklich auf oder handelt es sich um Stichprobenfehler (Messungenauigkeiten)?
In diesem Fall wird die Nullhypothese angewendet oder verworfen (alles als Fehler abgeschrieben, bzw. die Systemänderung als vollendete Tatsache erkannt). Der Lösungsprozess basiert auf dem Verhältnis von statistischer Gesamtsignifikanz (p-Wert) und Signifikanzniveau (α). Wenn p-Level< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Gebrauchte Werte
Das Signifikanzniveau hängt vom analysierten Material ab. In der Praxis werden folgende Festwerte verwendet:
- α = 0,1 (oder 10%);
- α = 0,05 (oder 5%);
- α = 0,01 (oder 1%);
- α = 0,001 (oder 0,1 %).
Je genauer die Berechnungen erforderlich sind, desto kleiner wird der Koeffizient α verwendet. Natürlich erfordern statistische Vorhersagen in Physik, Chemie, Pharmazie und Genetik eine größere Genauigkeit als in Politikwissenschaft und Soziologie.

Signifikanzschwellen in bestimmten Bereichen
In hochpräzisen Bereichen wie Teilchenphysik und Fertigung wird die statistische Signifikanz oft als Verhältnis der Standardabweichung (bezeichnet durch den Sigma-Koeffizienten – σ) relativ zu ausgedrückt Normalverteilung Wahrscheinlichkeiten (Gauß-Verteilung). σ ist ein statistischer Indikator, der die Streuung von Werten einer bestimmten Größe relativ zu bestimmt mathematische Erwartungen. Wird verwendet, um die Wahrscheinlichkeit von Ereignissen darzustellen.
Je nach Wissensgebiet variiert der Koeffizient σ stark. Beispielsweise ist bei der Vorhersage der Existenz des Higgs-Bosons der Parameter σ gleich fünf (σ=5), was dem p-Wert=1/3,5 Mio. Flächen entspricht.
Effizienz
Dabei ist zu berücksichtigen, dass die Koeffizienten α und p-Wert keine exakten Kenngrößen sind. Unabhängig vom Signifikanzniveau in der Statistik des untersuchten Phänomens ist dies keine unbedingte Grundlage für die Annahme der Hypothese. Je kleiner beispielsweise der Wert von α ist, desto größer ist die Wahrscheinlichkeit, dass die aufgestellte Hypothese signifikant ist. Es besteht jedoch ein Fehlerrisiko, das die statistische Aussagekraft (Signifikanz) der Studie verringert.
Forscher, die sich ausschließlich auf Statistik konzentrieren aussagekräftige Ergebnisse kann falsche Schlüsse ziehen. Gleichzeitig ist es schwierig, ihre Arbeit zu überprüfen, da sie Annahmen anwenden (die tatsächlich die Werte von α und p-Wert sind). Daher wird immer empfohlen, neben der Berechnung der statistischen Signifikanz einen weiteren Indikator zu bestimmen - die Größe des statistischen Effekts. Die Effektgröße ist ein quantitatives Maß für die Stärke eines Effekts.
Statistik ist seit langem ein fester Bestandteil des Lebens. Die Menschen sind überall damit konfrontiert. Anhand von Statistiken werden Rückschlüsse gezogen, wo und welche Krankheiten verbreitet sind, was in einer bestimmten Region oder bei einer bestimmten Bevölkerungsgruppe stärker nachgefragt wird. Sogar Konstruktionen basieren auf politische Programme Kandidaten für die Regierung. Sie werden auch von Einzelhandelsketten beim Wareneinkauf verwendet, und Hersteller orientieren sich bei ihren Vorschlägen an diesen Daten.
Statistiken spielen wichtige Rolle im Leben der Gesellschaft und betrifft jedes einzelne ihrer Mitglieder, auch im Kleinen. Zum Beispiel, wenn durch , bevorzugen die meisten Leute dunkle Farben In der Kleidung einer bestimmten Stadt oder Region wird es äußerst schwierig sein, in lokalen Geschäften einen leuchtend gelben Regenmantel mit Blumendruck zu finden. Aber was sind die Mengen, aus denen diese Daten bestehen, die eine solche Wirkung haben? Was ist zum Beispiel „statistisch signifikant“? Was genau ist mit dieser Definition gemeint?
Was ist das?
