Significância estatística ou nível de p-significância - o principal resultado do teste
hipótese estatística. conversando linguagem técnica, é a probabilidade de obter o dado
resultado estudo de amostra desde que, de facto, para a generalidade
definida, a hipótese nula é verdadeira - ou seja, não há relação. Em outras palavras, este
a probabilidade de que o relacionamento detectado seja aleatório e não uma propriedade
agregados. Exatamente Significado estatístico, o nível de significância p é
quantificação confiabilidade da conexão: quanto menor essa probabilidade, mais confiável é a conexão.
Suponha que, ao comparar duas médias amostrais, o valor do nível foi obtido
significância estatística p=0,05. Isso significa que testar a hipótese estatística sobre
igualdade de médias na população geral mostrou que, se for verdade, então a probabilidade
a ocorrência aleatória das diferenças detectadas não é superior a 5%. Em outras palavras, se
duas amostras foram repetidamente retiradas da mesma população geral, então em 1 de
20 casos mostrariam a mesma ou maior diferença entre as médias dessas amostras.
Ou seja, há 5% de chance de que as diferenças encontradas sejam aleatórias.
caráter, e não são uma propriedade do agregado.
Em uma relação hipótese científica o nível de significância estatística é o quantitativo
indicador do grau de desconfiança na conclusão sobre a presença de uma conexão, calculado a partir dos resultados
testes seletivos e empíricos dessa hipótese. Quão menos valor nível p, maior
significância estatística do resultado do estudo, confirmando a hipótese científica.
É útil saber o que influencia o nível de significância. Nível de significância, outras coisas sendo iguais
acima (valor p inferior) se:
A magnitude da conexão (diferença) é maior;
A variabilidade da(s) característica(s) é menor;
O(s) tamanho(s) da amostra é maior.
Unilateral Aqui estão os testes de significância bicaudais
Se o objetivo do estudo é revelar a diferença entre os parâmetros das duas
coleções que correspondem às suas várias condições naturais ( condições de vida,
a idade dos sujeitos, etc.), muitas vezes não se sabe qual desses parâmetros será maior, e
qual é menor.
Por exemplo, se você estiver interessado na variabilidade dos resultados no controle e
grupos experimentais, então, via de regra, não há confiança no sinal da diferença entre as variâncias ou
os desvios padrão dos resultados contra os quais a variabilidade é estimada. Nesse caso
a hipótese nula é que as variâncias são iguais entre si, e o objetivo do estudo é
provar o contrário, ou seja, há uma diferença entre as variâncias. Ao mesmo tempo, é permitido que
a diferença pode ser de qualquer sinal. Tais hipóteses são chamadas de duas faces.
Mas às vezes a tarefa é provar um aumento ou diminuição de um parâmetro;
Por exemplo, resultado médio maior no grupo experimental do que no grupo controle. Em que
não é mais permitido que a diferença possa ser de outro signo. Tais hipóteses são chamadas
Unilateral.
Os testes de significância usados para testar hipóteses bilaterais são chamados de
Bilateral, e para unilateral - unilateral.
Surge a questão de qual dos critérios deve ser escolhido em um caso particular. Responda
Esta pergunta está além do formal Métodos estatísticos e completamente
Depende do objetivo do estudo. Em nenhum caso um ou outro critério deve ser escolhido após
Realizar um experimento com base na análise de dados experimentais, pois isso pode
levar a conclusões erradas. Se, antes do experimento, for assumido que a diferença
Os parâmetros comparados podem ser positivos e negativos, segue
O nível de significância nas estatísticas é indicador importante, refletindo o grau de confiança na precisão, a verdade dos dados recebidos (previstos). O conceito é amplamente utilizado em vários campos: de segurar pesquisa sociológica, para testes estatísticos de hipóteses científicas.
Definição
O nível de significância estatística (ou resultado estatisticamente significativo) mostra qual é a probabilidade de ocorrência aleatória dos indicadores estudados. A significância estatística geral do fenômeno é expressa pelo valor-p (nível-p). Em qualquer experimento ou observação, existe a possibilidade de que os dados obtidos tenham surgido devido a erros de amostragem. Isso é especialmente verdadeiro para a sociologia.
