Wasserstoffbrückenbindungen werden zwischen der Aminogruppe einer Base und der Carbonylgruppe einer anderen sowie zwischen den Amid- und Imin-Stickstoffatomen gebildet. Beispielsweise bilden sich zwischen Adenin und Thymin zwei Wasserstoffbrückenbindungen, und diese heterocyclischen Basen bilden ein komplementäres Paar. Das bedeutet, dass die Adeninbase einer Kette der Thyminbase der anderen Kette entspricht. Ein weiteres Paar komplementärer Basen sind Guanin und Cytosin, zwischen denen drei Wasserstoffbrückenbindungen auftreten.
Die von Paaren komplementärer Basen besetzten Flächen sind ungefähr gleich.
Die Komplementarität der Basen liegt den von E. Chargaff formulierten Mustern zugrunde (Chargaffsche Regeln):
1. - die Anzahl der Purinbasen ist gleich der Anzahl der Pyrimidinbasen;
2. - die Menge an Adenin ist gleich der Menge an Thymin; die Menge an Guanin ist gleich der Menge an Cytosin;
3. - Die Summe von Adenin und Cytosin ist gleich der Summe von Guanin und Thymin
(A / T \u003d C / G \u003d 1).
Doppelsträngige DNA mit komplementären Polynukleotidketten bietet die Möglichkeit der Selbstverdopplung (Replikation) des Moleküls. Dieser komplexe Prozess kann wie folgt dargestellt werden: Vor der Verdoppelung werden die Wasserstoffbrückenbindungen aufgebrochen und die beiden Ketten wickeln sich ab und divergieren. Jeder Strang dient dann als Matrize für die Bildung eines komplementären Strangs darauf. Nach der Replikation entstehen zwei Tochter-DNA-Moleküle, bei denen jeweils eine Helix aus der Eltern-DNA entnommen und die andere (komplementär) neu synthetisiert wird.
Die DNA-Doppelhelix hat je nach Hydratationsgrad des Moleküls verschiedene Formen. Die Formen unterscheiden sich in der Lage der Ebene der Basenpaare in Bezug auf die Achse der Helix, zueinander, je nach Variante der Verdrillung der Helix (nach rechts, nach links) und anderen Merkmalen.
Zwischen den Ketten befinden sich zwei "Furchen" - groß und klein. In diesen Rillen können Proteine gezielt mit bestimmten Atomen interagieren. Nukleinsäuren, spezifische Nukleotidsequenzen erkennen, ohne zu stören komplementäre Wechselwirkungen Doppelhelix. Es wurde festgestellt, dass regulatorische Proteine aufgrund solcher Wechselwirkungen die Genexpression steuern können.


Formen der Sekundärstruktur des DNA-Moleküls
Sekundärstruktur der RNA
Ein RNA-Molekül ist aus einer einzelnen Polynukleotidkette aufgebaut. Die Anzahl der Nukleotide kann zwischen 75 und mehreren Tausend liegen molekulare Masse wird sich im Bereich von 25.000 bis zu mehreren Millionen ändern.
Die RNA-Polypeptidkette hat keine streng definierte Struktur. Es kann sich auf sich selbst falten und separate zweisträngige Abschnitte mit bilden Wasserstoffbrücken zwischen Purin- und Pyrimidinbasen. Wasserstoffbrückenbindungen in RNA gehorchen nicht strenge Regeln wie vDNA.
tRNA wurde im Detail untersucht. Das tRNA-Molekül hat eine Sekundärstruktur, die aus vier helikalen Abschnitten, drei, vier einzelsträngigen Schleifen besteht. Diese Struktur wird "Kleeblatt" genannt.
Rechts ist die größte menschliche DNA-Helix zu sehen, die von Menschen am Strand in Varna (Bulgarien) gebaut wurde und am 23. April 2016 in das Guinness-Buch der Rekorde aufgenommen wurde
Desoxyribonukleinsäure. Allgemeine Information
DNA (Desoxyribonukleinsäure) - eine Art Lebensplan, komplexer Code, die Daten über Erbinformationen enthält. Dieses komplexe Makromolekül ist in der Lage, Erbinformationen zu speichern und von Generation zu Generation weiterzugeben. Die DNA bestimmt solche Eigenschaften eines lebenden Organismus wie Vererbung und Variabilität. Die darin verschlüsselten Informationen bestimmen das gesamte Entwicklungsprogramm jedes lebenden Organismus. Genetisch eingebettete Faktoren bestimmen den gesamten Lebensverlauf sowohl eines Menschen als auch jedes anderen Organismus. Künstlicher oder natürlicher Einfluss Außenumgebung können den Gesamtschweregrad einzelner genetischer Merkmale nur geringfügig beeinflussen oder die Entwicklung programmierter Prozesse beeinflussen.
Desoxyribonukleinsäure(DNA) ist ein Makromolekül (eines der drei Hauptmoleküle, die anderen beiden sind RNA und Proteine), das für die Speicherung, Übertragung von Generation zu Generation und Umsetzung des genetischen Programms für die Entwicklung und Funktion lebender Organismen sorgt. DNA enthält Informationen über die Struktur verschiedene Sorten RNS und Proteine.
In eukaryotischen Zellen (Tiere, Pflanzen und Pilze) findet sich DNA im Zellkern als Teil von Chromosomen sowie in einigen Zellorganellen (Mitochondrien und Plastiden). In den Zellen prokaryotischer Organismen (Bakterien und Archaeen) wird ein ringförmiges oder lineares DNA-Molekül, das sogenannte Nukleoid, von innen angehängt Zellmembran. Sie und niedere Eukaryoten (z. B. Hefe) haben auch kleine autonome, meist kreisförmige DNA-Moleküle, sogenannte Plasmide.
Mit chemischer Punkt DNA ist ein langes Polymermolekül, das aus sich wiederholenden Einheiten besteht, die Nukleotide genannt werden. Jedes Nukleotid besteht aus einer stickstoffhaltigen Base, einem Zucker (Desoxyribose) und einer Phosphatgruppe. Die Bindungen zwischen Nukleotiden in einer Kette werden durch Desoxyribose ( Mit) und Phosphat ( F)-Gruppen (Phosphodiesterbindungen).

Reis. 2. Nukletid besteht aus einer stickstoffhaltigen Base, Zucker (Desoxyribose) und einer Phosphatgruppe
In der überwältigenden Mehrheit der Fälle (mit Ausnahme einiger Viren, die einzelsträngige DNA enthalten) besteht das DNA-Makromolekül aus zwei Ketten, die durch stickstoffhaltige Basen zueinander ausgerichtet sind. Dieses doppelsträngige Molekül ist spiralförmig verdrillt.
Es gibt vier Arten von stickstoffhaltigen Basen in der DNA (Adenin, Guanin, Thymin und Cytosin). Die stickstoffhaltigen Basen einer der Ketten sind mit den stickstoffhaltigen Basen der anderen Kette nach dem Prinzip der Komplementarität durch Wasserstoffbrückenbindungen verbunden: Adenin verbindet sich nur mit Thymin ( BEIM), Guanin - nur mit Cytosin ( GC). Diese Paare bilden die „Sprossen“ der helikalen „Leiter“ der DNA (siehe: Abb. 2, 3 und 4).

Reis. 2. Stickstoffbasen
Die Nukleotidsequenz ermöglicht es Ihnen, Informationen zu "kodieren". verschiedene Arten RNA, die wichtigsten davon sind Information oder Template (mRNA), ribosomal (rRNA) und Transport (tRNA). Alle diese Arten von RNA werden auf der DNA-Matrize synthetisiert, indem die DNA-Sequenz in die während der Transkription synthetisierte RNA-Sequenz kopiert wird, und nehmen an der Proteinbiosynthese (Translationsprozess) teil. Zusätzlich zu codierenden Sequenzen enthält Zell-DNA Sequenzen, die regulatorische und strukturelle Funktionen erfüllen.