Statistik als Wissenschaft besteht aus einer Kombination verschiedene Größen und Konzepte. Eines davon ist das Konzept der „statistischen Signifikanz“. Dies ist der Name des Werts Variablen, die Wahrscheinlichkeit des Auftretens anderer Indikatoren, in denen vernachlässigbar ist.
Zum Beispiel tragen 9 von 10 Menschen während dieser Zeit Gummischuhe an den Füßen Morgenspaziergang für Pilze drin Herbstwald nach einer regnerischen Nacht. Die Wahrscheinlichkeit, dass irgendwann 8 von ihnen Leinwandmokassins anziehen, ist vernachlässigbar. Also in diesem konkretes Beispiel die Zahl 9 ist ein Wert, der als „statistische Signifikanz“ bezeichnet wird.
Dementsprechend, wenn wir das Obige weiterentwickeln praktisches Beispiel, Schuhgeschäfte kaufen am Ende Sommersaison Gummistiefel in größerer Zahl als zu anderen Jahreszeiten. Ja, der Wert statistische Signifikanz wirkt sich auf den Alltag aus.
Bei komplexen Berechnungen, beispielsweise bei der Vorhersage der Ausbreitung von Viren, große Nummer Variablen. Das Wesen der Bestimmung eines signifikanten Indikators für statistische Daten ist jedoch ähnlich, unabhängig von der Komplexität der Berechnungen und der Anzahl nicht konstanter Werte.
Wie wird es berechnet?
Wird bei der Berechnung des Werts des Indikators "statistische Signifikanz" der Gleichung verwendet. Das heißt, man kann argumentieren, dass in diesem Fall alles von der Mathematik entschieden wird. bei den meisten einfache Möglichkeit Rechnen ist eine Kette mathematische Operationen, das die folgenden Parameter enthält:
- zwei Arten von Ergebnissen, die aus Umfragen oder dem Studium objektiver Daten gewonnen werden, zum Beispiel die Beträge, für die Einkäufe getätigt werden, bezeichnet mit a und b;
- Indikator für beide Gruppen - n;
- der Wert des Anteils der kombinierten Stichprobe - p;
- das Konzept des "Standardfehlers" - SE.
Der nächste Schritt besteht darin, den Gesamttestindikator zu bestimmen - t, sein Wert wird mit der Zahl 1,96 verglichen. 1,96 ist ein Durchschnittswert, der einen Bereich von 95 % gemäß der Student-t-Verteilung darstellt.
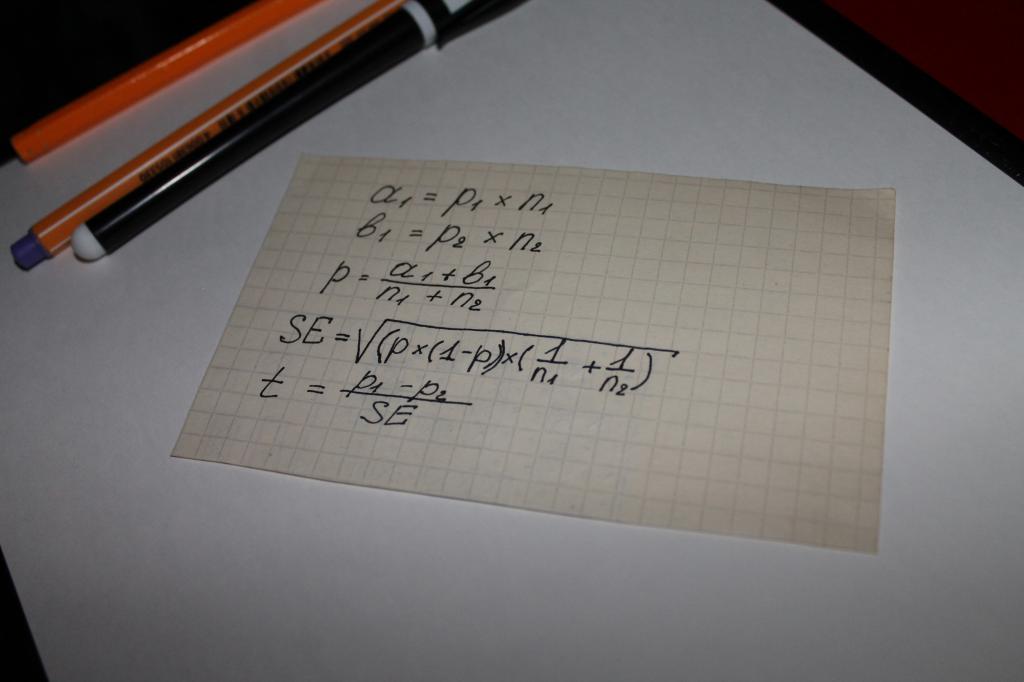
Oft stellt sich die Frage, was der Unterschied zwischen den Werten von n und p ist. Diese Nuance lässt sich leicht an einem Beispiel verdeutlichen. Angenommen, die statistische Signifikanz der Loyalität gegenüber einem Produkt oder einer Marke von Männern und Frauen wird berechnet.