Ou seja, um valor é estatisticamente significativo, cuja probabilidade de ocorrência aleatória é extremamente pequena ou tende a extremos. O extremo neste contexto é o grau de desvio das estatísticas da hipótese nula (uma hipótese que é testada quanto à consistência com os dados amostrais obtidos). NO prática científica o nível de significância é selecionado antes da coleta de dados e, via de regra, seu coeficiente é de 0,05 (5%). Para sistemas onde é crítico valores exatos, esse indicador pode ser 0,01 (1%) ou menos.

Fundo
O conceito de nível de significância foi introduzido pelo estatístico e geneticista britânico Ronald Fisher em 1925, quando ele estava desenvolvendo um método para testar hipóteses estatísticas. Ao analisar qualquer processo, há uma certa probabilidade de certos fenômenos. Dificuldades surgem ao trabalhar com porcentagens pequenas (ou não óbvias) de probabilidades que se enquadram no conceito de "erro de medição".
Ao trabalhar com estatísticas que não eram específicas o suficiente para serem testadas, os cientistas se depararam com o problema da hipótese nula, que “impede” operar com valores pequenos. Fisher propôs que tais sistemas determinassem a probabilidade de eventos a 5% (0,05) como um corte amostral conveniente que permite rejeitar a hipótese nula nos cálculos.

Introdução de um coeficiente fixo
Em 1933 Cientistas de Jerzy Neumann e Egon Pearson em seus artigos recomendaram estabelecer um certo nível de significância com antecedência (antes da coleta de dados). Exemplos do uso dessas regras são claramente visíveis durante as eleições. Suponha que haja dois candidatos, um dos quais é muito popular e o outro não é muito conhecido. É óbvio que o primeiro candidato vencerá a eleição, e as chances do segundo tendem a zero. Esforçar-se - mas não igual: há sempre a possibilidade de força maior, informações sensacionalistas, decisões inesperadas que podem alterar os resultados eleitorais previstos.
Neumann e Pearson concordaram que o nível de significância proposto por Fisher de 0,05 (indicado pelo símbolo α) é o mais conveniente. No entanto, o próprio Fischer em 1956 se opôs à fixação desse valor. Ele acreditava que o nível de α deveria ser definido de acordo com circunstâncias específicas. Por exemplo, na física de partículas é 0,01.

valor p
O termo valor-p foi usado pela primeira vez por Brownlee em 1960. O p-level (p-value) é um indicador encontrado em relação inversa sobre a validade dos resultados. O maior valor de p corresponde ao menor nível de confiança na relação amostrada entre as variáveis.
Este valor reflete a probabilidade de erros associados à interpretação dos resultados. Suponha valor p = 0,05 (1/20). Ele mostra uma chance de cinco por cento de que a relação entre as variáveis encontradas na amostra seja apenas uma característica aleatória da amostra. Ou seja, se essa dependência estiver ausente, então com vários experimentos semelhantes, em média, em cada vigésimo estudo, pode-se esperar a mesma ou maior dependência entre as variáveis. Muitas vezes, o nível p é considerado como a "margem" do nível de erro.
A propósito, o valor-p pode não refletir vício real entre as variáveis, mas mostra apenas algum valor médio dentro das premissas. Em particular, a análise final dos dados também dependerá dos valores escolhidos coeficiente dado. Com p-level = 0,05 haverá alguns resultados, e com um coeficiente igual a 0,01, outros.

Testando hipóteses estatísticas
O nível de significância estatística é especialmente importante ao testar hipóteses. Por exemplo, ao calcular um teste bilateral, a área de rejeição é dividida igualmente em ambas as extremidades da distribuição de amostragem (em relação à coordenada zero) e a verdade dos dados obtidos é calculada.
