სტატისტიკური მნიშვნელოვნება ანუ p-მნიშვნელოვნების დონე - ტესტის მთავარი შედეგი
სტატისტიკური ჰიპოთეზა. საუბარი ტექნიკური ენა, არის მოცემულის მიღების ალბათობა
შედეგი ნიმუშის კვლევაიმ პირობით, რომ ფაქტობრივად გენერალისთვის
კომპლექტი, ნულოვანი ჰიპოთეზა მართალია - ანუ არ არსებობს ურთიერთობა. სხვა სიტყვებით რომ ვთქვათ, ეს
ალბათობა იმისა, რომ აღმოჩენილი ურთიერთობა არის შემთხვევითი და არა საკუთრება
აგრეგატები. ზუსტად სტატისტიკური მნიშვნელობა, p-მნიშვნელოვნების დონე არის
რაოდენობრივი განსაზღვრაკავშირის საიმედოობა: რაც უფრო დაბალია ეს ალბათობა, მით უფრო საიმედოა კავშირი.
დავუშვათ, ორი ნიმუშის საშუალების შედარებისას მიღებულია დონის მნიშვნელობა
სტატისტიკური მნიშვნელობა p=0.05. ეს ნიშნავს, რომ ტესტირება სტატისტიკური ჰიპოთეზა შესახებ
საერთო პოპულაციაში საშუალებების თანასწორობამ აჩვენა, რომ თუ ეს მართალია, მაშინ ალბათობა
აღმოჩენილი განსხვავებების შემთხვევითი შემთხვევები არ არის 5% -ზე მეტი. სხვა სიტყვებით რომ ვთქვათ, თუ
ორი ნიმუში არაერთხელ იქნა აღებული ერთი და იგივე ზოგადი პოპულაციიდან, შემდეგ 1-ში
20 შემთხვევა აჩვენებს იგივე ან მეტ განსხვავებას ამ ნიმუშების საშუალებებს შორის.
ანუ, არის 5% შანსი, რომ ნაპოვნი განსხვავებები შემთხვევითი იყოს.
ხასიათი და არ არის აგრეგატის საკუთრება.
Ურთიერთობაში სამეცნიერო ჰიპოთეზასტატისტიკური მნიშვნელოვნების დონე არის რაოდენობრივი
უნდობლობის ხარისხის მაჩვენებელი კავშირის არსებობის შესახებ დასკვნაში, გამოითვლება შედეგებიდან
ამ ჰიპოთეზის შერჩევითი, ემპირიული ტესტირება. Როგორ ნაკლები ღირებულება p- დონე, რაც უფრო მაღალია
კვლევის შედეგის სტატისტიკური მნიშვნელობა, მეცნიერული ჰიპოთეზის დამადასტურებელი.
სასარგებლოა იმის ცოდნა, თუ რა გავლენას ახდენს მნიშვნელობის დონეზე. მნიშვნელობის დონე, სხვა თანაბარი
ზემოთ (ქვედა p-მნიშვნელობა) თუ:
კავშირის (განსხვავების) სიდიდე უფრო დიდია;
ნიშან(ებ)ის ცვალებადობა ნაკლებია;
ნიმუშის ზომა(ები) უფრო დიდია.
ცალმხრივიაქ არის ორმხრივი მნიშვნელობის ტესტები
თუ კვლევის მიზანია გამოავლინოს განსხვავება ორი ზოგადის პარამეტრებს შორის
კოლექციები, რომლებიც შეესაბამება მის სხვადასხვა ბუნებრივ პირობებს ( საცხოვრებელი პირობები,
სუბიექტების ასაკი და ა.შ.), ხშირად უცნობია, ამ პარამეტრებიდან რომელი იქნება მეტი და
რომელი უფრო პატარაა.
მაგალითად, თუ გაინტერესებთ შედეგების ცვალებადობა კონტროლში და
ექსპერიმენტული ჯგუფები, მაშინ, როგორც წესი, არ არსებობს ნდობა განსხვავებას შორის განსხვავებაზე ან
შედეგების სტანდარტული გადახრები, რომელთა მიხედვითაც ფასდება ცვალებადობა. Ამ შემთხვევაში
ნულოვანი ჰიპოთეზა არის, რომ დისპერსიები ერთმანეთის ტოლია და კვლევის მიზანია
დაამტკიცე საპირისპირო, ე.ი. განსხვავებას შორის არის განსხვავება. ამავე დროს, დასაშვებია
განსხვავება შეიძლება იყოს ნებისმიერი ნიშნით. ასეთ ჰიპოთეზებს ორმხრივს უწოდებენ.
მაგრამ ზოგჯერ ამოცანაა დაამტკიცოს პარამეტრის ზრდა ან შემცირება;
Მაგალითად, საშუალო შედეგიუფრო მაღალია ექსპერიმენტულ ჯგუფში, ვიდრე საკონტროლო ჯგუფში. სადაც
დაუშვებელია, რომ სხვაობა სხვა ნიშნის იყოს. ასეთ ჰიპოთეზებს ე.წ
ცალმხრივი.
ორმხრივი ჰიპოთეზების შესამოწმებლად გამოყენებული მნიშვნელობის ტესტები ეწოდება
ორმხრივი, ხოლო ცალმხრივი - ცალმხრივი.
ჩნდება კითხვა, კონკრეტულ შემთხვევაში რომელი კრიტერიუმებიდან უნდა შეირჩეს. უპასუხე
ეს კითხვა ფორმალურის მიღმაა სტატისტიკური მეთოდებიდა მთლიანად
დამოკიდებულია კვლევის მიზანზე. არავითარ შემთხვევაში არ უნდა აირჩეს ერთი ან მეორე კრიტერიუმი
ექსპერიმენტის ჩატარება ექსპერიმენტული მონაცემების ანალიზზე დაფუძნებული, ვინაიდან ეს შეიძლება
გამოიწვიოს არასწორი დასკვნები. თუ ექსპერიმენტის დაწყებამდე ვარაუდობენ, რომ განსხვავება
შედარებული პარამეტრები შეიძლება იყოს როგორც დადებითი, ასევე უარყოფითი
სტატისტიკაში მნიშვნელობის დონე არის მნიშვნელოვანი მაჩვენებელი, რომელიც ასახავს მიღებული (პროგნოზირებადი) მონაცემების სიზუსტის ნდობის ხარისხს. კონცეფცია ფართოდ გამოიყენება სხვადასხვა სფეროებში: ჩატარებიდან სოციოლოგიური კვლევა, სამეცნიერო ჰიპოთეზების სტატისტიკურ ტესტირებამდე.
