Semnificația statistică sau nivelul de p-semnificație - rezultatul principal al testului
ipoteza statistica. vorbind limbaj tehnic, este probabilitatea de a obține data
rezultat studiu eșantion cu condiţia ca de fapt pentru general
set, ipoteza nulă este adevărată - adică nu există nicio relație. Cu alte cuvinte, asta
probabilitatea ca relația detectată să fie aleatorie și nu o proprietate
agregate. Exact semnificație statistică, nivelul de semnificație p este
cuantificare fiabilitatea conexiunii: cu cât această probabilitate este mai mică, cu atât este mai fiabilă conexiunea.
Să presupunem că, la compararea a două medii eșantionare, s-a obținut valoarea nivelului
semnificație statistică p=0,05. Aceasta înseamnă că testarea ipotezei statistice despre
egalitatea de mijloace în populația generală a arătat că, dacă este adevărat, atunci probabilitatea
apariția aleatorie a diferențelor detectate nu este mai mare de 5%. Cu alte cuvinte, dacă
două probe au fost extrase în mod repetat din aceeași populație generală, apoi în 1 din
20 de cazuri ar arăta aceeași diferență sau mai mare între mediile acestor eșantioane.
Adică există o șansă de 5% ca diferențele găsite să fie aleatorii.
caracter și nu sunt o proprietate a agregatului.
Intr-o relatie ipoteza stiintifica nivelul de semnificaţie statistică este cantitativ
indicator al gradului de neîncredere în concluzia despre prezența unei conexiuni, calculat din rezultate
testarea selectivă, empirică a acestei ipoteze. Cum valoare mai mică p-level, cu atât mai mare
semnificația statistică a rezultatului studiului, confirmând ipoteza științifică.
Este util să știm ce influențează nivelul de semnificație. Nivel de semnificație, celelalte lucruri fiind egale
mai sus (valoare p mai mică) dacă:
Mărimea conexiunii (diferența) este mai mare;
Variabilitatea trăsăturii (trăsăturii) este mai mică;
Dimensiunea(ele) eșantionului este mai mare.
Unilateral Iată teste de semnificație cu două cozi
Dacă scopul studiului este de a releva diferența dintre parametrii celor doi generali
colecții care corespund diverselor sale condiții naturale ( conditii de viata,
vârsta subiecților etc.), adesea nu se știe care dintre acești parametri va fi mai mare și
care este mai mic.
De exemplu, dacă sunteți interesat de variabilitatea rezultatelor în control și
grupuri experimentale, atunci, de regulă, nu există încredere în semnul diferenței dintre varianțe sau
abaterile standard ale rezultatelor față de care se estimează variabilitatea. În acest caz
ipoteza nulă este că varianțele sunt egale între ele, iar scopul studiului este
demonstra contrariul, adică. există o diferență între variații. În același timp, este permis ca
diferența poate fi de orice semn. Astfel de ipoteze se numesc cu două fețe.
Dar uneori sarcina este de a dovedi o creștere sau o scădere a unui parametru;
de exemplu, rezultat mediu mai mare în lotul experimental decât în lotul martor. în care
nu mai este permis ca diferenta sa poata fi de alt semn. Astfel de ipoteze se numesc
Unilateral.
Se numesc teste de semnificație utilizate pentru a testa ipotezele cu două fețe
Bilateral, iar pentru unilateral - unilateral.
Se pune întrebarea care dintre criterii ar trebui ales într-un anumit caz. Răspuns
Această întrebare este dincolo de formală metode statistice si complet
Depinde de scopul studiului. În niciun caz nu trebuie ales unul sau altul criteriu după
Efectuarea unui experiment bazat pe analiza datelor experimentale, deoarece acest lucru poate
duce la concluzii greșite. Dacă, înainte de experiment, se presupune că diferența
Parametrii comparați pot fi atât pozitivi, cât și negativi, de aici rezultă
Nivelul de semnificație în statistică este indicator important, reflectând gradul de încredere în acuratețea, adevărul datelor primite (prevăzute). Conceptul este utilizat pe scară largă în domenii diverse: din exploatare cercetare sociologică, la testarea statistică a ipotezelor științifice.