Vamos supor que ao monitorar um determinado processo (fenômeno), descobriu-se que novas informações estatísticas indicam pequenas mudanças em relação aos valores anteriores. Ao mesmo tempo, as discrepâncias nos resultados são pequenas, não óbvias, mas importantes para o estudo. O especialista enfrenta um dilema: as mudanças realmente ocorrem ou são erros de amostragem (imprecisão de medição)?
Nesse caso, a hipótese nula é aplicada ou rejeitada (tudo é anulado como erro, ou a mudança no sistema é reconhecida como fato consumado). O processo de resolução do problema é baseado na razão entre a significância estatística geral (p-valor) e o nível de significância (α). Se o nível p< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Valores usados
O nível de significância depende do material analisado. Na prática, são utilizados os seguintes valores fixos:
- α = 0,1 (ou 10%);
- α = 0,05 (ou 5%);
- α = 0,01 (ou 1%);
- α = 0,001 (ou 0,1%).
Quanto mais precisos forem os cálculos, menor será o coeficiente α utilizado. Naturalmente, as previsões estatísticas em física, química, farmacêutica e genética exigem maior precisão do que em ciência política e sociologia.

Limiares de significância em áreas específicas
Em campos de alta precisão, como física de partículas e fabricação, a significância estatística é frequentemente expressa como a razão do desvio padrão (indicado pelo coeficiente sigma - σ) em relação a distribuição normal probabilidades (distribuição gaussiana). σ é um indicador estatístico que determina a dispersão de valores de uma certa quantidade em relação a expectativas matemáticas. Usado para traçar a probabilidade de eventos.
Dependendo da área de conhecimento, o coeficiente σ varia muito. Por exemplo, ao prever a existência do bóson de Higgs, o parâmetro σ é igual a cinco (σ=5), que corresponde ao valor p=1/3,5 milhões de áreas.
Eficiência
Deve-se levar em conta que os coeficientes α e p-value não são características exatas. Qualquer que seja o nível de significância nas estatísticas do fenômeno em estudo, não é uma base incondicional para aceitar a hipótese. Por exemplo, quanto menor o valor de α, maior a chance de que a hipótese que está sendo estabelecida seja significativa. No entanto, existe o risco de erro, o que reduz o poder estatístico (significância) do estudo.
Pesquisadores que se concentram exclusivamente em estatísticas resultados significativos pode tirar conclusões errôneas. Ao mesmo tempo, é difícil verificar novamente seu trabalho, pois eles aplicam suposições (que, na verdade, são os valores de α e p-value). Portanto, é sempre recomendável, juntamente com o cálculo da significância estatística, determinar outro indicador - a magnitude do efeito estatístico. O tamanho do efeito é uma medida quantitativa da força de um efeito.
A estatística tem sido uma parte integrante da vida. As pessoas enfrentam isso em todos os lugares. Com base nas estatísticas, são tiradas conclusões sobre onde e quais doenças são comuns, o que é mais procurado em uma determinada região ou entre um determinado segmento da população. Mesmo as construções são baseadas em programas políticos candidatos ao governo. Eles também são utilizados pelas redes varejistas na compra de mercadorias, e os fabricantes se orientam por esses dados em suas propostas.
estatísticas jogando papel importante na vida da sociedade e afeta cada um de seus membros individualmente, mesmo nas pequenas coisas. Por exemplo, se por , a maioria das pessoas prefere cores escuras em roupas em uma determinada cidade ou região, será extremamente difícil encontrar uma capa de chuva amarela brilhante com estampa floral em lojas locais. Mas quais são as quantidades que compõem esses dados que têm tanto impacto? Por exemplo, o que é “estatisticamente significativo”? O que exatamente se entende por esta definição?
O que é isso?
A estatística como ciência é composta de uma combinação tamanhos diferentes e conceitos. Um deles é o conceito de "significância estatística". Este é o nome do valor variáveis, a probabilidade de ocorrência de outros indicadores em que é desprezível.
Por exemplo, 9 em cada 10 pessoas usam sapatos de borracha nos pés durante Caminhada matinal para cogumelos em floresta de outono depois de uma noite chuvosa. A probabilidade de que em algum momento 8 deles coloquem mocassins de lona é desprezível. Assim, neste exemplo específico o número 9 é um valor que é chamado de "significado estatístico".