განმარტება
სტატისტიკური მნიშვნელოვნების (ან სტატისტიკურად მნიშვნელოვანი შედეგის) დონე გვიჩვენებს, რა არის შესწავლილი ინდიკატორების შემთხვევითი წარმოშობის ალბათობა. ფენომენის საერთო სტატისტიკური მნიშვნელობა გამოიხატება p-მნიშვნელობით (p-დონე). ნებისმიერ ექსპერიმენტსა თუ დაკვირვებაში არის შესაძლებლობა, რომ მიღებული მონაცემები აღმოცენდეს შერჩევის შეცდომების გამო. ეს განსაკუთრებით ეხება სოციოლოგიას.
ანუ, მნიშვნელობა არის სტატისტიკურად მნიშვნელოვანი, რომლის შემთხვევითი წარმოშობის ალბათობა ძალიან მცირეა ან მიდრეკილია უკიდურესობამდე. უკიდურესობა ამ კონტექსტში არის სტატისტიკის გადახრის ხარისხი ნულოვანი ჰიპოთეზიდან (ჰიპოთეზა, რომელიც მოწმდება მიღებული ნიმუშის მონაცემებთან შესაბამისობაში). AT სამეცნიერო პრაქტიკამნიშვნელოვნების დონე შეირჩევა მონაცემთა შეგროვებამდე და, როგორც წესი, მისი კოეფიციენტია 0,05 (5%). სისტემებისთვის, სადაც ეს კრიტიკულია ზუსტი ღირებულებები, ეს მაჩვენებელი შეიძლება იყოს 0.01 (1%) ან ნაკლები.

ფონი
მნიშვნელოვნების დონის კონცეფცია შემოიღო ბრიტანელმა სტატისტიკოსმა და გენეტიკოსმა რონალდ ფიშერმა 1925 წელს, როდესაც ის ავითარებდა ტესტირების მეთოდს. სტატისტიკური ჰიპოთეზები. ნებისმიერი პროცესის გაანალიზებისას არსებობს გარკვეული ფენომენის ალბათობა. სირთულეები წარმოიქმნება ალბათობის მცირე (ან არა აშკარა) პროცენტებთან მუშაობისას, რომლებიც მიეკუთვნება "გაზომვის შეცდომის" კონცეფციას.
სტატისტიკასთან მუშაობისას, რომელიც არ იყო საკმარისად სპეციფიკური შესამოწმებლად, მეცნიერებს დაუპირისპირდნენ ნულოვანი ჰიპოთეზის პრობლემას, რომელიც „აფერხებს“ მცირე მნიშვნელობებით მუშაობას. ფიშერმა შესთავაზა ასეთ სისტემებს, რათა განესაზღვრათ მოვლენების ალბათობა 5% (0.05), როგორც მოხერხებული ნიმუშის წყვეტა, რომელიც საშუალებას იძლევა უარყოს ნულოვანი ჰიპოთეზა გამოთვლებში.

ფიქსირებული კოეფიციენტის შემოღება
1933 წელს იერჟის მეცნიერებინეიმანმა და ეგონ პირსონმა თავიანთ ნაშრომებში რეკომენდაცია გაუწიეს წინასწარ (მონაცემების შეგროვებამდე) განსაზღვრული მნიშვნელობის დონის განსაზღვრა. ამ წესების გამოყენების მაგალითები აშკარად ჩანს არჩევნების დროს. დავუშვათ, არის ორი კანდიდატი, რომელთაგან ერთი ძალიან პოპულარულია და მეორე ცნობილი არ არის. აშკარაა, რომ პირველი კანდიდატი გაიმარჯვებს არჩევნებში, ხოლო მეორეს შანსები ნულისკენ მიდის. იბრძოლეთ - მაგრამ არა თანაბარი: ყოველთვის არის ფორსმაჟორის, სენსაციური ინფორმაციის, მოულოდნელი გადაწყვეტილებების შესაძლებლობა, რამაც შეიძლება შეცვალოს არჩევნების პროგნოზირებული შედეგები.
ნოიმანი და პირსონი შეთანხმდნენ, რომ ფიშერის მიერ შემოთავაზებული მნიშვნელოვნების დონე 0,05 (აღნიშნული α სიმბოლოთი) ყველაზე მოსახერხებელია. თუმცა, თავად ფიშერი 1956 წელს ეწინააღმდეგებოდა ამ ღირებულების დაფიქსირებას. მას სჯეროდა, რომ α-ს დონე უნდა განისაზღვროს კონკრეტული გარემოებების შესაბამისად. მაგალითად, ნაწილაკების ფიზიკაში ეს არის 0,01.

p-მნიშვნელობა
ტერმინი p-მნიშვნელობა პირველად გამოიყენა ბრაუნლიმ 1960 წელს. p- დონე (p-მნიშვნელობა) არის ინდიკატორი, რომელიც გვხვდება შებრუნებული ურთიერთობაშედეგების ნამდვილობაზე. უმაღლესი p-მნიშვნელობა შეესაბამება ცვლადებს შორის შერჩეულ ურთიერთობაში ნდობის ყველაზე დაბალ დონეს.
ეს მნიშვნელობა ასახავს შედეგების ინტერპრეტაციასთან დაკავშირებული შეცდომების ალბათობას. დავუშვათ p-მნიშვნელობა = 0.05 (1/20). ეს აჩვენებს ხუთ პროცენტიან შანსს, რომ ნიმუშში ნაპოვნი ცვლადებს შორის კავშირი მხოლოდ ნიმუშის შემთხვევითი მახასიათებელია. ანუ, თუ ეს დამოკიდებულება არ არის, მაშინ მრავალი მსგავსი ექსპერიმენტით, საშუალოდ, ყოველ მეოცე კვლევაში, შეიძლება ველოდოთ იგივე ან უფრო დიდ დამოკიდებულებას ცვლადებს შორის. ხშირად p- დონე განიხილება როგორც შეცდომის დონის „ზღვარი“.
სხვათა შორის, p-მნიშვნელობა შეიძლება არ აისახოს ნამდვილი დამოკიდებულებაცვლადებს შორის, მაგრამ აჩვენებს მხოლოდ გარკვეულ საშუალო მნიშვნელობას დაშვებების ფარგლებში. კერძოდ, მონაცემების საბოლოო ანალიზი ასევე დამოკიდებული იქნება არჩეულ მნიშვნელობებზე მოცემული კოეფიციენტი. p-დონე = 0,05 იქნება გარკვეული შედეგი, ხოლო კოეფიციენტის ტოლი 0,01, სხვები.

სტატისტიკური ჰიპოთეზების ტესტირება
ჰიპოთეზების ტესტირებისას განსაკუთრებით მნიშვნელოვანია სტატისტიკური მნიშვნელოვნების დონე. მაგალითად, ორმხრივი ტესტის გამოთვლისას უარყოფის ფართობი იყოფა სინჯის განაწილების ორივე ბოლოზე (ნულოვანი კოორდინატთან მიმართებაში) თანაბრად და გამოითვლება მიღებული მონაცემების ჭეშმარიტება.