Definiție
Nivelul de semnificație statistică (sau rezultat semnificativ statistic) arată care este probabilitatea de apariție aleatorie a indicatorilor studiați. Semnificația statistică generală a fenomenului este exprimată prin valoarea p (nivelul p). În orice experiment sau observație, există posibilitatea ca datele obținute să apară din cauza erorilor de eșantionare. Acest lucru este valabil mai ales pentru sociologie.
Adică o valoare este semnificativă statistic, a cărei probabilitate de apariție aleatorie este extrem de mică sau tinde spre extreme. Extrema în acest context este gradul de abatere a statisticilor de la ipoteza nulă (o ipoteză care este testată pentru coerența cu datele eșantionului obținut). LA practica stiintifica nivelul de semnificație este selectat înainte de colectarea datelor și, de regulă, coeficientul acestuia este de 0,05 (5%). Pentru sistemele în care este critic valori exacte, acest indicator poate fi 0,01 (1%) sau mai puțin.

fundal
Conceptul de nivel de semnificație a fost introdus de statisticianul și geneticianul britanic Ronald Fisher în 1925, când dezvolta o metodă de testare. ipotezele statistice. La analiza oricărui proces, există o anumită probabilitate pentru anumite fenomene. Dificultăți apar atunci când se lucrează cu procente mici (sau nu evidente) de probabilități care se încadrează sub conceptul de „eroare de măsurare”.
Când lucrează cu statistici care nu sunt suficient de specifice pentru a fi testate, oamenii de știință s-au confruntat cu problema ipotezei nule, care „împiedecă” operarea cu valori mici. Fisher a propus ca astfel de sisteme să determine probabilitatea evenimentelor la 5% (0,05) ca o limită convenabilă a eșantionului care permite respingerea ipotezei nule în calcule.

Introducerea unui coeficient fix
În 1933 Oamenii de știință Jerzy Neumann și Egon Pearson în lucrările lor au recomandat stabilirea unui anumit nivel de semnificație în avans (înainte de colectarea datelor). Exemple de utilizare a acestor reguli sunt clar vizibile în timpul alegerilor. Să presupunem că există doi candidați, dintre care unul este foarte popular, iar celălalt nu este bine cunoscut. Este evident că primul candidat va câștiga alegerile, iar șansele celui de-al doilea tind la zero. Străduiți-vă – dar nu egal: există întotdeauna posibilitatea de forță majoră, informații senzaționale, decizii neașteptate care pot modifica rezultatele alegerilor prezise.
Neumann și Pearson au fost de acord că nivelul de semnificație propus de Fisher de 0,05 (notat prin simbolul α) este cel mai convenabil. Cu toate acestea, Fischer însuși în 1956 s-a opus fixării acestei valori. El credea că nivelul α ar trebui stabilit în conformitate cu circumstanțe specifice. De exemplu, în fizica particulelor este 0,01.

valoarea p
Termenul de valoare p a fost folosit pentru prima dată de Brownlee în 1960. Nivelul p (valoarea p) este un indicator găsit în relatie inversa asupra validității rezultatelor. Cea mai mare valoare p corespunde celui mai scăzut nivel de încredere în relația eșantionată dintre variabile.
Această valoare reflectă probabilitatea erorilor asociate cu interpretarea rezultatelor. Presupunem valoarea p = 0,05 (1/20). Arată o șansă de cinci procente ca relația dintre variabilele găsite în eșantion să fie doar o caracteristică aleatorie a eșantionului. Adică, dacă această dependență este absentă, atunci cu mai multe experimente similare, în medie, în fiecare al douăzecilea studiu, se poate aștepta la aceeași dependență sau mai mare între variabile. Adesea, nivelul p este considerat „marja” nivelului de eroare.
Apropo, valoarea p poate să nu reflecte adevărată dependențăîntre variabile, dar arată doar o valoare medie în cadrul ipotezelor. În special, analiza finală a datelor va depinde și de valorile alese coeficient dat. Cu p-level = 0,05 vor fi unele rezultate, iar cu un coeficient egal cu 0,01, altele.

Testarea ipotezelor statistice
Nivelul de semnificație statistică este deosebit de important atunci când se testează ipoteze. De exemplu, atunci când se calculează un test cu două fețe, aria de respingere este împărțită în mod egal la ambele capete ale distribuției de eșantionare (față de coordonatele zero) și se calculează adevărul datelor obținute.