Reis. 3. DNA-Replikation
Ort der Grundkombinationen Chemische Komponenten DNS und quantitative Verhältnisse zwischen diesen Kombinationen sorgen für die Kodierung der Erbinformationen.
Bildung neue DNA (Replikation)
- Der Replikationsprozess: das Aufwickeln der DNA-Doppelhelix - die Synthese komplementärer Stränge durch die DNA-Polymerase - die Bildung von zwei DNA-Molekülen aus einem.
- Die Doppelhelix „entpackt“ sich in zwei Zweige, wenn Enzyme die Bindung zwischen den Basenpaaren chemischer Verbindungen aufbrechen.
- Jeder Zweig ist ein neues DNA-Element. Neue Basenpaare werden in der gleichen Reihenfolge wie im Stammzweig verbunden.
Nach Abschluss der Duplikation werden zwei unabhängige Helices gebildet, die aus den chemischen Verbindungen der Eltern-DNA entstanden sind und denselben genetischen Code haben. Auf diese Weise ist die DNA in der Lage, Informationen von Zelle zu Zelle zu übertragen.
Nähere Informationen:
STRUKTUR DER NUKLEINSÄUREN

Reis. 4 . Stickstoffbasen: Adenin, Guanin, Cytosin, Thymin
Desoxyribonukleinsäure(DNA) bezieht sich auf Nukleinsäuren. Nukleinsäuren ist eine Klasse unregelmäßiger Biopolymere, deren Monomere Nukleotide sind.
Nukleotide besteht aus Stickstoffbase, verbunden mit einem Kohlenhydrat mit fünf Kohlenstoffatomen (Pentose) - Desoxyribose(im Fall von DNA) oder Ribose(im Fall von RNA), die an den Rest bindet Phosphorsäure(H 2 PO 3 -).
Stickstoffbasen Es gibt zwei Arten: Pyrimidinbasen - Uracil (nur in RNA), Cytosin und Thymin, Purinbasen - Adenin und Guanin.

Reis. 5. Arten von stickstoffhaltigen Basen: Pyrimidin und Purin
Die Kohlenstoffatome in einem Pentosemolekül sind von 1 bis 5 nummeriert. Phosphat verbindet sich mit dem dritten und fünften Kohlenstoffatom. So werden Nukleinsäuren zu einer Kette von Nukleinsäuren verknüpft. So können wir die 3'- und 5'-Enden des DNA-Strangs isolieren:

Reis. 6. Isolierung Isolieren Sie die 3'- und 5'-Enden des DNA-Strangs
Es bilden sich zwei DNA-Stränge Doppelhelix. Diese Ketten in einer Spirale sind in entgegengesetzte Richtungen orientiert. BEIM verschiedene Ketten DNA stickstoffhaltige Basen sind miteinander verbunden durch Wasserstoffbrücken. Adenin verbindet sich immer mit Thymin und Cytosin verbindet sich immer mit Guanin. Das heißt Komplementaritätsregel.
Komplementaritätsregel:
| A-T G-C |
Zum Beispiel, wenn uns ein DNA-Strang gegeben wird, der die Sequenz hat
3'-ATGTCCTAGCTGCTCG - 5',
dann wird die zweite Kette dazu komplementär und darauf gerichtet sein entgegengesetzten Richtung- vom 5'-Ende zum 3'-Ende:
5'-TACAGGATCGACGAGC-3'.

Reis. 7. Die Richtung der Ketten des DNA-Moleküls und die Verbindung stickstoffhaltiger Basen durch Wasserstoffbrückenbindungen
REPRODUZIEREN
DNA Replikation ist der Prozess der Vervielfältigung eines DNA-Moleküls durch Matrixsynthese. Es findet eine Replikation statt halbkonservativer Mechanismus. Das bedeutet, dass sich die Doppelhelix der DNA auflöst und an jeder ihrer Ketten nach dem Prinzip der Komplementarität eine neue Kette vervollständigt wird. Das Tochter-DNA-Molekül enthält somit einen Strang aus dem Elternmolekül und einen neu synthetisierten. Die Replikation erfolgt in der 3'- bis 5'-Richtung des Elternstrangs.

Reis. 8. Replikation (Verdopplung) des DNA-Moleküls
DNA-Synthese- Dies ist kein so komplizierter Prozess, wie es auf den ersten Blick erscheinen mag. Wenn Sie darüber nachdenken, müssen Sie zuerst herausfinden, was Synthese ist. Es ist der Prozess, etwas zusammenzubringen. Die Bildung eines neuen DNA-Moleküls erfolgt in mehreren Schritten:
- DNA-Topoisomerase, die sich vor der Replikationsgabel befindet, schneidet die DNA, um ihr Abwickeln und Abwickeln zu erleichtern.
- Die DNA-Helikase beeinflusst nach der Topoisomerase den Prozess des "Abwickelns" der DNA-Helix.
- DNA-bindende Proteine führen die Bindung von DNA-Strängen durch und führen auch ihre Stabilisierung durch, wodurch verhindert wird, dass sie aneinander haften.
- DNA-Polymerase synthetisiert den führenden Strang der Tochter-DNA.

Reis. 9. Schematische Darstellung des Replikationsprozesses, die Zahlen geben an: (1) Verzögerungsstrang, (2) Leitstrang, (3) DNA-Polymerase (Polα), (4) DNA-Ligase, (5) RNA-Primer, (6) Primase , (7) Okazaki-Fragment, (8) DNA-Polymerase (Polδ), (9) Helikase, (10) Einzelstrang-DNA-bindende Proteine, (11) Topoisomerase
RNA-Struktur
Ribonukleinsäure(RNA) ist eines der drei wichtigsten Makromoleküle (die anderen beiden sind DNA und Proteine), die in den Zellen aller lebenden Organismen vorkommen.
Genau wie DNA besteht RNA aus einer langen Kette, in der jedes Glied Nukleotid genannt wird. Jedes Nukleotid besteht aus einer stickstoffhaltigen Base, einem Ribosezucker und einer Phosphatgruppe. Im Gegensatz zu DNA hat RNA jedoch normalerweise einen statt zwei Stränge. Pentose in RNA wird durch Ribose dargestellt, nicht durch Desoxyribose (Ribose hat eine zusätzliche Hydroxylgruppe am zweiten Kohlenhydratatom). Schließlich unterscheidet sich DNA von RNA in der Zusammensetzung der stickstoffhaltigen Basen: Anstelle von Thymin ( T) Uracil ist in RNA vorhanden ( U) , das ebenfalls zu Adenin komplementär ist.
Die Nukleotidsequenz ermöglicht es der RNA, genetische Informationen zu kodieren. Alles zelluläre Organismen verwenden RNA (mRNA), um die Proteinsynthese zu programmieren.
Zelluläre RNAs werden in einem Prozess namens gebildet Transkription , dh die Synthese von RNA auf einer DNA-Matrize, die von speziellen Enzymen - RNA-Polymerasen - durchgeführt wird.
Messenger-RNAs (mRNAs) nehmen dann an einem Prozess namens teil Übertragung, jene. Proteinsynthese auf der mRNA-Vorlage unter Beteiligung von Ribosomen. Andere RNAs werden nach der Transkription und nach der Bildung sekundärer und chemischer Modifikationen unterzogen tertiäre Strukturen Funktionen ausführen, die von der Art der RNA abhängen.