დავუშვათ, რომ გარკვეული პროცესის (ფენომენის) მონიტორინგის დროს აღმოჩნდა, რომ ახალი სტატისტიკური ინფორმაცია მიუთითებს მცირე ცვლილებებიწინა მნიშვნელობებთან შედარებით. ამავდროულად, შედეგების შეუსაბამობები მცირეა, არა აშკარა, მაგრამ მნიშვნელოვანია კვლევისთვის. სპეციალისტი დილემის წინაშე დგას: ცვლილებები ნამდვილად ხდება თუ არის შერჩევის შეცდომები (გაზომვის უზუსტობა)?
ამ შემთხვევაში, ნულოვანი ჰიპოთეზა გამოიყენება ან უარყოფილია (ყველაფერი ჩამოწერილია შეცდომის სახით, ან სისტემაში ცვლილება აღიარებულია როგორც დასრულებული ფაქტი). პრობლემის გადაჭრის პროცესი ეფუძნება საერთო სტატისტიკური მნიშვნელოვნების (p-მნიშვნელობის) და მნიშვნელოვნების დონის (α) თანაფარდობას. თუ p-დონე< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
გამოყენებული ღირებულებები
მნიშვნელოვნების დონე დამოკიდებულია გაანალიზებულ მასალაზე. პრაქტიკაში გამოიყენება შემდეგი ფიქსირებული მნიშვნელობები:
- α = 0,1 (ან 10%);
- α = 0,05 (ან 5%);
- α = 0,01 (ან 1%);
- α = 0.001 (ან 0.1%).
რაც უფრო ზუსტია საჭირო გამოთვლები, მით უფრო მცირეა კოეფიციენტი α. ბუნებრივია, სტატისტიკური პროგნოზები ფიზიკაში, ქიმიაში, ფარმაცევტულ და გენეტიკაში უფრო მეტ სიზუსტეს მოითხოვს, ვიდრე პოლიტიკურ მეცნიერებასა და სოციოლოგიაში.

მნიშვნელობის ზღურბლები კონკრეტულ სფეროებში
მაღალი სიზუსტის სფეროებში, როგორიცაა ნაწილაკების ფიზიკა და წარმოება, სტატისტიკური მნიშვნელობა ხშირად გამოიხატება როგორც სტანდარტული გადახრის თანაფარდობა (აღნიშნულია სიგმა კოეფიციენტით - σ) მიმართ ნორმალური დისტრიბუციაალბათობები (გაუსური განაწილება). σ არის სტატისტიკური მაჩვენებელი, რომელიც განსაზღვრავს გარკვეული რაოდენობის მნიშვნელობების დისპერსიას მიმართ მათემატიკური მოლოდინები. გამოიყენება მოვლენების ალბათობის გამოსათვლელად.
ცოდნის სფეროდან გამომდინარე, σ კოეფიციენტი ძალიან განსხვავდება. მაგალითად, ჰიგსის ბოზონის არსებობის პროგნოზირებისას პარამეტრი σ უდრის ხუთს (σ=5), რაც შეესაბამება p-მნიშვნელობას=1/3,5 მლნ ფართობს.
ეფექტურობა
გასათვალისწინებელია, რომ კოეფიციენტები α და p-მნიშვნელობა არ არის ზუსტი მახასიათებლები. როგორიც არ უნდა იყოს მნიშვნელოვნების დონე შესწავლილი ფენომენის სტატისტიკაში, ეს არ არის ჰიპოთეზის მიღების უპირობო საფუძველი. მაგალითად, რაც უფრო მცირეა α-ს მნიშვნელობა, მით მეტია შანსი იმისა, რომ ჰიპოთეზის ჩამოყალიბება მნიშვნელოვანი იყოს. თუმცა, არსებობს შეცდომის რისკი, რაც ამცირებს კვლევის სტატისტიკურ ძალას (მნიშვნელოვნებას).
მკვლევარები, რომლებიც ყურადღებას ამახვილებენ მხოლოდ სტატისტიკაზე მნიშვნელოვანი შედეგებიშეიძლება მცდარი დასკვნების გამოტანა. ამავე დროს, რთულია მათი მუშაობის ორმაგი შემოწმება, რადგან ისინი იყენებენ ვარაუდებს (რაც, ფაქტობრივად, არის α და p-მნიშვნელობის მნიშვნელობები). ამიტომ, ყოველთვის რეკომენდირებულია, სტატისტიკური მნიშვნელობის გამოთვლასთან ერთად, განისაზღვროს კიდევ ერთი ინდიკატორი - სტატისტიკური ეფექტის სიდიდე. ეფექტის ზომა არის ეფექტის სიძლიერის რაოდენობრივი საზომი.
სტატისტიკა დიდი ხანია ცხოვრების განუყოფელი ნაწილია. ხალხი მას ყველგან აწყდება. სტატისტიკის საფუძველზე კეთდება დასკვნები იმის შესახებ, თუ სად და რა დაავადებებია გავრცელებული, რა არის უფრო მოთხოვნადი კონკრეტულ რეგიონში თუ მოსახლეობის გარკვეულ სეგმენტში. კონსტრუქციებიც კი ეფუძნება პოლიტიკური პროგრამებიმთავრობის კანდიდატები. მათ ასევე იყენებენ საცალო ქსელები საქონლის შეძენისას და მწარმოებლები თავიანთ წინადადებებში ხელმძღვანელობენ ამ მონაცემებით.
სტატისტიკა თამაშობს მნიშვნელოვანი როლისაზოგადოების ცხოვრებაში და გავლენას ახდენს მის თითოეულ ცალკეულ წევრზე, თუნდაც წვრილმანებზე. მაგალითად, თუ , უმეტესობა ამჯობინებს მუქი ფერებიკონკრეტულ ქალაქში ან რეგიონში ტანსაცმელში, ადგილობრივ მაღაზიებში ძალიან რთული იქნება ნათელი ყვითელი საწვიმარის პოვნა ყვავილების პრინტით. მაგრამ რა რაოდენობითაა ეს მონაცემები, რომლებსაც აქვთ ასეთი გავლენა? მაგალითად, რა არის „სტატისტიკურად მნიშვნელოვანი“? კონკრეტულად რა იგულისხმება ამ განმარტებაში?
Რა არის ეს?
სტატისტიკა, როგორც მეცნიერება, შედგება კომბინაციისგან სხვადასხვა ზომისდა ცნებები. ერთ-ერთი მათგანია „სტატისტიკური მნიშვნელობის“ ცნება. ეს არის ღირებულების სახელი ცვლადები, სხვა ინდიკატორების გაჩენის ალბათობა, რომლებშიც უმნიშვნელოა.