Assim, se desenvolvermos ainda mais o exemplo prático, as lojas de calçados estão comprando até o final temporada de verão botas de borracha em maior número do que em outras épocas do ano. Sim, o valor Significado estatístico tem impacto na vida cotidiana.
Claro, em cálculos complexos, por exemplo, ao prever a propagação de vírus, grande número variáveis. Mas a própria essência de determinar um indicador significativo de dados estatísticos é semelhante, independentemente da complexidade dos cálculos e do número de valores não constantes.
Como é calculado?
Usado no cálculo do valor do indicador "significância estatística" da equação. Ou seja, pode-se argumentar que neste caso tudo é decidido pela matemática. pelo mais opção simples computação é uma cadeia operações matemáticas, que inclui os seguintes parâmetros:
- dois tipos de resultados obtidos de pesquisas ou do estudo de dados objetivos, por exemplo, os valores pelos quais as compras são feitas, denotadas por a e b;
- indicador para ambos os grupos - n;
- o valor da parcela da amostra combinada - p;
- o conceito de "erro padrão" - SE.
O próximo passo é determinar o indicador geral de teste - t, seu valor é comparado com o número 1,96. 1,96 é um valor médio que representa um intervalo de 95% de acordo com a distribuição t de Student.
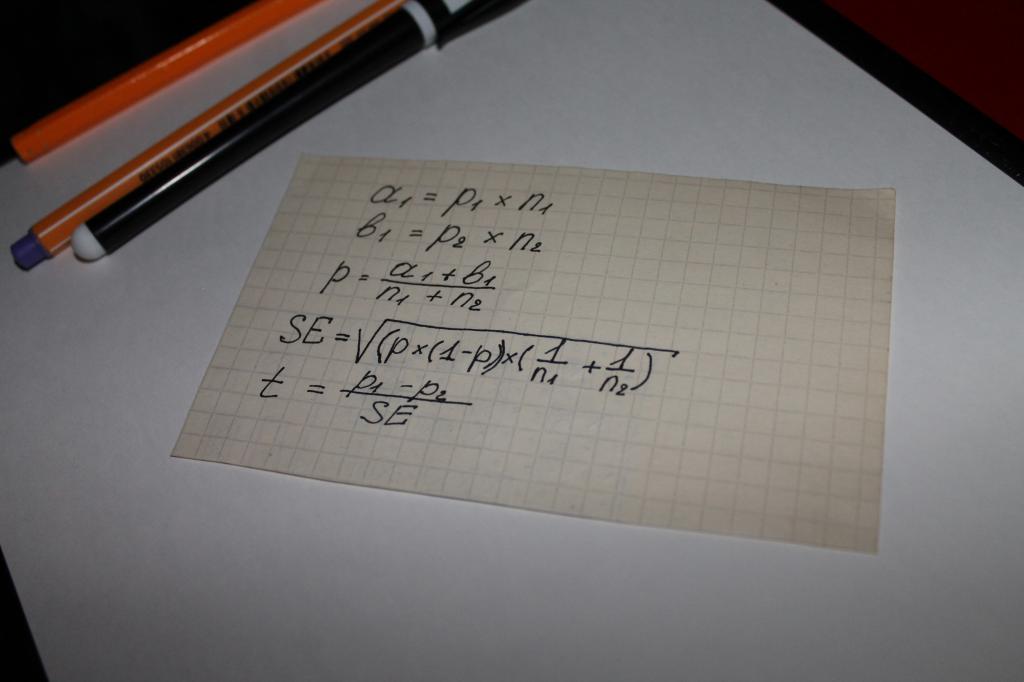
Muitas vezes surge a questão de qual é a diferença entre os valores de n e p. Essa nuance é fácil de esclarecer com um exemplo. Suponha que seja calculada a significância estatística da lealdade a qualquer produto ou marca de homens e mulheres.
Nesse caso, as letras serão seguidas do seguinte:
- n é o número de respondentes;
- p - o número de satisfeitos com o produto.