Reis. 10. Der Unterschied zwischen DNA und RNA in Bezug auf die stickstoffhaltige Base: Anstelle von Thymin (T) enthält RNA Uracil (U), das ebenfalls komplementär zu Adenin ist.
TRANSKRIPTION
Dies ist der Prozess der RNA-Synthese auf einer DNA-Matrize. DNA entwindet sich an einer der Stellen. Eine der Ketten enthält Informationen, die auf das RNA-Molekül kopiert werden müssen – diese Kette wird als Kodierung bezeichnet. Der zweite DNA-Strang, der komplementär zum codierenden Strang ist, wird als Matrizenstrang bezeichnet. Bei der Transkription auf der Matrizenkette in 3'-5'-Richtung (entlang der DNA-Kette) wird eine dazu komplementäre RNA-Kette synthetisiert. So entsteht eine RNA-Kopie des kodierenden Strangs.
![]()
Reis. 11. Schematische Darstellung der Transkription
Zum Beispiel, wenn uns die Sequenz des codierenden Strangs gegeben wird
3'-ATGTCCTAGCTGCTCG - 5',
dann trägt die Matrixkette gemäß der Komplementaritätsregel die Sequenz
5'- TACAGGATCGACGAGC- 3',
und die daraus synthetisierte RNA ist die Sequenz
ÜBERTRAGUNG
Betrachten Sie den Mechanismus Proteinsynthese auf der RNA-Matrix, sowie dem genetischen Code und seinen Eigenschaften. Zur Verdeutlichung empfehlen wir außerdem, sich unter dem folgenden Link ein kurzes Video über die Transkriptions- und Übersetzungsprozesse in einer lebenden Zelle anzusehen:

Reis. 12. Prozess der Proteinsynthese: DNA codiert für RNA, RNA codiert für Protein
GENETISCHER CODE
Genetischer Code - ein Verfahren zur Kodierung der Aminosäuresequenz von Proteinen unter Verwendung einer Nukleotidsequenz. Jede Aminosäure wird durch eine Sequenz von drei Nukleotiden kodiert – ein Codon oder ein Triplett.
Genetischer Code, der den meisten Pro- und Eukaryoten gemeinsam ist. Die Tabelle listet alle 64 Codons auf und listet die entsprechenden Aminosäuren auf. Die Basenreihenfolge verläuft vom 5"- zum 3"-Ende der mRNA.
Tabelle 1. Genetischer Standardcode
|
1 nie |
2. Basis |
3 nie |
|||||||
|
U |
C |
EIN |
G |
||||||
|
U |
U U U |
(Ph/F) |
U C U |
(Ser/S) |
U A U |
(Tyr/Y) |
U G U |
(Cys/C) |
U |
|
U U C |
U C C |
U A C |
UG C |
C |
|||||
|
U U A |
(Leu/L) |
U. C. A |
U A A |
Stoppcodon** |
U. G. A |
Stoppcodon** |
EIN |
||
|
U U G |
U C G |
U A G |
Stoppcodon** |
U G G |
(Trp/W) |
G |
|||
|
C |
C U U |
C C U |
(Stütze) |
C A U |
(Sein/H) |
C G U |
(Arg/R) |
U |
|
|
C U C |
C C C |
C A C |
C G C |
C |
|||||
|
CU A |
C C A |
C A A |
(Gln/Q) |
CGA |
EIN |
||||
|
CU G |
C C G |
C A G |
C G G |
G |
|||||
|
EIN |
A U U |
(Ile/I) |
A C U |
(Thr/T) |
A A U |
(Asn/N) |
A GU |
(Ser/S) |
U |
|
A U C |
A C C |
A A C |
A G C |
C |
|||||
|
A UA |
A C A |
A A A |
(Lys/K) |
A G A |
EIN |
||||
|
Ein UG |
(Erfüllt/M) |
Ein C G |
A A G |
A G G |
G |
||||
|
G |
G U U |
(Wert/V) |
G C U |
(Ala/A) |
GA U |
(Asp/D) |
G G U |
(Gly/G) |
U |
|
GU C |
G C C |
G A C |
G G C |
C |
|||||
|
GU A |
G C A |
G A A |
(Kleber) |
G G A |
EIN |
||||
|
G U G |
G C G |
G A G |
G G G |
G |
|||||
Unter den Drillingen gibt es 4 spezielle Sequenzen, die als "Satzzeichen" fungieren:
- *Triplett AUG, das auch für Methionin kodiert, heißt Startcodon. Dieses Codon beginnt die Synthese eines Proteinmoleküls. Daher ist während der Proteinsynthese die erste Aminosäure in der Sequenz immer Methionin.
- **Dreiergruppen UAA, UAG und UGA namens Codons stoppen und kodieren für keine Aminosäuren. An diesen Sequenzen stoppt die Proteinsynthese.
Eigenschaften des genetischen Codes
1. Triplett. Jede Aminosäure wird von einer Sequenz aus drei Nukleotiden kodiert – einem Triplett oder Codon.
2. Kontinuität. Es gibt keine zusätzlichen Nukleotide zwischen den Tripletts, Informationen werden kontinuierlich gelesen.
3. Nicht überlappend. Ein Nukleotid kann nicht gleichzeitig Teil von zwei Tripletts sein.
4. Einzigartigkeit. Ein Codon kann nur für eine Aminosäure kodieren.

5. Entartung. Eine Aminosäure kann von mehreren unterschiedlichen Codons kodiert werden.

6. Vielseitigkeit. Der genetische Code ist für alle lebenden Organismen gleich.
Beispiel. Wir erhalten die Sequenz des codierenden Strangs:
3’- CCGATTGCACGTCGATCGTATA- 5’.
Die Matrixkette hat die Reihenfolge:
5’- GGCTAACGTGCAGCTAGCATAT- 3’.
Aus dieser Kette „synthetisieren“ wir nun Informations-RNA:
3’- CCGAUUGCACGUCGAUCGUAUA- 5’.
Die Proteinsynthese verläuft in Richtung 5' → 3', daher müssen wir die Sequenz umdrehen, um den genetischen Code zu "lesen":
5’- AUAUGCUAGCUGCACGUUAGCC- 3’.
Finden Sie nun das Startcodon AUG:
5’- AU AUG CUAGCUGCACGUUAGCC- 3’.
Teilen Sie die Sequenz in Tripletts:
klingt so: Informationen von DNA werden auf RNA übertragen (Transkription), von RNA auf Protein (Translation). DNA kann auch durch Replikation vervielfältigt werden, auch ein Prozess ist möglich umgekehrte Transkription, wenn DNA aus der RNA-Matrize synthetisiert wird, aber ein solcher Prozess ist hauptsächlich für Viren charakteristisch.