მაგალითად, 10-დან 9 ადამიანი ატარებს რეზინის ფეხსაცმელს ფეხზე დილის გასეირნებასოკოსთვის in შემოდგომის ტყეწვიმიანი ღამის შემდეგ. ალბათობა იმისა, რომ რაღაც მომენტში მათგან 8-მა ტილოზე მოკასინი დადო, უმნიშვნელოა. ამრიგად, ამ კონკრეტული მაგალითირიცხვი 9 არის მნიშვნელობა, რომელსაც ეწოდება "სტატისტიკური მნიშვნელობა".
შესაბამისად, თუ შემდგომ განვავითარებთ ზემოაღნიშნულს პრაქტიკული მაგალითი, ფეხსაცმლის მაღაზიები ბოლომდე ყიდულობენ ზაფხულის სეზონირეზინის ჩექმები უფრო დიდი რაოდენობით, ვიდრე წლის სხვა დროს. დიახ, ღირებულება სტატისტიკური მნიშვნელობაგავლენას ახდენს ყოველდღიურ ცხოვრებაზე.
რა თქმა უნდა, კომპლექსურ გამოთვლებში, მაგალითად, ვირუსების გავრცელების პროგნოზირებისას, დიდი რიცხვიცვლადები. მაგრამ სტატისტიკური მონაცემების მნიშვნელოვანი ინდიკატორის განსაზღვრის არსი მსგავსია, მიუხედავად გამოთვლების სირთულისა და არასტაბილური მნიშვნელობების რაოდენობისა.
როგორ გამოითვლება?
გამოიყენება განტოლების ინდიკატორის „სტატისტიკური მნიშვნელობის“ მნიშვნელობის გაანგარიშებისას. ანუ შეიძლება ითქვას, რომ ამ შემთხვევაში ყველაფერს მათემატიკა წყვეტს. ყველაზე მეტად მარტივი ვარიანტიგამოთვლა არის ჯაჭვი მათემატიკური ოპერაციები, რომელიც მოიცავს შემდეგ პარამეტრებს:
- გამოკითხვების ან ობიექტური მონაცემების შესწავლის შედეგად მიღებული ორი სახის შედეგი, მაგალითად, თანხები, რომლებისთვისაც ხდება შესყიდვები, აღინიშნება a და b-ით;
- ინდიკატორი ორივე ჯგუფისთვის - n;
- გაერთიანებული ნიმუშის წილის ღირებულება - p;
- კონცეფცია "სტანდარტული შეცდომა" - SE.
შემდეგი ნაბიჯი არის საერთო ტესტის ინდიკატორის განსაზღვრა - t, მისი მნიშვნელობა შედარებულია რიცხვთან 1.96. 1.96 არის საშუალო მნიშვნელობა, რომელიც წარმოადგენს 95% დიაპაზონს Student-ის t-განაწილების მიხედვით.
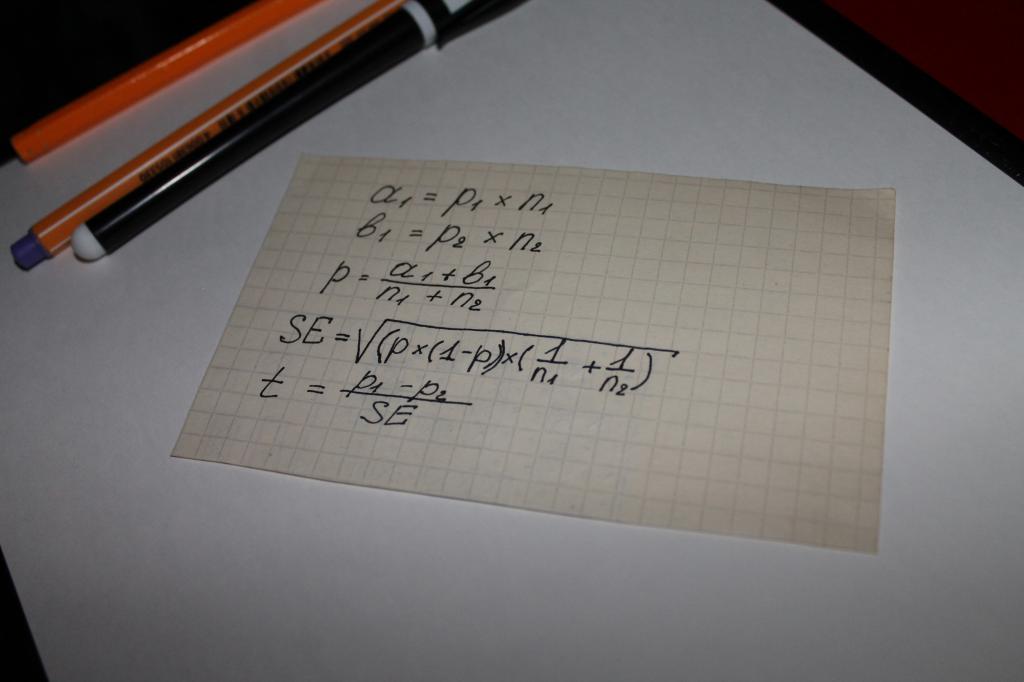
ხშირად ჩნდება კითხვა, რა განსხვავებაა n და p მნიშვნელობებს შორის. ამ ნიუანსის გარკვევა მარტივია მაგალითით. დავუშვათ, გამოითვლება ქალისა და მამაკაცის რომელიმე პროდუქტის ან ბრენდისადმი ლოიალობის სტატისტიკური მნიშვნელობა.
ამ შემთხვევაში, ასოებს მოჰყვება შემდეგი:
- n არის რესპონდენტთა რაოდენობა;
- p - პროდუქტით კმაყოფილთა რაოდენობა.
გამოკითხული ქალების რაოდენობა ამ შემთხვევაში იქნება n1. შესაბამისად, მამაკაცები - n2. იგივე მნიშვნელობა ექნება ნომრებს "1" და "2" სიმბოლო p.
ტესტის ინდიკატორის შედარება სტუდენტის გამოთვლის ცხრილების საშუალო მნიშვნელობებთან ხდება ის, რასაც ეწოდება "სტატისტიკური მნიშვნელობა".
რა იგულისხმება გადამოწმებაში?
ნებისმიერი მათემატიკური გაანგარიშების შედეგები ყოველთვის შეიძლება შემოწმდეს, ამას ბავშვებსაც კი ასწავლიან დაწყებითი სკოლა. ლოგიკურია ვივარაუდოთ, რომ რადგან სტატისტიკური მაჩვენებლები განისაზღვრება გამოთვლების ჯაჭვის გამოყენებით, მაშინ ისინი შემოწმდება.