O número de mulheres entrevistadas neste caso será designado como n1. Assim, os homens - n2. O mesmo valor terá os números "1" e "2" no símbolo p.
Comparar o indicador de teste com os valores médios das tabelas de cálculo do Aluno torna-se o que se chama de "significância estatística".
O que se entende por verificação?
Os resultados de qualquer cálculo matemático sempre podem ser verificados; isso é ensinado às crianças mesmo em escola primaria. É lógico supor que, como os indicadores estatísticos são determinados usando uma cadeia de cálculos, eles são verificados.
No entanto, testar a significância estatística não é apenas matemática. As estatísticas tratam grande quantidade variáveis e várias probabilidades, que nem sempre são passíveis de cálculo. Ou seja, se voltarmos ao exemplo dado no início do artigo com sapatos de borracha, então a construção lógica de dados estatísticos, nos quais os compradores de mercadorias para lojas confiarão, pode ser interrompida pelo clima seco e quente, o que não é típico do outono. Como resultado desse fenômeno, o número de pessoas que compram botas de borracha diminuirá e os pontos de venda sofrerão perdas. Antecipar uma anomalia climática fórmula matemática, claro, não pode. Este momento é chamado - "erro".

É precisamente a probabilidade de tais erros que a verificação do nível de significância calculado leva em consideração. Leva em conta tanto os indicadores calculados quanto os níveis de significância aceitos, bem como as quantidades convencionalmente chamadas de hipóteses.
O que é um nível de significância?
O conceito de "nível" está incluído nos principais critérios de significância estatística. É usado em estatística aplicada e prática. Este é um tipo de quantidade que leva em conta a probabilidade possíveis desvios ou erros.
O nível é baseado na identificação de diferenças em amostras prontas, permite estabelecer sua significância ou, inversamente, aleatoriedade. Esse conceito possui não apenas significados digitais, mas também suas interpretações peculiares. Eles explicam como o valor deve ser entendido, e o próprio nível é determinado pela comparação do resultado com o índice médio, isso revela o grau de confiabilidade das diferenças.

Assim, o conceito de nível pode ser apresentado de forma simples - é um indicador de um erro aceitável, provável ou erro nas conclusões tiradas dos dados estatísticos obtidos.
Que níveis de significância são usados?
A significância estatística dos coeficientes de probabilidade de erro na prática é baseada em três níveis básicos.
O primeiro nível é o limite no qual o valor é 5%. Ou seja, a probabilidade de erro não ultrapassa o nível de significância de 5%. Isso significa que a confiança na impecabilidade e infalibilidade das conclusões feitas com base nos dados da pesquisa estatística é de 95%.
O segundo nível é o limite de 1%. Assim, este valor significa que se pode guiar pelos dados obtidos durante os cálculos estatísticos com 99% de confiança.
O terceiro nível é de 0,1%. Com esse valor, a probabilidade de erro é igual a uma fração de um por cento, ou seja, os erros são praticamente eliminados.
O que é uma hipótese em estatística?
Os erros como conceito dividem-se em duas áreas quanto à aceitação ou rejeição da hipótese nula. Uma hipótese é um conceito por trás do qual, de acordo com a definição, um conjunto de outros dados ou declarações está oculto. Essa é a descrição distribuição de probabilidade algo relacionado ao assunto da contabilidade estatística.

Existem duas hipóteses em cálculos simples - zero e alternativa. A diferença entre elas é que a hipótese nula é baseada na ideia de que não há diferenças fundamentais entre as amostras envolvidas na determinação da significância estatística, e a alternativa é completamente oposta a ela. Ou seja hipótese alternativa com base na presença de uma diferença significativa nestas amostras.
Quais são os erros?
Os erros como conceito em estatística dependem diretamente da aceitação de uma ou outra hipótese como verdadeira. Eles podem ser divididos em duas direções ou tipos:
- o primeiro tipo deve-se à aceitação da hipótese nula, que se revelou incorreta;
- a segunda é causada por seguir a alternativa.