Reis. 13. Zentrales Dogma der Molekularbiologie
GENOM: Gene und Chromosomen
(allgemeine Konzepte)
Genom - die Gesamtheit aller Gene eines Organismus; seinen kompletten Chromosomensatz.
Der Begriff „Genom“ wurde 1920 von G. Winkler vorgeschlagen, um die Gesamtheit der im haploiden Chromosomensatz von Organismen enthaltenen Gene zu beschreiben Spezies. Die ursprüngliche Bedeutung dieses Begriffs weist darauf hin, dass der Begriff des Genoms im Gegensatz zum Genotyp steht genetisches Merkmal die Art als Ganzes, nicht das Individuum. Mit Entwicklung Molekulargenetik Die Bedeutung des Begriffs hat sich geändert. Es ist bekannt, dass die DNA, die in den meisten Organismen Träger der Erbinformation ist und damit die Grundlage des Genoms bildet, nicht nur Gene enthält modernen Sinn dieses Wort. Großer Teil Die DNA eukaryotischer Zellen wird durch nichtkodierende („redundante“) Nukleotidsequenzen dargestellt, die keine Informationen über Proteine und Nukleinsäuren enthalten. Somit ist der Hauptteil des Genoms eines jeden Organismus die gesamte DNA seines haploiden Chromosomensatzes.
Gene sind Segmente von DNA-Molekülen, die für Polypeptide und RNA-Moleküle kodieren.
Hinter letztes Jahrhundert Unser Verständnis von Genen hat sich dramatisch verändert. Früher war ein Genom eine Region eines Chromosoms, die ein Merkmal codiert oder bestimmt phänotypisch(sichtbare) Eigenschaft, wie Augenfarbe.
1940 schlugen George Beadle und Edward Tatham vor Molekulare Definition Gen. Wissenschaftler verarbeiteten Pilzsporen Neurospora crassa Röntgenstrahlen und andere Mittel, die Veränderungen in der DNA-Sequenz verursachen ( Mutationen) und fand Mutantenstämme des Pilzes, die einige spezifische Enzyme verloren, was in einigen Fällen zu einer Verletzung des Ganzen führte Stoffwechselweg. Beadle und Tatham kamen zu dem Schluss, dass ein Gen ein Abschnitt des genetischen Materials ist, der ein einzelnes Enzym definiert oder kodiert. So lautet die Hypothese "ein Gen, ein Enzym". Dieses Konzept wurde später auf die Definition erweitert "ein Gen - ein Polypeptid", da viele Gene für Proteine codieren, die keine Enzyme sind, und ein Polypeptid eine Untereinheit eines komplexen Proteinkomplexes sein kann.
Auf Abb. 14 zeigt ein Diagramm, wie DNA-Triplets ein Polypeptid, die Aminosäuresequenz eines Proteins, mRNA-vermittelt bestimmen. Einer der DNA-Stränge spielt die Rolle einer Matrize für die Synthese von mRNA, deren Nukleotid-Tripletts (Codons) zu den DNA-Tripletts komplementär sind. Bei einigen Bakterien und vielen Eukaryoten sind codierende Sequenzen durch nicht codierende Regionen (sog Introns).
Zeitgenössisch biochemische Definition Gen noch genauer. Gene sind alle DNA-Abschnitte, die die Primärsequenz von Endprodukten codieren, zu denen Polypeptide oder RNA gehören, die eine strukturelle oder katalytische Funktion haben.
Neben Genen enthält DNA auch andere Sequenzen, die ausschließlich funktionieren regulatorische Funktion. Regulatorische Sequenzen kann den Anfang oder das Ende von Genen markieren, die Transkription beeinflussen oder den Ort der Initiation der Replikation oder Rekombination anzeigen. Einige Gene können auf unterschiedliche Weise exprimiert werden, wobei dasselbe DNA-Stück als Vorlage für die Bildung verschiedener Produkte dient.
Wir können grob rechnen minimale Gengröße kodiert für das intermediäre Protein. Jede Aminosäure in einer Polypeptidkette wird durch eine Sequenz von drei Nukleotiden kodiert; die Sequenzen dieser Tripletts (Codons) entsprechen der Kette von Aminosäuren in dem Polypeptid, das von dem gegebenen Gen codiert wird. Eine Polypeptidkette aus 350 Aminosäureresten mittlere Länge) entspricht einer Sequenz von 1050 b.p. ( bp). Viele eukaryotische Gene und einige prokaryotische Gene sind jedoch durch DNA-Abschnitte unterbrochen, die keine Informationen über das Protein tragen, und fallen daher viel länger aus, als eine einfache Rechnung ergibt.
Wie viele Gene befinden sich auf einem Chromosom?
 Reis. 15. Ansicht von Chromosomen in prokaryotischen (links) und eukaryotischen Zellen. Histone sind eine breite Klasse von Kernproteinen, die zwei Hauptfunktionen erfüllen: Sie sind an der Verpackung von DNA-Strängen im Zellkern und an der epigenetischen Regulierung von Kernprozessen wie Transkription, Replikation und Reparatur beteiligt.
Reis. 15. Ansicht von Chromosomen in prokaryotischen (links) und eukaryotischen Zellen. Histone sind eine breite Klasse von Kernproteinen, die zwei Hauptfunktionen erfüllen: Sie sind an der Verpackung von DNA-Strängen im Zellkern und an der epigenetischen Regulierung von Kernprozessen wie Transkription, Replikation und Reparatur beteiligt.
Wie Sie wissen, haben Bakterienzellen ein Chromosom in Form eines DNA-Strangs, der in eine kompakte Struktur verpackt ist - ein Nukleoid. prokaryotisches Chromosom Escherichia coli, dessen Genom vollständig entschlüsselt ist, ist ein ringförmiges DNA-Molekül (tatsächlich ist es das nicht rechter Kreis, sondern eine Schleife ohne Anfang oder Ende), bestehend aus 4.639.675 b.p. Diese Sequenz enthält ungefähr 4300 Proteingene und weitere 157 Gene für stabile RNA-Moleküle. BEIM Menschliche DNA ungefähr 3,1 Milliarden Basenpaare, die fast 29.000 Genen entsprechen, die sich auf 24 verschiedenen Chromosomen befinden.
Prokaryoten (Bakterien).
 Bakterium E coli hat ein doppelsträngiges zirkuläres DNA-Molekül. Es besteht aus 4.639.675 b.p. und erreicht eine Länge von etwa 1,7 mm, was die Länge der Zelle selbst übersteigt E coli etwa 850 mal. Neben dem großen zirkulären Chromosom als Teil des Nukleoids enthalten viele Bakterien ein oder mehrere kleine zirkuläre DNA-Moleküle, die sich frei im Zytosol befinden. Diese extrachromosomalen Elemente werden genannt Plasmide(Abb. 16).
Bakterium E coli hat ein doppelsträngiges zirkuläres DNA-Molekül. Es besteht aus 4.639.675 b.p. und erreicht eine Länge von etwa 1,7 mm, was die Länge der Zelle selbst übersteigt E coli etwa 850 mal. Neben dem großen zirkulären Chromosom als Teil des Nukleoids enthalten viele Bakterien ein oder mehrere kleine zirkuläre DNA-Moleküle, die sich frei im Zytosol befinden. Diese extrachromosomalen Elemente werden genannt Plasmide(Abb. 16).
Die meisten Plasmide bestehen aus nur wenigen tausend Basenpaaren, einige enthalten mehr als 10.000 bp. Sie tragen genetische Informationen und replizieren sich unter Bildung von Tochterplasmiden, die ineinander übergehen Tochterzellen während der Teilung der Mutterzelle. Plasmide kommen nicht nur in Bakterien, sondern auch in Hefen und anderen Pilzen vor. Plasmide bieten den Wirtszellen in vielen Fällen keinen Vorteil und haben nur die Aufgabe, sich selbstständig zu vermehren. Einige Plasmide tragen jedoch Gene, die für den Wirt nützlich sind. Beispielsweise können in Plasmiden enthaltene Gene Resistenz gegen antibakterielle Mittel in Bakterienzellen verleihen. Plasmide das Gen trägtβ-Lactamasen verleihen Resistenz gegen β-Lactam-Antibiotika wie Penicillin und Amoxicillin. Plasmide können von antibiotikaresistenten Zellen auf andere Zellen der gleichen oder einer anderen Bakterienart übergehen, wodurch diese Zellen ebenfalls resistent werden. Die intensive Verwendung von Antibiotika ist ein starker Selektionsfaktor, der die Ausbreitung von Plasmiden fördert, die Antibiotikaresistenz codieren (sowie Transposons, die ähnliche Gene codieren). pathogenen Bakterien, und führt zur Entstehung von Bakterienstämmen mit Resistenzen gegen mehrere Antibiotika. Ärzte beginnen, die Gefahren des weit verbreiteten Einsatzes von Antibiotika zu verstehen und verschreiben sie nur, wenn es absolut notwendig ist. Aus ähnlichen Gründen ist die weit verbreitete Verwendung von Antibiotika zur Behandlung von Nutztieren begrenzt.
Siehe auch: Ravin N.V., Shestakov S.V. Genom von Prokaryoten // Vavilov Journal of Genetics and Breeding, 2013. V. 17. Nr. 4/2. S. 972-984.
Eukaryoten.
Tabelle 2. DNA, Gene und Chromosomen einiger Organismen
|
gemeinsame DNA, b.s. |
Anzahl der Chromosomen* |
Ungefähre Anzahl von Genen |
|
|
Escherichia coli(Bakterium) |
4 639 675 |
4 435 |
|
|
Saccharomyces cerevisiae(Hefe) |
12 080 000 |
16** |
5 860 |
|
Caenorhabditis elegans(Nematode) |
90 269 800 |
12*** |
23 000 |
|
Arabidopsis thaliana(Pflanze, Anlage) |
119 186 200 |
33 000 |
|
|
Drosophila melanogaster(Fruchtfliege) |
120 367 260 |
20 000 |
|
|
Oryza sativa(Reis) |
480 000 000 |
57 000 |
|
|
Mus-Muskel(Maus) |
2 634 266 500 |
27 000 |
|
|
Homo sapiens(Menschlich) |
3 070 128 600 |
29 000 |
Notiz. Informationen werden ständig aktualisiert; Weitere aktuelle Informationen finden Sie auf den Websites der einzelnen Genomik-Projekte.
* Für alle Eukaryoten außer Hefe ist der diploide Chromosomensatz angegeben. diploid Bausatz Chromosomen (aus dem Griechischen diploos - doppelt und eidos - Ansicht) - ein doppelter Chromosomensatz (2n), von denen jeder einen homologen hat.
**Haploider Satz. Wilde Hefestämme haben typischerweise acht (oktaploide) oder mehr Sätze dieser Chromosomen.
***Für Frauen mit zwei X-Chromosomen. Männer haben ein X-Chromosom, aber kein Y, also nur 11 Chromosomen.
Eine Hefezelle, einer der kleinsten Eukaryoten, hat 2,6-mal mehr DNA als eine Zelle E coli(Tabelle 2). Fruchtfliegenzellen Drosophila, klassisches Objekt genetische Forschung, enthalten 35-mal mehr DNA, und menschliche Zellen enthalten etwa 700-mal mehr DNA als Zellen E coli. Viele Pflanzen und Amphibien enthalten noch mehr DNA. Das genetische Material eukaryotischer Zellen ist in Form von Chromosomen organisiert. Diploider Chromosomensatz (2 n) hängt von der Art des Organismus ab (Tabelle 2).
Beispielsweise gibt es in einer menschlichen Körperzelle 46 Chromosomen ( Reis. 17). Jedes Chromosom in einer eukaryotischen Zelle, wie in Abb. 17, a, enthält ein sehr großes doppelsträngiges DNA-Molekül. Vierundzwanzig menschliche Chromosomen (22 gepaarte Chromosomen und zwei Geschlechtschromosomen X und Y) unterscheiden sich in der Länge um mehr als das 25-fache. Jedes eukaryotische Chromosom enthält einen bestimmten Satz von Genen.