Să presupunem că în timpul monitorizării unui anumit proces (fenomen), s-a dovedit că noi informații statistice indică mici modificări raportat la valorile anterioare. În același timp, discrepanțele în rezultate sunt mici, nu evidente, dar importante pentru studiu. Specialistul se confruntă cu o dilemă: modificările apar cu adevărat sau sunt erori de eșantionare (inecizie de măsurare)?
În acest caz, se aplică sau se respinge ipoteza nulă (totul este anulat ca o eroare, sau schimbarea sistemului este recunoscută ca fapt împlinit). Procesul de rezolvare a problemei se bazează pe raportul dintre semnificația statistică globală (valoarea p) și nivelul de semnificație (α). Dacă nivelul p< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Valori folosite
Nivelul de semnificație depinde de materialul analizat. În practică, se folosesc următoarele valori fixe:
- a = 0,1 (sau 10%);
- a = 0,05 (sau 5%);
- a = 0,01 (sau 1%);
- α = 0,001 (sau 0,1%).
Cu cât sunt necesare calculele mai precise, cu atât coeficientul α este mai mic. Desigur, prognozele statistice din fizică, chimie, farmaceutică și genetică necesită o acuratețe mai mare decât în știința politică și sociologie.

Praguri de semnificație în anumite zone
În domenii de înaltă precizie, cum ar fi fizica particulelor și producție, semnificația statistică este adesea exprimată ca raport al abaterii standard (notat cu coeficientul sigma - σ) în raport cu distributie normala probabilități (distribuția Gauss). σ este un indicator statistic care determină dispersia valorilor unei anumite cantități relativ la așteptări matematice. Folosit pentru a reprezenta grafic probabilitatea evenimentelor.
În funcție de domeniul de cunoaștere, coeficientul σ variază foarte mult. De exemplu, la prezicerea existenței bosonului Higgs, parametrul σ este egal cu cinci (σ=5), ceea ce corespunde valorii p=1/3,5 milioane de zone.
Eficienţă
Trebuie avut în vedere faptul că coeficienții α și p-valoarea nu sunt caracteristici exacte. Oricare ar fi nivelul de semnificație în statistica fenomenului studiat, nu este o bază necondiționată pentru acceptarea ipotezei. De exemplu, cu cât valoarea lui α este mai mică, cu atât este mai mare șansa ca ipoteza care se stabilește să fie semnificativă. Cu toate acestea, există riscul de eroare, care reduce puterea statistică (semnificația) studiului.
Cercetători care se concentrează exclusiv pe statistică rezultate semnificative poate trage concluzii eronate. În același timp, este dificil să-și verifice munca, deoarece aplică ipoteze (care, de fapt, sunt valorile valorii α și p). Prin urmare, se recomandă întotdeauna, împreună cu calculul semnificației statistice, să se determine un alt indicator - amploarea efectului statistic. Mărimea efectului este o măsură cantitativă a puterii unui efect.
Statistica a fost de mult timp o parte integrantă a vieții. Oamenii se confruntă peste tot. Pe baza statisticilor, se trag concluzii despre unde și ce boli sunt comune, ce este mai solicitat într-o anumită regiune sau în rândul unui anumit segment al populației. Chiar și construcțiile se bazează pe programe politice candidați la guvernare. Ele sunt, de asemenea, folosite de lanțurile de retail atunci când cumpără mărfuri, iar producătorii sunt ghidați de aceste date în propunerile lor.
statistici în joc rol importantîn viața societății și afectează fiecare dintre membrii săi individuali, chiar și în lucruri mărunte. De exemplu, dacă până la , majoritatea oamenilor preferă Culori închiseîn hainele dintr-un anumit oraș sau regiune, va fi extrem de dificil să găsești o pelerină de ploaie galben strălucitor cu imprimeu floral în magazinele locale. Dar care sunt cantitățile care alcătuiesc aceste date care au un asemenea impact? De exemplu, ce este „semnificativ statistic”? Ce se înțelege mai exact prin această definiție?
Ce este asta?
Statistica ca știință este alcătuită dintr-o combinație marimi diferiteși concepte. Unul dintre ele este conceptul de „semnificație statistică”. Acesta este numele valorii variabile, probabilitatea de apariție a altor indicatori în care este neglijabilă.
De exemplu, 9 din 10 oameni poartă pantofi de cauciuc în picioare în timpul plimbarea de dimineata pentru ciuperci în pădure de toamnă după o noapte ploioasă. Probabilitatea ca la un moment dat 8 dintre ei să pună mocasini de pânză este neglijabilă. Astfel, în aceasta exemplu concret numărul 9 este o valoare care se numește „semnificație statistică”.