In diesem Fall folgt auf die Buchstaben Folgendes:
- n ist die Anzahl der Befragten;
- p - die Anzahl der mit dem Produkt zufriedenen Personen.
Die Anzahl der befragten Frauen wird in diesem Fall mit n1 bezeichnet. Dementsprechend Männer - n2. Derselbe Wert hat die Nummern "1" und "2" beim Symbol p.
Der Vergleich des Testindikators mit den Durchschnittswerten der Berechnungstabellen von Student wird zu einer sogenannten "statistischen Signifikanz".
Was versteht man unter Verifizierung?
Die Ergebnisse jeder mathematischen Berechnung können immer überprüft werden, das wird Kindern sogar beigebracht Grundschule. Es ist logisch anzunehmen, dass, da die statistischen Indikatoren anhand einer Kette von Berechnungen ermittelt werden, diese überprüft werden.
Das Testen auf statistische Signifikanz ist jedoch nicht nur Mathematik. Statistiken behandeln große Menge Variablen und verschiedene Wahrscheinlichkeiten, die nicht immer einer Berechnung zugänglich sind. Das heißt, wenn wir zu dem am Anfang des Artikels angegebenen Beispiel zurückkehren Gummischuhe, dann kann die logische Konstruktion statistischer Daten, auf die sich Käufer von Waren für Geschäfte verlassen, durch trockenes und heißes Wetter gestört werden, was für den Herbst nicht typisch ist. Als Folge dieses Phänomens wird die Zahl der Käufer von Gummistiefeln sinken und die Verkaufsstellen werden Verluste erleiden. Erwarten Sie eine Wetteranomalie mathematische Formel, kann das natürlich nicht. Dieser Moment heißt - "Fehler".

Gerade die Wahrscheinlichkeit solcher Fehler wird bei der Überprüfung des berechneten Signifikanzniveaus berücksichtigt. Es berücksichtigt sowohl berechnete Indikatoren und akzeptierte Signifikanzniveaus als auch Größen, die herkömmlicherweise als Hypothesen bezeichnet werden.
Was ist ein Signifikanzniveau?
Das Konzept des "Niveaus" ist in den Hauptkriterien für die statistische Signifikanz enthalten. Es wird in der angewandten und praktischen Statistik verwendet. Das ist eine Art Größe, die die Wahrscheinlichkeit berücksichtigt mögliche Abweichungen oder Fehler.
Das Niveau basiert auf der Identifizierung von Unterschieden in vorgefertigten Proben und ermöglicht es Ihnen, deren Signifikanz oder umgekehrt die Zufälligkeit festzustellen. Dieses Konzept hat nicht nur digitale Bedeutungen, sondern auch ihre eigentümlichen Interpretationen. Sie erklären, wie der Wert zu verstehen ist, und das Niveau selbst wird bestimmt, indem das Ergebnis mit dem Durchschnittsindex verglichen wird. Dies zeigt den Grad der Zuverlässigkeit der Unterschiede.

Daher kann das Konzept eines Niveaus einfach dargestellt werden - es ist ein Indikator für einen akzeptablen, wahrscheinlichen Fehler oder Fehler in den Schlussfolgerungen, die aus den erhaltenen statistischen Daten gezogen werden.
Welche Signifikanzniveaus werden verwendet?
Die statistische Signifikanz der Irrtumsin der Praxis basiert auf drei Grundebenen.
Die erste Stufe ist die Schwelle, bei der der Wert 5 % beträgt. Das heißt, die Irrtumswahrscheinlichkeit überschreitet nicht das Signifikanzniveau von 5 %. Das bedeutet, dass das Vertrauen in die Eindeutigkeit und Unfehlbarkeit der auf Basis statistischer Forschungsdaten getroffenen Schlussfolgerungen 95 % beträgt.