Reis. 17. eukaryotische Chromosomen.a- ein Paar verbundener und kondensierter Schwesterchromatiden aus dem menschlichen Chromosom. In dieser Form verbleiben eukaryotische Chromosomen nach der Replikation und in der Metaphase während der Mitose. b- ein vollständiger Chromosomensatz aus einem Leukozyten eines der Autoren des Buches. Jede normale menschliche Körperzelle enthält 46 Chromosomen.
Verbindet man die DNA-Moleküle des menschlichen Genoms (22 Chromosomen und die Chromosomen X und Y bzw. X und X) miteinander, erhält man eine etwa einen Meter lange Sequenz. Hinweis: Bei allen Säugetieren und anderen heterogametischen männlichen Organismen haben die Weibchen zwei X-Chromosomen (XX) und die Männchen ein X-Chromosom und ein Y-Chromosom (XY).
Die meisten menschlichen Zellen, daher beträgt die gesamte DNA-Länge solcher Zellen etwa 2 m. Ein erwachsener Mensch hat etwa 10 14 Zellen, die Gesamtlänge aller DNA-Moleküle beträgt also 2・10 11 km. Zum Vergleich: Der Umfang der Erde beträgt 4 ・ 10 4 km und die Entfernung von der Erde zur Sonne 1,5 ・ 10 8 km. So erstaunlich kompakt verpackt ist die DNA in unseren Zellen!
In eukaryotischen Zellen gibt es andere Organellen, die DNA enthalten - dies sind Mitochondrien und Chloroplasten. Es wurden viele Hypothesen bezüglich des Ursprungs der mitochondrialen und Chloroplasten-DNA aufgestellt. Der heute allgemein anerkannte Standpunkt ist, dass es sich um die Rudimente der Chromosomen alter Bakterien handelt, die in das Zytoplasma der Wirtszellen eingedrungen sind und zu den Vorläufern dieser Organellen wurden. Mitochondriale DNA kodiert für mitochondriale tRNA und rRNA sowie mehrere mitochondriale Proteine. Mehr als 95 % der mitochondrialen Proteine werden von Kern-DNA kodiert.
STRUKTUR DER GENE
Betrachten Sie die Struktur des Gens in Prokaryoten und Eukaryoten, ihre Ähnlichkeiten und Unterschiede. Obwohl ein Gen ein DNA-Abschnitt ist, der nur für ein Protein oder eine RNA kodiert, enthält es neben dem direkt kodierenden Teil auch regulatorische und andere Strukturelemente haben unterschiedliche Struktur bei Prokaryoten und Eukaryoten.
codierende Sequenz- die wichtigste strukturelle und funktionelle Einheit des Gens, darin befinden sich die Nukleotidtripletts, die kodierenAminosäuresequenz. Es beginnt mit einem Startcodon und endet mit einem Stopcodon.
Vor und nach der Codiersequenz stehen untranslatierte 5'- und 3'-Sequenzen. Sie übernehmen regulatorische und Hilfsfunktionen, sorgen beispielsweise für die Landung des Ribosoms auf der mRNA.
Untranslatierte und codierende Sequenzen bilden die Einheit der Transkription - die transkribierte DNA-Region, dh die DNA-Region, aus der mRNA synthetisiert wird.
Terminator Eine nicht transkribierte DNA-Region am Ende eines Gens, wo die RNA-Synthese aufhört.
Am Anfang steht das Gen Regulierungsbereich, welches beinhaltet Promoter und Operator.
Promoter- die Sequenz, an die die Polymerase während der Transkriptionsinitiation bindet. Operator- das ist der Bereich, an den spezielle Proteine binden können - Unterdrücker, die die Aktivität der RNA-Synthese aus diesem Gen reduzieren - mit anderen Worten, reduzieren kann Ausdruck.
Die Struktur von Genen in Prokaryoten
Der allgemeine Plan für die Struktur von Genen in Prokaryoten und Eukaryoten unterscheidet sich nicht – beide enthalten eine regulatorische Region mit einem Promotor und Operator, eine Transkriptionseinheit mit codierenden und nicht-translatierten Sequenzen und einen Terminator. Die Organisation von Genen in Prokaryoten und Eukaryoten ist jedoch unterschiedlich.