În consecință, dacă dezvoltăm în continuare cele de mai sus exemplu practic, magazinele de încălțăminte cumpără până la sfârșit sezonul de vară cizme de cauciuc în număr mai mare decât în alte perioade ale anului. Da, valoarea semnificație statistică are un impact asupra vieții de zi cu zi.
Desigur, în calcule complexe, de exemplu, atunci când se prezică răspândirea virușilor, număr mare variabile. Dar însăși esența determinării unui indicator semnificativ al datelor statistice este similară, indiferent de complexitatea calculelor și de numărul de valori neconstante.
Cum se calculeaza?
Folosit la calcularea valorii indicatorului „semnificație statistică” a ecuației. Adică, se poate argumenta că în acest caz totul este decis de matematică. cu cel mai mult varianta simpla calcularea este un lanț operatii matematice, care include următorii parametri:
- două tipuri de rezultate obținute din sondaje sau studiul datelor obiective, de exemplu, sumele pentru care se fac achiziții, notate cu a și b;
- indicator pentru ambele grupuri - n;
- valoarea cotei eșantionului combinat - p;
- conceptul de „eroare standard” - SE.
Următorul pas este determinarea indicatorului general de testare - t, valoarea acestuia este comparată cu numărul 1,96. 1,96 este o valoare medie care reprezintă un interval de 95% conform distribuției t a lui Student.
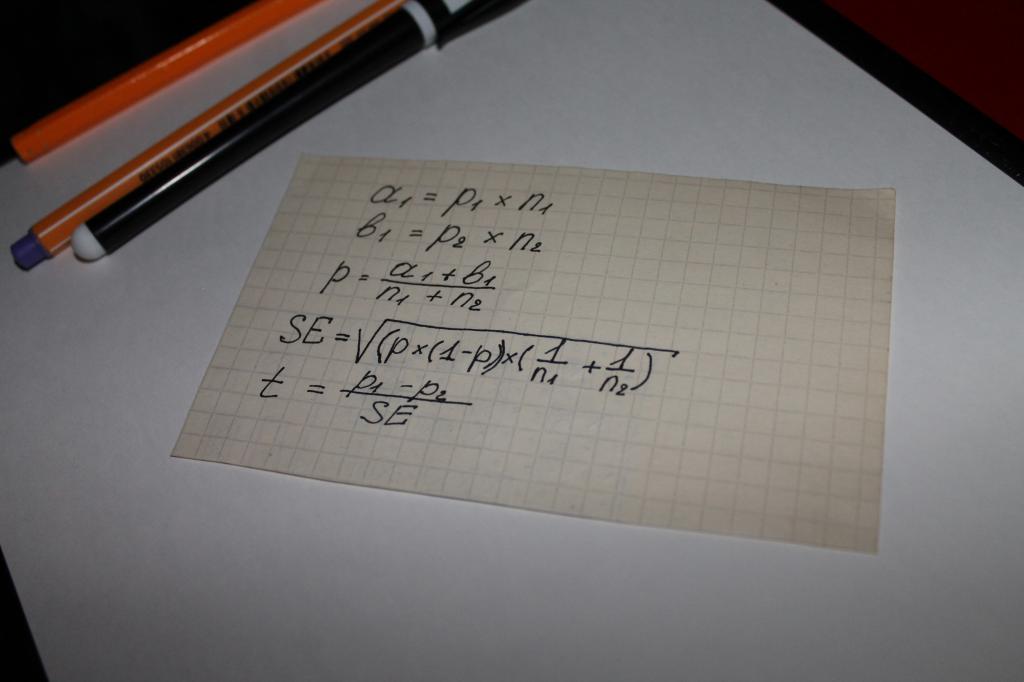
Se pune adesea întrebarea care este diferența dintre valorile lui n și p. Această nuanță este ușor de clarificat cu un exemplu. Să presupunem că se calculează semnificația statistică a loialității față de orice produs sau marcă de bărbați și femei.
În acest caz, literele vor fi urmate de următoarele:
- n este numărul de respondenți;
- p - numărul de mulțumiți de produs.
Numărul de femei intervievate în acest caz va fi desemnat n1. În consecință, bărbații - n2. Aceeași valoare va avea numerele „1” și „2” la simbolul p.