O primeiro tipo de erro é chamado de falso positivo e é bastante comum em todas as áreas onde as estatísticas são usadas. Assim, o erro do segundo tipo é chamado de falso negativo.
Por que a regressão é importante em estatística?
A significância estatística da regressão é que ela pode ser usada para estabelecer o quão realista é o modelo calculado com base nos dados. várias dependências; permite identificar a suficiência ou falta de fatores para contabilidade e conclusões.
O valor da regressão é determinado comparando os resultados com os dados listados nas tabelas de Fisher. Ou usando análise de variância. Importância indicadores de regressão têm com complexos estudos estatísticos e cálculos envolvendo um grande número de variáveis, dados aleatórios e mudanças prováveis.
Significado estatístico
Os resultados obtidos usando um determinado procedimento de pesquisa são chamados de estatisticamente significativo se a probabilidade de sua ocorrência aleatória for muito pequena. Este conceito pode ser ilustrado pelo exemplo do lançamento de uma moeda. Suponha que uma moeda seja lançada 30 vezes; Saiu 17 vezes cara e 13 vezes coroa. Será que significativo Isso é um desvio do resultado esperado (15 caras e 15 coroas) ou é uma coincidência? Para responder a essa pergunta, você pode, por exemplo, jogar a mesma moeda várias vezes 30 vezes seguidas e, ao mesmo tempo, observar quantas vezes a proporção de cara e coroa, igual a 17:13, é repetida. A análise estatística nos salva desse processo tedioso. Com sua ajuda, após os primeiros 30 lançamentos de moedas, é possível estimar o número possível de ocorrências aleatórias de 17 caras e 13 coroas. Tal estimativa é chamada de declaração probabilística.
NO Literatura científica na declaração probabilística da psicologia organizacional-industrial em forma matemática denotado pela expressão R(probabilidade)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (R< 0,01). Esse fato é importante para a compreensão da literatura, mas não deve ser entendido como sendo inútil fazer observações que não atendam a esses padrões. Os chamados resultados de pesquisa não significativos (observações que podem ser obtidas por acaso mais uma ou cinco vezes em 100) pode ser muito útil para identificar tendências e como guia para pesquisas futuras.
Deve-se notar também que nem todos os psicólogos concordam com os padrões e procedimentos tradicionais (por exemplo, Cohen, 1994; Sauley & Bedeian, 1989). As questões relacionadas às medições são elas próprias tema principal o trabalho de muitos pesquisadores que estudam a precisão dos métodos de medição e os pré-requisitos subjacentes métodos existentes e padrões, além de desenvolver novos médicos e instrumentos. Talvez em algum momento no futuro, a pesquisa neste poder levará a uma mudança nos padrões tradicionais para avaliar a significância estatística, e essas mudanças ganharão aceitação universal. (O Quinto Capítulo da American Psychological Association reúne psicólogos especializados no estudo de estimativas, medições e estatísticas.)
Em relatórios de pesquisa, uma declaração probabilística como R< 0,05, devido a alguns Estatisticas ou seja, um número que é obtido como resultado de um determinado conjunto de procedimentos computacionais matemáticos. A confirmação probabilística é obtida comparando essas estatísticas com dados de tabelas especiais que são publicadas para esse fim. Em industrial-organizacional pesquisa psicológica estatísticas frequentemente encontradas, como r, F, t, r>(leia "qui quadrado") e R(leia "vários R"). Em cada caso, as estatísticas (um número) obtidas a partir da análise de uma série de observações podem ser comparadas com os números da tabela publicada. Depois disso, é possível formular uma afirmação probabilística sobre a probabilidade de se obter aleatoriamente esse número, ou seja, tirar uma conclusão sobre a significância das observações.
Para entender os estudos descritos neste livro, basta ter uma compreensão clara do conceito de significância estatística e não necessariamente saber como as estatísticas mencionadas acima são calculadas. No entanto, seria útil discutir uma suposição subjacente a todos esses procedimentos. Esta é a suposição de que todas as variáveis observadas são distribuídas aproximadamente lei normal. Além disso, ao ler relatórios sobre pesquisa psicológica organizacional-industrial, muitas vezes surgem mais três conceitos que desempenham um papel importante - primeiro, correlação e correlação, em segundo lugar, a variável determinante/preditora e "ANOVA" ( análise de variação), em terceiro lugar, um grupo de métodos estatísticos sob nome comum"metanálise".