Reis. 18. Schema der Struktur des Gens in Prokaryoten (Bakterien) -das Bild wird vergrößert
Am Anfang und am Ende des Operons gibt es gemeinsame regulatorische Regionen für mehrere Strukturgene. Aus der transkribierten Region des Operons wird ein mRNA-Molekül abgelesen, das mehrere kodierende Sequenzen enthält, von denen jede ihr eigenes Start- und Stoppcodon hat. Aus jedem dieser Bereicheein Protein wird synthetisiert. Auf diese Weise, Aus einem i-RNA-Molekül werden mehrere Proteinmoleküle synthetisiert.
Prokaryoten kombinieren mehrere Gene zu einem einzigen funktionale Einheit -Operon. Die Arbeit des Operons kann durch andere Gene reguliert werden, die merklich vom Operon selbst entfernt werden können - Regler. Das Protein, das von diesem Gen übersetzt wird, wird genannt Unterdrücker. Es bindet an den Operator des Operons und reguliert gleichzeitig die Expression aller darin enthaltenen Gene.
Auch Prokaryoten sind durch das Phänomen gekennzeichnet Transkriptions- und Übersetzungskonjugationen.
![]()
Reis. 19 Das Phänomen der Konjugation von Transkription und Translation in Prokaryoten - das Bild wird vergrößert
In einer durch reverse Transkriptase katalysierten Reaktion.
cDNA wird häufig verwendet, um eukaryotische Gene in Prokaryoten zu klonieren. Komplementäre DNA wird auch von Retroviren (HIV-1, HIV-2, Simian Immunodeficiency Virus) produziert und dann in die Wirts-DNA integriert, um ein Provirus zu bilden.
Häufig können eukaryotische Gene in prokaryotischen Zellen exprimiert werden. In den meisten einfacher Fall umfasst das Verfahren das Einfügen von eukaryotischer DNA in das prokaryotische Genom, das anschließende Transkribieren der DNA in mRNA und das anschließende Übersetzen der mRNA in Proteine. Prokaryotische Zellen haben keine Intron-schneidenden Enzyme, und daher müssen Introns vor der Insertion in das prokaryotische Genom aus eukaryotischer DNA geschnitten werden. DNA, die zu reifer mRNA komplementär ist, wird daher als komplementäre DNA bezeichnet - cDNA(cDNA). Für eine erfolgreiche Expression von Proteinen, die in eukaryotischer cDNA kodiert sind, in Prokaryoten sind auch regulatorische Elemente von prokaryotischen Genen (z. B. Promotoren) erforderlich.
Eines der Verfahren zum Erhalt des erforderlichen Gens (DNA-Molekül), das der Replikation (Klonierung) unter Freisetzung einer beträchtlichen Anzahl von Replikaten unterzogen wird, ist die Konstruktion von komplementärer DNA (cDNA) auf mRNA. Dieses Verfahren erfordert die Verwendung von reverser Transkriptase, einem Enzym, das in einigen RNA-enthaltenden Viren vorhanden ist und die DNA-Synthese auf einer RNA-Matrize bereitstellt.
Das Verfahren ist weit verbreitet, um cDNA zu erhalten und umfasst die Isolierung von mRNA aus Gesamtgewebe-mRNA, die die Translation eines bestimmten Proteins (z. B. Interferon, Insulin) codiert, mit weiterer Synthese auf dieser mRNA als Vorlage der erforderlichen cDNA unter Verwendung von Reverse Transkriptase.
Das mit obigem Verfahren gewonnene Gen (cDNA) muss so in die Bakterienzelle eingebracht werden, dass es sich in ihr Genom integriert. Dafür bilden sie sich rekombinante DNA, das aus cDNA und einem speziellen DNA-Molekül besteht, das als Leiter oder Vektor fungiert und in der Lage ist, den Empfänger in die Zelle einzudringen. Als Vektoren für cDNA werden Viren oder Plasmide verwendet. Plasmide sind kleine ringförmige DNA-Moleküle, die vom Nukleoid getrennt sind. Bakterienzelle, enthalten mehrere Gene, die für die Funktion der gesamten Zelle wichtig sind (z. B. Antibiotikaresistenzgene und können sich unabhängig vom Hauptgenom (DNA) der Zelle replizieren. Biologisch wichtig und praktisch nützlich für Gentechnik Die Eigenschaften von Plasmiden sind ihre Fähigkeit, durch den Mechanismus der Transformation oder Konjugation von einer Zelle auf eine andere zu übertragen, sowie die Fähigkeit, in das bakterielle Chromosom aufgenommen zu werden und sich zusammen mit ihm zu replizieren.
Watson und Crick zeigten, dass die Bildung von Wasserstoffbrückenbindungen und einer regulären Doppelhelix nur möglich ist, wenn die größere Purinbase Adenin (A) in einer Kette eine kleinere Pyrimidinbase Thymin (T) als Partner in der anderen Kette hat, und Guanin (G) assoziiert mit Cytosin (C). Dieses Muster lässt sich wie folgt darstellen: Korrespondenz A "T und G" C heißt Komplementaritätsregel, und die Ketten selbst komplementär. Nach dieser Regel ist der Adeningehalt in der DNA immer gleich dem Thymingehalt und die Menge an Guanin immer gleich der Menge an Cytosin. Es ist zu beachten, dass zwei chemisch unterschiedliche DNA-Stränge die gleiche Information tragen, da der eine Strang aufgrund der Komplementarität den anderen eindeutig spezifiziert.Die Struktur der RNA ist weniger geordnet. Es ist normalerweise ein einzelsträngiges Molekül, obwohl die RNA einiger Viren aus zwei Strängen besteht. Aber auch solche RNA ist flexibler als DNA. Einige Abschnitte im RNA-Molekül sind zueinander komplementär und paaren sich, wenn die Kette gebogen wird, und bilden doppelsträngige Strukturen (Haarnadeln). Dies gilt zunächst für Transfer-RNAs (tRNAs). Einige Basen in tRNA werden nach der Synthese des Moleküls modifiziert. Beispielsweise sind manchmal Methylgruppen daran gebunden.
FUNKTION DER NUKLEINSÄUREN Eine der Hauptfunktionen von Nukleinsäuren ist die Bestimmung der Proteinsynthese. Informationen über die Struktur von Proteinen, die in der Nukleotidsequenz der DNA kodiert sind, müssen von einer Generation zur nächsten weitergegeben werden, und daher ist ihre unverwechselbare Kopie notwendig, d.h. Synthese genau desselben DNA-Moleküls (Replikation).Replikation und Transkription. Aus chemischer Sicht ist die Synthese einer Nukleinsäure eine Polymerisation, d.h. sequentielle Verbindung von Bausteinen. Solche Blöcke sind Nukleosidtriphosphate; Die Reaktion lässt sich wie folgt darstellen: Die für die Synthese benötigte Energie wird bei der Abspaltung von Pyrophosphat freigesetzt und spezielle Enzyme, DNA-Polymerasen, katalysieren die Reaktion.
Die für die Synthese benötigte Energie wird bei der Abspaltung von Pyrophosphat freigesetzt und spezielle Enzyme, DNA-Polymerasen, katalysieren die Reaktion. Als Ergebnis eines solchen Syntheseverfahrens würden wir ein Polymer mit einer zufälligen Basensequenz erhalten. Die meisten Polymerasen funktionieren jedoch nur in Gegenwart einer bereits vorhandenen Nukleinsäure, einer Matrize, die vorgibt, welches Nukleotid an das Ende der Kette angehängt wird. Dieses Nukleotid muss komplementär zum entsprechenden Template-Nukleotid sein, damit der neue Strang komplementär zum Original ist. Wenn wir dann den komplementären Strang als Matrix verwenden, erhalten wir exakte Kopie Original.
DNA besteht aus zwei zueinander komplementären Strängen. Während der Replikation divergieren sie und jeder von ihnen dient als Vorlage für die Synthese eines neuen Strangs:
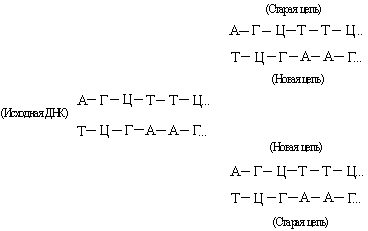 Dadurch bilden sich zwei neue Doppelhelices mit der gleichen Basensequenz wie die ursprüngliche DNA. Manchmal "schlägt" der Replikationsprozess fehl und es treten Mutationen auf (siehe auch
VERERBUNG).
Als Ergebnis der DNA-Transkription werden zelluläre RNAs (mRNA, rRNA und tRNA) gebildet:
Dadurch bilden sich zwei neue Doppelhelices mit der gleichen Basensequenz wie die ursprüngliche DNA. Manchmal "schlägt" der Replikationsprozess fehl und es treten Mutationen auf (siehe auch
VERERBUNG).
Als Ergebnis der DNA-Transkription werden zelluläre RNAs (mRNA, rRNA und tRNA) gebildet: Sie sind komplementär zu einem der DNA-Stränge und eine Kopie des anderen Strangs, außer dass Uracil den Platz von Thymin einnimmt. Auf diese Weise können viele RNA-Kopien eines der DNA-Stränge erhalten werden.In einer normalen Zelle werden Informationen nur in Richtung DNA übertragen.® DNA und DNA ® RNS. In virusinfizierten Zellen sind aber auch andere Prozesse möglich: RNA® RNA und RNA ® DNS. Das genetische Material vieler Viren wird durch ein RNA-Molekül dargestellt, das normalerweise einzelsträngig ist. In die Wirtszelle eingedrungen, repliziert sich diese RNA zu einem komplementären Molekül, auf dem wiederum viele Kopien der ursprünglichen viralen RNA synthetisiert werden:
Sie sind komplementär zu einem der DNA-Stränge und eine Kopie des anderen Strangs, außer dass Uracil den Platz von Thymin einnimmt. Auf diese Weise können viele RNA-Kopien eines der DNA-Stränge erhalten werden.In einer normalen Zelle werden Informationen nur in Richtung DNA übertragen.® DNA und DNA ® RNS. In virusinfizierten Zellen sind aber auch andere Prozesse möglich: RNA® RNA und RNA ® DNS. Das genetische Material vieler Viren wird durch ein RNA-Molekül dargestellt, das normalerweise einzelsträngig ist. In die Wirtszelle eingedrungen, repliziert sich diese RNA zu einem komplementären Molekül, auf dem wiederum viele Kopien der ursprünglichen viralen RNA synthetisiert werden: Virale RNA kann durch ein Enzym transkribiert werden-
umgekehrte Transkriptase-
in DNA, die manchmal in der chromosomalen DNA der Wirtszelle enthalten ist. Nun trägt diese DNA virale Gene, und nach der Transkription kann virale RNA in der Zelle erscheinen. Also nach lange Zeit, während der kein Virus in der Zelle gefunden wird, taucht es ohne erneute Infektion wieder in ihr auf. Viren, deren Erbgut in das Chromosom der Wirtszelle eingebaut wird, sind häufig die Ursache von Krebs.
Virale RNA kann durch ein Enzym transkribiert werden-
umgekehrte Transkriptase-
in DNA, die manchmal in der chromosomalen DNA der Wirtszelle enthalten ist. Nun trägt diese DNA virale Gene, und nach der Transkription kann virale RNA in der Zelle erscheinen. Also nach lange Zeit, während der kein Virus in der Zelle gefunden wird, taucht es ohne erneute Infektion wieder in ihr auf. Viren, deren Erbgut in das Chromosom der Wirtszelle eingebaut wird, sind häufig die Ursache von Krebs.
Nach der Entdeckung des Prinzips der molekularen Organisation einer solchen Substanz wie DNA im Jahr 1953 begann sich zu entwickeln Molekularbiologie. Darüber hinaus fanden die Wissenschaftler im Laufe der Forschung heraus, wie die DNA rekombiniert wird, wie sie zusammengesetzt ist und wie unser menschliches Genom angeordnet ist.
Jeden Tag an Molekulare Ebene passieren die komplexesten Prozesse. Wie ist das DNA-Molekül angeordnet, woraus besteht es? Welche Rolle spielen DNA-Moleküle in einer Zelle? Lassen Sie uns ausführlich über alle Prozesse sprechen, die innerhalb der Doppelkette ablaufen.
Was sind Erbinformationen?
Wie hat alles angefangen? Bereits 1868 in den Kernen von Bakterien gefunden. Und 1928 stellte N. Koltsov die Theorie auf, dass in der DNA alle genetischen Informationen über einen lebenden Organismus verschlüsselt sind. Dann fanden J. Watson und F. Crick 1953 ein Modell für die heute bekannte DNA-Helix, für das sie zu Recht Anerkennung und eine Auszeichnung erhielten – den Nobelpreis.
Was ist DNA überhaupt? Diese Substanz besteht aus 2 kombinierten Fäden, genauer gesagt Spiralen. Ein Abschnitt einer solchen Kette mit bestimmten Informationen wird als Gen bezeichnet.