Compararea indicatorului de test cu valorile medii ale tabelelor de calcul ale Studentului devine ceea ce se numește „semnificație statistică”.
Ce se înțelege prin verificare?
Rezultatele oricărui calcul matematic pot fi întotdeauna verificate; acest lucru este predat copiilor chiar și în scoala primara. Este logic să presupunem că, deoarece indicatorii statistici sunt determinați folosind un lanț de calcule, atunci aceștia sunt verificați.
Cu toate acestea, testarea semnificației statistice nu este doar matematică. Statistica se ocupa de cantitate mare variabile și diverse probabilități, care nu sunt întotdeauna susceptibile de calcul. Adică dacă revenim la exemplul dat la începutul articolului cu incaltaminte de cauciuc, atunci construcția logică a datelor statistice, pe care se vor baza cumpărătorii de mărfuri pentru magazine, poate fi perturbată de vremea uscată și caldă, care nu este tipică toamnei. Ca urmare a acestui fenomen, numărul de persoane care achiziționează cizme de cauciuc va scădea, iar punctele de vânzare vor suferi pierderi. Anticipați o anomalie meteorologică formula matematica, desigur, nu poate. Acest moment se numește - „greșeală”.

Tocmai probabilitatea unor astfel de erori ia în considerare verificarea nivelului de semnificație calculată. Ea ia în considerare atât indicatorii calculați, cât și nivelurile acceptate de semnificație, precum și cantitățile numite convențional ipoteze.
Ce este un nivel de semnificație?
Conceptul de „nivel” este inclus în principalele criterii de semnificație statistică. Este folosit în statistica aplicată și practică. Acesta este un fel de cantitate care ia în considerare probabilitatea posibile abateri sau greșeli.
Nivelul se bazează pe identificarea diferențelor în eșantioanele gata făcute, vă permite să stabiliți semnificația acestora sau, dimpotrivă, aleatorietatea. Acest concept nu are doar semnificații digitale, ci și interpretările lor specifice. Ei explică cum trebuie înțeleasă valoarea, iar nivelul în sine este determinat prin compararea rezultatului cu indicele mediu, acest lucru dezvăluie gradul de fiabilitate al diferențelor.

Astfel, conceptul de nivel poate fi prezentat simplu – este un indicator al unei erori sau erori acceptabile, probabile în concluziile desprinse din datele statistice obținute.
Ce niveluri de semnificație sunt utilizate?
Semnificația statistică a coeficienților de probabilitate de eroare în practică se bazează pe trei niveluri de bază.
Primul nivel este pragul la care valoarea este de 5%. Adică, probabilitatea de eroare nu depășește nivelul de semnificație de 5%. Aceasta înseamnă că încrederea în impecabilitatea și infailibilitatea concluziilor făcute pe baza datelor cercetării statistice este de 95%.
Al doilea nivel este pragul de 1%. În consecință, această cifră înseamnă că cineva poate fi ghidat de datele obținute în timpul calculelor statistice cu o încredere de 99%.
Al treilea nivel este de 0,1%. Cu această valoare, probabilitatea unei erori este egală cu o fracțiune de procent, adică erorile sunt practic eliminate.
Ce este o ipoteză în statistică?
Erorile ca concept sunt împărțite în două domenii privind acceptarea sau respingerea ipotezei nule. O ipoteză este un concept în spatele căruia, conform definiției, se ascunde un set de alte date sau enunțuri. Asta este descrierea distribuția probabilității ceva legat de subiectul contabilităţii statistice.

Există două ipoteze în calcule simple - zero și alternativă. Diferența dintre ele este că ipoteza nulă se bazează pe ideea că nu există diferențe fundamentale între eșantioanele implicate în determinarea semnificației statistice, iar cea alternativă este complet opusă acesteia. Acesta este ipoteză alternativă pe baza prezenței unei diferențe semnificative în aceste probe.
Care sunt erorile?
Erorile ca concept în statistică depind direct de acceptarea uneia sau alteia ipoteze ca adevărată. Ele pot fi împărțite în două direcții sau tipuri:
- primul tip se datorează acceptării ipotezei nule, care s-a dovedit a fi incorectă;
- al doilea este cauzat de urmarirea alternativei.