თუმცა, სტატისტიკური მნიშვნელოვნების ტესტირება არ არის მხოლოდ მათემატიკა. სტატისტიკა ეხება დიდი რაოდენობითცვლადები და სხვადასხვა ალბათობები, რომლებიც ყოველთვის არ ექვემდებარება გამოთვლას. ანუ თუ დავუბრუნდებით სტატიის დასაწყისში მოცემულ მაგალითს რეზინის ფეხსაცმელი, მაშინ სტატისტიკური მონაცემების ლოგიკურ კონსტრუქციას, რომელსაც დაეყრდნებიან მაღაზიებისთვის საქონლის მყიდველები, შეიძლება ჩაშალოს მშრალი და ცხელი ამინდი, რაც შემოდგომისთვის არ არის დამახასიათებელი. ამ ფენომენის შედეგად შემცირდება რეზინის ჩექმების შემსყიდველთა რიცხვი და ზარალს განიცდიან მაღაზიები. მოველით ამინდის ანომალიას მათემატიკური ფორმულარა თქმა უნდა, არ შეიძლება. ამ მომენტს ეწოდება - "შეცდომა".

სწორედ ასეთი შეცდომების ალბათობას ითვალისწინებს გათვლილი მნიშვნელობის დონის შემოწმება. იგი ითვალისწინებს როგორც გამოთვლილ ინდიკატორებს, ასევე მნიშვნელობის მიღებულ დონეებს, ასევე რაოდენობებს, რომლებსაც პირობითად უწოდებენ ჰიპოთეზებს.
რა არის მნიშვნელობის დონე?
„დონის“ ცნება შეტანილია სტატისტიკური მნიშვნელობის ძირითად კრიტერიუმებში. იგი გამოიყენება გამოყენებით და პრაქტიკულ სტატისტიკაში. ეს არის ერთგვარი რაოდენობა, რომელიც ითვალისწინებს ალბათობას შესაძლო გადახრებიან შეცდომები.
დონე დაფუძნებულია მზა ნიმუშებში განსხვავებების იდენტიფიცირებაზე, ის საშუალებას გაძლევთ დაადგინოთ მათი მნიშვნელობა ან, პირიქით, შემთხვევითობა. ამ კონცეფციას აქვს არა მხოლოდ ციფრული მნიშვნელობა, არამედ მათი თავისებური ინტერპრეტაცია. ისინი განმარტავენ, თუ როგორ უნდა იქნას გაგებული მნიშვნელობა და თავად დონე განისაზღვრება შედეგის საშუალო ინდექსთან შედარებით, ეს ავლენს განსხვავებების საიმედოობის ხარისხს.

ამრიგად, დონის ცნება შეიძლება წარმოვიდგინოთ მარტივად - ეს არის მისაღები, სავარაუდო შეცდომის ან შეცდომის მაჩვენებელი მიღებული სტატისტიკური მონაცემებით გამოტანილ დასკვნებში.
რა მნიშვნელობის დონეები გამოიყენება?
შეცდომის ალბათობის კოეფიციენტების სტატისტიკური მნიშვნელობა პრაქტიკაში ემყარება სამ ძირითად დონეს.
პირველი დონე არის ბარიერი, რომლის ღირებულებაა 5%. ანუ შეცდომის ალბათობა არ აღემატება მნიშვნელოვნების 5%-ს. ეს ნიშნავს, რომ სტატისტიკური კვლევის მონაცემების საფუძველზე გაკეთებული დასკვნების უზადოობასა და უტყუარობაში ნდობა 95%-ია.
მეორე დონე არის 1%-იანი ბარიერი. შესაბამისად, ეს მაჩვენებელი ნიშნავს, რომ სტატისტიკური გამოთვლების დროს მიღებული მონაცემებით შეიძლება იხელმძღვანელო 99%-იანი ნდობით.
მესამე დონეა 0.1%. ამ მნიშვნელობით, შეცდომის ალბათობა უდრის პროცენტის წილადს, ანუ შეცდომები პრაქტიკულად აღმოიფხვრება.
რა არის ჰიპოთეზა სტატისტიკაში?
შეცდომები, როგორც კონცეფცია, იყოფა ორ სფეროდ ნულოვანი ჰიპოთეზის მიღებასთან ან უარყოფასთან დაკავშირებით. ჰიპოთეზა არის კონცეფცია, რომლის მიღმაც, განმარტების მიხედვით, იმალება სხვა მონაცემების ან განცხადებების ნაკრები. ეს არის აღწერა ალბათობის განაწილებასტატისტიკური აღრიცხვის საგანთან დაკავშირებული რაღაც.

მარტივ გამოთვლებში ორი ჰიპოთეზაა – ნული და ალტერნატივა. მათ შორის განსხვავება ისაა, რომ ნულოვანი ჰიპოთეზა ემყარება იმ აზრს, რომ სტატისტიკური მნიშვნელობის განსაზღვრაში ჩართულ ნიმუშებს შორის ფუნდამენტური განსხვავებები არ არსებობს და ალტერნატიული სრულიად საპირისპიროა. ე.ი ალტერნატიული ჰიპოთეზაამ ნიმუშებში მნიშვნელოვანი განსხვავების არსებობის საფუძველზე.
რა არის შეცდომები?
შეცდომები, როგორც ცნება სტატისტიკაში, პირდაპირ არის დამოკიდებული ამა თუ იმ ჰიპოთეზის ჭეშმარიტად მიღებაზე. ისინი შეიძლება დაიყოს ორ მიმართულებად ან ტიპად:
- პირველი ტიპი გამოწვეულია ნულოვანი ჰიპოთეზის მიღებით, რომელიც არასწორი აღმოჩნდა;
- მეორე გამოწვეულია ალტერნატივის მიყოლებით.

შეცდომის პირველ ტიპს ეწოდება ცრუ დადებითი და საკმაოდ გავრცელებულია ყველა სფეროში, სადაც სტატისტიკა გამოიყენება. შესაბამისად, მეორე ტიპის შეცდომას ცრუ უარყოფითი ეწოდება.
რატომ არის რეგრესი მნიშვნელოვანი სტატისტიკაში?
რეგრესიის სტატისტიკური მნიშვნელობა არის ის, რომ მისი გამოყენება შესაძლებელია იმის დასადგენად, თუ რამდენად რეალურია მონაცემების საფუძველზე გამოთვლილი მოდელი. სხვადასხვა დამოკიდებულებები; საშუალებას გაძლევთ განსაზღვროთ აღრიცხვისა და დასკვნების ფაქტორების საკმარისობა ან ნაკლებობა.