Die DNA speichert alle Informationen darüber, welche Art von Proteinen in welcher Reihenfolge gebildet werden. Das DNA-Makromolekül ist Materialträger unglaublich umfangreiche Informationen, die in einer strengen Abfolge einzelner Bausteine - Nukleotide - aufgezeichnet sind. Es gibt insgesamt 4 Nukleotide, sie ergänzen sich chemisch und geometrisch. Dieses Prinzip der Ergänzung oder Komplementarität in der Wissenschaft wird später beschrieben. Diese Regel spielt Schlüsselrolle bei der Kodierung und Dekodierung genetischer Informationen.
Da der DNA-Strang unglaublich lang ist, gibt es in dieser Sequenz keine Wiederholungen. Jedes Lebewesen hat seinen eigenen einzigartigen DNA-Strang.
Funktionen der DNA
Zu den Funktionen gehören die Speicherung von Erbinformationen und deren Weitergabe an die Nachkommen. Ohne diese Funktion könnte das Genom einer Art nicht über Jahrtausende erhalten und weiterentwickelt werden. Organismen, die größere Genmutationen erfahren haben, überleben eher nicht oder verlieren ihre Fähigkeit, Nachkommen zu produzieren. Es besteht also ein natürlicher Schutz vor Artensterben.

Ein weiteres wesentliches wichtige Funktion— Implementierung der gespeicherten Informationen. Ohne die im Doppelstrang gespeicherten Anweisungen kann die Zelle kein lebenswichtiges Protein herstellen.
Zusammensetzung von Nukleinsäuren
Nun ist bereits zuverlässig bekannt, woraus die Nukleotide selbst, die Bausteine der DNA, bestehen. Sie beinhalten 3 Substanzen:
- Orthophosphorsäure.
- Stickstoffbase. Pyrimidinbasen - die nur einen Ring haben. Dazu gehören Thymin und Cytosin. Purinbasen mit 2 Ringen. Dies sind Guanin und Adenin.
- Saccharose. DNA enthält Desoxyribose, RNA enthält Ribose.
Die Anzahl der Nukleotide ist immer gleich der Anzahl der stickstoffhaltigen Basen. In Speziallabors wird das Nukleotid abgespalten und daraus isoliert Stickstoffbase. Also untersuchen sie die individuellen Eigenschaften dieser Nukleotide und mögliche Mutationen in ihnen.
Organisationsebenen von Erbinformationen
Es gibt 3 Organisationsebenen: Gen, Chromosomen und Genom. Alle Informationen, die für die Synthese eines neuen Proteins benötigt werden, sind in einem kleinen Abschnitt der Kette enthalten – dem Gen. Das heißt, das Gen gilt als die niedrigste und einfachste Ebene der Codierung von Informationen.

Gene wiederum werden zu Chromosomen zusammengesetzt. Dank einer solchen Organisation des Erbgutträgers wechseln sich nach bestimmten Gesetzmäßigkeiten Gruppen von Merkmalen ab und werden von Generation zu Generation weitergegeben. Es sollte beachtet werden, dass es unglaublich viele Gene im Körper gibt, aber Informationen nicht verloren gehen, selbst wenn sie viele Male neu kombiniert werden.
Es gibt verschiedene Arten von Genen:
- An funktionaler Zweck Es werden 2 Typen unterschieden: strukturelle und regulatorische Sequenzen;
- Je nach Einfluss auf die in der Zelle ablaufenden Prozesse unterscheiden sie: supervital, tödlich, bedingt tödliche Gene, sowie Mutator- und Antimutatorgene.
Gene befinden sich entlang des Chromosoms lineare Ordnung. In Chromosomen sind Informationen nicht zufällig konzentriert, es gibt eine bestimmte Reihenfolge. Es gibt sogar eine Karte, die Positionen oder Genorte zeigt. Es ist beispielsweise bekannt, dass Daten über die Augenfarbe eines Kindes in Chromosom Nummer 18 verschlüsselt sind.
Was ist ein Genom? Dies ist der Name des gesamten Satzes von Nukleotidsequenzen in der Körperzelle. Das Genom charakterisiert ganze Ansicht, kein einziges Individuum.
Was ist der genetische Code des Menschen?
Tatsache ist, dass all das riesige Potenzial menschliche Entwicklung zum Zeitpunkt der Empfängnis festgelegt. Alle Erbinformationen, die für die Entwicklung der Zygote und das Wachstum des Kindes nach der Geburt notwendig sind, sind in den Genen verschlüsselt. DNA-Abschnitte sind die grundlegendsten Träger von Erbinformationen.