Primul tip de eroare se numește fals pozitiv și este destul de comună în toate domeniile în care se folosesc statistici. În consecință, eroarea celui de-al doilea tip se numește fals negativ.
De ce este importantă regresia în statistică?
Semnificația statistică a regresiei este că poate fi utilizată pentru a stabili cât de realist este modelul calculat pe baza datelor. diverse dependențe; vă permite să identificați suficiența sau lipsa factorilor pentru contabilitate și concluzii.
Valoarea regresiei este determinată prin compararea rezultatelor cu datele enumerate în tabelele Fisher. Sau folosind analiza varianței. Importanţă indicatorii de regresie au cu complex studii statisticeşi calcule care implică un numar mare de variabile, date aleatorii și modificări probabile.
Semnificația statistică
Rezultatele obținute folosind o anumită procedură de cercetare se numesc semnificativ din punct de vedere statistic dacă probabilitatea apariţiei lor aleatoare este foarte mică. Acest concept poate fi ilustrat prin exemplul aruncării unei monede. Să presupunem că o monedă este răsturnată de 30 de ori; A apărut de 17 ori cu capul și de 13 ori cu cozi. este plin de înțeles Este aceasta o abatere de la rezultatul așteptat (15 capete și 15 cozi) sau este o coincidență? Pentru a răspunde la această întrebare, puteți, de exemplu, să aruncați aceeași monedă de multe ori de 30 de ori la rând și, în același timp, să observați de câte ori se repetă raportul dintre capete și cozi, egal cu 17:13. Analiza statistică ne salvează de acest proces obositor. Cu ajutorul acestuia, după primele 30 de aruncări de monede, este posibil să se estimeze numărul posibil de apariții aleatorii de 17 capete și 13 cozi. O astfel de estimare se numește declarație probabilistică.
LA literatura stiintificaîn psihologia industrial-organizațională enunț probabilistic în forma matematica notat prin expresia R(probabilitate)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (R< 0,01). Acest fapt este important pentru înțelegerea literaturii de specialitate, dar nu trebuie interpretat ca însemnând că este inutil să facem observații care nu îndeplinesc aceste standarde. Așa-numitele rezultate ale cercetării nesemnificative (observații care pot fi obținute întâmplător Mai mult una sau cinci ori din 100) poate fi foarte util pentru identificarea tendințelor și ca ghid pentru cercetările viitoare.
De asemenea, trebuie remarcat faptul că nu toți psihologii sunt de acord cu standardele și procedurile tradiționale (ex. Cohen, 1994; Sauley & Bedeian, 1989). Problemele legate de măsurători sunt ele însele tema principală munca multor cercetători care studiază acuratețea metodelor de măsurare și premisele care stau la baza metode existenteși standarde, precum și dezvoltarea de noi medici și instrumente. Poate cândva în viitor, cercetarea în această putere va duce la o schimbare a standardelor tradiționale de evaluare a semnificației statistice, iar aceste schimbări vor câștiga acceptare universală. (Al cincilea capitol al Asociației Americane de Psihologie reunește psihologi specializați în studiul estimărilor, măsurătorilor și statisticilor.)
În rapoartele de cercetare, o afirmație probabilistică precum R< 0,05, din cauza unora statistici adică un număr care se obţine ca urmare a unui anumit set de proceduri matematice de calcul. Confirmarea probabilistică se obține prin compararea acestor statistici cu datele din tabele speciale care sunt publicate în acest scop. În industrial-organizatoric cercetare psihologică statistici frecvent întâlnite precum r, F, t, r>(a se citi „chi pătrat”) și R(a se citi „multiplu R").În fiecare caz, statisticile (un număr) obținute în urma analizei unei serii de observații pot fi comparate cu cifrele din tabelul publicat. După aceea, este posibil să se formuleze o declarație probabilistică despre probabilitatea obținerii aleatoare a acestui număr, adică să se tragă o concluzie despre semnificația observațiilor.
Pentru a înțelege studiile descrise în această carte, este suficient să aveți o înțelegere clară a conceptului de semnificație statistică și să nu cunoașteți neapărat cum sunt calculate statisticile menționate mai sus. Cu toate acestea, ar fi util să discutăm o ipoteză care stă la baza tuturor acestor proceduri. Aceasta este presupunerea că toate variabilele observate sunt distribuite aproximativ legea normală. În plus, când se citesc rapoarte despre cercetarea psihologică industrial-organizațională, apar adesea încă trei concepte care joacă un rol important - în primul rând, corelația și corelație, în al doilea rând, variabila determinant/ predictor și „ANOVA” ( analiza variatiei), în al treilea rând, un grup de metode statistice sub denumirea comună„meta-analiză”.