O teste de hipóteses é realizado por meio de análise estatística. A significância estatística é encontrada usando o valor P, que corresponde à probabilidade este evento sob a suposição de que alguma afirmação (a hipótese nula) é verdadeira. Se o valor P for menor que um determinado nível de significância estatística (geralmente 0,05), o experimentador pode concluir com segurança que a hipótese nula é falsa e passar a considerar a hipótese alternativa. Usando o teste t de Student, você pode calcular o valor P e determinar a significância para dois conjuntos de dados.
Passos
Parte 1
Configurando um experimento- A hipótese nula (H 0) geralmente afirma que não há diferença entre os dois conjuntos de dados. Por exemplo: aqueles alunos que lêem o material antes da aula não obtêm notas mais altas.
- A hipótese alternativa (H a) é o oposto da hipótese nula e é uma afirmação que precisa ser confirmada com dados experimentais. Por exemplo: os alunos que lêem o material antes da aula obtêm notas mais altas.
-
Defina o nível de significância para determinar o quanto a distribuição dos dados deve diferir do usual para que seja considerado um resultado significativo. Nível de significância (também chamado de α (\displaystyle \alpha )-level) é o limite que você define para significância estatística. Se o valor P for menor ou igual ao nível de significância, os dados são considerados estatisticamente significativos.
- Como regra, o nível de significância (valor α (\displaystyle \alpha )) é considerado igual a 0,05, caso em que a probabilidade de detectar uma diferença aleatória entre diferentes conjuntos de dados é de apenas 5%.
- Quanto maior o nível de significância (e, portanto, menos valor-p), mais confiáveis são os resultados.
- Se você quiser resultados mais confiáveis, diminua o valor P para 0,01. Normalmente, valores P mais baixos são usados na produção quando é necessário detectar defeitos nos produtos. Nesse caso, é necessária alta confiança para garantir que todas as peças funcionem conforme o esperado.
- Para a maioria dos experimentos de hipóteses, um nível de significância de 0,05 é suficiente.
-
Decida quais critérios você usará: unilateral ou bilateral. Uma das suposições no teste t de Student é que os dados são normalmente distribuídos. A distribuição normal é uma curva em forma de sino com o número máximo resultados no meio da curva. O teste t de Student é método matemático validação de dados, que permite determinar se os dados estão fora da distribuição normal (mais, menos ou nas “caudas” da curva).
- Se você não tiver certeza se os dados estão acima ou abaixo grupo de controle valores, use um teste bicaudal. Isso permitirá que você determine o significado em ambas as direções.
- Se você souber em que direção os dados podem ficar fora da distribuição normal, use um teste unilateral. No exemplo acima, esperamos que as notas dos alunos subam, então um teste unilateral pode ser usado.
-
Determine o tamanho da amostra usando poder estatístico. O poder estatístico de um estudo é a probabilidade de que um determinado tamanho de amostra produza o resultado esperado. Um limite de potência comum (ou β) é de 80%. A análise de energia sem dados prévios pode ser complicada porque algumas informações são necessárias sobre as médias esperadas em cada conjunto de dados e seus desvios padrão. Use a calculadora de energia online para determinar o tamanho de amostra ideal para seus dados.
- Normalmente, os pesquisadores realizam um pequeno estudo piloto que fornece dados para análise de poder e determina o tamanho da amostra necessária para um estudo maior e mais completo.
- Se você não tiver a oportunidade de realizar um estudo piloto, tente estimar possíveis valores médios com base nos dados da literatura e nos resultados de outras pessoas. Isso pode ajudá-lo a determinar o tamanho ideal da amostra.