რეგრესიის მნიშვნელობა განისაზღვრება შედეგების შედარებით ფიშერის ცხრილებში ჩამოთვლილ მონაცემებთან. ან დისპერსიის ანალიზის გამოყენებით. მნიშვნელობარეგრესიის მაჩვენებლებს გააჩნიათ კომპლექსური სტატისტიკური კვლევებიდა გამოთვლები მოიცავს დიდი რიცხვიცვლადები, შემთხვევითი მონაცემები და სავარაუდო ცვლილებები.
სტატისტიკური მნიშვნელობა
გარკვეული კვლევის პროცედურის გამოყენებით მიღებულ შედეგებს ე.წ სტატისტიკურად ღირებულითუ მათი შემთხვევითი წარმოშობის ალბათობა ძალიან მცირეა. ეს კონცეფცია შეიძლება ილუსტრირებული იყოს მონეტის სროლის მაგალითით. დავუშვათ, რომ მონეტა გადატრიალებულია 30-ჯერ; იგი 17-ჯერ ამოვიდა თავებზე და 13-ჯერ ამოვიდა კუდებზე. აკეთებს მნიშვნელოვანიეს არის გადახრა მოსალოდნელი შედეგიდან (15 თავი და 15 კუდი), თუ ეს დამთხვევაა? ამ კითხვაზე პასუხის გასაცემად შეგიძლიათ, მაგალითად, ერთი და იგივე მონეტა ზედიზედ 30-ჯერ გადააგდოთ და ამავდროულად გაითვალისწინოთ, რამდენჯერ მეორდება თავებისა და კუდების თანაფარდობა, ტოლი 17:13. სტატისტიკური ანალიზი გვიხსნის ამ დამღლელი პროცესისგან. მისი დახმარებით, პირველი 30 მონეტის გადაყრის შემდეგ, შესაძლებელია შეფასდეს 17 თავისა და 13 კუდის შემთხვევითი შემთხვევების შესაძლო რაოდენობა. ასეთ შეფასებას ალბათობის დებულებას უწოდებენ.
AT სამეცნიერო ლიტერატურაინდუსტრიულ-ორგანიზაციულ ფსიქოლოგიაში სავარაუდო დებულება ინ მათემატიკური ფორმააღინიშნება გამოთქმით რ(ალბათობა)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (რ< 0.01). ეს ფაქტი მნიშვნელოვანია ლიტერატურის გასაგებად, მაგრამ არ უნდა მივიჩნიოთ, რომ უაზროა დაკვირვების გაკეთება, რომელიც არ შეესაბამება ამ სტანდარტებს. ე.წ. არამნიშვნელოვანი კვლევის შედეგები (დაკვირვებები, რომელთა მიღება შესაძლებელია შემთხვევით მეტი 100-დან ერთი ან ხუთჯერ) შეიძლება ძალიან სასარგებლო იყოს ტენდენციების იდენტიფიცირებისთვის და მომავალი კვლევის სახელმძღვანელოდ.
ასევე უნდა აღინიშნოს, რომ ყველა ფსიქოლოგი არ ეთანხმება ტრადიციულ სტანდარტებსა და პროცედურებს (მაგ. კოენი, 1994; Sauley & Bedeian, 1989). გაზომვებთან დაკავშირებული საკითხები თავად არის მთავარი თემამრავალი მკვლევარის ნამუშევარი, რომლებიც სწავლობენ გაზომვის მეთოდების სიზუსტეს და წინაპირობებს, რომლებიც საფუძვლად უდევს არსებული მეთოდებიდა სტანდარტები, ასევე ახალი ექიმებისა და ინსტრუმენტების შემუშავება. შესაძლოა, ოდესმე მომავალში, ამ ძალის კვლევამ გამოიწვიოს სტატისტიკური მნიშვნელობის შეფასების ტრადიციული სტანდარტების შეცვლა და ეს ცვლილებები საყოველთაო აღიარებას მოიპოვებს. (ამერიკის ფსიქოლოგთა ასოციაციის მეხუთე თავი აერთიანებს ფსიქოლოგებს, რომლებიც სპეციალიზირებულნი არიან შეფასებების, გაზომვების და სტატისტიკის შესწავლაში.)
კვლევის ანგარიშებში, სავარაუდო განცხადება, როგორიცაა რ< 0.05, ზოგიერთის გამო სტატისტიკაანუ რიცხვი, რომელიც მიღებულია გარკვეული მათემატიკური გამოთვლითი პროცედურების შედეგად. სავარაუდო დადასტურება მიიღება ამ სტატისტიკის შედარების შედეგად სპეციალური ცხრილების მონაცემებთან, რომლებიც გამოქვეყნებულია ამ მიზნით. სამრეწველო-ორგანიზაციულში ფსიქოლოგიური კვლევახშირად გვხვდება სტატისტიკა, როგორიცაა r, F, t, r>(წაიკითხეთ „ჩი კვადრატი“) და რ(წაიკითხეთ "მრავალჯერადი R").თითოეულ შემთხვევაში, დაკვირვების სერიის ანალიზით მიღებული სტატისტიკა (ერთი რიცხვი) შეიძლება შევადაროთ გამოქვეყნებული ცხრილის ციფრებს. ამის შემდეგ შესაძლებელია ამ რიცხვის შემთხვევით მოპოვების ალბათობის ალბათობის ფორმულირება, ანუ დაკვირვების მნიშვნელობის შესახებ დასკვნის გაკეთება.
ამ წიგნში აღწერილი კვლევების გასაგებად საკმარისია სტატისტიკური მნიშვნელობის ცნების მკაფიო გაგება და არ იცოდეთ, როგორ გამოითვლება ზემოთ აღნიშნული სტატისტიკა. თუმცა, სასარგებლო იქნება ერთი ვარაუდის განხილვა, რომელიც საფუძვლად უდევს ყველა ამ პროცედურას. ეს არის დაშვება, რომ ყველა დაკვირვებული ცვლადი განაწილებულია დაახლოებით ნორმალური კანონი. გარდა ამისა, ინდუსტრიულ-ორგანიზაციული ფსიქოლოგიური კვლევის შესახებ მოხსენებების კითხვისას ხშირად ჩნდება კიდევ სამი კონცეფცია, რომლებიც მნიშვნელოვან როლს თამაშობენ - პირველი, კორელაცია და კორელაციამეორეც, განმსაზღვრელი/პროგნოზირებადი ცვლადი და "ANOVA" ( დისპერსიის ანალიზი), მესამე, სტატისტიკური მეთოდების ჯგუფის ქვეშ საერთო სახელი"მეტაანალიზი".