Testarea ipotezelor se realizează cu ajutorul analizei statistice. Semnificația statistică se găsește folosind valoarea P, care corespunde probabilității acest eveniment sub presupunerea că o anumită afirmație (ipoteza nulă) este adevărată. Dacă valoarea P este mai mică decât un anumit nivel de semnificație statistică (de obicei 0,05), experimentatorul poate concluziona în siguranță că ipoteza nulă este falsă și poate continua să ia în considerare ipoteza alternativă. Folosind testul t al lui Student, puteți calcula valoarea P și puteți determina semnificația pentru două seturi de date.
Pași
Partea 1
Stabilirea unui experiment- Ipoteza nulă (H 0) afirmă de obicei că nu există nicio diferență între cele două seturi de date. De exemplu: acei elevi care citesc materialul înainte de curs nu primesc note mai mari.
- Ipoteza alternativă (H a) este opusul ipotezei nule și este o afirmație care trebuie confirmată cu date experimentale. De exemplu: acei elevi care citesc materialul înainte de oră obțin note mai mari.
-
Setați nivelul de semnificație pentru a determina cât de mult trebuie să difere distribuția datelor de cea obișnuită pentru ca aceasta să fie considerată un rezultat semnificativ. Nivel de semnificație (numit și α (\displaystyle \alpha)-level) este pragul pe care îl definiți pentru semnificația statistică. Dacă valoarea P este mai mică sau egală cu nivelul de semnificație, datele sunt considerate semnificative statistic.
- De regulă, nivelul de semnificație (valoare α (\displaystyle \alpha)) este luată egală cu 0,05, caz în care probabilitatea de a detecta o diferență aleatorie între diferitele seturi de date este de numai 5%.
- Cu cât este mai mare nivelul de semnificație (și, în consecință, mai puțină valoare p), cu atât rezultatele sunt mai fiabile.
- Dacă doriți rezultate mai fiabile, reduceți valoarea P la 0,01. De obicei, valorile P mai mici sunt utilizate în producție atunci când este necesar să se detecteze defectele produselor. În acest caz, este necesară o fidelitate ridicată pentru a se asigura că toate piesele funcționează conform așteptărilor.
- Pentru majoritatea experimentelor de ipoteze, un nivel de semnificație de 0,05 este suficient.
-
Decideți ce criterii veți folosi: unilateral sau cu două fețe. Una dintre ipotezele testului t al lui Student este că datele sunt distribuite în mod normal. Distribuția normală este o curbă în formă de clopot cu numărul maxim rezultă în mijlocul curbei. Testul t al studentului este metoda matematica validarea datelor, care vă permite să determinați dacă datele se încadrează în afara distribuției normale (mai mult, mai puțin sau în „cozile” curbei).
- Dacă nu sunteți sigur dacă datele sunt deasupra sau dedesubt grupul de control valori, utilizați un test cu două cozi. Acest lucru vă va permite să determinați semnificația în ambele direcții.
- Dacă știți în ce direcție datele ar putea cădea în afara distribuției normale, utilizați un test cu o singură coadă. În exemplul de mai sus, ne așteptăm ca notele elevilor să crească, așa că poate fi folosit un test cu o singură coadă.
-
Determinați dimensiunea eșantionului folosind puterea statistică. Puterea statistică a unui studiu este probabilitatea ca o anumită dimensiune a eșantionului să producă rezultatul așteptat. Un prag de putere comun (sau β) este de 80%. Analiza puterii fără date prealabile poate fi dificilă, deoarece sunt necesare anumite informații despre mijloacele așteptate în fiecare set de date și abaterile standard ale acestora. Utilizați calculatorul de putere online pentru a determina dimensiunea optimă a eșantionului pentru datele dvs.
- De obicei, cercetătorii efectuează un mic studiu pilot care oferă date pentru analiza puterii și determină dimensiunea eșantionului necesară pentru un studiu mai amplu și mai complet.
- Dacă nu aveți ocazia să efectuați un studiu pilot, încercați să estimați posibile valori medii pe baza datelor din literatură și a rezultatelor altor persoane. Acest lucru vă poate ajuta să determinați dimensiunea optimă a eșantionului.