Parte 2
Calcular desvio padrão-
Escreva a fórmula do desvio padrão. O desvio padrão indica quão grande é a dispersão dos dados. Ele permite que você conclua o quão próximos os dados obtidos em uma determinada amostra. À primeira vista, a fórmula parece bastante complicada, mas as explicações abaixo ajudarão você a entendê-la. A fórmula tem próxima visualização: s = √∑((x i – µ) 2 /(N – 1)).
- s - desvio padrão;
- o sinal ∑ indica que todos os dados obtidos na amostra devem ser somados;
- xi corresponde ao i-ésimo valor, ou seja, um resultado separado obtido;
- µ é o valor médio para este grupo;
- N- número total dados na amostra.
-
Encontre a média em cada grupo. Para calcular o desvio padrão, primeiro você deve encontrar a média para cada grupo de estudo. O valor médio é indicado letra gregaµ (mu). Para encontrar a média, basta somar todos os valores resultantes e dividi-los pela quantidade de dados (tamanho da amostra).
- Por exemplo, para encontrar nota média no grupo daqueles alunos que estudam o material antes da aula, considere um pequeno conjunto de dados. Para simplificar, usamos um conjunto de cinco pontos: 90, 91, 85, 83 e 94.
- Vamos somar todos os valores juntos: 90 + 91 + 85 + 83 + 94 = 443.
- Divida a soma pelo número de valores, N = 5: 443/5 = 88,6.
- Assim, o valor médio para este grupo é de 88,6.
-
Subtraia cada valor obtido da média. Próxima Etapaé calcular a diferença (x i - µ). Para fazer isso, subtraia do encontrado tamanho médio cada valor recebido. Em nosso exemplo, precisamos encontrar cinco diferenças:
- (90 - 88,6), (91 - 88,6), (85 - 88,6), (83 - 88,6) e (94 - 88,6).
- Como resultado, obtemos os seguintes valores: 1,4, 2,4, -3,6, -5,6 e 5,4.
-
Eleve ao quadrado cada valor obtido e some-os. Cada uma das quantidades encontradas deve ser elevada ao quadrado. Tudo vai desaparecer nesta etapa. valores negativos. Se após esta etapa você tiver números negativos, então você esqueceu de esquadrá-los.
- Para o nosso exemplo, obtemos 1,96, 5,76, 12,96, 31,36 e 29,16.
- Somamos os valores obtidos: 1,96 + 5,76 + 12,96 + 31,36 + 29,16 = 81,2.
-
Divida pelo tamanho da amostra menos 1. Na fórmula, a soma é dividida por N - 1 devido ao fato de não levarmos em consideração população geral, mas tomamos para avaliação uma amostra de todos os alunos.
- Subtrair: N - 1 = 5 - 1 = 4
- Divida: 81,2/4 = 20,3
-
Extrair Raiz quadrada. Depois de dividir a soma pelo tamanho da amostra menos um, tire a raiz quadrada do valor encontrado. Este é o último passo no cálculo do desvio padrão. Existem programas estatísticos que, após inserir os dados iniciais, realizam todos os cálculos necessários.
- Em nosso exemplo, o desvio padrão das notas dos alunos que leram o material antes da aula é s = √20,3 = 4,51.
Parte 3
Determinar a significância-
Calcule a variância entre os dois grupos de dados. Até esta etapa, consideramos o exemplo para apenas um grupo de dados. Se você deseja comparar dois grupos, obviamente deve obter os dados de ambos os grupos. Calcule o desvio padrão para o segundo grupo de dados e, em seguida, encontre a variância entre os dois grupos experimentais. A dispersão é calculada usando a seguinte fórmula: s d = √((s 1 /N 1) + (s 2 /N 2)).
Defina sua hipótese. O primeiro passo para avaliar a significância estatística é escolher a pergunta que você quer que seja respondida e formular uma hipótese. Uma hipótese é uma afirmação sobre dados experimentais, sua distribuição e propriedades. Para qualquer experimento, existe uma hipótese nula e uma hipótese alternativa. De um modo geral, você terá que comparar dois conjuntos de dados para determinar se eles são semelhantes ou diferentes.