Die zweite Stufe ist die 1%-Schwelle. Dementsprechend bedeutet diese Zahl, dass man sich mit 99%iger Sicherheit an den Daten orientieren kann, die bei statistischen Berechnungen gewonnen wurden.
Die dritte Stufe liegt bei 0,1 %. Bei diesem Wert liegt die Fehlerwahrscheinlichkeit bei einem Bruchteil eines Prozents, dh Fehler sind praktisch ausgeschlossen.
Was ist eine Hypothese in der Statistik?
Fehler als Konzept werden in zwei Bereiche bezüglich der Annahme oder Ablehnung der Nullhypothese unterteilt. Eine Hypothese ist ein Konzept, hinter dem sich laut Definition eine Menge anderer Daten oder Aussagen verbirgt. Das ist die Beschreibung Wahrscheinlichkeitsverteilung irgendetwas zum Thema statistische Buchführung.

Bei einfachen Berechnungen gibt es zwei Hypothesen - Null und Alternative. Der Unterschied zwischen ihnen besteht darin, dass die Nullhypothese auf der Idee basiert, dass es keine grundlegenden Unterschiede zwischen den Stichproben gibt, die an der Bestimmung der statistischen Signifikanz beteiligt sind, und die Alternative dazu völlig entgegengesetzt ist. Also alternative Hypothese basierend auf dem Vorhandensein eines signifikanten Unterschieds in diesen Proben.
Was sind die Fehler?
Fehler als Begriff in der Statistik sind direkt abhängig von der Annahme der einen oder anderen Hypothese als wahr. Sie können in zwei Richtungen oder Typen unterteilt werden:
- der erste Typ ist auf die Annahme der Nullhypothese zurückzuführen, die sich als falsch herausstellte;
- der zweite wird durch das Befolgen der Alternative verursacht.

Die erste Art von Fehler wird falsch positiv genannt und ist in allen Bereichen, in denen Statistiken verwendet werden, recht häufig. Dementsprechend wird der Fehler der zweiten Art falsch negativ genannt.
Warum ist Regression in der Statistik wichtig?
Die statistische Signifikanz der Regression besteht darin, dass mit ihr festgestellt werden kann, wie realistisch das auf Basis der Daten berechnete Modell ist. verschiedene Abhängigkeiten; ermöglicht es Ihnen, die Angemessenheit oder das Fehlen von Faktoren für die Rechnungslegung und Schlussfolgerungen zu identifizieren.
Der Regressionswert wird bestimmt, indem die Ergebnisse mit den in den Fisher-Tabellen aufgeführten Daten verglichen werden. Oder mit Varianzanalyse. Bedeutung Regressionsindikatoren haben mit Komplex statistische Studien und Berechnungen mit große Menge Variablen, zufällige Daten und wahrscheinliche Änderungen.
Statistische Signifikanz
Die Ergebnisse, die mit einem bestimmten Forschungsverfahren erzielt werden, werden genannt statistisch signifikant wenn die Wahrscheinlichkeit ihres zufälligen Auftretens sehr gering ist. Dieses Konzept kann am Beispiel des Münzwurfs verdeutlicht werden. Angenommen, eine Münze wird 30 Mal geworfen; Es kam 17 Mal Kopf und 13 Mal Zahl. Macht es sinnvoll Ist dies eine Abweichung vom erwarteten Ergebnis (15 Kopf und 15 Zahl) oder ist dies ein Zufall? Um diese Frage zu beantworten, können Sie zum Beispiel dieselbe Münze 30 Mal hintereinander werfen und gleichzeitig notieren, wie oft sich das Verhältnis von Kopf und Zahl von 17:13 wiederholt. Die statistische Auswertung erspart uns diesen langwierigen Prozess. Mit seiner Hilfe lässt sich nach den ersten 30 Münzwürfen die mögliche Anzahl zufälliger Vorkommnisse von 17 Kopf und 13 Zahl abschätzen. Eine solche Schätzung wird als probabilistische Aussage bezeichnet.
BEIM Wissenschaftliche Literatur in der Betriebsorganisationspsychologie probabilistische Aussage in mathematische Form bezeichnet durch den Ausdruck R(Wahrscheinlichkeit)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (R< 0,01). Diese Tatsache ist wichtig für das Verständnis der Literatur, sollte aber nicht so verstanden werden, dass es sinnlos ist, Beobachtungen zu machen, die diesen Standards nicht genügen. Sogenannte nicht signifikante Forschungsergebnisse (zufällig gewonnene Beobachtungen). mehr ein- oder fünfmal von 100) kann sehr nützlich sein, um Trends zu erkennen und als Leitfaden für zukünftige Forschung.