Partea 2
calculati deviație standard-
Scrieți formula pentru abaterea standard. Abaterea standard indică cât de mare este răspândirea datelor. Vă permite să concluzionați cât de aproape sunt datele obținute pe un anumit eșantion. La prima vedere, formula pare destul de complicată, dar explicațiile de mai jos vă vor ajuta să o înțelegeți. Formula are următoarea vedere: s = √∑((x i – µ) 2 /(N – 1)).
- s - abaterea standard;
- semnul ∑ indică faptul că trebuie adăugate toate datele obținute în eșantion;
- x i corespunde valorii i-a, adică un rezultat separat obţinut;
- µ este valoarea medie pentru acest grup;
- N- numărul total datele din eșantion.
-
Găsiți media în fiecare grupă. Pentru a calcula abaterea standard, trebuie mai întâi să găsiți media pentru fiecare grup de studiu. Se notează valoarea medie Literă greacă p (mu). Pentru a găsi media, pur și simplu adăugați toate valorile rezultate și împărțiți-le la cantitatea de date (dimensiunea eșantionului).
- De exemplu, pentru a găsi nota medieîn grupul acelor elevi care studiază materialul înainte de oră, luați în considerare un mic set de date. Pentru simplitate, folosim un set de cinci puncte: 90, 91, 85, 83 și 94.
- Să adunăm toate valorile împreună: 90 + 91 + 85 + 83 + 94 = 443.
- Împărțiți suma la numărul de valori, N = 5: 443/5 = 88,6.
- Astfel, valoarea medie pentru acest grup este de 88,6.
-
Scădeți fiecare valoare obținută din medie. Urmatorul pas este de a calcula diferența (x i - µ). Pentru a face acest lucru, scădeți din găsit mărime medie fiecare valoare primită. În exemplul nostru, trebuie să găsim cinci diferențe:
- (90 - 88,6), (91 - 88,6), (85 - 88,6), (83 - 88,6) și (94 - 88,6).
- Drept urmare, obținem următoarele valori: 1,4, 2,4, -3,6, -5,6 și 5,4.
-
Patratează fiecare valoare obținută și adună-le. Fiecare dintre cantitățile tocmai găsite ar trebui să fie pătrată. Toate vor dispărea la acest pas. valori negative. Dacă după acest pas ai numere negative, atunci ai uitat să le pătrați.
- Pentru exemplul nostru, obținem 1,96, 5,76, 12,96, 31,36 și 29,16.
- Adăugăm valorile obţinute: 1,96 + 5,76 + 12,96 + 31,36 + 29,16 = 81,2.
-
Împărțiți la dimensiunea eșantionului minus 1.În formulă, suma este împărțită la N - 1 datorită faptului că nu ținem cont populația generală, dar luăm spre evaluare un eșantion din toți studenții.
- Scăderea: N - 1 = 5 - 1 = 4
- Împărțire: 81,2/4 = 20,3
-
Extrage Rădăcină pătrată. După împărțirea sumei la dimensiunea eșantionului minus unu, luați rădăcina pătrată a valorii găsite. Acesta este ultimul pas în calcularea abaterii standard. Există programe statistice care, după introducerea datelor inițiale, efectuează toate calculele necesare.
- În exemplul nostru, abaterea standard a notelor acelor elevi care citesc materialul înainte de oră este s = √20,3 = 4,51.
Partea 3
Determinați semnificația-
Calculați varianța dintre cele două grupuri de date. Până la acest pas, am luat în considerare exemplul pentru un singur grup de date. Dacă doriți să comparați două grupuri, evident că ar trebui să luați datele pentru ambele grupuri. Calculați abaterea standard pentru al doilea grup de date și apoi găsiți varianța dintre cele două grupuri experimentale. Dispersia se calculează folosind următoarea formulă: s d = √((s 1 /N 1) + (s 2 /N 2)).
Definiți-vă ipoteza. Primul pas în evaluarea semnificației statistice este să alegeți întrebarea la care doriți să primiți răspuns și să formulați o ipoteză. O ipoteză este o afirmație despre datele experimentale, distribuția și proprietățile acestora. Pentru orice experiment, există atât o ipoteză nulă, cât și una alternativă. În general, va trebui să comparați două seturi de date pentru a determina dacă sunt similare sau diferite.