ჰიპოთეზის ტესტირება ტარდება სტატისტიკური ანალიზის გამოყენებით. სტატისტიკური მნიშვნელოვნება გვხვდება P-მნიშვნელობის გამოყენებით, რომელიც შეესაბამება ალბათობას ეს ღონისძიებაიმ ვარაუდით, რომ ზოგიერთი განცხადება (ნულოვანი ჰიპოთეზა) არის ჭეშმარიტი. თუ P-მნიშვნელობა ნაკლებია სტატისტიკური მნიშვნელობის მოცემულ დონეზე (ჩვეულებრივ 0.05), ექსპერიმენტატორს შეუძლია უსაფრთხოდ დაასკვნას, რომ ნულოვანი ჰიპოთეზა მცდარია და გადავიდეს ალტერნატიული ჰიპოთეზის განხილვაზე. სტუდენტის t-ტესტის გამოყენებით შეგიძლიათ გამოთვალოთ P-მნიშვნელობა და დაადგინოთ მნიშვნელობა ორი მონაცემთა ნაკრებისთვის.
ნაბიჯები
Ნაწილი 1
ექსპერიმენტის დაყენება- ნულოვანი ჰიპოთეზა (H 0) ჩვეულებრივ აცხადებს, რომ არ არსებობს განსხვავება ორ მონაცემთა ნაკრებს შორის. მაგალითად: ის მოსწავლეები, რომლებიც გაკვეთილის წინ წაიკითხავენ მასალას, არ იღებენ მაღალ ქულას.
- ალტერნატიული ჰიპოთეზა (H a) არის ნულოვანი ჰიპოთეზის საპირისპირო და არის განცხადება, რომელიც უნდა დადასტურდეს ექსპერიმენტული მონაცემებით. მაგალითად: ის მოსწავლეები, რომლებიც მასალას გაკვეთილის დაწყებამდე კითხულობენ, უფრო მაღალ ქულას იღებენ.
-
დააყენეთ მნიშვნელობის დონე იმის დასადგენად, თუ რამდენად უნდა განსხვავდებოდეს მონაცემთა განაწილება ჩვეულებრივისგან, რათა ის ჩაითვალოს მნიშვნელოვან შედეგად. მნიშვნელობის დონე (ასევე ე.წ α (\displaystyle \alpha)-დონე) არის ბარიერი, რომელსაც თქვენ განსაზღვრავთ სტატისტიკური მნიშვნელოვნებისთვის. თუ P- მნიშვნელობა ნაკლებია ან ტოლია მნიშვნელოვნების დონეზე, მონაცემები სტატისტიკურად მნიშვნელოვანია.
- როგორც წესი, მნიშვნელობის დონე (მნიშვნელობა α (\displaystyle \alpha)) მიღებულია 0,05-ის ტოლი, ამ შემთხვევაში მონაცემთა სხვადასხვა სიმრავლეს შორის შემთხვევითი სხვაობის გამოვლენის ალბათობა მხოლოდ 5%-ია.
- რაც უფრო მაღალია მნიშვნელობის დონე (და, შესაბამისად, ნაკლები p- მნიშვნელობა), მით უფრო სანდოა შედეგები.
- თუ გსურთ უფრო საიმედო შედეგები, შეამცირეთ P-მნიშვნელობა 0.01-მდე. როგორც წესი, ქვედა P- მნიშვნელობები გამოიყენება წარმოებაში, როდესაც აუცილებელია პროდუქტების დეფექტების გამოვლენა. ამ შემთხვევაში, საჭიროა მაღალი ერთგულება, რათა უზრუნველყოს ყველა ნაწილის მუშაობა ისე, როგორც მოსალოდნელია.
- ჰიპოთეზური ექსპერიმენტების უმეტესობისთვის საკმარისია მნიშვნელოვნების დონე 0.05.
-
გადაწყვიტეთ რომელ კრიტერიუმებს გამოიყენებთ:ცალმხრივი ან ორმხრივი. სტუდენტის t-ტესტში ერთ-ერთი დაშვება არის ის, რომ მონაცემები ჩვეულებრივ განაწილებულია. ნორმალური განაწილება არის ზარის ფორმის მრუდი მაქსიმალური რაოდენობაშედეგი არის მრუდის შუაში. სტუდენტის t-ტესტი არის მათემატიკური მეთოდიმონაცემთა ვალიდაცია, რომელიც საშუალებას გაძლევთ განსაზღვროთ არის თუ არა მონაცემები ნორმალური განაწილების მიღმა (მეტი, ნაკლები ან მრუდის „კუდებში“).
- თუ არ ხართ დარწმუნებული, მონაცემები ზემოთ არის თუ ქვემოთ საკონტროლო ჯგუფიმნიშვნელობები, გამოიყენეთ ორმხრივი ტესტი. ეს საშუალებას მოგცემთ განსაზღვროთ მნიშვნელობა ორივე მიმართულებით.
- თუ იცით, რომელი მიმართულებით შეიძლება იყოს მონაცემები ნორმალურ განაწილებას მიღმა, გამოიყენეთ ცალმხრივი ტესტი. ზემოთ მოყვანილ მაგალითში, ჩვენ ველით, რომ სტუდენტების ქულები გაიზრდება, ამიტომ შეიძლება გამოყენებულ იქნას ცალმხრივი ტესტი.
-
განსაზღვრეთ ნიმუშის ზომა სტატისტიკური სიმძლავრის გამოყენებით.კვლევის სტატისტიკური ძალა არის იმის ალბათობა, რომ მოცემული ნიმუშის ზომა გამოიღებს მოსალოდნელ შედეგს. საერთო სიმძლავრის ბარიერი (ან β) არის 80%. სიმძლავრის ანალიზი ყოველგვარი წინასწარი მონაცემების გარეშე შეიძლება იყოს სახიფათო, რადგან საჭიროა გარკვეული ინფორმაცია თითოეულ მონაცემთა ნაკრებში მოსალოდნელი საშუალებებისა და მათი სტანდარტული გადახრების შესახებ. გამოიყენეთ ონლაინ დენის კალკულატორი თქვენი მონაცემების ნიმუშის ოპტიმალური ზომის დასადგენად.
- როგორც წესი, მკვლევარები ატარებენ მცირე საპილოტე კვლევას, რომელიც უზრუნველყოფს მონაცემებს სიმძლავრის ანალიზისთვის და განსაზღვრავს ნიმუშის ზომას, რომელიც საჭიროა უფრო დიდი და სრულყოფილი კვლევისთვის.
- თუ არ გაქვთ შესაძლებლობა ჩაატაროთ საპილოტე კვლევა, შეეცადეთ შეაფასოთ შესაძლო საშუალო მნიშვნელობები ლიტერატურის მონაცემებზე და სხვა ადამიანების შედეგებზე დაყრდნობით. ეს დაგეხმარებათ განსაზღვროთ ნიმუშის ოპტიმალური ზომა.