Es sollte auch beachtet werden, dass nicht alle Psychologen mit traditionellen Standards und Verfahren einverstanden sind (z. B. Cohen, 1994; Sauley & Bedeian, 1989). Probleme im Zusammenhang mit Messungen sind selbst Hauptthema die Arbeit vieler Forscher, die die Genauigkeit von Messmethoden und die zugrunde liegenden Voraussetzungen untersuchen bestehende Methoden und Standards sowie die Entwicklung neuer Schaber und Instrumente. Vielleicht wird die Forschung in dieser Größenordnung irgendwann in der Zukunft zu einer Änderung der traditionellen Standards zur Bewertung der statistischen Signifikanz führen, und diese Änderungen werden universelle Akzeptanz finden. (Das fünfte Kapitel der American Psychological Association bringt Psychologen zusammen, die sich auf das Studium von Schätzungen, Messungen und Statistiken spezialisiert haben.)
In Forschungsberichten ist eine probabilistische Aussage wie z R< 0,05, aufgrund einiger Statistiken das heißt, eine Zahl, die als Ergebnis einer bestimmten Reihe mathematischer Rechenverfahren erhalten wird. Eine probabilistische Bestätigung erhält man, indem man diese Statistiken mit Daten aus speziellen Tabellen vergleicht, die zu diesem Zweck veröffentlicht werden. In Industrie-Organisation psychologische Forschung häufig anzutreffende Statistiken wie z r, F, t, r>(lesen Sie "Chi-Quadrat") und R(lesen Sie "mehrere R"). In jedem Fall können die aus der Analyse einer Reihe von Beobachtungen gewonnenen Statistiken (eine Zahl) mit den Zahlen aus der veröffentlichten Tabelle verglichen werden. Danach ist es möglich, eine probabilistische Aussage über die Wahrscheinlichkeit zu formulieren, diese Zahl zufällig zu erhalten, also einen Rückschluss auf die Signifikanz der Beobachtungen zu ziehen.
Um die in diesem Buch beschriebenen Studien zu verstehen, reicht es aus, ein klares Verständnis des Konzepts der statistischen Signifikanz zu haben und nicht unbedingt zu wissen, wie die oben genannten Statistiken berechnet werden. Es wäre jedoch nützlich, eine Annahme zu diskutieren, die all diesen Verfahren zugrunde liegt. Dies ist die Annahme, dass alle beobachteten Variablen ungefähr verteilt sind normales Gesetz. Darüber hinaus tauchen beim Lesen von Berichten über betriebspsychologische Forschung oft drei weitere Begriffe auf, die eine wichtige Rolle spielen - erstens, Korrelation und Korrelation, zweitens die Determinanten-/Prädiktorvariable und "ANOVA" ( Varianzanalyse), drittens eine Gruppe statistischer Methoden unter gemeinsamen Namen„Metaanalyse“.
Hypothesentests werden anhand statistischer Analysen durchgeführt. Die statistische Signifikanz wird anhand des P-Werts gefunden, der der Wahrscheinlichkeit entspricht diese Veranstaltung unter der Annahme, dass eine Aussage (die Nullhypothese) wahr ist. Wenn der P-Wert unter einem bestimmten statistischen Signifikanzniveau liegt (normalerweise 0,05), kann der Experimentator sicher schlussfolgern, dass die Nullhypothese falsch ist, und mit der Betrachtung der Alternativhypothese fortfahren. Mit dem Student-t-Test können Sie den p-Wert berechnen und die Signifikanz für zwei Datensätze bestimmen.
Schritte
Teil 1
Aufbau eines Experiments- Die Nullhypothese (H 0) besagt normalerweise, dass es keinen Unterschied zwischen den beiden Datensätzen gibt. Zum Beispiel: Die Schüler, die den Stoff vor dem Unterricht gelesen haben, bekommen keine besseren Noten.
- Die Alternativhypothese (H a) ist das Gegenteil der Nullhypothese und eine Aussage, die durch experimentelle Daten bestätigt werden muss. Zum Beispiel: Die Schüler, die den Stoff vor dem Unterricht gelesen haben, bekommen bessere Noten.