Menschen haben 46 Chromosomen oder 22 somatische Paare plus ein geschlechtsbestimmendes Chromosom von jedem Elternteil. Dieser diploide Chromosomensatz codiert das gesamte körperliche Erscheinungsbild eines Menschen, seine geistigen und körperlichen Fähigkeiten und seine Veranlagung zu Krankheiten. Somatische Chromosomen sind äußerlich nicht zu unterscheiden, tragen aber unterschiedliche Informationen, da eines vom Vater, das andere von der Mutter stammt.
Der männliche Code unterscheidet sich vom weiblichen Code im letzten Chromosomenpaar - XY. Das weibliche diploide Set ist das letzte Paar, XX. Männer bekommen ein X-Chromosom von ihrer leiblichen Mutter und dann wird es an ihre Töchter weitergegeben. Das Geschlechts-Y-Chromosom wird an Söhne weitergegeben.
Menschliche Chromosomen variieren stark in der Größe. Das kleinste Chromosomenpaar ist zum Beispiel Nr. 17. Und das größte Paar ist 1 und 3.
Der Durchmesser der Doppelhelix beim Menschen beträgt nur 2 nm. Die DNA ist so eng gewickelt, dass sie in den kleinen Zellkern passt, obwohl sie abgewickelt bis zu 2 Meter lang ist. Die Länge der Helix beträgt Hunderte Millionen Nukleotide.
Wie wird der genetische Code übertragen?
Welche Rolle spielen also DNA-Moleküle in einer Zelle bei der Teilung? Gene – Träger von Erbinformationen – befinden sich in jeder Körperzelle. Um ihren Code an einen Tochterorganismus weiterzugeben, teilen viele Lebewesen ihre DNA in 2 identische Helices auf. Dies wird als Replikation bezeichnet. Im Prozess der Replikation wird die DNA abgewickelt und spezielle „Maschinen“ vervollständigen jede Kette. Nachdem sich die genetische Helix gegabelt hat, beginnen sich der Zellkern und alle Organellen zu teilen, und dann die ganze Zelle.
Aber eine Person hat einen anderen Prozess des Gentransfers - sexuell. Die Zeichen von Vater und Mutter sind gemischt, der neue genetische Code enthält Informationen von beiden Elternteilen.
Die Speicherung und Übertragung von Erbinformationen ist möglich aufgrund komplexe Organisation DNA-Stränge. Schließlich ist, wie gesagt, die Struktur von Proteinen in Genen verschlüsselt. Einmal zum Zeitpunkt der Empfängnis erstellt, kopiert sich dieser Code während des gesamten Lebens. Der Karyotyp (persönlicher Chromosomensatz) ändert sich bei der Erneuerung von Organzellen nicht. Die Informationsübertragung erfolgt mit Hilfe von Geschlechtsgameten - männlich und weiblich.
Nur Viren, die einen einzigen RNA-Strang enthalten, können ihre Informationen nicht an ihre Nachkommen weitergeben. Daher benötigen sie zur Fortpflanzung menschliche oder tierische Zellen.
Umsetzung der Erbinformation
Im Kern einer Zelle gibt es Konstante wichtige Prozesse. Alle in Chromosomen gespeicherten Informationen werden verwendet, um Proteine aus Aminosäuren aufzubauen. Aber der DNA-Strang verlässt den Zellkern nie, also ist hier die Hilfe einer anderen Person erforderlich. wichtige Verbindung= RNS. Nur RNA ist in der Lage, die Kernmembran zu durchdringen und mit der DNA-Kette zu interagieren.
Durch das Zusammenspiel von DNA und 3 Arten von RNA werden alle verschlüsselten Informationen realisiert. Auf welcher Ebene befindet sich die Implementierung von Erbinformationen? Alle Wechselwirkungen finden auf Nukleotidebene statt. Boten-RNA kopiert ein Segment der DNA-Kette und bringt diese Kopie zum Ribosom. Hier beginnt die Synthese der Nukleotide eines neuen Moleküls.
Damit die mRNA den notwendigen Teil der Kette kopieren kann, entfaltet sich die Helix und wird nach Abschluss des Umkodierungsprozesses wieder hergestellt. Darüber hinaus kann dieser Prozess gleichzeitig auf 2 Seiten eines Chromosoms stattfinden.
Das Prinzip der Komplementarität
Sie bestehen aus 4 Nukleotiden – das sind Adenin (A), Guanin (G), Cytosin (C), Thymin (T). Sie sind nach der Komplementaritätsregel durch Wasserstoffbrückenbindungen verbunden. Die Arbeiten von E. Chargaff halfen, diese Regel aufzustellen, da der Wissenschaftler einige Muster im Verhalten dieser Substanzen bemerkte. E. Chargaff entdeckte, dass das Molverhältnis von Adenin zu Thymin gleich eins ist. Und ebenso ist das Verhältnis von Guanin zu Cytosin immer gleich eins.
Basierend auf seiner Arbeit haben Genetiker eine Regel für die Wechselwirkung von Nukleotiden aufgestellt. Die Komplementaritätsregel besagt, dass sich Adenin nur mit Thymin und Guanin mit Cytosin verbindet. Bei der Entschlüsselung der Helix und der Synthese eines neuen Proteins im Ribosom hilft diese Alternierungsregel dabei, schnell die benötigte Aminosäure zu finden, die an die Transfer-RNA angehängt ist.
RNA und ihre Typen
Was sind Erbinformationen? Nukleotide im DNA-Doppelstrang. Was ist RNA? Was arbeitet sie? RNA oder Ribonukleinsäure hilft dabei, Informationen aus der DNA zu extrahieren, sie zu entschlüsseln und basierend auf dem Prinzip der Komplementarität zu erstellen von Zellen benötigt Proteine.
Insgesamt werden 3 Arten von RNA isoliert. Jeder von ihnen erfüllt streng seine Funktion.
- Informativ (mRNA), oder sie wird auch Matrix genannt. Es geht direkt in die Mitte der Zelle, in den Zellkern. Es findet in einem der Chromosomen das notwendige genetische Material zum Aufbau eines Proteins und kopiert eine der Seiten der Doppelkette. Das Kopieren erfolgt wieder nach dem Prinzip der Komplementarität.
- Transport- Das kleines Molekül, das auf der einen Seite Nukleotid-Decoder und auf der anderen Seite dem Hauptcode entsprechende Aminosäuren aufweist. Die Aufgabe der tRNA besteht darin, sie zur „Werkstatt“, also zum Ribosom zu liefern, wo sie die notwendige Aminosäure synthetisiert.
- rRNA ist ribosomal. Es steuert die Menge des produzierten Proteins. Besteht aus 2 Teilen - Aminosäure- und Peptidstelle.
Der einzige Unterschied bei der Dekodierung besteht darin, dass RNA kein Thymin enthält. Statt Thymin ist hier Uracil enthalten. Aber dann, im Prozess der Proteinsynthese, mit tRNA, stellt es immer noch alle Aminosäuren richtig her. Wenn bei der Dekodierung von Informationen Fehler auftreten, tritt eine Mutation auf.
Reparatur eines beschädigten DNA-Moleküls
Der Prozess der Reparatur eines beschädigten Doppelstrangs wird als Reparatur bezeichnet. Während des Reparaturprozesses werden beschädigte Gene entfernt.

Dann wird die benötigte Elementsequenz exakt reproduziert und kracht wieder an die gleiche Stelle der Kette, an der sie extrahiert wurde. All dies geschieht dank spezieller Chemikalien- Enzyme.
Warum treten Mutationen auf?
Warum beginnen manche Gene zu mutieren und erfüllen ihre Funktion nicht mehr – die Speicherung lebenswichtiger Erbinformationen? Dies ist auf einen Dekodierungsfehler zurückzuführen. Zum Beispiel, wenn Adenin versehentlich durch Thymin ersetzt wird.
Es gibt auch chromosomale und genomische Mutationen. Chromosomale Mutationen entstehen, wenn Teile der Erbinformation herausfallen, sich verdoppeln oder generell übertragen und in ein anderes Chromosom integriert werden.

Genomische Mutationen sind die schwerwiegendsten. Ihre Ursache ist eine Veränderung der Chromosomenzahl. Das heißt, wenn anstelle eines Paares - eines diploiden Satzes - ein triploider Satz im Karyotyp vorhanden ist.
Die meisten berühmtes Beispiel Eine triploide Mutation ist das Down-Syndrom, bei dem der persönliche Chromosomensatz 47 beträgt. Bei solchen Kindern werden anstelle des 21. Paares 3 Chromosomen gebildet.
Es gibt auch eine solche Mutation wie Polyploidie. Aber Polyploidie kommt nur bei Pflanzen vor.