Მე -2 ნაწილი
გამოთვალეთ სტანდარტული გადახრა-
ჩაწერეთ სტანდარტული გადახრის ფორმულა.სტანდარტული გადახრა მიუთითებს, თუ რამდენად დიდია მონაცემთა გავრცელება. ეს საშუალებას გაძლევთ დაასკვნათ, რამდენად ახლოსაა მოცემული ნიმუშის მონაცემები. ერთი შეხედვით, ფორმულა საკმაოდ რთული ჩანს, მაგრამ ქვემოთ მოცემული ახსნა დაგეხმარებათ ამის გაგებაში. ფორმულა აქვს შემდეგი ხედი: s = √∑((x i – μ) 2 /(N – 1)).
- s - სტანდარტული გადახრა;
- ∑ ნიშანი მიუთითებს, რომ ნიმუშში მიღებული ყველა მონაცემი უნდა დაემატოს;
- x i შეესაბამება i-ის მნიშვნელობას, ანუ ცალკე მიღებულ შედეგს;
- μ არის საშუალო მნიშვნელობა ამ ჯგუფისთვის;
- N- საერთო რაოდენობამონაცემები ნიმუშში.
-
იპოვეთ საშუალო თითოეულ ჯგუფში.სტანდარტული გადახრის გამოსათვლელად, ჯერ უნდა იპოვოთ საშუალო თითოეული სასწავლო ჯგუფისთვის. საშუალო მნიშვნელობა აღინიშნება ბერძნული ასოμ (mu). საშუალოს საპოვნელად, უბრალოდ დაამატეთ ყველა მიღებული მნიშვნელობა და გაყავით ისინი მონაცემთა რაოდენობაზე (ნიმუშის ზომა).
- მაგალითად, იპოვონ საშუალო შეფასებაიმ სტუდენტების ჯგუფში, რომლებიც სწავლობენ მასალას გაკვეთილის დაწყებამდე, განიხილეთ მცირე მონაცემთა ნაკრები. სიმარტივისთვის ვიყენებთ ხუთი პუნქტის კომპლექტს: 90, 91, 85, 83 და 94.
- მოდით დავამატოთ ყველა მნიშვნელობა ერთად: 90 + 91 + 85 + 83 + 94 = 443.
- ჯამი გავყოთ მნიშვნელობების რაოდენობაზე, N = 5: 443/5 = 88.6.
- ამრიგად, ამ ჯგუფის საშუალო მნიშვნელობა არის 88.6.
-
გამოვაკლოთ თითოეული მიღებული მნიშვნელობა საშუალოს. Შემდეგი ნაბიჯიარის სხვაობის გამოთვლა (x i - μ). ამისათვის გამოაკლეთ ნაპოვნი საშუალო ზომისთითოეული მიღებული ღირებულება. ჩვენს მაგალითში უნდა ვიპოვოთ ხუთი განსხვავება:
- (90 - 88.6), (91 - 88.6), (85 - 88.6), (83 - 88.6) და (94 - 88.6).
- შედეგად, ჩვენ ვიღებთ შემდეგი მნიშვნელობები: 1.4, 2.4, -3.6, -5.6 და 5.4.
-
მიღებული თითოეული მნიშვნელობის კვადრატი და დაამატეთ ისინი ერთად.ახლა ნაპოვნი თითოეული რაოდენობა უნდა იყოს კვადრატში. ამ ეტაპზე ყველაფერი გაქრება. უარყოფითი მნიშვნელობები. თუ ამ ნაბიჯის შემდეგ გაქვთ უარყოფითი რიცხვები, მაშინ დაგავიწყდათ მათი კვადრატი.
- ჩვენი მაგალითისთვის ვიღებთ 1.96, 5.76, 12.96, 31.36 და 29.16.
- მიღებულ მნიშვნელობებს ვამატებთ: 1,96 + 5,76 + 12,96 + 31,36 + 29,16 = 81,2.
-
გავყოთ ნიმუშის ზომაზე მინუს 1.ფორმულაში ჯამი იყოფა N - 1-ზე იმის გამო, რომ არ ვითვალისწინებთ საერთო მოსახლეობა, მაგრამ შეფასებისთვის ვიღებთ ყველა მოსწავლის ნიმუშს.
- გამოკლება: N - 1 = 5 - 1 = 4
- გაყოფა: 81.2/4 = 20.3
-
ამონაწერი Კვადრატული ფესვი. ჯამის გაყოფის შემდეგ ნიმუშის ზომაზე მინუს ერთი, აიღეთ ნაპოვნი მნიშვნელობის კვადრატული ფესვი. ეს არის ბოლო ნაბიჯი სტანდარტული გადახრის გამოთვლისას. არის სტატისტიკური პროგრამები, რომლებიც საწყისი მონაცემების შეყვანის შემდეგ ახორციელებენ ყველა საჭირო გამოთვლას.
- ჩვენს მაგალითში, იმ სტუდენტების ნიშნების სტანდარტული გადახრა, რომლებიც კითხულობენ მასალას გაკვეთილის დაწყებამდე, არის s = √20.3 = 4.51.
ნაწილი 3
განსაზღვრეთ მნიშვნელობა-
გამოთვალეთ სხვაობა მონაცემთა ორ ჯგუფს შორის.ამ საფეხურამდე ჩვენ განვიხილეთ მაგალითი მონაცემთა მხოლოდ ერთი ჯგუფისთვის. თუ გსურთ ორი ჯგუფის შედარება, ცხადია, ორივე ჯგუფის მონაცემები უნდა აიღოთ. გამოთვალეთ სტანდარტული გადახრა მეორე ჯგუფის მონაცემებისთვის და შემდეგ იპოვნეთ განსხვავება მათ შორის ექსპერიმენტული ჯგუფები. დისპერსია გამოითვლება შემდეგი ფორმულის გამოყენებით: s d = √((s 1 /N 1) + (s 2 /N 2)).
განსაზღვრეთ თქვენი ჰიპოთეზა.სტატისტიკური მნიშვნელობის შეფასების პირველი ნაბიჯი არის კითხვის არჩევა, რომელზეც გსურთ პასუხის გაცემა და ჰიპოთეზის ჩამოყალიბება. ჰიპოთეზა არის განცხადება ექსპერიმენტული მონაცემების, მათი განაწილებისა და თვისებების შესახებ. ნებისმიერი ექსპერიმენტისთვის არსებობს როგორც ნულოვანი, ასევე ალტერნატიული ჰიპოთეზა. ზოგადად, თქვენ მოგიწევთ მონაცემთა ორი ნაკრების შედარება, რათა დადგინდეს, მსგავსია თუ განსხვავებული.