-
Legen Sie das Signifikanzniveau fest, um festzulegen, wie stark die Verteilung der Daten von der üblichen abweichen muss, damit sie als signifikantes Ergebnis betrachtet wird. Signifikanzniveau (auch genannt α (\displaystyle \alpha)-Level) ist der Schwellenwert, den Sie für die statistische Signifikanz definieren. Wenn der P-Wert kleiner oder gleich dem Signifikanzniveau ist, gelten die Daten als statistisch signifikant.
- In der Regel ist das Signifikanzniveau (Wert α (\displaystyle \alpha)) gleich 0,05 genommen, in diesem Fall beträgt die Wahrscheinlichkeit, einen zufälligen Unterschied zwischen verschiedenen Datensätzen zu entdecken, nur 5 %.
- Je höher das Signifikanzniveau (und dementsprechend weniger p-Wert), desto zuverlässiger sind die Ergebnisse.
- Wenn Sie zuverlässigere Ergebnisse wünschen, verringern Sie den P-Wert auf 0,01. Typischerweise werden niedrigere P-Werte in der Produktion verwendet, wenn Fehler in Produkten erkannt werden müssen. In diesem Fall ist eine hohe Wiedergabetreue erforderlich, um sicherzustellen, dass alle Teile wie erwartet funktionieren.
- Für die meisten Hypothesenexperimente ist ein Signifikanzniveau von 0,05 ausreichend.
-
Entscheiden Sie, welche Kriterien Sie verwenden werden: einseitig oder zweiseitig. Eine der Annahmen im Student-t-Test ist, dass die Daten normalverteilt sind. Die Normalverteilung ist eine glockenförmige Kurve mit die maximale Anzahl ergibt sich in der Mitte der Kurve. Student's t-Test ist mathematische Methode Datenvalidierung, mit der Sie feststellen können, ob die Daten außerhalb der Normalverteilung liegen (mehr, weniger oder in den „Schwänzen“ der Kurve).
- Wenn Sie sich nicht sicher sind, ob die Daten darüber oder darunter liegen Kontrollgruppe Werte, verwenden Sie einen zweiseitigen Test. Dadurch können Sie die Signifikanz in beide Richtungen bestimmen.
- Wenn Sie wissen, in welche Richtung die Daten außerhalb der Normalverteilung fallen könnten, verwenden Sie einen einseitigen Test. Im obigen Beispiel erwarten wir, dass die Noten der Schüler steigen, sodass ein einseitiger Test verwendet werden kann.
-
Bestimmen Sie die Stichprobengröße mit statistischer Power. Die statistische Aussagekraft einer Studie ist die Wahrscheinlichkeit, dass eine bestimmte Stichprobengröße das erwartete Ergebnis liefert. Eine übliche Leistungsschwelle (oder β) ist 80 %. Eine Leistungsanalyse ohne vorherige Daten kann schwierig sein, da einige Informationen über die erwarteten Mittelwerte in jedem Datensatz und ihre Standardabweichungen erforderlich sind. Verwenden Sie den Online-Power-Rechner, um die optimale Stichprobengröße für Ihre Daten zu bestimmen.
- In der Regel führen Forscher eine kleine Pilotstudie durch, die Daten für die Leistungsanalyse liefert und die für eine größere und vollständigere Studie erforderliche Stichprobengröße bestimmt.
- Wenn Sie keine Möglichkeit haben, eine Pilotstudie durchzuführen, versuchen Sie, mögliche Durchschnittswerte anhand der Literaturdaten und der Ergebnisse anderer Personen abzuschätzen. Dies kann Ihnen helfen, die optimale Stichprobengröße zu bestimmen.
Teil 2
Berechnung Standardabweichung-
Schreiben Sie die Formel für die Standardabweichung auf. Die Standardabweichung gibt an, wie groß die Streuung der Daten ist. Daraus können Sie schließen, wie nah die an einer bestimmten Probe erhaltenen Daten sind. Auf den ersten Blick erscheint die Formel ziemlich kompliziert, aber die folgenden Erklärungen helfen Ihnen, sie zu verstehen. Die Formel hat nächste Ansicht: s = √∑((x i – µ) 2 /(N – 1)).
- s - Standardabweichung;
- das ∑-Zeichen zeigt an, dass alle in der Stichprobe erhaltenen Daten hinzugefügt werden sollten;
- x i entspricht dem i-ten Wert, d. h. einem getrennt erhaltenen Ergebnis;
- µ ist der Durchschnittswert für diese Gruppe;
- N- Gesamtzahl Daten in der Probe.
-
Finden Sie den Durchschnitt in jeder Gruppe. Um die Standardabweichung zu berechnen, müssen Sie zunächst den Mittelwert für jede Studiengruppe finden. Der Mittelwert ist angegeben griechischer Briefµ (mu). Um den Durchschnitt zu finden, addieren Sie einfach alle resultierenden Werte und dividieren sie durch die Datenmenge (Stichprobengröße).
- Zum Beispiel zu finden Durchschnittsnote Betrachten Sie in der Gruppe der Schüler, die den Stoff vor dem Unterricht studieren, einen kleinen Datensatz. Der Einfachheit halber verwenden wir einen Satz von fünf Punkten: 90, 91, 85, 83 und 94.
- Addieren wir alle Werte zusammen: 90 + 91 + 85 + 83 + 94 = 443.
- Teilen Sie die Summe durch die Anzahl der Werte, N = 5: 443/5 = 88,6.
- Somit liegt der Durchschnittswert für diese Gruppe bei 88,6.
-
Subtrahieren Sie jeden erhaltenen Wert vom Durchschnitt. Nächster Schritt ist die Differenz (x i - µ) zu berechnen. Subtrahieren Sie dazu von dem Gefundenen mittlere Größe jeder empfangene Wert. In unserem Beispiel müssen wir fünf Unterschiede finden:
- (90–88,6), (91–88,6), (85–88,6), (83–88,6) und (94–88,6).
- Als Ergebnis erhalten wir die folgenden Werte: 1,4, 2,4, -3,6, -5,6 und 5,4.
-
Quadriere jeden erhaltenen Wert und addiere sie zusammen. Jede der gerade gefundenen Größen sollte quadriert werden. Alle werden bei diesem Schritt verschwinden. negative Werte. Wenn Sie nach diesem Schritt haben negative Zahlen, dann hast du vergessen, sie zu quadrieren.
- Für unser Beispiel erhalten wir 1,96, 5,76, 12,96, 31,36 und 29,16.
- Wir addieren die erhaltenen Werte: 1,96 + 5,76 + 12,96 + 31,36 + 29,16 = 81,2.
-
Teilen Sie durch die Stichprobengröße minus 1. In der Formel wird die Summe durch N - 1 geteilt, da wir sie nicht berücksichtigen Durchschnittsbevölkerung, aber wir nehmen für die Auswertung eine Stichprobe aller Studenten.
- Subtrahiere: N - 1 = 5 - 1 = 4
- Teilen: 81,2/4 = 20,3
-
Extrakt Quadratwurzel. Nachdem Sie die Summe durch den Stichprobenumfang minus eins dividiert haben, ziehen Sie die Quadratwurzel des gefundenen Werts. Dies ist der letzte Schritt zur Berechnung der Standardabweichung. Es gibt Statistikprogramme, die nach Eingabe der Ausgangsdaten alle notwendigen Berechnungen durchführen.
- In unserem Beispiel beträgt die Standardabweichung der Noten der Schüler, die den Stoff vor dem Unterricht gelesen haben, s = √20,3 = 4,51.
Teil 3
Bestimmen Sie die Bedeutung-
Berechnen Sie die Varianz zwischen den beiden Datengruppen. Bis zu diesem Schritt haben wir das Beispiel nur für eine Gruppe von Daten betrachtet. Wenn Sie zwei Gruppen vergleichen möchten, sollten Sie natürlich die Daten beider Gruppen nehmen. Berechnen Sie die Standardabweichung für die zweite Datengruppe und finden Sie dann die Varianz zwischen den beiden experimentelle Gruppen. Die Streuung wird nach folgender Formel berechnet: s d = √((s 1 /N 1) + (s 2 /N 2)).
Definiere deine Hypothese. Der erste Schritt bei der Bewertung der statistischen Signifikanz besteht darin, die zu beantwortende Frage auszuwählen und eine Hypothese zu formulieren. Eine Hypothese ist eine Aussage über experimentelle Daten, deren Verteilung und Eigenschaften. Für jedes Experiment gibt es sowohl eine Null- als auch eine Alternativhypothese. Im Allgemeinen müssen Sie zwei Datensätze vergleichen, um festzustellen, ob sie ähnlich oder unterschiedlich sind.
